1. Introduction
Accurate wheat-yield projections are critical for sustaining agricultural practices and reducing the negative effects of climate change. Unlike prior studies, which mostly use traditional statistical methods, our research incorporates powerful machine learning algorithms to forecast wheat yield under various climate change scenarios [
1]. Wheat is a vital cereal grain source, providing food for approximately 40% of the world’s population [
2,
3]. Most farmers, particularly those in developing nations, depend exclusively on their limited knowledge and prior experience. This limited knowledge makes it challenging for them to compete globally and fulfill expanding demands [
4]. This study employs cutting-edge tools to investigate the complex interaction between climate conditions and wheat yield, providing more precise and useful findings.
Extreme weather, changing trends of rainfall, and rising temperatures are all things that could hurt food security and agriculture production. Uncertainty about the weather makes it hard to predict wheat yields, which are very important. Things like frost during the flowering and grain-filling stages, temperatures above 30 °C, and not enough rain at key times can all lead to production losses [
5]. These problems already exist, and climate change will only make them worse. This will make it harder to plan and handle crops well.
The climate, management techniques, and personal standards can all affect the growth of a crop. Researchers use process-based and statistical methods, such as biological data and remote sensing [
6,
7,
8], to keep an eye on production. Process-based models can be used for certain crops, like rice, wheat, and corn, to help with resource management and agriculture growth [
9]. These models use correct data and algorithms to give farmers information that helps them make smart decisions. Statistical methods can also predict results in a wide range of situations by looking at how weather and land quality are linked to crops. Classical statistical methods based on mathematical models are often used to test ideas with crop samples. Their success, however, depends on having easy access to relevant farming data [
10].
Global climate models (GCMs) are mostly used to guess how much food will be grown around the world in different weather and management situations. The best way to find out how climate change will affect crop growth is to use a GCM. GCMs have been used to model weather, land, management, and other aspects of agricultural development in order to predict food growth and output on a global and regional level. Different parts of the world have different weather, land, and ways of growing. Peng (2023) says that GCMs usually have a spatial resolution of 50 km × 50 km, which is good enough to obtain a good idea of national farming results. By adding these area factors, downscaling makes it possible to make more accurate and reliable estimates of crop yields. As Zhang (2019) says, the Coupled Model Intercomparison Phase 3 (CMIP3) collects GCM data from various sources to look into trends of climate change now and in the future. Using crop models and high-resolution climate data together, machine learning-based downscaling helps look at how climate change affects farming in specific areas. This study gives us useful information about how to change.
It is important to keep an eye on weather conditions like air temperature, CO
2, rainfall, and growing times when you are trying to adapt to a changing climate. Many studies have been conducted around the world to look at how climate change affects the output of crops. To show how climate change affects crop yields, Reference [
11] used techniques for increasing yields that were part of the CMIP5 plan. As for Ishaque et al. [
12], one way Pakistan might be able to change would be to move the best times to plant wheat to cooler months.
Using machine learning to fix problems has shown a lot of promise [
13,
14]. They are able to work with data that have a lot of dimensions, find relationships that are not straight, and see complex trends [
15]. ML algorithms find links between dependent and independent factors by training them through spatiotemporal observational training on very large datasets. Machine learning techniques have been used in a number of ways to identify crops and predict their yields.
ML algorithms help with planning and running farms, and they are often used to guess how much food crops will produce. Models like artificial neural networks (ANNs), multiple linear regression (MLR) [
16], random forest regression (RFR) [
13,
17], and XGboost [
18] are used to estimate yields. These models consider things like temperature, humidity, wind speed, rainfall, and atmospheric gases. Overfitting is a problem with these models, which makes them less useful even when they do a good job of dealing with climate-related problems in agriculture. Using ensemble methods with multiple models makes yield predicting more accurate while reducing overfitting [
19,
20]. Ensemble methods, such as meta-machine learning, may improve the accuracy of wheat growth predictions by combining the results of many models.
When it comes to predicting climate change, statistical models and old methods that are based on past data often fall short. We suggest that this gap be filled by teaching a machine-learning model to predict wheat yields even when weather trends change. Machine learning algorithms may use enormous datasets to learn complicated correlations between variables and produce accurate predictions. The proposed solution integrates weather station data and CO
2 future emission scenarios to develop a precise machine-learning model capable of forecasting wheat yields. By accounting for climate change impacts on crop yields, our model empowers farmers to adapt their practices. The expected outcome is improved prediction accuracy, enhancing wheat production and food security. Similar studies using analogous methodologies have been conducted in other countries for different crops [
21]. However, they did not use ensemble models, exposing a gap our research seeks to remedy. Our research stands out by combining ensemble modeling techniques, which aim to increase the robustness and accuracy of crop-yield projections.
Several studies have focused on forecasting crop production, especially in Pakistan, utilizing various predictors like rainfall, fertilizer, temperature, tractors, and labor. Previous research has highlighted the significant correlation between fertilizer application, remote sensing techniques, and wheat output [
22,
23,
24,
25].
More comprehensive studies that integrate multiple machine learning models specifically for wheat-yield prediction under climate change scenarios need to be conducted. While individual models have been explored, ensemble techniques that incorporate the advantages of many algorithms are required to improve forecast accuracy. Unlike previous studies that primarily relied on traditional statistical methods or focused on other regions [
26], this work presents a novel way to predict wheat yield under climate change scenarios that employs a complex ensemble of machine learning models. The fundamental novelty of this research is the integration of many advanced machine learning algorithms to estimate wheat output based on climate data, which involves utilizing historical climate data as well as projections from GCMs. our research uniquely combines historical climate data, global climate model (GCM) projections, and advanced machine learning techniques. By doing so, we provide a comprehensive and accurate forecast of wheat yields specifically for Punjab, Pakistan. Our interdisciplinary approach advances agricultural yield prediction and offers practical insights for developing climate-resilient farming practices. These studies aim to enhance crop-forecasting accuracy by analyzing different factors’ effects on agriculture productivity, especially wheat production in Pakistan.
The key objective of this study is to construct a model for forecasting wheat yields via ANNs using meteorological and GCM data. To achieve this goal, the following tasks have been formulated:
Identifying the key factors influencing wheat production
Modeling and testing wheat-yield responses to rainfall and temperature variables using various methods such as boosting tree, ANNs, random forest regression, multiple linear regression, and ensemble models, based on observed yield and climatic data
Anticipating and analyzing the potential influence of climate change on wheat crop trends up to the year 2052.
2. Materials and Methods
Certain materials and methods were used to conduct our experiments and analyze the data. We employed a novel combination of machine learning models to predict wheat yield. We carefully integrated random forest regression, boosted tree regression, artificial neural networks, and an ensemble model. Additionally, we preprocessed climate and yield data and applied advanced downscaling techniques to enhance the accuracy of localized prediction.
