
Optimal Energy Consumption Path Planning for Unmanned Aerial Vehicles Based on Improved Particle Swarm Optimization


 ,
,  ,
,
Abstract
1. Introduction
- (1)
- Aiming at the problem of UAV energy waste due to unreasonable flight paths in mountainous terrain environments, this research proposes an objective cost function that integrally considers the UAV energy consumption, flight cost, terrain range and terrain collision constraints, which simplifies the optimal energy-consuming path planning problem for UAV into an objective function optimization problem based on the PSO algorithm.
- (2)
- In order to solve the disadvantage that the PSO algorithm easily falls into local optimum when solving complex high-dimensional problems, this research proposes an adaptive parameter control method based on the DDPG model, which effectively improves the global convergence of the PSO algorithm.
2. Preliminaries
2.1. Particle Swarm Optimization Algorithm
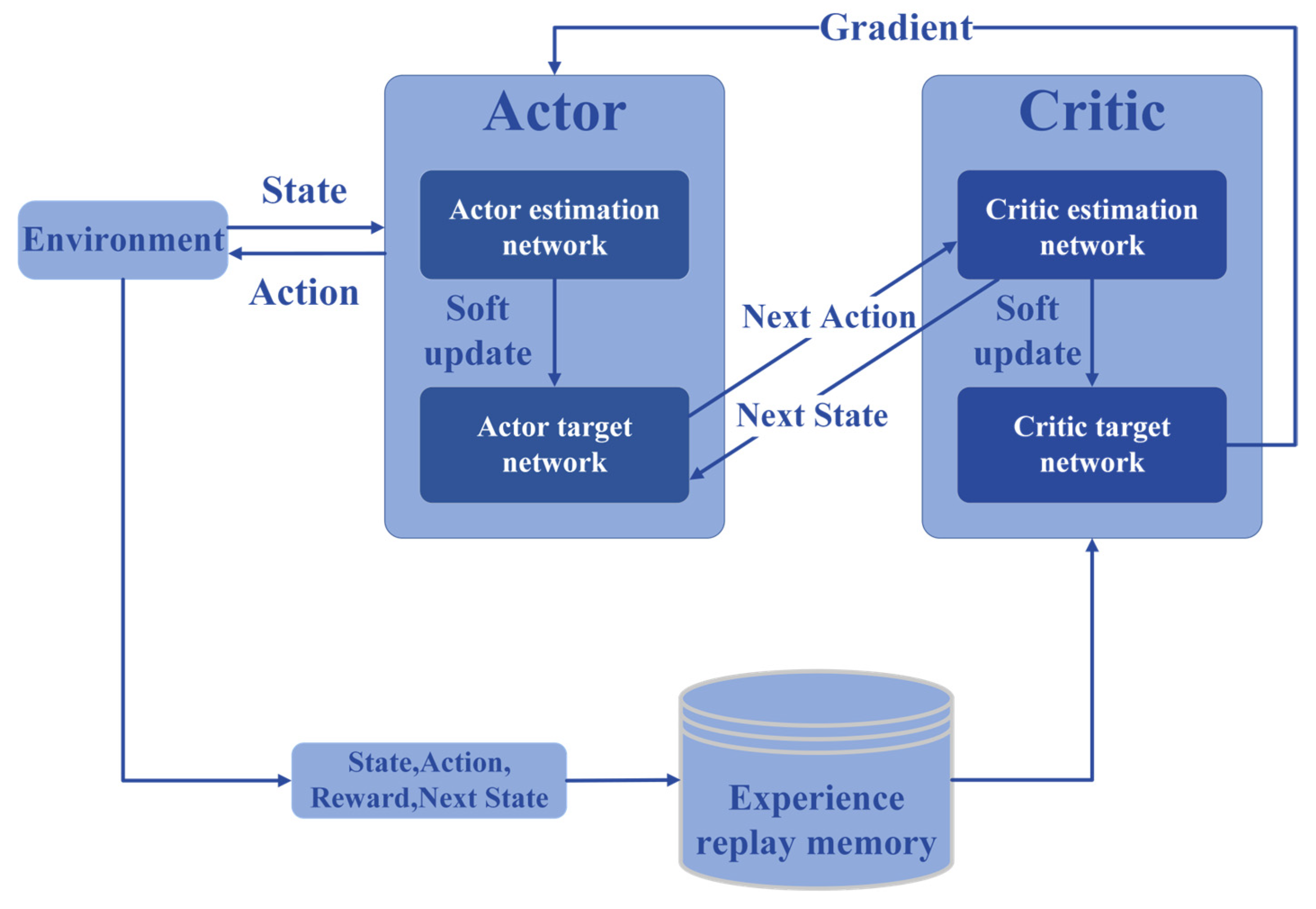
2.2. Deep Deterministic Policy Gradient
2.3. Calculation of the Total Output Power of the Quadcopter Battery
3. Optimal Energy Consumption Path Planning Based on PSO-DDPG
3.1. Problem Modelling
3.1.1. Environmental Model
3.1.2. Basic PSO Design for Path Planning
3.2. DDPG-Based Parameter Adaptation Method for PSO Algorithm
3.2.1. State Space
- The chosen states should have relevance to the task objective;
- The chosen states should be as mutually independent as possible and encompass all task indicators;
- The chosen states should be capable of mapping to the same value range.
3.2.2. Action Space
3.2.3. Reward Function
3.3. PSO-DDPG for Path Planning
| Algorithm 1 PSO-DDPG based 3D environment UAV path planning |
|
4. Simulation Analysis and Discussion
4.1. Experimental Environment
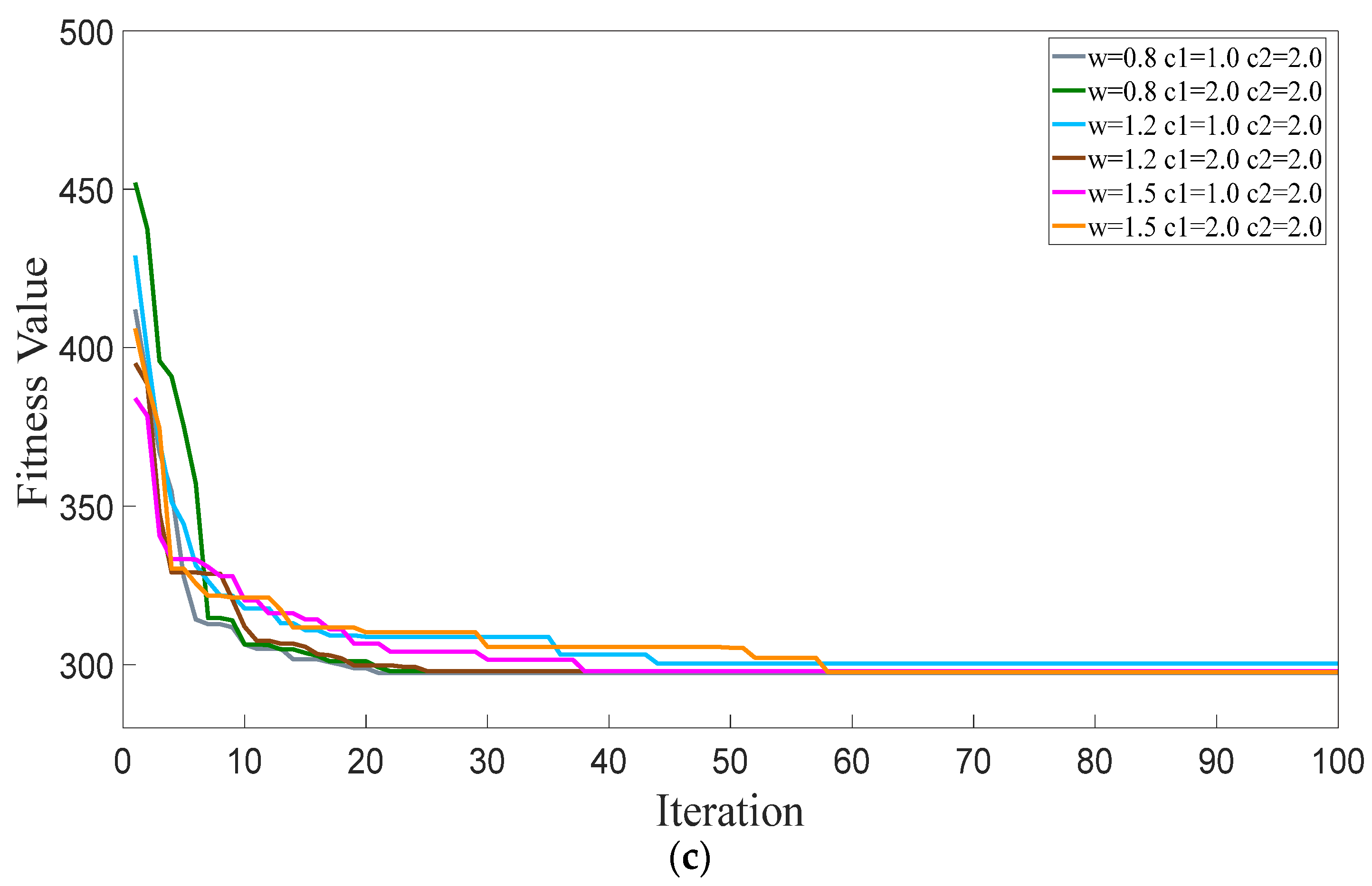
4.2. Case 1: Comparative Analysis under the Different Initial Values of Parameters
4.3. Case 2: Simulation Analysis in Different Terrain Environments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- De Vivo, F.; Battipede, M.; Johnson, E. Infra-red line camera data-driven edge detector in UAV forest fire monitoring. Aerosp. Sci. Technol. 2021, 111, 106574. [Google Scholar] [CrossRef]
