1. Introduction
Drought is a natural climatic event that significantly affects living things and can bring about serious problems. As a result of the precipitation falling significantly below the recorded normal levels, it causes the land and water resources to be adversely affected and the hydrological balance to deteriorate. Many problems arise as a result of drought, such as a decrease in water quantity and quality, land and soil degradation, decrease in agricultural productivity, and desertification [
1,
2,
3].
Drought is divided into four subtitles as meteorological, agricultural, hydrological, and socioeconomic [
4]. The decrease in precipitation below the average for a certain period is defined as meteorological drought, and it is the difference between the annual, seasonal, or monthly precipitation totals from the average [
5]. Agricultural drought, which expresses the lack of water in the soil to meet the needs of the plant, causes a slowdown in plant growth, loss of crops, and is an important threat to animals [
6]. As a result of the hydrological drought that develops after a prolonged meteorological drought, groundwater, springs, runoff, and soil moisture are affected, and sharp decreases are observed in lakes, rivers, and groundwater [
7]. Drought begins as a meteorological drought, develops as an agricultural and hydrological drought, and its effects become visible as a socioeconomic drought. Unlike natural disasters, drought severely affects a wide variety of lands, agriculture, and socioeconomic infrastructure and is a far more complex natural hazard [
8]. The intensity and characteristics of drought vary from region to region, and many regions of the world are in danger of drought. Due to drought, more than 650,000 deaths were reported by the World Meteorological Organization (WMO) from 1970 to 2019 [
3,
9]. In recent years, the issue of drought has been addressed in studies on climate change, and many studies have been carried out to analyze and predict drought risk. For this reason, many modeling approaches are being developed that give an idea about the amount of the precipitation and ultimately improve the ability to monitor droughts. Drought risk analysis aims to improve drought management and forecasting techniques, and drought risk analysis focuses on the size, duration, intensity, and spatial extent of droughts, taking into account the spatial variability of the drought [
10]. The drought formation time is slow, and the consequences of a drought appear over a long period of time relative to its onset and the time it is perceived by ecosystems and hydrological systems. For this reason, a forecasting system that can warn about a drought at the beginning will be able to significantly reduce the negative effects of the drought [
11]. While all types of the droughts begin with a lack of precipitation in time and/or space, an early stage of a lack of precipitation accumulation often manifests as a meteorological drought. In order to monitor and predict droughts, various existing drought indices are used to determine the deviation of meteorological variables, such as precipitation, from their long-term averages [
12]. Drought monitoring relies on various indices, including the Standardized Precipitation Evapotranspiration Index (SPEI) [
13], Palmer Drought Severity Index (PDSI) [
14], Effective Drought Index (EDI) [
15], Reconnaissance Drought Index (RDI) [
16], Keetch–Byram Drought Index (KBDI) [
17], and Weighted Anomaly Standardized Precipitation Index (WASP), as well as Standardized Drought Indices (SDIs) [
18,
19] A comprehensive list of these indices and their descriptions is available in Reference [
20]. However, the most widely used method for drought monitoring globally is the SDI-type procedure [
19]. Some recently developed SDI-type drought indices include the Standardized Precipitation Index (SPI) [
21].
The Standardized Precipitation Index (SPI), developed by McKee et al., is used as a global drought monitoring tool following the Lincoln Drought Declaration of the World Meteorological Organization [
21,
22,
23]. SPI calculations are easier than other indices, because it only requires precipitation data. Thus, it is very useful in drought risk analysis and estimations in regions where data are scarce and where other parameters, such as stream flow, evapotranspiration, and soil moisture information, may not be readily available. The SPI is comparable in both time and space, and also, it can be calculated for multiple time scales [
24,
25]. Thus, it allows to determine the duration, size, and intensity of droughts and defines various drought types as hydrological, agricultural, or environmental. Its calculation based on a probabilistic basis has led to an important place in drought analysis and is widely used for drought analysis in many regions of the world. Therefore, the SPI estimation is important in drought analysis.
To date, numerous research papers have been published to estimate drought indices using data-driven techniques. In the development of data-based drought forecasting models from these studies, linear approaches, in which recursive moving average (ARMA) models are used, have been replaced by nonlinear approaches based on Artificial Intelligence models in recent years [
26,
27].
In a previous study by Mokhtarzad et al., drought prediction was conducted using the Standardized Precipitation Index (SPI) with three different modeling techniques: Artificial Neural Network (ANN), Support Vector Machine (SVM), and Adaptive Neuro-Fuzzy Interface System (ANFIS). Notably, the SVM model outperformed both the ANN and ANFIS models in terms of predictive performance [
26]. Pande et al. evaluated various machine learning (ML) models, including Artificial Neural Network (ANN) and M5P Tree, for predicting the Standardized Precipitation Index (SPI) at different time scales (SPI-3 and SPI-6). The research utilized rainfall data from two Indian stations, Angangaon and Dahalewadi. Among the models tested, the M5P model outperformed the others, particularly in terms of r values and RMSE values, making it the superior choice for drought prediction at both stations [
28]. In addition, in a literature study, a SPI estimation study was performed on a time scale of 1–12 months using different Adaptive Neuro-Fuzzy Inference System (ANFIS) models, and it was shown to be a suitable model for SPI estimations [
29]. In another study performed for the estimation of the drought index, a wavelet-based drought model using the extreme learning machine (W-ELM) algorithm was used, and it was seen that the wavelet transform increased the prediction performance in drought prediction [
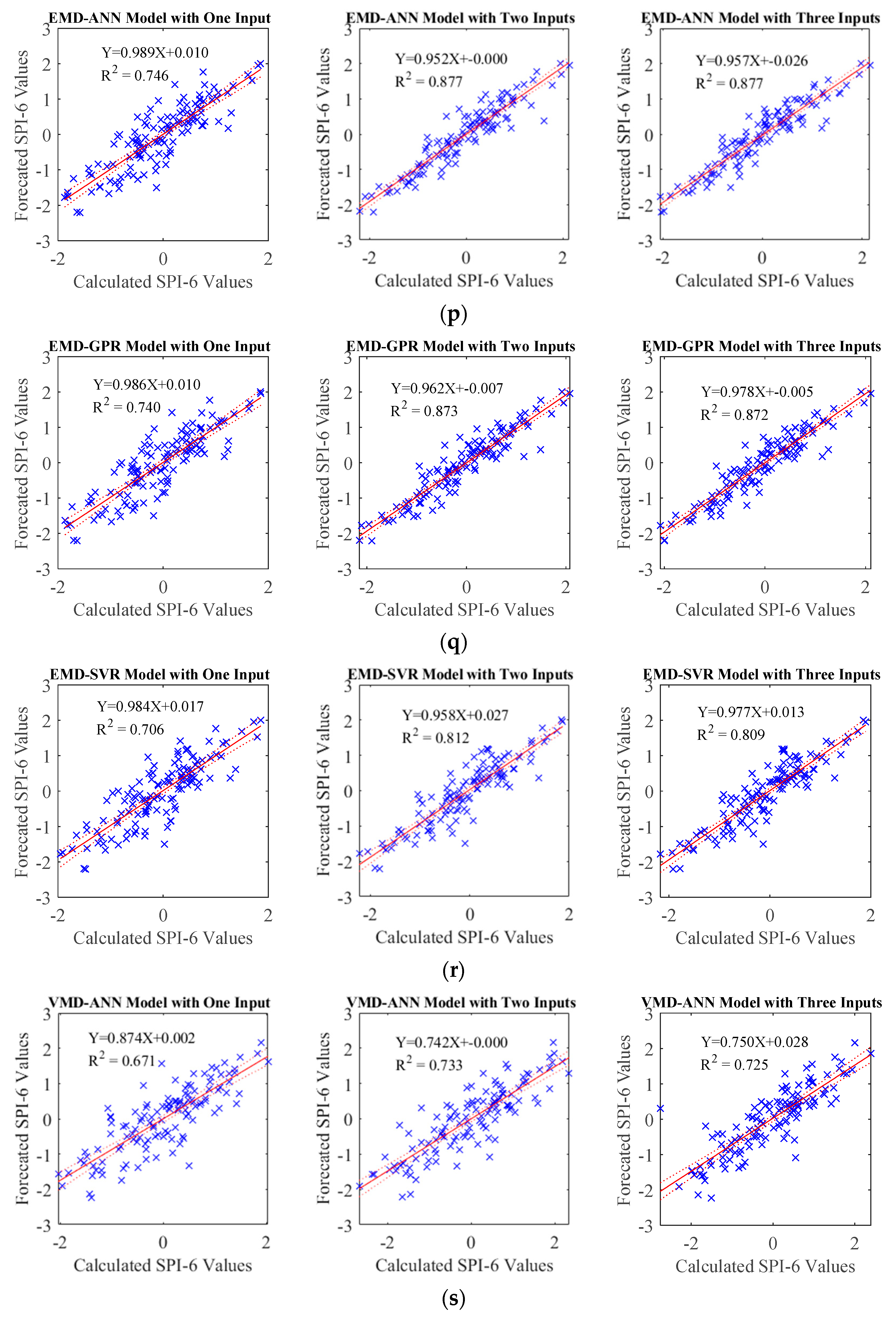
30]. In a study showing that subband decomposition methods increase the estimation performance in SPI estimations with the Variational Mode Decomposition (VMD), Discrete Wavelet Transform (DWT), and Empirical Mode Decomposition (EMD) methods. In this study, it was observed that the VMD-GPR model demonstrated a better forecasting performance for the 1- and 3-month time scale SPI, while the DWT-ANN model exhibited superior performance in forecasting the 6-month time scale SPI data [
31]. In another study, SPI data werewere estimated using wavelet packet-genetic programming, the performance of this model was compared with the Autoregressive (AR1), GP, and Random Forest (RF) models, and the forecasting success of wavelet packet-genetic programming was demonstrated [
32]. As evident from the literature, hybrid approaches that estimate the SPI from subband signals by decomposing the data using preprocessing methods have shown an enhanced forecasting performance. Nevertheless, it is crucial to note that boundary effects pose significant challenges, particularly in methods like EMD and WT [
33,
34]. In addition, it is seen that the estimation performance changes depending on the wavelet function used in the wavelet transform [
31].
