1. Introduction
Electricity is the fundamental power source in modern society, supporting industry, transportation, communication, and daily life. It is beneficial to promote sustainability by driving renewable energy utilization, reducing greenhouse gas emissions, and facilitating energy structure transformation. With the vigorous construction of the country’s power, the Internet of Things (IoT) and its work [
1,
2], power load forecasting is receiving more and more attention [
3,
4]. Electric load is crucial in the operation and administration of power systems [
5], ensuring efficient power resource utilization and seamless power grid operation [
6,
7,
8]. Reasonable and effective forecasting models can not only help the operation plan of the internal units of the power grid but also provide support for its operation and maintenance. They even can give guidance and suggestions for the plan of power grid transformation and expansion, facilitating the transformation of traditional power grids into smart grids [
9,
10]. Improving the accuracy of electricity load forecasting helps address the uncertainty and variability of renewable energy generation, facilitating the better integration of clean energy sources such as wind and solar power into the grid. Improving energy efficiency contributes to the development of smart grids and distributed energy systems [
11,
12]. For example, to achieve accurate predictions of power grid load aligning with real-world requirements, Lv and colleagues [
13] suggested a mixed approach involving the elimination of seasonal factors and error correction using variational mode decomposition and LSTM. They conducted a comprehensive analysis utilizing four authentic load datasets originating from Singapore and the United States to validate the efficiency and practicability of the recommended method [
14]. This model has the potential to guarantee the security and efficiency of power grid functioning. Therefore, the establishment of a reasonable and efficient power load-forecasting model has great practical significance [
15,
16].
However, the power load-forecasting problem still faces many challenges [
17,
18], such as poor data quality, uncertain load changes, and high model complexity. Traditional load-forecasting methods primarily include linear models and simple statistical models such as linear regression models, autoregressive integrated moving average models, and exponential smoothing methods [
19]. These methods are constrained by data limitations and algorithmic deficiencies [
10,
20], such as difficulty in capturing nonlinear relationships, limited ability to handle long-term time series data, and susceptibility to overfitting or underfitting issues. Consequently, they fall short of meeting the power system’s requirements for high accuracy, robustness, and generalization capability [
3,
21]. These limitations have driven the development of more advanced forecasting methods, such as those employing machine learning and deep learning techniques, to enhance prediction accuracy and robustness [
22]. For instance, Kong and Tan, along with their respective collaborators [
23,
24], utilized the LSTM model in power load forecasting. The results showed an improvement in forecasting accuracy. Wang et al. [
7] proposed a unified machine-learning approach for load forecasting. The results showed that this method improved the prediction accuracy. Yazici and colleagues [
25] suggested employing a one-dimensional convolutional neural network. This method outperformed other predictive models at some levels. However, power load data are inherently unstable and nonlinear, and a single forecasting model has limited capacity for data processing.
To further enhance the accuracy of power load forecasting, researchers have suggested various combination forecasting models to overcome the difficulties in power load forecasting, and the research results of various combination forecasting models showed that the combined forecasting model integrated the strengths of individual models [
26]. For example, Chu et al. [
27] used improved LSTM networks. Bayram et al. [
28] proposed a dynamic drift-adaptive learning framework with LSTM. Fang et al. [
29] used a novel reinforced deep recurrent neural network and LSTM algorithm. Li and colleagues [
30] introduced an enhanced short-term load-forecasting approach, mixed logistic regression, and LSTM. Lv and his colleagues [
13] proposed hybrid predictive models combining variational mode decomposition and LSTM. Jiang et al. [
31] combined LSTM and convolutional neural networks for power load prediction. Ng R W et al. [
26] proposed an enhanced self-organizing incremental neural network model for short-term time series load forecasting. All these approaches demonstrated improved prediction accuracy using hybrid models. In recent years, due to the swift progress of deep learning methods, power load forecasting has shifted from conventional time series analysis to deep learning approaches [
7,
32]. This is a new development direction [
33,
34], opening avenues to enhance power load forecasting accuracy.
