

Comprehensive Review on Waste Generation Modeling

 ,
,  ,
,  ,
,
Abstract
1. Introduction
1.1. Application-Based Targeting
1.1.1. Waste Management Legislation and Policy
1.1.2. Strategic Decision-Making on Waste Management Infrastructure
1.1.3. Operational Decision-Making in Waste Management
1.2. Tasks Encountered in Waste Generation Modeling
1.2.1. Prediction
1.2.2. Forecasting
1.2.3. Projection
1.3. Research Questions
- What are the common shortcomings of the available data, and how many data points in a time series are sufficient? Response: Section 2.1 and Section 3.
- Which approaches and methods are suitable for certain applications? Response: Section 3.
- Can general recommendations be formulated for data processing? Response: Section 4.
- Can prediction models be used to estimate future data? Under what conditions? Response: Section 5.
- How to implement changes and interventions in WM (legislative interventions, changes in data reporting methodology, introduction of new waste catalogue numbers) within mathematical models? Response: Section 5.
2. Literature Review
2.1. Summary of the Results
- Publication details (columns B–H): title, authors, journal, year, nationality according to the affiliation of the main author, number of citations, keywords.
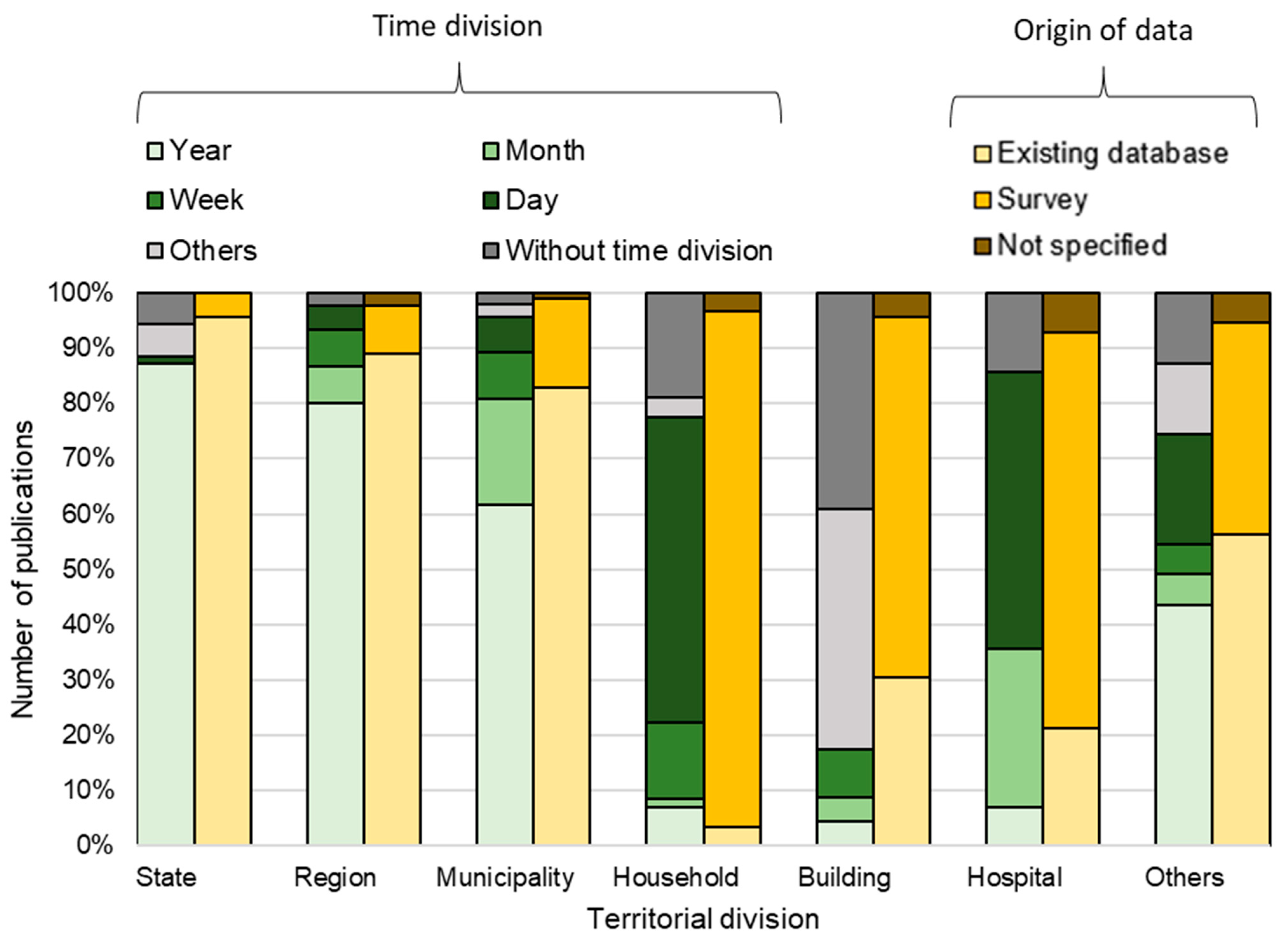
- Origin of data (columns I–K): state, continent, the source of WM data.
- Data details (columns L–R): number of dependent variables, time interval, number of time intervals, territorial division, number of territories.
- Forecasting (columns S, T): forecasting (yes/no), forecasting period length.
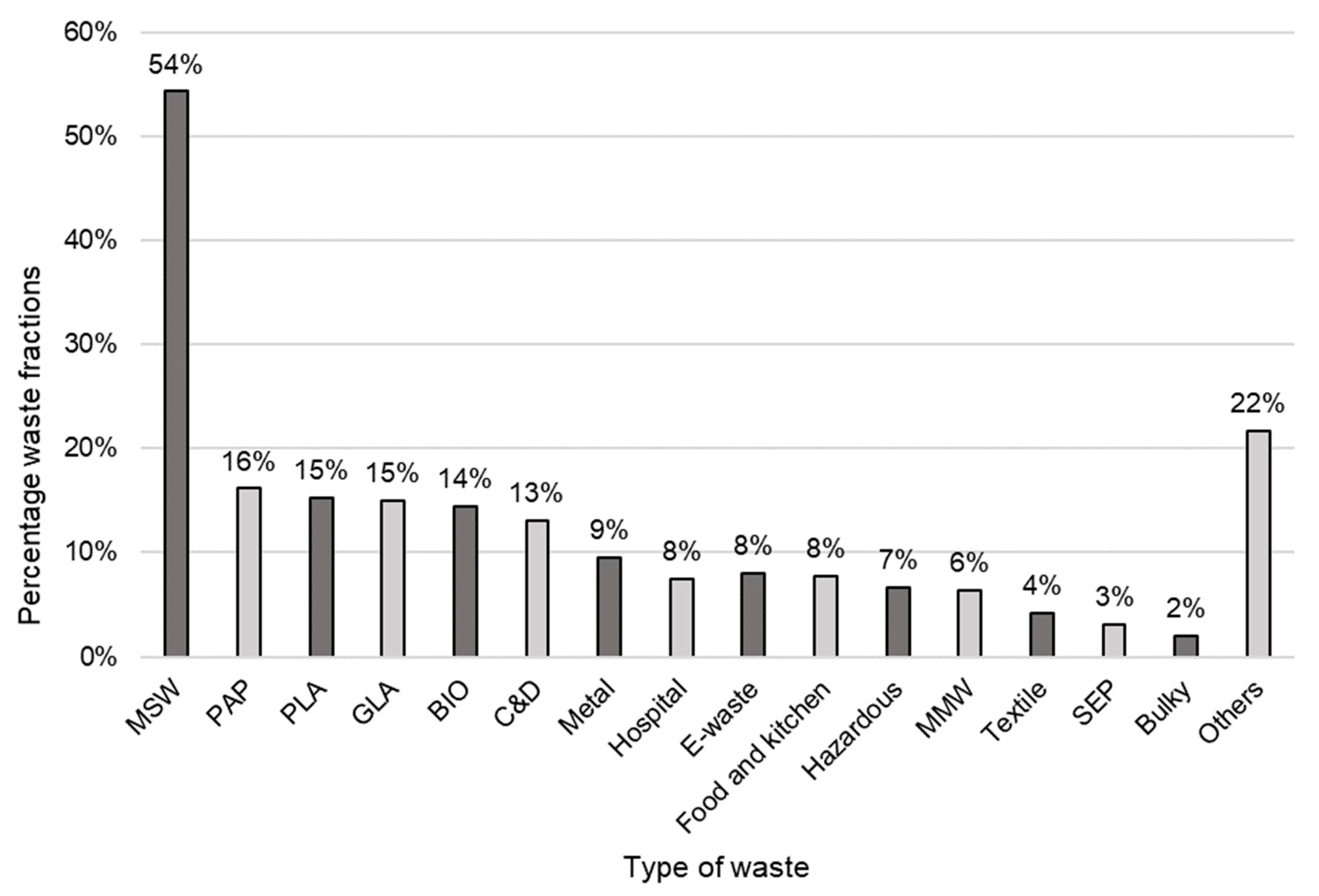
- Waste streams (columns U–AK): MSW, MMW, bio-waste, paper, plastics, glass, etc.
