

Enhancing Sustainable Transportation: AI-Driven Bike Demand Forecasting in Smart Cities

 ,
,  ,
,
Abstract
:1. Introduction
- How can historical bike usage data be effectively utilized to predict future demand in a BSS, and which time series forecasting and regression algorithms are most suitable for predicting bike demand in a BSS? Can we generalize the models for different BSSs?
- 2.
- How can the integration of temporal factors, such as day of the week, time of day, and seasonality, improve the accuracy of bike demand predictions using time series and regression algorithms?
- Conduct an exploratory analysis of trends, patterns, outliers, and unsettled points in bike prediction
- Analyze the fine-grained temporal factors, such as the day of the week, time of day, and seasonality, which play a crucial role in shaping bike demand patterns in urban environments and utilize AI techniques to capture and leverage these patterns for better forecasting.
- Develop AI-driven forecasting models tailored for bike demand prediction using time series and regression algorithms and evaluate their performance using MAE, RMSE, and MSE.
- Validate the developed models against a new dataset: the London Bike Sharing System.
2. Literature Review
3. Materials and Methods
3.1. Dataset Description
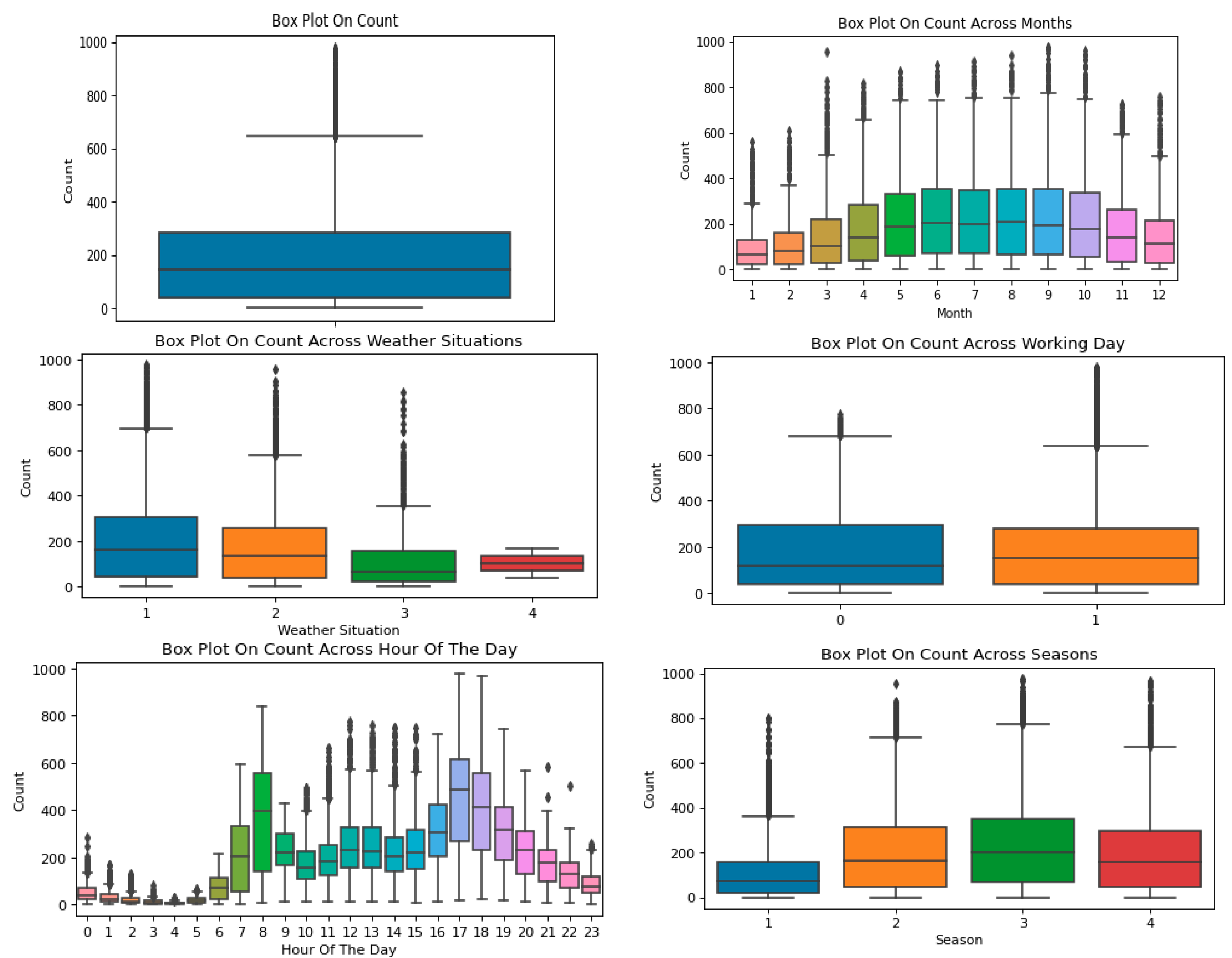
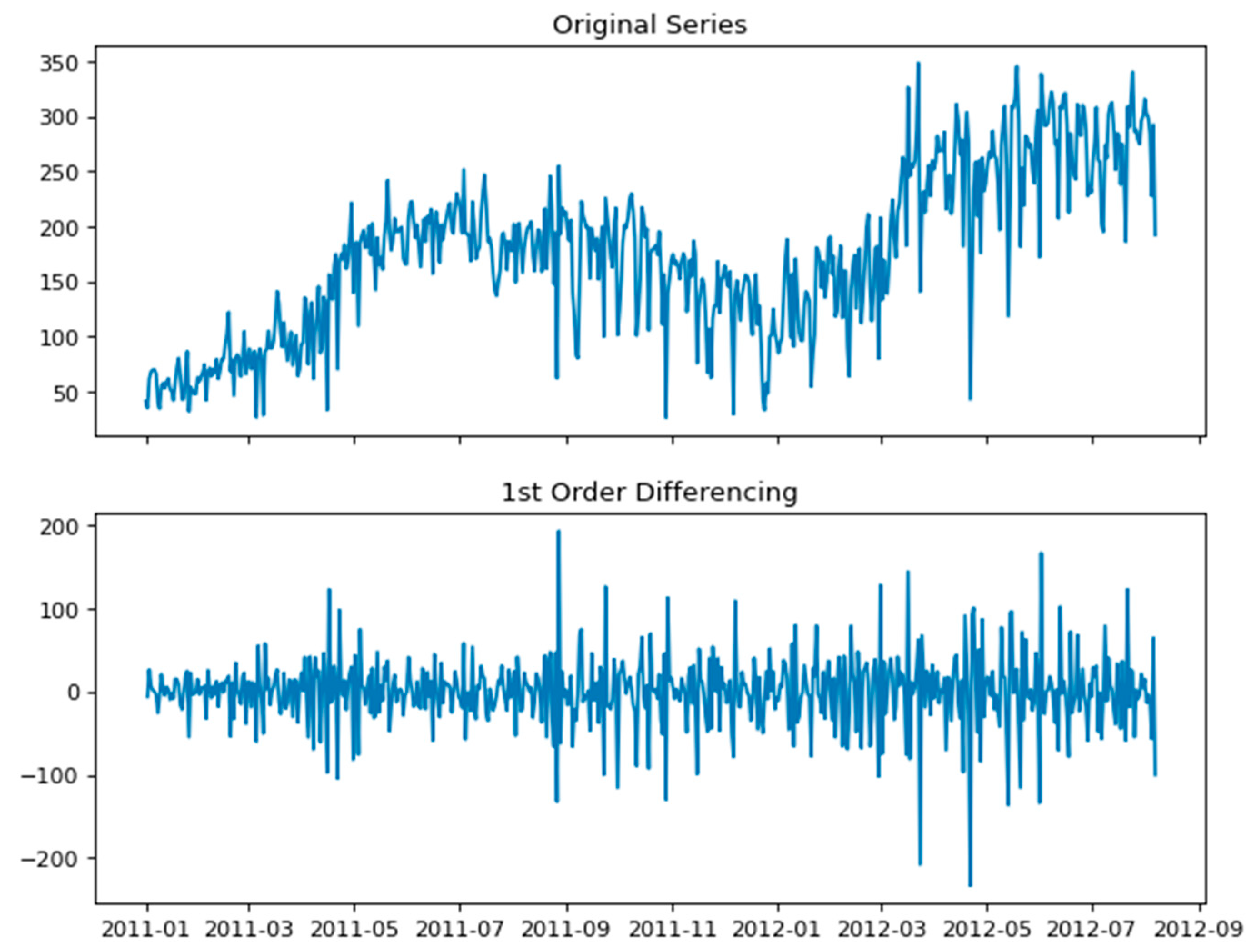
3.2. Exploring the Data and Outlier Analysis
3.3. Modeling Approach for Demand Forecasting
3.3.1. Random Forest
3.3.2. ARIMA
- If the ACF plot shows a gradual decline and becomes statistically insignificant after a few lags, it suggests an AR component. The lag at which the ACF plot crosses the significance level for the first time indicates the value of p for the AR component.
