
Artificial Intelligence-Empowered Art Education: A Cycle-Consistency Network-Based Model for Creating the Fusion Works of Tibetan Painting Styles

Abstract
1. Introduction
- The TPSF model is proposed to solve problems regarding the limited content and the similar styles of Thangka. Additionally, a digital approach to the fusion of Tibetan-Chinese painting styles is provided.
- We propose that the use of a TPSF model in art learning empowers art education and provides learners with a new model of interactive learning.
- Comparison experiments were performed on real data sets. Firstly, the converged objective function proved the feasibility of the model. Secondly, the TPSF model outperformed the other four comparison models according to the Frechet Inception Distance (FID) metric, which proves how advanced it is. Finally, the questionnaire method was used to evaluate the visual appeal of the generated images.
2. Related Work
2.1. Artificial Intelligence Education
2.2. Image Domain Adaption
3. TPSF Model Design
3.1. TPSF Generators
- The input is two real three-channel image sets that are 256 × 256 pixels and are named and .
- This image set enters the decoder for undersampling, and the first layer uses a convolution kernel with the number 64 and a size of 7 × 7. The sliding step length is one and the fill size is three. Then, the instance normalization occurs, and the ReLU is finally implemented.
- The second and third layers use 128 and 256 convolutional kernels of size 3 × 3, respectively, and both the second and third layers slide two steps. Additionally, they have a padding size of one, undergo instance normalization, and finally implement ReLU activation.
- The last layers use the nine residual block model. Nine convolutional kernels are present in the residual module, each with 256 3 × 3 convolutional kernels. They slide one step, undergo instance normalization, and finally implement ReLU activation.
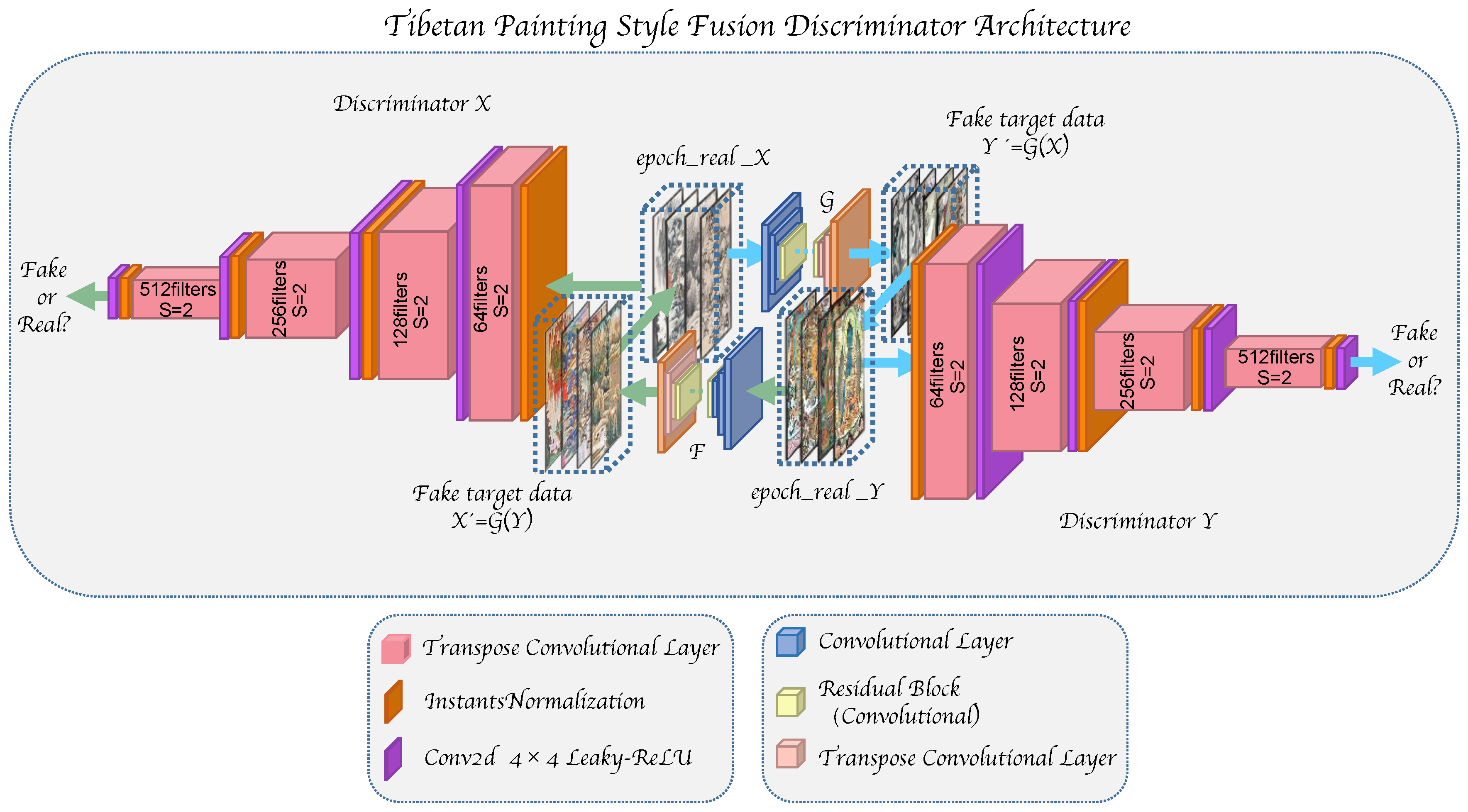
3.2. TPSF Discriminators
- The input is a real three-channel image set, each channel of which is 256 × 256 pixels, and are named and . The output is the fake target data and .
- The first layer has 64 four × four convolutional kernels with a sliding step of two and a fill size of one. Additionally, it undergoes an instance normalization process and, finally, a ReLU activation process.
- The reason for the ReLu activation is that the second to fifth layers all use four × four convolutional kernels, which are 128, 256. That has 521 in number with a sliding step size of two, and padding of one, and they are subjected to average pooling.
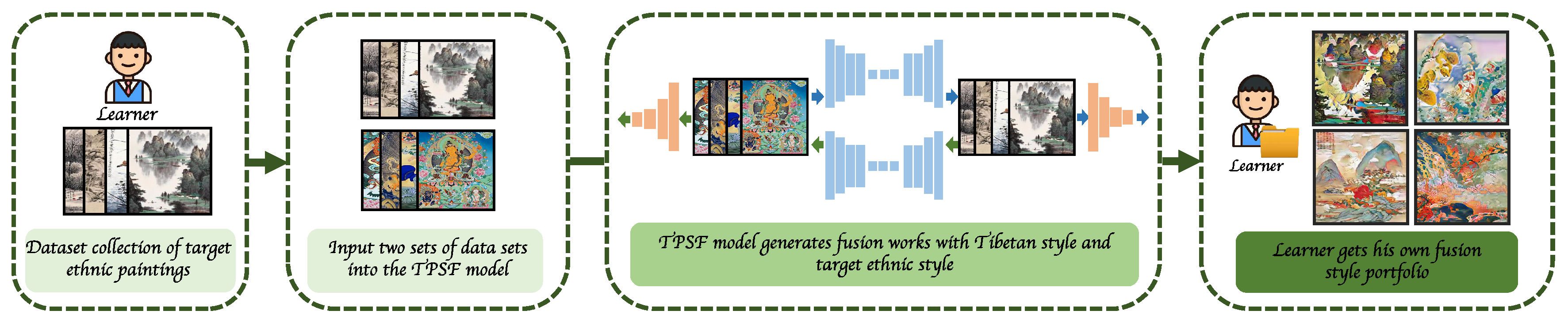
3.3. Interactive Learning Process of TPSF Model
3.4. Objective Function of TPSF Model
