

Tourism Demand Prediction after COVID-19 with Deep Learning Hybrid CNN–LSTM—Case Study of Vietnam and Provinces


Abstract
1. Introduction
1.1. Previous Works
1.2. Main Contributions
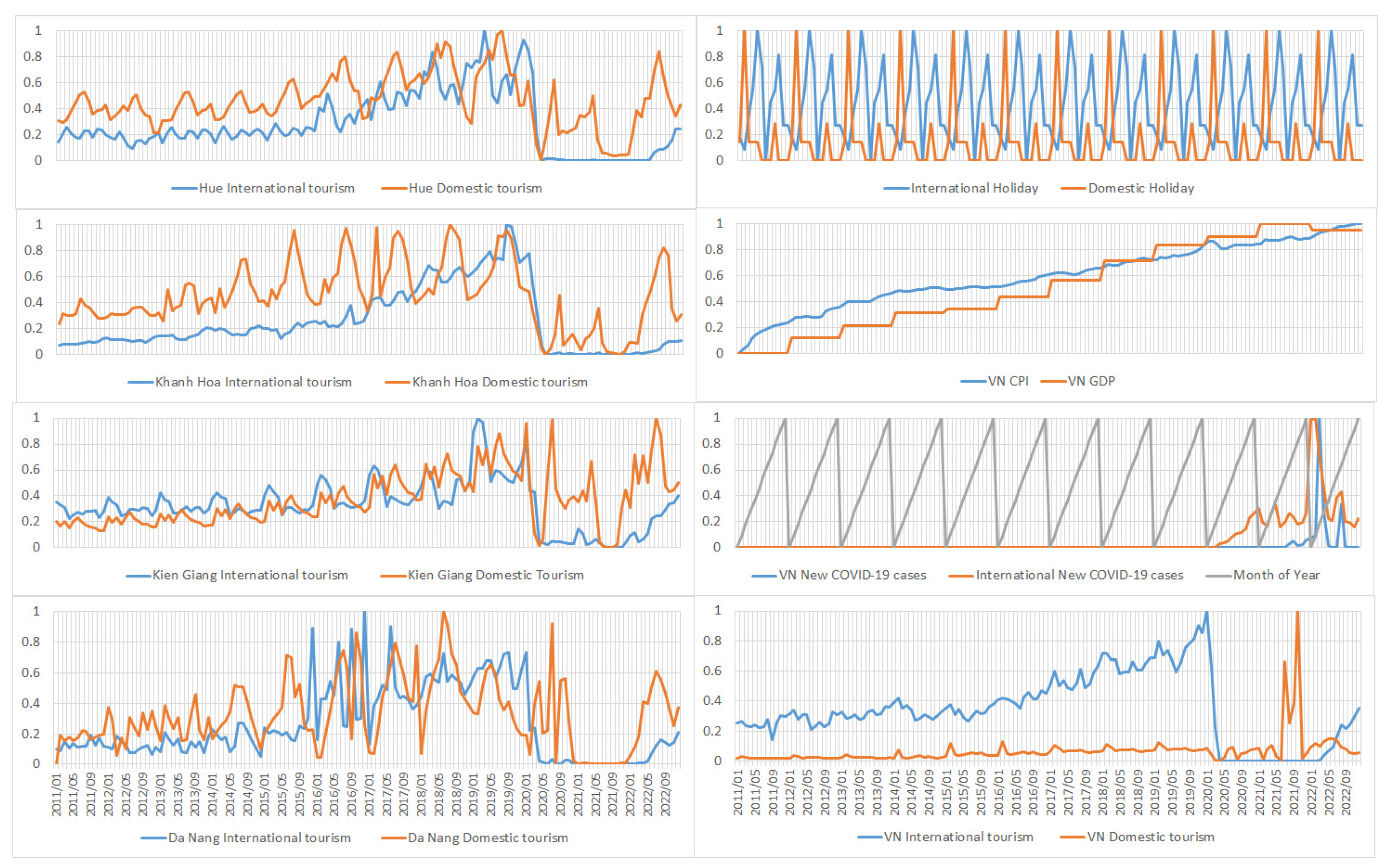
- The number of international and domestic tourism in Vietnam and some provinces, including Hue, Da Nang, Khanh Hoa, and Kien Giang, have been collected monthly. Moreover, the sequential GDP, monthly CPI, number of international public holidays, number of domestic holidays, month-of-year, number of new COVID-19 cases in Vietnam, and number of new COVID-19 cases worldwide are also collected. The Pearson correlations matrixes between collected features are computed. The most relevant features with target outputs are selected as appropriate inputs in the proposed algorithm.
