

Self-Paced Ensemble-SHAP Approach for the Classification and Interpretation of Crash Severity in Work Zone Areas
 ,
,
Abstract
1. Introduction
2. Materials and Methods
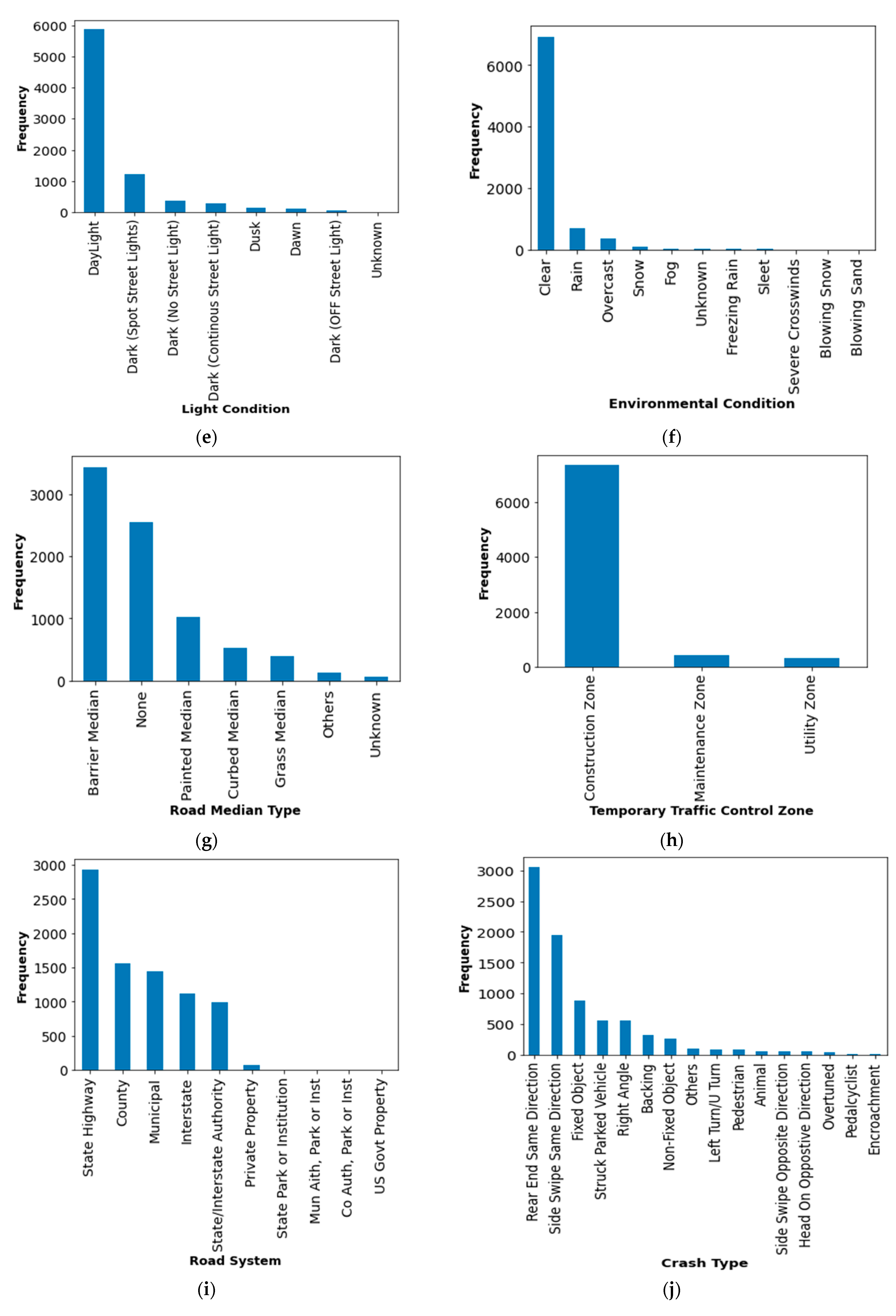
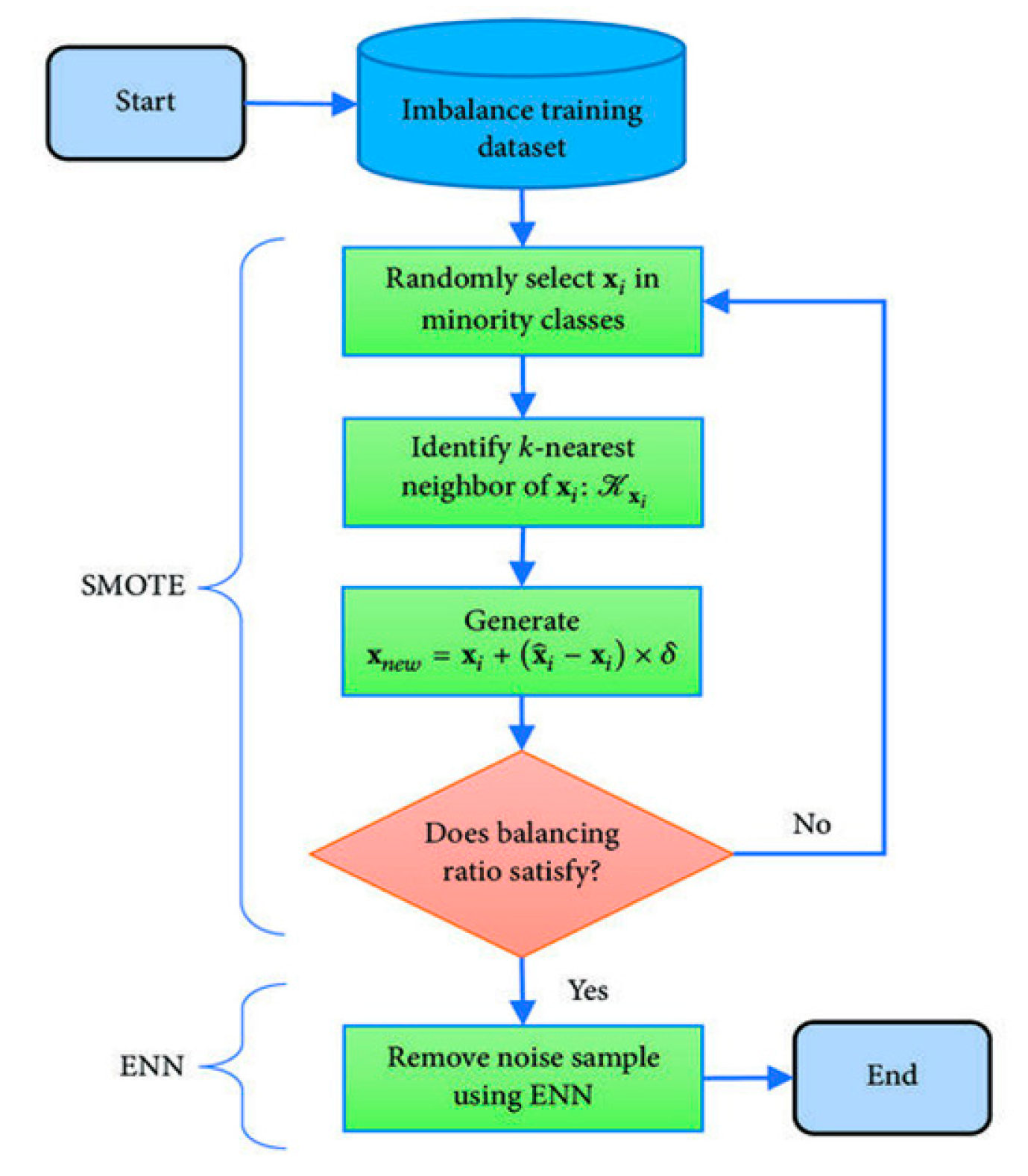
2.1. Data Description and Augmentation
2.2. Self-Paced Ensemble (SPE) Model for Imbalanced Crash Data
2.2.1. Hardness Harmonize
2.2.2. Self-Paced Factor
| Algorithm 1: SPE model | ||
| Input: Hardness function , training data , base estimators , number of base estimators , number or amount of bins | ||
| Initialize: is the minority class instances in , is the minority class instances , | ||
| The estimator is trained by employing randomly under-sampled majority subsets, and , where | ||
| for do | ||
| Create ensemble of base estimators | ||
| Split the majority subset into bins w.r.t : | ||
| The mean hardness contribution in the bin is given as: | ||
| The self-paced factors is updated as | ||
| Un-normalized sampling weight of the bin is: | ||
| Under-sampling is performed from the bin with instances | ||
| Train the estimator by employing newly generated under-sampled set | ||
| End | ||
| Output Robust ensemble model | ||
2.3. Tree-Based ML Models
2.3.1. Classification and Regression Tree (CART)
2.3.2. Adaptive Boosting (AdaBoost)
| Algorithm 2: Adaptive Boosting (AdaBoost) | ||
| Input: Training dataset: , weak learner | ||
| Initialize the distribution of weight as | ||
| for do | ||
| By the utilization of weight distribution , the weak learner is trained | ||
| For , determine the weight | ||
| Over the training data set, the weight distribution is updated. Here, is a factor that is known as a normalization factor. It is chosen such that will be a distribution. | ||
| End for | ||
| Return as well as | ||
2.3.3. Light Gradient Boosting Machine (LGBM)
2.3.4. Binary Logistic Regression (BLR)
2.4. Hyperparameter Tuning
2.5. Model Evaluation
2.6. SHAP Interpretation
3. Results
3.1. Data Treatment for ML Models and BLR Model
3.2. Hyperparameter Tuning using Bayesian Optimization
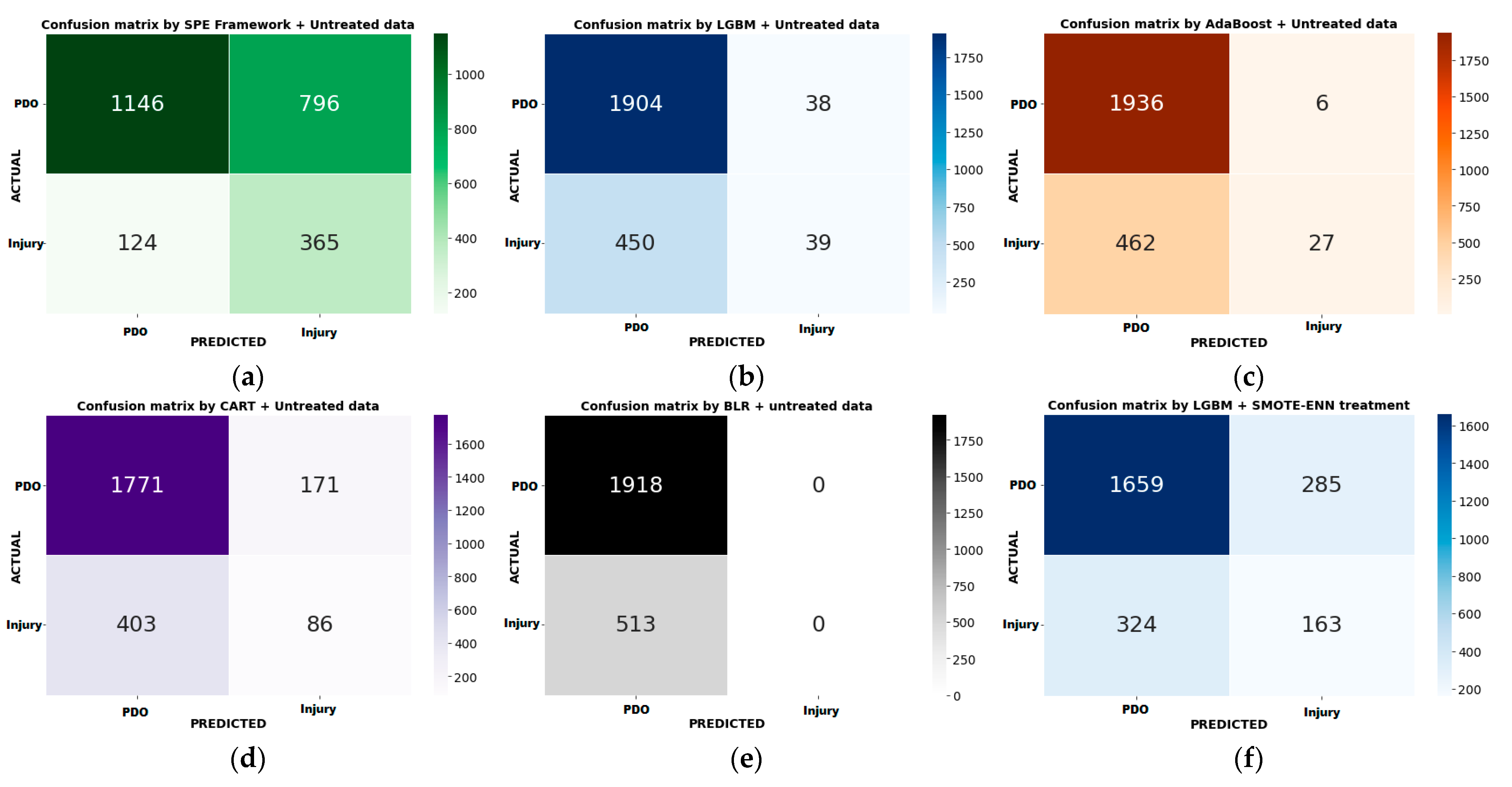
3.3. Model Performance Assessment and Comparison
3.4. Discussion of Model Result by SHAP
