
Ada-XG-CatBoost: A Combined Forecasting Model for Gross Ecosystem Product (GEP) Prediction


Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Data Source
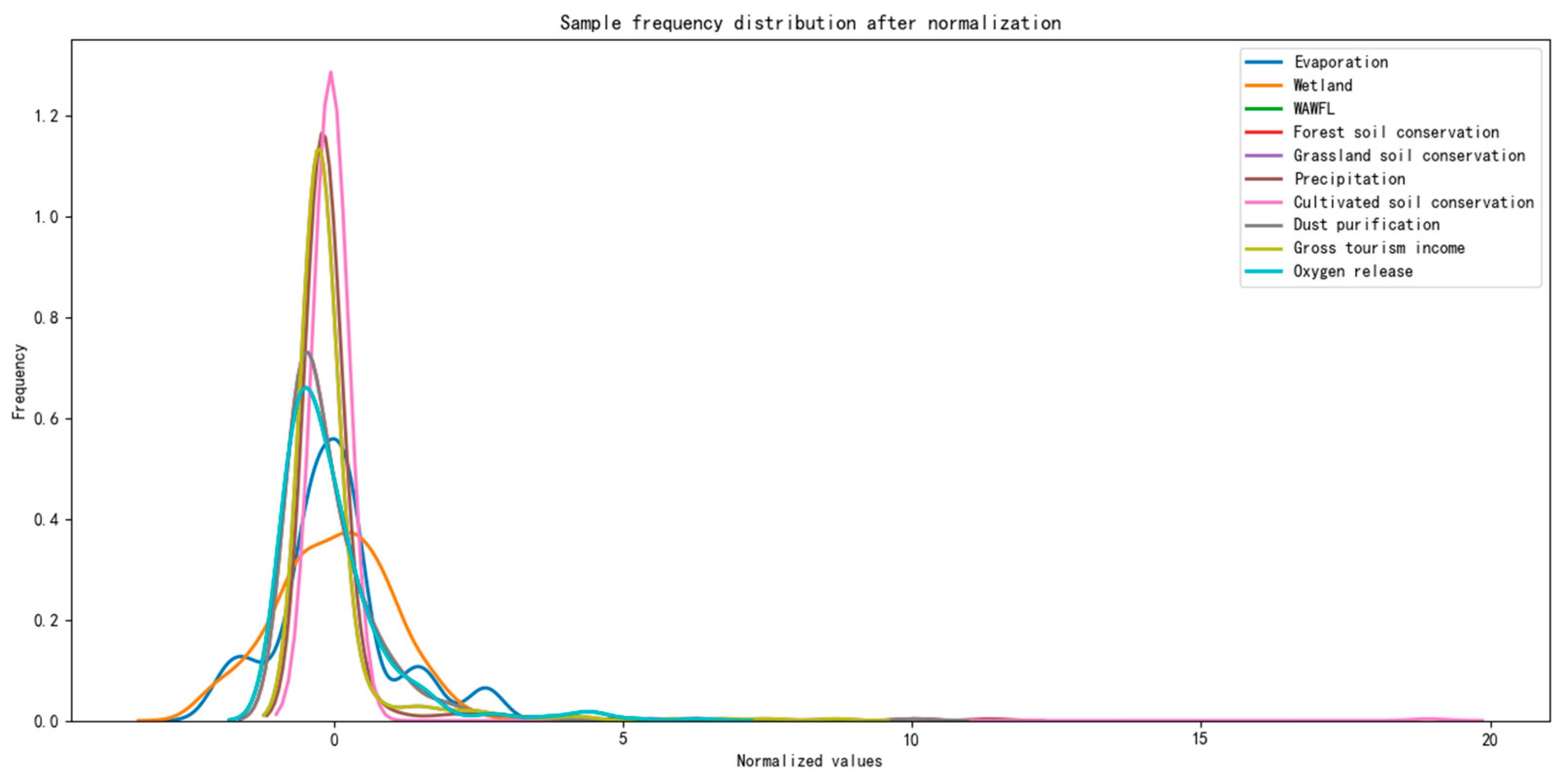
2.2. Data Preprocessing
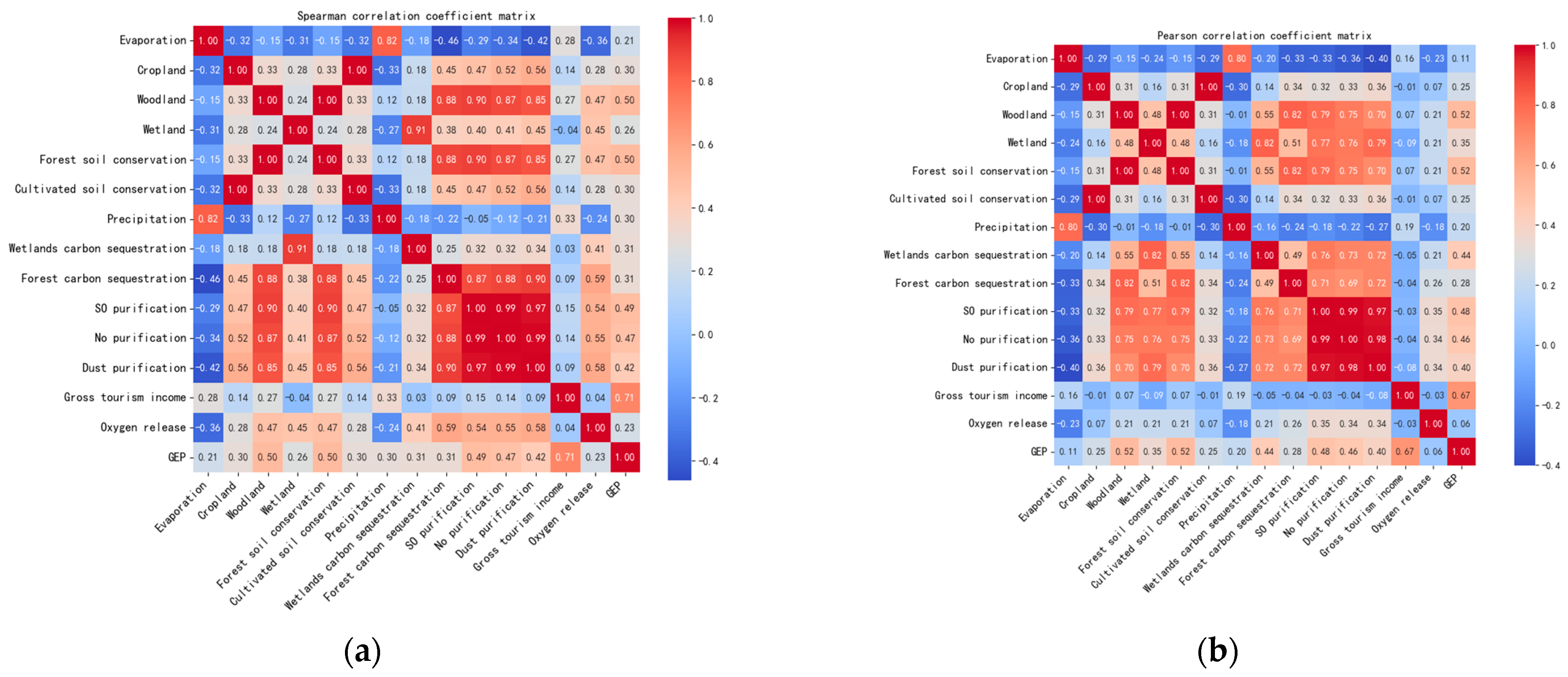
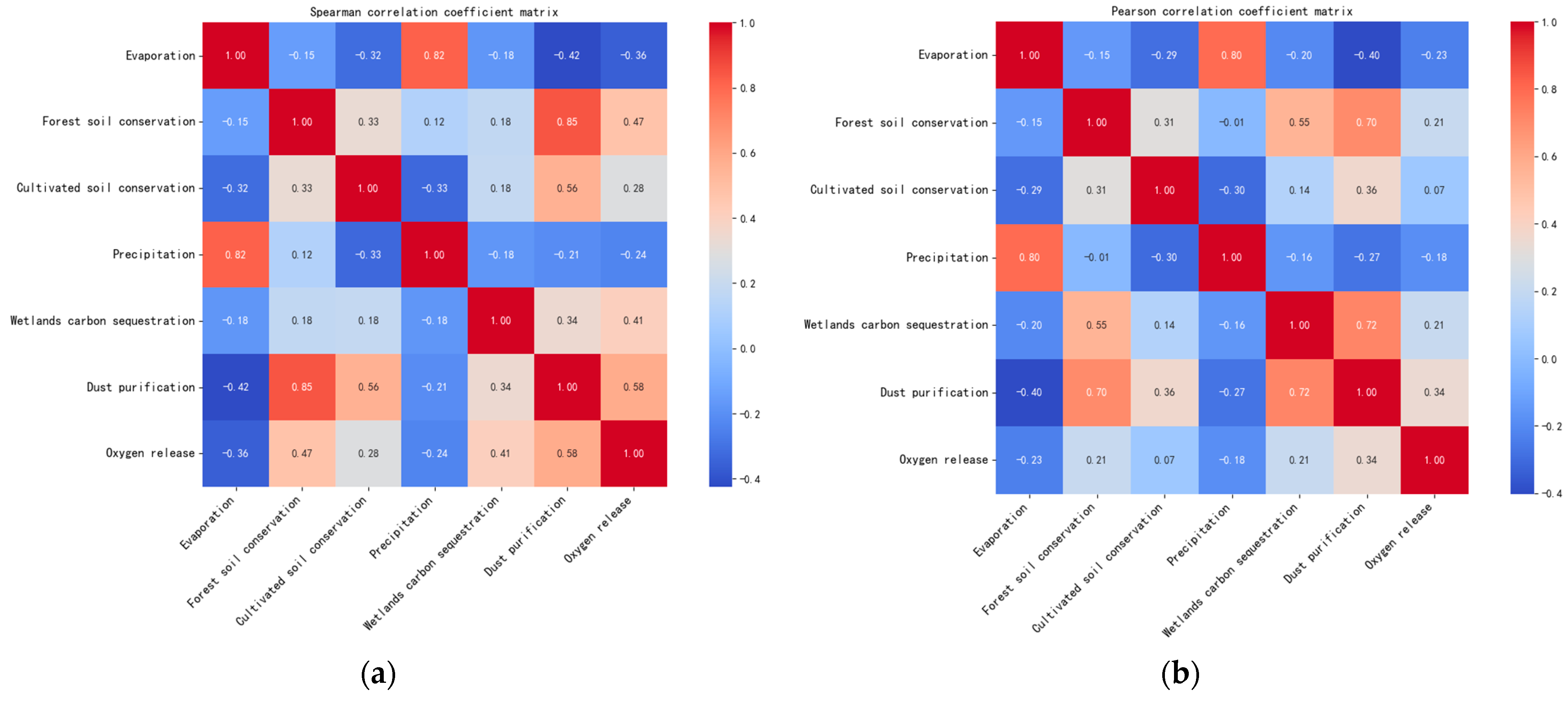
2.3. Feature Correlation Analysis
2.4. Feature Selection
2.5. Parameter Tuning
2.6. Evaluation Indicator
2.7. Introduction to the Model
2.7.1. CatBoost
- Solves the problem of prediction bias: CatBoost uses a fully symmetric tree as a base model. It utilizes sort boosting to counteract anomalies in the dataset, which avoids the bias of gradient estimation and solves the problem of prediction bias.
- Effectively avoids overfitting: Leaf nodes are also calculated to select the structure of the tree when dealing with categorical features during the training process. CatBoost algorithm can deal with categorical features better on the basis of GBDT. CatBoost optimally upgrades the GBDT algorithm by adding a priori terms to reduce the influence of unfavorable factors such as noise and low-frequency data, as shown in Equation (6).
2.7.2. XGBoost
- High fitting accuracy: The XGBoost model utilizes a second-order Taylor’s formula to expand the loss function using both first-order and second-order derivatives as a way to improve the prediction accuracy.
