1. Introduction
Predictive maintenance (PdM) has become the most promising maintenance strategy in Industry 4.0 [
1], which can significantly reduce maintenance costs and ensure critical components’ reliability and safety [
2]. Remaining useful life (RUL) prediction of engineering components and systems is one of the essential tasks in PdM. RUL prediction generally refers to the study of predicting the specific time length from the current time to the end of the useful life of an asset or system [
3]. It is a critical step to minimise catastrophic failures, and it has become an important measurement to achieve the ultimate goal of zero-downtime performance in industrial systems [
4].
Approaches for RUL prediction can be catalogued into model-based, data-driven, and hybrid methods. Model-based approaches, also called physics-based approaches, evaluate the health condition of a system by building mathematical models based on the failure mechanisms or the first principle of damage [
5,
6]. The complex and noisy working conditions often impede the construction of a physical model; cooperating in the model is usually tricky [
6]. Meanwhile, it is often difficult to determine the parameters of the physical model. In data-driven approaches, RUL is computed through statistical and probabilistic methods by utilising historical information and routinely monitored data of the system [
6]. With the presence of multivariate time sequence signals derived from parallel measurement of hundreds of process variables with various sensors, the application of many machine learning (ML) models for RUL prediction has significantly been promoted [
7]. Hybrid approaches, combining model-based and data-driven approaches, aim to leverage the advantages of both categories. Deep learning (DL), a subset of data-driven approaches attracting significant investigations in the last few years in RUL prediction, can extract multilevel features from data [
8]. As an end-to-end ML method, DL algorithms can automatically process the original signal, identify discriminative and trend features in the input data layer by layer, and improve generalisation performance [
9]. Because of its strength in self-learning features, DL has already achieved great success in the manufacturing industry [
10].
An inherent challenge for predicting the RUL of a system is to determine the desired output value for each input data point. Without an accurate physics-based model, it is impossible to accurately identify the system health status at each time step in real-world applications [
10]. Generally, there are two solutions to this problem. One is to simply assign the desired output as the actual time left before functional failure, and another is to derive the desired output values based on a suitable degradation model. We would like to discuss this challenge based on NASA’s Commercial Modular Aero-Propulsion System Simulation (C-MAPSS) dataset as one of the most popular multivariate benchmark datasets for evaluating predictive DL algorithms. For C-MAPSS, a piece-wise linear degradation model has been proposed [
11]. This model assumes that the degradation of the system typically only begins after a certain degree of usage. The threshold value is determined based on the observations, and its numerical value differs for each dataset. Since then, this model has been adopted by most of the related research.
It should be noted that the threshold value achieved in this paper is 130 based on the first subset (FD001). However, the application of this threshold value has been extended to other subsets (FD00x) in plenty of later research without sufficient justification. Yuan et al. [
12] proposed a novel dynamic differential technology that extracts inter-frame information, promoting cognition about the model degradation process. A support vector machine (SVM) is used as an anomaly detector to identify where the system starts degrading, while SVM tends to overfit because the involved kernel and penalty parameters need to be determined [
13]. An RUL prediction approach based on degradation pattern learning using a back-propagation neural network [
14]. A piece-wise linear distribution function promotes a proportion of the tail samples with a threshold of 120. Ahmed et al. [
15] designed a new LSTM architecture that uses the sensor readings to estimate the system’s health, which is then mapped to the target RUL. It is claimed that the proposed method requires no assumptions about the degradation function patterns or the point at which the degradation starts. A Denoising Online Sequential Extreme Learning Machine with Double Dynamic Forgetting Factors (DDFF) and Updated Selection Strategy (USS) is proposed by Berghout et al. [
16]. The Online Sequential Extreme Learning Machine (OS-ELM) is used to fit the non-accumulative linear degradation function of the engine to address dynamic programming by tracking the new coming data and gradually forgetting the old ones based on DDFF. The piece-wise linear function is used as the RUL target function, and the threshold is 130. Chen et al. [
17] presented a Gated Recurrent Unit (GRU) based neural network that has also been used to extract and learn the nonlinear degradation patterns in the dataset, where the linear function is used as the RUL target function. An unsupervised pre-trained model for turbofan RUL prediction is proposed by Listou Ellefsen et al. [
4]. This approach utilised an unsupervised and semi-supervised method to train a model to extract the features and then use the Genetic Algorithm (GA) to determine the threshold value. Shi & Chehade [
4] proposed a dual LSTM with changing detection capability. A health index construction function is utilised to help detect change points in sensor measurements and determine the threshold value. A causal augmented convolution network (CaConvNet) has been presented by Ayodeji et al. [
7]. The network is further optimised with a dynamic hyperparameter search algorithm to reduce uncertainties and minimise manual selection. A piece-wise linear function and a threshold value of 130 are adopted. Shi and Chehade proposed a dual-LSTM framework [
18] that combines change point detection and RUL prediction. They adopted the piece-wise RUL target function but assumed the threshold value to be the midpoint of the degradation process for every engine. Li et al. [
19] proposed a GRU-based high-level feature fusion block to replace the traditional fully connected layer and introduced a novel activation function Mish to perform the RUL prediction of aero-engine. They also used the piece-wise linear function, with a fixed threshold of 120 for all four subsets [
20]. Zhang et al. [
21] used the piece-wise linear function with a novel approach to identify the threshold [
19]. The thresholds for all engines are different and determined using a health status assessment evaluated by a bidirectional gated recurrent unit (BiGRU) and multi-gate mixture-of-experts (MMoE).