4. Experiment and Results
4.1. Setup of Experiment
4.2. Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Béguin, G.; Colinart, S. Les Peintures du Bouddhisme Tibétain; Réunion des Musées Nationaux: Paris, France, 1995; p. 258. [Google Scholar]
- Jackson, D.; Jackson, J. Tibetan Thangka Painting: Methods and Materials; Serindia Publications: London, UK, 1984; p. 10. [Google Scholar]
- Elgar, J. Tibetan thang kas: An overview. Pap. Conserv. 2006, 30, 99–114. [Google Scholar] [CrossRef]
- Beer, R. The Encyclopedia of Tibetan Symbols and Motifs; Serindia Publications: London, UK, 2004; p. 373. [Google Scholar]
- Cetinic, E.; She, J. Understanding and creating art with AI: Review and outlook. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Hao, K. China has started a grand experiment in AI education. It could reshape how the world learns. MIT Technol. Rev. 2019, 123, 1. [Google Scholar]
- Song, J.; Li, P.; Fang, Q.; Xia, H.; Guo, R. Data Augmentation by an Additional Self-Supervised CycleGAN-Based for Shadowed Pavement Detection. Sustainability 2022, 14, 14304. [Google Scholar] [CrossRef]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.; Wierstra, D. Draw: A recurrent neural network for image generation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1462–1471. [Google Scholar]
- Hertzmann, A. Non-photorealistic rendering and the science of art. In Proceedings of the 8th International Symposium on Non-Photorealistic Animation and Rendering, Annecy, France, 7–10 June 2010; pp. 147–157. [Google Scholar]
- Park, J.; Kim, D.H.; Kim, H.N.; Wang, C.J.; Kwak, M.K.; Hur, E.; Suh, K.Y.; An, S.S.; Levchenko, A. Directed migration of cancer cells guided by the graded texture of the underlying matrix. Nat. Mater. 2016, 15, 792–801. [Google Scholar] [CrossRef]
- AlAmir, M.; AlGhamdi, M. The Role of generative adversarial network in medical image analysis: An in-depth survey. ACM Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Mo, Y.; Li, C.; Zheng, Y.; Wu, X. DCA-CycleGAN: Unsupervised single image dehazing using Dark Channel Attention optimized CycleGAN. J. Vis. Commun. Image Represent. 2022, 82, 103431. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Liu, Y.; Sangineto, E.; Chen, Y.; Bao, L.; Zhang, H.; Sebe, N.; Lepri, B.; Wang, W.; De Nadai, M. Smoothing the disentangled latent style space for unsupervised image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10785–10794. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Chen, J.; Liu, G.; Chen, X. AnimeGAN: A novel lightweight GAN for photo animation. In Proceedings of the International Symposium on Intelligence Computation and Applications, Guangzhou, China, 16–17 November 2019; Springer: New York, NY, USA, 2019; pp. 242–256. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Cao, K.; Liao, J.; Yuan, L. Carigans: Unpaired photo-to-caricature translation. arXiv 2018, arXiv:1811.00222. [Google Scholar] [CrossRef]
