
Analysis of Popular Social Media Topics Regarding Plastic Pollution


Abstract
1. Introduction
- 1.
- What are popular topics related to plastic pollution discussed in the Twitter-sphere?
- 2.
- How are those topics related?
2. Literature Review
2.1. Sentiment Analysis towards Social Network
2.2. Textual Analysis
How Does Society Respond to Plastic Pollution?
2.3. Twitter
2.4. Topic Modelling
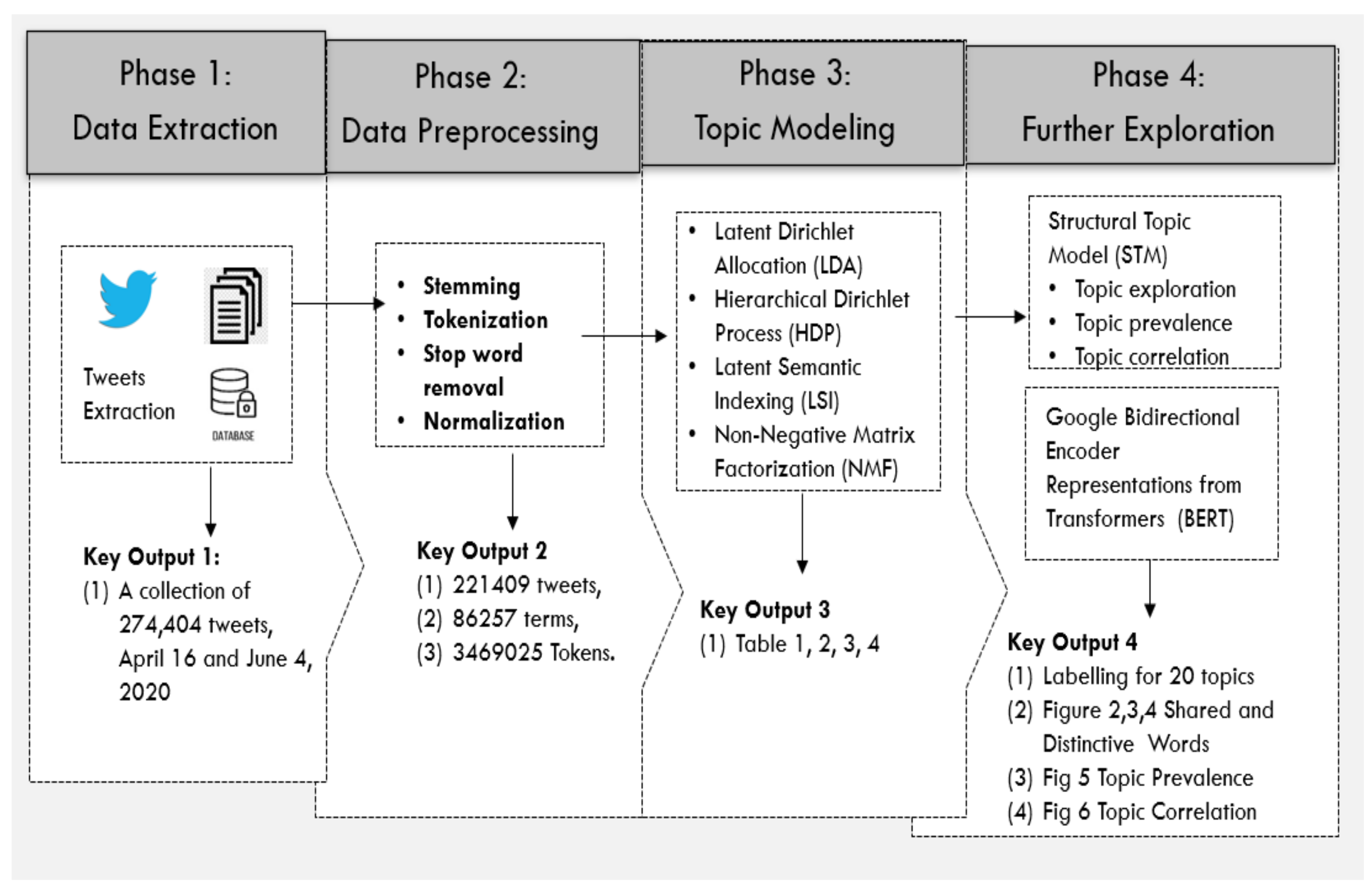
3. Data and Methodology
3.1. Data Extraction
3.2. Methods and Tools for Topic Analysis
3.3. Data Pre-Processing
3.4. Topic Labelling
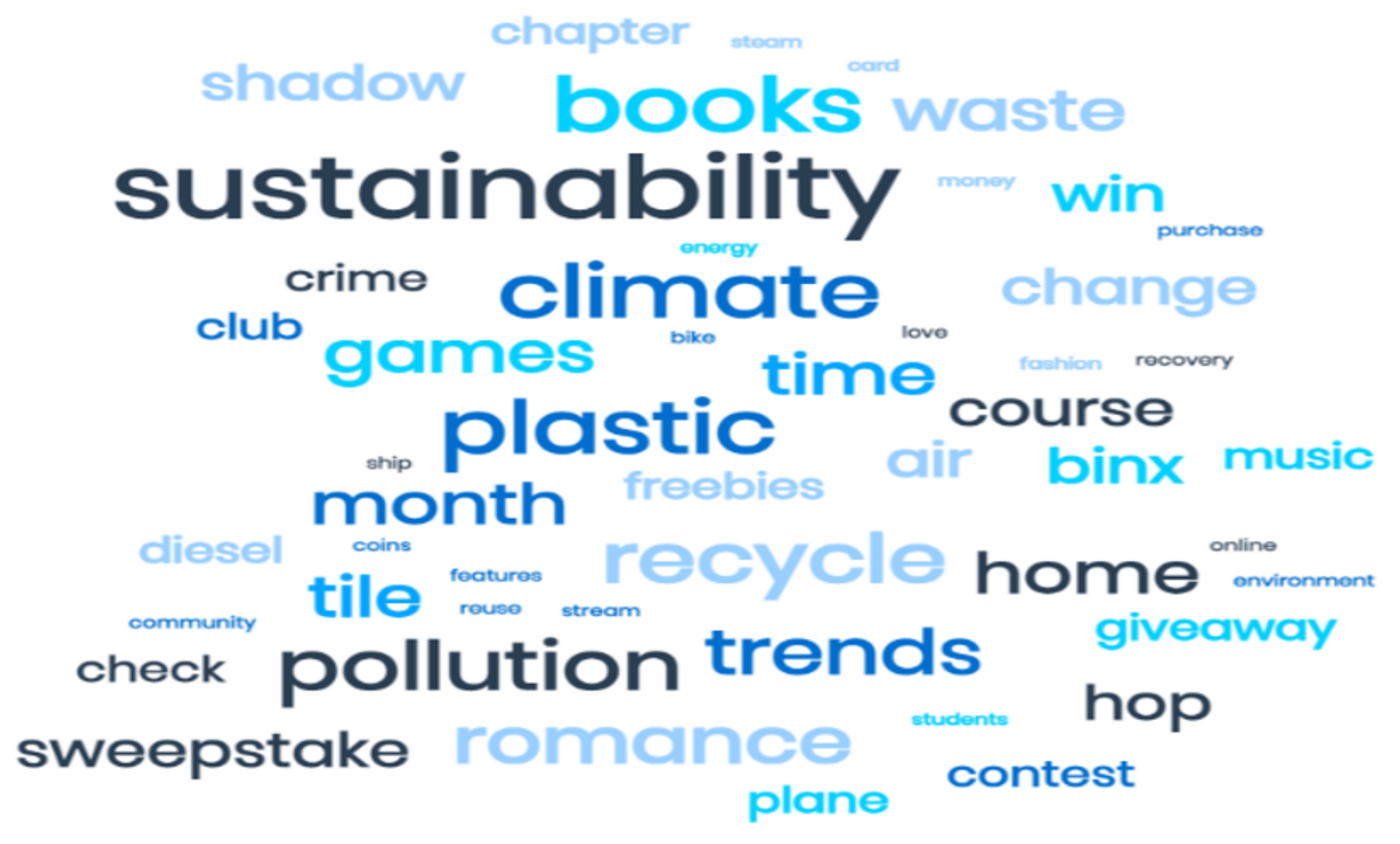
4. Topic Extraction and Analysis
4.1. Topic Extraction with LDA, LSI, HDP, NMF
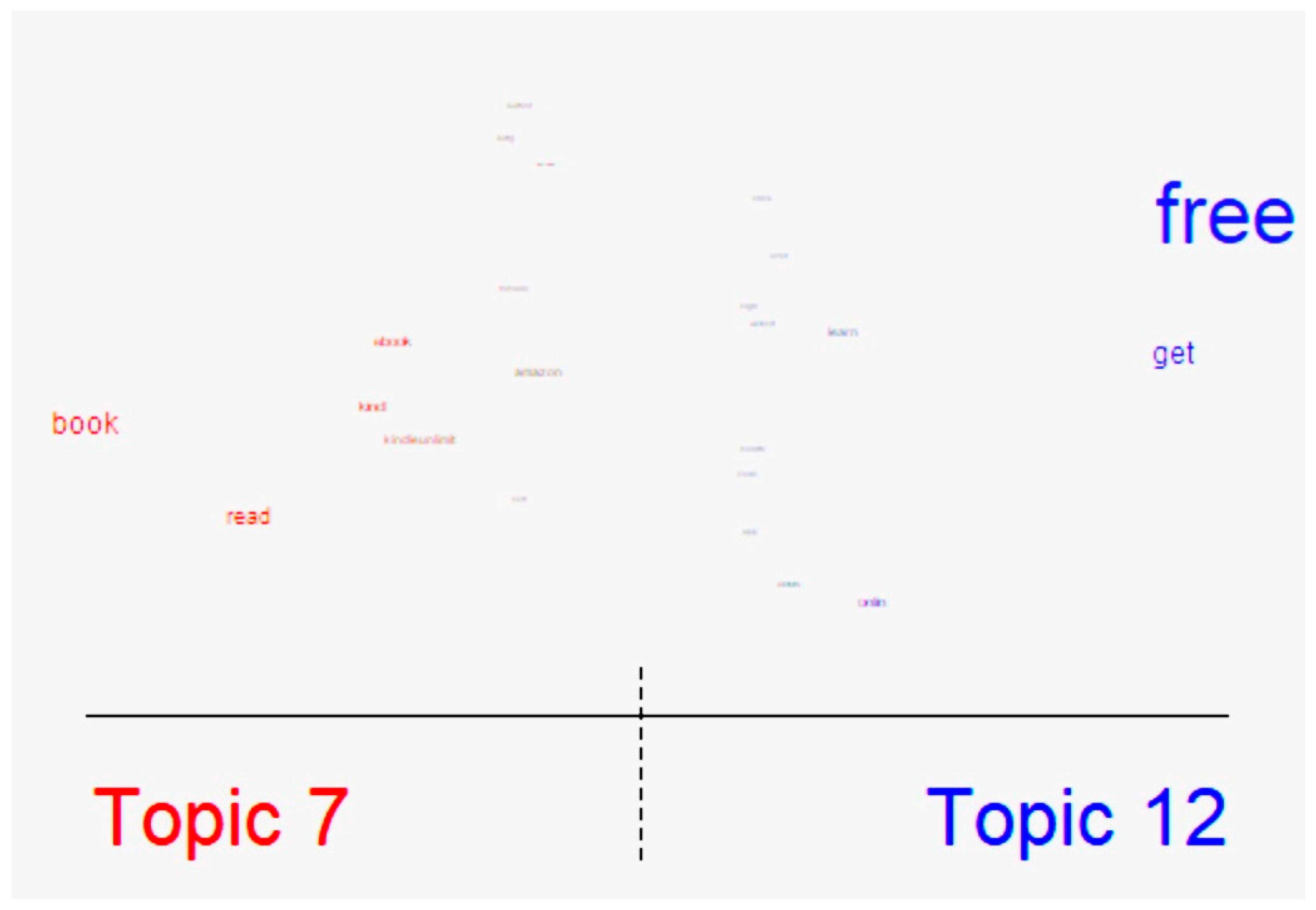
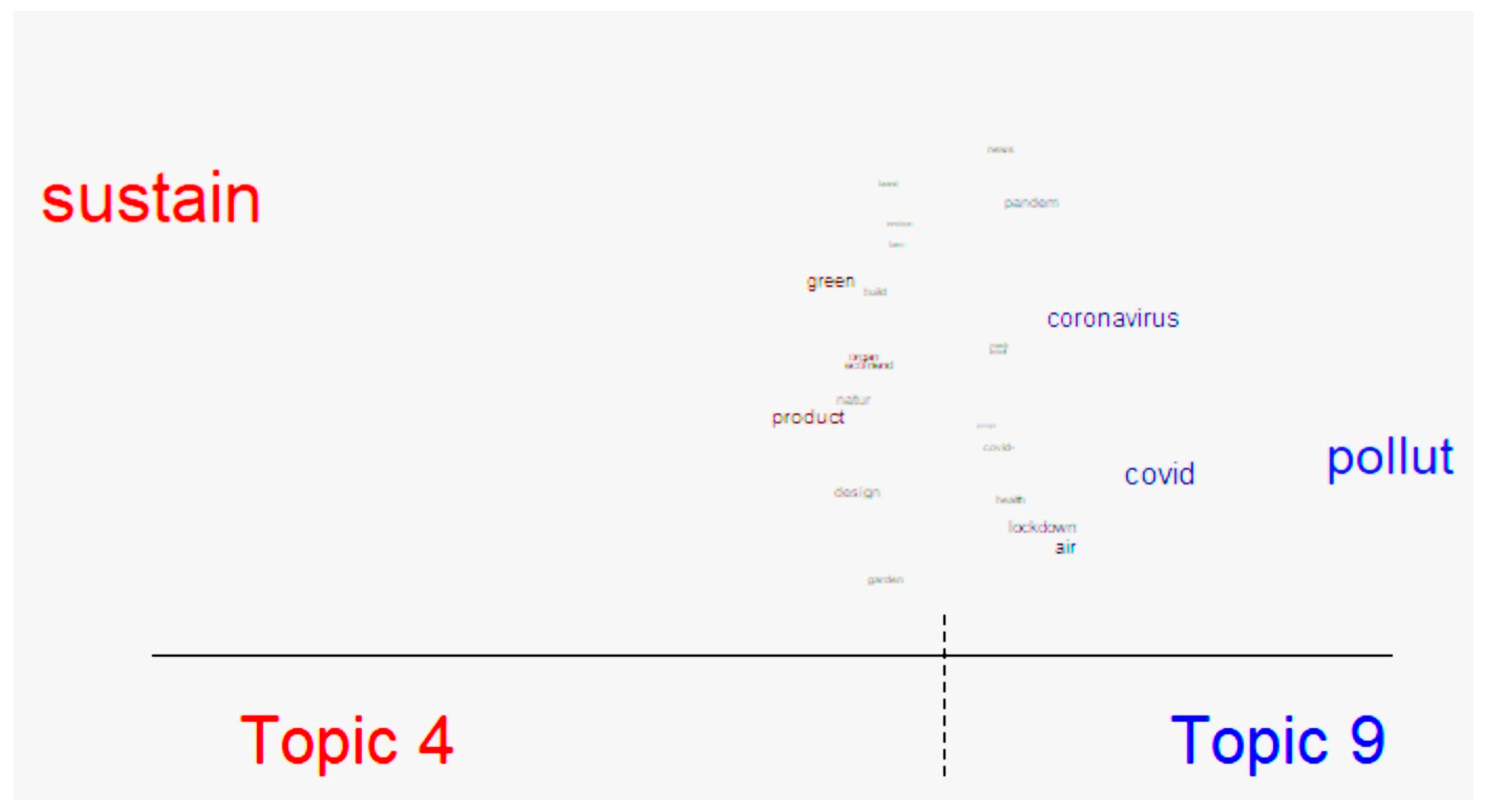
4.2. Topic Exploration with STM Package
4.2.1. Topic Extraction
4.2.2. Topic Prevalence
4.2.3. Topic Correlation
5. Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
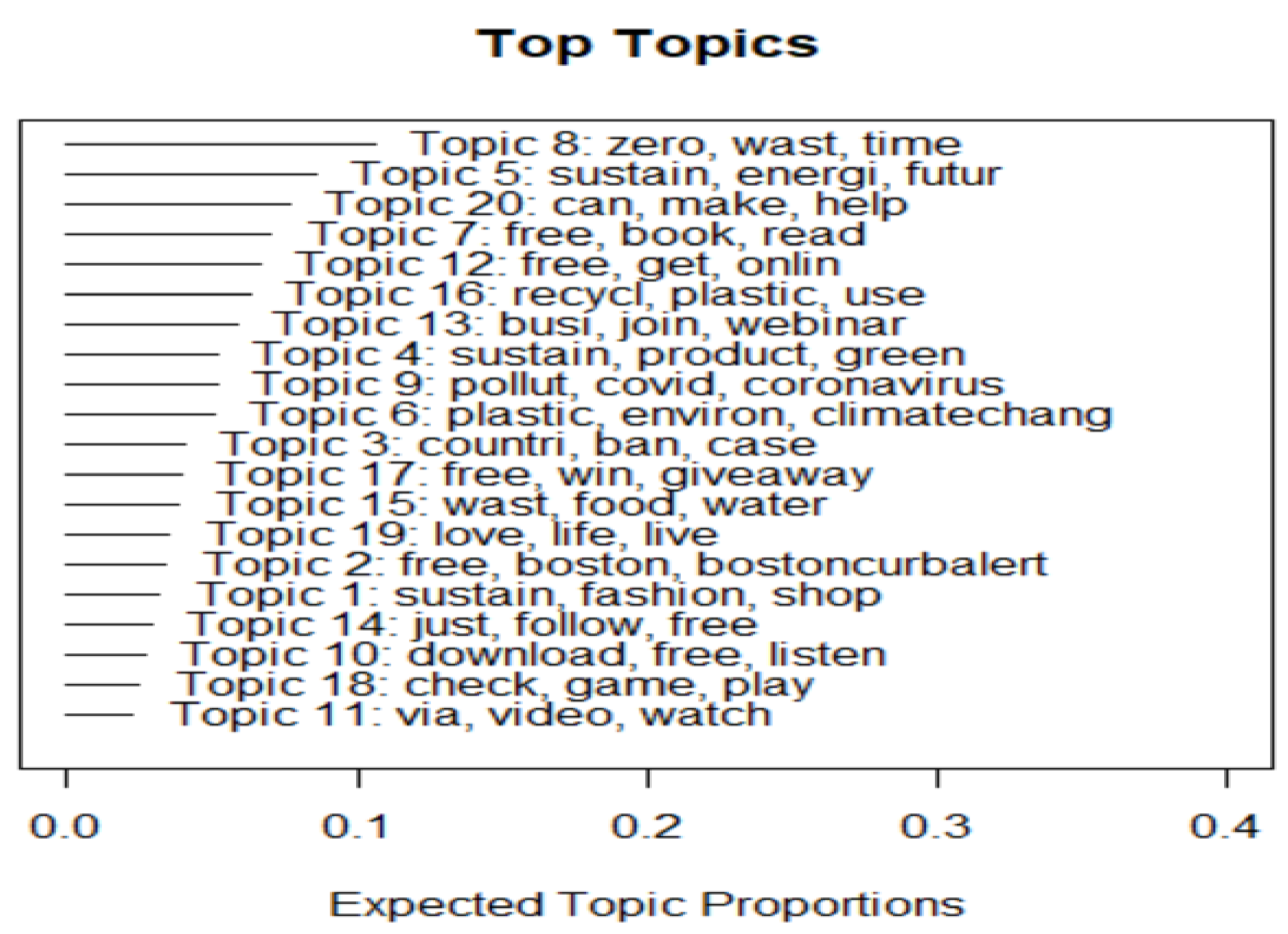
| Label | Top Words | A Sample of Original Tweet | Expected Topic Proportions |
|---|---|---|---|
| T1 Fashion | Sustain, fashion, shop, cloth, size | Vintage 1980s does 1950s full skirt|80s novelty print black, red and white skirt|size medium #vintageclothing #sustainable #onlineshopping #fashion #vintagefashion #retrouverbiz #Vintagelifestyle | 0.035 |
| T2 Boston free stuff | Free, Boston, Boston curb alert, freebies, wood | Wood #BostonCurbAlert #Boston #Free | 0.04 |
| T3 Ban on countries | Countries, ban, case, government, state | The Turkish national #government just declared a 48-hour complete #ban for citizens of most cities around the country, including #Istanbul and #Ankara effective tonight at midnight because of #coronavirus. The ban was announced ONE HOUR BEFORE it took effect. | 0.044 |
