
Deep Learning Method for Recognition and Classification of Images from Video Recorders in Difficult Weather Conditions

 ,
,  ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Theoretical Background
3. Materials and Methods
3.1. Finding an Edge in a Nonblurred Image Area
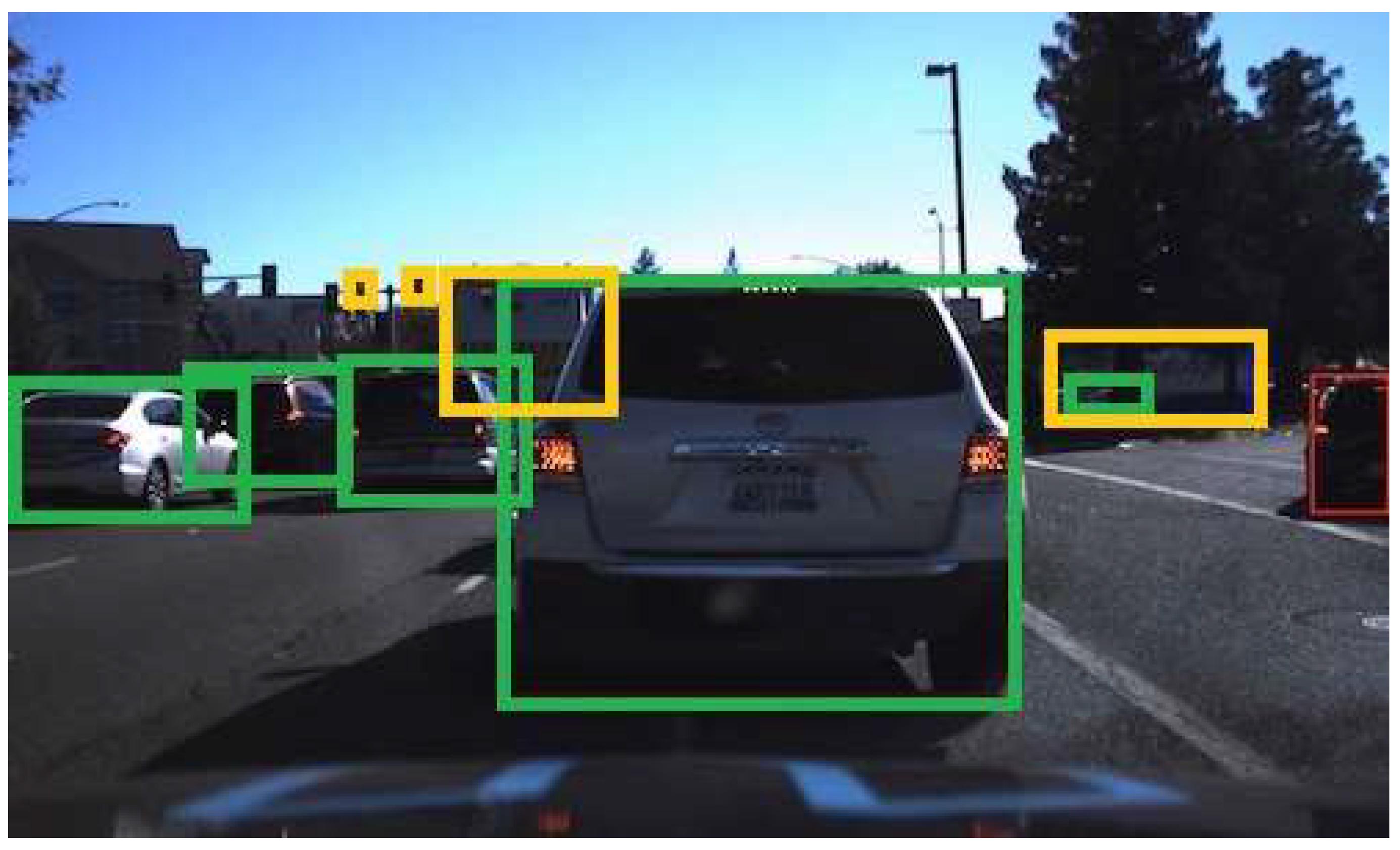
3.2. Applying the IoU Metric to Transform Our Images with True and Predicted Areas
3.3. Using a Descriptor
3.4. Image Classification Using BoVW
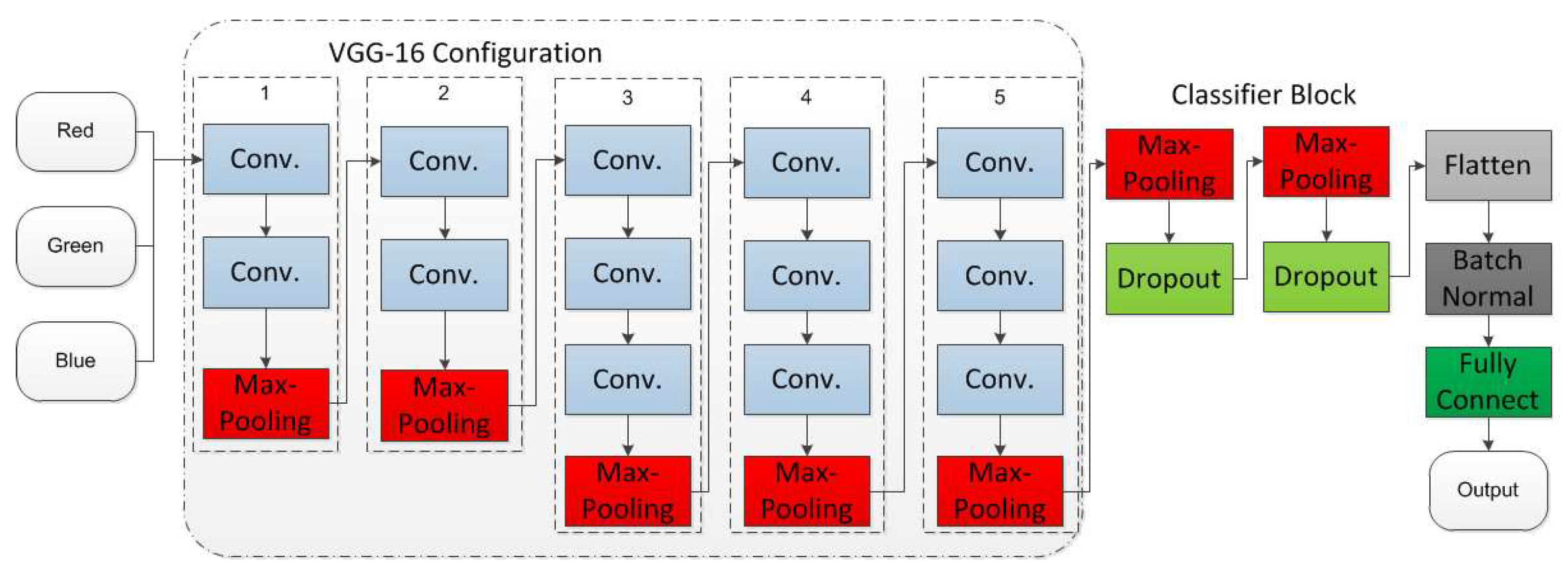
3.5. CNN Image Classification
4. Experiments and Results
4.1. Image Preprocessing
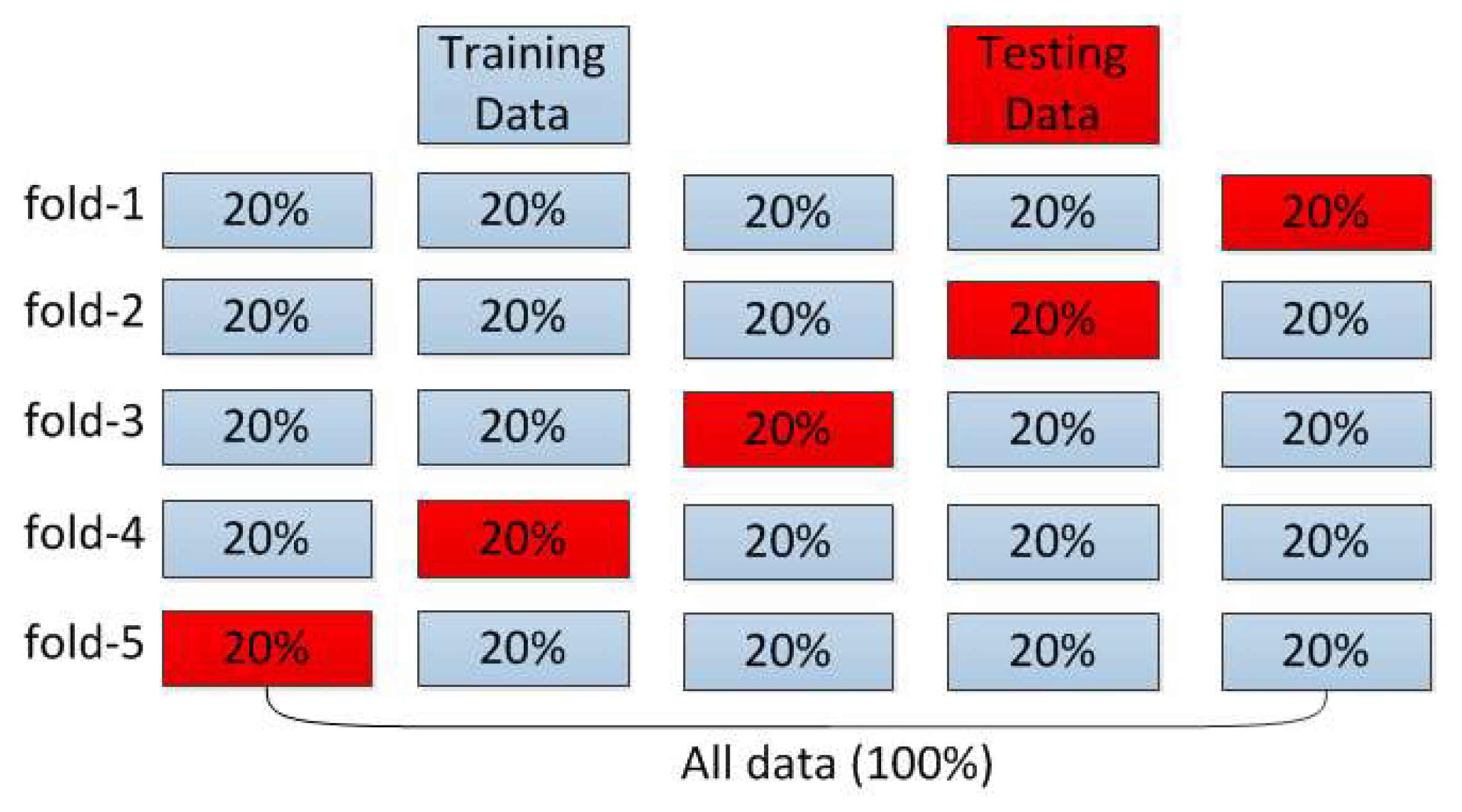
4.2. Data Preparation and Evaluation Metrics
4.3. Intelligent System
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Finogeev, A.; Parygin, D.; Schevchenko, S.; Finogeev, A.; Ather, D. Collection and Consolidation of Big Data for Proactive Monitoring of Critical Events at Infrastructure Facilities in an Urban Environment. In Creativity in Intelligent Technologies and Data Science, Proceedings of the 4th International Conference CIT&DS 2021, Volgograd, Russia, 20–23 September 2021; Springer: Cham, Switzerland, 2021; Volume 1448. [Google Scholar] [CrossRef]
- Anokhin, A.; Burov, S.; Parygin, D.; Rent, V.; Sadovnikova, N.; Finogeev, A. Development of Scenarios for Modeling the Behavior of People in an Urban Environment. In Society 5.0: Cyberspace for Advanced Human-Centered Society; Studies in Systems, Decision and Control; Springer: Cham, Switzerland, 2021; Volume 333, pp. 103–114. [Google Scholar] [CrossRef]
- Kolimenakis, A.; Solomou, A.D.; Proutsos, N.; Avramidou, E.V.; Korakaki, E.; Karetsos, G.; Maroulis, G.; Papagiannis, E.; Tsagkari, K. The Socioeconomic Welfare of Urban Green Areas and Parks; A Literature Review of Available Evidence. Sustainability 2021, 13, 7863. [Google Scholar] [CrossRef]
- Solomou, A.D.; Topalidou, E.T.; Germani, R.; Argiri, A.; Karetsos, G. Importance, utilization and health of urban forests: A review. Not. Bot. Horti Agrobot. Cluj-Napoca 2019, 47, 10–16. [Google Scholar] [CrossRef] [Green Version]
- Grima, N.; Corcoran, W.; Hill-James, C.; Langton, B.; Sommer, H.; Fisher, B. The importance of urban natural areas and urban ecosystem services during the COVID-19 pandemic. PLoS ONE 2020, 15, e0243344. [Google Scholar] [CrossRef] [PubMed]