3.4.1. Global Variable Interpretation
- The “Crash Type” variable coded by lower numbers (blue dots), such as 1: Same Direction Rear-End Collision, 2: Side Swipe Same Direction, and 3: Right Angle Collision, has a high positive SHAP value, which increases the likelihood of injuries. Similarly, most of the higher values (red dots), such as collisions with 13: Pedestrian, 14: Pedal Cyclist, and 15: Non-Fixed Object, result in the likelihood of PDO;
- The “Road System” variable coded by lower numbers as well as middle numbers, such as 1: Interstate, 2: State Highway, 3: State/Interstate Authority, 4: State Park or Institution, and 5: County, increases the likelihood of injuries in work zone crashes, whereas most of the higher values, such as 9: Private Property and 10: US Government Property, and few lower numbers increase the likelihood of occurrence of PDO;
- The “Road Medium Type” variable with lower numbers, such as 1: Barrier Median and 2: Curbed Median, increases the likelihood of injuries and vice versa.
3.4.2. Local Variable Interpretation
3.4.3. Variable Interaction Analysis
4. Conclusions and Recommendations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Federal Highway Administration (FHWA) 2019. Work Zone Facts and Statistics. Available online: https://ops.fhwa.dot.gov/wz/resources/facts_stats.htm#ftn2 (accessed on 17 June 2022).
- Federal Highway Administration (FHWA) 2017. Facts and Statistics—Work Zone Safety. Available online: http://www.ops.fhwa.dot.gov/wz/resources/factsstats/injuriesfatalities.htm (accessed on 10 July 2017).
- Theofilatos, A.; Ziakopoulos, A.; Papadimitriou, E.; Yannis, G.; Diamandouros, K. Meta-analysis of the effect of road work zones on crash occurrence. Accid. Anal. Prev. 2017, 108, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Chen, E.; Tarko, A.P. Modeling safety of highway work zones with random parameters and random effects models. Anal. Methods Accid. Res. 2014, 1, 86–95. [Google Scholar] [CrossRef]
- Ozturk, O.; Ozbay, K.; Yang, H. Estimating the impact of work zones on highway safety. In Proceedings of the Transportation Research Board 93rd Annual Meeting, Washington, DC, USA, 12–16 January 2014. [Google Scholar]
