
Using Generic Direct M-SVM Model Improved by Kohonen Map and Dempster–Shafer Theory to Enhance Power Transformers Diagnostic


 ,
,  and
and
Abstract
:1. Introduction
- -
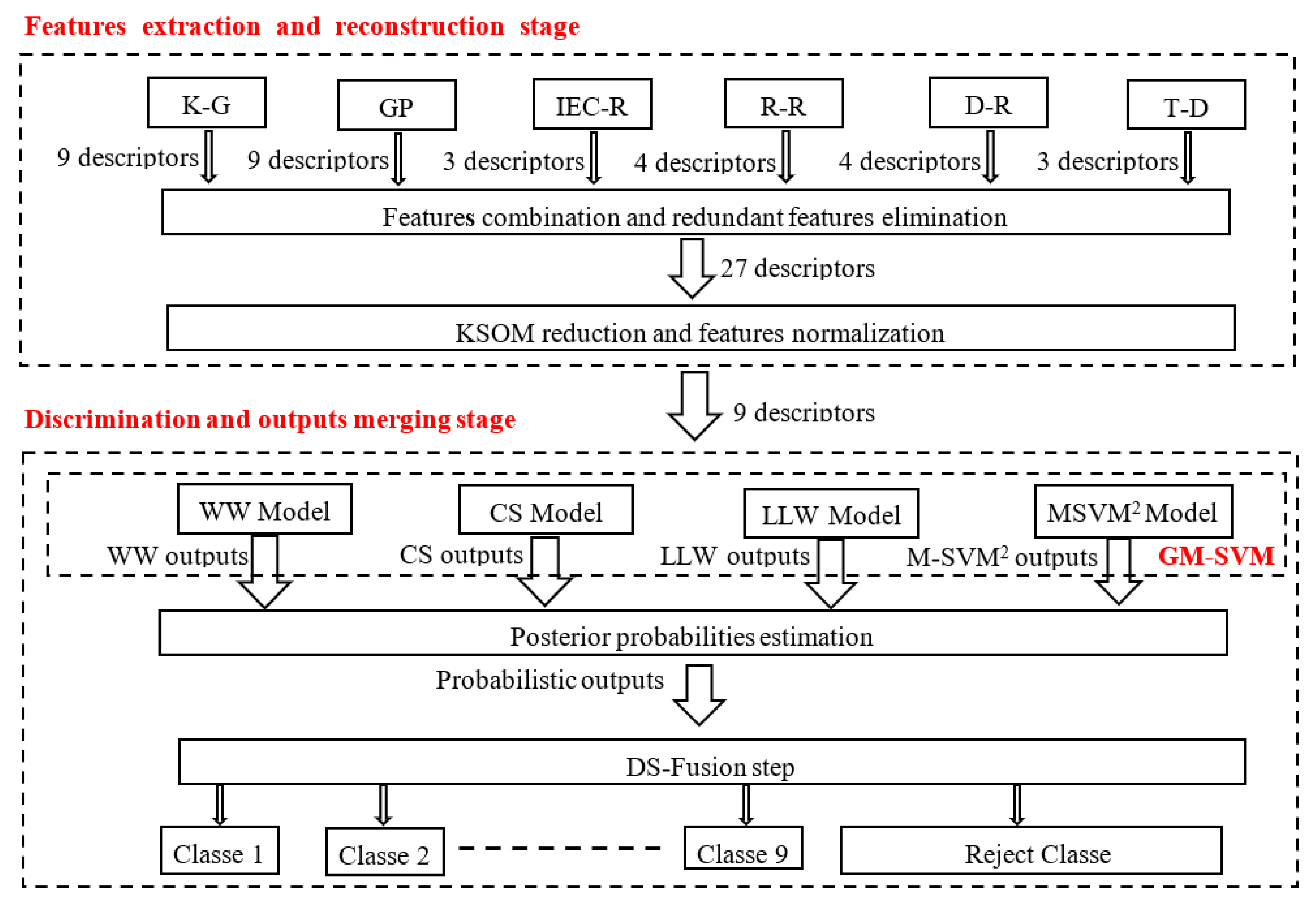
- In the first stage (Stage-1), a relevant descriptor space is constructed. Six descriptor sets extracted according to six distinct DGA techniques are firstly retained: K-G, IEC-R, R-R, D-R, D-T and Gases Percentage (G-P). These parameters are then combined. This is followed by a redundant parameters elimination phase. After that, a standardization process is considered to formalize all the parameters to the same interval. Finally, a novel descriptor reconstruction stage based on the Kohonen Self-Organizing Maps (KSOM) [15] is proposed to decrease the data model and facilitate the discriminator’s work while keeping all the information.
- -
- In the second stage (Stage-2), four direct probabilistic Multiclass Support Vector Machines (M-SVM) are implemented for the first time, via a Generic M-SVM Model (GM-SVM) [16]: the Weston and Watkins (WW) model [17], the Crammer and Singer (CS) model [18], the Lee et al. (LLW) model [19], and the Quadratic Loss Multi-Class Support Vector machine (M-SVM2) model [20]. These four models are used as a solution to overcome the weaknesses of the indirect M-SVM models widely used in this problem. Each used M-SVM considers the returned parameters set by Stage-1, and calculates the belonging probabilities to each of the considered nine classes.
- -
- Then, to approve the final outputs, the Dempster–Shafer (DS) [21,22] fusion is applied to combine the four M-SVM outputs within the beliefs and evidence model framework. Also, this stage proposes an alternative to post-process the after-fusion outputs: the example is considered well-classified if its probability exceeds a decision threshold; otherwise, the example is assigned to the reject class.
2. Study Motivations and Innovations
- -
- Embedded in real-time processes (low execution time);
- -
- Applied to randomly distributed and unknown data;
- -
- Ensure a global optimum due to the convex optimization principle;
- -
- Do not suffer from overfitting and over-learning problems;
- -
- Decrease the curse of dimensionality.
- -
- Increase the four M-SVM performance by facilitating their classification task, thanks to the proposed descriptors reconstruction approach;
- -
- Reduce complexity and save execution time by implementing direct M-SVM instead of M-SVM based on decomposition methods;
- -
- Strengthen M-SVM outputs by translating them into posterior probabilities;
- -
- Strengthen decision-making, gain sensitivity and minimize false alarms by applying the DS fusion and the rejection class introduction.