- Kondo, M.C.; Fluehr, J.M.; McKeon, T.; Branas, C.C. Urban green space and its impact on human health. Int. J. Environ. Res. Public Health 2018, 15, 445. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Braubach, M.; Egorov, A.; Mudu, P.; Wolf, T. Effects of urban green space on environmental health, equity and resilience. In Nature-Based Solutions to Climate Change Adaptation in Urban Areas; Springer: Cham, Switzerland, 2017; pp. 187–205. [Google Scholar]
- Chiesura, A. The role of urban parks for the sustainable city. Landsc. Urban Plan. 2004, 68, 129–138. [Google Scholar] [CrossRef]
- Chattopadhyay, D.; Rasheed, S.; Yan, L.; Lopez, A.A.; Farmer, J.; Brown, D.E. Machine Learning for Real-Time Vehicle Detection in All-Electronic Tolling System. In Proceedings of the 2020 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 24 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Deng, C.-X.; Wang, G.-B.; Yang, X.-R. Image edge detection algorithm based on improved Canny operator. In Proceedings of the 2013 International Conference on Wavelet Analysis and Pattern Recognition, Tianjin, China, 14–17 July 2013; pp. 168–172. [Google Scholar] [CrossRef]
- Krakhmalev, O.; Korchagin, S.; Pleshakova, E.; Nikitin, P.; Tsibizova, O.; Sycheva, I.; Liang, K.; Serdechnyy, D.; Gataullin, S.; Krakhmalev, N. Parallel Computational Algorithm for Object-Oriented Modeling of Manipulation Robots. Mathematics 2021, 9, 2886. [Google Scholar] [CrossRef]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. On a formal model of safe and scalable self-driving cars. arXiv 2017, arXiv:1708.06374. [Google Scholar]
- Mancini, M.; Costante, G.; Valigi, P.; Ciarfuglia, T.A. Fast robust monocular depth estimation for obstacle detection with fully convolutional networks. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4296–4303. [Google Scholar]
- Jia, B.; Feng, W.; Zhu, M. Obstacle detection in single images with deep neural networks. Signal Image Video Process 2015, 10, 1033–1040. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, K.; Li, J.; Zhu, Y.; Zhang, Y. Various Frameworks and Libraries of Machine Learning and Deep Learning: A Survey. Arch. Comput. Methods Eng. 2019, 1–24. [Google Scholar] [CrossRef]