- Influencing factors (columns AL–AT): influencing factors (yes/no), population size, education, age, income, gross domestic product (GDP), etc.
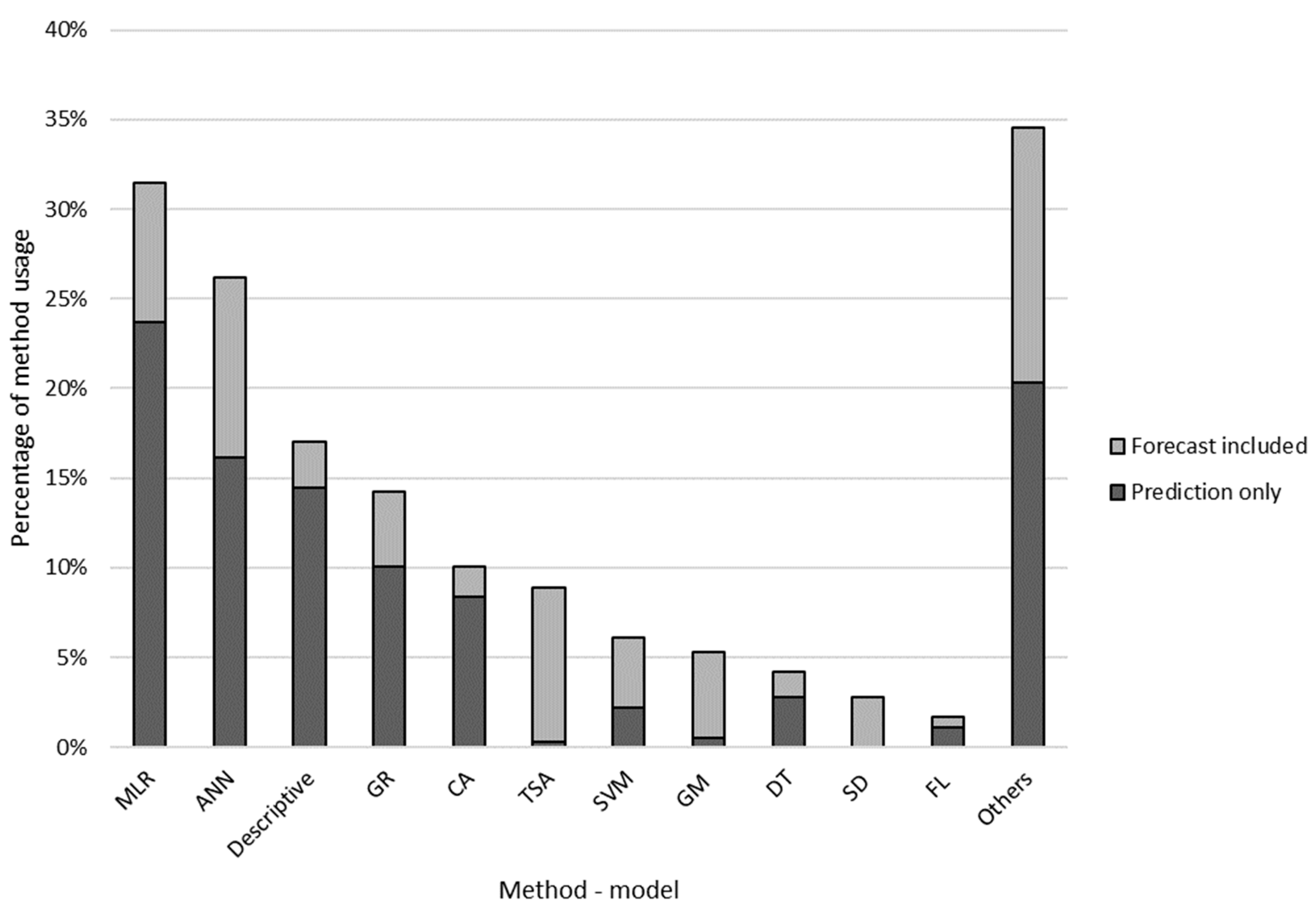
- Utilized methods (columns AU–BF): LR, general regression (GR), TSA, ANN, etc.
- Processing (columns BG–BH): pre-processing (yes/no), verification of assumptions for LR.
- Model quality (columns BI–BM): coefficient of determination (R2), mean absolute error (MAE), mean absolute percentage error (MAPE), etc.