- Zhao, Y.; Wu, R.; Dong, H. Unpaired image-to-image translation using adversarial consistency loss. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: New York, NY, USA, 2020; pp. 800–815. [Google Scholar]
- Timms, M.J. Letting artificial intelligence in education out of the box: Educational cobots and smart classrooms. Int. J. Artif. Intell. Educ. 2016, 26, 701–712. [Google Scholar] [CrossRef]
- Cairns, L.; Malloch, M. Computers in education: The impact on schools and classrooms. Life in Schools and Classrooms: Past, Present and Future; Springer: Berlin, Germany, 2017; pp. 603–617. [Google Scholar]
- Hwang, G.J.; Xie, H.; Wah, B.W.; Gašević, D. Vision, challenges, roles and research issues of Artificial Intelligence in Education. In Computers and Education: Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 2020; Volume 1, p. 100001. [Google Scholar]
- Al Darayseh, A. Acceptance of artificial intelligence in teaching science: Science teachers’ perspective. Comput. Educ. Artif. Intell. 2023, 4, 100132. [Google Scholar] [CrossRef]
- Chen, X.; Xie, H.; Li, Z.; Zhang, D.; Cheng, G.; Wang, F.L.; Dai, H.N.; Li, Q. Leveraging deep learning for automatic literature screening in intelligent bibliometrics. Int. J. Mach. Learn. Cybern. 2022, 14, 1483–1525. [Google Scholar] [CrossRef]
- Chiu, M.C.; Hwang, G.J.; Hsia, L.H.; Shyu, F.M. Artificial intelligence-supported art education: A deep learning-based system for promoting university students’ artwork appreciation and painting outcomes. Interact. Learn. Environ. 2022, 1–19. [Google Scholar] [CrossRef]
- Lin, H.C.; Hwang, G.J.; Chou, K.R.; Tsai, C.K. Fostering complex professional skills with interactive simulation technology: A virtual reality-based flipped learning approach. Br. J. Educ. Technol. 2023, 54, 622–641. [Google Scholar] [CrossRef]
- Zhu, D.; Deng, S.; Wang, W.; Cheng, G.; Wei, M.; Wang, F.L.; Xie, H. HDRD-Net: High-resolution detail-recovering image deraining network. Multimed. Tools Appl. 2022, 81, 42889–42906. [Google Scholar] [CrossRef]
- Ma, Y.; Liu, Y.; Xie, Q.; Xiong, S.; Bai, L.; Hu, A. A Tibetan Thangka data set and relative tasks. Image Vis. Comput. 2021, 108, 104125. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, K.; Peng, R.; Yu, J. Parametric modeling and generation of mandala thangka patterns. J. Comput. Lang. 2020, 58, 100968. [Google Scholar] [CrossRef]
- Qian, J.; Wang, W. Main feature extraction and expression for religious portrait Thangka image. In Proceedings of the 2008 the 9th International Conference for Young Computer Scientists, Hunan, China, 18–21 November 2008; pp. 803–807. [Google Scholar]