- Zha, L.; Lord, D.; Zou, Y. The Poisson inverse Gaussian (PIG) generalized linear regression model for analyzing motor vehicle crash data. J. Transp. Saf. Secur. 2016, 8, 18–35. [Google Scholar] [CrossRef]
- Li, Z.; Wang, W.; Liu, P.; Bigham, J.M.; Ragland, D.R. Using geographically weighted Poisson regression for county-level crash modeling in California. Saf. Sci. 2013, 58, 89–97. [Google Scholar] [CrossRef]
- Chen, F.; Chen, S. Injury severities of truck drivers in single-and multi-vehicle accidents on rural highways. Accid. Anal. Prev. 2011, 43, 1677–1688. [Google Scholar] [CrossRef]
- Ye, F.; Lord, D. Investigation of effects of under reporting crash data on three commonly used traffic crash severity models: Multinomial logit, ordered probit, and mixed logit. Transp. Res. Rec. 2011, 2241, 51–58. [Google Scholar] [CrossRef]
- Marzoug, R.; Lakouari, N.; Ez-Zahraouy, H.; Téllez, B.C.; Téllez, M.C.; Villalobos, L.C. Modeling and simulation of car accidents at a signalized intersection using cellular automata. Phys. A Stat. Mech. Its Appl. 2022, 589, 126599. [Google Scholar] [CrossRef]
- Weng, J.; Meng, Q.; Wang, D.Z. Tree-based logistic regression approach for work zone casualty risk assessment. Risk Anal. 2013, 33, 493–504. [Google Scholar] [CrossRef]
- Morgan, J.F.; Duley, A.R.; Hancock, P.A. Driver responses to differing urban work zone configurations. Accid. Anal. Prev. 2010, 42, 978–985. [Google Scholar] [CrossRef]
- Weng, J.; Xue, S.; Yang, Y.; Yan, X.; Qu, X. In-depth analysis of drivers’ merging behavior and rear-end crash risks in work zone merging areas. Accid. Anal. Prev. 2015, 77, 51–61. [Google Scholar] [CrossRef]
- Bai, Y.; Yang, Y.; Li, Y. Determining the effective location of a portable changeable message sign on reducing the risk of truck-related crashes in work zones. Accid. Anal. Prev. 2015, 83, 197–202. [Google Scholar] [CrossRef] [PubMed]
- McAvoy, D.S.; Duffy, S.; Whiting, H.S. Simulator study of primary and precipitating factors in work zone crashes. Transp. Res. Rec. 2011, 2258, 32–39. [Google Scholar] [CrossRef]
- Weng, J.; Du, G.; Ma, L. Driver injury severity analysis for two work zone types. In Proceedings of the Institution of Civil Engineers-Transport; Thomas Telford Ltd.: London, UK, 2016; Volume 169, pp. 97–106. [Google Scholar]