The VMD method employs spectral segmentation of the Fourier spectrum for signal decomposition into subbands. Consequently, it shares a common constraint with the Fourier spectrum [
35]. TQWT, on the other hand, is a method that, unlike conventional signal preprocessing techniques based on frequency bands such as WT and EMD, can decompose the targeted signal into specific components with different structures according to their oscillation characteristics and eliminate in-band noise [
35].
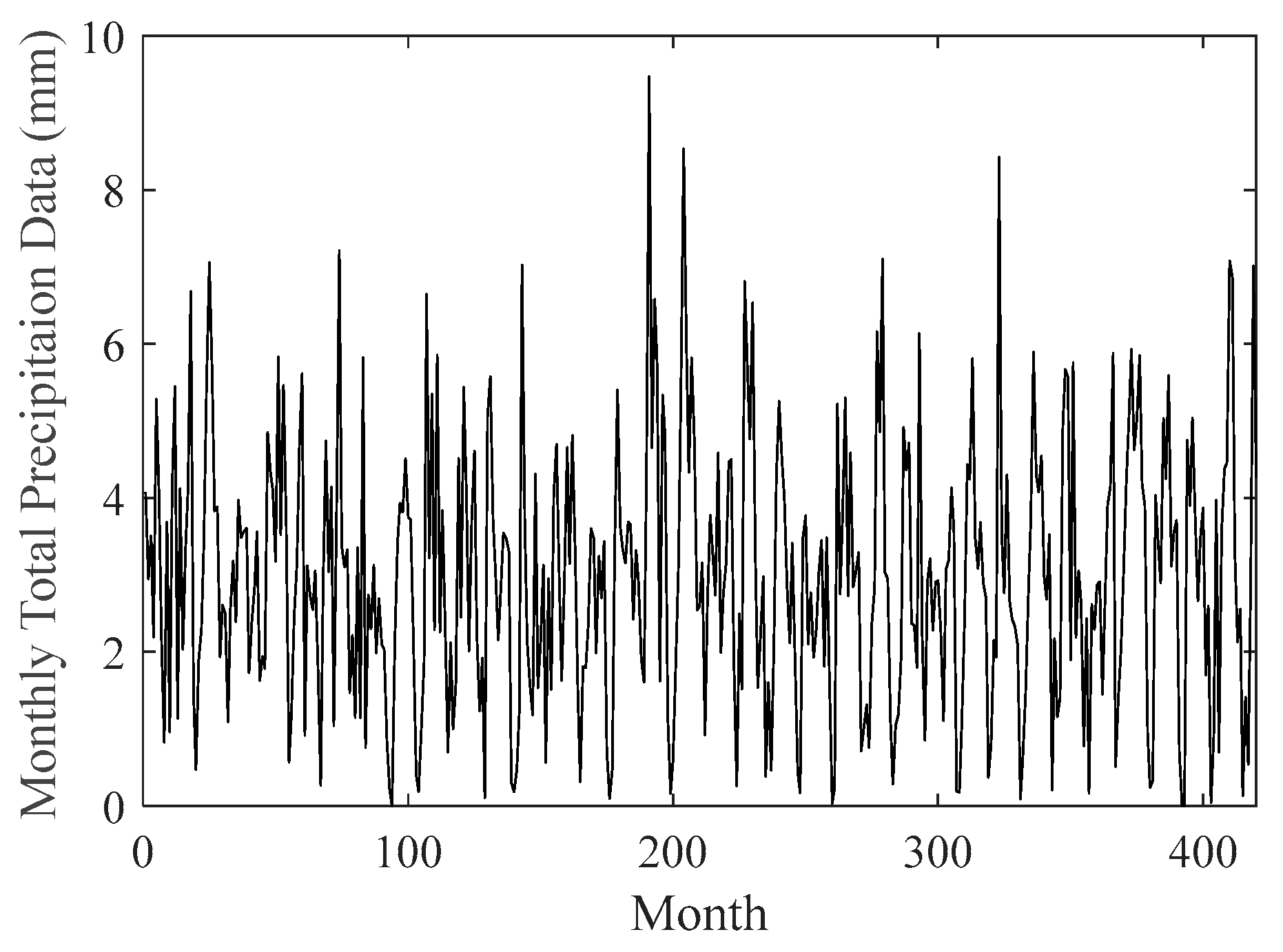
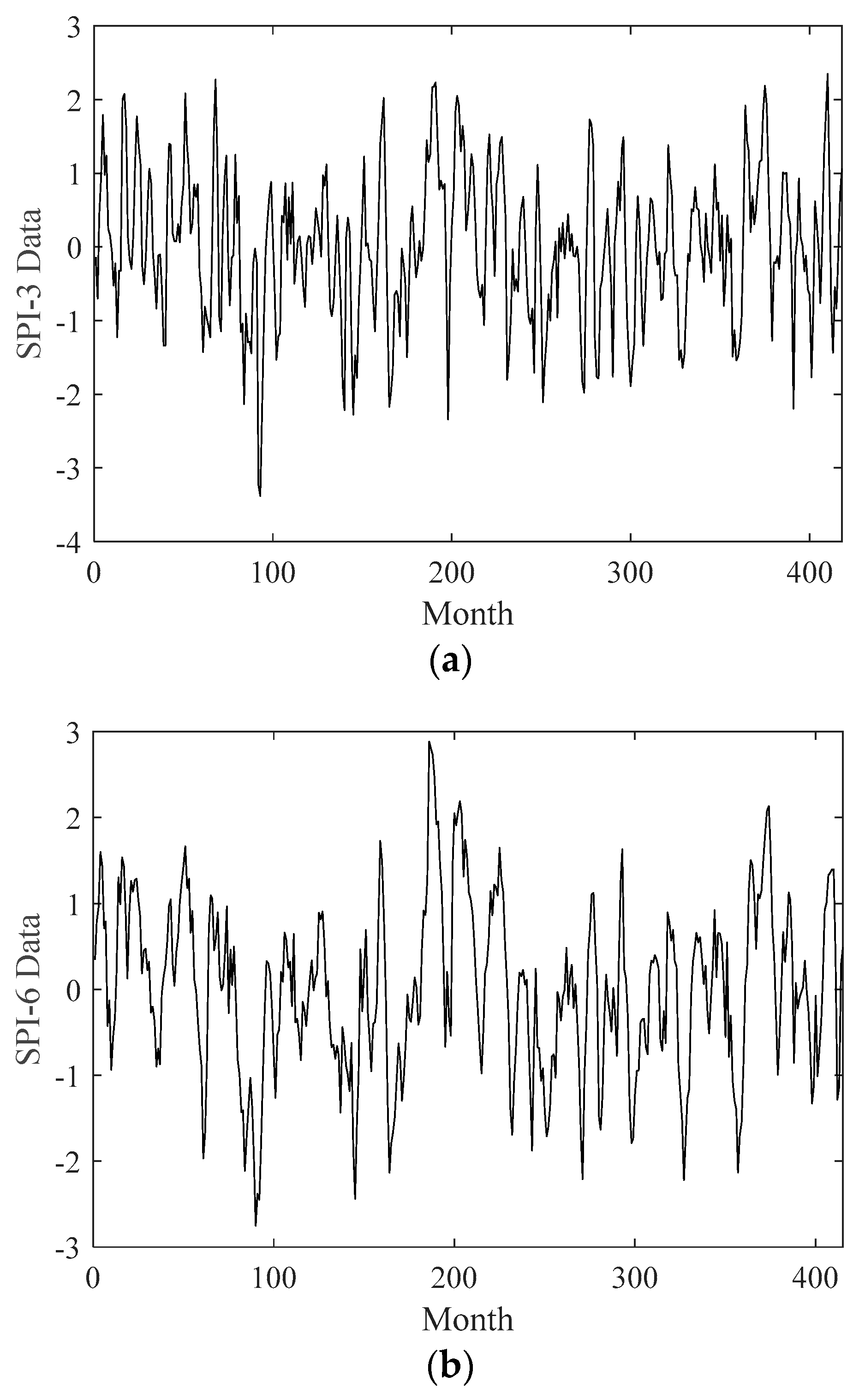
In this study, a novel forecasting framework has been introduced for SPI data on 3- and 6-month time scales. The notation SPI-3 is used for the 3-month time scale, while SPI-6 is used for the 6-month time scale.
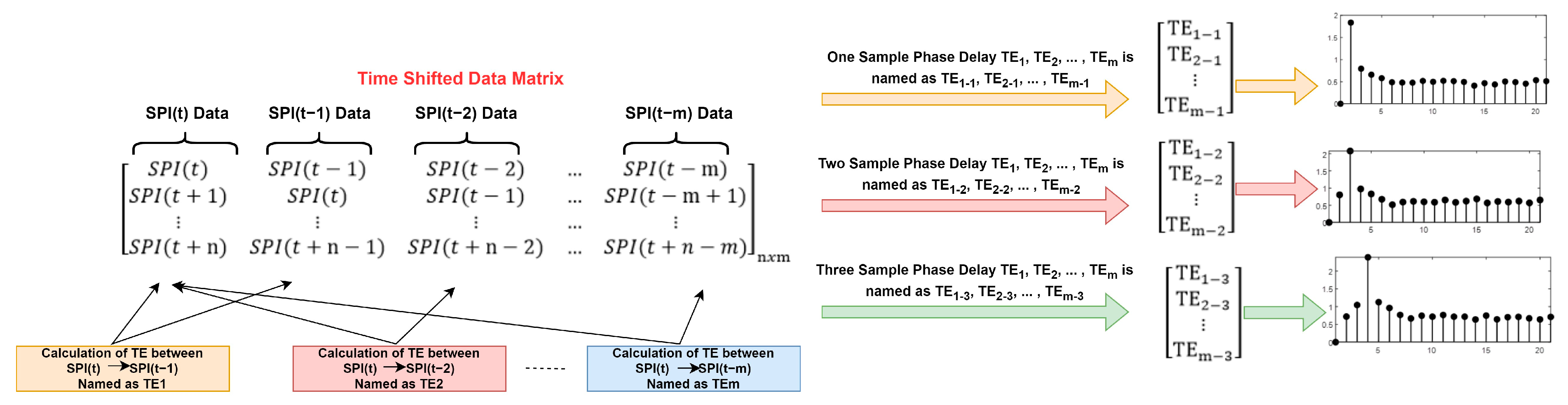
One of the unique contributions of this study is the utilization of a connectivity analysis using the pTE approach for SPI data prediction, specifically focusing on determining the optimal time lag values and SPI values at these time indices for input in the forecasting model. This novel approach represents the first time in the literature for identifying the most suitable input SPI-3 and SPI-6 data with the optimal time indices for the prediction model. In this method, the PTE values were calculated using a 1–3 phase delay from the Hankelization matrix obtained through time lag operations, thereby enabling the identification of time lags where the information flow is at its maximum and minimum. By concentrating on time lags with maximum information flow, a methodology has been established for determining the most appropriate time indices and SPI inputs for use as input in SPI prediction. Additionally, the TQWT method was employed to decompose SPI-3 and SPI-6 data into subbands, and the subband signals were subsequently estimated using ANN, SVR, and GPR models. The optimization of the TQWT method involved adjusting parameters like the Q Factor, subband decomposition level, and the parameters of the machine learning models. This optimization was achieved through the GWO algorithm, resulting in the introduction of the GWO-TQWT-ML method, a novel approach in the literature known for its high forecasting performance with SPI data. To evaluate the performance of the GWO-TQWT-ML method, we compared it against various models, including EMD-ANN, EMD-SVR, EMD-GPR, VMD-ANN, VMD-SVR, VMD-GPR, ANN, SVR, and GPR models, with the aim of benchmarking