
Enhancing Self-Explanation Learning through a Real-Time Feedback System: An Empirical Evaluation Study

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Work
2.1. Effects of Self-Explanation in Mathematics
2.2. Utilization of Self-Explanation
2.3. Consideration on Existing Intelligent Tutoring Systems
2.4. Contribution of This Study
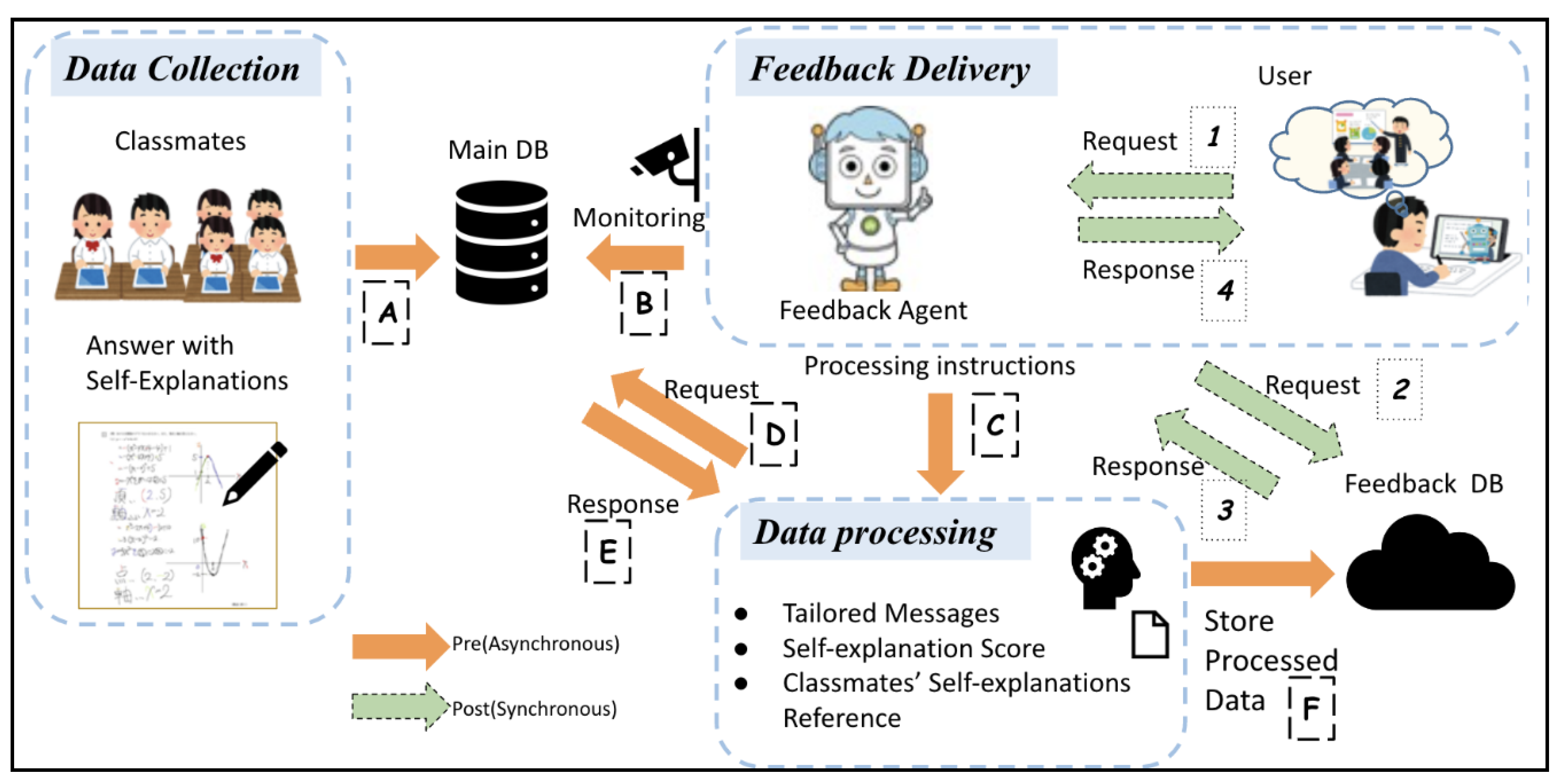
3. The Architecture of the SEAF System
3.1. Data Collection
3.2. Feedback Delivery
3.3. Data Processing
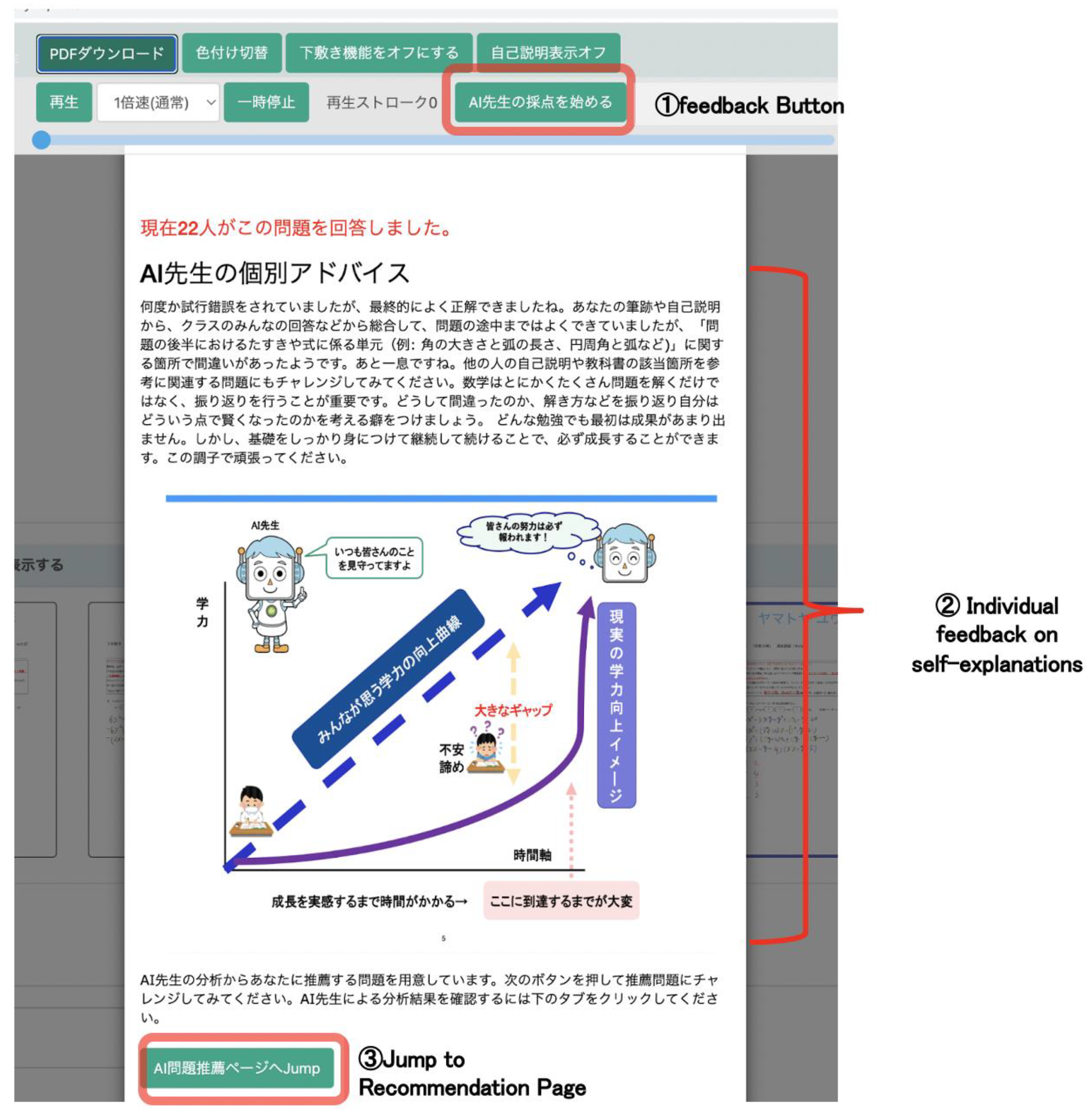
3.3.1. Personalized Message Feature
| Algorithm 1: Personalized Message Selection |
| Input: user performance data (UPD), past interactions data (PID), current task context (CTC) |
| Begin with an empty list for potential feedback: FeedbackList = [] |
| Evaluate UPD for frequent errors in specific areas: |
| a. Retrieve relevant feedback messages associated with that area from the database. |
| b. Add these messages to FeedbackList. |
| Analyze PID for recurrent challenges the learner has faced: |
| a. Procure encouraging messages tailored to that specific challenge. |
| b. Incorporate these into FeedbackList. |
| In light of CTC: |
| a. Obtain contextual guidance messages. |
| b. Integrate these into FeedbackList. |
| Organize messages in FeedbackList based on a relevance score, which is calculated using a blend of UPD, PID, and CTC. |
| Present the learner with the top-ranked message from FeedbackList. |
| End algorithm |
- ①
- “The problem was tackled by many students in five distinct steps. The table below elucidates the formulas and methodologies employed in solving each step, extrapolated from the introductory statements of the entire student body. This resource can serve as a valuable reference for your forthcoming studies. It is noteworthy that the AI’s assessment did not detect any points where you encountered collective difficulties”.
- ②
- “Solution and SE for Each Step: The process involves subtracting the upper triangle from the larger triangle, intersected by the plane passing through points A, H, and D. This yields the volume containing point H. 2 Step: Utilizing the three-square theorems, the area ratio between the large triangle and the trapezoid is employed to determine the area” (sample).