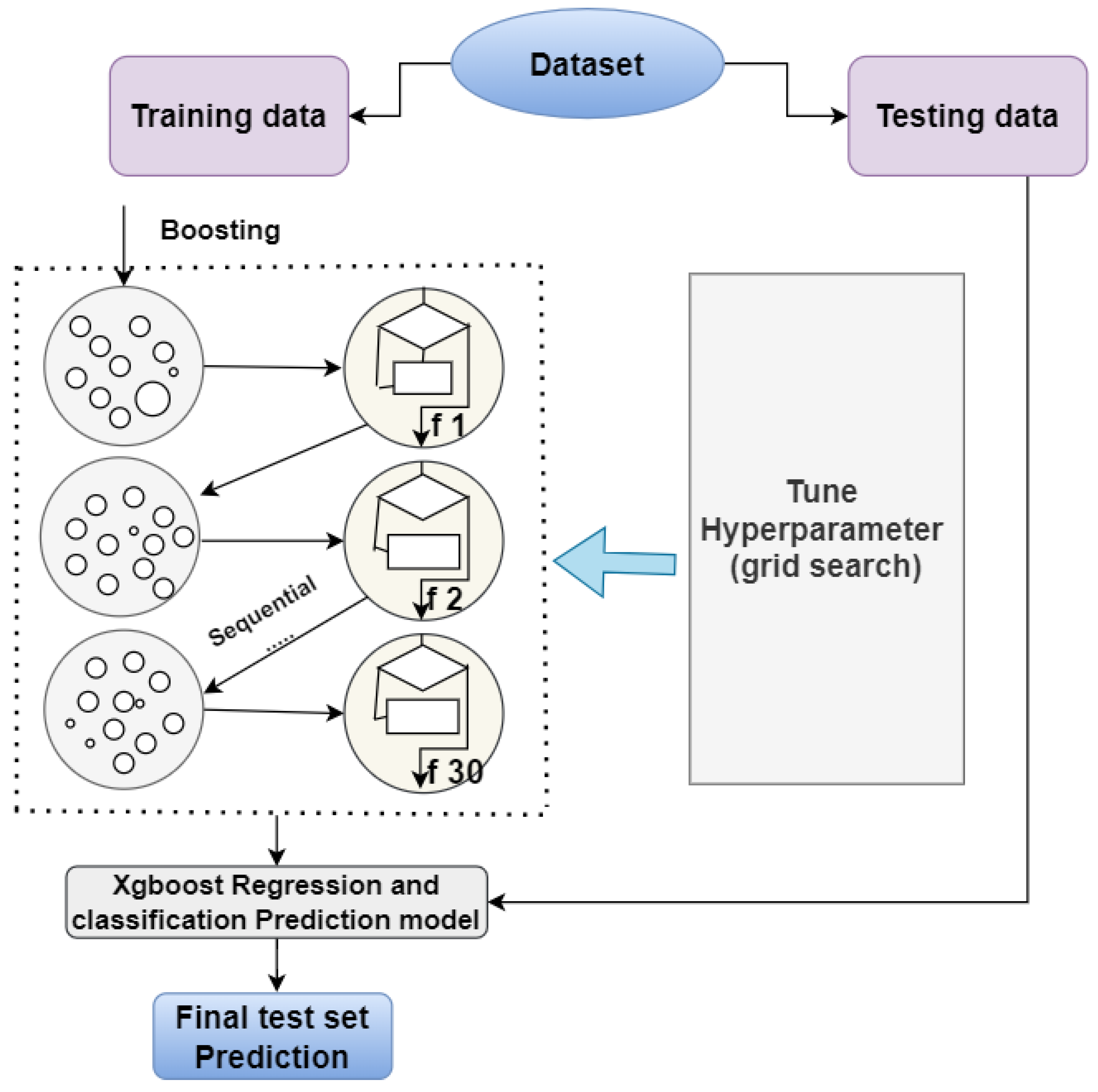
2.1. Research Workflow
The research process workflow is outlined in
Figure 1.
Initially, historical data on temperature, rainfall, and crop yield are gathered and subjected to preprocessing. Various machine learning models, such as ANNs, MLR, RFR, and boosting trees, are assessed using the preprocessed data. An ensemble model is then constructed by leveraging the strengths of these individual models. Simultaneously, global climate model (GCM) data are incorporated, considering emission scenarios from multiple modeling centers. They operate at coarse spatial resolutions (hundreds of kilometers), but local applications like agriculture, water management, and urban planning require finer-scale climate data. Downscaling bridges this gap by providing localized climate projections and correcting biases in GCMs, enhancing reliability. Accurate precipitation and temperature data are crucial for wheat-yield modeling. XGboost is an ideal tool for downscaling tasks due to its balance of efficiency, accuracy, and execution speed. It provides feature importance scores for interpretability and uses regularization to prevent overfitting. Additionally, XGboost efficiently handles large datasets, scales well, and allows fine-tuning for specific needs. The XGboost model is utilized for downscaling, with GCM data serving as predictors and observed data as predictands. Subsequently, the XGboost model generates new values for climate variables. These newly generated values are utilized as input for model selection to make predictions extending to 2052.
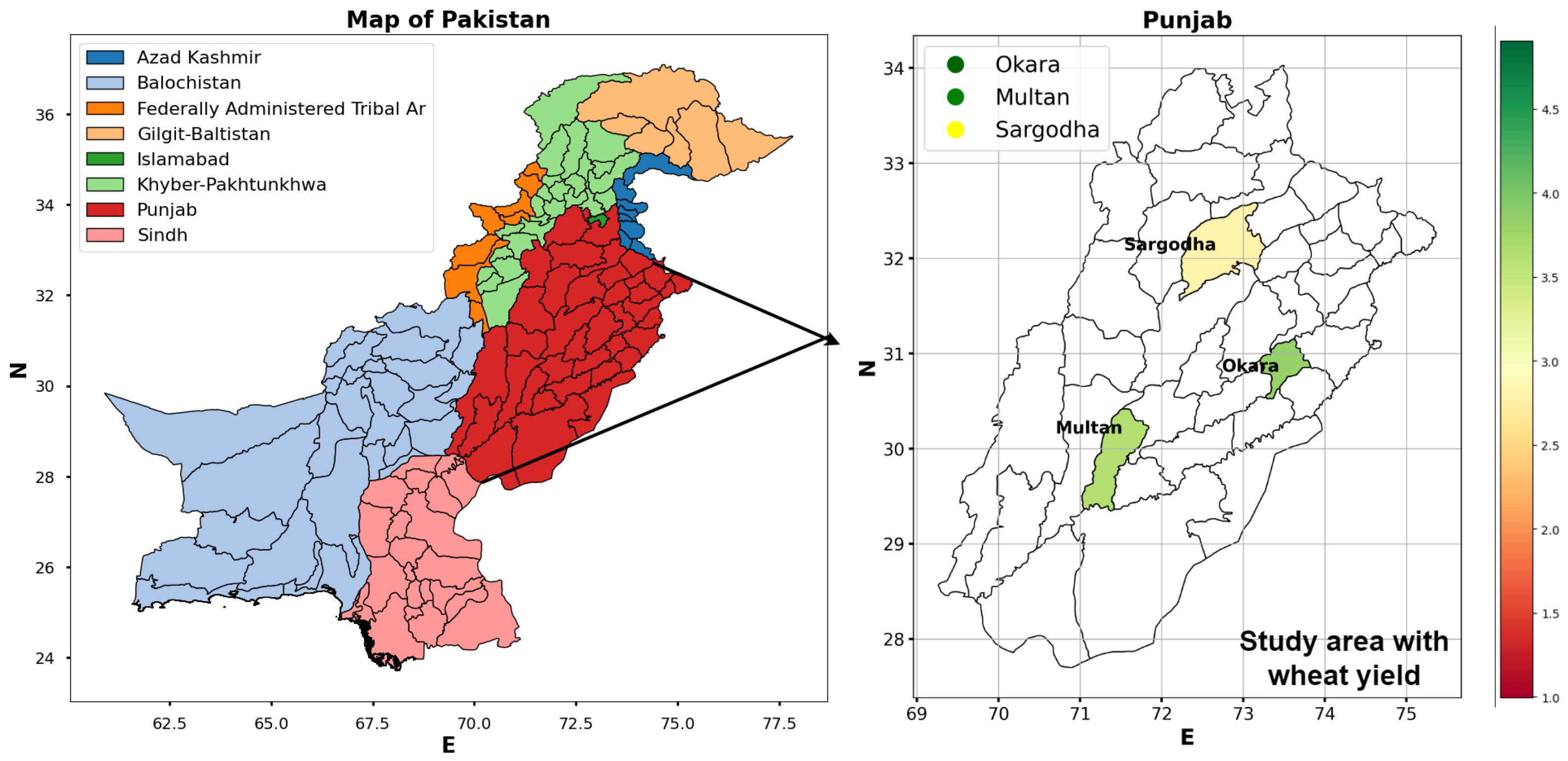
2.2. Study Area
The Okara, Multan, and Sargodha districts in Punjab province were chosen for their significant contributions to wheat production. The study area with wheat yield is mapped in
Figure 2. Okara district, located in central Punjab at latitude
N and longitude
E, spans 2969 square kilometers. It boasts fertile agricultural lands irrigated by the Sutlej River and its tributaries, making it an ideal region for wheat cultivation. Multan district, situated in southern Punjab at latitude
N and longitude
E, covers an area of 3177 square kilometers. Known for its arid climate, Multan provides suitable conditions for wheat cultivation. Sargodha district, positioned in northern Punjab at latitude
N and longitude
E, encompasses 3139 square kilometers. Sargodha is a crucial area for wheat production in the region.