2.1.1. Data Pre-Processing
2.1.2. The Detail of a Dataset
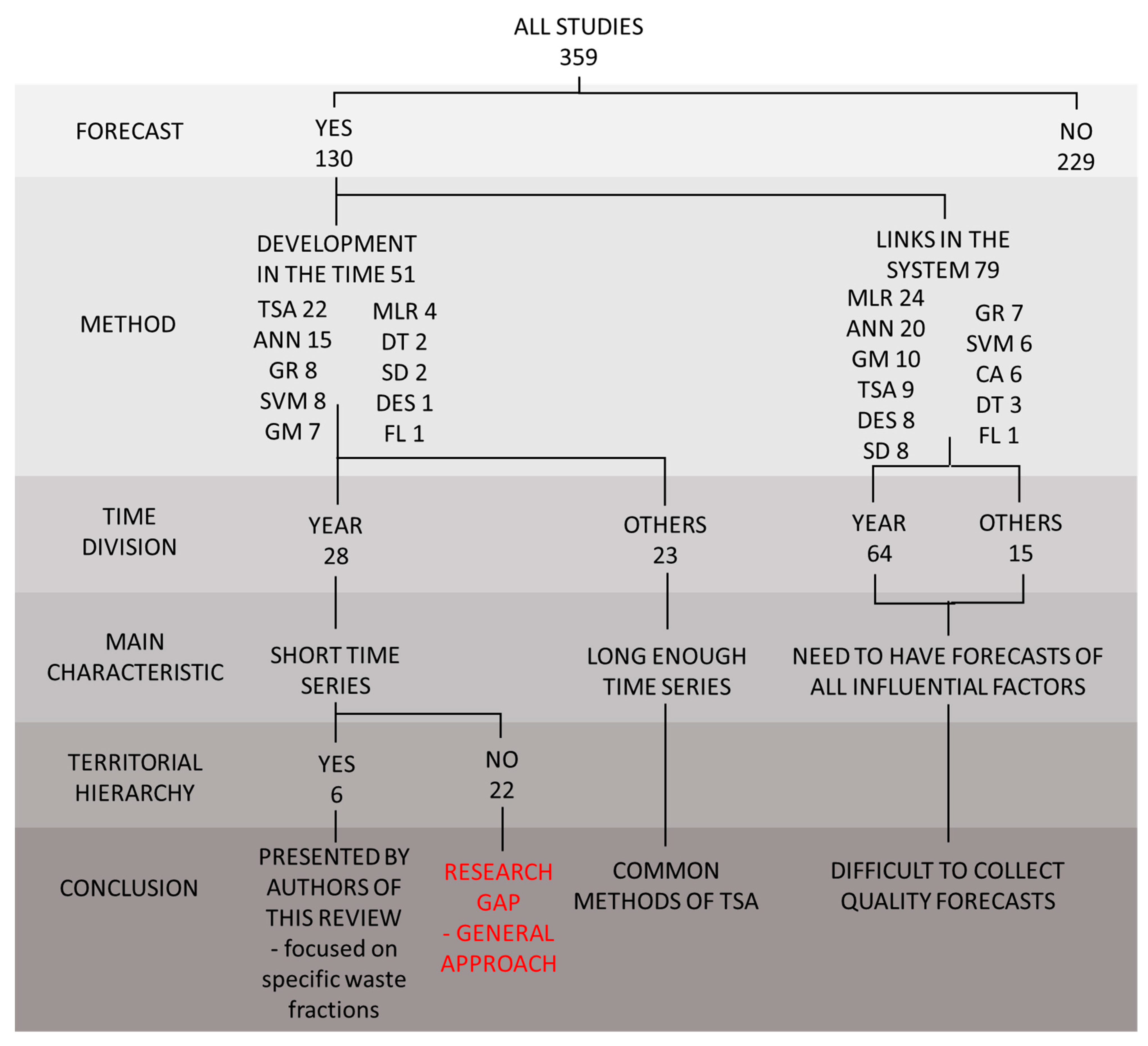
2.1.3. Approaches Applied
2.2. Evaluation of Review
- The general approach of waste generation forecasting (Section 5)
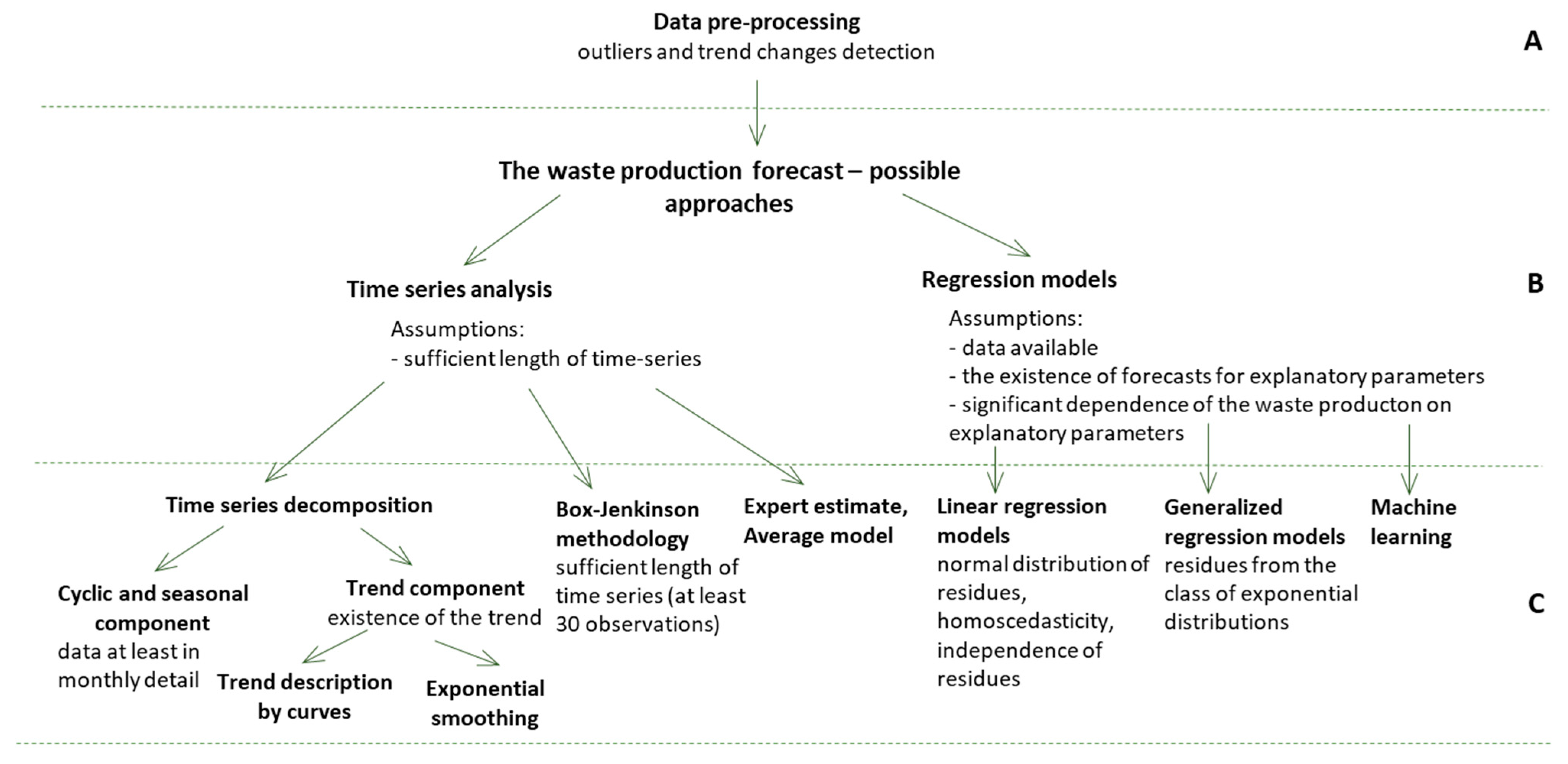
3. The Decision Process for Method Selection
- I. Conversion of data to unit quantity (with respect to activity rate) and data transformation
- 2.
- II. Data pre-processing (level A in Figure 5)
- 3.
- III. Assessment of significant parameters
- 4.
- IV. Selection of the modeling method (level B in Figure 5)
- 5.
- V. Forecasting via the selected method (level C in Figure 5)

- Compliance with balances and interactions: balance of estimates on different hierarchy levels. The hierarchical structure of territorial units and waste fractions should be maintained [33], see Section 4.3.3.
- Confidence intervals: the expected uncertainty is integral to the results [58]. In most cases, however, information on model uncertainty is missing.
- Evaluation of the model quality: most models involve at least some quality assessment. Several commonly used criteria are R2, MAPE, and prediction errors. It is also recommended to verify the quality of the forecast based on the testing data. Before the forecast is made, a certain part of the data at the end of the time series is allocated for this purpose, and then the prediction provided by the model is compared to this pre-allocated data set.
