
ROA and ROE Forecasting in Iron and Steel Industry Using Machine Learning Techniques for Sustainable Profitability

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Set
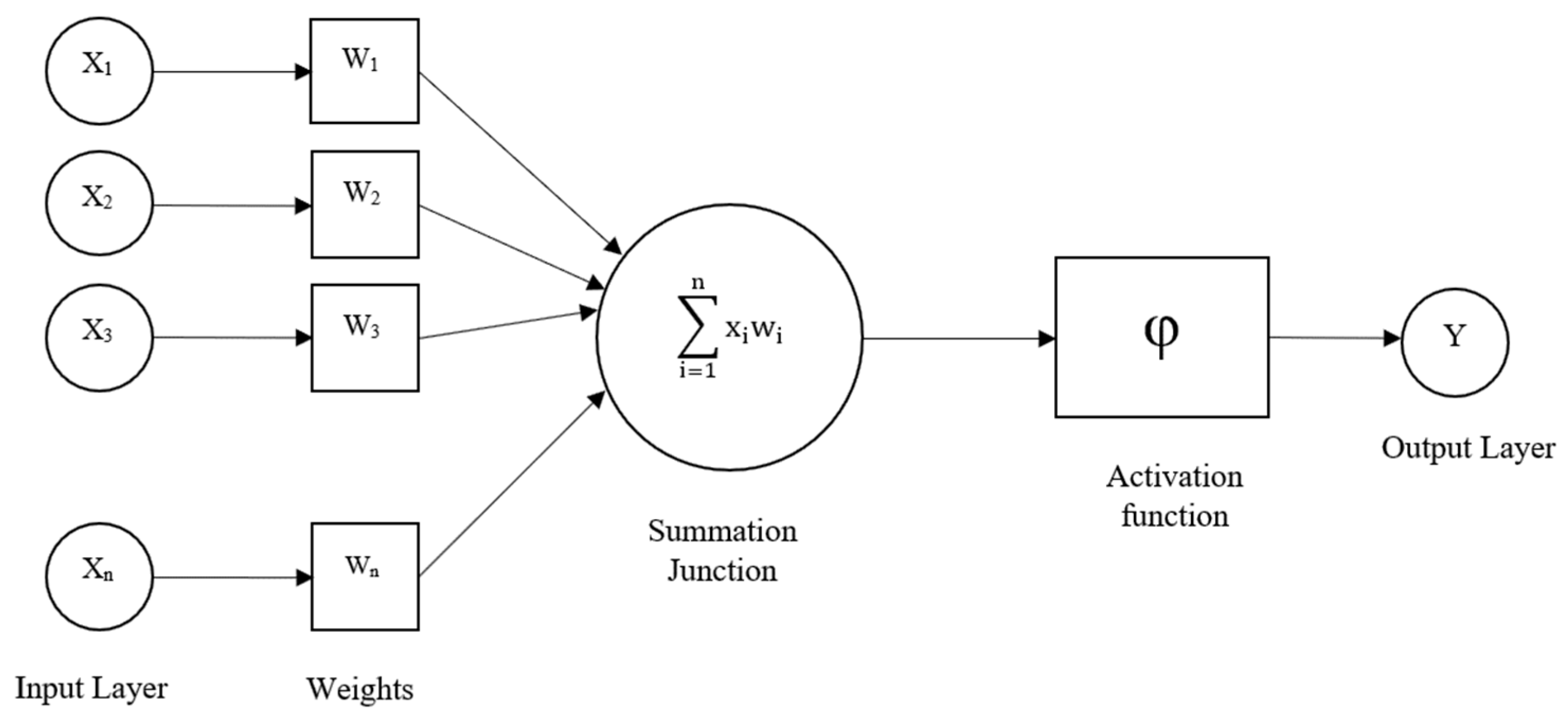
2.2. Artificial Neural Networks
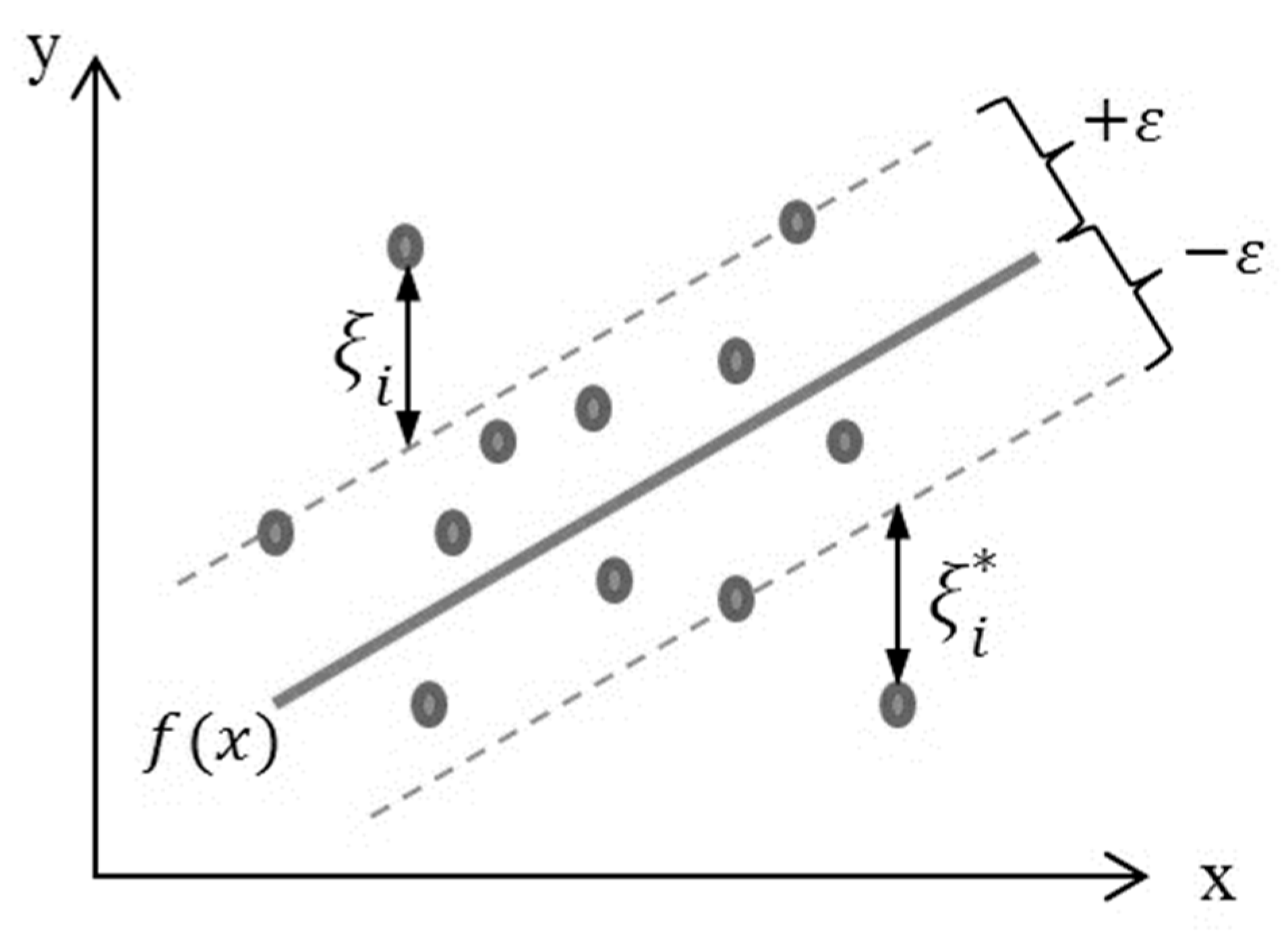
2.3. Support Vector Regression
2.4. Multiple Linear Regression
3. Result and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- The Ministry of Industry and Technology. Iron and Steel Industry Report. Available online: https://www.sanayi.gov.tr/plan-program-raporlar-ve-yayinlar/sektor-raporlari/mu1406011405 (accessed on 2 December 2022).