| T4 Going green | Sustain, product, green, nature, design | Would you prefer a contractor that used green products? …… #yqr #regina #sask #sk #saskatchewan #construction #conservation #renovation #custom #interiordesign #design #nature #greenproducts #eco #sustainable #ecofriendly #earth #green | 0.05 |
| T5 Sustainable energy | Sustain, energy, future, develop, industries | Global partnerships to accelerate a #CleanEnergy future continue to grow. 7 companies based in #Singapore and #Japan have joined forces to help Singapore develop a #sustainable energy system with #hydrogen as a key element. #HydrogenNow | 0.08 |
| T6 Plastic pollution | Plastic, environment, climate change, world, pollution | Wake up before it’s too late, save the environment, save nature, save forests, save water Air pollution, climate change, global warming, plastic pollution, water pollution are the biggest threats to the environment #ForNature #biodiversity #environment #WorldEnvironmentDay #india #Earth | 0.05 |
| T7 Reading | Free, book, read, kindle, ebook | #Lockdown #stayathome #staysafe #Read #FREE #eBooks on #Kindle Also available for free download, two of my titles #AnArrangedMatch #Madeinheavendotcom Download the Kindle app on your phones/tablets or use a Kindle eReader and start reading! #KindleIndia | 0.07 |
| T8 Zero waste | Zero, waste, time, just, people | The environment is just nurturing us since time immemorial, It is time to give back. Let’s pledge to protect it. here are some zero waste tips that u can implement in your daily life. let’s try to be more sustainable! #WorldEnvironmentDay #foharmalai #saveocean @ | 0.11 |
