
A Software Framework for Predicting the Maize Yield Using Modified Multi-Layer Perceptron


Abstract
:1. Introduction
- Acquiring the crop-related data for training the model and analyzing the factors influencing crop production.
- Performing Feature Engineering for localizing the features contributing to precise crop yield analysis.
- Training the model and analyzing the hyperparameters to read the data’s insights adequately.
- The Spider Monkey Optimization technique optimizes the Multi-Layer Perceptron model for analyzing the outcome.
- Analyzing the model’s performance with various evolution metrics such as sensitivity, specificity, F1- Score, and accuracy measures.
- The prediction efficiency of the model is being analyzed against the other state of art techniques used in crop yield prediction.
2. Literature Review
3. Background
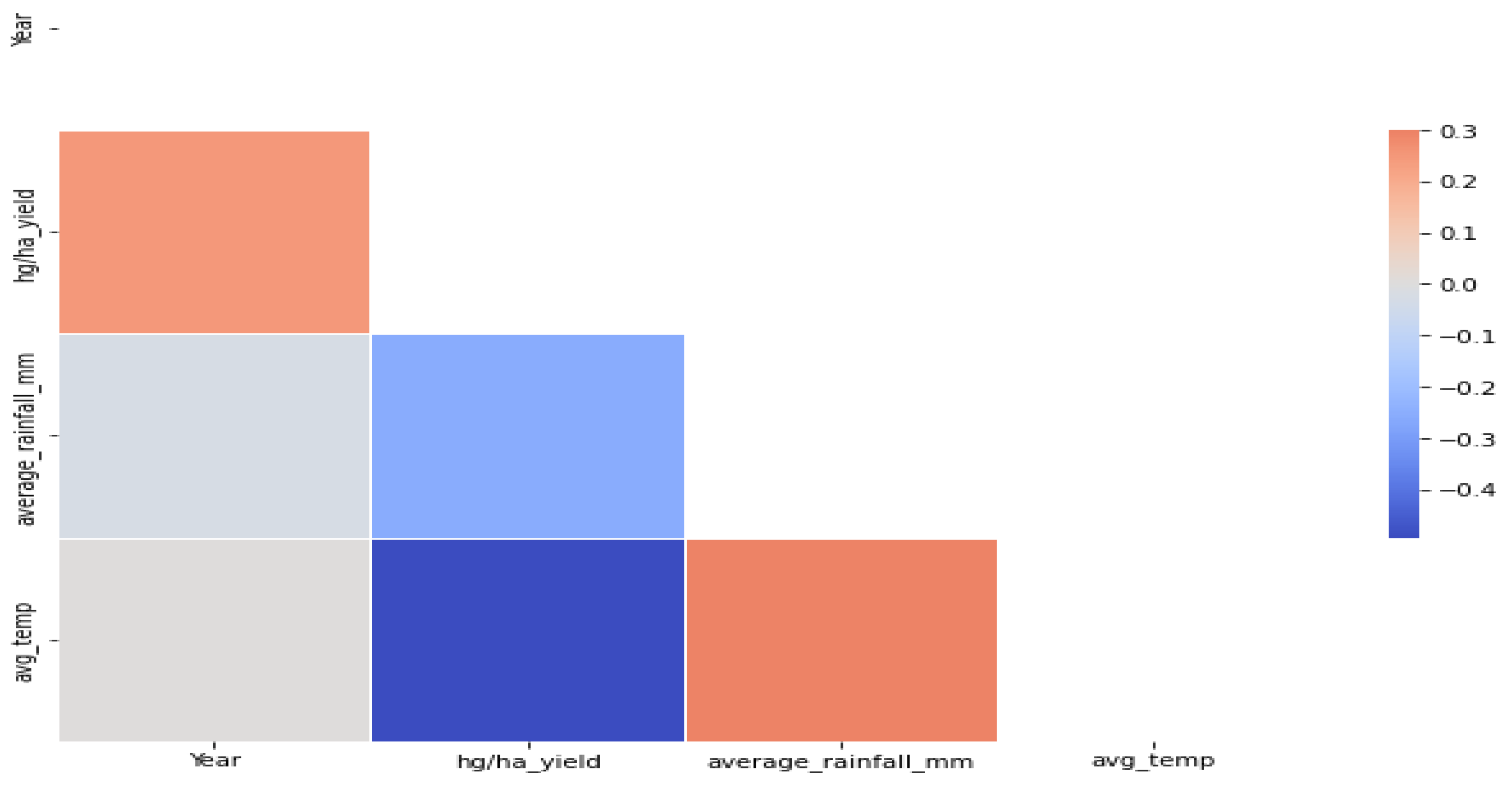
3.1. Data Normalization
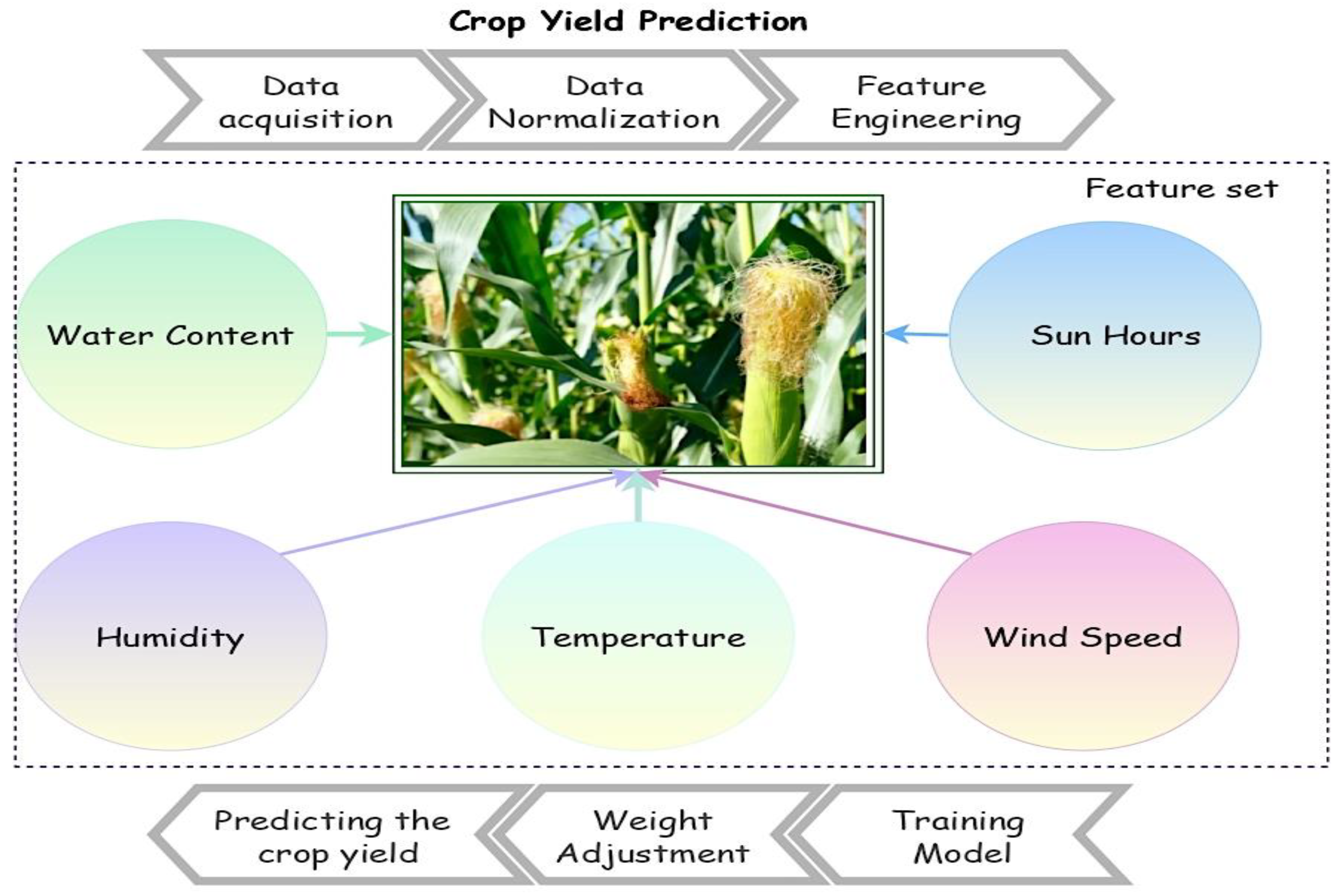
3.2. Feature Engineering
4. Proposed Method
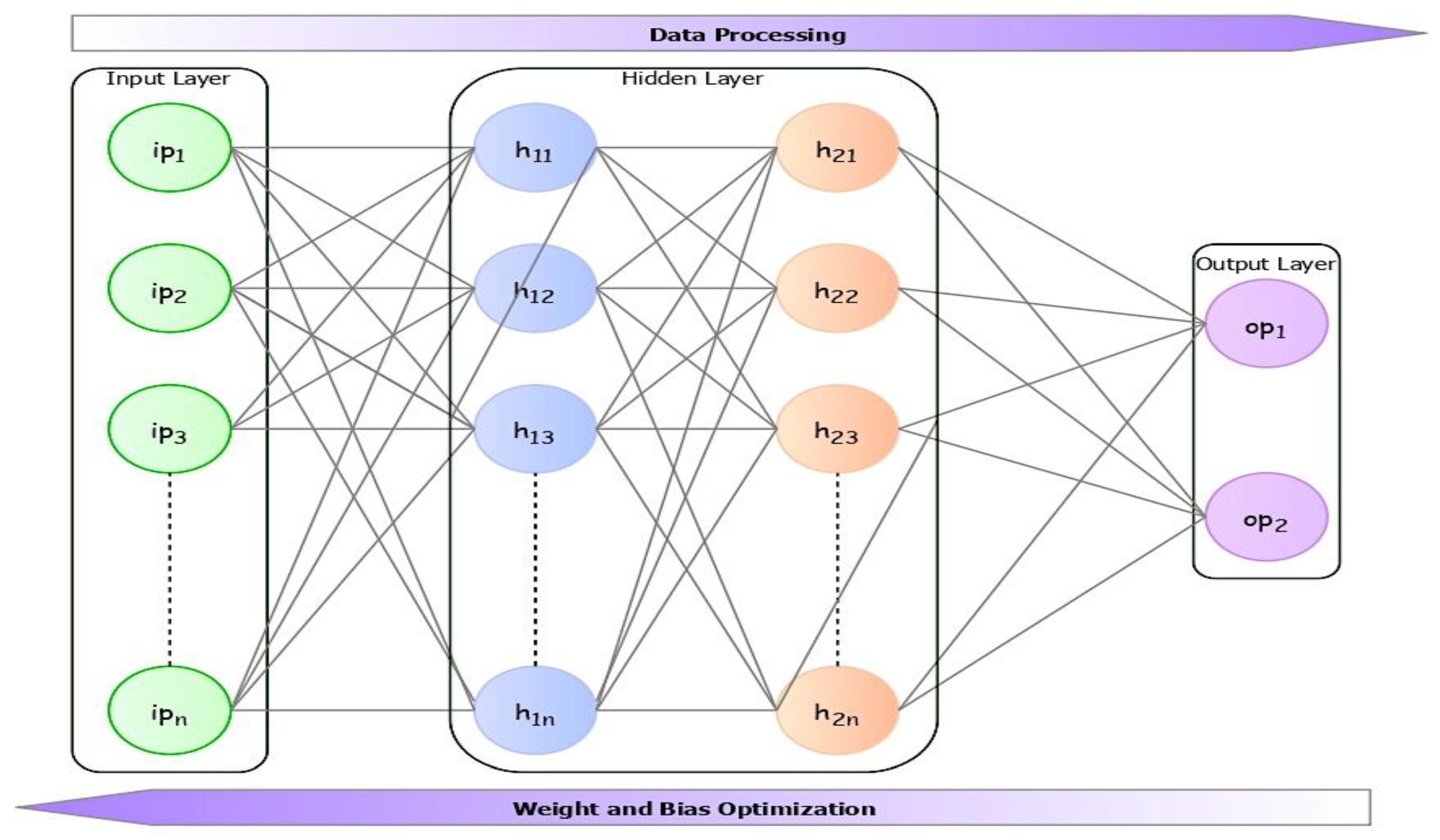
4.1. Multi-Layer Perceptron Model
4.2. Neuron Selection Using Spider Monkey Optimization
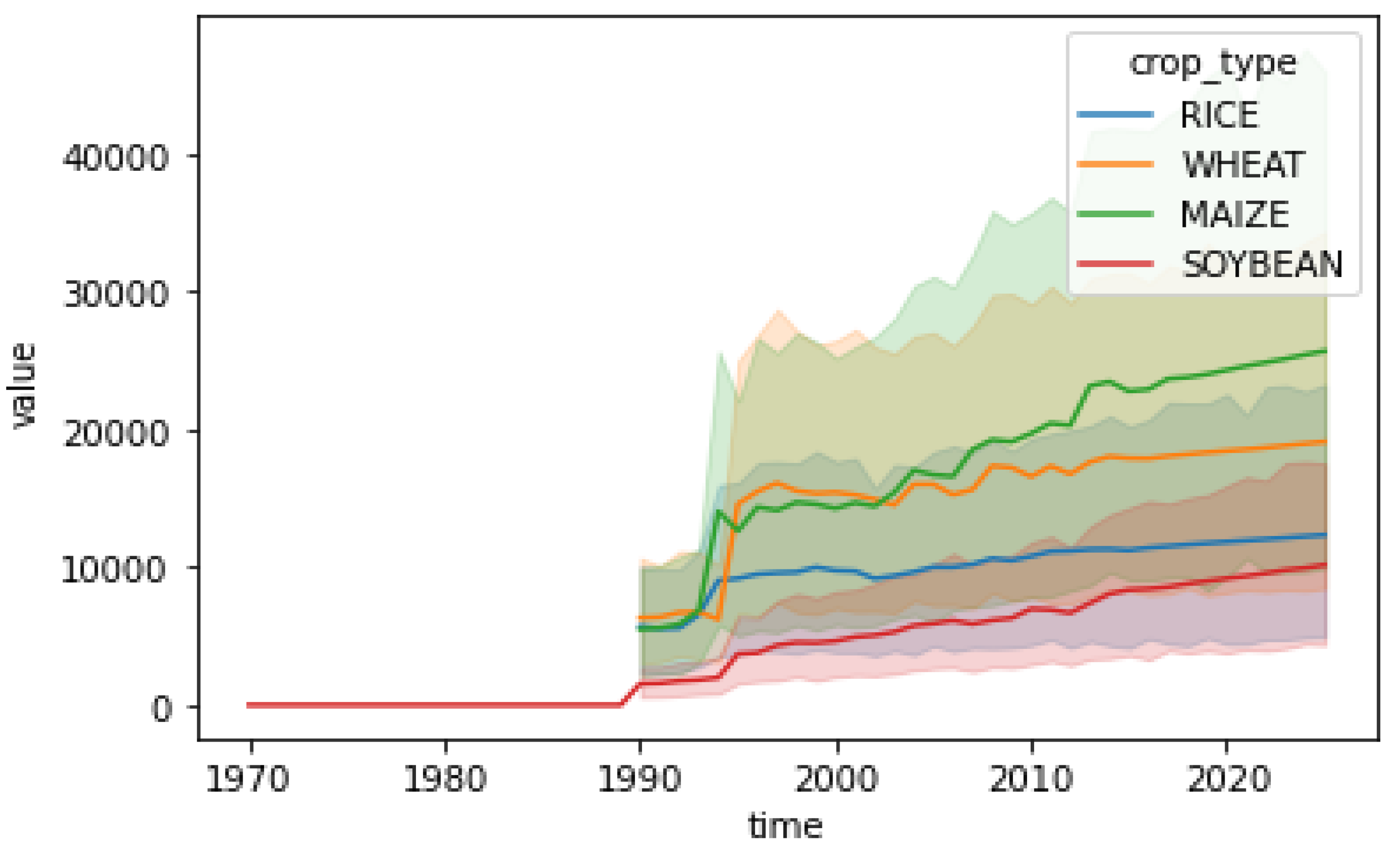
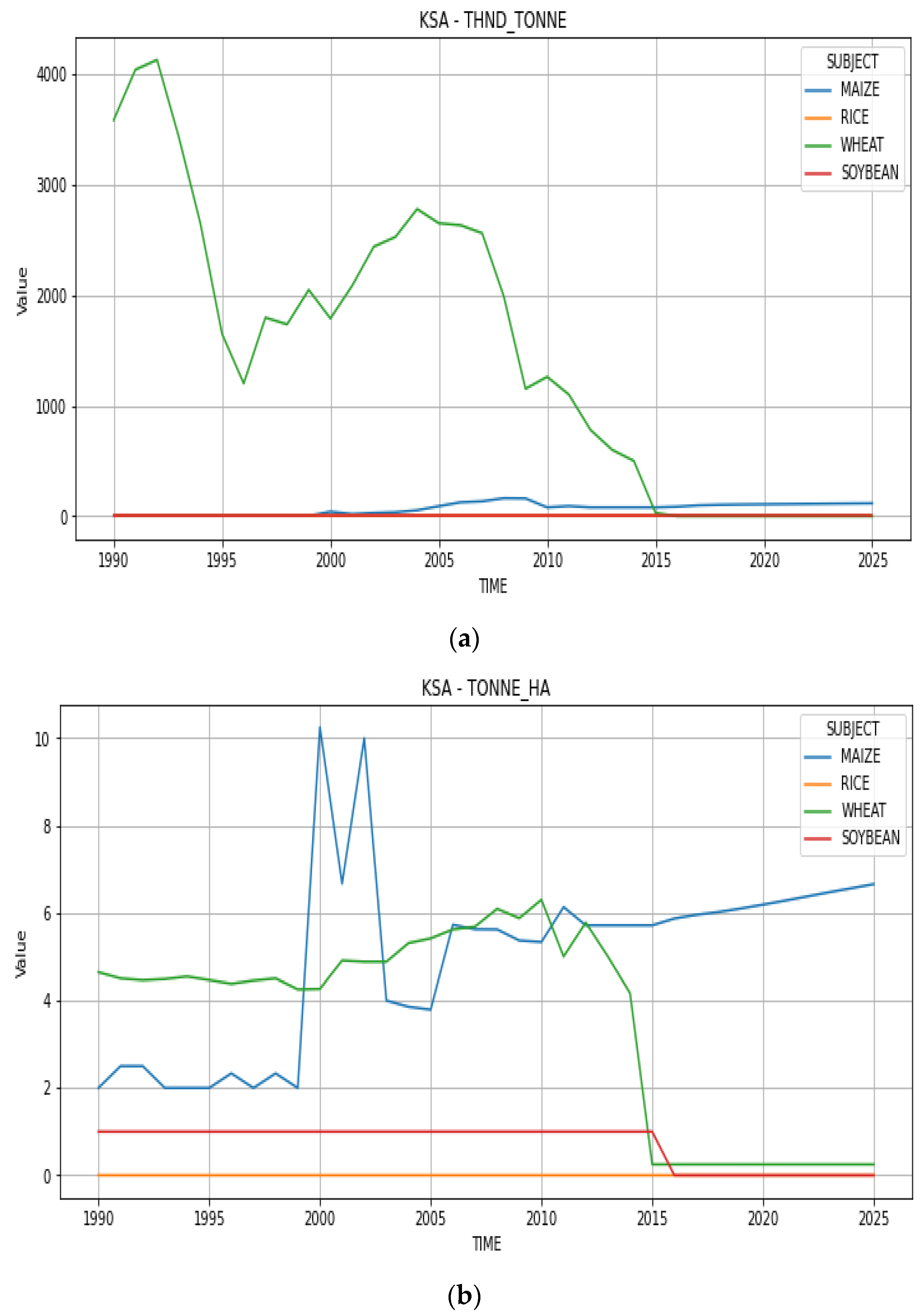
4.3. Dataset Collection
4.4. Details of Implementation Platform
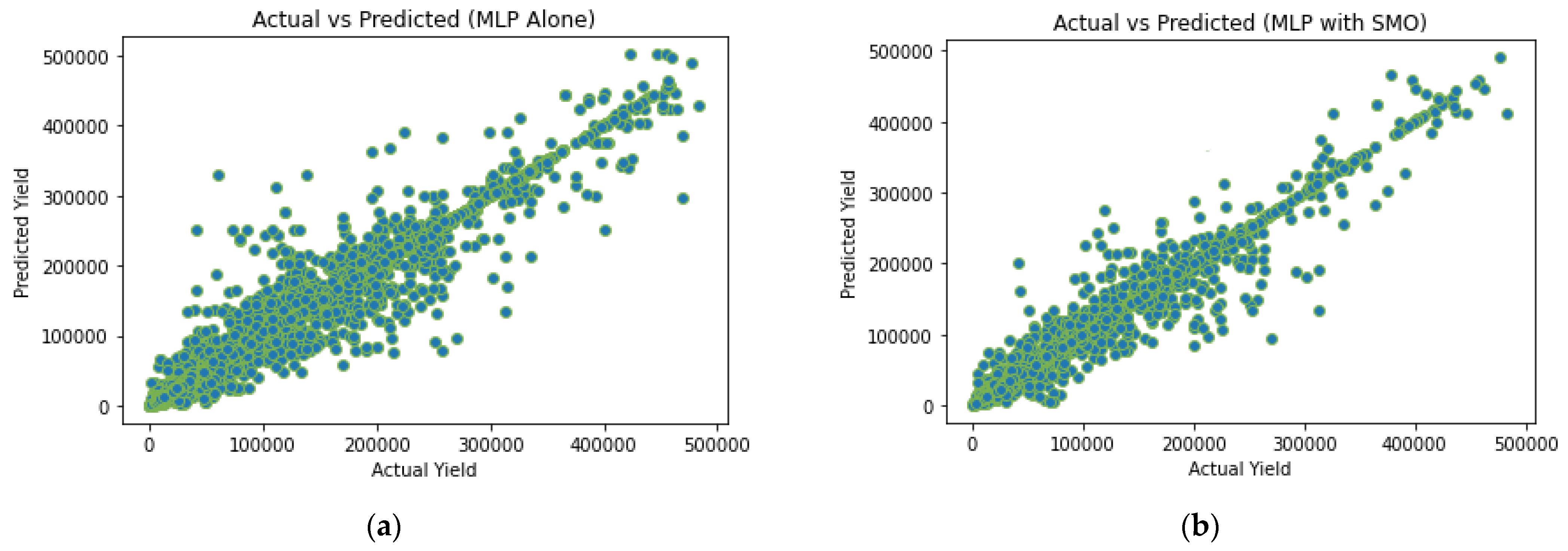
5. Results and Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Adhaileh, M.H.; Aldhyani, T.H. Artificial intelligence framework for modeling and predicting crop yield to enhance food security in Saudi Arabia. PeerJ Comput. Sci. 2022, 8, e1104. [Google Scholar] [CrossRef] [PubMed]
- Jayagopal, P.; Muthukumaran, V.; Koti, M.S.; Kumar, S.S.; Rajendran, S.; Mathivanan, S.K. Weather-based maize yield forecast in Saudi Arabia using statistical analysis and machine learning. Acta Geophys. 2022, 70, 2901–2916. [Google Scholar] [CrossRef]
- Elzaki, R.M.; Elrasheed, M.; Elmulthum, N.A. Optimal crop combination under soaring oil and energy prices in the kingdom of Saudi Arabia. Socio-Econ. Plan. Sci. 2022, 83, 101367. [Google Scholar] [CrossRef]
- Gana, R. Ridge Regression and the Elastic Net: How Do They Do as Finders of True Regressors and Their Coefficients? Mathematics 2022, 10, 3057. [Google Scholar] [CrossRef]
- Botana, I.L.-R.; Eiras-Franco, C.; Alonso-Betanzos, A. Regression Tree Based Explanation for Anomaly Detection Algorithm. Proceedings 2020, 54, 7. [Google Scholar] [CrossRef]
