
Fire-YOLO: A Small Target Object Detection Method for Fire Inspection



Abstract
:1. Introduction
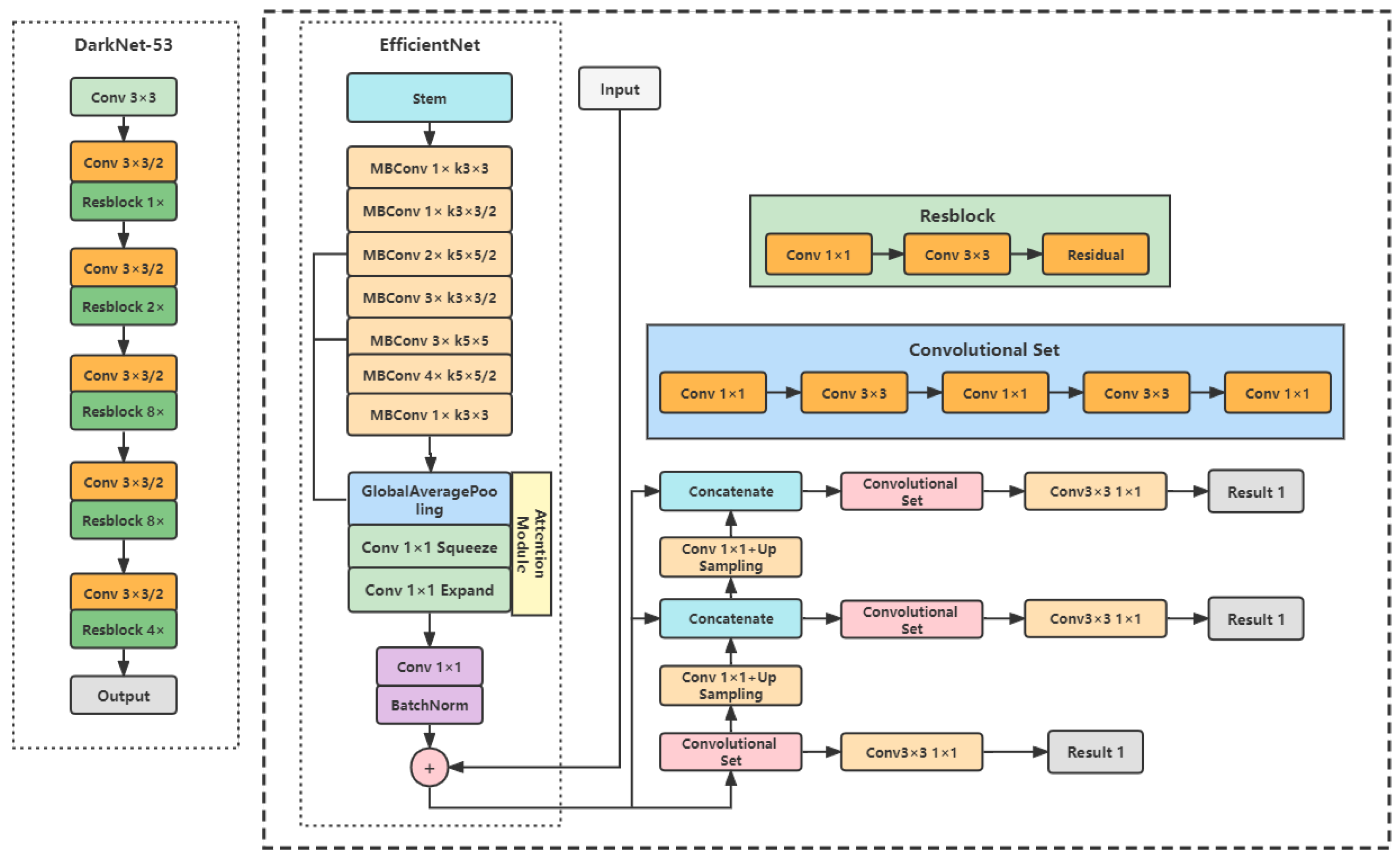
2. Method
2.1. YOLO-V3
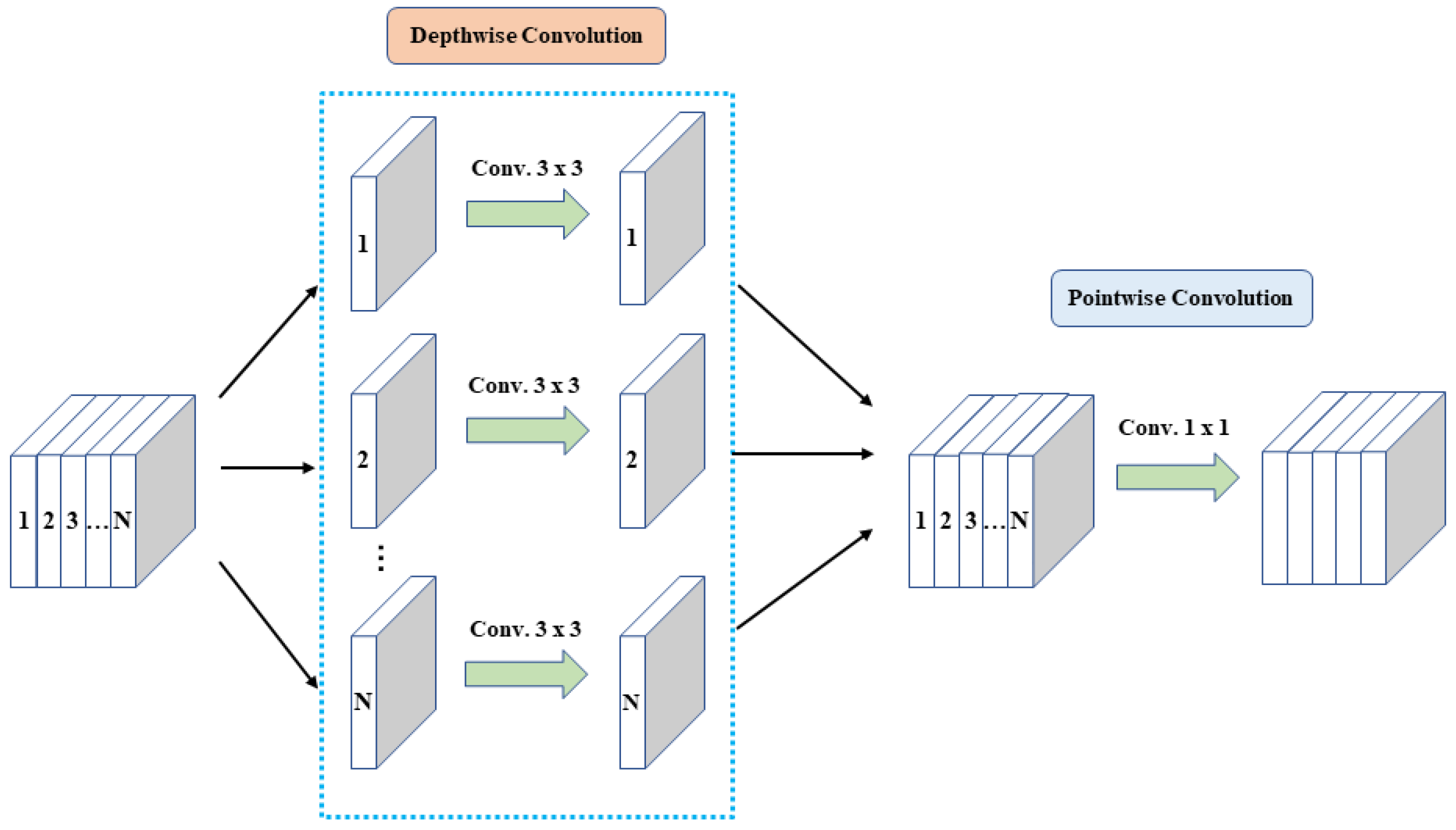
2.2. Fire-YOLO
2.3. Performance Indicators
3. Experimental Analysis
3.1. Dataset Acquisition
3.1.1. Fire Dataset
3.1.2. Small Target Dataset
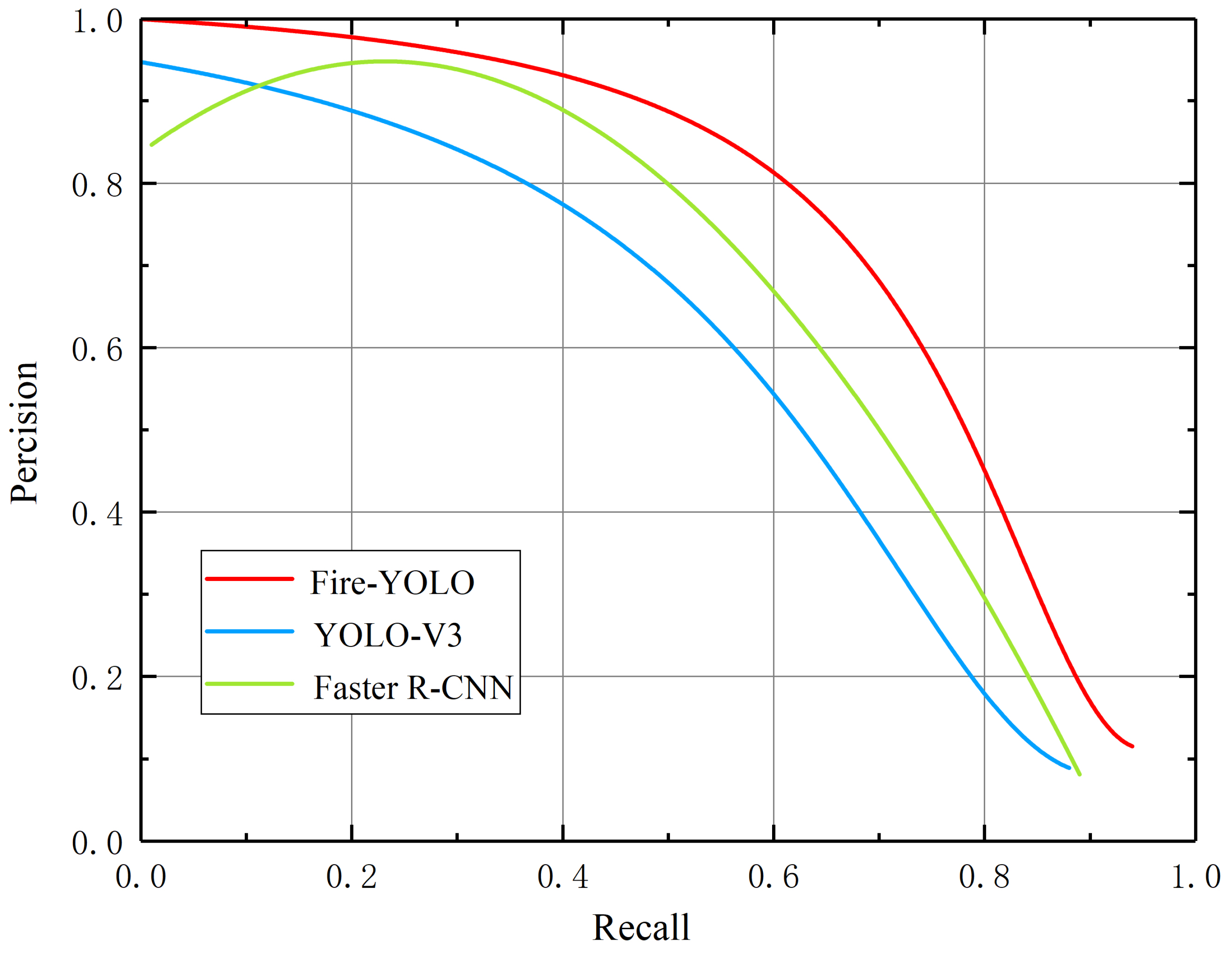
3.2. Algorithm Comparison Analysis
3.3. Detection Performance of Small Targets
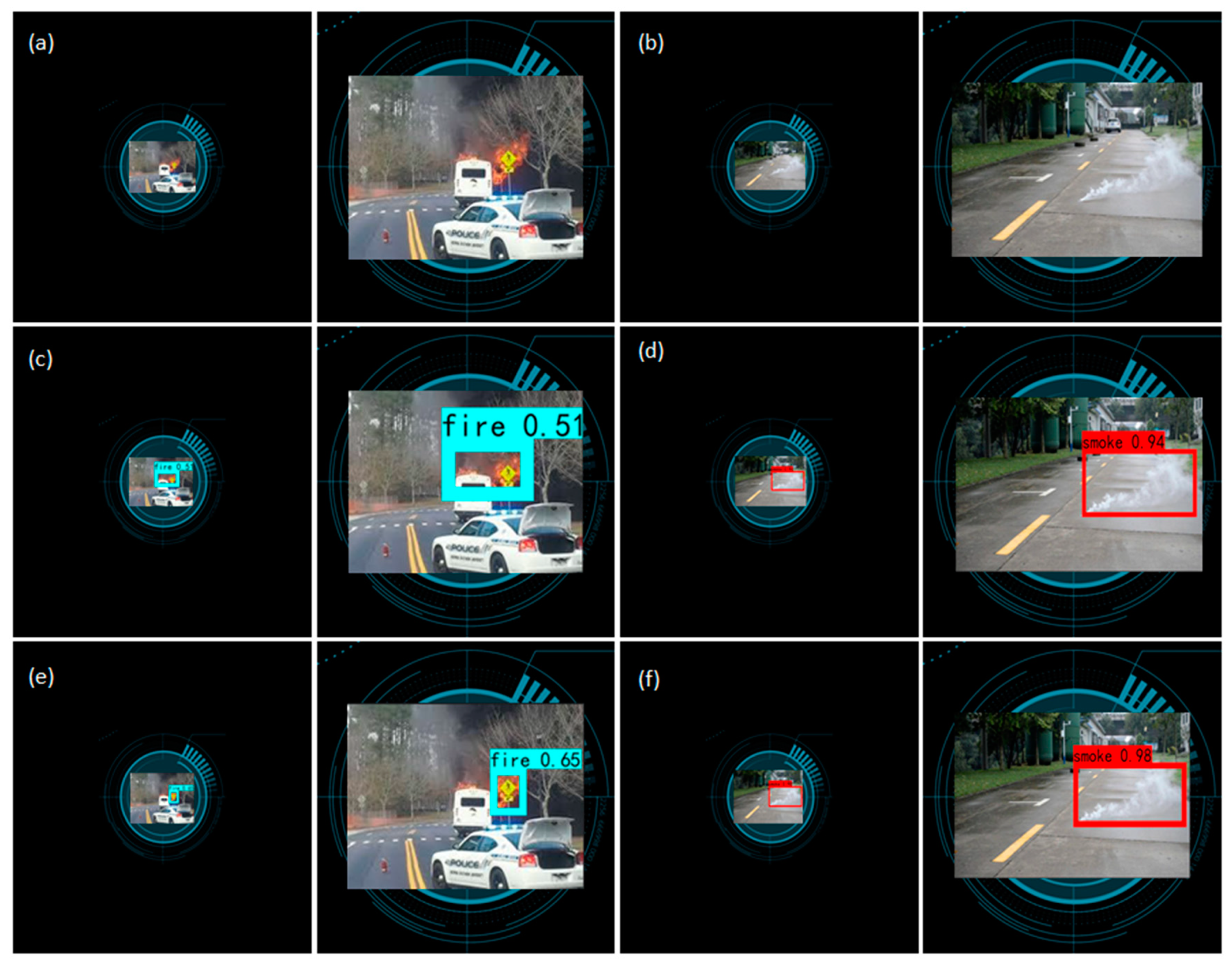
3.4. Detection Performance of Fire-Like and Smoke-Like Targets
3.5. The Detection Performance of the Model under Different Natural Lights
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goyal, S.; Shagill, M.D.; Kaur, A.; Vohra, H.; Singh, A. A YOLO based Technique for Early Forest Fire Detection. Int. J. Innov. Technol. Explor. Eng. (IJITEE) Vol. 2020, 9, 1357–1362. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Premal, C.E.; Vinsley, S.S. Image processing based forest fire detection using YCbCr colour model. In Proceedings of the 2014 International Conference on Circuit, Power and Computing Technologies, Nagercoil, India, 20–21 March 2014; pp. 1229–1237. [Google Scholar]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef] [PubMed]
- Habiboğlu, Y.H.; Günay, O.; Çetin, A.E. Covariance matrix-based fire and flame detection method in video. Mach. Vis. Appl. 2012, 23, 1103–1113. [Google Scholar] [CrossRef]
