

Enhancing Power Grid Resilience through Real-Time Fault Detection and Remediation Using Advanced Hybrid Machine Learning Models


Abstract
:1. Introduction
- Utilization of real-time fault collection data from a working power grid station situated in Saudi Arabia, which is a significant contribution to the research. The rarity of faults in the station made the data collection process time-consuming, making it a valuable addition to the literature.
- Implementation of artificial intelligence techniques in this research for a power grid station, which is a unique idea and has not been implemented before. This innovation challenges the traditional software currently in use in most grid stations.
- Acknowledgment of the need for further improvement in this research area and the intention to explore similar ideas.
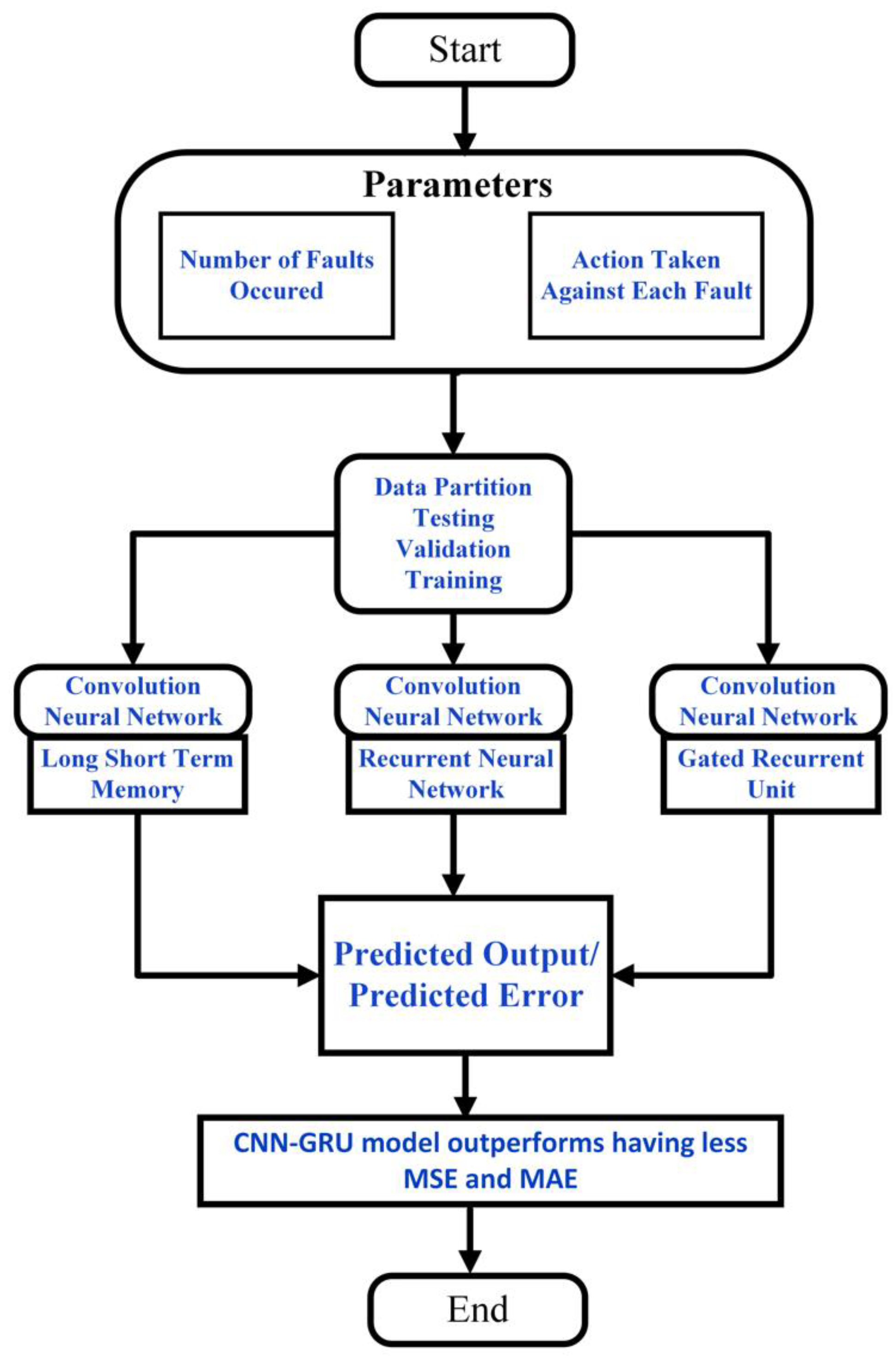
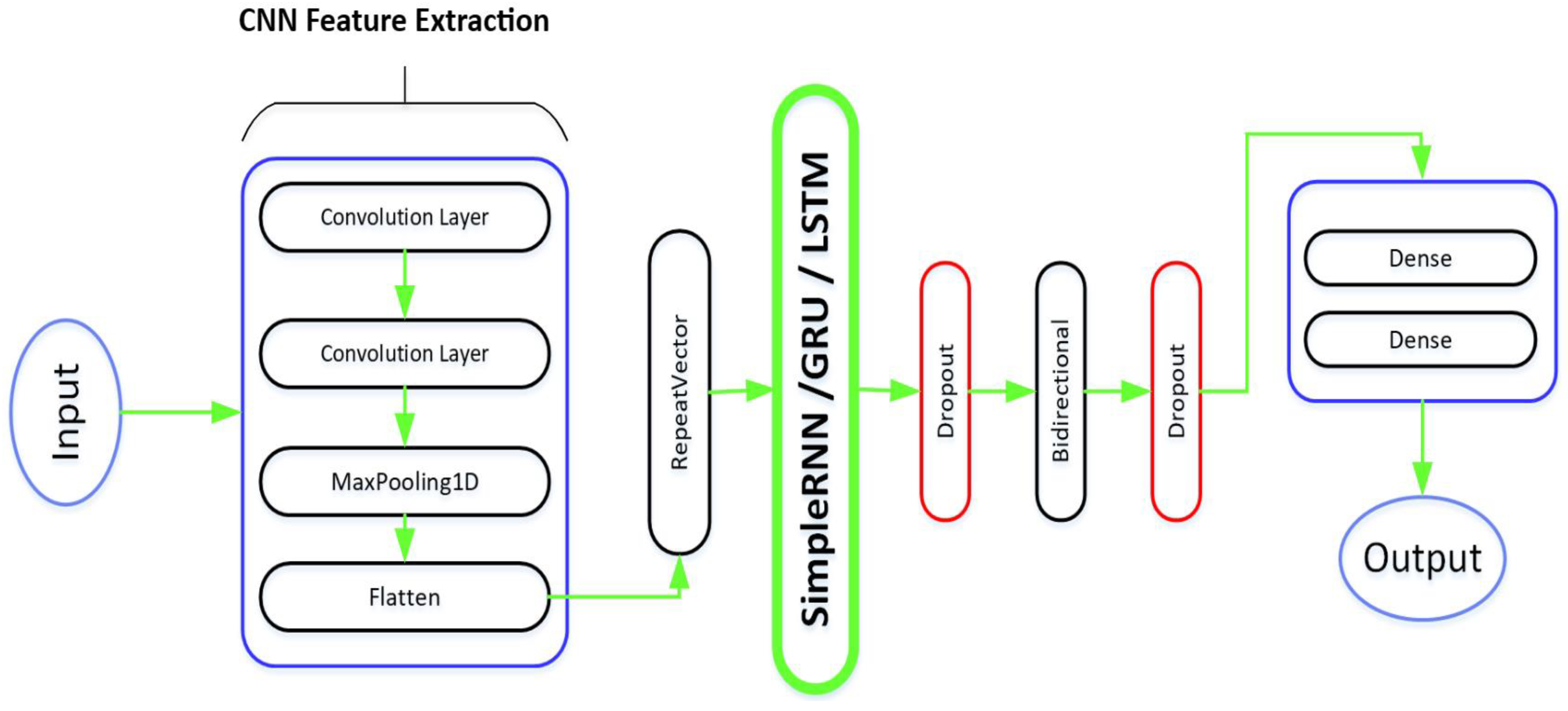
2. Proposed Framework for Fault Prediction and Elimination
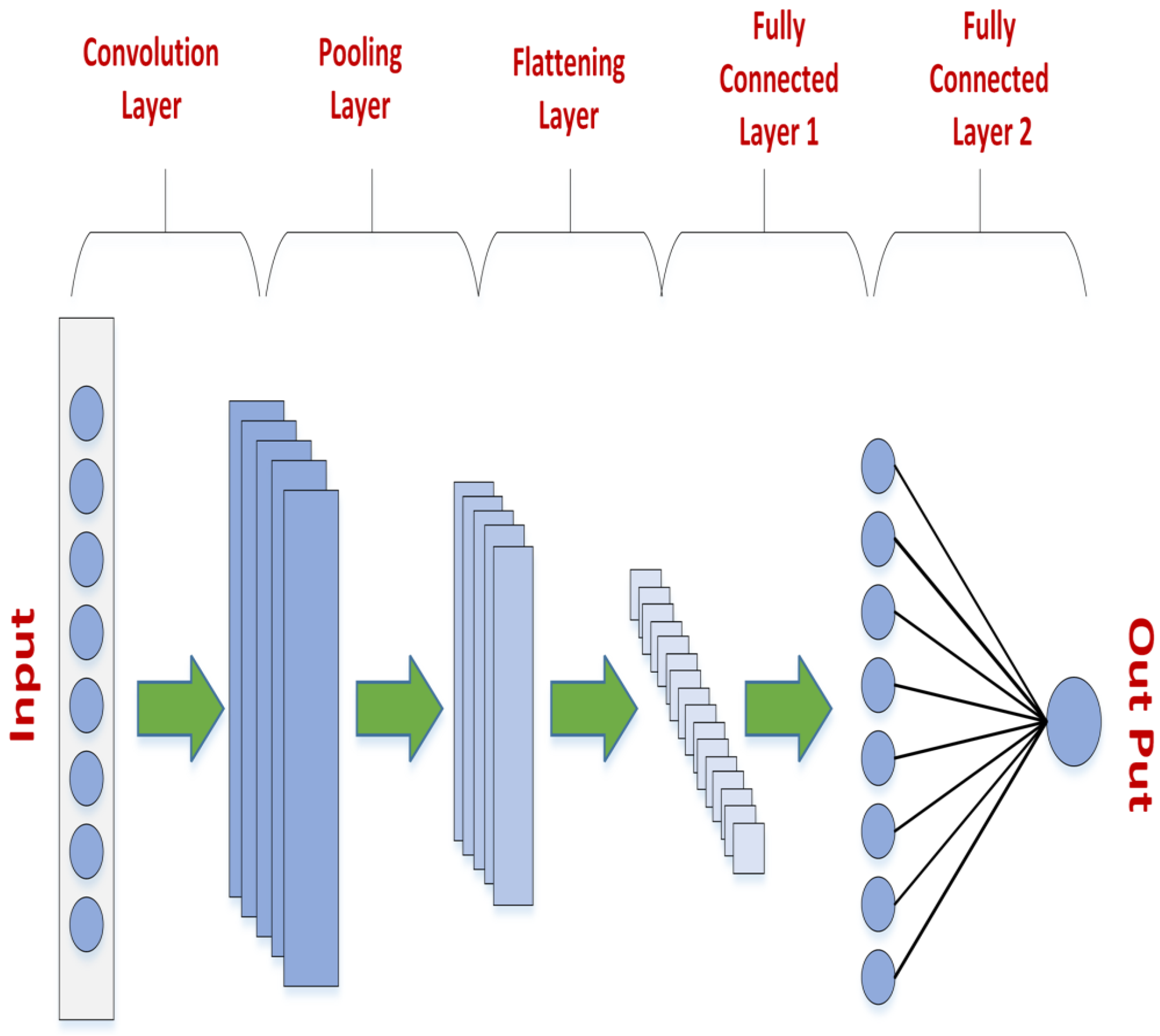
2.1. Structure of Convolutional Neural Network
2.1.1. Convolution Layer
2.1.2. Non-Linearity
2.1.3. Pooling Layer
2.1.4. Dropout
2.1.5. Fully Connected Layer
2.2. Structure of RNN, GRU, and LSTM
2.2.1. Recurrent Neural Networks (RNNs)