- If the ACF plot exhibits a significant spike at a specific lag followed by a sharp drop, it suggests a MA component. The lag at which the spike occurs in the ACF plot indicates the value of q for the MA component.
3.3.3. SARIMA
- Analyze the data for any trends, seasonality, or other patterns.
- Determine the appropriate values for p, d, q (non-seasonal components), P, D, Q, and S (Seasonal SARIMA components) based on data analysis and ACF plots.
- Fit the SARIMA model using the training data.
- Evaluate the model’s performance on the test set using appropriate metrics.
- Fine-tune the model by adjusting the parameter values or trying different combinations.
- Make predictions for future periods using the trained model.
3.3.4. LSTM
3.3.5. GRU
4. Experiments and Results
4.1. Performance Metrics
4.2. Experimental Settings and Results
4.2.1. Experimental Settings
4.2.2. Experimental Results
5. Findings and Discussion
- i.
- Special events and occasions can influence bike demand.
- ii.
- Changes in infrastructure, such as new bike lanes or changes in public transportation routes, can influence bike demand patterns.
- iii.
- Latency in real-time or near-real-time predictions for dynamic bike demand
- iv.
- Unforeseen events, such as road closure for maintenance, natural calamities, public health crises (like COVID-19), etc., and social-environmental issues, such as equity and accessibility, can disrupt regular demand patterns.
- i.
- Data from a single BSS might not be representative of the bike demand patterns of other locations in the city. It could be biased toward specific user demographics, usage patterns, or geographic locations.
- ii.
- A BSS in one location may not exhibit the full range of demand patterns that occur across different lotions of a city.
- iii.
- Bike demand patterns may change over time due to various factors, including changing user behaviors, weather patterns, and urban developments. The models trained on historical data might struggle to adapt to these evolving patterns.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, X.; Xu, Y.; Zhang, X.; Shi, W.; Yue, Y.; Li, Q. Improving short-term bike sharing demand forecast through an irregular convolutional neural network. Transp. Res. Part C Emerg. Technol. 2023, 147, 103984. [Google Scholar] [CrossRef]
- Litman, T.; Burwell, D. Issues in sustainable transportation. Int. J. Glob. Environ. Issues 2006, 6, 331–347. [Google Scholar] [CrossRef]
- Jabbarpour, M.R.; Zarrabi, H.; Khokhar, R.H.; Shamshirband, S.; Choo, K.-K.R. Applications of computational intelligence in vehicle traffic congestion problem: A survey. Soft Comput. 2018, 22, 2299–2320. [Google Scholar] [CrossRef]
- Midgley, P. The role of smart bike-sharing systems in urban mobility. Journeys 2009, 2, 23–31. [Google Scholar]
- Zhao, S.; Zhao, K.; Xia, Y.; Jia, W. Hyper-clustering enhanced spatio-temporal deep learning for traffic and demand prediction in bike-sharing systems. Inf. Sci. 2022, 612, 626–637. [Google Scholar] [CrossRef]
- De Chardon, C.M.; Caruso, G.; Thomas, I. Bike-share rebalancing strategies, patterns, and purpose. J. Transp. Geogr. 2016, 55, 22–39. [Google Scholar] [CrossRef]
- Schuijbroek, J.; Hampshire, R.C.; Van Hoeve, W.-J. Inventory rebalancing and vehicle routing in bike sharing systems. Eur. J. Oper. Res. 2017, 257, 992–1004. [Google Scholar] [CrossRef]
- Gao, C.; Chen, Y. Using machine learning methods to predict demand for bike sharing. In Information and Communication Technologies in Tourism 2022, Proceedings of the ENTER 2022 eTourism Conference, Online, 11–14 January 2022; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Guerrero, V.M. Time-series analysis supported by power transformations. J. Forecast. 1993, 12, 37–48. [Google Scholar] [CrossRef]
- Boufidis, N.; Nikiforiadis, A.; Chrysostomou, K.; Aifadopoulou, G. Development of a station-level demand prediction and visualization tool to support bike-sharing systems’ operators. Transp. Res. Procedia 2020, 47, 51–58. [Google Scholar] [CrossRef]
- Capital Bikeshare. 2016. Available online: http://capitalbikeshare.com/system-data (accessed on 2 May 2023).
