


A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset

 ,
,  , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
1.1. Prior Works on Temperature Forecasting
1.2. Paper Contribution
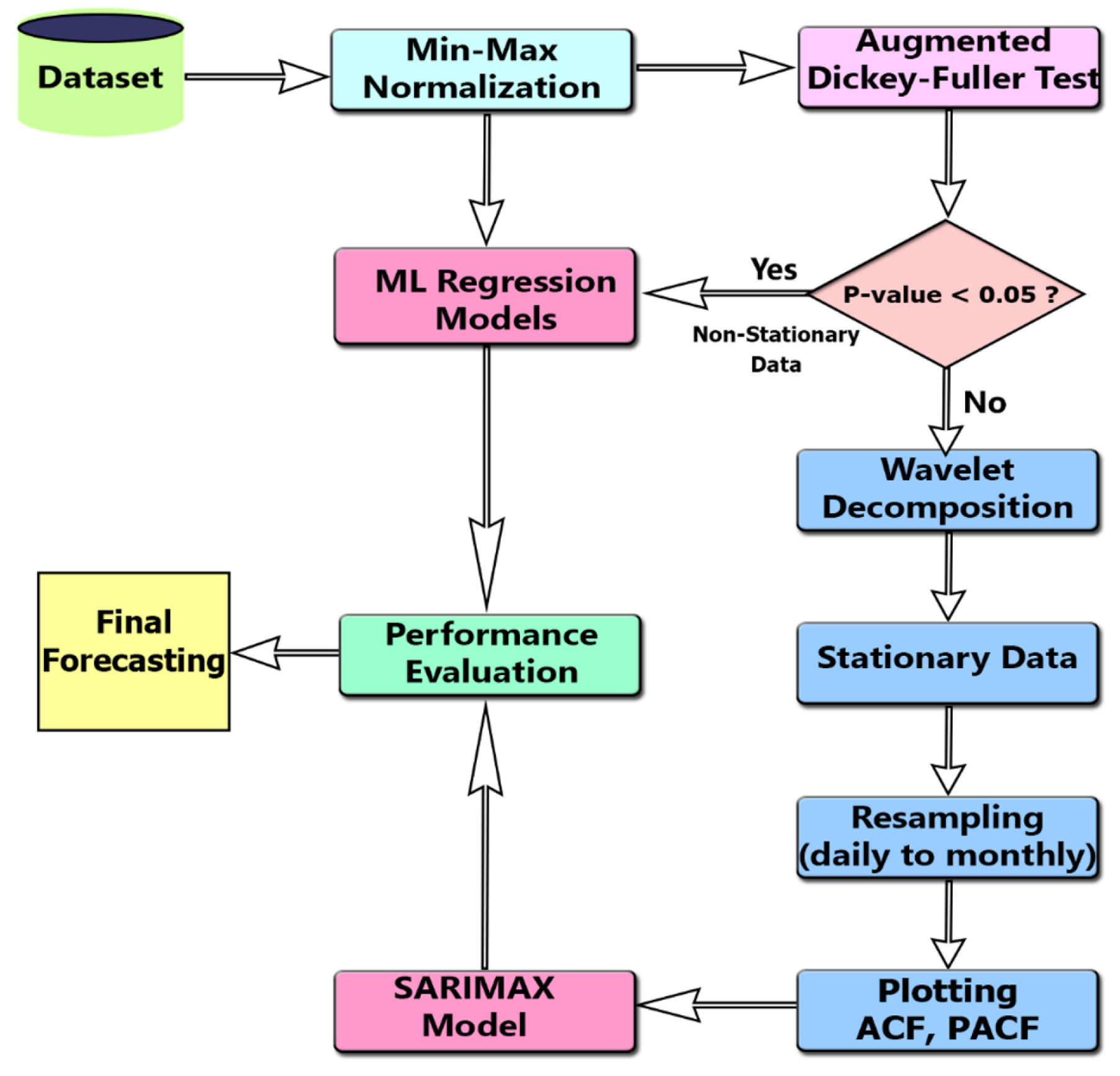
2. The Proposed Methodology
2.1. Augmented Dickey-Fuller (ADF) Test
2.2. Preprocessing of Data
2.3. Wavelet Decomposition (WD) and Resampling
2.4. Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF)
2.5. Seasonal ARIMA with Exogenous Variables (SARIMAX)
2.6. The Proposed WD-SARIMAX Algorithm
| Algorithm 1 The proposed WD-SARIMAX model. |
