1. Introduction
Artificial intelligence (AI) has emerged as one of the most transformative technologies of the 21st century, offering substantial potential to reshape economies, societies, and the environment. As a machine-based system capable of making predictions, generating recommendations, and supporting decision making in both physical and digital environments [
1], AI plays a critical role in advancing sustainable development when applied responsibly. In alignment with the United Nations’ Sustainable Development Goals (SDGs), AI can support progress across sectors such as health, education, urban planning, and climate action.
In particular, the integration of AI in public infrastructure has significantly enhanced the efficiency and quality of services in urban environments. For example, AI-driven intelligent transportation systems, smart energy grids, and digital healthcare solutions have improved mobility, energy management, and health outcomes in large cities [
2]. These implementations demonstrate AI’s capacity to contribute positively to sustainability-related objectives.
However, the rapid proliferation of AI technologies has also led to a surge in computational demands. AI models, particularly those based on deep learning, require substantial computing power and storage, often housed in large-scale data centers. As a result, the electricity consumption associated with training these models have increased considerably [
3]. For instance, the training of GPT-3 consumed approximately 1.29 million kWh of electricity and produced over 550 metric tons of carbon dioxide emissions—comparable to 550 transcontinental flights between New York and San Francisco [
4]. This challenge is exacerbated in more complex models, such as GPT-4, whose training energy demand reached 50 million kWh, marking a 3875% increase from its predecessor [
3].
Given these energy-intensive processes, there is an urgent need to align AI development with environmental sustainability goals. The dual nature of AI—its potential to promote sustainable development and its significant carbon footprint—presents a policy and technological dilemma. While AI can drive economic growth, improve societal well-being, and support environmental sustainability, its energy requirements during the training phase risk undermine the very SDGs it is intended to support.
To resolve this tension, the optimization of AI training processes emerges as a critical strategy. Environmental policies are essential in this context, as they offer regulatory frameworks and strategic guidance to ensure that AI implementation supports sustainable resource use and climate resilience. Addressing energy efficiency during model training is particularly vital, given that training is one of the most resource-intensive stages of AI deployment.
Several studies have examined the environmental impact of AI from various perspectives. For example, ref. [
5] quantified CO
2 emissions associated with centralized and federated learning architectures, hardware types, and geographic factors, highlighting that model architecture and deployment context significantly affect energy usage. Another study [
6] compared hyperparameter optimization techniques—such as Hyperband, Bayesian Optimization Hyperband (BOHP), Population-Based Training (PBT), and the Asynchronous Successive Halving Algorithm (ASHA)—within the framework of green AI and red AI, focusing on energy efficiency. Meanwhile, ref. [
7] categorized energy-efficient optimizers into gradient-based (e.g., RMSprop, Adam, Adagrad) and swarm-based (e.g., PSO, GWO) optimizers; however, their analysis did not extend to CPU/GPU energy consumption.
Despite these efforts, the effect of key training configuration parameters on both energy consumption and model performance has not been thoroughly investigated. To address this gap, the present study focuses on three fundamental parameters—early-stopping epochs, training data size, and batch size—to explore their impact on energy usage and accuracy. The novelty of this study lies in its exploration of trade-offs between AI model performance and environmental impact, providing insights that promote environmentally responsible AI practices. By identifying strategies to reduce carbon emissions during AI training without compromising model effectiveness, this research makes a significant contribution to environmental policy development. Moreover, in alignment with the Sustainable Development Goals (SDGs), it offers evidence-based recommendations to policymakers in order to support the achievement of the SDGs.
Accordingly, the study aims to answer the following research questions:
How should AI training parameters—specifically early-stopping epochs, training data size, and batch size—be configured to balance model accuracy and energy consumption in the AI training process?
What are the lessons can be derived from the findings in contributing to environmental policy to achieve SDGs, particularly on dealing with energy consumption in AI models without compromising accuracy?
To address these questions, we employ experimental simulations to compare the effects of different training parameters on energy consumption. This approach allows us to evaluate the trade-offs between energy efficiency and model accuracy that occur in some configuration scenarios, ensuring that AI training processes remain both sustainable and effective. To offer a clear and systematic understanding of how the lessons translate into practical applications, we further explore the implementation of an AI-based smart building attendance system using facial recognition technology within the Ecocampus environment—an example that illustrates the real-world relevance of configuring AI training for both performance and energy efficiency. A related implementation using energy-efficient IoT for smart attendance has also been demonstrated by Hayati and Nugraha [
8].
The remainder of this paper is structured as follows:
Section 2 reviews the relevant literature on AI and energy consumption, its relationship with SDGs and environmental policy, and a short technical theory related to AI training parameters.
Section 3 outlines the research methodology, detailing the simulation scenarios and the hardware used.
Section 4 presents the results, comparing different scenarios of AI training configurations and their impact on energy consumption. It also presents the lessons that have been learned in terms of environmental policy and their alignment with the SDGs.
Section 5 provides examples of their application in real-world use case scenarios.
Section 6 concludes the study.
2. Literature Review
2.1. Energy Consumption in AI
With its promising benefits and vast potential, the global artificial intelligence (AI) market is expanding rapidly, driven by the widespread adoption of digital technologies.
Figure 1 reflects such a growth in the global market size. This accelerated growth is further fueled by advancements in AI-related fields, including robotics, autonomous systems, sensor technologies, computer vision, machine learning, natural language processing, and generative AI [
9]. The rise in the use of artificial intelligence (AI) in 2021 was influenced by post-COVID-19 conditions. AI was utilized in various areas, including disease prevention, healthcare services, and data analysis [
10]. The COVID-19 pandemic also pushed more countries toward adopting integrated green energy systems [
11]. In the industrial sector, significant changes occurred with the introduction of AI-powered robots in manufacturing processes [
12]. The rapid rise of AI is also primarily driven by the growing demand for personalized and efficient solutions. Consumers increasingly seek AI-powered products and services, such as virtual assistants and chatbots, to simplify daily tasks and enhance user experiences. This trend is motivated by a desire for convenience and efficiency, alongside an increasing reliance on technology in everyday life. Moreover, businesses are embracing AI to harness data-driven insights and improve decision making, leveraging the vast amounts of digital data available in the modern era.
As the use of AI applications continues to expand, supportive digital infrastructures are also expected to grow. The rise in infrastructure such as cellular networks will contribute to increased carbon emissions [
13]. Furthermore, the number of data centers is likely to increase due to their critical role in the AI training process. By the end of 2024, the global count of colocation data centers is expected to reach 5186. With a Compound Annual Growth Rate (CAGR) of 6.6%, this number is projected to rise to 7640 by 2030. Currently, the Asia–Pacific region leads in the number of data centers, with 1811 sites, followed by Europe (1558 sites) and North America (1357 sites). The countries with the highest concentration of data centers in these regions include China, the United States, Germany, the United Kingdom, Japan, Australia, Canada, and France [
14]. By 2030, the Asia–Pacific region will maintain its lead with 2126 sites, while Europe and North America will follow with 2108 and 1803 sites, respectively.
Consequently, the growing number of data centers has a direct impact on electricity consumption. Research by [
15] estimates that global data center energy demand will exceed 2000 terawatt-hours (TWh) by 2028 and could reach 2967 TWh by 2030. This increasing demand for electricity will significantly contribute to carbon emissions, underscoring the need for effective energy policies.
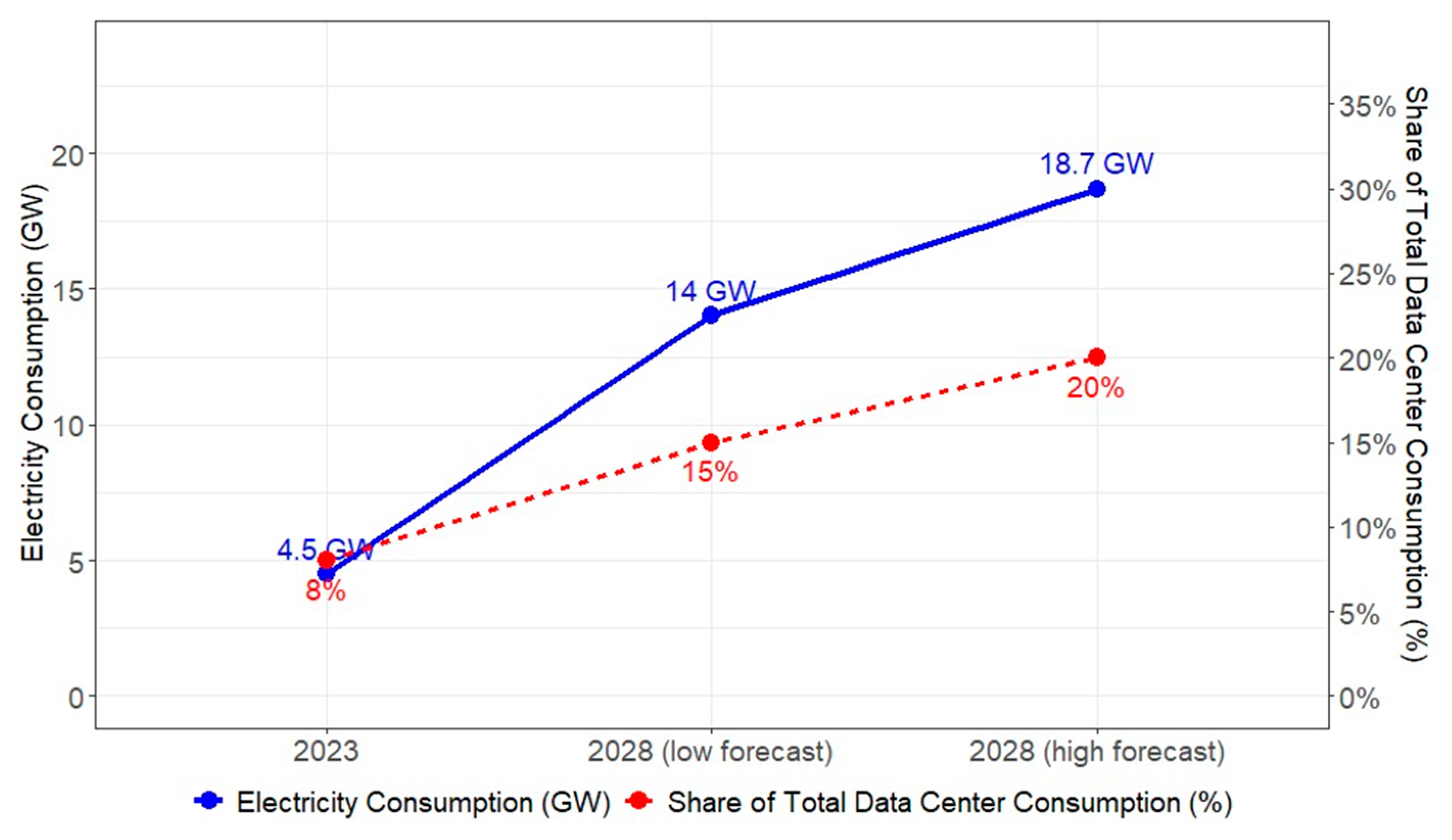
Figure 2 has pointed out that power consumption by AI was estimated to reach 4.5 gigawatts globally in 2023, accounting for 8% of total data center energy consumption that year. AI’s power demand is projected to rise significantly, reaching 14 to 18.7 gigawatts by 2028. This means that, by 2028, AI-related power consumption could constitute up to 20% of total data center energy usage [
16]. However, this surge in energy consumption raises concerns about environmental impact. Thus, as AI continues to evolve, it is crucial for government to develop environmental policy to deal with such an issue.
