


Assessing Forest Quality through Forest Growth Potential, an Index Based on Improved CatBoost Machine Learning

Abstract
1. Introduction
1.1. Forest Quality Indicators
1.2. Traditional Forest Quality Indicators
1.3. Construction of a Forest Growth-Potential Index
1.4. General Introduction
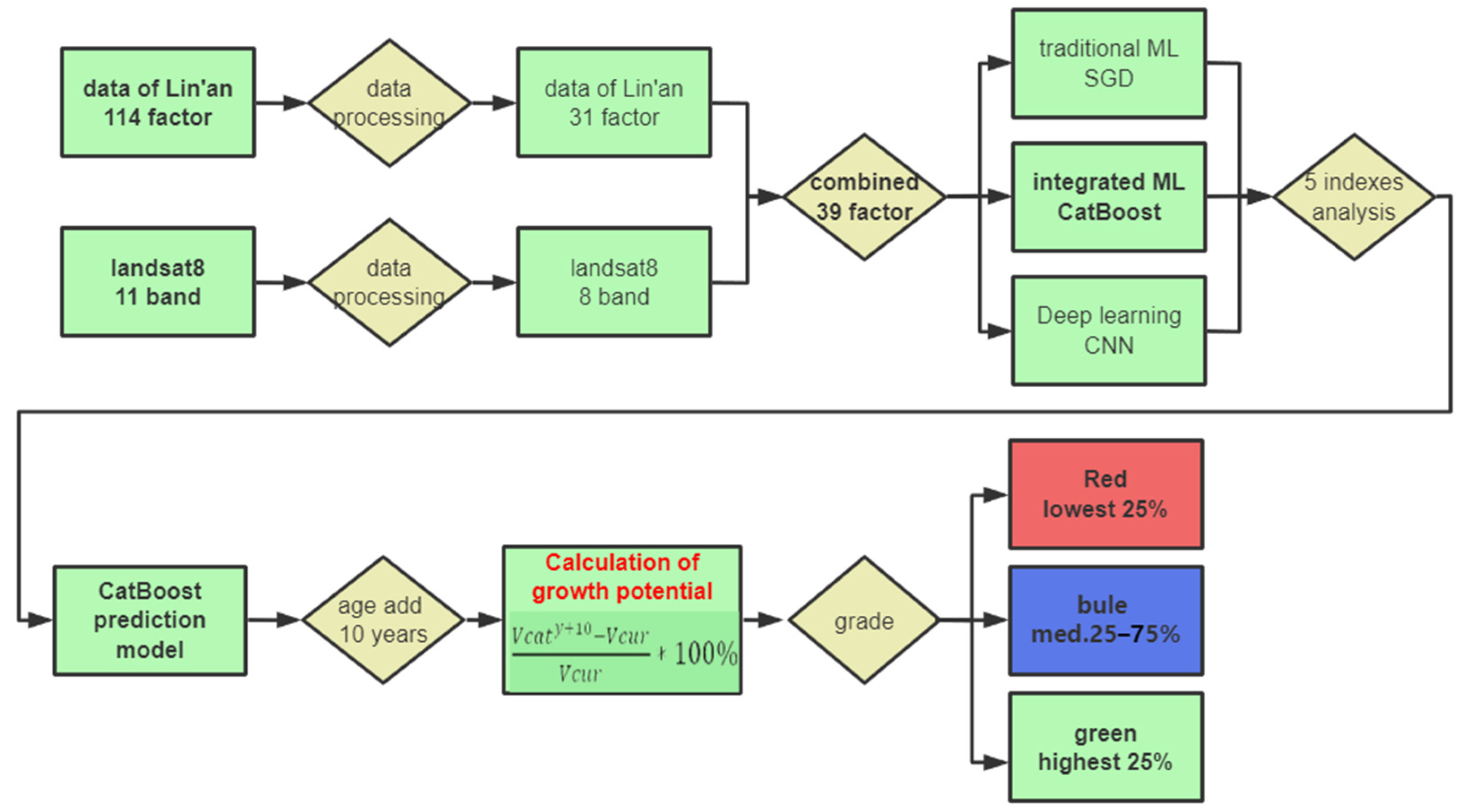
2. Materials and Methods
2.1. Research Area and Data Source
2.2. Data Preparation
2.3. Machine-Learning Training
2.3.1. Feature Engineering
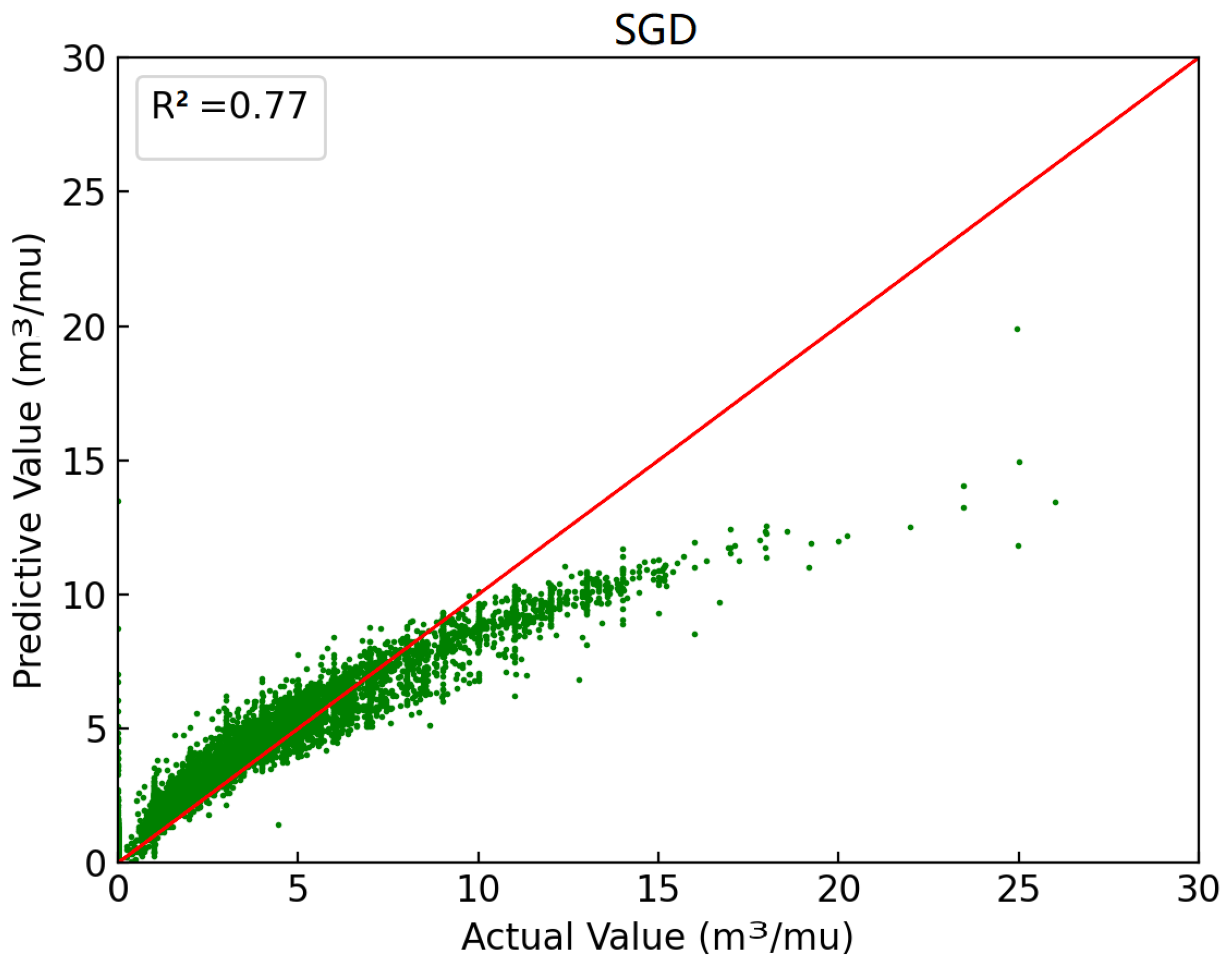
2.3.2. Stochastic Gradient Descent SGD
2.3.3. Integrated Machine Learning Algorithm CatBoost
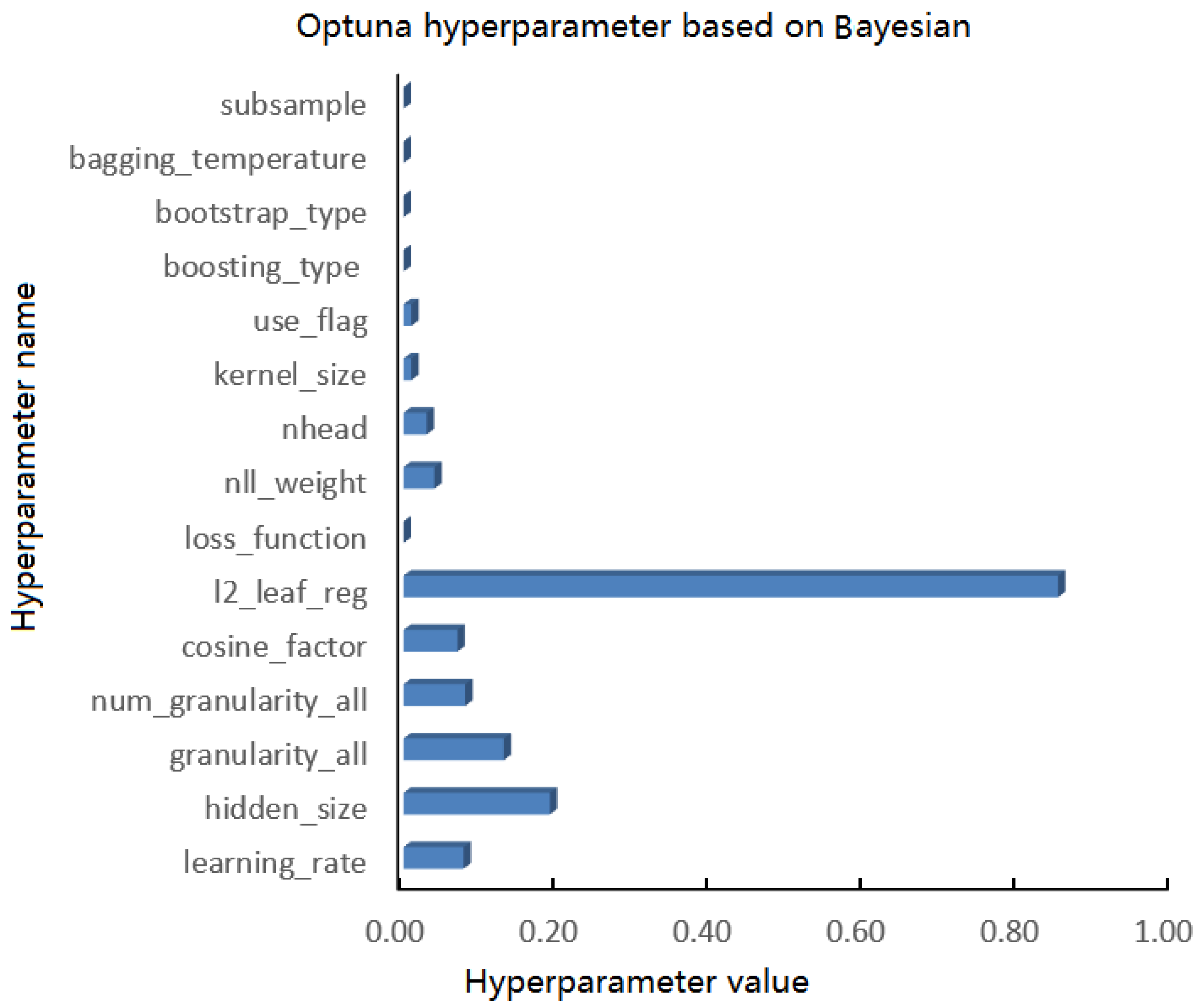
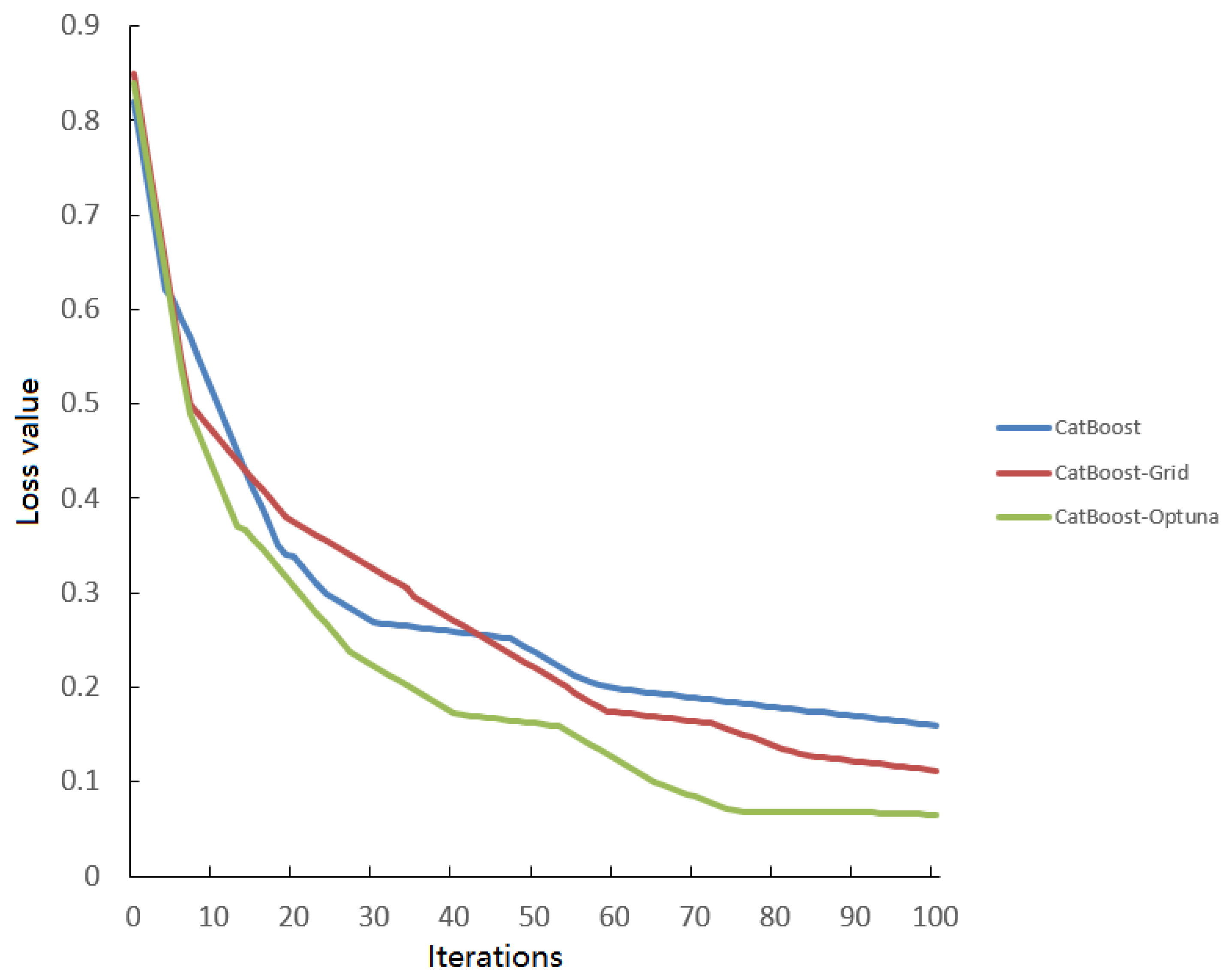
2.3.4. Improved CatBoost Based on Optuna
2.3.5. Ablation Experiment
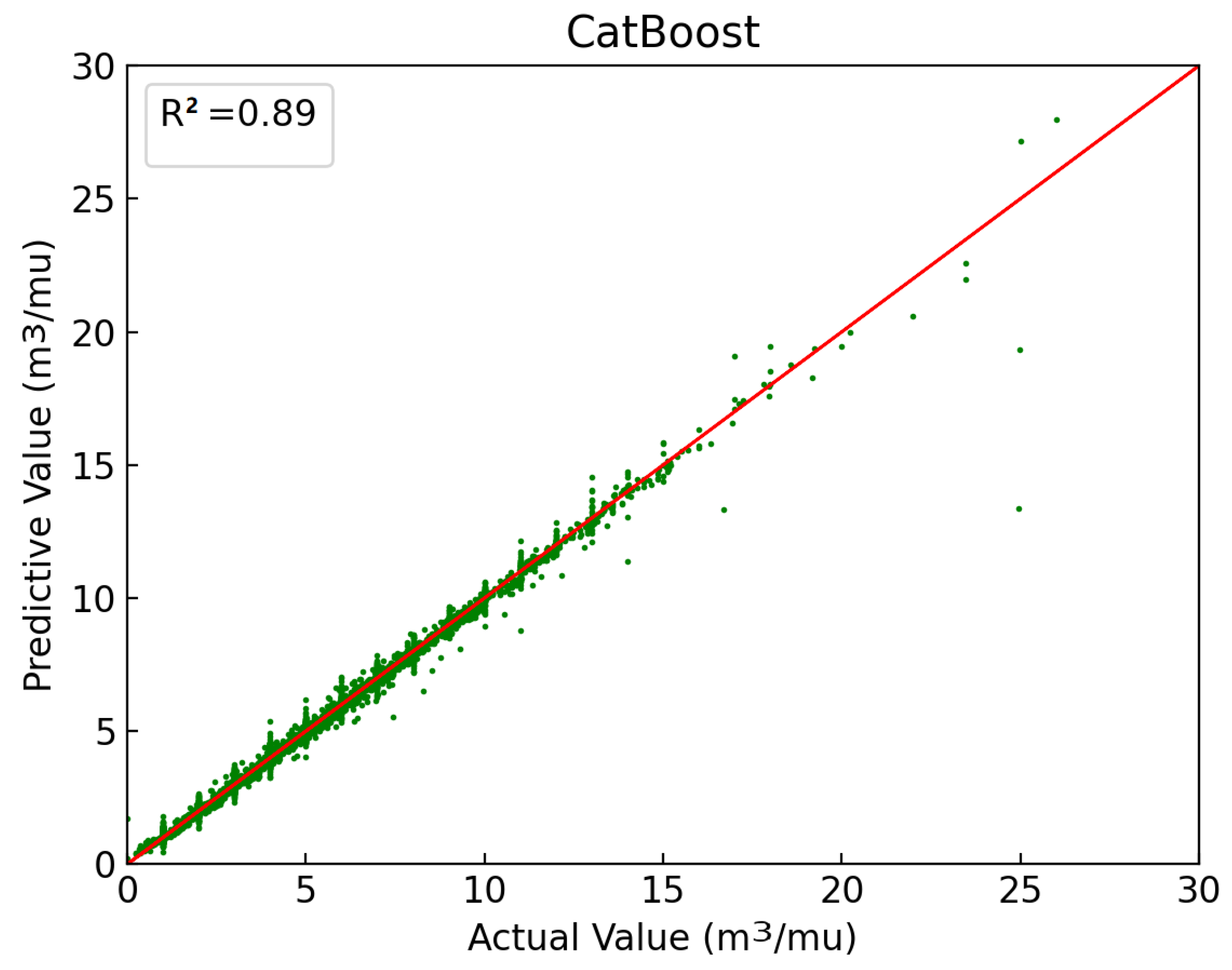
2.3.6. Experimental Effect of Improved CatBoost
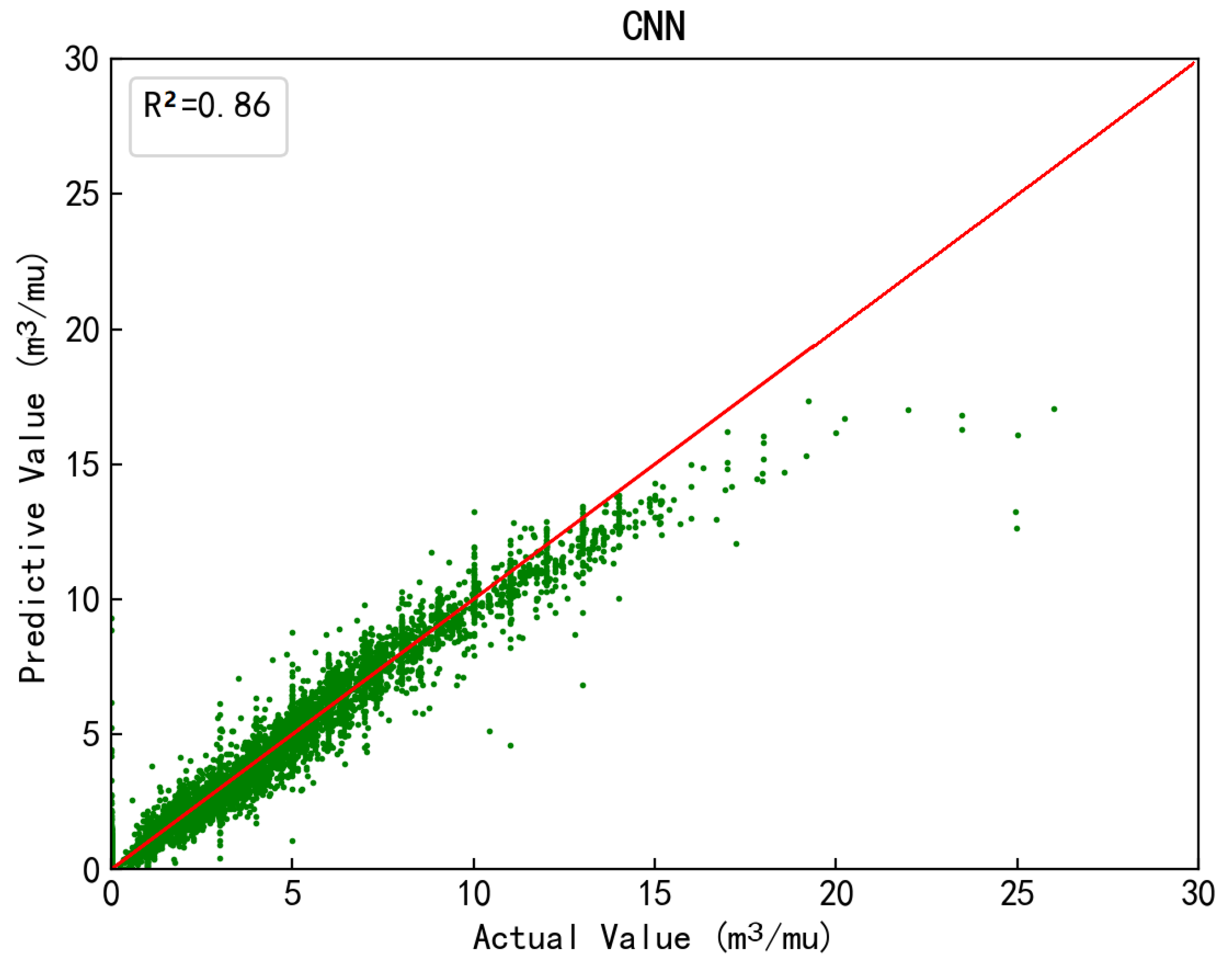
2.3.7. Deep-Learning CNN
2.3.8. Evaluating Indicator
2.4. Calculating Forest Growth-Potential Value
3. Results
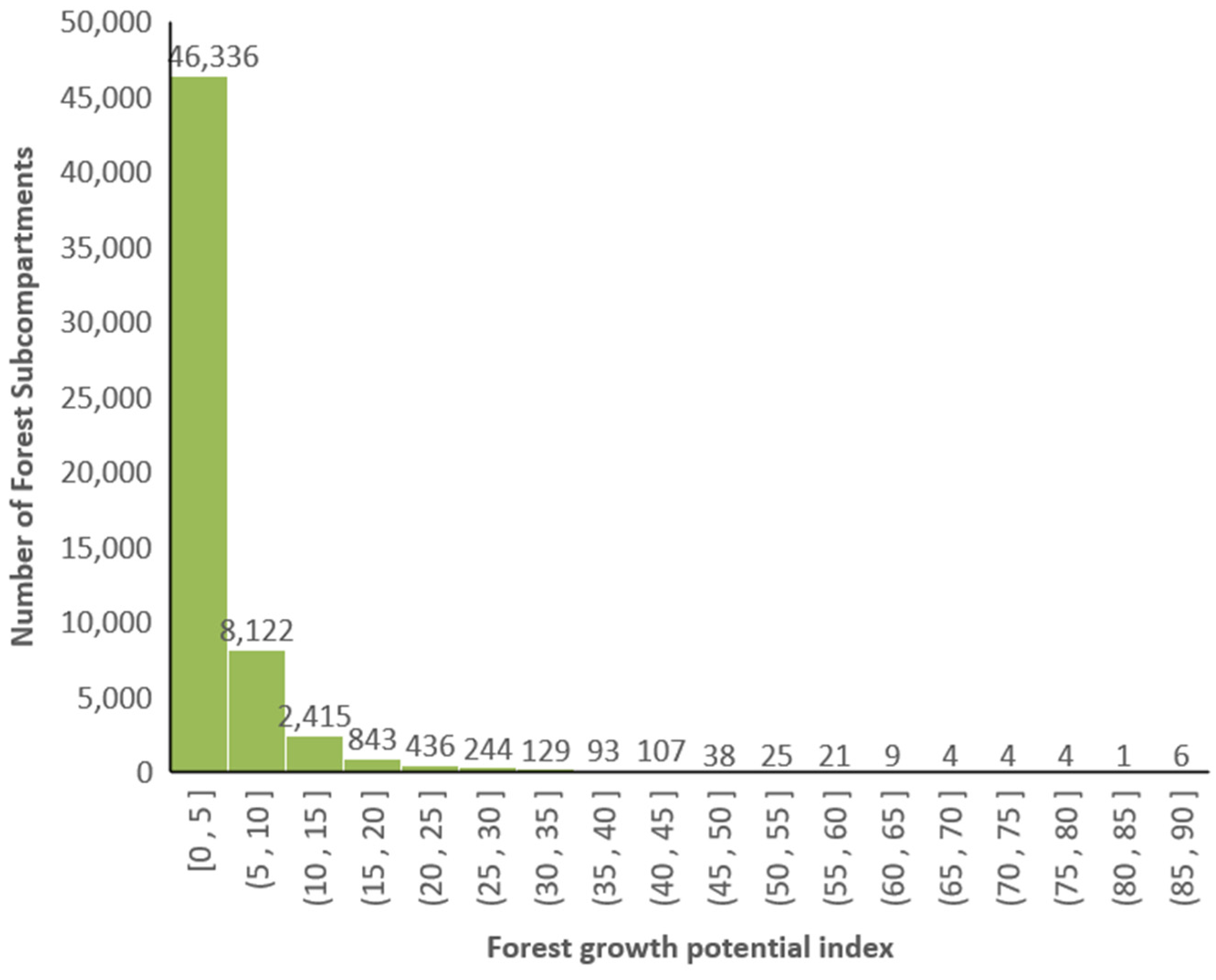