- Li, Y.; Bai, Y. Highway work zone risk factors and their impact on crash severity. J. Transp. Eng. 2009, 135, 694–701. [Google Scholar] [CrossRef]
- Osman, M.; Paleti, R.; Mishra, S.; Golias, M.M. Analysis of injury severity of large truck crashes in work zones. Accid. Anal. Prev. 2016, 97, 261–273. [Google Scholar] [CrossRef]
- Akhter, M.N.; Mekhilef, S.; Mokhlis, H.; Mohamed Shah, N. Review on forecasting of photovoltaic power generation based on machine learning and metaheuristic techniques. IET Renew. Power Gener. 2019, 13, 1009–1023. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Z.; Pu, Z.; Xu, C. Comparing prediction performance for crash injury severity among various machine learning and statistical methods. IEEE Access 2018, 6, 60079–60087. [Google Scholar] [CrossRef]
- Sarkar, S.; Pramanik, A.; Maiti, J.; Reniers, G. Predicting and analyzing injury severity: A machine learning-based approach using class-imbalanced proactive and reactive data. Saf. Sci. 2020, 125, 104616. [Google Scholar] [CrossRef]
- Beam, A.L.; Kohane, I.S. Big data and machine learning in health care. Jama 2018, 319, 1317–1318. [Google Scholar] [CrossRef]
- Dixon, M.F.; Halperin, I.; Bilokon, P. Machine Learning in Finance; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Dong, S.; Khattak, A.; Ullah, I.; Zhou, J.; Hussain, A. Predicting and analyzing road traffic injury severity using boosting-based ensemble learning models with SHAPley Additive exPlanations. Int. J. Environ. Res. Public Health 2022, 19, 2925. [Google Scholar] [CrossRef]
- Yang, C.; Chen, M.; Yuan, Q. The application of XGBoost and SHAP to examining the factors in freight truck-related crashes: An exploratory analysis. Accid. Anal. Prev. 2021, 158, 106153. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving prediction of the minority class in boosting. In Proceedings of the InKnowledge Discovery in Databases: PKDD 2003: 7th European Conference on Principles and Practice of Knowledge Discovery in Databases, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 107–119. [Google Scholar]
