
An Improved Real-Time Detection Transformer Model for the Intelligent Survey of Traffic Safety Facilities


Abstract
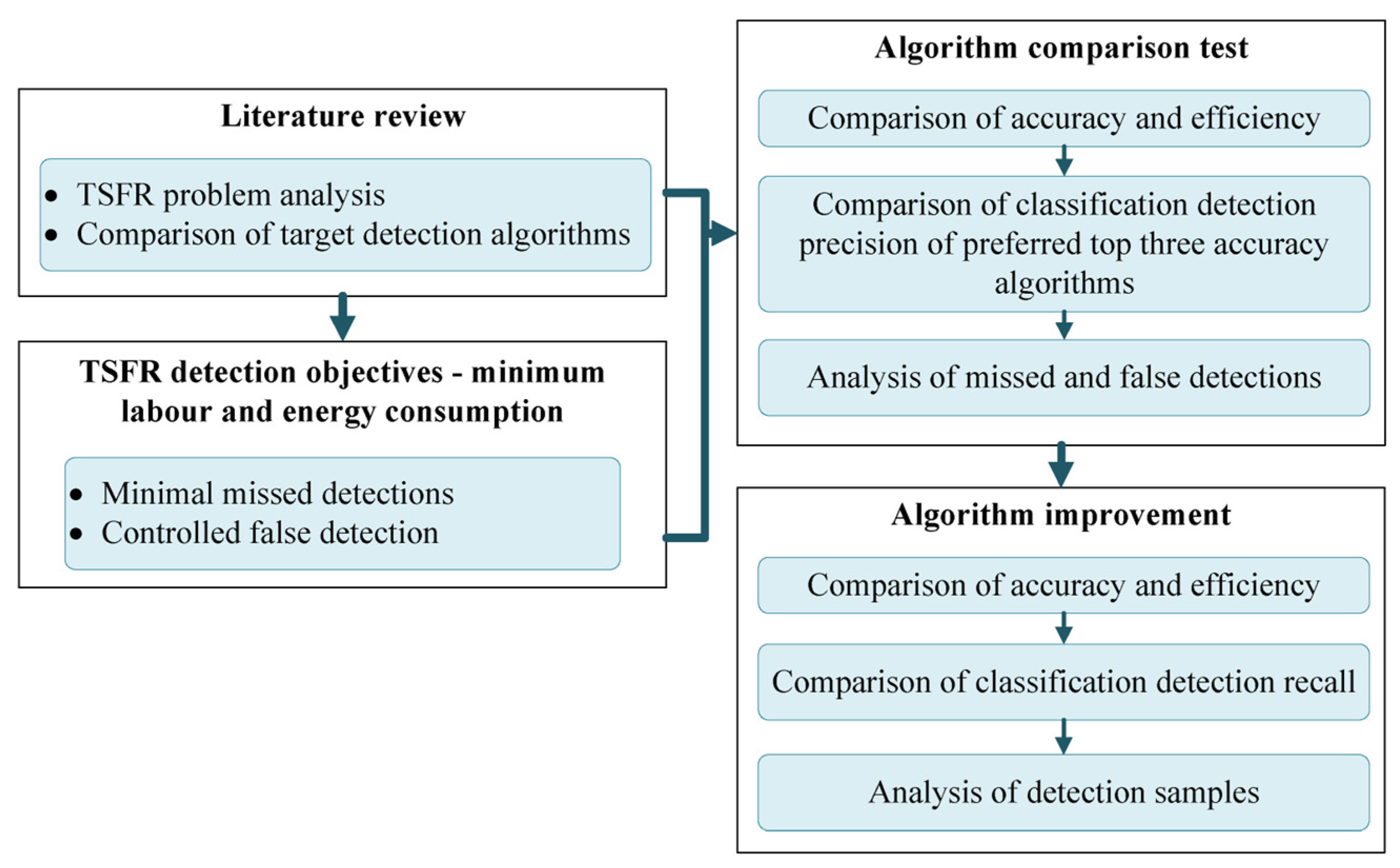
1. Introduction
2. Literature Review
3. Methods
3.1. YOLO Series
3.1.1. YOLOv7–YOLOv11
3.1.2. YOLO-World
3.2. Detection Based on Transformer
3.2.1. DINO
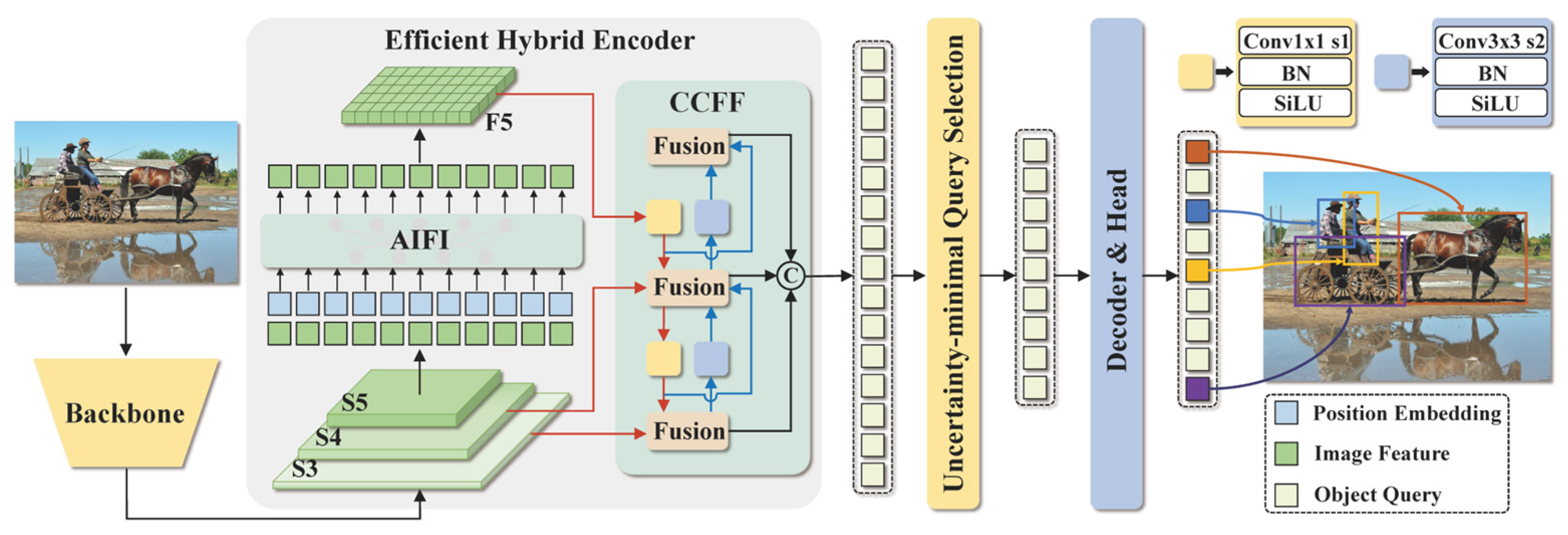
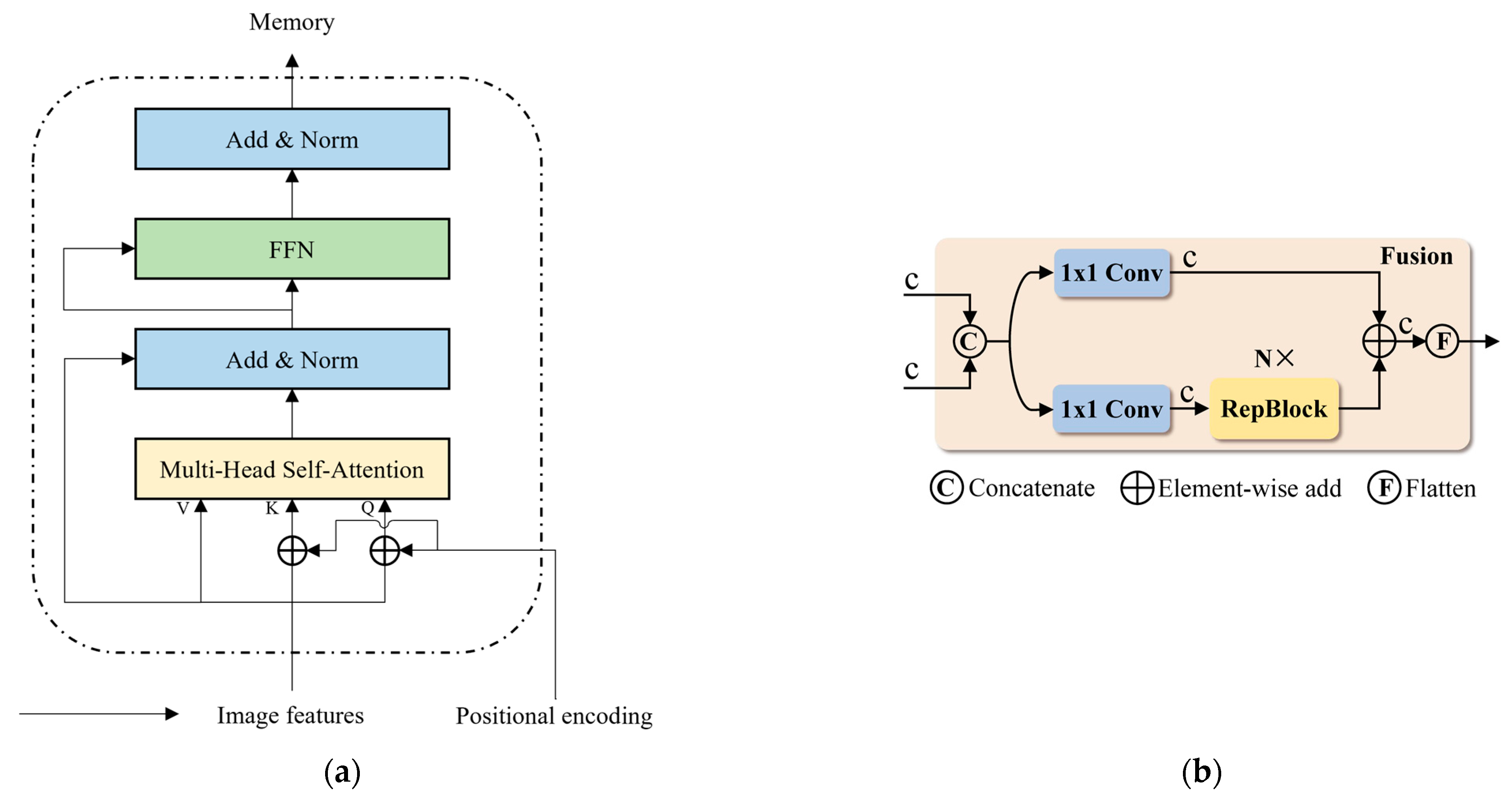
3.2.2. Real-Time Detection Transformer (RT-DETR)
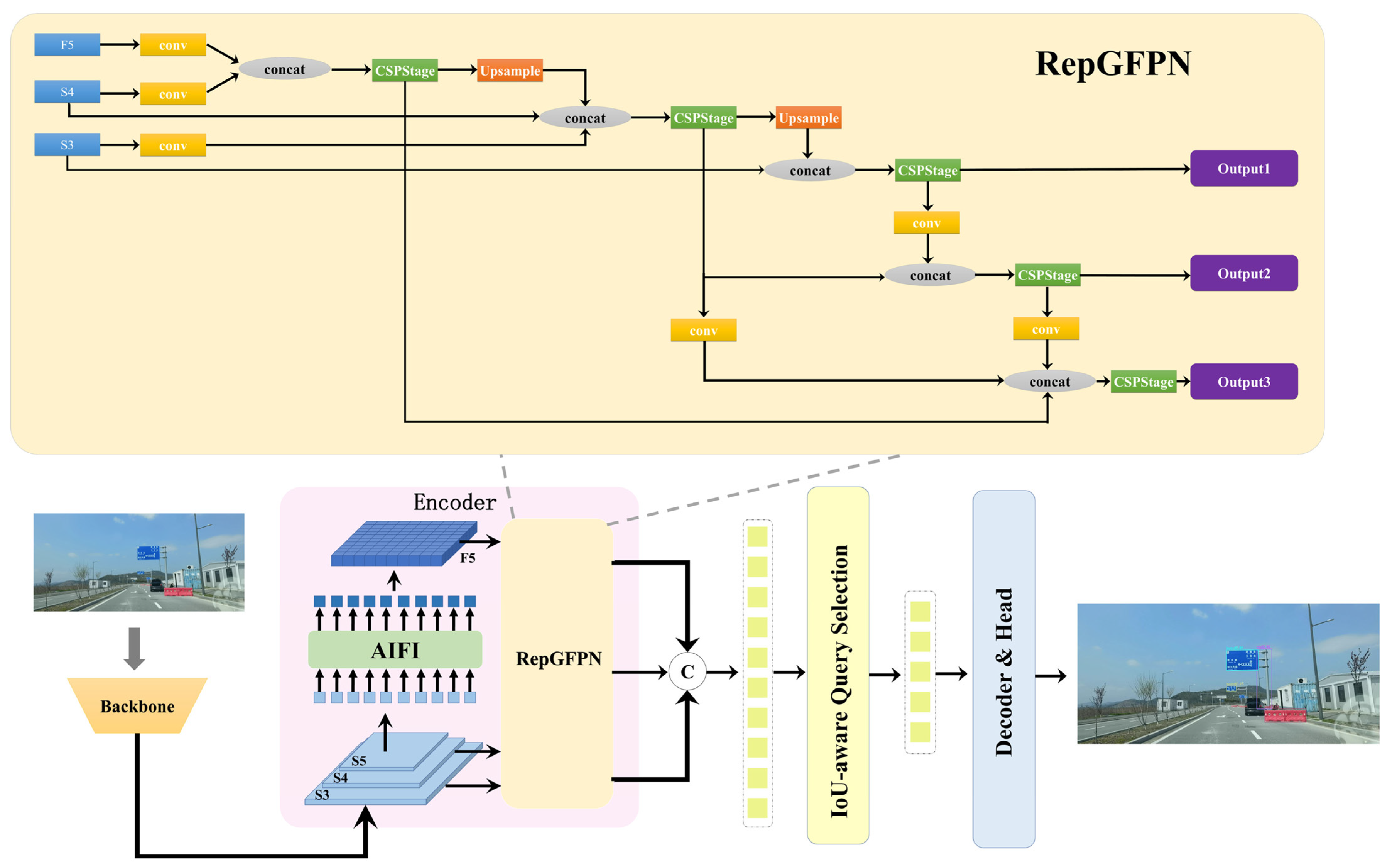
3.3. Improved RT-DETR with Reparameterized Generalized Feature Pyramid Network Module (RT-DETR-RepGFPN)
4. Experiment
4.1. Data
4.2. Experiment Configuration
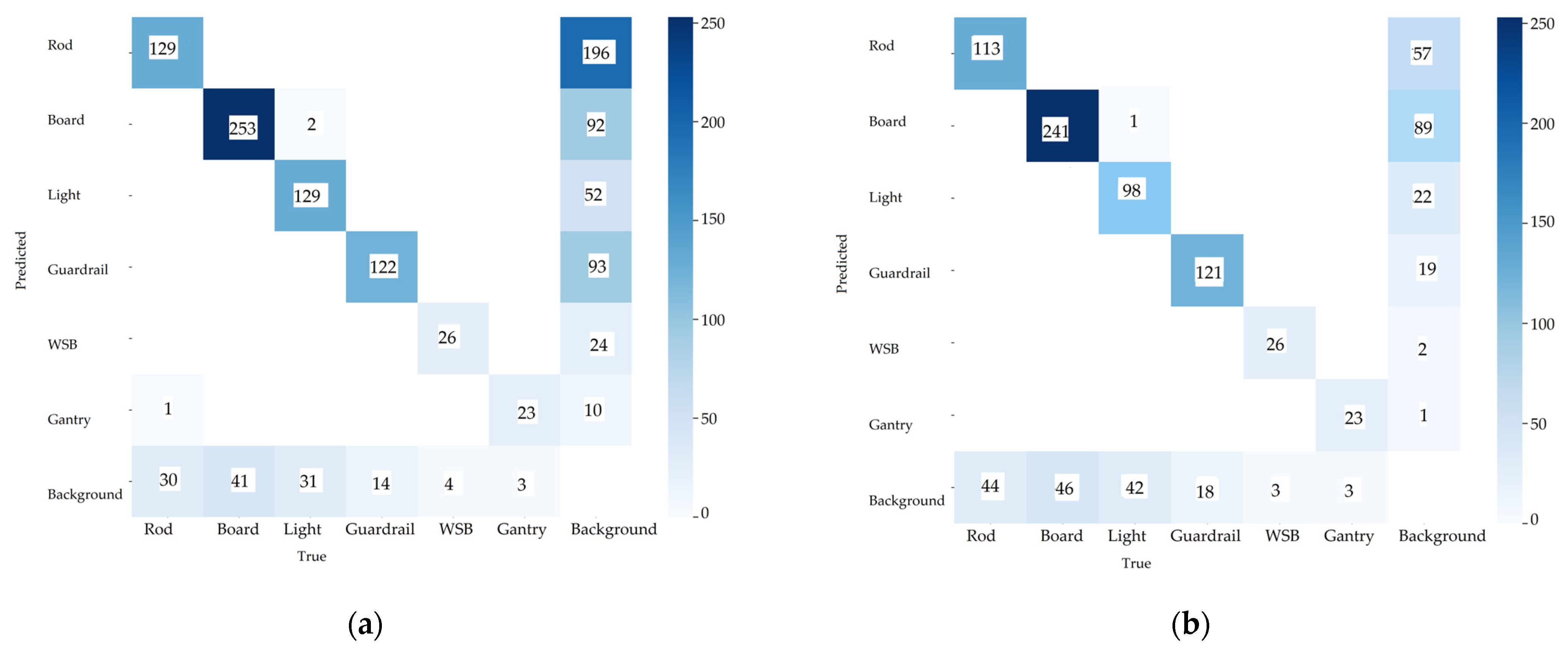
4.3. Confusion Matrix
- (1)
- True positive (TP): the number of samples that the model correctly predicts as positive categories;
- (2)
- True negative (TN): the number of samples correctly predicted by the model to be in the negative category;
- (3)
- False positive (FP): the number of samples incorrectly predicted by the model to be in the positive category;
- (4)
- False negative (FN): the number of samples that the model incorrectly predicts to be in the negative category.
4.4. Evaluation Metrics
5. Results and Discussion
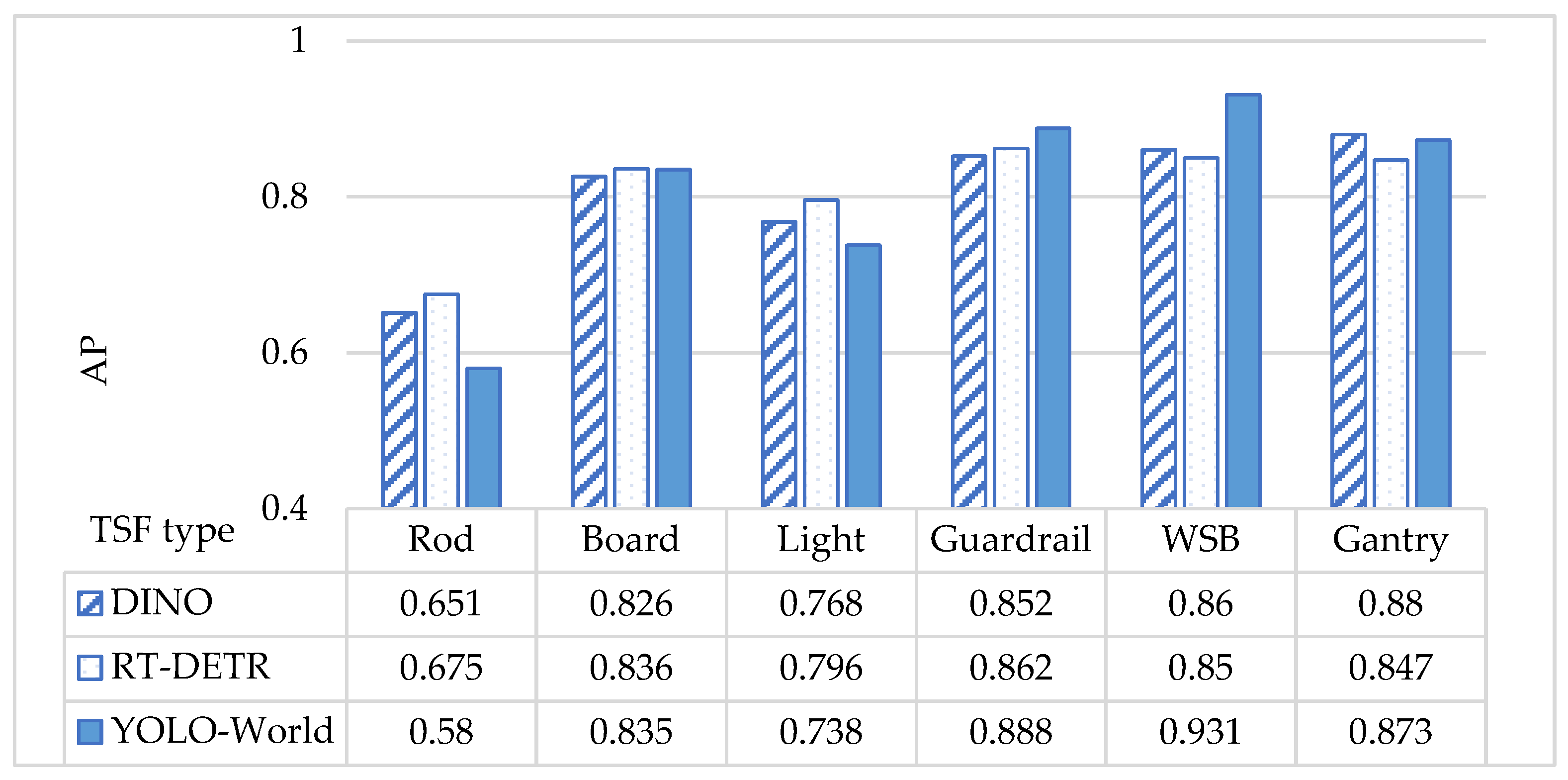
5.1. Evaluation Results for Comparison of Different Models
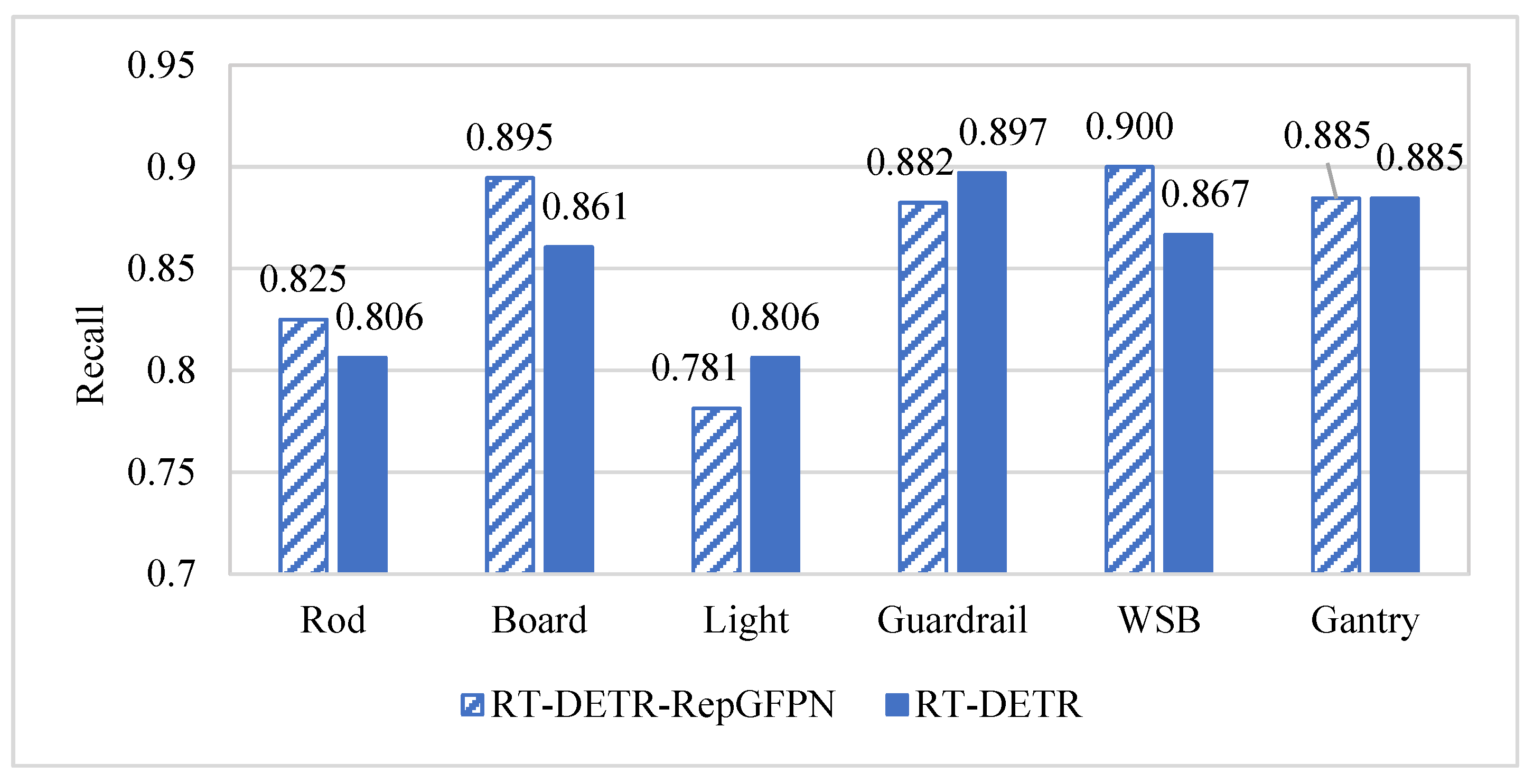
5.2. Model Improvement Results
6. Conclusions
