
Gap Filling Method and Estimation of Net Ecosystem CO2 Exchange in Alpine Wetland of Qinghai–Tibet Plateau

Abstract
1. Introduction
2. Materials and Methods
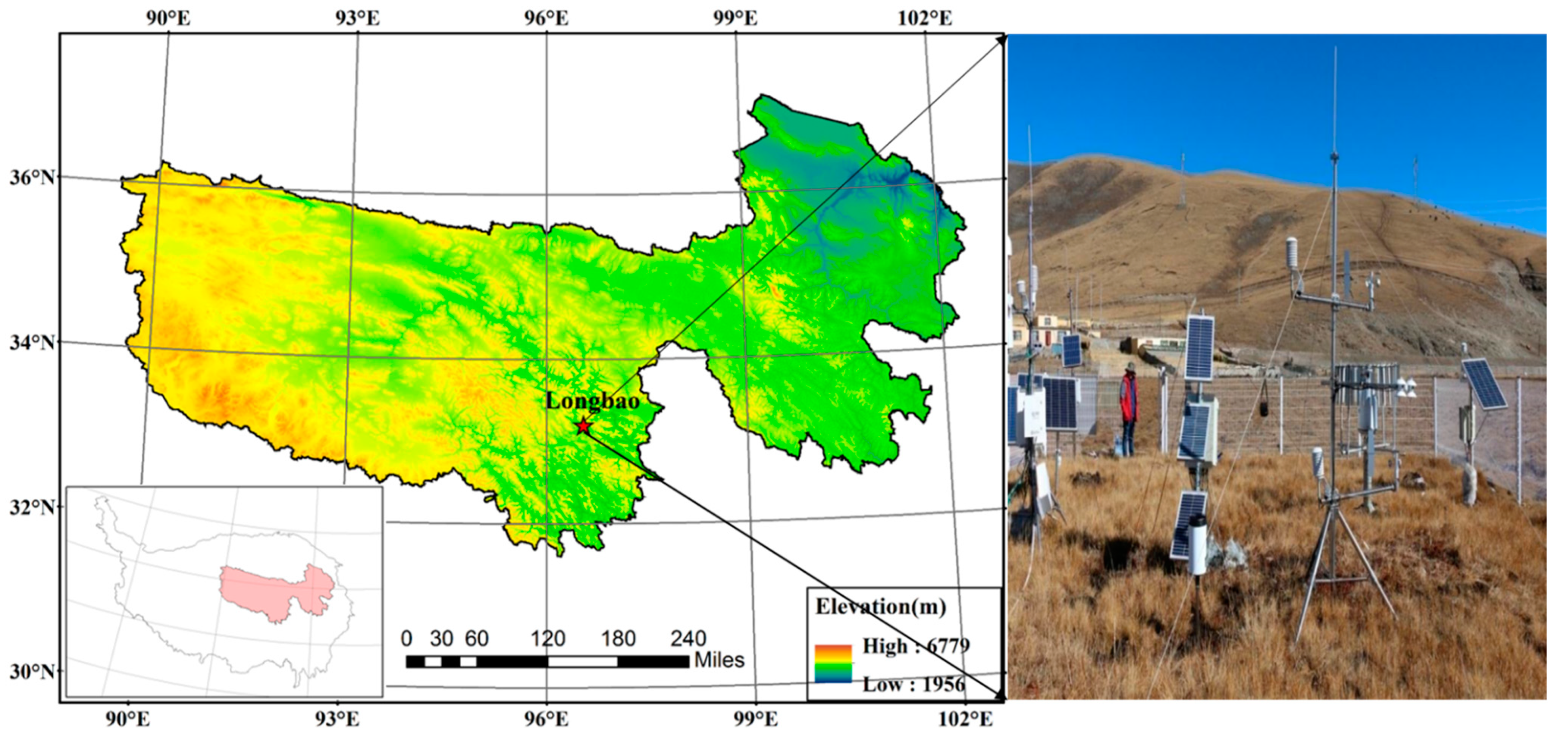
2.1. Sampling Site and Data Survey
2.2. Studying Methods
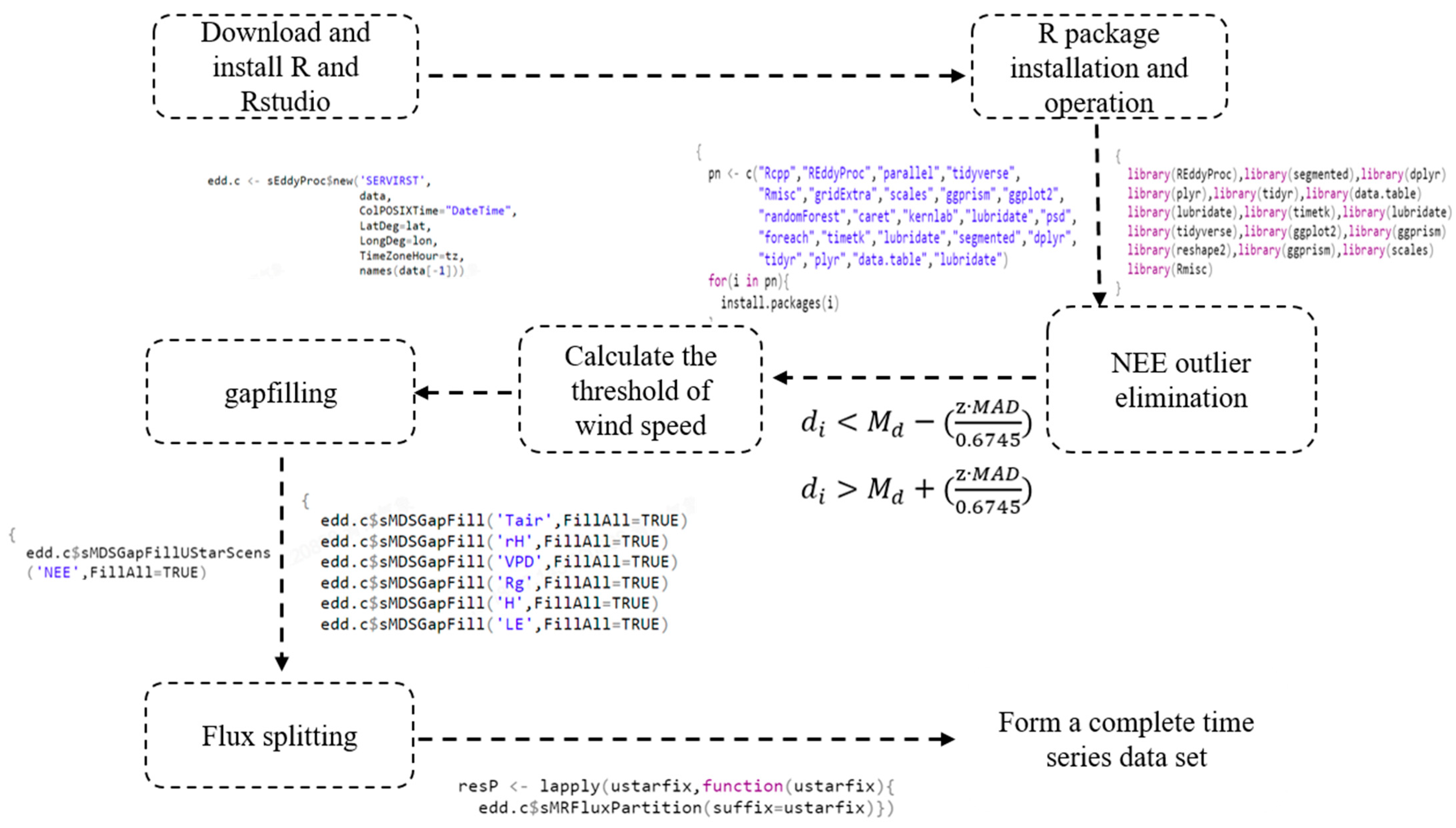
2.2.1. Reddyproc Algorithm
2.2.2. Machine Learning Algorithm
2.2.3. Model Evaluation Indicators
3. Results
3.1. Reddyproc Interpolation
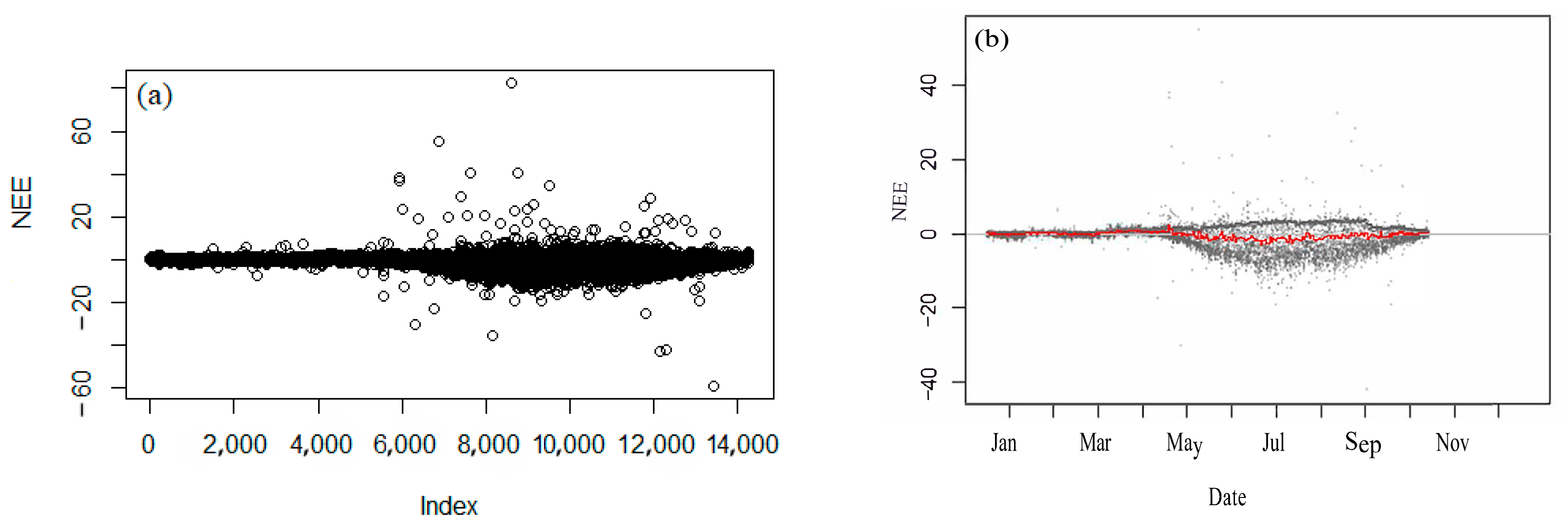
3.1.1. NEE Outlier Detection and Elimination
3.1.2. Interpolation Precision
3.2. Machine Learning Interpolation
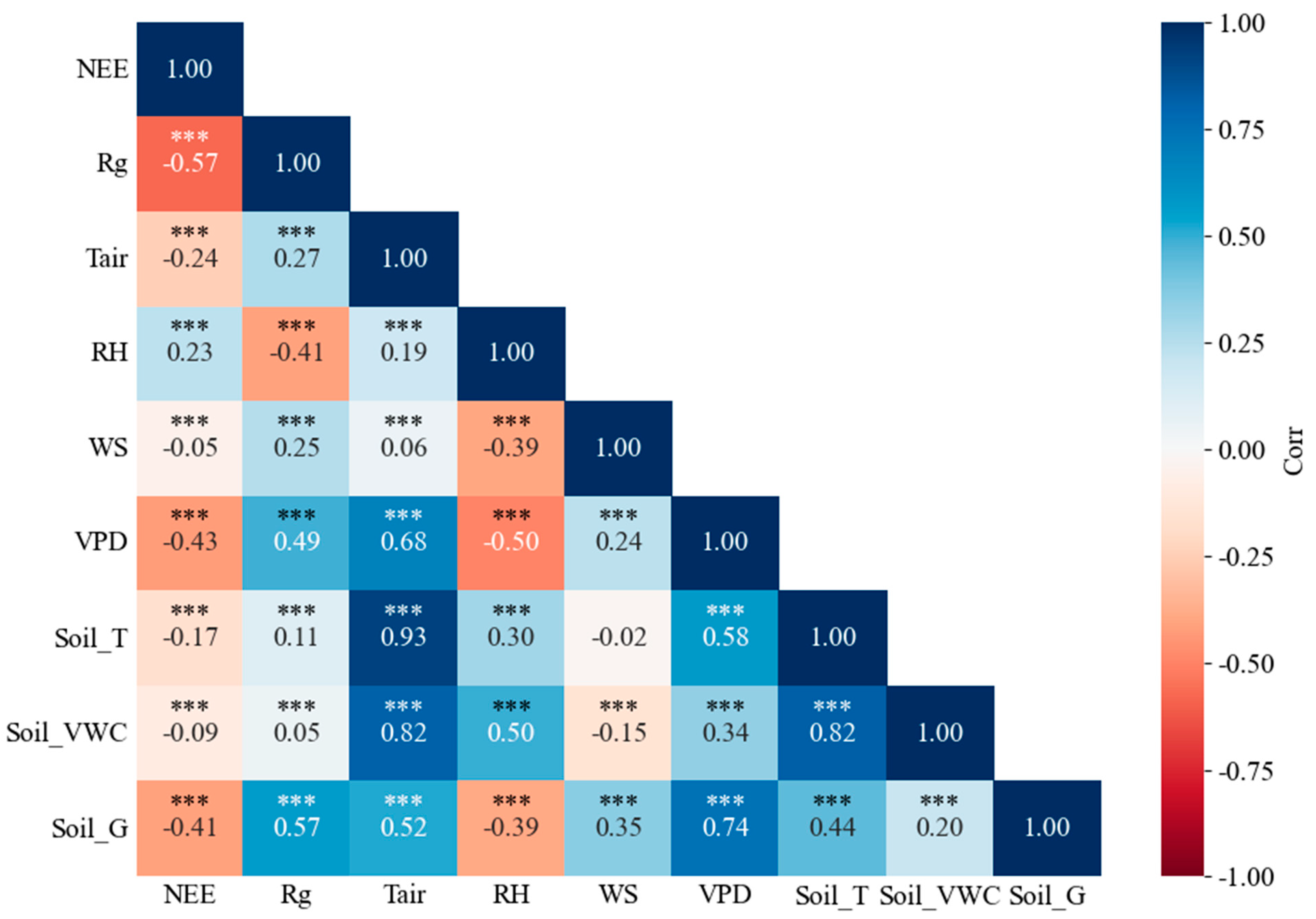
3.2.1. Correlation Analysis between NEE and Meteorological Factors
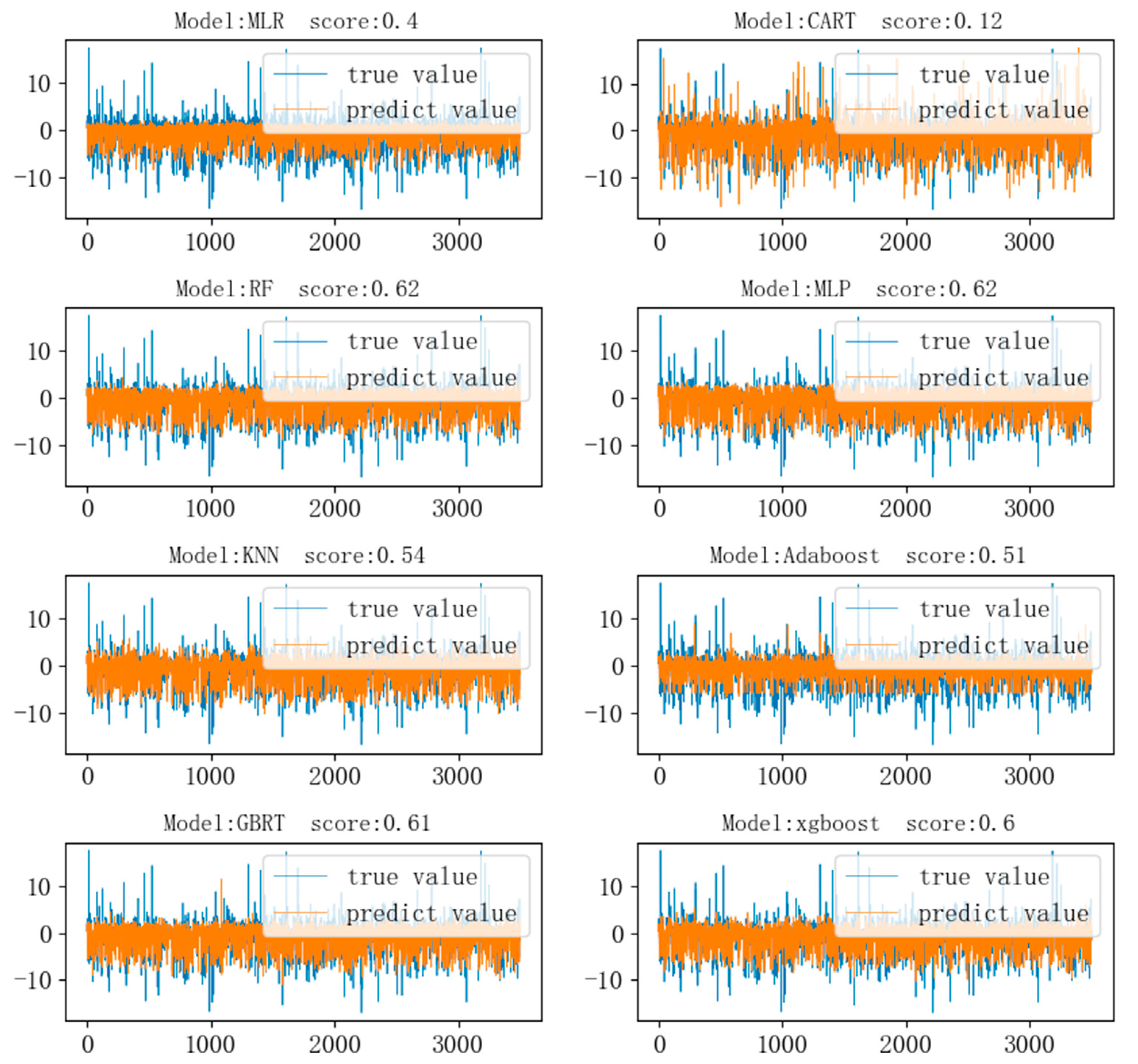
3.2.2. The Accuracy Comparison of Each Model Algorithm under Different Meteorological Factor Input Combinations
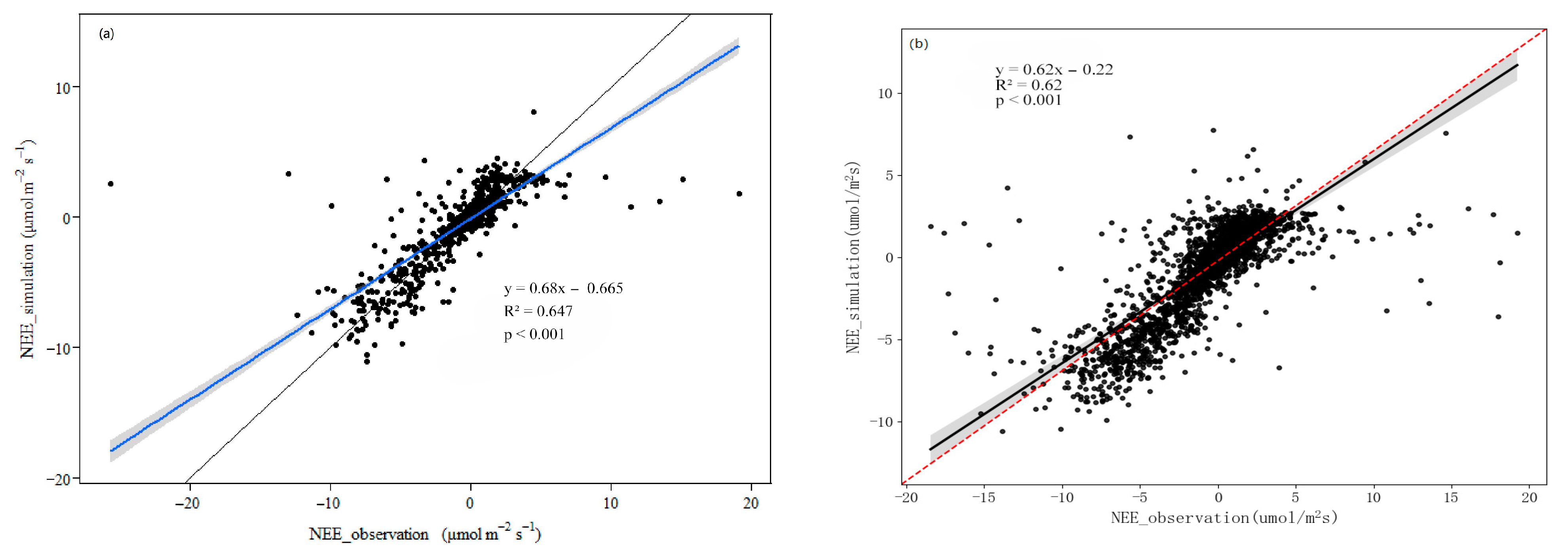
3.3. Comparison of Reddyproc and MLP Interpolation Effect
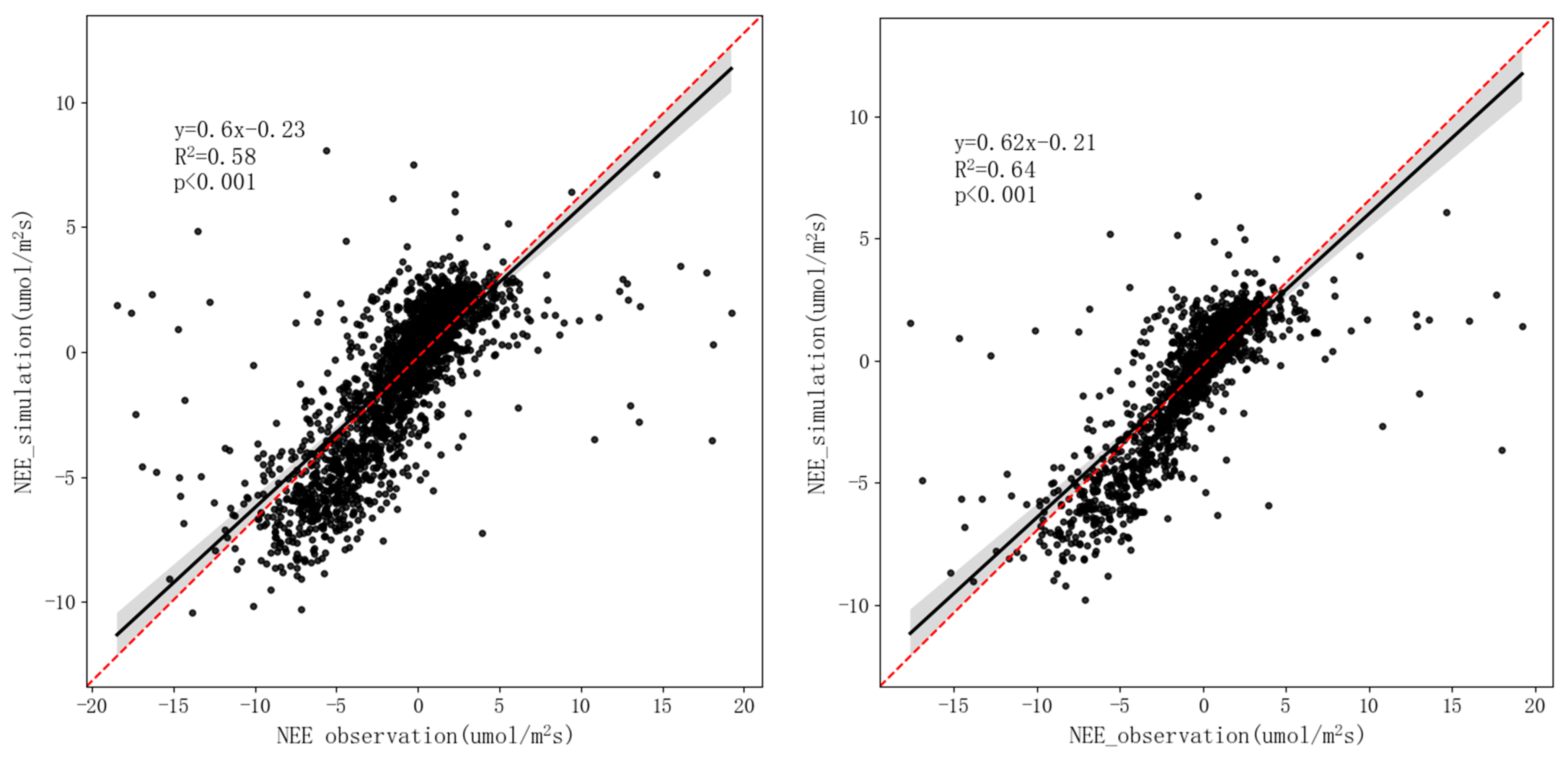
3.3.1. Interpolation Precision
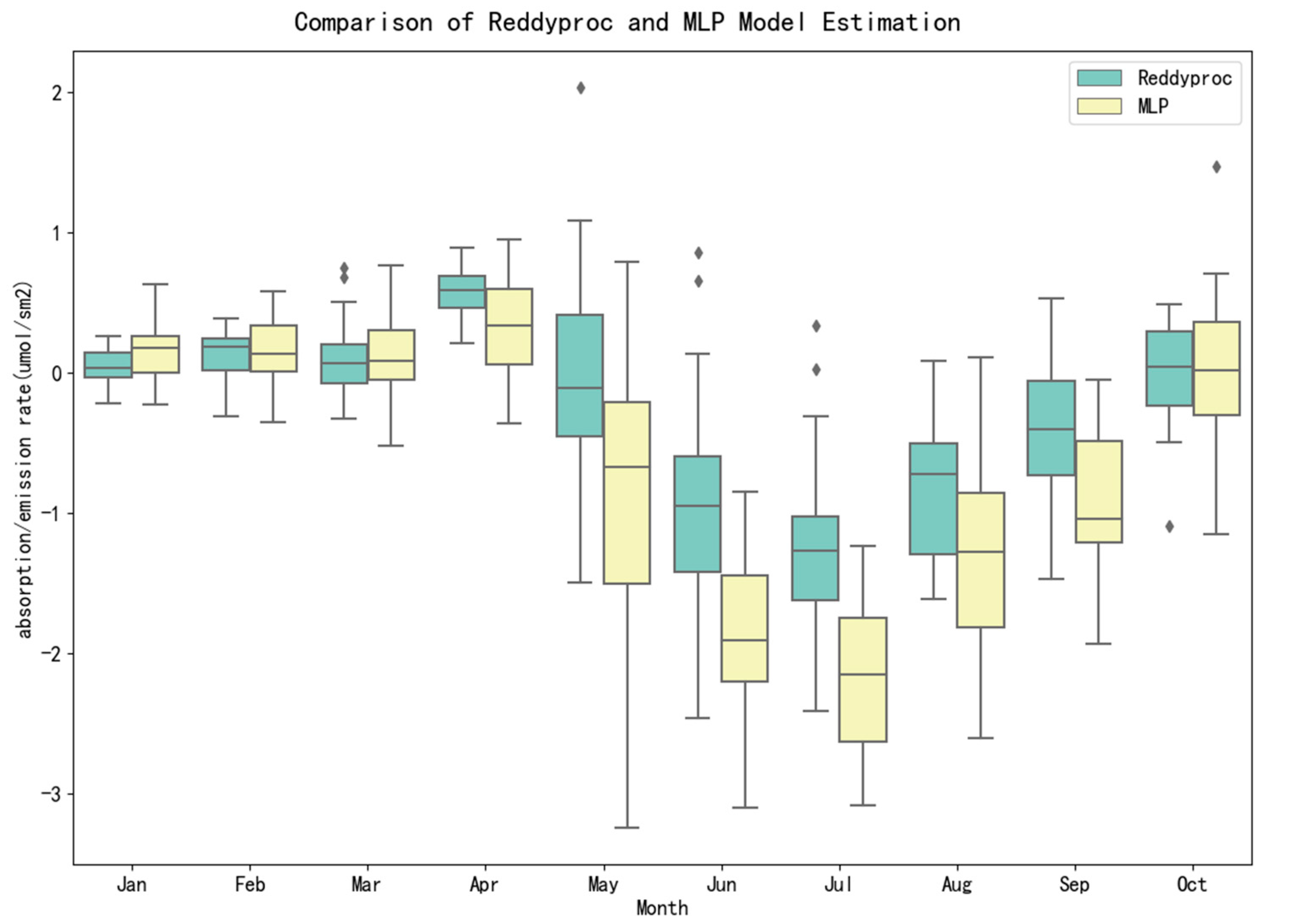
3.3.2. Monthly Scale NEE Variation Characteristics
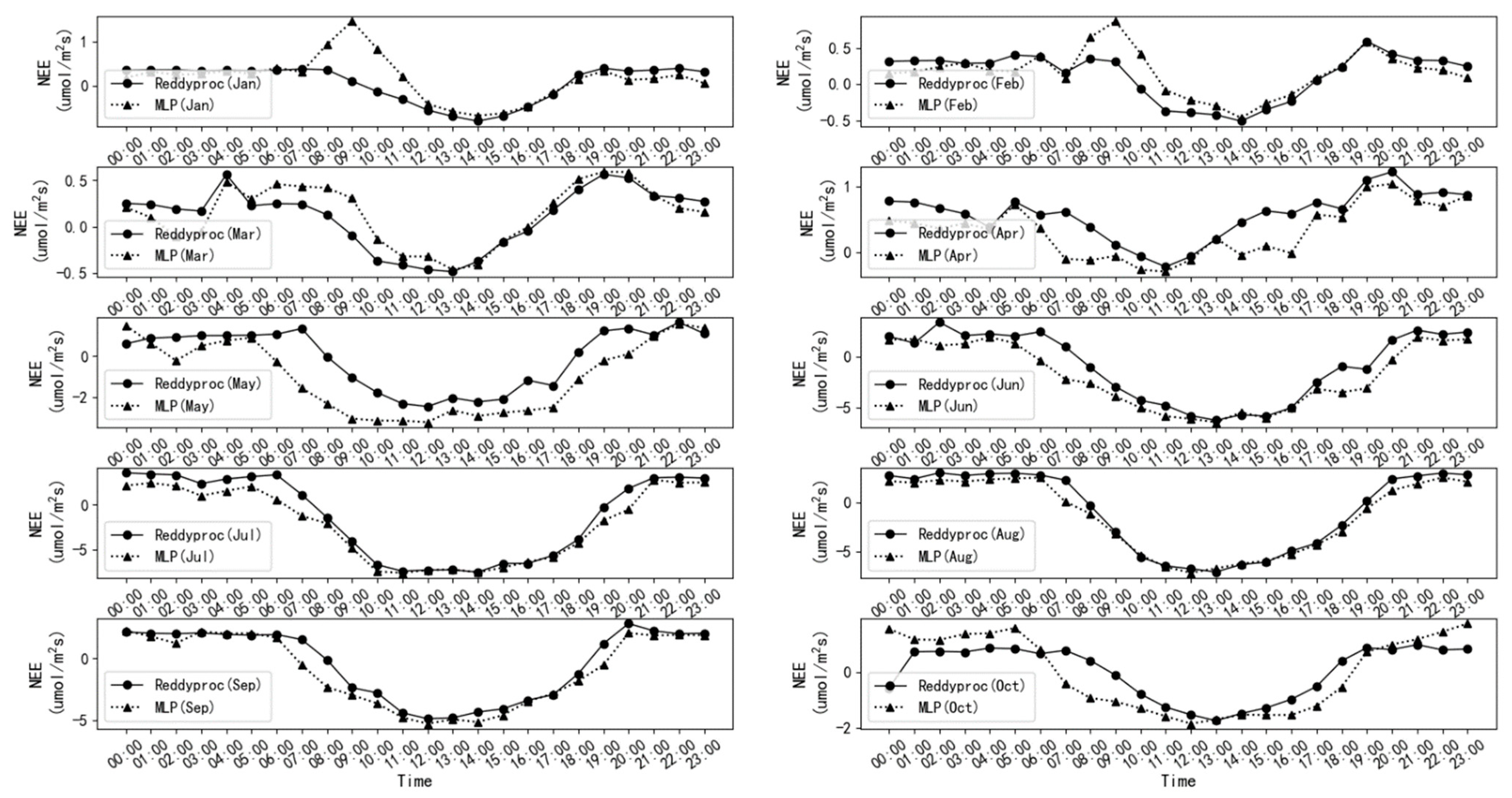
3.3.3. Hourly Scale NEE Variation Characteristics
4. Discussion
4.1. Input Factor Selection in the Model
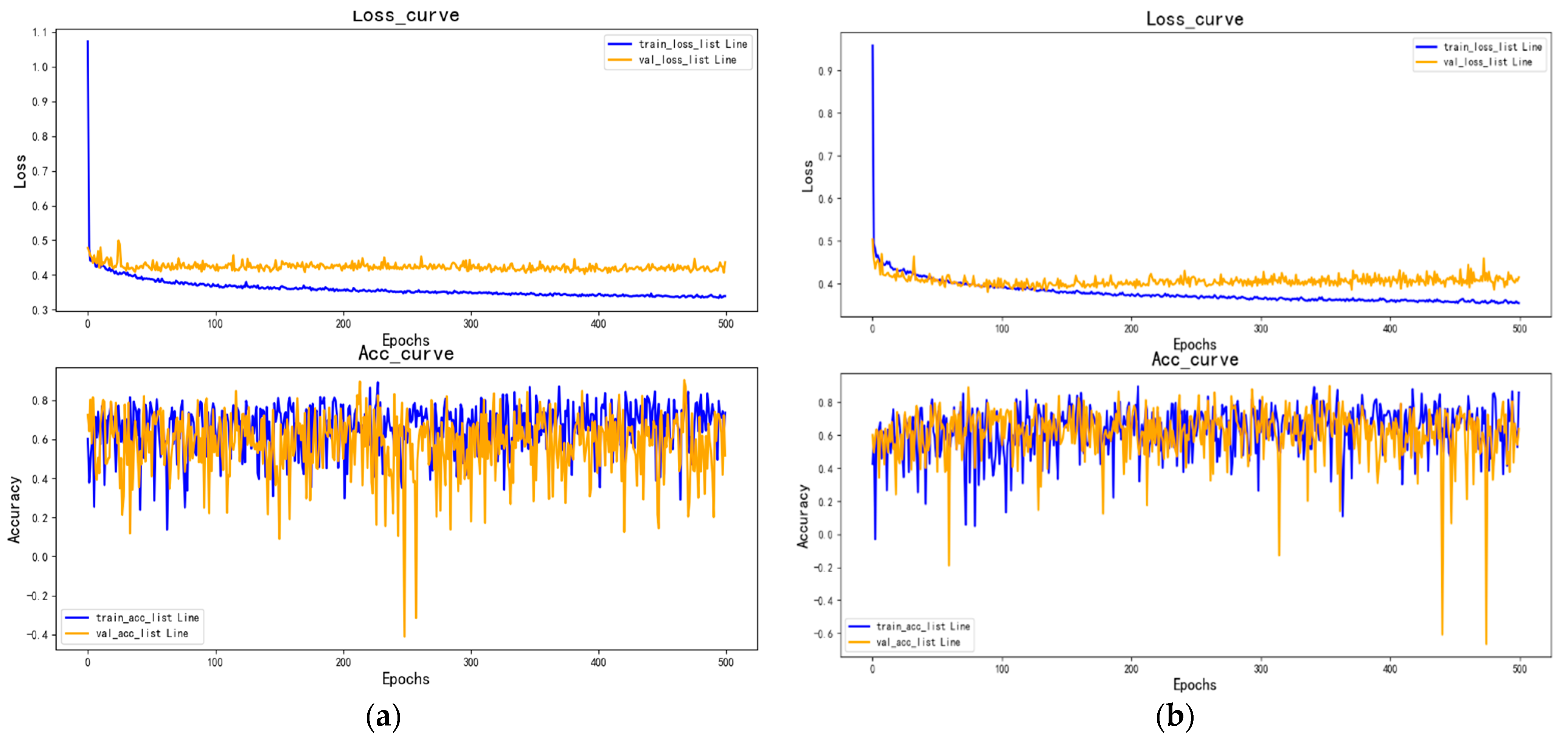
4.2. Improved MLP Deep Learning Model
4.3. Timing Anomaly Detection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Zhang, Y.; Meng, X.; Song, M.; Shang, L.; Su, Y.; Li, Z. Fill the Gaps of Eddy Covariance Fluxes Using Machine Learning Algorithms. Plateau Meteorol. 2020, 39, 1348–1360. [Google Scholar]
- Papale, D.; Reichstein, M.; Aubinet, M.; Canfora, E.; Bernhofer, C.; Kutsch, W.; Longdoz, B.; Rambal, S.; Valentini, R.; Vesala, T.; et al. Towards a standardized processing of Net Ecosystem Exchange measured with eddy covariance technique: Algorithms and uncertainty estimation. Biogeosciences 2006, 3, 571–583. [Google Scholar] [CrossRef]