4. Problems and Recommendations for Waste Generation Forecasting
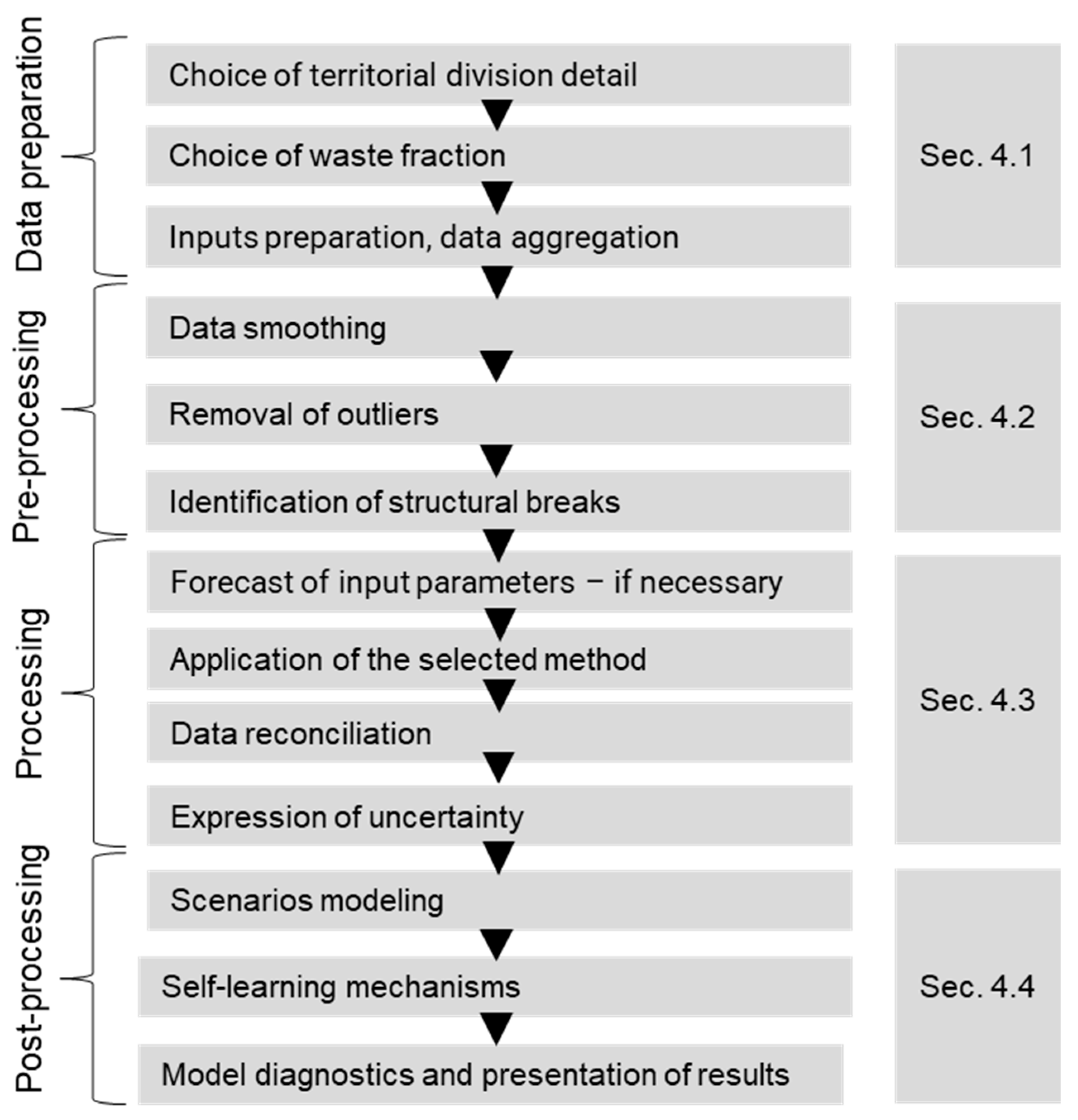
4.1. Data Preparation
4.2. Data Pre-Processing
- Historical data should be standardized. This makes it possible to specify the same critical limit for each time series.
- Use data visualization if the amount of time series allows.
- Do not identify multiple changepoints in one time series if it is not long enough.
- Focus on the angles between the partial subsequences of the time series and the angles of the historical data lines with the x-axis.
- For further calculations, use the part of the time series behind the changepoint.
4.3. Data Processing
4.3.1. Forecasting of Input Parameters
4.3.2. Application of the Selected Method
- Monotony—the trend over the forecasting horizon should not change from rising to declining and vice versa, so the trend is assumed to be monotonous. Oscillations around the trend caused by the seasonal or cyclical component are not possible to describe in short time series. Requiring monotony will also reduce the risk of model overfitting. It is recommended to use the power function for trend modeling. The advantage is its wide application for both rising and declining trends [34].
- Limited growth—some time series have a very significant growth in historical data (resp. decline), which may be exponential. Such a trend is usual after the system change, e.g., by collecting a new waste fraction. It cannot be expected to continue this trend over the entire forecast horizon. The more likely development is that the waste generation will slow down the growth. In such cases, it is appropriate to model the trend using an S-shaped curve [34].
- By excluding data after pre-processing, the time series remains too short for trend estimation. The minimum number of data can be adjusted to the specific length of the time series.
- The trend model in the data using the functions described above is of poor quality. As a criterion recommends using R2, the critical limit R2 can be customized.
- A simple model with a constant value leads to results that are comparable to a more complex model.
- As a special case, time series containing zero generation of waste in recent years should be extrapolated as a zero value–it is not expected to start generating this waste again.
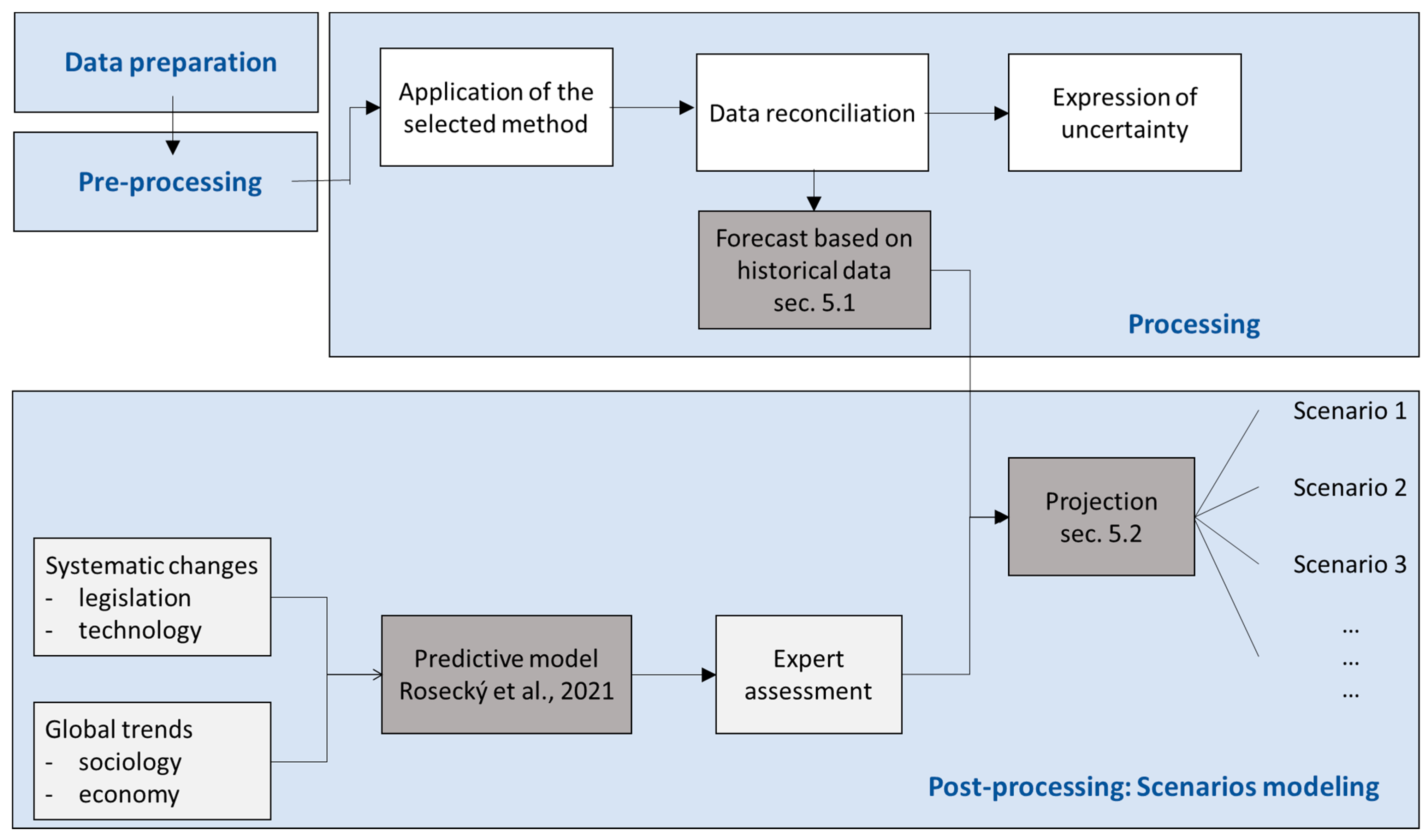
4.3.3. Data Reconciliation
4.3.4. Expression of Uncertainty
4.4. Data Post-Processing
4.4.1. Modeling of Scenarios
- The scenario does not exceed the potential for change which was set for a specific territorial unit.
