1. Introduction
The rapid development of industrialisation and urbanisation has led to an increased focus on the dispersion of atmospheric pollutants as a key research topic in the field of environmental sustainability [
1,
2]. The dispersion of pollutants exhibits dynamic complexity in time and space and is influenced by a variety of interrelated factors. For instance, the formation of a night-time inversion layer or the occurrence of storms can lead to rapid and non-stationary fluctuations in pollutant dispersion. The intricacy of these challenges renders it challenging to adapt conventional dispersion prediction techniques to this intricate scenario, compelling researchers to pursue novel methodologies and strategies to surmount the constraints of the conventional paradigm [
3,
4].
Deep learning models help to better understand pollutant dispersion patterns by analysing and extracting temporal relationships and spatial trends, providing valuable predictive and decision support [
5,
6]. Previous studies have used Convolution Neural Networks (CNNs) to extract spatial information from pollutant dispersion data and Recurrent Neural Networks (RNNs) to discover temporal correlations between data [
7,
8,
9]. However, these models still have some limitations. For example, CNNs may lose edge and detail information when processing high-dimensional data, which is unacceptable for representing fine-scale variations in pollutant dispersion [
10,
11,
12]. Conversely, RNNs are prone to the problem of gradient vanishing or gradient explosion when dealing with long sequential data, which affects the ability of the models to capture complex temporal dependencies [
13,
14,
15]. Therefore, there is a need to develop new modelling approaches to overcome these limitations and improve the accuracy and reliability of predictions.
In this study, we proposed a deep learning architecture incorporating a Residual Neural Network (ResNet) and a Temporal Convolutional Network (TCN), called SAResNet-TCN, which aims to adequately capture the spatial and temporal features of pollutant dispersion. ResNet solves the degradation problem in training deep CNNs by introducing residual learning, which allows the network to learn a deeper representation of the features [
16,
17]. With residual connectivity, the model effectively avoids information loss when training deep models and mitigates the problem of gradient vanishing [
18,
19]. In contrast, a TCN effectively captures long-term dependencies in sequence data while maintaining temporal consistency by introducing a causal convolution and diffusion layer structure [
9,
