1. Introduction
Demand forecasting is a critical component of a business’s operations and its ability to gain a competitive advantage in the market. Reliable and precise forecasts help businesses better adjust to market needs and meet customer demands more effectively [
1,
2]. In addition, they support process optimization, cost minimization, and reduce inventory problems [
3,
4,
5]. Many companies, however, do not use mathematical forecasting at all, basing decisions on orders or inventory levels solely on subjective judgment or qualitative approaches [
6,
7,
8,
9].
One reason for this is the inherent difficulty of designing accurate forecasts. Demand is affected by numerous, often unidentified or unknown factors, such as seasonality, promotional effects, social events, new trends, unexpected crisis, terrorism, changes in weather conditions, commercial behavior of competitors in the market, etc. [
1,
4,
5]. The problem lies both in the complexity of supply chains [
10,
11] and in the companies having limited access to information, often narrowed only to sales observations [
1,
12]. Data use is also limited due to different formats of archived data, lack of data integration tools, time of data collection, and timeliness of observations [
13,
14,
15].
The need to reduce uncertainty in production, delivery planning, etc., means that organizations need methods to anticipate market needs in order to effectively manage all important aspects of the supply chain. This is why many researchers are looking into this issue. Modern demand forecasting methods using artificial intelligence and machine learning are the most popular nowadays [
16].
One of the rapidly evolving trends in mathematical analysis involves the use of models that utilize big data [
17,
18]. In business management, the analysis of large data sets makes it possible to obtain more accurate forecasts that better reflect the needs of customers. It facilitates management, planning, as well as increases supply chain efficiency and reduces risk [
19,
20,
21]. Current enterprise data-mining capabilities, the functioning Internet of Things, and other advances of the Fourth Industrial Revolution enable the collection of huge amounts of information [
22]; hence, the rapid development of machine learning methods, while less and less attention is being paid to traditional analytical models [
23,
24,
25]—which, as studies have shown—can prove to be more effective and justified for certain demand patterns [
26].
The authors agree that both in the literature and in commercial systems (e.g., ERP) there is a steady increase in complex and complicated forecasting algorithms [
26]. Meanwhile, the literature shows that often the data sets held by companies are too small relative to the expectations of models, such as neural networks, making it impossible to conduct tests or producing unreliable results [
27,
28]. The problem lies in the accuracy of demand forecasting models, especially in the case of significant distribution asymmetry [
29], as well as the non-stationarity of the time series; neural network models perform better for stationary time series [
30].
Based on the literature review, it seems that companies that are large in size, have a dominant position in the market, and a greater capacity for experimentation, are more prepared organizationally and receive greater support from top management for implementing information systems that allow the acquisition of accurate real-time data [
31]. However, most companies lack such solutions and thus the ability to acquire accurate and precise information about the ongoing processes. It can take several years or even decades for them to achieve full IT integration [
32]. It also turns out that many companies that have implemented IT systems fail to fully utilize their potential [
33]. This is primarily because the dynamic development of such systems and the accompanying data analysis methods have become a perfect business opportunity. Numerous vendors offer advanced and sophisticated tools for data acquisition, storage, and forecasting, which, due to their complexity, are often not utilized [
33]. Numerous studies show that, in such cases, forecasting is still done based on the knowledge and experience of managers, even despite obtaining unsatisfactory results [
34,
35].
This is due, according to many authors, to the use of very complex forecasting models. The authors emphasize that those responsible in companies for assessing future trends are often not econometricians and need simple, reliable information based on rational, understandable factors [
36,
37,
38,
39] so that the relationships between models, forecasts, and decisions are not complicated and are easily understood by decision-makers [
38,
39]. In general, cost savings are often recommended as one of the criteria for choosing between forecasting models [
36], especially since many studies have shown that model complexity does not improve forecasting accuracy [
38,
40,
41,
42].
Nevertheless, model complexity is very popular among researchers and forecasters. The literature review indicates the greater prevalence of complex models, postulating even that researchers are rewarded for publishing in highly rated journals that favor the complexity of the solutions presented [
37,
38,
39].
Meanwhile, the simplicity of forecasting encourages the use of such predictions and the abandonment of methods based solely on the knowledge and experience of experts.