- Ni, J.; Chen, Y.; Chen, Y.; Zhu, J.; Ali, D.; Cao, W. A survey on theories and applications for self-driving cars based on deep learning methods. Appl. Sci. 2020, 10, 2749. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Akter, R.; Hosen, I. CNN-based Leaf Image Classification for Bangladeshi Medicinal Plant Recognition. In Proceedings of the 2020 Emerging Technology in Computing, Communication and Electronics (ETCCE), Bangladesh, 21–22 December 2020; pp. 1–6. [Google Scholar]
- Marino, S.; Beauseroy, P.; Smolarz, A. Weakly-supervised learning approach for potato defects segmentation. Eng. Appl. Artif. Intell. 2019, 85, 337–346. [Google Scholar] [CrossRef]
- Afonso, M.; Blok, P.M.; Polder, G.; van der Wolf, J.M.; Kamp, J. Blackleg Detection in Potato Plants using Convolutional Neural Networks. IFAC-PapersOnLine 2019, 52, 6–11. [Google Scholar] [CrossRef]
- Wu, A.; Zhu, J.; Ren, T. Detection of apple defect using laser-induced light backscattering imaging and convolutional neural network. Comput. Electr. Eng. 2020, 81, 106454. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Korchagin, S.; Serdechny, D.; Kim, R.; Terin, D.; Bey, M. The use of machine learning methods in the diagnosis of diseases of crops. E3S Web Conf. 2020, 176, 04011. [Google Scholar] [CrossRef]
- Marino, S.; Beauseroy, P.; Smolarz, A. Unsupervised adversarial deep domain adaptation method for potato defects classification. Comput. Electron. Agric. 2020, 174, 105501. [Google Scholar] [CrossRef]
- Puno, J.C.V.; Billones, R.K.D.; Bandala, A.A.; Dadios, E.P.; Calilune, E.J.; Joaquin, A.C. Quality Assessment of Mangoes using Convolutional Neural Network. In Proceedings of the 2019 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Bangkok, Thailand, 18–20 November 2019; pp. 491–495. [Google Scholar]
- Sharma, D.K.; Malikov, V.; Parygin, D.; Golubev, A.; Lozhenitsina, A.; Sadovnikov, N. GPU-Card Performance Research in Satellite Imagery Classification Problems Using Machine Learning. Procedia Comput. Sci. 2020, 178, 55–64. [Google Scholar] [CrossRef]
- Yin, H.; Gong, Y.; Qiu, G. Fast and efficient implementation of image filtering using a side window convolutional neural network. Signal Process. 2020, 176, 107717. [Google Scholar] [CrossRef]
- Maksimovic, V.; Petrovic, M.; Savic, D.; Jaksic, B.; Spalevic, P. New approach of estimating edge detection threshold and application of adaptive detector depending on image complexity. Optik 2021, 238, 166476. [Google Scholar] [CrossRef]