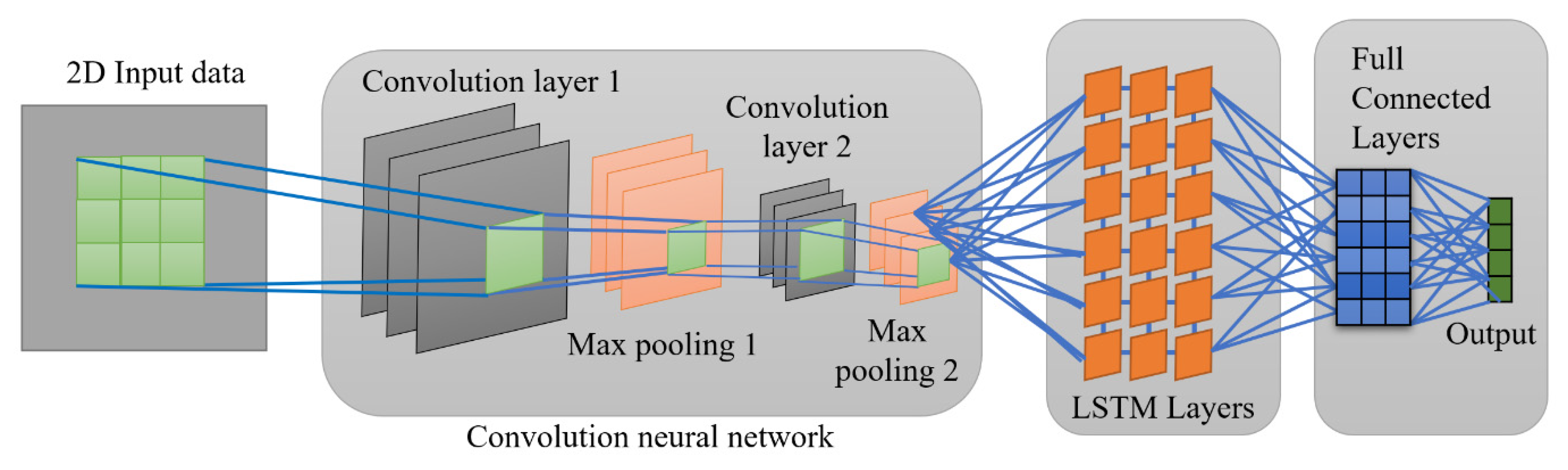
- The hybrid deep learning CNN and LSTM methodologies are developed for predicting global and domestic arrival tourists in Vietnam and some provinces. The CNN could extract critical patterns from high-frequency data, which is transferred to the LSTM for processing the sequential information. Then, the outputs from LSTM layers are shifted to the fully connected layers, which output the international and domestic arrivals.
- Hyperparameter fine-tuning is deployed to optimize the architecture of the proposed CNN–LSTM algorithm. In addition, the effectiveness of varying configurations of the CNN–LSTM on the prediction accuracy is also evaluated and analyzed.
- The predicting performance and reliability of the proposed CNN–LSTM algorithm are compared and analyzed with other traditional methods, including BPNN, CNN, RNN, LSTM, and GRU, with different evaluation benchmarks. K-fold cross-validation is deployed for deeply comparing the predicted performance between algorithms.
2. General Methodology
- The data collection: The numbers of international and domestic arrival tourism in Vietnam and some provinces were collected every month for many years. In addition, the number of international and domestic holidays and the number of new COVID-19 cases in Vietnam and worldwide each month are also gathered, which are novel contributions to this research. Moreover, the CPI and GDP are also selected as the correlated variables with the target data. The month-of-year data are also considered an input variable in the proposed methodology.
- Data preprocessing: All the collected data are merged and need to be preprocessed before utilizing in the deep learning methodology [19]. Some missing data are refilled by the average values of nearby rows [20]. The outline data, which are the abnormal values, are removed from the data set. The min–max normalization method is utilized as the standard procedure, which converted all collected features into the same ranges [21]. The min–max normalization scales different variables into the [0, 1] range, as computed in Equation (1). All the normalized data are computed in the Pearson correlation matrix, which measures the correlation status between the input and the target variable. The feature selection process selects the most influential features and identifies the unrelated features to improve the prediction accuracy [22]. The Pearson correlation values measure the relationship between two variables and are calculated as in Equation (2) [23,24,25]. The most appropriate variables with strong correlation values are chosen for developing the model by the learning and validating operations.