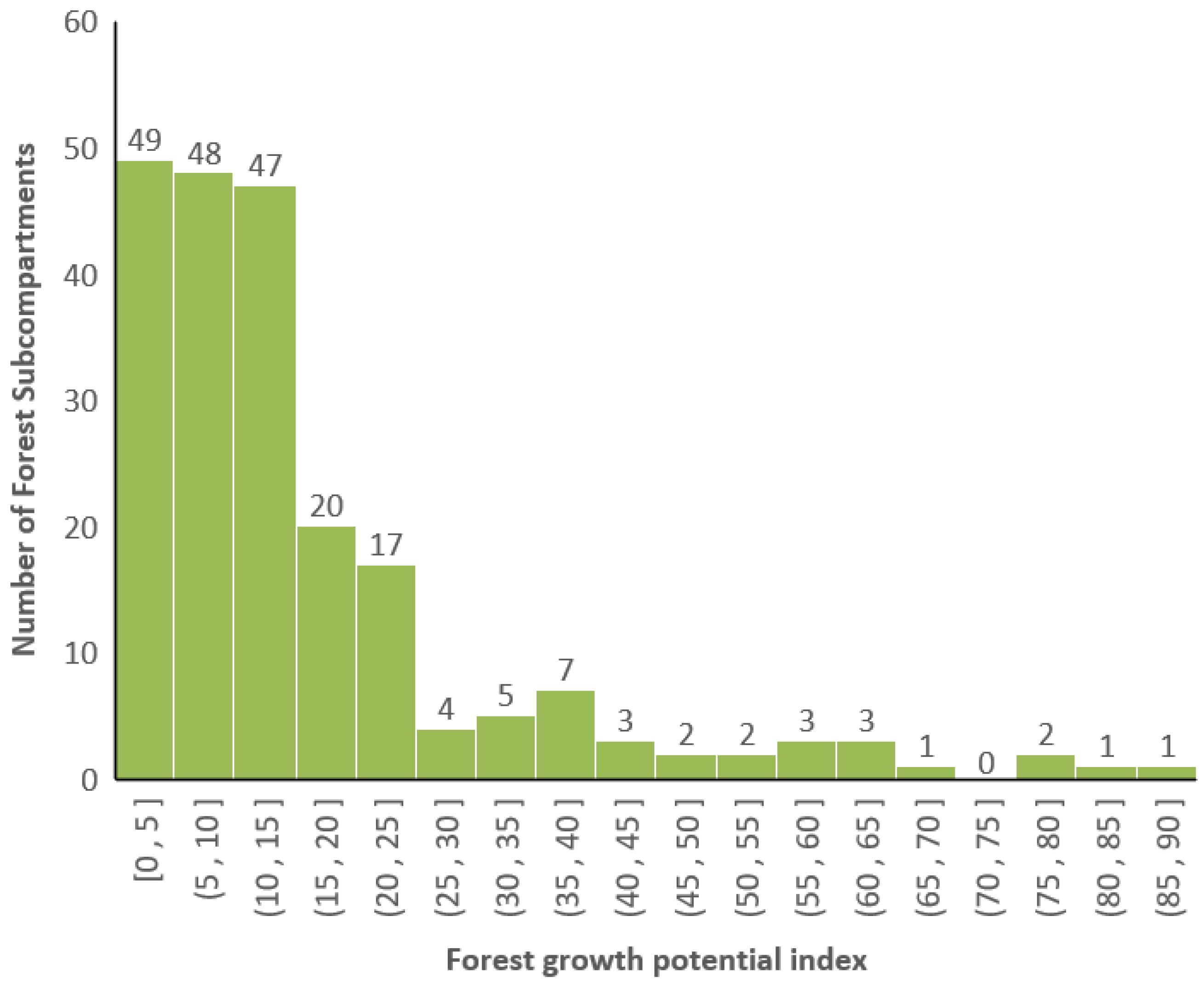
3.1. Application of the Forest Growth Potential Value
3.2. Forest Growth Potential of Arbor Forest Land
3.3. Forest Growth Potential of Sparse Forest Land
4. Discussion
4.1. Comparison with Other Studies
4.2. The Main Significance of Forest Growth Potential
4.3. Design Ideas for Forest Growth Potential
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, J.; Wu, Q. Marx and Engels’ Thought on the Relationship between Man and Nature and Its Contemporary Value. Marx. Res. 2020, 3, 58–66. (In Chinese) [Google Scholar]
- Lu, Y.; Gan, J.; Wang, X.; Liu, X.; Jiang, J. Supporting the Development of Ecological Civilization and Society in Beijing through Plain and Urban Forest Construction. For. Resour. Manag. 2012, 4, 24–28. (In Chinese) [Google Scholar]
- Valero, E.; Picos, J.; Álvarez, X. Characterization of riparian forest quality of the Umia River for a proposed restoration. Ecol. Eng. 2014, 67, 216–222. [Google Scholar] [CrossRef]