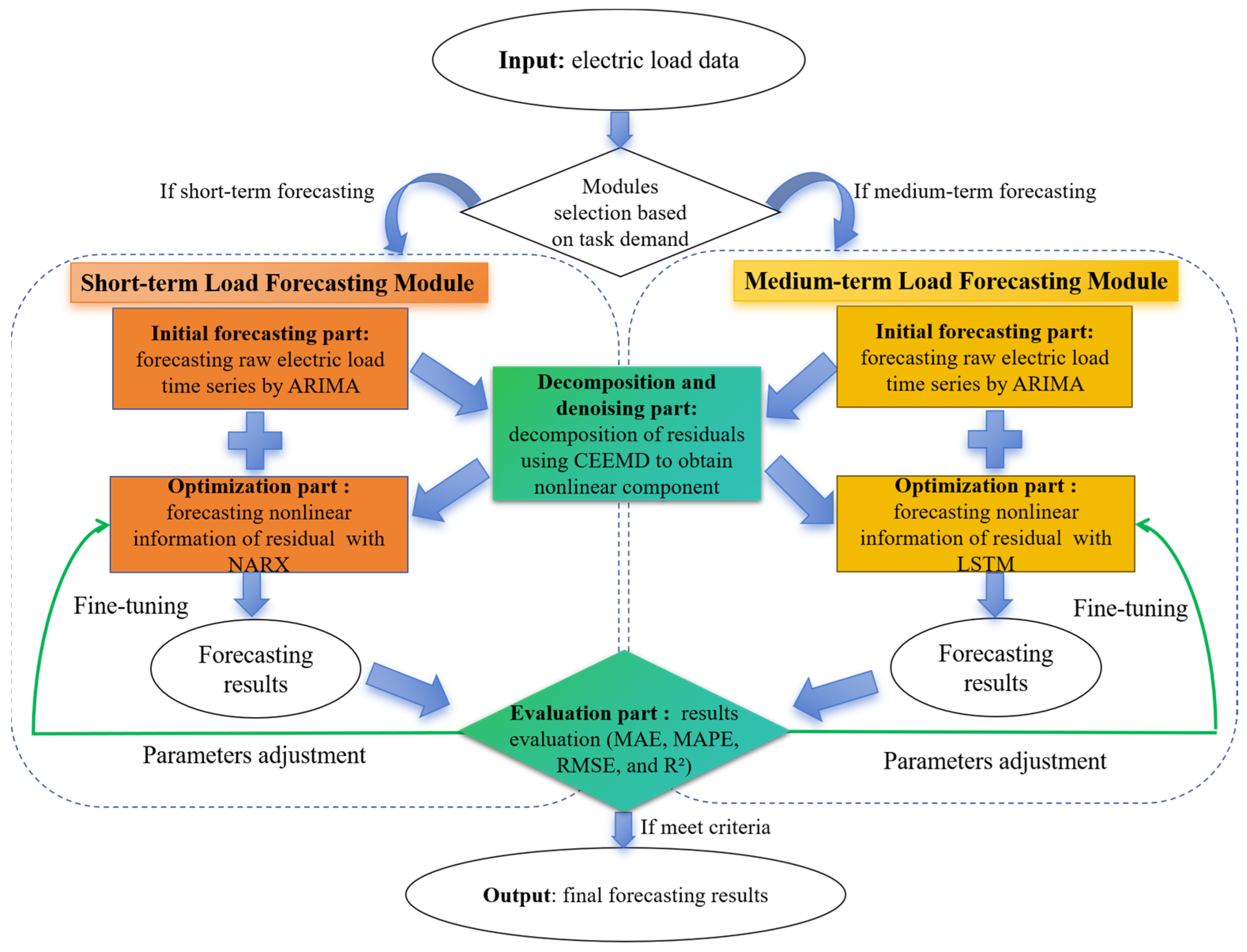
A CMPLF method that fuses hierarchical optimization models is proposed in this study to address the challenge of fitting the nonlinear residuals, aiming to improve the accuracy of short- and medium-term power load forecasting. The method divides the power load-forecasting problem into short-term and medium-term forecasting based on the dataset’s time unit length. Specifically, for short-term power load prediction [
35,
36], we chose the ARIMA model to finish preliminary load forecasting and mined its internal linear information. After deriving the forecast residuals, we used the CEEMD algorithm to decompose the nonlinear components in the residuals. The NARX model then was used to analyze the short-term dependence between the load residuals and power load to make a comprehensive prediction. For medium-term load prediction [
37,
38], considering the extensive data period, the ARIMA model, utilized for forecasting the linear aspects of the data, remained unchanged. The LSTM model was employed to fit the nonlinear elements within the residuals of the ARIMA model, analyzing the long-term dependencies among the load residuals. The final forecasting results were derived by integrating predictions from both linear and nonlinear models. This fusion approach also incurs certain costs. Model integration increases system complexity, requiring more computational resources and time for training and validation. However, our method significantly improves the accuracy of power load forecasting. The primary contributions of this work can be condensed into three aspects:
A hierarchical optimization method is developed for accurate power load prediction, including the initial forecasting model, decomposition and denoising strategy, and efficient nonlinear optimization algorithms based on two forecasting modules.
In this highly precise forecasting method, by breaking through bottlenecks in hierarchical model fusion, three emerging models, i.e., an ARIMA model, a NARX model, and LSTM networks are effectively fused.
The superiority and validity of the CMPLF method are confirmed through two forecasting experiments using 30 min interval power load data from Queensland provided by the Australian Energy Market Operator (AEMO). This work proves that the proposed CMPLF method is suitable for the samples of different regions.
