
Convolutional Neural Network-Based Vehicle Classification in Low-Quality Imaging Conditions for Internet of Things Devices



Abstract
:1. Introduction
- A simple CNN-based model is proposed for the classification of low-quality vehicle images in low lighting and adverse weather conditions.
- A new dataset containing low-quality vehicle images collected in various environmental conditions is created.
- The efficiency of the proposed model is verified by conducting a comparative analysis with several well-known CNN-based models. Due to its lower computational requirements and acceptable accuracy, it is shown that the proposed model could be implemented on edge devices in IoT-based ITS applications.
2. Related Work and Problem Statement
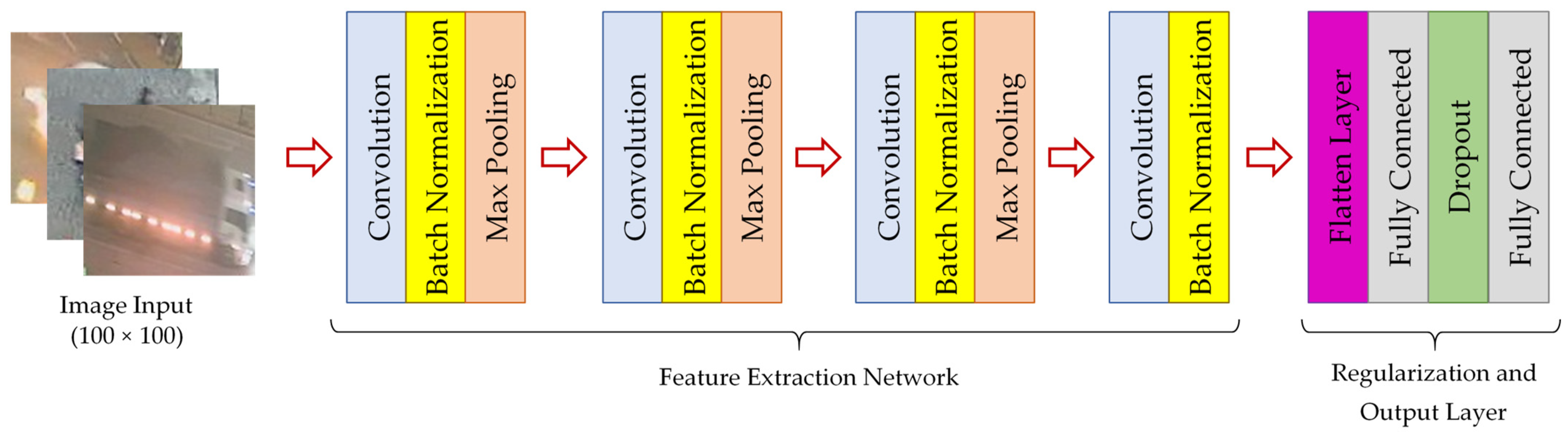
3. Overview of the Proposed CNN-Based Model
4. Experiments
4.1. Dataset and Preprocessing
4.2. Implementation Details
5. Results
5.1. Performance of the Proposed Model
5.2. Comparison with Well-Known CNN Models
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bilotta, S.; Collini, E.; Nesi, P.; Pantaleo, G. Short-Term Prediction of City Traffic Flow via Convolutional Deep Learning. IEEE Access 2022, 10, 113086–113099. [Google Scholar] [CrossRef]
- Mandal, V.; Mussah, A.R.; Jin, P.; Adu-Gyamfi, Y. Artificial Intelligence-Enabled Traffic Monitoring System. Sustainability 2020, 12, 9177. [Google Scholar] [CrossRef]
- Hsu, C.-M.; Chen, J.-Y. Around View Monitoring-Based Vacant Parking Space Detection and Analysis. Appl. Sci. 2019, 9, 3403. [Google Scholar] [CrossRef]
- Jang, C.; Kim, C.; Lee, S.; Kim, S.; Lee, S.; Sunwoo, M. Re-Plannable Automated Parking System With a Standalone Around View Monitor for Narrow Parking Lots. IEEE Trans. Intell. Transp. Syst. 2020, 21, 777–790. [Google Scholar] [CrossRef]
- Cui, G.; Zhang, W.; Xiao, Y.; Yao, L.; Fang, Z. Cooperative Perception Technology of Autonomous Driving in the Internet of Vehicles Environment: A Review. Sensors 2022, 22, 5535. [Google Scholar] [CrossRef] [PubMed]
- Claussmann, L.; Revilloud, M.; Gruyer, D.; Glaser, S. A Review of Motion Planning for Highway Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1826–1848. [Google Scholar] [CrossRef]
- Gholamhosseinian, A.; Seitz, J. Vehicle Classification in Intelligent Transport Systems: An Overview, Methods and Software Perspective. IEEE Open J. Intell. Transp. Syst. 2021, 2, 173–194. [Google Scholar] [CrossRef]
- Won, M. Intelligent Traffic Monitoring Systems for Vehicle Classification: A Survey. IEEE Access 2020, 8, 73340–73358. [Google Scholar] [CrossRef]
- Shokravi, H.; Shokravi, H.; Bakhary, N.; Heidarrezaei, M.; Rahimian Koloor, S.S.; Petrů, M. A Review on Vehicle Classification and Potential Use of Smart Vehicle-Assisted Techniques. Sensors 2020, 20, 3274. [Google Scholar] [CrossRef]
- Maity, S.; Bhattacharyya, A.; Singh, P.K.; Kumar, M.; Sarkar, R. Last Decade in Vehicle Detection and Classification: A Comprehensive Survey. Arch. Comput. Methods Eng. 2022, 29, 5259–5296. [Google Scholar] [CrossRef]