- : The “hidden state” at time t – 1, which is a vector that summarizes the previous input sequence up to time t – 1. It is computed as the output of a sigmoid activation function (σ) applied to the weighted sum of the previous hidden state ∗ and the current input plus a bias term .
- : The input to the SRNN at time t.
- : The output of the SRNN at time t, which is a transformed version of the hidden state computed using a hyperbolic tangent activation function (tanh), and a weight matrix plus a bias term .
- : The weight matrix that determines the influence of the previous hidden state on the current hidden state.
- : The weight matrix that determines the influence of the current input on the current hidden state.
- : The bias term that determines the baseline activation level of the hidden state.
- : The weight matrix that determines how the hidden state is transformed into the output.
- : The bias term that determines the baseline activation level of the output.
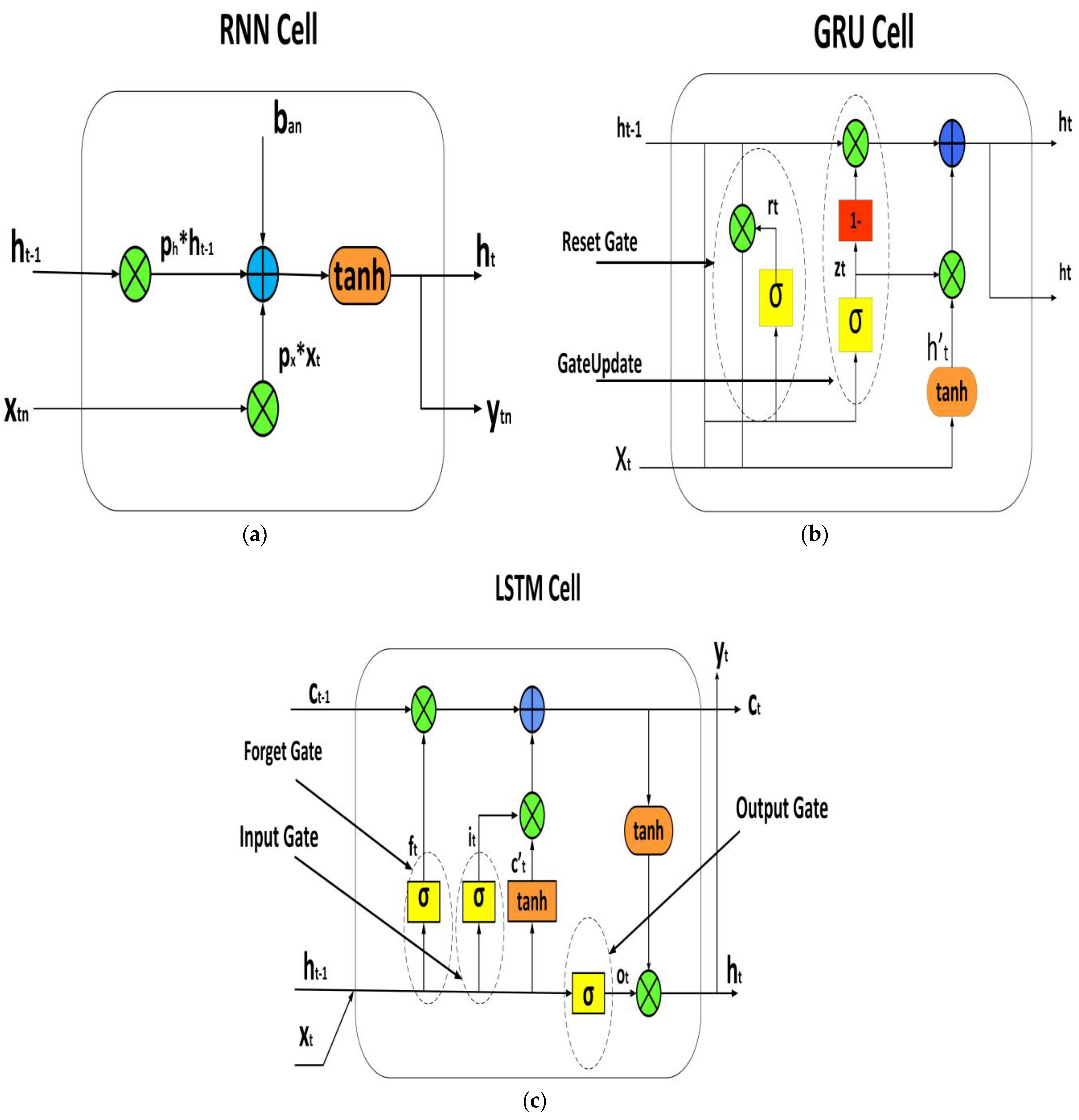
2.2.2. Gated Recurrent Units
- : The “reset gate” controls how much of the previous hidden state is retained and how much is reset based on the current input . It is computed as the element-wise multiplication of the output of a sigmoid activation function (σ) applied to the weighted sum of the previous hidden state and the current input .
