
Identification of Potential Valid Clients for a Sustainable Insurance Policy Using an Advanced Mixed Classification Model



Abstract
:1. Introduction
2. Literature Review
2.1. Life Insurance
2.2. Data Mining Technology
2.3. Attribute Selection Method
2.4. Data Discretization Technology
2.5. Different and Important Classification Algorithm
- Decision tree: Decision tree is a very popular classification and prediction tool used for data analysis and decision-making assistance; it uses the graph of a tree and the possible results to form a special tree structure for the establishment of a target decision model. Decision tree is used to classify a large number of documents in a regular way that can clearly explain the classification [25]. In this study, the decision tree algorithm is used as a prediction tool for the repurchase, referral, and renewal of insurance premiums, mainly presented as a decision tree graph. Trees in this study mainly include J48 [26], LMT [27], and REP Tree [28] classifiers.
- Bayes: Naïve Bayes (NB) is a statistical classification method. Graphical models are used to represent relationships between attributes [29]. Possible values can be classified and calculated to achieve a complete and reasonable prediction. Bayes in this study include Bayes Net [30] and Naïve Bayes classifiers.
- Function: Logistic regression is one of the models of discretization choice methods, which belongs to the category of multivariate analysis and is a common method of statistical empirical analysis in sociology, biostatistics, quantitative psychology, econometrics, and marketing [31]. Function in this study includes SMO, SGD, Simple Logistic, and SGD Text.
- Lazy: A multi-classifier integration algorithm based on dynamic programming. Lazy is relatively gentle and better than other methods in terms of dynamic adaptability to concepts. It can reasonably adjust the proportion of each classifier in the prediction and achieve better results. Different learning algorithms can also be integrated to complete the new training data. Lazy in this study includes IBK [32], K-Star, and LWL.
- Meta: Group learning. Meta in this study mainly includes Stacking, Vote, and AdaBoostM1 [33].
- Rule: Rule contains a variety of different algorithms, such as JRip, OneR, PART, ZeroR, Decision Table, etc., which have different calculation methods and can be widely used in classification methods of different industries.
- Mise: Other classifiers different from the above six categories belong to Mise, which is represented by InputMappedClassifier in this study.
3. Research Methods
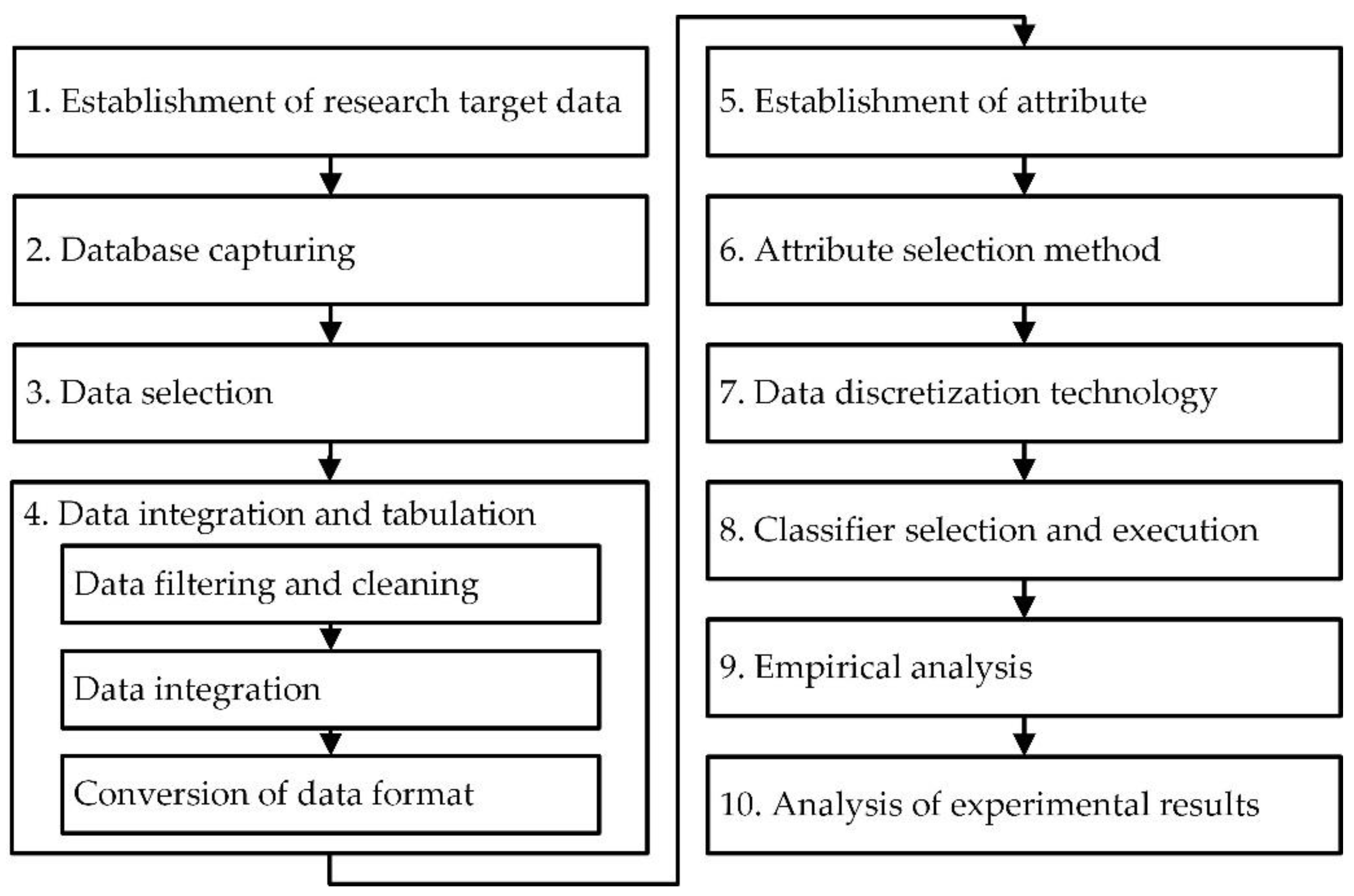
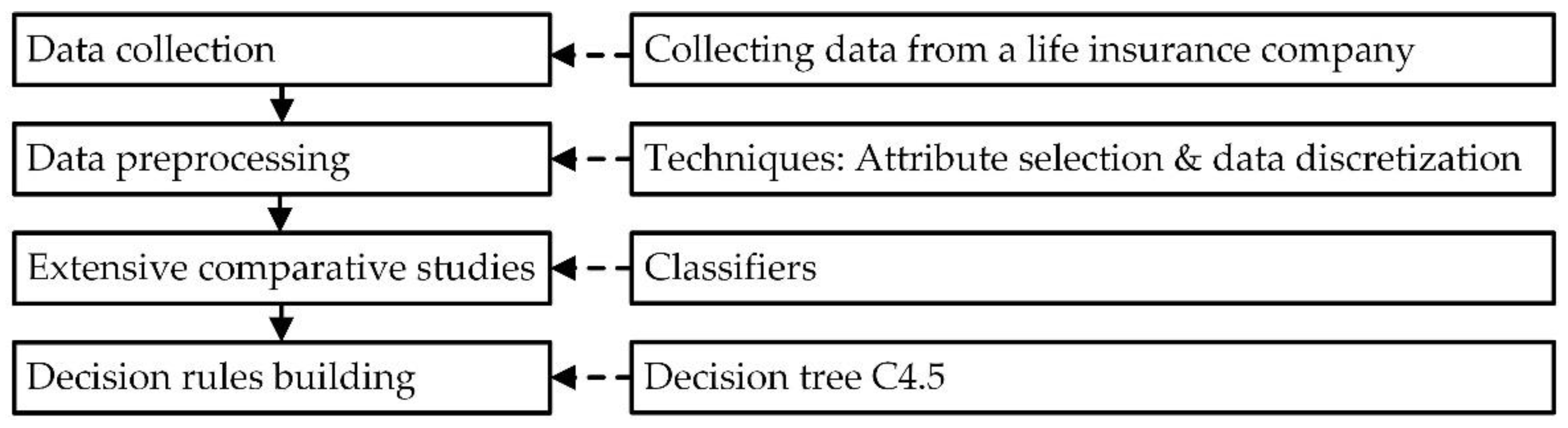
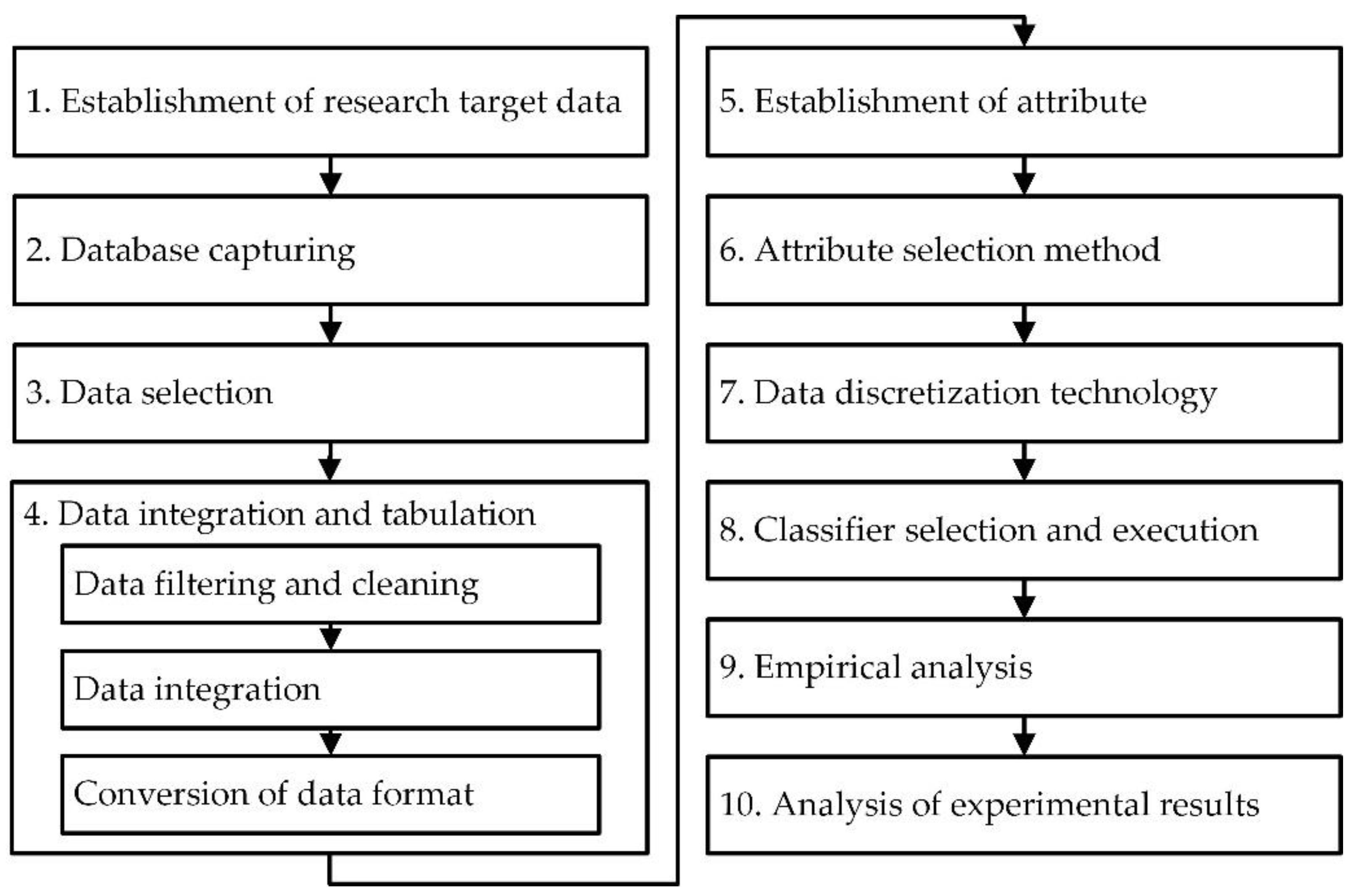
3.1. Research Framework
3.2. Research Steps of Proposed Mixed Classification Model Algorithm and Example Illustration
- Data filtering and cleaning: Relevant sub-steps include (a) selecting client and policy data from the database, deleting personal privacy data such as name and ID card, and verifying similar repeated data; (b) the number of policies, which was numerical, and the types of insurance, which were classified as life insurance, critical illness insurance, investment insurance, and savings insurance; (c) the total number of policies and the amount of insurance; (d) recording the number of valid policies; (e) calculating time to first purchase; (f) removing redundant, incomplete, or similar repeated conditional attribute data to maintain the integrity and validity of the data and thus improve the accuracy of data mining technology.