- Pohjankukka, J.; Tuominen, S.; Heikkonen, J. Bayesian Approach for Optimizing Forest Inventory Survey Sampling with Remote Sensing Data. Forests 2022, 13, 1692. [Google Scholar] [CrossRef]
- Miettinen, J.; Carlier, S.; Häme, L.; Mäkelä, A.; Minunno, F.; Penttilä, J.; Pisl, J.; Rasinmäki, J.; Rauste, Y.; Seitsonen, L.; et al. Demonstration of large area forest volume and primary production estimation approach based on Sentinel-2 imagery and process based ecosystem modelling. Int. J. Remote Sens. 2021, 42, 9467–9489. [Google Scholar] [CrossRef]
- State Forestry Administration. China Forest Resources Report; China Forestry Publishing House: Beijing, China, 2020. (In Chinese) [Google Scholar]
- FAO. Global Forest Resources Assessment; FAO: Rome, Italy, 2015. (In Chinese) [Google Scholar]
- Anonymous. World Forest and Forestry Development Status and Trend. China For. Ind. 2018, 4, 77–80. (In Chinese) [Google Scholar]
- Rajarethinam, J.; Aik, J.; Tian, J. The Influence of South East Asia Forest Fires on Ambient Particulate Matter Concentrations in Singapore: An Ecological Study Using Random Forest and Vector Autoregressive Models. Int. J. Environ. Res. Public Health 2020, 17, 9345. [Google Scholar] [CrossRef]
