1. Introduction
Sustainable management of large tracts of public forests requires formulating management plans based on three pillars of sustainability, i.e., social, economic, and environmental [
1]. A top-down hierarchical planning framework is generally adopted for this purpose [
2]. This framework consists of three distinct levels, i.e., strategic, tactical, and operational. Long-term strategic planning determines the annual allowable cut (AAC), which is generally derived using a linear programming optimization model. As such, it is an aspatial model that determines the maximum sustainable volumes of wood by tree species that can be harvested in the long term [
3]. The tactical planning spatially disaggregates the volume targets set at the strategic level with the consideration of three pillars of sustainability [
4]. The process determines the precise location of cutblocks available for harvest during different time periods. Further down the hierarchy, output from the tactical level aids in developing operational plans that provide a detailed harvesting schedule to meet industrial demand [
5].
It has become increasingly important to incorporate forest carbon budgeting in forest management planning given the imminent threat posed by climate change [
6]. Forests are believed to have a substantial role in mitigating climate change [
7]. It is therefore crucial for forest planners and researchers to keep track of past and present carbon flux and stock dynamics to develop sound land-use policies [
8,
9]. Net ecosystem productivity (NEP) is an indicator of carbon flux within an ecosystem during a given period [
10]. When the NEP exhibits a negative value, it is considered as a source of CO
2, while a positive value often signifies its ability to act as a sink for CO
2 [
11,
12]. Understanding carbon storage within the forest ecosystem is also equally important. This is because forests have the unique ability to store significant amounts of carbon in the form of woody biomass (dead and living), litter and soil [
13]. Carbon budget modelling is often a preferred tool to understand the carbon stock under different management scenarios [
8,
14] and different carbon flux dynamics. For such applications, the Carbon Budget Model of the Canadian Forest Sector (CBM-CFS) has been commonly used [
8,
15,
16,
17]. Moreover, the recent version, i.e., CBM-CFS3, has implemented a Tier 3 Good Practice Guidance standard for carbon budget modelling [
8,
9]. Therefore, CBM-CFS3 is widely used for forest carbon accounting at the operational scale [
14,
18]. Typically, this model allows forest practitioners to estimate carbon metrics during the calculation of AAC. Nevertheless, CBM-CFS provides spatial carbon budgeting only for a limited area, which is a major shortcoming, because forest management planning is conducted in large tracts of forests. The Generic Carbon Budget Model (GCBM) uses the same basic foundations as CBM-CFS3, but in addition to being spatial, GCBM is fully capable of operating in a larger forest territory [
19,
20].
In forest management planning, consideration of carbon metrics in the spatial allocation phase is a major challenge [
21]. It is worth pointing out that spatial allocation is a challenging numerical problem even when simply allocating volume [
22,
23]. Mixed integer programming is commonly used, and it presents computational limitations for large combinatorial problems [
22,
24]. The inclusion of GCBM, in this already complex process, would further exacerbate the problem as the timeframe required to obtain output is too lengthy for practitioners. This prevents evaluation of carbon metrics to select an optimal plan under different scenarios. We hypothesize that machine learning algorithms can help overcome this challenge by rapidly generating alternative plans which can subsequently be evaluated for carbon metrics in spatial forest planning. While the standalone GCBM model has been successfully implemented in various studies like [
10,
25], the issue of intensive computational cost still persists. This work is, to the best of our knowledge, among the first to operationalize ML training on GCBM outputs at a regional scale.
Machine learning approaches have already been successfully applied for forest structure prediction [
26] and carbon mapping [
27]. Machine learning algorithms can provide an accurate estimation within a practical time frame and with much lower computational requirements [
26,
27,
28]. In this regard, the broad aim of this research is to limit the use of computationally complex approaches, such as GCBM, with machine learning algorithms that can provide instantaneous output so that multiple forest planning scenarios can rapidly be evaluated. The specific objective of this study is therefore to evaluate the capacity of machine learning algorithms to estimate net ecosystem productivity (NEP) and carbon pools in the context of spatial forest planning.