- Mauder, M.; Foken, T.; Clement, R.; Elbers, J.A.; Eugster, W.; Grünwald, T.; Heusinkveld, B.; Kolle, O. Quality control of CarboEurope flux data-Part 2: Inter-comparison of eddy- covariance software. Biogeosciences 2008, 5, 451–462. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, S.; Gong, L.; Wang, J.; Li, X. A Study on the Data Processing and Quality Assessment of the Eddy Covariance System. Advancesinearthscience 2008, 23, 357–370. [Google Scholar]
- Wang, S.; Zhang, Y.; Lv, S.; Ao, Y.; Li, S.; Cheng, S. The Preliminary Study on Turbulence Data Quality Control of Jinta Oasis. Plateau Meteorol. 2009, 28, 1260–1273. [Google Scholar]
- Lu, S.; Wen, J.; Zhang, Y.; Wang, S.; Zhang, T.; Tian, H.; Liu, R. Influence of the Different Averaging Period on Computing the Turbulent Fluxes Using LOPEX10 Data. Plateau Meteorol. 2012, 31, 1530–1538. [Google Scholar]
- Zhuang, J.; Wang, W.; Wang, J. Flux Calculation of Eddy-Covariance Method and Comparison of Three Main Softwares. Plateau Meteorol. 2013, 32, 78–87. [Google Scholar]
- Xu, X.; Zhou, G.; Du, H.; Shi, Y.; Zhou, Y. Effects of Interpolation and Window Sizes in Phyllostachys edulis forest for Parameter Estimation on Calculation of CO2 Flux. Sci. Silvae Sin. 2015, 51, 141–149. [Google Scholar]
- Pastorello, G.; Trotta, C.; Canfora, E.; Chu, H.; Christianson, D.; Cheah, Y.W.; Poindexter, C.; Chen, J.; Elbashandy, A.; Humphrey, M.; et al. The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data. Sci. Data 2020, 7, 225. [Google Scholar] [CrossRef]
- Beringer, J.; McHugh, I.; Hutley, L.B.; Isaac, P.; Kljun, N. Technical note:Dynamic integrated gap-filling and partitioning for OzFlux (DINGO). Biogeosciences 2017, 14, 1457–1460. [Google Scholar] [CrossRef]