The high energy consumption involved in training artificial intelligence (AI) models has led several studies to propose strategies for reducing this consumption. These strategies include algorithmic improvements [
7,
17,
18,
19,
20,
21], hardware optimization [
17,
18,
22,
23,
24,
25,
26,
27], and system innovation [
17]. Other studies have focused on data center optimization [
28,
29,
30,
31,
32] and hyperparameter optimization [
6,
33,
34,
35]. However, there has been limited discussion specifically addressing parameter optimization.
2.2. AI’s Three Training Configuration Parameters
According to Arkerkar (2014), artificial intelligence (AI) is a field of computer science dedicated to developing intelligent systems capable of performing tasks traditionally carried out by humans [
36]. AI employs both symbolic and non-algorithmic approaches to problem solving, enabling the creation of computer systems that exhibit human-like intelligence and behavior. It encompasses various techniques and methodologies designed to replicate cognitive abilities in machines.
At the core of AI is machine learning (ML), a subset of AI that focuses on developing algorithms that enable machines to learn from data. This learning mechanism, known as the training process, allows AI models to refine their accuracy and improve performance over time. In the AI training process, improving accuracy has been the ultimate target. During the training process, parameter adjustments are also essential in optimizing model performance, improving energy efficiency, and preventing overfitting or underfitting.
In this study, three training configuration parameters will be investigated, i.e., training data size, batch size, and early-stopping epochs. Training data comprise a collection of samples utilized to train AI models. These samples are often pre-processed and optimized to enhance both efficiency and accuracy before being introduced into the neural network architecture [
37]. According to Barry-Straumer et al. (2018), a larger training data size leads to higher accuracy [
38], while a small data size can lead to overfitting [
39]. When the training data are too limited, they may not include enough samples to represent all possible input variations accurately. A small data size can also cause underfitting, where the model fails to learn relevant patterns due to insufficient sample diversity [
40]. This issue is particularly common when the model is too simple to handle complex problems. Therefore, if the available training data are limited, it is crucial to ensure high data quality and minimal noise to achieve optimal performance.
Batch size denotes the number of training samples processed in a single iteration during model training [
41]. Selecting an appropriate batch size is essential, as this influences training efficiency and model performance, optimizing resource usage and promoting quicker convergence. The research presented in [
42] suggests that larger batch sizes improve accuracy, while [
43,
44] indicate that increasing the batch size does not always result in improved accuracy. Concerning the data size and hardware resources, if they are limited, then a small batch size (16–32) is recommended, as it requires more iterations to complete one epoch. It makes the training process slower and consumes less memory, meaning this approach is suitable for GPUs with limited RAM. For faster and more powerful training, a large batch size (64–512+) can be used, while larger batch sizes (64–1024+) speed up training by utilizing GPU vector computing more efficiently [
45]. However, using large batch sizes can lead to out-of-memory (OOM) errors on GPUs. It also comes with the risk of overfitting. Later in this study, we configure the batch size to analyze its impact on both accuracy and energy consumption.
The final parameter is early-stopping epochs, which is defined as the regularization technique used in training machine learning models to prevent overfitting by stopping the training process once the performance on a validation set starts to degrade [
46]. According to the research presented in [
5], an increase in the number of epochs leads to higher energy consumption. In this study, the early-stopping epochs method was applied with the objective to reduce energy consumption during training process. On the other hand, early stopping also helps prevent overfitting in machine learning models. Overfitting occurs when a model performs well on training data but struggles to generalize to new data, leading to unreliable predictions [
39]. One of the primary causes of overfitting is excessive training, where the model continues learning patterns that do not generalize well. By applying early stopping, training is halted before the model overfits, ensuring better generalization and improved overall performance.
2.3. AI Regulation, Environmental Policy, and SDGs
Since the late 1960s, environmental policy has evolved from addressing localized pollution issues (such as air and water pollution) to broader sustainability goals. According to [
47], environmental policy refers to a framework of government initiatives designed to enhance environmental quality and ensure the sustainable management of natural resources. This policy framework consists of laws, regulations, legal precedents, and enforcement mechanisms, shaped by public officials. Environmental policy includes both proactive measures (such as government-led initiatives to safeguard natural resources) and non-interventionist approaches, where authorities allow private sector decisions and market dynamics to influence environmental outcomes [
47]. Over time, new principles and strategies have emerged, emphasizing damage prevention and cost-effective environmental programs.
In the context of AI Regulation and Environmental Policy, the key actors involved in the implementation of policies and regulations include primarily the Regulator (policy maker), who is responsible for establishing guidelines that ensure AI developers align their system designs and operations with the Regulator’s objectives. The Regulator plays a crucial role in shaping policies that promote sustainability, guiding AI developers to integrate energy-efficient practices into their technologies. Specifically, the Regulator is the driving force behind the creation and enforcement of environmental policies, ensuring that AI systems contribute positively to environmental goals while balancing technological advancement with ecological responsibility.
Research on AI regulation has primarily focused on configuring training parameters to reduce energy consumption in AI models. For example, ref. [
48] introduced the concept of sustainability through training data design and limitations. Several other studies have developed frameworks to assess the environmental impact of AI-based systems [
49,
50,
51,
52]. Additionally, some have proposed data compression strategies within models to lower energy usage [
49]. Regulatory frameworks addressing AI risks and the importance of reducing carbon emissions from AI systems have also been suggested [
53,
54]. However, no studies to date have proposed regulatory guidelines specifically addressing parameter configurations such as early-stopping epochs and batch size. Therefore, this study addresses this gap in the existing literature by systematically investigating the effects of three key parameters—early-stopping epochs, training data size, and batch size—on model performance.
In 2015, the United Nations defined the 17 Sustainable Development Goals (SDG), reflecting a global commitment effort to shape the better future for society, addressing issues of poverty, environmental sustainability, and global well-being by 2030. Meanwhile, environmental policy serves as the foundation for achieving the SDGs.
Figure 3 illustrates the 17 SDGs.
AI has a dual impact on SDG targets, influencing environmental, economic, and social aspects both positively and negatively [
56]. Focusing on the three SDGs that are most directly related to environmental issues, AI plays a dual role—acting as both an enabler and a challenge to achieve the SDGs. The latter comprises a dilemma whereby AI’s high energy consumption during the training process eventually contributes to carbon emissions and impacts environmental sustainability.
For SDG 7 (Affordable and Clean Energy), AI enhances energy efficiency and supports the transition to renewable energy sources. However, AI itself is highly energy-intensive, requiring vast computational resources that can counteract these benefits. In the context of SDG 11 (Sustainable Cities and Communities), AI fosters smart city development by optimizing resource management and reducing environmental impact. Yet, the expansion of smart cities, which is mainly supported by AI, drives the construction of high-performance computing (HPC) systems, which consume substantial amounts of energy. Similarly, for SDG 13 (Climate Action), AI has the potential to reduce greenhouse gas emissions through energy-efficient technologies. AI also supports low-carbon systems by enabling circular economies and optimizing urban resource usage [
57,
58]. Ironically, AI’s growing computational demands contribute to carbon emissions, complicating efforts to combat climate change. This paradox stresses the need for policies that balance AI’s benefits with its environmental costs to ensure a truly sustainable future.
This dilemma has led to the promotion of Sustainable AI; according to [
59], this is a movement aiming to integrate ecological integrity and social justice throughout the entire lifecycle of AI products—from ideation, training, resetting, implementation, to governance. Rather than focusing solely on AI applications, Sustainable AI addresses the entire socio-technical system of AI. The research presented in [
59] distinguishes two branches of Sustainable AI: AI for Sustainability—AI applications designed to promote sustainability in various sectors; AI Sustainability—the development of energy-efficient AI models, such as reusable data and reducing carbon emissions from AI training.
Several countries have already begun regulating AI technology to ensure its responsible development. The European Union introduced the Artificial Intelligence Act (AI Act) in 2025, setting a legal framework for AI governance [
60]. In the United States, the National Institute of Standards and Technology (NIST) implemented the Trustworthy and Responsible AI standards, including NIST AI 600-1 and NIST AI 100-1: Artificial Intelligence Risk Management Framework (AI RMF 1.0) [
61,
62]. Meanwhile, Colorado has enacted the Colorado AI Act [
63]. China has also issued an official government policy document: Governance Principles for New Generation AI: Developing Responsible Artificial Intelligence [
64]. Meanwhile, Indonesia is currently in the process of drafting its AI policy. To ensure long-term sustainability, it is crucial that environmental considerations be integrated as a core component of AI regulations worldwide.
3. Research Method
In order to derive the lessons presented in this study, we conducted an experimental simulation using an AI model, focusing on the configuration of three key training parameters. These parameters—early-stopping epochs, training data size, and batch size—were systematically adjusted to assess their impact on both energy consumption and model accuracy. Through this simulation, we were able to identify optimal configurations that minimize energy usage while maintaining the model’s performance, providing valuable insights for environmental policy.
3.1. Training Configuration Scenario
To extract meaningful lessons on the impact of AI training configurations on energy consumption and model accuracy, this study conducts a series of computational simulations of training configuration scenarios, focusing on three key parameters: early-stopping epochs, training data size, and batch size. The simulations assess how these parameters interact and affect two main performance indicators: energy consumption and accuracy—the latter being evaluated through training accuracy, validation accuracy, and testing accuracy.