|
3. Machine Learning Regression Models
3.1. Extra Trees (ET) Regressor
3.2. Dummy Regressor (DR)
3.3. Bayesian Ridge (BR) Regressor
3.4. Lasso Regressor (LR)
3.5. Elastic Net (EN) Regressor
4. Experimental Results
4.1. Dataset
4.2. Evaluation Measures
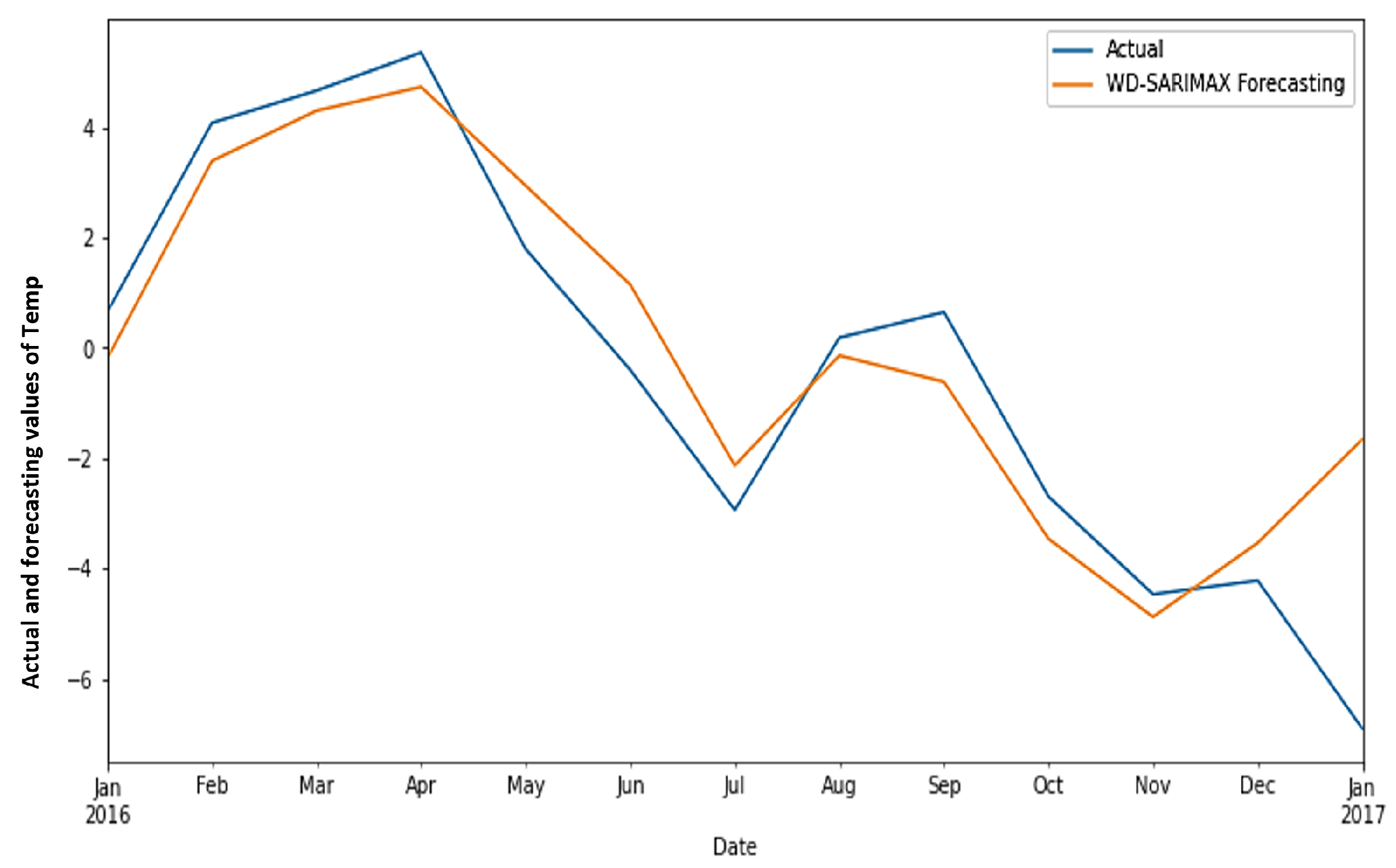
4.3. Results Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pachauri, R.K.; Reisinger, A. Climate Change 2007. Synthesis Report. Contribution of Working Groups I, II and III to the Fourth Assessment Report; IPCC: Geneva, Switzerland, 2008; Volume 1, pp. 1–103.