- Naga Srinivasu, P.; Srinivasa Rao, T.; Dicu, A.M.; Mnerie, C.A.; Olariu, I. A comparative review of optimisation techniques in segmentation of brain MR images. J. Intell. Fuzzy Syst. 2020, 38, 6031–6043. [Google Scholar] [CrossRef]
- Guleria, P.; Naga Srinivasu, P.; Ahmed, S.; Almusallam, N.; Alarfaj, F.K. XAI Framework for Cardiovascular Disease Prediction Using Classification Techniques. Electronics 2022, 11, 4086. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Linna, P.; Lipping, T. Assessment of Crop Yield Prediction Capabilities of CNN Using Multisource Data. In New Developments and Environmental Applications of Drones; Lipping, T., Linna, P., Narra, N., Eds.; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Feng, P.; Wang, B.; Li Liu, D.; Waters, C.; Xiao, D.; Shi, L.; Yu, Q. Dynamic wheat yield forecasts are improved by a hybrid approach using a biophysical model and machine learning technique. Agric. For. Meteorol. 2020, 285–286, 107922. [Google Scholar] [CrossRef]
- Nyéki, A.; Neményi, M. Crop Yield Prediction in Precision Agriculture. Agronomy 2022, 12, 2460. [Google Scholar] [CrossRef]
- Yli-Heikkila, M.; Wittke, S.; Luotamo, M.; Puttonen, E.; Sulkava, M.; Pellikka, P.; Heiskanen, J.; Klami, A. Scalable Crop Yield Prediction with Sentinel-2 Time Series and Temporal Convolutional Network. Remote Sens. 2022, 14, 4193. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop yield prediction using deep neural networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Tang, S.; Li, P.; Zhang, H. Empirical Study on the Grain Output Based on Regression Analysis. J. Sensors 2022, 2022, 2567790. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Huber, I.; Archontoulis, S.V. Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt. Sci. Rep. 2021, 11, 1606. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; An, S.; Xu, Y.; Hou, H.; Chen, F.; Yang, Y.; Zhang, S.; Liu, R. A Back Propagation Neural Network Model Optimized by Mind Evolutionary Algorithm for Estimating Cd, Cr, and Pb Concentrations in Soils Using Vis-NIR Diffuse Reflectance Spectroscopy. Appl. Sci. 2020, 10, 51. [Google Scholar] [CrossRef]
- Maritz, J.; Lubbe, F.; Lagrange, L. A Practical Guide to Gaussian Process Regression for Energy Measurement and Verification within the Bayesian Framework. Energies 2018, 11, 935. [Google Scholar] [CrossRef]