- Data integration: Continuing the above steps to check and verify the data to ensure data correctness, and check and confirm whether the setting of each conditional field in the Excel spreadsheet was correct, such as age, total premium, and total insurance amount. Interestingly, because the accuracy and completeness of data are positively correlated with the quantity and quality of data in the data mining, this affects the research results of data mining. Therefore, this step is critical.
- Conversion of data format: According to the data files after integration, 300 useful data points were confirmed and converted into the format files required for the experimental data of this study for further data analysis.
- Conditional attributes: Gender, education background, marriage, job nature, whether the spouse is employed, family salary structure, payment method, amount of life insurance, insurance payer, amount of critical illness insurance, whether there is an investment insurance policy, amount of long-term care insurance, premium of long-term care insurance, total number of purchased insurance policies, number of valid policies, time to first purchase, total premium of personal annual valid insurance policy, amount of life insurance/10,000, and total amount of life insurance (including long-term care insurance). Detailed information and codes are shown in Table 1.
- Decision attribute: Three different categories, including whether to repurchase a new insurance policy, whether to introduce new clients, and whether to pay the renewal insurance premium. The binary classification method was used to test and verify the experimental research data. The detailed data are shown in Table 2. In Table 2, “Y” refers to yes, and “N” refers to no.
- Coding: The codes X1, X2, X3...X22 in this study represent the conditional attributes and decision attributes.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Conditional Attribute | Reference | Data type | Code |
|---|---|---|---|---|
| 1 | Gender | [34] | Text | X1 |
| 2 | Education background | [34] | Text | X2 |
| 3 | Marriage | [35] | Text | X3 |
| 4 | Job nature | [36] | Text | X4 |
| 5 | Whether the spouse is employed | * [By expert] | Text | X5 |
| 6 | Family salary structure | * [By expert] | Text | X6 |
| 7 | Payment method | * [By expert] | Numeric | X7 |
| 8 | Amount of life insurance | [37] | Numeric | X8 |
| 9 | Insurance payer | * [By expert] | Text | X9 |
| 10 | Amount of critical illness insurance | [38] | Numeric | X10 |
| 11 | Whether there is an investment insurance policy | [39] | Text | X11 |
| 12 | Amount of long-term care insurance | [40] | Numeric | X12 |
| 13 | Premium of long-term care insurance | [40] | Numeric | X13 |
| 14 | Total number of purchased policies | * [By expert] | Numeric | X14 |
| 15 | Number of valid insurance policies | * [By expert] | Numeric | X15 |
| 16 | Time to first purchase | * [By expert] | Numeric | X16 |
| 17 | Total premium of personal annual valid insurance policy | * [By expert] | Numeric | X17 |
| 18 | Amount of life insurance/10,000 | [37] | Numeric | X18 |
| 19 | Total amount of life insurance (including long-term care insurance) | [41,42,43,44] | Numeric | X19 |
| Attribute | Classification |
|---|---|
| Whether to repurchase the new insurance policy (X20) | Y and N |
| Whether to introduce new clients (X21) | Y and N |
| Whether to pay the renewal insurance premium (X22) | Y and N |
4. Analysis of Empirical Results
- Advanced Step 1: Sample data were tested for the decision to repurchase a new insurance policy or not (X20) as an example. The data mining ratio was 67% and 33%; the 300 data samples were divided into 1–100, 1–150, 1–200, 1–250 and 1–300, and 23 types of classifiers were used for analysis. The results are shown in Table 4. It can be seen from Table 4 that the accuracy of most classifiers is low when the amount of data is larger. When the number of sample data is small not all data attributes can be shown, and the presented ratio will be more concentrated.