- Maray, M.; Alghamdi, M.; Alrayes, F.S.; Alotaibi, S.S.; Alazwari, S.; Alabdan, R.; Al Duhayyim, M. Intelligent metaheuristics with optimal machine learning approach for malware detection on IoT-enabled maritime transportation systems. Expert Syst. 2022, 39, e13155. [Google Scholar] [CrossRef]
- Shaiba, H.; Marzouk, R.; Nour, M.K.; Negm, N.; Hilal, A.M.; Mohamed, A.; Motwakel, A.; Yaseen, I.; Zamani, A.S.; Rizwanullah, M.; et al. Weather forecasting prediction using ensemble machine learning for big data applications. Comput. Mater. Contin. 2022, 73, 3367–3382. [Google Scholar] [CrossRef]
- Bartos, I.; Jánosi, I.M. Nonlinear correlations of daily temperature records over land. Nonlinear Process. Geophys. 2006, 13, 571–576. [Google Scholar] [CrossRef]
- Bonsal, B.R.; Zhang, X.; Vincent, L.A.; Hogg, W.D. Characteristics of daily and extreme temperatures over Canada. J. Clim. 2001, 14, 1959–1976. [Google Scholar] [CrossRef]
- Mengash, H.A.; Hussain, L.; Mahgoub, H.; Al-Qarafi, A.; Nour, M.K.; Marzouk, R.; Qureshi, S.A.; Hilal, A.M. Smart cities-based improving atmospheric particulate matters prediction using chi-square feature selection methods by employing machine learning techniques. Appl. Artif. Intell. 2022, 36, 2067647. [Google Scholar] [CrossRef]
- Alhakami, H.; Kamal, M.; Sulaiman, M.; Alhakami, W.; Baz, A. A Machine Learning Strategy for the Quantitative Analysis of the Global Warming Impact on Marine Ecosystems. Symmetry 2022, 14, 2023. [Google Scholar] [CrossRef]
- Kim, S.; Lee, P.-Y.; Lee, M.; Kim, J.; Na, W. Improved State-of-health prediction based on auto-regressive integrated moving average with exogenous variables model in overcoming battery degradation-dependent internal parameter variation. J. Energy Storage 2022, 46, 103888. [Google Scholar] [CrossRef]
- Cifuentes, J.; Marulanda, G.; Bello, A.; Reneses, J. Air temperature forecasting using machine learning techniques: A review. Energies 2020, 13, 4215. [Google Scholar] [CrossRef]
- Oo, Z.Z.; Sabai, P. Time Series Prediction Based on Facebook Prophet: A Case Study, Temperature Forecasting in Myintkyina. Int. J. Appl. Math. Electron. Comput. 2020, 8, 263–267. [Google Scholar] [CrossRef]