- Lascio, R.D.; Greco, A.; Saggese, A.; Vento, M. Improving fire detection reliability by a combination of videoanalytics. In International Conference Image Analysis and Recognition; Springer: Cham, Switzerland, 2014; pp. 477–484. [Google Scholar]
- Zhao, C.; Feng, Y.; Liu, R.; Zheng, W. Application of Lightweight Convolution Neural Network in Cancer Diagnosis. In Proceedings of the 2020 Conference on Artificial Intelligence and Healthcare, Taiyuan, China, 23–25 October 2020; pp. 249–253. [Google Scholar]
- He, L.; Gong, X.; Zhang, S.; Wang, L.; Li, F. Efficient attention based deep fusion CNN for smoke detection in fog environment—ScienceDirect. Neurocomputing 2021, 434, 224–238. [Google Scholar] [CrossRef]
- Gagliardi, A.; Villella, M.; Picciolini, L.; Saponara, S. Analysis and Design of a Yolo like DNN for Smoke/Fire Detection for Low-cost Embedded Systems. In International Conference on Applications in Electronics Pervading Industry, Environment and Society; Springer: Cham, Switzerland, 2020; pp. 12–22. [Google Scholar]
- Jindal, P.; Gupta, H.; Pachauri, N.; Sharma, V.; Verma, O.P. Real-Time Wildfire Detection via Image-Based Deep Learning Algorithm. In Soft Computing: Theories and Applications. Advances in Intelligent Systems and Computing; Sharma, T.K., Ahn, C.W., Verma, O.P., Panigrahi, B.K., Eds.; Springer: Singapore, 2021; Volume 1381. [Google Scholar] [CrossRef]