| Classify | Classifier | 1–100 | 1–150 | 1–200 | 1–250 | 1–300 |
|---|---|---|---|---|---|---|
| Tree | J48 | 90.9091 | 81.6327 | 89.3939 | 81.7073 | 75.7576 |
| LMT | 90.9091 | 73.4694 | 84.8485 | 78.0488 | 78.7879 | |
| REP Tree | 75.7576 | 79.5918 | 74.2424 | 78.0488 | 63.6364 | |
| Bayes | Bayes Net | 90.9091 | 83.6735 | 92.4242 | 79.2683 | 84.8485 |
| Naïve Bayes | 84.8485 | 79.5918 | 80.3030 | 56.0976 | 59.5960 | |
| Function | Logistic | 87.8788 | 81.6327 | 72.7273 | 79.2683 | 79.7980 |
| Simple Logistic | 90.9091 | 73.4694 | 84.8485 | 78.0488 | 80.8081 | |
| SGD | 75.7576 | 79.5918 | 81.8182 | 78.0488 | 78.7879 | |
| SGD Text | 66.6667 | 61.2245 | 57.5758 | 63.4146 | 61.6162 | |
| SMO | 81.8182 | 73.4694 | 80.3030 | 71.9512 | 70.7071 | |
| Lazy | IBK | 63.6364 | 75.5102 | 66.6667 | 69.5122 | 63.6364 |
| K-Star | 75.7576 | 79.5918 | 65.1515 | 64.6341 | 63.6364 | |
| LWL | 90.9091 | 81.6327 | 87.8788 | 81.7073 | 84.8485 | |
| Meta | Stacking | 66.6667 | 61.2245 | 57.5758 | 63.4146 | 61.6162 |
| Vote | 66.6667 | 61.2245 | 57.5758 | 63.4146 | 61.6162 | |
| AdaBoostM1 | 90.9091 | 69.3878 | 86.3636 | 81.7073 | 83.8384 | |
| Bagging | 84.8485 | 81.6327 | 90.9091 | 82.9268 | 80.8081 | |
| Rule | JRip | 90.9091 | 81.6327 | 86.3636 | 81.7073 | 76.7677 |
| OneR | 90.9091 | 85.7143 | 93.9394 | 81.7073 | 84.8485 | |
| PART | 78.7879 | 75.5102 | 80.3030 | 75.6098 | 76.7677 | |
| ZeroR | 66.6667 | 61.2245 | 57.5758 | 63.4146 | 61.6162 | |
| Decision Table | 87.8788 | 85.7143 | 86.3636 | 82.9268 | 75.7576 | |
| Mise | InputMappedClassifier | 66.6667 | 61.2245 | 57.5758 | 63.4146 | 61.6162 |
- 2.
- Advanced Step 2: Take the example of whether to repurchase a new insurance policy (X20). According to past academic studies, J48 had the best performance, so J48 was selected as an example to find the main conditional attributes. J48 analysis data took the disassembly in proportion (1–100, 1–150, 1–200, 1–250, and 1–300) for data evaluation analysis from Model A to Model E and identified the conditional attributes. Since the attributes of Models C–J were the same, Model A and Model B were selected as examples. Data analysis content is shown in Table 5. It can be seen from Table 5 that the accuracy of Model B–E is 84.8485% better than that of Model A without attribute selection when testing the conditional attributes after attribute selection. Through the decision tree analysis of Model A, we discerned that these factors might be affected: X1, X4, X6, X9, X12, X13, X14, X16, and X19. Accuracy was 83.8384% based on nine factors that might be affected in 300 data samples, which was 8.0808% higher than the original 300 data sample’s accuracy of 75.7576%. This indicates that the accuracy of the test with nine important conditional attributes is higher than 75.7576% without attribute selection. As shown Table 6, X14 was the most important conditional attribute, with X12 appearing three times, X1 and X4 twice, and X6, X9, X13, X16, and X19 each appearing once. According to the decision tree analysis of Model B, the possible influencing factors were X2, X6, X12, X13, X14, X15, X16, X18, and X19. Based on nine conditional attributes of 300 data samples, the accuracy of possible influencing factors was 83.8384%, which was 1.0101% lower than the original 300 data sample’s accuracy of 84.8485%. Table 7 lists a total of nine important attributes: X2, X6, X12, X13, X14, X15, X16, X18, and X19.
- 3.
- Advanced Step 3: Take the example of whether to repurchase a new insurance policy (X20). The 300 research data points adopted disassembly in five proportional models. Ten different ratios (training value/test value: 50/50, 55/45, 60/40, 65/45, 70/30, 75/25, 80/20, 85/15, 90/10, and 95/5) of 23 classifiers in seven categories were used for evaluation tests, as shown in Table 8. It can be seen from Table 8 that Model E and Model D have the same accuracy, indicating that the sequence of attribute selection and data discretization does not affect accuracy evaluation, so Model D also represents Model E. The four models have the same maximum and minimum accuracies and difference values of 10 proportions.
- 4.
- Advanced Step 4: Take the example of whether to introduce new clients (X21). For the 300 research data samples, Models F J of 23 classifiers in seven categories were used for cross-validation accuracy evaluation, as shown in Table 9. It can be seen from Table 9 that the accuracy of Model J and Model I are the same, indicating that attribute selection and data discretization sequence do not affect accuracy evaluation, so Model I also represents Model J.
- 5.
- Advanced Step 5: Take the example of whether to repurchase a new insurance policy (X20). The empirical results were based on the proportional accuracy evaluation of disassembly of 23 classifiers from Model A to Model D, and the best model was selected by comparing the following models, as listed below:
- (a)
- Comparison of Model B and Model A:Classifiers with increased accuracy: J48, Logistic, IBK, K-Star, Bagging, and PART. Classifiers with decreased accuracy: Bayes Net and SMO. Classifiers with unchanged accuracy: SGD Text, Stacking, Vote, OneR, ZeroR, and InputMappedClassifier. Among other classifiers, LMT, Naïve Bayes, Simple Logistic, SGD, JRip, and decision tree showed that only one proportion decreased, while the accuracy of other classifiers showed positive growth. Overall, Model B was better than Model A, indicating that attribute selection is important and effective.
- (b)
- Comparison of Model C and Model A:Classifiers with increased accuracy: J48, Naïve Bayes, Logistic, SGD, SMO, IBK, K-Star, and Bagging, indicating that Model C had higher accuracy than Model A and showed positive growth. Classifier with decreased accuracy: Bayes Net. However, since both Model A and Model C were above 80% in Bayes Net, the accuracy of the two models was the same if the proportion was above 80/20. Classifiers with unchanged accuracy: SGD Text, LWL, Stacking, Vote, OneR, ZeroR, and InputMappedClassifier. Among other classifiers, LMT, REP Tree, Simple Logistic, AdaBoostM1, JRip, PART, and decision tree showed that only disassemblies 1–3 decreased proportionally, while the accuracy of other classifiers also showed positive growth. The accuracy of Model C was better than that of Model A, indicating that data discretization is important and effective.
- (c)
- Comparison of Model D and Model B:Naïve Bayes, SGD, SMO, IBK, Bagging, JRip, PART, and ZeroR increased or went without change, and Model D was better than Model B.
- (d)
- Comparison of Model D and Model C:J48, Logistic, IBK, K-Star, JRip, PART, and ZeroR increased or went without change, indicating that Model D was better than Model C.
- 6.
- Advanced Step 6: Take the example of whether to repurchase a new insurance policy (X20). The comparison accuracies of Model F–Model I were cross-verified, and the results are described as follows:
- (a)
- Comparison of Model I and Model F:Classifiers with increased accuracy: J48, LMT, REP Tree, Bayes Net, Naïve Bayes, Logistic, Simple Logistic, SGD, SMO, IBK, K-Star, Bagging, JRip, OneR, PART, and Decision Table. J48: 0.6666%, LMT: 1.3333%, REP Tree: 2.3334%, Bayes Net: 2.3333%, Naïve Bayes: 23.3333%, Logistic: 6.3333%, Simple Logistic: 4.3333%, SGD: 4%, SMO: 12%, IBK: 14.6667%, K-Star: 17%, Bagging: 1.3333%, JRip: 0.6666%, OneR: 0.3333%, PART: 9.3333%, Decision Table: 1%. Naïve Bayes (23.3333%) increased the most, and K-Star (17%) the second-most. Classifiers with decreased accuracy: AdaBoostM1: −1.3333%, LWL: −0.6666%. Although slightly decreased, these two classifiers’ evaluated accuracies were above 82%. Classifiers with unchanged accuracy: Stacking, Vote, ZeroR, and InputMappedClassifier, indicating that regardless of whether there is attribute selection or not, the accuracy is the same. Overall, the accuracy of Model I is better than Model F, indicating that attribute selection and data discretization are important and effective, and the mixed model is better than the single model.