- Liu, N.; Babushkin, V.; Afshari, A. Short-term forecasting of temperature driven electricity load using time series and neural network model. J. Clean Energy Technol. 2014, 2, 327–331. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Chen, D.; Feng, D.; You, X.; Wu, W. Temperature Forecasting Correction Based on Operational GRAPES-3km Model Using Machine Learning Methods. Atmosphere 2022, 13, 362. [Google Scholar] [CrossRef]
- Zhang, Z.; Dong, Y. Temperature forecasting via convolutional recurrent neural networks based on time-series data. Complexity 2020, 2020, 3536572. [Google Scholar] [CrossRef]
- Nandi, A.; De, A.; Mallick, A.; Middya, A.I.; Roy, S. Attention based long-term air temperature forecasting network: ALTF Net. Knowl.-Based Syst. 2022, 252, 109442. [Google Scholar] [CrossRef]
- Ajewole, K.P.; Adejuwon, S.O.; Jemilohun, V.G. Test for stationarity on inflation rates in Nigeria using augmented dickey fuller test and Phillips-persons test. J. Math. 2020, 16, 11–14. [Google Scholar]
- Zhang, S.; Monekosso, D.; Remagnino, P. Data pre-processing and model selection strategies for human posture recognition. In Proceedings of the 2018 11th International Symposium on Communication Systems, Networks Digital Signal Processing (CSNDSP), Budapest, Hungary, 18–20 July 2018; pp. 1–6. [Google Scholar]
- Rhif, M.; Abbes, A.B.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet transform application for/in non-stationary time-series analysis: A review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef]
- Paul, R.K.; Paul, A.K.; Bhar, L.M. Wavelet-based combination approach for modeling sub-divisional rainfall in India. Theor. Appl. Climatol. 2020, 139, 949–963. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, Q.; Xing, X.; Gui, T.; Huang, X.; Jiang, Y.G.; Ding, K.; Chen, Z. Trainable undersampling for class-imbalance learning. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4707–4714. [Google Scholar] [CrossRef]
- Kim, K.-R.; Park, J.-E.; Jang, I.-T. Outpatient forecasting model in spine hospital using ARIMA and SARIMA methods. J. Hosp. Manag. Health Policy 2020, 2020, 1–8. [Google Scholar] [CrossRef]
- Tiwari, D.; Bhati, B.S. A deep analysis and prediction of covid-19 in India: Using ensemble regression approach. In Artificial Intelligence and Machine Learning for COVID-19; Springer: Berlin/Heidelberg, Germany, 2021; pp. 97–109. [Google Scholar]