14]. When ResNet is combined with a TCN, a more comprehensive feature representation and modelling capability can be created, enhancing the model’s ability to represent complex patterns and improving prediction accuracy. In addition, a sparse attention (SA) mechanism was specifically incorporated in this study to take advantage of the sparsity that it introduces to strengthen the model’s focus on key features in time-series data [
20]. This strategy greatly improves the sensitivity of the model to key temporal nodes and features in the prediction of pollutant dispersion peaks, providing strong support for accurate prediction. These advantages enable SAResNet-TCN to predict pollutant dispersion patterns, especially the unconventional dispersion behaviours caused by unexpected events.
The main contributions of this study can be summarised as follows:
1. An innovative deep learning model named SAResNet-TCN is introduced. This model is uniquely designed with an attention branch that operates in parallel with ResNet to extract and integrate key features, thereby enhancing the model’s ability to identify and capture significant features. In addition, the integration of the TCN module ensures that the model effectively captures the temporal dependencies between features. Validated through case studies, the proposed model demonstrated improved accuracy in predicting pollutant dispersion, providing a novel approach to support environmental sustainability.
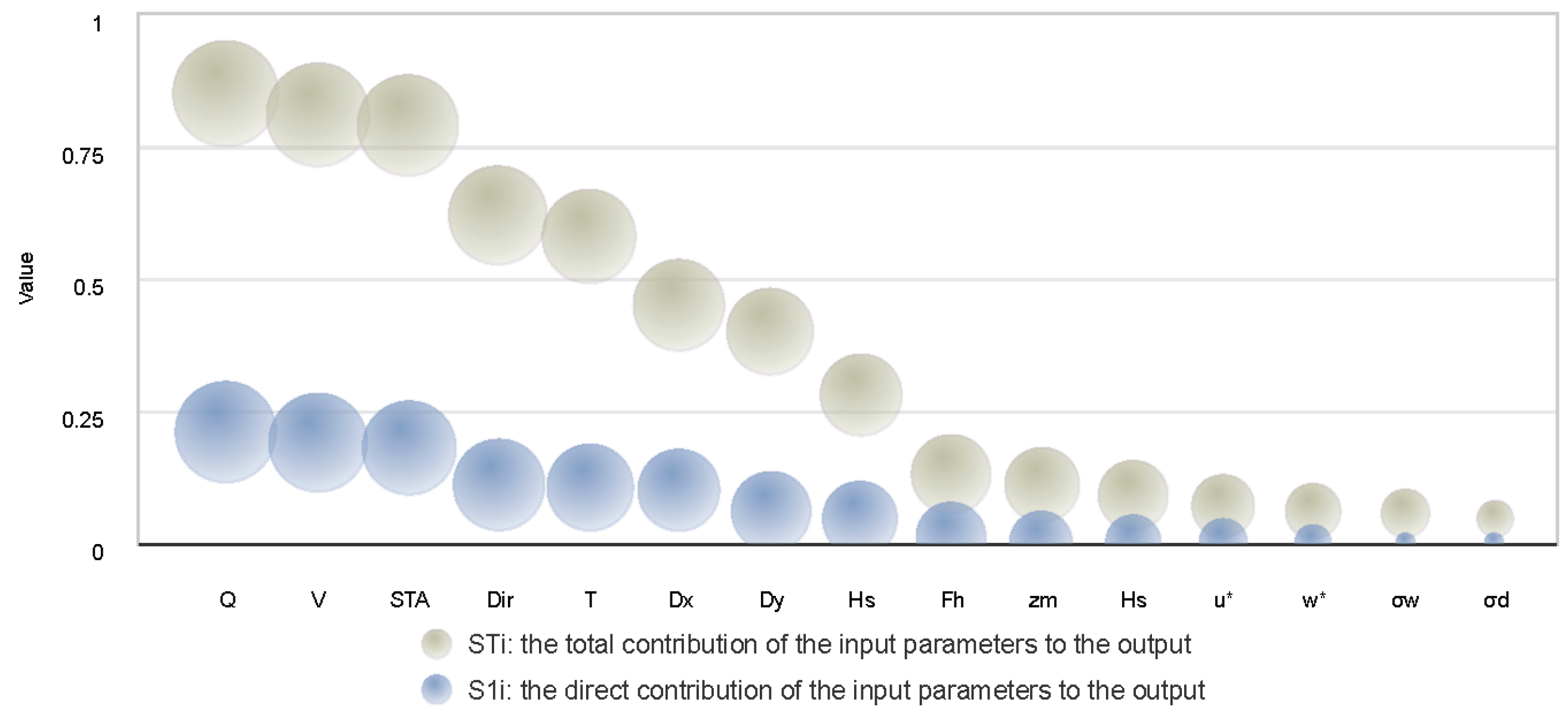
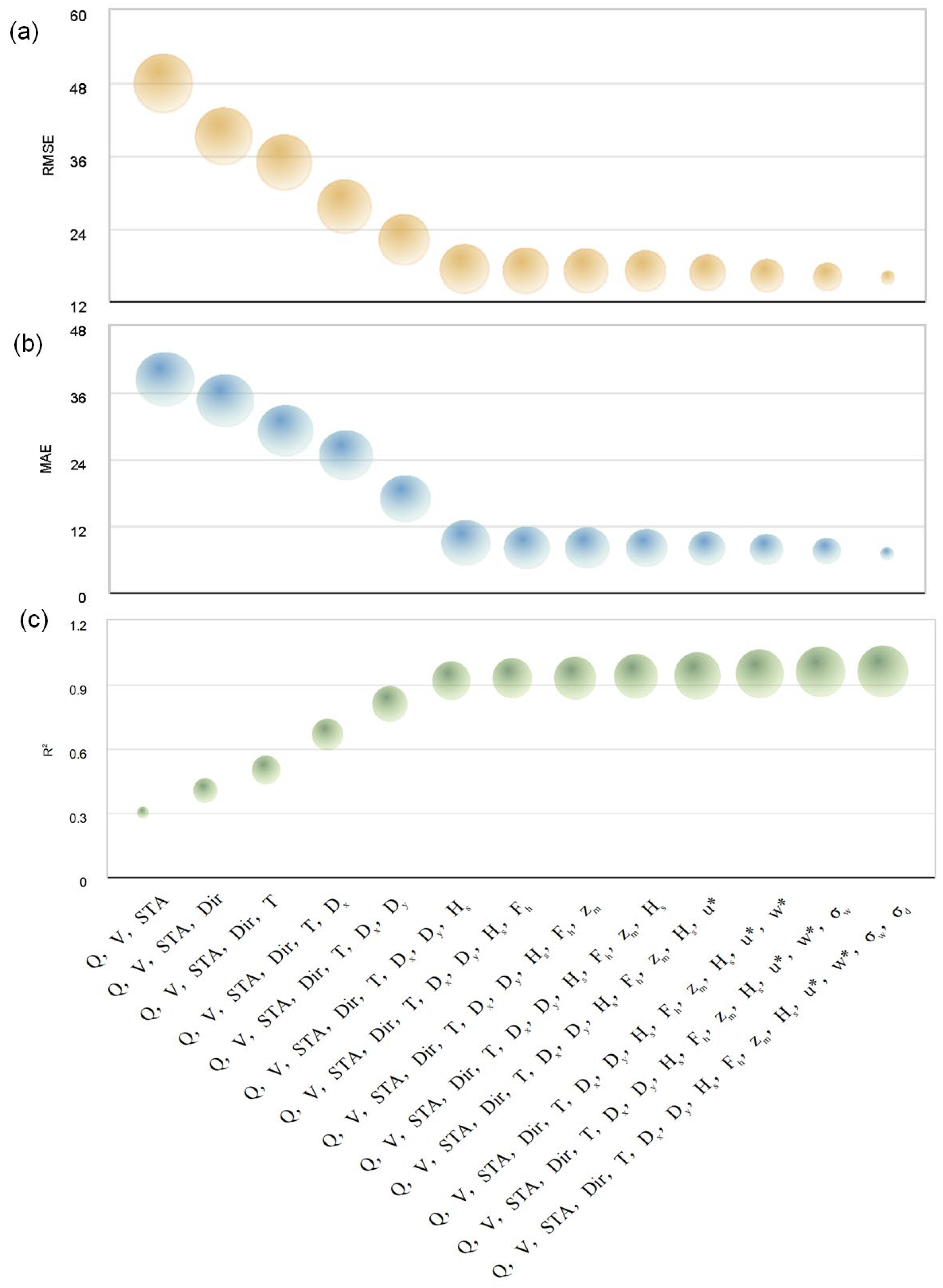
2. A global sensitivity analysis (GSA) was used to improve the interpretability and practical value of deep learning models in environmental management. Using the Sobol method, the impact of input parameters on model outputs was quantitatively analysed, identifying factors such as wind speed, atmospheric stability level, and pollution source strength as dominant influences on pollutant dispersion. Through the incremental addition of parameters into the experiments, this study further identified the key parameters that should be prioritised in resource-constrained scenarios and provides recommendations for effective resource allocation.
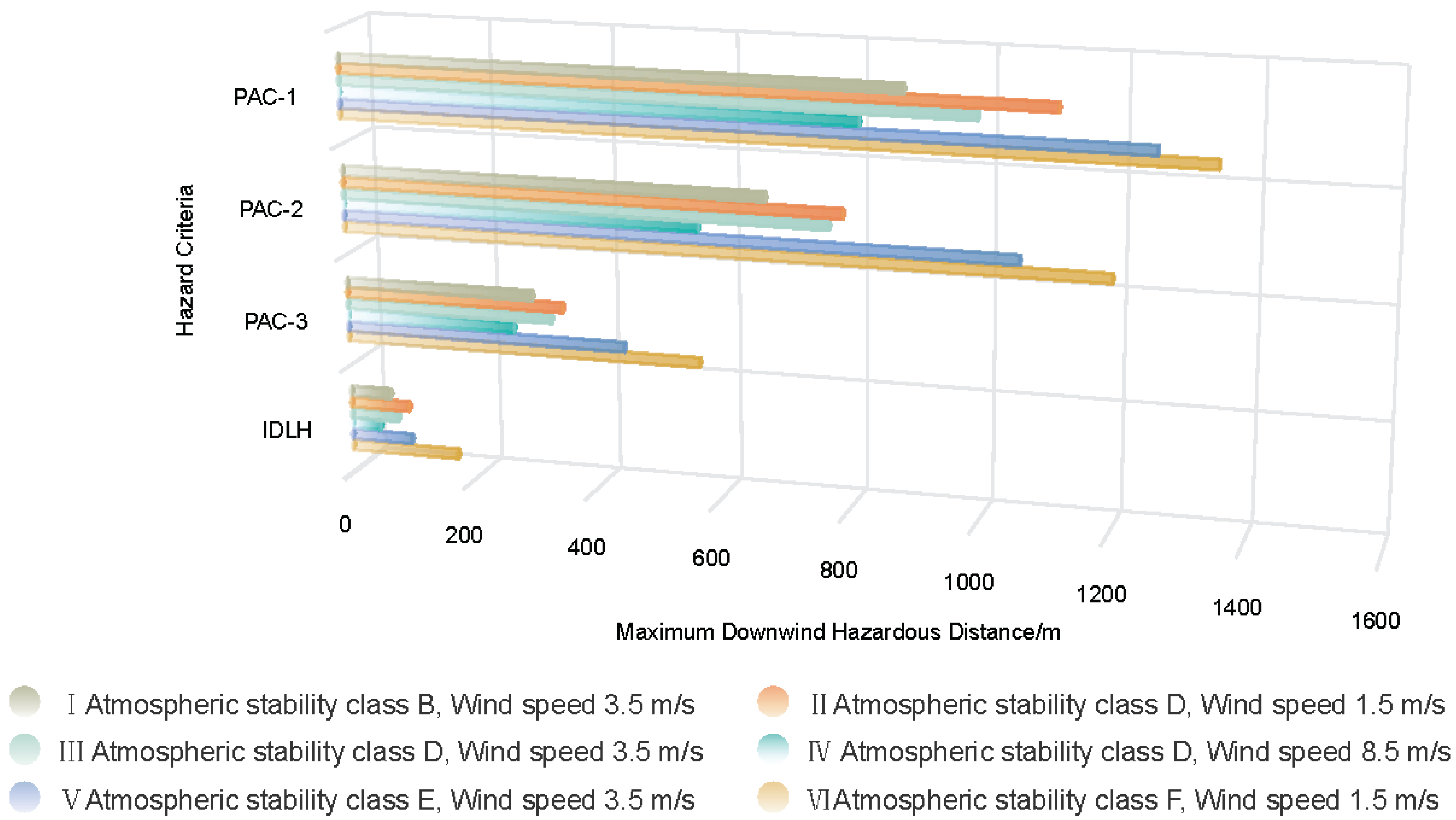
3. By applying standards such as the Protective Action Criteria (PAC) and Immediately Dangerous to Life or Health (IDLH) values, the maximum distances to hazard (MDH-distances) were visualised at different sulphur dioxide (SO
2) concentration hazard thresholds according to the six weather conditions defined in GBT37243-2019 [
21]. The results not only help to assess the serious consequences of uncontrolled toxic releases but also provide an important basis for worker protection in industrial environments.