- Furuya, D.E.G.; Aguiar, J.A.F.; Estrabis, N.V.; Pinheiro, M.M.F.; Furuya, M.T.G.; Pereira, D.R.; Gonçalves, W.N.; Liesenberg, V.; Li, J.; Marcato Junior, J.; et al. A Machine Learning Approach for Mapping Forest Vegetation in Riparian Zones in an Atlantic Biome Environment Using Sentinel-2 Imagery. Remote Sens. 2020, 12, 4086. [Google Scholar] [CrossRef]
- Shi, C.N.; Wang, L.Q. A review of research on evaluation system of forest resources quality in China. World For. Res. 2007, 20, 68–72. (In Chinese) [Google Scholar]
- Mao, S.J.; Hu, Y.M. Discuss on evaluation of forest quality. Guangdong For. Sci. Technol. 2007, 23, 67–71. (In Chinese) [Google Scholar]
- Zhang, H.; Lei, X.; Zhang, C.; Zhao, X.; Hu, X. Research on theory and technology of forest quality evaluation and precision improvement. J. Beijing For. Univ. 2019, 41, 1–18. (In Chinese) [Google Scholar]
- Food and Agriculture Organization of the United Nations. Global Forest Resources Assessment[EB/OL]; FAO: Rome, Italy, 2020; Available online: https://www.fao.org/documents/card/en/c/ca9825en (accessed on 17 February 2023).
- National Forestry and Grassland Administration. Main Results of the Eighth National Forest Resources Inventory. 2014. Available online: http://www.forestry.gov.cn/main/65/20140225/659670.html (accessed on 17 May 2022).
- Feng, J.G.; Wang, J.S.; Yao, S.C.; Ding, L. Dynamic assessment of forest resources quality at the provincial level using AHP and cluster analysis. Comput. Electron. Agric. 2016, 124, 184–193. [Google Scholar] [CrossRef]
- State Forestry Administration. Guidelines for The Construction of Public Welfare Forests; China Standards Press: Beijing, China, 2001. (In Chinese) [Google Scholar]
- Wang, N.J.; Zhang, W.H.; Tong, J.X.; Fan, S.; Lu, Y.; Callie, J.S. Forest quality evaluation in Caijiachuan State Forest Station on Loess Plateau. Sci. Silvae Sin. 2010, 46, 7–13. (In Chinese) [Google Scholar]
