1. Introduction
Air pollution is associated with the presence of certain substances in the atmosphere in large enough quantities as to have a negative impact on the flora and fauna, or on the environment in general. Air pollution has a strong negative impact on human health and can cause both acute reactions and various chronic diseases [
1]. Pollutants can differ in their chemical composition, properties, and origin. The main air pollutants are gases, such as carbon monoxide (CO), carbon dioxide (CO
2), nitrogen dioxide (NO
2), sulfur dioxide (SO
2), ozone (O
3), etc., as well as particulate matters (PM
2.5 and PM
10). The main sources of air pollution related to human activity are automobiles, industrial activities, power plants, biomass combustion, and others. Particulate matter (PM) includes liquid or solid particles of various sizes and chemical compositions that are suspended in the atmosphere. Of these, PM
2.5 (particles with an aerodynamic diameter of 2.5 µm or smaller) are of particular importance when it comes to human health due to their ability to penetrate deep into the respiratory tract [
2]. In addition to that, these small particles tend to remain suspended in the atmosphere for long periods of time, and can also be transported over long distances [
2]. Both short-term and long-term exposure to PM
2.5, even at low concentrations, are associated with an increased risk of disease and premature death [
3]. In addition to being associated with cardiovascular [
4] and respiratory diseases [
5], PM
2.5 has recently been linked to neurocognitive effects and diabetes, as well as birth outcomes [
3]. According to [
6] in 2017, ambient and household PM
2.5 pollution was responsible for 4.58 million deaths globally. It is estimated that PM
2.5 lowers global life expectancy by about 1 year [
7]. The global economic cost due to deaths from ambient PM
2.5 was estimated at USD 4.09 trillion for 2016 [
8], and is expected to increase further as the population ages.
An air quality forecast can provide important information to both government institutions and individuals, and allow them to take appropriate action. Modern models for predicting air pollution can be divided into two main types—deterministic and statistical [
9]. Deterministic models simulate atmospheric processes related to the emission, dispersion, transformation and elimination of pollutants, which makes these models computationally heavy. Such models are difficult to develop because they require good knowledge of the involved processes and sources of pollution, and often suffer from inaccurate representations due to approximations and incomplete knowledge. Some of the popular deterministic models are WRF-Chem [
10], CMAQ [
11,
12] and CHIMERE [
13,
14,
15]. Statistical models are based on determining regularities in the data itself, without the need to take into account physical and chemical factors. These models are simpler, lighter, and easier to implement, and when enough historical data are provided, statistical models show better forecast results for specific locations. Popular statistical models for predicting the air quality include artificial neural networks [
16,
17,
18,
19,
20,
21,
22,
23,
24], multiple linear regression [
25], autoregressive integrated moving average (ARIMA) [
26], support vector machine (SVM) [
27], nonlinear regression [
28] and random forest [
29]. Neural networks (NN) are a popular choice for air pollution forecasting, since they do not require any prior assumptions about the data distribution, and are capable of modeling complex nonlinear processes.
Unlike traditional shallow NN models, deep NN models can find patterns in large and multidimensional datasets, making them particularly suitable for modeling the air quality. Recurrent neural networks perform well in modeling temporal dependencies, but the vanishing gradient problem prevents them from modeling long-term dependencies. Long short-term memory networks (LSTM) [
30] address this problem through the use of memory cells that can store and retrieve information, allowing the system to model longer time dependencies and making them popular in the field of air quality modeling [
31,
32,
33,
34,
35,
36]. Another popular deep NN is the convolutional neural network (CNN) [
37], which is a specific type of a feedforward NN, in which some of the hidden layers perform the convolution operation. CNN is characterized by some translational invariance, as well as an ability to take advantage of local dependencies in the data. 1D CNNs have been used to predict air pollution [
33,
38]. Hybrid approaches such as combinations of CNN and LSTM are becoming increasingly popular in the field of air quality modeling [
39,
40,
41,
42,
43]. The addition of a CNN to LSTM usually leads to better results compared to a pure LSTM models [
40,
41].
Some important issues need to be addressed in order to successfully develop a statistical model for predicting air pollution. For various reasons, there are missing values in the time series that need to be filled in before the data can be used to train the respective model. There are various strategies for filling in the missing values; among them, linear interpolation and the use of the nearest valid value are very popular due to their simplicity, but regression models and machine learning models can also be used. How appropriate an imputation strategy is depends on the amount of missing data and their characteristics [
44]. A very important part of the development of successful statistical models is the selection of input variables [
45], as the use of an inappropriate set of features can significantly impair the overall performance of the model.
However, many studies in the field of air pollution forecasting do not use any additional automated technique to find the optimal subset of input variables, instead utilizing all available ones from the data set, which usually leads to the inclusion of redundant information. In addition, the quality of the air at a particular location depends not only on the local conditions, but also to a large extent on the conditions of the surrounding environment, as pollutants released into the atmosphere are dispersed and carried away by air currents. This means that the inclusion of spatial information has the potential to improve the performance of the prediction model. However, few proposed models consider spatial relationships. Moreover, the proposed models are optimized manually, which is not a very effective means of optimization, especially in the absence of significant experience. Using an automated model optimization approach could improve and facilitate the whole procedure of developing an efficient model for air pollution forecasting.
Different machine learning techniques are a good and efficient approach to the prediction of different problems in that domain. For example, the reference evapotranspiration prediction and uncertainty analysis under climate change was carried out using multiple linear regression, multiple non-linear regression, multivariate adaptive regression splines, model tree M5, random forest and least-squares boost [
46], the last of which showing better results. In addition, a novel least square support vector machine (LSSVM) model integrated with a gradient-based optimizer (GBO) algorithm is introduced for the assessment of water quality parameters, which has shown good performance among all benchmark datasets and algorithms [
47].
In order to take into account the above-mentioned problems in air pollution forecasting, a hybrid CNN-LSTM spatiotemporal deep model for air pollution forecasting has been developed with the automatic selection of input variables and the optimization of model hyperparameters. In addition, a hybrid strategy is here proposed for filling in the missing values in the data.
4. Experimental Testing and Results
4.1. Experimental Setup
The Keras library is used to implement the models and the Adam algorithm is used in the training, with a learning rate of 0.001, β1 = 0.9, β2 = 0.999, ε = 1.0 × 10−7 and batch size of 16. The training of the network architectures is performed on NVIDIA GeForce RTX 2060. ReLU is used as an activation function not only for the convolutional layers, but also for the LSTM layers. The strides of the convolutional layers are set to (1, 1), and the padding to valid. Max-pooling is used with size (2, 2), strides (2, 2) and valid padding. For the evolutionary optimization, the population size is set to 20, the number of generations to 50, and elitism of size 2 is also used. The maximum number of convolutional layers is set to 10, and the maximum number of LSTM layers to 5.
Due to the limited computational resources, experiments are conducted on 3 of the 12 stations—Dongsi, Wanliu and Changping. All these three stations are selected prior to the experiments so that the target stations are surrounded by other stations. A separate model is optimized for each station, and due to the stochastic nature of the evolutionary search, the optimization of the architecture for each station is repeated three times.
Besides the main experiment for architecture optimization, some additional experiments are also conducted, such as forming various ensembles using the already trained models, validating the proposed hybrid missing data imputation strategy, and validating some components of the proposed spatiotemporal model. In order to make correct comparisons with the results of the main experiment, separate models are optimized for each additional experiment involving the spatiotemporal model, using the already outlined procedure. As in the main experiment, the evolutionary optimization is repeated three times. Due to the limited computational resources, the additional experiments are conducted for only one station—Wanliu (unless explicitly stated otherwise).
