


An Approach for the Classification of Rock Types Using Machine Learning of Core and Log Data


Abstract
1. Introduction
2. Geological Settings
3. Data and Methodology
3.1. Data
3.2. Methods
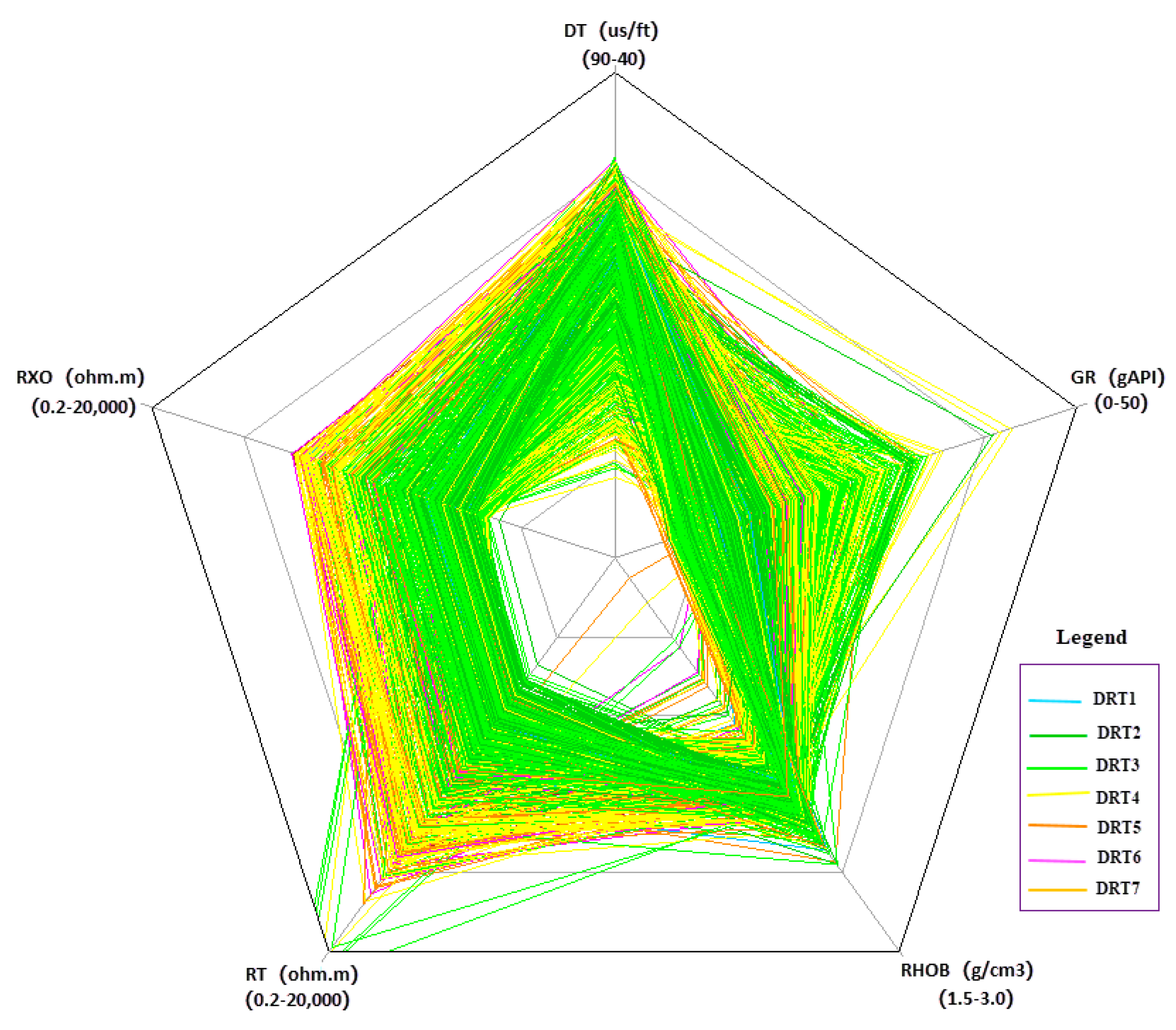
3.2.1. Rock Types
3.2.2. Data Preprocessing
3.2.3. Machine Learning

3.3. K-Fold Cross-Validation