2. Materials and Methods
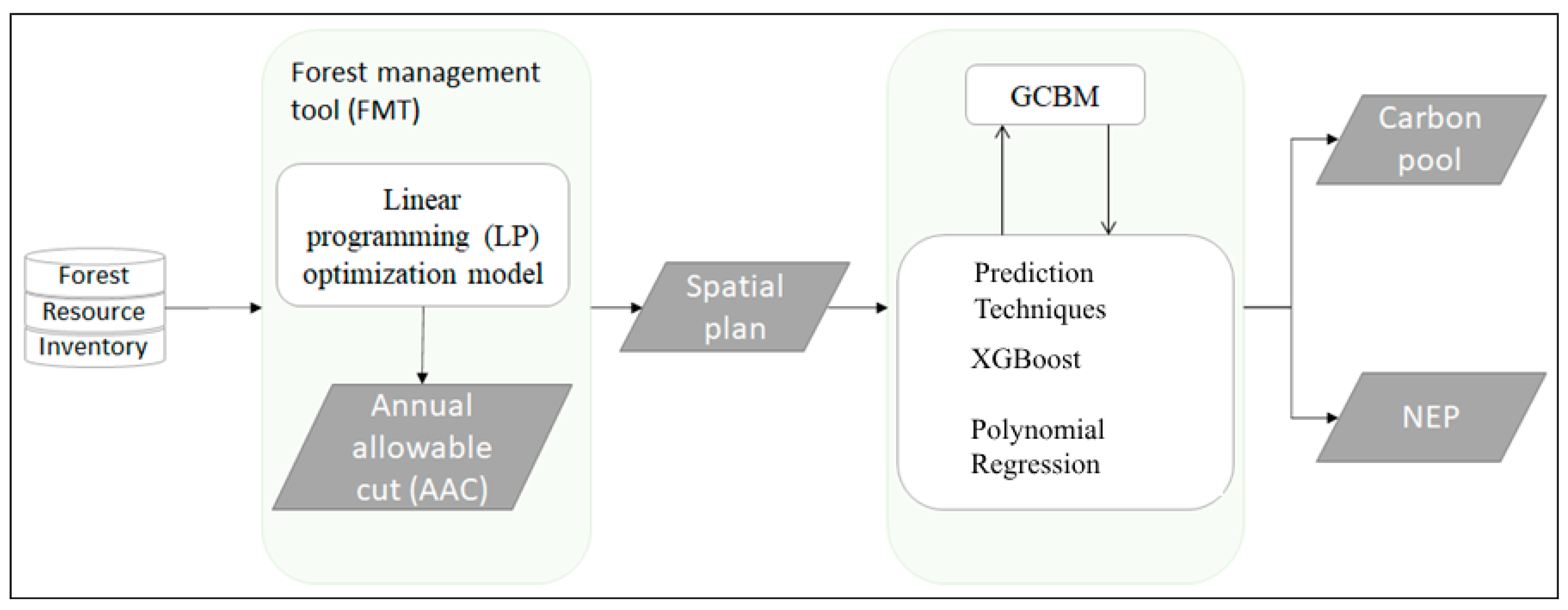
The methodology adopted in this study is summarized in
Figure 1. First, the AACs for each study area were calculated using forest resource inventory data and a linear programming (LP) optimization model. Forest management tool (FMT) [
29] was used to generate spatial output based on the aspatial solution generated by the LP model. Next, the GCBM model was used to estimate NEP and the carbon pool for the spatial solution. The carbon pool includes aboveground biomass, belowground biomass, deadwood, litter and soil carbon content. The output generated by GCBM was used to train the XGBoost (Extreme Gradient Boosting), a machine learning algorithm. As an added validation benchmark, polynomial regression was also carried out. The NEP and carbon pool were subsequently predicted using the trained ML model to evaluate their performance. A description of the study area is provided in the next subsection followed by description of AAC and carbon calculations, data preparation methods, and model building and evaluating procedures.
2.1. Study Area
This study was conducted in the province of Quebec, Canada where 12 management units (MUs) were selected from the following administrative regions: Côte Nord, Saguenay-Lac Saint-Jean, Capitale-Nationale and Nord-du-Québec (
Figure 2). All 12 MUs are predominantly situated within the Canadian boreal forest and mostly consist of conifer tree species. The total area within each MU and their respective managed and unmanaged forest areas are presented in
Table 1.
2.2. AAC and Carbon Calculations
First, AAC was determined using LP model II in the Woodstock Forest modeling system [
30]. The output of the AAC was the determination of the maximum volume that can be harvested in the MU per period, by species. As such, it disregarded the spatial aspect. FMT was used to spatialize the disturbances and forest inventory at a 14.4 ha resolution. FMT is an open-source object-oriented library in C++ and was used through the Python programming language version 3.12 for spatial interpretation of Woodstock output.