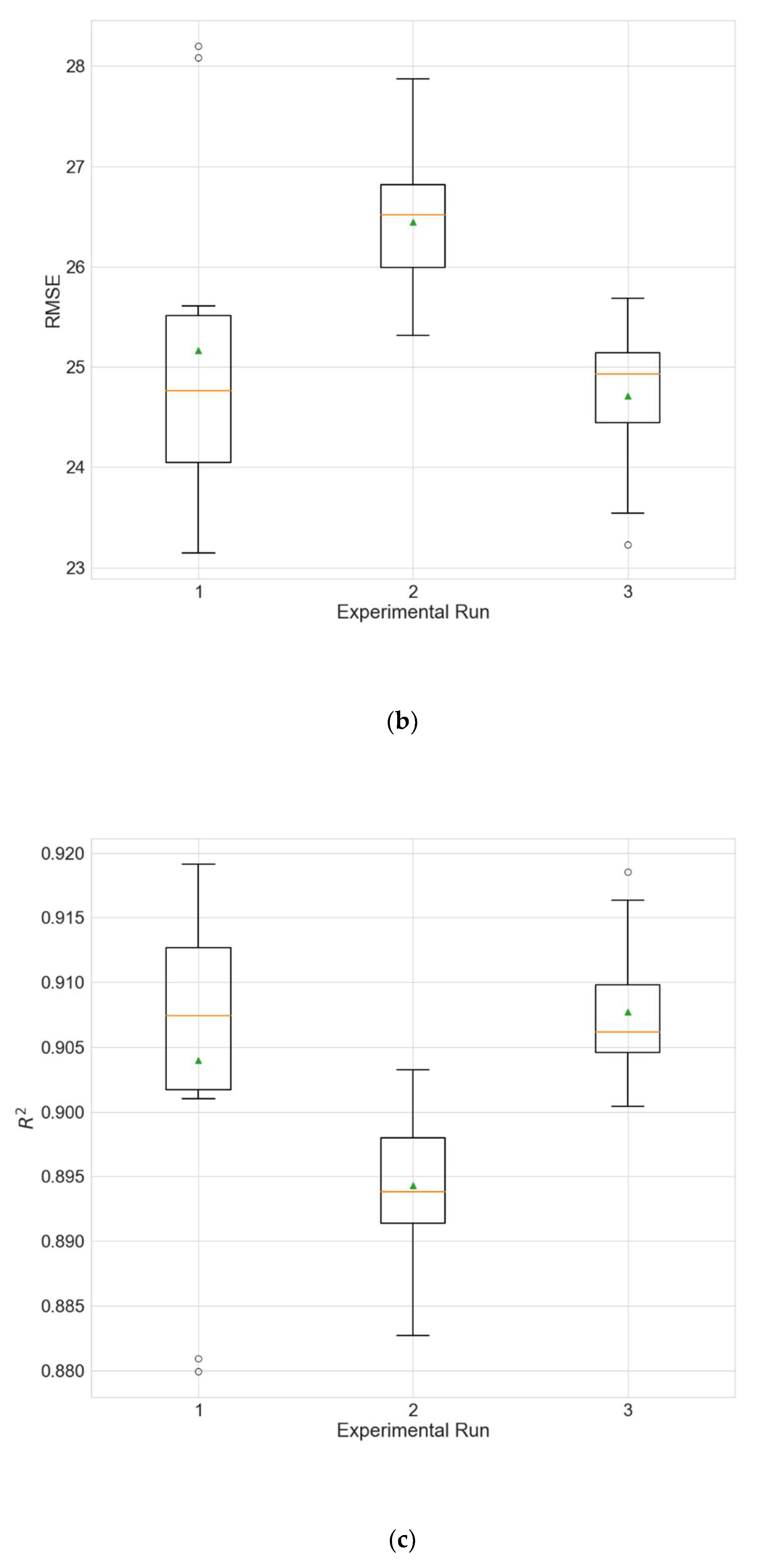
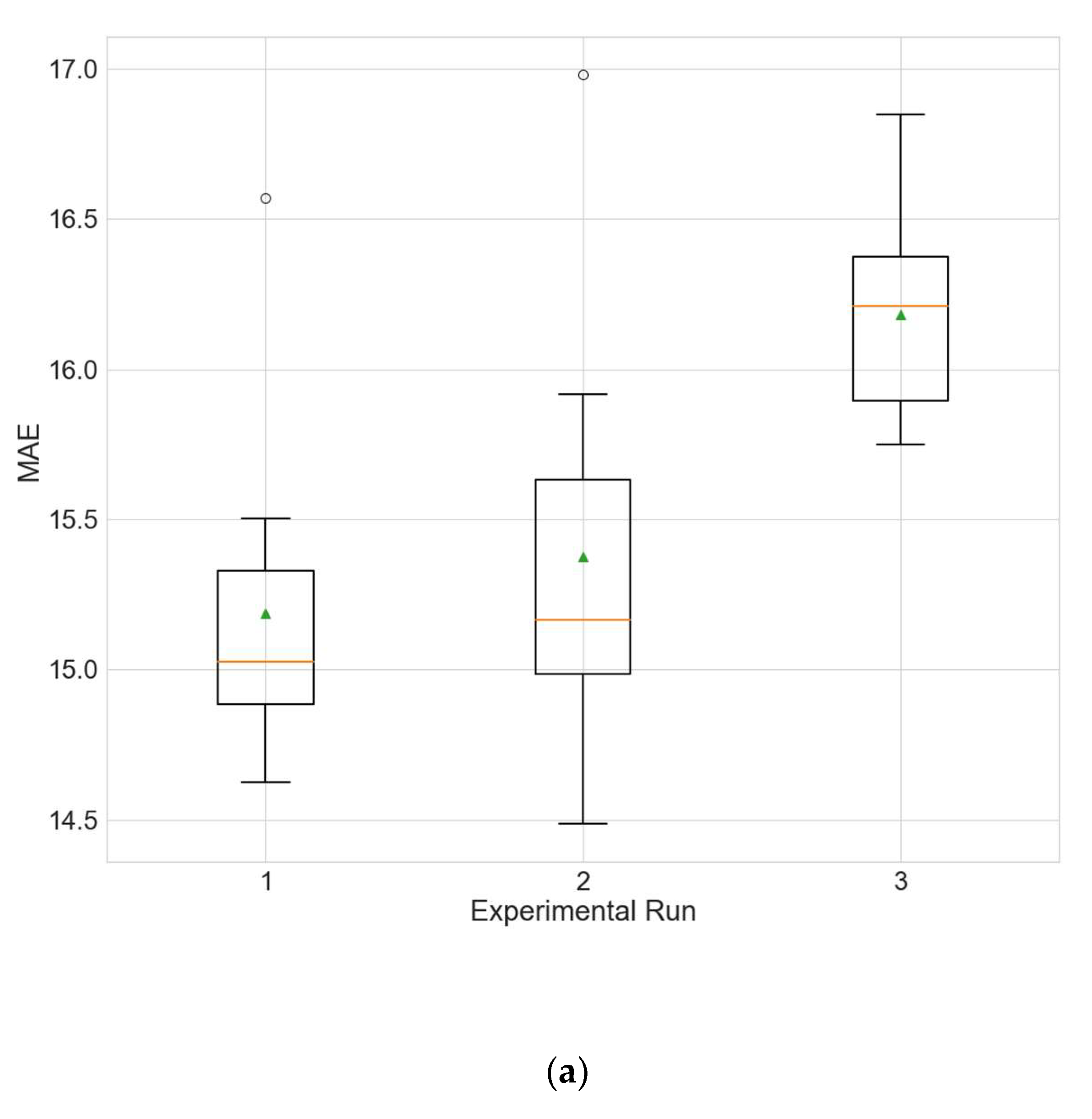
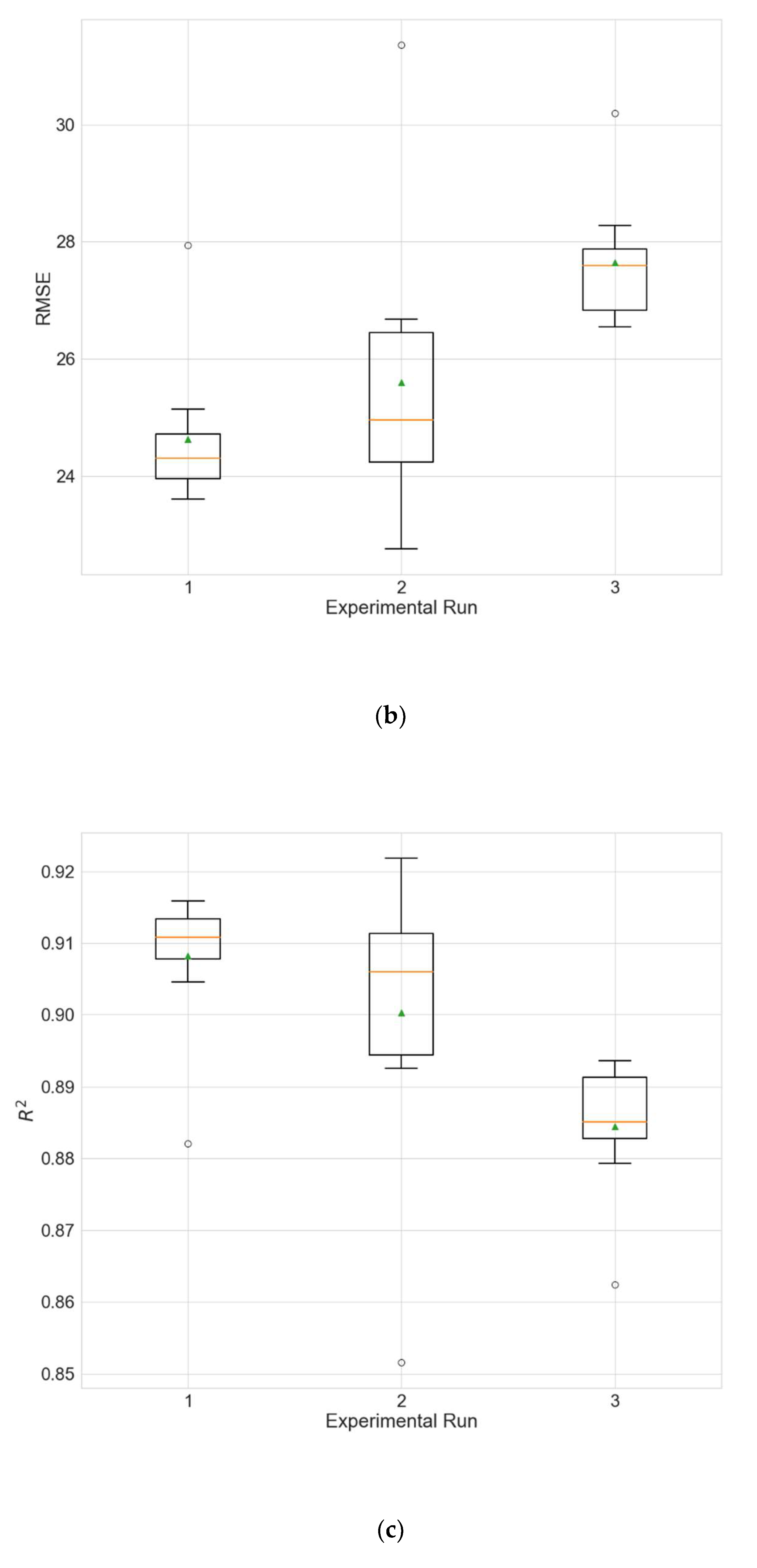
4.2. Experimental Results for Architecture Optimization
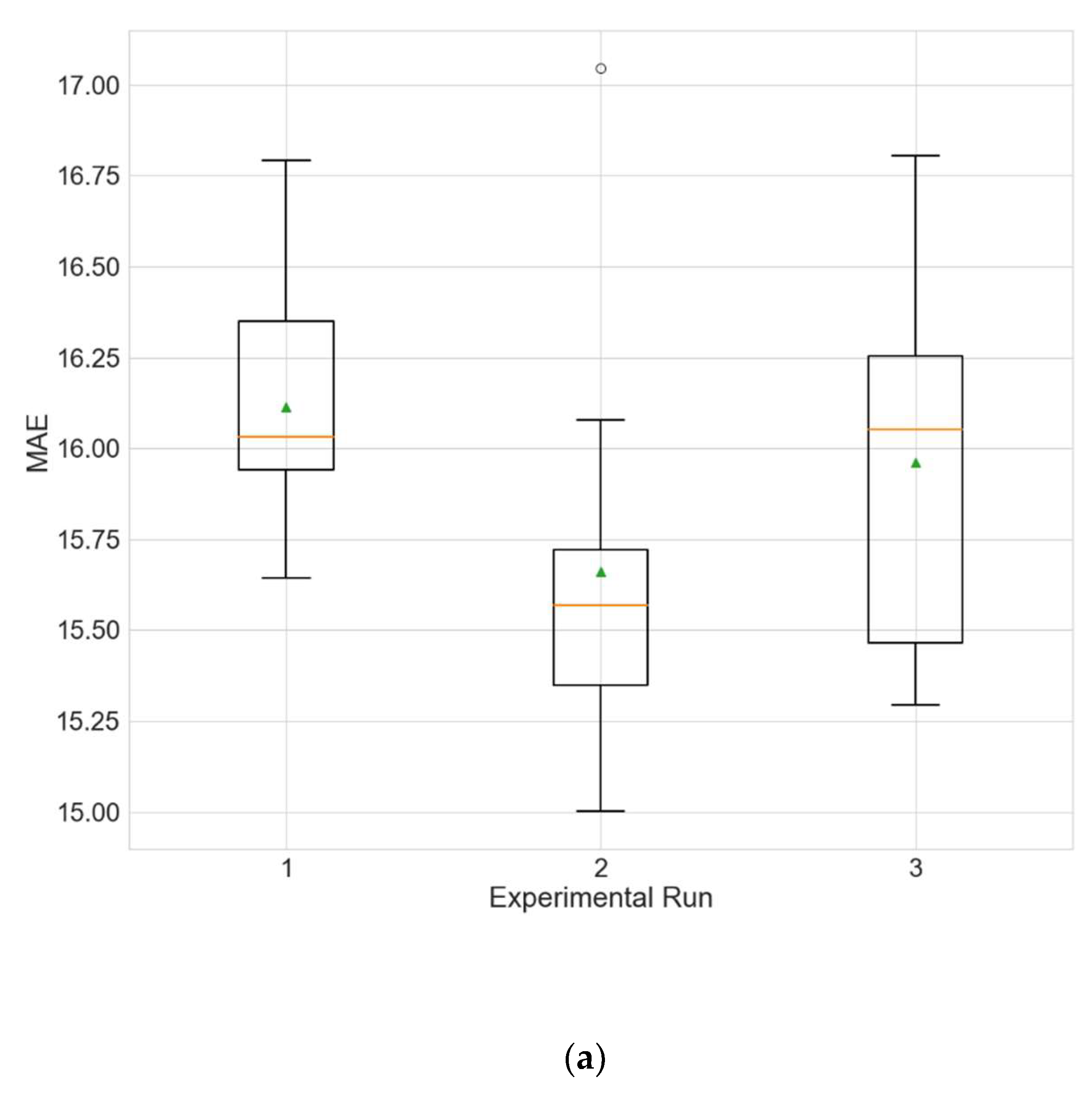
The experimental results for the architecture optimization of the three independent experimental runs for each of the three selected stations are given in
Table 3,
Table 4 and
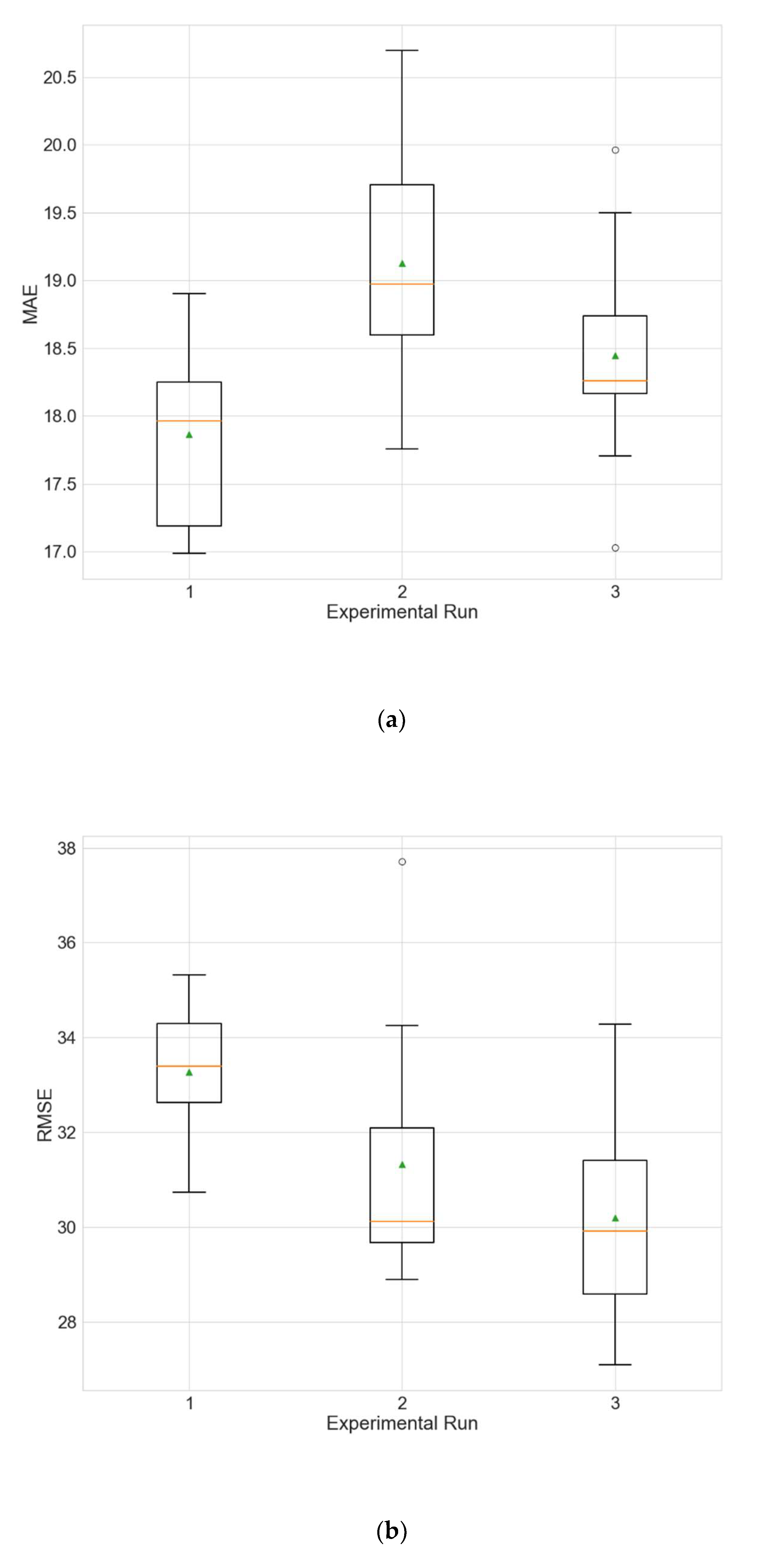
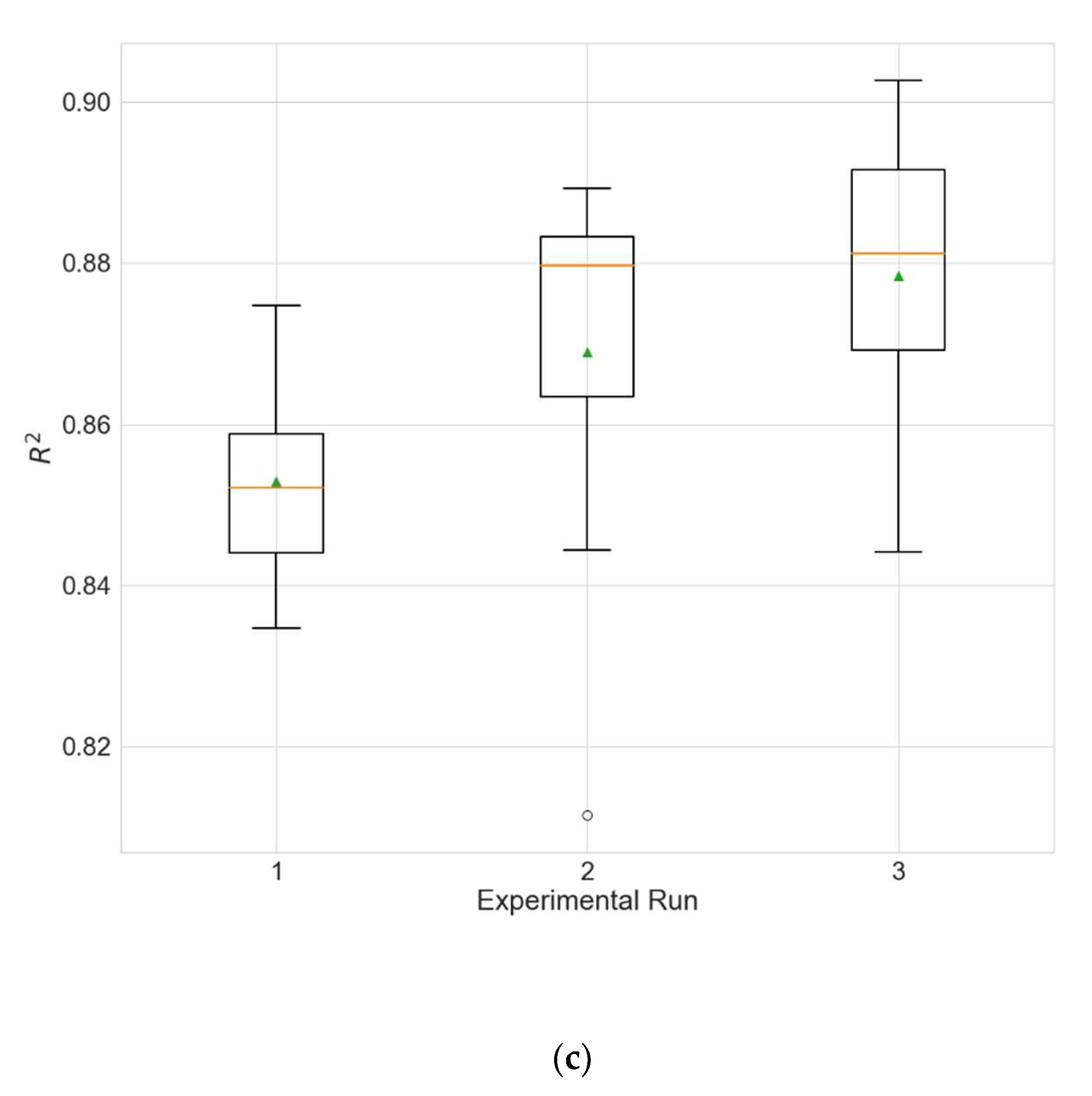