- 3.
- Hyperparameter fine-tuning (HFT) is utilized to optimize the architecture of the proposed CNN–LSTM [26,27,28]. Different parameters are varied to evaluate the effectiveness of the CNN–LSTM’s prediction accuracy, including the number of layers and number of filters in CNN architecture, the number of layers and neural nodes in LSTM structures, and the optimizing methodology during training and validating operations. The configurations that achieved the global optimum solution are selected as the most appropriate setting parameters for the developed CNN–LSTM algorithm. During the HFT operations, the effectiveness of varying CNN–LSTM architecture in predicting tourism demand is interpreted.
- 4.
- The optimized CNN–LSTM architecture is proposed to compare and evaluate with other traditional and deep learning methodologies, including BPNN, CNN, GRU, LSTM, and RNN algorithms. The collected data are completely deployed in the evaluating operation by utilizing K-fold cross-validation [29,30,31]. During the developing model operations, the training data set is split into K fold, one fold for evaluating and the other fold for learning. Different benchmarks are selected to evaluate and compare the accuracy and reliability, including the mean square error (MSE), mean absolute percentage error (MAPE), cosine proximity (CP), and mean absolute error (MAE), which are calculated as in Equations (3)–(6). The closer these benchmarks are to zero, the better the predicting performance obtained. The loss function during the developing process is the MSE benchmark, which is gradually smaller during the learning activity of the proposed CNN–LSTM algorithm.
2.1. Data Collection and Pearson Correlation Calculation for Selecting Input Features
- For predicting the international and domestic arrival tourism in Vietnam: The number of international arrival tourism in Vietnam has a strong negative correlation with the international new COVID-19 cases, which is a −0.5151 Pearson value, a moderate negative relationship with the new COVID-19 cases in Vietnam, which is −0.1975. International holidays have a low relationship with the target international tourism, which could be considered input features in the prediction methodology. For Vietnam’s domestic arrival tourism, the national GDP, CPI, and global new COVID-19 cases are the most correlated factors with the target domestic arrival tourism, which have 0.3855, 0.3562, and 0.2475 Pearson coefficients. The domestic holiday and month-of-year have very low correlations with target variables, which could be negligible. Therefore, to predict the international and domestic arrival tourism in Vietnam, the international holidays, CPI, GDP, Vietnam, and global new COVID-19 cases are selected as input parameters during the training and validating operations.
- For predicting the international and domestic arrival tourism in Da Nang province: The level of international arrival tourism has the strongest correlation with the international new COVID-19 case factor, the Vietnam new COVID-19 case, and Vietnam GDP, which have −0.3798, −0.1462, and 0.0946 Pearson values, respectively. In addition, domestic arrival tourism has strong correlations with international new COVID-19 cases, domestic holidays, and month-of-year, which have −0.2354, −0.2035, and 0.1542 Pearson coefficients, respectively. Therefore, these abovementioned features, which possess strong correlations, are selected to predict international and domestic tourism in Da Nang province.
- For Hue province, international arrival tourism in Hue has negative correlations with the international new COVID-19 cases, the Vietnam new COVID-19 cases, and the international holidays, which comprise −0.4403, −0.1779, and −0.1276 Pearson values, respectively. For the number of domestic tourists, the international new COVID-19 cases, the month-of-year, and domestic holidays could be considered as affected factors, which have −0.2536, −0.0956, and −0.091 Pearson quantities, respectively. Therefore, these affected factors will be selected for forecasting the number of arrival tourists in Hue province.
- For Khanh Hoa province, the numbers of international customers are affected by the international new COVID-19 cases, the GDP, the CPI, and the Vietnam new COVID-19 cases, which have −0.3823, 0.1975, 0.1659, and −0.1473 Pearson values, respectively. Moreover, the international new COVID-19 cases also affected domestic tourism in Khanh Hoa province, which has a −0.3365 Pearson coefficient. Other factors, including the number of global and domestic holidays and the month-of-year, have weak correlations with target variables, which were negligible. Therefore, the above four selected features are the most appropriate input features for predicting the arrival of customers in Khanh Hoa province.