It should be noted that most of the previous research adopted a nonlinear RUL target function except in which the degradation process of the system is assumed to be linear with usage [
16]. The widely used piece-wise linear RUL target function with a fixing threshold of 130 accepts the degradation process of a system transitions directly from a plateau to a linear decline, and the yielding point is located at the RUL of 130. In a real-life application, once the yielding point is reached, the system’s degradation speed will accelerate until the failure occurs. The maintenance strategy should be based on the degradation rate. Most of the solutions are to predict the RUL directly using the whole past data. However, the prediction accuracy varies from engine to engine due to the inconsistent volumes of data collected from different engines and different initial conditions. Therefore, the prediction performance can be unreliable for some engines.
This paper proposes a multi-scale RUL prediction solution using LSTM with a novel RUL target function. The new RUL target function includes a transition stage between the non-degradation and linear degradation stages, aiming to better represent the engine system’s degradation process. The multi-scale prediction solution consists of a small-scale RUL prediction, where the system’s condition is classified into these three stages, and a large-scale RUL prediction, which refers to the prediction of the RUL value for the last two stages. Besides the higher RUL prediction accuracy, the proposed approach also aims to provide more flexibility in the maintenance strategy with this multi-scale RUL prediction solution. For instance, based on the small-scale RUL prediction, maintenance can be arranged when the engine system steps into the linear degradation stage. Or, based on the large-scale RUL prediction, maintenance can be arranged when the prediction value is lower than a certain threshold.
Four main contributions are presented in this paper in order to predict the RUL:
- (1)
Extracting the valuable features by using Pearson’s correlation coefficient. Pearson’s correlation coefficient is used to find the correlation between the signals from sensors and the output RUL, as well as the correlation between the signals from sensors.
- (2)
Adopting the operation-based normalisation approach. An operation-based normalisation is proposed for the engine system working under multiple operation conditions to reveal the actual degradation patterns concealed in the sensor data.