3. Features Extraction and Reconstruction Methods
3.1. Feature Extraction Approaches
3.1.1. Key Gases (K-G)
3.1.2. Gases Percentage (G-P)
3.1.3. IEC Ratios (IEC-R)
3.1.4. Rogers Ratios (R-R)
3.1.5. Dornenburg Ratios (D-R)
3.1.6. Duval’s Triangle (D-T)
3.2. Features Combination and Redundant Features Elimination
3.3. Features Standardization
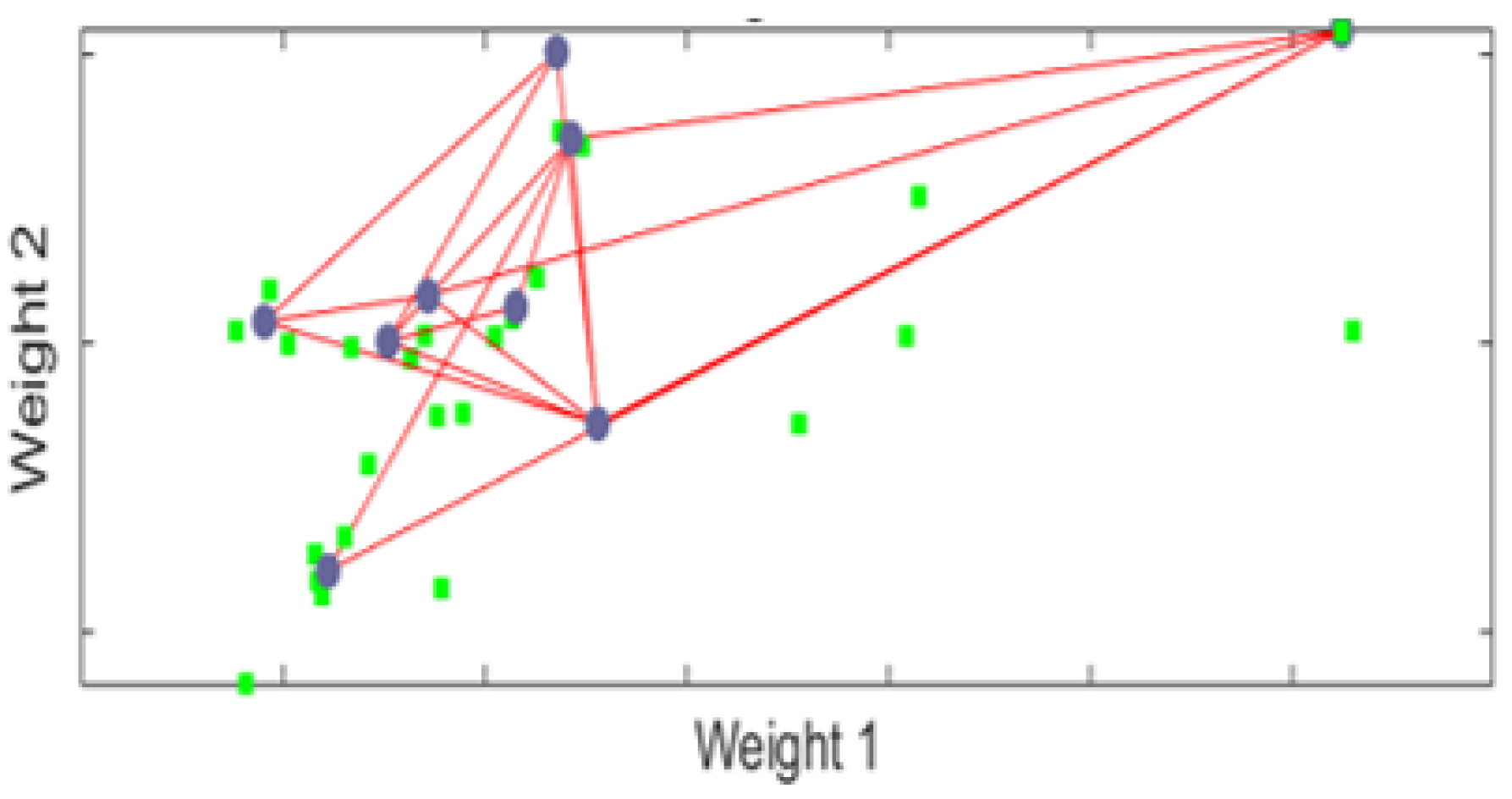
3.4. Kohonen Self-Organizing Map Reduction
- -
- Step 1: Elect cluster with maximum response.
- Apply to the map input a learning vector .
- Determine the best matching unit , whose vector is closest to the input :
- Winning neuron .
- -
- Step 2: neighborhood construction around the winning neuron.
- -
- Step 3: adaptation of winning cluster weights:where is the learning step which decreases according to the iterations .
- -
- Back to step 1 until the algorithm converges.