| T9 Covid-19 | Pollution, covid, coronavirus, air, lockdown | The positive impact of the world’s biggest coronavirus lockdown in an India recent report of SAFAR the graph of PM2.5 and NO2 fell during this lockdown. Source: #airpollution #pollution #covid19 #lockdowneffect #lockdown #coronavirus | 0.05 |
| T10 Free music | Download, free, listen, art, new | Want to download free (No Copyright Music) then click the link to see a new Youtube Channel called Sound Studio and start listening to some music. #YouTube #free #music #new #sound #YouTubers #youtubechannel #StayHome #StayAtHome #staysafe #soundtrack | 0.025 |
| T11 Watch video | Via, video, watch, full, share | Free Udacity nano degree course FREE Subscribe the channel plzz and watch video step by step carefully #share #udacity #free #freecourses #YouTube #Twitter #StayHomeStaySafe #QuarantineTime #studywithflow #Saturday | 0.015 |
| T12 Online learning | Free, get, online, learn, course | Learn about #sustainability and take action with our #online course in#environmental natural resources and sustainable development. 100% #scholarship offered by Government of #India on #iLearn- #StudyiLearn #eVBAB @IndiainDRC @indiainzambia @IndiainUganda | 0.065 |
| T13 Webinar | Business, join, webinar, may, support | Join to support this webinar for an overview of the sustainable plastics marketplace and businesses that have developed sustainable solutions. #EENcanhelp RT @KTN-Creative: Now Live Designing Sustainable Plastic Solutions comp. @innovateuk will invest up to “800k to fund early-stage, human-centered design projects to reduce the harm that plastics have on our environment and increase productivity and amp; growth of the UK economy. | 0.055 |