- Trenchevski, A.; Kalendar, M.; Gjoreski, H.; Efnusheva, D. Prediction of air pollution concentration using weather data and regression models. Proc. Int. Conf. Appl. Innov. IT 2020, 8, 55–61. [Google Scholar]
- Mardhiyyah, Y.S.; Rasyidi, M.A.; Hidayah, L. Factors affecting crowdfunding investor number in agricultural projects: The dummy regression model. J. Manaj. Agribisnis 2020, 17, 14. [Google Scholar] [CrossRef]
- Saqib, M. Forecasting COVID-19 outbreak progression using hybrid polynomial-Bayesian ridge regression model. Appl. Intell. 2021, 51, 2703–2713. [Google Scholar] [CrossRef] [PubMed]
- Ranstam, J.; Cook, J.A. LASSO regression. J. Br. Surg. 2018, 105, 1348. [Google Scholar] [CrossRef]
- Johnsen, T.K.; Gao, J.Z. Elastic net to forecast COVID-19 cases. In Proceedings of the 2020 International Conference on Innovation and Intelligence for Informatics, Computing and Technologies (3ICT), Sakhir, Bahrain, 20–21 December 2020; pp. 1–6. [Google Scholar]
- Antonicelli, M.; Maggino, F. Big data and official statistics: General Concepts and Statistical Instruments. In Big Data and Official Statistics, 1st ed.; Egea editor: Milano, Italy, 2022; Volume 2022, pp. 160–168. [Google Scholar]
- Nagappan, K.; Rajendran, S.; Alotaibi, Y. Trust Aware Multi-Objective Metaheuristic Optimization Based Secure Route Planning Technique for Cluster Based IIoT Environment. IEEE Access 2022, 10, 112686–112694. [Google Scholar] [CrossRef]
- El-Kenawy, E.-S.M.; Mirjalili, S.; Alassery, F.; Zhang, Y.; Eid, M.M.; El-Mashad, S.Y.; Aloyaydi, B.A.; Ibrahim, A.; Abdelhamid, A.A. Novel meta-heuristic algorithm for feature selection, unconstrained functions and engineering problems. IEEE Access 2022, 10, 40536–40555. [Google Scholar] [CrossRef]
- Abdelhamid, A.; El-kenawy, E.-S.M.; Alotaibi, B.; Abdelkader, M.; Ibrahim, A.; Eid, M.M. Robust speech emotion recognition using CNN+LSTM based on stochastic fractal search optimization algorithm. IEEE Access 2022, 10, 49265–49284. [Google Scholar] [CrossRef]
- Khafaga, D.; Alhussan, A.; El-Kenawy, E.-S.M.; Ibrahim, A.; Eid, M.M.; Abdelhamid, A. Solving optimization problems of metamaterial and double T-shape antennas using advanced meta-heuristics algorithms. IEEE Access 2022, 10, 74449–74471. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Count | Mean | Std | Min | 25% | 50% | 75% | Max | |