- : The “update gate” determines how much of the previous hidden state should be updated with the new candidate hidden state H′(t). It is computed as the output of a sigmoid activation function (σ) applied to the weighted sum of the previous hidden state () and the current input ().
- : The “candidate hidden state” represents a new candidate for the next hidden state based on the current input and the previous hidden state modified by the reset gate. It is computed as the output of a hyperbolic tangent activation function (tanh) applied to the weighted sum of the reset gate and the previous hidden state and the current input .
- : The “hidden state” represents the output of the LSTM cell at time t, which is a combination of the previous hidden state and the new candidate hidden state based on the update gate. It is computed as a weighted sum of the previous hidden state () and the new candidate hidden state ().
- : The input to the LSTM cell at time t.
- : The previous hidden state of the LSTM cell at time t − 1.
2.2.3. Long Short-Term Memory (LSTM)
- : The “hidden state” at time t − 1, which is a vector that summarizes the previous input sequence up to time t − 1.
- : The input to the LSTM network at time t.
- : The “forget gate” at time t, which determines how much of the previous cell state should be kept and how much should be forgotten. It is computed as the output of a sigmoid activation function (σ) applied to the weighted sum of the previous hidden state and the current input.
- : The “input gate” at time t, which determines how much of the new input should be added to the cell state. It is computed as the output of a sigmoid activation function (σ) applied to the weighted sum of the previous hidden state and the current input.
- : The “candidate cell state” at time t, which represents the candidate new values that could be added to the cell state. It is computed as the output of a hyperbolic tangent activation function (tanh) applied to the weighted sum of the previous hidden state and the current input.
- : The “cell state” at time t, which represents the memory of the LSTM network at time t. It is computed as the combination of the previous cell state multiplied by the forget gate, and the current candidate cell state multiplied by the input gate, .
- : The “output gate” at time t, which determines how much of the cell state should be output as the hidden state. It is computed as the output of a sigmoid activation function (σ) applied to the weighted sum of the previous hidden state and the current input.