This paper is organised as follows:
Section 2 outlines the specific details of the proposed pollutant dispersion prediction model.
Section 3 presents the experimental results and describes the results for different hazard thresholds. Finally, the main conclusions of this study are summarised in
Section 4.
2. Methodology and Proposed Model
2.1. Methods
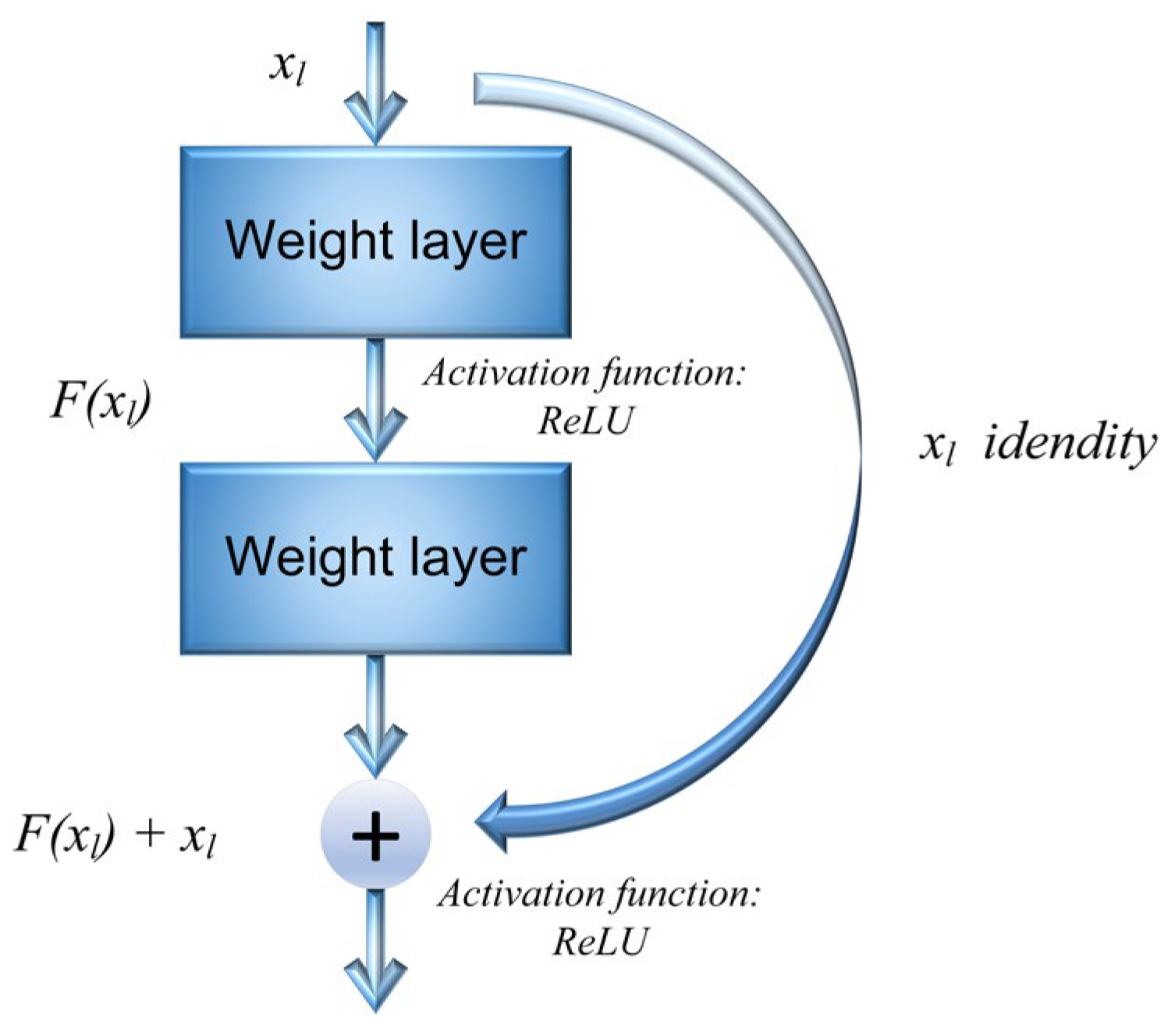
2.1.1. ResNet
When tackling the task of pollutant dispersion modelling, ResNet uses convolution kernels to capture the distribution of pollutant concentrations in a local area and identify local concentration variations and spatial relationships. This local perceptivity allows ResNet to effectively capture the local characteristics of pollutant dispersion, thereby improving the accuracy of the model. Compared to a CNN, ResNet incorporates residual connections. This structure boosts the network’s propagation efficiency by combining residual units with directly connected edges. Thus, the model’s loss of original information is significantly reduced [
22]. ResNet is composed of basic residual blocks, as shown in
Figure 1. Each basic residual block comprises a mapping section and a residual section, with the core formula shown in Equation (1).
In the formula, and are the feature inputs of the l + 1th and lth layers of the model, respectively; refers to the weight parameters of the residual cells.