- Guleria, P.; Ahmed, S.; Alhumam, A.; Srinivasu, P.N. Empirical Study on Classifiers for Earlier Prediction of COVID-19 Infection Cure and Death Rate in the Indian States. Healthcare 2022, 10, 85. [Google Scholar] [CrossRef]
- VGeetha, V.; Punitha, A.; Abarna, M.; Akshaya, M.; Illakiya, S.; Janani, A. An Effective Crop Prediction Using Random Forest Algorithm. In Proceedings of the 2020 International Conference on System, Computation, Automation, and Networking (ICSCAN), Puducherry, India, 3–4 July 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Koduri, S.B.; Gunisetti, L.; Ramesh, C.R.; Mutyalu, K.V.; Ganesh, D. Prediction of crop production using adaboost regression method. J. Physics Conf. Ser. 2019, 1228, 012005. [Google Scholar] [CrossRef]
- Kopal, I.; Labaj, I.; Vršková, J.; Harničárová, M.; Valíček, J.; Ondrušová, D.; Krmela, J.; Palková, Z. A Generalized Regression Neural Network Model for Predicting the Curing Characteristics of Carbon Black-Filled Rubber Blends. Polymers 2022, 14, 653. [Google Scholar] [CrossRef]
- Bacanin, N.; Miodrag, Z.; Sarac, M.; Petrovic, A.; Strumberger, I.; Antonijevic, M.; Petrovic, A.; Venkatachalam, K.A.; Strumberger, I.; Antonijevic, M.; et al. A Novel Multiswarm Firefly Algorithm: An Application for Plant Classification. In Intelligent and Fuzzy Systems; Kahraman, C., Tolga, A.C., Cevik Onar, S., Cebi, S., Oztaysi, B., Sari, I.U., Eds.; INFUS 2022. Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2022; Volume 504. [Google Scholar] [CrossRef]
- Haque, F.F.; Abdelgawad, A.; Yanambaka, V.P.; Yelamarthi, K. Crop Yield Prediction Using Deep Neural Network. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–4. [Google Scholar] [CrossRef]
- El-Kenawy, E.-S.M.; Khodadadi, N.; Mirjalili, S.; Makarovskikh, T.; Abotaleb, M.; Karim, F.K.; Alkahtani, H.K.; Abdelhamid, A.A.; Eid, M.M.; Horiuchi, T.; et al. Metaheuristic Optimization for Improving Weed Detection in Wheat Images Captured by Drones. Mathematics 2022, 10, 4421. [Google Scholar] [CrossRef]
- Oikonomidis, A.; Catal, C.; Kassahun, A. Hybrid Deep Learning-based Models for Crop Yield Prediction. Appl. Artif. Intell. 2022, 36, 1. [Google Scholar] [CrossRef]
- Batool, D.; Shahbaz, M.; Shahzad Asif, H.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Ramzan, Z.; Waheed, A.; Aljuaid, H.; Luo, S. A Hybrid Approach to Tea Crop Yield Prediction Using Simulation Models and Machine Learning. Plants 2022, 11, 1925. [Google Scholar] [CrossRef] [PubMed]