- -
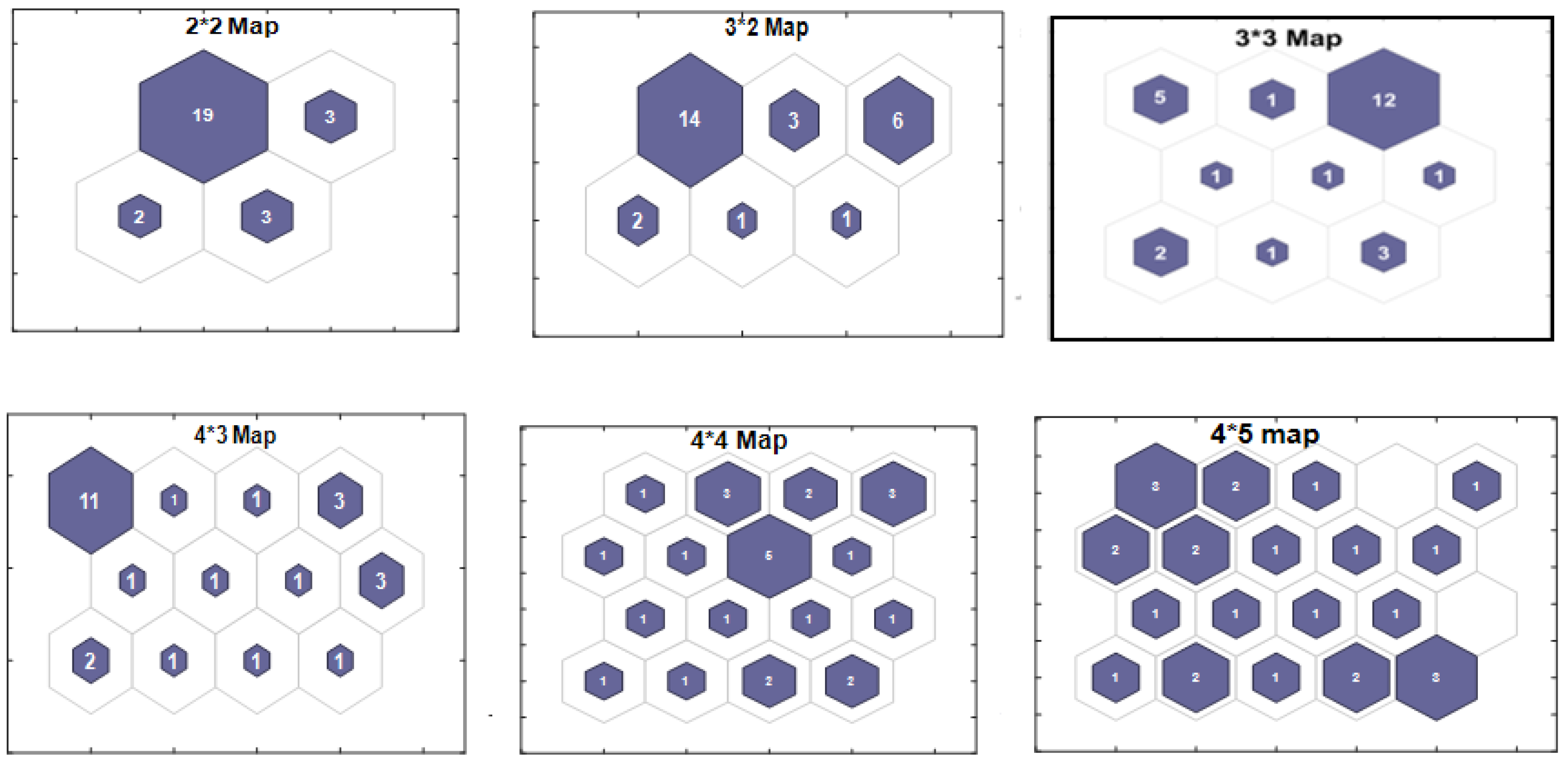
- The minimum extreme dimension choice (the number of neurons in the map) is based on the fact that the majority of conventional methods use on average four ratios for decision-making. So a set of four parameters is to be reconstructed.
- -
- The maximum extreme dimension choice is fixed after dead neurons’ appearance, whose external connections do not represent any parameter; just as it is important to not go beyond the initial parameter number (final set < initial set).
- -
- The final map choice ( configuration) among the six selected topologies is based on a trade-off between the neuron number and the maximum generalization rate, plus the dead neurons’ absence.
- -
- The new vector dimension is equal to the retained final map neuron number (for a total of nine parameters).
- -
- The value of each new descriptor is obtained by averaging the parameters associated with a given cluster.
- -
- Neuron 2 (D2) represents the initial descriptor . This ratio is used by the three conventional methods: IEC-R, R-R and D-R, which considers it important.
- -
- Neuron 4 (D4) evokes the initial Dornenburg R3 report, considered very important for detecting the low-energy thermal fault category from other categories.
- -
- Neuron 6 (D6) is seen as being a support and confirmation element of the partial discharge fault if it is greater than 30%.
- -
- Neuron 1 (D1) brings together the two descriptors , , which model the same information revealing the presence of the partial discharge type defect.
- -
- Neuron 7 (D7) brings together five descriptors involved in an insulation fault identification.
4. Discrimination and Outputs Merging Stage
4.1. Direct Probabilistic Multiclass Support Vector Machines (M-SVM)
4.1.1. Generic M-SVM Model
4.1.2. Probabilistic Direct M-SVM
4.2. Dempster–Shafer (DS) Theory
4.2.1. Mass, Plausibility and Belief Functions
4.2.2. Merging Rule
4.2.3. Final Decision Rule
- -
- Two or more classifiers are in conflict and do not agree on the class to which the example belongs, despite the fact that each classifier individually indicates a high probability of membership (the existence or not of a defect). In this case, the result provided by the classifiers lacks precision; and by classifying it as a rejection, the merger calls out the need to seek expert advice.
- -
- The classifiers entirely agree on a dominant class absence and distribute the output probabilities in a uniform manner across several categories. In this case, the data reliability concerning the example is strongly called into question.