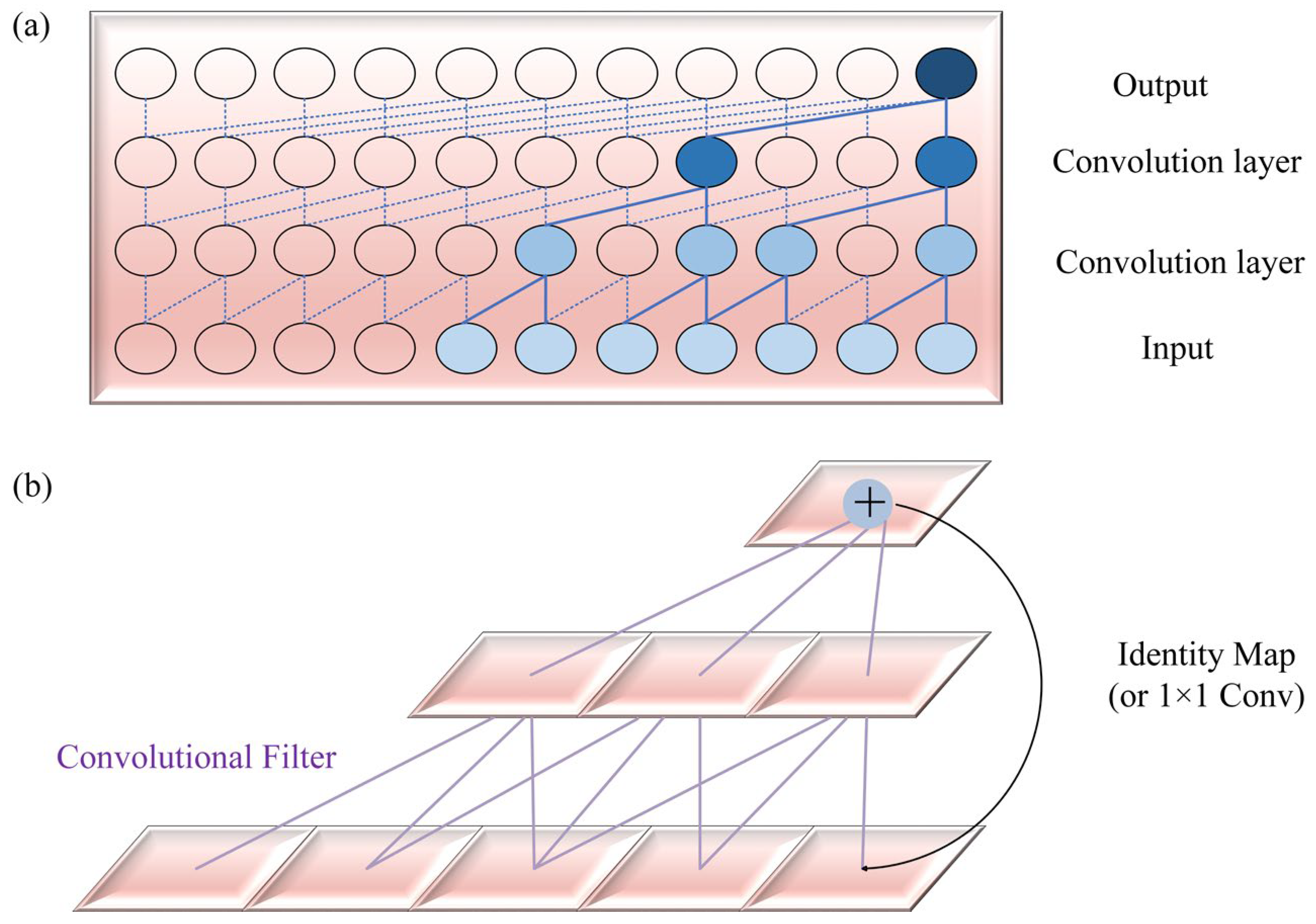
2.1.2. TCN
A TCN possesses superior time-series data processing capabilities and has demonstrated better performance than LSTM and GRU [
23,
24]. The fundamental elements of a TCN comprise dilated causal convolution and residual concatenation. Dilation causal convolution introduces both causality and dilation. By incorporating dilation into the convolutional kernel, dilation causal convolution can widen the receptive field of the kernel without sacrificing causality, thereby capturing a greater amount of contextual information. This technique is highly valuable for handling time-series data, permitting the TCN to model long-term dependencies effectively while maintaining causality. Residual connectivity serves the purpose of mitigating the issue of gradient vanishing while augmenting the flow of information through the network. Furthermore, it encourages the stability of the training process, allowing the network to acquire complex feature representations at a deeper level [
25]. Please refer to
Figure 2 for a diagram of the basic modules of a TCN.
2.1.3. SA Mechanism
The roots of attentional mechanisms can be traced back to the examination of human cognitive processes and explorations in neuroscience. Early attention mechanisms played an important role in deep learning by allowing models to selectively focus on specific information while processing input [
26,
27]. Nonetheless, traditional attention mechanisms generally have a global scope that assigns attention weights to all elements in the input. As a result, the computational and storage requirements are substantial [
28]. The recently proposed SA mechanism, however, improves the traditional attention mechanism by introducing sparsity, which significantly reduces the time complexity [
29]. The calculation formula is displayed in Equation (2). The SA mechanism allows the model to prioritise task-relevant key information and disregard irrelevant elements by selectively assigning attention weights. This precise allocation of attention improves the model’s efficiency and scalability while mitigating the risk of overfitting [
29,
30].
where
K and
V represent the key matrix and the value matrix;
denotes the sparse matrix;
d represents the dimension of
; and
T stands for the transpose operation of the matrix.
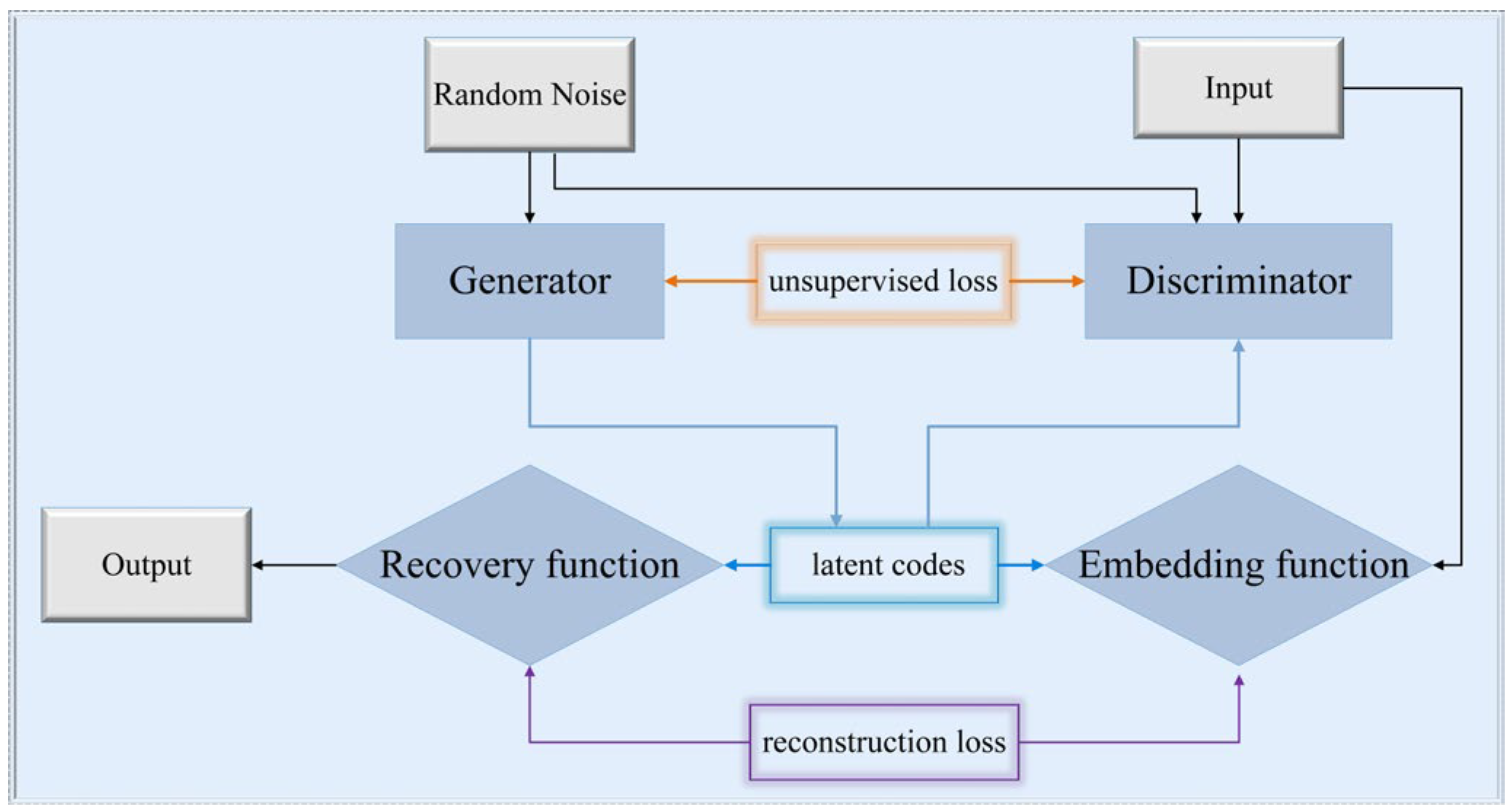
2.1.4. TimeGAN
TimeGAN is a Generative Adversarial Network (GAN) variant that combines the flexibility of unsupervised learning with the precise control of supervised learning, allowing for finer-grained dynamic tuning of the network [
31]. In the standard GAN framework, the core component is an adversarial module consisting of two networks: a generator and a discriminator [
32]. Through adversarial training between the generator and the discriminator, the GAN can continuously improve the data generated by the generator, making it increasingly more realistic, while at the same time improving the ability of the discriminator to discriminate between real and generated data.