- Agarwal, D.; Pastorello, G.; Poindexter, C.; Papale, D.; Trotta, C.; Ribeca, A.; Canfora, E.; Faybishenko, B.; Samak, T. The data postprocessing pipeline for AmeriFlux data products. In Proceedings of the AGU Fall Meeting, New Orleans, LA, USA, 11–15 December 2017. [Google Scholar]
- Moffat, A.M.; Papale, D.; Reichstein, M.; Hollinger, D.Y.; Richardson, A.D.; Barr, A.G.; Beckstein, C.; Braswell, B.H.; Churkina, G.; Desai, A.R.; et al. Comprehensive comparison of gap-filling techniques for eddy covariance net carbon fluxes. Agric. For. Meteorol. 2007, 147, 209–232. [Google Scholar] [CrossRef]
- Dou, X. Applications of Machine Learning Methods in Modeling Carbon and Water Fluxes of Terrestrial Ecosystems; Xuzhou, China, 2018; pp. 1–145. [Google Scholar]
- Zhu, X. Estimation of Ecosystem Respiration in the Grasslands of Northern China Using Deep Learning; Chongqing, China, 2020; pp. 1–101. [Google Scholar]
- Quan, C.; Zhou, B.; Han, Y.; Zhao, T.; Xiao, J. A study of evapotranspiration on the degraded alpine wetland surface in the Yangtze River source area. J. Glaciol. Geocryol. 2016, 38, 1249–1257. [Google Scholar] [CrossRef]
- Webb, E.K.; Pearman, G.I.; Leuning, R. Correction of flux measurements for density effects due to heat and water vapour transfer. Q. J. R. Meteorol. Soc. 1980, 106, 85–100. [Google Scholar] [CrossRef]
- Li, H.Q.; Wang, C.Y.; Zhang, F.W.; He, Y.T.; Shi, P.L.; Guo, X.W.; Wang, J.B.; Zhang, L.M.; Li, Y.N.; Cao, G.M.; et al. Atmospheric water vapor and soil moisture jointly determine the spatiotemporal variations of CO2 fluxes and evapotranspiration across the Qinghai-Tibetan Plateau grasslands. Sci. Total Environ. 2021, 791, 148379. [Google Scholar] [CrossRef]
- Reichstein, M.; Falge, E.; Baldocchi, D.; Papale, D.; Aubinet, M.; Berbigier, P.; Bernhofer, C.; Buchmann, N.; Gilmanov, T.; Granier, A.; et al. On the separation of net ecosystem exchange into assimilation and ecosystem respiration: Review and improved algorithm. Glob. Change Biol. 2005, 11, 1424–1439. [Google Scholar] [CrossRef]