Projected climate changes, including temperature increases and altered rainfall patterns, are expected to significantly impact wheat production by mid-century. From 1980 to 2010, wheat yields fell by 5.5%, with a 0.13 °C temperature rise per decade. By 2050, global wheat output could drop by 1.9%, with severe impacts in Africa and South Asia, where yields might decline by 15% and 16% [
27]. Major producers like Pakistan may also see reduced yields, threatening the global wheat supply. This study examines the factors driving climate change and its impact on essential crops like wheat.
2.3. Observed Data
The study utilized meteorological data encompassing monthly rainfall and minimum and maximum temperatures, manually collected from the weather database [
28], spanning 1991 to 2021. Additionally, historical wheat-yield data (measured in tons/ha) from producing fields were sourced from the Government of Punjab [
29] from 1991 to 2021.
2.4. GCM Data
Global Climate Models (GCMs) are widely recognized for their effectiveness and accuracy in assessing global climate change. In this study, we leveraged ensemble data to forecast future climate conditions in the study area. We collected data for AR4 SRB1, A2, and A1B mean composite emission scenarios from 24 international modeling centers, using baseline years 1971–2012 and 2011–2052. Recent research in climate modeling guided our decision to focus on these three specific GCMs (emission scenarios), particularly due to their suitability for simulating climatic conditions in the Punjab regions [
21]. According to this study, these three GCMs are the best options for climatic simulation conditions in the Punjab. The AR4 Intergovernmental Panel on Climate Change provided monthly statistics [
30] for 20 years and 30 years, encompassing the same geographic coordinates as the research area.
The IPCC Fourth Assessment Report (AR4, 2007) provided greenhouse gas concentration trajectories for SR emission scenarios. A1B predicted medium emissions, with atmospheric CO
2 levels reaching 703 ppm by 2100. A2 represented high emissions, resulting in 836 ppm CO
2, whereas B1 simulated lesser emissions, with CO
2 at 540 ppm in 2100. The study retrieved monthly climatic variables at a
resolution, downscaled from three GCMs under the above-mentioned scenarios. Data collected included total precipitation (mm/day), maximum and minimum near-surface air temperature (°C), average air temperature (°C), surface downward motion shortwave heat (W/m
2), and average wind speed at 10 (m/s). The XGboost model is employed to downscale GCM and observed data as predictors. The XGboost was chosen for its effective performance in solving nonlinear problems [
18,
31].
2.5. Data Processing
The methodology for data preprocessing and crop-yield projections involved several key steps. Data were gathered from various sources, processed, and used to calibrate models and validate results. To provide robust analysis, missing or irregular values must be addressed carefully.
Firstly, daily historical weather data, including maximum and minimum temperature and rainfall, was collected from a weather database [
28]. Following the validation of the daily climatic data, several quality checks were carried out to assure reliability. These checks included data validation against preset acceptable ranges, logical sequence consistency tests (for example, temperature consistency), interpolation to handle missing data, and removing duplicate records. To manage missing data, linear interpolation was utilized, with each missing value estimated by averaging the values before and after it. To maintain data integrity, duplicate records were identified, and only the first instance of each duplicate entry was retained. This was then aggregated into monthly averages to match the timelines of the future estimates. The processed historical monthly climate datasets were combined into a single Excel file with pertinent modeling inputs and transformed into annual averages. The time series data yielded a uniform length of 31 years of records for each region.
The climate-prediction data utilized in this study were obtained from GCM AR4 for three future emissions scenarios: SRA2, B1, and A1B. The data were originally stored in netCDF format and must be preprocessed before analysis. We used Google Colab (Python) to convert the netCDF files to comma-separated values (.csv) for easy use in spreadsheet tools. As a result, Excel’s filtering tools allow us to reduce our focus to certain geographic places relevant to our research. Detailed documentation and metadata are critical for cooperation, comprehension, and validation. LAT and LONG filters were used to separate the study areas from the data. At first, the numbers were shown as monthly means over 20 or 30 years. Before making predictions about the average temperatures and amounts of rain and snow from 2022 to 2052, we changed them to yearly means.
The original GCM data were in Kelvin, but our history data are in degrees Celsius (°C), so we changed them. We need to change information so that they are consistent with each other so that we can make useful comparisons. Also, to match previous records, the amount of rain was changed from kg/m2/h to mm. The suggested ensemble forecasting method used both estimates about the future and data from the past to give a more accurate picture of how climate affects wheat yields. This method helps us understand seasonal changes and long-term climate trends better by focusing on bigger patterns instead of small changes that happen every day. This method could help farmers and farming groups make better decisions.
Data Splitting
ML models are less likely to be biased when datasets are split up. We carefully split our temperature and yield data into training and testing groups so that we could build models that could accurately predict crop yields. The dataset is split into training and testing groups so that different split ratios can be used to test how accurate the model’s predictions are. Nguyen (2021) says that the ratios of training to tests were as follows: 10–90, 20–80, 30–70, 40–60, 50–50, 60–40, 70–30, 80–20, and 90–10. We tried to avoid overfitting by giving the model the right amount of time to be trained and tested. We used an 80/20 split to train the model with of the data. The other 20% were saved so that we could test the out-of-sample model. This method makes sure that our models will be able to handle new data while they are being tested, which will give us a fair idea of their performance.
For datasets with between 100,000 and 100,000 records, our downscaling scoring method used a 60:20:20 split. In particular, around 60% of the data were used for training the model. A separate 20% portion were the test set for assessing model predictive performance. The final 20% constituted an independent validation set, allowing us to fine-tune hyperparameters. The training set enabled our models to learn underlying patterns from historical data. Hyperparameter tuning was guided by the validation set, optimizing model performance. By exploring various split ratios, we comprehensively understood our model’s forecast ability under different conditions. This exploration informed our final model selection, ensuring robustness when applied at scale.
2.6. Experimental Setup
For developing the machine learning models, historical daily weather data (including minimum temperature, maximum temperature, and rainfall) from 1991 to 2021 and corresponding wheat-yield data were obtained from the weather database and the Government of Punjab. The data were divided into 80% training and 20% testing sets. Six different supervised learning algorithms were used—artificial neural networks (ANNs) with LR, GFF, PNN, and MLP architectures, MLR, RFR, boosted tree regression, and a stacking ensemble model. The ANN models were developed using the Keras library in Python (specifically, Google Colab) with the Adam optimizer, binary cross-entropy loss, and varying numbers of hidden layers (10–7). They were trained for 90–1100 epochs on this architecture.
MLR was performed using the sci-kit-learn library. The boosted tree models were developed with maximum depth (from 10 to 90), learning rate (0.01), number of estimators (ranging from 100 to 1500), and 8-fold cross-validation. RFR model was built using maximum depth ranging from 10 to 90, several estimators of 80, and cross-validation of 8-fold. A GFF model was created using dense layers of (100, 92, 1) for the ANN. We used ’relu’ activation, ’adam’ optimizer, and ’lbfgs’ solver for training in Keras.