| T14 Giveaways | Just, follow, free, giveaway, post | Don’t forget !! CashApp Giveaway tomorrow!! #CashAppFriday #cashapp #stocks #robinhood #webull #m1 #stash #freemoney #moneygiveaway #Stimuluscheck #free #freecash RT @bdippr: @Bdippr @Bdippr @bdippr Weekly Cash App Giveaway (x3) CashApp Prizes FREE money! Invest it ,It’s super easy to enter!! 1. Follow @bdippr 2. Tag a friend 3. Retweet this post. | 0.03 |
| T15 Wastage | Waste, food, water, time, service | Want to produce delivered to your door AND save money or time? Imperfect provides produce too ugly for the grocery store but still perfectly edible! Less food waste means less water waste #climatechange, #pollution | 0.044 |
| T16 3R concept | Recycle, plastic, use, reuse, package | From villain to the hero during #COVID19. Demand for #plastic masks, gloves and packaged goods are soaring. Plastics seem now indispensable: cheap and amp; disposable. A backlash to the #recycling and amp; ban #singleuse plastic movements? Getting back to the #circulareconomy will take some effort | 0.06 |
| T17 Gift cards giveaways | Free, win, giveaway, gift, card | I am running in a #free #giveaway by @ameel-rahimi for a chance to win a 2GAME Gift card, Make sure you enter as well! #free #Fortnite #vbucks #steam #game #lockdown #paypal #entertowin #Giveaway #GiveawayAlert #COVID19 | 0.044 |
| T18 Free games | Check, game, play, free, fun | Give your kids something super fun to do with Seussville! They can watch videos, play games, and explore the wonderful world of Dr. Suess here! > . #DrSeuss #reading #imagination #fun #learning #activities #games #kids #free | 0.018 |