3.3.2. Self-Explanation Scoring Feature
| Algorithm 2: Scatter Plot of Self-explanation Score vs. Length |
| Input: list of students (U = {u_1, u_2, …, u_n}), self-explanation scores (SESs), length of self-explanation (L) Initialize an empty scatter plot: ScatterPlot = {} |
| For each student u in U: a. Extract the self-explanation score for student u: Score_u = SES[u] b. Extract the length of self-explanation for student u: Length_s = L [u] c. Plot point (Length_u, Score_u) on ScatterPlot with: I. X-axis representing Length_u II. Y-axis representing Score_u |
| Customize ScatterPlot: a. Label X-axis as “Length of Self-Explanation” b. Label Y-axis as “Self-Explanation Score” c. Add title “Scatter Plot of Length of Self-Explanation vs. Self-Explanation Score” d. Highlight regions of high concentration, if any, to elucidate trends |
| Display ScatterPlot for visual analysis and interpretation. |
| End |
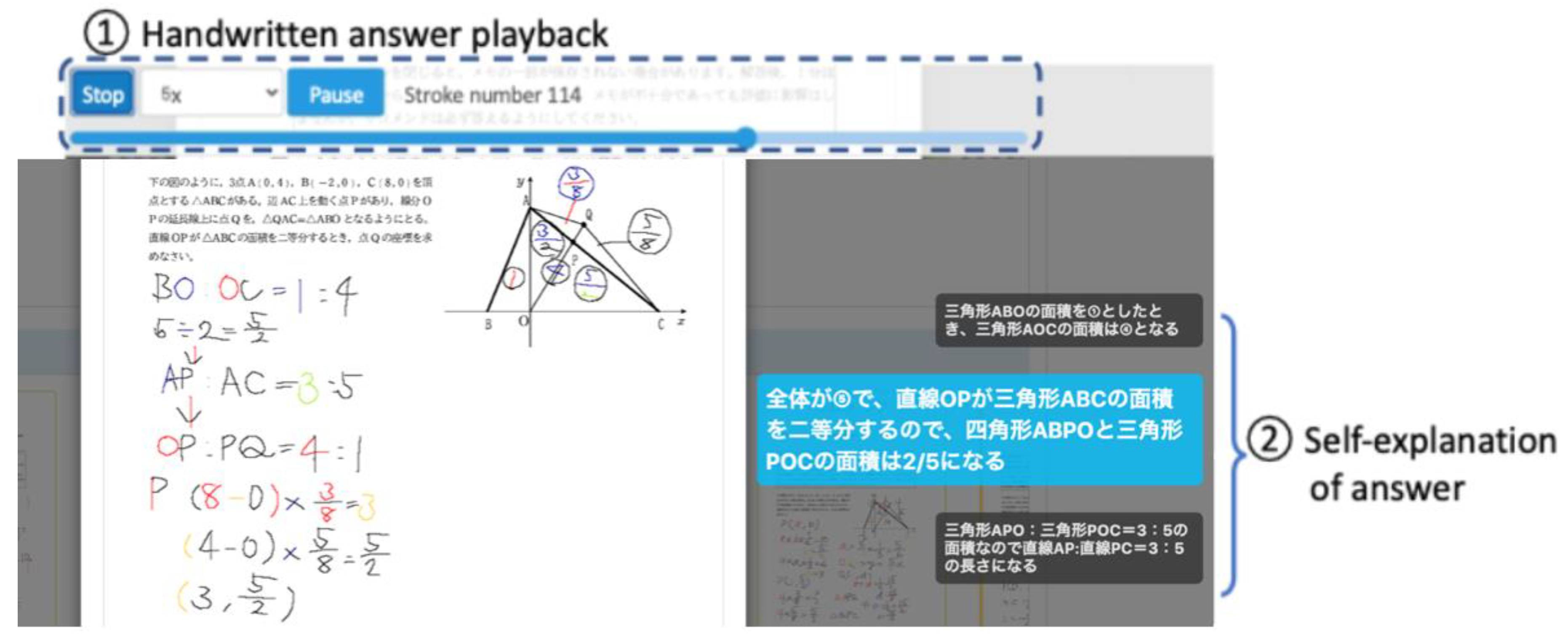
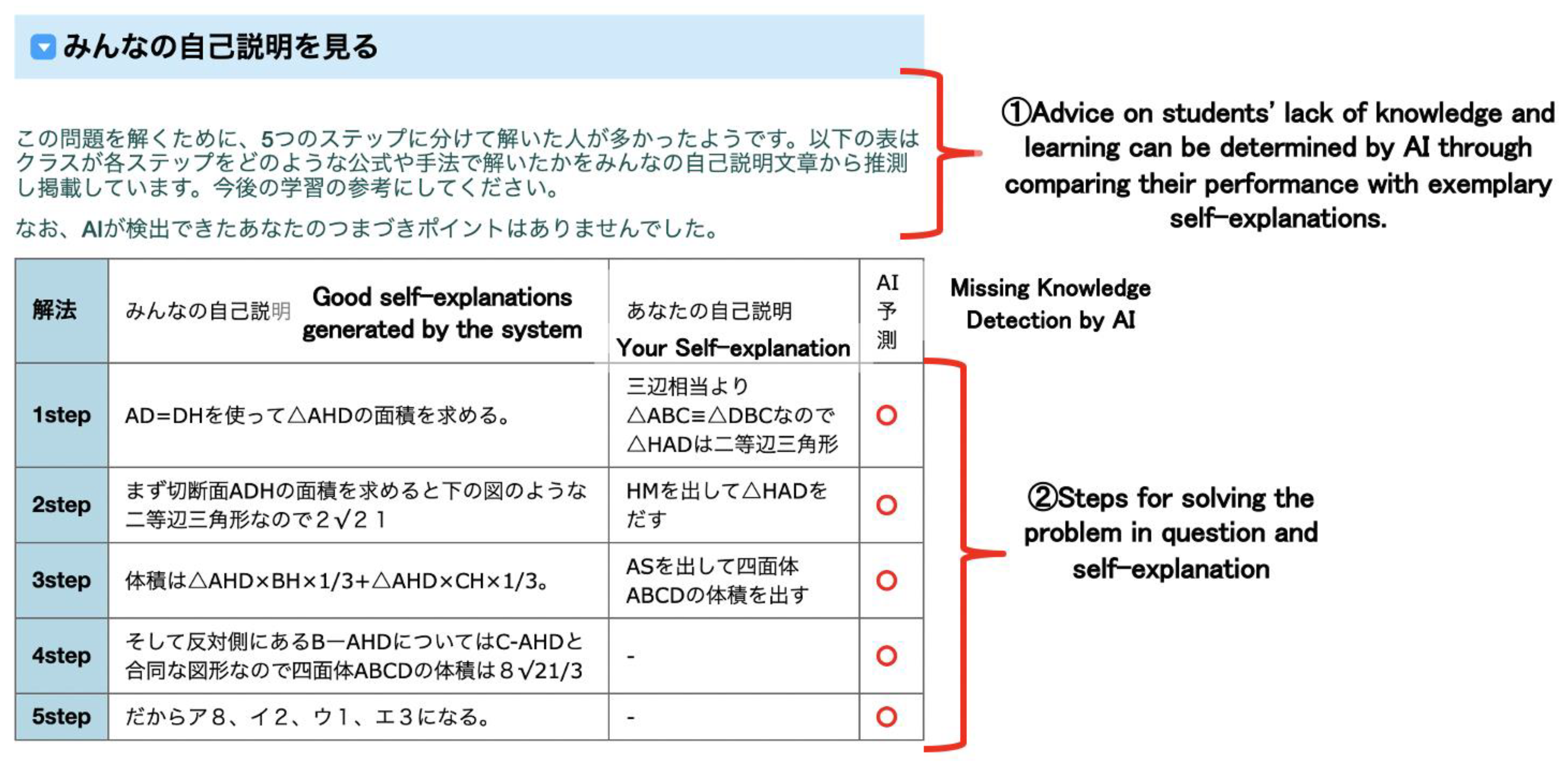
3.3.3. Classmates’ Self-Explanations Reference Feature
4. Analytical Methods and Framework for Analysis
4.1. Experiment Methodology
- Before Experiment: This served as the baseline data acquisition period, where students wrote self-explanations without the intervention of SEAF, thereby capturing their innate self-explanation abilities.
- Preliminary Experiment: Here, students were introduced to the SEAF tool for the first time. This phase was conducted from November 2021 to March 2022. They were directed to pen their self-explanations, checking their pen strokes, and upon completion, press a button to garner feedback on their self-explanations. This phase allowed for initial observations on SEAF’s immediate effects on self-explanation quality.
- Actual Experiment: Extending from April 2022 to June 2022, this phase saw students’ continued use of SEAF, reinforcing the habits developed during the Preliminary Experiment and providing insights into the tool’s longer-term impact on students’ self-explanation skills. During this phase, the 49 questions were administered on a weekly basis over the course of three months to gauge the students’ understanding and evolution in self-explanation abilities.
4.2. Analysis Preparations
4.2.1. Evaluation of Self-Explanations Based on Three Principal Criteria
- Scoring system: two independent raters employed rubrics developed for this study to assess the self-explanations. A scale ranging from one to five was utilized for scoring.
- Rater consistency: quadratic weighted Cohen’s kappa coefficient [47] was employed to determine the level of agreement between the raters. A coefficient value of 0.749 indicates substantial agreement.