- Pawar, K.B.; Nalbalwar, S.L. Distributed canny edge detection algorithm using morphological filter. In Proceedings of the IEEE International Conference on Recent Trends in Electronics Information & Communication Technology (RTEICT), Bangalore, India, 20–21 May 2016; pp. 1523–1527. [Google Scholar]
- Dinesh Kumar, M.; Babaie, M.; Zhu, S.; Kalra, S.; Tizhoosh, H.R. A comparative study of CNN, BoVW and LBP for classification of histopathological images. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Tseng, D.-C.; Wei, R.-Y.; Lu, C.-T.; Wang, L.-L. Image restoration using hybrid features improvement on morphological component analysis. J. Electron. Sci. Technol. 2019, 17, 100014. [Google Scholar] [CrossRef]
- Sharifrazi, D.; Alizadehsani, R.; Roshanzamir, M.; Joloudari, J.H.; Shoeibi, A.; Jafari, M.; Hussain, S.; Sani, Z.A.; Hasanzadeh, F.; Khozeimeh, F.; et al. Fusion of convolution neural network, support vector machine and Sobel filter for accurate detection of COVID-19 patients using X-ray images. Biomed. Signal Process. Control 2021, 68, 102622. [Google Scholar] [CrossRef] [PubMed]
- Ravivarma, G.; Gavaskar, K.; Malathi, D.; Asha, K.; Ashok, B.; Aarthi, S. Implementation of Sobel operator based image edge detection on FPGA. Mater. Today Proc. 2021, 45 Pt 2, 2401–2407. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskiy, A.G. Detection of objects in the images: From likelihood relationships toward scalable and efficient neural networks. J. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415. Symmetry 2022, 14, 148. [Google Scholar] [CrossRef]
- Sebyakin, A.; Soloviev, V.; Zolotaryuk, A. Spatio-Temporal Deepfake Detection with Deep Neural Networks. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). In Proceedings of the LNCS, 16th International Conference on Diversity, Divergence, Dialogue, iConference 2021, Beijing, China, 17–31 March 2021. [Google Scholar]
- Pavlyutin, M.; Samoyavcheva, M.; Kochkarov, R.; Pleshakova, E.; Korchagin, S.; Gataullin, T.; Nikitin, P.; Hidirova, M. COVID-19 Spread Forecasting, Mathematical Methods vs. Machine Learning, Moscow Case. Mathematics 2022, 10, 195. [Google Scholar] [CrossRef]
- Imani, E.; Javidi, M.; Pourreza, H.-R. Improvement of retinal blood vessel detection using morphological component analysis. Comput. Methods Programs Biomed. 2015, 118, 263–279. [Google Scholar] [CrossRef]