- All territorial units show a shift towards meeting the scenario if the potential allows it.
- The individual territories do not overtake in terms of the fulfillment of potential and are monotonous.
4.4.2. Self-Learning Mechanisms
4.4.3. Model Diagnostics and Presentation of Results
5. Modeling Future Waste Generation and Treatment Based on Short Time Series
5.1. Waste Generation and Treatment Forecast
5.2. Waste Generation and Treatment Projection
- percentage waste prevention (: —marking the scenario, —territorial level NUTS1),
- separation rate of individual assessed waste fractions (: —unseparated waste fraction, —modelled waste fraction).
- Separated waste .
- Waste in unseparated waste : .
- Total unseparated waste .
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. SWOT Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strengths |
| It allows to quantify the influence of individual predictors (including the significance) or their interaction on the dependent variable. It provides a general information on the functioning of the modeled process from both a qualitative (dependency direction) and a quantitative (size) perspective. It is easy to obtain the confidence intervals (CI) and the prediction intervals (PI). It is simple, computational efficient and easy interpretable. |
| Weaknesses |
| Necessity of strong assumptions compliance (especially for the normality of residues, homoscedasticity of data and linear dependence with respect to the coefficients), which is often violated in practice. The dependence is restricted to approximately linear/linearizable with respect to the regression coefficients. The risk of multi-collinearity of data, especially in more complex (multidimensional) problems. Accuracy, especially for complex non-linear problems. |
| Opportunities |
| The possibility of identification and correction in case of unexpected behavior of the model, leading to better control of the model creation. Data pre-processing methods such as principal component analysis (PCA) can be useful to reduce the dimension and ensure the independence variables [69]. Its main task in WM is to reveal the factors that have fundamental influence [16]. Thus, MLR is useful especially for policy planning and infrastructure decision making (Section 1.1). As grouping municipalities into clusters based on their characteristics can lead to models featuring higher accuracy [70], separate models were then created for each cluster. Implemented in all standard statistical SW tools, often with automatic creation of outputs (especially the graphical ones), which may warn even less experienced users that some prerequisites are not met. |
| Threats |
| “Necessity” of manual selection of predictors or of the order of interactions means that smaller number of potential predictors can be used in practice (correlation analysis can be used to reduce their number, but it is also recommended to check the results and it also requires closer inspection of predictors and their dependence). The assumptions are quite strict, and it usually is quite difficult to meet them with WM data, especially at lower territorial levels. WM systems are complex and nonlinear in nature, and the analysis of residuals should be used to evaluate the appropriateness of linear approximation. In case of non-homogeneous data, there are problems with the form of the dependence or with the applicability of created model on the type of data, which was not sufficiently represented in the model creation phase. |
| Strengths |
| It provides information on the proportion of the explained variability of the dependent variable through the included predictors (independent variables). It provides general information on the functioning of the modeled process from both a qualitative (dependency direction) and a quantitative (size) perspective. Computationally not demanding. |
| Weaknesses |
| Assumptions on the distribution of residues, homoscedasticity of data and linear dependence with respect to coefficients. A risk of multi-collinearity of data, especially in more complex (multidimensional) problems. There is no analytical way to estimate the model parameters. Knowledge in WM is essential to determining suitable initial estimates. It also is possible to use the results of MLR as the starting point for another GLM. CI and PI generally do not exist, but there are attempts to construct them for some special cases (e.g., for gamma regression) [71]. Lower accuracy, especially for complex non-linear problems. |
| Opportunities |
| The possibility of identification and correction in case of unexpected behavior of the model, leading to better control of the model creation. Better flexibility (compared to MRL). The possibility to include expert knowledge of the process by selection of distribution of dependent variable or by including known effects (offset). The possibility to specify the smoothness or the monotonicity of dependency (suitable also for maintaining the same structure of the model when using new data). Relation of other models such as generalized additive models (GAM), penalized regression (Ridge, Lasso, Elastic Net) or mixed models. Implemented in all standard statistical SW tools, often with automatic creation of outputs (especially the graphical ones), which may warn even less experienced users that some prerequisites are not met. |
| Threats |
| “Necessity” of manual selection of predictors or of the order of interactions means that smaller number of potential predictors (of order of tens) can be used in practice (correlation analysis can be used to reduce their number but it is also recommended to check the results and it requires closer inspection of predictors and their dependence). In case of non-homogeneous data, there are problems with the form of the dependence or with the applicability of created model on the type of data, which was not sufficiently represented in the model creation phase. In general, a global optimum, when searching for parameter values, is not guaranteed (does not apply for some special cases). Some GLM types can model negative values. For waste generation modeling it is recommended to use GLM types for which the acquisition of only positive values can be guaranteed (e.g., gamma regression). |
| Strengths |
| It allows to describe even complex non-linear dependencies, which often appear in WM. High accuracy, especially in comparison with traditional methods [72]. Models are robust and not as sensitive to the choice of influencing factors as MLR or GLM. Robustness of random forest (RF) and Gradient boosted regression tree (GBRT) [73]. |
| Weaknesses |
| Computationally demanding, especially for complex models and large number of observations. Interpretation is challenging for RF and GBRT. DT loses high accuracy. |
| Opportunities |
| Data assumptions. The selection of a specific DT model also depends on the size of the data set (detail of the territorial division, monitored waste fractions). Automated process with predictors enabling to work with large number of independent variables. Information on the importance of each variable is provided, this helps with their selection. Parameter tuning is less demanding (compared to ANN). The computation of RF can easily be parallelized. |
| Threats |
| Generally, the PI construction is more complicated (compared to MLR). Quantile regression or resampling methods may be used. For DT, the intervals construction method was not found, but the intervals of individual models in tree leaves could be theoretically used. GBRT is computationally intensive. In case of RF and GBRT, there is insufficient insight into internal functioning of the model. This means that it is difficult to find the root cause if the model behaves unexpectedly (except for DT). Threat of the model over-fitting. |
| Strengths |
| They allow to describe even complex non-linear dependencies. ANN models have few assumptions about the data in the terms of distribution. From this point of view, one could utilize most data sets coming from WM. It is possible to work with many independent variables that influence the form of WM. High accuracy, in comparison with traditional methods [74]. |
| Weaknesses |
| Computationally demanding, especially for complex models and large number of observations [75]. Requires model specific experience [75]. ANN are not suitable for “on-the-fly” decision making. |
| Opportunities |
| Low data assumptions. Input data can be compiled in pre-processing to achieve the highest possible model accuracy. If the parameters are set correctly, the results are most accurate for nonlinear dependencies. However, choosing appropriate parameter values is not trivial, and understanding of WM is required. Automated process with predictors enabling to work with large number of independent variables (even hundreds of variables but considering the computational complexity). |
| Threats |
| There is insufficient insight into internal functioning of the model. In general, a global optimum for parameters is not guaranteed. CI and PI are solvable, but it is advisable to keep caution (as with methods using decision trees). Training an ANN is computationally intensive. Models are typically used on large data sets (ideally thousands of data points). Application to smaller data sets, which are common in WM, is problematic. Threat of the model over-fitting. Interpretation challenge (black box models). |
| Strengths |
| It allows to capture the dynamic of development of the observed process. Good theoretical basis. CI and PI creation clear and straightforward (this is similar to MLR). |
| Weaknesses |
| Disadvantageous ratio for amount of data needed for modeling and the length of the prediction (high tens or better hundreds of observed values are needed for prediction of order of units). It is difficult to take into consideration external influences (socio-economic, demographic, etc.). Lack of data in the WM area. |
| Opportunities |
| Recommended when revealing the links in the system is not important, but only the time development (even in the future). The possibility to better understand the behavior of the dependent variable itself (seasonality, trend, autocorrelation function, etc.), but only provided enough data is available (i.e., seasonal effects on annual data cannot be ascertained). |
| Threats |
| Disproportionate confidence in the model built on insufficient data (since it is a “white box” model). |
| Strengths |
| Combination of benefits of the TSA and the “correlation” approaches. Waste generation can be forecasted including possible interventions which have not yet been reflected in the historical data [34]. Possibility to model different scenarios. |
| Weaknesses |
| It is difficult to handle uncertainty (especially in case of input predictions from external sources with insufficient specification). |
| Opportunities |
| Possibility to incorporate expert estimates and domain knowledge (e.g., goals and legislative changes). Suitable for modeling of extremes such as the worst/best case scenario (e.g., meeting the legislative objectives) with the current state of WM and after certain interventions. |
| Threats |
| There is a risk of models’ usage outside the area where they are intended to be used. Each scenario should reflect a potential for change, such as changing separated waste and MMW production [10]. Dependence on the quality of inputs (scenarios). |
References
- Directive 2008/98/EC of the European Parliament and of the Council of 19 November 2008 on Waste and Repealing Certain Directives (Text with EEA Relevance). Available online: https://eur-lex.europa.eu/legal-content/ES/TXT/PDF/?uri=CELEX:32008L0098&from=EN (accessed on 23 June 2020).