- Data processing: to maintain consistency in the evaluation, the mean score from both raters were used for further analysis.
- Categorization of scores: for a clear distribution, the self-explanation scores were categorized, aiming for uniformity. Participants were divided into two groups based on average self-explanation quality scores:
- High-self-explanation group: scores of three or above.
- Low-self-explanation group: scores below three. This cutoff score was determined as the minimum level of knowledge or skills that can be acquired through self-explanation.
- Criteria for quality assessment: a high-quality self-explanation should:
- (1)
- Encompass all pertinent concepts.
- (2)
- Exhibit logical structuring.
- (3)
- Use appropriate conjunctions for connecting ideas.
4.2.2. Participant Categorization Based on Engagement
5. Results of SEAF Learning Effects Experiments
5.1. Results of Statistical Analysis Based on Self-Explanation Level
5.2. Repeated Measures ANOVA
5.3. Perception Analysis
6. Discussion and Limitations
6.1. RQ1. Can a Classmate’s Self-Explanations Be Presented and Useful to the Learner as Feedback?
6.2. RQ2. Which Students Benefit Most from Using the SEAF System?
6.3. Limitations
- Sample Size: The study involved a sample size of 50 participants, which, while providing valuable insights, may not be sufficiently large to establish the full effectiveness of SEAF. Future research endeavors should include larger samples and additional experiments to enhance the robustness of our findings.
- SEAF's Adaptability: It's important to acknowledge that SEAF may not be universally suitable for every student. Future efforts should focus on enhancing the flexibility and personalization of SEAF to cater to a broader range of learning styles and preferences.
- Quality of Explanations: The success of SEAF hinges on the consistency and quality of self-explanations provided by students. Improving the quality of these self-explanations is of paramount importance. Consideration could be given to implementing incentive mechanisms, such as rewards, to encourage students to generate top-notch self-explanations.
- Feedback Representation: While we actively sought feedback from all participants, it's noteworthy that the majority of feedback came from the high-engagement group. This emphasizes the intricate relationship between motivation and effective self-explanation. The limited response from the less-engaged group underscores the challenges of simultaneously evaluating motivation and learning. Further research should explore strategies to engage all participants effectively in the feedback process.