- A comparison of the YOLO and DETR series of models demonstrated that the detection accuracy of RT-DETR and YOLO-World was comparable, with the former exhibiting superior accuracy and the latter demonstrating a higher efficiency. However, the TSFR model size and complexity of RT-DETR remained considerably higher than that of the YOLO-World.
- The RT-DETR-RepGFPN model was proposed for the TSFR task, which further enhanced the model with a mAP of 0.823, increasing the number of parameters by 4 M while only reducing the operational efficiency of FPS by six.
- The introduction of RepGFPN significantly enhanced recall for the categories of rod, board, and WSB but reduced the detection rate of lights and guardrails.
- The problem of duplicate detection was somewhat ameliorated.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- GB50688-2011(2019); Code for the Design of Urban Road Traffic Facility. Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2019. (In Chinese)
- Cui, T. Research on design technology of safety facilities in highway traffic engineering. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2020; Volume 587, p. 012006. [Google Scholar] [CrossRef]
- Chen, R.; Hei, L.; Lai, Y. Image Recognition and Safety Risk Assessment of Traffic Sign Based on Deep Convolution Neural Network. IEEE Access 2020, 8, 201799–201805. [Google Scholar] [CrossRef]
- Lv, Z.; Shang, W. Impacts of intelligent transportation systems on energy conservation and emission reduction of transport systems: A comprehensive review. Green Technol. Sustain. 2023, 1, 100002. [Google Scholar] [CrossRef]
- Arcos-García, Á.; Álvarez-García, J.A.; Soria-Morillo, L.M. Deep neural network for traffic sign recognition systems: An analysis of spatial transformers and stochastic optimisation methods. Neural Netw. Off. J. Int. Neural Netw. Soc. 2018, 99, 158–165. [Google Scholar] [CrossRef] [PubMed]
- Min, W.; Liu, R.; He, D.; Han, Q.; Wei, Q.; Wang, Q. Traffic Sign Recognition Based on Semantic Scene Understanding and Structural Traffic Sign Location. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15794–15807. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Li, Y.; Wang, S. Traffic Sign Recognition With Lightweight Two-Stage Model in Complex Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1121–1131. [Google Scholar] [CrossRef]
- Zhu, Y.; Yan, W.Q. Traffic sign recognition based on deep learning. Multimed. Tools Appl. 2022, 81, 17779–17791. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA; pp. 2110–2118. [Google Scholar] [CrossRef]
- Philipsen, M.P.; Jensen, M.B.; Mogelmose, A.; Moeslund, T.B.; Trivedi, M.M. Traffic Light Detection: A Learning Algorithm and Evaluations on Challenging Dataset. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2341–2345. [Google Scholar] [CrossRef]