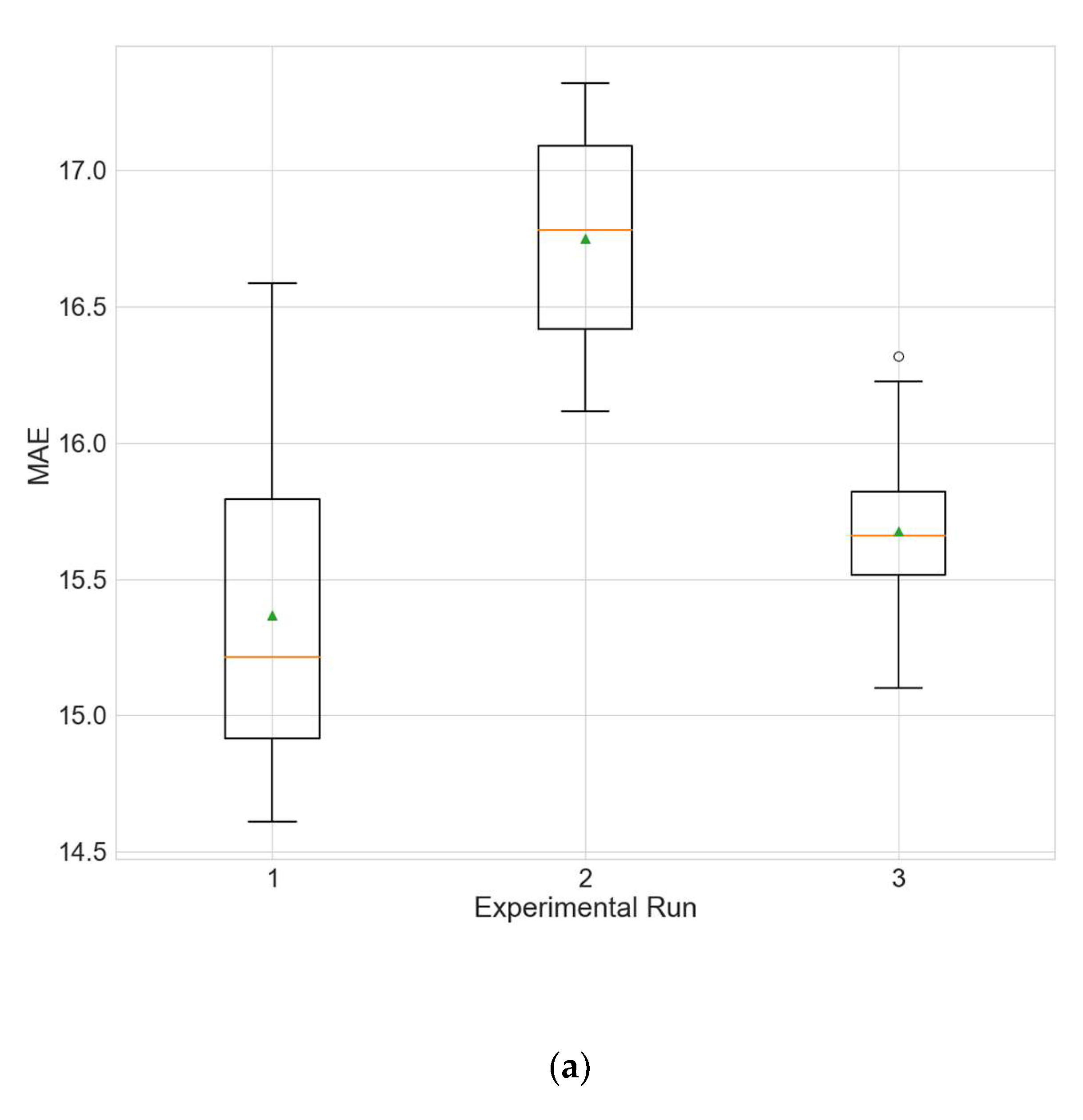
Table 5. Additionally, the distributions of the performance metrics for each station are depicted as boxplots (including the mean shown as a green triangle) in
Figure 3,
Figure 4 and
Figure 5. The results prove that architectures have been successfully found for each of the stations. Moreover, the models trained using the best architecture provide good and consistent results, with the best performance being achieved for station Wanliu.
For comparison of the results achieved by the suggested model, the experimental results for the same three stations from other research studies, using the same data set for PM
2.5 forecasting, are given in
Table 6,
Table 7 and
Table 8. As can be seen, for most of the compared cases, the suggested model does not lag far behind other proposed models according to the MAE, and the results for station Wanliu are comparable to those of some other deep NN models.