- (b)
- Comparison of Model G and Model F:Classifiers with increased accuracy: Bayes Net (2.3333%), Naïve Bayes (16%), Logistic (6.3333%), Simple Logistic (5%), SGD (3.6667%), IBK (14%), K-Star (17%), bagging (1.3333%), JRip (0.6666%), PART (9.3333%), and Decision Table (1%). K-Star (17%) increased the most, and Naïve Bayes (16%) the second-most. Classifiers with decreased accuracy: LMT (−0.6667%), AdaBoostM1 (−1.3333%), and SMO (−7%). SMO (−7%) decreased significantly, LMT and AdaBoostM1 had small difference values. Classifiers with unchanged accuracy: J48, REP Tree, SGD Text, LWL, Stacking, Vote, OneR, ZeroR, and InputMappedClassifier, indicating that regardless of whether there is attribute selection or not, the accuracy is the same. Overall, the accuracy of Model G is better than Model F, indicating that attribute selection is important and effective.
- (c)
- Comparison of Model H and Model F:Classifiers with increased accuracy: LMT (2.3333%), REP Tree (1%), Naïve Bayes (20.6667%), Logistic (4.6666%), Simple Logistic (5.3333%), SGD (4%), SMO (12%), IBK (8.3334%), K-Star (11.3334%), JRip (0.6666%), OneR (0.3333%), PART (5.3333%), and Decision Table (1.3334%). Naïve Bayes (20.6667%) increased the most, and K-Star (11.3334%) the second-most. Classifiers with decreased accuracy: AdaBoostM1 (−0.6667%). Classifiers with unchanged accuracy: J48, Bayes Net, SGD Text, LWL, Stacking, Vote, Bagging, ZeroR, and InputMappedClassifier, indicating that regardless of whether there is attribute selection or not, the accuracy is the same. Overall, except for the classifier with unchanged accuracy and slightly decreased accuracy of AdaBoostM1 (−0.6667%), Model H is better than Model F without attribute selection and data discretization, indicating that data discretization is important and effective.
- (d)
- Comparison of Model I and Model G:Classifiers with increased accuracy: Naïve Bayes (7.3333%), SGD (0.3333%), SMO (19%), IBK (0.6667%), and OneR (0.3333%). SMO (19%) increased the most, and Naïve Bayes (7.3333%) second. Classifiers with decreased accuracy: LMT and Simple Logistic (−0.6667%), and LWL (−0.6666%). Classifiers with unchanged accuracy: J48, REP Tree, Bayes Net, Logistic, SGD Text, K-Star, Stacking, Vote, AdaBoostM1, Bagging, JRip, PART, ZeroR, Decision Table, and InputMappedClassifier, indicating that the accuracy of Model I is the same as Model G. Overall, Model I is better than Model G.
- (e)
- Comparison of Model I and Model H:Classifiers with increased accuracy: J48 (0.6666%), REP Tree (1.3334%), Bayes Net (2.3333%), Naïve Bayes (2.6666%), Logistic (1.6667%), IBK (6.3333%), K-Star (5.6666%), Bagging (1.3333%), and PART (4%). IBK (6.3333%) increased the most, and K-Star (5.6666%) second. Classifiers with decreased accuracy: LMT and Simple Logistic (−1%), LWL and AdaBoostM1 (−0.6666%), and Decision Table (−0.3334%), with slight decreases. Classifiers with unchanged accuracy: SGD, SGD Text, SMO, Stacking, Vote, JRip, OneR, ZeroR, and InputMappedClassifier. The accuracy of Model I is the same as Model H. Overall, the accuracy of Model I is better than Model F, indicating that attribute selection and data discretization are important and effective, and the mixed model is better than the single model.
- 7.
- Advanced Step 7: Take the example of whether to repurchase a new insurance policy (X20). The maximum and minimum accuracy and difference values of disassembly in proportion (90/10) and cross validation model (A–J, except E and J) are shown in Table 10. It can be seen from Table 10 that the accuracy of proportion evaluation (90/10) of Model A–Model E is the same. The accuracy of proportion evaluation of Model A–Model E is higher than that of cross-validation of Model G–Model J.
- 8.
- Advanced Step 8: Take the example of whether to repurchase a new insurance policy (X20). The disassembly in proportion (90/10) Model A–Model E and cross-validation of Models F– J are compared and analyzed, as shown in Table 11. It can be seen from Table 11 that the maximum and minimum accuracy differences of Models B and G, D and I, and E and J are the same. The minimum accuracy difference of Model A and F is 0%.
- 9.
- Advanced Step 9: Take the example of whether to repurchase a new insurance policy (X20). For the accuracy of disassembly in proportion (90/10) and cross-validation, except for the classifiers with poor accuracy (Naïve Bayes, SGD Text, Stacking, Vote, ZeroR, and InputMappedClassifier), 17 other classifiers with better accuracy had 10 subsequent validation evaluations.
- 10.
- Advanced Step 10: Take the example of whether to repurchase a new insurance policy (X20). The summary comparison of cross-validation of whether to repurchase a new policy once and 10 times is shown in Table 12.
- 11.
- Advanced Step 11: Take the example of whether to repurchase a new insurance policy (X20). The summary comparison of disassembly in proportion of whether to repurchase new policies once and 10 times is shown in Table 13.
- 12.
- Advanced Step 12:
- (1)
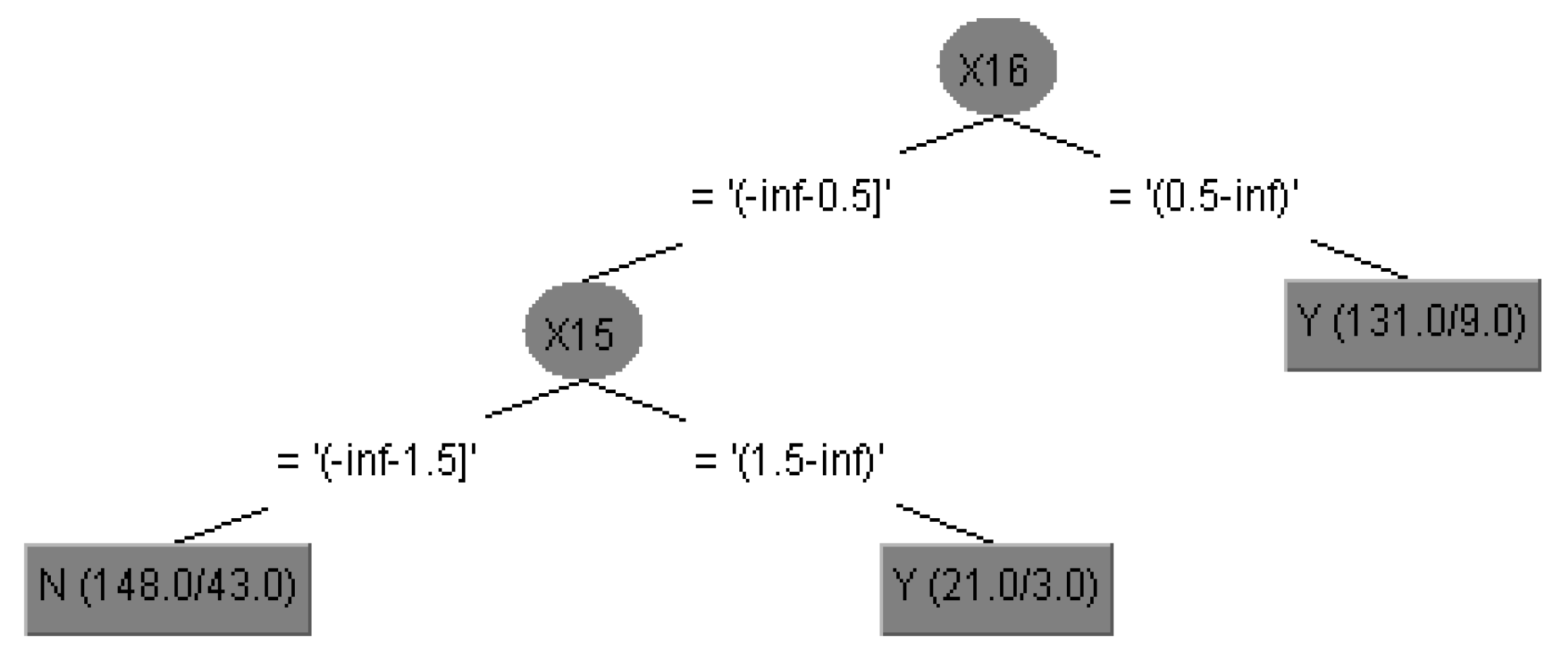
- Take whether to repurchase a new insurance policy (X20) as an example. In this study, cross-validation is the evaluation method to generate a decision tree and save calculation time to proactively find the best combination and obtain the knowledge rules and models of the decision tree, which can be used as the model of this study and provide a reference for investors. The decision tree analysis diagram of whether to repurchase a new policy (X20) is shown in Figure 3.The decision tree analysis diagram is described as follows.Rule 1: IF X16 > 0.5, THEN X20 = Y. Note: If the time to first purchase is more than 0.5 years (i.e., more than 1 year), the client will repurchase.Rule 2: IF X16 ≤ 0.5, THEN X15 ≥ 1.5, X20 = Y. Note: If the time to first purchase is less than 0.5 years, and the number of valid policies is more than 1.5 (i.e., two), the client will repurchase a new policy.Rule 3: IF X16 ≤ 0.5, THEN X15 ≤ 1.5, X20 = N. Note: If the time to first purchase is less than 0.5 years, and the number of valid policies is less than 1.5 (only one), the client will not purchase a new policy.