To facilitate this analysis, an AI model was trained using the MNIST dataset (Modified National Institute of Standards and Technology), which contains 70,000 handwritten digit images (0–9), each measuring 28 × 28 pixels. The dataset was accessed via the Keras library’s built-in dataset module. The MNIST dataset was chosen due to its widespread use as a benchmark in machine learning research, allowing for standardized comparisons of model performance under different configurations. The model architecture is a fully connected multilayer perceptron implemented using Python and the Keras library (version 2.10) with a TensorFlow backend. It begins with a Flatten input layer that reshapes input images into 784-dimensional vectors, followed by a dense layer consisting of 128 neurons with RelU activation. A dropout layer is also added to prevent overfitting. The output layer is another dense layer with 10 neurons using SoftMax activation to classify the input into one of the ten-digit categories. The model is compiled using the Adam optimizer, with a learning rate of 0.001 and the loss calculated using Sparse Categorical Cros-Entropy with logits. The total trainable parameter is 101,770, which allows the model to capture the features of the dataset while maintaining computational efficiency for benchmarking purposes.
Table 1 summarizes the six simulation scenarios used to explore the effects of early-stopping epochs, training data size, and batch size. Each scenario was designed to isolate and analyze the individual impact of these parameters on both energy consumption and accuracy. Scenarios #1a and #1b focus on the early-stopping mechanism, which monitors validation loss and halts the training if no improvement is obtained over five consecutive epochs. Scenarios #2a and #2b explore variations in training data size, while scenarios #3a and #3b investigate the influence of batch size. These scenarios compare models trained with and without early stopping to provide a comprehensive understanding of how training configurations can be optimized for energy-efficient AI development.
3.2. Hardware Setup for Training Configuration Scenarios
To ensure the simulations’ results are robust and applicable across various computational environments, the simulations were conducted on three different devices with distinct hardware specifications (see
Table 2). Devices #1 and #2 are equipped with GPUs and high-performance CPUs, commonly used in AI training for enhanced computational efficiency. In contrast, Device #3, lacking a GPU but featuring a high-performance CPU, allows for a comparative analysis between GPU-accelerated and CPU-only training environments. By using multiple devices, this study ensures that the identified patterns in energy consumption and accuracy are consistent across different hardware configurations, making the learned lessons more generalizable for various practical applications.
To assess hardware performance during model training, CPU and GPU usage was monitored using HWiNFO64 (version 8.06), a hardware monitoring tool developed by Martin Malik (Realix, Malacky, Slovakia). This allowed for observation of real-time resource usage across different devices and training scenarios.
4. Results and Discussions
4.1. Trade-Off Between Energy Consumption and Early-Stopping Epochs
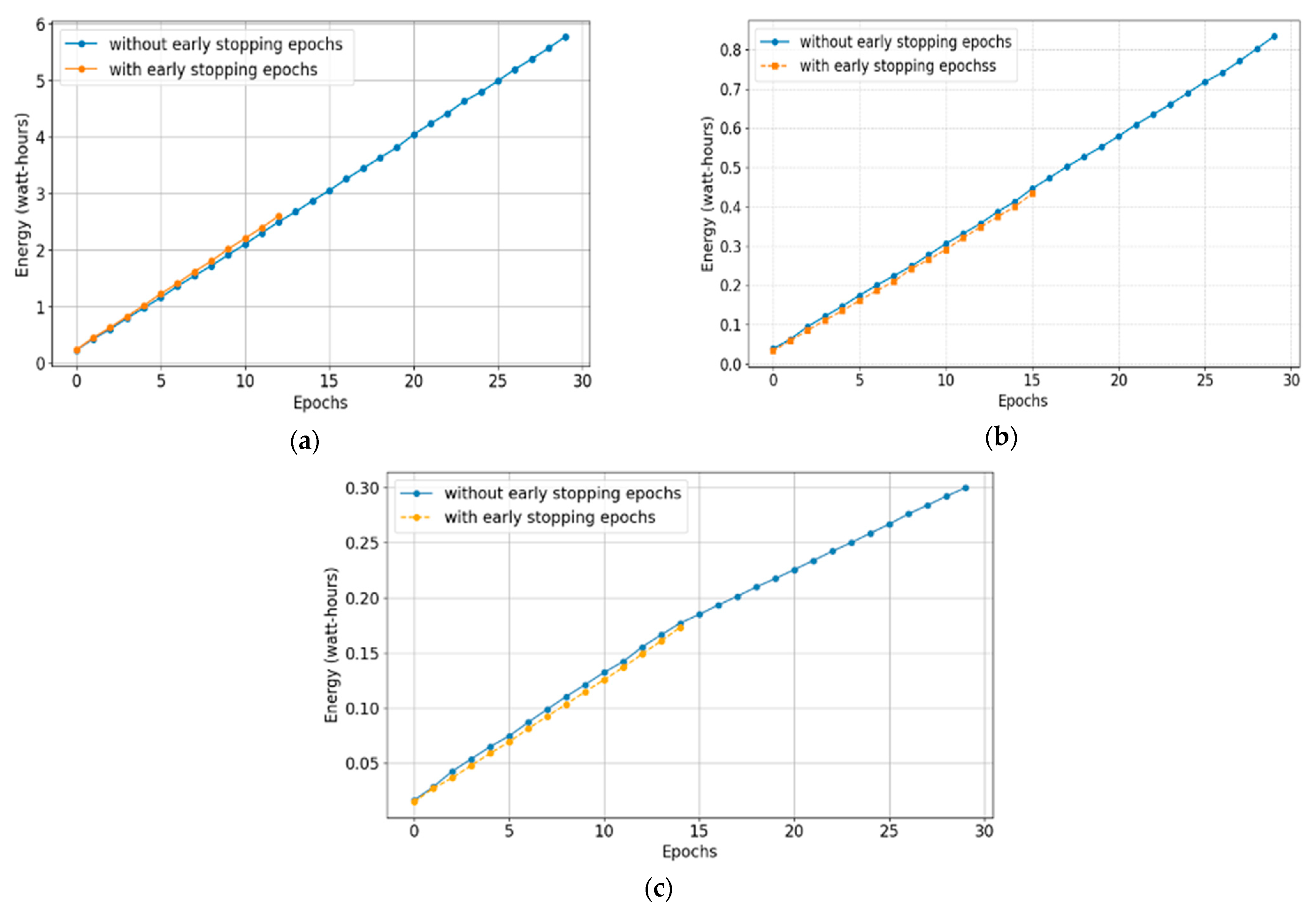
The first finding has indicated that early stopping significantly reduces energy consumption. The simulations of scenarios #1a and #1b provide comparative data on energy consumption during the AI training process, as well as training and validation accuracy across epochs. The energy comparison between the model without early-stopping epochs and the model with the early-stopping epochs is illustrated in
Figure 4. In this study, the training data comprise 80% of the overall data size, the testing data comprise 20% of the overall data size, validation data comprise 50% of the training data, and the batch size is 32.
Figure 4a illustrates that applying early stopping during training significantly reduces energy consumption. With early stopping applied at the 12th epoch, the model consumes only 2.5954 watt-hours, compared to 5.7684 watt-hours when training continues until the 30th epoch without early stopping. This indicates a 55% reduction in energy usage. Similarly,
Figure 4b shows, that on Device #2, early stopping at the 16th epoch results in a 48% decrease in energy consumption—0.4331 watt-hours versus 0.8334 watt-hours without early stopping. On Device #3, early stopping yields a 42% reduction in energy usage compared to training without early stopping.
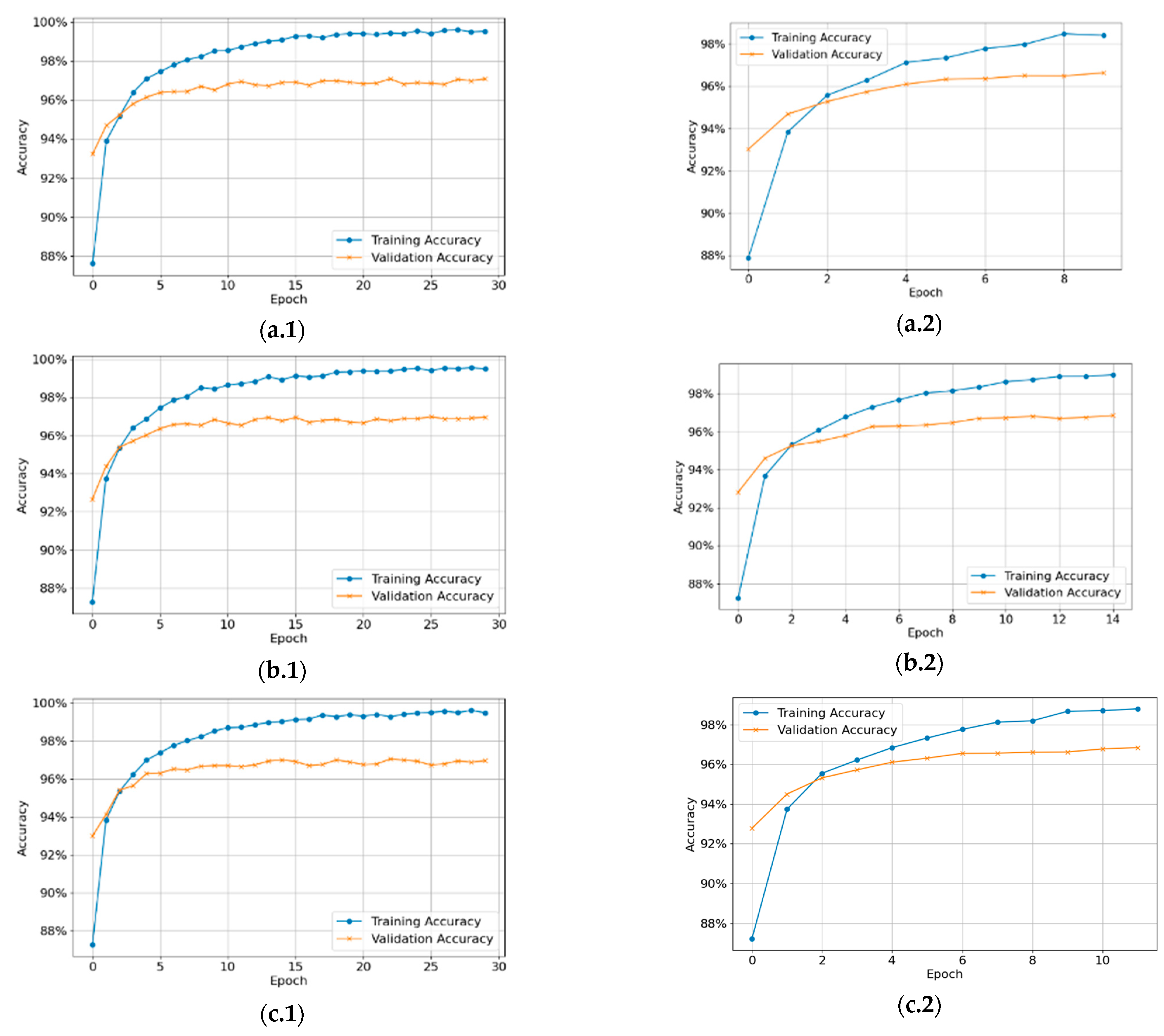
Figure 5 compares the training accuracy and validation accuracy of model with early-stopping epochs and without early-stopping epochs. The model with early stopping halts training if there is no significant improvement in validation accuracy for five consecutive epochs. In contrast, the model without early stopping continues training for the full 30 predefined epochs, while the early stopping stops at the 12th epoch.