- Lasslop, G.; Reichstein, M.; Papale, D.; Richardson, A.D.; Arneth, A.; Barr, A.; Stoy, P.; Wohlfahrt, G. Separation of net ecosystem exchange into assimilation and respiration using a light response curve approach: Critical issues and global evaluation. Glob. Change Biol. 2010, 16, 187–208. [Google Scholar] [CrossRef]
- Wutzler, T.; Lucas-Moffat, A.; Migliavacca, M.; Knauer, J.; Sickel, K.; Šigut, L.; Menzer, O.; Reichstein, M. Basic and extensible post-processing of eddy covariance flux data with REddyProc. Biogeosciences 2018, 15, 5015–5030. [Google Scholar] [CrossRef]
- Desai, A.R.; Richardson, A.D.; Moffat, A.M.; Kattge, J.; Hollinger, D.Y.; Barr, A.; Falge, E.; Noormets, A.; Papale, D.; Reichstein, M.; et al. Cross-site evaluation of eddy covariance GPP and RE decomposition techniques. Agric. For. Meteorol. 2008, 148, 821–838. [Google Scholar] [CrossRef]
- Aubinet, M.; Vesala, T.; Papale, D. Eddy Covariance; Springer: Dordrecht, The Netherlands, 2012. [Google Scholar]
- Liu, M.; He, H.; Yu, G.; Sun, X.; Zhu, X.; Zhang, L.; Zhao, X.; Wang, H.; Shi, P.; Han, S. Impacts of uncertainty in data processing on estimation of CO2 flux components. Chin. J. Appl. Ecol. 2010, 21, 2389–2396. [Google Scholar]
- Huang, K.; Wang, S.; Wang, H.; Yi, C.; Zhou, L.; Liu, Y.; Shi, H. An analysis of carbon flux partition differences of a mid-subtropical planted coniferous forest in southeastern China. Acta Ecol. Sini-Cavol. 2013, 33, 5252–5265. [Google Scholar] [CrossRef]
- Li, Y.M. Wheat Yield Forecasting: A Machine Learning Approach Based on Meteorological Factors; Henan Agricultural University: Zhengzhou, China, 2019; pp. 1–43. [Google Scholar]
- Liu, K.; He, Q.S.; Jing, S.L.; Li, J.Y.; Chen, L. Gap filling method for evapotranspiration based on machine learning. J. Hohai Univ. Nat. Sci. 2020, 48, 109–115. [Google Scholar]