- Wang, Y.-J. Liquidity management, operating performance, and corporate value: Evidence from Japan and Taiwan. J. Multinatl. Financ. Manag. 2002, 12, 159–169. [Google Scholar] [CrossRef]
- Eljelley, A.M. Liquidity-profitability tradeoff: An empirical investigation in an emerging market. Int. J. Commer. Manag. 2004, 14, 48–62. [Google Scholar] [CrossRef]
- Lazaridis, I.; Tryfonidis, D. Relationship between working capital management and profitability of listed companies in the Athens stock exchange. J. Financ. Manag. Anal. 2006, 19, 1–12. [Google Scholar]
- García-Teruel, P.J.; Martínez-Solano, P. Effects of working capital management on SME profitability. Int. J. Manag. Financ. 2007, 3, 164–177. [Google Scholar] [CrossRef]
- Zariyawati, M.A.; Annuar, M.N.; Taufiq, H.; Rahim, A.A. Working capital management and corporate performance: Case of Malaysia. J. Mod. Account. Audit. 2009, 5, 47–54. [Google Scholar]
- Sharma, A.K.; Kumar, S. Effect of working capital management on firm profitability: Empirical evidence from India. Glob. Bus. Rev. 2011, 12, 159–173. [Google Scholar] [CrossRef]
- Mary, O.I.; Okelue, U.D.; Uchenna, A.S. An examination of the factors that determine the profitability of the Nigerian beer brewery firms. Asian Econ. Financ. Rev. 2012, 2, 741–750. [Google Scholar]
- Makori, D.M.; Jagongo, A. Working capital management and firm profitability: Empirical evidence from manufacturing and construction firms listed on Nairobi securities exchange, Kenya. Int. J. Account. Tax. 2013, 1, 1–14. [Google Scholar]
- Muhammad, S.; Jibril, R.; Wambai, U.S.K.; Ibrahim, F.B.; Ahmad, T.H. The effect of working capital management on corporate profitability: Evidence from Nigerian Food Product Firms. Appl. Financ. Account. 2015, 1, 55–63. [Google Scholar] [CrossRef]
- Postula, M.; Chmielewski, W. The impact of intangible assets and R&D expenditure on the market capitalization and EBITDA of selected ICT sector enterprises in the European Union. Int. J. Econ. Financ. 2019, 11, 117–128. [Google Scholar]
- Tadić, J.; Jevtić, J.; Jančev, N. Modeling of critical profitability factors: Empirical research from food industry in Serbia. Екoнoмика Пoљoпривреде 2019, 66, 411–422. [Google Scholar] [CrossRef]
- Pechlivanidis, E.; Ginoglou, D.; Barmpoutis, P. Can intangible assets predict future performance? A deep learning approach. Int. J. Account. Inf. Manag. 2021, 30, 61–72. [Google Scholar] [CrossRef]
- Mousa, G.A.; Elamir, E.A.; Hussainey, K. Using machine learning methods to predict financial performance: Does disclosure tone matter? Int. J. Discl. Gov. 2022, 19, 93–112. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Liu, D. A Contrastive Study of Machine Learning on Energy Firm Value Prediction. IEEE Access 2019, 8, 11635–11643. [Google Scholar] [CrossRef]
- Erdal, H.; Karahanoğlu, İ. Bagging ensemble models for bank profitability: An emprical research on Turkish development and investment banks. Appl. Soft Comput. 2016, 49, 861–867. [Google Scholar] [CrossRef]
- JC, T.G.; Ateeq, K.; Rafiuddin, A.; Alzoubi, H.; Ghazal, T.; Ahanger, T.; Chaudhary, S.; Viju, G. AI-Based Prediction of Capital Structure: Performance Comparison of ANN SVM and LR Models. Comput. Intell. Neurosci. 2022, 2022, 8334927. [Google Scholar]
- Saberi, M.; Rostami, M.R.; Hamidian, M.; Aghami, N. Forecasting the profitability in the firms listed in Tehran Stock Exchange using data envelopment analysis and artificial neural network. Adv. Math. Financ. Appl. 2016, 1, 95–104. [Google Scholar]