its performance. The study’s results were meticulously assessed using performance metrics such as MSE, MAE, R, R2, and scatter plots. In summary, this study represents a significant advancement in SPI drought index estimations by introducing the novel pTE-GWO-TQWT-GPR approach. This approach leverages the maximum information flow to determine input features for the forecasting model, and its incorporation significantly enhances the forecasting accuracy.
4. Discussion and Conclusions
The importance of SPI prediction lies in its ability to provide valuable insights into future precipitation patterns, aiding in water resource management, drought monitoring, and climate adaptation efforts. In the literature, there have been many methods that use the machine learning (ML) approach for high-performance predictions of the SPI in recent years. A comprehensive review study on these methods can be found in the references. As observed in the literature [
62], ML methods have proven to be highly effective in SPI prediction, yielding high-performance results. In this study, as a new approach compared to previous works, the optimal time lag value for SPI prediction using the past values of SPI data has been determined using phase transfer entrophy (pTE). Additionally, a novel pTE-Grey Wolf Optimization (GWO)-Tunable Q Wavelet Transform (TQWT)-ML method, utilizing preprocessed data with parameters optimized by GWO and the TQWT technique, has been proposed to enhance the performance of ML methods in SPI prediction.
In this study, a high-performance SPI drought index estimation model was developed with an end-to-end approach. In this method, a connectivity analysis was performed for the first time in the literature for SPI data. The phase transfer entropy method was used for the connectivity analysis, and the interconnected time indices of the SPI data were obtained. Thus, the most important lag time for the SPI input data for the forecasting models was determined.
As can be seen in
Figure 6 and
Table 3,
Table 4 and
Table 5, the input data with the highest information flow for a certain time index that can be applied to forecasting models were obtained for SPI-3 and SPI-6 data. As seen in
Table 6, when the method utilizing the recommended pTE approach with a specified time lag for SPI data is compared to the prediction results using consecutive time lag SPI data, it is evident that the prediction performance using input indices from the recommended method is superior.