- Altan, A.; Hacıoğlu, R. Model predictive control of three-axis gimbal system mounted on UAV for real-time target tracking under external disturbances. Mech. Syst. Signal Process. 2020, 138, 106548. [Google Scholar] [CrossRef]
- Shahi, T.B.; Xu, C.-Y.; Neupane, A.; Guo, W. Recent Advances in Crop Disease Detection Using UAV and Deep Learning Techniques. Remote Sens. 2023, 15, 2450. [Google Scholar] [CrossRef]
- Silvagni, M.; Tonoli, A.; Zenerino, E.; Chiaberge, M. Multipurpose UAV for search and rescue operations in mountain avalanche events. Geomat. Nat. Hazards Risk 2017, 8, 18–33. [Google Scholar] [CrossRef]
- Lozano, Y.; Gutiérrez, O. Design and Control of a Four-Rotary-Wing Aircraft. IEEE Lat. Am. Trans. 2016, 14, 4433–4438. [Google Scholar] [CrossRef]
- Belge, E.; Altan, A.; Hacıoğlu, R. Metaheuristic Optimization-Based Path Planning and Tracking of Quadcopter for Payload Hold-Release Mission. Electronics 2022, 11, 1208. [Google Scholar] [CrossRef]
- Citroni, R.; Di Paolo, F.; Livreri, P. A Novel Energy Harvester for Powering Small UAVs: Performance Analysis, Model Validation and Flight Results. Sensors 2019, 19, 1771. [Google Scholar] [CrossRef]
- Wang, Y.; Kumar, L.; Raja, V.; Al-bonsrulah, H.A.Z.; Kulandaiyappan, N.K.; Amirtharaj Tharmendra, A.; Marimuthu, N.; Al-Bahrani, M. Design and Innovative Integrated Engineering Approaches Based Investigation of Hybrid Renewable Energized Drone for Long Endurance Applications. Sustainability 2022, 14, 16173. [Google Scholar] [CrossRef]
- Li, Y.; Liu, M. Path Planning of Electric VTOL UAV Considering Minimum Energy Consumption in Urban Areas. Sustainability 2022, 14, 13421. [Google Scholar] [CrossRef]
- Baras, N.; Dasygenis, M. UGV Coverage Path Planning: An Energy-Efficient Approach through Turn Reduction. Electronics 2023, 12, 2959. [Google Scholar] [CrossRef]
- Zhang, X.; Duan, H. An improved constrained differential evolution algorithm for unmanned aerial vehicle global route planning. Appl. Soft Comput. 2015, 26, 270–284. [Google Scholar] [CrossRef]