Lastly, a stacking ensemble model was created for training using the weighted average of the base models in sci-kit-learn. Final model evaluation was conducted on the unseen testing dataset, using performance metrics such as mean absolute error, root mean squared error, , normalized root mean square error, mean biased error, and correlation coefficient to select the optimal hyperparameters for each algorithm. Regression graphs are generated using the matplotlib library in Google Colab to visualize the performance of all models.
The coarse resolution is downscaled by three GCM outputs from CMIP3 using the XGboost algorithm to project yields under future climates. XGboost was trained on 60% of the weather data for parameter tuning, validated on 20%, and tested on the remaining 20% to map large-scale climate variables to local observations. Hyperparameters such as maximum tree depth 30 and estimators ranging from 4 to 6 were optimized through 2-fold cross-validation. The downscaled climate projections were inputs to the top-performing ML models selected earlier. XGboost demonstrated vital skill in bridging global and regional scales, with downscaled outputs closely matching the validation data distribution. This validated XGboost’s ability to learn complex non-linear relationships between weather factors and crop yields and translate them to future conditions. Its efficient tree ensemble approach allowed for seamlessly incorporating climate model projections into crop forecasts.
3. Machine Learning Algorithms
The wheat-yield prediction was conducted using a range of algorithms, including ANN(LR), ANN(PNN), ANN(GFF), boosting tree, MLR, RFR, and ensemble methods, in conjunction with climate variables. These algorithms were chosen based on their proven effectiveness, as evidenced by previous research studies [
16,
18,
32,
33].
3.1. Multiple Linear Regression
Multiple linear regression models demonstrate the connection using a linear equation. One or more accessible (or predictive) variables can be related to a distinct reliant (or responsive) variable, i.e., every independent variable Xi is associated with the dependent variable Y. The multiple regression equation takes the following generic form:
where Y is the yield variable;
,
, and
denote the rainfall,
, and
, respectively;
,
, and
stand for the rainfall
,
, and
, respectively; and
is the error in the observed value.
3.2. XGboost
Chen and Guestrin proposed the XGboost technique, a specific gradient boosting approach [
34]. In
Figure 3, one tree is included while developing sequential trees to optimize the goal further. The model combines slow learners’ predictions to generate a high learner using additive training procedures based on boosting. The model utilizes parallel calculations to enhance speed. It has the excellent fitting abilities of an ensemble tree, which is extremely effective (at most ten times quicker than RF to train) [
9]. The fundamental form of the prediction at point t is given in this order:
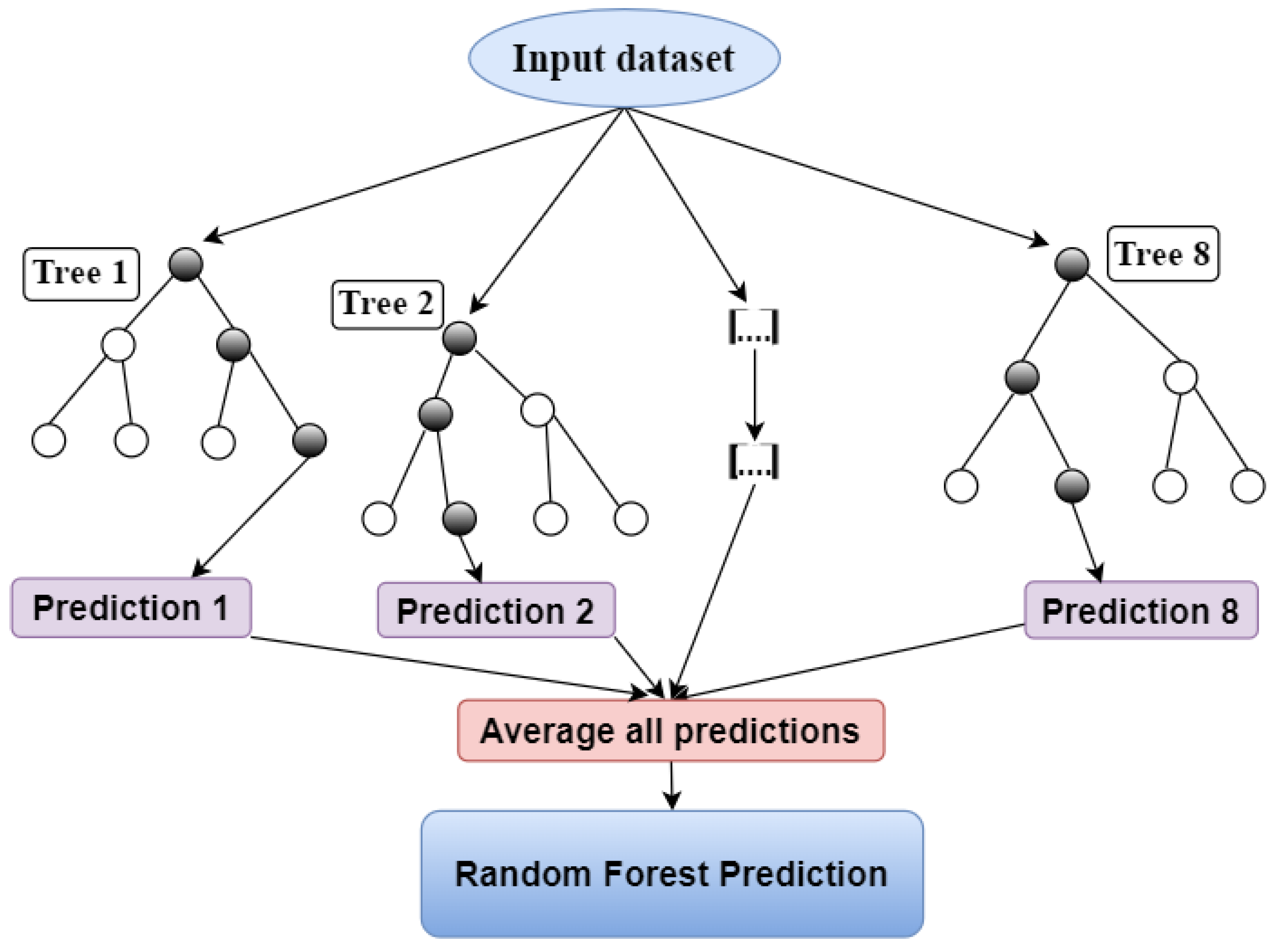
3.3. Random Forest Regression
RFR is a popular technique for digitization because of its capacity to handle complex datasets with non-linear correlations and intricate feature relationships. The model resists excessive fitting, and value gaps are suitable for noisy and incomplete data [
35]. The RF algorithm uses many decision forests, each created using random sample data for training and covariance, as shown in
Figure 4. The models have the advantage of picking prospective variables and training data for every split, minimizing overfitting, and improving prediction accuracy. Additionally, the model indicates the significance of each variable employed in the prediction. We used the Scikit-learn toolkit’ to identify RF features and important functions and rank the value of specific features in our RFR models. This helped us to grasp the fundamental processes that impact model reliability and yield. It was optimized through 20-max depth with a minimum splitting size of 2. The margin function for the training dataset taken at random from the distribution of the random vectors X, Y, and an ensemble of classifiers
is as follows:
where I(.) is the indicator function. The margin measures the extent to which the mean number of votes at X and Y for the correct class exceeds the mean vote for any other class.
3.4. Artificial Neural Networks (ANNs) Model
An ANN is a nonlinear machine learning approach (
Figure 5). The network comprises three interlinked layers: input (nodes), hiding (one to three layers of neurons), and output. Each link is assigned a numerical value known as its weight. Neuron j in the deep layer produces the output
[
36].