- Hussain, K.F.; Afifi, M.; Moussa, G. A Comprehensive Study of the Effect of Spatial Resolution and Color of Digital Images on Vehicle Classification. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1181–1190. [Google Scholar] [CrossRef]
- Pavel, M.I.; Tan, S.Y.; Abdullah, A. Vision-Based Autonomous Vehicle Systems Based on Deep Learning: A Systematic Literature Review. Appl. Sci. 2022, 12, 6831. [Google Scholar] [CrossRef]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle Type Classification Using a Semisupervised Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Yu, S.; Wu, Y.; Li, W.; Song, Z.; Zeng, W. A Model for Fine-Grained Vehicle Classification Based on Deep Learning. Neurocomputing 2017, 257, 97–103. [Google Scholar] [CrossRef]
- Zhuo, L.; Jiang, L.; Zhu, Z.; Li, J.; Zhang, J.; Long, H. Vehicle Classification for Large-Scale Traffic Surveillance Videos Using Convolutional Neural Networks. Mach. Vis. Appl. 2017, 28, 793–802. [Google Scholar] [CrossRef]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Vision-Based Occlusion Handling and Vehicle Classification for Traffic Surveillance Systems. IEEE Intell. Transp. Syst. Mag. 2018, 10, 80–92. [Google Scholar] [CrossRef]
- Maungmai, W.; Nuthong, C. Vehicle Classification with Deep Learning. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; pp. 294–298. [Google Scholar]
- Wang, X.; Zhang, W.; Wu, X.; Xiao, L.; Qian, Y.; Fang, Z. Real-Time Vehicle Type Classification with Deep Convolutional Neural Networks. J. Real-Time Image Process. 2019, 16, 5–14. [Google Scholar] [CrossRef]
- Jahan, N.; Islam, S.; Foysal, M.F.A. Real-Time Vehicle Classification Using CNN. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–6. [Google Scholar]
- Sharma, P.; Singh, A.; Singh, K.K.; Dhull, A. Vehicle Identification Using Modified Region Based Convolution Network for Intelligent Transportation System. Multimed. Tools Appl. 2022, 81, 34893–34917. [Google Scholar] [CrossRef]
- Ma, Z.; Chang, D.; Xie, J.; Ding, Y.; Wen, S.; Li, X.; Si, Z.; Guo, J. Fine-Grained Vehicle Classification with Channel Max Pooling Modified CNNs. IEEE Trans. Veh. Technol. 2019, 68, 3224–3233. [Google Scholar] [CrossRef]
- Chauhan, M.S.; Singh, A.; Khemka, M.; Prateek, A.; Sen, R. Embedded CNN Based Vehicle Classification and Counting in Non-Laned Road Traffic. In Proceedings of the Tenth International Conference on Information and Communication Technologies and Development, Ahmedabad, India, 4–7 January 2019; pp. 1–11. [Google Scholar]
- Hasan, M.M.; Wang, Z.; Hussain, M.A.I.; Fatima, K. Bangladeshi Native Vehicle Classification Based on Transfer Learning with Deep Convolutional Neural Network. Sensors 2021, 21, 7545. [Google Scholar] [CrossRef]
- Mittal, U.; Potnuru, R.; Chawla, P. Vehicle Detection and Classification Using Improved Faster Region Based Convolution Neural Network. In Proceedings of the 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 4–5 June 2020; pp. 511–514. [Google Scholar] [CrossRef]