- Shingade, S.D.; Mudhalwadkar, R.P. Hybrid deep-Q Elman neural network for crop prediction and recommendation based on environmental changes. Concurr. Computat. Pract. Exper. 2022, 34, e6991. [Google Scholar] [CrossRef]
- Jambekar, S.; Nema, S.; Saquib, Z. Prediction of Crop Production in India Using Data Mining Techniques. In Proceedings of the Pune, Pune, India, 16–18 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Vidhya, R.; Mathur, P.; Valluri, S.S. Crop yield prediction using random forest. Int. J. Adv. Sci. Technol. 2020, 29, 3084–3086. [Google Scholar]
- Sangeeta, S. Design and implementation of crop yield prediction model in agriculture. Int. J. Sci. Technol. Res. 2020, 8, 544–549. [Google Scholar]
- Deepalakshmi, P.; Prudhvi, K.T.; Siri, C.S.; Lavanya, K.; Srinivasu, P.N. Plant Leaf Disease Detection Using CNN Algorithm. Int. J. Inf. Syst. Model. Des. 2021, 12, 1–21. [Google Scholar] [CrossRef]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep Gaussian process for crop yield prediction based on remote sensing data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI’17); AAAI Press: Washington, DC, USA, 2017; pp. 4559–4565. [Google Scholar]
- Fegade, T.K.; Pawar, B. Crop Prediction Using Artificial Neural Network and Support Vector Machine. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 311–324. [Google Scholar]
- Tiwari, P.; Shukla, P.K. A hybrid approach of TLBO and EBPNN for crop yield prediction using spatial feature vectors. J. Artif. Intell. 2019, 1, 45–59. [Google Scholar] [CrossRef]
- Sajid, S.S.; Shahhosseini, M.; Huber, I.; Hu, G.; Archontoulis, S.V. County-scale crop yield prediction by integrating crop simulation with machine learning models. Front. Plant Sci. 2022, 13, 1000224. [Google Scholar] [CrossRef]
- Krithika, K.M.; Maheswari, N.; Sivagami, M. Models for feature selection and efficient crop yield prediction in the groundnut production. Res. Agric. Eng. 2022, 68, 131–141. [Google Scholar] [CrossRef]
- Ikram, A.; Aslam, W.; Aziz, R.H.H.; Noor, F.; Mallah, G.A.; Ikram, S.; Ahmad, M.S.; Abdullah, A.M.; Ullah, I. Crop Yield Maximization Using an IoT-Based Smart Decision. J. Sens. 2022, 2022, 2022923. [Google Scholar] [CrossRef]
- Kumar, R. IoT Enabled Crop Prediction and Irrigation Automation System Using Machine Learning. Recent Adv. Comput. Sci. Commun. 2022, 15, 88–97. [Google Scholar] [CrossRef]