The rest of this paper is structured as follows:
Section 2 presents the overview and flowchart of our proposed CMPLF method via deep learning. The short-term load-forecasting and medium-term load-forecasting modules in the CMPLF method are then described. Subsequently, every part and the algorithms in the two modules are introduced in detail. In
Section 3, we used the dataset from the 10th Teddy Cup Data Mining Challenge in 2022 to train the models to improve the accuracy of power load forecasting. To verify the superiority and validity of the CMPLF method, we accomplished three experiments via different datasets in
Section 4. Eventually,
Section 5 provides a summary of the entire paper, drawing conclusions and proposing future work directions.
4. Performance Evaluation
In this section, three experiments are introduced objectively to validate the performance and superiority of the proposed CMPLF method. Before that, the dataset involved in the experiments must be set up.
4.1. Dataset Setting
The experiments in this paper used 30 min interval power load data from Queensland, Australia in 2023, which is available at
https://aemo.com.au/ accessed on 11 August 2023. The 30 min interval power load data of Queensland is from 8 June 2023, to 12 July 2023. We divided the operational load data into 5 groups according to weeks, of which 70% was chosen as the training set and the remaining 30% was automatically included in the testing set.
4.2. Experiment I: Performance of the CMPLF Method Compared with Basic Models
4.2.1. Comparison of Short-Term Load-Forecasting Models
To test the effect of the ARIMA-NARX model on short-term forecasting, the MAPE, RMSE, and R
2 of the ARIMA model, NARX model, and ARIMA-NARX model were calculated on the dataset, respectively. The results are shown in
Table 3:
Table 3 shows that the ARIMA-NARX model fits with less error than the conventional ARIMA model and NARX model, i.e., it has a better prediction effect. Compared with the original ARIMA model, the MAPE and RMSE of the ARIMA-NARX model for the test set predictions are reduced by 60.1% and 64.9%, respectively. The R
2 of the ARIMA-NARX model is enhanced by 9.6% over the ARIMA model. Compared with the original NARX model, the MAPE and RMSE of the ARIMA-NARX model for the test set predictions are reduced by 28.7% and 40.4%, respectively. Moreover, the R
2 of the ARIMA-NARX model is improved by 7.0% over the NARX model. It is clear that ARIMA-NARX has a significant performance improvement over the basic models in short-term power load forecasting.
4.2.2. Comparison of Medium-Term Load-Forecasting Models
To test the performance of the ARIMA-LSTM model on medium-term forecasting, the MAPE, RMSE, and R
2 of the ARIMA model, LSTM model, and ARIMA-LSTM model were calculated on the dataset, respectively. The results are shown in
Table 4:
From the analysis of the data in
Table 4, it is evident that the ARIMA-LSTM model fits with less error than the traditional ARIMA model and LSTM model, i.e., it has better prediction results. Compared with the original ARIMA model, the MAPE and RMSE of the ARIMA-LSTM model for the test set predictions are reduced by 61.5% and 66.9%, respectively. The R
2 of the ARIMA-LSTM model is enhanced by 10.0% over the ARIMA model. Compared with the original LSTM model, the ARIMA-LSTM model reduces its MAPE and RMSE by 29.9% and 39.7%, respectively. Moreover, the R
2 of the ARIMA-LSTM model is improved by 6.8% over the LSTM model. It can be concluded that ARIMA-LSTM has a significant performance improvement over the original models in medium-term power load forecasting.
The experimental data in Part 4.2 shows the proposed ARIMA-NARX model and the ARIMA-LSTM model provide good performance in forecasting the daily power load of a region in mainland China with much better accuracy than the simple, existing deep learning models. Therefore, we combine the two hybrid models to integrate the CMPLF method. The method is a recommended deep learning method for forecasting the short- and medium-term power load of a region.
4.3. Experiment II: Validity of the CMPLF Method on Cross-Regional Datasets
To verify the validity of our proposed CMPLF method, we used the dataset from Queensland to examine the accuracy of the models. MATLAB was used to finish this experiment to show the validity of this forecasting method on cross-regional datasets.
Figure 10 shows the fitness of short-term load forecasting. The horizontal coordinate of this graph is the true load, while the vertical coordinate is the load predicted by the ARIMA-NARX model. The line band Y = x refers to the case where the predicted and actual loads are equal. The distance of each point (blue) plotted with the data predicted by our model from this center line represents the magnitude of the error. The lower the dispersion of all the scattered points, the greater the model. Conversely, the lower the accuracy of the model. It shows that the prediction results have a low degree of discretization from this center line. Therefore, we can obtain that the ARIMA-NARX algorithm has an accurate prediction effect on short-term power load forecasting.