- Gardiner, R.; Hajek, P. Municipal waste gener ation, R&D intensity, and economic growth nexus—A case of EU regions. Waste Manag. 2020, 114, 124–135. [Google Scholar] [CrossRef]
- Directive EU 2018/851 of the European Parliament and of the Council of 30 May 2018 amending Directive 2008/98/EC on Waste (Text with EEA Relevance). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32018L0851&rid=5 (accessed on 23 June 2020).
- Directive EU 2018/850 of the European Parliament and of the Council of 30 May 2018 amending Directive 1999/31/EC on the landfill of waste (Text with EEA relevance). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32018L0850&rid=3 (accessed on 23 June 2020).
- Ghinea, C.; Drăgoi, E.N.; Comăniţă, E.-D.; Gavrilescu, M.; Câmpean, T.; Curteanu, S.; Gavrilescu, M. Forecasting municipal solid waste generation using prognostic tools and regression analysis. J. Environ. Manag. 2016, 182, 80–93. [Google Scholar] [CrossRef] [PubMed]
- Ayeleru, O.O.; Okonta, F.N.; Ntuli, F. Municipal solid waste generation and characterization in the City of Johannesburg: A pathway for the implementation of zero waste. Waste Manag. 2018, 79, 87–97. [Google Scholar] [CrossRef]
- Mena-Nieto, A.; Estay-Ossandon, C.; dos Santos, S.P. Will the Balearics and the Canary Islands meet the European Uniontargets for municipal waste? A comparative study from 2000 to 2035. Sci. Total Environ. 2021, 783, 147081. [Google Scholar] [CrossRef]
- Tomić, T.; Dominković, D.F.; Pfeifer, A.; Schneider, D.R.; Pedersen, A.S.; Duić, N. Waste to energy plant operation under the influence of market and legislation conditioned changes. Energy 2017, 137, 1119–1129. [Google Scholar] [CrossRef]
- Ilbahar, E.; Kahraman, C.; Cebi, S. Location selection for waste-to-energy plants by using fuzzy linear programming. Energy 2021, 234, 121189. [Google Scholar] [CrossRef]
- Pavlas, M.; Šomplák, R.; Smejkalová, V.; Stehlík, P. Municipal Solid Waste Fractions and Their Source Separation: Forecasting for Large Geographical Area and Its Subregions. Waste Biomass Valorization 2020, 11, 725–742. [Google Scholar] [CrossRef]
- Bramati, C.M. Waste generation and regional growth of marine activities an econometric model. Mar. Pollut. Bull. 2016, 112, 151–165. [Google Scholar] [CrossRef] [PubMed]
- Ghiani, G.; Laganà, D.; Manni, E.; Triki, C. Capacitated location of collection sites in an urban waste management system. Waste Manag. 2012, 32, 1291–1296. [Google Scholar] [CrossRef] [PubMed]
- Nie, X.H.; Huang, G.H.; Li, Y.P.; Liu, L. IFRP: A hybrid interval-parameter fuzzy robust programming approach for waste management planning under uncertainty. J. Environ. Manag. 2007, 84, 1–11. [Google Scholar] [CrossRef]
- Koç, C.; Bektaş, T.; Jabali, O.; Laporte, G. Thirty years of heterogeneous vehicle routing. Eur. J. Oper. Res. 2016, 249, 1–21. [Google Scholar] [CrossRef]
- Rosecký, M.; Šomplák, R.; Slavík, J.; Kalina, J.; Bulková, G.; Bednář, J. Predictive modelling as a tool for effective municipal waste management policy at different territorial levels. J. Environ. Manag. 2021, 291, 112584. [Google Scholar] [CrossRef] [PubMed]
- Beigl, P.; Lebersorger, S.; Salhofer, S. Modelling municipal solid waste generation: A review. Waste Manag. 2008, 28, 200–214. [Google Scholar] [CrossRef] [PubMed]
- Cherian, J.; Jacob, J. Management models of municipal solid waste: A review focusing on socio economic factors. Int. J. Econ. Financ. 2012, 4, 131–139. [Google Scholar] [CrossRef]
- Kolekar, K.A.; Hazra, T.; Chakrabarty, S.N. A review on prediction of municipal solid waste generation models. Procedia Environ. Sci. 2016, 35, 238–244. [Google Scholar] [CrossRef]
- Goel, S.; Ranjan, V.P.; Bardhan, B.; Hazra, T. Forecasting solid waste generation rates. Modelling Trends in Solid and Hazardous. Waste Manag. 2017, 20, 35–64. [Google Scholar] [CrossRef]
- Alzamora, B.R.; Barros, R.T.D.V.; de Oliveira, L.K.; Gonçalves, S.S. Forecasting and the influence of socioeconomic factors on municipal solid waste generation: A literature review. Environ. Dev. 2022, 44, 100734. [Google Scholar] [CrossRef]
- Abdallah, M.; Talib, M.A.; Feroz, S.; Nasir, Q.; Abdalla, H.; Mahfood, B. Artificial intelligence applications in solid waste management: A systematic research review. Waste Manag. 2020, 109, 231–246. [Google Scholar] [CrossRef]
- Guo, H.-N.; Wu, S.-B.; Tian, Y.-J.; Zhang, J.; Liu, H.-T. Application of machine learning methods for the prediction of organic solid waste treatment and recycling processes: A review. Bioresour. Technol. 2021, 319, 124114. [Google Scholar] [CrossRef]
- Xu, A.; Chang, H.; Xu, Y.; Li, R.; Li, X.; Zhao, Y. Applying artificial neural networks (ANNs) to solve solid waste-related issues: A critical review. Waste Manag. 2021, 124, 385–402. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A review on outlier/anomaly detection in time series data. arXiv 2020, arXiv:abs/2002.04236. [Google Scholar] [CrossRef]
- Aggarwal, V.; Gupta, V.; Singh, P.; Sharma, K.; Sharma, N. Detection of spatial outlier by using improved Z-score test. In Proceedings of the International Conference on Trends in Electronics and Informatics, Tirunelveli, India, 23–25 April 2019; pp. 788–790. [Google Scholar] [CrossRef]
- De Muth, J.E. Tests to Evaluate Potential Outliers. APS Adv. Pharm. Sci. Ser. 2019, 40, 197–210. [Google Scholar] [CrossRef]
- Ibáñez, M.V.; Prades, M.; Simó, A. Modelling municipal waste separation rates using generalized linear models and beta regression. Resour. Conserv. Recycl. 2011, 55, 1129–1138. [Google Scholar] [CrossRef]
- Karpušenkaitė, A.; Ruzgas, T.; Denafas, G. Forecasting medical waste generation using short and extra short datasets: Case study of Lithuania. Waste Manag. Res. 2016, 34, 378–387. [Google Scholar] [CrossRef]
- Kannangara, M.; Dua, T.; Ahmadi, L.; Bensebaa, F. Modeling and prediction of regional municipal solid waste generation and diversion in Canada using machine learning approaches. Waste Manag. 2018, 74, 3–15. [Google Scholar] [CrossRef]
- Petridis, N.E.; Stiakakis, E.; Petridis, K.; Dey, P. Estimation of computer waste quantities using forecasting techniques. J. Clean. Prod. 2016, 112, 3072–3085. [Google Scholar] [CrossRef]