4. Evaluation and Application of Machine Learning
4.1. Model Accuracy and Machine Learning Results
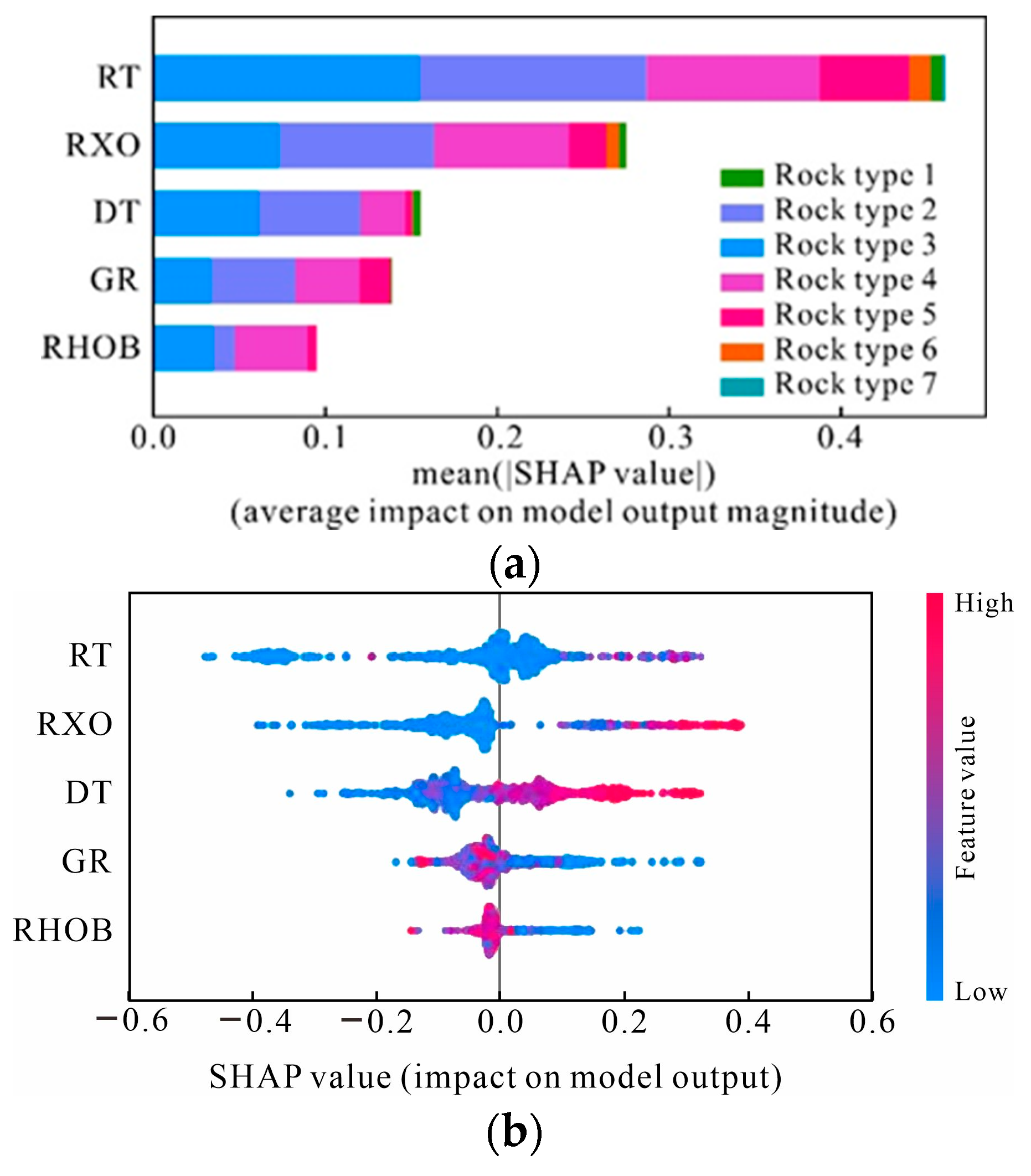
4.2. Importance of Predictors and Model Interpretation
5. Conclusions
- (1)
- Based on core data and the FZI method, the Callovian–Oxfordian formation in the study area can be divided into seven rock types.