The best architectures obtained from each of the three experimental runs for the three selected stations are given in
Table 9,
Table 10 and
Table 11. In most of the cases, a large value of the neighborhood size is used, often 1, i.e., all 12 stations are taken into account, and for Wanliu, in every experimental run, the best architecture uses the maximum size. A large time lag (7 or 8) is also often applied. The results obtained demonstrate the benefits of including spatial information from as many surrounding stations as possible, as well as using as much historical information as possible. Most of the models have one convolutional layer. The convolutional layers most often have a relatively small number of kernels and a small kernel size. In about half of the cases, the convolutional layers are followed by a max-pooling layer. After the convolutional part, one or two LSTM layers are utilized. In about half of the cases, dropout regularization is applied to the LSTM layer using relatively small values of
p—0.1, 0.2 and 0.3.
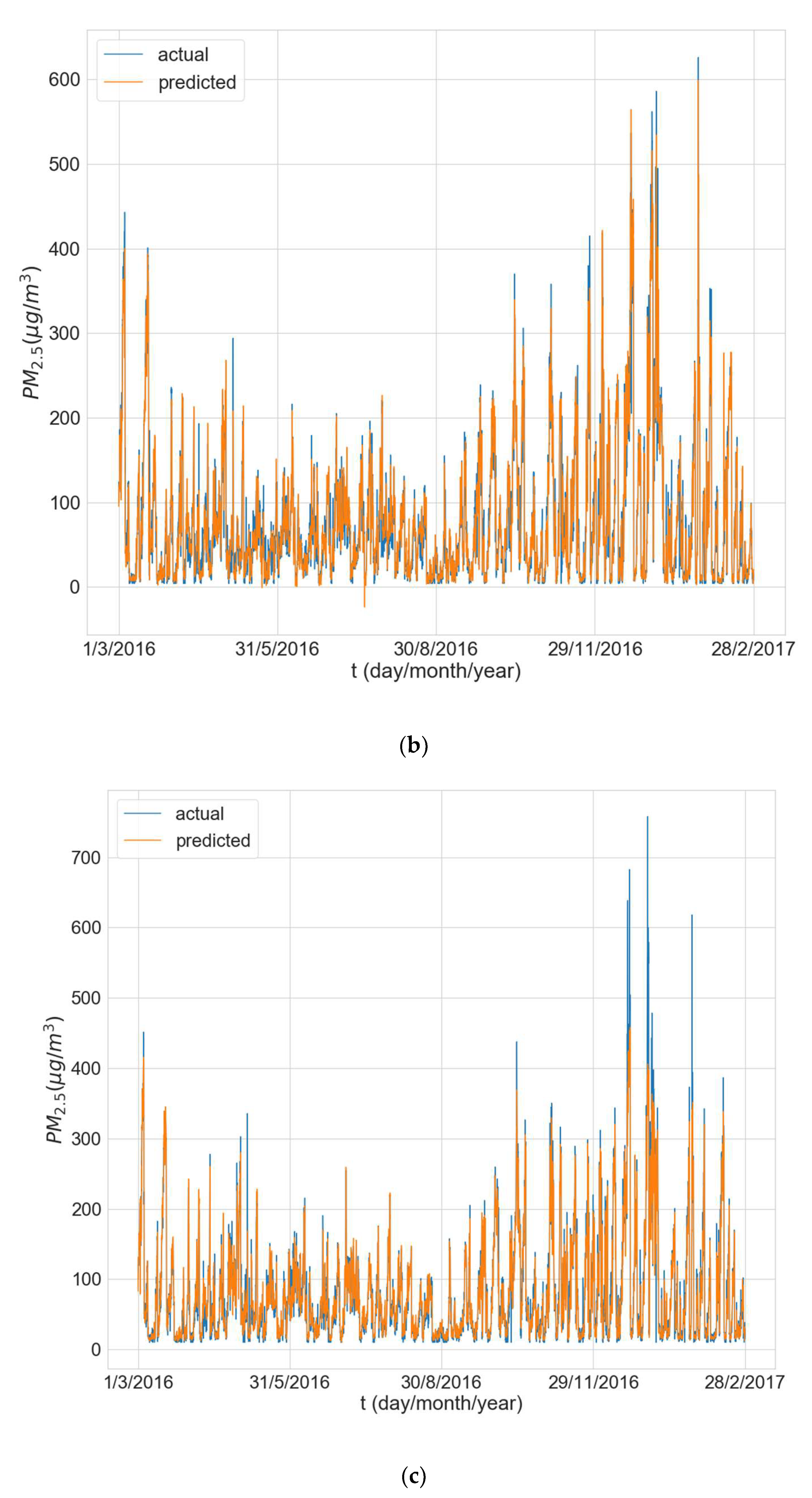
Figure 6 shows the predictions made by the model (averaged over all 10 training runs) over the entire test period vs. the actual values for one of the experimental runs for each of the three stations. The results reveal that the models experience some difficulty in predicting peak concentrations, especially when the peaks are very large, and this is most evident for Changping (
Figure 6c).
4.3. Using the Trained Models to Form Ensembles
Additional experiments have been conducted with the formation of ensembles from the already trained models from the main experiment for architecture optimization. Two different strategies for inclusion in the ensembles are tested; the first uses the models from the 10 training runs of the best architecture obtained from a single optimization run (i.e., an ensemble of models with the same architecture), and the other uses the k best models from the training runs from each experimental run (i.e., an ensemble including models with different architectures). In all cases, the final forecast is obtained by averaging the individual forecasts of the models in the ensemble.
Table 12,
Table 13 and
Table 14 show the results of the ensembles of models with the same architecture and
Table 15,
Table 16 and
Table 17 show the results of the ensemble models with different architectures. As can be seen in all cases, the results improve when using an ensemble of models compared to the individual models from the main experiment (
Table 3,
Table 4 and
Table 5).
With the exception of station Changping, in most cases, an ensemble of k best models from each experimental run gives better results than the strategy of using only models with the same architecture, and the observation is valid for most of the values of k. The comparison between the results of the ensembles with the k best models and the average results (over the three experimental runs) of the ensembles with the same architectures proves that the strategy with the k best models provides better results for all stations.
The overall evaluation of the results indicates that the strategy with the k best models shows better results; for station Dongsi, the best results using that strategy are achieved using k = 3, while for Wanliu they are obtained using k = 8, and for Changping using k = 2. A possible explanation for the higher value of k for Wanliu could be that in the main experiment of architecture optimization, the results for this station are the most consistent, which allows the inclusion of a larger number of models in the ensemble without deteriorating its overall performance.
Comparing the results with those of other research studies using the same data set and predicting PM
2.5 (
Table 6,
Table 7 and
Table 8) demonstrates that for stations Dongsi and Changping, the ensembles have MAE values comparable to most models from [
33], but fall behind according to the RMSE, which means that the models probably make big errors more often. However, on the other hand, it should be noted that the forecasts reported in [
33] are made on a daily basis, while in the current study, the data in the used dataset are gathered hourly, which may offer an explanation for the lower RMSE. For Wanliu, the ensembles surpass the results achieved in [
33] when MAE is used as a metric, and for RMSE the results surpass two of the models—CNN and LSTM, and are slightly behind the other two.
4.4. Validation of the Hybrid Strategy for Missing Data Imputation
Two types of experiments have been performed to validate the proposed strategy for missing data imputation. For the first type, random artificial gaps are generated in the data of each variable (except for the wind direction, which is not included in this experiment), i.e., valid values are removed from randomly selected time intervals. In this way, an additional ~5% of the valid values have been removed for each time series. The gaps sizes are generated using a geometric distribution with p = 0.05. Three strategies are used to fill in the missing values—linear interpolation (LI), the average between the previous value and the average value for the same hour of the same day and month for other years (MTP), and a hybrid approach (HS) that is a combination of the first two. The performance of the strategies is evaluated by R2 only on the simulated gaps, i.e., the original missing values are not taken into account in the evaluation.
Due to the stochastic nature of the gap generation, each strategy is evaluated for each variable by 100 independent runs with different simulated gaps. The Kruskal–Wallis (KW) test is used to check for differences between the strategies. The performances of the three strategies applied to data from the three selected stations (Dongsi, Wanliu and Changping) are presented in
Table 18,
Table 19 and
Table 20. The presented values of
p in the tables have not been corrected for multiple comparisons.
As seen from the results, taking into account the multiple comparisons (11 variables per station), in most cases there is no significant difference between the linear interpolation and the hybrid strategy for the pollutant data (except for ozone, where the hybrid strategy shows better results for two of the stations).
The MTP strategy gives the weakest results for all pollutants except ozone, where it outperforms both linear interpolation and the hybrid strategy. Regarding the meteorological variables, there is no significant difference in the performances of the three strategies for precipitation and wind speed in almost all cases. The MTP strategy performs best compared to the other two for the temperature, and shows the weakest results for pressure and dew point temperature. Compared to the other two strategies, linear interpolation performs worst for temperature, but shows the best results for pressure and dew point temperature. For these variables, the hybrid strategy gives results between those of the other two strategies. Out of all variables, linear interpolation and the hybrid strategy show the weakest results for precipitation and wind speed, which may be due to the complex and chaotic nature of these two phenomena. The results reveal that the hybrid strategy is not inferior to the linear interpolation strategy in most cases, and even surpasses it for some specific variables, such as ozone and temperature. For these variables, the seasonal patterns are characterized by less noise than other variables in the selected data set, and the hybrid strategy manages to account better for the seasonal dependencies.