- Jiang, W. Bike sharing usage prediction with deep learning: A survey. Neural Comput. Appl. 2022, 34, 15369–15385. [Google Scholar] [CrossRef]
- Sathish Kumar, V.E.; Cho, Y. A rule-based model for Seoul Bike sharing demand prediction using weather data. Eur. J. Remote Sens. 2020, 53 (Suppl. 1), 166–183. [Google Scholar]
- Brownlee, J. How to use StandardScaler and MinMaxScaler transforms in Python. Available online: https://machinelearningmastery.com/standardscaler-and-minmaxscaler-transforms-in-python/ (accessed on 2 May 2023).
- Box, G.E.; Cox, D.R. An analysis of transformations. J. R. Stat. Soc. Ser. B Stat. Methodol. 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.B.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Ljung, G.M.; Box, G.E. On a measure of lack of fit in time series models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and tuning strategies for random forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Zhou, X. Understanding spatiotemporal patterns of biking behavior by analyzing massive bike sharing data in Chicago. PLoS ONE 2015, 10, e0137922. [Google Scholar] [CrossRef]
- Lin, F.; Jiang, J.; Fan, J.; Wang, S. A stacking model for variation prediction of public bicycle traffic flow. Intell. Data Anal. 2018, 22, 911–933. [Google Scholar] [CrossRef]
- Mehdizadeh Dastjerdi, A.; Morency, C. Bike-sharing demand prediction at community level under COVID-19 using deep learning. Sensors 2022, 22, 1060. [Google Scholar] [CrossRef]
- Lee, S.-H.; Ku, H.-C. A dual attention-based recurrent neural network for short-term bike sharing usage demand prediction. IEEE Trans. Intell. Transp. Syst. 2022, 24, 4621–4630. [Google Scholar] [CrossRef]
- Fanaee, T.H.; Gama, J. Event labeling combining ensemble detectors and background knowledge. Prog. Artif. Intell. 2014, 2, 113–127. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Elhenawy, M.; Rakha, H.A.; Almannaa, M.; House, L. Network and station-level bike-sharing system prediction: A San Francisco bay area case study. J. Intell. Transp. Syst. 2022, 26, 602–612. [Google Scholar] [CrossRef]
- Ning, Y.; Kazemi, H.; Tahmasebi, P. A comparative machine learning study for time series oil production forecasting: ARIMA, LSTM, and Prophet. Comput. Geosci. 2022, 164, 105126. [Google Scholar] [CrossRef]
- Dubey, A.K.; Kumar, A.; García-Díaz, V.; Sharma, A.K.; Kanhaiya, K. Study and analysis of SARIMA and LSTM in forecasting time series data. Sustain. Energy Technol. Assess. 2021, 47, 101474. [Google Scholar]
- Wang, J.; Li, X.; Li, J.; Sun, Q.; Wang, H. NGCU: A new RNN model for time-series data prediction. Big Data Res. 2022, 27, 100296. [Google Scholar] [CrossRef]
- Mavrodiev, H. London Bike Sharing Dataset. Available online: https://www.kaggle.com/datasets/hmavrodiev/london-bike-sharing-dataset (accessed on 27 August 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Search Space | Optimal Value |
|---|---|---|
| n_estimators | [400, 500, 700, 800, 1000, 1300, 1600, 1900, 2000] | 1600 |
| Max features | [‘auto’, ‘sqrt’] | auto |