Next, GCBM was used for carbon calculations as it is designed specifically to evaluate the carbon stock and fluxes of a forest [
20]. The spatially explicit plan generated by Woodstock and FMT was input into GCBM along with yield curves, forest inventory data and historical disturbance information to simulate tree growth-related changes in the carbon stock. GCBM also takes into consideration aboveground and belowground biomass, deadwood biomass, litter and soil carbon based on the forest management practice adopted. It explicitly considers biomass mortality dynamics by accounting for the transfer from living to dead biomass [
31]. It also incorporates the carbon emission due to the decomposition of dead biomass or direct oxidation within the atmosphere caused by fire disturbance. The list of variables essential to run the GCBM is listed as an
Appendix A (
Table A1). The next step required was to train machine learning algorithms to partly substitute for GCBM. As mentioned earlier, one of the significant limitations of GCBM is its high computational requirements. This can make it more challenging for forest practitioners to evaluate multiple scenarios.
2.3. Data Preparation and Dimensionality Reduction
This section provides a detailed description of the data preprocessing that serves as the inputs for the machine learning algorithms. The independent variables for the machine learning algorithms were the same as those used in GCBM (
Table A1). This is because GCBM is a state-of-the-art spatial forest carbon model which considers different relevant inputs for its operation [
10]. A total of 7.56 million samples were compiled for NEP forecasting and 13.53 million samples for carbon pool prediction. For validation purposes, the effectiveness of the machine learning algorithm was compared to the output of GCBM. Here, the objective was to predict the NEP and the carbon pools; therefore, it was deemed important to apply two different preprocessing approaches. For NEP forecasting, we selected two forest strata because it measures the carbon flux between two periods. For the carbon pool, a single stratum was used because it measures the amount of carbon stored at a given period. The selection of strata was followed by a data cleaning phase. Initially, duplicates as well as null or “NaN” were removed from the list of dependent and independent variables. After the elimination of “NaN” and duplicates, there were approximately 6.77 million samples with 18 independent variables for NEP forecasting and 13.52 million samples with 11 independent variables for carbon pool forecasting. Even after eliminating duplicates and null entries, the dataset was sufficiently large and considered adequate for training and testing the machine learning models.
Since the numbers of dependent variables were large i.e., 18 for NEP and 11 for carbon pools, Principal Component Analysis (PCA) was conducted as a dimensionality reduction technique. It is a technique for simplifying large datasets by transforming them into a lower dimensional space while retaining most of the original information. It works by identifying new axes which are called principal components. Principal components capture the maximum variance in the data, with each component being orthogonal (uncorrelated) to the others [
32].
Initially, the data was standardized to have a mean of zero and unit variance using the StandardScaler from the sklearn.preprocessing module. PCA was then applied via the PCA class from sklearn.decomposition. A total of 5 principal components for carbon pool and 6 principal components for NEP were selected as they explained about 85% of the cumulative explained variance of the original data. The transformed principal components were subsequently used for downstream analysis. Then, the dataset was randomly split into two parts, i.e., training (80% of data) and testing (20%), using Scikit-learn with a fixed random seed (random_state = 42). This criterion was adopted for both NEP and carbon pool forecasting.
2.4. Model Selection
In this study, Extreme Gradient Boosting (XGBoost) was used to predict the carbon pool and NEP. To serve as a validation benchmark, polynomial regression was also used to predict the independent variables. A detailed description of the regression techniques utilized is given in the subsection below.
2.4.1. Polynomial Regression
A polynomial regression is a special type of multiple linear regression in which a curvilinear relationship is established between independent and dependent variables (Maulud and Abdulazeez 2020) [
33]. The polynomial regression is given as:
where
y is the intended outcome (NEP and carbon pool) and
β0 is the intercept, while
βn represents the slope for each explanatory variable
x (from
Table A1) and
∊ is the error.
One of the major drawbacks of polynomial regression is its inability to deal with the presence of outliers within the dataset, which is believed to reduce performance of these models. Nevertheless, this study uses polynomial regression as a benchmark model and compares prediction with XGBoost.
For polynomial regression model building, the dataset was first split into training (80%) and testing (20%). To determine the optimal model complexity, a systematic grid search was conducted over polynomial degrees from 1 to 4. Similarly, the model was regularized with alpha values of 0.01, 0.1, 1, 10 and 100 using RidgeCV. The parameter combination of polynomial degree and regularization parameter yielding the highest R2 value was selected as the best model.