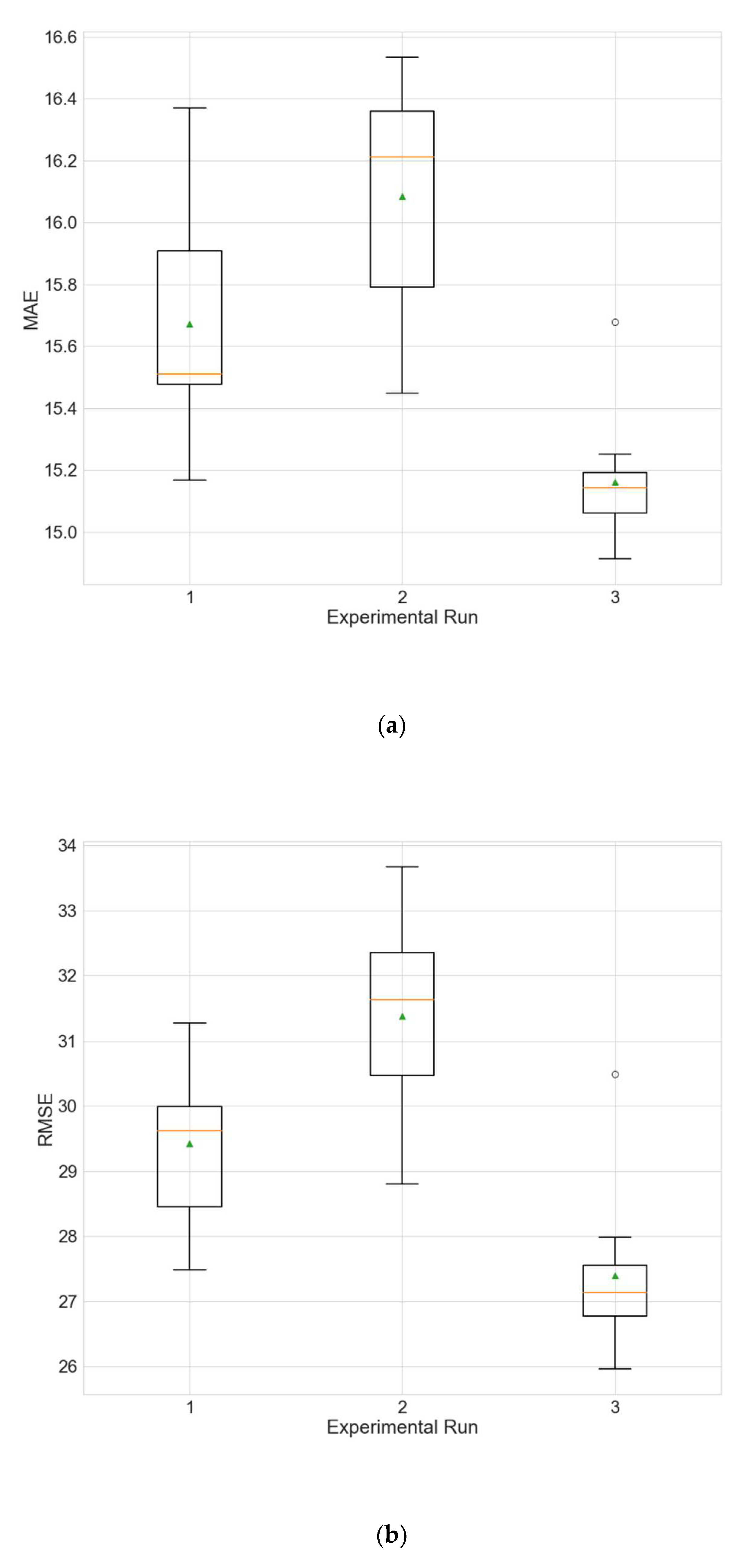
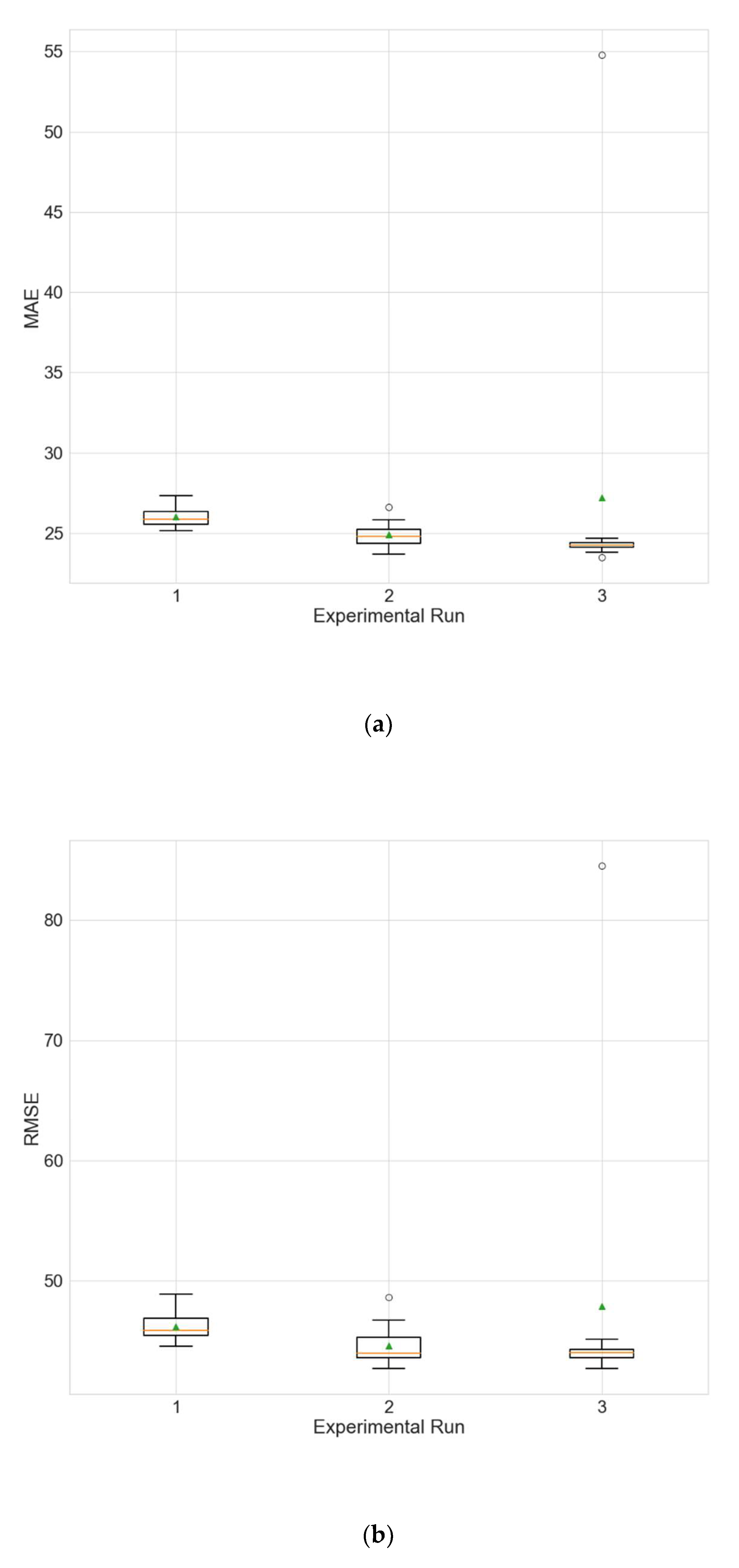
In the second type of experiments, the missing value imputation strategies are evaluated by the performance of models trained with the filled data. Two additional experiments are performed; the first one utilizes models optimized using data imputation by linear interpolation, and the second one utilizes models using data imputation with the MTP strategy. These two experiments are performed using the data from station Changping due to the presence of a larger number of large gaps compared to the data at station Wanliu, which makes Changping a better choice for the testing of the different imputation strategies.
Table 21 and
Table 22 show the results of the two above described experiments.