Table 3 shows the testing accuracy of scenarios #1a and #1b. The testing accuracy of the model without early stopping is slightly higher than that of the early-stopping model, achieving 97.84% compared to 97.04%. Considering the trade-off between energy consumption and accuracy, the early stopping approach is preferable due to its higher energy efficiency, despite the slight reduction in accuracy.
Table 3 presents energy consumption and accuracy across Device #1, Device #2, and Device #3. The highest energy consumption occurs in Device #1, followed by Device #2, with the lowest energy usage in Device #3. The technical specifications in
Table 2 explain this pattern: Device #1 is equipped with one CPU and two GPUs, Device #2 has one CPU and one GPU, while Device #3 relies solely on one CPU. These findings indicate that increasing the number of processors leads to higher energy consumption.
4.2. Trade-Off Between Energy Consumption and Training Data Size
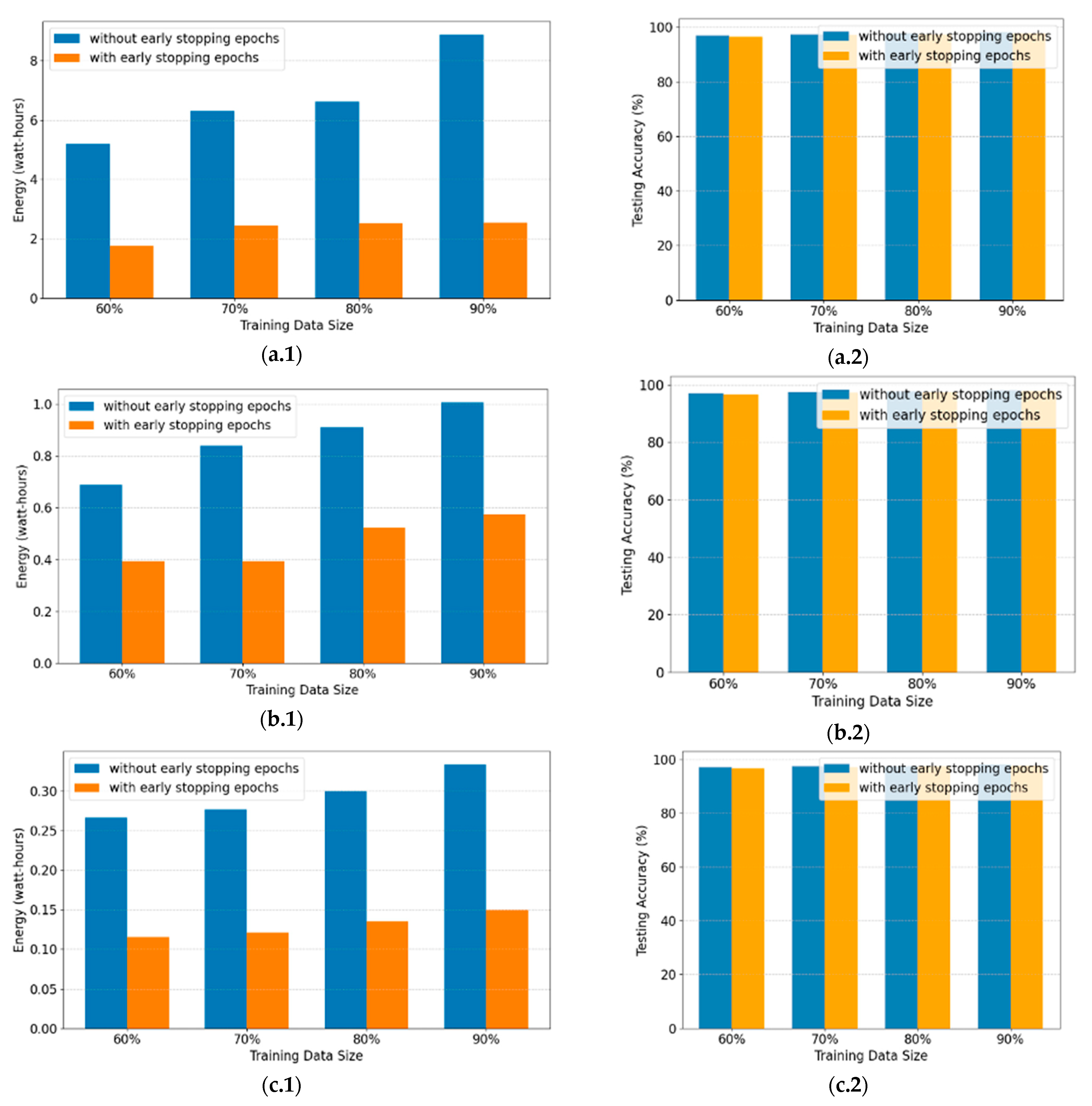
The second finding highlights that the larger the training data size, the higher the energy consumption. This study compares the energy consumption and accuracy of the model using different training data proportions—namely, 60%, 70%, 80%, and 90% of the overall data size. The data were obtained from the simulation results of scenarios #2a and #2b.
Figure 6 illustrates how energy consumption and testing accuracy vary with the percentage of training data. For example, on Device #1, the model without early stopping consumes 5.1991 watt-hours with 60% training data, increasing to 6.303 watt-hours with 70% training data, 6.6231 watt-hours with 80% training data, and 8.8686 watt-hours with 90% training data.
Figure 6 and
Table 4 present the energy consumption across Device #1, Device #2, and Device #3, showing a consistent pattern: as the training data size increases, energy consumption also increases, regardless of whether early-stopping epochs are used. Similarly,
Figure 6 and
Table 5 display the testing accuracy results for Device #1, Device #2, and Device #3. Although a larger training data size tends to yield slightly higher accuracy, the differences are minimal. Notably, models using early stoppings demonstrate marginally lower accuracy, but the reduction is not significant compared to the model without early-stopping epochs.
4.3. Trade-Off Between Energy Consumption and Batch Sizes
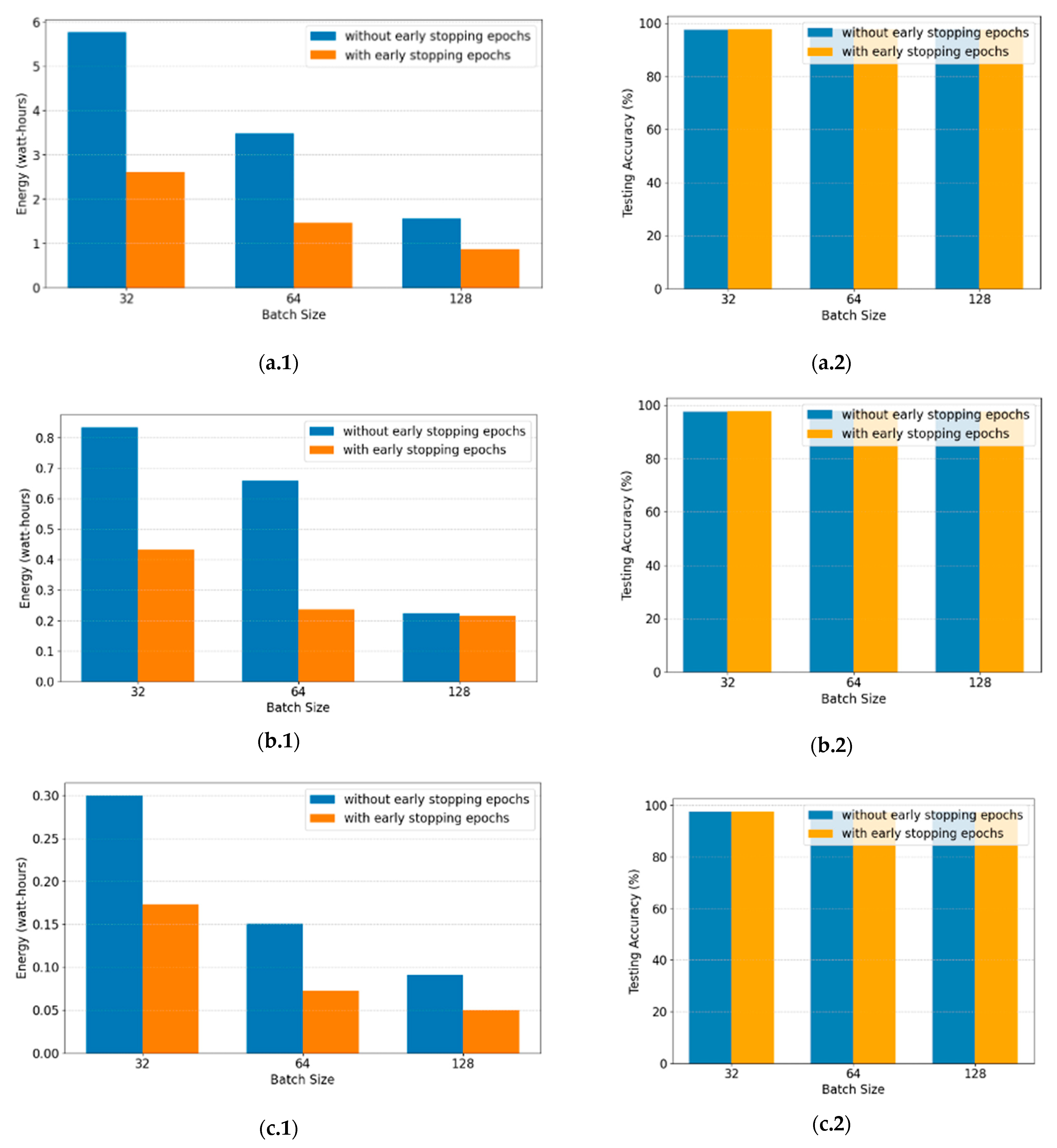
The third finding has signified that the larger the batch size, the lower the energy consumption. The simulation results show the impact of batch size on energy consumption and testing accuracy during AI training, comparing batch sizes of 32, 64, and 128. Simulation scenarios #3a and #3b indicate that larger batch size leads to lower energy consumption during training. As shown in
Figure 7 and
Table 6, on Device #1, the model without early stopping experiences 39.6% reduction in energy consumption when increasing the batch size from 32 to 64 and 55.42% energy reduction when increasing from 64 to 128. A similar trend is observed in the model with early stopping, where energy consumption decreases by 43.3% from batch size 32 to 64 and by 40.8% from batch size 64 to 128.
