
Automatic and Efficient Detection of Loess Landslides Based on Deep Learning


Abstract
1. Introduction
2. Materials and Methods
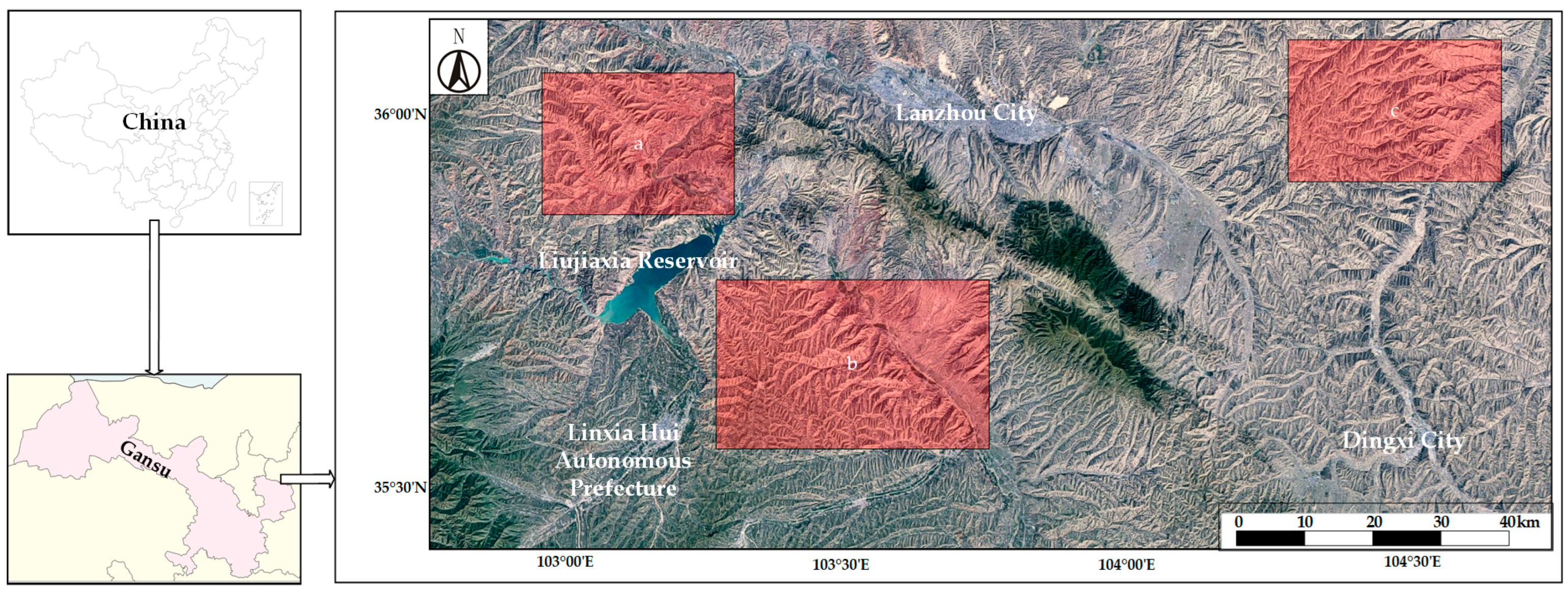
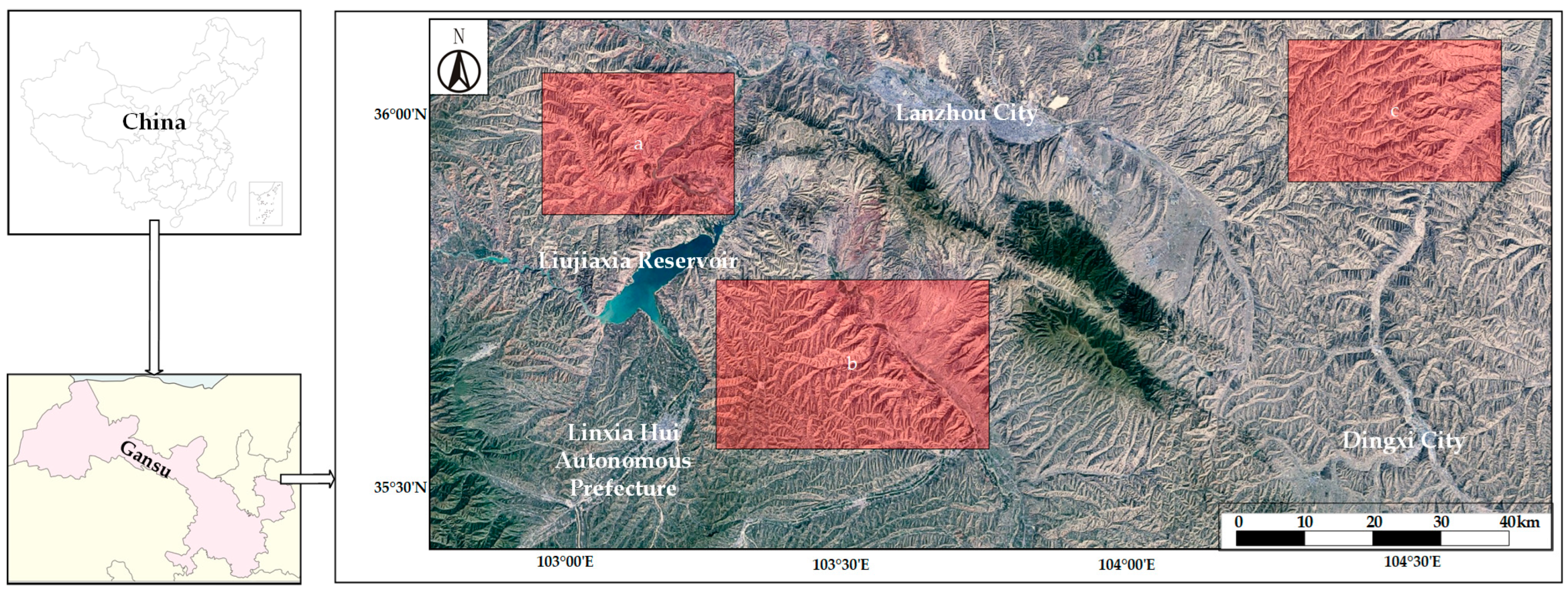
2.1. Data Collection
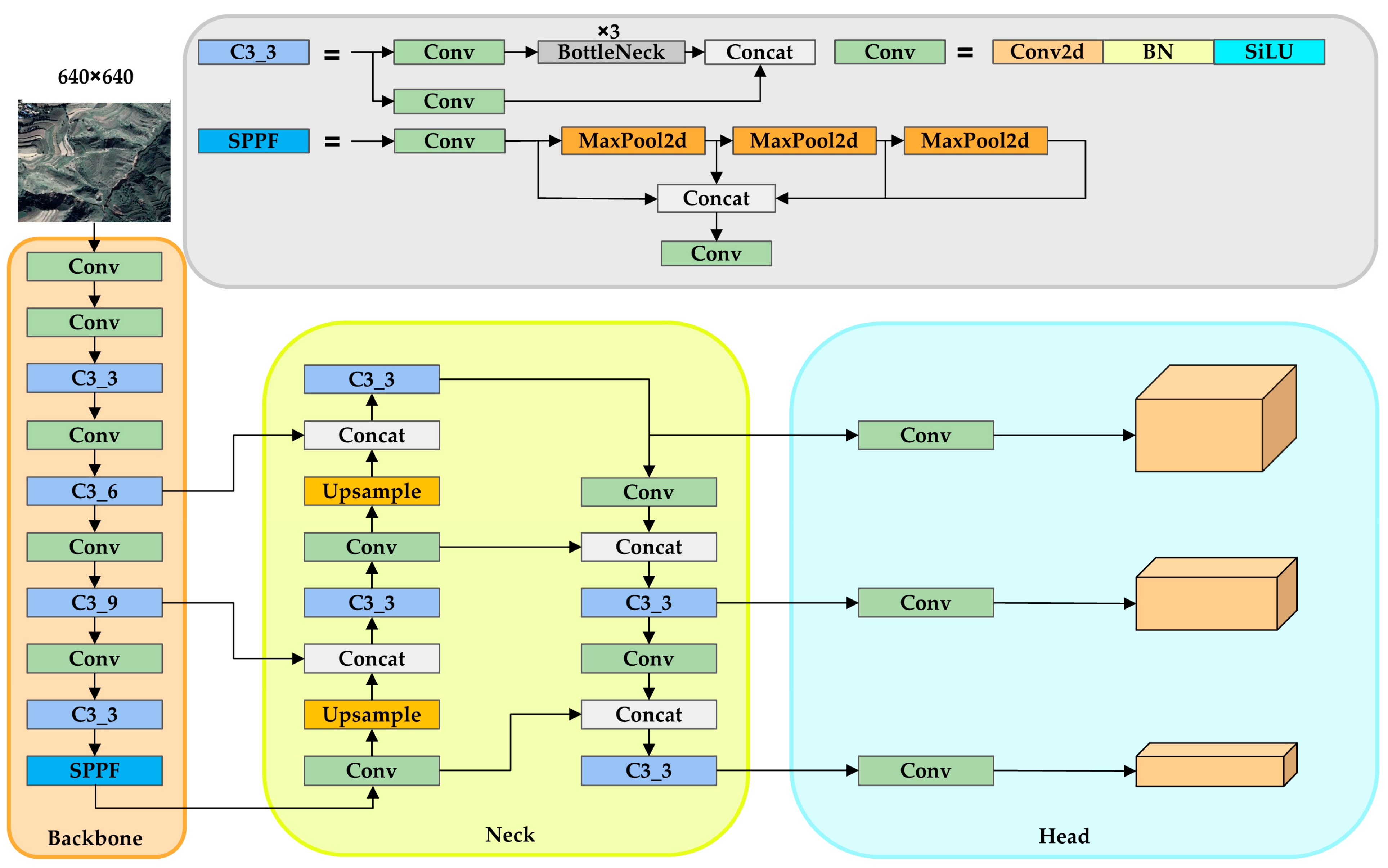
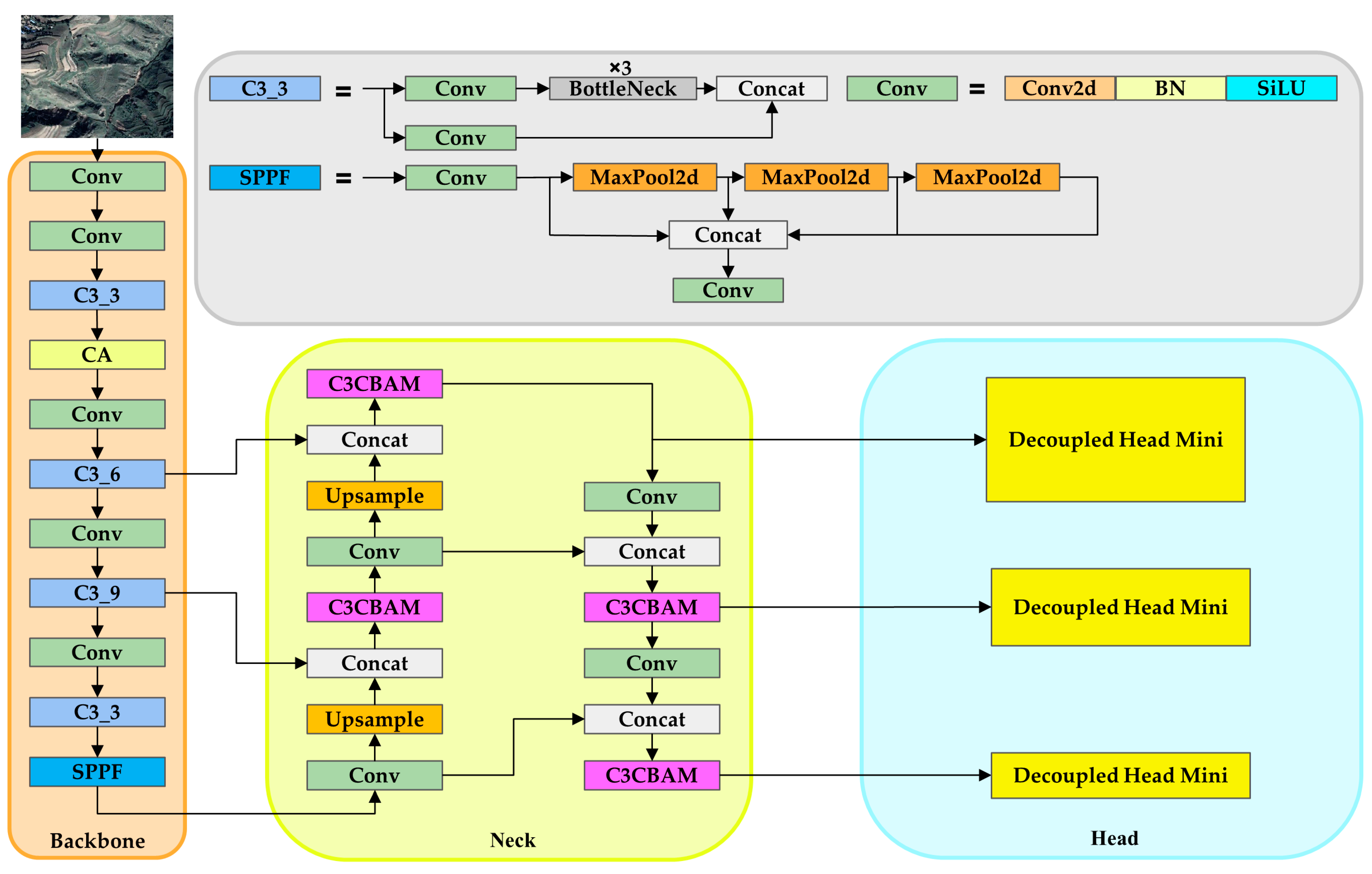
2.2. YOLO Model
Traditional YOLO Architecture
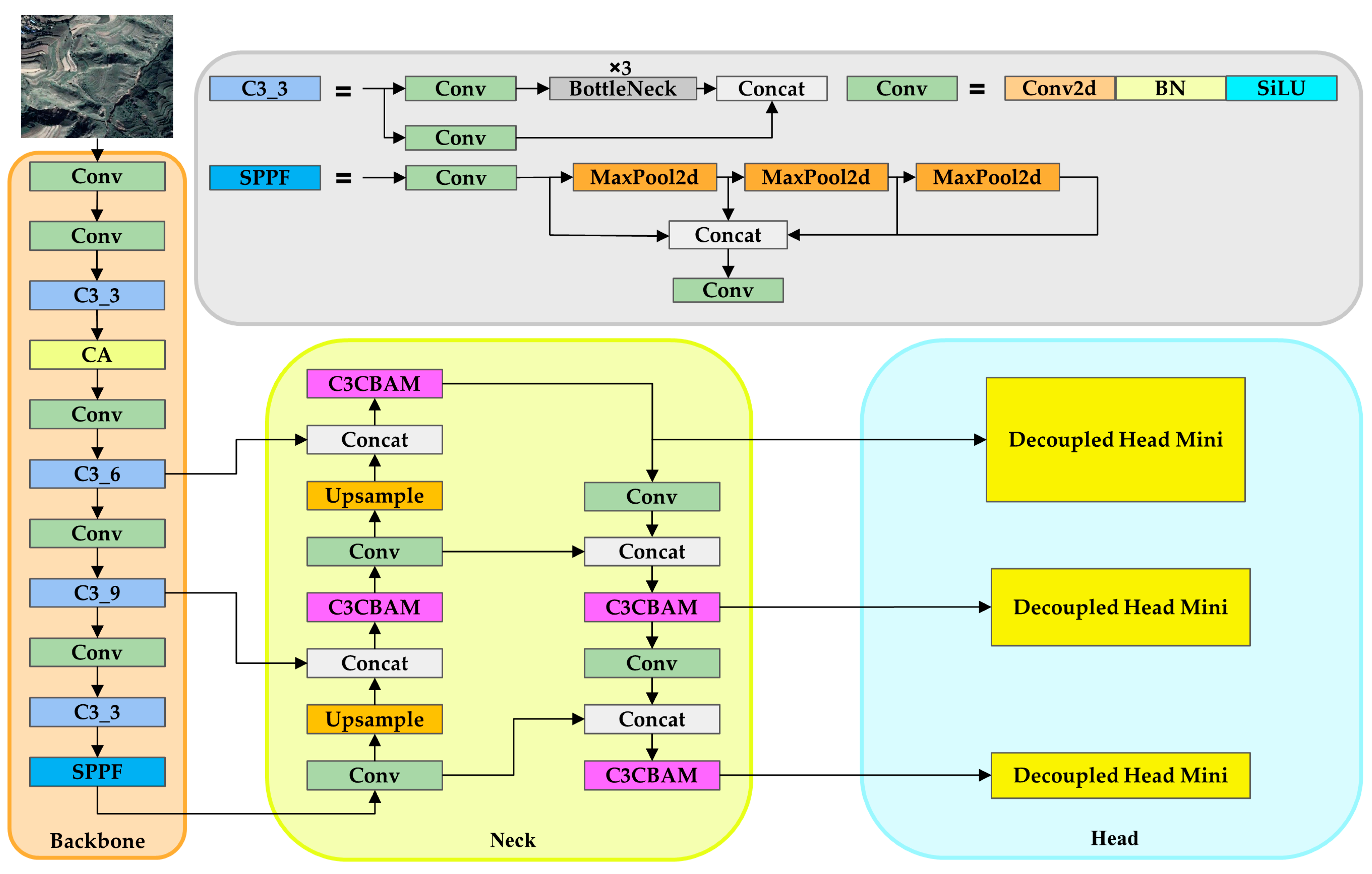
2.3. Model Adjustment for Landslide Objectives
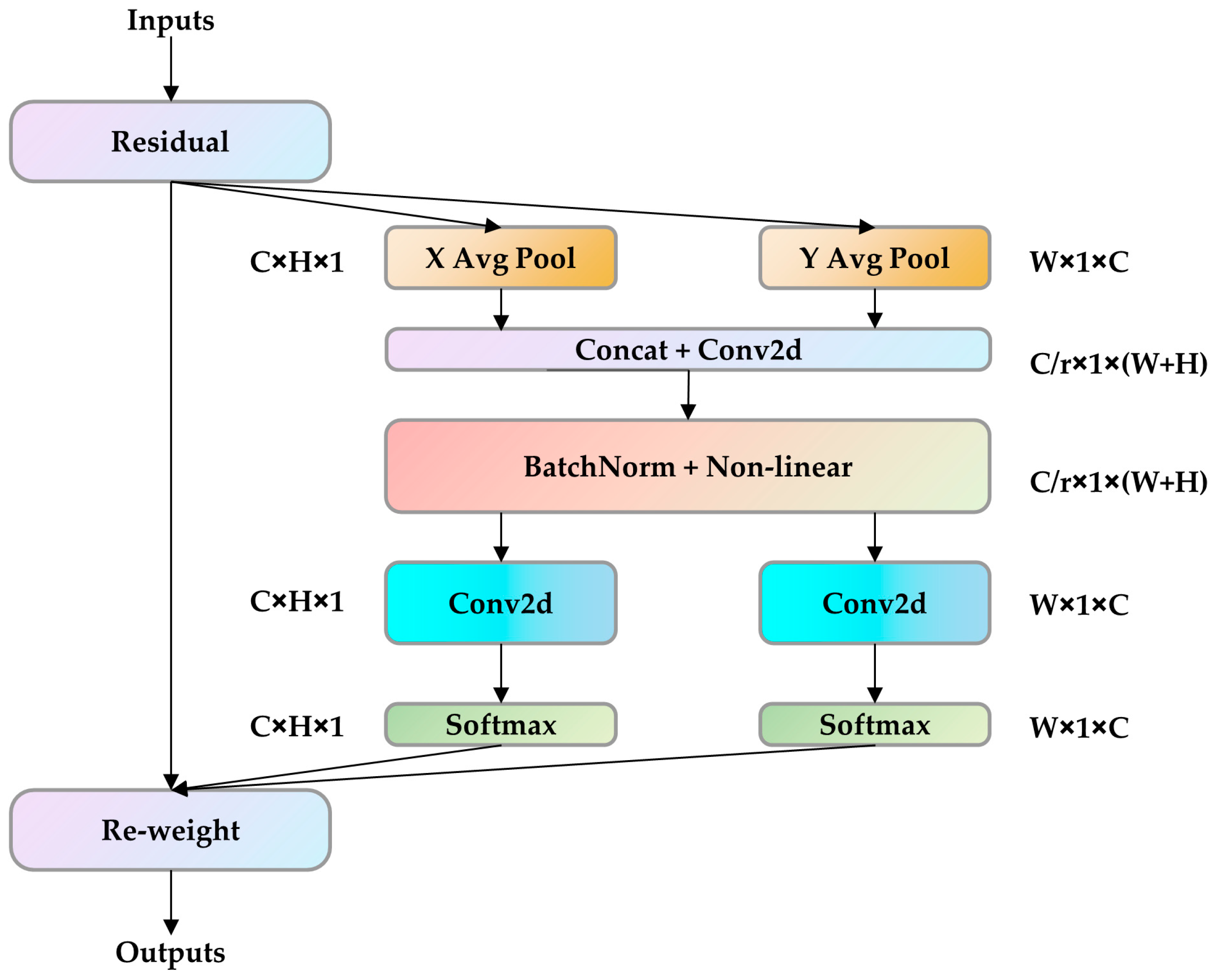
2.3.1. Introducing Coordinate Attention
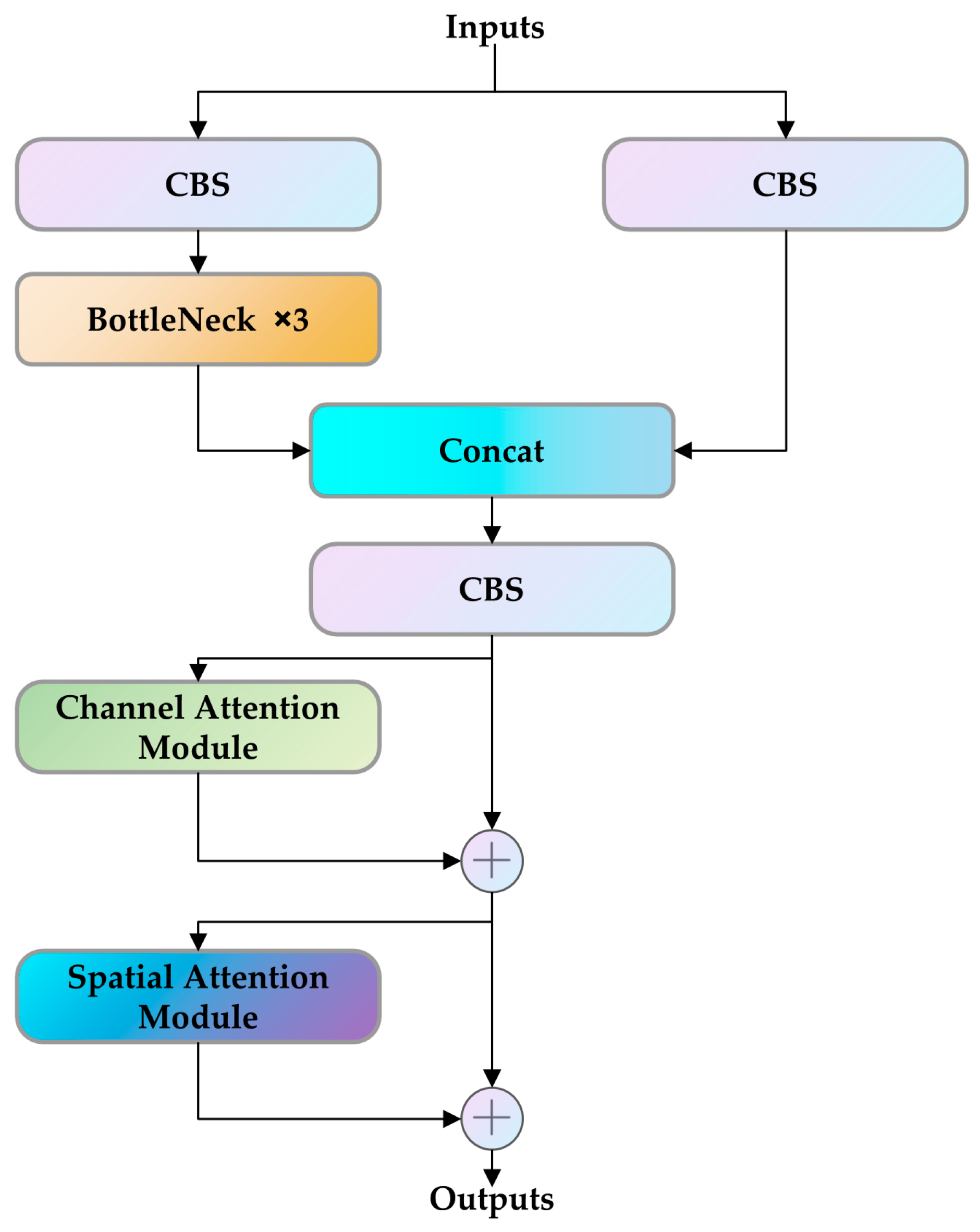
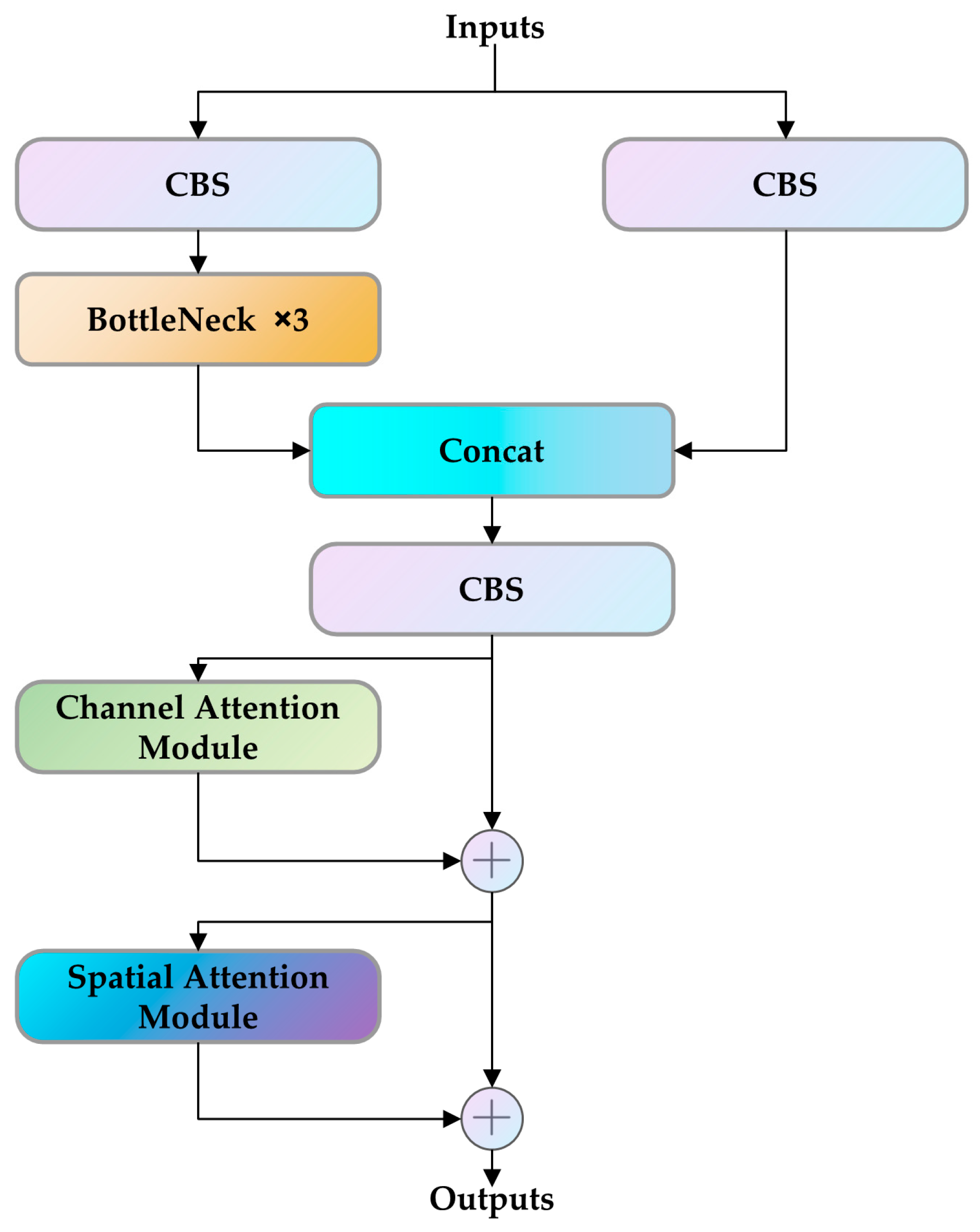
2.3.2. C3 Module Combined with CBAM
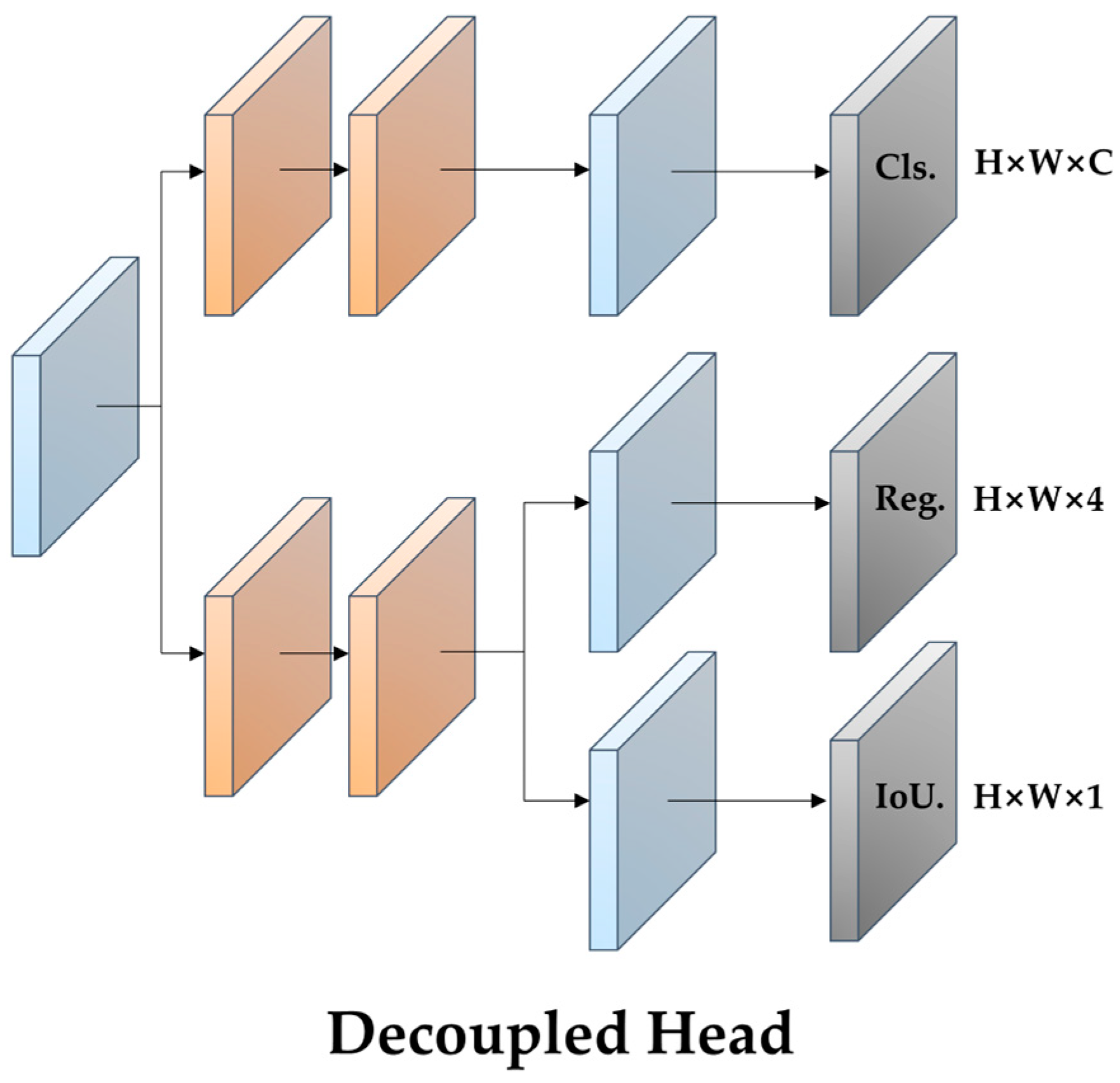
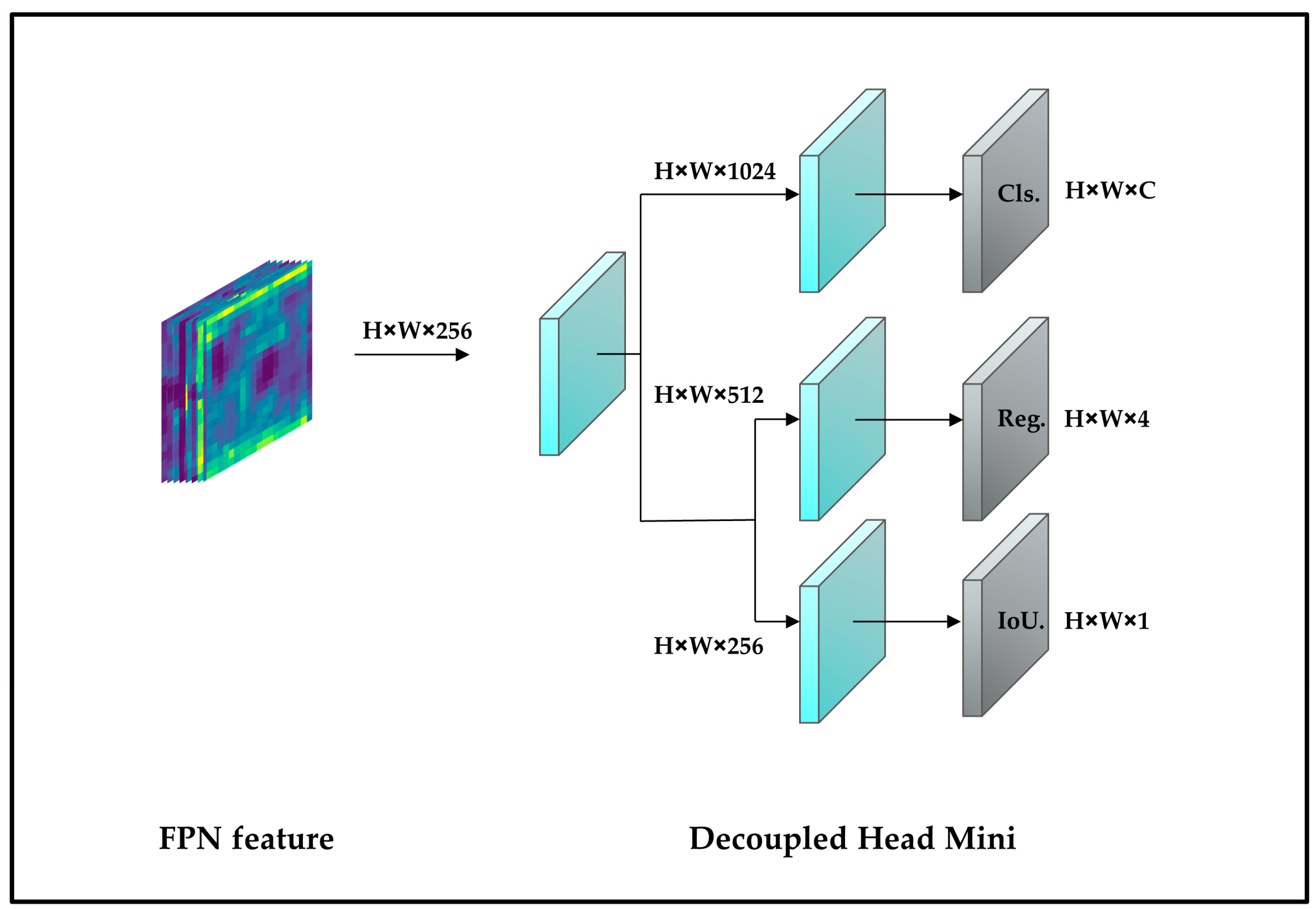
2.3.3. Replacement of Head
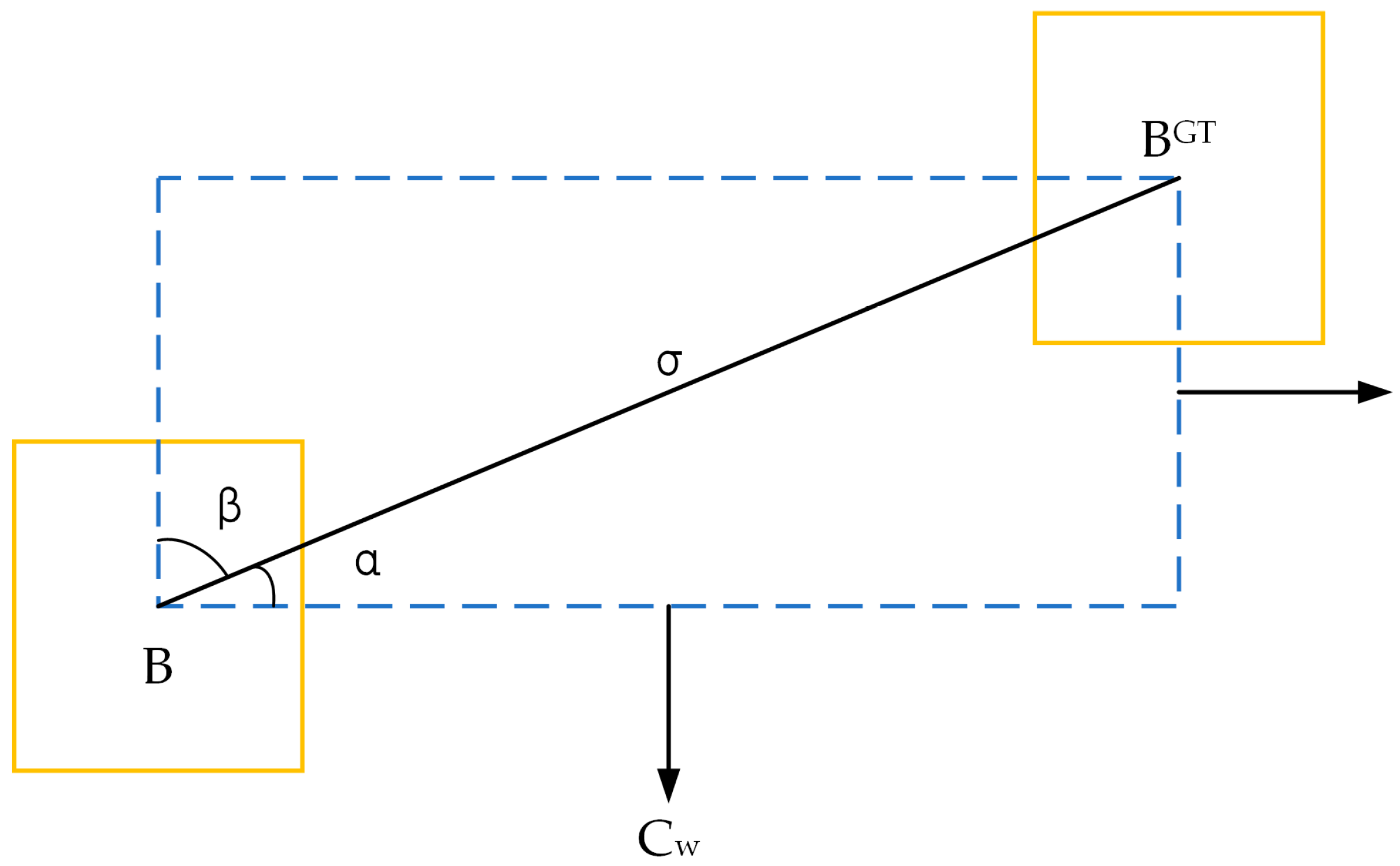
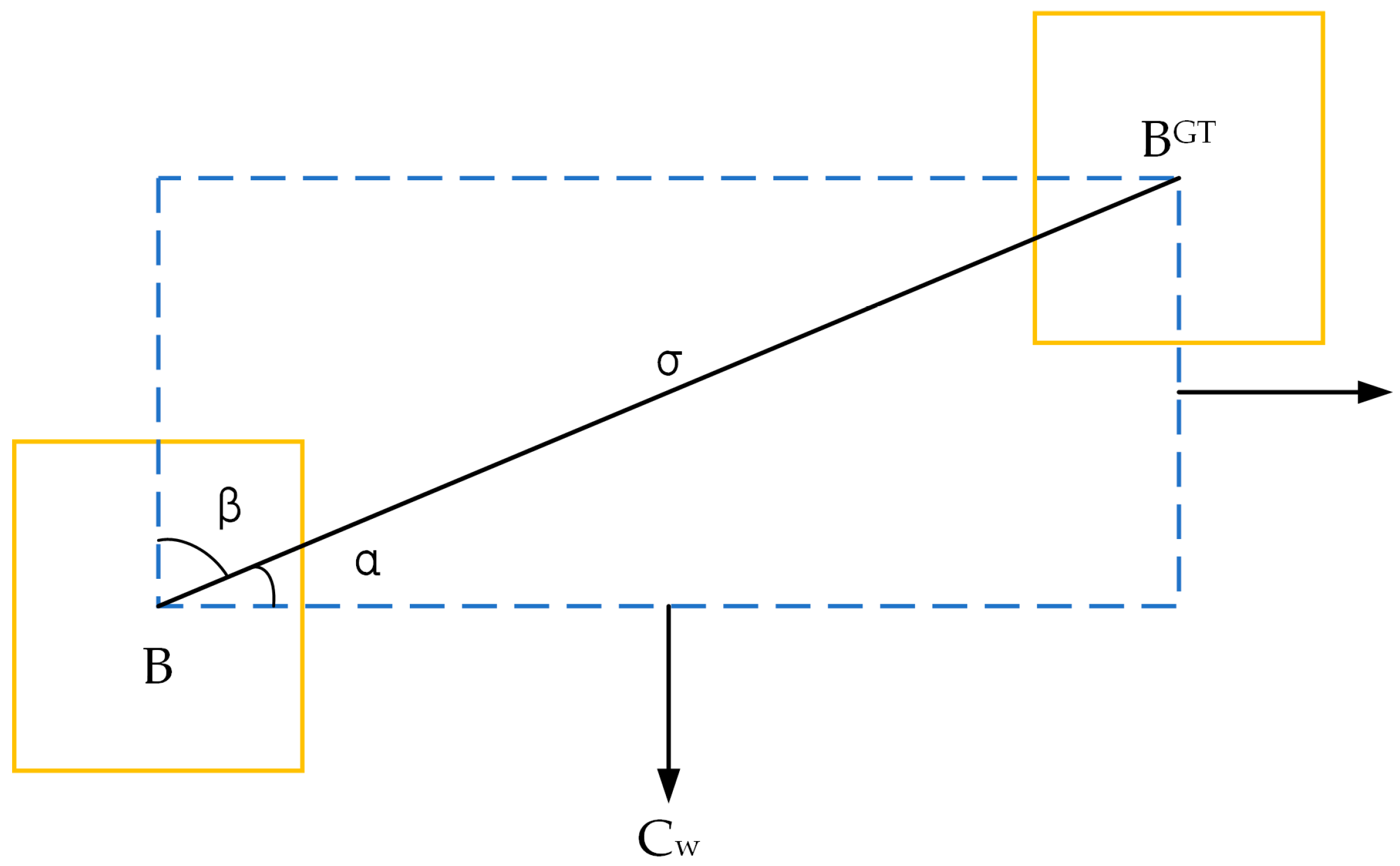
2.3.4. Loss Function