- Liu, Z.; Cao, W.; Gao, Z.; Bian, J.; Chen, H.; Chang, Y.; Liu, T.Y. Self-paced ensemble for highly imbalanced massive data classification. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 841–852. [Google Scholar]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Dimitrijevic, B.; Khales, S.D.; Asadi, R.; Lee, J.; Kim, K. Segment-Level Crash Risk Analysis for New Jersey Highways Using Advanced Data Modeling; Center for Advanced Infrastructure and Transportation, Rutgers University: New Brunswick, NJ, USA, 2020. [Google Scholar]
- Dimitrijevic, B.; Khales, S.D.; Asadi, R.; Lee, J. Short-term segment-level crash risk prediction using advanced data modeling with proactive and reactive crash data. Appl. Sci. 2022, 12, 856. [Google Scholar] [CrossRef]
- Koilada, K.; Mane, A.S.; Pulugurtha, S.S. Odds of work zone crash occurrence and getting involved in advance warning, transition, and activity areas by injury severity. IATSS Res. 2020, 44, 75–83. [Google Scholar] [CrossRef]
- Lee, C.; Li, X. Analysis of injury severity of drivers involved in single-and two-vehicle crashes on highways in Ontario. Accid. Anal. Prev. 2014, 71, 286–295. [Google Scholar] [CrossRef]
- Dimitrijevic, B.; Asadi, R.; Spasovic, L. Application of hybrid support vector Machine models in analysis of work zone crash injury severity. Transp. Res. Interdiscip. Perspect. 2023, 19, 100801. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Risk Variable | Codes and Description |
|---|---|
| Road Character–Road Horizontal Alignment | 0: ‘Unknown’, 1: ‘Straight’, 2: ‘Curved Left’, 3: ‘Curved Right’, |
| Road Character–Road Grade | 0: ‘Unknown’, 4: ‘Level’, 5: ‘Down Hill’, 6: ‘Up Hill’, 7: ‘Hill Crest’, 8: ‘Sag’ |
| Road Surface Type | 0: ‘Unknown’, 1: ‘Concrete’, 2: ‘Black Top’,3: ‘Gravel’, 4: ‘Steel Grid’, 5: ‘Dirt’, 6: ‘Others’ |
| Road Surface Condition | 0: ‘Unknown’, 1: ‘Dry’, 2: ‘Wet’, 3: ‘Snowy’, 4: ‘Icy’, 5: ‘Slush’, 6: ‘Standing Water’, 7: ‘Sand’, 8: ‘Oil’, 9: ‘Mud’, 10: “Others” |
| Light Condition | 0: ‘Unknown’, 1: ‘Daylight’, 2: ‘Dawn’, 3: ‘Dusk’, 4: ‘Dark (Off Street Light)’, 5: ‘Dark (No Street Light)’, 6: ‘Dark (Spot Street Lights)’, 7: ‘Dark (Continuous Street Light)’ |