- Skobic, D.; Kraljevic, G.; Mandic, M. Machine learning algorithms in the profitability analysis of casco insurance. Age 2020, 1, 18–30. [Google Scholar]
- de Andrés, J.; Lorca, P.; Bahamonde, A.; del Coz, J.J. The Use of Machine Learning Algorithms for the Study of Business Profitability: A New Approach Based on Preferences. Int. J. Digit. Account. Res. 2004, 4, 99–124. [Google Scholar]
- Kuzey, C.; Uyar, A.; Delen, D. The impact of multinationality on firm value: A comparative analysis of machine learning techniques. Decis. Support Syst. 2014, 59, 127–142. [Google Scholar] [CrossRef]
- Zahariev, A.; Angelov, P.; Zarkova, S. Estimation of Bank Profitability Using Vector Error Correction Model and Support Vector Regression. Econ. Altern. 2022, 2, 157–170. [Google Scholar]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef]
- Günther, F.; Fritsch, S. Neuralnet: Training of neural networks. R J. 2010, 2, 30. [Google Scholar] [CrossRef]
- Ding, S.; Li, H.; Su, C.; Yu, J.; Jin, F. Evolutionary artificial neural networks: A review. Artif. Intell. Rev. 2013, 39, 251–260. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation functions in neural networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Herzog, S.; Tetzlaff, C.; Wörgötter, F. Evolving artificial neural networks with feedback. Neural Netw. 2020, 123, 153–162. [Google Scholar] [CrossRef]
- Gupta, A.K. Predictive modelling of turning operations using response surface methodology, artificial neural networks and support vector regression. Int. J. Prod. Res. 2010, 48, 763–778. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Williams, C.K. Prediction with Gaussian processes: From linear regression to linear prediction and beyond. In Learning in Graphical Models; Springer: Berlin/Heidelberg, Germany, 1998; pp. 599–621. [Google Scholar]
- Darlington, R.B.; Hayes, A.F. Regression Analysis and Linear Models; Guilford: New York, NY, USA, 2017; pp. 603–611. [Google Scholar]
- Kayakuş, M. Yazılım Çaba Tahmininde Yapay Sinir Ağları İçin Optimum Yapının Belirlenmesi. Eur. J. Sci. Technol. 2021, 22, 43–48. [Google Scholar] [CrossRef]
- Kayakuş, M.; Terzioğlu, M. The Prediction of Pension Fund Net Asset Values Using Artificial Neural Networks and Multiple Linear Regression Methods. J. Inf. Technol. 2021, 14, 95–103. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Kayakuş, M. The Estimation of Turkey’s Energy Demand through Artificial Neural Networks and Support Vector Regression Methods. Alphanumeric J. 2020, 8, 227–236. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Author/Year | Article Title | Variables | Machine Learning Technique |
|---|---|---|---|
| (Mousa et al., 2022) [14] | Using Machine Learning Methods to Predict Financial Performance: Does Disclosure Tone Matter? | Output: Financial Performance (Earnings per Share) Input: Financial Leverage, Bank Size, Market to Book Ratio, Beta of The Company, Bank Age | Linear Discriminant Analysis, Quadratic Discriminant Analysis, and Random Forest |
| (Zhang et al., 2019) [15] | A Contrastive Study of Machine Learning on Energy Firm Value Prediction | Output: Deal value Input: EBIT, ROE, ROA, CAPEX, M&A Type, Asset Turnover, Cash Debit Ratio, Total Debt to Assets, Firm Type, Nationality, Acquisition Year, Share | Decision Tree Regression, Supported Vector Regression, Artificial Neural Network |