- Lower model complexity: The XGBoost model adds regularization terms to the loss function of the gradient boosting decision tree (GBDT) to effectively reduce the model complexity. Its learning process is explained as follows:
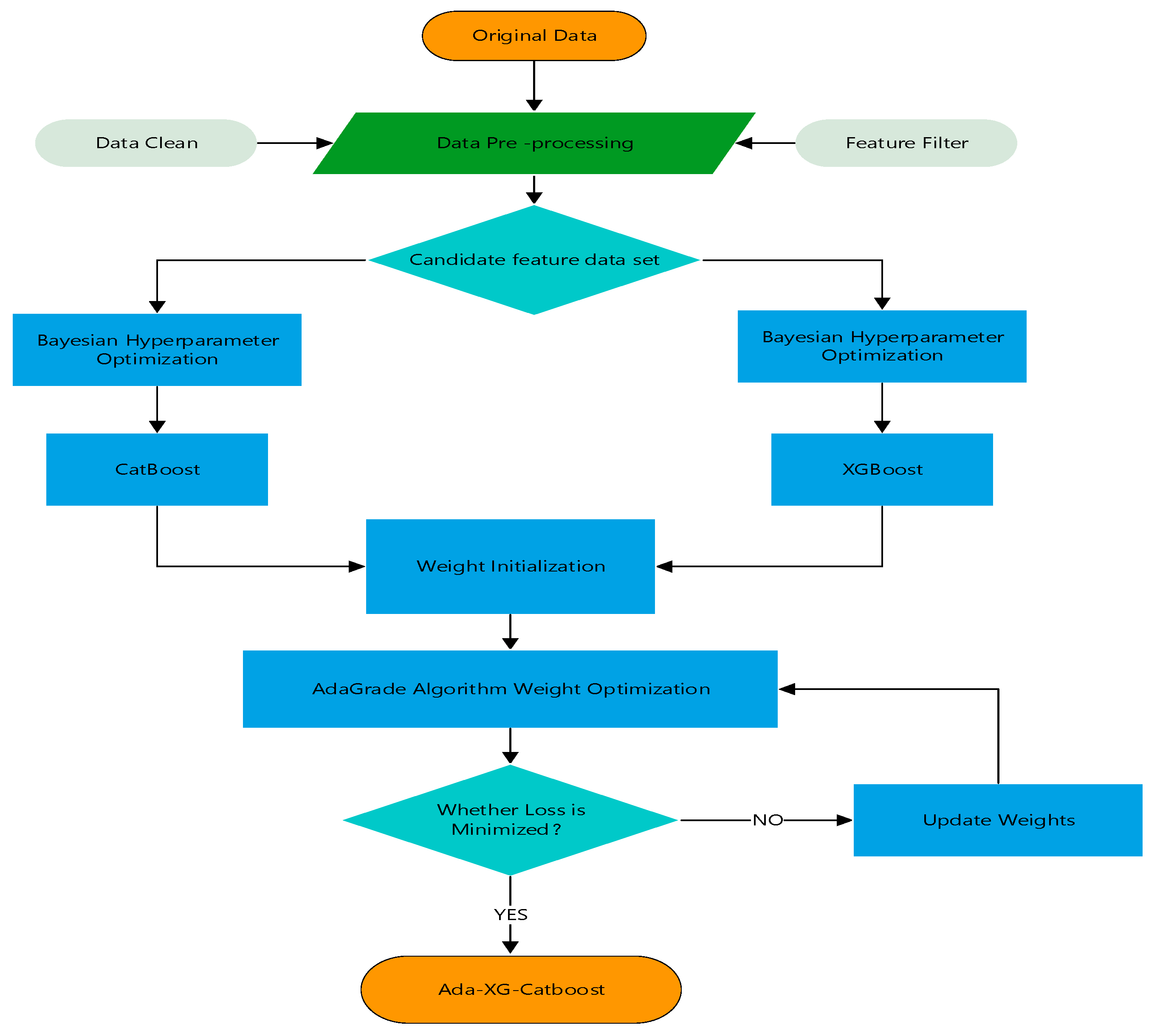
2.7.3. Ada-XGBoost-CatBoost
2.7.4. Combinatorial Modeling Strategies
3. Results and Discussion
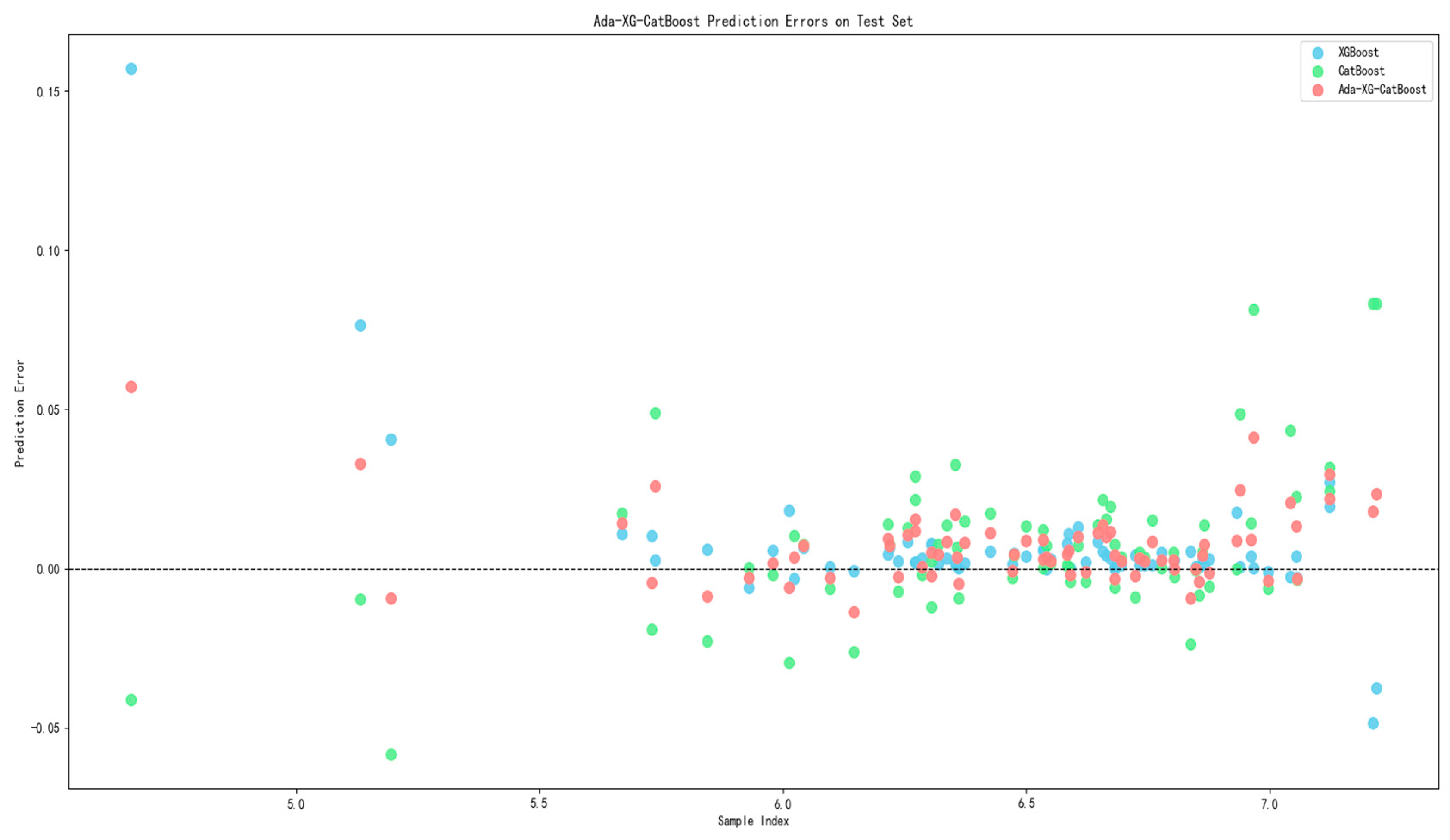
3.1. Models Performance Comparison and Analysis
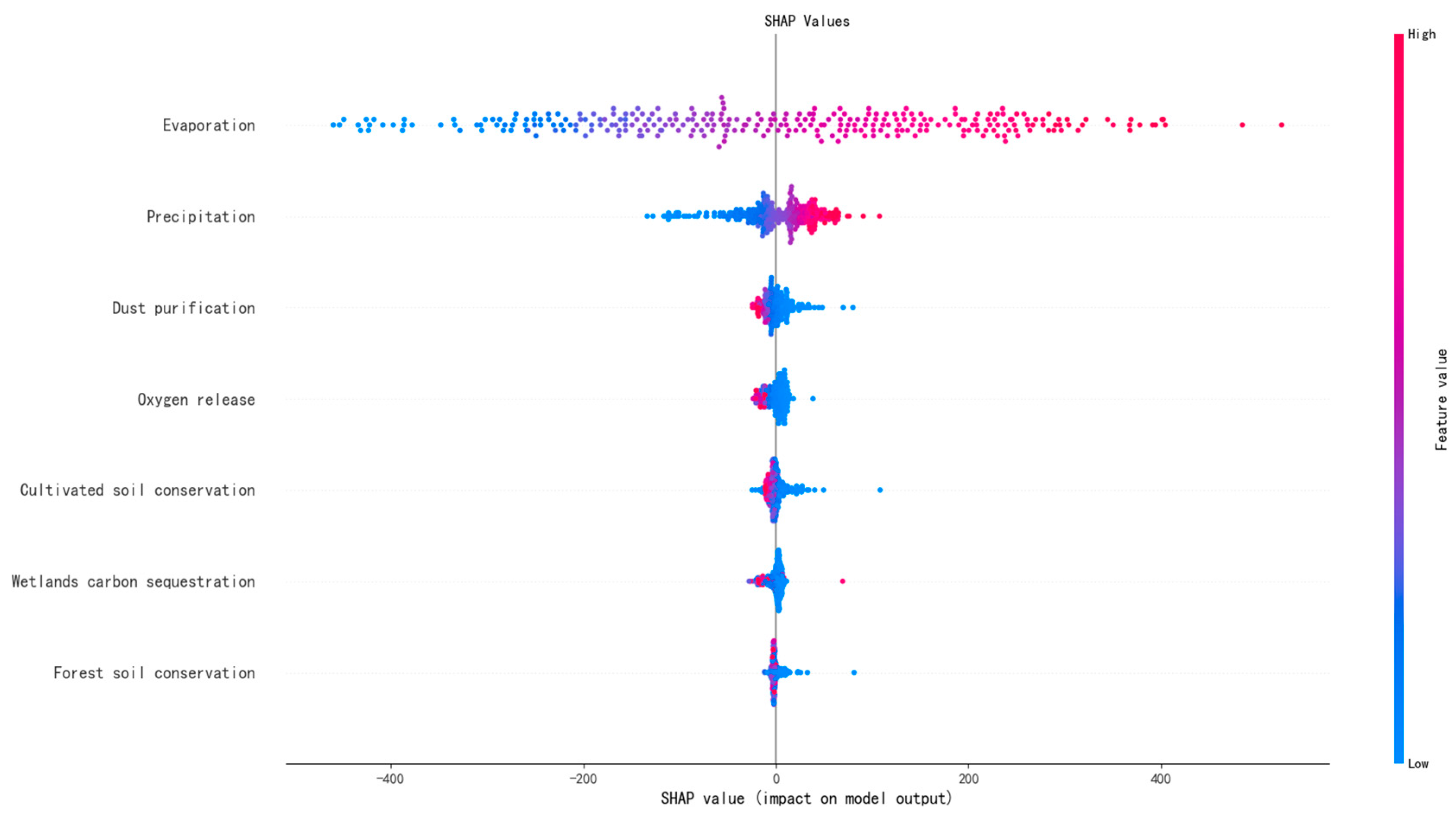
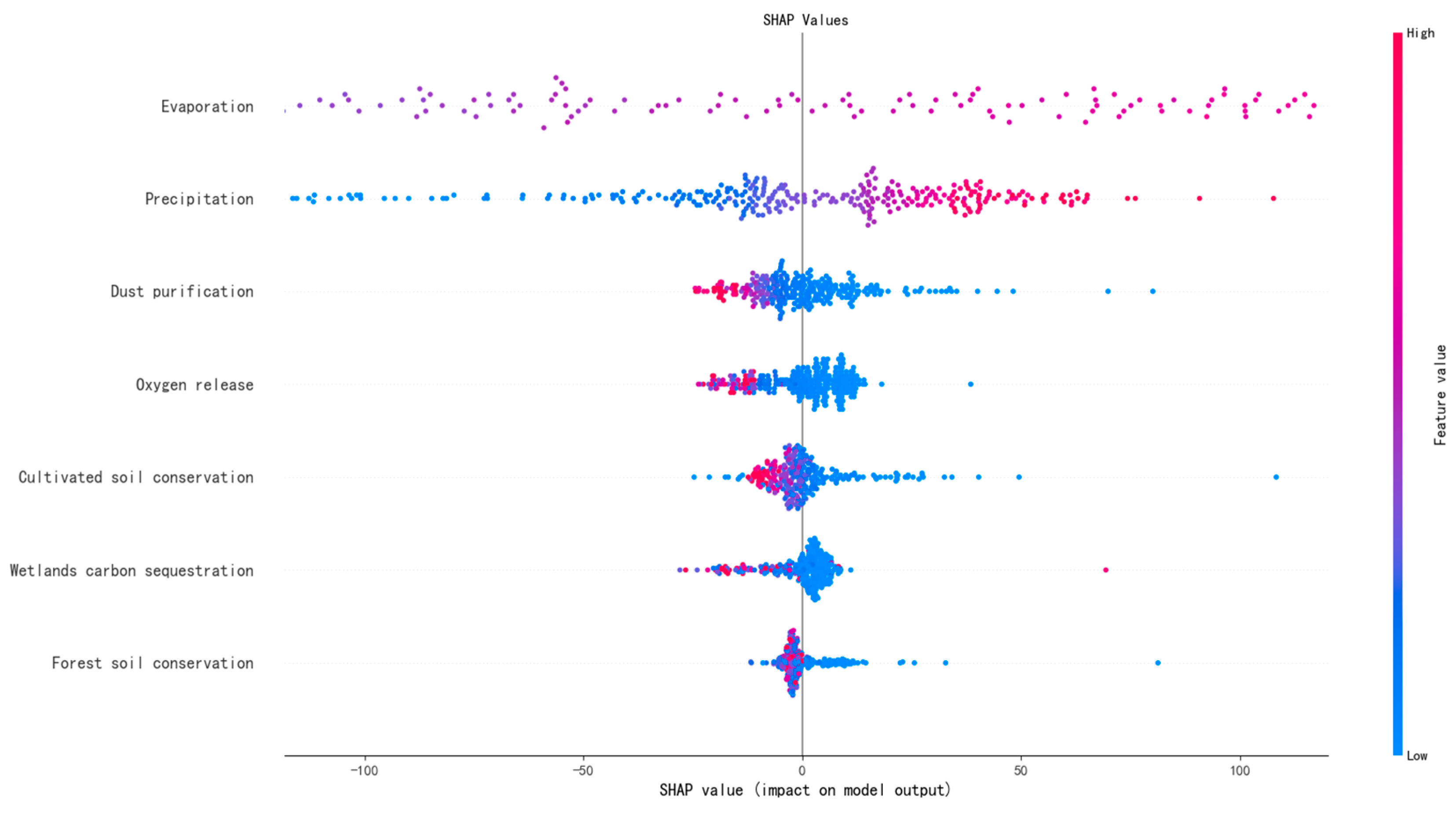
3.2. Model SHAP Value Interpretability Analysis
4. Conclusions
4.1. Research Content
- In terms of GEP prediction, the Ada-XG-CatBoost model is superior to the single models of XGBoost and CatBoost, with relatively high prediction accuracy and relatively good generalization ability. Compared to a single model, introducing a combined model enhances the mitigation of prediction bias, bolsters the model’s generalization performance and accuracy, and addresses the limitations of the individual models, resulting in more pronounced advantages.