- (2)
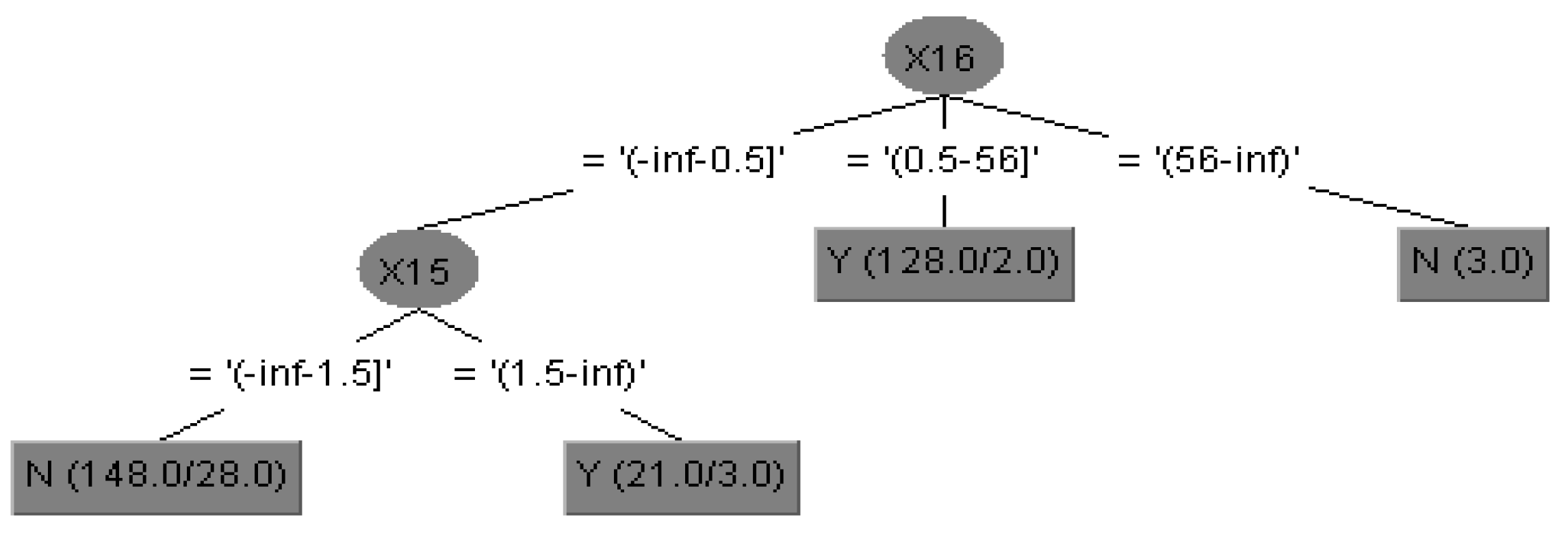
- Take whether to introduce new clients (X21) as an example. The decision tree analysis diagram of whether to introduce new clients (X21) generated by the influential important conditional factors is shown in Figure 4.The decision tree analysis diagram is described as follows.Rule 1: IF 0.5 > X16 > 56, THEN X21 = Y.Note: If the time to the first purchase is less than 0.5–56 years (i.e., 1–56 years), the client will introduce new clients.
- (3)
- Take whether to pay the renewal insurance premium (X22) as an example. The decision tree analysis diagram of whether to pay the renewal insurance premium (X22) generated by the influential important conditional factors is shown in Figure 5.The Decision Tree analysis diagram is described as follows.Rule 1: IF X14 < 4.5, THEN X22 = Y.Note: If the number of policies purchased by the client is less than 4.5, the client will pay the renewal insurance premium.
5. Findings and Management Implications of Empirical Results
5.1. Research Findings
- 1.
- Whether to repurchase a new insurance policy.
- (1)
- Disassembly in proportion of whether to repurchase a new insurance policy.
- (a)
- The best model is Model D with attribute selection and data discretization.
- (b)
- The best classifier is J48 (maximum accuracy 96.6667%, minimum 88.8889%).
- (c)
- In Model D, Naïve Bayes increases the most, by 46.6666%.
- (d)
- The performance of InputMappedClassifier is the worst.
- (2)
- Cross validation of whether to repurchase a new insurance policy.
- (a)
- The best model is Model D with attribute selection and data discretization.
- (b)
- The classifiers with the best accuracy of 83.3333% are J48, K-Star, Bagging, JRip, OneR, PART, and Decision Table.
- (c)
- In Model I, Naïve Bayes increases the most, by 23.3333%.
- (d)
- The performance of InputMappedClassifier is the worst.
- 2.
- Whether to introduce new clients.
- (1)
- Disassembly in proportion of whether to introduce new clients.
- (a)
- The best model is Model D with attribute selection and data discretization.
- (b)
- The best classifier is J48 (maximum accuracy 96.6667%, minimum 88.8889%).
- (c)
- In Model D, Naïve Bayes increases the most, by 46.6666%, and the performance of InputMappedClassifier is the worst.
- (d)
- The higher the proportion of most classifiers is, the higher the accuracy is, and the smaller the difference of the same classifier is.
- (2)
- Cross validation of whether to introduce new clients.
- (a)
- The best model is Model D with attribute selection and data discretization.
- (b)
- The best accuracy is 89%, with 14 suitable classifiers, including J48.
- (c)
- In Model I, Naïve Bayes increases the most, by 23.6667%.
- (d)
- The performance of InputMappedClassifier is the worst.
- 3.
- Whether to pay the renewal insurance premium.
- (1)
- Disassembly in proportion of whether to pay the renewal insurance premium.
- (a)
- The best model is Model D with attribute selection and data discretization.
- (b)
- The best classifier is LMT (maximum accuracy 96.6667%, minimum 89.6926%).
- (c)
- In Model D, IBK increases the most, by 20%.
- (d)
- The accuracy of disassembly in proportion in all classifiers is above 70%, and Model D is above 83%.
- (2)
- Cross validation of whether to pay the renewal insurance premium.
- (a)
- The best model is Model D with attribute selection and data discretization.
- (b)
- The best classifier is LMT, with 11 suitable classifiers in total (maximum accuracy 96.6667%, minimum 88.8889%).
- (c)
- In Model I, IBK increases the most, by 9.6666%.
- (d)
- The accuracy of all classifiers is above 70%, and Model I is above 85%.
5.2. Managerial Implications
- Whether to repurchase a new policy: In the practice of client management, the transaction takes time, the exploration is time-consuming, and the realistic performance often cannot wait for long-term operation. If we can conduct research and generate rules through technology from the client information, make a list for development, and visit it again, this can save salespeople from having to make fruitless visits to strangers and conducting cold call marketing. Rather, insurers who care about their clients can stimulate their demand and budget and improve the rate of clients who purchase new insurance policies.
- Whether to introduce new clients: In the insurance industry, where service and client relationships are paramount, client sourcing has always been an important issue, and referrals represent the best source of new clients. By the scientific method, data mining can screen for the appropriate referral center and make leveraging effortless, which is important for business development.
- Whether to pay the renewal insurance premium: The client renewal premium is the main focus of the insurer and the insurance salesperson. In this study, we mined client data and used the empirical results to explore the conditional attribute data. These data explore the possible problems of different clients and facilitate client relationship management and adjustment as soon as possible. The topic of client value is often discussed in the industry and in academia. With the steady and sophisticated development of data mining technology, the integration and application of essential data is a major breakthrough for existing clients to engage in redevelopment (including referrals) and to provide reference for insurers and insurance salespeople in client data management.
5.3. Research Limitations
6. Conclusions and Future Research
6.1. Conclusions
- 1.
- Prediction model: Model A, Model B, Model C, Model D, and Model E. Model D with attribute selection and data discretization performed the best of all the models.
- 2.
- The mixed model is better than the single model in the improvement of evaluation accuracy.
- 3.
- There is little difference in the accuracy between disassembly in proportion and cross-validation.