- Meng, X.N.; Jiao, R.L.; Liu, N.; Xia, J.J.; Yan, Z.W.; Yu, S.; Lou, X.; Li, H.C.; Wang, L.Z.; Chen, L.; et al. Extreme summer high-temperature changes in Central Asia based on interpolated data from random forest. Arid. Zone Res. 2020, 37, 966–973. [Google Scholar]
- Zhang, L.; Wang, L.L.; Zhang, X.D.; Liu, S.R.; Sun, P.S.; Sang, T.L. The basic principle of random forest and its applications in ecology: A case study of Pinus yunnanensis. Acta Ecol. Sin. 2014, 34, 650–659. [Google Scholar]
- Nie, X.Q.; Wang, D.; Chen, Y.Z.; Yang, L.C.; Zhou, G.Y. Storage, distribution, and associated controlling factors of soil total phosphorus across the northeastern Tibetan Plateau shrublands. J. Soil Sci. Plant Nutr. 2022, 22, 2933–2942. [Google Scholar] [CrossRef]
- Guevara-Escobar, A.; González-Sosa, E.; Cervantes-Jiménez, M.; Suzán-Azpiri, H.; Queijeiro-Bolaños, M.E.; Carrillo-Ángeles, I.; Cambrón-Sandoval, V.H. Machine learning estimates of eddy covariance carbon flux in a scrub in the Mexican highland. Biogeosciences 2021, 18, 367–392. [Google Scholar] [CrossRef]
- Kim, Y.; Johnson, M.S.; Knox, S.H.; Black, T.A.; Dalmagro, H.J.; Kang, M.; Kim, J.; Baldocchi, D. Gap-filling approaches for eddy covariance methane fluxes: A comparison of three machine learning algorithms and a traditional method with principal component analysis. Glob. Change Biol. 2020, 26, 1499–1518. [Google Scholar] [CrossRef] [PubMed]
- Qi, J. Application of Aliificial Neural Network in Modeling Carbon Flux; Beijing, China, 2019; pp. 1–52. [Google Scholar]
- Liu, X.H.; Wei, B.G.; Wu, L.F.; Yang, P. Applicability of four kinds of artificial intelligent models on prediction of reference crop evapotranspiration in Jiangxi province. J. Drain. Irrig. Mach. Eng. 2020, 38, 102–108. [Google Scholar]