- In practical GEP prediction studies, the Ada-XG-CatBoost combined model derived from the combination strategy serves as a more precise, efficient, and reliable generalization model. It offered a fresh approach and methodology for machine learning, offering significant reference value for government and local strategic planning.
- AdaGrad adaptively adjusted the learning rate based on the historical gradients of each parameter, eliminating the need for a globally fixed rate. The model achieved optimal weights after just 250 iterations, significantly reducing the iteration count and cutting down operational costs.
4.2. Limitations for Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, G.; Yu, F.; Wang, J. Measuring gross ecosystem product (GEP) of 2015 terrestrial ecosystem in China. China Environ. Sci. 2017, 37, 1474–1482. [Google Scholar]
- Ouyang, Z.; Song, C.; Zheng, H.; Polasky, S.; Xiao, Y.; Bateman, I.J.; Liu, J.; Ruckelshaus, M.; Shi, F.; Xiao, Y.; et al. Using gross ecosystem product (GEP) to value nature in decision making. Proc. Natl. Acad. Sci. USA 2020, 117, 14593–14601. [Google Scholar] [CrossRef] [PubMed]
- Costanza, R.; de Groot, R.; Braat, L.; Kubiszewski, I.; Fioramonti, L.; Sutton, P.; Farber, S.; Grasso, M. Twenty years of ecosystem services: How far have we come and how far do we still need to go? Ecosyst. Serv. 2017, 28, 1–16. [Google Scholar] [CrossRef]
- Jiang, W.; Wu, T.; Fu, B.J. The value of ecosystem services in China: A systematic review for twenty years. Ecosyst. Serv. 2021, 52, 101365. [Google Scholar] [CrossRef]
- Aedasong, A.; Roongtawanreongsri, S.; Hajisamae, S.; James, D. Ecosystem services of a wetland in the politically unstable southernmost provinces of Thailand. Trop. Conserv. Sci. 2019, 12, 1940082919871827. [Google Scholar] [CrossRef]
- Costanza, R.; de Groot, R.; Farber, S.; Grasso, M.; Hannon, B.; Limburg, K.; Naeem, S.; Paruelo, J.; Raskin, R.G.; Sutton, P.; et al. The value of the world’s ecosystem services and natural capital. Nature 1997, 387, 253–260. [Google Scholar] [CrossRef]
- Xia, Q.-Q.; Chen, Y.-N.; Zhang, X.-Q.; Ding, J.-L. Spatiotemporal Changes in Ecological Quality and Its Associated Driving Factors in Central Asia. Remote Sens. 2022, 14, 3500. [Google Scholar] [CrossRef]
- Nie, Z.; Li, N.; Pan, W.; Yang, Y.; Chen, W.; Hong, C. Quantitative Research on the Form of Traditional Villages Based on the Space Gene—A Case Study of Shibadong Village in Western Hunan, China. Sustainability 2022, 14, 8965. [Google Scholar] [CrossRef]
- Ouyang, Z.; Zhu, C.; Yang, G.; Xu, W.; Zheng, H.; Zhang, Y.; Xiao, Y. Gross ecosystem product: Concept, accounting framework and case study. Acta Ecol. Sin. 2013, 33, 6747–6761. [Google Scholar] [CrossRef]
- Bo, W.; Wang, L.; Cao, J.; Wang, X.; Xiao, Y.; Ouyang, Z. Valuation of China’s ecological assets in forests. Acta Ecol. Sin. 2017, 37, 4182–4190. [Google Scholar]
- Cheng, M.; Huang, B.; Kong, L.; Ouyang, Z. Ecosystem Spatial Changes and Driving Forces in the Bohai Coastal Zone. Int. J. Environ. Res. Public Health 2019, 16, 536. [Google Scholar] [CrossRef] [PubMed]
- Gowdy, J.; Howarth, R.; Tisdell, C. The Economics of Ecosystems and Biodiversity: Ecological and Economic Foundations; Rensselaer Polytechnic Institute: Troy, NY, USA, 2010. [Google Scholar]
- Yu, M.; Jin, H.; Li, Q.; Yao, Y.; Zhang, Z. Gross Ecosystem Product (GEP) Accounting for Chenggong District. J. West China For. Sci. 2020, 49, 41–48. [Google Scholar]
- Wang, P.; Chen, Y.; Liu, K.; Li, X.; Zhang, L.; Chen, L.; Shao, T.; Li, P.; Yang, G.; Wang, H.; et al. Coupling Coordination Relationship and Driving Force Analysis between Gross Ecosystem Product and Regional Economic System in the Qinling Mountains in China. Land 2024, 13, 234. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Q.; Zhang, R.; Ren, B.; Wu, X.; Wu, Y.; Tang, J. A Spatiotemporal Analysis of Hainan Island’s 2010–2020 Gross Ecosystem Product Accounting. Sustainability 2022, 14, 15624. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Liu, C.; Sun, J.; Ran, Q. Optimizing the Valuation and Implementation Path of the Gross Ecosystem Product: A Case Study of Tonglu County, Hangzhou City. Sustainability 2024, 16, 1408. [Google Scholar] [CrossRef]
- Gao, J.; Yu, Z.; Wang, L.; Vejre, H. Suitability of regional development based on ecosystem service benefits and T losses: A case study of the Yangtze River Delta urban agglomeration China. Ecol. Indic. 2019, 107, 105579. [Google Scholar] [CrossRef]
- Andersson, E.; Barthel, S.; Bergstrom, S.; Colding, J.; Elmqvist, T.; Folke, C. Reconnecting cities to the biosphere: Stewardship of green infrastructure and urban ecosystem services. MBIO 2014, 43, 445–453. [Google Scholar]
- Liu, J.; Zhang, Q.; Wang, Q.; Liv, Y.; Tang, Y. Gross Ecosystem Product Accounting of a Globally Important Agricultural Heritage System: The Longxian Rice–Fish Symbiotic System. Sustainability 2023, 15, 10407. [Google Scholar] [CrossRef]
- Boumans, R.; Roman, J.; Altman, I.; Kaufman, L. The Multiscale Integrated Model of Ecosystem Services (MIMES): Simulating the interactions of coupled human and natural systems. Ecosyst. Serv. 2015, 12, 30–41. [Google Scholar] [CrossRef]
- Rao, N.; Ghermandi, A.; Portela, R.; Wang, X. Global values of coastal ecosystem services: A spatial economic analysis of shoreline protection values. Ecosyst. Serv. 2015, 11, 95–105. [Google Scholar] [CrossRef]