- Bayili, S.; Polat, F. Limited-Damage A*: A path search algorithm that considers damage as a feasibility criterion. Knowl.-Based Syst. 2011, 24, 501–512. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Pehlivanoglu, Y.V. A new vibrational genetic algorithm enhanced with a Voronoi diagram for path planning of autonomous UAV. Aerosp. Sci. Technol. 2012, 16, 47–55. [Google Scholar] [CrossRef]
- Xie, S.; Hu, J.; Bhowmick, P.; Ding, Z.; Arvin, F. Distributed Motion Planning for Safe Autonomous Vehicle Overtaking via Artificial Potential Field. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21531–21547. [Google Scholar] [CrossRef]
- Wen, J.; Yang, J.; Wang, T. Path Planning for Autonomous Underwater Vehicles Under the Influence of Ocean Currents Based on a Fusion Heuristic Algorithm. IEEE Trans. Veh. Technol. 2021, 70, 8529–8544. [Google Scholar] [CrossRef]
- Wu, X.; Bai, J.; Hao, F.; Cheng, G.; Tang, Y.; Li, X. Field Complete Coverage Path Planning Based on Improved Genetic Algorithm for Transplanting Robot. Machines 2023, 11, 659. [Google Scholar] [CrossRef]
- Ma, Y.N.; Gong, Y.J.; Xiao, C.F.; Gao, Y.; Zhang, J. Path Planning for Autonomous Underwater Vehicles: An Ant Colony Algorithm Incorporating Alarm Pheromone. IEEE Trans. Veh. Technol. 2019, 68, 141–154. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, R.; Yang, T.; Xu, J.; Meng, Y. Robot navigation path planning in power plant based on improved wolf pack algorithm. In Proceedings of the 2021 4th International Conference on Information Systems and Computer Aided Education 2021, Dalian China, 24–26 September 2021; pp. 2824–2829. [Google Scholar]
- Yin, S.; Jin, M.; Lu, H.; Gong, G.; Mao, W.; Chen, G.; Li, W. Reinforcement-learning-based parameter adaptation method for particle swarm optimization. Complex Intell. Syst. 2023. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Shi, Y.; Eberhart, R. A modified particle swarm optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No.98TH8360), Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar]
