
A Deep Learning-Based Approach to Generating Comprehensive Building Façades for Low-Rise Housing



Abstract
1. Introduction
2. Materials and Methods
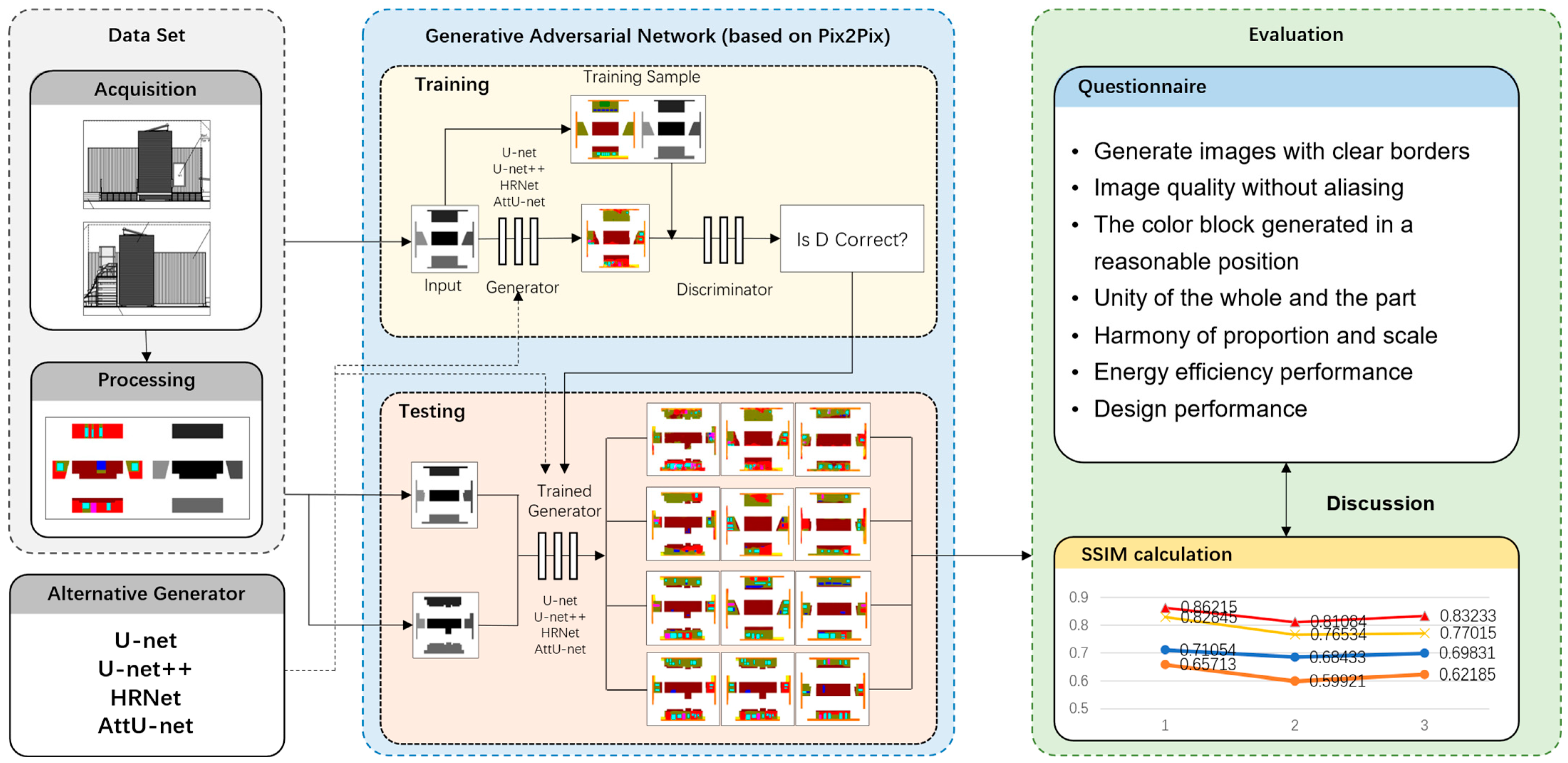
2.1. Research Framework
2.2. Data Set Acquisition
2.3. Data Set Processing
2.4. Generating Network Selection
2.4.1. U-Net Generation Network
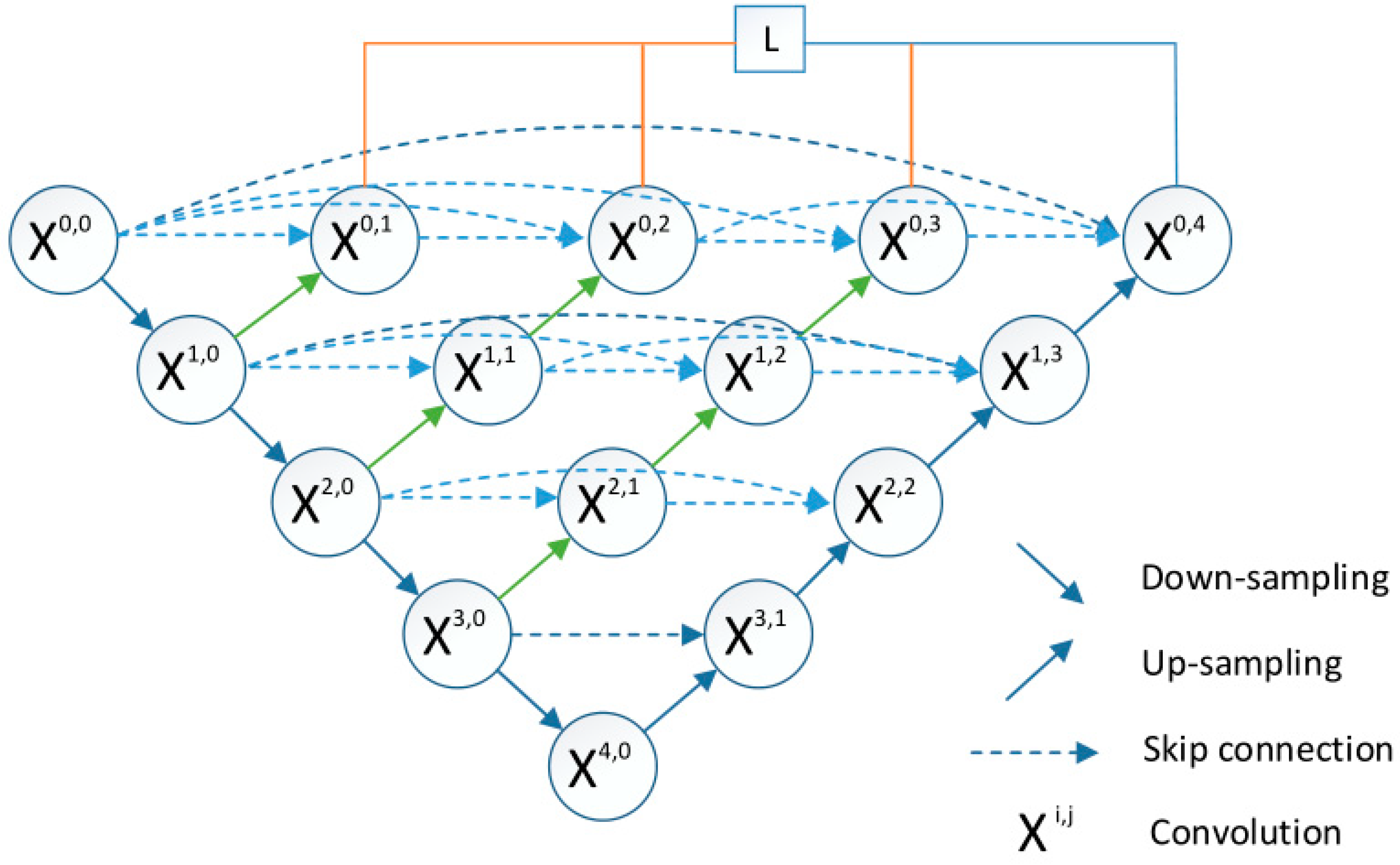
2.4.2. U-Net++ Generation Network
2.4.3. HRNet Generation Network
2.4.4. AttU-Net Generation Network
2.5. Evaluation
2.5.1. Subjective Evaluation
2.5.2. Structural Similarity Evaluation (SSIM)
3. Results
3.1. Data Screening
3.2. Experimental Configuration and Parameter Settings
3.2.1. Experimental Environment Configuration
3.2.2. Parameter Setting
- Learning rate
- 2.
- Number of iterations Epoch
3.3. Generating Results by Using the U-Net Network
3.4. Generating Results by Using the U-Net++ Network
3.5. Generating Results by Using the HRNet Network
3.6. Generating Results by Using the AttU-Net Network
4. Discussion
4.1. Subjective Evaluation
4.2. Objective Evaluation
5. Conclusions
- The subjective evaluation showed that the AttU-net generator and the HRNet generator had acceptable façade design results in terms of façade design results.
- The generated results show a certain degree of energy efficiency, especially the reasonable shape and position of the photovoltaic panel.