| T19 Happy life | Love, life, live, happiness, families | IDENTIFY and REMOVE TOXINS: REJUVENATE YOUR #BODY #health #love #life #live #money #travel #vegan #wisdom #wellness #motivation #inspiration #nature #family #Covid-19 #fitness #FamiliesFirst #children #art #free #ThursdayThoughts #ThursdayMotivation #style | 0.04 |
| T20 Help needed | Can, make, help, need, will | This coming week we want to help solve the single-use plastic problem that is facing our planet. What are some of the ways we can reuse single-use plastic? #Reuse #Plastic #Pollution #CleanBeaches #Trash #Garbage #Environment #LoveEarth #Green #Recycle #SturdyWings #StaySturdy | 0.075 |
References
- Koelmans, A.A.; Nor, N.H.M.; Hermsen, E.; Kooi, M.; Mintenig, S.M.; De France, J. Microplastics in freshwaters and drinking water: Critical review and assessment of data quality. Water Res. 2019, 155, 410–422. [Google Scholar] [CrossRef] [PubMed]
- McGoran, A.R.; Cowie, P.R.; Clark, P.F.; McEvoy, J.P.; Morritt, D. Ingestion of plastic by fish: A comparison of Thames Estuary and Firth of Clyde populations. Mar. Pollut. Bull. 2018, 137, 12–23. [Google Scholar] [CrossRef]
- Kaza, S.; Yao, L.; Bhada-Tata, P.; Van Woerden, F. What a Waste 2.0: A Global Snapshot of Solid Waste Management to 2050. Urban Development, World Bank Publications. 2018. Available online: https://openknowledge.worldbank.org/handle/10986/30317 (accessed on 1 November 2021).
- Parker, L. Hereś How Much Plastic Trash Is Littering the Earth. 2018. Available online: https://www.nationalgeographic.com/science/article/plastic-produced-recycling-waste-ocean-trash-debris-environment (accessed on 19 March 2021).