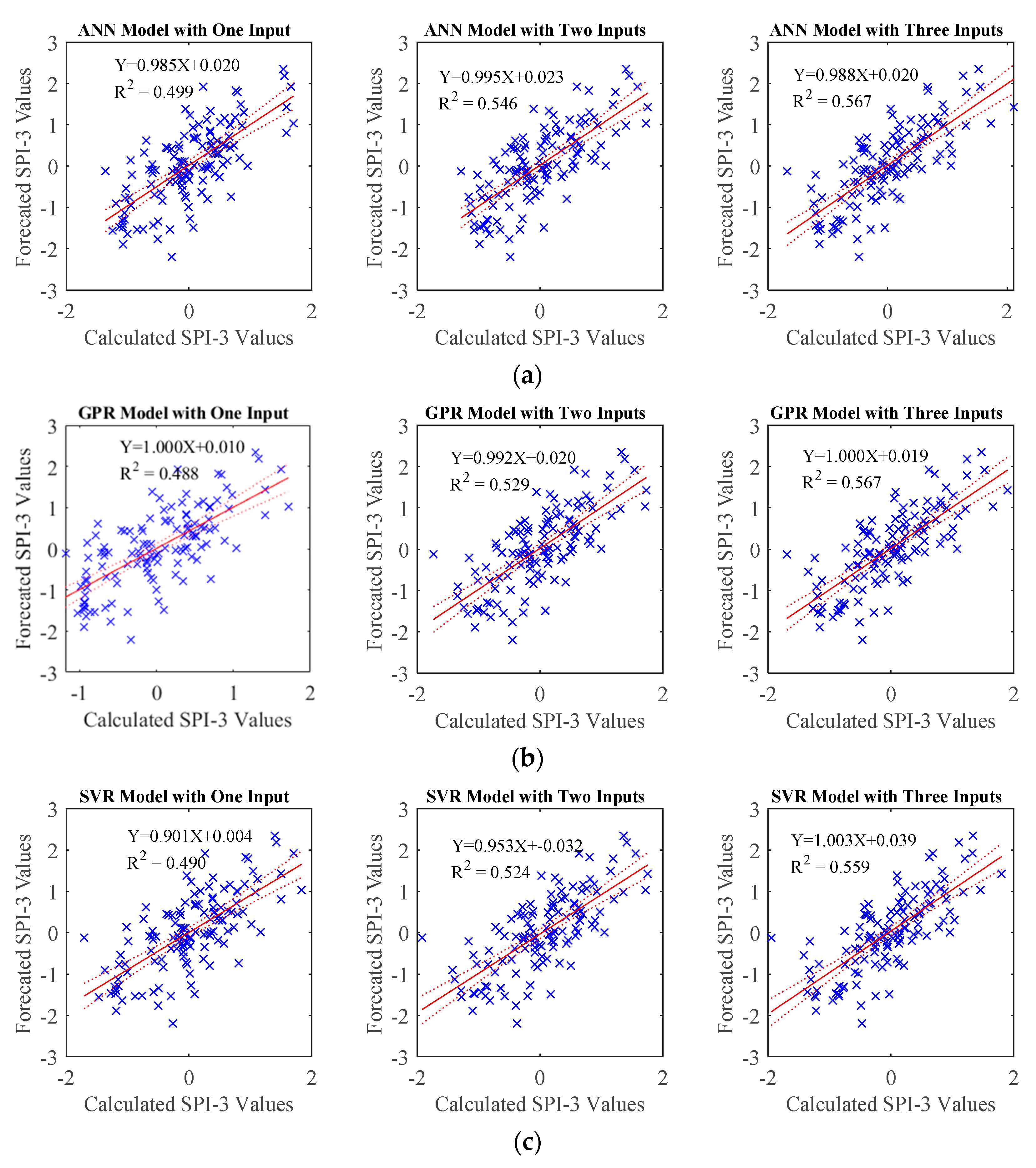
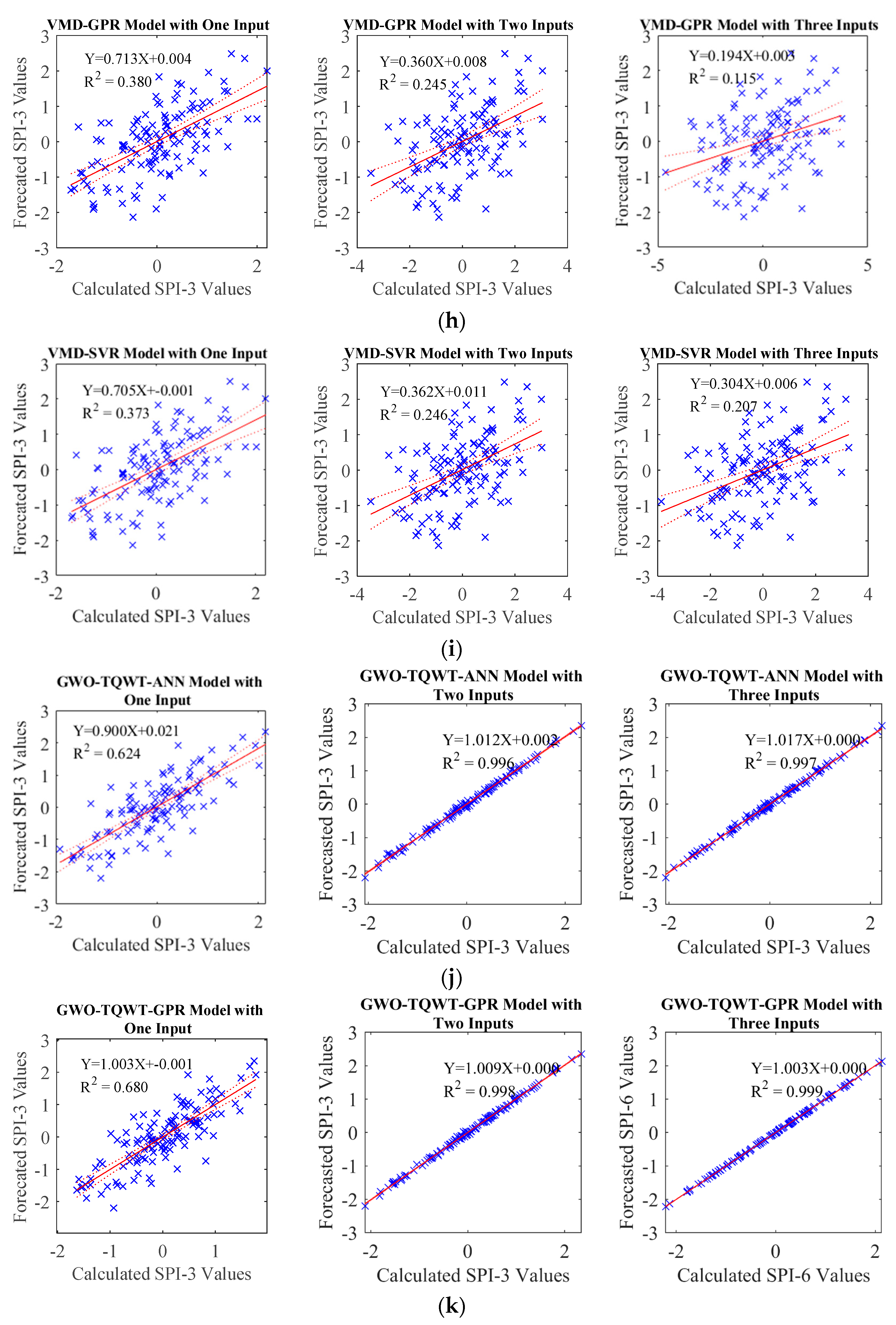
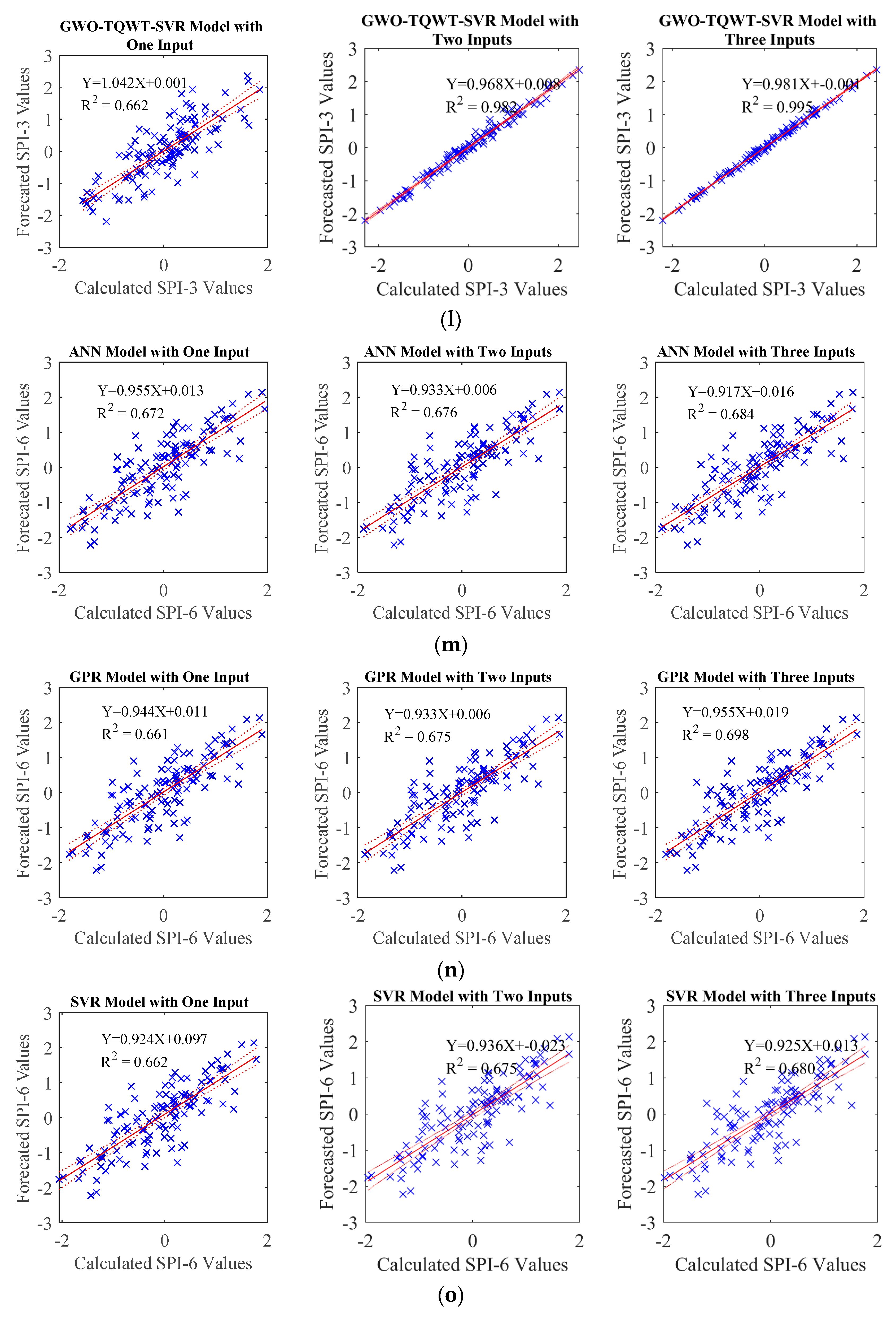
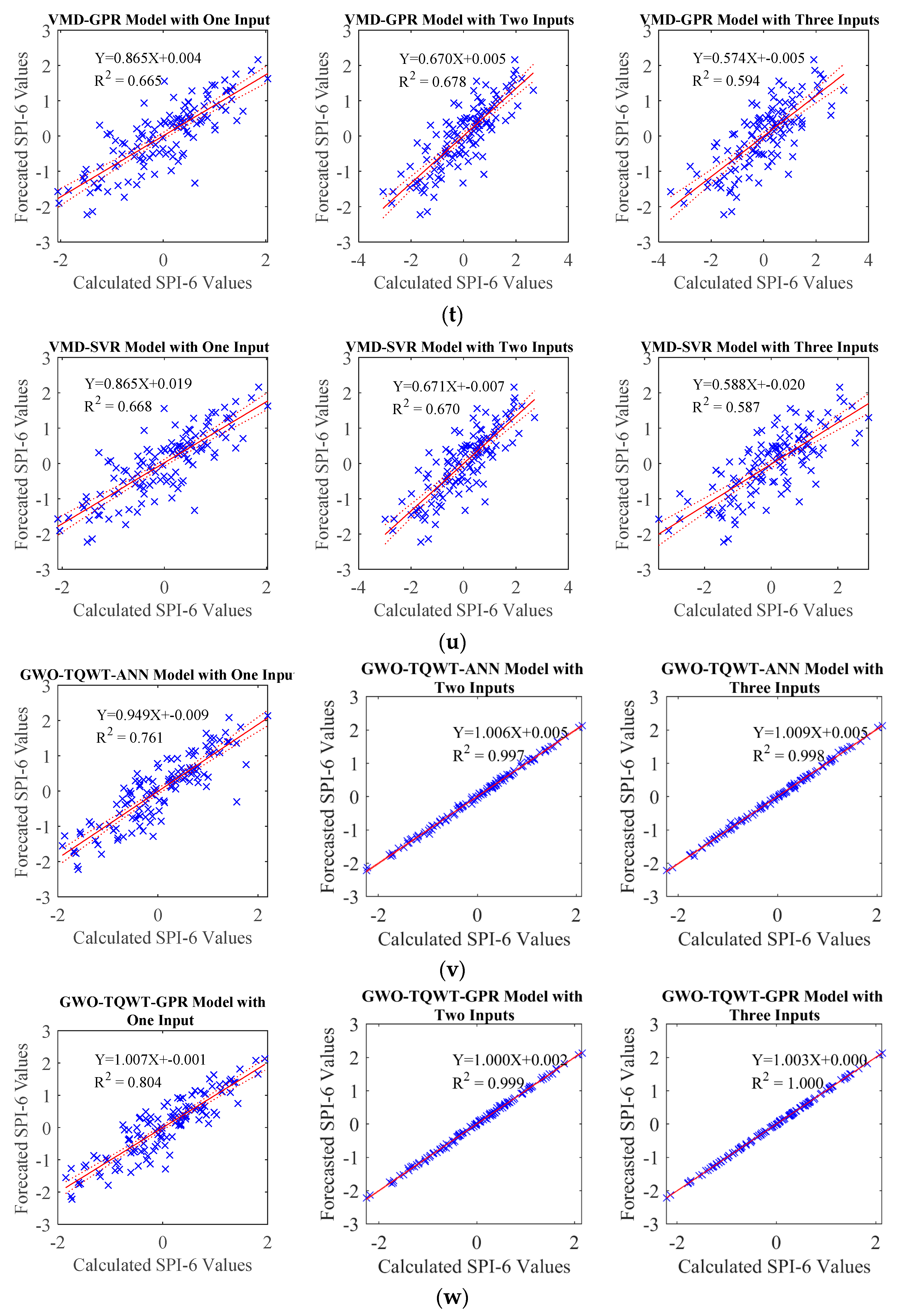
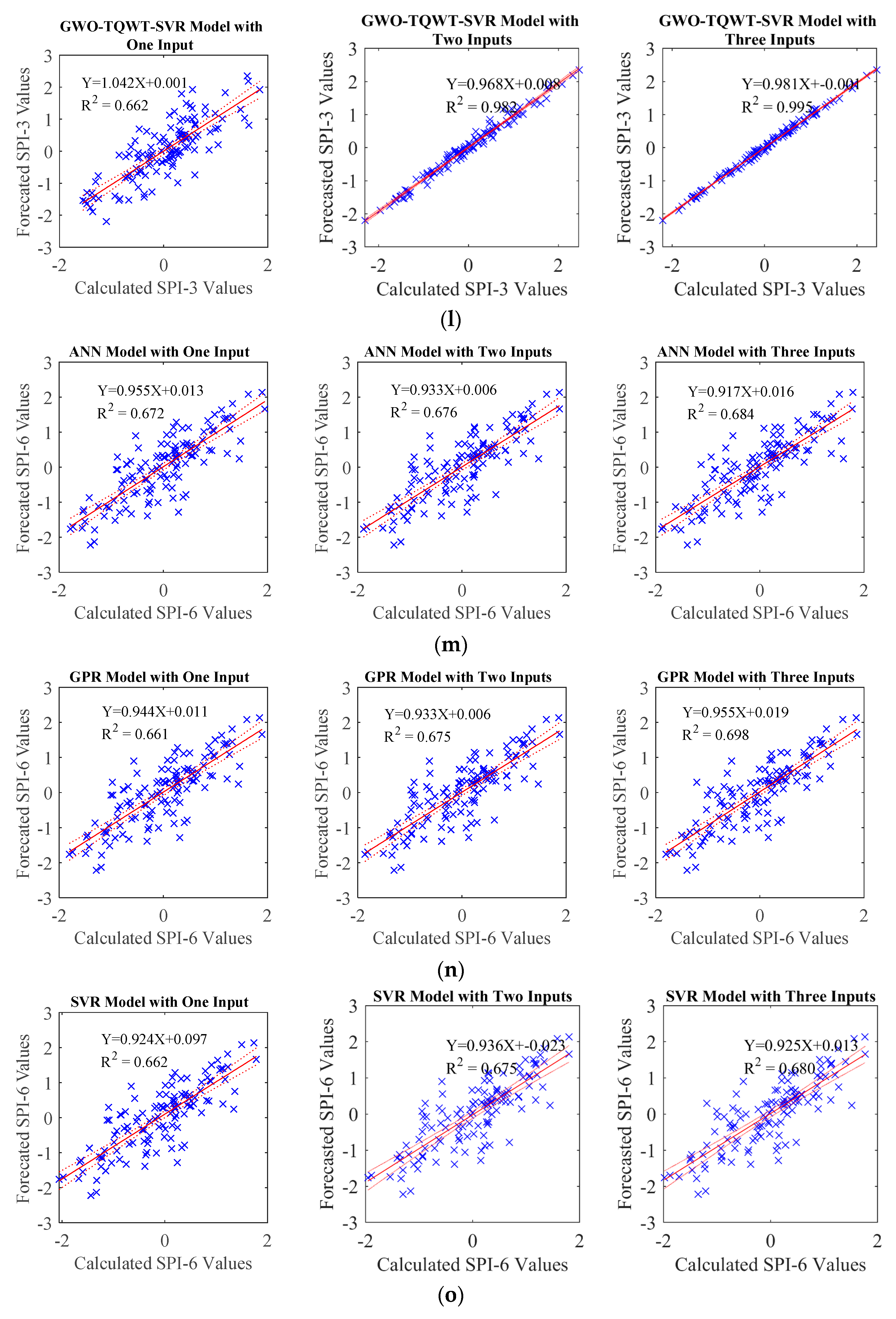
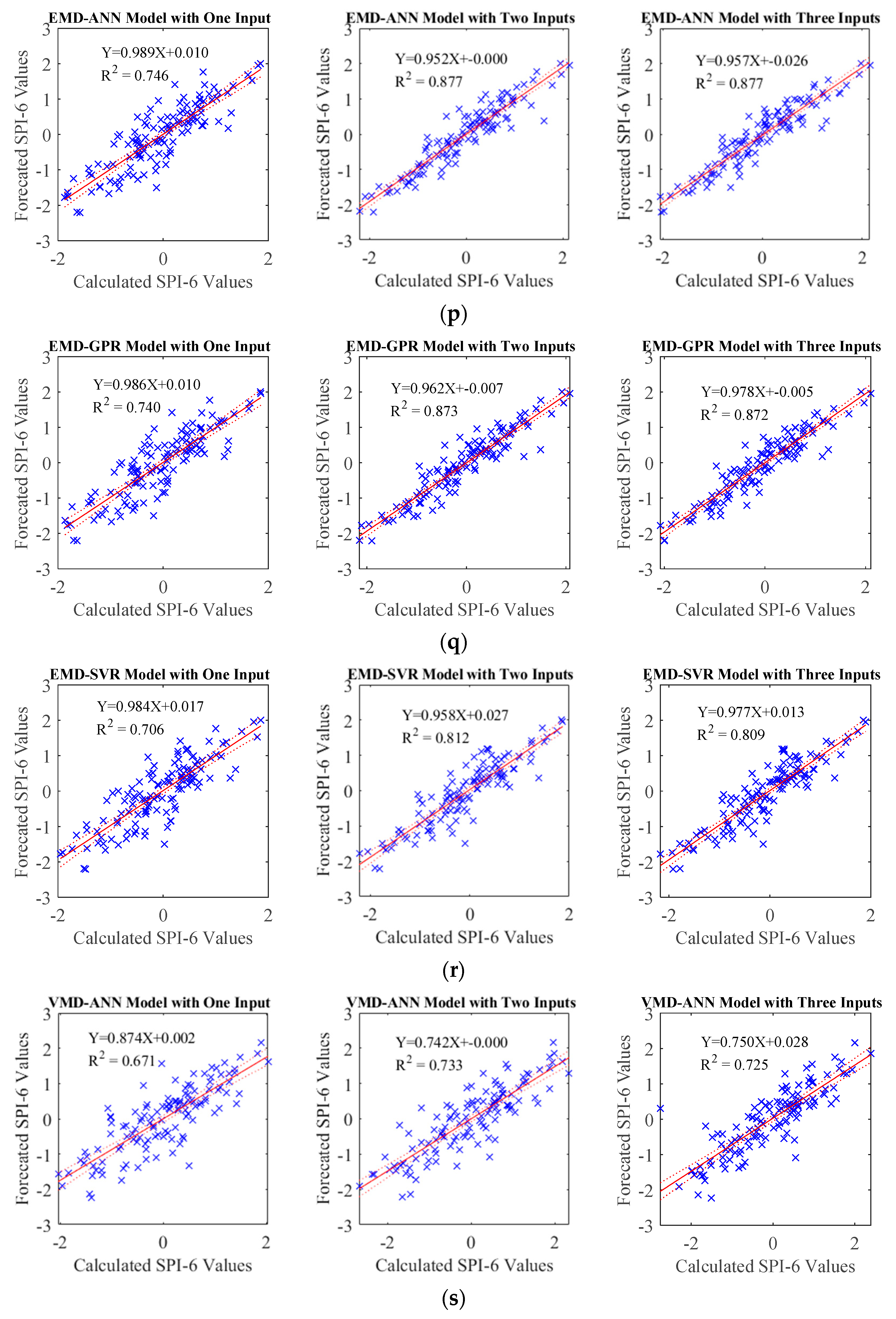
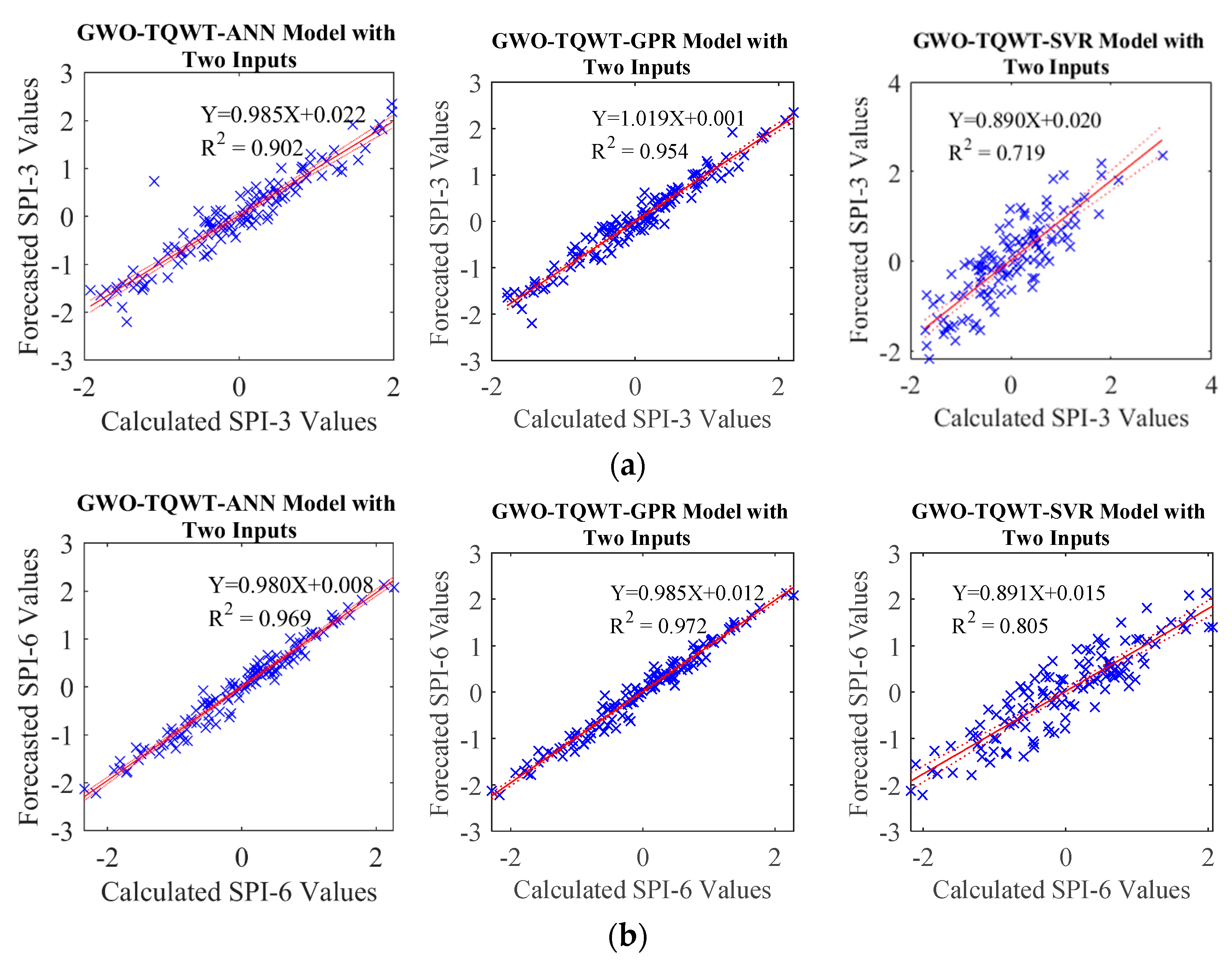
In the TQWT and ML models, those parameters were optimized with GWO and employed in developing forecasting models. During this process, the SPI data underwent decomposition into subband signals using TQWT, and subsequently, these derived subband signals were predicted using ML algorithms, specifically