In this equation, represents the simulating function, N represents the count of input neurons, represents the weight, represents the neuron input, and represents the hidden neuron threshold.
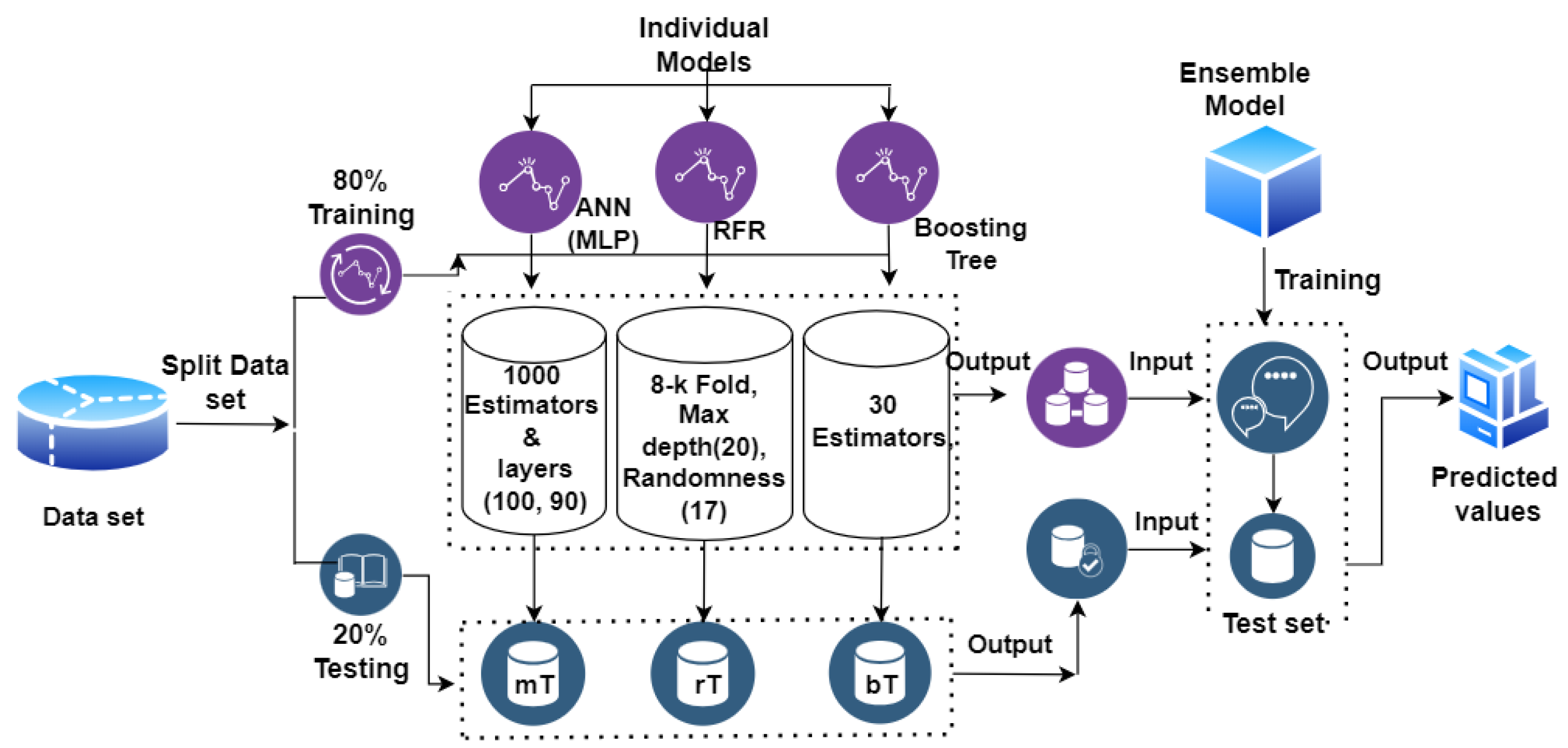
3.5. Ensemble Model
Anurag Satpathi [
20] and Xuan Yang [
37] compared traditional ML models to improved ensemble models. Ensemble models are highly precise as they mix numerous varieties of a single method to aggregate predictions from many basic learners. In the present research, we have employed three models to develop an ensemble model: random forest regression, ANN (multilayer perceptron), and boosting tree. The algorithm steps of the ensemble model for the wheat-production system diagram are shown in
Figure 6.
The multilayer perceptron model is trained with 1000 n-estimators, using input and output layers (100, 90). The RF model is trained with altered parameters on eight folds (excluding fold1), and the fold1 results are forecasted. Repeating this technique eight times generates predicted values in the training set. For RF, we set max-depth to 20 and randomness to 17. The Boosting Tree model is trained with 30 estimators and randomness set to 24.
The training batch now comprises three sets of expected values combined to generate a new training set. The trained RF, ANN(MLP), and boosting tree models are applied to predict three sets of projected values for the test set (containing N3 samples). Finally, these three trained models train and validate a secondary layer ensemble model. The test sample is fed into the prepared ensemble model, which produces its final predicted result. This ensemble approach improves the accuracy of predictions and generalization, addressing the limitations of individual machine-learning techniques in crop-production prediction.
3.6. Evaluation Metrics
A machine learning model’s performance is assessed using several statistical measures that quantify how closely the model predicts the results. Metrics guide us during model fine-tuning and hyperparameter optimization and provide insights into various aspects of model accuracy, reliability, and potential biases [
38]. The mean absolute error (MAE), correlation coefficient (R), root mean squared error (RMSE), mean biased Error (MBE), normalized root mean square error (MSE), and normalized mean square error (NMSE) were utilized to assess the downscaling capabilities [
39,
40]. Better model performance is indicated by
and R near 1 and by values of MAE, MBE, and RMSE close to zero. Positive MBE values suggest overestimation, whereas negative values imply underestimating. The model effectiveness is categorized as outstanding, good, fair, or poor based on the nRMSE value, which ranges from 0 to 10%, 10 to 20%, 20 to 30% or >30%, respectively. The statistics index formulas are provided below:
Here, , is the observed yield values, , is the produced yield values for the value, , and , indicate the median values of the pertinent factors, N denotes the amount of data points analyzed. To evaluate downscaling performance, , and , show historical and downscaled meteorological variables. The model’s capacity to generate the yield of wheat function and downscaled meteorological parameters for the research area is evaluated using a linear regression . The variable that is dependent (y) is the response (or target) variable, while the independent variable (x) is the predictor (or feature) variable. The intercept is , and the slope is . The wheat-yield function is evaluated by regressing observed and forecasted yield data.
4. Results
The results of the proposed machine learning models concentrate on:
Conduct a correlation analysis between climate factors and wheat yields and identify the climate variables most significantly correlated with wheat production through statistical hypothesis testing of relationships.
Apply various machine learning models (RF, MLR, boosting tree, MLP, PNN, GFF) to the historical climate and wheat-yield data to generate predictions and compare against actual historical yields.
Evaluate the various machine learning models using training performance metrics such as , R, nRMSE, MAE, MBE, and RMSE to identify the best performers.
To downscale coarse resolution GCM climate projections to local scales under three emission scenarios (SRA1B, SRB1, SRA2) using the XGboost statistical downscaling model.
Applying the best-performing machine learning model to project wheat yields over periods for three locations and emission scenarios using the downscaled generated climate variables data.
4.1. Importance of the Climate Parameters on Wheat Yield
Descriptive statistics for all variables are summarized in
Table 1.