- Sheng, L.; Jin, Y.; Huang, J. Value Estimation of Conserving Water and Soil of Ecosystem in China. J. Nat. Resour. 2010, 25, 1105–1113. [Google Scholar]
- Bai, Y.; Li, H.; Wang, X.; Juha, M.A.; Jiang, B.; Wang, M.; Liu, W. Evaluating Natural Resource Assets and Gross Ecosystem Products Using Ecological Accounting System: A Case Study in Yunnan Province. J. Nat. Resour. 2017, 32, 1100–1112. [Google Scholar]
- Xie, G.D.; Zhen, L.; Lu, C.X.; Xiao, Y.; Chen, C. Expert Knowledge Based Valuation Method of Ecosystem Services in China. J. Nat. Resour. 2008, 23, 911–919. [Google Scholar]
- Liao, Z.; Zhou, B.; Zhu, J.; Jia, H. A critical review of methods, principles and progress for estimating the gross primary productivity of terrestrial ecosystems. Front. Environ. Sci. 2023, 11, 1093095. [Google Scholar] [CrossRef]
- Qiu, X.; Zhao, R.; Chen, S. Review of Research on Value Realization of Ecological Products. China For. Prod. Ind. 2023, 6, 79–84. [Google Scholar]
- Zou, Z.; Wu, T.; Xiao, Y.; Song, C.; Wang, K.; Ouyang, Z. Valuing natural capital amidst rapid urbanization: Assessing the gross ecosystem product (GEP) of China’s ‘Chang-Zhu-Tan’ megacity. Environ. Res. Lett. 2020, 15, 124019. [Google Scholar] [CrossRef]
- Wang, W.; Xu, C.; Li, Y. Priority areas and benefits of ecosystem restoration in Beijing. Environ. Sci. Pollut. Res. Int. 2023, 30, 83600–83614. [Google Scholar] [CrossRef] [PubMed]
- Zang, Z.; Zhang, Y.; Xi, X. Analysis of the Gross Ecosystem Product—Gross Domestic Product Synergistic States, Evolutionary Process, and Their Regional Contribution to the Chinese Mainland. Land 2022, 11, 732. [Google Scholar] [CrossRef]
- Piyathilake, I.D.U.H.; Udayakumara, E.P.N.; Ranaweera, L.V.; Gunatilake, S.K. Modeling predictive assessment of carbon storage using invest model in Uva province, Sri Lanka. Model. Earth Syst. Environ. 2021, 8, 2213–2223. [Google Scholar] [CrossRef]
- Ouyang, Z.; Lin, Y.; Song, C. Research on Gross Ecosystem Product (GEP): Case study of Lishui City, Zhejiang Province. Environ. Sustain. Dev. 2020, 45, 80–85. [Google Scholar]
- Feng, M.; Liu, S.; Euliss, N.H., Jr.; Young, C.; Mushet, D.M. Prototyping an online wetland ecosystem services model using open model sharing standards. Environ. Model. Softw. 2011, 26, 458–468. [Google Scholar] [CrossRef]
- Ondiek, R.A.; Kitaka, N.; Oduor, S.O. Assessment of provisioning and cultural ecosystem services in natural wetlands and rice fields in Kano floodplain. Kenya. Ecosyst. Serv. 2016, 21, 166–173. [Google Scholar] [CrossRef]
- Wang, L.; Su, K.; Jiang, X.; Zhou, X.; Yu, Z.; Chen, Z.; Wei, C.; Zhang, Y.; Liao, Z. Measuring Gross Ecosystem Product (GEP) in Guangxi, China, from 2005 to 2020. Land 2022, 11, 1213. [Google Scholar] [CrossRef]
- Costanza, R.; Groot, R.; Sutton, P.; van der Ploeg, S.; Anderson, S.J.; Kubiszewski, I.; Farber, S.; Turner, R.K. Changes in the global value of ecosystem services. Glob. Environ. Chang. 2014, 26, 152–158. [Google Scholar] [CrossRef]
- Jiang, H.; Wu, W.; Wang, J.; Yang, W.; Gao, Y.; Duan, Y.; Ma, G.; Wu, C.; Shao, J. Mapping global value of terrestrial ecosystem services by countries. Ecosyst. Serv. 2021, 52, 101361. [Google Scholar] [CrossRef]
- He, F.; Wei, X.; Zhou, J. Machine Learning-Driven Assessment of Ecological Resources: A Case Study in the Pudatso National Park. Yunnan Geogr. Environ. Res. 2023, 35, 1001–7852. [Google Scholar]
- Wang, H.; Shao, W.; Hu, Y.; Cao, W.; Zhang, Y. Assessment of Six Machine Learning Methods for Predicting Gross Primary Productivity in Grassland. Remote Sens. 2023, 15, 3475. [Google Scholar] [CrossRef]
- Yi, Z.; Wu, L. Identification of factors influencing net primary productivity of terrestrial ecosystems based on interpretable machine learning—Evidence from the county-level administrative districts in China. J. Environ. Manag. 2023, 326, 116798. [Google Scholar] [CrossRef]
- Zhu, X.; He, H.; Ma, M.; Ren, X.; Zhang, L.; Zhang, F.; Li, Y.; Shi, P.; Chen, S.; Wang, Y.; et al. Estimating Ecosystem Respiration in the Grasslands of Northern China Using Machine Learning: Model Evaluation and Comparison. Sustainability 2020, 12, 2099. [Google Scholar] [CrossRef]
- Xiao, J.F.; Zhuang, Q.L.; Baldocchi, D.D.; Law, B.E.; Richardson, A.D.; Chen, J.Q.; Oren, R.; Starr, G.; Noormets, A.; Ma, S.Y.; et al. Estimation of net ecosystem carbon exchange for the conterminous United States by combining MODIS and AmeriFlux data. Agric. For. Meteorol. 2008, 148, 1827–1847. [Google Scholar] [CrossRef]
- Prakash Sarkar, D.; Shankar, U.; Parida, B.R. Machine learning approach to predict terrestrial gross primary productivity using topographical and remote sensing data. Ecol. Inform. 2022, 70, 101697. [Google Scholar] [CrossRef]
- Wang, H.; Wu, N.; Han, G.; Li, W. Analysis of spatial-temporal variations of grassland gross ecosystem product based on machine learning algorithm and multi-source remote sensing data: A case study of Xilinhot, China. Glob. Ecol. Conserv. 2024, 51, 2942. [Google Scholar] [CrossRef]
- Taamneh, M.M.; Taamneh, S.; Alomari, A.H.; Abuaddous, M. Analyzing the Effectiveness of Imbalanced Data Handling Techniques in Predicting Driver Phone Use. Sustainability 2023, 15, 10668. [Google Scholar] [CrossRef]
- Amirivojdan, A.; Nasiri, A.; Zhou, S.; Zhao, Y.; Gan, H. ChickenSense: A Low-Cost Deep Learning-Based Solution for Poultry Feed Consumption Monitoring Using Sound Technology. AgriEngineering 2024, 6, 2115–2129. [Google Scholar] [CrossRef]