- The average structural similarity between the results of the AttU-net generation network and the target color block diagram was greater than 0.8. Indicates that the replacement of the U-net generation network of Pix2Pix with the AttU-net generation network in this study can generate a more reasonable comprehensive building façade layout.
- Compared with traditional parametric design, the method used in this study is able to use deep learning to discover the patterns in the façade layout without human intervention. It can generate façade layouts efficiently.
- AttU-net has the best comprehensive performance. Considering that approximately 25% of training time can be saved, HRNet is another acceptable choice in scenarios where there is a need for fast training and generation. The subjective scores of its generated results are 7% lower than AttU-net and 6% lower in SSIM value.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Merrell, P.; Schkufza, E.; Koltun, V. Computer-generated residential building layouts. ACM Trans. Graph. 2010, 29, 1–12. [Google Scholar] [CrossRef]
- Huang., W.; Zheng., H. Architectural Drawings Recognition and Generation through Machine Learning. In Proceedings of the 38th Annual Conference of the Association for Computer Aided Design in Architecture (ACADIA), Mexico City, Mexico, 18–20 October 2018; pp. 156–165. [Google Scholar] [CrossRef]
- Liu, Y.B.; Lin, W.Q.; Deng, Q.M.; Liang, L.Y. Exploring the building form generation by neural networks—Taking the Free University of Berlin as an example. In Proceedings of the 14th National Conference on Architecture Digital Technologies in Education and Research, Chongqing, China, 21 September 2019; pp. 67–75. [Google Scholar]
- Kolata, J.; Zierke, P. The Decline of Architects: Can a Computer Design Fine Architecture without Human Input? Buildings 2021, 11, 338. [Google Scholar] [CrossRef]
- Wan, D.; Zhao, X.; Lu, W.; Li, P.; Shi, X.; Fukuda, H. A Deep Learning Approach toward Ener-gy-Effective Residential Building Floor Plan Generation. Sustainability 2022, 14, 8074. [Google Scholar] [CrossRef]
- Eisenstadt., V.; Langenhan., C.; Althoff., K.-D.; Althof., K.-D. Generation of Floor Plan Variations with Convolutional Neural Networks and Case-Based Reasoning—An Approach for Unsupervised Adaptation of Room Configurations within a Framework for Support of Early Conceptual Design. In Proceedings of the eCAADe 37/SIGraDi 23, Porto, Portugal, 11–13 September 2019; pp. 79–84. [Google Scholar] [CrossRef]
- Azizi, V.; Usman., M.; Patel., S.; Schaumann., D.; Zhou., H.; Faloutsos., P.; Kapadia., M. Floorplan Embedding with Latent Semantics and Human Behavior Annotations. In Proceedings of the 11th Annual Symposium on Simulation for Architecture and Urban Design, Virtual Event, 25–27 May 2020; Society for Computer Simulation International: San Diego, CA, USA, 2020; pp. 337–344. [Google Scholar]
- As, I.; Pal, S.; Basu, P. Artificial Intelligence in Architecture: Generating Conceptual Design via Deep Learning. Int. J. Archit. Comput. 2018, 16, 306–327. [Google Scholar] [CrossRef]
- Pan, Y.; Qian, J.; Hu, Y. A Preliminary Study on the Formation of the General Layouts on the Northern Neighborhood Community Based on GauGAN Diversity Output Generator. In Proceedings of the 2nd International Conference on Computational Design and Robotic Fabrication (CDRF), Shanghai, China, 5–6 July 2020; pp. 179–188. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Conference on Advances in Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8107–8116. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Hao, Z.; Ren, Y. Machine Learning Neural Networks Construction and Analysis in Vectorized Design Drawings. In Proceedings of the 25th International Conference on Computer-Aided Architectural Design Research in Asia (CAADRIA), Bangkok, Thailand, 5–8 August 2020; pp. 709–718. [Google Scholar] [CrossRef]
- Brock, A.; Lim, T.; Ritchie, J.M.; Weston, N. Generative and Discriminative Voxel Modeling with Convolutional Neural Networks. arXiv 2016, arXiv:1608.04236. [Google Scholar]
- Peters, N. Enabling Alternative Architectures: Collaborative Frameworks for Participatory Design. Ph.D. Thesis, Harvard Graduate School of Design, Cambridge, MA, USA, 2017. [Google Scholar]
- Available online: https://www.xkool.ai (accessed on 9 January 2023).