- Kang, S.; Iwana, B.K.; Uchida, S. Complex image processing with less data—Document image binarization by integrating multiple pre-trained U-Net modules. Pattern Recognit. 2021, 109, 107577. [Google Scholar] [CrossRef]
- Pratikakis, I.; Zagori, K.; Kaddas, P.; Gatos, B. ICFHR 2018 competition on handwritten document image binarization (H-DIBCO 2018). In Proceedings of the 2018 IEEE International Conference on Frontiers in Handwriting Recognition, Niagara Falls, NY, USA, 5–8 August 2018; pp. 489–493. [Google Scholar] [CrossRef]
- Manoharan, S. An improved safety algorithm for artificial intelligence enabled processors in self driving cars. J. Artif. Intell. Capsul. Netw. 2019, 1, 95–104. [Google Scholar] [CrossRef]
- Wu, D.; Xu, L.; Wei, T.; Qian, Z.; Cheng, C.; Guoyi, Z.; Hailong, Z. Research of Multi-dimensional Improved Canny Algorithm in 5G Smart Grid Image Intelligent Recognition and Monitoring Application. In Proceedings of the 2021 IEEE 6th International Conference on Computer and Communication Systems (ICCCS), Chengdu, China, 23–26 April 2021; pp. 400–404. [Google Scholar]
- Yang, Y.; Zhao, X.; Huang, M.; Wang, X.; Zhu, Q. Multispectral image based germination detection of potato by using supervised multiple threshold segmentation model and Canny edge detector. Comput. Electron. Agric. 2021, 182, 106041. [Google Scholar] [CrossRef]
- Yuan, L.; Xu, X. Adaptive Image Edge Detection Algorithm Based on Canny Operator. In Proceedings of the 4th International Conference on Advanced Information Technology and Sensor Application (AITS), Harbin, China, 21–23 August 2015; pp. 28–31. [Google Scholar] [CrossRef]
- Xin, G.; Ke, C.; Xiaoguang, H. An improved Canny edge detection algorithm for color image. In Proceedings of the IEEE 10th International Conference on Industrial Informatics, Beijing, China, 25–27 July 2012; pp. 113–117. [Google Scholar] [CrossRef]
- Boonarchatong, C.; Ketcham, M. Performance analysis of edge detection algorithms with THEOS satellite images. In Proceedings of the International Conference on Digital Arts Media and Technology (ICDAMT), Chiang Mai, Thailand, 1–4 March 2017; pp. 235–239. [Google Scholar]
- Blin, R.; Ainouz, S.; Canu, S.; Meriaudeau, F. Road scenes analysis in adverse weather conditions by polarization-encoded images and adapted deep learning. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 27–32. [Google Scholar] [CrossRef] [Green Version]