| (Erdal & Karahanoğlu, 2016) [16] | Bagging ensemble models For Bank Profitability: Empirical Research on Turkish Development and Investment Banks | Output: ROE Input: Non-Interest Income/Total Income, Other Revenues/Total Assets, Equity/Total Assets, Loans/Total Assets, Liquid Assets/Total Assets, Non-Performing Loan/Total Loans, Personnel Expenditure/Other Expenditure, Foreign Currency Assets/Total Assets, Total Credits/Total Assets, Net Currency Position/Total Equity | Decision Stump, Reduced Error Pruning Tree, Random Tree |
| (JC et al., 2022) [17] | AI-Based Prediction of Capital Structure: Performance Comparison of ANN SVM and LR Models | Output: Total Debt/Equity Input: Total Liabilities/Equity, Revenues/Cash and Equivalents, Revenues/Current Assets, Revenues/Equity, Net Income/Equity, Gross Margin, EBITDA Margin, Net Income Margin, Current Assets/Current Liabilities, Current Liabilities/Equity, Total Liabilities/Total Assets, EBIT/Interest Expenses | Artificial Neural Network, Support Vector Regression, and Linear Regression |
| (Saberi et al., 2016) [18] | Forecasting the Profitability in the Firms Listed in Tehran Stock Exchange Using Data Envelopment Analysis and Artificial Neural Network | Output: ROA Input: Return on Investment, Capitalization of Exploration Cost, Dupont Ratios | Artificial Neural Network |
| (Skobic et al., 2020) [19] | Machine learning algorithms in the profitability analysis of Casco insurance | Output: Client Profitability Input: Client Age, Client Gender, Discount, Casco claims through history, Car insurance claims through history, Number of Casco policies through history, Casco profit through history, Casco profit for client | Logistic regression, Artificial Neural Network, Decision tree |
| (de Andrés et al., 2004) [20] | The Use of Machine Learning Algorithms for the Study of Business Profitability: A New Approach Based on Preferences | Output: Business Profitability Input: Use of Fixed Capital, Debt Quality, Indebtedness, Short-Term Liquidity, Debt Cost, Share of Labor Costs, Average Sales per Employee, Net Sales | Learning to Assess from Comparison Examples and Recursive Feature Elimination Algorithms |
| (Kuzey et al., 2014) [21] | The Impact of Multinationalism on Firm Value: A Comparative Analysis Of Machine Learning Techniques | Input: Firm Value Output: Asset Structure and Growth Rate, Size, Leverage, Asset Structure and Growth Rate, Sales Growth, Capital Expenditure, Profitability, Liquidity | Artificial Neural Networks and Decision Trees |
| (Zahariev et al., 2022) [22] | Estimation of Bank Profitability Using Vector Error Correction Model and Support Vector Regression | Input: ROE and ROA Output: Inflation and other macroeconomic determinants | Support Vector Regression and Vector Error Correction Model |
| Company Code | Company Name | Operating Country |
|---|---|---|
| BOW PL | Bowim sa | Poland |
| CHMF RUM | Severstal | Russia |
| COG PL | Cognor holding sa | Poland |
| EREGL IS | Eregli demir celik | Turkey |
| FER PL | Ferrum sa | Poland |
| IZS PL | Izostal sa | Poland |
| KRDMA IS | Kardemir | Turkey |
| MAGN RUM | Mmk | Russia |
| OZBAL IS | Ozbal celik boru | Turkey |
| SZR PL | Stalprodukt sa | Poland |
| TRMK RUM | Tmk | Russia |
| URKZ RUM | Uralskaya kuznica | Russia |
| ZRE PL | Zremb-chojnice sa | Poland |
| Output Variables | Input Variables |
|---|---|
| ROA | Total Assets |
| ROE | Current Ratio |
| Leverage Ratio | |
| Assets Turnover | |
| Working Capital |
| Company Code | ANN | SVR | MLR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MSE | RMSE | R2 | MSE | RMSE | R2 | MSE | RMSE | R2 | |
| BOW PL | 0.004 | 0.064 | 0.921 | 0.001 | 0.030 | 0.887 | 0.001 | 0.009 | 0.991 |