- 4.
- The better classifiers and the less accurate classifiers were selected by experiments.
- (1)
- Classifiers with better accuracy (disassembly in proportion): Tree (J48), Bayes (Bayes Net), Function (Simple Logistic), Lazy (LWL), Meta (AdaBoostM1), and Rule (OneR).
- (2)
- Classifiers with better accuracy (cross-validation): Tree (J48), Bayes (Bayes Net), Function (Simple Logistic), Lazy (LWL and K-Star), Meta (Bagging), Rule (OneR), and Mise (InputMappedClassifier)
- (3)
- Classifiers with worse accuracy: Naïve Bayes, SMO, SGD Text, Stacking, Vote, ZeroR, and InputMappedClassifier.
- 5.
- According to the binary classification and different decision attributes, there are different important conditional attributes in the empirical analysis influencing the data, and the decision attributes are explained as follows:
- (1)
- Important conditional attributes and degree of influence of conditional factors regarding whether to repurchase a new insurance policy (X20): gender (X1): 1.0101%; whether the job is in an office (X4): 1.0101%; the amount of long-term care insurance (X13): 3.0303%; the total number of purchased policies (X14): 11.1111%.
- (2)
- Important conditional attributes and degree of influence of conditional factors regarding whether to introduce new clients (X21): amount of critical illness insurance (X10): 0%; whether there is an investment insurance policy (X11): 6.0606%; number of valid policies (X15): 10.1010%; time to first purchase (X16): 2.0101%; total amount of life insurance including long-term care insurance (X19): 0.0101%.
- (3)
- Important conditional attributes and degree of influence of conditional factors regarding whether to pay the renewal insurance premium (X22): gender (X1): 1.0101%; family salary structure (X6): 1.0101%; amount of critical illness insurance (X10): 0%; amount of long-term care insurance (X12): −1.0101%; total number of purchased policies (X14): −2.0202%; total premium of personal annual valid insurance policy (X17): 1.0101%; total amount of life insurance including long-term care insurance (X19): 1.0101%; whether to introduce new clients (X21): 0%.
- 6.
- The number of valid policies (X15) and time to first purchase (X6) are the conditional attributes selected by the common attributes of the three decision attributes; the decision attribute of whether to pay the renewal insurance premium (X22) is an important conditional factor, and the two decision attributes influence each other. With the impact of the Silver Tsunami, the government and insurance industry vigorously promote long-term care insurance, and the conditional attributes of amount of long-term care insurance (X12) and premium of long-term care insurance (X13) are the important factors affecting the decision attributes. Regarding the pre-processing of research data, the sequence of attribute selection and data discretization does not affect the accuracy evaluation performance.
- 7.
- Generation of decision tree: The generated rules are easy to understand and can be applied to insurance practices to help salespeople acquire new behavior patterns, make plans that are favorable to clients, and create an ideal situation for clients, companies, and salespeople.
- 8.
- The prediction model also has different performance in different decision attributes. According to the three decision attributes, different classifiers have different performances in the evaluation of disassembly in proportion and cross-verification. The prediction model proposed in this study can be applied to other industries and have different supporting results for different practical problems.
6.2. Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Santos, F.P.; Pacheco, J.M.; Santos, F.C.; Levin, S.A. Dynamics of informal risk sharing in collective index insurance. Nat. Sustain. 2021, 4, 426–432. [Google Scholar] [CrossRef]
- Harris, T.F.; Yelowitz, A.; Courtemanche, C. Did COVID-19 Change Life Insurance Offerings? J. Risk Insur. 2020, 88, 831–861. [Google Scholar] [CrossRef] [PubMed]
- Jimenez-Carvelo, A.M.; Cuadros-Rodríguez, L. Data mining/machine learning methods in foodomics. Curr. Opin. Food Sci. 2020, 37, 76–82. [Google Scholar] [CrossRef]
- Khan, A.; Ghosh, S.K. Student performance analysis and prediction in classroom learning: A review of educational data mining studies. Educ. Inf. Technol. 2010, 26, 205–240. [Google Scholar] [CrossRef]
- Schorn, M.A.; Verhoeven, S.; Ridder, L.; Huber, F.; Acharya, D.D.; Aksenov, A.A.; van der Hooft, J.J. A community resource for paired genomic and metabolomic data mining. Nat. Chem. Biol. 2021, 17, 363–368. [Google Scholar] [CrossRef] [PubMed]
- Ageed, Z.S.; Zeebaree, S.R.M.; Sadeeq, M.M.; Kak, S.F.; Rashid, Z.N.; Salih, A.A.; Abdullah, W.M. A Survey of Data Mining Implementation in Smart City Applications. Qubahan Acad. J. 2021, 1, 91–99. [Google Scholar] [CrossRef]
- Samerei, S.A.; Aghabayk, K.; Mohammadi, A.; Shiwakoti, N. Data mining approach to model bus crash severity in Australia. J. Saf. Res. 2020, 76, 73–82. [Google Scholar] [CrossRef] [PubMed]
- So, B.; Boucher, J.-P.; Valdez, E.A. Cost-Sensitive Multi-Class Adaboost for Understanding Driving Behavior Based on Telematics. ASTIN Bull. 2021, 51, 719–751. [Google Scholar] [CrossRef]
- Guillen, M.; Nielsen, J.P.; Pérez-Marín, A.M.; Elpidorou, V. Can Automobile Insurance Telematics Predict the Risk of Near-Miss Events? North Am. Actuar. J. 2020, 24, 141–152. [Google Scholar] [CrossRef] [Green Version]
- Tiller, J.; Winship, I.; Otlowski, M.F.; Lacaze, P.A. Monitoring the genetic testing and life insurance moratorium in Australia: A national research project. Med. J. Aust. 2021, 214, 157–159. [Google Scholar] [CrossRef]
- Schwegler, U.; Trezzini, B.; Schiffmann, B. Current challenges in disability evaluation and the need for a goal-oriented approach based on the ICF: A qualitative stakeholder analysis in the context of the Swiss accident insurance. Disabil. Rehabil. 2021, 43, 2110–2122. [Google Scholar] [CrossRef] [PubMed]
- George, N.; Grant, R.; James, A.; Mir, N.; Politi, M.C. Burden Associated With Selecting and Using Health Insurance to Manage Care Costs: Results of a Qualitative Study of Nonelderly Cancer Survivors. Med. Care Res. Rev. 2021, 78, 48–56. [Google Scholar] [CrossRef] [PubMed]
- Azzawi, F.J.I.A. Data mining in a credit insurance information system for bank loans risk management in developing countries. Int. J. Bus. Intell. Data Min. 2021, 18, 291–308. [Google Scholar] [CrossRef]
- Choi, S.E.; Simon, L.; Riedy, C.A.; Barrow, J.R. Modeling the Impact of COVID-19 on Dental Insurance Coverage and Utilization. J. Dent. Res. 2020, 100, 50–57. [Google Scholar] [CrossRef] [PubMed]