- Liu, H.T.; Hu, D.W. Construction and Analysis of Machine Learning Based Transportation Carbon Emission Prediction Model. Environ. Sci. 2024, 45, 3421–3432. [Google Scholar]
- Amir, A.; Henry, M. Reverse Engineering of Maintenance Budget Allocation Using Decision Tree Analysis for Data-Driven Highway Network Management. Sustainability 2023, 15, 10467. [Google Scholar] [CrossRef]
- Bouguerra, H.; Tachi, S.E.; Bouchehed, H.; Gilja, G.; Aloui, N.; Hasnaoui, Y.; Aliche, A.; Benmamar, S.; Navarro-Pedreño, J. Integration of High-Accuracy Geospatial Data and Machine Learning Approaches for Soil Erosion Susceptibility Mapping in the Mediterranean Region: A Case Study of the Macta Basin, Algeria. Sustainability 2023, 15, 10388. [Google Scholar] [CrossRef]
- Zhai, W.; Li, C.; Cheng, Q.; Ding, F.; Chen, Z. Exploring Multisource Feature Fusion and Stacking Ensemble Learning for Accurate Estimation of Maize Chlorophyll Content Using Unmanned Aerial Vehicle Remote Sensing. Remote Sens. 2023, 15, 3454. [Google Scholar] [CrossRef]
- Alavi, S.H.; Bahrami, A.; Mashayekhi, M.; Zolfaghari, M. Optimizing Interpolation Methods and Point Distances for Accurate Earthquake Hazard Mapping. Buildings 2024, 14, 1823. [Google Scholar] [CrossRef]
- Akbar, T.; Haq, S.; Arifeen, S.U.; Iqbal, A. Numerical Solution of Third-Order Rosenau–Hyman and Fornberg–Whitham Equations via B-Spline Interpolation Approach. Axioms 2024, 13, 501. [Google Scholar] [CrossRef]
- Liu, R.; Gao, Z.-Y.; Li, H.-Y.; Liu, X.-J.; Lv, Q. Research on Molten Iron Quality Prediction Based on Machine Learning. Metals 2024, 14, 856. [Google Scholar] [CrossRef]
- Song, W.; Feng, A.; Wang, G.; Zhang, Q.; Dai, W.; Wei, X.; Hu, Y.; Amankwah, S.O.Y.; Zhou, F.; Liu, Y. Bi-Objective Crop Mapping from Sentinel-2 Images Based on Multiple Deep Learning Networks. Remote Sens. 2023, 15, 3417. [Google Scholar] [CrossRef]
- Hissou, H.; Benkirane, S.; Guezzaz, A.; Azrour, M.; Beni-Hssane, A. A Novel Machine Learning Approach for Solar Radiation Estimation. Sustainability 2023, 15, 10609. [Google Scholar] [CrossRef]
- Wang, L.A. Study of China’s population forecast based on a combination model. Acad. J. Comput. Inf. Sci. 2022, 5, 76–81. [Google Scholar]
- Zeng, J.; Dai, X.; Li, W.; Xu, J.; Li, W.; Liu, D. Quantifying the Impact and Importance of Natural, Economic, and Mining Activities on Environmental Quality Using the PIE-Engine Cloud Platform: A Case Study of Seven Typical Mining Cities in China. Sustainability 2024, 16, 1447. [Google Scholar] [CrossRef]
- Zhu, H.; You, X.; Liu, S. Multiple Ant Colony Optimization Based on Pearson Correlation Coefficient. IEEE Access 2019, 7, 61628–61638. [Google Scholar] [CrossRef]
- Saccenti, E.; Hendriks, M.H.W.B.; Smilde, A.K. Corruption of the Pearson correlation coefficient by measurement error and its estimation, bias, and correction under different error models. Sci. Rep. 2020, 10, 438. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, Y.; Liu, D. Using machine learning to quantify drivers of aerosol pollution trend in China from 2015 to 2022. Appl. Geochem. 2023, 151, 105614. [Google Scholar] [CrossRef]
- Muse, N.M.; Tayfur, G.; Safari, M.J.S. Meteorological Drought Assessment and Trend Analysis in Puntland Region of Somalia. Sustainability 2023, 15, 10652. [Google Scholar] [CrossRef]
- Aviral Kumar, T.; Niyati, B.; Aasif, S. Stock Market Integration in Asian Countries: Evidence from Wavelet Multiple Correlations. J. Econ. Integr. 2013, 28, 441–456. [Google Scholar] [CrossRef]
- Kim, G.Y.; Chung, D.B. Data-driven Wasserstein distributionally robust dual-sourcing inventory model under uncertain demand. Omega 2024, 127, 103112. [Google Scholar] [CrossRef]
- Bian, L.H.; Ji, M.Q. Research on influencing factors and prediction of transportation carbon emissions in Qinghai. Ecol. Econ. 2019, 35, 35–39. [Google Scholar]
- Mahjoub, S.; Labdai, S.; Chrifi-Alaoui, L.; Marhic, B.; Delahoche, L. Short-Term Occupancy Forecasting for a Smart Home Using Optimized Weight Updates Based on GA and PSO Algorithms for an LSTM Network. Energies 2023, 16, 1641. [Google Scholar] [CrossRef]
- Skubleny, D.; Spratlin, J.; Ghosh, S.; Greiner, R.; Schiller, D.E. Individual Survival Distributions Generated by Multi-Task Logistic Regression Yield a New Perspective on Molecular and Clinical Prognostic Factors in Gastric Adenocarcinoma. Cancers 2024, 16, 786. [Google Scholar] [CrossRef]
- Lukman, A.F.; Adewuyi, E.T.; Alqasem, O.A.; Arashi, M.; Ayinde, K. Enhanced Model Predictions through Principal Components and Average Least Squares-Centered Penalized Regression. Symmetry 2024, 16, 469. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, X.; Huang, H. Predicting compressive strength of fiber-reinforced coral aggregate concrete: Interpretable optimized XGBoost model and experimental validation. Structures 2024, 64, 106516. [Google Scholar] [CrossRef]
- Chen, Y.; Yao, K.; Zhu, B.; Gao, Z.; Xu, J.; Li, Y.; Hu, Y.; Lin, F.; Zhang, X. Water Quality Inversion of a Typical Rural Small River in Southeastern China Based on UAV Multispectral Imagery: A Comparison of Multiple Machine Learning Algorithms. Water 2024, 16, 553. [Google Scholar] [CrossRef]
- Tita, M.; Onutu, I.; Doicin, B. Prediction of Total Petroleum Hydrocarbons and Heavy Metals in Acid Tars Using Machine Learning. Appl. Sci. 2024, 14, 3382. [Google Scholar] [CrossRef]
- Bobak, S.; Kevin, S.; Wang, Z. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar]