- Almeida, T.; Macedo, H.; Matos, L.; Prado, B.; Bispo, K. Frequency Maps as Expert Instructions to lessen Data Dependency on Real-time Traffic Light Recognition. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1463–1468. [Google Scholar] [CrossRef]
- Behrendt, K.; Novak, L.; Botros, R. A deep learning approach to traffic lights: Detection, tracking, and classification. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 1370–1377. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, Q.; Liang, X.; Wang, Y.; Zhou, C.; Mikulovich, V.I. Traffic lights detection and recognition method based on the improved YOLOv4 algorithm. Sensors 2022, 22, 200. [Google Scholar] [CrossRef]
- Ning, Z.; Wang, H.; Li, S.; Xu, Z. YOLOv7-RDD: A Lightweight Efficient Pavement Distress Detection Model. IEEE Transation Intel. Transp. Syst. 2024, 25, 6994–7003. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, H.; Xu, Z. A method for surveying road pavement distress based on front-view image data using a lightweight segmentation approach. J. Comput. Civ. Eng. 2024, 38, 04024026. [Google Scholar] [CrossRef]
- Lu, L.; Wang, H.; Wan, Y.; Xu, F. A Detection Transformer-Based Intelligent Identification Method for Multiple Types of Road Traffic Safety Facilities. Sensors 2024, 24, 3252. [Google Scholar] [CrossRef]