- Liu, Y.; Lu, H.; Cheng, S.; Shi, Y. An Adaptive Online Parameter Control Algorithm for Particle Swarm Optimization Based on Reinforcement Learning. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 815–822. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D.J.C. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wu, D.; Wang, G.G. Employing reinforcement learning to enhance particle swarm optimization methods. Eng. Optim. 2022, 54, 329–348. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 1944, pp. 1942–1948. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 32, pp. I–387–I–395. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Thu, K.M.; Gavrilov, A.I. Designing and Modeling of Quadcopter Control System Using L1 Adaptive Control. Procedia Comput. Sci. 2017, 103, 528–535. [Google Scholar] [CrossRef]
- Shi, D.; Dai, X.; Zhang, X.; Quan, Q. A Practical Performance Evaluation Method for Electric Multicopters. IEEE/ASME Trans. Mechatron. 2017, 22, 1337–1348. [Google Scholar] [CrossRef]
- Song, B.; Wang, Z.; Zou, L. An improved PSO algorithm for smooth path planning of mobile robots using continuous high-degree Bezier curve. Appl. Soft Comput. 2021, 100, 106960. [Google Scholar] [CrossRef]
- Xia, L.; Jun, X.; Manyi, C.; Ming, X.; Zhike, W. Path planning for UAV based on improved heuristic A* algorithm. In Proceedings of the 2009 9th International Conference on Electronic Measurement & Instruments, Beijing, China, 16–19 August 2009; pp. 3-488–3-493. [Google Scholar]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization, Technical Report-TR06; Erciyes University: Talas, Turkey, 2005. [Google Scholar]
- Zhang, Y.; Guan, G.; Pu, X. The Robot Path Planning Based on Improved Artificial Fish Swarm Algorithm. Math. Probl. Eng. 2016, 2016, 3297585. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantity | Symbol | Value |
|---|---|---|
| Number of total group | M | 50 |
| Number of total iterations | N | 100 |
| Current particle number | i | \ |
| Current iterations | t | \ |