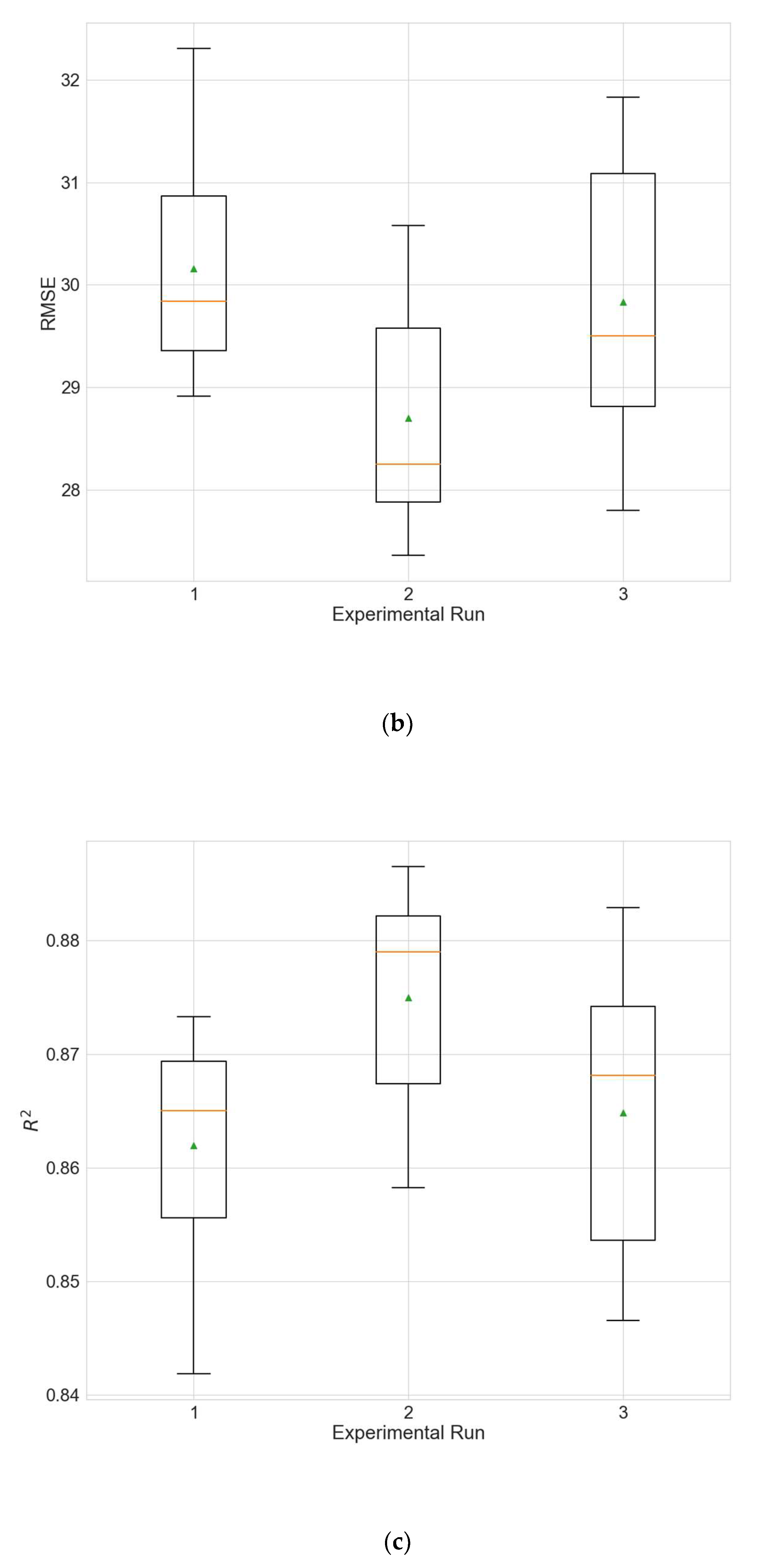
Figure 7 and
Figure 8 depict the distributions of the different performance metrics as a boxplot. The results obtained for the training runs from all experimental runs are compared with those for the main experiment that uses the hybrid strategy (
Table 5) via a KW test. No significant differences can be observed between the hybrid strategy and the linear interpolation (for all metrics
p is above 0.05). A possible explanation for this observation, given the results of the first type of experiments (
Table 18,
Table 19 and
Table 20), is that the variables for which the hybrid strategy has an advantage over linear interpolation (ozone and temperature) are not selected by the initial random search as input variables. The hybrid strategy produces better MAE compared to the MTP strategy (
p = 0.0014).
4.5. Selection of Input Variables by Random Search
In order to evaluate whether the selection of input variables by random searching leads to improved model performance, two additional experiments are accomplished. In the first experiment, the models use only PM
2.5 as input, and in the second experiment all 12 available variables are used as input. The results of these two experiments are given in
Table 23 and
Table 24.
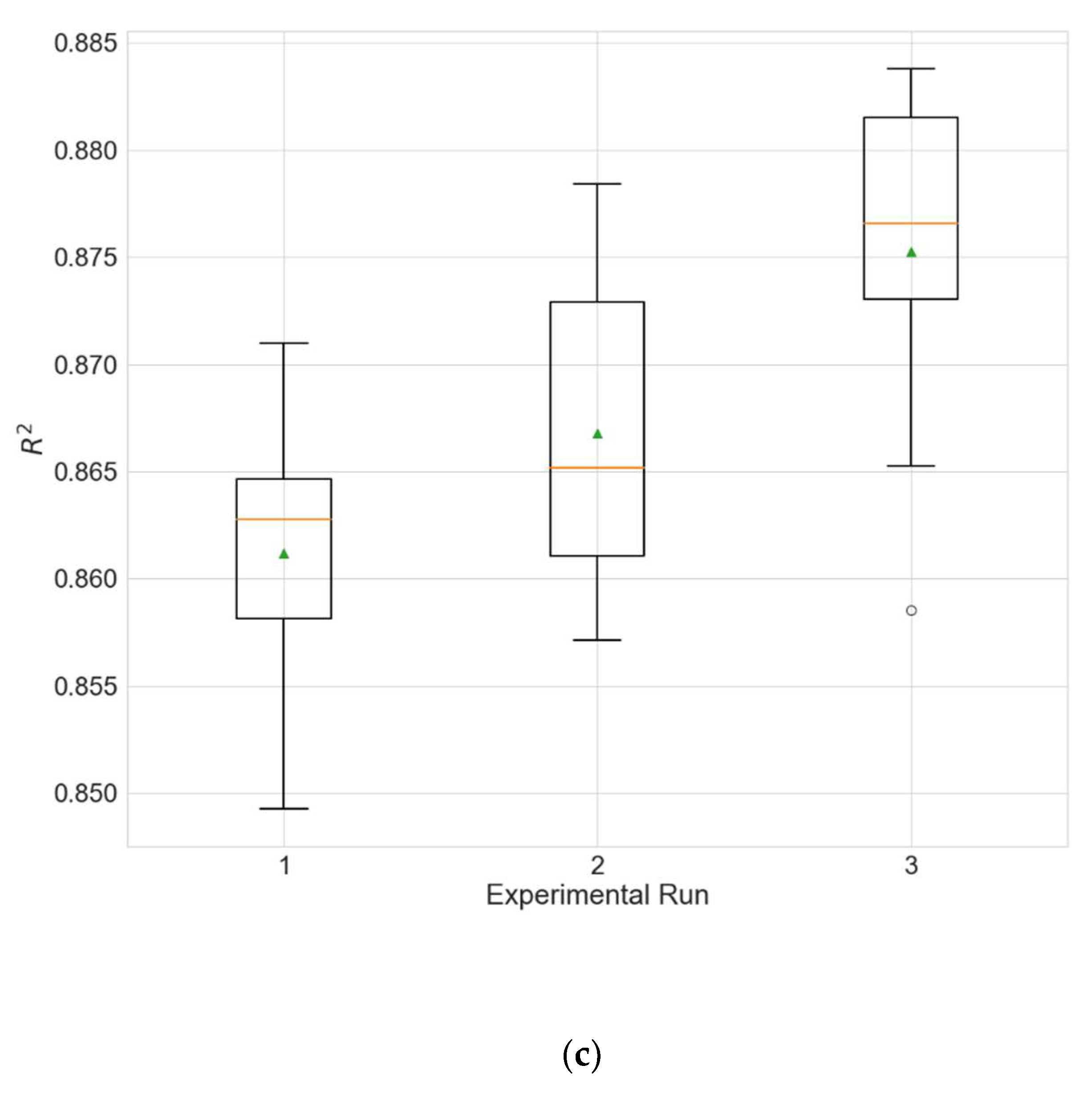
Figure 9 and
Figure 10 show the distributions of the different performance metrics as boxplots. As can be seen, the employment of additional variables besides the historical data of the predicted variable (PM
2.5 in this case) improves the performance of the model (
p much less than 0.05 for all metrics).
The use of all variables produces similar results to those in the main experiment (
Table 4) (
p > 0.5 for all metrics), but the full training of the models takes a significantly longer time (
p = 2.28 × 10
−07, one full training when using all variables takes an average of 1.84 h compared to an average of 0.84 h when the input variables are selected by random search).