5. Results and Discussion
5.1. DGA Training, Validation and Evaluation Data
5.2. M-SVM Hyper Parameters Selection
5.3. Statistical Evaluation Parameters
- -
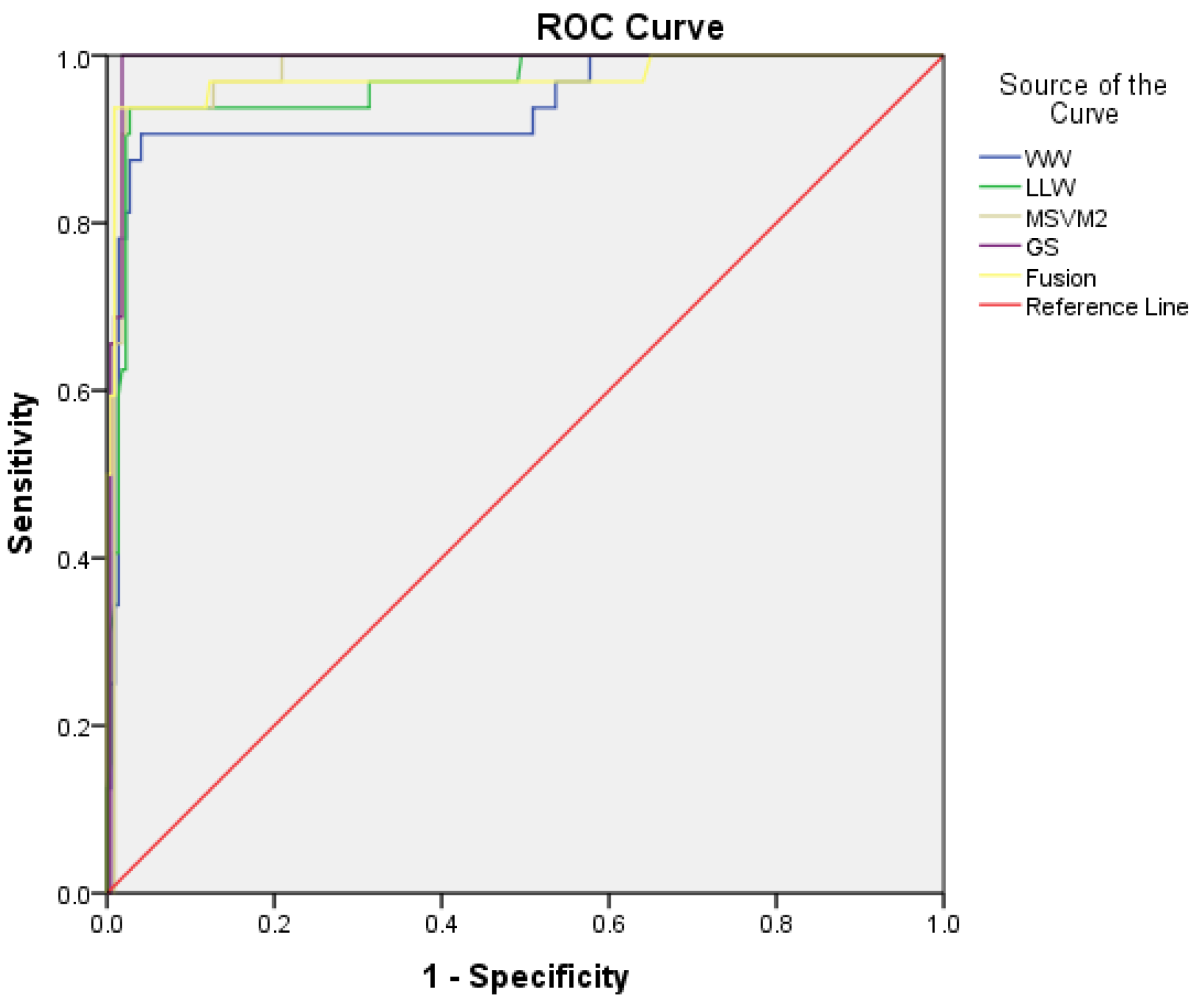
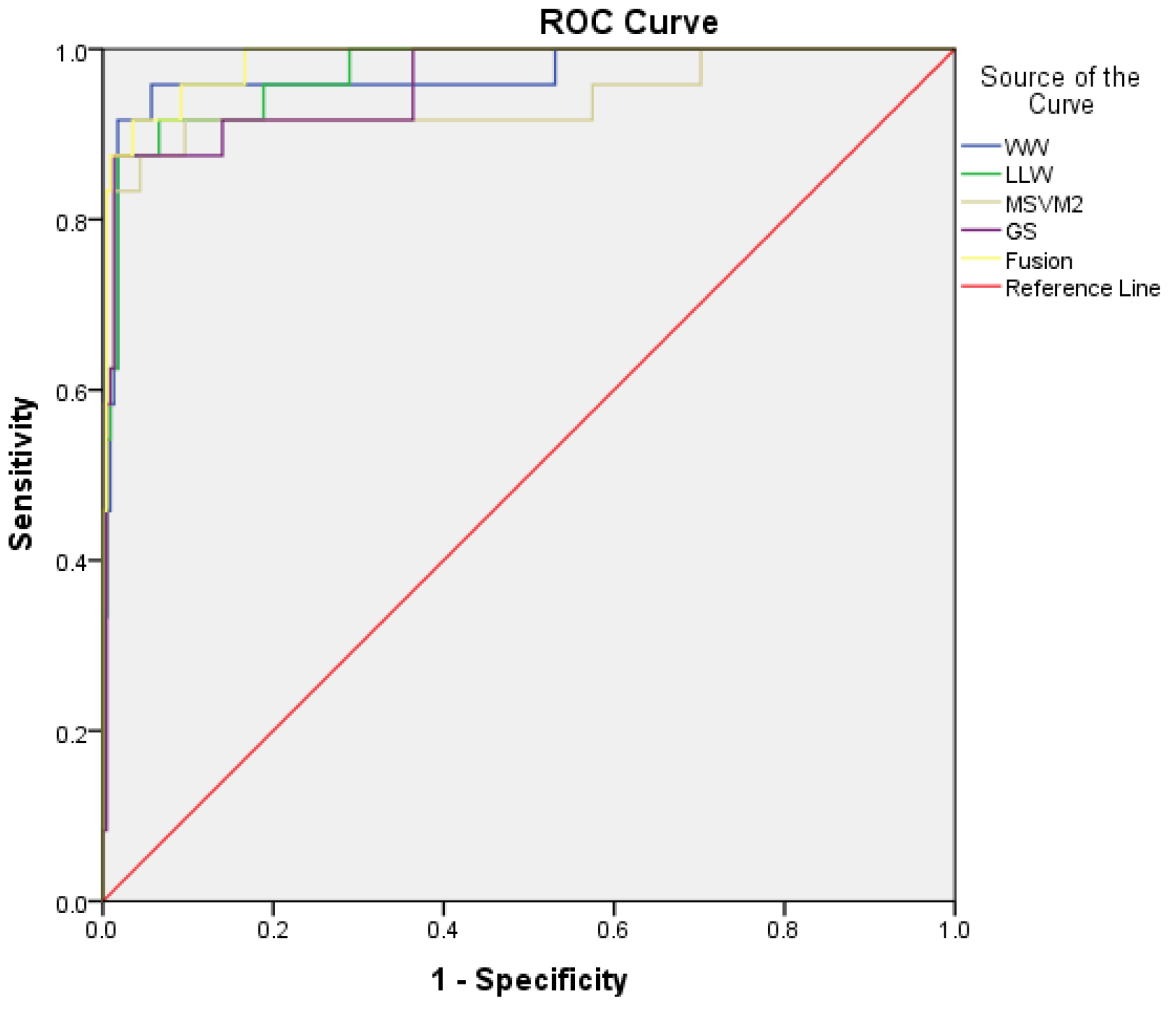
- Receiver Operating Characteristic (ROC) curve: is a graphical representation that illustrates the classifier performances (Sensitivity and 1-Specificity) variation at all probability thresholds.