6.4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional encoder representations from transformers |
| NLP | Natural language processing |
| SEAF | Self-explanation automated feedback |
Appendix A. Generating Personalized Messages
Appendix B. Analyzing Self-Explanation Score
Appendix C. Extracting Example Sentences
References
- Hattie, J.; Biggs, J.; Purdie, N. Effects of learning skills interventions on student learning: A meta-analysis. Rev. Educ. Res. 1996, 66, 99–136. [Google Scholar] [CrossRef]
- Rattle-Johnson, B. Developing Mathematics Knowledge. Child Dev. Perspect. 2017, 11, 184–190. [Google Scholar] [CrossRef]
- Bisra, K.; Liu, Q.; Nesbit, J.C.; Salimi, F.; Winne, P.H. Inducing Self-Explanation: A Meta-Analysis. Educ. Psychol. Rev. 2018, 30, 703–725. [Google Scholar] [CrossRef]
- Chi, M.T.H.; Bassok, M.; Lewis, M.W.; Reimann, P.; Glaser, R. Self-explanations: How students study and use examples in learning to solve problems. Cogn. Sci. 1989, 13, 145–182. [Google Scholar]
- Rattle-Johnson, B. Promoting transfer: Effects of self-explanation and direct instruction. Child Dev. 2006, 77, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Chi, M.; Leeuw, N.; Chiu, M.; Lavancher, C. Eliciting self-explanations improves understanding. Cogn. Sci. 1994, 18, 439–477. [Google Scholar]
- Renkl, A. Learning from worked-out examples: A study on individual differences. Cogn. Sci. 1997, 21, 1–29. [Google Scholar]
- Berthold, K.; Eysink, T.H.; Renkl, A. Assisting self-explanation prompts are more effective than open prompts when learning with multiple representations. Instr. Sci. 2009, 37, 345–363. [Google Scholar] [CrossRef]
- Berthold, K.; Renkl, A. Instructional aids to support a conceptual understanding of multiple representations. J. Educ. Psychol. 2009, 101, 70. [Google Scholar] [CrossRef]
- Rattle-Johnson, B.; Loehr, A.M.; Durkin, K. Promoting self-explanation to improve mathematics learning: A meta-analysis and instructional design principles. ZDM 2017, 49, 599–611. [Google Scholar] [CrossRef]
- Arne, T.; McCarthy, K.; McNamara, D. Start Stair Stepper—Using Comprehension Strategy Training to Game the Test. Computers 2021, 10, 48. [Google Scholar] [CrossRef]
- Hattie, J. Visible Learning: A Synthesis of 800+ Meta-Analyses on Achievement; Routledge: Abingdon, UK, 2009. [Google Scholar]
- Colglazier, W. Sustainable development agenda: 2030. Science 2015, 349, 1048–1050. [Google Scholar] [CrossRef] [PubMed]
- Lu, V.N.; Wirtz, J.; Kunz, W.H.; Paluch, S.; Gruber, T.; Martins, A.; Patterson, P.G. Service robots, customers, and service em-ployees: What can we learn from the academic literature and where are the gaps? J. Serv. Theory Pract. 2020, 30, 361–391. [Google Scholar] [CrossRef]
- Hwang, G.J.; Xie, H.; Wah, B.W.; Gašević, D. Vision, challenges, roles and research issues of Artificial Intelligence in Education. Comput. Educ. Artif. Intell. 2020, 1, 100001. [Google Scholar] [CrossRef]
- Su, P.Y.; Zhao, Z.Y.; Shao, Q.G.; Lin, P.Y.; Li, Z. The Construction of an Evaluation Index System for Assistive Teaching Robots Aimed at Sustainable Learning. Sustainability 2023, 15, 13196. [Google Scholar] [CrossRef]
- McNamara, D.S.; Levinstein, I.B.; Boonthum, C. start: Interactive strategy training for active reading and thinking. Behav. Res. Methods Instrum. Comput. 2004, 36, 222–233. [Google Scholar] [CrossRef] [PubMed]
- Boonthum, C.; Levinstein, I.B.; McNamara, D.S. Evaluating Self-Explanations in start: Word Matching, Latent Semantic Analysis, and Topic Models. In Natural Language Processing and Text Mining; Kao, A., Poteet, S.R., Eds.; Springer: London, UK, 2007. [Google Scholar] [CrossRef]
- Levinstein, I.B.; Boonthum, C.; Pillarisetti, S.P.; Bell, C.; McNamara, D.S. start 2: Improvements for efficiency and effectiveness. Behav. Res. Methods 2007, 39, 224–232. [Google Scholar] [CrossRef]
- O’Neil, H.F.; Chung, G.K.W.K.; Kerr, D.; Vendlinski, T.P.; Buschang, R.E.; Mayer, R.E. Adding self-explanation prompts to an educational computer game. Comput. Hum. Behav. 2014, 30, 23–28. [Google Scholar] [CrossRef]
- Renkl, A. Learning from worked-examples in mathematics: Students relate procedures to principles. ZDM 2017, 49, 571–584. [Google Scholar] [CrossRef]
- Chi, M.T.H. Self-Explaining: The Dual Processes of Generating Inference and Repairing Mental Models Advances in Instructional Psychology: Educational Design and Cognitive Science; Erlbaum: Mahwah, NJ, USA, 2000; Volume 5, pp. 161–238. [Google Scholar]
- McEldoon, K.L.; Durkin, K.L.; Rattle-Johnson, B. Is self-explanation worth the time? A comparison to additional practice. Br. J. Educ. Psychol. 2013, 83, 615–632. [Google Scholar] [CrossRef]
- Rattle-Johnson, B.; Schneider, M. Developing Conceptual and Procedural Knowledge of Mathematics; Cohen Kadosh, R., Dowker, A., Eds.; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Rattle-Johnson, B.; Schneider, M.; Star, J.R. Not a one-way street: Bidirectional relations between procedural and conceptual knowledge of mathematics. Educ. Psychol. Rev. 2015, 27, 587–597. [Google Scholar] [CrossRef]
- Rattle-Johnson, B.; Siegler, R.S.; Alibali, M.W. Developing conceptual understanding and procedural skill in mathematics: An iterative process. J. Educ. Psychol. 2001, 93, 346–362. [Google Scholar] [CrossRef]