- Ronneberger, O.; Fischer. P.; Brox. T. U-net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-assisted Intervention; Springer: Cham, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh., N.; Liang, J. Unet++: A Nested U-net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Germany, 2018; pp. 3–11. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5686–5696. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Competition | Location | Entries | Retained |
|---|---|---|---|
| SD2007 | Washington, DC, USA | 20 | 13 |
| SD2009 | Washington, DC, USA | 21 | 15 |
| SDE2010 | Madrid, Spain | 17 | 5 |
| SD2011 | Washington, DC, USA | 19 | 10 |
| SDE2012 | Madrid, Spain | 18 | 5 |
| SD2013 | Irvine, CA, USA | 20 | 15 |
| SD2015 | Irvine, CA, USA | 15 | 12 |
| SD2017 | Irvine, CA, USA | 11 | 9 |
| SDEM2018 | Dubai, UAE | 14 | 9 |
| Total | - | 155 | 93 |
| Name | Color (R, G, B) | Name | Color (R, G, B) | Name | Color (R, G, B) |
|---|---|---|---|---|---|
| Photovoltaic panels |  (128, 0, 0) | Door |  (255, 0, 255) | Windows |  (0, 255, 255) |
| Plain walls |  (128, 128, 0) | Wooden walls |  (255, 0, 0) | High windows |  (0, 0, 255) |
| Greening |  (0, 128, 0) | Railings |  (255, 255, 0) | Steps |  (255, 115, 0) |
| Marking Content | Score |
|---|---|
| Generate images with clear borders | 0~5 |
| Image quality without aliasing | 0~5 |
| The color block generated in a reasonable position | 0~5 |
| Unity of the whole and the part | 0~5 |
| Harmony of proportion and scale | 0~5 |
| Energy efficiency performance | 0~5 |
| Design performance | 0~5 |
| Item | Configuration | Item | Configuration |
|---|---|---|---|
| Operating systems | Windows10 | Compilers | PyCharm |
| CPU | AMD2600X | CUDA | CUDA10.1 |
| GPU | RTX2080Ti | CuDNN | CuDNN7.6.5 |
| Development Languages | Python3.7 | Deep Learning Framework | Pytorch1.7.1 |
| Input | Output | Ground Truth |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
| Input | Output | Ground Truth |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
| Input | Output | Ground Truth |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
| Input | Output | Ground Truth |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
| Questionnaire Item | U-Net | U-Net++ | HRNet | AttU-Net |
|---|---|---|---|---|
| Generate images with clear borders | 3 | 3.4 | 4 | 4.1 |
| Image quality without aliasing | 2.5 | 3.1 | 3.7 | 4 |
| The color block generated in a reasonable position | 2.7 | 3.2 | 3.8 | 3.9 |
| Unity of the whole and the part | 2..7 | 3.2 | 3.8 | 4.2 |
| Harmony of proportion and scale | 3 | 3.3 | 4.1 | 4.2 |
| Energy efficiency performance | 2.6 | 3.1 | 3.7 | 4.1 |
| Design performance | 2.7 | 3.1 | 3.8 | 4.1 |
| Average score | 2..7 | 3..2 | 3.8 | 4.1 |
| Generators Category | U-Net | U-Net++ | HRNet | AttU-Net |
|---|---|---|---|---|
| Sample 1 SSIM values | 0.65713 | 0.71054 | 0.82845 | 0.86215 |
| Sample 2 SSIM values | 0.59921 | 0.68433 | 0.76534 | 0.81084 |
| Sample 3 SSIM values | 0.62185 | 0.69831 | 0.77015 | 0.83233 |
| SSIM average | 0.626 | 0.697 | 0.788 | 0.835 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, D.; Zhao, R.; Zhang, S.; Liu, H.; Guo, L.; Li, P.; Ding, L. A Deep Learning-Based Approach to Generating Comprehensive Building Façades for Low-Rise Housing. Sustainability 2023, 15, 1816. https://doi.org/10.3390/su15031816
Wan D, Zhao R, Zhang S, Liu H, Guo L, Li P, Ding L. A Deep Learning-Based Approach to Generating Comprehensive Building Façades for Low-Rise Housing. Sustainability. 2023; 15(3):1816. https://doi.org/10.3390/su15031816
Chicago/Turabian StyleWan, Da, Runqi Zhao, Sheng Zhang, Hui Liu, Lian Guo, Pengbo Li, and Lei Ding. 2023. "A Deep Learning-Based Approach to Generating Comprehensive Building Façades for Low-Rise Housing" Sustainability 15, no. 3: 1816. https://doi.org/10.3390/su15031816
APA StyleWan, D., Zhao, R., Zhang, S., Liu, H., Guo, L., Li, P., & Ding, L. (2023). A Deep Learning-Based Approach to Generating Comprehensive Building Façades for Low-Rise Housing. Sustainability, 15(3), 1816. https://doi.org/10.3390/su15031816