TimeGAN not only contains the adversarial module of the traditional GAN but also adds a self-coding module [
15]. The main function of this self-coding module is to perform dimensionality reduction on the data. It consists of two parts, namely, an embedding function and a recovery function, which are connected by latent codes. The embedding function uses the hidden function to convert the data into a low-dimensional representation, and then the data are sent to the discriminator for screening. After screening by the discriminator, the data are inversely transformed by the recovery function to produce an enhanced dataset. To introduce time-series relationships between the data in the GAN network, TimeGAN uses a supervised loss function based on an autoregressive learning algorithm. This allows the network to learn and model time-dependent probabilities, which, in turn, generates data with time-series properties [
33].
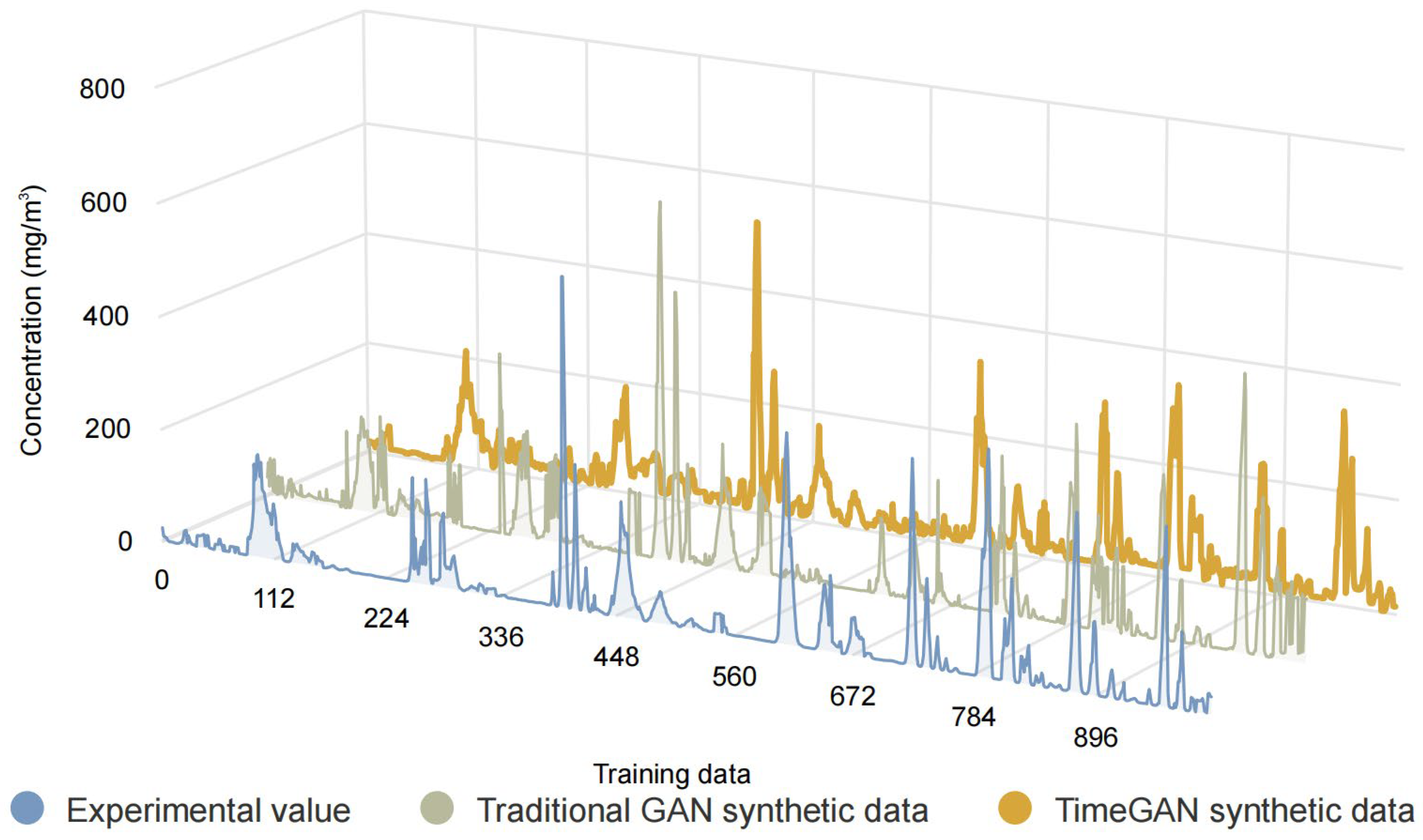
Figure 3 shows how data are processed and generated by the different modules of the network in TimeGAN.
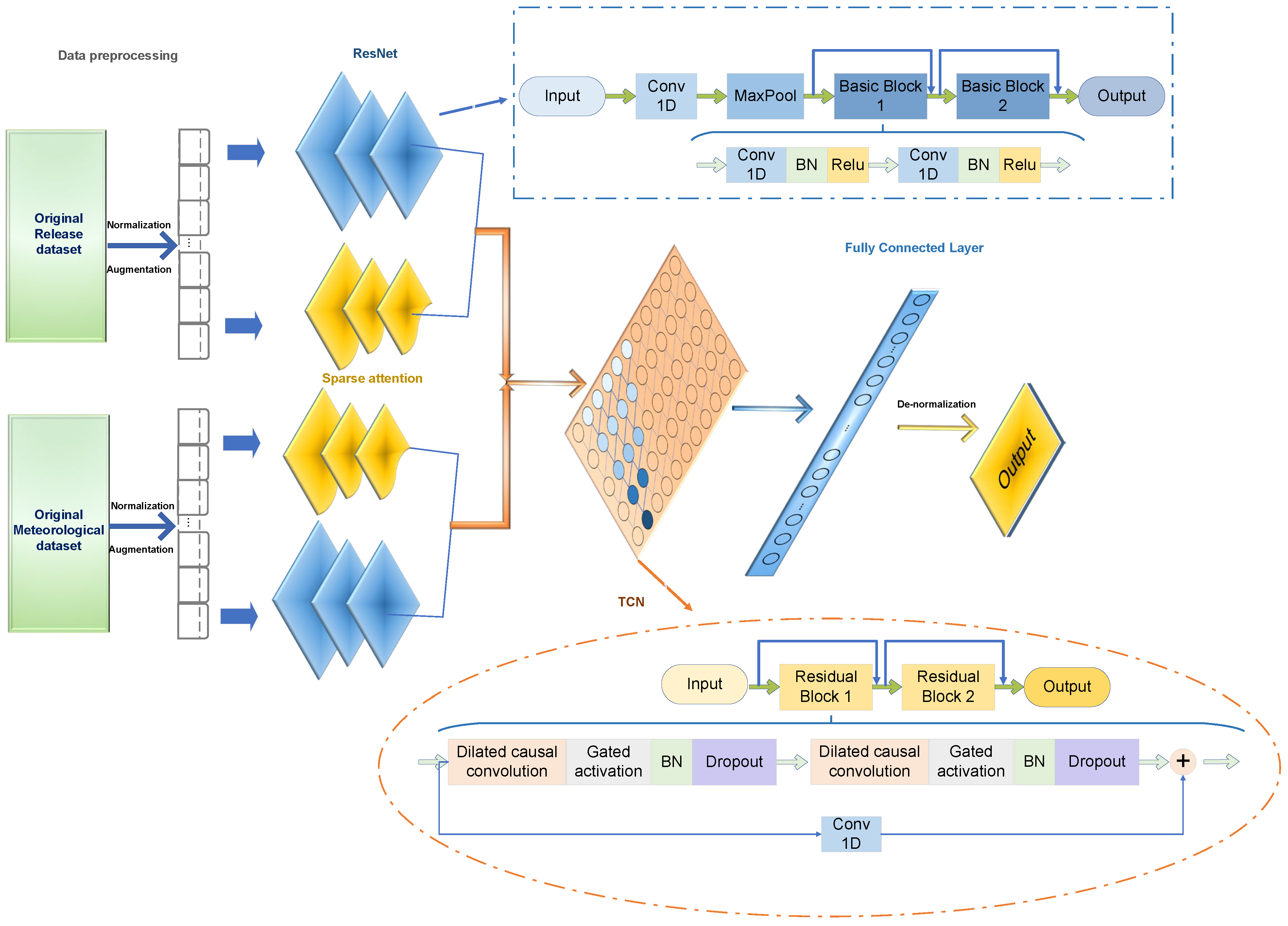
2.2. The Proposed Model: SAResNet-TCN
Figure 4 depicts the SAResNet-TCN framework, followed by a sequential explanation of its fundamental stages.