- Setiawan, B.D.; Rusydi, A.N.; Pradityo, K. Lake edge detection using Canny algorithm and Otsu thresholding. In Proceedings of the 2017 International Symposium on Geoinformatics (ISyG), Malang, Indonesia, 24–25 November 2017; pp. 72–76. [Google Scholar]
- Gunawan, T.S.; Yaacob, I.Z.; Kartiwi, M.; Ismail, N.; Za’bah, N.F.; Mansor, H. Artificial neural network based fast edge detection algorithm for MRI medical images. Indones. J. Electr. Eng. Comput. Sci. 2017, 7, 123–130. [Google Scholar] [CrossRef]
- Parthasarathy, G.; Ramanathan, L.; Anitha, K.; Justindhas, Y. Predicting Source and Age of Brain Tumor Using Canny Edge Detection Algorithm and Threshold Technique. Asian Pac. J. Cancer Prev. 2019, 20, 1409. [Google Scholar]
- Wu, G.; Yang, D.; Chang, C.; Yin, L.; Luo, B.; Guo, H. Optimizations of Canny Edge Detection in Ghost Imaging. J. Korean Phys. Soc. 2019, 75, 223–228. [Google Scholar] [CrossRef]
- Johari, N.; Singh, N. Bone fracture detection using edge detection technique. In Soft Computing: Theories and Applications; Springer: Singapore, 2018; pp. 11–19. [Google Scholar]
- Kalbasi, M.; Nikmehr, H. Noise-Robust, Reconfigurable Canny Edge Detection and its Hardware Realization. IEEE Access 2020, 8, 39934–39945. [Google Scholar] [CrossRef]
- Ahmed, A.S. Comparative study among Sobel, Prewitt and Canny edge detection operators used in image processing. J. Theor. Appl. Inf. Technol. 2018, 96, 6517–6525. [Google Scholar]
- Xiao, Z.; Zou, Y.; Wang, Z. An improved dynamic double threshold Canny edge detection algorithm. In MIPPR 2019: Pattern Recognition and Computer Vision, Proceedings of the Eleventh International Symposium on Multispectral Image Processing and Pattern Recognition (MIPPR2019), Wuhan, China, 2–3 November 2019; SPIE: Bellingham, WA, USA, 2020; Volume 11430, p. 1143016. [Google Scholar]
- Wu, F.; Zhu, C.; Xu, J.; Bhatt, M.W.; Sharma, A. Research on image text recognition based on canny edge detection algorithm and k-means algorithm. Int. J. Syst. Assur. Eng. Manag. 2021, 1–9. [Google Scholar] [CrossRef]
- Lynn, N.D.; Sourav, A.I.; Santoso, A.J. Implementation of Real-Time Edge Detection Using Canny and Sobel Algorithms. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1096, 012079. [Google Scholar] [CrossRef]