- Star, J.R. Reconceptualizing procedural knowledge. J. Res. Math. Educ. 2005, 36, 404–411. [Google Scholar]
- Crippen, K.J.; Earl, B.L. The impact of web-based worked examples and self-explanation on performance, problem solving, and self-efficacy. Comput. Educ. 2007, 49, 809–821. [Google Scholar] [CrossRef]
- Jackson, G.T.; Guess, R.H.; McNamara, D.S. Assessing cognitively complex strategy use in an untrained domain. Top. Cogn. Sci. 2010, 2, 127–137. [Google Scholar] [CrossRef] [PubMed]
- Alevin, V.; Ogan, A.; Popescu, O.; Torrey, C.; Koedinger, K. Evaluating the effectiveness of a tutorial dialogue system for self-explanation. In Intelligent Tutoring Systems, Proceedings of the 7th International Conference, ITS, Alagoas, Brazil, 30 August–3 September 2004; Proceedings 7; Springer: Berlin/Heidelberg, Germany, 2004; pp. 443–454. [Google Scholar] [CrossRef]
- Fyfe, E.R.; Rattle-Johnson, B. Feedback both helps and hinders learning: The causal role of prior knowledge. J. Educ. Psychol. 2016, 108, 82–97. [Google Scholar] [CrossRef]
- Ritter, S.; Anderson, J.R.; Koedinger, K.R.; Corbett, A. Cognitive Tutor: Applied research in mathematics education. Psychon. Bull. Rev. 2007, 14, 249–255. [Google Scholar] [CrossRef] [PubMed]
- Carnegie Learning. Why CL: Research. 2023. Available online: https://www.carnegielearning.com/why-cl/research/ (accessed on 2 September 2023).
- Heffernan, N.T.; Heffernan, C. The Assessment’s Ecosystem: Building a Platform that Brings Scientists and Teachers Together for Minimally Invasive Research on Human Learning and Teaching. Int. J. Artif. Intell. Educ. 2014, 24, 470–497. [Google Scholar] [CrossRef]
- Assessment’s. 2023. Available online: https://new.assistments.org/ (accessed on 2 September 2023).
- Flanagan, B.; Ogata, H. Learning Analytics Platform in Higher Education in Japan. Knowl. Manag. E-Learn. (KMEL) 2018, 10, 469–484. [Google Scholar]
- Dodeen, H. Teaching test-taking strategies: Importance and techniques. Psychol. Res. 2015, 5, 108–113. [Google Scholar]
- Hong, E.; Sas, M.; Sas, J.C. Test-taking strategies of high and low mathematics achievers. J. Educ. Res. 2006, 99, 144–155. [Google Scholar] [CrossRef]
- Bandura, A. ; National Inst of Mental Health. Social Foundations of Thought and Action: A Social Cognitive Theory; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1986. [Google Scholar]
- Schunk, D.H.; Pajares, F. Competence Perceptions and Academic Functioning. In Handbook of Competence and Motivation; Elliot, A.J., Dweck, C.S., Eds.; Guilford Publications: New York, NY, USA, 2005; pp. 85–104. [Google Scholar]
- Hall, S.; Vance, E.A. Improving Self-Efficacy in Statistics: Role of Self-Explanation & Feedback. J. Stat. Educ. 2010, 18, 3. [Google Scholar] [CrossRef]
- Takallou, F.; Vahdany, F.; Araghi, S.M.; Tabrizi, A.R.N. The effect of test taking strategy instruction on Iranian high school students’ performance on English section of the University entrance examination and their attitude towards using these strategies. Int. J. Appl. Linguist. Engl. Lit. 2015, 4, 119–129. [Google Scholar]
- Nakamoto, R.; Flanagan, B.; Takam, K.; Dai, Y.; Ogata, H. Identifying Students’ Missing Knowledge s Using Self-Explanations and Pen Stroke Data in a Mathematics Quiz. ICCE 2021, 2021, 22–26. [Google Scholar]
- Nakamoto, R.; Flanagan, B.; Dai, Y.; Takami, K.; Ogata, H. Unsupervised techniques for generating a standard sample self-explanation answer with knowledge components in a math quiz. Res. Pract. Technol. Enhanc. Learn. 2024, 19, 016. [Google Scholar] [CrossRef]
- Fyfe, E.R.; Rattle-Johnson, B. The benefits of computer-generated feedback for mathematics problem solving. J. Exp. Child Psychol. 2016, 147, 140–151. [Google Scholar] [CrossRef] [PubMed]
- Thompson, D.R.; Senk, S.L. Using rubrics in high school mathematics courses. Math. Teach. Learn. Teach. PK-12 1998, 91, 786–793. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Blumenfeld, P.; Kempler, T.M.; Krajcik, J.S. The Cambridge Handbook of the Learning Sciences: Motivation and Cognitive Engagement in Learning Environments; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Sinha, S.; Rogat, T.K.; Adams-Wiggins, K.R.; Hmelo-Silver, C.E. Collaborative group engagement in a computer-supported inquiry learning environment. Int. J. Comput.-Support. Collab. Learn. 2015, 10, 273–307. [Google Scholar] [CrossRef]
- Friedman, M. The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Marozzi, M. Testing for concordance between several criteria. J. Stat. Comput. Simul. 2014, 84, 1843–1850. [Google Scholar] [CrossRef]
- Conover, W.J.; Iman, R.L. Multiple-Comparisons Procedures. Informal Report; Los Alamos National Lab.: Los Alamos, NM, USA, 1979. [Google Scholar] [CrossRef]
- Tasaki, K.; Shin, J. Japanese response bias: Cross-level and cross-national comparisons on response styles. Shinrigaku Kenkyu Jpn. J. Psychol. 2017, 88, 32–42. [Google Scholar] [CrossRef]
- Chen, C.; Lee, S.; Stevenson, H.W. Response Style and Cross-Cultural Comparisons of Rating Scales Among East Asian and North American Students. Psychol. Sci. 1995, 6, 170–175. [Google Scholar] [CrossRef]
- Suzuki, M. Pretrained Japanese BERT Models, GitHub Repository. 2019. Available online: https://github.com/cl-tohoku/bert-japanese (accessed on 2 April 2021).