- (1)
Data Preprocessing
In the construction of deep learning models, the diversity of the dataset, which may include a variety of data types, can cause higher numerical features to have a more significant influence on the model, while the influence of features with lower numerical values is reduced. To address this issue, this study used the min–max normalisation method in the data preprocessing stage. This method effectively scales or transforms the data and reduces the scale differences between features, thereby improving the generalisation ability of the model to new data and helping to mitigate the phenomenon of overfitting. The calculation formula for this method is shown in Equation (3).
In the equation, is the value obtained after normalisation; represents the data to be normalised; is the minimum value in the data; and is the maximum value in the data.
- (2)
Data Augmentation
During the training process, the goal of TimeGAN is to generate time-series data that are statistically similar to the real data. First, the embedding network transforms the input time-series data into a low-dimensional representation that captures the intrinsic structure and patterns of the data. The recovery network then reverses this process, converting the low-dimensional representation back into the original time-series data, which helps the network learn the key features of the data. The generator then uses the mechanism of Generative Adversarial Networks to generate new time-series data to closely approximate the distribution of the real data. Finally, the discriminator discriminates between the generated time-series data and the real data, helping the generator to better simulate the distribution of the real data.
- (3)
Feature extraction and fusion
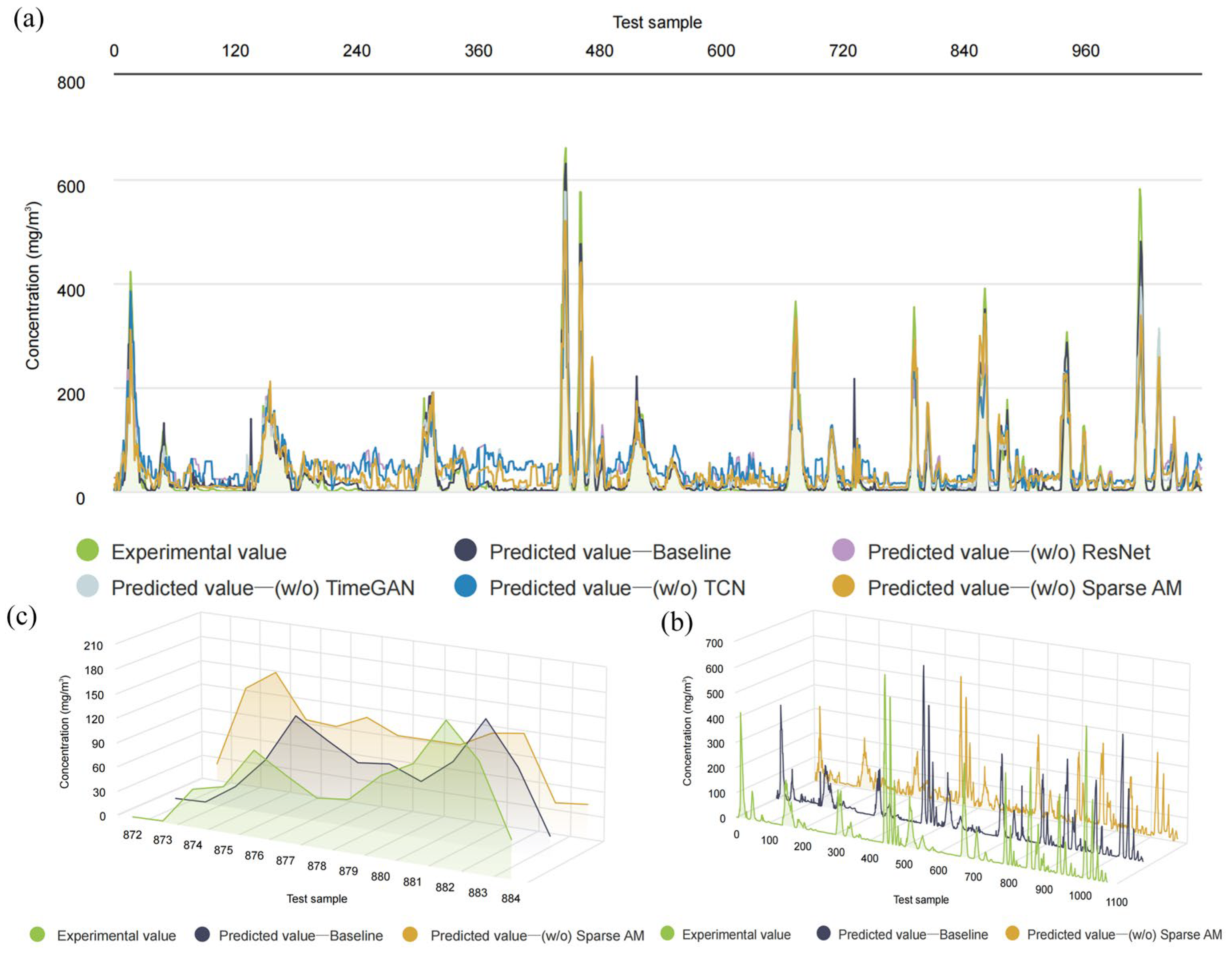
This study used a combination of ResNet and a sparse attention mechanism to complete this crucial step. An attention branch parallel to ResNet was developed to improve the model’s ability to capture salient features. ResNet consists of several layers of one-dimensional networks, with the core structure consisting of convolutional, batch normalisation (BN), and pooling layers. The convolutional layers are responsible for local perception and feature extraction; the BN layers aim to accelerate the training process and improve model robustness; the pooling layers perform statistical operations on high-level features within the pooling region to output effective statistical features and achieve dimensionality reduction. The ResNet module contains two basic blocks, each consisting of successive convolutional layers, BN layers, and activation functions. The introduction of residual connections allows the network to learn complex feature representations more deeply. To further improve the model’s focus on important features and reduce the interference of unimportant features, a sparse attention module was introduced to address the limitations of ResNet in distinguishing the importance of temporal features. Following the literature [
34,
35], an element-wise multiplication method was used to fuse the outputs of the ResNet and attention mechanism modules, and these fused features are subsequently used as inputs to the TCN module.