| Environmental Condition | 0: ‘Unknown’, 1: ‘Clear’, 2: ‘Rain’, 3: ‘Snow’, 4: ‘Fog’, 5: ‘Overcast’, 6: ‘Sleet’, 7: ‘Freezing Rain’,8: ‘Blowing Snow’, 9: ‘Blowing Sand’, 10: ‘Severe Crosswinds’ |
| Road Median Type | 0: ‘Unknown’, 1: ‘Barrier Median’, 2: ‘Curbed Median’, 3: ‘Grass Median’, 4: ‘Painted Median’, 5: ‘None’, 6: ‘Others’ |
| Temporary Traffic Control Zone | 2: ‘Construction Zone’, 3: ‘Maintenance Zone’, 4: ‘Utility Zone’ |
| Crash Type | 1: ‘Rear End Same Direction’, 2: ‘Side Swipe Same Direction’, 3: ‘Right Angle’, 4: ‘Head On Opposite Direction’, 5: ‘Side Swipe Opposite Direction’, 6: ‘Struck Parked Vehicle’, 7: ‘Left Turn/U Turn’, 8: ‘Backing’, 9: ‘Encroachment’, 10: ‘Overtuned’, 11: ‘Fixed Object’, 12: ‘Animal’, 13: ‘Pedestrian’, 14: ‘Pedalcyclist’, 15: ‘Non-Fixed Object’, 16: ‘Others’ |
| Road System | 1: ‘Interstate’, 2: ‘State Highway’, 3: ‘State/Interstate Authority’, 4: ‘State Park or Institution’, 5: ‘County’, 6: ‘Co Auth, Park or Inst’, 7: ‘Municipal’, 8: ‘Mun Aith, Park or Inst’, 9: ‘Private Property’, 10: ‘US Govt Property’ |
| Type of Day | 1: ‘Weekday’, 0: ‘Weekend’ |
| Number of Vehicles Involved | 1: ‘Multiple Vehicles’, 0: ‘Single Vehicle’ |
| Treatment | Model | Hyperparameters | Range | Optimal Values |
|---|---|---|---|---|
| No treatment | SPE | Number of trees | [100–3000] | 949 |
| Max depth | [0–10] | 6 | ||
| Learning rate | [0.01–0.1] | 0.056 | ||
| LGBM | Number of trees | [100–3000] | 2466 | |
| Learning rate | [0.01–0.5] | 0.081 | ||
| Max depth | [0–10] | 7 | ||
| Lambda l1 | [0.01–10] | 0.49 | ||
| Lambda l2 | [0.01–10] | 0.15 | ||
| AdaBoost | Number of trees | [100–3000] | 1200 | |
| Learning rate | [0.01–0.5] | 0.095 | ||
| CART | Min samples leaf | [0.05–0.1] | 0.07 | |
| Max depth | [0–10] | 2 | ||
| SMOTE-ENN | LGBM | Number of trees | [100–3000) | 1968 |
| Learning rate | [0.01–0.50] | 0.066 | ||
| Max depth | [0–10] | 6 | ||
| Lambda l1 | [0.01–5] | 0.41 | ||
| Lambda l2 | [0.01–5] | 0.27 | ||
| AdaBoost | Number of trees | [100–3000] | 1107 | |
| Learning rate | [0.01–0.50] | 0.088 | ||
| CART | Min samples leaf | [0.05–0.1] | 0.04 | |
| Max depth | [0–10] | 3 |
| Models | Treatments | Class | Precision | Recall | G-Mean | MCC |
|---|---|---|---|---|---|---|