- Bashir, N.H. Plastic problem in Africa. Jpn. J. Vet. Res. 2013, 61, S1–S11. [Google Scholar]
- Brandt, T.; Bendler, J.; Neumann, D. Social media analytics and value creation in urban smart tourism ecosystems. Inf. Manag. 2017, 54, 703–713. [Google Scholar] [CrossRef]
- Banu, S.H.; Chitrakala, S. Trending Topic Analysis using novel sub topic detection model. In Proceedings of the 2016 2nd International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 27–28 February 2016; pp. 157–161. [Google Scholar]
- Kusiak, A.; Zhang, Z.; Verma, A. Prediction, operations, and condition monitoring in wind energy. Energy 2013, 60, 1–12. [Google Scholar] [CrossRef]
- Del Vecchio, P.; Mele, G.; Ndou, V.; Secundo, G. Open innovation and social big data for sustainability: Evidence from the tourism industry. Sustainability 2018, 10, 3215. [Google Scholar] [CrossRef]
- Tumasjan, A.; Sprenger, T.; Sandner, P.; Welpe, I. Predicting elections with twitter: What 140 characters reveal about political sentiment. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4. [Google Scholar]
- Gu, Y.; Qian, Z.S.; Chen, F. From Twitter to detector: Real-time traffic incident detection using social media data. Transp. Res. Part C Emerg. Technol. 2016, 67, 321–342. [Google Scholar] [CrossRef]
- Kumar, S.; Kumar, N.; Vivekadhish, S. Millennium development goals (MDGS) to sustainable development goals (SDGS): Addressing unfinished agenda and strengthening sustainable development and partnership. Indian J. Community Med. Off. Publ. Indian Assoc. Prev. Soc. Med. 2016, 41, 1. [Google Scholar] [CrossRef]
- Mihi-Ramírez, A.; García-Rodríguez, Y.; Cuenca-García, E. Innovation and international high skilled migration. Eng. Econ. 2016, 27, 452–461. [Google Scholar] [CrossRef]
- Pedercini, M.; Zuellich, G.; Dianati, K.; Arquitt, S. Toward achieving sustainable development goals in Ivory Coast: Simulating pathways to sustainable development. Sustain. Dev. 2018, 26, 588–595. [Google Scholar] [CrossRef]
- Vladimirova, K.; Le Blanc, D. Exploring links between education and sustainable development goals through the lens of UN flagship reports. Sustain. Dev. 2016, 24, 254–271. [Google Scholar] [CrossRef]
- Fuster Morell, M.; Espelt, R. A framework for assessing democratic qualities in collaborative economy platforms: Analysis of 10 cases in Barcelona. Urban Sci. 2018, 2, 61. [Google Scholar] [CrossRef]
- Hubert, M.; Blut, M.; Brock, C.; Backhaus, C.; Eberhardt, T. Acceptance of smartphone-based mobile shopping: Mobile benefits, customer characteristics, perceived risks, and the impact of application context. Psychol. Mark. 2017, 34, 175–194. [Google Scholar] [CrossRef]
- Porcher, S.; Renault, T. Social distancing beliefs and human mobility: Evidence from Twitter. PLoS ONE 2021, 16, e0246949. [Google Scholar] [CrossRef]
- Mellon, J.; Prosser, C. Twitter and Facebook are not representative of the general population: Political attitudes and demographics of British social media users. Res. Politics 2017, 4. [Google Scholar] [CrossRef]
- Pavalanathan, U.; Eisenstein, J. Confounds and consequences in geotagged Twitter data. arXiv 2015, arXiv:1506.02275. [Google Scholar]
- Malik, M.M.; Lamba, H.; Nakos, C.; Pfeffer, J. Population bias in geotagged tweets. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Palomino, M.; Taylor, T.; Göker, A.; Isaacs, J.; Warber, S. The online dissemination of nature–health concepts: Lessons from sentiment analysis of social media relating to “nature-deficit disorder”. Int. J. Environ. Res. Public Health 2016, 13, 142. [Google Scholar] [CrossRef] [PubMed]
- Bennett, D.; Yábar, D.P.B.; Saura, J.R. University incubators may be socially valuable, but how effective are they? A case study on business incubators at universities. In Entrepreneurial Universities; Springer: Berlin, Germany, 2017; pp. 165–177. [Google Scholar]
- John, L.K.; Emrich, O.; Gupta, S.; Norton, M.I. Does “liking” lead to loving? The impact of joining a brand’s social network on marketing outcomes. J. Mark. Res. 2017, 54, 144–155. [Google Scholar] [CrossRef]
- Saura, J.R.; Palos-Sanchez, P.; Rios Martin, M.A. Attitudes expressed in online comments about environmental factors in the tourism sector: An exploratory study. Int. J. Environ. Res. Public Health 2018, 15, 553. [Google Scholar] [CrossRef] [PubMed]
- Ekenga, C.C.; McElwain, C.A.; Sprague, N. Examining public perceptions about lead in school drinking water: A mixed-methods analysis of Twitter response to an environmental health hazard. Int. J. Environ. Res. Public Health 2018, 15, 162. [Google Scholar] [CrossRef]
- Zhou, X.; Chen, L. Event detection over twitter social media streams. VLDB J. 2014, 23, 381–400. [Google Scholar] [CrossRef]
- Pak, A.; Paroubek, P. Twitter as a corpus for sentiment analysis and opinion mining. In Proceedings of the International Conference on Language Resources and Evaluation, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Chisholm, E.; O’Sullivan, K. Using Twitter to explore (un) healthy housing: Learning from the# Characterbuildings campaign in New Zealand. Int. J. Environ. Res. Public Health 2017, 14, 1424. [Google Scholar]
- Tlebere, T.; Scholtz, B.; Calitz, A.P. Using social media to improve environmental awareness in higher education institutions. In Information Technology in Environmental Engineering; Springer: Berlin, Germany, 2016; pp. 101–111. [Google Scholar]
- Cao, X.; MacNaughton, P.; Deng, Z.; Yin, J.; Zhang, X.; Allen, J.G. Using Twitter to better understand the spatiotemporal patterns of public sentiment: A case study in Massachusetts, USA. Int. J. Environ. Res. Public Health 2018, 15, 250. [Google Scholar] [CrossRef]
- Worldmeter. 2021. Available online: https://www.worldometers.info/world-population (accessed on 1 March 2021).
- Plastic Statistics. 2018. Available online: https://oceancrusaders.org/tag/plastic-statistics/ (accessed on 1 March 2021).