- (2)
- The results of this study show that the rock types in uncored wells can be accurately classified by core data using machine learning and well log data. Accurate classification of rocks can greatly improve the accuracy of well log interpretation and the reliability of research results with respect to sedimentary microfacies.
- (3)
- Four machine learning algorithms were evaluated, including KNN, GBM, random forest, and MLP. Based on the cross-validation and evaluation results, the GBM has been selected for the identification of rock types in the study area. The accuracy of this algorithm for lithology identification can reach 79%.
- (4)
- In this study, SHAP values were used to interpret “black box” (machine learning) models, which demonstrate high robustness and practicability and provide an effective means of global and local interpretation for rock classification models based on machine learning.
- (5)
- The results of this study suggested that Rock type 4 (grainstones) are the best reservoir rocks in the study area. These rocks are characterized by high porosity, high permeability, low GR values, low RHOB values, high DT values, low RT values, and low RXO values.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brendon Hall. Facies classification using machine learning. Lead. Edge 2016, 35, 906–909. [Google Scholar] [CrossRef]
- Nishitsuji, Y.; Exley, R. Elastic impedance-based facies classification using support vector machine and deep learning. Geophys. Prospect. 2019, 67, 1040–1054. [Google Scholar] [CrossRef]
- Xiao, Y.; Wang, Z.; Zhou, Z.; Wei, Z.; Qu, K.; Wang, X.; Wang, R. Lithology classification of acidic volcanic rocks based on parameter-optimized Ada Boost algorithm. Acta Pet. Sin. 2019, 40, 457–467. [Google Scholar]
- Valentin, M.B.; Bom, C.R.; Coelho, J.M.; Correia, M.D.; De Albuquerque, M.P.; de Albuquerque, M.P.; Faria, E.L. A deep residual convolutional neural network for automatic lithological facies identification in Brazilian pre-salt oilfield wellbore image logs. J. Pet. Sci. Eng. 2019, 179, 474–503. [Google Scholar] [CrossRef]
- Ning, D. An Improved Semi Supervised Clustering of Given Density and Its Application in Lithology Identification; China University of Geosciences: Beijing, China, 2018. [Google Scholar]
- Ju, W.; Han, X.H.; Zhi, L.F. A lithology identification method in Es4 reservoir of xin 176 block with bayes stepwise discriminant method. Comput. Tech. Geophys. Geochem. Explor. 2012, 34, 576–581. [Google Scholar]
- Duan, Y.; Wang, Y.; Sun, Q. Application of selective ensemble learning model in lithology-porosity prediction. Sci. Technol. Eng. 2020, 20, 1001–1008. [Google Scholar]
- Ma, L.; Xiao, H.; Tao, J.; Su, Z. Intelligent lithology classification method based on GBDT algorithm. Pet. Geol. Recovery Effic. 2022, 29, 21–29. [Google Scholar]
- Tang, J.; Fan, B.; Xiao, L.; Tian, S.; Zhang, F.; Zhang, L.; Weitz, D. A New Ensemble Machine Learning Framework for Searching Sweet Spots in Shale Reservoirs. SPE J. 2021, 26, 482–497. [Google Scholar] [CrossRef]