- Xie, F.; Zheng, G. Traffic Sign Object Detection with the Fusion of SSD and FPN. In Proceedings of the 2023 IEEE International Conference on Electrical, Automation and Computer Engineering (ICEACE), Changchun, China, 29–31 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 995–998. [Google Scholar] [CrossRef]
- Wang, W.; He, F.; Li, Y.; Tang, S.; Li, X.; Xia, J.; Lv, Z. Data information processing of traffic digital twins in smart cities using edge intelligent federation learning. Inf. Process. Manag. 2023, 60, 103171. [Google Scholar] [CrossRef]
- Purwar, S.; Chaudhry, R. A Comprehensive Study on Traffic Sign Detection in ITS. In Proceedings of the 2023 International Conference on Disruptive Technologies (ICDT), Greater Noida, India, 11–12 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 173–179. [Google Scholar] [CrossRef]
- Bu, T.; Zhu, J.; Ma, T. A UAV Photography–Based Detection Method for Defective Road Marking. J. Perform. Constr. Facil. 2022, 36, 04022035. [Google Scholar] [CrossRef]
- Fang, L.; Shen, G.; Luo, H.; Chen, C.; Zhao, Z. Automatic Extraction of Roadside Traffic Facilities From Mobile Laser Scanning Point Clouds Based on Deep Belief Network. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1964–1980. [Google Scholar] [CrossRef]
- Thanh Ha, T.; Chaisomphob, T. Automated Localization and Classification of Expressway Pole-Like Road Facilities from Mobile Laser Scanning Data. Adv. Civ. Eng. 2020, 2020, 5016783. [Google Scholar] [CrossRef]