Okara experiences moderate rainfall (average 500.65 mm), while Sargodha receives higher rainfall (average 725.62 mm). Multan has the lowest rainfall (average 337.68 mm). Overall, the combined average rainfall across all sites is 521.31 mm. Okara has an average of 32.48 °C, Sargodha averages 31.59 °C, and Multan experiences higher temperatures with an average of 33.02 °C. The overall average is 32.36 °C. Okara’s averages 21.00 °C, Sargodha at 20.59 °C, and Multan at 21.74 °C. The overall average is 21.11 °C. Okara has the highest yield (average 3.428), followed by Multan (average 2.822) and Sargodha (average 2.613). The overall average yield is 2.954. Sargodha stands out for high rainfall but lower yield, while Multan experiences the highest temperatures. Okara strikes a balance between these factors.
Table 2 demonstrates how climate conditions influence wheat yields in different locations.
The results of statistical hypothesis testing (
p-values) indicate the maximum temperature variable significantly influences wheat-yield responses. This finding is reinforced by analyzing the correlation and covariance relationships between climate factors and yield data. As shown in
Table 2, there is a negligible negative coefficient (−0.0001) for rainfall. Still, it is statistically insignificant (
p = 0.9179) in Okara, suggesting that these parameters do not substantially impact the local climate variables. In Sargodha, rainfall has a slight positive coefficient (0.0001) and is also statistically insignificant (
p = 0.793). Similarly, in Multan, rainfall has a positive coefficient (0.0003) but lacks statistical significance (
p = 0.5960). Overall, the impact of rainfall on yield appears minimal across all sites.
has a favorable coefficient in all locations (ranging from 0.084 to 0.1185). However, only the coefficient for
in Multan is statistically significant (
p < 0.05), indicating its critical role in the region. Higher maximum temperatures may affect wheat yield.
has positive coefficients in all locations (ranging from 0.114 to 0.2482). The coefficient for
in Sargodha is statistically significant (
p < 0.001).
likely plays a role in wheat yield, especially in Sargodha.
Meanwhile, the
p-values lacked significance for the relationships tested in Okara. The R-values from linear regression models using rainfall, maximum, and minimum temperature as predictors ranged from 0.1842 to 0.7106 across locations. Given the study area’s climate-yield dataset characteristics, this suggests that linear regression may not be the optimal approach for modeling crop yields. The results show that increasing temperatures hurt the wheat yield. Our results correlate with previous research, suggesting that rising heat stress due to climate change will affect wheat yield and production [
41,
42]. These results emphasize the need for region-specific climate models and localized climate adaptation strategies. Future research should explore these regional differences and underlying mechanisms further.
4.2. Selection of Predictors and Predicted Variables
Wheat-production functions were developed based on environmental factors, including rainfall, minimum temperature (
), and maximum temperature (
) as shown in
Figure 7. The dataset used for yield modeling contained climate variables (predictor values) and recorded yield observations (response values). Various ML techniques were applied to model the relationships between climate drivers and wheat yields, including multiple regression, boosted tree regression, artificial neural networks, random forest modeling, and ensemble methods. The objective was to compare the performance of these statistical and ML approaches for projecting crop production under changing climatic conditions.
4.3. Performance Metrics of Different MLA
After implementing the ML models in Google Colab using existing libraries, we achieved the results provided in
Table 3, where the red highlighted model represents the best outcome. The statistical comparison of calibrated yield response functions among different research models reveals that the ensemble model demonstrates the best overall performance, with the lowest MAE (0.099), RMSE (0.107), and nRMSE (8.0%), indicating high accuracy. It also shows the highest correlation (R = 0.988) and explanatory power (
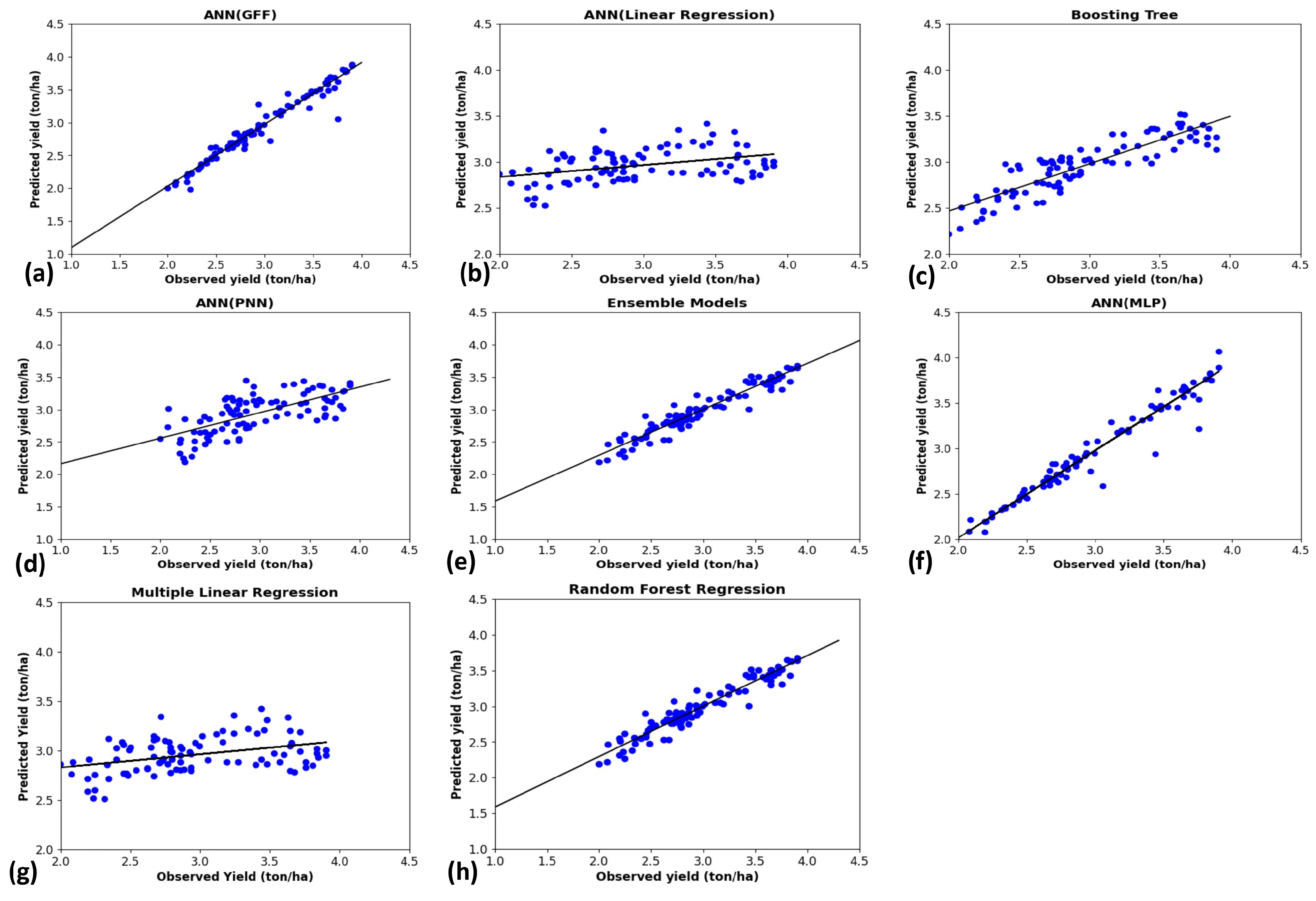
= 0.953), with minimal bias (MBE = 0.022). Following the ensemble model, the RFR and boosting tree models perform well, with RFR having an MAE of 0.182, RMSE of 0.227, and R of 0.909, while the boosting tree has an MAE of 0.198, RMSE of 0.253, and R of 0.902. Both models exhibit low bias and high explanatory power. Among the ANN models, ANN(MLP) shows good performance with an MAE of 0.230, RMSE of 0.266, and R of 0.902, followed by ANN(GFF) with an MAE of 0.220, RMSE of 0.301, and R of 0.888.