- -
- Area Under the ROC Curve (AUROC-95\% CI): returns an overall performance estimate for all possible discrimination probability thresholds. A confidence interval is also associated to each measurement.
- -
- Sensitivity and Specificity: these are two elementary and complementary metrics for the expert-performance evaluation. In fact, they are based on all the confusion matrix elements and constitute the ROC curve base.
- -
- Positive Predictive Value (PPV): returns the truly positive individual proportion within a population classified as positive, .
- -
- Negative Predictive Value (NPV): returns the truly negative individual proportion within a population classified as negative,
- -
- False Negatives (FN): is a positive population for which the test is negative,
- -
- False Positives (FP): is a negative population for which the test is positive
5.4. Obtained Results
5.5. Comparison with Previous Work Results
- -
- The categories number taken into account in this research is high compared to all other studies. Likewise, the present work offers a generalization rate which surpasses the obtained rates from other studies, except for the works [12,14,26]. This can be justified by the fact that the authors considered fewer classes and test examples.
- -
- The samples number is comparable to other studies with the exception of work [7]. This is justified by the fact that the latter considers a KNN type classifier, which necessarily needs a relatively large training sample for efficient performance. Contrary to this work, M-SVM-type discriminators are implemented, one of the advantages of which is to offer high generalization rates from a reduced learning sample.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DGA | Dissolved Gas Analysis |
| M-SVM | Direct Multiclass Support Vector Machines |
| IA | Artificial Intelligence |
| D-T | Duval Triangle |
| R-R | Rogers Ratios |
| D-R | Dornenburg Ratios |
| IEC-R | IEC Ratios |
| KG | Key Gases |
| PTD | Power Transformers Diagnosis |
| G-P | Gases Percentage |
| TG | Total combustible and non-combustible Gases sum |
| TS | Total Sum |
| KSOM | Kohonen Self-Organizing Maps |
| GM-SVM | Generic M-SVM Model |
| WW | Weston and Watkins model |
| CS | Crammer and Singer model |
| LLW | Lee et al. model |
| M-SVM2 | Quadratic Loss Multi-Class Support Vector Machine |
| DS | Dempster–Shafer fusion |
| PSO | Practical Swarm Optimization |
| GA | Genetic Algorithm |
| H2 | Hydrogen |
| O2 | Oxygen |
| N2 | Nitrogen |
| CO | Carbon Monoxide |
| CH4 | Methane |
| CO2 | Carbon Dioxide |
| C2H6 | Ethane |
| C2H4 | Ethylene |
| C2H2 | Ethylene |
| VQ | Vector Quantification process |
| MSVMpack | MSVM software package |
| Bel | Belief function |
| Pl | Plausibility function |
| M | Mass function |
| ROC | Receiver Operating Characteristic curve |
| AUROC | Area Under the ROC Curve |
| TPR | True Positive Rate |
| TNR | True Negative Rate |
| PPV | Positive Predictive Value |
| NPV | Negative Predictive Value |
| FN | False Negatives |
| FP | False Positives |
| TP | True Positives |
| TN | True Negatives |
| STE | Sonelgaz Transport Electricity |
| PD | Partial Discharge |
| LED | Low Energy Discharge |
| HED | High Energy Discharge |
| OH1 | Thermal fault (t < 700 °C) |
| OH2 | Thermal fault (t > 700 °C) |
| CD | Cellulose Degradation |
| OH2-CD | Thermal (t > 700 °C) and Cellulose Degradation |
| ED-CD | Energy Discharge and Cellulose Degradation |
| N | Healthy samples |
| C-Set | Normalized data set approach |
| FCM | Fuzzy C-means clustering algorithm |
| KELM | Kernel extreme learning machine |
| HHO | Harris-Hawks-optimization algorithm |
| CVT | Cumulative Voting Technique merged |
| KNN | k-Nearest Neighbors algorithm |
| LDA | Linear Discriminant Analysis |
| RVM | Relevance Vector machines |
| MLP | Multilayer Perceptron |
| PA | Probabilistic output Algorithms |
| IKH | Krill herd algorithm |
References
- Muniz, R.N.; da Costa Júnior, C.T.; Buratto, W.G.; Nied, A.; González, G.V. The Sustainability Concept: A Review Focusing on Energy. Sustainability 2023, 15, 14049. [Google Scholar] [CrossRef]
- Zhang, N.; Sun, Q.; Yang, L.; Li, Y. All Authors Event-Triggered Distributed Hybrid Control Scheme for the Integrated Energy System. IEEE Trans. Ind. Inform. 2022, 18, 835–846. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Wu, Q.H.; Zhang, H. Real-time Dispatchable Region of Renewable Generation Constrained by Reactive Power and Voltage Profiles in AC Power Networks. CSEE J. Power Energy Syst. 2020, 6, 681–692. [Google Scholar] [CrossRef]
- Muangpratoom, P.; Suriyasakulpong, C.; Maneerot, S.; Vittayakorn, W.; Pattanadech, N. Experimental Study of the Electrical and Physiochemical Properties of Different Types of Crude Palm Oils as Dielectric Insulating Fluids in Transformers. Sustainability 2023, 15, 14269. [Google Scholar] [CrossRef]
- Shufali, A.W.; Ankur, S.R.; Shiraz, S.; Obaidur, R.; Shaheen, P.; Shakeb, A.K. Advances in DGA based condition monitoring of transformers: A review. Renew. Sustain. Energy Rev. 2021, 149, 111347. [Google Scholar] [CrossRef]
- Abbasi, A.R. Fault detection and diagnosis in power transformers: A comprehensive review and classification of publications and methods. Electr. Power Syst. Res. 2022, 209, 107990. [Google Scholar] [CrossRef]
- Mominul, M.I.; Gareth, L.; Sujeewa, N.H. A nearest neighbor clustering approach for incipient fault diagnosis of power transformers. Electr. Eng. 2017, 99, 1109–1119. [Google Scholar] [CrossRef]
- Irungu, G.K.; Akumu, A.O.; Munda, A.O. A new fault diagnostic technique in oil-filled electrical equipment; the dual of Duval triangle. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 3405–3410. [Google Scholar] [CrossRef]