- For Kien Giang province: The international arrival customers have strong correlations with international new COVID-19 cases, the month-of-year, the international the domestic holidays, and the Vietnam new COVID-19 cases, which maintain −0.4649, −0.2468, 0.2143, −0.2057, −0.1984 Pearson impact factors. In addition, the Kien Giang domestic tourism has powerful positive relationships with the CPI, GDP, and international new COVID-19 cases, which comprise 0.533, 0.5301, and 0.1913, respectively. Therefore, to effectively predict the international and domestic arrival customers in Kien Giang province, all the collected variables are considered in the developed CNN–LSTM algorithm.
2.2. The Traditional Back Propagation Neural Network and Deep Learning Algorithms
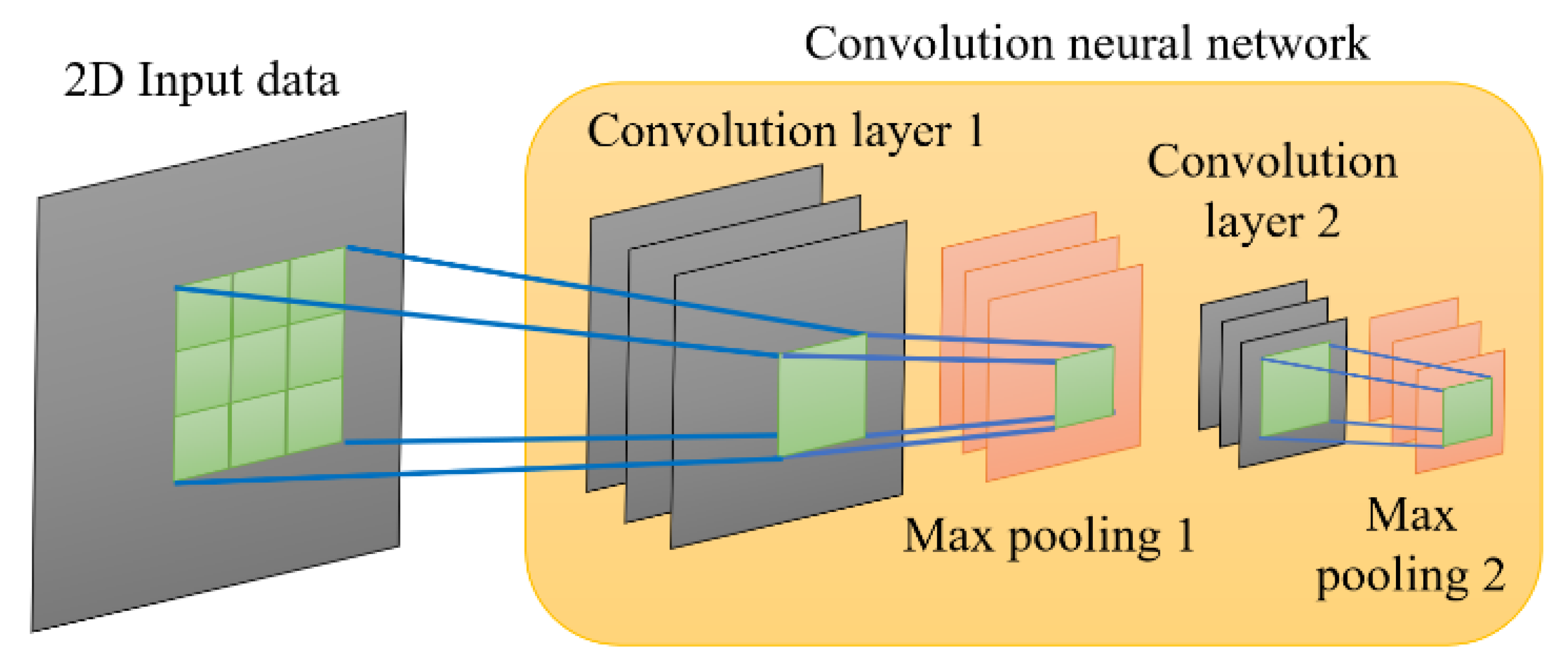
2.3. The Convolution Neural Network
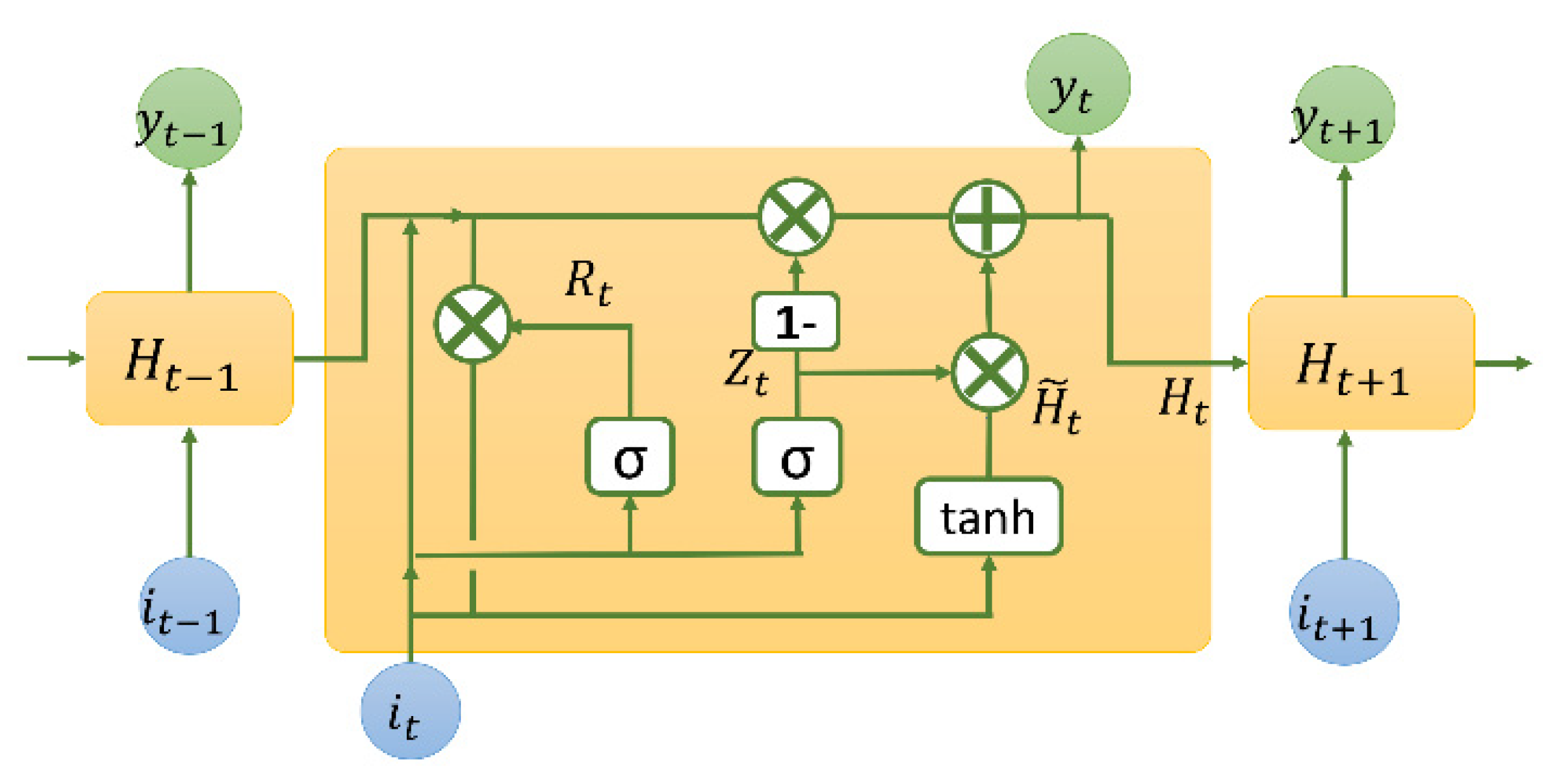
2.4. The Developed Convolution Neural Network and Lstm Algorithms
3. Hyperparameter for Developed CNN–LSTM Algorithms
4. Comparing Predicting Performance between Methodologies
5. Findings and Discussion
- The new international and domestic COVID-19 cases are considered the most effective features that control the number of arrived tourists, through the Pearson correlation values. Improvements in the GPD and CPI indexes have increased the size of the middle class in Vietnam society, which is the main fraction of domestic tourists in Vietnam and some provinces. In addition, the numbers of international and domestic tourists in Kien Giang and Da Nang provinces make up a significant proportion of the total number of international and domestic holidays. Therefore, the authority in these provinces could extend the number of domestic holidays, combined with traditional festivals and cultural ceremonies, to attract more tourists. The Pearson correlations between arrived tourists and other holiday and COVID-19 factors are novel in this research.