| Max depth | [None, 10 to 110 in steps of 10] | 90 |
| Min samples split | [2, 4, 5, 8, 10 ] | 5 |
| Min samples leaf | [1, 2, 4, 8] | 1 |
| Bootstrap | [True, False] | True |
| Metrics | RF | ARIMA | SARIMA | LSTM | GRU |
|---|---|---|---|---|---|
| MSE | 5155.89 | 7258.02 | 5802.4 | 3242.16 | 3188.86 |
| RMSE | 71.80 | 85.19 | 76.17 | 56.94 | 56.47 |
| MAE | 44.49 | 64.09 | 56.35 | 35.21 | 33.76 |
| Attributes Selected | Models | MSE | RMSE | MAE |
|---|---|---|---|---|
| month, hour, weekday (Feature Set 1) | RF | 9893.978 | 99.47 | 63.948 |
| ARIMA | 4371.854 | 66.12 | 54.712 | |
| SARIMA | 5801.870 | 76.17 | 56.354 | |
| LSTM | 3316.49 | 57.589 | 35.381 | |
| GRU | 3120.22 | 55.859 | 33.281 | |
| month, hour, weekday, year (Feature Set 2) | RF | 6120.259 | 78.232 | 44.392 |
| ARIMA | 7258.02 | 63.62 | 52.493 | |
| SARIMA | 5802.37 | 68.52 | 54.653 | |
| LSTM | 3582.50 | 59.854 | 36.084 | |
| GRU | 2676.82 | 51.738 | 31.875 | |
| month, hour, weekday, year, season (Feature Set 3) | RF | 5625.067 | 75.00 | 42.367 |
| ARIMA | 7258.02 | 71.19 | 50.521 | |
| SARIMA | 5802.37 | 73.84 | 56.356 | |
| LSTM | 3979.34 | 63.082 | 38.207 | |
| GRU | 3646.95 | 60.39 | 35.584 | |
| month, hour, weekday, year, season, holiday, working day (Feature Set 4) | RF | 5062.746 | 71.15 | 39.926 |
| ARIMA | 4162.959 | 64.521 | 37.231 | |
| SARIMA | 3966.984 | 62.984 | 35.956 | |
| LSTM | 3713.07 | 60.935 | 36.973 | |
| GRU | 2641.24 | 51.393 | 30.764 | |
| month, hour, weekday, year, season, holiday, working day, weathersit and temp (Feature Set 5) | RF | 3123.477 | 55.89 | 30.360 |
| ARIMA | 3508.311 | 59.231 | 36.621 | |
| SARIMA | 3493.164 | 59.103 | 36.001 | |
| LSTM | 3381.42 | 58.15 | 35.890 | |
| GRU | 3276.53 | 57.241 | 34.500 |
| Metrics | RF | ARIMA | SARIMA | LSTM | GRU |
|---|---|---|---|---|---|
| MSE | 5992.64 | 8413.57 | 6319.83 | 4302.41 | 3965.34 |
| RMSE | 77.41 | 91.72 | 79.49 | 65.59 | 62.97 |
| MAE | 52.03 | 70.92 | 61.27 | 39.52 | 35.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Subramanian, M.; Cho, J.; Veerappampalayam Easwaramoorthy, S.; Murugesan, A.; Chinnasamy, R. Enhancing Sustainable Transportation: AI-Driven Bike Demand Forecasting in Smart Cities. Sustainability 2023, 15, 13840. https://doi.org/10.3390/su151813840
Subramanian M, Cho J, Veerappampalayam Easwaramoorthy S, Murugesan A, Chinnasamy R. Enhancing Sustainable Transportation: AI-Driven Bike Demand Forecasting in Smart Cities. Sustainability. 2023; 15(18):13840. https://doi.org/10.3390/su151813840
Chicago/Turabian StyleSubramanian, Malliga, Jaehyuk Cho, Sathishkumar Veerappampalayam Easwaramoorthy, Akash Murugesan, and Ramya Chinnasamy. 2023. "Enhancing Sustainable Transportation: AI-Driven Bike Demand Forecasting in Smart Cities" Sustainability 15, no. 18: 13840. https://doi.org/10.3390/su151813840
APA StyleSubramanian, M., Cho, J., Veerappampalayam Easwaramoorthy, S., Murugesan, A., & Chinnasamy, R. (2023). Enhancing Sustainable Transportation: AI-Driven Bike Demand Forecasting in Smart Cities. Sustainability, 15(18), 13840. https://doi.org/10.3390/su151813840