- Joshua, S.V.; Priyadharson, A.S.M.; Kannadasan, R.; Khan, A.A.; Lawanont, W.; Khan, F.A.; Rehman, A.U.; Ali, M.J. Crop yield prediction using machine learning approaches on a wide spectrum. Comput. Mater. Contin. 2022, 72, 5663–5679. [Google Scholar]
- Vignesh, K.; Askarunisa, A.; Abirami, A.M. Optimized Deep Learning Methods for Crop Yield Prediction. Comput. Syst. Sci. Eng. 2023, 44, 1051–1067. [Google Scholar] [CrossRef]
- Paudel, D.; Boogaard, H.; de Wit, A.; Janssen, S.; Osinga, S.; Pylianidis, C.; Athanasiadis, I.N. Machine learning for large-scale crop yield forecasting. Agric. Syst. 2020, 187, 103016. [Google Scholar] [CrossRef]
- Bali, N.; Singla, A. Deep Learning Based Wheat Crop Yield Prediction Model in Punjab Region of North India. Appl. Artif. Intell. 2021, 35, 1304–1328. [Google Scholar] [CrossRef]
- Rajagopal, A.; Jha, S.; Khari, M.; Ahmad, S.; Alouffi, B.; Alharbi, A. A Novel Approach in Prediction of Crop Production Using Recurrent Cuckoo Search Optimization Neural Networks. Appl. Sci. 2021, 11, 9816. [Google Scholar] [CrossRef]
- Ansarifar, J.; Wang, L.; Archontoulis, S.V. An interaction regression model for crop yield prediction. Sci. Rep. 2021, 11, 17754. [Google Scholar] [CrossRef]
- Uddin, M.F.; Lee, J.; Rizvi, S.; Hamada, S. Proposing Enhanced Feature Engineering and a Selection Model for Machine Learning Processes. Appl. Sci. 2018, 8, 646. [Google Scholar] [CrossRef]
- Lee, C.-H.; Gutierrez, F.; Dou, D. Calculating Feature Weights in Naive Bayes with Kullback-Leibler Measure. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11 December 2011; pp. 1146–1151. [Google Scholar] [CrossRef]
- Isabona, J.; Imoize, A.L.; Ojo, S.; Karunwi, O.; Kim, Y.; Lee, C.-C.; Li, C.-T. Development of a Multilayer Perceptron Neural Network for Optimal Predictive Modeling in Urban Microcellular Radio Environments. Appl. Sci. 2022, 12, 5713. [Google Scholar] [CrossRef]
- Rojas, M.G.; Olivera, A.C.; Vidal, P.J. Optimising Multilayer Perceptron weights and biases through a Cellular Genetic Algorithm for medical data classification. Array 2022, 14, 100173. [Google Scholar] [CrossRef]
- Ethala, S.; Kumarappan, A. A Hybrid Spider Monkey and Hierarchical Particle Swarm Optimization Approach for Intrusion Detection on Internet of Things. Sensors 2022, 22, 8566. [Google Scholar] [CrossRef]
- Crop Yield Prediction Dataset. Available online: https://www.kaggle.com/datasets/patelris/crop-yield-prediction-dataset (accessed on 25 December 2022).