- He, X. Preliminary Study nn Monitoring Carbon Tuxes and its Response Mechanisms during Non-Growing Season in E bin u r Lake Area; Urumqi, China, 2012; pp. 1–102. [Google Scholar]
- Wang, S.; Fu, Z.; Chen, H.; Ding, Y.; Wu, L.; Wang, K. Simulation of Reference Evapotranspiration Based on Random Forest Method. Trans. Chin. Soc. Agric. Mach. 2017, 48, 302–309. [Google Scholar]
- Mao, Y.P.; Fang, S.F. Research of reference evapotranspiration’s simulation based on machine learning. J. Geo-Inf. Sci. 2020, 22, 1692–1701. [Google Scholar] [CrossRef]
- Hassan, M.A.; Khalil, A.; Kaseb, S.; Kassem, M.A. Exploring the potential of tree-based ensemble methods in solar radiation modeling. Appl. Energy 2017, 203, 897–916. [Google Scholar] [CrossRef]
- Huang, K.; Wang, G.; Song, C.; Yu, Q. Runoff simulation and prediction of a typical small watershed in permafrost region of the Qinghai-Tibet Plateau based on LSTM. J. Glaciol. Geocryol. 2021, 43, 1–13. [Google Scholar]
- Peng, X.R.; Ye, T.D.; Wanc, Y.S. Research and design of precision irrigation system based on artificial neural network. In Proceedings of the Chinese Control And Decision Conference(CCDC), Shenyang, China, 9–11 June 2018; pp. 3865–3870. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Deng, M.; Xu, X.; Ma, Y.; Gong, W.; Jin, S.; Hu, R. Multi-layer Perceptron Combined with Radiative Transfer Model for Complex Land Surface Cloud Detection. Acta Electron. Sin. 2022, 50, 932–942. [Google Scholar]
- Xia, G.; Tang, Q.; Zhang, X. Improved Multi-layer Perceptron Applied to Customer Churn Prediction. Comput. Eng. Appl. 2020, 56, 257–263. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Toledano, M.; Cohen, I.; Ben-Simhon, Y.; Tadeski, I. Real-time anomaly detection system for time series at scale. In Proceedings of the SIGKDD Workshop, Halifax, NS, Canada, 14 August 2017; pp. 56–65. [Google Scholar]