3. Experimental Settings
3.1. Experimental Environment
3.2. Training Detail
3.3. Evaluation Indicator
4. Comparison of Experimental Results and Models
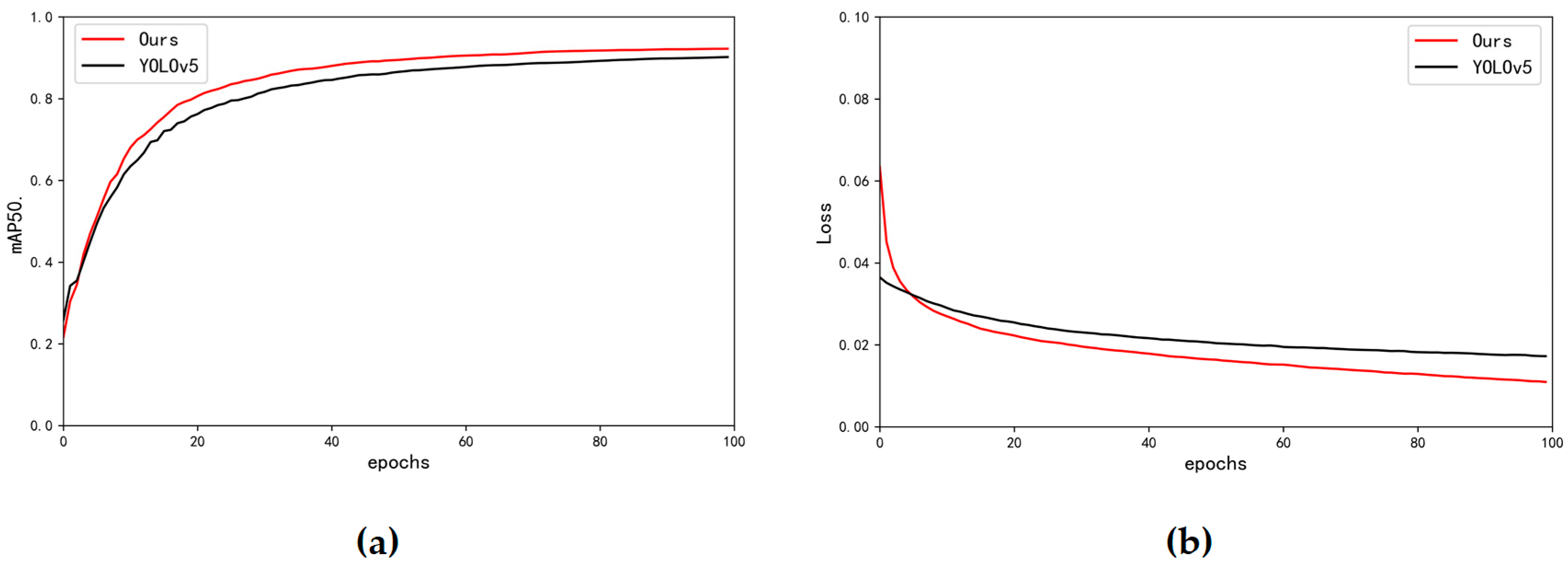
4.1. Model Comparison
4.2. Ablation Experiment
5. Discussion
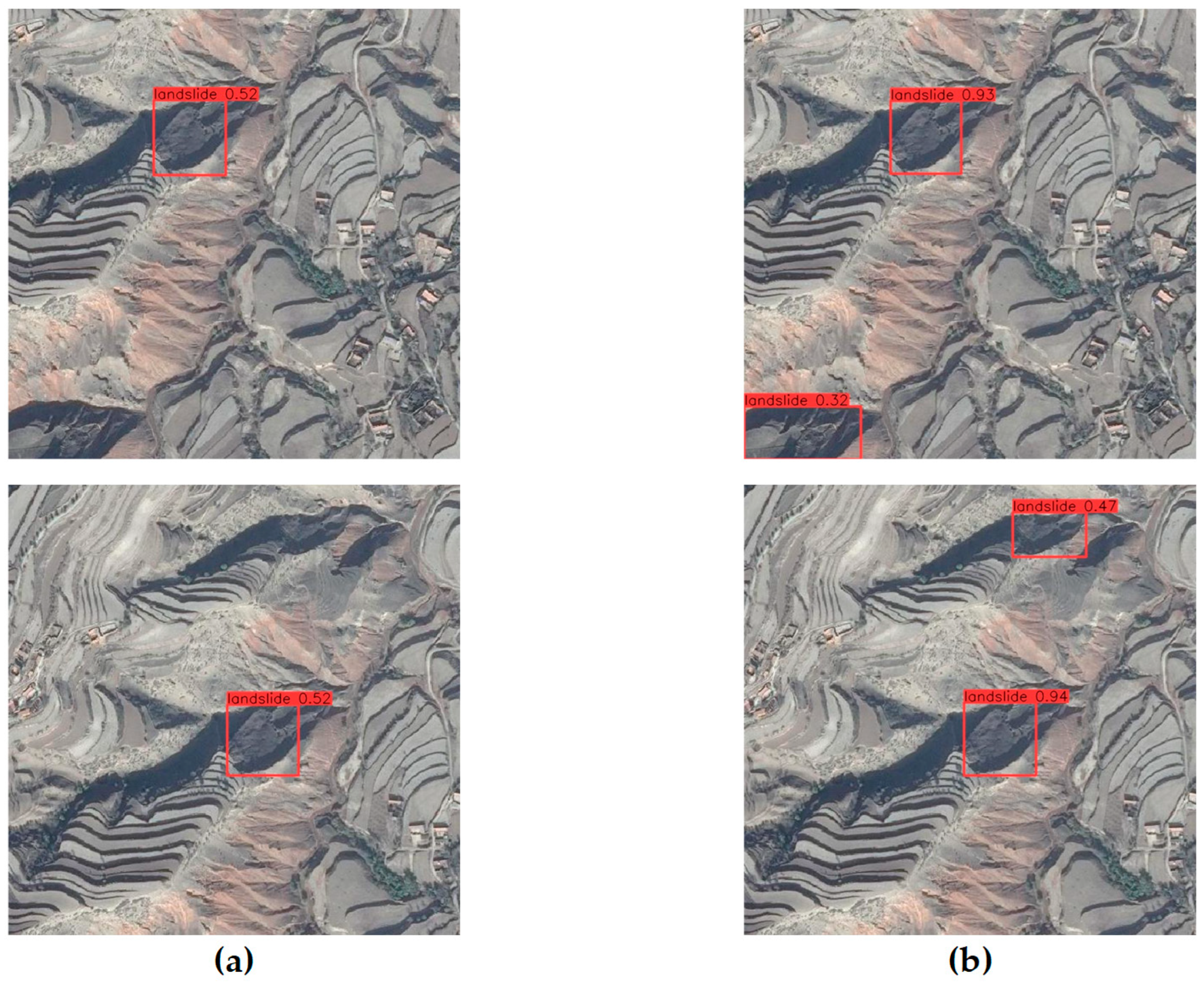
5.1. Landslide Detection Accuracy of Different Models
5.2. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hölbling, D.; Füreder, P.; Antolini, F.; Cigna, F.; Casagli, N.; Lang, S. A Semi-Automated Object-Based Approach for Landslide Detection Validated by Persistent Scatterer Interferometry Measures and Landslide Inventories. Remote Sens. 2012, 4, 1310–1336. [Google Scholar] [CrossRef]
- Ansari, A.; Zaray, A.H.; Rao, K.S.; Jain, A.K.; Hashmat, P.A.; Ikram, M.K.; Wahidi, A.W. Reconnaissance surveys after June 2022 Khost earthquake in Afghanistan: Implication towards seismic vulnerability assessment for future design. Innov. Infrastruct. Solut. 2023, 8, 108. [Google Scholar] [CrossRef]