2.4.2. XGBoost
XGBoost is a powerful machine learning algorithm based on the gradient boosting framework and belongs to the family of ensemble learning methods. In this model, a series of decision trees are built, in which each tree attempts to correct the mistakes of the previous one. It incorporates features like regularization, which helps to prevent overfitting, and parallelization, which enables parallel computation during tree construction. Because of these advantages, it is an ideal choice for large-scale datasets due to its significantly faster performance compared to many other implementations. Despite its advantages, XGBoost can still be prone to overfitting if not properly tuned, particularly when dealing with noisy data [
34].
2.5. Model Building
XGBoost regression was implemented using the XGBRegressor class from the xgboost python package. To accelerate model training, a histogram-based tree construction algorithm was used in conjunction with GPU acceleration using cuda.
For hyperparameter tuning, a Bayesian optimization approach was employed using the BayesSearchCV utility from the scikit-optimize library to find the best parameter from the given range of possible alternatives (
Table 2). Bayesian optimization uses a probabilistic model to make informed decisions about where in the parameter space to sample next. It focuses on regions of the parameter space that are more likely to yield performance improvements based on the prior observations. Since Bayesian optimization avoids wasting resources on unpromising combinations, it is sample-efficient and faster [
35].
Three-fold cross validation was used for internal performance validation. Since XGBoost is a tree-based algorithm, it is not sensitive to the scale of the features. Hence, data transformation methods like standardization and normalization are not required as tree-based models divide the data based on feature thresholds, not distance or magnitude [
36]. Since PCA was already applied in advance, which required data scaling, no further data transformation was carried out for XGBoost.
As machine learning models are susceptible to overfitting and susceptible to noisy data, some precautions were also taken into account. First, the incorporation of PCA as a dimensionality reduction step helped to reduce feature collinearity and noise, in turn improving generalization. Likewise, as mentioned previously in the description of the XGBoost model, its inherent ensemble structure and decision tree-based approach are comparatively less sensitive to noisy or unscaled features, as splits are based on thresholds rather than distances.
2.6. Model Evaluation Criteria
Three metrics, namely coefficient of determination (R
2), mean absolute error (MAE), and root mean squared error (RMSE), were used to evaluate overall model performance. The coefficient of determinants, R
2, is an extensively used evaluation metric for a variety of applications [
37]. The R
2 value ranges between 0 and 1 and the model is considered to be effective if its value is close to 1. The two other metrics, namely RMSE and MAE, measure the deviation of modelled output from the observed value. The values of both MSE and MAE range between 0 and ∞ and the model with a value close to 0 is regarded as the best-performing. Among these three indicators, the R
2 was the main performance metric used to assess performance of tested models. It is also worth pointing out that the results obtained with the testing dataset are linked to its distribution and it is impossible to guarantee that another dataset with completely different distributions would yield the same results. It should also be noted that all the processing was carried out in the Python programming language within the Anaconda environment using the sklearn package. Likewise, to determine the robustness of the model across different data partitions, a repeated sub sampling method was implemented using the ShuffleSplit method from the scikit-learn library. The methodology involved generation of 10 independent train–test splits (80–20 ratio). For each split, the machine learning model was retrained using the optimal hyperparameters previously identified through the Bayesian optimization and evaluated using the performance metrics.