- Courbage, C.; Nicolas, C. Trust in insurance: The importance of experiences. J. Risk Insur. 2021, 88, 263–291. [Google Scholar] [CrossRef]
- Landais, C.; Spinnewijn, J. The Value of Unemployment Insurance. Rev. Econ. Stud. 2021, 88, 3041–3085. [Google Scholar] [CrossRef]
- Wang, R.; Rejesus, R.M.; Aglasan, S. Warming Temperatures, Yield Risk and Crop Insurance Participation. Eur. Rev. Agric. Econ. 2021, 48, 1109–1131. [Google Scholar] [CrossRef]
- Yun, Y.; Ma, D.; Yang, M. Human–computer interaction-based Decision Support System with Applications in Data Mining. Futur. Gener. Comput. Syst. 2021, 114, 285–289. [Google Scholar] [CrossRef]
- Scheidler, A.A.; Rabe, M. Integral verification and validation for knowledge discovery procedure models. Int. J. Bus. Intell. Data Min. 2021, 18, 73–87. [Google Scholar] [CrossRef]
- Jain, P.K.; Quamer, W.; Pamula, R. Sports result prediction using data mining techniques in comparison with base line model. Opsearch 2021, 58, 54–70. [Google Scholar] [CrossRef]
- Alweshah, M.; Alkhalaileh, S.; Albashish, D.; Mafarja, M.; Bsoul, Q.; Dorgham, O. A hybrid mine blast algorithm for feature selection problems. Soft Comput. 2021, 25, 517–534. [Google Scholar] [CrossRef]
- Cardoso-Ribeiro, F.L.; Matignon, D.; Lefèvre, L. A partitioned finite element method for power-preserving discretization of open systems of conservation laws. IMA J. Math. Control Inf. 2021, 38, 493–533. [Google Scholar] [CrossRef]
- Ahmed, B.; Wang, L. Discretization based framework to improve the recommendation quality. Int. Arab J. Inf. Technol. 2021, 18, 365–371. [Google Scholar] [CrossRef]
- Charbuty, B.; Abdulazeez, A. Classification Based on Decision Tree Algorithm for Machine Learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Sahin, E.K.; Colkesen, I. Performance analysis of advanced decision tree-based ensemble learning algorithms for landslide susceptibility mapping. Geocarto Int. 2021, 36, 1253–1275. [Google Scholar] [CrossRef]
- Nandhini, M. Ensemble human movement sequence prediction model with Apriori based Probability Tree Classifier (APTC) and Bagged J48 on Machine learning. J. King Saud Univ. Comput. Inf. Sci. 2021, 33, 408–416. [Google Scholar]
- Mohanty, M.; Subudhi, A.; Mohanty, M.N. Detection of supraventricular tachycardia using decision tree model. Int. J. Comput. Appl. 2021, 65, 378–388. [Google Scholar] [CrossRef]
- Tundo, T. Perbandingan Decision Tree J48, REPTREE, dan Random Tree dalam Menentukan Prediksi Produksi Minyak Kelapa Sawit Menggunakan Fuzzy Tsukamoto. J. Teknol. Inf. Dan Ilmu Komput. 2021, 8, 473–484. [Google Scholar] [CrossRef]
- Abu El-Magd, S.A.; Ali, S.A.; Pham, Q.B. Spatial modeling and susceptibility zonation of landslides using random forest, naïve bayes and K-nearest neighbor in a complicated terrain. Earth Sci. Inform. 2021, 14, 1227–1243. [Google Scholar] [CrossRef]
- Kannan, R.P. Prediction Of Consumer Review Analysis Using Naive Bayes And Bayes Net Algorithms. Turk. J. Comput. Math. Educ. 2021, 12, 1865–1874. [Google Scholar]
- Trangenstein, P.J.; Whitehill, J.M.; Jenkins, M.C.; Jernigan, D.H.; Moreno, M.A. Cannabis Marketing and Problematic Cannabis Use Among Adolescents. J. Stud. Alcohol Drugs 2021, 82, 288–296. [Google Scholar] [CrossRef]
- Comin, H.B.; Sollero, B.P.; Gapar, E.B.; Domingues, R.; Cardoso, F.F. Genome-wide association study of resistance/susceptibility to infectious bovine keratoconjunctivitis in Brazilian Hereford cattle. Anim. Genet. 2021, 52, 881–886. [Google Scholar] [CrossRef] [PubMed]
- Yadav, D.C.; Pal, S. Analysis of Heart Disease Using Parallel and Sequential ensemble Methods with Feature Selection Techniques: Heart Disease Prediction. Int. J. Big Data Anal. Health 2021, 6, 40–56. [Google Scholar] [CrossRef]
- Zarifis, A.; Kawalek, P.; Azadegan, A. Evaluating If Trust and Personal Information Privacy Concerns Are Barriers to Using Health Insurance That Explicitly Utilizes AI. J. Internet Commer. 2021, 20, 66–83. [Google Scholar] [CrossRef]
- Mikucka, M.; Becker, O.A.; Wolf, C. Revisiting marital health protection: Intraindividual health dynamics around transition to legal marriage. J. Marriage Fam. 2021, 83, 1439–1459. [Google Scholar] [CrossRef]
- Marinescu, I.; Skandalis, D. Unemployment Insurance and Job Search Behavior. Q. J. Econ. 2021, 136, 887–931. [Google Scholar] [CrossRef]
- Fang, H.; Kung, E. Why do life insurance policyholders lapse? The roles of income, health, and bequest motive shocks. J. Risk Insur. 2021, 88, 937–970. [Google Scholar] [CrossRef]
- Meagher, T.; Guzman, G.; Heltemes, B.; Senn, A.; Wiseman, S.; Armuss, A.; Wang, Y. Navigating a Pandemic: The Unique Role of the Medical Director. J. Insur. Med. 2021, 49, 11–18. [Google Scholar] [CrossRef] [PubMed]
- Sharma, Y.; Mukherjee, K.; Shrivastav, H. A Study on Factors Impacting the Investment in Life Insurance Policy. Int. J. Manag. Hum. Sci. 2021, 5, 11–15. [Google Scholar] [CrossRef]
- He, A.J.; Qian, J.; Chan, W.-S.; Chou, K.-L. Preferences for private long-term care insurance products in a super-ageing society: A discrete choice experiment in Hong Kong. Soc. Sci. Med. 2020, 270, 113632. [Google Scholar] [CrossRef]
- Martinez-Lacoba, R.; Pardo-Garcia, I.; Escribano-Sotos, F. The reverse mortgage: A tool for funding long-term care and increasing public housing supply in Spain. Neth. J. Hous. Built Environ. 2021, 36, 367–391. [Google Scholar] [CrossRef] [PubMed]
- Terdpaopong, K.; Rickards, R.C. Thai Non-Life Insurance Companies’ Resilience and the Historic 2011 Floods: Some Recommendations for Greater Sustainability. Sustainability 2021, 13, 8890. [Google Scholar] [CrossRef]
- Dash, G.; Chakraborty, D. Digital Transformation of Marketing Strategies during a Pandemic: Evidence from an Emerging Economy during COVID-19. Sustainability 2021, 13, 6735. [Google Scholar] [CrossRef]
- Wolny-Dominiak, A.; Żądło, T. The Measures of Accuracy of Claim Frequency Credibility Predictor. Sustainability 2021, 13, 11959. [Google Scholar] [CrossRef]

| Model | A | B | C | D | E | F | G | H | I | J |
|---|---|---|---|---|---|---|---|---|---|---|
| Attribute selection | V | V (1) | V (2) | V | V (1) | V (2) | ||||
| Data discretization | V | V (2) | V (1) | V | V (2) | V (1) | ||||
| 23 classifiers | V | V | V | V | V | V | V | V | V | V |
| Disassembly in proportion | V | V | V | V | V | |||||
| Cross validation | V | V | V | V | V | |||||
| Attribute selection | V | V (1) | V (2) | V | V (1) | V (2) |
| Data Model | 1–100 | 1–150 | 1–200 | 1–250 | 1–300 |
|---|---|---|---|---|---|
| Model A | 90.9091 | 81.6327 | 89.3939 | 81.8073 | 75.7576 |
| Model B | 90.9091 | 81.6327 | 86.3636 | 81.8073 | 84.8485 |