- Rogers, R.R. IEEE and IEC codes to interpret incipient faults in transformers, using gas in oil analysis. IEEE Trans. Electr. Insul. 1978, EL-13, 349–354. [Google Scholar] [CrossRef]
- Khan, S.A.; Equbal, M.D.; Islam, T.A. Comprehensive comparative study of DGA based ANFIS models. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 590–596. [Google Scholar] [CrossRef]
- Bakar, N.A.; Abu Siada, A.; Islam, S. A review of dissolved gas analysis measurement and interpretation techniques. IEEE Electr. Insul. Mag. 2014, 30, 39–49. [Google Scholar] [CrossRef]
- Xie, L.; Zhao, Y.; Yan, K.; Shao, M.; Liu, W.; Lui, D. Interpretation of DGA for Transformer Fault Diagnosis with Step-by-step feature selection and SCA-RVM. In Proceedings of the IEEE 16th Conference on Industrial Electronics and Applications, Chengdu, China, 1–4 August 2021. [Google Scholar] [CrossRef]
- Kari, T.; Gao, W.; Zhao, D.; Abiderexiti, K.; Mo, W.; Wang, Y.; Luan, L. Hybrid feature selection approach for power transformer fault diagnosis based on support vector machine and genetic algorithm. Inst. Eng. Technol. 2018, 12, 5672–5680. [Google Scholar] [CrossRef]
- Peimankar, A.; Weddell, S.J.; Thahirah, J.; Lapthorn, A.C. Evolutionary Multi-Objective Fault Diagnosis of Power Transformers. Swarm Evol. Comput. 2017, 36, 62–75. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Map; Springer: Berlin/Heidelberg, Germany, 1997; Volume 30. [Google Scholar] [CrossRef]
- Guermeur, Y. A generic model of multi-class support vector machine. J. Intell. Inf. Database Syst. 2012, 6, 555–577. Available online: https://dl.acm.org/doi/abs/10.1504/IJIIDS.2012.050094 (accessed on 2 October 2012). [CrossRef]
- Weston, J.; Watkins, C. Multi-Class Support Vector Machines; Technical Report CSD-TR-98-04; Royal Holloway, University of London, Department of Computer Science: Egham, UK, 1998. [Google Scholar]
- Crammer, K.; Singer, Y. On the algorithmic implementation of multiclass kernel based vector machines. J. Mach. Learn. Res. 2001, 2, 265–292. Available online: https://dl.acm.org/doi/10.5555/944790.944813 (accessed on 2 December 2001).
- Lee, Y.; Lin, Y.; Wahba, G. Multicategory support vector machines: Theory and application to the classification of microarray data and satellite radiance data. J. Am. Stat. Assoc. 2004, 99, 67–81. [Google Scholar] [CrossRef]
- Guermeur, Y.; Monfrini, E. A quadratic loss multi-class svm for which a radius margin bound applies. Informatica 2011, 22, 73–96. Available online: https://dl.acm.org/doi/10.5555/2019505.2019511 (accessed on 2 January 2011). [CrossRef]
- Dempster, A.P. A generalisation of Bayesian inference. J. R. Stat. Soc. 1968, 2, 205–247. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar] [CrossRef]
- Senoussaoui, M.A.; Brahami, M.; Fofana, I. Combining and comparing various machine learning algorithms to improve dissolved gas analysis interpretation. Inst. Eng. Technol. 2018, 12, 3673–3679. [Google Scholar] [CrossRef]
- Bacha, K.; Souahlia, S.; Gossa, M. Power transformer fault diagnosis based on dissolved gas analysis by support vector machine. Electr. Power Syst. Res. 2012, 83, 73–79. [Google Scholar] [CrossRef]
- Han, X.; Ma, S.; Shi, Z.; An, G.; Du, Z.; Zhao, C. A Novel Power Transformer Fault Diagnosis Model Based on Harris-Hawks-Optimization Algorithm Optimized Kernel Extreme Learning Machine. J. Electr. Eng. Technol. 2022, 17, 1993–2001. [Google Scholar] [CrossRef]
- Guardado, J.L.; Naredo, J.L.; Moreno, P.; Fuerte, C.R. A Comparative Study of Neural Network Efficiency in Power Transformers Diagnosis Using Dissolved Gas Analysis. IEEE Trans. Power Deliv. 2001, 16, 643–647. [Google Scholar] [CrossRef]
- Senoussaoui, M.A.; Brahami, M.; Bousmaha, I.S. Improved Gas Ratios Models for DGA Interpretation Using Artificial Neural Networks; Association of Computer Electronics and Electrical Engineers: New York City, NY, USA, 2019; pp. 167–175. [Google Scholar]
- Mansouri, D.E.K.; Benabdeslem, K. Towards Multi-label Feature Selection by Instance and Label Selections. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2021; pp. 233–244. [Google Scholar] [CrossRef]
- Zhang, P.; Liu, G.; Gao, W.; Song, J. Multi-label feature selection considering label supplementation. Pattern Recognit. 2021, 120, 108137. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Zheng, H.; Yao, H.; Liu, J.; Zhang, C.; Peng, H.; Jiao, J. A Fault Diagnosis Model of Power Transformers Based on Dissolved Gas Analysis Features Selection and Improved Krill Herd Algorithm Optimized Support Vector Machine. IEEE Access 2019, 7, 102803–102811. [Google Scholar] [CrossRef]
- Abdo, A.; Liu, H.; Zhang, H.; Guo, J.; Li, Q. A new model of faults classification in power transformers based on data optimization method. Electr. Power Syst. Res. 2021, 200, 107446. [Google Scholar] [CrossRef]
- Hua, Y.; Sun, Y.; Xu, G.; Sun, S.; Wang, E.; Pang, Y. A fault diagnostic method for oil-immersed transformer based on multiple probabilistic output algorithms and improved DS evidence theory. Int. J. Electr. Power Energy Syst. 2022, 137, 107828. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York City, NY, USA, 1995. [Google Scholar]
- Berlinet, A.; Thomas-Agnan, C. Reproducing Kernel Hilbert Spaces in Probability and Statistics; Kluwer Academic Publishers: Boston, MA, USA, 2004. [Google Scholar] [CrossRef]
- Lauer, F.; Guermeur, Y. MSVMpack: A multi-class support vector machine package. J. Mach. Learn. Res. 2012, 12, 2269–2272. Available online: https://dl.acm.org/doi/10.5555/1953048.2021073 (accessed on 2 July 2011).