It is also necessary to emphasize that many companies lack the ability to collect accurate data on the phenomenon under study, lack IT systems making it possible, and, consequently, can only rely on modest data on past sales [
40], often lacking information on additional variables that could affect the sales being made [
41]. The problem of access to the desired data is a significant challenge for many companies, especially small ones, and it is therefore necessary to present methods dedicated to such cases.
Furthermore, many entrepreneurs still prefer analytical time series models [
1,
11]. Moreover, the effectiveness of the developed learning algorithms is often ultimately compared with analytical ones anyway, which leads to the conclusion that the accuracy of deep learning methods is not statistically significantly better than that of regression [
30,
43], moving average [
7,
44], naive [
45,
46], autoregressive, as well as ARMA [
47], ARIMA [
9], SARIMA [
47,
48] models or the Poisson process [
49,
50]. Meanwhile, as the authors point out, analytical models are easier to configure and parameterize [
45] and, above all, more readable in terms of interpreting individual parameters and assessing their impact on the dependent variable [
51]. The authors also contend that the forecasting system should be stable [
28], hence simpler forecasting methods and procedures are preferred to avoid issues with estimating and verifying the parameters.
This problem is pointed out by many authors in their search for effective methods. For example, in [
51] the author points out the weakness of the statistical data held by companies, the inability to determine the distribution of the variable, and the use of inappropriate methods that do not reflect seasonality, especially in periods when demand reaches very low values. The problem with forecasting is also indicated by the authors in [
28], pointing to the time-consuming nature of the forecasting process, its susceptibility to errors, and the noise that usually exists in such data, as well as its high dimensionality. That is why there is such a great need to verify and compare different forecasting methods in order to indicate the existing differences as well as the benefits of choosing specific models [
27,
28].
Accordingly, this paper responds to several problems identified in the literature and discussed above. As shown, advanced forecasting methods, especially those based on machine learning methods, are very popular in the literature, but they are inaccessible to many companies due to the inability to obtain accurate information in real time, as well as due to the difficulty in understanding and interpreting complex models. Therefore, the paper shows that simple analytical methods can also provide reliable forecasts, while increasing their sophistication does not clearly improve the results achieved. In addition, these methods can be used for simple time series concerning only past sales observations, without any additional factors—as in the cited example. Such methods are particularly useful for less developed companies. In addition, they are reproducible and thus easy to interpret, while being able to capture the most important relationships of the process under study. All the mathematical models proposed in the paper concern the analysis of seasonal data and allow for short-term forecasting of demand for products characterized by significant seasonal variations and a development trend. The literature review indicates the need for constructing such models, especially in situations of significant demand decline and irregular variations. This is particularly valuable for readers expecting specific guidelines on implementable solutions in their enterprises.
Seasonality of observations, limited availability of empirical data, and dynamic development of advanced forecasting methods therefore became the genesis of this paper. Its main purpose was to expose the existing problem, but primarily to verify selected forecasting methods applicable to seasonal demand on the basis of real data. Seasonality, as mentioned earlier, is one of the difficulties in forecasting demand, so the authors analyzed time series models specific to seasonal variations in observations.
The problems discussed and methods”prop’sed can inspire many companies and encourage the use of forecasting tools instead of the subjective opinion of experts.
On the other hand, the paper advocates the simplicity and usefulness of mathematical modeling and a discourse on the limitation of moving towards increasingly complex models.
At the same time, the presented solutions are an alternative to popular machine learning models, which are more complicated to interpret, while their effectiveness is often similar [
52,
53,
54,
55].
Thus, the adopted objectives of the research allowed the formulation of a hypothesis assuming that it is possible to forecast sales of products characterized by strong seasonal fluctuations and a trend in the supply chain by means of simple mathematical methods, and the indicated solutions can be implemented in any enterprise regardless of the level of its development and the level of computerization, since they require only simple time series of occurred observations.
The paper presents, after the Introduction, the methodology used in the research, then characterizes the subject of the research and collected observations, followed by a presentation of the mathematical models constructed. Finally, it presents their comparison, the selection of the best one and its detailed evaluation. The whole is concluded with a summary of the results obtained, conclusions, and indications of directions for further research.