- Pickett, S.T.A.; White, P.S. The Ecology of Natural Disturbance and Patch Dynamics; Academic Press: Salt Lake City, UT, USA, 1985. (In Chinese) [Google Scholar]
- State Forestry Administration. China Forest Resources Report; China Forestry Publishing House: Beijing, China, 2014. (In Chinese) [Google Scholar]
- Chang, W.; Wang, X.; Yang, J.; Qin, T. An Improved CatBoost-Based Classification Model for Ecological Suitability of Blueberries. Sensors 2023, 23, 1811. [Google Scholar] [CrossRef]
- Fu, Y.; Li, B.; Zhao, J.; Bi, Q. Research on the Prediction of A-Share “High Stock Dividend” Phenomenon—A Feature Adaptive Improved Multi-Layers Ensemble Model. Entropy 2021, 23, 416. [Google Scholar] [CrossRef]
- Xiang, C.; Zhou, J.; Han, B.; Li, W.; Zhao, H. Fault Diagnosis of Rolling Bearing Based on a Priority Elimination Method. Sensors 2023, 23, 2320. [Google Scholar] [CrossRef]
- Hangzhou Lin’an District People’s Government. Lin’an Geogr. 2022. Available online: https://www.linan.gov.cn/col/col1229664740/index.html (accessed on 7 April 2022).