- Zhang, W.; Wei, J. Improved YOLO v3 Fire Detection Algorithm for Embedded DenseNet Structure and Hollow Convolutional module. J. Tianjin Univ. (Nat. Sci. Eng. Technol. Ed.) 2020, 53, 976–983. [Google Scholar]
- Li, J.; Guo, S.; Kong, L.; Tan, S.; Yuan, Y. An improved YOLOv3-tiny method for fire detection in the construction industry. In E3S Web of Conferences; EDP Sciences: Les Ulis, France, 2021; p. 253. [Google Scholar]
- Yue, C.; Ye, J. Research on Improved YOLOv3 Fire Detection Based on Enlarged Feature Map Resolution and Cluster Analysis. J. Phys. Conf. Ser. 2021, 1757, 012094. [Google Scholar] [CrossRef]
- Qin, Y.Y.; Cao, J.T.; Ji, X.F. Fire Detection Method Based on Depthwise Separable Convolution and YOLOv3. Int. J. Autom. Comput. 2021, 18, 300–310. [Google Scholar] [CrossRef]
- Cheng, X.; Qiu, G.; Jiang, Y.; Zhu, Z. An improved small object detection method based on Yolo V3. Pattern Anal. Appl. 2021, 24, 1347–1355. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems 28, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Robert Singh, A.; Athisayamani, S.; Sankara Narayanan, S.; Dhanasekaran, S. Fire Detection by Parallel Classification of Fire and Smoke Using Convolutional Neural Network. In Computational Vision and Bio-Inspired Computing; Springer: Singapore, 2021; pp. 95–105. [Google Scholar]