2. Materials and Methods
The paper uses methods to identify time series with seasonal fluctuations. The seasonal ARIMA (autoregressive integrated moving average) model, ARIMA with Fourier terms model, ETS (exponential smoothing) model, and TBATS (Trigonometric Exponential Smoothing State Space Model with Box–Cox transformation, ARMA errors, Trend and Seasonal component) model were selected. A simple seasonal exponential smoothing model was used as a point of reference and comparison of the results obtained, as it enables assessment of the validity of constructing complex models. All calculations were performed using the R environment.
Selected time series models allow for short-term forecasting, as well as identification of the time series under study. Thus, they provide information on the demand for a given product and what can be expected in the near future. This information is more reliable compared to a subjective assessment based solely on the experience of managers, and, at the same time, obtained from the analysis of a simple time series. Such data is usually available in companies that lack advanced IT systems and do not use complex forecasting methods. In the paper, the difficulty of selected models is gradually increased to determine whether greater complexity results in better information, or whether simple models, such as the seasonal naive model discussed first below, are sufficient.
2.1. Seasonal Naive Model
Naive methods belong to the group of simple forecasting methods and are used for constructing short-term forecasts. They are most often used at a constant level of the phenomenon and small random fluctuations, but they can be extended to take into account seasonality, in which case the forecast at time
is the last value of the observation in the corresponding period:
where:
2.2. ARMA Class Models
Stationary models are popular among time series models. Depending on the time correlation structure, the following are distinguished [
56,
57,
58,
59]:
- −
Autoregressive model of order AR()
- −
Moving Average model of order MA()
Let be a stationary time series.
The Moving Average model is the
that satisfies the equation:
where
is a sequence of independent random variables with distribution
.
Such a series takes into account the existence of time correlation of the random component. Its strength and nature are determined by the parameter —i.e., the order of the Moving Average model and individual model coefficients ().
The Autoregressive model is the series
that satisfies the equation:
where
is a sequence of independent random variables with distribution
.
Such a series takes into account the existence of time correlation of the past realizations of the dependent variable. The value of the dependent variable at time is a linear combination of its time-lagged values and white noise interference.
By combining the AR and MA models, we obtain the ARMA time series of the form:
or its seasonal form ARMA
.
ARMA class models deal with stationary series. If this assumption is not met, transformations—e.g., differencing—are needed to obtain it. This results in the ARIMA (Autoregressive Integrated Moving Average) model and its seasonal version, SARIMA (Seasonal ARIMA). These are models that use a lagged differencing operation .
2.3. ARIMA with Fourier Terms
ARIMA models regress the current value of data in a time series against its historical values, so they do not always deal with multiple seasonality. This allows the addition of external regressors [
1]. In order to take seasonality into account in the time series under study, additional Fourier series were added to the ARIMA model.
where
is the ARIMA process.
—number of periods
—Fourier coefficients
—Maximum order(s) of Fourier terms
value is selected by minimizing the AIC criterion
2.4. ETS Exponential Smoothing Models
The basic idea of exponential smoothing is to assign (exponentially) decreasing weights to historical observations when determining the forecast of a future observation. A general class of models, called ETS (exponential smoothing state space model), occupies a special place among the methods based on exponential smoothing. The individual letters of the acronym stand for error, trend, and seasonality, respectively. Its elements can be combined in an additive, multiplicative, or mixed way. The trend in exponential smoothing is a combination of two components—i.e., level
and increment
combined with each other, taking into account the damping parameter
in five possible ways. Denoting the trend forecast for
subsequent periods as
, we obtain [
49]:
N—no trend (none)
A—Additive
Ad—Additive damped
M—Multiplicative: =
Md—Multiplicative damped: =
Taking into account only the seasonal component (no seasonality, additive variant and multiplicative variant) and the trend, we obtain 15 exponential smoothing models. Additionally taking into account additive or multiplicative random disturbances, we obtain 30 different models, presented in
Table 1 [
49].
The value optimizing the model form can be the minimization of the selected information criterion (AIC, AICC, BIC) or the forecast error (MSE, MAPE). In this paper, the models were compared using the Akaike Information Criterion (AIC).
Let
denote the number of estimated parameters, and
the maximum model reliability function. The AIC value is calculated from the formula:
The smaller the value of the Information Criterion, the better the model fit.