- Xu, L.; Gao, P.; Cui, S.; Liu, C. A hybrid procedure for MSW generation forecasting at multiple time scales in Xiamen City, China. Waste Manag. 2013, 33, 1324–1331. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Peng, Y.; Chen, X.; Skitmore, M.; Zhang, X. The S-curve for forecasting waste generation in construction projects. Waste Manag. 2016, 56, 23–34. [Google Scholar] [CrossRef] [PubMed]
- Pavlas, M.; Šomplák, R.; Smejkalová, V.; Nevrlý, V.; Zavíralová, L.; Kůdela, J.; Popela, P. Spatially distributed generation data for supply chain models—Forecasting with hazardous waste. J. Clean. Prod. 2017, 161, 1317–1328. [Google Scholar] [CrossRef]
- Smejkalová, V.; Šomplák, R.; Pluskal, J.; Rybová, K. Hierarchical optimisation model for waste management forecasting in EU. Optim. Eng. 2022, 23, 2143–2175. [Google Scholar] [CrossRef]
- Andersen, F.M.; Larsen, H.V. FRIDA: A model for the generation and handling of solid waste in Denmark. Resour. Conserv. Recycl. 2012, 65, 47–56. [Google Scholar] [CrossRef]
- Hřebíček, J.; Kalina, J.; Soukopová, J.; Horáková, E.; Prášek, J.; Valta, J. Modelling and forecasting waste generation—DECWASTE information system. IFIP Adv. Inf. Commun. Technol. 2017, 507, 433–445. [Google Scholar] [CrossRef]
- Awasthi, A.K.; Cucchiella, F.; D’Adamo, I.; Li, J.; Rosa, P.; Terzi, S.; Wei, G.; Zeng, X. Modelling the correlations of e-waste quantity with economic increase. Sci. Total Environ. 2017, 613, 46–53. [Google Scholar] [CrossRef]
- Chhay, L.; Reyad, M.A.H.; Suy, R.; Islam, M.R.; Mian, M.M. Municipal solid waste generation in China: Influencing factor analysis and multi-model forecasting. J. Mater. Cycles Waste Manag. 2018, 20, 1761–1770. [Google Scholar] [CrossRef]
- Yusoff, S.H.; Din, U.N.K.A.; Mansor, H.; Midi, N.S.; Zaini, S.A. Neural network prediction for efficient waste management in Malaysia. Indones. J. Electr. Eng. Comput. Sci. 2018, 12, 738–747. [Google Scholar] [CrossRef]
- Karpušenkaitė, A.; Ruzgas, T.; Denafas, G. Time-series-based hybrid mathematical modelling method adapted to forecast automotive and medical waste generation: Case study of Lithuania. Waste Manag. Res. 2018, 36, 454–462. [Google Scholar] [CrossRef]
- Islam, M.T.; Huda, N. E-waste in Australia: Generation estimation and untapped material recovery and revenue potential. J. Clean. Prod. 2019, 237, 117787. [Google Scholar] [CrossRef]
- Cole, C.; Quddus, M.; Wheatley, A.; Osmani, M.; Kay, K. The impact of Local Authorities’ interventions on household waste collection: A case study approach using time series modelling. Waste Manag. 2014, 34, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Klavenieks, K.; Blumberga, D. Forecast of Waste Generation Dynamics in Latvia. Energy Procedia 2016, 95, 200–207. [Google Scholar] [CrossRef]
- Lebersorger, S.; Beigl, P. Municipal solid waste generation in municipalities: Quantifying impacts of household structure, commercial waste and domestic fuel. Waste Manag. 2011, 31, 1907–1915. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.M.-C.; Bodirsky, B.L.; Krueger, T.; Mishra, A.; Popp, A. The world’s growing municipal solid waste: Trends and impacts. Environ. Res. Lett. 2020, 15, 074021. [Google Scholar] [CrossRef]
- Johnson, N.E.; Ianiuk, O.; Cazap, D.; Liu, L.; Starobin, D.; Dobler, G.; Ghandehari, M. Patterns of waste generation: A gradient boosting model for short-term waste prediction in New York City. Waste Manag. 2017, 62, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Vu, H.L.; Ng, K.T.W.; Bolingbroke, D. Time-lagged effects of weekly climatic and socio-economic factors on ANN municipal yard waste prediction models. Waste Manag. 2019, 84, 129–140. [Google Scholar] [CrossRef] [PubMed]
- Sunayana; Kumar, S.; Kumar, R. Forecasting of municipal solid waste generation using nonlinear autoregressive (NAR) neural models. Waste Manag. 2021, 121, 206–214. [Google Scholar] [CrossRef]
- Denafas, G.; Ruzgas, T.; Martuzevičius, D.; Shmarin, S.; Hoffmann, M.; Mykhaylenko, V.; Ogorodnik, S.; Romanov, M.; Neguliaeva, E.; Chusov, A.; et al. Seasonal variation of municipal solid waste generation and composition in four East European cities. Resour. Conserv. Recycl. 2014, 89, 22–30. [Google Scholar] [CrossRef]
- Dwivedy, M.; Mittal, R.K. Future trends in computer waste generation in India. Waste Manag. 2010, 30, 2265–2277. [Google Scholar] [CrossRef]
- Komwit, S.; Chompoonuh, K.P. Effects of area characteristics and municipal waste collection fees on household waste generation. J. Mater. Cycles Waste Manag. 2020, 22, 89–96. [Google Scholar] [CrossRef]
- Gu, B.; Fujiwara, T.; Jia, R.; Duan, R.; Gu, A. Methodological aspects of modeling household solid waste generation in Japan: Evidence from Okayama and Otsu cities. Waste Manag. Res. 2017, 35, 1237–1246. [Google Scholar] [CrossRef]
- Yang, Y.; Yuan, G.; Cai, J.; Wei, S. Forecasting of disassembly waste generation under uncertainties using digital twinning-based hidden Markov model. Sustainability 2021, 13, 5391. [Google Scholar] [CrossRef]
- Song, J.; He, J.; Zhu, M.; Tan, D.; Zhang, Y.; Ye, S.; Shen, D.; Zou, P. Simulated annealing based hybrid forecast for improving daily municipal solid waste generation prediction. Scinetific World J. 2014, 834357. [Google Scholar] [CrossRef]
- Rimaityté, I.; Ruzgas, T.; Denafas, G. Application and evaluation of forecasting methods for municipal solid waste generation in an eastern-European city. Waste Manag. Res. 2012, 30, 89–98. [Google Scholar] [CrossRef]
- Montecinos, J.; Ouhimmou, M.; Chauhan, S.; Paquet, M. Forecasting multiple waste collecting sites for the agro-food industry. J. Clean. Prod. 2018, 187, 932–939. [Google Scholar] [CrossRef]
- Long, F.; Song, B.; Wang, Q.; Xia, X.; Xue, L. Scenarios simulation on municipal plastic waste generation of different functional areas of Beijing. J. Mater. Cycles Waste Manag. 2012, 14, 250–258. [Google Scholar] [CrossRef]
- Abbasi, M.; Abduli, M.A.; Omidvar, B.; Baghvand, A. Results uncertainty of support vector machine and hybrid of wavelet transform-support vector machine models for solid waste generation forecasting. Environ. Prog. Sustain. Energy 2014, 33, 220–228. [Google Scholar] [CrossRef]
- Petropoulos, F.; Apiletti, D.; Assimakopoulos, V.; Babai, M.Z.; Barrow, D.K.; Ben Taieb, S.; Bergmeir, C.; Bessa, R.J.; Bijak, J.; Boylan, J.E.; et al. Forecasting: Theory and practice. Int. J. Forecast. 2022, 38, 705–871. [Google Scholar] [CrossRef]