| SPE | No Treatment | PDO | 0.90 | 0.56 | 0.68 | 0.26 |
| Injury | 0.30 | 0.78 | ||||
| Average | 0.60 | 0.67 | ||||
| LGBM | PDO | 0.82 | 0.97 | 0.55 | 0.19 | |
| Injury | 0.54 | 0.14 | ||||
| Average | 0.68 | 0.55 | ||||
| ADABOOST | PDO | 0.81 | 0.91 | 0.48 | 0.15 | |
| Injury | 0.64 | 0.06 | ||||
| Average | 0.72 | 0.48 | ||||
| CART | PDO | 0.82 | 0.89 | 0.54 | 0.11 | |
| Injury | 0.32 | 0.20 | ||||
| Average | 0.57 | 0.55 | ||||
| BLR | PDO | 0.79 | 1.00 | 0.50 | 0.01 | |
| Injury | 0.00 | 0.00 | ||||
| Average | 0.39 | 0.50 | ||||
| LGBM | SMOTE-ENN Treatment | PDO | 0.84 | 0.85 | 0.59 | 0.19 |
| Injury | 0.36 | 0.33 | ||||
| Average | 0.60 | 0.59 | ||||
| ADABOOST | PDO | 0.83 | 0.84 | 0.58 | 0.16 | |
| Injury | 0.34 | 0.31 | ||||
| Average | 0.59 | 0.58 | ||||
| CART | PDO | 0.83 | 0.85 | 0.57 | 0.15 | |
| Injury | 0.33 | 0.29 | ||||
| Average | 0.58 | 0.57 | ||||
| BLR | PDO | 0.80 | 0.90 | 0.52 | 0.08 | |
| Injury | 0.28 | 0.15 | ||||
| Average | 0.54 | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asadi, R.; Khattak, A.; Vashani, H.; Almujibah, H.R.; Rabie, H.; Asadi, S.; Dimitrijevic, B. Self-Paced Ensemble-SHAP Approach for the Classification and Interpretation of Crash Severity in Work Zone Areas. Sustainability 2023, 15, 9076. https://doi.org/10.3390/su15119076
Asadi R, Khattak A, Vashani H, Almujibah HR, Rabie H, Asadi S, Dimitrijevic B. Self-Paced Ensemble-SHAP Approach for the Classification and Interpretation of Crash Severity in Work Zone Areas. Sustainability. 2023; 15(11):9076. https://doi.org/10.3390/su15119076
Chicago/Turabian StyleAsadi, Roksana, Afaq Khattak, Hossein Vashani, Hamad R. Almujibah, Helia Rabie, Seyedamirhossein Asadi, and Branislav Dimitrijevic. 2023. "Self-Paced Ensemble-SHAP Approach for the Classification and Interpretation of Crash Severity in Work Zone Areas" Sustainability 15, no. 11: 9076. https://doi.org/10.3390/su15119076
APA StyleAsadi, R., Khattak, A., Vashani, H., Almujibah, H. R., Rabie, H., Asadi, S., & Dimitrijevic, B. (2023). Self-Paced Ensemble-SHAP Approach for the Classification and Interpretation of Crash Severity in Work Zone Areas. Sustainability, 15(11), 9076. https://doi.org/10.3390/su15119076