- Food and Agriculture Organization. Available online: http://www.fao.org/home/en/ (accessed on 25 December 2022).
- World Data Bank. Available online: https://data.worldbank.org/ (accessed on 25 December 2022).
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Srinivasu, N.P.; Rao, S.T.; Srinivas, G.; Reddy, P.P.V.G.D. A Computationally Efficient Skull Scraping Approach for Brain MR Image. Recent Adv. Comput. Sci. Commun. 2020, 13, 833–844. [Google Scholar] [CrossRef]
- Çetiner, H.; Kara, B. Recurrent Neural Network based model development for wheat yield forecasting. Adıyaman Üniversitesi Mühendislik Bilim. Derg. 2022, 9, 204–218. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, H.; Saleem, G.; Muhammad, M. Development of Crop Yield Estimation Model using Soil and Environmental Parameters. arXiv preprint 2021, arXiv:2102.05755. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]
- Elavarasan, D.; Vincent, P.M.D. Crop Yield Prediction Using Deep Reinforcement Learning Model for Sustainable Agrarian Applications. IEEE Access 2020, 8, 86886–86901. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Year | Crop | Technique | Outcome |
|---|---|---|---|---|
| Krithika K.M. et al. [35] | 2022 | Groundnut |
|
|
| Amna Ikram et al. [36] | 2022 | General Analysis |
|
|
| Kumar Raj and Singhal Vivek [37] | 2022 | General Analysis |
|
|
| Vinson Joshua et al. [38] | 2022 | General Analysis |
|
|
| Vignesh et al. [39] | 2022 | General Analysis |
|