- tanh : The hyperbolic tangent function applied to the cell state at time t.
- : The “output” or “hidden state” at time t, which is the final output of the LSTM network at time t. It is computed as the element-wise multiplication of the output gate and the hyperbolic tangent of the cell state tanh .
- , , , and : The weight matrices that determine how much each input and hidden state element affects the forget gate, input gate, candidate cell state, and output gate, respectively.
3. Case Study
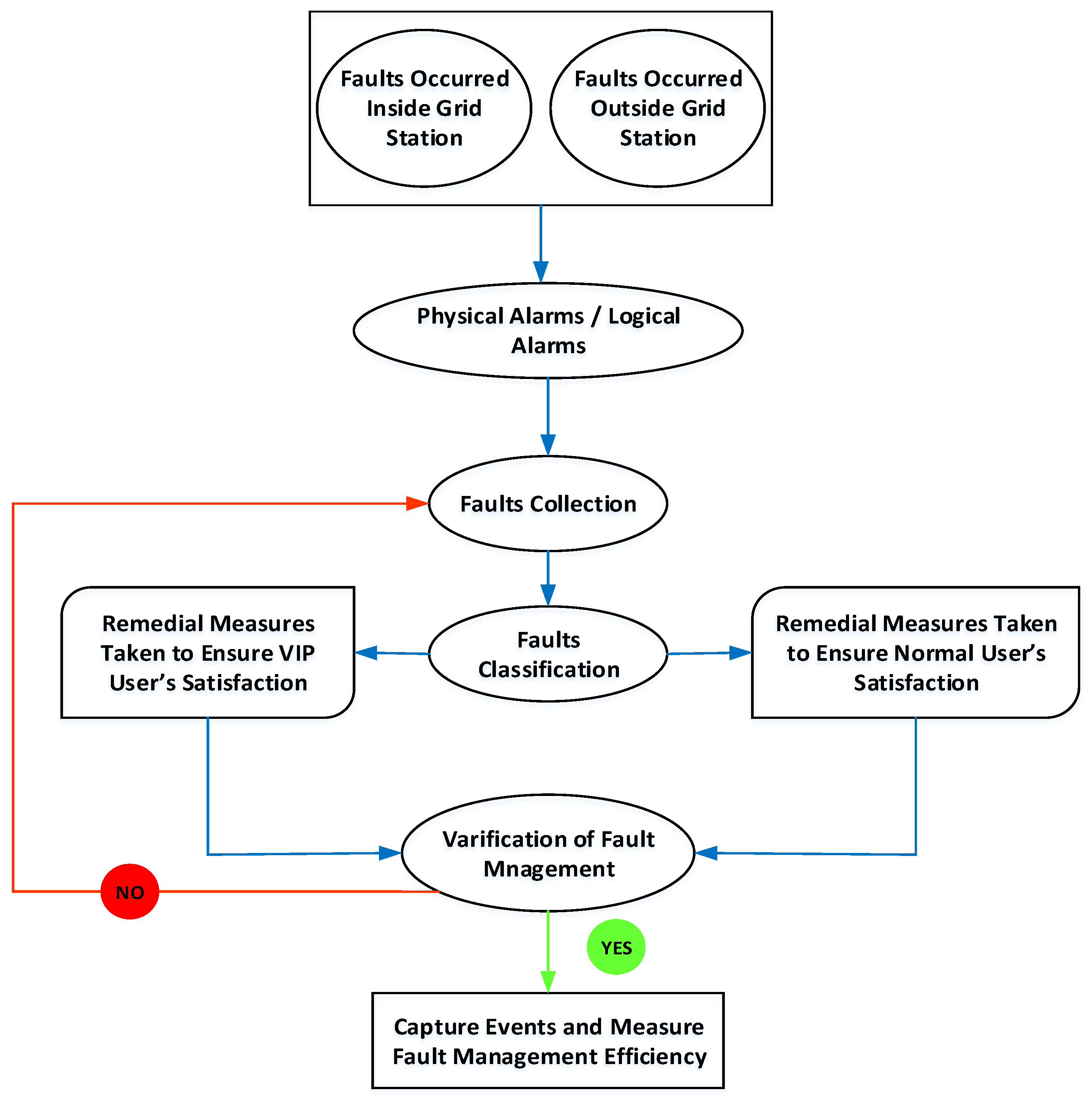
3.1. Data-Collection and Fault-Elimination Process
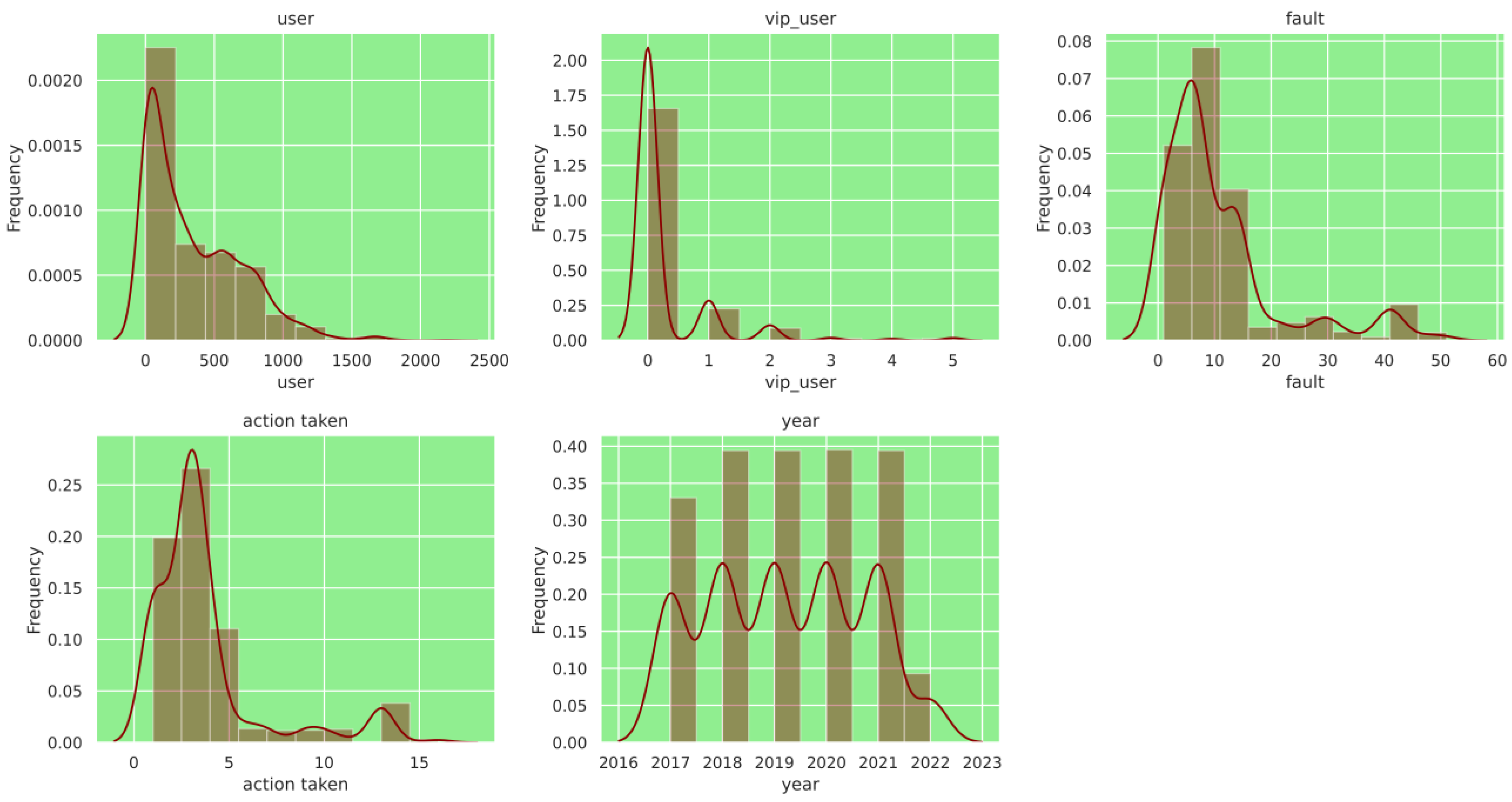
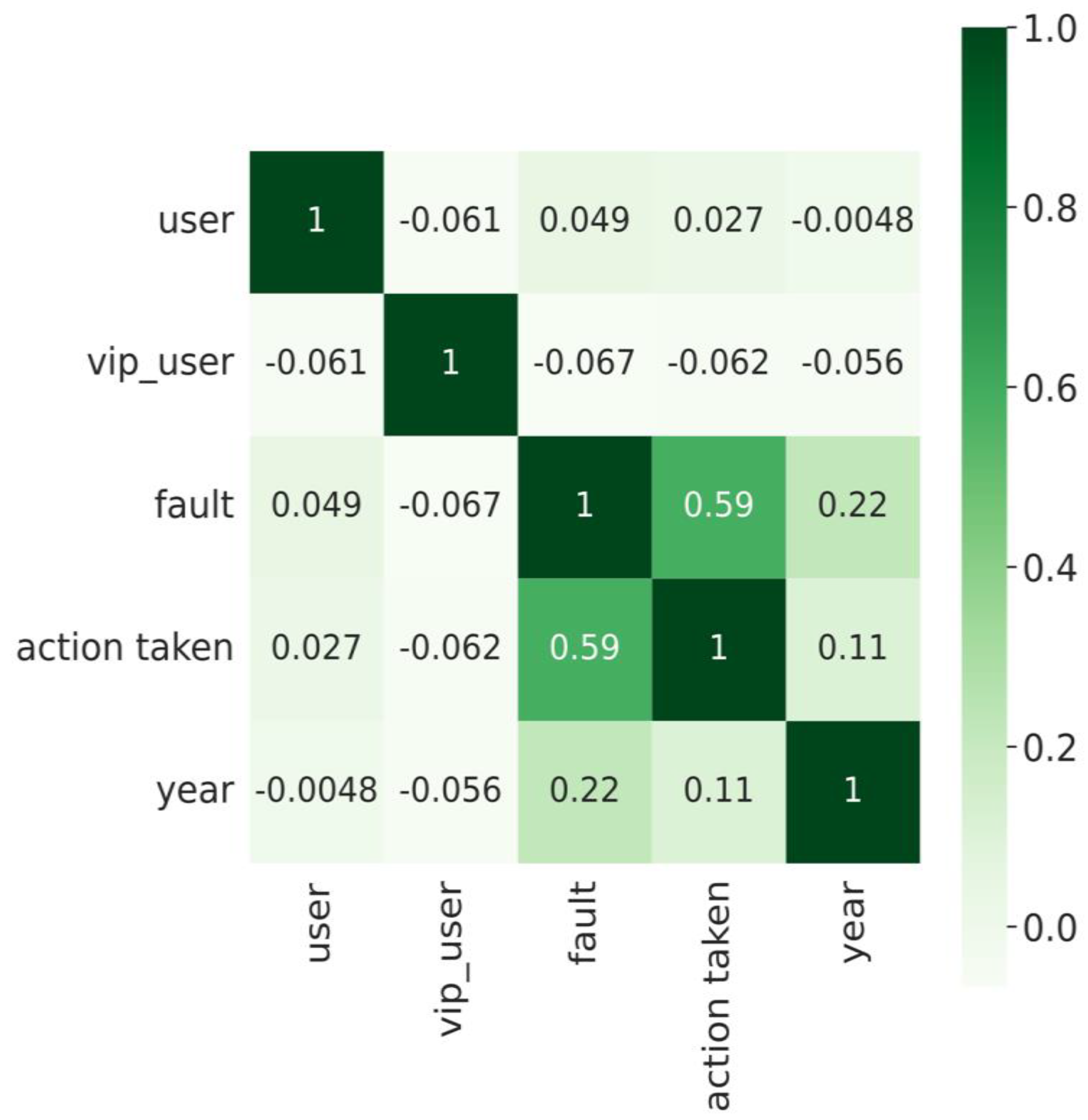
3.2. Data Analysis
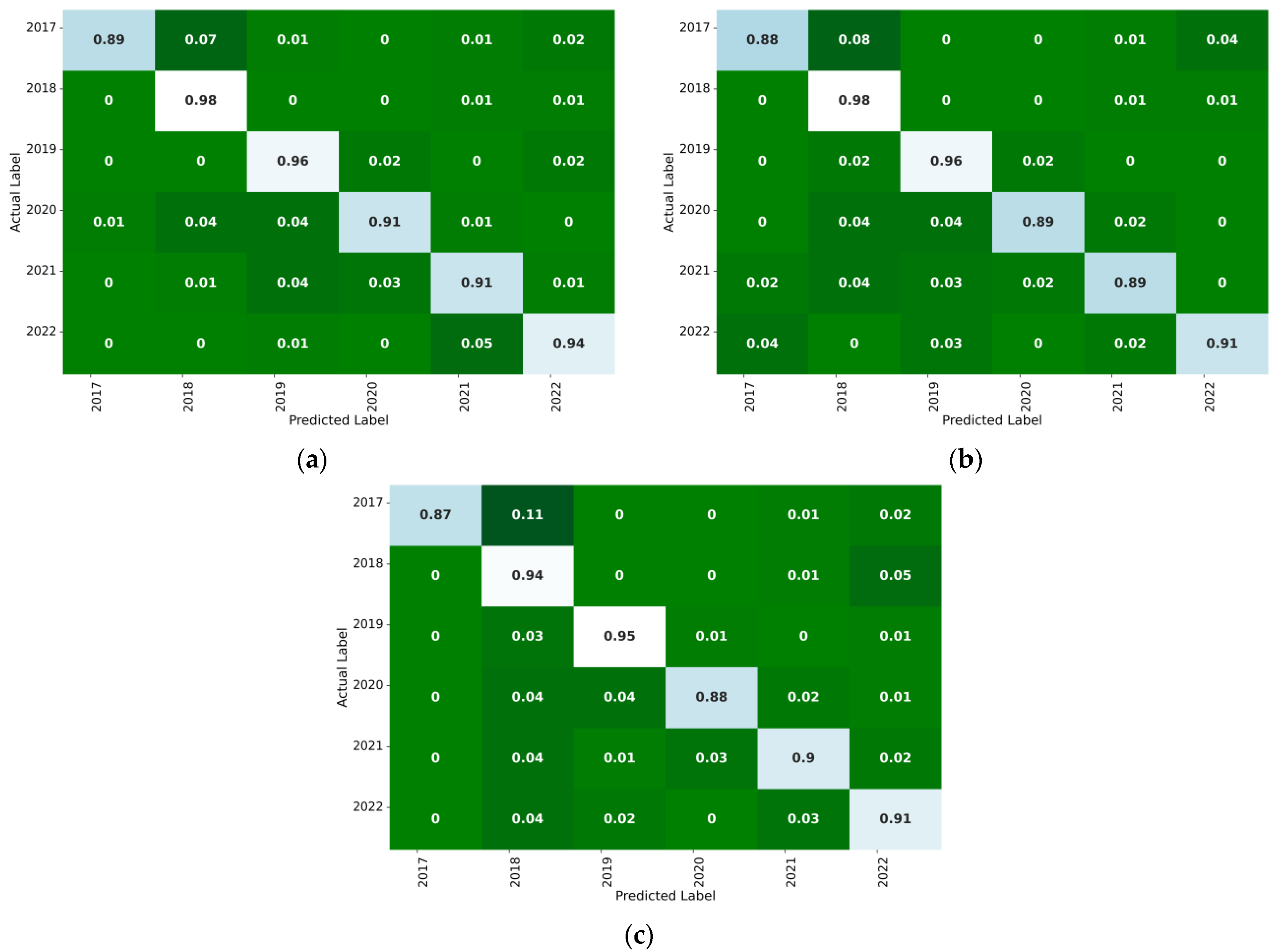
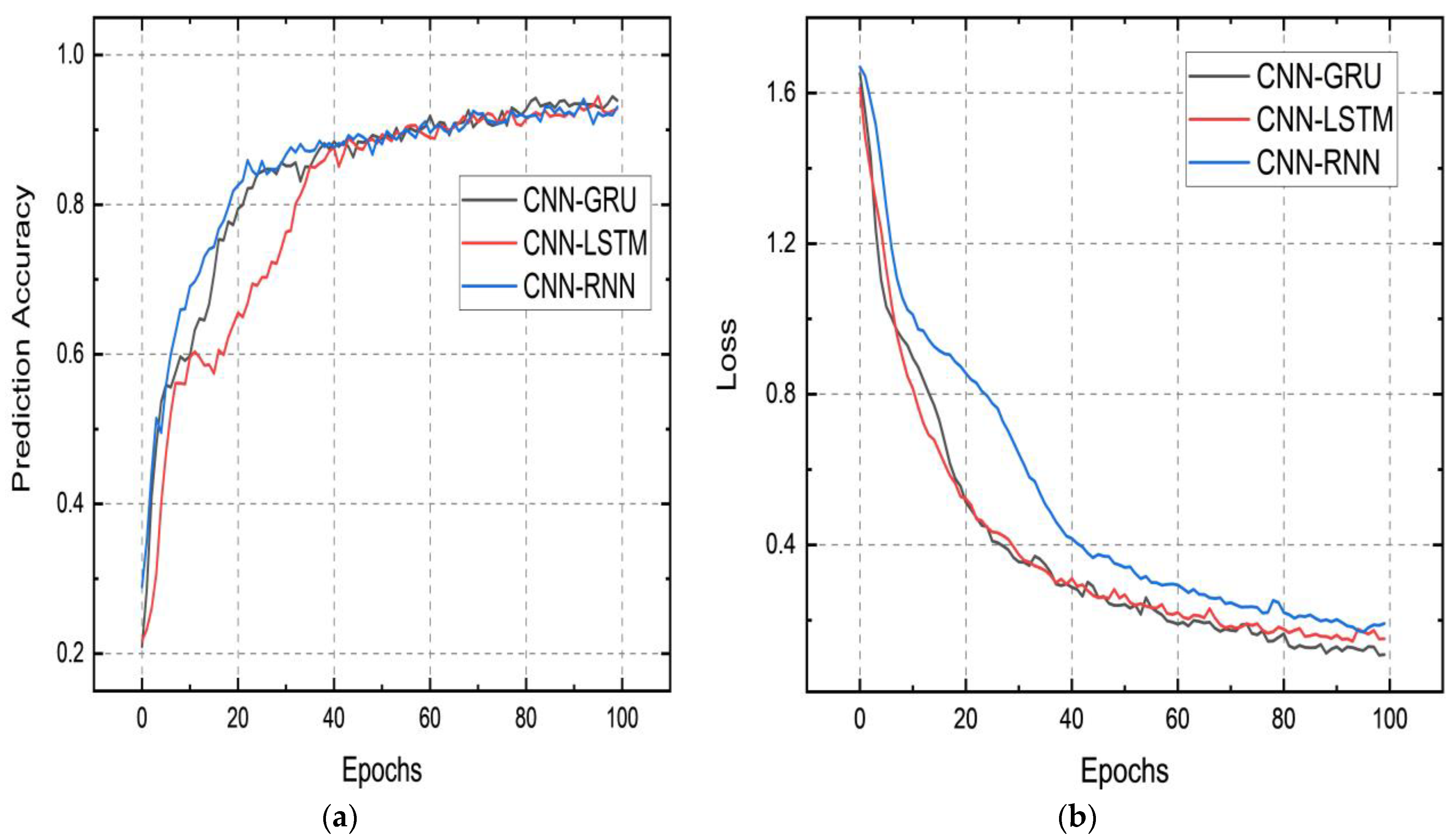
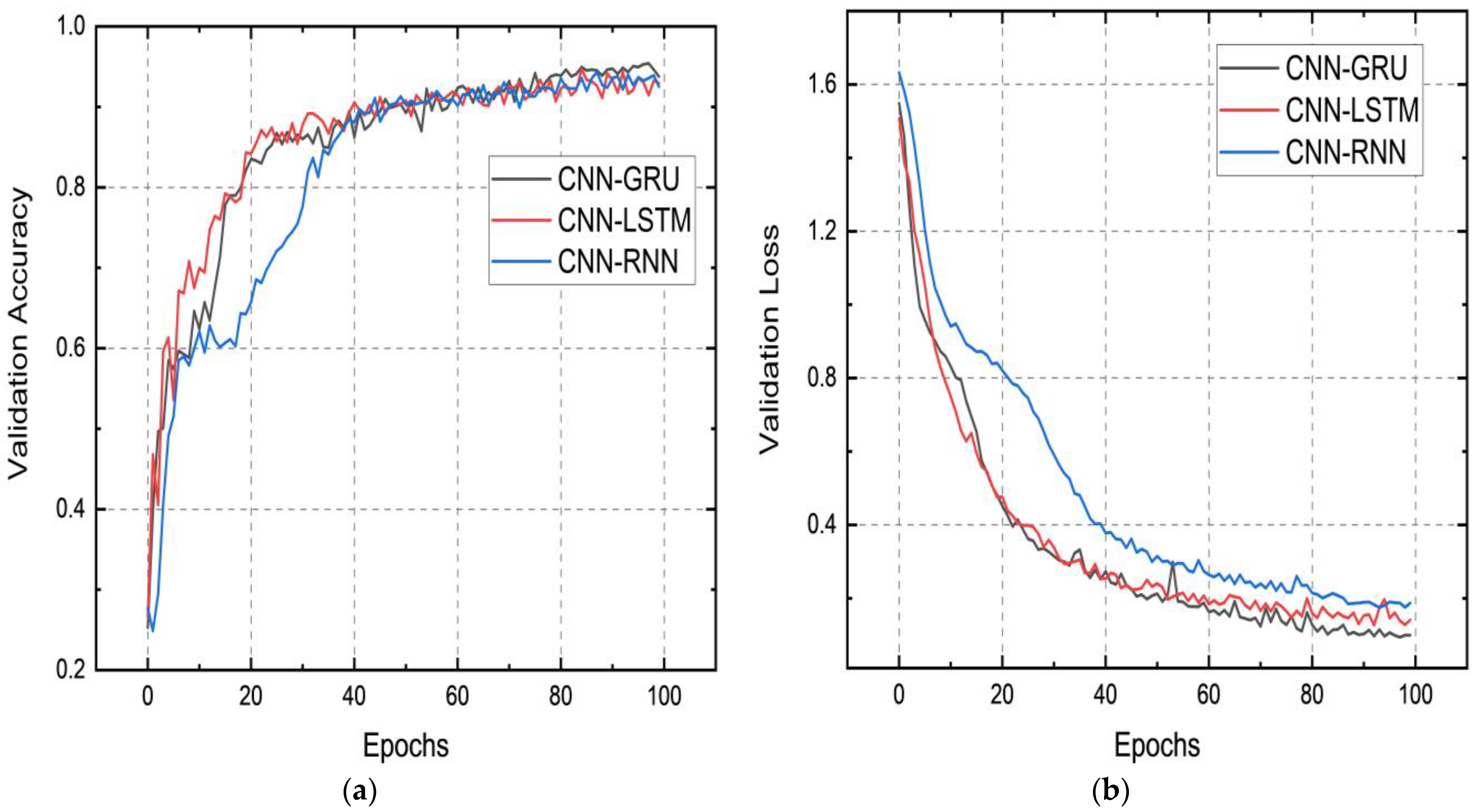
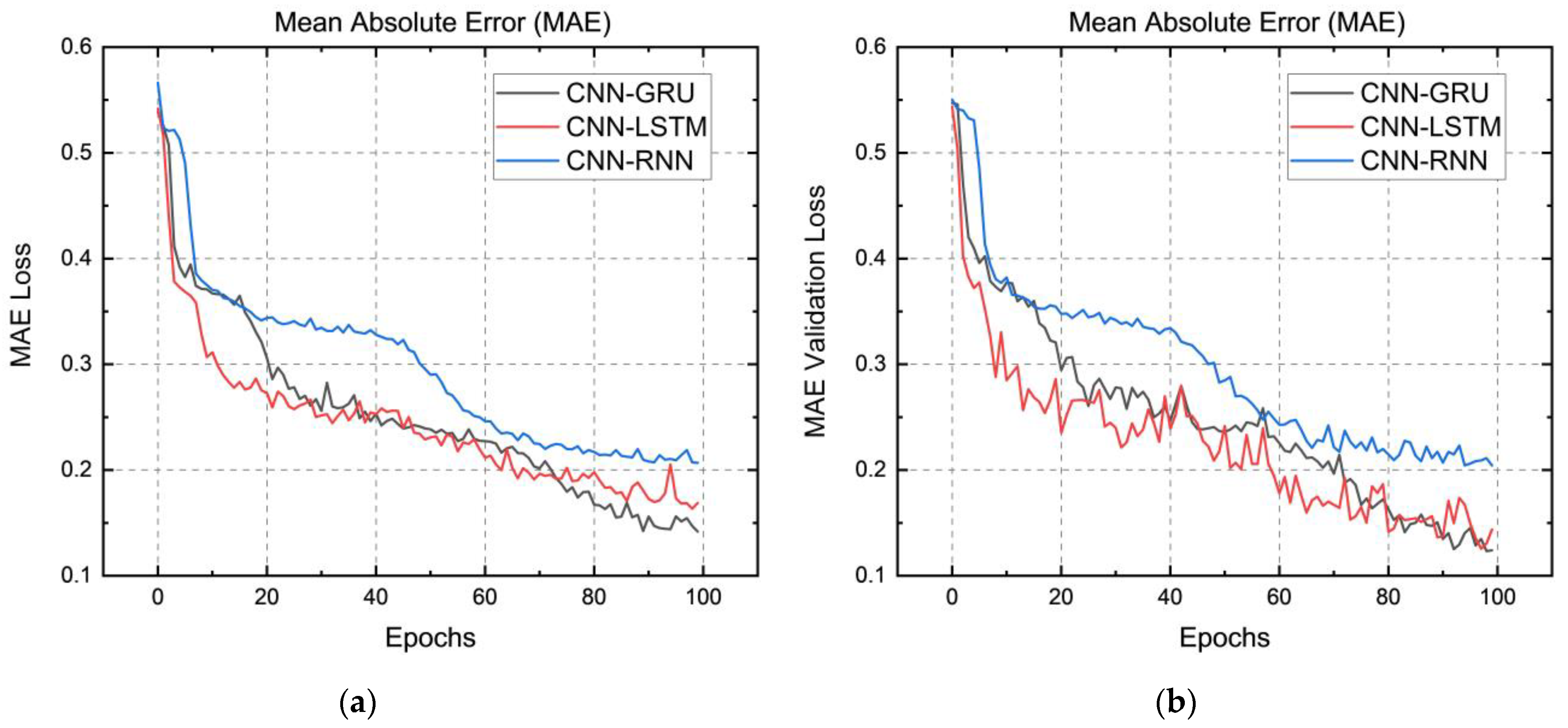
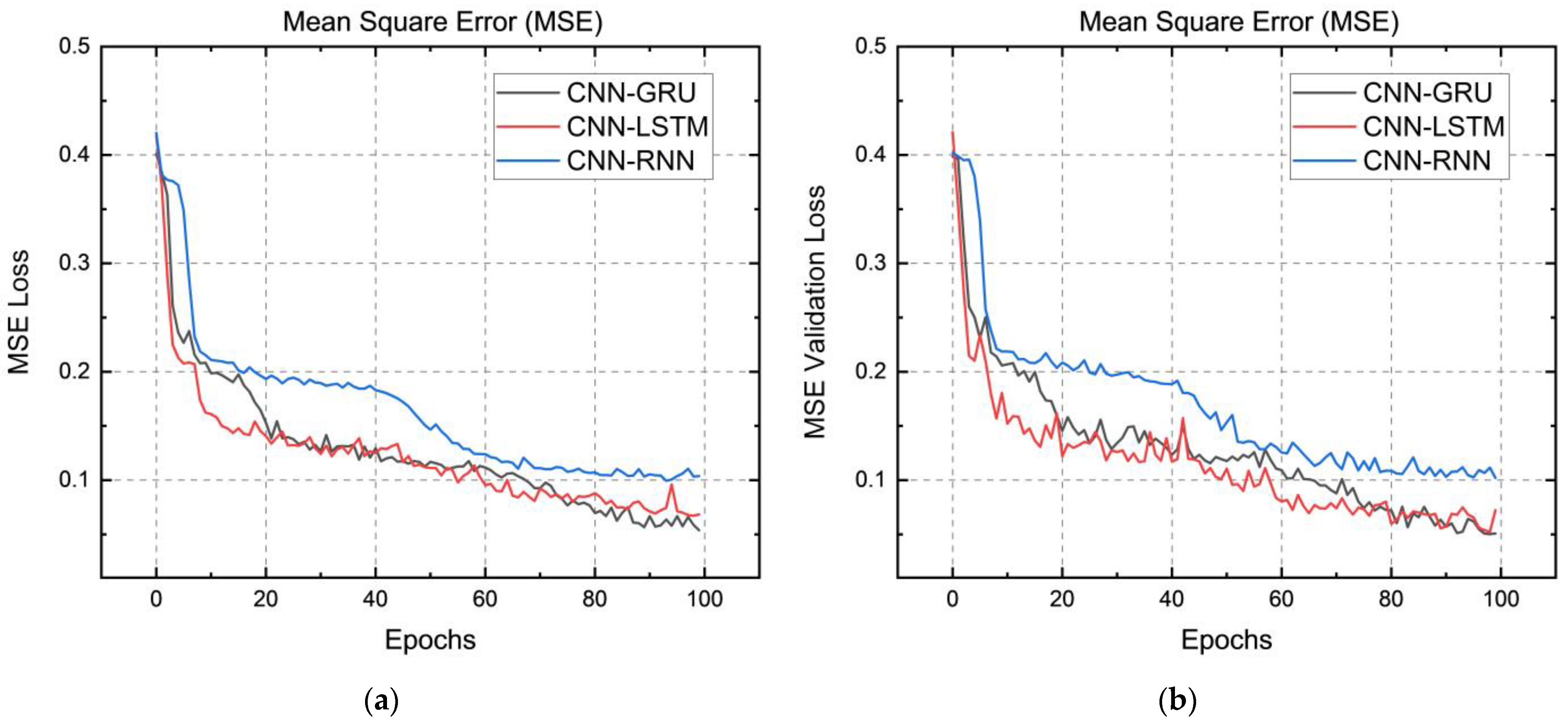
4. Results and Discussion
5. Experimental Setup Used
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fu, X.; Zhou, Y. Collaborative Optimization of PV Greenhouses and Clean Energy Systems in Rural Areas. IEEE Trans. Sustain. Energy 2022, 14, 642–656. [Google Scholar] [CrossRef]
- Fu, X. Statistical machine learning model for capacitor planning considering uncertainties in photovoltaic power. Prot. Control Mod. Power Syst. 2022, 7, 5. [Google Scholar] [CrossRef]
- Meng, A.; Wang, H.; Aziz, S.; Peng, J.; Jiang, H. Kalman filtering based interval state estimation for attack detection. Energy Procedia 2019, 158, 6589–6594. [Google Scholar] [CrossRef]
- Yang, W.; Wang, M.; Aziz, S.; Kharal, A.Y. Magnitude-reshaping strategy for harmonic suppression of VSG-based inverter under weak grid. IEEE Access 2020, 8, 184399–184413. [Google Scholar] [CrossRef]
- Ma, Z.; Guo, S.; Xu, G.; Aziz, S. Meta learning-based hybrid ensemble approach for short-term wind speed forecasting. IEEE Access 2020, 8, 172859–172868. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Bu, S.; Aziz, S.; Qureshi, R. Data-driven cooperative trading framework for a risk-constrained wind integrated power system considering market uncertainties. Int. J. Electr. Power Energy Syst. 2023, 144, 108566. [Google Scholar] [CrossRef]
- Chen, W.; Liu, B.; Nazir, M.S.; Abdalla, A.N.; Mohamed, M.A.; Ding, Z.; Bhutta, M.S.; Gul, M. An energy storage assessment: Using frequency modulation approach to capture optimal coordination. Sustainability 2022, 14, 8510. [Google Scholar] [CrossRef]