4. Discussion
To investigate the carbon fluxes and the stock dynamics of managed forests in Quebec, a set of 12 management units were chosen, and subsequently analysed using GCBM, a robust tool for carbon budgeting [
10,
19,
20]. As expected, in these MUs, we observed site-wise variability for carbon pools and NEP. Several past studies have already provided detailed information regarding the role of forest age, structure, management, climate and disturbances which cause variability in carbon storage and flux [
7,
10,
14,
38,
39], as is the case in these MUs. Moreover, our results, illustrated in
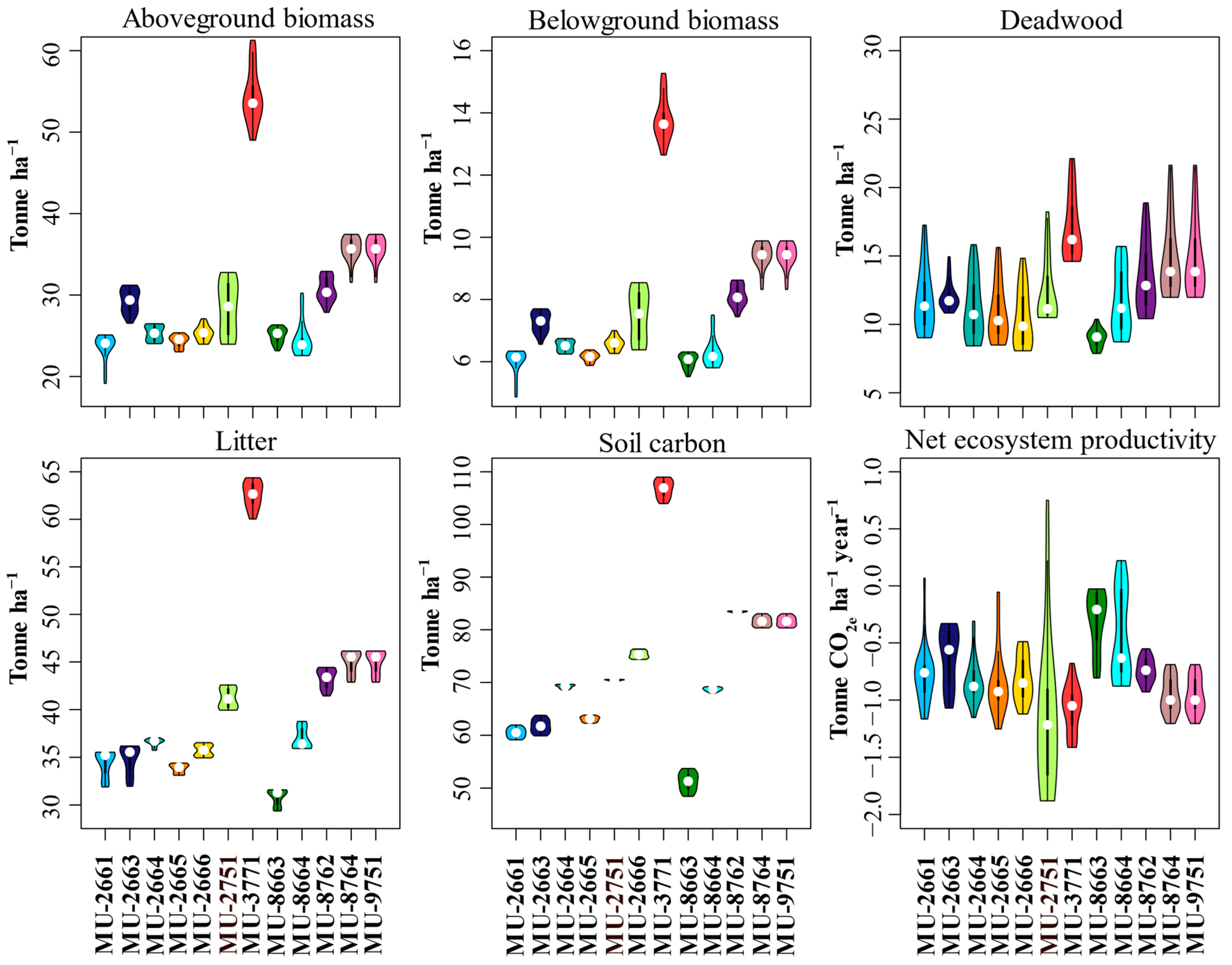
Figure 3, indicate that the soil stored a significant proportion of carbon while deadwood stored the lowest amount. Our results are comparable to other studies that indicate that boreal forest stores a significant proportion of carbon in soil rather than in vegetation [
40,
41]. This can be attributed to the reduced organic carbon decomposition rates, particularly in the northern regions with colder climates [
40]. The geographical distribution along with the adopted management practices also contributes to the variability in overall carbon content for these individual carbon pool components. These differences contribute to variability in the composition and structure of forests which in turn have substantial influence on soil carbon properties [
42].
Based on the GCBM model results, MU-3771, located in Capitale-Nationale, exhibited greater mean carbon stock (
Figure 3) than all other management units. As displayed in
Figure 1, MU-3771 is situated in the southernmost region. Here, a favorable climate supports the existence of mixed wood forests. Such diverse forests often have an effective ability to capture a significant proportion of carbon [
43]. For instance, [
44] compared the variability in soil carbon sequestration potential for temperate and boreal forest tree species. The authors concluded that mixed forests had larger potential to store soil carbon than the spruce forest. On the contrary, it is also worth pointing out that the northern forests, with less diverse tree species, showcased variability in carbon pools. Several past studies have already highlighted the importance of species composition and carbon capture. Therefore, one can see the variability in the carbon pools across our management units. We also evaluated the NEP values derived using GCBM. Most of the strata had a negative NEP value which can be explained by logging activities that took place in the area [
45], or the successional stage (late) of the forests [
46,
47]. The MUs are mostly viewed as carbon sinks over the long term > 100 years [
31]. Our data is composed of a majority of carbon source strata, but these only represent a small amount of area for each MU.