- Jiang, X.; Cui, Q.; Wang, C.; Wang, F.; Zhao, Y.; Hou, Y.; Zhuang, R.; Mei, Y.; Shi, G. A Model for Infrastructure Detection along Highways Based on Remote Sensing Images from UAVs. Sensors 2023, 23, 3847. [Google Scholar] [CrossRef]
- Liu, Y.; Shi, G.; Li, Y.; Zhao, Z. M-YOLO: Traffic Sign Detection Algorithm Applicable to Complex Scenarios. Symmetry 2022, 14, 952. [Google Scholar] [CrossRef]
- Sanjeewani, P.; Verma, B. Optimization of Fully Convolutional Network for Road Safety Attribute Detection. IEEE Access 2021, 9, 120525–120536. [Google Scholar] [CrossRef]
- Yang, Z.; Zhao, C.; Maeda, H.; Sekimoto, Y. Development of a Large-Scale Roadside Facility Detection Model Based on the Mapillary Dataset. Sensors 2022, 22, 9992. [Google Scholar] [CrossRef]
- Zhang, X.; Hsieh, Y.-A.; Yu, P.; Yang, Z.; Tsai, Y.J. Multiclass Transportation Safety Hardware Asset Detection and Segmentation Based on Mask-RCNN with RoI Attention and IoMA-Merging. J. Comput. Civ. Eng. 2023, 37, 04023024. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern RecognitionSeattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial CNN for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The Apolloscape open dataset for autonomous driving and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed]
- Johner, F.M.; Wassner, J. Efficient evolutionary architecture search for CNN optimization on GTSRB. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 56–61. [Google Scholar] [CrossRef]