- Rahman, M.A.; Amin, M.F.I.; Hamada, M. Edge Detection Technique by Histogram Processing with Canny Edge Detector. In Proceedings of the 2020 3rd IEEE International Conference on Knowledge Innovation and Invention (ICKII), Kaohsiung, Taiwan, 21–23 August 2020; pp. 128–131. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Yu, J.; Xu, J.; Chen, Y.; Li, W.; Wang, Q.; Yoo, B.; Han, J.J. Learning Generalized Intersection Over Union for Dense Pixelwise Prediction. In Proceedings of the International Conference on Machine Learning, Online. 18–24 July 2021; pp. 12198–12207. [Google Scholar]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4413–4421. [Google Scholar]
- Lin, K.; Zhao, H.; Lv, J.; Zhan, J.; Liu, X.; Chen, R.; Li, C.; Huang, Z. Face detection and segmentation with generalized intersection over union based on mask R-CNN. In Proceedings of the International Conference on Brain Inspired Cognitive Systems, Guangzhou, China, 13–14 July 2019; Springer: Cham, Switzerland, 2019; pp. 106–116. [Google Scholar]
- Kamyshova, G.; Osipov, A.; Gataullin, S.; Korchagin, S.; Ignar, S.; Gataullin, T.; Terekhova, N.; Suvorov, S. Artificial neural networks and computer vision’s based Phytoindication systems for variable rate irrigation improving. IEEE Access 2022, 10, 8577–8589. [Google Scholar] [CrossRef]
- Wu, S.; Yang, J.; Yu, H.; Gou, L.; Li, X. Gaussian Guided IoU: A Better Metric for Balanced Learning on Object Detection. arXiv 2021, arXiv:2103.13613. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar]
- Abouzahir, S.; Sadik, M.; Sabir, E. Bag-of-visual-words-augmented Histogram of Oriented Gradients for efficient weed detection. Biosyst. Eng. 2021, 202, 179–194. [Google Scholar] [CrossRef]
- Jogin, M.; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature extraction using convolution neural networks (CNN) and deep learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Bykov, A.; Grecheneva, A.; Kuzichkin, O.; Surzhik, D.; Vasilyev, G.; Yerbayev, Y. Mathematical Description and Laboratory Study of Electrophysical Methods of Localization of Geodeformational Changes during the Control of the Railway Roadbed. Mathematics 2021, 9, 3164. [Google Scholar] [CrossRef]
- Nasiri, A.; Taheri-Garavand, A.; Zhang, Y.-D. Image-based deep learning automated sorting of date fruit. Postharvest Biol. Technol. 2019, 153, 133–141. [Google Scholar] [CrossRef]