|
| Paudel et al. [40] | 2021 | Soft wheat Spring barley Sunflower Sugar beet Potatoes |
|
|
| Bali et al. [41] | 2021 | Wheat |
|
|
| Rajagopal [42] | 2021 | General Analysis |
|
|
| Implementation Environment | Details |
|---|---|
| Processor | Intel Core i7-1260P (12 Gen) |
| Make | HP Pavilion 15-EG2039TU |
| Architecture | 64 |
| Operating System | Windows 11 |
| Memory Allotted | 3 GB |
| GPU | Iris Xe |
| Coding language | Python |
| Framework | Jupiter Notebook v6.5.1 |
| Libraries used | sklearn, PyTorch, NumPy, pandas |
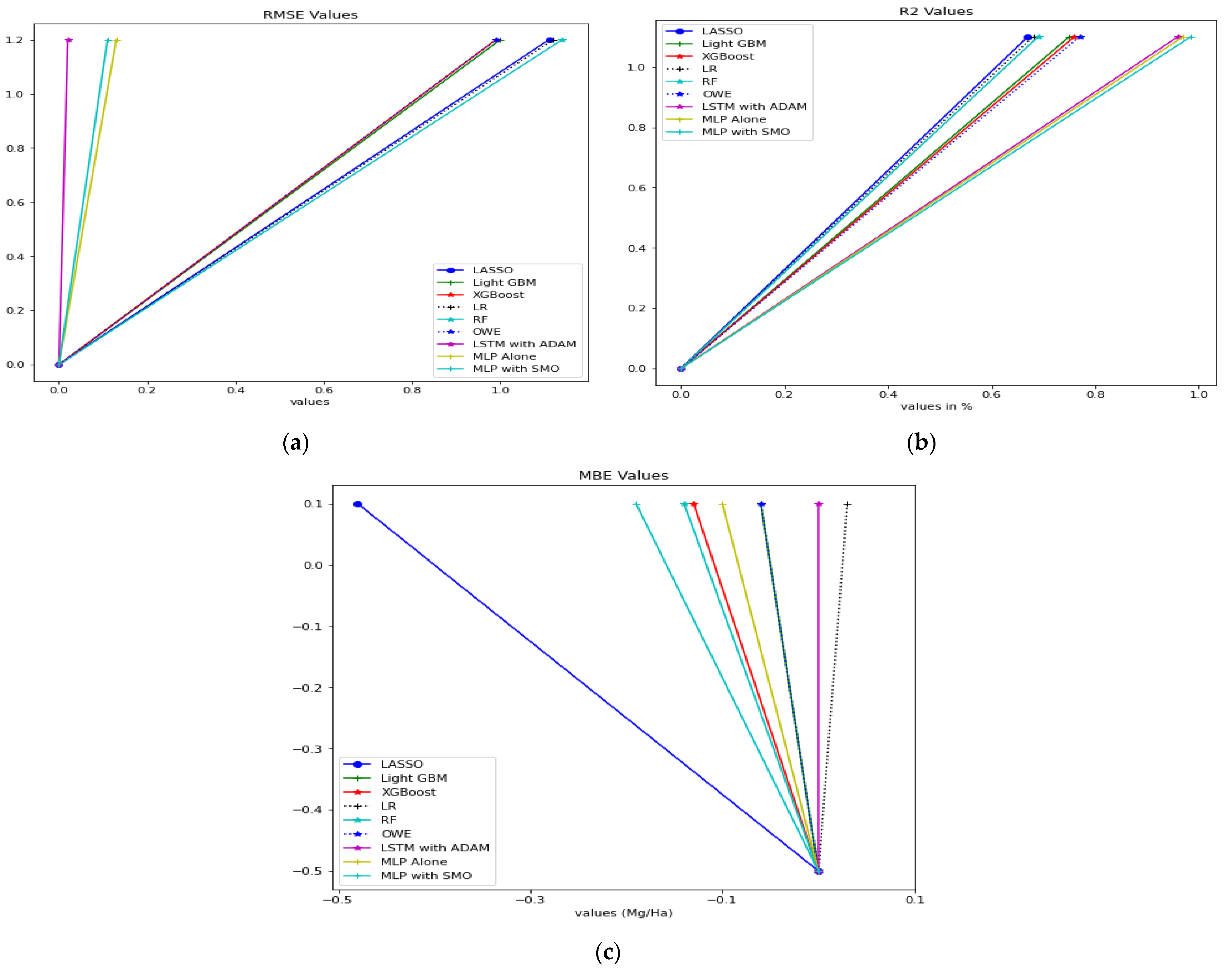
| Approach | RMSE (Mg/Ha) | R2 | MBE (Mg/Ha) |
|---|---|---|---|
| LASSO [34] | 1.11 | 0.67 | −0.48 |
| LightGBM [34] | 1.0 | 0.75 | −0.06 |
| XGBoost [34] | 0.99 | 0.75 | −0.13 |
| RF [34] | 1.12 | 0.68 | −0.14 |
| LR [34] | 1.12 | 0.68 | 0.03 |
| OWE [34] | 0.99 | 0.75 | −0.06 |
| LSTM Model with Adam [54] | 0.02 | 0.96 | |
| MLP alone | 0.13 | 0.96 | −0.10 |
| MLP with SMO | 0.11 | 0.98 | −0.19 |
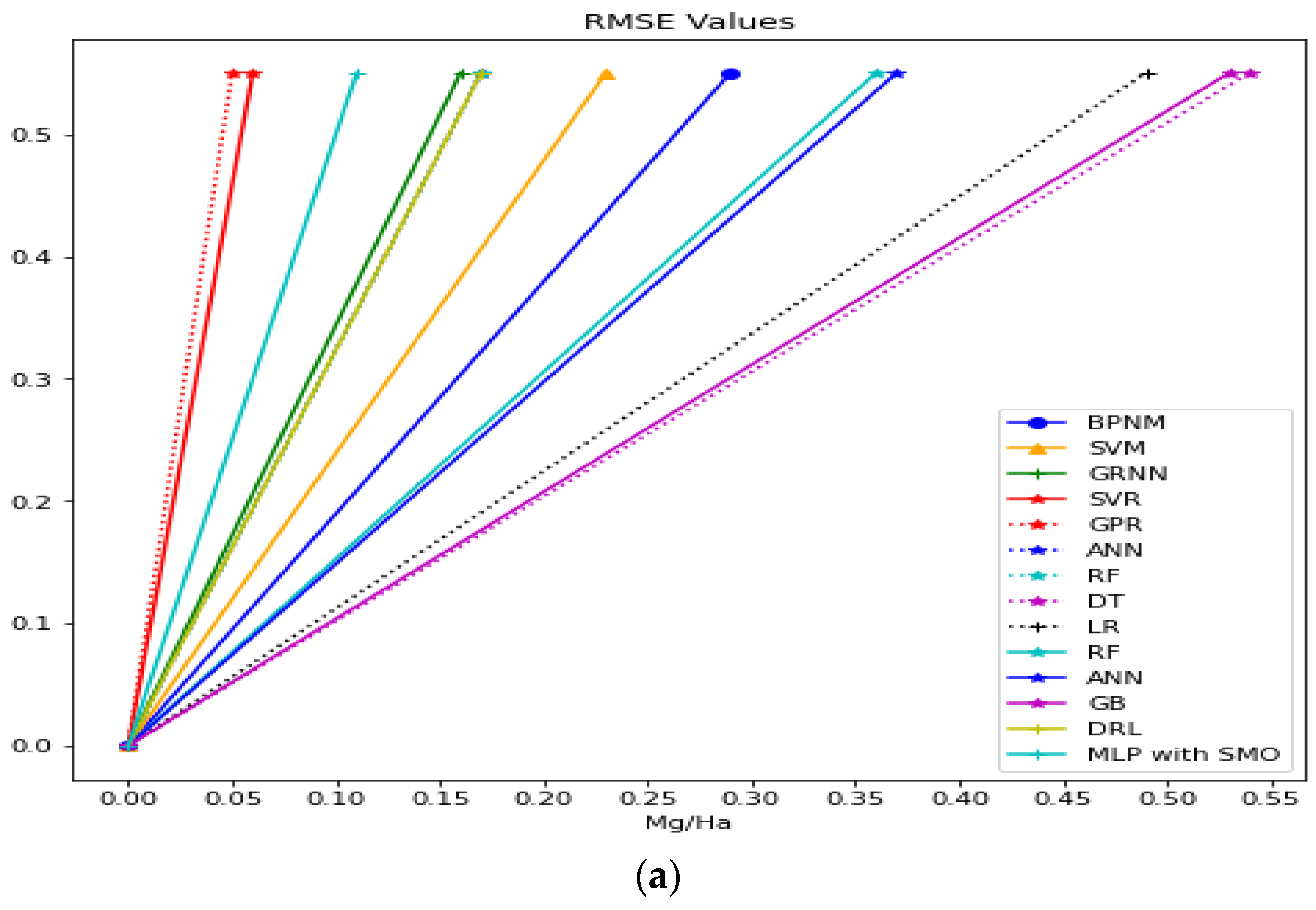
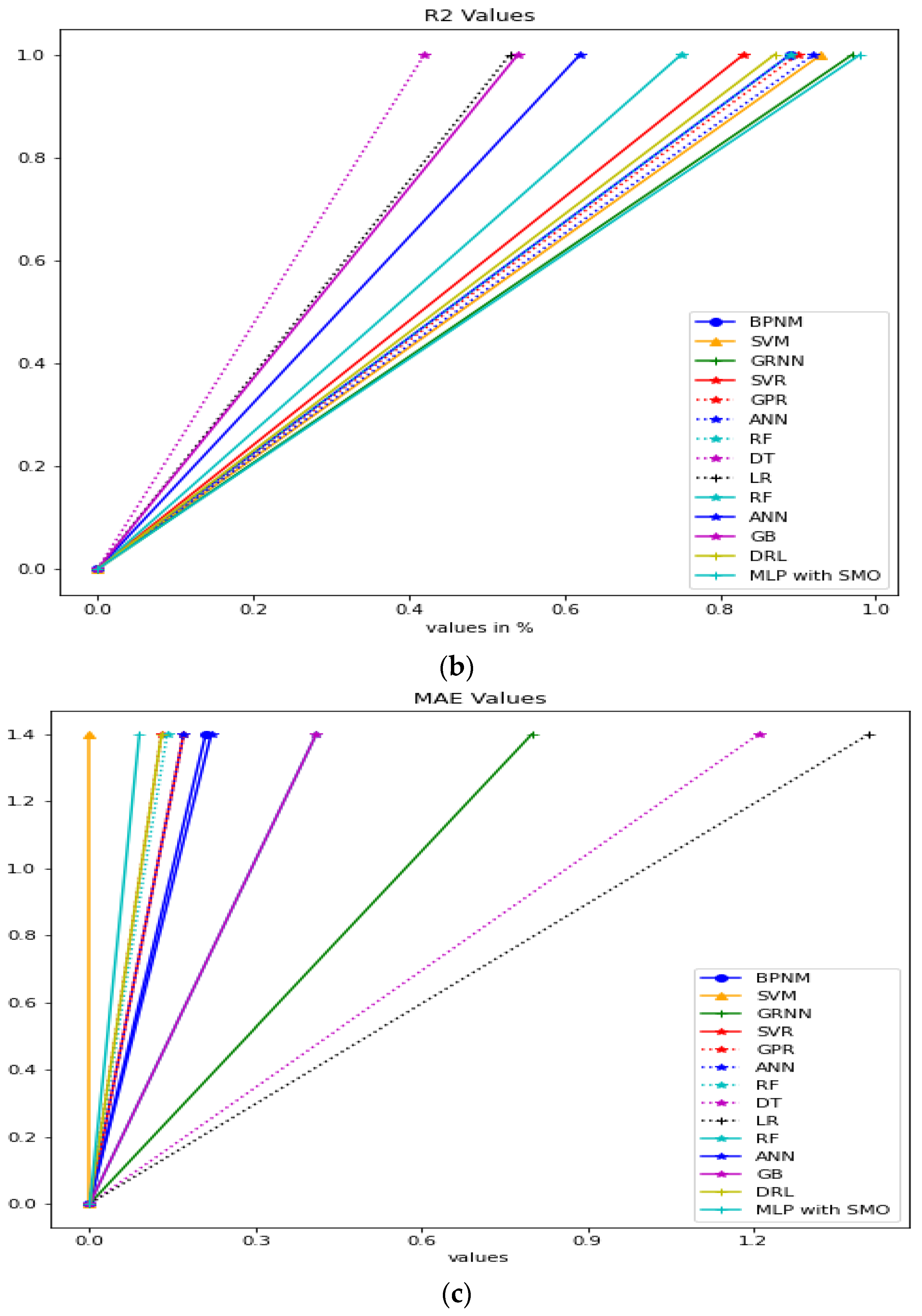
| Approach | RMSE (Mg/Ha) | R2 | MAE |
|---|---|---|---|
| BPNM [38] | 0.29 | 0.89 | 0.21 |
| SVM [38] | 0.23 | 0.93 | |
| GRNN [38] | 0.16 | 0.97 | 0.08 |
| SVR [55] | 0.06 | 0.83 | 0.17 |
| GPR [55] | 0.05 | 0.90 | 0.13 |
| ANN [55] | 0.17 | 0.92 | 0.17 |
| RF [55] | 0.17 | 0.89 | 0.14 |
| DT [56] | 0.54 | 0.42 | 1.21 |
| LR [56] | 0.49 | 0.53 | 1.41 |
| RF [56] | 0.36 | 0.75 | 0.41 |
| ANN [56] | 0.37 | 0.62 | 0.22 |