|---|---|---|---|---|---|---|---|---|
| Temp (°C) | 1462 | 25.5 | 7.3 | 6 | 18.8 | 27.7 | 31.3 | 38.7 |
| Humidity (g·m−3) | 1462 | 60.7 | 16.7 | 13.4 | 50.37 | 62.6 | 72.2 | 100 |
| Wind (kmph) | 1462 | 6.8 | 4.56 | 0 | 3.47 | 6.2 | 9.2 | 42.2 |
| Meanpressure (atm) | 1462 | 1011.1 | 180.2 | −3.04 | 1001.5 | 1008.5 | 1014.9 | 7679.3 |
| Metric | Value | |
|---|---|---|
| MSE | (19) | |
| MAE | (20) | |
| MedAE | (21) | |
| RMSE | (22) | |
| MAPE | (23) | |
| (24) |
| Models | Parameters |
|---|---|
| ET | N_estimators = 10, criterion = squared |
| DR | Strategy = mean |
| EN | Alpha = 0.1, fit_intercept = true |
| BR | N_iter = 200, fit_intercept = true |
| LR | Alpha = 0.01 |
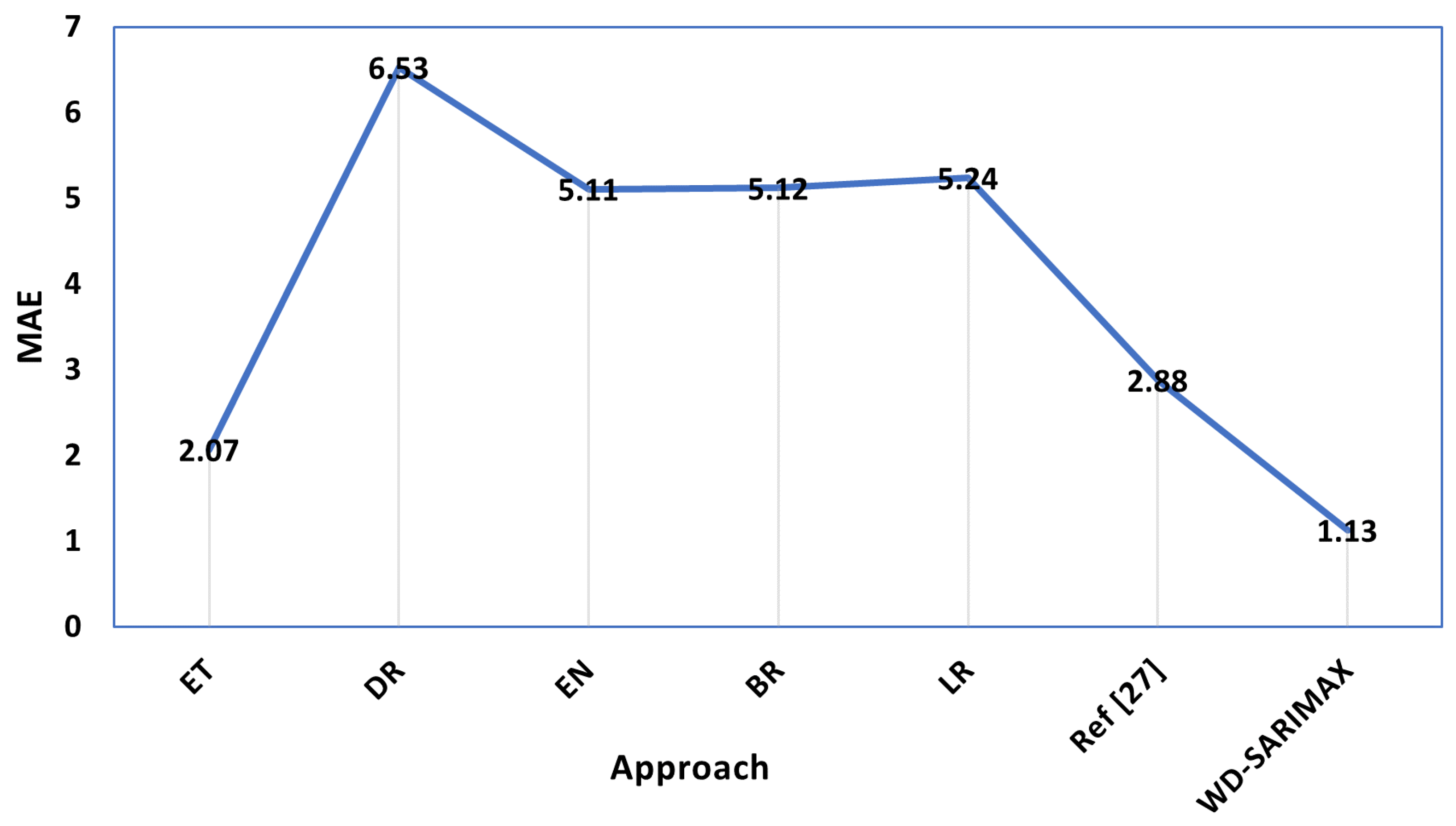
| Models | MSE | MAE | MedAE | RMSE | MAPE | |
|---|---|---|---|---|---|---|
| ET | 7.6 | 2.07 | 1.45 | 2.76 | 10.49 | 0.86 |
| DR | 66 | 6.53 | 5.37 | 8.12 | 37.3 | 0.21 |
| EN | 36.78 | 5.11 | 4.95 | 6.06 | 25.7 | 0.364 |
| BR | 36.83 | 5.12 | 4.97 | 6.08 | 25.9 | 0.36 |
| LR | 37.5 | 5.24 | 5 | 6.12 | 26.5 | 0.35 |
| WD-SARIMAX | 2.8 | 1.13 | 0.76 | 1.67 | 4.9 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elshewey, A.M.; Shams, M.Y.; Elhady, A.M.; Shohieb, S.M.; Abdelhamid, A.A.; Ibrahim, A.; Tarek, Z. A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset. Sustainability 2023, 15, 757. https://doi.org/10.3390/su15010757
Elshewey AM, Shams MY, Elhady AM, Shohieb SM, Abdelhamid AA, Ibrahim A, Tarek Z. A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset. Sustainability. 2023; 15(1):757. https://doi.org/10.3390/su15010757
Chicago/Turabian StyleElshewey, Ahmed M., Mahmoud Y. Shams, Abdelghafar M. Elhady, Samaa M. Shohieb, Abdelaziz A. Abdelhamid, Abdelhameed Ibrahim, and Zahraa Tarek. 2023. "A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset" Sustainability 15, no. 1: 757. https://doi.org/10.3390/su15010757
APA StyleElshewey, A. M., Shams, M. Y., Elhady, A. M., Shohieb, S. M., Abdelhamid, A. A., Ibrahim, A., & Tarek, Z. (2023). A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset. Sustainability, 15(1), 757. https://doi.org/10.3390/su15010757