- Hassan, R.; Qamar, F.; Hasan, M.K.; Aman, A.H.M.; Ahmed, A.S. Internet of Things and Its Applications: A Comprehensive Survey. Symmetry 2020, 12, 1674. [Google Scholar] [CrossRef]
- Derawi, M.; Dalveren, Y.; Cheikh, F.A. Internet-of-Things-Based Smart Transportation Systems for Safer Roads. In Proceedings of the 2020 IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 2–16 June 2020; pp. 1–4. [Google Scholar]
- Biswas, A.; Wang, H.-C. Autonomous Vehicles Enabled by the Integration of IoT, Edge Intelligence, 5G, and Blockchain. Sensors 2023, 23, 1963. [Google Scholar] [CrossRef]
- Chmaj, G.; Lazeroff, M. IoT Machine Learning Based Parking Management System with Anticipated Prediction of Available Parking Spots. In Proceedings of the ITNG 2022 19th International Conference on Information Technology-New Generations, Las Vegas, NV, USA, 10–13 April 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 341–350. [Google Scholar]
- Babu, K.R.M. IOT for ITS: An IOT Based Dynamic Traffic Signal Control. In Proceedings of the 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11–12 July 2018; pp. 532–537. [Google Scholar]
- Bautista, C.M.; Dy, C.A.; Mañalac, M.I.; Orbe, R.A.; Cordel, M. Convolutional Neural Network for Vehicle Detection in Low Resolution Traffic Videos. In Proceedings of the 2016 IEEE Region 10 Symposium (TENSYMP), Bali Island, Indonesia, 9–11 May 2016; pp. 277–281. [Google Scholar]
- Chen, W.; Sun, Q.; Wang, J.; Dong, J.-J.; Xu, C. A Novel Model Based on AdaBoost and Deep CNN for Vehicle Classification. IEEE Access 2018, 6, 60445–60455. [Google Scholar] [CrossRef]
- Roecker, M.N.; Costa, Y.M.; Almeida, J.L.; Matsushita, G.H. Automatic Vehicle Type Classification with Convolutional Neural Networks. In Proceedings of the 2018 25th International Conference on Systems, Signals and Image Processing (IWSSIP), Maribor, Slovenia, 20–22 June 2018; pp. 1–5. [Google Scholar]
- Tsai, C.-C.; Tseng, C.-K.; Tang, H.-C.; Guo, J.-I. Vehicle Detection and Classification Based on Deep Neural Network for Intelligent Transportation Applications. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1605–1608. [Google Scholar]
- Wang, X.; Chen, X.; Wang, Y. Small Vehicle Classification in the Wild Using Generative Adversarial Network. Neural Comput. Appl. 2021, 33, 5369–5379. [Google Scholar] [CrossRef]
- Butt, M.A.; Khattak, A.M.; Shafique, S.; Hayat, B.; Abid, S.; Kim, K.-I.; Ayub, M.W.; Sajid, A.; Adnan, A. Convolutional Neural Network Based Vehicle Classification in Adverse Illuminous Conditions for Intelligent Transportation Systems. Complexity 2021, 2021, 6644861. [Google Scholar] [CrossRef]
- Tas, S.; Sari, O.; Dalveren, Y.; Pazar, S.; Kara, A.; Derawi, M. Deep Learning-Based Vehicle Classification for Low Quality Images. Sensors 2022, 22, 4740. [Google Scholar] [CrossRef] [PubMed]
- Maiga, B.; Dalveren, Y.; Kara, A.; Derawi, M. A Dataset Containing Tiny Vehicle Images Collected in Low Quality Imaging Conditions. Available online: https://zenodo.org/records/8282760 (accessed on 23 November 2023).