- Xu, H.Q.; Tang, F. Analysis of new characteristics of the first Landsat8 image and their ecological environment significance. Acta Ecol. Sin. 2013, 33, 3249–3257. (In Chinese) [Google Scholar]
- Snider, L.A.; Swedo, S.E. PANDAS: Current status and directions for research. Mol. Psychiatry 2004, 9, 900–907. [Google Scholar] [CrossRef]
- Li, H.; Wang, R.; Tian, Z.; Xu, J.; Sun, W.; Duan, R.; Fu, H.; Li, Y.; Zhang, Y.; Dong, L. Phenotypic Variation and Diversity in Fruit, Leaf, Fatty Acid, and Their Relationships to Geoclimatic Factors in Seven Natural Populations of Malania oleifera Chun et S.K. Lee. Forests 2022, 13, 1733. [Google Scholar] [CrossRef]
- Sklearn Doc Zh, Sklearn Chinese Document [OL]. Available online: http://scikitlearn.com.cn/ (accessed on 22 March 2023).
- Dorogush, A.V.; Gulin, A.; Gusev, G.; Kazeev, N.; Prokhorenkova, L.O.; Vorobev, A. Fighting biases with dynamic boosting. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- Lezama, F.; Faia, R.; Faria, P.; Vale, Z. Demand Response of Residential Houses Equipped with PV-Battery Systems: An Application Study Using Evolutionary Algorithms. Energies 2020, 13, 2466. [Google Scholar] [CrossRef]
- Vasey, C.; McBride, J.; Penta, K. Circadian Rhythm Dysregulation and Restoration: The Role of Melatonin. Nutrients 2021, 13, 3480. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Naderi, G.; Lafleur, P.G.; Dubois, C. Microstructure-properties correlations in dynamically vulcanized nanocomposite thermoplastic elastomers based on pp/epdm. Polym. Eng. Sci. 2007, 47, 207–217. [Google Scholar] [CrossRef]
- Optuna Contributors. Optuna: A Hyperparameter Optimization Framework [OL]. Available online: https://optuna.readthedocs.io/en/stable/ (accessed on 24 March 2023).
- Baudach, S.; Bonse, J.; Kautek, W. Ablation experiments on polyimide with femtosecond laser pulses. Appl. Phys. 1999, A69, S395–S398. [Google Scholar] [CrossRef]
- She, L.; Zhang, H.K.; Li, Z.; de Leeuw, G.; Huang, B. Himawari-8 Aerosol Optical Depth (AOD) Retrieval Using a Deep Neural Network Trained Using AERONET Observations. Remote Sens. 2020, 12, 4125. [Google Scholar] [CrossRef]
- Hu, A.; Xie, Z.; Xu, Y.; Xie, M.; Wu, L.; Qiu, Q. Unsupervised Haze Removal for High-Resolution Optical Remote-Sensing Images Based on Improved Generative Adversarial Networks. Remote Sens. 2020, 12, 4162. [Google Scholar] [CrossRef]
- Leng, Z.; Zhang, J.; Ma, Y.; Zhang, J. Underwater Topography Inversion in Liaodong Shoal Based on GRU Deep Learning Model. Remote Sens. 2020, 12, 4068. [Google Scholar] [CrossRef]
- Huang, Q.; Wu, D.; Huang, H.; Zhang, Y.; Han, Y. Tool Wear Prediction Based on a Multi-Scale Convolutional Neural Network with Attention Fusion. Information 2022, 13, 504. [Google Scholar] [CrossRef]
- Maeda, M.; Kadokura, M.; Aoki, R.; Komatsu, N.; Kawakami, M.; Koyama, Y.; Watanabe, K.; Nishiyama, M. A Fiber-Optic Non-Invasive Swallowing Assessment Device Based on a Wearable Pressure Sensor. Sensors 2023, 23, 2355. [Google Scholar] [CrossRef] [PubMed]
- Aquize, R.; Cajahuaringa, A.; Machuca, J.; Mauricio, D.; Mauricio Villanueva, J.M. System Identification Methodology of a Gas Turbine Based on Artificial Recurrent Neural Networks. Sensors 2023, 23, 2231. [Google Scholar] [CrossRef]
- Blades, S.; Jensen, M.; Stellingwerff, T.; Hundza, S.; Klimstra, M. Characterization of the Kinetyx SI Wireless Pressure-Measuring Insole during Benchtop Testing and Running Gait. Sensors 2023, 23, 2352. [Google Scholar] [CrossRef] [PubMed]
- Parra, L.; Viciano-Tudela, S.; Carrasco, D.; Sendra, S.; Lloret, J. Low-Cost Microcontroller-Based Multiparametric Probe for Coastal Area Monitoring. Sensors 2023, 23, 1871. [Google Scholar] [CrossRef] [PubMed]
- Shah, V.V.; Brumbach, B.H.; Pearson, S.; Vasilyev, P.; King, E.; Carlson-Kuhta, P.; Mancini, M.; Horak, F.B.; Sowalsky, K.; McNames, J.; et al. Opal Actigraphy (Activity and Sleep) Measures Compared to ActiGraph: A Validation Study. Sensors 2023, 23, 2296. [Google Scholar] [CrossRef] [PubMed]
- Kellerhals, S.A.; De Leeuw, F.; Rodriguez Rivero, C. Cloud Nowcasting with Structure-Preserving Convolutional Gated Recurrent Units. Atmosphere 2022, 13, 1632. [Google Scholar] [CrossRef]
- Han, R.; Wu, D.; Fang, L.; Huang, Y. Estimation of forest stock based on Boruta and extreme random tree method. For. Resour. Manag. 2020, 4, 127–133. (In Chinese) [Google Scholar]
- Li, K.; Wu, D.; Fang, L.; Liu, J. Estimation of forest stock using Sentinel-2 remote sensing image data. J. Northeast. For. Univ. 2021, 49, 59–66. (In Chinese) [Google Scholar]