| Number of iterations to reach the neural network learning condition | \ | |
| Number of path points | n | 1000 |
| Capacity of experience replay memory | R | 10 |
| Inertia weight | 0.4~2.0 | |
| Social weight | 0.8~2.0 | |
| Cognitive weight | 0.8~2.0 | |
| Discount factor | 0.95 |
| Algorithm | Parameter |
|---|---|
| PSO | , , |
| ABC | , , , |
| AFSA | , , |
| Algorithm |
Average Fitness Value |
Best Fitness Value |
Worst Fitness Value |
Average Optimization Rates |
|---|---|---|---|---|
| PSO | 323.592 | 322.76 | 325.59 | \ |
| ABC | 305.518 | 304.91 | 307.25 | 0.056 |
| AFSA | 299.77 | 298.13 | 301.47 | 0.074 |
| PSO-DDPG | 299.47 | 295.36 | 301.48 | 0.075 |
| Algorithm |
Average Fitness Value |
Best Fitness Value |
Worst Fitness Value |
Average Optimization Rates |
|---|---|---|---|---|
| PSO | 334.39 | 334.48 | 338.36 | \ |
| ABC | 324.03 | 318.19 | 327.45 | 0.031 |
| AFSA | 306.66 | 306.17 | 307.21 | 0.083 |
| PSO-DDPG | 303.84 | 301.35 | 306.01 | 0.092 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Na, Y.; Li, Y.; Chen, D.; Yao, Y.; Li, T.; Liu, H.; Wang, K. Optimal Energy Consumption Path Planning for Unmanned Aerial Vehicles Based on Improved Particle Swarm Optimization. Sustainability 2023, 15, 12101. https://doi.org/10.3390/su151612101
Na Y, Li Y, Chen D, Yao Y, Li T, Liu H, Wang K. Optimal Energy Consumption Path Planning for Unmanned Aerial Vehicles Based on Improved Particle Swarm Optimization. Sustainability. 2023; 15(16):12101. https://doi.org/10.3390/su151612101
Chicago/Turabian StyleNa, Yiwei, Yulong Li, Danqiang Chen, Yongming Yao, Tianyu Li, Huiying Liu, and Kuankuan Wang. 2023. "Optimal Energy Consumption Path Planning for Unmanned Aerial Vehicles Based on Improved Particle Swarm Optimization" Sustainability 15, no. 16: 12101. https://doi.org/10.3390/su151612101
APA StyleNa, Y., Li, Y., Chen, D., Yao, Y., Li, T., Liu, H., & Wang, K. (2023). Optimal Energy Consumption Path Planning for Unmanned Aerial Vehicles Based on Improved Particle Swarm Optimization. Sustainability, 15(16), 12101. https://doi.org/10.3390/su151612101