This pattern is consistent across Device #2 and Devices #3. On Device #2, energy consumption decreases by 20.8% and 45.5% from batch size 32 to 64 for models without early-stopping epochs and with early-stopping epochs, respectively. When increasing from batch size 64 to 128, the reduction is 65.8% for the model without early stopping and 9% for the model with early stopping. Similarly, on Device #3, energy consumption decreases by 49.7% and 58.2% from batch size 32 to 64 for models without and with early stopping, respectively. From batch size 64 to 128, the reduction is 39.7% for the model without early stopping and 30.52% for the model with early-stopping epochs.
The testing accuracy comparison across different batch sizes is presented in
Figure 7 and
Table 7. The simulation results suggest that batch size does not significantly impact accuracy, and the patterns vary across Devices #1, Device #2, and Device #3, regardless of whether early stopping is applied. On Device #1, the highest accuracy is observed at batch size 32 for both models with early-stopping epochs and without early-stopping epochs. In contrast, Device #2 achieves its highest accuracy at batch size 64 for both configurations. On Device #3, the highest accuracy occurs at batch size 64 for the model without early-stopping epochs and at batch size 32 for the model with early-stopping epochs.
Considering both energy efficiency and accuracy, using a batch size of 128 with the early-stopping epoch model provides the best overall efficiency.
4.4. Lesson Learned
The findings reflect three lessons learned about the importance of integrating energy-efficient AI practices into environmental policies to balance technological growth with sustainable development.
4.4.1. Lesson 1: Promoting Early-Stopping Epochs as an Energy-Efficient AI Practice
As seen in
Figure 4, the use of the early-stopping epochs method can reduce energy consumption by up to 55%. However, this comes at the cost of slightly lower testing accuracy compared to training without early-stopping epochs. The early-stopping method works by terminating the training process if there is no significant improvement in the validation accuracy after five consecutive epochs. In contrast, without early-stopping epochs, training continues until the predefined number of epochs is reached. By shortening the training duration, early stopping effectively reduces energy usage. Despite the slight accuracy trade-off, the early-stopping approach is recommended due to its substantial energy savings and minimal accuracy loss. This method is both effective and easy to implement, as the required algorithm syntax is simple. Moreover, early stopping does not negatively impact model performance, making it a highly recommended optimization technique for AI engineers. As a result, this study makes a recommendation for a policy to implement early-stopping epochs in AI models.
4.4.2. Lesson 2: Limiting Data Size for Energy Efficiency
The study results indicate that training data size is a key parameter influencing energy consumption. As an AI engineer, it is essential to carefully consider the data size to ensure energy efficiency. While using a smaller training data size reduces energy consumption, it comes with a trade-off—lower accuracy compared to larger data size (see
Figure 6,
Table 4 and
Table 5). Simulation results show that increasing the training data size improves accuracy, although the difference is not highly significant. Among the three devices used in the simulation, testing accuracy consistently exceeded 0.96. The results also show that using 60% of the overall data size for training can reduce energy consumption by up to 30%. To balance energy efficiency and accuracy, a training data size of 60% is recommended.
The finding signifies an important policy concern, that there should be limitation in the proportion of training data used in AI models. The study results confirm that larger data size leads to higher energy consumption, though the impact of a large data size on accuracy is not highly significant. While a larger training data size can improve accuracy, the improvement is often marginal beyond a certain threshold. Therefore, if sufficiently large and high-quality data are available, AI engineers should use a moderate training data size rather than an excessively large one. This approach ensures energy efficiency without significantly compromising model accuracy.
4.4.3. Lesson 3: Developing Guidelines for Batch Size Optimization
The simulation results of this study align with those presented in [
43,
44], showing that batch size does not have a significant impact on accuracy. The results also align with those in [
45], indicating that increasing the batch size reduces energy consumption during AI training. Specifically, this research shows that using a batch size of 128 can reduce energy consumption by more than 70% compared to a batch size of 32, as seen in
Figure 7 and
Table 6. Additionally, batch sizes of 32, 64, and 128 do not show a significant difference in model accuracy (see
Table 7). To optimize energy efficiency while maintaining accuracy, a relevant policy should recommend AI engineers use a batch size of 128 as a standard for AI training. This guideline would help reduce power consumption in AI infrastructure while ensuring that models can perform effectively.
4.5. Aligning Lesson Learned with Sustainable Development Goals (SDGs)
From the experiment conducted, the ‘lesson learned’ is not yet at the stage of detailed technical policy formulation; rather, it focuses on the paradigm of policymaking itself. This insight emphasizes the need for a shift in the underlying approach and framework, highlighting the importance of rethinking how policies are conceived and implemented in response to evolving challenges. It emphasizes the need for a strategic policy shift that embeds energy efficiency as a foundational principle in AI innovation and infrastructure, aligning technological advancements with sustainability objectives. This study provides valuable insights that contribute to environmental policy in alignment with the Sustainable Development Goals (SDGs), particularly SDG 7 (Affordable and Clean Energy), SDG 11 (Sustainable Cities and Communities), and SDG 13 (Climate Action). By addressing the energy consumption of AI training processes, the findings support efforts to promote sustainability while balancing technological advancements with environmental responsibility.
SDG 7 aims to ensure universal access to affordable, reliable, and sustainable energy. One key challenge in AI development is its high energy demand, which can strain power resources, including water used in electricity generation. Although water is a renewable resource due to the hydrological cycle, its availability is increasingly threatened by climate change, rising global temperatures, and overuse. AI training processes must be optimized to improve energy efficiency and reduce dependency on non-renewable energy sources. Implementing sustainable AI training strategies can help minimize their environmental footprints while supporting the transition to clean energy.
SDG 11 focuses on making urban environments more inclusive, resilient, and sustainable. Modern cities rely on AI-driven infrastructure, including smart systems and high-performance computing (HPC) centers, which consume vast amounts of electricity. This study highlights the importance of optimizing AI energy consumption to enhance the efficiency of HPC systems, reduce strain on urban power grids, and lower carbon footprints. By integrating energy-efficient AI training practices, cities can advance technological innovations while maintaining environmental sustainability.
SDG 13 emphasizes the need to combat climate change by reducing greenhouse gas emissions and adopting sustainable energy practices. AI technology, if not managed properly, can contribute significantly to carbon emissions due to its energy-intensive operations. This study identifies strategies to improve energy efficiency in AI training, helping mitigate its environmental impact. By promoting the adoption of energy-conscious AI policies, governments and industries can align AI development with global climate action efforts, ensuring that technological progress supports rather than hinders sustainability goals.
5. Application of Lessons Learned in Practice: Use Case Examples
To provide a clear and systematic understanding of the strategies and policies derived from the training configuration scenarios, the following use case example illustrates the implementation of an AI-based smart building attendance system using facial recognition technology within the Ecocampus environment, as shown in
Figure 8. In our experimental simulation, we used handwritten digit images from the MNIST dataset to train an AI model. Although it cannot be used directly due to differences in data and objectives, MNIST can serve as an educational and methodological starting point for prototyping or developing a conceptual model before progressing to more complex tasks, such as facial recognition.
Many sustainable campuses have adopted smart building initiatives, leveraging AI applications to optimize energy management, improve occupant comfort, and enhance operational efficiency. As seen in
Figure 8, The Ecocampus smart building serves as a modern and sustainable infrastructure within the campus, catering to both students and campus visitors. It utilizes an advanced AI system for managing the attendance of individuals, specifically identifying students and visitors via facial recognition technology. By processing data locally at the edge, the system ensures real-time attendance monitoring while minimizing reliance on external data centers. These AI-driven systems depend heavily on big data and require extensive training, which necessitates a reliable IT infrastructure with considerable energy consumption. As a result, smart buildings equipped with computing systems for AI operations may inadvertently contribute to increased energy use, potentially offsetting the sustainability goals of the Ecocampus if not properly managed. Training AI models at the edge can lead to significant energy demands, which could potentially conflict with the Ecocampus’s broader sustainability goals. This is where the implementation of energy-efficient AI practices becomes essential.
To address these concerns, training configuration scenarios were analyzed to examine the impact of three key parameters—early-stopping epochs, training data size, and batch size—on both energy consumption and model accuracy. Although these scenarios were not directly tied to the operational data of the Ecocampus, the lessons learned provide valuable insights for developing energy-efficient AI policies in smart building environments that promote sustainability.
The first lesson emphasizes the importance of implementing early-stopping epochs in AI training. The analysis showed that early stopping can significantly reduce energy usage by halting training when there is no notable improvement in validation accuracy over several consecutive epochs. For the Ecocampus smart building’s facial recognition system, early stopping prevents unnecessarily prolonged training cycles when working with large image datasets of students and campus visitors. This method reduces energy consumption by shortening training time and speeds up the development of the model without compromising accuracy. For instance, if we assume that training without early stopping consumes 10 watt-hours of energy, then applying early stopping may reduce the consumption to as low as 4.5 watt-hours. As a result, the attendance monitoring system becomes more energy-efficient while maintaining real-time operational capabilities, directly contributing to the Ecocampus’s goal of reducing environmental impact while still benefiting from advanced AI technology.