- Liu, H.; Wang, W.; Xie, H. Thangka image inpainting using adjacent information of broken area. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 19–21 March 2008; Volume 1. [Google Scholar]
- Hu, W.; Ye, Y.; Zeng, F.; Meng, J. A new method of Thangka image inpainting quality assessment. J. Vis. Commun. Image Represent. 2019, 59, 292–299. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: New York, NY, USA, 2016; pp. 694–711. [Google Scholar]
- Risser, E.; Wilmot, P.; Barnes, C. Stable and controllable neural texture synthesis and style transfer using histogram losses. arXiv 2017, arXiv:1701.08893. [Google Scholar]
- Li, S.; Xu, X.; Nie, L.; Chua, T.S. Laplacian-steered neural style transfer. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1716–1724. [Google Scholar]
- Li, Y.; Wang, N.; Liu, J.; Hou, X. Demystifying neural style transfer. arXiv 2017, arXiv:1701.01036. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Ratliff, L.J.; Burden, S.A.; Sastry, S.S. Characterization and computation of local Nash equilibria in continuous games. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; pp. 917–924. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Li, S.Z. Markov random field models in computer vision. In Proceedings of the European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; Springer: New York, NY, USA, 1994; pp. 361–370. [Google Scholar]
- Castillo, L.; Seo, J.; Hangan, H.; Gunnar Johansson, T. Smooth and rough turbulent boundary layers at high Reynolds number. Exp. Fluids 2004, 36, 759–774. [Google Scholar] [CrossRef]
- Champandard, A.J. Semantic style transfer and turning two-bit doodles into fine artworks. arXiv 2016, arXiv:1603.01768. [Google Scholar]
- Chen, Y.L.; Hsu, C.T. Towards Deep Style Transfer: A Content-Aware Perspective. In Proceedings of the BMVC, York, UK, 19–22 September 2016; pp. 8.1–8.11. [Google Scholar]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Mechrez, R.; Talmi, I.; Zelnik-Manor, L. The contextual loss for image transformation with non-aligned data. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 768–783. [Google Scholar]
- Liu, J.; Zha, Z.J.; Chen, D.; Hong, R.; Wang, M. Adaptive transfer network for cross-domain person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7202–7211. [Google Scholar]
- Chen, J.; Li, S.; Liu, D.; Lu, W. Indoor camera pose estimation via style-transfer 3D models. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 335–353. [Google Scholar] [CrossRef]
- Zach, C.; Klopschitz, M.; Pollefeys, M. Disambiguating visual relations using loop constraints. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1426–1433. [Google Scholar]