- van Gorsel, E.; Leuning, R.; Cleugh, H.A.; Keith, H.; Suni, T. Nocturnal carbon efflux: Reconciliation of eddy covariance and chamber measurements using an alternative to the u:-threshold filtering technique. Tellus B 2007, 59, 397–403. [Google Scholar] [CrossRef]
- Massman, W.J.; Lee, X. Eddy covariance flux corrections and uncertainties in long-term studies of carbon and energy exchanges. Agr. Forest Meteorol. 2002, 113, 121–144. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station Name | Percentage of Level 0 | Percentage of Level 1 | Percentage of Level 2 | Missing Rate |
|---|---|---|---|---|
| Longbao | 47.22 | 24.26 | 10.60 | 17.92 |
| Station Name | Pearson | R2 | RMSE | MAE |
|---|---|---|---|---|
| Longbao | 0.80 | 0.65 | 1.91 | 1.34 |
| Feature Combination | Input Characteristics | Feature Number |
|---|---|---|
| combination 1 | RG, VPD, Soil_G | 3 |
| combination 2 | RG, VPD, Soil_G, Tair | 4 |
| combination 3 | RG, VPD, Soil_G, Tair, RH | 5 |
| combination 4 | RG, VPD, Soil_G, Tair, RH, Soil_T | 6 |
| combination 5 | RG, VPD, Soil_G, Tair, RH, Soil_T, Soil_VWC | 7 |
| combination 6 | RG, VPD, Soil_G, Tair, RH, Soil_T, Soil_VWC, WS | 8 |
| Feature combination | MLR | CART | RF | MLP | ||||||||
| R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | |
| combination 1 | 0.32 | 2.60 | 1.65 | 0.22 | 2.99 | 1.64 | 0.58 | 2.19 | 1.16 | 0.57 | 2.17 | 1.11 |
| combination 2 | 0.36 | 2.54 | 1.57 | 0.24 | 2.93 | 1.64 | 0.60 | 2.17 | 1.14 | 0.60 | 2.10 | 1.14 |
| combination 3 | 0.36 | 2.54 | 1.57 | 0.25 | 2.87 | 1.57 | 0.60 | 2.22 | 1.21 | 0.61 | 2.10 | 1.14 |
| combination 4 | 0.36 | 2.54 | 1.57 | 0.22 | 3.03 | 1.57 | 0.59 | 2.17 | 1.15 | 0.61 | 2.11 | 1.14 |
| combination 5 | 0.36 | 2.53 | 1.57 | 0.22 | 2.98 | 1.51 | 0.60 | 2.15 | 1.10 | 0.61 | 2.10 | 1.14 |
| combination 6 | 0.38 | 2.51 | 1.55 | 0.25 | 2.86 | 1.46 | 0.62 | 2.10 | 1.08 | 0.62 | 2.18 | 1.12 |