| Model C | 90.9091 | 81.6327 | 89.3939 | 81.7073 | 84.8485 |
| Model D | 90.9091 | 81.6327 | 86.3636 | 81.7073 | 84.8485 |
| Model E | 90.9091 | 81.6327 | 86.3636 | 81.7073 | 84.8485 |
| Data | Important Conditional Attribute |
|---|---|
| Data 1–100 | X12, X14 |
| Data 1–150 | X12, X14 |
| Data 1–200 | X6, X9, X14, X19 |
| Data 1–250 | X1, X4, X12, X14 |
| Data 1–300 | X1, X4, X13, X14 |
| Data | Important Conditional Attribute |
|---|---|
| Data 1–100 | X2, X13, X14, X16, X19 |
| Data 1–150 | X2, X13, X14, X16, X18 |
| Data 1–200 | X6, X6, X14, X16 |
| Data 1–250 | X2, X14, X16 |
| Data 1–300 | X2, X6, X14, X15, X16 |
| Model | A | B | C | D |
|---|---|---|---|---|
| Maximum | 96.6667 | 96.6667 | 96.6667 | 96.6667 |
| Minimum | 46.6667 | 46.6667 | 46.6667 | 46.6667 |
| Difference value | 50.0000 | 50.0000 | 50.0000 | 50.0000 |
| Model | F | G | H | I |
|---|---|---|---|---|
| Maximum | 89.0000 | 89.0000 | 96.6667 | 89.0000 |
| Minimum | 57.3333 | 52.3333 | 57.3333 | 57.3333 |
| Difference value | 31.6667 | 36.6667 | 39.3334 | 31.6667 |
| Model | A | B | C | D | F | G | H | I |
|---|---|---|---|---|---|---|---|---|
| Maximum | 96.6667 | 96.6667 | 96.6667 | 96.6667 | 84.0000 | 83.3333 | 83.6667 | 83.3333 |
| Minimum | 56.6667 | 56.6667 | 56.6667 | 56.6667 | 56.6667 | 61.0000 | 61.0000 | 61.0000 |
| Difference value | 40.0000 | 40.0000 | 40.0000 | 40.0000 | 27.3333 | 22.3333 | 22.6667 | 22.3333 |
| Model | A and F | B and G | C and H | D and I | E and J |
|---|---|---|---|---|---|
| Maximum accuracy difference | 12.6667 | 13.3334 | 13.0000 | 13.3334 | 13.3334 |
| Minimum accuracy difference | 0.0000 | 4.3333 | 4.3333 | 4.3333 | 4.3333 |
| Model | A | B | C | D | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | 1. | 10 s. | Std. | 1. | 10 s. | Std. | 1. | 10 s. | Std. | 1. | 10 s. | Std. | |
| J48 | 82.67 | 82.00 | 6.58 | 83.33 | 83.33 | 6.77 | 82.67 | 82.63 | 6.50 | 82.67 | 83.33 | 6.77 | |
| LMT | 80.67 | 79.70 | 7.57 | 82.67 | 82.87 | 6.83 | 80.67 | 82.67 | 6.60 | 80.67 | 82.80 | 6.70 | |
| REPTree | 80.33 | 82.27 | 6.65 | 82.67 | 82.90 | 6.66 | 80.33 | 82.67 | 6.67 | 80.33 | 82.90 | 6.66 | |
| Bayes Net | 79.67 | 79.73 | 7.15 | 82.00 | 82.33 | 6.69 | 79.67 | 79.97 | 7.35 | 79.67 | 82.33 | 6.69 | |
| Logistic | 75.67 | 76.80 | 7.71 | 82.00 | 82.27 | 6.88 | 75.67 | 80.20 | 6.80 | 75.67 | 82.27 | 6.71 | |
| SimpleLogistic | 77.67 | 78.03 | 8.03 | 82.67 | 82.77 | 6.88 | 77.67 | 87.73 | 6.61 | 77.67 | 82.80 | 6.70 | |
| SGD | 78.00 | 79.27 | 7.24 | 81.67 | 81.97 | 6.70 | 78.00 | 82.30 | 6.70 | 78.00 | 82.30 | 6.70 | |
| SMO | 70.00 | 69.73 | 8.54 | 63.00 | 62.20 | 6.75 | 70.00 | 82.30 | 6.70 | 70.00 | 82.30 | 6.70 | |
| IBK | 67.33 | 68.00 | 7.49 | 81.33 | 81.63 | 6.92 | 67.33 | 75.57 | 7.97 | 67.33 | 82.30 | 6.70 | |
| K-Star | 66.33 | 66.10 | 8.11 | 83.33 | 83.33 | 6.77 | 66.33 | 78.40 | 7.51 | 66.33 | 83.33 | 6.77 | |
| LWL | 83.33 | 83.33 | 6.77 | 83.33 | 83.33 | 6.77 | 83.33 | 83.33 | 6.77 | 83.33 | 82.93 | 6.85 | |
| AdaBoostM1 | 84.00 | 83.30 | 6.45 | 82.67 | 83.00 | 6.86 | 84.00 | 83.10 | 6.97 | 84.00 | 82.67 | 6.67 | |
| Bagging | 82.00 | 81.63 | 6.69 | 83.33 | 83.23 | 6.77 | 82.00 | 81.80 | 6.67 | 82.00 | 83.27 | 6.77 | |
| JRip | 82.67 | 82.43 | 6.85 | 83.33 | 83.33 | 6.77 | 82.67 | 83.23 | 6.79 | 82.67 | 83.33 | 6.77 | |
| OneR | 83.00 | 83.07 | 6.68 | 83.00 | 83.07 | 6.68 | 83.00 | 83.33 | 6.77 | 83.00 | 83.33 | 6.77 | |
| PART | 74.00 | 74.37 | 7.32 | 83.33 | 83.33 | 6.77 | 74.00 | 77.93 | 7.37 | 74.00 | 83.33 | 6.77 | |
| Decision Table | 82.33 | 81.97 | 6.67 | 83.33 | 83.33 | 6.75 | 82.33 | 83.33 | 6.30 | 82.33 | 83.33 | 6.77 | |
| Model | A | B | C | D | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | 1. | 10 s. | Std. | 1. | 10 s. | Std. | 1. | 10 s. | Std. | 1. | 10 s. | Std. | |
| J48 | 96.67 | 82.05 | 5.06 | 96.67 | 82.37 | 4.83 | 96.67 | 81.04 | 5.55 | 96.67 | 82.37 | 4.83 | |
| LMT | 96.67 | 79.69 | 6.89 | 96.67 | 82.37 | 4.83 | 96.67 | 81.37 | 6.21 | 93.33 | 82.37 | 4.83 | |
| REPTree | 90.00 | 81.72 | 4.84 | 96.67 | 82.37 | 4.83 | 86.67 | 81.37 | 6.21 | 96.67 | 82.37 | 4.83 | |
| Bayes Net | 93.33 | 77.05 | 8.16 | 93.33 | 82.37 | 4.83 | 93.33 | 77.37 | 8.24 | 93.33 | 82.37 | 4.83 | |
| Logistic | 86.67 | 76.06 | 7.88 | 93.33 | 82.69 | 6.19 | 90.00 | 79.06 | 5.89 | 93.33 | 82.37 | 4.83 | |
| Simple Logistic | 93.33 | 78.74 | 5.66 | 96.67 | 82.37 | 4.83 | 96.67 | 81.37 | 6.21 | 93.33 | 82.37 | 4.83 | |
| SGD | 90.00 | 78.69 | 6.46 | 93.33 | 81.69 | 4.97 | 93.33 | 81.37 | 6.21 | 93.33 | 82.37 | 4.83 | |
| SMO | 76.67 | 66.44 | 4.76 | 63.33 | 63.42 | 6.32 | 93.33 | 81.37 | 6.21 | 93.33 | 82.37 | 4.83 | |
| IBK | 83.33 | 69.10 | 7.33 | 90.00 | 82.04 | 4.83 | 86.67 | 73.70 | 7.36 | 93.33 | 82.37 | 4.83 | |
| K-Star | 73.33 | 67.41 | 7.15 | 96.67 | 82.37 | 4.83 | 93.33 | 77.70 | 6.04 | 96.67 | 82.37 | 4.83 | |
| LWL | 96.67 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | |
| AdaBoostM1 | 96.67 | 82.36 | 4.87 | 96.67 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | 93.33 | 82.37 | 4.83 | |
| Bagging | 93.33 | 79.03 | 7.54 | 93.33 | 82.37 | 4.83 | 96.67 | 79.03 | 7.18 | 93.33 | 82.37 | 4.83 | |
| JRip | 96.67 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | 93.33 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | |
| OneR | 96.67 | 81.70 | 5.36 | 96.67 | 81.70 | 5.36 | 96.67 | 82.37 | 4.83 | 96.67 | 82.37 | 4.83 | |
| PART | 80.00 | 73.74 | 8.25 | 96.67 | 82.37 | 4.83 | 96.67 | 77.73 | 7.22 | 96.67 | 82.37 | 4.83 | |
| Decision Table | 83.33 | 80.04 | 4.83 | 96.67 | 82.37 | 4.83 | 96.67 | 81.05 | 5.51 | 96.67 | 82.37 | 4.83 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Lin, C.-K.; Lin, Y.-S.; Chen, S.-F.; Tsao, H.-H. Identification of Potential Valid Clients for a Sustainable Insurance Policy Using an Advanced Mixed Classification Model. Sustainability 2022, 14, 3964. https://doi.org/10.3390/su14073964
Chen Y-S, Lin C-K, Lin Y-S, Chen S-F, Tsao H-H. Identification of Potential Valid Clients for a Sustainable Insurance Policy Using an Advanced Mixed Classification Model. Sustainability. 2022; 14(7):3964. https://doi.org/10.3390/su14073964
Chicago/Turabian StyleChen, You-Shyang, Chien-Ku Lin, Yu-Sheng Lin, Su-Fen Chen, and Huei-Hua Tsao. 2022. "Identification of Potential Valid Clients for a Sustainable Insurance Policy Using an Advanced Mixed Classification Model" Sustainability 14, no. 7: 3964. https://doi.org/10.3390/su14073964
APA StyleChen, Y.-S., Lin, C.-K., Lin, Y.-S., Chen, S.-F., & Tsao, H.-H. (2022). Identification of Potential Valid Clients for a Sustainable Insurance Policy Using an Advanced Mixed Classification Model. Sustainability, 14(7), 3964. https://doi.org/10.3390/su14073964