- de Charette, R.; Nashashibi, F. Real time visual traffic lights recognition based on Spot Light Detection and adaptive traffic lights templates. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 358–363. [Google Scholar] [CrossRef]
- Zhang, J.; Zou, X.; Kuang, L.D.; Wang, J.; Sherratt, R.S.; Yu, X. CCTSDB 2021: A more comprehensive traffic sign detection benchmark. Hum.-Centric Comput. Inf. Sci. 2022, 12, 23. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; Available online: http://arxiv.org/pdf/2304.08069v3 (accessed on 21 July 2024).
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Jiang, S.; Wang, H.; Ning, Z.; Li, S. Lightweight pruning model for road distress detection using unmanned aerial vehicles. Autom. Constr. 2024, 168, 105789. [Google Scholar] [CrossRef]
- Xu, F.; Wan, Y.; Ning, Z.; Wang, H. Comparative Study of Lightweight Target Detection Methods for Unmanned Aerial Vehicle-Based Road Distress Survey. Sensors 2024, 24, 6159. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Viso.AI Gaudenz Boesch. Yolov11: A New Iteration of “You Only Look Once. 2024. Available online: https://viso.ai/computer-vision/yolov11/ (accessed on 10 October 2024).
- Ultralytics. Ultralytics yolov11. 2024. Available online: https://docs.ultralytics.com/models/yolo11/ (accessed on 10 October 2024).