- Zhang, J. Research on the Difficulties and Countermeasures of China’s Green Finance Development under the Double Carbon Target. Southwest Financ. 2022, 494, 81–93. (In Chinese) [Google Scholar]
- Savero, A.M.; Kim, J.-H.; Purusatama, B.D.; Prasetia, D.; Park, S.-H.; Kim, N.-H. A Comparative Study on the Anatomical Characteristics of Acacia mangium and Acacia hybrid Grown in Vietnam. Forests 2022, 13, 1700. [Google Scholar] [CrossRef]
- Bonetti, A.; Martínez-Sober, M.; Torres, J.C.; Vega, J.M.; Pellerin, S.; Vila-Francés, J. Comparison between Machine Learning and Deep Learning Approaches for the Detection of Toxic Comments on Social Networks. Appl. Sci. 2023, 13, 6038. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source of Forest Quality Indicators | Year | Main Indicators of Forest Quality |
|---|---|---|
| Global Forest Resources Assessment [14] | Production capacity (storage capacity, etc.) | |
| Forest area (timber forest, etc.) | ||
| 2020 | Damaged forest area | |
| Sustainably managed forest area | ||
| Forest-related socio-economic conditions | ||
| National Forest Resources Inventory [15] | Stock volume per hectare | |
| Average annual growth per hectare | ||
| 2014 | Number of plants per hectare, average DBH | |
| Total biomass of forest vegetation in nation | ||
| Carbon storage, solid soil quantity, etc. | ||
| Feng J G, etc. [16] | 2016 | Quantity |
| Structure | ||
| Productivity | ||
| Healthy | ||
| State Forestry Administration [17] | Biodiversity | |
| Crown density of forest stand | ||
| 2001 | Community level | |
| Vegetation coverage | ||
| Litter layer | ||
| Wang Naijiang, etc. [18] | Forest structure | |
| Productivity or economic value | ||
| 2010 | Succession or renewal trend | |
| Crown density | ||
| Arbor stock volume |
| No. | Average DBH (cm) | Density | Average Height (m) | Plants per mu (Plants) | Crown Density | Age | Soil | Vegetation Height (m) |
|---|---|---|---|---|---|---|---|---|
| 0 | 15.3 | 0.51 | 10.1 | 54 | 0.8 | 33 | red | 2 |
| 1 | 15.3 | 0.42 | 10.1 | 45 | 0.7 | 33 | red | 2 |
| 2 | 0 | 0 | 1.2 | 200 | 0.7 | 4 | red | 0.6 |
| 3 | 14.3 | 0.51 | 9.1 | 58 | 0.8 | 31 | red | 2 |
| 4 | 17.3 | 0.51 | 11.1 | 43 | 0.8 | 38 | red | 2 |
| 5 | 9.3 | 0.18 | 6.1 | 37 | 0.4 | 18 | red | 2 |
| … | … | … | … | … | … | … | … | … |
| Algorithm | Evaluating Indicator | Abbreviation | Value |
|---|---|---|---|
| Random gradient descent SGD | Coefficient of determination | R2 | 0.77 |
| Mean square error | MSE | 1.58 | |
| Root mean square error | RMSE | 1.26 | |
| Mean absolute error | MAE | 0.88 | |
| Symmetrical mean absolute percentage error | SMAPE | 97.56 | |
| Improved CatBoost | Coefficient of determination | R2 | 0.89 |
| Mean square error | MSE | 0.05 | |
| Root mean square error | RMSE | 0.22 | |
| Mean absolute error | MAE | 0.08 | |
| Symmetrical mean absolute percentage error | SMAPE | 85.98 | |
| Deep learning CNN | Coefficient of determination | R2 | 0.86 |
| Mean square error | MSE | 0.32 | |
| Root mean square error | RMSE | 0.56 | |
| Mean absolute error | MAE | 0.29 | |
| Symmetrical mean absolute percentage error | SMAPE | 153.67 |
| Studies | Year | Geographical Area | Number of Data | R2 |
|---|---|---|---|---|
| Estimation of forest stock based on the Boruta and extreme random tree methods | 2020 | Longquan city | 4002 | 0.92 |
| Estimation of forest stock using Sentinel-2 remote sensing image data | 2021 | Linhai city | 19,840 | 0.77 |
| Estimation of forest stock using Sentinel-2 remote sensing image data | 2021 | Chun’an area | 40,216 | 0.83 |
| This article | 2023 | Lin’an city | 111,435 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, L.; He, X.; Chen, S.; Fang, L. Assessing Forest Quality through Forest Growth Potential, an Index Based on Improved CatBoost Machine Learning. Sustainability 2023, 15, 8888. https://doi.org/10.3390/su15118888
Cao L, He X, Chen S, Fang L. Assessing Forest Quality through Forest Growth Potential, an Index Based on Improved CatBoost Machine Learning. Sustainability. 2023; 15(11):8888. https://doi.org/10.3390/su15118888
Chicago/Turabian StyleCao, Lianjun, Xiaobing He, Sheng Chen, and Luming Fang. 2023. "Assessing Forest Quality through Forest Growth Potential, an Index Based on Improved CatBoost Machine Learning" Sustainability 15, no. 11: 8888. https://doi.org/10.3390/su15118888
APA StyleCao, L., He, X., Chen, S., & Fang, L. (2023). Assessing Forest Quality through Forest Growth Potential, an Index Based on Improved CatBoost Machine Learning. Sustainability, 15(11), 8888. https://doi.org/10.3390/su15118888