- Wang, Z.; Zhang, H.; Hou, M.; Shu, X.; Wu, J.; Zhang, X. A Study on Forest Flame Recognition of UAV Based on YOLO-V3 Improved Algorithm. In Recent Advances in Sustainable Energy and Intelligent Systems (LSMS 2021, ICSEE 2021); Communications in Computer and Information Science; Li, K., Coombs, T., He, J., Tian, Y., Niu, Q., Yang, Z., Eds.; Springer: Singapore, 2021; Volume 1468. [Google Scholar] [CrossRef]
- Hou, F.; Zhang, Y.; Fu, X.; Jiao, L.; Zheng, W. The Prediction of Multistep Traffic Flow Based on AST-GCN-LSTM. J. Adv. Transp. 2021, 2021, 9513170. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, J.; Wang, R.; Fang, F.; Zheng, W. Multi-Step Sequence Flood Forecasting Based on MSBP Model. Water 2021, 13, 2095. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; p. 2. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. arXiv 2018, arXiv:1801.04381v2. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Wey, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhao, C.; Zheng, W. Fast Traffic Sign Recognition Algorithm Based on Multi-scale Convolutional Neural Network. In Proceedings of the 2020 Eighth International Conference on Advanced Cloud and Big Data (CBD), Taiyuan, China, 5–6 December 2020; pp. 125–130. [Google Scholar]
- Wang, R.; Fang, F.; Cui, J.; Zheng, W. Learning self-driven collective dynamics with graph networks. Sci. Rep. 2022, 12, 500. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Zhang, S.; Xu, N. Jamming of packings of frictionless particles with and without shear. Chin. Phys. B 2018, 27, 066102. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Qian, K.; Jing, K.; Yang, J.; Yu, H. Fire Detection based on Convolutional Neural Networks with Channel Attention. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 3080–3085. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Proc. 2021, 18, 889–900. [Google Scholar] [CrossRef]
- Li, W.; Yu, Z. A Lightweight Convolutional Neural Network Flame Detection Algorithm. In Proceedings of the 2021 IEEE 11th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 18–20 June 2021; pp. 83–86. [Google Scholar]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks Based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Luo, D.; Wang, D.; Guo, H.; Zhao, X.; Gong, M.; Ye, L. Detection method of tubular target leakage based on deep learning. In Proceedings of the Seventh Symposium on Novel Photoelectronic Detection Technology and Application, Kunming, China, 5–7 November 2020; Volume 11763, p. 1176384. [Google Scholar]
- Mumuni, A.; Mumuni, F. CNN architectures for geometric transformation-invariant feature representation in computer vision: A review. SN Comput. Sci. 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Kayhan, O.S.; Gemert, J.C. On translation invariance in cnns: Convolutional layers can exploit absolute spatial location. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14274–14285. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Labeled Name | Predicted | Confusion Matrix |
|---|---|---|
| Positive | Positive | TP |
| Positive | Negative | FN |
| Negative | Positive | FP |
| Negative | Negative | TP |
| Dataset | Training Set | Validation Set | Test Set | Total Number |
|---|---|---|---|---|
| Number of images | 13,873 | 3964 | 1982 | 19,819 |
| Number of annotated samples | 28,031 | 8009 | 4004 | 40,044 |
| Faster R-CNN | YOLO-V3 | Fire-YOLO | |
|---|---|---|---|
| Precision | 58.17% | 88.92% | 91.50% |
| Recall | 81.19% | 55.65% | 59.62% |
| F1 | 51.50% | 68.50% | 73.00% |
| mAP | 67.08% | 73.69% | 80.23% |
| Model Size | 108 MB | 234 MB | 62 MB |
| Faster R-CNN | YOLO-V3 | Fire-YOLO | |
|---|---|---|---|
| Precision | 29.83% | 53.71% | 75.48% |
| Recall | 15.70% | 29.50% | 27.29% |
| mAP | 10.36% | 28.10% | 39.50% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability 2022, 14, 4930. https://doi.org/10.3390/su14094930
Zhao L, Zhi L, Zhao C, Zheng W. Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability. 2022; 14(9):4930. https://doi.org/10.3390/su14094930
Chicago/Turabian StyleZhao, Lei, Luqian Zhi, Cai Zhao, and Wen Zheng. 2022. "Fire-YOLO: A Small Target Object Detection Method for Fire Inspection" Sustainability 14, no. 9: 4930. https://doi.org/10.3390/su14094930
APA StyleZhao, L., Zhi, L., Zhao, C., & Zheng, W. (2022). Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability, 14(9), 4930. https://doi.org/10.3390/su14094930