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16901–16911. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making VGG-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar] [CrossRef]
- Jiang, Y.; Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. Giraffedet: A heavy-neck paradigm for object detection. arXiv 2022, arXiv:2202.04256. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Chamm Switzerland, 2022; pp. 649–667. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Data Collection Area | Description | Data Type | Application Scenarios |
|---|---|---|---|---|
| Cityscapes [29] | Berlin, Germany, | Cityscape dataset | Images, segmentation labeling | Image segmentation, scene understanding |
| etc. | ||||
| KITTI [30] | Karlsruhe, Germany, etc. | The largest computer vision algorithm evaluation dataset for autonomous driving scenarios in the world | Images, LiDAR data, inertial measurement unit data | Evaluation of stereoscopic images, 3D object detection, 3D tracking, etc. |
| nuScenes [31] | Boston, USA; Singapore | Large-scale multimodal dataset for autonomous driving research | Images, LiDAR data, inertial measurement unit data, etc. | Target detection, target tracking, image segmentation, etc. |
| Waymo Open [32] | Six cities in the USA | Large-scale sensor dataset for autonomous driving research | Images, LiDAR data, inertial measurement unit data | Detection, tracking, motion prediction, and planning |
| BDD100K [33] | New York and San Francisco, USA | Large-scale dataset for autonomous driving perception and understanding | Images, LiDAR data, inertial measurement unit data | Target detection, image segmentation, behavioral recognition, etc. |
| CULane [34] | Beijing, China | Lane line detection and tracking dataset for automated driving research | Images, LiDAR data, inertial measurement unit data | Lane line detection and tracking |
| ApolloScape [35] | Four cities in China | Large-scale multimodal dataset for autonomous driving from Baidu Inc. | Images, LiDAR data, inertial measurement unit data | Target detection, image segmentation, target tracking, etc. |
| GTSRB [36] | Multiple cities in Germany | German traffic sign recognition benchmark | Images, bounding box labeling | Traffic sign detection |
| TT100k [9] | Several cities in China | Tsinghua-Tencent traffic sign dataset | Images, bounding box labeling | Traffic sign detection |
| LaRa [37] | Riga, Latvia | TSR dataset | Images, bounding box labeling | Traffic signal detection |
| LISA [10] | California, USA | TLR dataset | Images, bounding box labeling | Traffic signal detection |
| TSF-CQU [16] | Shanghai, Chongqing, and Ningbo, China | Traffic facility dataset | Images, bounding box labeling | Target detection, image segmentation, target tracking, etc. |
| CCTSDB 2021 [38] | China | TSR dataset | Images; bounding box labeling; and attributes including category meanings (three types), weather conditions (six types), and sign sizes (five types) | Traffic sign detection |
| Category | Number | Training Set |
|---|---|---|
| Rod | 1897 | 1661 |
| Board | 2961 | 2530 |
| Light | 1547 | 1337 |
| Guardrail | 1483 | 1275 |
| WSB | 239 | 200 |
| Gantry | 283 | 241 |
| Total | 8410 | 7244 |
| Models | Params (M) | FLOPs (G) | TT for 100 Epochs (h) | GMT (G) | mAP |
|---|---|---|---|---|---|
| DINO | 46.606 | 279 | 9.58 | 9.75 | 0.806 |
| RT-DETR | 20.094 | 58.6 | 4.2 | 3.48 | 0.811 |
| Yolov7-tiny | 6.021 | 13.1 | 1.62 | 11.7 | 0.800 |
| Yolov9-t | 2.618 | 10.7 | 1.28 | 5.8 | 0.789 |
| Yolov10-n | 2.696 | 8.2 | 0.4 | 5.5 | 0.753 |
| Yolov11-n | 2.583 | 6.3 | 0.27 | 5.2 | 0.788 |
| Yolo-World | 12.749 | 33.3 | 0.58 | 24.6 | 0.807 |
| Models | Params (M) | FPS | mAP | Precision | Recall |
| RT-DETR | 20.0941 | 153 | 0.811 | 0.594 | 0.846 |
| RT-DETR-RGFP | 24.9633 | 147 | 0.823 | 0.584 | 0.856 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, Y.; Wang, H.; Lu, L.; Lan, X.; Xu, F.; Li, S. An Improved Real-Time Detection Transformer Model for the Intelligent Survey of Traffic Safety Facilities. Sustainability 2024, 16, 10172. https://doi.org/10.3390/su162310172
Wan Y, Wang H, Lu L, Lan X, Xu F, Li S. An Improved Real-Time Detection Transformer Model for the Intelligent Survey of Traffic Safety Facilities. Sustainability. 2024; 16(23):10172. https://doi.org/10.3390/su162310172
Chicago/Turabian StyleWan, Yan, Hui Wang, Lingxin Lu, Xin Lan, Feifei Xu, and Shenglin Li. 2024. "An Improved Real-Time Detection Transformer Model for the Intelligent Survey of Traffic Safety Facilities" Sustainability 16, no. 23: 10172. https://doi.org/10.3390/su162310172
APA StyleWan, Y., Wang, H., Lu, L., Lan, X., Xu, F., & Li, S. (2024). An Improved Real-Time Detection Transformer Model for the Intelligent Survey of Traffic Safety Facilities. Sustainability, 16(23), 10172. https://doi.org/10.3390/su162310172