- Zhao, X.; Jin, F.; Liu, X.; Zhang, Z.; Cong, Z.; Li, Z.; Tang, J. Numerical study of fracture dynamics in different shale fabric facies by integrating machine learning and 3-D lattice method: A case from Cangdong Sag, Bohai Bay basin, China. J. Pet. Sci. Eng. 2022, 218, 110861. [Google Scholar] [CrossRef]
- Ulmishek, G.F. Petroleum Geology and Resources of the Amu Darya Basin, Turkmenistan, Uzbekistan, Afghanistan and Iran; USGS: Reston, VA, USA, 2004; pp. 1–38. [Google Scholar]
- Kolodzie, S. Analysis of pore throat size and use of the Waxman-Smits equation to determine OOIP in Spindle field, Colorado. In Proceedings of the SPE Annual Technical Conference and Exhibition, Dallas, TX, USA, 21–24 September 1980. SPE-9382-MS. [Google Scholar]
- Pittman, E.D. Relationship of porosity and permeability to various parameters derived from mercury injection-capillary pressure curves for sandstone. AAPG Bull. 1992, 76, 191–198. [Google Scholar]
- Amaefule, J.O.; Altunbay, M.; Tiab, D.; Kersey, D.G.; Keelan, D.K. Enhanced reservoir description using core and log data to identify hydraulic flow units and predict permeability in un-cored intervals/wells. In Proceedings of the SPE Annual Technical Conference and Exhibition, Houston, TX, USA, 3–6 October 1993. [Google Scholar]
- Tang, Q. DPS Data Processing System—Experimental Design, Statistical Analysis and Data Mining, 2nd ed.; Science Press: Beijing, China, 2010. [Google Scholar]
- Barnett, V.; Lewis, T. Outliers in Statistical Data, 3rd ed.; John Wiley & Sons: Chichester, UK, 1995. [Google Scholar]
- Hu, L.; Gao, W.; Zhao, K.; Zhang, P.; Wang, F. Feature Selection Considering Two Types of Feature Relevancy and Feature Interdependency. Expert Syst. Appl. 2018, 93, 423–434. [Google Scholar] [CrossRef]
- Breiman, L. Arcing the Edge; Technical Report 486; Statistics Department, University of California, Berkeley: Berkeley, CA, USA, 1997. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kuhn, S.; Cracknell, M.J.; Reading, A.M. Lithological mapping in the Central African copper belt using random forests and clustering: Strategies for optimised results. Ore Geol. Rev. 2019, 112, 103015. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: New York, NY, USA, 2013. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Nielson, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015. [Google Scholar]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rock Types | Median Porosity (%) | Median Permeability (mD) | Lithology |
|---|---|---|---|
| DRT1 | 4.18 | 0.002 | Wackstone with microporosity |
| DRT2 | 8.60 | 0.300 | Mud-dominated packstone |
| DRT3 | 11.90 | 5.100 | Grainstone with some separate-vug pore space |
| DRT4 | 12.00 | 30.300 | Grainstone |
| DRT5 | 1.68 | 1.750 | Grain-dominated packstone |
| DRT6 | 1.00 | 1.840 | Wackstone with microfracture |
| DRT7 | 0.38 | 0.490 | Mudstone with microfracture |
| DT | GR | RHOB | RT | RXO | |
|---|---|---|---|---|---|
| (us/ft) | (gAPI) | (g/cm3) | (ohm·m) | (ohm·m) | |