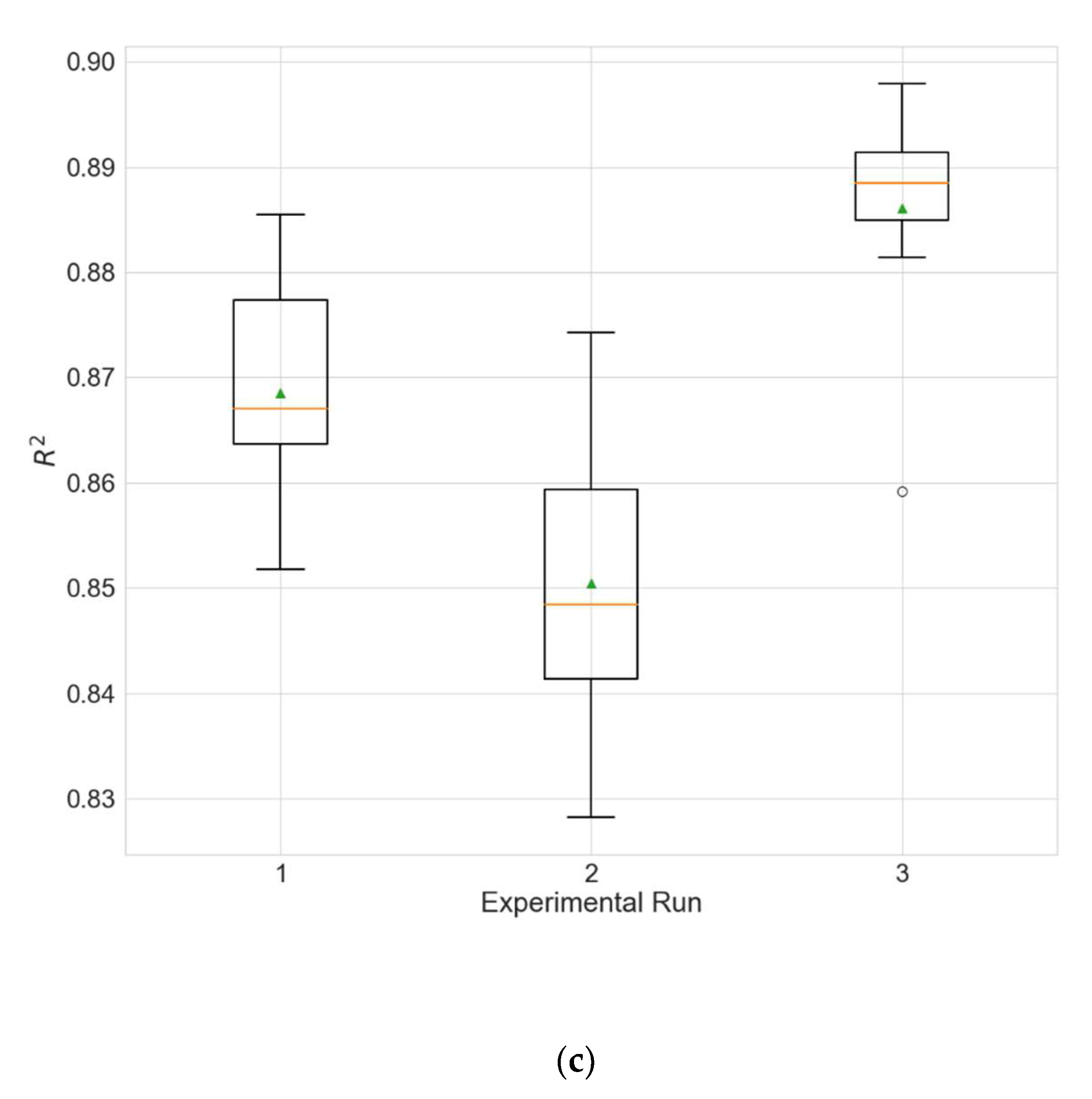
4.6. Inclusion of Spatial Information
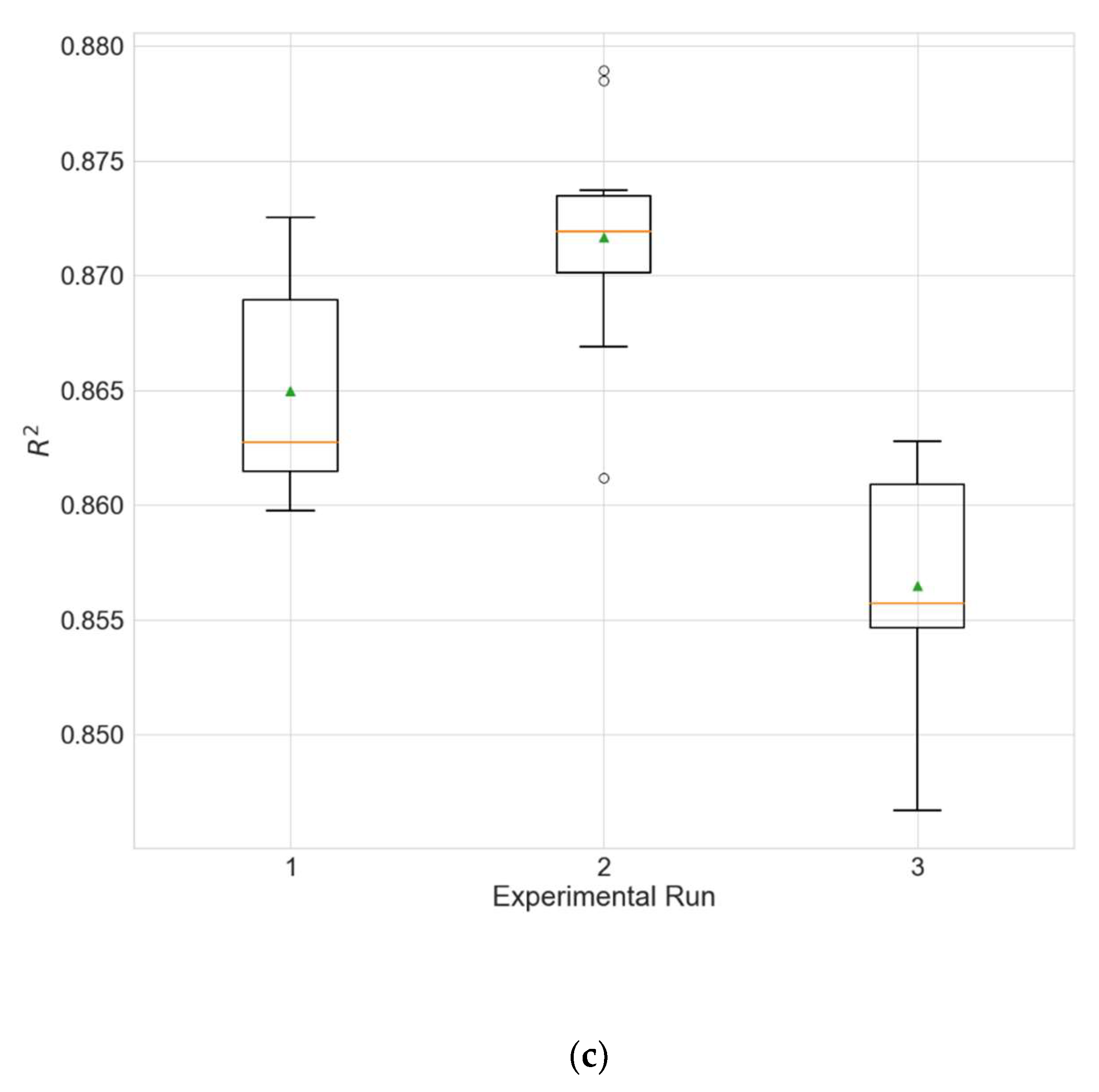
In order to evaluate the influence of the inclusion of spatial information on the performance of the model, an experiment is carried out in which models with a fixed neighborhood size of 0 are evolved, i.e., data from other neighboring stations are not taken into account, and only data from the target station are used. The results are given in
Table 25, and the comparison with the results of the main experiment (
Table 4) confirms that the inclusion of spatial information significantly improves the performance of the model (
p much less than 0.05 for all metrics).
Figure 11 shows the distributions of the different performance metrics as a boxplot.
5. Conclusions
Air pollution has a negative impact on human health and the environment, thus necessitating the development of effective air quality forecasting systems that would allow appropriate measures to be taken in a timely manner.
The suggested deep spatiotemporal model for predicting air pollution with the automatic selection of input variables uses a genetic algorithm for the optimization of network architecture and hyperparameters. In addition, a hybrid strategy for filling in the missing values in time series is proposed. The experimental evaluation using a publicly available data set demonstrates that even with limited computational resources, the evolved architectures provide good and consistent results. The inclusion of the trained models in different ensembles further improves the results, bringing them closer to those obtained with some modern deep models using the same data set, and in some cases even showing superior performance.
The hybrid strategy for missing value imputation has advantages over linear interpolation, especially for data with very clear seasonality, without lagging behind in many other cases. The experimental results also reveal that random searching is a simple and effective strategy for selecting the input variables. Moreover, the inclusion of spatial information significantly improves the predictive results obtained with the models.
Future work will be aimed at improving the spatial component of the model by making the size of the neighborhood window dynamic and dependent on the local meteorological conditions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}