- Eskandarpour, R.; Khodaei, A.; Arab, A. Improving Power Grid Resilience Through Predictive Outage Estimation. In Proceedings of the 2017 North American Power Symposium (NAPS), Morgantown, WV, USA, 17–19 September 2017; IEEE: Piscataway, NY, USA; pp. 1–5. [Google Scholar]
- Jamborsalamati, P.; Hossain, M.J.; Taghizadeh, S.; Konstantinou, G.; Manbachi, M.; Dehghanian, P. Enhancing power grid resilience through an IEC61850-based ev-assisted load restoration. IEEE Trans. Ind. Inform. 2019, 16, 1799–1810. [Google Scholar] [CrossRef]
- Barik, A.K.; Das, D.C.; Latif, A.; Hussain, S.S.; Ustun, T.S. Optimal voltage–frequency regulation in distributed sustainable energy-based hybrid microgrids with integrated resource planning. Energies 2021, 14, 2735. [Google Scholar] [CrossRef]
- Nazir, M.S.; Abdalla, A.N.; Zhao, H.; Chu, Z.; Nazir, H.M.J.; Bhutta, M.S.; Javed, M.S.; Sanjeevikumar, P. Optimized economic operation of energy storage integration using improved gravitational search algorithm and dual stage optimization. J. Energy Storage 2022, 50, 104591. [Google Scholar] [CrossRef]
- Bhutta, M.S.; Sarfraz, M.; Ivascu, L.; Li, H.; Rasool, G.; ul Abidin Jaffri, Z.; Farooq, U.; Ali Shaikh, J.; Nazir, M.S. Voltage Stability Index Using New Single-Port Equivalent Based on Component Peculiarity and Sensitivity Persistence. Processes 2021, 9, 1849. [Google Scholar] [CrossRef]
- Abubakar, M.; Che, Y.; Ivascu, L.; Almasoudi, F.M.; Jamil, I. Performance Analysis of Energy Production of Large-Scale Solar Plants Based on Artificial Intelligence (Machine Learning) Technique. Processes 2022, 10, 1843. [Google Scholar] [CrossRef]
- Sarfraz, M.; Naseem, S.; Mohsin, M.; Bhutta, M.S. Recent analytical tools to mitigate carbon-based pollution: New insights by using wavelet coherence for a sustainable environment. Environ. Res. 2022, 212, 113074. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Chen, Z. A rule-based fault detection and diagnosis method for hydropower generating units. Energies 2018, 11, 114. [Google Scholar]
- Abbas, M.H.; Datta, R.L.; Li, S. An expert system for power transformer fault diagnosis. IEEE Trans. Power Deliv. 1999, 14, 1142–1148. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.K.; Pardasani, K.R.; Tripathi, R.K. Review of artificial intelligence techniques for prognostics and health management of machinery systems. Mech. Syst. Signal Process. 2018, 109, 357–380. [Google Scholar]