- Burgess, R.M.; Ho, K.T.; Mallos, N.J.; Leonard, G.H.; Hidalgo-Ruz, V.; Cook, A.M.; Christman, K. Microplastics in the aquatic environment—Perspectives on the scope of the problem. Environ. Toxicol. Chem. 2017, 36, 2259–2265. [Google Scholar] [CrossRef]
- FE Online. 2018. Available online: https://www.financialexpress.com/india-news/which-countries-are-way-ahead-of-india-in-curbing-plastic-pollution/1201608/ (accessed on 1 March 2021).
- Kamaruddin, R.; Yusuf, M.M. Selangor Government’s “No plastic Bag Day” Campaign: Motivation and acceptance level. Procedia-Soc. Behav. Sci. 2012, 42, 205–211. [Google Scholar] [CrossRef][Green Version]
- Plastic Bags Will Be Charged RM1 Each In Penang Starting January 2021—Penang Foodie. 2021. Available online: https://penangfoodie.com/ (accessed on 1 February 2021).
- Smith, L.R.; Pegoraro, A.; Cruikshank, S.A. Tweet, retweet, favorite: The impact of Twitter use on enjoyment and sports viewing. J. Broadcast. Electron. Media 2019, 63, 94–110. [Google Scholar] [CrossRef]
- Phua, J.; Jin, S.V.; Kim, J. The roles of celebrity endorsers’ and consumers’ vegan identity in marketing communication about veganism. J. Mark. Commun. 2020, 26, 813–835. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Cho, H.W. Topic Modeling. Osong Public Health Res. Perspect. 2019, 10, 115. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Tang, L.; Dong, W.; Yao, S.; Zhou, W. An overview of topic modeling and its current applications in bioinformatics. SpringerPlus 2016, 5, 1–22. [Google Scholar] [CrossRef]
- Liu, X.; Burns, A.C.; Hou, Y. An investigation of brand-related user-generated content on Twitter. J. Advert. 2017, 46, 236–247. [Google Scholar] [CrossRef]
- Geva, H.; Oestreicher-Singer, G.; Saar-Tsechansky, M. Using retweets when shaping our online persona: Topic modeling approach. MIS Q. 2019, 43, 501–524. [Google Scholar] [CrossRef]
- Jiang, S.; Qian, X.; Shen, J.; Mei, T. Travel recommendation via author topic model based collaborative filtering. In International Conference on Multimedia Modeling; Springer: Berlin, Germany, 2015; pp. 392–402. [Google Scholar]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Lindstedt, N.C. Structural Topic Modeling For Social Scientists: A Brief Case Study with Social Movement Studies Literature, 2005–2017. Soc. Curr. 2019, 6, 307–318. [Google Scholar] [CrossRef]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Sharing clusters among related groups: Hierarchical Dirichlet processes. In Proceedings of the Advances in Neural Information Processing Systems Conference, Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Févotte, C.; Idier, J. Algorithms for nonnegative matrix factorization with the β-divergence. Neural Comput. 2011, 23, 2421–2456. [Google Scholar] [CrossRef]
- Shi, T.; Kang, K.; Choo, J.; Reddy, C.K. Short-text topic modeling via non-negative matrix factorization enriched with local word-context correlations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1105–1114. [Google Scholar]
- Roberts, M.E.; Stewart, B.M.; Tingley, D. Stm: An R package for structural topic models. J. Stat. Softw. 2019, 91, 1–40. [Google Scholar] [CrossRef]
- Chae, B.K.; Park, E.O. Corporate social responsibility (CSR): A survey of topics and trends using Twitter data and topic modeling. Sustainability 2018, 10, 2231. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Airoldi, E.M. A model of text for experimentation in the social sciences. J. Am. Stat. Assoc. 2016, 111, 988–1003. [Google Scholar] [CrossRef]
- Milner, H.V.; Tingley, D. Sailing the Water’s Edge; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Davidson, T.; Bhattacharya, D. Examining racial bias in an online abuse corpus with structural topic modeling. arXiv 2020, arXiv:2005.13041. [Google Scholar]
- Chandelier, M.; Steuckardt, A.; Mathevet, R.; Diwersy, S.; Gimenez, O. Content analysis of newspaper coverage of wolf recolonization in France using structural topic modeling. Biol. Conserv. 2018, 220, 254–261. [Google Scholar] [CrossRef]
- Vanhala, M.; Lu, C.; Peltonen, J.; Sundqvist, S.; Nummenmaa, J.; Järvelin, K. The usage of large data sets in online consumer behaviour: A bibliometric and computational text-mining–driven analysis of previous research. J. Bus. Res. 2020, 106, 46–59. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Lucas, C.; Leder-Luis, J.; Gadarian, S.K.; Albertson, B.; Rand, D.G. Structural topic models for open-ended survey responses. Am. J. Political Sci. 2014, 58, 1064–1082. [Google Scholar] [CrossRef]
- Netzer, O.; Feldman, R.; Goldenberg, J.; Fresko, M. Mine your own business: Market-structure surveillance through text mining. Mark. Sci. 2012, 31, 521–543. [Google Scholar] [CrossRef]
- Fan, W.; Wallace, L.; Rich, S.; Zhang, Z. Tapping the power of text mining. Commun. ACM 2006, 49, 76–82. [Google Scholar] [CrossRef]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage Publications: Sauzende Oaks, CA, USA, 2018. [Google Scholar]
- Teh, P.L.; Yap, W.L. GoVegan: Exploring motives and opinions from tweets. In World Conference on Information Systems and Technologies; Springer: Berlin, Germany, 2021; pp. 3–12. [Google Scholar]
- Kenski, K.; Filer, C.R.; Conway-Silva, B.A. Lying, liars, and lies: Incivility in 2016 presidential candidate and campaign tweets during the invisible primary. Am. Behav. Sci. 2018, 62, 286–299. [Google Scholar] [CrossRef]