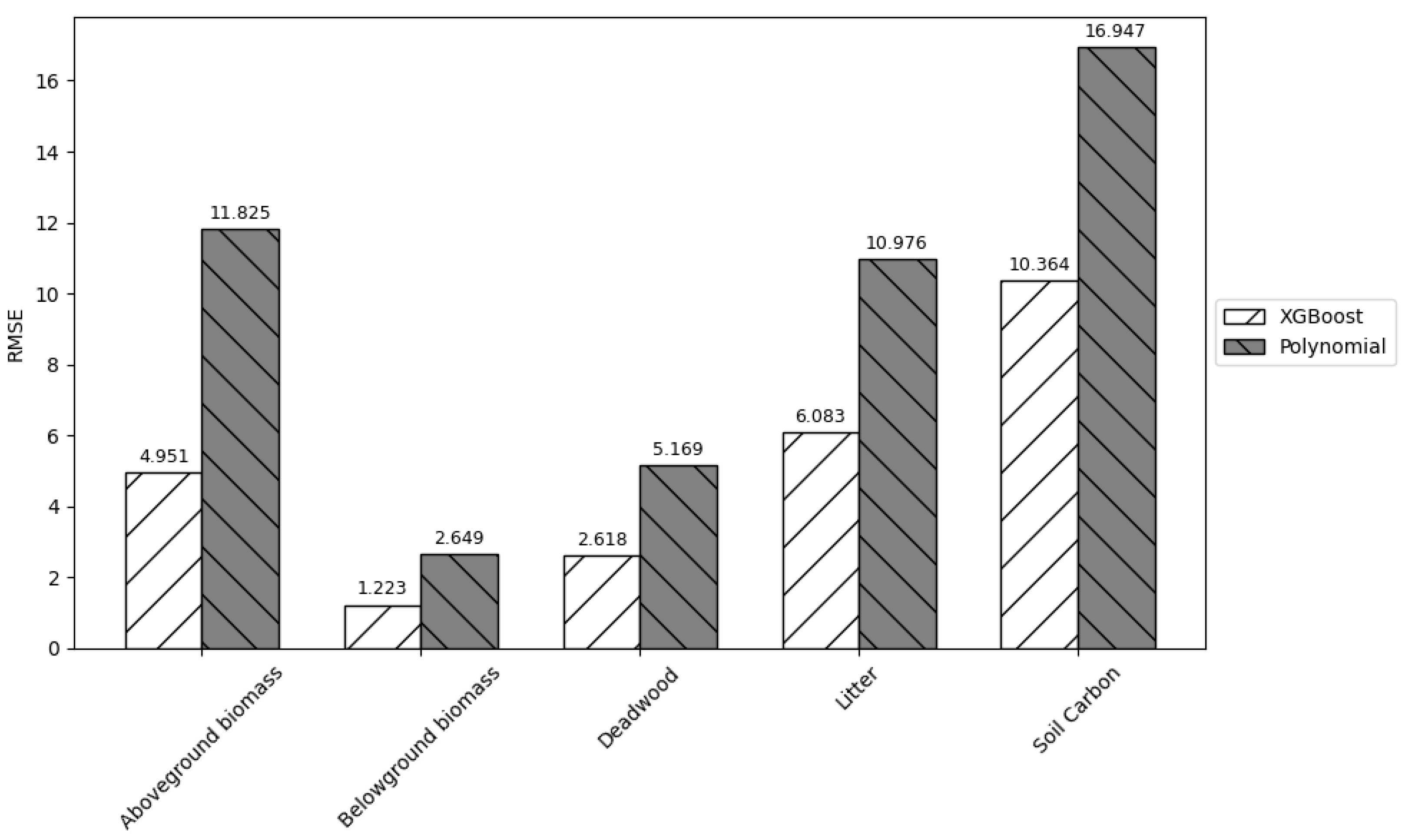
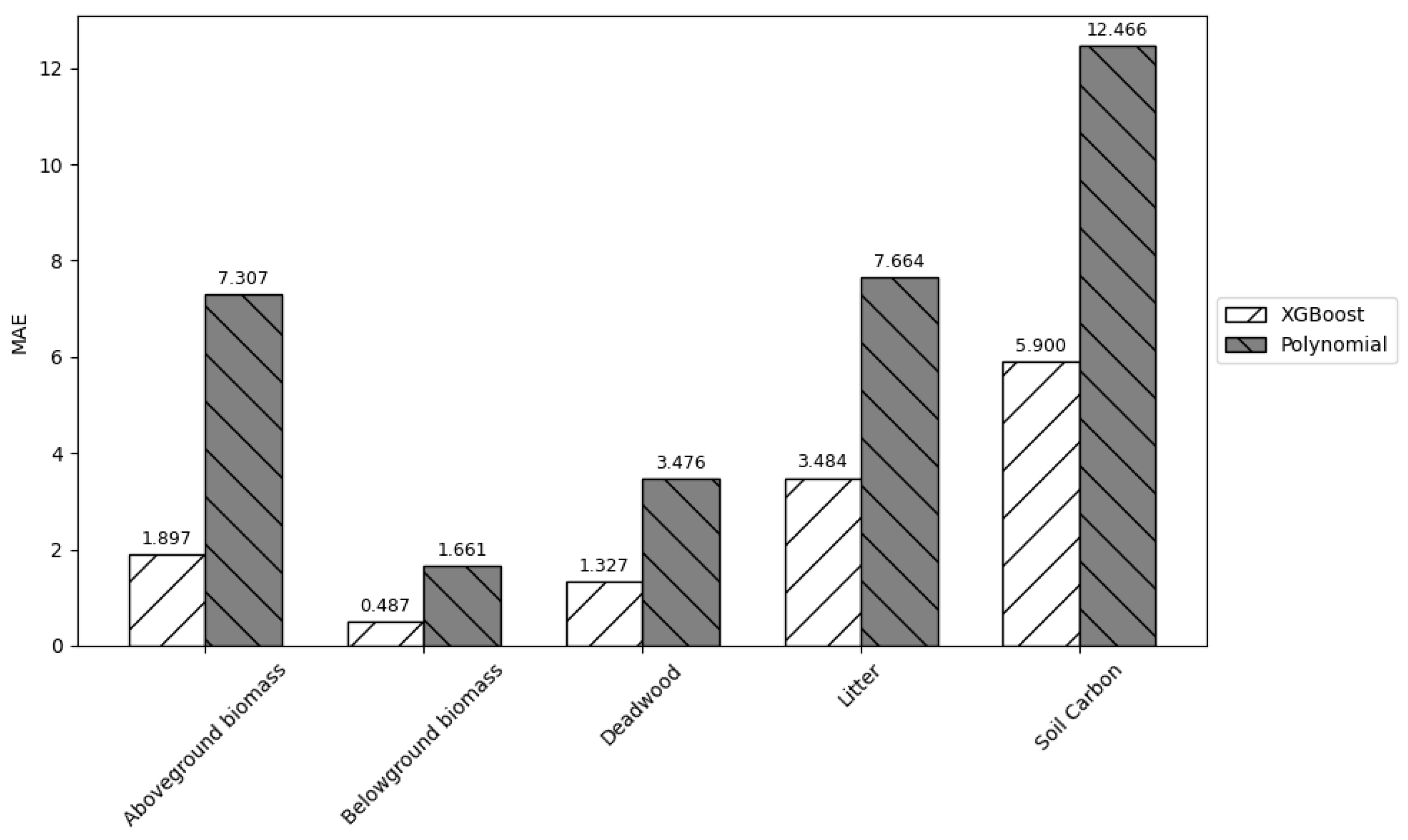
Likewise, the results indicate that XGBoost model was effective in replicating the results of the GCBM model. The model demonstrated high accuracy and generalization capacity, as evidenced by the R
2 value. XGBoost’s success as compared to the normal polynomial regression can be largely attributed to its ability to efficiently handle large datasets, and its superior abilities to capture non-linear feature interactions and mitigate overfitting through integrated regularization mechanisms [
34]. Among the predicted variables, aboveground and belowground were predicted with the highest accuracy with R
2 exceeding 0.96. Litter and soil carbon also exhibited high predictive performance with values around 0.90. NEP and deadwood had relatively lower predictive performance as compared to the others. Nevertheless, these deviations are minor, and the overall performance still remained within the acceptable limits. This variation is likely due to the inherent variability within the individual dataset and measurement uncertainty across the individual components.