- Erkan, G.; Radev, D. LexRank: Graph-based Lexical Centrality as Salience in Text Summarization. J. Artif. Intell. Res.-JAIR 2011, 22, 457–479. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature/Aspect | SEAF (Ours) | Mathia | Assessment’s | I-START |
|---|---|---|---|---|
| Main focus area | Mathematics | Mathematics | Mathematics | Reading comprehension |
| Personalization | Yes, personalized message | Real-time adjustments | Adaptive learning | Adaptive to text complexity |
| Feedback mechanism | Peer-based explanations | Immediate, step-by-step | Hints and immediate feedback | Immediate on self-explanations |
| Self-explanation emphasis | High (core feature) | Moderate (within problem-solving context) | Moderate (user responses to hints/questions) | High (core training) |
| Peer-based learning | Yes (pen strokes, explanations) | No | Collaborative problem-solving (in some cases) | No |
| Real-world application | Not specified | Contextual word problems | Real-world problem sets | Complex real-world texts |
| Customizability | High (based on users’ data) | Not specified | Yes (teacher-customizable content) | Not specified |
| Number | Rubric | Sample Answer of Self-Explanations |
|---|---|---|
| Step 1 | Be able to find the equation of a linear function from two points. | Substituting the y-coordinate of p into the equation of the line AC. |
| Step 2 | Be able to find the equation of the line that bisects the area of a triangle. | Find the area of triangle ABC, then find the area of triangle OPC. |
| Step 3 | Be able to represent a point on a straight-line using letters (P-coordinates). | With the line OC as the base, find the y-coordinate of p, which is the height. P’s coordinate is (t, −1/2t + 4). |
| Step 4 | Be able to represent a point on a straight-line using letters (Q-coordinate). | Since the coordinates of P are (3.5/2), the line OP is y = ⅚x, and the coordinates of Q are (t, 5/6). |
| Step 5 | Be able to formulate an equation for area based on relationships among figures. | Finally, the area of ΔQAC was found from ΔAQO and ΔOQC, and the coordinates of Q were found. |
| Graded Score | Description |
|---|---|
| 1 (unacceptable) | The number of steps for which self-explanation is filled in for the steps required for the solution is minimal, and there were problematic expressions in the students’ self-explanation (e.g., mistaken patterns, boredom). |
| 2 (poor) | Self-explanations are mainly provided for the steps required for the solution. Still, they are more like bullet points than explanations. |
| 3 (fair) | Self-explanations are mainly provided for the steps required for the answer—the average self-explanation level among all respondents. |
| 4 (very good) | Self-explanations are provided for most of the steps required for the answer, but there is room for improvement as an explanation (logic, expressions). |
| 5 (excellent) | Self-explanations are mainly provided for the steps required for the answer, and the explanation is logical and well-written. |
| Period | Duration | Months | Num of Quizzes | Total Self-Explanation Answers | Unique Users | Sentence Length M (SD) | Quality Score M (SD) |