- Wong, S.C.; Teh, P.L.; Cheng, C.B. How different genders use profanity on Twitter? In Proceedings of the 4th International Conference on Compute and Data Analysis (ICCDA 2020), Silicon Valley, CA, USA, 9–12 March 2020; pp. 1–9. [Google Scholar]
- Zhang, M.; Geng, G.; Zeng, S.; Jia, H. Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information. Entropy 2020, 22, 1168. [Google Scholar] [CrossRef] [PubMed]
- Xiang, Z.; Schwartz, Z.; Gerdes, J.H., Jr.; Uysal, M. What can big data and text analytics tell us about hotel guest experience and satisfaction? Int. J. Hosp. Manag. 2015, 44, 120–130. [Google Scholar] [CrossRef]
- Silva, A.L.P.; Prata, J.C.; Walker, T.R.; Duarte, A.C.; Ouyang, W.; Barcelò, D.; Rocha-Santos, T. Increased plastic pollution due to COVID-19 pandemic: Challenges and recommendations. Chem. Eng. J. 2021, 405, 126683. [Google Scholar]
- Yang, Y.; Pan, B.; Song, H. Predicting hotel demand using destination marketing organization’s web traffic data. J. Travel Res. 2014, 53, 433–447. [Google Scholar] [CrossRef]
- Calafat, A.M.; Weuve, J.; Ye, X.; Jia, L.T.; Hu, H.; Ringer, S.; Huttner, K.; Hauser, R. Exposure to bisphenol A and other phenols in neonatal intensive care unit premature infants. Environ. Health Perspect. 2009, 117, 639–644. [Google Scholar] [CrossRef] [PubMed]
- Gregory, M.R. Environmental implications of plastic debris in marine settings—Entanglement, ingestion, smothering, hangers-on, hitch-hiking and alien invasions. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 2013–2025. [Google Scholar] [CrossRef] [PubMed]











| Research | Social Network | Aim | Analysis of Unit |
|---|---|---|---|
| Palomino et al. [22] | Identifying public opinion and examining discourse connected to nature-deficit disorder and other nature-health notions in order to better understand the impact of the natural environment on people’s well-being and health. | HashTag | |
| Ekenga et al. [26] | By monitoring the public response on the Twitter social network to comments about rising water levels, by determining the issues that most concerned the community about environmental risks. | Posts | |
| Saura et al. [25] | To determine the good, neutral, and negative elements reported by hotel guests in Spain | Posts | |
| Chisholm and O’Sullivan et al. [29] | To demonstrate how Twitter may be used to give information about housing as a relating to public health issue, in the case study #characterbuildings campaign that launched in New Zealand in 2014. | HashTag | |
| Woo et al. [30] | To investigate tweets posted in response to a natural disaster in Korea and to determine changes in user attitude | Posts | |
| Cao et al. [31] | To find time and space-related behaviour patterns that contribute to user well-being and enjoyment. | Posts |
| Topic Model | Coheren | Meaningful Topics Labelled Manually | Topic Types |
|---|---|---|---|
| NFP | 0.4956 | 3R Concept, Plastic Pollution, Climate Change, Sustainable, Audiobook, Romance, Bear Market, Free Stuff, Online Learning, Game, Music, stock, writing, Free books | 4/14/20 |
| LDA | 0.4014 | 3R Plastic Pollution, Environment, Sustainable, Poems, Present, Experience, Peace and violent | 3/7/20 |
| HDP | 0.3503 | Waste Management, Plastic Pollution, Plastic Pollution2, Plastic Pollution3, Plastic Waste, Plastic Waste2, Plastic Waste3, Environment, Environment2 | 9/9/20 |
| LSI | 0.3440 | 3R Concept, 3R Concept2, Recycling, Recycling2, Climate Change, Renewable Energy, Sustainable, Sustainability, Sustainability2, Giveaways | 9/10/20 |
| Climate Change | Plastic Pollution |
|---|---|
| pollution | plastic |
| air | use |
| climate | bag |
| change | bottle |
| environment | ocean |
| lockdown | recycle |
| clean | recycling |
| level | single |
| see | plasticfree |
| water | packaging |
| Climate Change (LSI) | Plastic Pollution (HDP) |
|---|---|
| climate | swear |
| month | trigger |
| change | well |
| trial | handle |
| free | become |
| student | doll |
| click | plastic |
| faster | waste |
| ship | idk |
| purchase | rank |
| Topic | Frequency |
|---|---|
| Plastic Pollution | 5 |
| Sustainable/Sustainability | 5 |
| Plastic Waste | 3 |
| Environment | 3 |
| 3R Concept | 3 |
| Recycling | 2 |
| Climate Change | 2 |
| Waste Management | 1 |
| Renewable Energy | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teh, P.L.; Piao, S.; Almansour, M.; Ong, H.F.; Ahad, A. Analysis of Popular Social Media Topics Regarding Plastic Pollution. Sustainability 2022, 14, 1709. https://doi.org/10.3390/su14031709
Teh PL, Piao S, Almansour M, Ong HF, Ahad A. Analysis of Popular Social Media Topics Regarding Plastic Pollution. Sustainability. 2022; 14(3):1709. https://doi.org/10.3390/su14031709
Chicago/Turabian StyleTeh, Phoey Lee, Scott Piao, Mansour Almansour, Huey Fang Ong, and Abdul Ahad. 2022. "Analysis of Popular Social Media Topics Regarding Plastic Pollution" Sustainability 14, no. 3: 1709. https://doi.org/10.3390/su14031709
APA StyleTeh, P. L., Piao, S., Almansour, M., Ong, H. F., & Ahad, A. (2022). Analysis of Popular Social Media Topics Regarding Plastic Pollution. Sustainability, 14(3), 1709. https://doi.org/10.3390/su14031709