In contrast, ANN(LR) and MLR models show similar and moderate performance, each with an MAE of 0.305, RMSE of 0.361, and a correlation coefficient of 0.746. ANN(PNN) exhibits the lowest performance among ANN models, with a high MAE of 0.422, RMSE of 0.466, and a relatively low R of 0.659. The overall analysis indicates that advanced ensemble and tree-based models significantly outperform traditional regression and specific neural network models in accuracy, correlation, and explanatory power, highlighting their suitability for yield response-prediction tasks.
However, the moderate performance of ANN(LR) and MLR and the poor performance of ANN(PNN) highlight that not all neural network configurations are equally effective. These results emphasize the importance of model selection and tuning in achieving optimal predictive performance and suggest that more complex or specialized models offer substantial advantages over more straightforward, more traditional approaches in specific contexts like yield response prediction.
Indeed, the models were ranked in order of performance by the ensemble model, RFR, ANN(MLP), boosting tree, ANN(GFF), ANN(LR), and ANN(PNN) according to a cross-comparison thereof in
Table 3.
Figure 8 displays the scatter plots of predicted yields against observed yields. The ensemble model performance was deemed adequate since the regression line had a slope close to 1, indicating predictions closely matched observed values. The intercept was nearly 0, showing little overall bias in the model’s estimates. Predicted and actual data points are closely aligned along the 1:1 reference line with minimal dispersion.
Figure 9 compares yield curves for calibrated model outputs and observed data from 1991 to 2021. The ensemble model, ANN(MLP), RFR, and ANN(GFF) predicted time series yield data closely matching the observed yields, as evidenced by the comparing curves. Ensemble modeling showed a particularly strong performance for this climate-yield dataset. Small residual errors and close alignment between ensemble predictions and observations demonstrate its reliable representation of patterns.
According to the model evaluation findings, the ensemble model was the most accurate and sufficiently good to assess future yield change trends for 2021–2052 under different scenarios: AR4 SRA2, B1, and A1B. Consequently, we discovered that the yield function may be expressed using artificial neural network methods based on climate factors. The ensemble model is an effective computational tool for simulating wheat-yield response functions under typical meteorological circumstances.
4.4. Downscaling Climate Projections Using the XGboost Algorithm
We first downscaled climate variables across the study area to project wheat yields under future climates using the averaged ensemble of IPCC AR4 emissions scenarios. This multi-model mean incorporated high (A2), medium (A1B), and low (B1) CO
2 emissions scenarios. The XGboost algorithm was selected to downscale climate data from 1991 to 2052, as prior work has effectively applied it in similar contexts [
18]. We employed a 60%, 20%, and 20% split to train, test, and validate the XGboost model on observed historical climate records from 1991 to 2052 for the three regions. Projections from global climate models served as predictors. By downscaling the multi-model mean using XGboost—a method proven skillful by others—we generated high-resolution climate inputs to drive our crop modeling while accounting for emissions uncertainty.
Table 4 represents the statistical performance of the XGboost for downscaling all three parameters. All scenarios’ mean error values for
during training ranged between 0.107 and 0.416 (RMSE), 0.030 and 1.08% (nRMSE), and 0.09 and 0.121 (MAE) (°C). The mean error values for
during the training ranged between 0.222 and 0.369 (RMSE), 0.79 and 1.27% (nRMSE), and 0.095 and 0.95 (MAE) (°C).
The mean error values for precipitation during the training period ranged between 0.073 and 0.416, 0.159 and 0.174%, and 0.009 and 0.07 (mm/month) for the RMSE, nRMSE, and MAE. R values for , , and precipitation ranged between 0.966 and 0.998, 0.908 and 0.99, and 0.909 and 0.993. During testing, overall mean error values ranged between 0.067 and 0.437 (RMSE), 0.030 and 1.27% (RMSE), and 0.010 and 0.200 (MAE), and during validation, accuracy was higher than testing, i.e., 0.067–0.291 (RMSE) and 0.00–0.009 (MAE), respectively. Additionally, the nRMSE value for all three regions in the emission scenario SRB1 for variable and rain gives an outstanding performance comparison to the variable in the Multan region. In the emission scenario SRA2, the value of nRMSE also indicates outstanding performance for all three region variables.
In the SRA1B scenario, the Okara region performs better for and Rain, Multan performs well for all three variables, and Sargodha gives excellent results for Rain. We discovered that the model’s downscaling ability changed with average emission scenarios. Precipitation was downscaled with the SRA2 scenario, providing the highest performance (R = 0.90–0.996). However, SRB1 resulted in R values ranging from 0.909 to 0.92, and SRA1B ranged from 0.917 to 0.957. In SRA2, we also found that Sargodha’s precipitation performance was best, with R = 0.996. performance in SRB1 ranged from R = 0.908 to 0.99, in SRA2 from R = 0.944 to 0.988, and in SRA1B from R = 0.958 to 0.989, with SRA1B giving the most accurate performance in Okara (R = 0.989). performance in SRB1 ranged from R = 0.979 to 0.994, SRA2 from R = 0.973 to 0.985, and SRA1B from R = 0.966 to 0.984. When evaluating the downscaled temperature projections against observations, the XGboost approach appeared to capture patterns in daily high temperatures more accurately than in daily low temperatures.
The scatter plots comparing downscaled XGboost outputs to observed climate data showed strong, statistically significant correlations. For maximum temperature (
), the model captured between 0.913 and 0.951 of observed variation for Okara, 0.926 and 0.979 for Multan, and 0.951 and 0.961 for Sargodha during training, as seen in
Figure 10. Similarly,
Figure 11 showed for minimum temperature (
), the R-squared values ranged from 0.863 to 0.950 for Okara, 0.908 to 0.949 for Multan and 0.863 to 0.942 for Sargodha. While performance was higher for
than
, both remained within acceptable ranges.
Figure 12 Precipitation outputs also correlated strongly with observations, with R-squared values ranging from 0.860 to 0.970 for Okara, 0.861 to 0.925 for Multan, and 0.837 to 0.970 for Sargodha during testing. This confirms that the downscaled projections generated by XGboost capture observed temperature and rainfall patterns with high fidelity, validating its use for impact modeling at local scales under future climates. The XGboost model demonstrated excellent downscaling performance for all variables during training, testing, and validation in the SRA1B, SRA2, and SRB1 scenarios.
The study leveraged the XGboost algorithm to downscale precipitation, minimum temperature, and maximum temperature projections for 2021–2052. These climate variables were derived from the averaged multi-model ensemble of IPCC AR4 baseline simulations. The downscaled climate projections, spanning 2021–2052, served as inputs to the crop-yield-modeling process. Specifically, we utilized these high-resolution climate data streams within the “Ensemble model”, a previously validated yield estimation function shown to achieve the highest accuracy levels.
4.5. Wheat-Yield Prediction over 2052
Our study leveraged the ensemble yield model with statistically downscaled climate variables under three IPCC emissions pathways (A1B, A2, B1).
Figure 13 shows the predicted yields over 31 years for Okara, Multan, and Sargodha. Interestingly, while yields varied substantially year-to-year, we observed no statistically significant differences between the scenarios within each site. The yields with SRA1B are
less than SRA2; SRB1 is also higher than SRA1B and SRA2, with 6.67% and 9.97% in Multan. In Sargodha, SR-A2 is higher than SRA1B and SRB1 at 6.2% and 6%. On the other hand, the greatest values in historical yield were 3.90, 2.99, and 3.64 (ton/ha) for Okara, Sargodha, and Multan. Specifically, field measurements across locations indicated an average peak yield of 0.95 tons per hectare. However, when using climate projections from GCMs within our crop modeling, the average maximum yield forecast was 0.90 tons per hectare, which means that yield decreased by 5.56%. According to these findings, climate change is projected to reduce wheat output in these regions by at least 5.5%. In our research, we discovered that ML models greatly improve the accuracy of wheat-yield predictions. Unlike traditional statistical methods, which struggle to consider the nonlinear and intricate connections between climate variables and crop yield, ML models—especially ensemble approaches—can effectively handle high-dimensional data and capture complex patterns, resulting in more dependable predictions.