Figure 11 shows the fitness of medium-term load forecasting. The horizontal coordinate of this graph is the true load while the vertical coordinate is the load predicted by the ARIMA-LSTM model. The line band Y = x refers to the case where the predicted and actual loads are equal. The distance of each point (red) plotted with the data predicted by our model from this center line represents the magnitude of the error. The lower the dispersion of all the scattered points, the greater the model. Conversely, the lower the accuracy of the model. It shows that the prediction results have a low degree of discretization from this center line. Therefore, we can obtain that the ARIMA-LSTM algorithm has an accurate prediction effect on medium-term power load forecasting.
Therefore, Experiment II can verify the CMPLF method applies to cross-regional datasets.
4.4. Experiment III: Superiority of the CMPLF Method Compared with the SOTA Prediction Methods
To show the superiority of our models in the CMPLF method on power load forecasting and to compare with some existing mainstream models, the experiment took two deep learning methods: the PSO-LSTM model and the GWO-BP model into comparison. Our simulation referred to the actual data collected from June 2023 to July 2023 by AEMO.
Figure 12 exhibits the comparison between the forecasting results and real data on short-term load forecasting using the ARIMA-NARX model, PSO-LSTM model, and GWO-BP model.
Based on the prediction results, this experiment also calculated the MAE, MAPE, and R
2 for the different models. These two conventional error criteria can show the specific effect of each forecasting model. The detailed results are displayed in
Table 5.
From the above table, we can clearly know that the proposed ARIMA + NARX combining method performs the best result in short-term power load forecasting compared with the other methods.
Figure 13, on the other hand, shows the comparison between the prediction results and real data on medium-term load forecasting using the ARIMA-LSTM model, PSO-LSTM model, and GWO-BP model.
Based on the forecasted data, this experiment also calculated the MAE, MAPE, and R
2 for the different models. These two conventional error criteria can show the specific effect of each forecasting model. The detailed results are shown in
Table 6.
From the above table, we can clearly know that the proposed ARIMA + LSTM combining method performs the best result in medium-term power load forecasting compared with the other methods.
Furthermore, to better represent the superiority of our proposed ARIMA-NARX model and the ARIMA-LSTM model on short- and medium-term load forecasting, we made two relative error box-scatter plots based on the forecasted data. See
Figure 14.
From
Figure 14, these unevenly distributed points can also clearly verify that the combined models in our proposed CMPLF method have a superior forecasting effect on short- and medium-term load forecasting compared with some existing mainstream models.
Although the CMPLF method uses a combination of the ARIMA model and time series networks and outperforms a single model in terms of evaluation metrics, it still suffers from some errors. These errors may arise from the fact that the ARIMA model assumes that the time series are linear and that the statistical properties do not vary over time. In addition, the time series networks may be deficient in handling long time dependencies and incomplete data noise rejection. Also, the ARIMA model and the time series networks have inadequate hyperparameter optimization, as well as the complexity of the power system and external factors can generate errors.
Considering the development of the models, the errors can be further reduced by introducing more advanced models and automated parameter optimization techniques using data cleaning and feature engineering to remove noise, and incorporating external factors to increase the sensitivity of the models to external changes.
5. Conclusions and Future Work
Our study proposes a CMPLF method based on the fusion of hierarchical optimization models, namely ARIMA-NARX and ARIMA-LSTM, which is utilized to forecast short- and medium-term load. In this work, a combination to fuse the ARIMA model with the NARX model and the LSTM model is worked to the problem of fitting the nonlinear part of the residuals. The CMPLF method has two modules to forecast short-term load and medium-term load, respectively. Experiment I reveals that the fitting performance of both ARIMA-NARX and ARIMA-LSTM is better than that of ARIMA, NARX, and LSTM on the dataset from a region of mainland China. Included among these, the R2 of the ARIMA-NARX and ARIMA-LSTM models are 0.983 and 0.987 on this dataset, respectively. Therefore, this forecasting method, based on the hybrid algorithm of ARIMA-NARX and ARIMA-LSTM, can predict the short-term and medium-term power load more accurately. In Experiment II, the goodness-of-fit values are 97.174% for the ARIMA-NARX model and 97.162% for the ARIMA-LSTM model based on the data of the Queensland power grid. The results of this experiment using the power grid dataset from Queensland fully demonstrate the validity of the CMPLF method proposed in this paper. Furthermore, to more clearly verify the superiority of our proposed CMPLF method, Experiment III takes some existing mainstream forecasting methods into comparison. The data illustrates that the CMPLF method has the best performance. Our work will be instructive for achieving sustainability in energy management systems.
Although the proposed CMPLF method shows good results on the provided power load dataset, the models are based on the basic assumption that the future power load is only influenced by its historical value. This simplifies the real situation. In practice, there are many factors affecting the region’s electric load. For example, government policies and the socioeconomic environment also have a significant impact on the industry’s electric consumption. Therefore, it is the future research direction to combine more reasonable factors influencing power load and establish more accurate power load-forecasting models.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}