The second lesson highlights the significance of limiting the training data size in achieving a balance between energy consumption and model accuracy. The study indicated that larger datasets increase energy usage, with only marginal improvements in accuracy after a certain threshold. For the Ecocampus, where facial recognition is primarily used to track the attendance of students and campus visitors, using excessively large image datasets would unnecessarily increase energy consumption without providing substantial accuracy improvements. By limiting the training data size to an optimal level—such as 60% of the total dataset—the system can achieve significant energy savings of up to 30% while ensuring reliable face detection performance. For illustrative purposes, training without data size limitations might consume about 10 watt-hours of energy, whereas restricting the data size to 60% of the total dataset has the potential to reduce energy usage to approximately 7 watt-hours. This approach ensures that the Ecocampus smart building operates efficiently, with faster processing times and a reduced environmental footprint, contributing to the overall goal of making the campus greener and more sustainable.
The third lesson underscores the importance of optimizing batch size for reducing energy consumption. The analysis revealed that increasing the batch size significantly reduces energy use without a noticeable decrease in model accuracy. For the Ecocampus smart building, which processes numerous facial images of students and visitors, selecting a larger batch size (e.g., 128) during training minimizes energy usage and shortens training durations. For instance, if training with a batch size of 32 consumes approximately 10 watt-hours of energy, then increasing the batch size to 128 can potentially reduce energy consumption to around 3 watt-hours. This is particularly beneficial when the system requires periodic updates, such as incorporating new student profiles or refining facial recognition algorithms. Optimizing batch size ensures that the model retraining process is energy-efficient, aligning with the Ecocampus’s sustainability goals while maintaining the system’s responsiveness and accuracy. This contributes to the building’s overall energy efficiency, helping reduce operational costs and supporting its environmental policy.
By adopting these three energy-efficient AI practices, the Ecocampus smart building not only improves its operational efficiency but also aligns with the campus’s environmental policy. The policy aims to minimize energy consumption, reduce carbon emissions, and foster sustainability across all building operations. These energy-saving techniques directly support the policy by reducing the environmental impact of AI training processes while maintaining the smart technological capabilities of the building.
By incorporating these lessons into the Ecocampus’s energy-management strategy, the building not only becomes smarter, it also becomes greener. The policies ensure that AI technologies are used responsibly and sustainably, aligning with global sustainability goals such as those outlined in the United Nations Sustainable Development Goals (SDGs). Specifically, SDG 7 (Affordable and Clean Energy) and SDG 11 (Sustainable Cities and Communities) are supported by reducing energy consumption, while SDG 13 (Climate Action) is furthered by mitigating the environmental impact of AI technologies.
6. Conclusions
This study has answered how the configuration of AI training parameters—namely early-stopping epochs, training data size, and batch size—can influence the balance between model performance and energy consumption. Through a series of experimental simulations, we examined the trade-offs associated with different parameter settings and identified key strategies for optimizing energy efficiency without compromising accuracy. The results have provided a framework for balancing AI performance and energy consumption through strategic training configurations. These findings hold practical value for AI engineers, policymakers, and sustainability advocates alike, offering actionable guidance for designing environmentally responsible AI systems that align with the long-term vision of sustainable development.
The results provide three main lessons. First, the use of early-stopping epochs proves to be a simple yet powerful strategy to reduce energy consumption significantly—up to 55% of the model without early stopping. While this method may slightly reduce model accuracy, the trade-off is minimal and acceptable in most scenarios. Given its effectiveness and ease of implementation, early stopping should be widely adopted as a standard practice in sustainable AI development, and it should be formally recommended in energy-conscious AI policies.
Second, the study highlights the importance of limiting training data size to optimize energy use. Using 60% of the dataset for training resulted in over 140% reduction in energy consumption, with only a marginal loss in accuracy. This suggests that model developers should prioritize data efficiency over data volume, especially when training resources are limited or when sustainability is a key concern. This approach not only conserves energy but also encourages more thoughtful, purposeful data curation.
Third, batch size optimization plays a critical role in minimizing energy consumption. The findings show that larger batch sizes, such as 128, significantly reduce energy usage by more than 70% without any noticeable decrease in accuracy. This supports existing research and affirms the need for clear policy guidelines that standardize energy-efficient batch size settings for AI training.
Beyond the technical findings, this study also contributes to the broader discourse on aligning AI practices with the Sustainable Development Goals (SDGs). Specifically, the lessons learned are relevant to SDG 7 (Affordable and Clean Energy), SDG 11 (Sustainable Cities and Communities), and SDG 13 (Climate Action). The study suggests a paradigm shift in policy formulation—one that places energy efficiency at the core of AI innovation and infrastructure planning. By integrating energy-conscious practices into AI development, stakeholders can ensure that technological progress complements, rather than compromises, global sustainability efforts.
Moreover, the practical application of these insights was illustrated through the case of an AI-based smart building attendance system using facial recognition technology within an Ecocampus environment. This example demonstrates how Sustainable AI configurations can be translated into real-world solutions, supporting urban sustainability initiatives and reducing the carbon footprint of digital infrastructure.
A limitation in this study is that the experimental simulations were conducted solely on the MNIST dataset. The dataset was chosen for its simplicity and well-understood characteristics, providing a clear and focused foundation for our analysis. For future work, we plan to include more complex datasets to better capture diverse energy consumption characteristics and validate our findings across a wider range of tasks and data types.
Author Contributions
Conceptualization, S.A. and M.S.; Data curation, A.I.N. and N.H.; Formal analysis, S.A.; Funding acquisition, M.S.; Investigation, A.S.A.; Methodology, S.A.; Resources, M.S.; Software, S.A., A.S.A., A.I.N. and N.H.; Supervision, M.S. and A.S.A.; Validation, S.A., A.S.A. and A.I.N.; Visualization, A.I.N. and N.H.; Writing—original draft, S.A. and M.S.; Writing—review and editing, N.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Indonesian Endowment Fund for Education (LPDP) on behalf of the Ministry of Higher Education, Science and Technology, Republic of Indonesia, and managed by Universitas Indonesia under the Indonesia—Nanyang Technological University Singapore Institute of Research for Sustainability and Innovation (INSPIRASI) Mandatory Innovative Productive Research Program for 2023–2028, Batch II (contract No. 2966/E4/AL.04/2024 and 307/PKS/WRIII/UI/2024, dated 2 May 2024).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
In this paper, the authors utilized AI-generated text assistance for improving aspects of language, including grammar, some translations, clarity, and readability, including refining and organizing the narration to ensure a well-structured and coherent presentation.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pilat, D. OECD AI Principles—The Role of MPS in Leveraging The Benefits of AI. OECD 2019, 15, 9–25. [Google Scholar]
- Ullah, Z.; Al-Turjman, F.; Mostarda, L.; Gagliardi, R. Applications of Artificial Intelligence and Machine learning in smart cities. Comput. Commun. 2020, 154, 313–323. [Google Scholar] [CrossRef]
- Jia, Y. Analysis of the Impact of Artificial Intelligence on Electricity Consumption. In Proceedings of the 2024 3rd International Conference on Artificial Intelligence, Internet of Things and Cloud Computing Technology, AIoTC, Wuhan, China, 13–15 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 57–60. [Google Scholar]
- Walker, C. The Generative AI Race Has a Dirty Secret. Wired, 10 February 2023. Available online: https://www.wired.com/story/the-generative-ai-search-race-has-a-dirty-secret/ (accessed on 2 April 2024).
- Qiu, X.; Parcollet, T.; Fernandez-Marques, J.; de Gusmao, P.P.B.; Gao, Y.; Beutel, D.J.; Topal, T.; Mathur, A.; Lane, N.D. A first look into the carbon footprint of federated learning. J. Mach. Learn. Res. 2021, 24, 1–23. Available online: http://arxiv.org/abs/2102.07627 (accessed on 30 September 2024).
- Castellanos-Nieves, D.; García-Forte, L. Strategies of Automated Machine Learning for Energy Sustainability in Green Artificial Intelligence. Appl. Sci. 2024, 14, 6196. [Google Scholar] [CrossRef]
- Adhikary, S.; Dutta, S.; Dwivedi, A.D. TinyWolf—Efficient on-device TinyML training for IoT using enhanced Grey Wolf Optimization. Internet Things 2024, 28, 101365. [Google Scholar] [CrossRef]
- Hayati, N.; Eka Nugraha, A. Design and Implementation Proximity Based IoT for Smart Attendance System. Bul. Pos Dan Telekomun. 2023, 21, 16–31. [Google Scholar] [CrossRef]
- Statista Artificial Intelligence—Global. Statista Market Forecast. Statista Market Insight 2024. Available online: https://www.statista.com/outlook/tmo/artificial-intelligence/worldwide (accessed on 28 January 2025).
- Agarwal, P.; Swami, S.; Malhotra, S.K. Artificial Intelligence Adoption in the Post COVID-19 New-Normal and Role of Smart Technologies in Transforming Business: A Review. J. Sci. Technol. Policy Manag. 2024, 15, 506–529. [Google Scholar] [CrossRef]
- Arsad, S.R.; Hasnul Hadi, M.H.; Mohd Afandi, N.A.; Ker, P.J.; Tang, S.G.H.; Mohd Afzal, M.; Ramanathan, S.; Chen, C.P.; Krishnan, P.S.; Tiong, S.K. The Impact of COVID-19 on the Energy Sector and the Role of AI: An Analytical Review on Pre- to Post-Pandemic Perspectives. Energies 2023, 16, 6510. [Google Scholar] [CrossRef]
- Ardolino, M.; Bacchetti, A.; Dolgui, A.; Franchini, G.; Ivanov, D.; Nair, A. The Impacts of digital technologies on coping with the COVID-19 pandemic in the manufacturing industry: A systematic literature review. Int. J. Prod. Res. 2022, 62, 1953–1976. [Google Scholar] [CrossRef]
- Setiawan, A.E.B.; Maulana, M.I.; Suryanegara, M. Carbon Footprint of 4G-LTE Networks at 900 MHz and 1800 MHz: A Life Cycle Assessment (LCA). In Proceedings of the 2024 IEEE Asia Pacific Conference on Wireless and Mobile, Virtual, 28–30 November 2024; pp. 73–79. [Google Scholar] [CrossRef]
- ABI Research. How Many Data Centers Are There and Where Are They Being Built? 2024. Available online: https://www.abiresearch.com/blog/data-centers-by-region-size-company (accessed on 28 January 2025).
- Andrae, A.; Edler, T. On Global Electricity Usage of Communication Technology: Trends to 2030. Challenges 2015, 6, 117–157. [Google Scholar] [CrossRef]
- Statista. Statista AI Global Power Consumption Forecast 2028. Statista Research Department. 2024. Available online: https://www.statista.com/statistics/1536969/ai-electricity-consumption-worldwide/#:~:text=In (accessed on 28 January 2025).