2.5. TBATS Model
The TBATS (Trigonometric Exponential Smoothing State Space model with Box–Cox transformation, ARMA errors, Trend and Seasonal component) model is a forecasting method for modeling non-stationary time series with complex seasonality using exponential smoothing. The structural form of the model is as follows:
where:
—Box–Cox transformation parameter
—damping parameter
and —number of AR and MA parameters
—seasonal period
—number of pairs of Fourier series
The model has the following form:
where:
—theoretical values of the ARMA model
smoothing parameters
—local level of the phenomenon under study over the period or at time
—trend factor/value
—value of the seasonal component over the period
—seasonal period
This method takes into account the Box–Cox transformation, seasonal variables and trend component, as well as autocorrelation of model residuals through the ARMA process.
The Box–Cox transformation is one of the transformations used in time series analysis to stabilize variance. It is also used as a transformation that transforms a continuous distribution of a random variable into a normal distribution (normalizing transformation).
We define the Box–Cox transformation as a transformation family of the form:
For .
For time series, after applying the Box–Cox transformation, we obtain the series .
The parameter
can take any real value. In practice,
(logarithmic transformation) or
elemental transformation [
60] are often used.
2.6. ADF Test
Unit root tests: the Augmented Dickey–Fuller test (ADF test) and the Kwiatkowski–Phillips–Schmidt–Shin test (KPSS test) [
11,
61] are most commonly used to test the stationarity of time series. In this paper, the ADF test is used to test for stationarity.
We represent the time series
as:
where
is a sequence of independent random variables with a normal distribution
.
The
order of autoregression should be selected to remove the correlations between the elements of the series
. At the significance level of
, we formulate a working hypothesis that the time series
is non-stationary (i.e., we assume
, therefore
, and
). As an alternative hypothesis, the time series
is assumed to be stationary (i.e.,
, therefore
). The test statistic:
is characterized by the Dickey–Fuller distribution, where
is an estimator of the parameter
, while
is the standard deviation of this parameter. The value of the estimator of the parameter
and the standard deviation are determined using the least squares method.
4. Conclusions
The market conditions in which companies operate are complex, characterized by intense competition and dynamic, often unpredictable transformations. To ensure success and continuity, businesses must be vigilant and quickly adapt to changes in their environment. Reliable forecasts, particularly in areas such as production management, inventory, distribution, or orders, can greatly assist in making key decisions within the supply chain.
It is undeniable that in sustainable supply chain management, the application of predictive models is of crucial importance, as such models enable companies to prepare in advance for future situations in order to meet customer demands and properly respond to the dynamics of market demand. Therefore, forecasting, even in the short-term, is a significant lever for improving supply chain performance and contributes to the sustainable business development in line with market needs and competition activity.
In the literature on demand forecasting, artificial intelligence is strongly emphasized as one of the key techniques used in Industry 4.0, along with other methods based on the Internet of Things and modern data acquisition technologies. This is facilitated by the dynamic development of companies, their computerization and digitization. However, there are also many small businesses that are less advanced, and even those that rely solely on managers’ experience rather than mathematical methods for forecasting. Such companies are the target audience for the analyses presented here, which have demonstrated that it is possible to create easy-to-interpret and easy-to-use forecasts based solely on historical data on the phenomenon being studied using simple time series.
Therefore, the aim of this study was to employ and contrast a selection of mathematical models for short-term demand forecasting for products whose sales are characterized by high seasonal variations and a development trend.
The mathematical models presented in this paper are a response to the possibility of making predictions using observations related to time series exhibiting seasonal fluctuations, which are characteristic of many products. The presented possibility of constructing a reliable forecast of sales volume is an excellent way to counteract the effects of seasonality, enabling the determination of the nature of the analyzed phenomenon, as well as forecasting its size within a specified time horizon.