- Platt, J.C. Probabilities for SV machines. In Advances in Large Margin Classifiers; Smola, A.J., Bartlett, P.L., Schölkopf, B., Schuurmans, D., Eds.; The MIT Press: Cambridge, MA, USA, 1999; Chapter 5; pp. 61–73. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Map Size | Generalization Rate (%) | Map Size | Generalization Rate (%) |
|---|---|---|---|
| 2 Map | 82.94 | 3 Map | 88.10 |
| 2 Map | 85.32 | 4 Map | 87.30 |
| 3 Map | 88.10 | 5 Map | 87.30 |
| The Nine New Descriptors | Initial Descriptors They Represent |
|---|---|
| D1 | , |
| D2 | |
| D3 | , , |
| D4 | |
| D5 | |
| D6 | |
| D7 | |
| D8 | |
| D9 |
| M-SVM | M | p | K1 | K2 | K3 |
|---|---|---|---|---|---|
| WW Model | 1 | 1 | 1 | 0 | |
| CS Model | 1 | 1 | 1 | 1 | |
| LLW Model | 1 | 0 | 0 | ||
| M-SVM2 | 2 | 0 | 0 |
| H2 | CO | O2 | N2 | CO2 | CH4 | C2H2 | C2H4 | C2H6 |
|---|---|---|---|---|---|---|---|---|
| 127 | 847 | 16,973 | 89,517 | 3726 | 17 | 67 | <1 | 3 |
| 127 | 847 | 16,973 | 89,517 | 3726 | 17 | 67 | 0.2 | 3 |
| 127 | 847 | 16,973 | 89,517 | 3726 | 17 | 67 | 0.4 | 3 |
| 127 | 847 | 16,973 | 89,517 | 3726 | 17 | 67 | 0.6 | 3 |
| 127 | 847 | 16,973 | 89,517 | 3726 | 17 | 67 | 0.8 | 3 |
| 127 | 847 | 16,973 | 89,517 | 3726 | 17 | 67 | 1 | 3 |
| Predicted | |||
|---|---|---|---|
| Considered category | Other categories | ||
| Reality | Considered category | True positive (TP) | False negative (FN) |
| Other categories | False positive (FP) | True negative (TN) | |
| Class | Statistical Parameters (%) | WW-MSVM | LLW-MSVM | MSVM2 | CS-MSVM | Fusion |
|---|---|---|---|---|---|---|
| N | AUROC | 0.938 [0.883–0.993] | 0.963 [0.927–0.999] | 0.984 [0.969–0.999] | 0.991 [0.980–1.000] | 0.994 [0.985–1.000] |
| Sensitivity | 87.5 | 90.62 | 93.75 | 100 | 100 (1 Reject) | |
| Specificity | 97.73 | 98.18 | 98.18 | 98.18 | 98.58 | |
| False positive | 2.27 | 1.82 | 1.82 | 1.82 | 1.42 | |
| False negative | 12.5 | 9.38 | 6.25 | 0 | 0 | |
| VPP | 84.85 | 87.88 | 88.24 | 88.89 | 91.18 | |
| VPN | 98.17 | 98.63 | 99.08 | 100 | 100 | |
| PD | AUROC | 0.956 [0.901–1.000] | 0.970 [0.935–1.000] | 0.940 [0.896–1.000] | 0.975 [0.940–1.000] | 0.985 [0.960–1.000] |
| Sensitivity | 90.62 | 87.50 | 87.50 | 90.62 | 93.54 (1 Reject) | |
| Specificity | 98.63 | 98.63 | 99.09 | 100 | 100 | |
| False positive | 1.37 | 1.37 | 0.91 | 0 | 0 | |
| False negative | 9.38 | 12.50 | 12.50 | 9.38 | 6.46 | |
| VPP | 90.63 | 90.32 | 93.33 | 100 | 100 | |
| VPN | 98.64 | 98.19 | 98.64 | 98.65 | 99.53 | |
| LED | AUROC | 0.966 [0.937–0.996] | 0.959 [0.925–0.993] | 0.968 [0.941–0.996] | 0.968 [0.938–0.998] | 0.977 [0.949–1.000] |
| Sensitivity | 87.5 | 93.75 | 90.62 | 90.62 | 90.32 (1 Reject) | |
| Specificity | 98.63 | 99.10 | 98.18 | 98.18 | 99.05 | |
| False positive | 1.37 | 0.90 | 1.82 | 2.82 | 0.95 | |
| False negative | 12.5 | 6.25 | 9.38 | 9.38 | 9.68 | |
| VPP | 90.32 | 93.75 | 87.88 | 87.88 | 93.33 | |
| VPN | 98.18 | 99.09 | 98.63 | 98.63 | 98.59 | |
| HED | AUROC (95% CI) | 0.968 [0.925–1.000] | 0.971 [0.943–1.000] | 0.938 [0.867–1.000] | 0.958 [0.916–1.000] | 0.986 [0.970–1.000] |
| Sensitivity | 83.33 | 87.5 | 83.33 | 79.16 | 86.96 (1 Reject) | |
| Specificity | 98.24 | 98.24 | 98.68 | 99.12 | 99.54 | |
| False positive | 1.76 | 1.76 | 1.32 | 0.88 | 0.46 | |
| False negative | 16.67 | 12.5 | 16.67 | 20.84 | 13.04 | |
| VPP | 83.33 | 84 | 86.96 | 90.47 | 95.24 | |
| VPN | 98.25 | 98.68 | 98.25 | 97.84 | 98.65 | |
| OH1 | AUROC (95% CI) | 0.962 [0.931–0.993] | 0.971 [0.934–1.000] | 1.000 [1.000–1.000] | 0.996 [0.989–1.000] | 0.999 [0.996–1.000] |
| Sensitivity | 89.28 | 92.85 | 100 | 96.42 | 96.42 | |
| Specificity | 98.66 | 100 | 100 | 100 | 99.53 | |
| False positive | 1.34 | 0 | 0 | 0 | 0.47 | |
| False negative | 10.72 | 7.15 | 0 | 3.58 | 3.58 | |
| VPP | 89.29 | 100 | 100 | 100 | 96.43 | |
| VPN | 98.66 | 99.12 | 100 | 99.56 | 99.53 | |
| OH2 | AUROC (95% CI) | 0.965 [0.935–0.995] | 0.966 [0.928–1.000] | 0.981 [0.955–1.000] | 0.994 [0.955–1.000] | 0.999 [0.996–1.000] |
| Sensitivity | 82.14 | 89.28 | 96.42 | 96.42 | 100 (2 Rejects) | |