|---|---|---|---|---|---|---|---|
| Before experiment | January 2021 to October 2021 | 7 | 20 | 790 | 48 | 70.6 (59.2) | 3.08 (1.36) |
| Preliminary experiment | November 2021 to February 2022 | 4 | 13 | 257 | 48 | 72.4 (54.4) | 3.15 (1.17) |
| Actual experiment | April 2022 to June 2022 | 3 | 16 | 427 | 50 | 83.7 (62.0) | 3.08 (1.28) |
| Self-Explanation Level | Low-Engagement Group (N = 18) | High-Engagement Group N = 28 | Welch’s t-Test | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| N | Self-Explanation Answers | M | SD | N | Self-Explanation Answers | M | SD | DF | t | |
| High | 9 | 29 | 3.034 | 0.973 | 16 | 198 | 3.76 | 1.097 | 38.9 | 3.631 *** |
| Low | 9 | 69 | 2.05 | 1.05 | 12 | 131 | 2.62 | 1.11 | 144.6 | 3.520 *** |
| Self-Explanation Level | Engagement | M(SD) | Statistics | |||||
|---|---|---|---|---|---|---|---|---|
| N | T1 | T2 | T3 | DF | W | χ2 | ||
| High | High | 16 | 0.852 (0.43) | 0.827 (0.56) | 0.779 (0.70) | 2 | 0.0152 | 0.375 |
| Low | 9 | 0.653 (0.42) | 0.351 (0.68) | 0.451 (0.54) | - | - | - | |
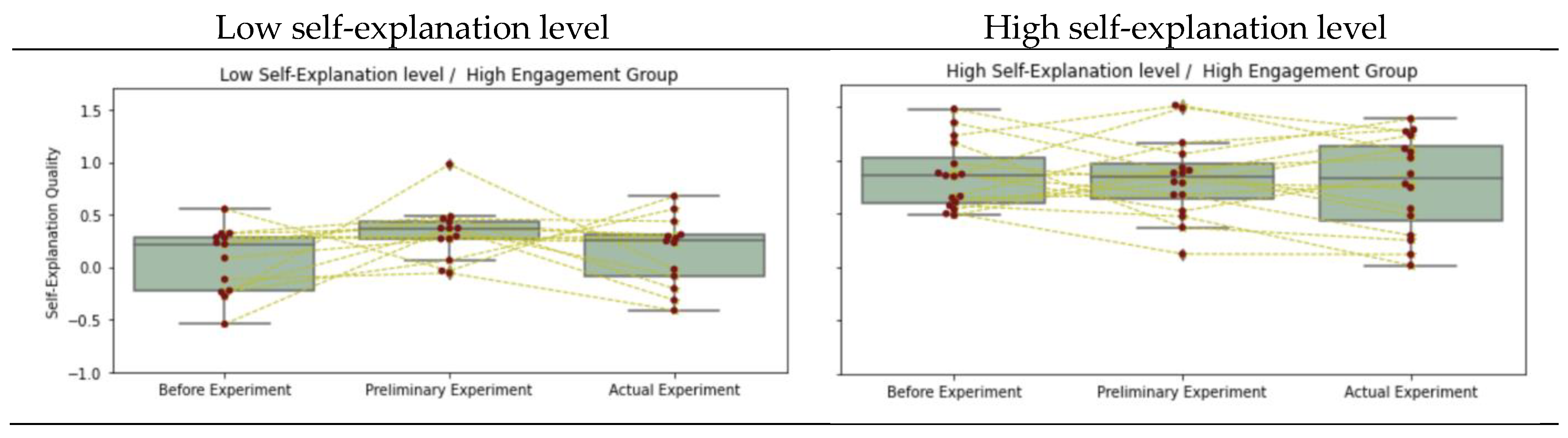
| Low | High | 12 | 0.069 (0.45) | 0.329 (0.50) | 0.153 (0.28) | 2 | 0.337 | 8.77 ** |
| Low | 9 | −0.193 (0.51) | 0.167 (0.55) | −0.110 (0.48) | - | - | - | |
| Experimental Period | T1 | T2 | T3 |
|---|---|---|---|
| T1 | - | 0.021 | 0.251 |
| T2 | - | - | 0.135 |
| No. | Question | Self-Explanation Level | N | M(SD) |
|---|---|---|---|---|
| 1 | Did you try your best to write a good self-explanation after receiving AI advice? | Low | 12 | 2.92 (0.76) |
| High | 15 | 2.93 (0.85) | ||
| 2 | Were you able to clarify your weak points and missing knowledge by reading classmates’ self-explanations? | Low | 12 | 2.83 (0.90) |
| High | 15 | 3.07 (0.85) | ||
| 3 | Was the feedback you received helpful for your study (e.g., did it help you to solve problems, learn new solutions, etc.)? | Low | 12 | 3.00 (0.41) |
| High | 15 | 2.87 (0.81) | ||
| 4 | Do you think the feedback feature is useful for learning? | Low | 12 | 3.08 (0.49) |
| High | 15 | 2.93 (0.85) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakamoto, R.; Flanagan, B.; Dai, Y.; Yamauchi, T.; Takami, K.; Ogata, H. Enhancing Self-Explanation Learning through a Real-Time Feedback System: An Empirical Evaluation Study. Sustainability 2023, 15, 15577. https://doi.org/10.3390/su152115577
Nakamoto R, Flanagan B, Dai Y, Yamauchi T, Takami K, Ogata H. Enhancing Self-Explanation Learning through a Real-Time Feedback System: An Empirical Evaluation Study. Sustainability. 2023; 15(21):15577. https://doi.org/10.3390/su152115577
Chicago/Turabian StyleNakamoto, Ryosuke, Brendan Flanagan, Yiling Dai, Taisei Yamauchi, Kyosuke Takami, and Hiroaki Ogata. 2023. "Enhancing Self-Explanation Learning through a Real-Time Feedback System: An Empirical Evaluation Study" Sustainability 15, no. 21: 15577. https://doi.org/10.3390/su152115577
APA StyleNakamoto, R., Flanagan, B., Dai, Y., Yamauchi, T., Takami, K., & Ogata, H. (2023). Enhancing Self-Explanation Learning through a Real-Time Feedback System: An Empirical Evaluation Study. Sustainability, 15(21), 15577. https://doi.org/10.3390/su152115577