- (4)
Temporal Relationship Extraction
The model effectively captures the temporal dependencies between features through the TCN module and integrates them into the final prediction process. In this process, the input feature fusion results are first subjected to extended causal convolution operations, followed by processing through the ReLU activation function. To prevent model overfitting, a dropout layer is then introduced to randomly discard some nodes. The results of this process not only serve as input for further processing in the following diluted causal convolution, activation, and dropout layers but are also sent to a one-dimensional convolution layer for processing. The results of these two parts are linearly combined to form an output result with a residual connection, which is then sent to subsequent residual blocks for further computation. When the computation of all residual blocks is complete, the output of the residual blocks is combined with a fully connected layer and a softmax layer to produce the final prediction results.
- (5)
Output of prediction results
In the previous processing, the data are normalised to eliminate the dimensional differences between different features. To obtain the final prediction results, the original scale of the predicted data is restored through a de-normalisation process, ensuring consistency with other relevant data and guaranteeing the interpretability and usability of the results. This step is an essential part of the entire prediction process and allows us to interpret and use the model output in a meaningful way. The calculation formula is shown in Equation (4).
where
is the predicted value after inverse normalisation;
is the predicted value output from the model; and
and
denote the maximum and minimum values of the original data, respectively.
The choice of model parameters is closely related to the type of task and dataset. Based on other similar studies, this study experimentally determined the appropriate parameters for the model [