- (3)
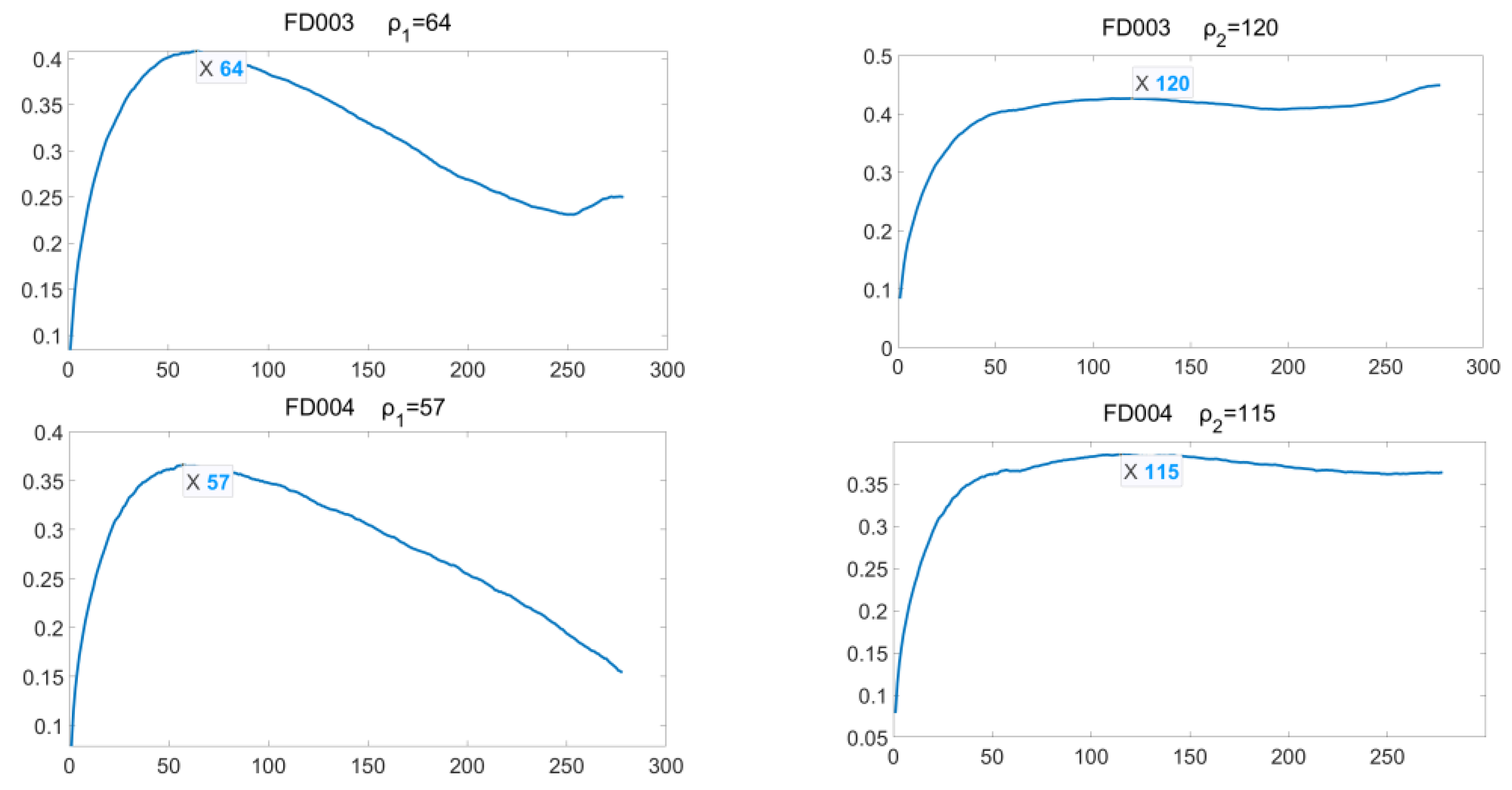
Proposing a new RUL target function for the training process. To define an approximation of the actual RUL, we assume the degradation process of the engine system goes through a constant stage, a transition stage and a linear degradation stage. The turning points of these three stages differ from engine to engine because of the different initial, operating and fault conditions. This paper proposes a correlation-based method to detect these turning points.