The improving accuracy of ML models allows farmers to build better adaptation techniques. Farmers may make informed decisions about planting schedules, irrigation timing, and crop selection based on precise production estimates. These decisions help to increase resistance to adverse climate circumstances. Farmers can protect crop yields by predicting probable losses due to rising temperatures and implementing mitigation measures, such as selecting heat-tolerant wheat cultivars or modifying agricultural practices.
6. Discussion
This work presents a novel way to predict wheat yield under climate change scenarios that employs a complex ensemble of machine learning models. The fundamental novelty of this research is the integration of many advanced machine learning algorithms to estimate wheat output based on climate data, which involves utilizing historical climate data as well as projections from GCMs. We applied a range of ML models, including RFR, MLR, boosted tree regression, artificial neural networks (ANNs), XGboost, and ensemble models, to forecast wheat yield to varying climate conditions. Subsequently, observed climate factors and yield data were used to evaluate and refine the predicted wheat-yield function. The downscaled GCMs output for different CO2 emissions scenarios AR4 SRB1, A2, and A1B were incorporated into the calibrated output response model to anticipate yield trends through 2052. Focusing on local wheat data, our research aims to capture growth characteristics, predict future trends, and enhance crop-yield projections for the specified area.
In our study, we found that maximum temperature () and minimum temperature () are crucial in influencing wheat yield, while rainfall has minimal impact. Notably, the ensemble model—combining the strengths of various machine learning models—outperformed traditional methods. With an impressive value of 0.953 and an RMSE of 0.107, the ensemble model outperformed individual models in capturing the complicated connections between climatic conditions and crop yield. Policymakers can use insights from ML models to create policies that promote sustainable agriculture practices. For example, prioritizing investments in climate-resilient crop types and encouraging advanced irrigation practices can help to boost agricultural adaptability. Integrating ML models into national agricultural planning allows for more effective resource allocation, which helps to ensure food security in the face of climate change.
Previous research on the impacts of climate change on wheat production in China found that winter wheat yields are projected to decline by 7.1% over the next 50 years, according to their modeling. Meanwhile, their analysis anticipated spring wheat yields will decrease by 17.5% over the same time. This separate study examined the potential effects of global warming, specifically on winter wheat cultivation in Gansu Province, China. Their results revealed little to moderate impacts on the suitable growing region for winter wheat under various climate change scenarios forecasted for the province.
The researchers [
48,
49] used two regional climate projection models with RCP 4.5 and RCP 8.5 scenarios. The study found that environmental degradation, specifically temperature trends, has a statistically significant impact on crop yield in this region. The impacts analysis found that wheat yields may rise by up to 14% in some areas but fall 7.9–11% in others depending on temperature trends. This demonstrates that climate change, through its effects on warming, presents statistically significant risks to regional agricultural productivity.
The research findings suggest that under projected drought conditions in South Asia, there could be a substantial decrease in wheat yield, with estimates indicating a potential reduction of around 29.30% compared to normal yield levels [
40]. By utilizing advanced climate and crop models, the study aims to provide insights into the future risk of yield reduction under different drought intensities, highlighting the significant impact of extreme weather events on crop production in the region. Ref. [
50] examined wheat-yield variability under expected future climates using previous wheat-yield sensitivity data. As well [
51], this study found that increasing temperature has a detrimental impact on wheat yields, but cumulative precipitation had a favorable impact. Future climate scenarios are expected to increase temperature, decreasing wheat yields in Punjab.
Pakistan has the fourth largest irrigation system globally, contributing around 90% of agricultural production. However, the country lacks sufficient weather observatories across all regions and provinces to properly examine the relationship between climate and agriculture.
Here are some fundamental approaches to improve wheat yield while adapting to changing climate conditions:
More weather stations are needed across Pakistan to thoroughly examine nationwide climate-agriculture relationships at the district and provincial levels.
Developing and promoting wheat varieties that exhibit heat tolerance, drought resistance, and disease resilience is crucial. These climate-smart cultivars can withstand extreme temperatures and water scarcity, ensuring stable yields.
Early sowing and climate-informed planting dates help avoid extreme heat stress during grain filling. Adjusting planting windows based on weather forecasts improves yield outcomes.
Efficient irrigation systems, rainwater harvesting, and proper water scheduling are essential. Consistent water supply during critical growth stages enhances yield.
Mapping suitable crop habitats can aid precautionary measures and innovations to boost agricultural output and food security amid climate shifts.
Although our study focused on the Punjab region of Pakistan, the methodologies and models we employed can be adapted to other areas and crops. This scalability underscores the importance of ML models as crucial tools for global agricultural planning and improving food security strategies. Future research could explore applying these models in diverse geographical contexts and with various crops to validate their effectiveness and adaptability. The results will equip policymakers to craft innovative crop-management strategies for crops like wheat and maize locally and nationally. Collaboration across disciplines will increase our collective potential to construct climate-resilient food systems in the face of urgent climate hazards. Future research should consider other variables such as soil health, pest and disease prevalence, and socioeconomic characteristics to improve the robustness and accuracy of crop-production estimates. Furthermore, more complex ensemble approaches and real-time data can improve machine learning models’ adaptability and reactivity. Collaboration among data scientists, agronomists, and policymakers will be critical to realizing the full promise of machine learning in agriculture.
7. Conclusions
The study used various advanced modeling techniques, including random forest regression, BTR, ANN, MLR, and ensemble models, to forecast site-specific wheat-yield responses based on weather conditions and yield data. The ensemble model, RFR, and ANN(MLP) were better than boosted tree regression when it came to calibrating wheat output models for Punjab. The ensemble model did better than the others, with an R2 of 0.953 and an RMSE of 0.107. The study also showed that artificial neural networks are good at predicting crop yields in both current and future climate scenarios. This was achieved by using GCM results for many CO2 emission scenarios to do this up until 2052. The study found that higher temperatures in Punjab are more to blame for lower wheat yields than lower temps. According to the study, higher temperatures during key stages of growth may lead to lower wheat yields. You cannot say enough about how important it is to think about the highest temperatures when making climate-resilient plans to protect world farming output and ways of making a living. The yield response model we used is based on downscaled GCM predictions. It shows that under different climate change scenarios, wheat yield will drop by 5.5% by 2052. Because of climate change, wheat output is going down, which shows how important it is to have flexible growing methods. Make climate forecasts for the years up to 2052 by putting together the results of global warming models with different scenarios for CO2 emissions. By incorporating machine learning (ML) models to predict wheat yield under climate change scenarios, we gain several advantages over traditional methods. These models offer improved predictive accuracy, enabling us to guide adaptation strategies and inform policy decisions. Their transformative potential in agriculture underscores the importance of advanced data analytics. As we progress, refining these models and exploring their applicability across diverse regions and agricultural systems will be crucial for ensuring global food security.
Our research identified a need for more research on crop prediction in specific areas of Pakistan, particularly regarding wheat-yield forecasting in Punjab using GCM data. This study explores machine learning models’ potential in enhancing wheat-yield prediction in these regions. Through advanced techniques applied to agricultural data, our research contributes to understanding climate change impacts on agriculture, offering crucial insights for developing targeted adaptation strategies in Punjab, Pakistan. Our interdisciplinary approach underscores the importance of collaborative efforts in addressing climate change challenges to global food security, providing actionable insights for policymakers, agricultural experts, and farmers to develop adaptive measures and resilient crop management practices.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}