- The optimized structures of the proposed CNN–LSTM during the hyperparameter process are identified in this research. Moreover, the optimized window sizes, which are the number of historical sequential information, combined with the number of layers and cells in LSTM structure, and the number of filters in CNN layers for each data collection, are discovered in this research.
- This research proves the effectiveness when combining the CNN and LSTM algorithms, which outperforms the single CNN and LSTM algorithms in different evaluating benchmarks. Moreover, this research also demonstrates the higher performance of proposed algorithms in comparison to the BPNN, RNN, and GRU methodologies.
- This research verifies an effective CNN–LSTM methodology combined with the Pearson correlation matrix to identify the most appropriate input features, which create a reliable methodology for resource planning, efficiently maximizing, and deeply utilizing the available resource in Vietnam and some provinces. The developed methodology could boost the tourism industry not only in Vietnam but also all over the world after the COVID-19 pandemic.
6. Results
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, F.; Yang, Y.; Jiang, L. Spatial Spillover of Transport Improvement on Tourism Growth. Tour. Econ. 2022, 28, 1416–1432. [Google Scholar] [CrossRef]
- Tien, N.H.; Dung, H.T.; Vu, N.T.; Doan, L.; Duc, M. Risks of Unsustainable Tourism Development in Vietnam. Int. J. Res. Financ. Manag. 2019, 2, 81–85. [Google Scholar]
- Alamsyah, A.; Friscintia, P.B.A. Artificial Neural Network for Indonesian Tourism Demand Forecasting. In Proceedings of the 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–7. [Google Scholar]
- Assaf, A.G.; Li, G.; Song, H.; Tsionas, M.G. Modeling and Forecasting Regional Tourism Demand Using the Bayesian Global Vector Autoregressive (BGVAR) Model. J. Travel Res. 2019, 58, 383–397. [Google Scholar] [CrossRef]
- Bangwayo-Skeete, P.F.; Skeete, R.W. Can Google Data Improve the Forecasting Performance of Tourist Arrivals? Mixed-Data Sampling Approach. Tour. Manag. 2015, 46, 454–464. [Google Scholar] [CrossRef]
- Baldigara, T.; Mamula, M. Modelling International Tourism Demand Using Seasonal ARIMA Models. Tour. Hosp. Manag. 2015, 21, 19–31. [Google Scholar] [CrossRef]
- Cai, Z.; Lu, S.; Zhang, X. Tourism Demand Forecasting by Support Vector Regression and Genetic Algorithm. In Proceedings of the 2009 2nd IEEE International Conference on Computer Science and Information Technology, Beijing, China, 8–11 August 2009; pp. 144–146. [Google Scholar]
- Cankurt, S. Tourism Demand Forecasting Using Ensembles of Regression Trees. In Proceedings of the 2016 IEEE 8th International Conference on Intelligent Systems (IS), Sofia, Bulgaria, 4–6 September 2016; pp. 702–708. [Google Scholar]
- Claveria, O.; Monte, E.; Torra, S. Tourism Demand Forecasting with Neural Network Models: Different Ways of Treating Information. Int. J. Tour. Res. 2015, 17, 492–500. [Google Scholar] [CrossRef]
- Akın, M. A Novel Approach to Model Selection in Tourism Demand Modeling. Tour. Manag. 2015, 48, 64–72. [Google Scholar] [CrossRef]
- Athanasopoulos, G.; Hyndman, R.J. Modelling and Forecasting Australian Domestic Tourism. Tour. Manag. 2008, 29, 19–31. [Google Scholar] [CrossRef]
- Chu, F.-L. Analyzing and Forecasting Tourism Demand with ARAR Algorithm. Tour. Manag. 2008, 29, 1185–1196. [Google Scholar] [CrossRef]
- Gunter, U.; Önder, I. Forecasting International City Tourism Demand for Paris: Accuracy of Uni-and Multivariate Models Employing Monthly Data. Tour. Manag. 2015, 46, 123–135. [Google Scholar] [CrossRef]
- Huang, B.; Hao, H. A Novel Two-Step Procedure for Tourism Demand Forecasting. Curr. Issues Tour. 2021, 24, 1199–1210. [Google Scholar] [CrossRef]
- Hsieh, S.-C. Tourism Demand Forecasting Based on an LSTM Network and Its Variants. Algorithms 2021, 14, 243. [Google Scholar] [CrossRef]