- Chen, X. Optimization Strategies for Reducing Energy Consumption in AI Model Training. Adv. Comput. Sci. 2023, 6, 1–7. [Google Scholar]
- Ariyanti, S.; Suryanegara, M.; Kautsarina. Current Research Themes and Future Research Needs on Making AI’s Energy Consumption Efficient: A Review. In Proceedings of the ICE3IS 2024: 4th International Conference on Electronic and Electrical Engineering and Intelligent System: Leading-Edge Technologies for Sustainable Societies, Yogyakarta, Indonesia, 7–8 August 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 99–104. [Google Scholar]
- Agiollo, A.; Bellavista, P.; Mendula, M.; Omicini, A. EneA-FL: Energy-aware orchestration for serverless federated learning. Futur. Gener. Comput. Syst. 2024, 154, 219–234. [Google Scholar] [CrossRef]
- Ghoshal, S.C.; Hossain, M.M.; Das, B.C.; Roy, P.; Razzaque, M.A.; Azad, S.; Fortino, G. VESBELT: An energy-efficient and low-latency aware task offloading in Maritime Internet-of-Things networks using ensemble neural networks. Futur. Gener. Comput. Syst. 2024, 161, 572–585. [Google Scholar] [CrossRef]
- Zhao, L.; Han, Y.; Hawbani, A.; Wan, S.; Guo, Z.; Guizani, M. MEDIA: An Incremental DNN Based Computation Offloading for Collaborative Cloud-Edge Computing. IEEE Trans. Netw. Sci. Eng. 2024, 11, 1986–1998. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Q.; Shi, S.; He, X.; Tang, Z.; Zhao, K.; Chu, X. Benchmarking the Performance and Energy Efficiency of AI Accelerators for AI Training. In Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing, CCGRID 2020, Melbourne, Australia, 11–14 May 2020; pp. 744–751. [Google Scholar]
- Muralidhar, R.; Borovica-Gajic, R.; Buyya, R. Energy Efficient Computing Systems: Architectures, Abstractions and Modeling to Techniques and Standards. ACM Comput. Surv. 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Zhao, D.; Samsi, S.; McDonald, J.; Li, B.; Bestor, D.; Jones, M.; Gadepally, V. Sustainable Supercomputing for AI: GPU Power Capping at HPC Scale. In Proceedings of the SoCC 2023—2023 ACM Symposium on Cloud Computing, Santa Cruz, CA, USA, 30 October–1 November 2023; pp. 588–596. [Google Scholar] [CrossRef]
- Qasaimeh, M.; Denolf, K.; Lo, J.; Vissers, K.; Zambreno, J.; Jones, P.H. Comparing energy Efficiency of CPU, GPU and FPGA implementations for vision kernels. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019. [Google Scholar] [CrossRef]
- Ahmed, M.R.; Koike-Akino, T.; Parsons, K.; Wang, Y. Joint Software-Hardware Design for Green AI. In Midwest Symposium on Circuits and Systems; Mitsubishi Electric Research Laboratories: Cambridge, MA, USA, 2023; pp. 1108–1112. [Google Scholar] [CrossRef]
- Desislavov, R.; Martínez-Plumed, F.; Hernández-Orallo, J. Trends in AI inference energy consumption: Beyond the performance-vs-parameter laws of deep learning. Sustain. Comput. Inform. Syst. 2023, 38, 100857. [Google Scholar] [CrossRef]
- Prathiba, S.; Sankar, S. Architecture to minimize energy consumption in cloud datacenter. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems, Madurai, India, 15–17 May 2019; pp. 1044–1048. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, W.; Jiang, C.; Hossain, M.S.; Muhammad, G.; Amin, S.U. AI-powered green cloud and data center. IEEE Access 2019, 7, 4195–4203. [Google Scholar] [CrossRef]
- Acun, B.; Lee, B.; Kazhamiaka, F.; Maeng, K.; Chakkaravarthy, M.; Gupta, U.; Brooks, D.; Wu, C.-J. Carbon Explorer: A Holistic Framework for Designing Carbon Aware Datacenters. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems—ASPLOS, Vancouver, BC, Canada, 25–29 March 2023; Volume 2, pp. 118–132. [Google Scholar] [CrossRef]
- Koronen, C.; Åhman, M. Data centres in future European energy systems—energy efficiency, integration and policy. Energy Effic. 2020, 13, 129–144. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, D.; Goh, H.H.; Wang, S.; Ahmad, T.; Mao, D.; Liu, T.; Zhao, H.; Wu, T. Future data center energy-conservation and emission-reduction technologies in the context of smart and low-carbon city construction. Sustain. Cities Soc. 2023, 89, 104322. [Google Scholar] [CrossRef]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2018, 18, 1–52. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C.J., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25. Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/05311655a15b75fab86956663e1819cd-Paper.pdf (accessed on 2 March 2025).
- Arkerkar, R. Introduction to Artificial Intelligence, Eastern Economy Edition; IBM: Armonk, NY, USA, 2014; pp. 2–3. [Google Scholar]
- Takano, S. Machine Learning and Its Hardware Implementation. In Thinking Machines; Elsevier: Amsterdam, The Netherlands, 2021; pp. 1–18. [Google Scholar]
- Barry-Straume, J.; Tschannen, A.; Engels, D.W.; Fine, E. An Evaluation of Training Size Impact on Validation Accuracy for Optimized Convolutional Neural Networks. SMU Data Sci. Rev. 2018, 1, 12. Available online: https://scholar.smu.edu/datasciencereview/vol1/iss4/12/ (accessed on 17 February 2025).
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- IBM. What Is Underfitting? 2024. Available online: https://www.ibm.com/think/topics/underfitting (accessed on 12 February 2025).
- Lyzr. Understanding Batch Size: Impact on Training Efficiency and Model Performance. 2024. Available online: https://www.lyzr.ai/glossaries/batch-size/ (accessed on 10 February 2025).
- Radiuk, P.M. Impact of Training Set Batch Size on the Performance of Convolutional Neural Networks for Diverse Datasets. Inf. Technol. Manag. Sci. 2017, 20, 20–24. [Google Scholar] [CrossRef]
- Aldin, N.B.; Aldin, S.S.A.B. Accuracy Comparison of Different Batch Size for a Supervised Machine Learning Task with Image Classification. In Proceedings of the 2022 9th International Conference on Electrical and Electronics Engineering, ICEEE 2022, Alanya, Turkey, 29–31 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 316–319. [Google Scholar] [CrossRef]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Ghosh, B.; Dutta, I.K.; Carlson, A.; Totaro, M.; Bayoumi, M. An Empirical Analysis of Generative Adversarial Network Training Times with Varying Batch Sizes. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics and Mobile Communication Conference, UEMCON 2020, New York, NY, USA, 28–31 October 2020; pp. 0643–0648. [Google Scholar] [CrossRef]
- Hussein, B.M.; Shareef, S.M. An Empirical Study on the Correlation between Early Stopping Patience and Epochs in Deep Learning. In Proceedings of the ITM Web of Conferences, Erbil, Iraq, 20–21 May 2024; Volume 64, p. 01003. Available online: https://www.itm-conferences.org/articles/itmconf/pdf/2024/07/itmconf_icacs2024_01003.pdf (accessed on 10 February 2025).
- Kraft, M.E. Environmental Policy BT—Environmental Geology; Springer: Dordrecht, The Netherlands, 1999; pp. 216–221. ISBN 978-1-4020-4494-6. [Google Scholar]
- Bolón-Canedo, V.; Morán-Fernández, L.; Cancela, B.; Alonso-Betanzos, A. A review of green artificial intelligence: Towards a more sustainable future. Neurocomputing 2024, 599, 128096. [Google Scholar] [CrossRef]
- Díaz-Rodríguez, N.; Del Ser, J.; Coeckelbergh, M.; López de Prado, M.; Herrera-Viedma, E.; Herrera, F. Connecting the dots in trustworthy Artificial Intelligence: From AI principles, ethics, and key requirements to responsible AI systems and regulation. Inf. Fusion 2023, 99, 101896. [Google Scholar] [CrossRef]
- Kindylidi, I.; Cabral, T.S. Sustainability of ai: The case of provision of information to consumers. Sustainability 2021, 13, 2064. [Google Scholar] [CrossRef]
- Pagallo, U.; Ciani Sciolla, J.; Durante, M. The environmental challenges of AI in EU law: Lessons learned from the Artificial Intelligence Act (AIA) with its drawbacks. Transform. Gov. People Process Policy 2022, 16, 359–376. [Google Scholar] [CrossRef]
- Al Hashlamoun, N.; Al Barghuthi, N.; Tamimi, H. Exploring the Intersection of AI and Sustainable Computing: Opportunities, Challenges, and a Framework for Responsible Applications. In Proceedings of the 2023 9th International Conference on Information Technology Trends, ITT 2023, Dubai, United Arab Emirates, 24–25 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 220–225. [Google Scholar] [CrossRef]
- Zhao, J.; Gómez Fariñas, B. Artificial Intelligence and Sustainable Decisions. Eur. Bus. Organ. Law Rev. 2023, 24, 1–39. [Google Scholar] [CrossRef]
- Rêgo de Almeida, P.G.; dos Santos, C.D.; Farias, J.S. Artificial intelligence regulation: A meta-framework for formulation and governance. In Proceedings of the Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 2020; Volume 2020, pp. 5257–5266. [Google Scholar] [CrossRef]
- United Nations. Communications Materials—United Nations Sustainable Development. Available online: https://www.un.org/sustainabledevelopment/news/communications-material/ (accessed on 28 May 2025).
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Felländer, A.; Langhans, S.D.; Tegmark, M.; Fuso Nerini, F. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 2020, 11, 233. [Google Scholar] [CrossRef] [PubMed]
- The International Energy Agency. Digitalization & Energy. OECD/IEA, Paris, France. 2017. Available online: https://www.oecd.org/en/publications/digitalization-energy_9789264286276-en.html (accessed on 23 December 2024).
- Truby, J. Governing Artificial Intelligence to benefit the UN Sustainable Development Goals. Sustain. Dev. 2020, 28, 946–959. [Google Scholar] [CrossRef]
- van Wynsberghe, A. Sustainable AI: AI for sustainability and the sustainability of AI. AI Ethics 2021, 1, 213–218. [Google Scholar] [CrossRef]
- EU. EU Artificial Intelligence Act|Up-to-Date Developments and Analyses of the EU AI Act. EU Artificial Intelligence Act 2025. Available online: https://artificialintelligenceact.eu/ (accessed on 14 February 2025).