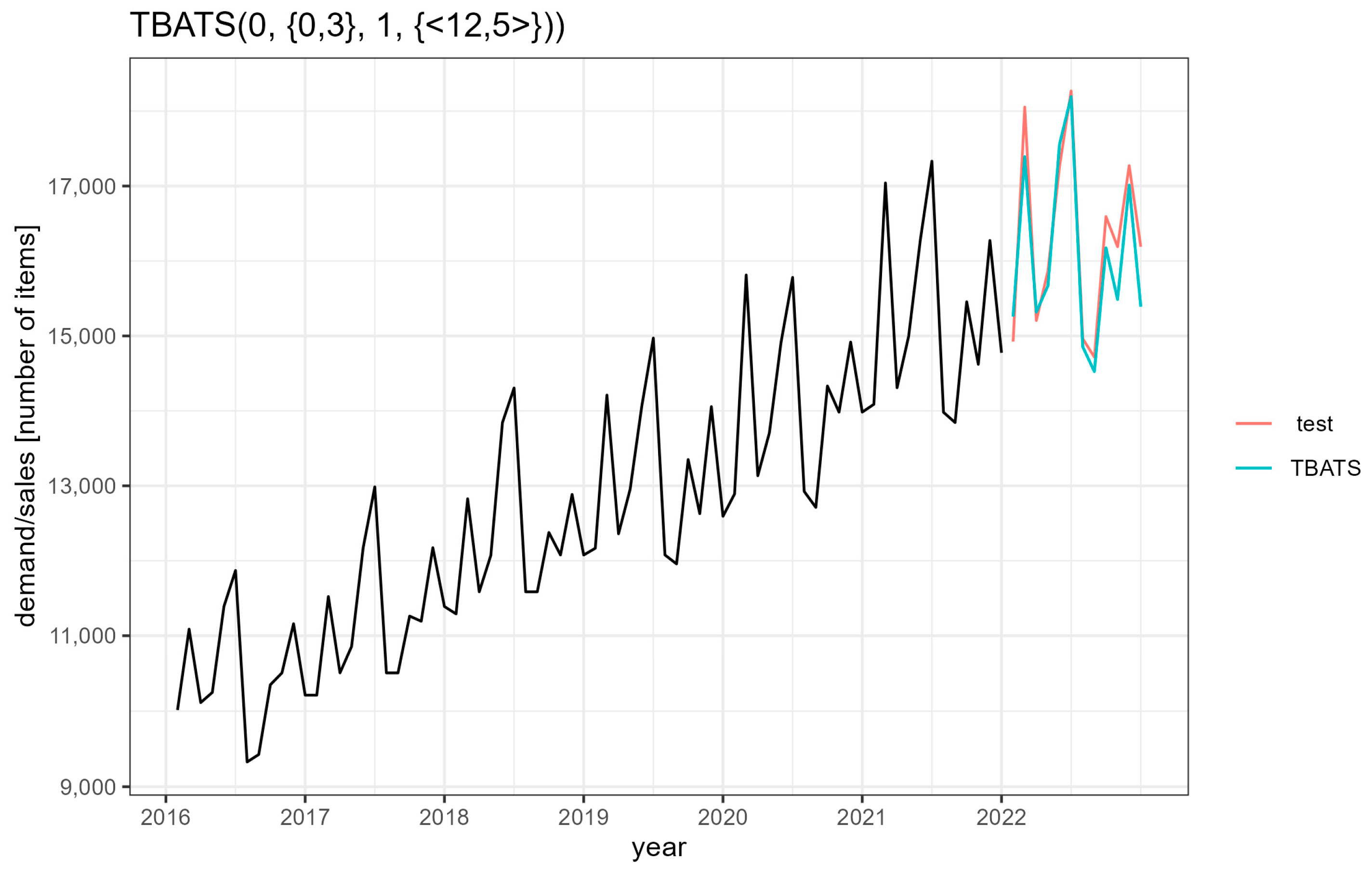
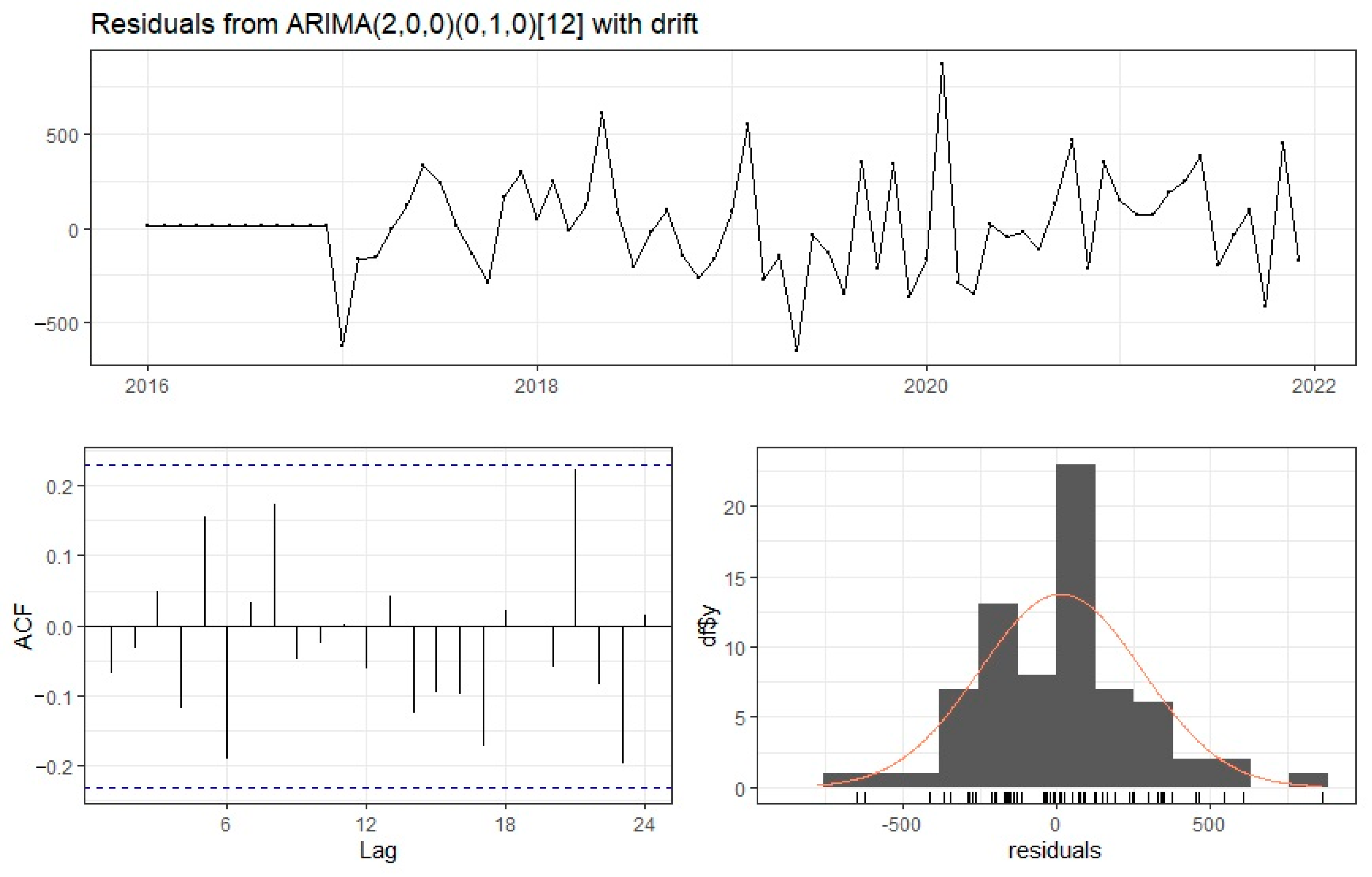
Short-term forecasts play an important role in a company’s planning and management. Their accuracy contributes to cost reduction, process streamlining and increased customer satisfaction, which directly translates into profits and improves operational safety. This paper considers several models dedicated to data with clear seasonality. The seasonal ARIMA (autoregressive integrated moving average) model, ARIMA model with Fourier terms, ETS (exponential smoothing) model, and TBATS (Trigonometric Exponential smoothing state space model with Box–Cox transformation, ARMA errors, Trend and Seasonal component) model were selected. The results obtained were compared with the simple exponential smoothing model. It was noticed that all the presented models fulfilled the assumed postulates, and increasing their complexity did not significantly improve the calculated forecast errors. Therefore, a naive seasonal model may be sufficient for basic analysis.
This made it possible to verify the adopted hypothesis: it is possible to forecast the sales of products characterized by strong seasonal fluctuations and a trend using simple mathematical methods, while the proposed solutions can be implemented in any enterprise regardless of its level of development and level of computerization.
In further research, the presented methods will be developed using predictors other than past observations. The strong need for such research can be attributed to the fact that creating a forecast should be the first stage of planning the functioning strategy of each enterprise. Of course, the potential of innovative forecasting models should not be underestimated, but they should be adapted to the capabilities of the enterprise and specific applications. However, the principle of simplicity and ease of interpreting the results as well as usefulness for the enterprise should always be taken into account.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}