- (4)
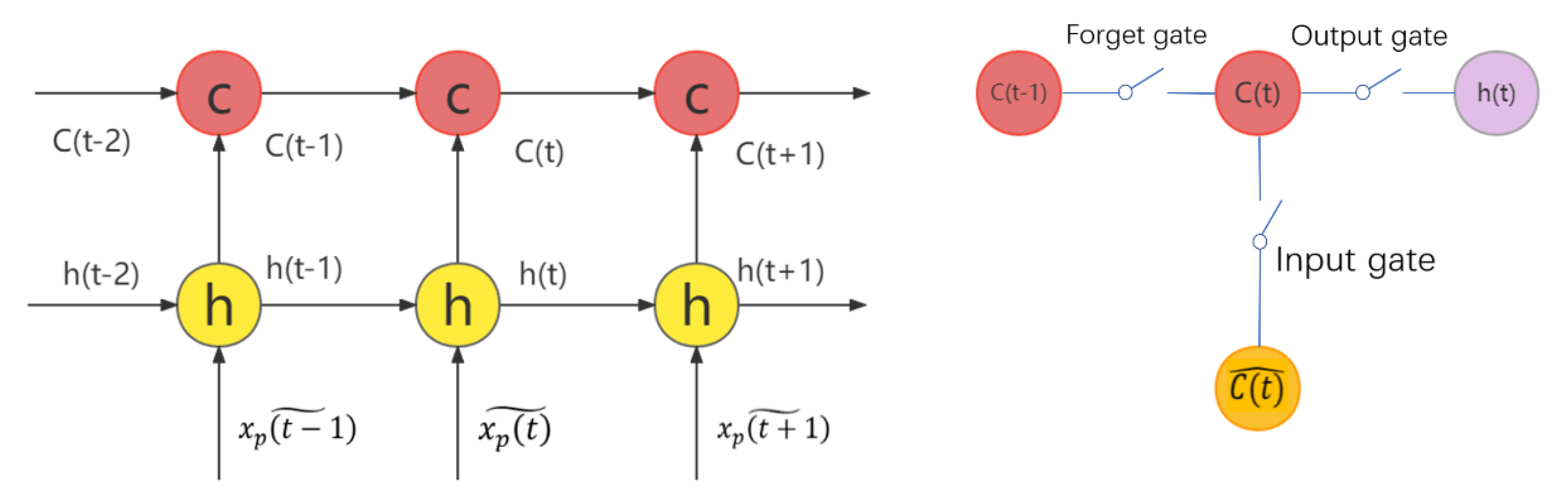
Proposing a multi-scale RUL prediction solution using LSTM. An LSTM-based classification model is used to sort each input data point into the three stages defined in the new RUL target function as the small-scale RUL prediction. Then, the data in the transition and linear degradation stage is fed into another LSTM-based regression model to achieve the large-scale RUL prediction.
The paper is structured as follows:
Section 2 describes the C-MAPSS datasets.
Section 3 introduces the proposed multi-scale RUL prediction approach.
Section 4 reports the performance of the proposed method and the comparison with the state-of-the-art techniques for RUL prediction, and the conclusion is given in
Section 5.
2. Dataset Description
NASA’s C-MAPSS project is a high-fidelity computer model that models the damage propagation of aircraft gas turbine engines [
18].
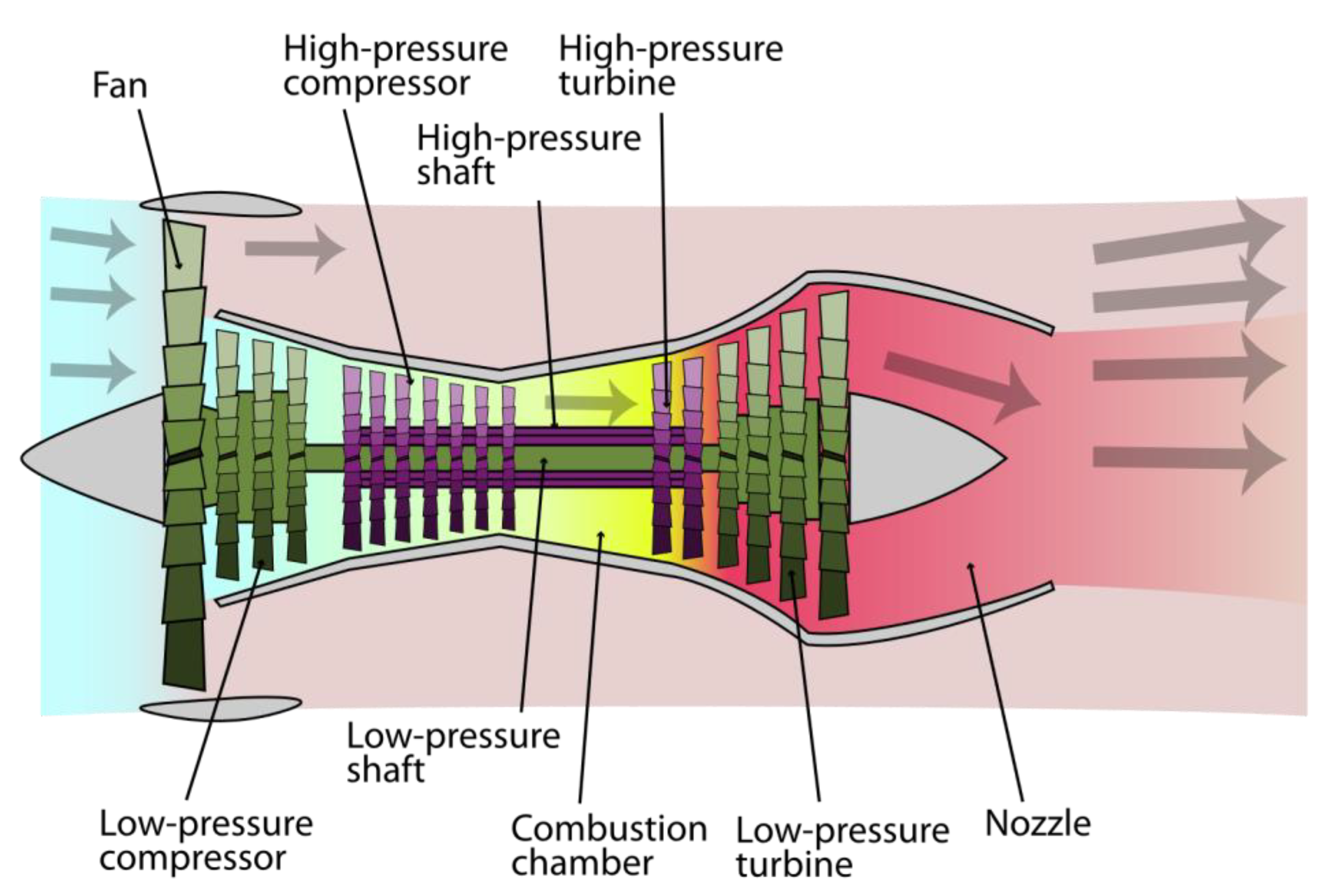
Figure 1 shows the diagram of the simulated run-to-failure trajectories of a small fleet of turbofan engines with the main elements. The simulated engine is a tow spool turbofan engine with a high level of thrust of up to 400,340 N, which operates under operating conditions ranging from sea level to 12,192 (m) of altitude and ambient temperature varying from −51 to 39 °C [
22]. The air is introduced into the low-pressure compressor (LPC) through the fan at first in this type of engine. Then, it travels through the high-pressure compressor (HPC) and is heated in the combustor. In the combustor, the compressed air is mixed with fuel and ignited. The fuel combustion provides enough thrust to drive both low-pressure turbines (LPT) and high-pressure turbines (HPT) [
16]. A more in-depth explanation can be found in the C-MAPSS User’s Guide [
23].
Retrieved data from C-MAPSS software is provided for the public as a benchmark for research on RUL prediction for aircraft engines [