- Chen, N.; Shi, Y.; Zhang, C.; Chen, W. Fault detection, fault collection, and fault management using artificial intelligence and machine learning techniques: A review. IEEE Access 2019, 7, 124485–124497. [Google Scholar]
- Hu, B.G.; Tan, G.Q.; Zhang, W.H. A review of data-driven approaches for fault detection and diagnosis in industrial processes. IEEE Trans. Ind. Inform. 2018, 14, 3204–3216. [Google Scholar]
- Zhao, D.; Huang, Y.; Lei, Y. A survey on deep learning-based fault diagnosis of rotating machinery. IEEE Trans. Ind. Electron. 2018, 65, 4269–4281. [Google Scholar]
- Almasoudi, F.M. Grid Distribution Fault Occurrence and Remedial Measures Prediction/Forecasting through Different Deep Learning Neural Networks by Using Real Time Data from Tabuk City Power Grid. Energies 2023, 16, 1026. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L.; Jia, S. A survey of fault diagnosis methods with deep learning. J. Sens. 2019, 2019, 2936725. [Google Scholar]
- Raza, M.F.; Iqbal, S.Z.; Iqbal, M.Z. Fault detection and diagnosis in industrial systems using machine learning techniques: A review. J. Ind. Inf. Integr. 2020, 20, 100136. [Google Scholar]
- Zeng, D.; Song, Q.; Li, D. Machine learning and artificial intelligence for fault diagnosis and prognosis of rotating machinery: A review. Measurement 2021, 173, 108–121. [Google Scholar]
- El-Feky, S.S.; Elsayed, S.T.; Zaher, A.H. A review of artificial intelligence applications in fault diagnosis of rotating machinery. Arch. Comput. Methods Eng. 2021, 28, 1303–1323. [Google Scholar]
- Liu, Y.; Sun, H.; Lin, Z.; Zhang, H. Data-driven fault detection and diagnosis methods: A review. J. Process Control 2019, 73, 28–44. [Google Scholar]
- Hohman, F.; Otterbacher, J.; Klasnja, P. Towards Interpretable Machine Learning for Healthcare: Predicting ICU Readmission Using Tree-Based Models. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Xue, Y.; Zhang, J. Machine learning applications in power systems. IEEE Access 2018, 6, 21912–21926. [Google Scholar]
- Bello, O.; Li, N.; Chen, W. Machine learning applications in power systems: A review. Energies 2019, 12, 1554. [Google Scholar]
- Han, X.; Zhang, P.; Wang, H. Fault diagnosis in power systems using a hybrid convolutional and recurrent neural network model. Energies 2019, 12, 464. [Google Scholar]