- He, K.; Ji, L.; Wu, C.W.D.; Tso, K.F.G. Using SARIMA–CNN–LSTM Approach to Forecast Daily Tourism Demand. J. Hosp. Tour. Manag. 2021, 49, 25–33. [Google Scholar] [CrossRef]
- Kulshrestha, A.; Krishnaswamy, V.; Sharma, M. Bayesian BILSTM Approach for Tourism Demand Forecasting. Ann. Tour. Res. 2020, 83, 102925. [Google Scholar] [CrossRef]
- Salamanis, A.; Xanthopoulou, G.; Kehagias, D.; Tzovaras, D. LSTM-Based Deep Learning Models for Long-Term Tourism Demand Forecasting. Electronics 2022, 11, 3681. [Google Scholar] [CrossRef]
- Shapi, M.K.M.; Ramli, N.A.; Awalin, L.J. Energy Consumption Prediction by Using Machine Learning for Smart Building: Case Study in Malaysia. Dev. Built Environ. 2021, 5, 100037. [Google Scholar] [CrossRef]
- Newgard, C.D.; Lewis, R.J. Missing Data: How to Best Account for What Is Not Known. JAMA 2015, 314, 940–941. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Zhang, L.; Wu, X.; Wang, X. Energy Consumption Prediction and Diagnosis of Public Buildings Based on Support Vector Machine Learning: A Case Study in China. J. Clean. Prod. 2020, 272, 122542. [Google Scholar] [CrossRef]
- Zhao, H.-X.; Magoulès, F. Feature Selection for Predicting Building Energy Consumption Based on Statistical Learning Method. J. Algorithm. Comput. Technol. 2012, 6, 59–77. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Zhou, H.; Deng, Z.; Xia, Y.; Fu, M. A New Sampling Method in Particle Filter Based on Pearson Correlation Coefficient. Neurocomputing 2016, 216, 208–215. [Google Scholar] [CrossRef]
- Adler, J.; Parmryd, I. Quantifying Colocalization by Correlation: The Pearson Correlation Coefficient Is Superior to the Mander’s Overlap Coefficient. Cytom. Part A 2010, 77, 733–742. [Google Scholar] [CrossRef]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–33. [Google Scholar]
- Yang, L.; Shami, A. On Hyperparameter Optimization of Machine Learning Algorithms: Theory and Practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the International Conference on Machine Learning; PMLR: Atlanta, GA, USA, 2013; pp. 115–123. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity Analysis of K-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of Prediction Error by Using K-Fold Cross-Validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Jung, Y. Multiple Predicting K-Fold Cross-Validation for Model Selection. J. Nonparametr. Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Chen, H.; Shi, L.; Zhang, Y.; Wang, X.; Sun, G. A Cross-Country Core Strategy Comparison in China, Japan, Singapore and South Korea during the Early COVID-19 Pandemic. Glob. Health 2021, 17, 22. [Google Scholar] [CrossRef]
- Xu, W.; Wu, J.; Cao, L. COVID-19 Pandemic in China: Context, Experience and Lessons. Health Policy Technol. 2020, 9, 639–648. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Goh, A.T.C. Back-Propagation Neural Networks for Modeling Complex Systems. Artif. Intell. Eng. 1995, 9, 143–151. [Google Scholar] [CrossRef]
- Li, J.; Cheng, J.; Shi, J.; Huang, F. Brief Introduction of Back Propagation (BP) Neural Network Algorithm and Its Improvement. In Advances in Computer Science and Information Engineering; Springer: Berlin/Heidelberg, Germany, 2012; pp. 553–558. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent Is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Rizal, A.A.; Soraya, S.; Tajuddin, M. Sequence to Sequence Analysis with Long Short Term Memory for Tourist Arrivals Prediction. Proc. J. Phys. Conf. Ser. 2019, 1211, 12024. [Google Scholar] [CrossRef]
- Kanjanasupawan, J.; Chen, Y.-C.; Thaipisutikul, T.; Shih, T.K.; Srivihok, A. Prediction of Tourist Behaviour: Tourist Visiting Places by Adapting Convolutional Long Short-Term Deep Learning. In Proceedings of the 2019 International Conference on System Science and Engineering (ICSSE), Dong Hoi, Vietnam, 20–21 July 2019; pp. 12–17. [Google Scholar]