- Huang, Q.X.; Guibas, L. Consistent shape maps via semidefinite programming. In Proceedings of the Computer Graphics Forum, Guangzhou, China, 16–18 November 2013; Wiley Online Library: Hoboken, NJ, USA, 2013; Volume 32, pp. 177–186. [Google Scholar]
- Wang, F.; Huang, Q.; Guibas, L.J. Image co-segmentation via consistent functional maps. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 849–856. [Google Scholar]
- Zhou, T.; Jae Lee, Y.; Yu, S.X.; Efros, A.A. Flowweb: Joint image set alignment by weaving consistent, pixel-wise correspondences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1191–1200. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Zhou, T.; Krahenbuhl, P.; Aubry, M.; Huang, Q.; Efros, A.A. Learning dense correspondence via 3d-guided cycle consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 117–126. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Convolution Number | Kernel | Strides | Padding | Norm | Activation |
|---|---|---|---|---|---|
| Conv | (7,7,64) | 1 | 1 | InstanceNorm | ReLU |
| Conv | (3,3,128) | 2 | 1 | InstanceNorm | ReLU |
| Conv | (3,3,256) | 2 | 1 | InstanceNorm | ReLU |
| Resblock | (3,3,256) | 1 | 1 | InstanceNorm | ReLU |
| Transposed Conv | (3,3,128) | 2 | 1 | InstanceNorm | ReLU |
| Transposed Conv | (3,3,64) | 2 | 1 | InstanceNorm | ReLU |
| Transposed Conv | (3,3,64) | 1 | 1 | InstanceNorm | ReLU |
| Convolution Number | Kernel | Strides | Padding |
|---|---|---|---|
| Conv | (4,4,64) | 2 | 1 |
| Conv | (4,4,128) | 2 | 1 |
| Conv | (4,4,256) | 2 | 1 |
| Conv | (4,4,512) | 2 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wang, L.; Liu, X.; Wang, H. Artificial Intelligence-Empowered Art Education: A Cycle-Consistency Network-Based Model for Creating the Fusion Works of Tibetan Painting Styles. Sustainability 2023, 15, 6692. https://doi.org/10.3390/su15086692
Chen Y, Wang L, Liu X, Wang H. Artificial Intelligence-Empowered Art Education: A Cycle-Consistency Network-Based Model for Creating the Fusion Works of Tibetan Painting Styles. Sustainability. 2023; 15(8):6692. https://doi.org/10.3390/su15086692
Chicago/Turabian StyleChen, Yijing, Luqing Wang, Xingquan Liu, and Hongjun Wang. 2023. "Artificial Intelligence-Empowered Art Education: A Cycle-Consistency Network-Based Model for Creating the Fusion Works of Tibetan Painting Styles" Sustainability 15, no. 8: 6692. https://doi.org/10.3390/su15086692
APA StyleChen, Y., Wang, L., Liu, X., & Wang, H. (2023). Artificial Intelligence-Empowered Art Education: A Cycle-Consistency Network-Based Model for Creating the Fusion Works of Tibetan Painting Styles. Sustainability, 15(8), 6692. https://doi.org/10.3390/su15086692