- Wei, Y.; Tian, Q.; Guo, J.; Huang, W.; Cao, J. Multi-vehicle detection algorithm through combining Harr and HOG features. Math. Comput. Simul. 2019, 155, 130–145. [Google Scholar] [CrossRef]
- Chitra, J.; Muthulakshmi, K.; Devi, K.G.; Balasubramanian, K.; Chitral, L. Review on intelligent prediction transportation system for pedestrian crossing using machine learning. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
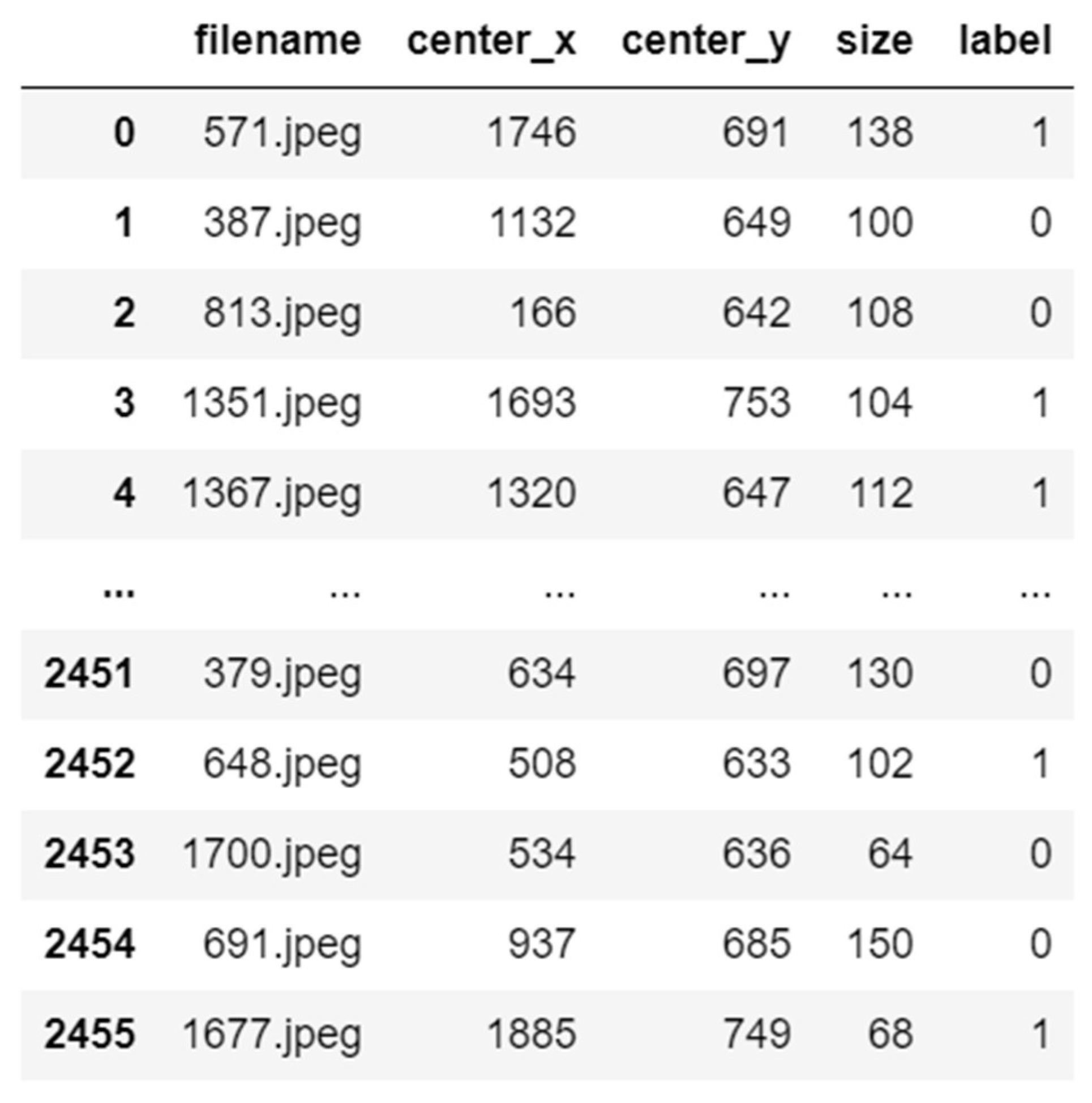
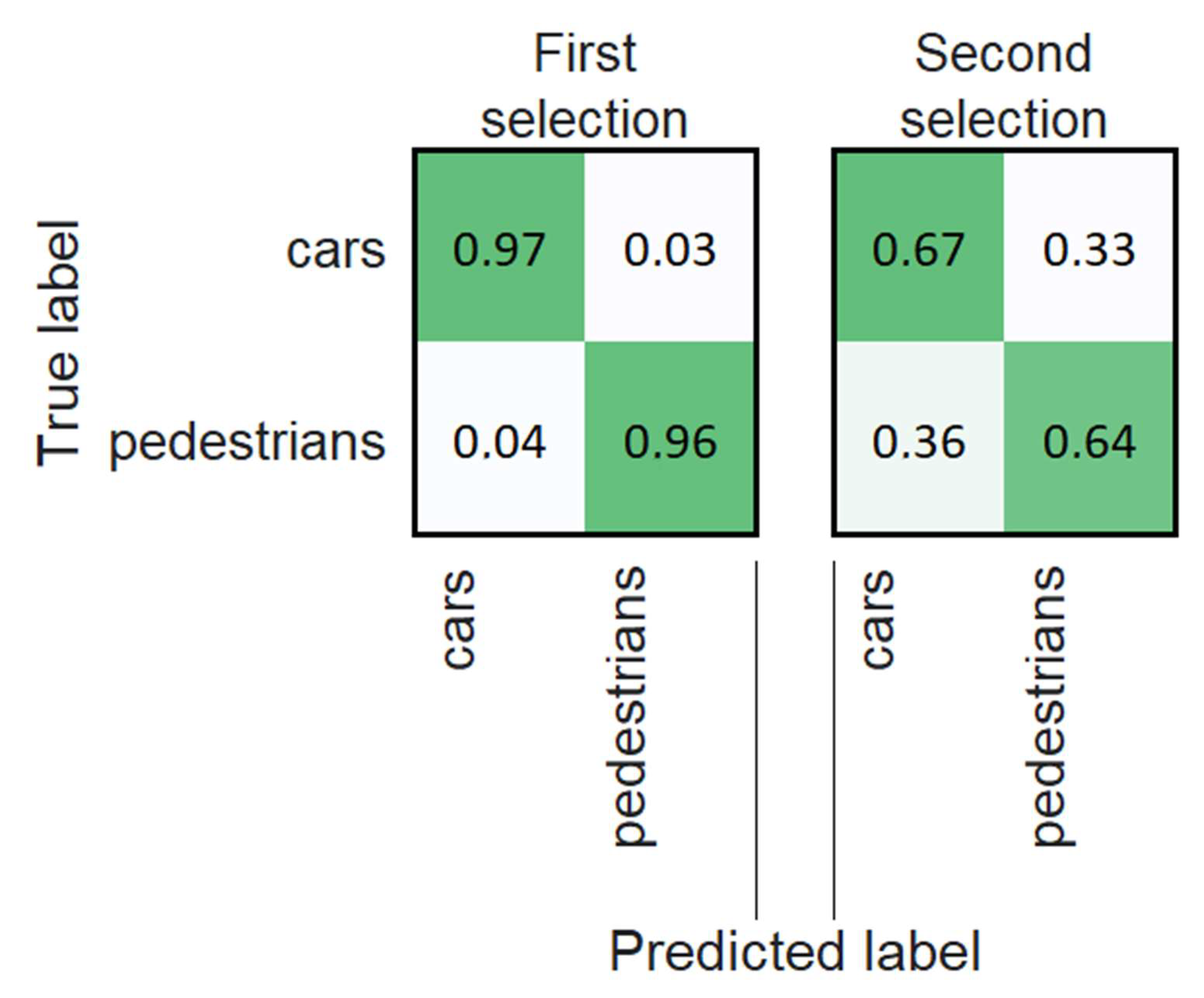
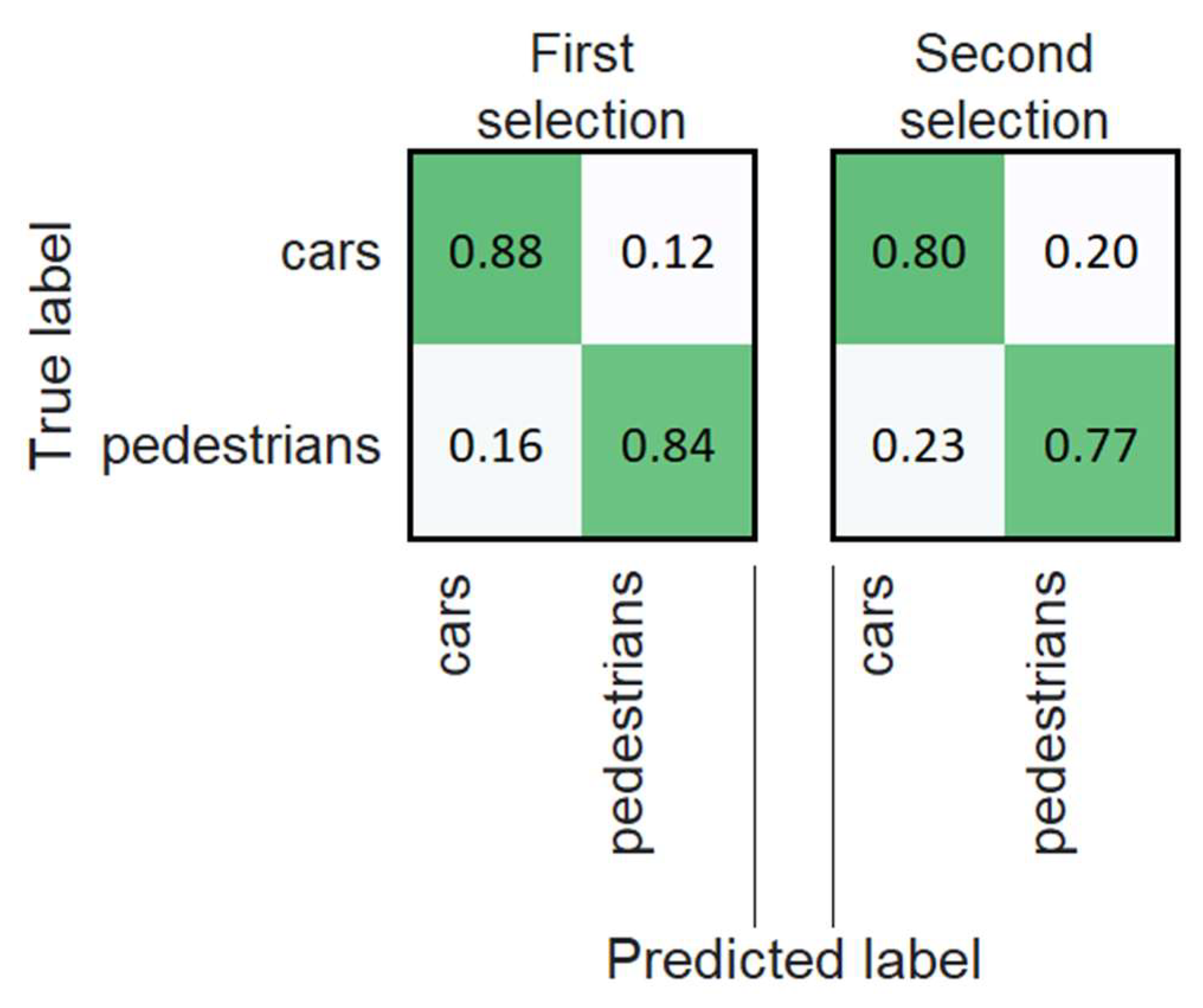
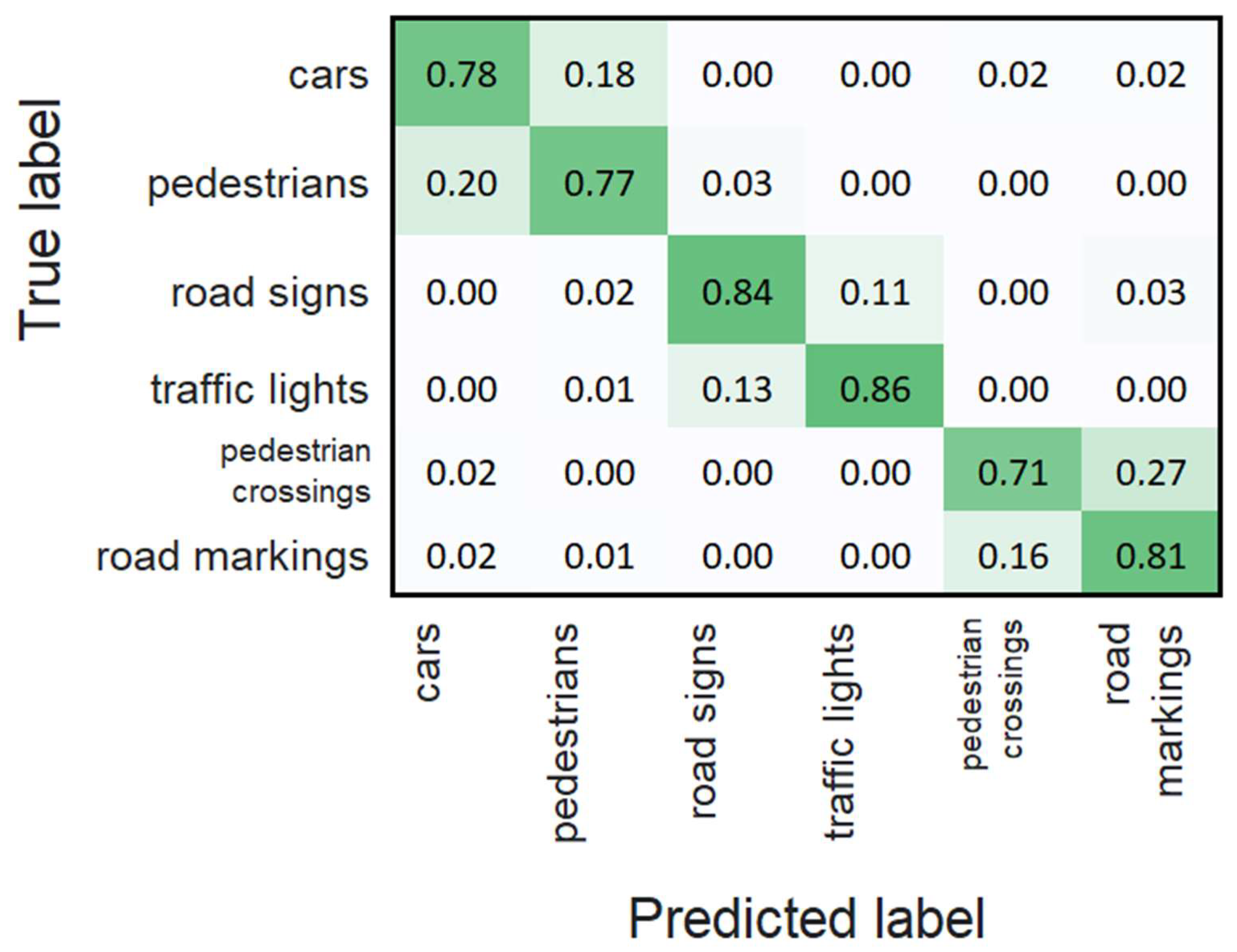
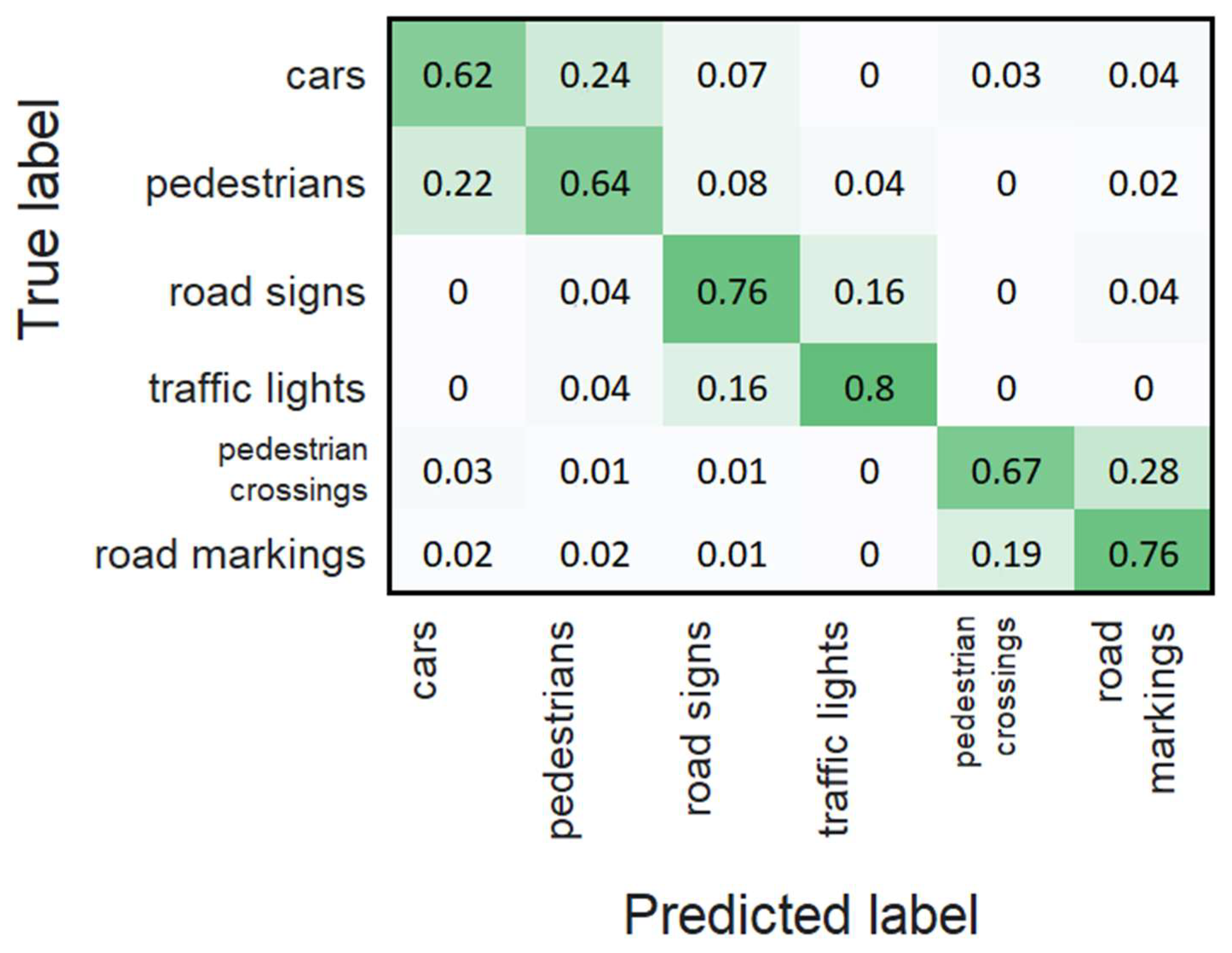
| Objects | Images Were Taken through Clear Protective Glass | Images Were Taken through Protective Glass Covered with Drops of Water or Dirt | ||
|---|---|---|---|---|
| Multiclass Classification | Binary Classification | Multiclass Classification | Binary Classification | |
| Cars | 1942 | 1942 | 360 | 360 |
| Pedestrians | 1856 | 1856 | 345 | 345 |
| Road signs | 1125 | 385 | ||
| Traffic lights | 830 | 320 | ||
| Pedestrian crossings | 985 | 240 | ||
| Road markings | 1430 | 380 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Osipov, A.; Pleshakova, E.; Gataullin, S.; Korchagin, S.; Ivanov, M.; Finogeev, A.; Yadav, V. Deep Learning Method for Recognition and Classification of Images from Video Recorders in Difficult Weather Conditions. Sustainability 2022, 14, 2420. https://doi.org/10.3390/su14042420
Osipov A, Pleshakova E, Gataullin S, Korchagin S, Ivanov M, Finogeev A, Yadav V. Deep Learning Method for Recognition and Classification of Images from Video Recorders in Difficult Weather Conditions. Sustainability. 2022; 14(4):2420. https://doi.org/10.3390/su14042420
Chicago/Turabian StyleOsipov, Aleksey, Ekaterina Pleshakova, Sergey Gataullin, Sergey Korchagin, Mikhail Ivanov, Anton Finogeev, and Vibhash Yadav. 2022. "Deep Learning Method for Recognition and Classification of Images from Video Recorders in Difficult Weather Conditions" Sustainability 14, no. 4: 2420. https://doi.org/10.3390/su14042420
APA StyleOsipov, A., Pleshakova, E., Gataullin, S., Korchagin, S., Ivanov, M., Finogeev, A., & Yadav, V. (2022). Deep Learning Method for Recognition and Classification of Images from Video Recorders in Difficult Weather Conditions. Sustainability, 14(4), 2420. https://doi.org/10.3390/su14042420