- Ghimire, D.; Kil, D.; Kim, S. A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration. Electronics 2022, 11, 945. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:14091556. [Google Scholar]
- Shafiq, M.; Gu, Z. Deep Residual Learning for Image Recognition: A Survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, Boston, MA, USA, 7–12 July 2015; IEEE: New York, NY, USA, 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv170404861. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1251–1258. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Kim, P. MATLAB Deep Learning; Machine Learning, Neural Networks and Artificial Intelligence; Apress: Berkeley, CA, USA, 2017; ISBN 978-1-4842-2845-6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Model | Data/Image Properties | Environmental Conditions | Camera Settings |
|---|---|---|---|---|
| [30] | CNN |
|
| Low-resolution cameras set close to the ROI with a depression angle view |
| [31] | AdaBoost algorithm and deep CNNs |
|
| Traffic surveillance cameras set close to the ROI with a depression angle view |
| [32] | Modified CNN |
|
| |
| [33] | Faster R-CNN |
|
| Traffic surveillance cameras set close to the ROI with both depression angle and dashcam view |
| [34] | GAN |
|
| Cameras set close to the ROI with a dashcam view |
| [35] | ResNet |
|
| Traffic surveillance cameras set close to the ROI with a depression angle view |
| [36] | Modified CNN |
|
| Security surveillance camera distant from the ROI with a wide depression angle view |
| Our Work | Modified CNN |
|
| Models | Accuracy (%) | Loss (%) | # Layers | # Parameters (Million) | Training Time (min) | Inference Time (ms) | F1-Score (%) | Recall(%) | Precision (%) |
|---|---|---|---|---|---|---|---|---|---|
| DenseNet121 | 97.4 | 22.8 | 431 | ~7 | 27 | 1.8 | 97.41 | 97.11 | 97.75 |
| ResNet50 | 97.4 | 24.7 | 179 | ~24 | 32 | 1.7 | 97.4 | 97.11 | 97.74 |
| Proposed Model | 95.8 | 30.1 | 15 | ~4 | 9 | 0.9 | 95.52 | 95 | 96.26 |
| Inception-ResNet v2 | 95.3 | 22.2 | 784 | ~54 | 48 | 2.8 | 95.03 | 94.69 | 95.4 |
| Xception | 95.2 | 25.6 | 136 | ~21 | 35 | 1.6 | 94.87 | 94.3 | 95.63 |
| VGG19 | 94.4 | 47.6 | 26 | ~20 | 49 | 6.9 | 93.92 | 93.67 | 94.24 |
| Inception v3 | 93.3 | 37.3 | 315 | ~22 | 25 | 1.4 | 93.19 | 93.12 | 93.28 |
| Models | Accuracy (%) | |||||
|---|---|---|---|---|---|---|
| Bike | Car | Juggernaut | Minibus | Pickup | Truck | |
| DenseNet121 | 99.38 | 99.06 | 93.33 | 93.12 | 92.57 | 96.68 |
| ResNet50 | 100 | 99.06 | 95.62 | 92.5 | 92.35 | 96.88 |
| Proposed Model | 100 | 98.75 | 91.22 | 90.62 | 93.46 | 95.62 |
| Inception-ResNet v2 | 98.75 | 97.19 | 93.49 | 86.88 | 90.62 | 95.94 |
| Xception | 99.38 | 96.56 | 92.54 | 83.75 | 90.47 | 95.4 |
| VGG19 | 98.12 | 95.62 | 89.6 | 86.25 | 85.99 | 93.75 |
| Inception v3 | 96.88 | 95.61 | 96.23 | 81.12 | 86.24 | 91.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maiga, B.; Dalveren, Y.; Kara, A.; Derawi, M. Convolutional Neural Network-Based Vehicle Classification in Low-Quality Imaging Conditions for Internet of Things Devices. Sustainability 2023, 15, 16292. https://doi.org/10.3390/su152316292
Maiga B, Dalveren Y, Kara A, Derawi M. Convolutional Neural Network-Based Vehicle Classification in Low-Quality Imaging Conditions for Internet of Things Devices. Sustainability. 2023; 15(23):16292. https://doi.org/10.3390/su152316292
Chicago/Turabian StyleMaiga, Bamoye, Yaser Dalveren, Ali Kara, and Mohammad Derawi. 2023. "Convolutional Neural Network-Based Vehicle Classification in Low-Quality Imaging Conditions for Internet of Things Devices" Sustainability 15, no. 23: 16292. https://doi.org/10.3390/su152316292
APA StyleMaiga, B., Dalveren, Y., Kara, A., & Derawi, M. (2023). Convolutional Neural Network-Based Vehicle Classification in Low-Quality Imaging Conditions for Internet of Things Devices. Sustainability, 15(23), 16292. https://doi.org/10.3390/su152316292