- Wang, H.; Cao, Y.; Zhou, B. Power system fault diagnosis based on convolutional neural network and gated recurrent unit. IEEE Access 2019, 7, 53627–53634. [Google Scholar]
- Hu, Y.; Xiang, Y.; Zhang, Y. Improved fault diagnosis method for power system based on XGBoost and convolutional neural network. IET Gener. Transm. Distrib. 2019, 13, 763–770. [Google Scholar]
- Singh, J.; Kumar, R. Hybrid support vector machine and convolutional neural network for fault detection in power transmission systems. IET Gener. Transm. Distrib. 2020, 14, 1325–1331. [Google Scholar]
- Lu, Y.; Li, H.; Guo, Q. An improved ensemble learning model based on random forest for power system fault diagnosis. IEEE Access 2020, 8, 156478–156487. [Google Scholar]
- Li, Y.; Xu, C. A hybrid fault diagnosis model based on PCA and SVM optimized by bat algorithm. Energies 2018, 11, 799. [Google Scholar]
- Li, Y.; Wang, C. Fault diagnosis of power systems based on a hybrid deep belief network and self-organizing map. Energies 2020, 13, 3411. [Google Scholar]
- Zhang, J.; Li, D.; Zhang, Y. Hybrid fault diagnosis model based on stacked denoising auto encoder and deep neural network. IEEE Access 2020, 8, 114114–114122. [Google Scholar]
- Sun, L.; Cai, X. A hybrid power transformer fault diagnosis model based on wavelet transform, PCA, and BP neural network. Energies 2021, 14, 306. [Google Scholar]
- Lv, T.; Wang, X.; Li, Y. A hybrid model for short-term load forecasting based on deep learning and ARIMA. Appl. Sci. 2020, 10, 1284. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model: “sequential_8” | ||
|---|---|---|
| Layer (Type) | Output Shape | Param # |
| conv1d_14 (Conv1D) | (None, 3, 128) | 384 |
| conv1d_15 (Conv1D) | (None, 2, 64) | 16,448 |
| max_pooling1d_7 (MaxPooling 1D) | (None, 1, 64) | 0 |
| flatten_7 (Flatten) | (None, 64) | 0 |
| repeat_vector_7 (RepeatVector) | (None, 10, 64) | 0 |
| gru_6 (GRU) | (None, 10, 200) | 159,600 |
| dropout_12 (Dropout) | (None, 10, 200) | 0 |
| bidirectional_6 (Bidirectional) | (None, 256) | 253,440 |
| dropout_13 (Dropout) | (None, 256) | 0 |
| dense_12 (Dense) | (None, 100) | 25,700 |
| dense_13 (Dense) | (None, 1) | 101 |
| Total params: 455,673 | ||
| Trainable params: 455,673 | ||
| Non-trainable params: 0 |
| Model: “sequential_8” | ||
|---|---|---|
| Layer (Type) | Output Shape | Param # |
| conv1d_4 (Conv1D) | (None, 3, 128) | 384 |
| conv1d_5 (Conv1D) | (None, 2, 64) | 16,448 |
| max_pooling1d_2 (MaxPooling1D) | (None, 1, 64) | 0 |