| Number of values | 1093.00 | 1093.00 | 1093.00 | 1093.00 | 1093.00 |
| Number of missing | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| Min value | 48.86 | 5.29 | 1.57 | 4.51 | 3.53 |
| Max value | 81.70 | 42.94 | 2.67 | 72,207.00 | 618.60 |
| Mode | 55.08 | 8.76 | 2.41 | 26.86 | 10.24 |
| Arithmetic mean | 61.83 | 16.25 | 2.38 | 372.28 | 56.98 |
| Geometric mean | 61.41 | 14.74 | 2.38 | 52.46 | 22.87 |
| Median | 60.87 | 15.01 | 2.39 | 33.46 | 15.92 |
| Average deviation | 6.17 | 5.87 | 0.07 | 566.01 | 65.06 |
| Standard deviation | 7.35 | 7.04 | 0.10 | 3307.82 | 103.48 |
| Variance | 54.05 | 49.58 | 0.01 | 10,941,600.00 | 10,707.70 |
| Skewness | 0.39 | 0.59 | −1.82 | 17.44 | 2.91 |
| Kurtosis | −0.73 | −0.30 | 8.88 | 325.68 | 8.34 |
| Q1 [10%] | 52.79 | 7.64 | 2.27 | 15.81 | 7.31 |
| Q2 [25%] | 55.55 | 10.58 | 2.33 | 22.55 | 9.68 |
| Q3 [50%] | 60.87 | 15.01 | 2.39 | 33.46 | 15.92 |
| Q4 [75%] | 67.03 | 21.50 | 2.44 | 79.79 | 37.78 |
| Q5 [90%] | 72.31 | 26.29 | 2.48 | 488.06 | 176.45 |
| Rock Types | GR | RHOB | DT | RT | RXO |
|---|---|---|---|---|---|
| (gAPI) | (g/cm3) | (us/ft) | (ohm·m) | (ohm·m) | |
| DRT1 | 16.70 | 2.41 | 54.50 | 50.70 | 41.00 |
| DRT2 | 17.00 | 2.41 | 59.50 | 30.30 | 17.90 |
| DRT3 | 11.30 | 2.39 | 62.70 | 38.60 | 17.10 |
| DRT4 | 13.00 | 2.34 | 63.80 | 90.90 | 30.10 |
| DRT5 | 16.30 | 2.32 | 59.30 | 262.10 | 91.10 |
| DRT6 | 16.80 | 2.29 | 54.50 | 650.00 | 208.90 |
| DRT7 | 17.20 | 2.31 | 57.60 | 786.00 | 311.50 |
| Methods | Optimal Hyperparameter Values |
|---|---|
| KNN | Number of neighbors = 40 |
| MLP neural network | Layer1: units = 15; Layer2: units = 20; Layer3: units = 14 |
| Random forest | N-Estimators = 11 |
| GBM | N-Estimators = 172, maximum tree depth = 3, n.minobsinnode = 1 (minimum number of observations in the leaf nodes = 1) |
| Machine Learning Algorithms | Cross Validation Accuracy (%) | Cross Validation Standard Deviation (%) |
|---|---|---|
| GBM | 67.86 | 3.22 |
| MLP | 67.01 | 2.37 |
| KNN | 67.03 | 0.10 |
| Random forest | 66.88 | 2.69 |
| Machine Learning Algorithms | AUC | Model Accuracy (%) |
|---|---|---|
| GBM | 0.83 | 79.25 |
| MLP | 0.78 | 73.94 |
| KNN | 0.75 | 70.85 |
| Random forest | 0.74 | 70.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, Y.; Yang, H.; Yu, W. An Approach for the Classification of Rock Types Using Machine Learning of Core and Log Data. Sustainability 2023, 15, 8868. https://doi.org/10.3390/su15118868
Xing Y, Yang H, Yu W. An Approach for the Classification of Rock Types Using Machine Learning of Core and Log Data. Sustainability. 2023; 15(11):8868. https://doi.org/10.3390/su15118868
Chicago/Turabian StyleXing, Yihan, Huiting Yang, and Wei Yu. 2023. "An Approach for the Classification of Rock Types Using Machine Learning of Core and Log Data" Sustainability 15, no. 11: 8868. https://doi.org/10.3390/su15118868
APA StyleXing, Y., Yang, H., & Yu, W. (2023). An Approach for the Classification of Rock Types Using Machine Learning of Core and Log Data. Sustainability, 15(11), 8868. https://doi.org/10.3390/su15118868