| Average | 0.36 | 2.54 | 1.58 | 0.23 | 2.94 | 1.57 | 0.60 | 2.17 | 1.14 | 0.61 | 2.13 | 1.13 |
| Feature combination | KNN | Adaboost | GBRT | XGBoost | ||||||||
| R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | |
| combination 1 | 0.52 | 2.16 | 1.35 | 0.40 | 2.29 | 1.24 | 0.56 | 2.20 | 1.17 | 0.58 | 2.17 | 1.11 |
| combination 2 | 0.54 | 2.14 | 1.37 | 0.42 | 2.33 | 1.24 | 0.59 | 2.19 | 1.12 | 0.59 | 2.19 | 1.54 |
| combination 3 | 0.54 | 2.24 | 1.37 | 0.44 | 2.27 | 1.27 | 0.56 | 2.22 | 1.15 | 0.61 | 2.19 | 1.54 |
| combination 4 | 0.52 | 2.24 | 1.37 | 0.44 | 2.29 | 1.27 | 0.57 | 2.20 | 1.15 | 0.61 | 2.11 | 1.54 |
| combination 5 | 0.56 | 2.23 | 1.41 | 0.42 | 2.28 | 1.21 | 0.57 | 2.19 | 1.10 | 0.60 | 2.10 | 1.54 |
| combination 6 | 0.56 | 2.21 | 1.40 | 0.46 | 2.28 | 1.26 | 0.59 | 2.20 | 1.10 | 0.62 | 2.10 | 1.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Ma, Y.; Li, F.; Chen, Q.; Sun, S.; Ma, H.; Zhang, R. Gap Filling Method and Estimation of Net Ecosystem CO2 Exchange in Alpine Wetland of Qinghai–Tibet Plateau. Sustainability 2023, 15, 4652. https://doi.org/10.3390/su15054652
Wang X, Ma Y, Li F, Chen Q, Sun S, Ma H, Zhang R. Gap Filling Method and Estimation of Net Ecosystem CO2 Exchange in Alpine Wetland of Qinghai–Tibet Plateau. Sustainability. 2023; 15(5):4652. https://doi.org/10.3390/su15054652
Chicago/Turabian StyleWang, Xiuying, Yuancang Ma, Fu Li, Qi Chen, Shujiao Sun, Honglu Ma, and Rui Zhang. 2023. "Gap Filling Method and Estimation of Net Ecosystem CO2 Exchange in Alpine Wetland of Qinghai–Tibet Plateau" Sustainability 15, no. 5: 4652. https://doi.org/10.3390/su15054652
APA StyleWang, X., Ma, Y., Li, F., Chen, Q., Sun, S., Ma, H., & Zhang, R. (2023). Gap Filling Method and Estimation of Net Ecosystem CO2 Exchange in Alpine Wetland of Qinghai–Tibet Plateau. Sustainability, 15(5), 4652. https://doi.org/10.3390/su15054652