A critical factor in achieving high model performance is the careful selection and tuning of hyperparameters, as the accuracy of a machine learning model is highly dependent upon the appropriate hyperparameters. While the hyperparameter space was optimized to a practical extent, the process was constrained by the computational burden posed by the large dataset. A wider search could have potentially improved the model accuracy even further; however, it was limited by time and hardware restrictions. Hence, there should be an optimal balance of computational efficiency and model accuracy.
Moving towards computational efficiency, other machine learning algorithms, particularly random forest and artificial neural networks, were also considered in the pilot phase, but ultimately discarded due to their relative inefficiency in handling large datasets. In preliminary comparisons, it took more than 4 h to train a single dependent variable for an artificial neural network as compared to XGBoost, which only took an average of 30 min. Likewise, random forest also took more than 7 h in the training phase. In addition to this, ANNs, while offering high representational capacity, are also sensitive to data transformation methods like scaling and normalization and require extensive training time. Hence, XGBoost was selected as the best machine learning model in our pilot study phase which offered a good balance of accuracy and efficiency.
It seems that XGBoost is best suited for scenarios where rapid decision-making is required, such as generating multiple forest management scenarios in tactical planning, conducting preliminary carbon assessments, or supporting stakeholder engagement through scenario comparison. Its speed and scalability make it particularly advantageous when hundreds or thousands of alternative management scenarios must be evaluated quickly. However, XGBoost is not a replacement for GCBM in contexts that demand high precision, or mechanistic understanding of carbon dynamics, for instance, in regulatory reporting, policy evaluation, carbon credit verification or long-term national carbon accounting. GCBM remains more suitable when detailed representations of ecological processes, forest succession, and disturbance interactions are critical. Therefore, we recommend a hybrid use, where XGBoost can rapidly screen options and GCBM is applied to a select set of high-priority scenarios for more robust carbon evaluation.
The objective of this study was to achieve the maximum possible accuracy within an acceptable time frame. Note that the models presented in this study exclusively rely on the datasets from the management units in Quebec. While the XGBoost model developed in this study demonstrated high predictive accuracy within Quebec’s boreal forest context, its applicability to other forest regions needs to be evaluated. The model was trained using region-specific variables, forest inventory data, disturbance regimes and climatic conditions unique to Quebec’s boreal forest. As such, applying the model to other provinces or countries with different ecological characteristics, forest compositions or management practices could lead to reduced accuracy. Model retraining or transfer learning with local data from other places should be used in future work to examine the transferability and applicability of the model in other ecological contexts.
5. Conclusions
The Generic Carbon Budget Model (GCBM) is a robust and widely utilized tool used for simulating carbon stocks and fluxes in forest ecosystems. However, its high computational demand poses a significant barrier for rapid scenario assessments, limiting its practical integration into dynamic forest management planning workflows. To address this limitation, we investigated the potential of machine learning, specifically XGBoost, to predict key carbon metrics. Our results demonstrated that XGBoost can effectively replicate the output of GCBM with high accuracy while drastically reducing computation time. For instance, the trained model achieved R2 values of 0.883 for NEP and 0.967 for aboveground biomass carbon. It was able to predict millions of outputs in less than a minute after model training. Polynomial regression, used as a benchmark, consistently underperformed as compared to XGBoost, further validating the model’s suitability.
Based on the results, it is proposed that machine learning models like XGBoost are suitable for tasks that involve rapid evaluation of multiple forest management scenarios. GCBM, in contrast, remains better suited for applications which demand high accuracy. A hybrid approach using a machine learning model to filter a wide set of management options and then applying GCBM to a smaller subset could offer a promising pathway for balancing speed and precision in carbon-informed forest planning.
Practically, our findings suggest that machine learning can be effectively integrated into existing spatial planning workflows to enable faster carbon evaluation without significantly compromising on accuracy. However, care must be taken when applying the trained models outside their original context, as the accuracy of the model is tied to the structure and conditions of the training dataset. For future work, we recommend developing streamlined methods to integrate ML models like XGBoost directly into forest planning tools. In addition, more extensive benchmarking against other machine learning algorithms and application of the model to forest regions outside Quebec would further test its generalizability and operational utility.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}