- NIST. Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024. [CrossRef]
- NIST. Artificial Intelligence Risk Management NIST AI 100-1 Artificial Intelligence Risk Management; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023.
- Levi, S.; Kumayama, K.; Ridgwey, W.; Ghaemmaghami, M.; Neal, M. Colorado’s Landmark AI Act: What Companies Need to Know. Insights. Skadden, Arps, Slate, Meagher & Flom LLP. 2014. Available online: https://www.skadden.com/insights/publications/2024/06/colorados-landmark-ai-act (accessed on 20 February 2025).
- Sheehan, M. China’s AI Regulations and How They Get Made—Carnegie Endowment for International Peace. 2023. Available online: https://carnegieendowment.org/2023/07/10/china-s-ai-regulations-and-how-they-get-made-pub-90117 (accessed on 6 February 2025).
Figure 1.
Global market size of artificial intelligence; dashed line shows the trendline [
9].
Figure 1.
Global market size of artificial intelligence; dashed line shows the trendline [
9].
Figure 2.
Artificial intelligence power consumption and share of total data center consumption worldwide in 2023, with forecasts to 2028 [
16].
Figure 2.
Artificial intelligence power consumption and share of total data center consumption worldwide in 2023, with forecasts to 2028 [
16].
Figure 3.
Sustainable Development Goals [
55].
Figure 3.
Sustainable Development Goals [
55].
Figure 4.
Energy consumption of scenarios #1a and #1b: (a) Device #1; (b) Device #2; (c) Device #3.
Figure 4.
Energy consumption of scenarios #1a and #1b: (a) Device #1; (b) Device #2; (c) Device #3.
Figure 5.
Training and validation accuracy of scenarios #1a and #1b: (a.1) Device #1, without early-stopping epochs; (a.2) Device #1, with early-stopping epochs; (b.1) Device #2, without early-stopping epochs; (b.2) Device #2, with early-stopping epochs; (c.1) Device #3, without early-stopping epochs; (c.2) Device #3, with early-stopping epochs.
Figure 5.
Training and validation accuracy of scenarios #1a and #1b: (a.1) Device #1, without early-stopping epochs; (a.2) Device #1, with early-stopping epochs; (b.1) Device #2, without early-stopping epochs; (b.2) Device #2, with early-stopping epochs; (c.1) Device #3, without early-stopping epochs; (c.2) Device #3, with early-stopping epochs.
Figure 6.
Energy consumption and testing accuracy by training data size of scenarios #2a and #2b: Device #1 (a.1,a.2), Device #2 (b.1,b.2), and Device #3 (c.1,c.2).
Figure 6.
Energy consumption and testing accuracy by training data size of scenarios #2a and #2b: Device #1 (a.1,a.2), Device #2 (b.1,b.2), and Device #3 (c.1,c.2).
Figure 7.
The energy and accuracy comparison by batch sizes: Device #1 (a.1,a.2), Device #2 (b.1,b.2), and Device #3 (c.1,c.2).
Figure 7.
The energy and accuracy comparison by batch sizes: Device #1 (a.1,a.2), Device #2 (b.1,b.2), and Device #3 (c.1,c.2).
Figure 8.
Illustration of AI-based attendance system installed in a smart building in Ecocampus environment.
Figure 8.
Illustration of AI-based attendance system installed in a smart building in Ecocampus environment.
Table 1.
Simulation scenarios.
Table 1.
Simulation scenarios.
| Simulation Scenario | Description | Output |
|---|
| Scenario #1a | - -
Training data size: 80% of overall data size. - -
Testing data size: 20% of overall data size. - -
Validation data size: 50% of training data size. - -
Batch size: 32. - -
Epochs: 30. - -
No early-stopping epochs.
| - -
Training energy consumption. - -
Training and validation accuracy. - -
Testing accuracy.
|
| Scenario #1b | - -
Training data size: 80% of overall data size. - -
Testing data size: 20% of overall data size. - -
Validation data size: 50% of training data size. - -
Batch size: 32. - -
Epochs: 30. - -
With early-stopping epochs.
| - -
Training energy consumption. - -
Training and validation accuracy. - -
Testing accuracy.
|
| Scenario #2a | - -
Training data size variation: 60%, 70%, 80%, and 90% of overall data size. - -
Validation data size: 50% of training data size. - -
Batch size: 32. - -
Epoch: 30. - -
No early-stopping epochs.
| - -
Training energy consumption. - -
Testing accuracy.
|
| Scenario #2b | - -
Training data size variation: 60%, 70%, 80%, and 90% of overall data size. - -
Validation data size: 50% of training data size. - -
Batch size: 32. - -
Epoch: 30. - -
With early-stopping epochs.
| - -
Training energy consumption. - -
Testing accuracy.
|
| Scenario #3a | - -
Training data size: 80% of overall data size. - -
Validation data size: 50% of training data size. - -
Batch size variation: 32, 64, and 128. - -
Epoch: 30. - -
No early-stopping epochs.
| - -
Training energy consumption. - -
Testing accuracy.
|
| Scenario #3b | - -
Training data size: 80% of overall data size. - -
Validation data size: 50% of training data size. - -
Batch size variation: 32, 64, and 128. - -
Epoch: 30. - -
With early-stopping epochs.
| - -
Training energy consumption. - -
Testing accuracy.
|
Table 2.
The specification of three devices.
Table 2.
The specification of three devices.
| | Device #1 | Device #2 | Device #3 |
|---|
| Type | HP Z8 G4 Workstation | Razer Blade Stealth 13 (2020) | LENOVO LNVNB161216 |
| Manufacturer | HP Inc., Palo Alto, CA, USA | Razer Inc., Irvine, CA, USA | Lenovo Group Ltd., Beijing, China |
| Type CPU | Intel Xeon Platinum 8280 | Intel Core i7-1065G7 | CPU Intel Core Ultra 7 155H |
| TDP CPU | 205 W | 15 Watt | 25 Watt |
| Number of CPU | 1 | 1 | 1 |
| Type GPU | NVIDIA Quadro RTX 6000 | NVIDIA GeForce GTX 1650 Ti | - |
| TDP GPU | 295 W | 50 Watt | - |
| Number GPU | 2 | 1 | - |
| DRAM capacity | 48 GB | 16 GB | 16 GB |
| Operating System | Windows 11 Pro for
Workstations | Windows 11 Home | Windows 11 |
| CUDA version | 12.4 | 12.4 | - |
Table 3.
Energy consumption and testing accuracy of scenarios #1a and #1b.
Table 3.
Energy consumption and testing accuracy of scenarios #1a and #1b.
| | Device #1 | Device #2 | Device #3 |
|---|
| Without Early-Stopping Epochs | With Early-Stopping Epochs | Without Early-Stopping Epochs | With Early-Stopping Epochs | Without Early-Stopping Epochs | With Early-Stopping Epochs |
|---|
| Energy Consumption (watt-hours) | 5.7684 | 2.5954 | 0.8334 | 0.4331 | 0.3000 | 0.1732 |
Testing Accuracy
(percentage) | 97.84% | 97.04% | 97.56% | 97.55% | 97.51% | 97.52% |
Table 4.
Energy consumption by training data size of scenarios #2a and #2.
Table 4.
Energy consumption by training data size of scenarios #2a and #2.
| Training Data Size | Energy Consumption (Watt-Hours) |
|---|
| Device #1 | Device #2 | Device #3 |
|---|
| Without Early-Stopping Epochs | With Early-Stopping Epochs | Without Early-Stopping Epochs | With Early-Stopping Epochs | Without Early-Stopping Epochs | With Early-Stopping Epochs |
|---|
| 60% | 5.1991 | 1.7512 | 0.6884 | 0.3926 | 0.2662 | 0.1149 |
| 70% | 6.3026 | 2.4350 | 0.8370 | 0.3925 | 0.2759 | 0.1211 |
| 80% | 6.6231 | 2.5201 | 0.9093 | 0.5215 | 0.3000 | 0.1349 |
| 90% | 8.8686 | 2.5368 | 1.0051 | 0.5743 | 0.3326 | 0.1493 |
Table 5.
Testing accuracy by training data size of scenarios #2a and #2b.
Table 5.
Testing accuracy by training data size of scenarios #2a and #2b.
| Training Data Size | Device #1 | Device #2 | Device #3 |
|---|
| Without Early-Stopping Epochs | With Early-Stopping Epochs | Without Early-Stopping Epochs | With Early-Stopping Epochs | Without Early-Stopping Epochs | With Early-Stopping Epochs |
|---|
| 60% | 96.99% | 96.34% | 96.92% | 96.75% | 96.99% | 96.55% |
| 70% | 97.27% | 96.98% | 97.35% | 97.13% | 97.38% | 97.23% |
| 80% | 97.84% | 97.04% | 97.56% | 97.55% | 97.51% | 97.52% |
| 90% | 98.09% | 97.64% | 97.99% | 97.99% | 98.16% | 97.93% |
Table 6.
Energy comparison by different batch sizes.
Table 6.
Energy comparison by different batch sizes.
| | Device #1 | Device #2 | Device #3 |
|---|
| Batch Sizes | Without Early Stopping | With Early Stopping | Without Early Stopping | With Early Stopping | Without Early Stopping | With Early Stopping |
|---|
| 32 | 5.7684 | 2.5954 | 0.8334 | 0.4331 | 0.3000 | 0.1732 |
| 64 | 3.4826 | 1.4711 | 0.6596 | 0.2359 | 0.1507 | 0.0724 |
| 128 | 1.5524 | 0.8708 | 0.2250 | 0.2148 | 0.0909 | 0.0503 |
Table 7.
Accuracy comparison by different batch sizes.
Table 7.
Accuracy comparison by different batch sizes.
| | Device #1 | Device #2 | Device #3 |
|---|
| Batch Sizes | Without Early Stopping | With Early Stopping | Without Early Stopping | With Early Stopping | Without Early Stopping | With Early Stopping |
|---|
| 32 | 0.9784 | 0.9746 | 0.9756 | 0.9755 | 0.9751 | 0.9752 |
| 64 | 0.9769 | 0.9718 | 0.9782 | 0.9761 | 0.9771 | 0.9737 |
| 128 | 0.9781 | 0.9729 | 0.9775 | 0.9714 | 0.9759 | 0.9734 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}