| Specificity | 99.55 | 98.66 | 99.11 | 99.11 | 99.53 | |
| False positive | 0.45 | 1.34 | 0.89 | 0.89 | 0.47 | |
| False negative | 17.86 | 10.72 | 3.58 | 3.58 | 0 | |
| VPP | 95.83 | 89.29 | 93.10 | 93.10 | 96.30 | |
| VPN | 97.81 | 98.66 | 99.55 | 99.55 | 100 | |
| CD | AUROC (95% CI) | 0.981 [0.949–1.000] | 1.000 [1.000–1.000] | 0.996 [0.989–1.000] | 1.000 [1.000–1.000] | 1.000 [1.000–1.000] |
| Sensitivity | 96.87 | 100 | 96.87 | 100 | 100 | |
| Specificity | 99.55 | 100 | 100 | 100 | 100 | |
| False positive | 0.45 | 0 | 0 | 0 | 0 | |
| False negative | 3.13 | 0 | 3.13 | 0 | 0 | |
| VPP | 96.88 | 100 | 100 | 100 | 100 | |
| VPN | 99.55 | 100 | 99.55 | 100 | 100 | |
| OH2-CD | AUROC (95% CI) | 0.975 [0.950–0.999] | 0.930 [0.853–1.000] | 0.936 [0.851–1.000] | 0.966 [0.920–1.000] | 0.978 [0.945–1.000] |
| Sensitivity | 95 | 80 | 85 | 90 | 89.47 | |
| Specificity | 97.84 | 99.14 | 99.14 | 99.14 | 100 | |
| False positive | 2.16 | 0.86 | 0.86 | 0.86 | 0 | |
| False negative | 5 | 20 | 15 | 10 | 10.53 | |
| VPP | 79.17 | 88.89 | 89.47 | 90 | 100 | |
| VPN | 99.56 | 98.29 | 98.71 | 99.14 | 99.12 | |
| ED-CD | AUROC (95% CI) | 0.965 [0.920–1.000] | 0.966 [0.936–0.996] | 0.932 [0.847–1.000] | 0.959 [0.916–1.000] | 0.972 [0.926–1.000] |
| Sensitivity | 83.33 | 91.66 | 87.50 | 87.50 | 100 (2 Rejects) | |
| Specificity | 98.68 | 97.80 | 98.68 | 98.25 | 98.64 | |
| False positive | 1.32 | 2.2 | 1.32 | 1.75 | 1.36 | |
| False negative | 16.67 | 8.34 | 12.50 | 12.50 | 0 | |
| VPP | 86.96 | 81.48 | 84 | 84 | 88 | |
| VPN | 98.25 | 99.11 | 98.68 | 98.68 | 100 |
| WW-MSVM | LLW-MSVM | MSVM2 | CS-MSVM | Fusion | |
|---|---|---|---|---|---|
| AUROC (95% CI) (p-value < 0.001) | 96.40 | 96.62 | 96.39 | 97.86 | 98.78 |
| Sensitivity | 88.39 | 90.35 | 91.22 | 92.30 | 95.19 |
| Specificity | 98.61 | 98.86 | 99.01 | 99.10 | 99.43 |
| False positive | 1.39 | 1.14 | 0.99 | 0.90 | 0.57 |
| False negative | 11.61 | 9.65 | 8.71 | 7.7 | 4.81 |
| VPP | 88.58 | 90.62 | 91.44 | 92.70 | 95.61 |
| VPN | 98.56 | 98.86 | 99.01 | 99.11 | 99.49 |
| WW-MSVM | LLW-MSVM | MSVM2 | CS-MSVM | Fusion | |
|---|---|---|---|---|---|
| Prediction time (s) | 0.018 ±0.004 | 0.015 ±0.002 | 0.010 ±0.003 | 0.014 ±0.004 | 0.085 ±0.009 |
| Study | Sample Count | Categories Number | Classification Rates (%) | ||||
|---|---|---|---|---|---|---|---|
| CT-CVT-KNN [7] | 396 | 7 | 93 | ||||
| SCA-RVM [12] | 135 | 6 | 97.07 | ||||
| 2-ADOPT [14] | 101 | 4 | 97.94 | ||||
| KELM-HHO [25] | 118 | 5 | 88 | ||||
| MLP [27] | 102 | 6 | MLP-MRR | MLP-RR | MLP-IECR | MLP-KG | MLP-DR |
| 87.88 | 90.91 | 93.94 | 100 | 90.91 | |||
| AG-IKH-SVM [30] | 113 | 5 | 85.71 | ||||
| Cset-FCM-SVM [31] | 177 | 6 | 86.11 | ||||
| PA-DS [32] | 156 | 6 | RVM | SVM | MLP | DS-Fusion | |
| 87.8 | 85.3 | 82.6 | 89.1 | ||||
| Proposed Approach | 252 | 9 | WW | LLW | MSVM2 | CS | Fusion |
| 88.39 | 90.35 | 91.22 | 92.30 | 95.19 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hendel, M.; Meghnefi, F.; Senoussaoui, M.E.A.; Fofana, I.; Brahami, M. Using Generic Direct M-SVM Model Improved by Kohonen Map and Dempster–Shafer Theory to Enhance Power Transformers Diagnostic. Sustainability 2023, 15, 15453. https://doi.org/10.3390/su152115453
Hendel M, Meghnefi F, Senoussaoui MEA, Fofana I, Brahami M. Using Generic Direct M-SVM Model Improved by Kohonen Map and Dempster–Shafer Theory to Enhance Power Transformers Diagnostic. Sustainability. 2023; 15(21):15453. https://doi.org/10.3390/su152115453
Chicago/Turabian StyleHendel, Mounia, Fethi Meghnefi, Mohamed El Amine Senoussaoui, Issouf Fofana, and Mostefa Brahami. 2023. "Using Generic Direct M-SVM Model Improved by Kohonen Map and Dempster–Shafer Theory to Enhance Power Transformers Diagnostic" Sustainability 15, no. 21: 15453. https://doi.org/10.3390/su152115453
APA StyleHendel, M., Meghnefi, F., Senoussaoui, M. E. A., Fofana, I., & Brahami, M. (2023). Using Generic Direct M-SVM Model Improved by Kohonen Map and Dempster–Shafer Theory to Enhance Power Transformers Diagnostic. Sustainability, 15(21), 15453. https://doi.org/10.3390/su152115453