| flatten_2 (Flatten) | (None, 64) | 0 |
| repeat_vector_2 (RepeatVector) | (None, 10, 64) | 0 |
| lstm_4 (LSTM) | (None, 10, 200) | 212,000 |
| dropout_4 (Dropout) | (None, 10, 200) | 0 |
| bidirectional_2 (Bidirectional) | (None, 256) | 336,896 |
| dropout_5 (Dropout) | (None, 256) | 0 |
| dense_4 (Dense) | (None, 100) | 25,700 |
| dense_5 (Dense) | (None, 1) | 101 |
| Total params: 591,529 | ||
| Trainable params: 591,529 | ||
| Non-trainable params: 0 |
| Model: “sequential_8” | ||
|---|---|---|
| Layer (Type) | Output Shape | Param # |
| conv1d_16 (Conv1D) | (None, 3, 128) | 384 |
| conv1d_17 (Conv1D) | (None, 2, 64) | 16,448 |
| max_pooling1d_8 (MaxPooling1D) | (None, 1, 64) | 0 |
| flatten_8 (Flatten) | (None, 64) | 0 |
| repeat_vector_8 (RepeatVector) | (None, 10, 64) | 0 |
| simple_rnn (SimpleRNN) | (None, 10, 200) | 53,000 |
| dropout_14 (Dropout) | (None, 10, 200) | 0 |
| bidirectional_7 (Bidirectional) | (None, 256) | 84,224 |
| dropout_15 (Dropout) | (None, 256) | 0 |
| dense_14 (Dense) | (None, 100) | 25,700 |
| dense_15 (Dense) | (None, 1) | 101 |
| Total params: 179,857 | ||
| Trainable params: 179,857 | ||
| Non-trainable params: 0 |
| Hybrid Models for Prediction | Accuracy (%) | MAE Loss | Loss | RMSE Loss |
|---|---|---|---|---|
| CNN-RNN | 92.85 | 0.21 | 0.19 | 0.10 |
| CNN-LSTM | 93.05 | 0.17 | 0.15 | 0.07 |
| CNN-GRU | 93.92 | 0.14 | 0.10 | 0.05 |
| RNN [22] | 89.21 | 0.45 | 0.28 | 0.47 |
| LSTM [22] | 91.69 | 0.42 | 0.22 | 0.40 |
| GRU [22] | 92.13 | 0.37 | 0.21 | 0.39 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almasoudi, F.M. Enhancing Power Grid Resilience through Real-Time Fault Detection and Remediation Using Advanced Hybrid Machine Learning Models. Sustainability 2023, 15, 8348. https://doi.org/10.3390/su15108348
Almasoudi FM. Enhancing Power Grid Resilience through Real-Time Fault Detection and Remediation Using Advanced Hybrid Machine Learning Models. Sustainability. 2023; 15(10):8348. https://doi.org/10.3390/su15108348
Chicago/Turabian StyleAlmasoudi, Fahad M. 2023. "Enhancing Power Grid Resilience through Real-Time Fault Detection and Remediation Using Advanced Hybrid Machine Learning Models" Sustainability 15, no. 10: 8348. https://doi.org/10.3390/su15108348
APA StyleAlmasoudi, F. M. (2023). Enhancing Power Grid Resilience through Real-Time Fault Detection and Remediation Using Advanced Hybrid Machine Learning Models. Sustainability, 15(10), 8348. https://doi.org/10.3390/su15108348