- Thoithi, W.; Blamey, R.C.; Reason, C.J.C. April 2022 Floods over East Coast South Africa: Interactions between a Mesoscale Convective System and a Coastal Meso-Low. Atmosphere 2023, 14, 78. [Google Scholar] [CrossRef]
- Hungr, O.; Leroueil, S.; Picarelli, L. The Varnes classification of landslide types, an update. Landslides 2014, 11, 167–194. [Google Scholar] [CrossRef]
- Sassa, K.; Fukuoka, H.; Wang, F.; Wang, G. Progress in Landslide Science; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; Volume 7. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Lu, P.; Yan, L.; Wang, Q.; Miao, Z. Landslide mapping from aerial photographs using change detection-based Markov random field. Remote Sens. Environ. 2016, 187, 76–90. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; Wang, Y.; Chen, G.; Liu, S. Forested landslide detection using LiDAR data and the random forest algorithm: A case study of the Three Gorges, China. Remote Sens. Environ. 2014, 152, 291–301. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Brown, M.K.; Panter, K.; Onasch, C.M.; Simic, A.; Snyder, J. Landslide detection and susceptibility mapping using LiDAR and an artificial neural network approach: A case study in the Cuyahoga Valley National Park, Ohio. Landslides 2016, 13, 467–484. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. preprint. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. preprint. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:2016.2577031. preprint. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. preprint. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, B.; Lyu, S.; Wang, C.; Zhang, H. TPH-YOLOv5++: Boosting Object Detection on Drone-Captured Scenarios with Cross-Layer Asymmetric Transformer. Remote Sens. 2023, 15, 1687. [Google Scholar] [CrossRef]
- Cheng, L.; Li, J.; Duan, P.; Wang, M. A small attentional YOLO model for landslide detection from satellite remote sensing images. Landslides 2021, 18, 2751–2765. [Google Scholar] [CrossRef]
- Niu, C.; Ma, K.; Shen, X.; Wang, X.; Xie, X.; Tan, L.; Xue, Y. Attention-Enhanced Region Proposal Networks for Multi-Scale Landslide and Mudslide Detection from Optical Remote Sensing Images. Land 2023, 12, 313. [Google Scholar] [CrossRef]
- Ju, Y.; Xu, Q.; Jin, S.; Li, W.; Su, Y.; Dong, X.; Guo, Q. Loess Landslide Detection Using Object Detection Algorithms in Northwest China. Remote Sens. 2022, 14, 1182. [Google Scholar] [CrossRef]
- Yu, Z.; Chang, R.; Chen, Z. Automatic Detection Method for Loess Landslides Based on GEE and an Improved YOLOX Algorithm. Remote Sens. 2022, 14, 4599. [Google Scholar] [CrossRef]
- Han, Z.; Fang, Z.; Li, Y.; Fu, B. A novel Dynahead-Yolo neural network for the detection of landslides with variable proportions using remote sensing images. Front. Earth Sci. 2023, 10, 1077153. [Google Scholar] [CrossRef]
- Zhuang, J.; Peng, J.; Wang, G.; Javed, I.; Wang, Y.; Li, W. Distribution and characteristics of landslide in Loess Plateau: A case study in Shaanxi province. Eng. Geol. 2018, 236, 89–96. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. preprint. [Google Scholar] [CrossRef]
- Neubeck, A.; Gool, L.V. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. preprint. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. preprint. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. preprint. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. preprint. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. preprint. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. arXiv 2016, arXiv:1608.01471. preprint. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:34i07.6999. preprint. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | mAP (%) | FPS |
|---|---|---|---|---|
| YOLOX | 91.58 | 78.40 | 86.08 | 70.6 |
| Fast R-CNN | 90.15 | 61.13 | 77.92 | 28.23 |
| SSD | 89.61 | 79.26 | 82.38 | 76.2 |
| Our landslide detection model | 96.45 | 86.79 | 92.28 | 81.2 |
| Model | CA | C3CBAM | Decoupled Head Mini | SIoU | mAP (%) |
|---|---|---|---|---|---|
| Baseline model(YOLOv5) | - | - | - | - | 88.27 |
| +CA | √ | - | - | - | 90.49 |
| +CA+C3CBAM | √ | √ | - | - | 91.85 |
| +CA+C3CBAM+Decoupled Head Mini | √ | √ | √ | - | 92.09 |
| Our landslide detection model | √ | √ | √ | √ | 92.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Q.; Liang, Y.; Xie, F.; Yu, Z.; Wang, Y. Automatic and Efficient Detection of Loess Landslides Based on Deep Learning. Sustainability 2024, 16, 1238. https://doi.org/10.3390/su16031238
Ji Q, Liang Y, Xie F, Yu Z, Wang Y. Automatic and Efficient Detection of Loess Landslides Based on Deep Learning. Sustainability. 2024; 16(3):1238. https://doi.org/10.3390/su16031238
Chicago/Turabian StyleJi, Qingyun, Yuan Liang, Fanglin Xie, Zhengbo Yu, and Yanli Wang. 2024. "Automatic and Efficient Detection of Loess Landslides Based on Deep Learning" Sustainability 16, no. 3: 1238. https://doi.org/10.3390/su16031238
APA StyleJi, Q., Liang, Y., Xie, F., Yu, Z., & Wang, Y. (2024). Automatic and Efficient Detection of Loess Landslides Based on Deep Learning. Sustainability, 16(3), 1238. https://doi.org/10.3390/su16031238