| CHMF RUM | 0.011 | 0.104 | 0.797 | 0.003 | 0.053 | 0.698 | 0.001 | 0.038 | 0.878 |
| COG PL | 0.001 | 0.031 | 0.981 | 0.040 | 0.199 | 0.840 | 0.015 | 0.124 | 0.833 |
| EREGL IS | 0.014 | 0.119 | 0.835 | 0.019 | 0.137 | 0.750 | 0.001 | 0.030 | 0.506 |
| FER PL | 0.010 | 0.099 | 0.911 | 0.146 | 0.383 | 0.834 | 0.012 | 0.108 | 0.309 |
| IZS PL | 0.014 | 0.118 | 0.811 | 0.052 | 0.228 | 0.776 | 0.015 | 0.121 | 0.694 |
| KRDMA IS | 0.017 | 0.131 | 0.698 | 0.010 | 0.098 | 0.737 | 0.005 | 0.074 | 0.711 |
| MAGN RUM | 0 | 0 | 0.996 | 0.046 | 0.214 | 0.729 | 0.012 | 0.110 | 0.887 |
| OZBAL IS | 0.015 | 0.123 | 0.805 | 0.001 | 0.035 | 0.778 | 0.025 | 0.159 | 0.69 |
| SZR PL | 0.004 | 0.065 | 0.943 | 0.074 | 0.272 | 0.809 | 0.038 | 0.195 | 0.716 |
| TRMK RUM | 0.029 | 0.170 | 0.626 | 0.070 | 0.265 | 0.917 | 0.016 | 0.126 | 0.84 |
| URKZ RUM | 0.003 | 0.051 | 0.966 | 0.001 | 0.019 | 0.722 | 0.016 | 0.126 | 0.781 |
| ZRE PL | 0.005 | 0.067 | 0.941 | 0.005 | 0.069 | 0.910 | 0.013 | 0.114 | 0.789 |
| Average | 0.010 | 0.089 | 0.864 | 0.036 | 0.154 | 0.799 | 0.013 | 0.103 | 0.740 |
| Company Code | ANN | SVR | MLR | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MSE | RMSE | R2 | MSE | RMSE | R2 | MSE | RMSE | R2 | |
| BOW PL | 0.004 | 0.066 | 0.919 | 0.034 | 0.185 | 0.974 | 0.148 | 0.384 | 0.513 |
| CHMF RUM | 0.004 | 0.062 | 0.916 | 0.527 | 0.726 | 0.681 | 0.065 | 0.255 | 0.699 |
| COG PL | 0.003 | 0.053 | 0.947 | 0.212 | 0.461 | 0.738 | 0.110 | 0.331 | 0.458 |
| EREGL IS | 0.015 | 0.121 | 0.833 | 0.252 | 0.502 | 0.716 | 0.079 | 0.28 | 0.880 |
| FER PL | 0.005 | 0.069 | 0.883 | 1.040 | 1.020 | 0.865 | 0.179 | 0.423 | 0.963 |
| IZS PL | 0.008 | 0.087 | 0.929 | 0.068 | 0.260 | 0.875 | 0.205 | 0.453 | 0.629 |
| KRDMA IS | 0.017 | 0.132 | 0.628 | 1.822 | 1.350 | 0.992 | 0.045 | 0.212 | 0.575 |
| MAGN RUM | 0.003 | 0.050 | 0.95 | 0.360 | 0.600 | 0.761 | 0.510 | 0.226 | 0.909 |
| OZBAL IS | 0.008 | 0.090 | 0.816 | 1.671 | 1.293 | 0.900 | 0.138 | 0.371 | 0.804 |
| SZR PL | 0.007 | 0.081 | 0.904 | 0.494 | 0.703 | 0.638 | 0.187 | 0.432 | 0.659 |
| TRMK RUM | 0.010 | 0.099 | 0.865 | 0.203 | 0.450 | 0.802 | 0.057 | 0.238 | 0.305 |
| URKZ RUM | 0.005 | 0.068 | 0.937 | 0.190 | 0.436 | 0.871 | 0.149 | 0.387 | 0.524 |
| ZRE PL | 0.017 | 0.129 | 0.627 | 0.437 | 0.661 | 0.701 | 0.028 | 0.167 | 0.377 |
| Average | 0.008 | 0.085 | 0.858 | 0.562 | 0.665 | 0.809 | 0.146 | 0.320 | 0.638 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kayakus, M.; Tutcu, B.; Terzioglu, M.; Talaş, H.; Ünal Uyar, G.F. ROA and ROE Forecasting in Iron and Steel Industry Using Machine Learning Techniques for Sustainable Profitability. Sustainability 2023, 15, 7389. https://doi.org/10.3390/su15097389
Kayakus M, Tutcu B, Terzioglu M, Talaş H, Ünal Uyar GF. ROA and ROE Forecasting in Iron and Steel Industry Using Machine Learning Techniques for Sustainable Profitability. Sustainability. 2023; 15(9):7389. https://doi.org/10.3390/su15097389
Chicago/Turabian StyleKayakus, Mehmet, Burçin Tutcu, Mustafa Terzioglu, Hasan Talaş, and Güler Ferhan Ünal Uyar. 2023. "ROA and ROE Forecasting in Iron and Steel Industry Using Machine Learning Techniques for Sustainable Profitability" Sustainability 15, no. 9: 7389. https://doi.org/10.3390/su15097389
APA StyleKayakus, M., Tutcu, B., Terzioglu, M., Talaş, H., & Ünal Uyar, G. F. (2023). ROA and ROE Forecasting in Iron and Steel Industry Using Machine Learning Techniques for Sustainable Profitability. Sustainability, 15(9), 7389. https://doi.org/10.3390/su15097389