- Li, Y.; Abdallah, S. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Storman, D.; Świerz, M.J.; Storman, M.; Jasińska, K.W.; Jemioło, P.; Bała, M.M. Psychological Interventions and Bariatric Surgery among People with Clinically Severe Obesity—A Systematic Review with Bayesian Meta-Analysis. Nutrients 2022, 14, 1592. [Google Scholar] [CrossRef] [PubMed]
- Apostolos, A. Forecasting hotel demand uncertainty using time series Bayesian VAR models. Tour. Econ. 2018, 25, 734–756. [Google Scholar]
- Osisanwo, F.; Akinsola, J.; Awodele, O.; Hinmikaiye, J.; Olakanmi, O. Supervised machine learning algorithms: Classification and comparison. Int. J. Comput. Trends Technol. 2017, 48, 128–138. [Google Scholar]
- Praveena, M.; Jaiganesh, V. A literature review on supervised machine learning algorithms and boosting process. Int. J. Comput. Appl. 2017, 169, 32–35. [Google Scholar] [CrossRef]
- Shao, Z.; Ahmad, M.N.; Javed, A. Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface. Remote Sens. 2024, 16, 665. [Google Scholar] [CrossRef]
- Xiang, Q.; Wang, N.; Xiang, R. Prediction of Gas Concentration Based on LSTM-LightGBM Variable Weight Combination Model. Energies 2022, 15, 827. [Google Scholar] [CrossRef]
- Xu, C.; Yi, W.; Biao, Z. Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model. Atmosphere 2021, 12, 1211. [Google Scholar] [CrossRef]
- Kim, Y.O.; Jeong, D.; Ko, I.H. Combining Rainfall-Runoff Model Outputs for Improving Ensemble Streamflow Prediction. J. Hydrol. Eng. 2006, 11, 578–588. [Google Scholar] [CrossRef]
- Muhammad, A.; Stadnyk, T.A.; Unduche, F.; Coulibaly, P. Multi-Model Approaches for Improving Seasonal Ensemble Streamflow Prediction Scheme with Various Statistical Post-Processing Techniques in the Canadian Prairie Region. Water 2018, 10, 1604. [Google Scholar] [CrossRef]
- Wang, X.; Wu, Z.; Wang, R.; Gao, X. UniproLcad: Accurate Identification of Antimicrobial Peptide by Fusing Multiple Pre-Trained Protein Language Models. Symmetry 2024, 16, 464. [Google Scholar] [CrossRef]
- Mosso, D.; Rajteri, L.; Savoldi, L. Integration of Land Use Potential in Energy System Optimization Models at Regional Scale: The Pantelleria Island Case Study. Sustainability 2024, 16, 1644. [Google Scholar] [CrossRef]
- Hjelkrem, L.O.; Lange, P.E.d. Explaining Deep Learning Models for Credit Scoring with SHAP: A Case Study Using Open Banking Data. J. Risk Financ. Manag. 2023, 16, 221. [Google Scholar] [CrossRef]
- Airiken, M.; Li, S. The Dynamic Monitoring and Driving Forces Analysis of Ecological Environment Quality in the Tibetan Plateau Based on the Google Earth Engine. Remote Sens. 2024, 16, 682. [Google Scholar] [CrossRef]
- Xie, H.; Li, Z.; Xu, Y. Study on the Coupling and Coordination Relationship between Gross Ecosystem Product (GEP) and Regional Economic System: A Case Study of Jiangxi Province. Land 2022, 11, 1540. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | Ecological Indicators | Secondary Indicators | Units | Data Source |
|---|---|---|---|---|
| Provisioning Service | Agricultural products | Agricultural product value | Billions | Statistical surveys |
| Forestry products | Forestry product value | Billions | ||
| Fishery products | Fishery product value | Billions | ||
| Livestock products | Livestock product value | Billions | ||
| Regulating Services | Water conservation | Evaporation | mm | Local meteorological bureau, water conservancy bureau, and related departments |
| Precipitation | ||||
| Soil conservation | Soil conservation | |||
| Flood water storage | Heavy rainfall | mm | ||
| Oxygen release and carbon sequestration | Nitrogen fixation | |||
| Climate regulation | High-temperature days | days | ||
| Air purification | NO purification | |||
| SO purification | ||||
| Dust purification | ||||
| Cultural Services | Tourism income | Gross tourism income | Billions | Statistical Surveys |
| Parameters | Hyperparameter Settings |
|---|---|
| depth | 3 |
| iterations | 2000 |
| learning rate | 0.0099 |
| subsample | 0.6 |
| colsample bytree | 1.0 |
| l2_leaf_reg | 0.5 |
| Parameters | Hyperparameter Settings |
|---|---|
| n_estimators | 2000 |
| max_depth | 3 |
| learning rate | 0.027 |
| subsample | 1.0 |
| Colsample bytree | 1.0 |
| reg_alpha | 0.1 |
| reg_lambda | 1.0 |
| MSE | MAE | R2 | |
|---|---|---|---|
| XGBoost | 0.00052 | 0.0097 | 0.9976 |
| CatBoost | 0.00060 | 0.0162 | 0.9973 |
| Ada-XG-CatBoost | 0.00018 | 0.0093 | 0.9992 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Yang, T.; Tian, L.; Huang, B.; Yang, J.; Zeng, Z. Ada-XG-CatBoost: A Combined Forecasting Model for Gross Ecosystem Product (GEP) Prediction. Sustainability 2024, 16, 7203. https://doi.org/10.3390/su16167203
Liu Y, Yang T, Tian L, Huang B, Yang J, Zeng Z. Ada-XG-CatBoost: A Combined Forecasting Model for Gross Ecosystem Product (GEP) Prediction. Sustainability. 2024; 16(16):7203. https://doi.org/10.3390/su16167203
Chicago/Turabian StyleLiu, Yang, Tianxing Yang, Liwei Tian, Bincheng Huang, Jiaming Yang, and Zihan Zeng. 2024. "Ada-XG-CatBoost: A Combined Forecasting Model for Gross Ecosystem Product (GEP) Prediction" Sustainability 16, no. 16: 7203. https://doi.org/10.3390/su16167203
APA StyleLiu, Y., Yang, T., Tian, L., Huang, B., Yang, J., & Zeng, Z. (2024). Ada-XG-CatBoost: A Combined Forecasting Model for Gross Ecosystem Product (GEP) Prediction. Sustainability, 16(16), 7203. https://doi.org/10.3390/su16167203