18]. The dataset consists of 4 subsets, and each subset has different numbers of engines with varied operational cycles. In this dataset, engine profiles were simulated with different initial degradation conditions. The maintenance was not considered during the simulation. The dataset includes one training set and one testing set for each engine, which contains a multivariate time series of 26 features (engine number, time cycles, three operating condition measurements and 21 sensor measurements). The objective is to predict the RUL of each engine based on the given sensor measurements. The information on the four subsets is listed in
Table 1. Specifically, FD001 refers to the engine failure arising from the high-pressure compressor under a single operating condition. FD002 refers to the engine failure from the high-pressure compressor under six operation conditions. FD003 refers to the engine failure from the high-pressure compressor and the fan under a single operating condition. FD004 refers to the engine failure from the high-pressure compressor and the fan under six operation conditions. In this study, FD001 was primarily used to demonstrate the proposed solution because the data volume is relatively small to achieve time efficiency. The other three datasets were also tested to validate this method.
The employed dataset comprises information relating to 100 different turbines with a total number of observations varying from 128 to 362. The descriptive statistics of the response and the predictor variables are summarised in
Table 2. The location of each sensor is illustrated in
Figure 2.
Since Root Mean Square Error (RMSE) is the most widely used indicator in residual life prediction [
24]. It was used to evaluate the performance of the trained neural networks in this case study. The mathematical expression is:
where
is the total number of actual RUL targets in the related testing dataset and
refers to the true RUL and
refers to the predicted RUL at the time cycle
i.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}