Artificial Neural Network (ANN), support vector machine (SVM), and Gaussian Process Regression (GPR). In order to compare the performance of the GWO-TQWT-ML model, ML-based approaches undergoing Empirical Mode Decomposition and Variational Mode Decomposition preprocessing and stand-alone models (ANN, SVR, and GPR) in which the SPI data itself were used were estimated. As a result of these studies, it is seen that the performance of the GWO-TQWT-ML models is quite good in the one ahead forecasting of SPI data, as shown in
Table 7, and R
2 values up to 0.999 are obtained. From the scatter plots (
Figure 7), it is seen that the performance of the proposed model is significantly superior to the other models. In addition, two and three ahead estimation GWO-TQWT-ML models of SPI data were performed. Among the GWO-TQWT-ML models, it can be seen from
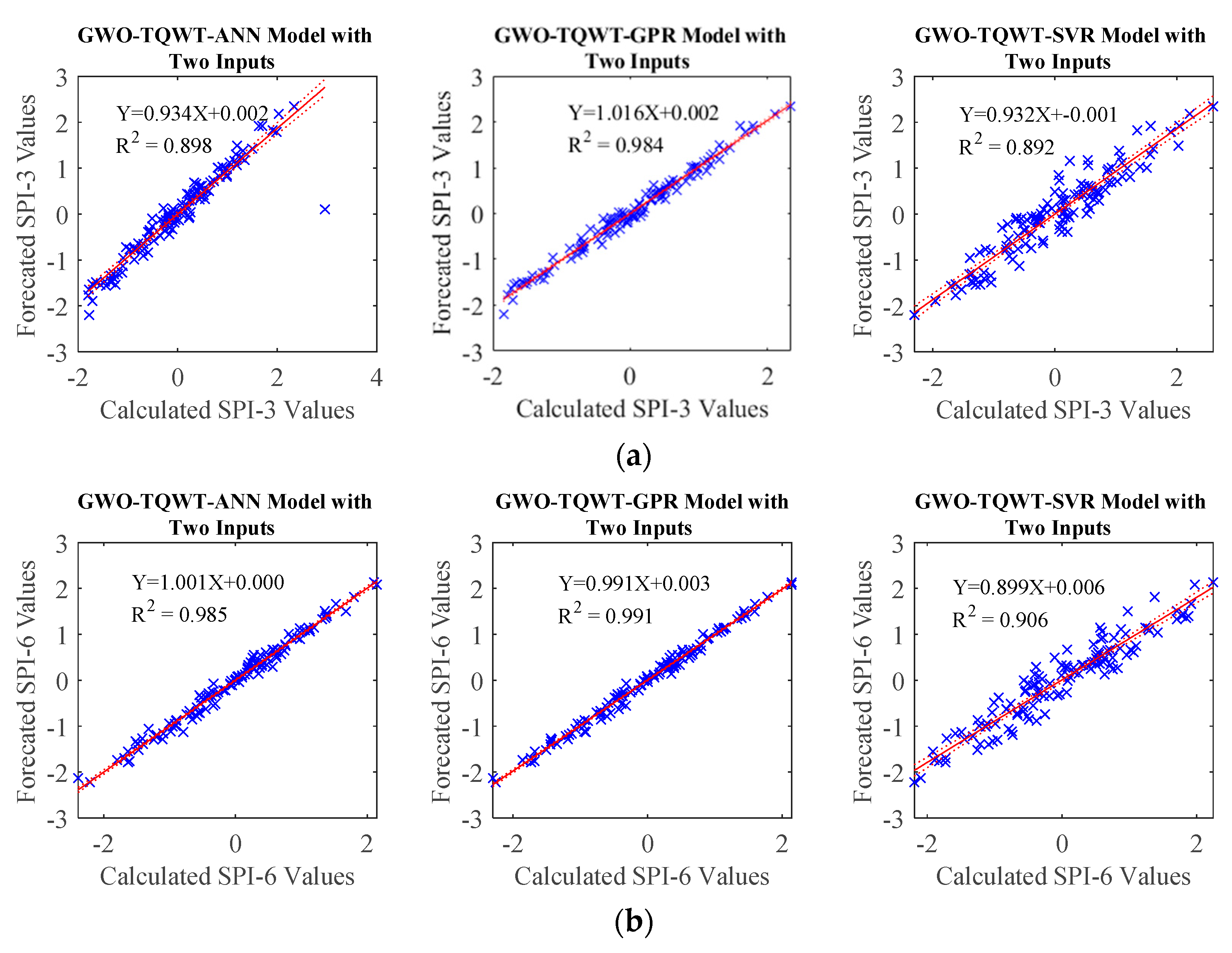
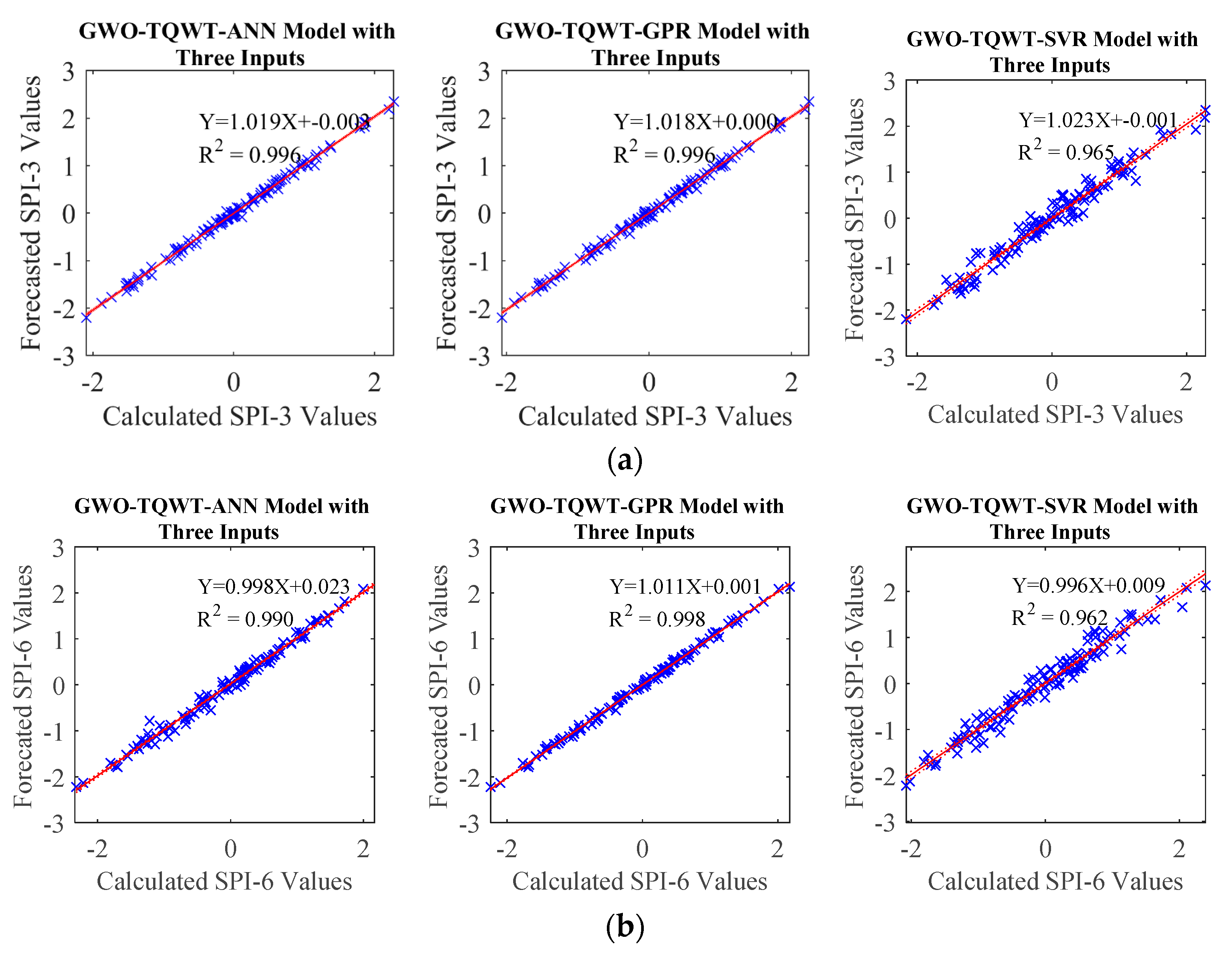
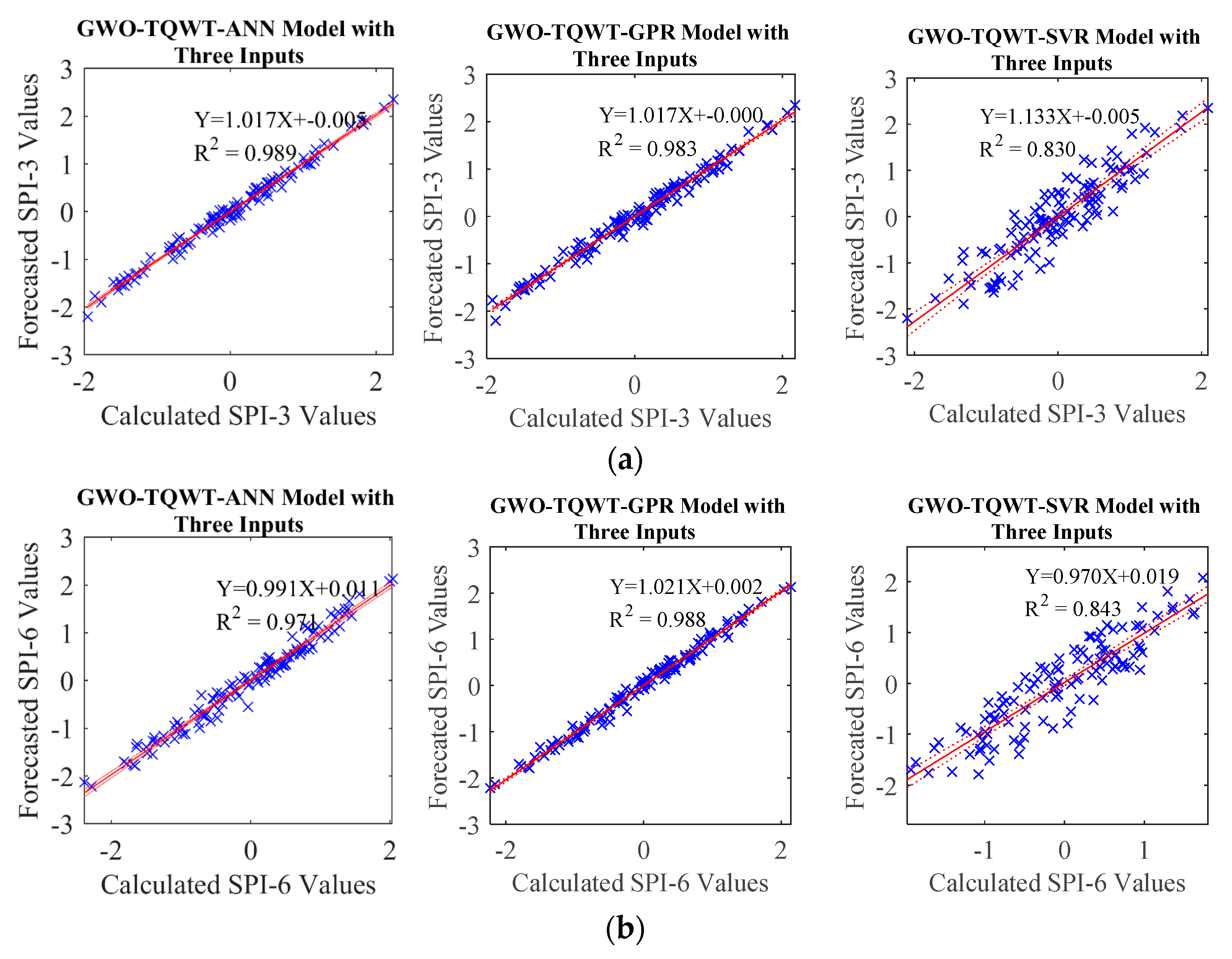
Table 8 and
Figure 8,
Figure 9,
Figure 10 and
Figure 11 that the performance of the GWO-TQWT-GPR model was slightly better than the prediction performance of the GWO-TQWT-ANN and GWO-TQWT-SVR models.
The key results that address these contributions are as follows:
The introduction of a novel method incorporating time-shifting processes and the phase transfer entropy approach for analyzing connectivity in time series data, marking the first use of this approach in the field, thus the identification of input data for SPI estimations using connectivity values derived from this method.
The utilization of TQWT subband signals in SPI estimation, which enhances the accuracy of predictions.
The optimization of TQWT and ML model parameters through the GWO, improving the overall performance of the forecasting models.
Development of the pTE-GWO-TQWT-GPR model, which demonstrated the highest forecasting performance for SPI data used in drought forecasting.
The potential applicability of the proposed approach not only for SPI data but also for estimating other time series related to hydrological processes and forecasting studies.
These results collectively contribute to the advancement of methodologies for time series analysis and forecasting, particularly in the context of drought prediction and hydrological processes.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}