- Fischer, T.; Krauss, C. Deep Learning with Long Short-Term Memory Networks for Financial Market Predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Wu, W.; Liao, W.; Miao, J.; Du, G. Using Gated Recurrent Unit Network to Forecast Short-Term Load Considering Impact of Electricity Price. Energy Procedia 2019, 158, 3369–3374. [Google Scholar] [CrossRef]
- Zhang, Z.; Qin, H.; Liu, Y.; Wang, Y.; Yao, L.; Li, Q.; Li, J.; Pei, S. Long Short-Term Memory Network Based on Neighborhood Gates for Processing Complex Causality in Wind Speed Prediction. Energy Convers. Manag. 2019, 192, 37–51. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent Advances in Convolutional Neural Networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a Convolutional Neural Network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D Convolutional Neural Networks and Applications: A Survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2010; pp. 92–101. [Google Scholar]
- Lu, J.; Zhang, Q.; Yang, Z.; Tu, M. A Hybrid Model Based on Convolutional Neural Network and Long Short-Term Memory for Short-Term Load Forecasting. In Proceedings of the 2019 IEEE Power & Energy Society General Meeting (PESGM), Atlanta, GA, USA, 4–8 August 2019; pp. 1–5. [Google Scholar]
- Li, Y.; Cao, H. Prediction for Tourism Flow Based on LSTM Neural Network. Procedia Comput. Sci. 2018, 129, 277–283. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Bi, J.-W.; Liu, Y.; Li, H. Daily Tourism Volume Forecasting for Tourist Attractions. Ann. Tour. Res. 2020, 83, 102923. [Google Scholar] [CrossRef]
- Polyzos, S.; Samitas, A.; Spyridou, A.E. Tourism Demand and the COVID-19 Pandemic: An LSTM Approach. Tour. Recreat. Res. 2021, 46, 175–187. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), {USENIX} Association. Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Goldsborough, P. A Tour of Tensorflow. arXiv 2016, arXiv:1610.01178. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 2011. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-Parameter Optimization: A Review of Algorithms and Applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. Encycl. Database Syst. 2009, 5, 532–538. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter Setting | ||
|---|---|---|
| Learning rate | 0.001 | |
| Cost function | MSE | |
| Optimizer algorithm | ADAM | |
| Batch size | 32 | |
| Dropout Rate | 0.1 | |
| Learning/Validating/Testing split | 80:10:10 | |
| Training epoch | 100 | |
| Input data | Window size | (6, 9, 12, 15) |
| CNN layers | Depth CNN layers | 1 |
| Activation function | Relu | |
| Number filters | (8, 16, 32, 64) | |
| Padding & Stride | 1 | |
| CNN filter size | 3 × 3 | |
| LSTM Layers | Depth LSTM layers | (2, 3, 4) |
| Activation function | Relu | |
| LSTM neuron | (32, 64, 128) | |
| FC layers | Depth | 2 |
| Activation function | Relu | |
| Neuron | 64 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen-Da, T.; Li, Y.-M.; Peng, C.-L.; Cho, M.-Y.; Nguyen-Thanh, P. Tourism Demand Prediction after COVID-19 with Deep Learning Hybrid CNN–LSTM—Case Study of Vietnam and Provinces. Sustainability 2023, 15, 7179. https://doi.org/10.3390/su15097179
Nguyen-Da T, Li Y-M, Peng C-L, Cho M-Y, Nguyen-Thanh P. Tourism Demand Prediction after COVID-19 with Deep Learning Hybrid CNN–LSTM—Case Study of Vietnam and Provinces. Sustainability. 2023; 15(9):7179. https://doi.org/10.3390/su15097179
Chicago/Turabian StyleNguyen-Da, Thao, Yi-Min Li, Chi-Lu Peng, Ming-Yuan Cho, and Phuong Nguyen-Thanh. 2023. "Tourism Demand Prediction after COVID-19 with Deep Learning Hybrid CNN–LSTM—Case Study of Vietnam and Provinces" Sustainability 15, no. 9: 7179. https://doi.org/10.3390/su15097179
APA StyleNguyen-Da, T., Li, Y.-M., Peng, C.-L., Cho, M.-Y., & Nguyen-Thanh, P. (2023). Tourism Demand Prediction after COVID-19 with Deep Learning Hybrid CNN–LSTM—Case Study of Vietnam and Provinces. Sustainability, 15(9), 7179. https://doi.org/10.3390/su15097179