| Gradient Boosting [57] | 0.53 | 0.54 | 0.41 |
| DRL [57] | 0.17 | 0.87 | 0.13 |
| MLP with SMO | 0.11 | 0.98 | 0.09 |
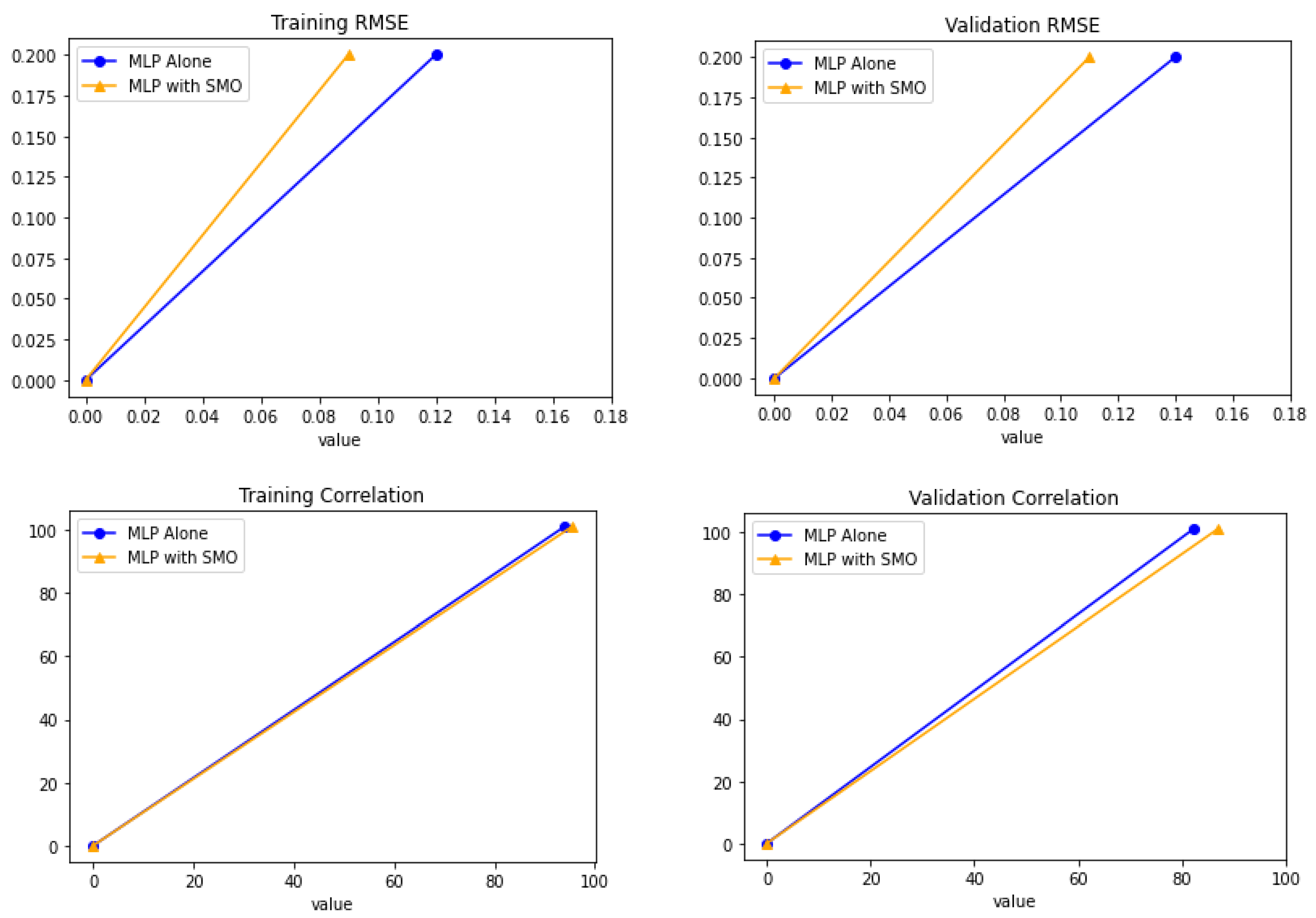
| Approach | Training RMSE | Validation RMSE | Training Correlation | Validation Correlation |
|---|---|---|---|---|
| MLP | 0.12 | 0.14 | 93.9% | 82.2% |
| MLP with SMO | 0.09 | 0.11 | 95.4% | 86.9% |
| MLP | MLP with SMO | |
|---|---|---|
| Wins (+) | 2000 | 2061 |
| Loses (−) | 139 | 78 |
| MLP | MLP with SMO | |
|---|---|---|
| Average error | 0.197 | 0.183 |
| Average Fitness | 0.271 | 0.259 |
| Best Fitness | 0.187 | 0.165 |
| Worst Fitness | 0.292 | 0.274 |
| R+ | 51 | 51 |
| R− | 0 | 0 |
| Significant(alpha) | 0.05 | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, S. A Software Framework for Predicting the Maize Yield Using Modified Multi-Layer Perceptron. Sustainability 2023, 15, 3017. https://doi.org/10.3390/su15043017
Ahmed S. A Software Framework for Predicting the Maize Yield Using Modified Multi-Layer Perceptron. Sustainability. 2023; 15(4):3017. https://doi.org/10.3390/su15043017
Chicago/Turabian StyleAhmed, Shakeel. 2023. "A Software Framework for Predicting the Maize Yield Using Modified Multi-Layer Perceptron" Sustainability 15, no. 4: 3017. https://doi.org/10.3390/su15043017
APA StyleAhmed, S. (2023). A Software Framework for Predicting the Maize Yield Using Modified Multi-Layer Perceptron. Sustainability, 15(4), 3017. https://doi.org/10.3390/su15043017