- Šomplák, R.; Smejkalová, V.; Kůdela, J. Mixed-integer quadratic optimization for waste flow quantification. Optim. Eng. 2022, 23, 2177–2201. [Google Scholar] [CrossRef]
- Adeleke, O.; Akinlabi, S.A.; Jen, T.-C.; Dunmade, I. Prediction of municipal solid waste generation: An investigation of the effect of clustering techniques and parameters on ANFIS model performance. Environ. Technol. 2020, 43, 1634–1647. [Google Scholar] [CrossRef] [PubMed]
- Kalina, J.; Hřebíček, J.; Bulková, G. Case study: Prognostic model of Czech municipal waste generation and treatment. In Proceedings of the 7th International Congress on Environmental Modelling and Software: Bold Visions for Environmental Modeling iEMSs, San Diego, CA, USA, 15–19 June 2014; Volume 2, pp. 932–939. [Google Scholar]
- Bleha, B.; Burcin, B.; Kučera, T.; Šprocha, B.; Vaňo, B. The population prospects of Czechia and Slovakia until 2060. Demografie 2018, 60, 219–233. [Google Scholar]
- Smejkalová, V.; Šomplák, R.; Nevrlý, V.; Burcin, B.; Kučera, T. Trend forecasting for waste generation with structural break. J. Clean. Prod. 2020, 266, 121814. [Google Scholar] [CrossRef]
- Jiang, P.; Liu, X. Hidden Markov model for municipal waste generation forecasting under uncertainties. Eur. J. Oper. Res. 2016, 250, 639–651. [Google Scholar] [CrossRef]
- De Weerdta, L.; Sasaoc, T.; Compernolleb, T.; Van Passela, S.; De Jaegerd, S. The effect of waste incineration taxation on industrial plastic waste generation: A panel analysis. Resour. Conserv. Recycl. 2020, 157, 104717. [Google Scholar] [CrossRef]
- Papamichael, I.; Pappas, G.; Siegel, J.E.; Zorpas, A.A. Unified waste metrics: A gamified tool in next-generation strategic planning. Sci. Total Environ. 2022, 833, 154835. [Google Scholar] [CrossRef]
- Pappas, G.; Papamichael, I.; Zorpas, A.; Siegel, J.E.; Rutkowski, J.; Politopoulos, K. Modelling key performance indicators in a gamified waste management tool. Modelling 2022, 3, 27–53. [Google Scholar] [CrossRef]
- Azadi, S.; Karimi-Jashni, A. Verifying the performance of artificial neural network and multiple linear regression in predicting the mean seasonal municipal solid waste generation rate: A case study of Fars province, Iran. Waste Manag. 2016, 48, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Oribe-Garcia, I.; Kamara-Esteban, O.; Martin, C.; Macarulla-Arenaza, A.M.; Alonso-Vicario, A. Identification of influencing municipal characteristics regarding household waste generation and their forecasting ability in Biscay. Waste Manag. 2015, 39, 26–34. [Google Scholar] [CrossRef]
- Krishnamoorthy, K.; Mathew, T.; Mukherjee, S. Normal-Based Methods for a Gamma Distribution. Technometrics 2008, 50, 69–78. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Azar, E.; Woon, W.L.; Kontokosta, C.E. Evaluation of tree-based ensemble learning algorithms for building energy performance estimation. J. Build. Perform. Simul. 2018, 11, 322–332. [Google Scholar] [CrossRef]
- Mao, H.; Meng, J.; Ji, F.; Zhang, Q.; Fang, H. Comparison of Machine Learning Regression Algorithms for Cotton Leaf Area Index Retrieval Using Sentinel-2 Spectral Bands. Appl. Sci. 2019, 9, 1459. [Google Scholar] [CrossRef]
- Khan, M.; Noor, S. Performance Analysis of Regression-Machine Learning Algorithms for Predication of Runoff Time. Agrotechnology 2019, 8, 1–12. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2017. [Google Scholar]






| Citation | Time Range | Number of Publications | Criteria |
|---|---|---|---|
| (Beigl et al., 2008 [16]); | Until 2005 | 45 | regional scale, MSW waste streams, independent variables, modeling methods |
| (Cherian and Jacob, 2012 [17]) | Until 2011 | 9 | regional scale, MSW waste streams, independent variables, modeling methods, socio-economic factors |
| (Kolekar et al., 2016 [18]) | 2006–2014 | 20 | modeling methods, territorial division, amount and frequency of time-dependent data, independent variables, waste stream |
| (Goel et al., 2017 [19]) | 1972–2016 | 106 | classification into typical (multiple linear regression—MLR, time series analysis—TSA, factor analysis) and unconventional (fuzzy methods, artificial neural networks—ANN) approaches |
| (Alzamora et al., 2022 [20]) | 2008–2021 | 120 | MSW stream, geographic scale, data type, modeling technique, independent variables |
| (Abdallah et al., 2020 [21]) | 2004–2019 | 85 | artificial intelligence in WM, identified six applications; described multiple models incl. hybrid ones |
| (Guo et al., 2021 [22]) | 2003–2020 | 40 | machine learning methods in organic solid waste treatment |
| (Xu et al., 2021 [23]) | 2010–2020 | 177 | ANN models, categories of review scales: macroscale (mainly focused on waste generation), mesoscale (waste properties and process parameters), meso-microscale (waste process efficiencies), microscale (reaction mechanisms or microstructures) |
| Application | Most Common Features | Model | Reference |
|---|---|---|---|
| Waste management legislation and policy |
| MLR | [35,36,37] |
| ANN | [38,39] | ||
| TSA | [40,41] | ||
| Scenario models | [7,42,43] | ||
| Strategic decision-making on waste management infrastructure |
| MLR | [6,44,45] |
| DT | [46] | ||
| ANN | [29,47,48] | ||
| TSA | [5,49] | ||
| Scenario models | [50,51] | ||
| Operational decision-making in waste management |
| MLR | [49,52] |
| ANN | [53,54] | ||
| TSA | [55,56] | ||
| Scenario models | [57] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Šomplák, R.; Smejkalová, V.; Rosecký, M.; Szásziová, L.; Nevrlý, V.; Hrabec, D.; Pavlas, M. Comprehensive Review on Waste Generation Modeling. Sustainability 2023, 15, 3278. https://doi.org/10.3390/su15043278
Šomplák R, Smejkalová V, Rosecký M, Szásziová L, Nevrlý V, Hrabec D, Pavlas M. Comprehensive Review on Waste Generation Modeling. Sustainability. 2023; 15(4):3278. https://doi.org/10.3390/su15043278
Chicago/Turabian StyleŠomplák, Radovan, Veronika Smejkalová, Martin Rosecký, Lenka Szásziová, Vlastimír Nevrlý, Dušan Hrabec, and Martin Pavlas. 2023. "Comprehensive Review on Waste Generation Modeling" Sustainability 15, no. 4: 3278. https://doi.org/10.3390/su15043278
APA StyleŠomplák, R., Smejkalová, V., Rosecký, M., Szásziová, L., Nevrlý, V., Hrabec, D., & Pavlas, M. (2023). Comprehensive Review on Waste Generation Modeling. Sustainability, 15(4), 3278. https://doi.org/10.3390/su15043278