36,
37,
38,
39,
40,
41]. The main parameter settings are presented in
Table 1.
4. Conclusions
This paper presented exploratory research aimed at addressing the problem of predicting pollutant dispersion using deep learning techniques. The main contributions are outlined below.
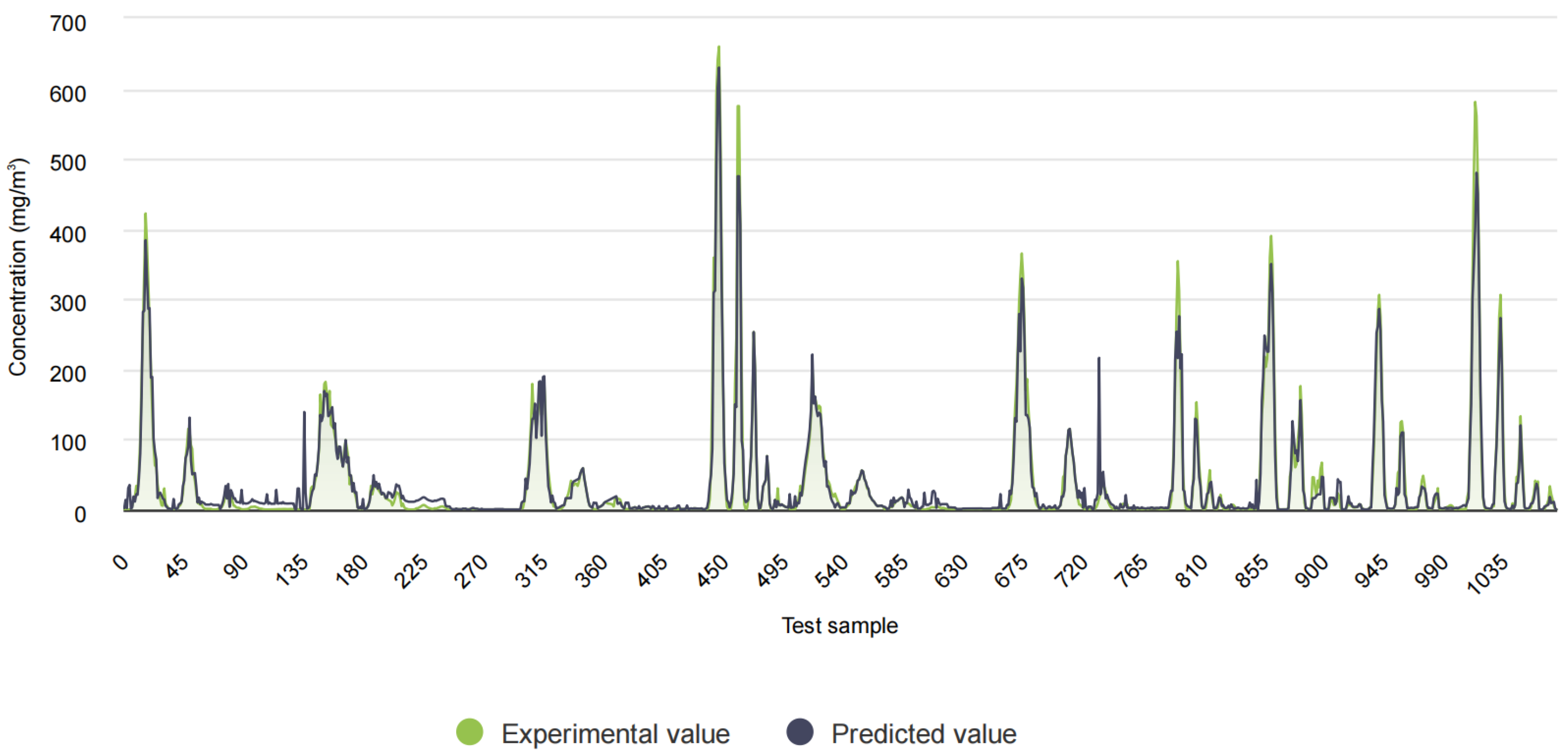
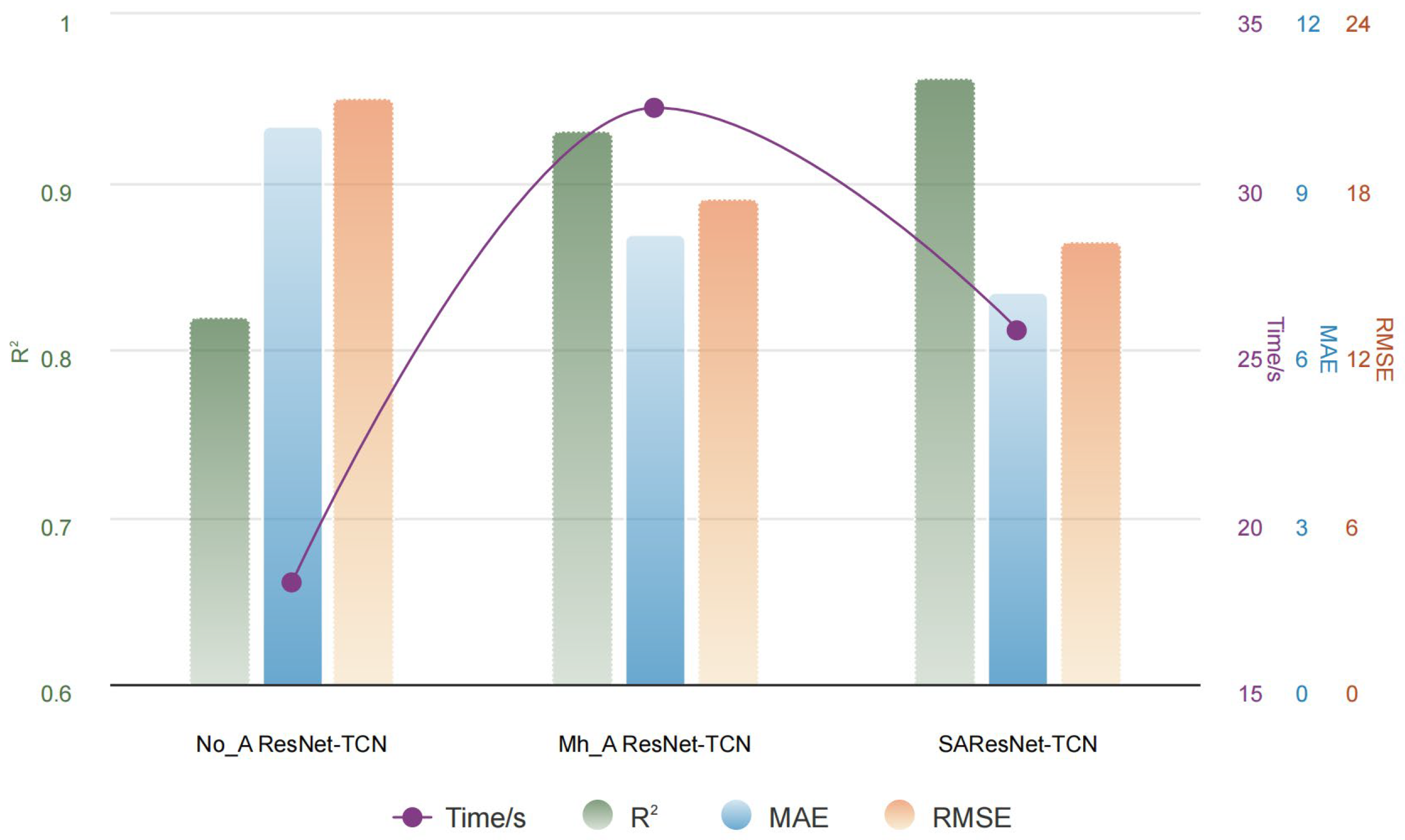
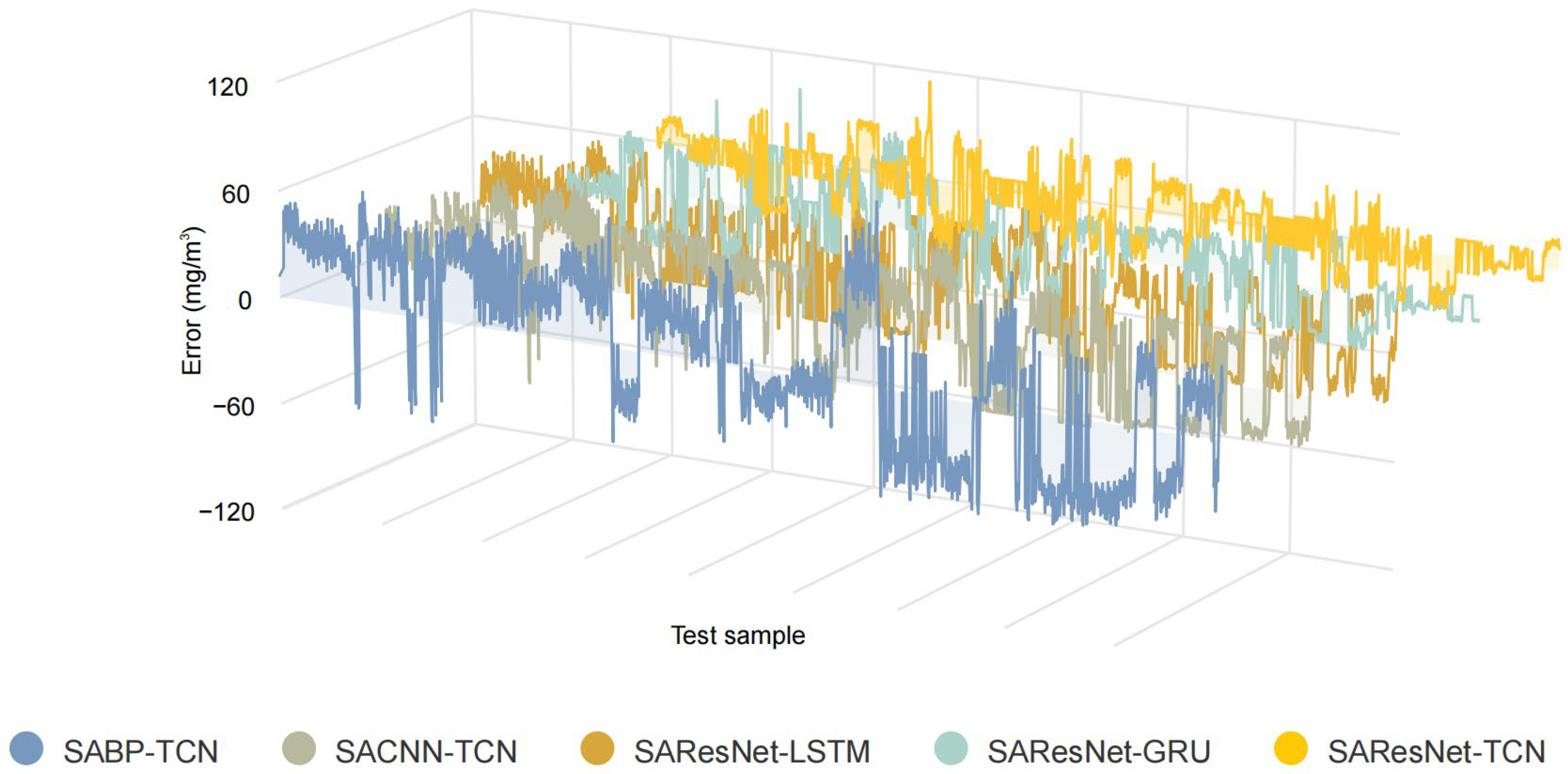
1. The proposed model exhibited remarkable predictive efficacy. Ablation experiments were conducted to further substantiate the significant impact of key components, including TimeGAN, SA, TCN, and ResNet, on the overall model performance. Notably, the removal of the SA mechanism led to an increase of over 25% in the model’s RMSE value, which serves to underscore the critical importance of the SA mechanism in enhancing the model’s performance. Furthermore, the results of the comparative experiments demonstrated a clear advantage of the proposed model over other models with different configurations. This was confirmed by the superior performance of the proposed model in terms of the RMSE, MAE, and R2 values, which were 3.6521, 6.6283, and 0.9697, respectively.
2. This study used GSA to improve the interpretability of the results. The results of the additive-by-addition method identified less significant indicators and the optimal combination of inputs for different scenarios. This provides a practical solution for forecasting tasks, particularly in situations where resources are limited and it is difficult to obtain all the parameters.
3. This study calculated the MDH-distance for different wind speeds and atmospheric stability conditions, using PAC and IDLH values as hazard thresholds. Such an analysis will assist relevant authorities in accurately predicting and assessing the impact of air pollution incidents, thereby improving the effectiveness and credibility of emergency responses.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}