
Students’ Academic Performance and Engagement Prediction in a Virtual Learning Environment Using Random Forest with Data Balancing



Abstract
1. Introduction
- 1.
- We construct students’ profiles by combining their assessment scores and engagement with a VLE.
- 2.
- We utilize random forest in conjunction with a data-balancing technique to predict the students’ academic performance from their profiles.
- 3.
- We investigate the performance of our proposed model by exploiting data from six different intervals, including the data for first 120 days, 150 days, 180 days, 210 days, 230 days, and 260 days.
2. Related Work
3. Materials and Methods
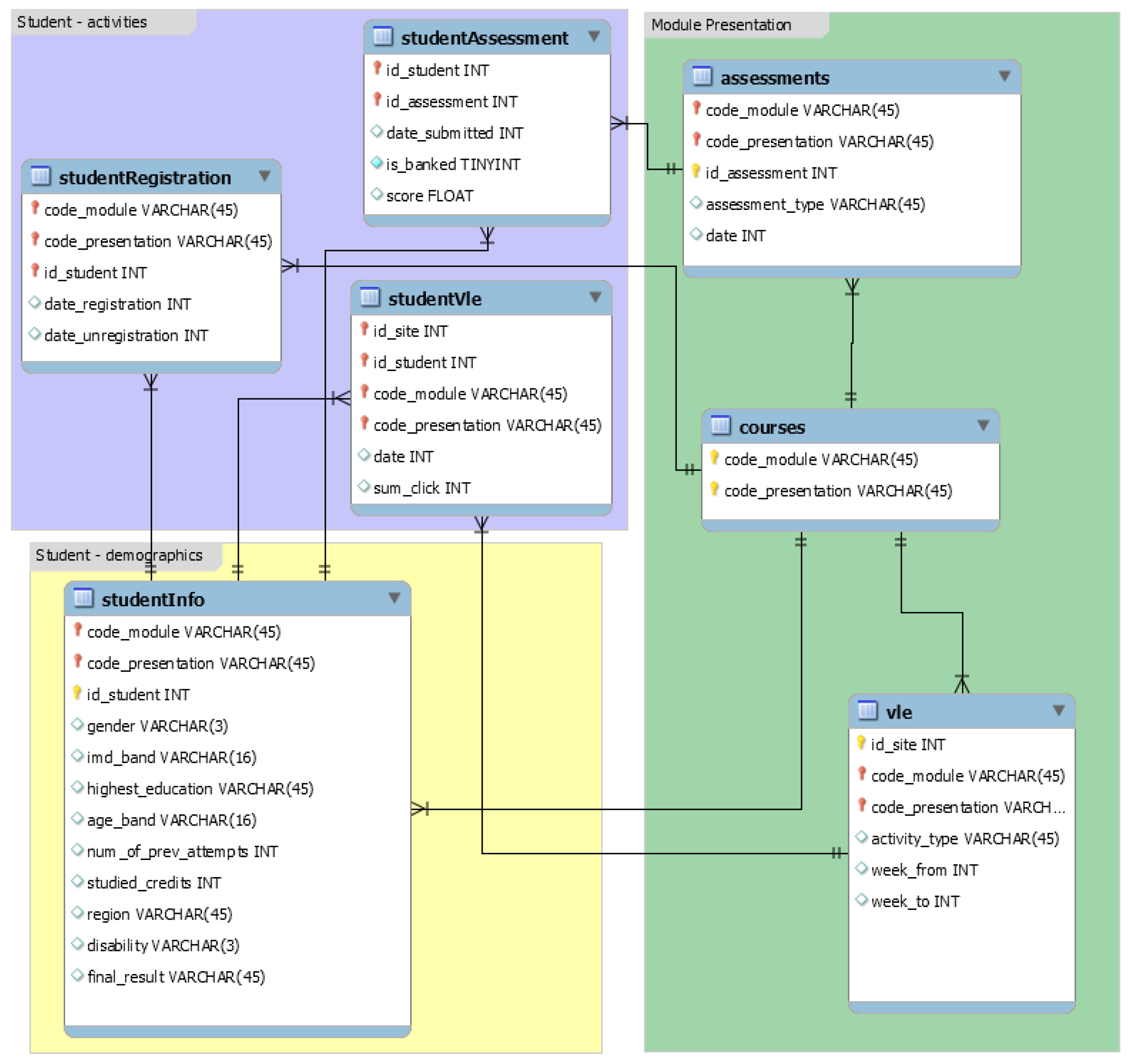
3.1. Dataset
3.2. Data Collection
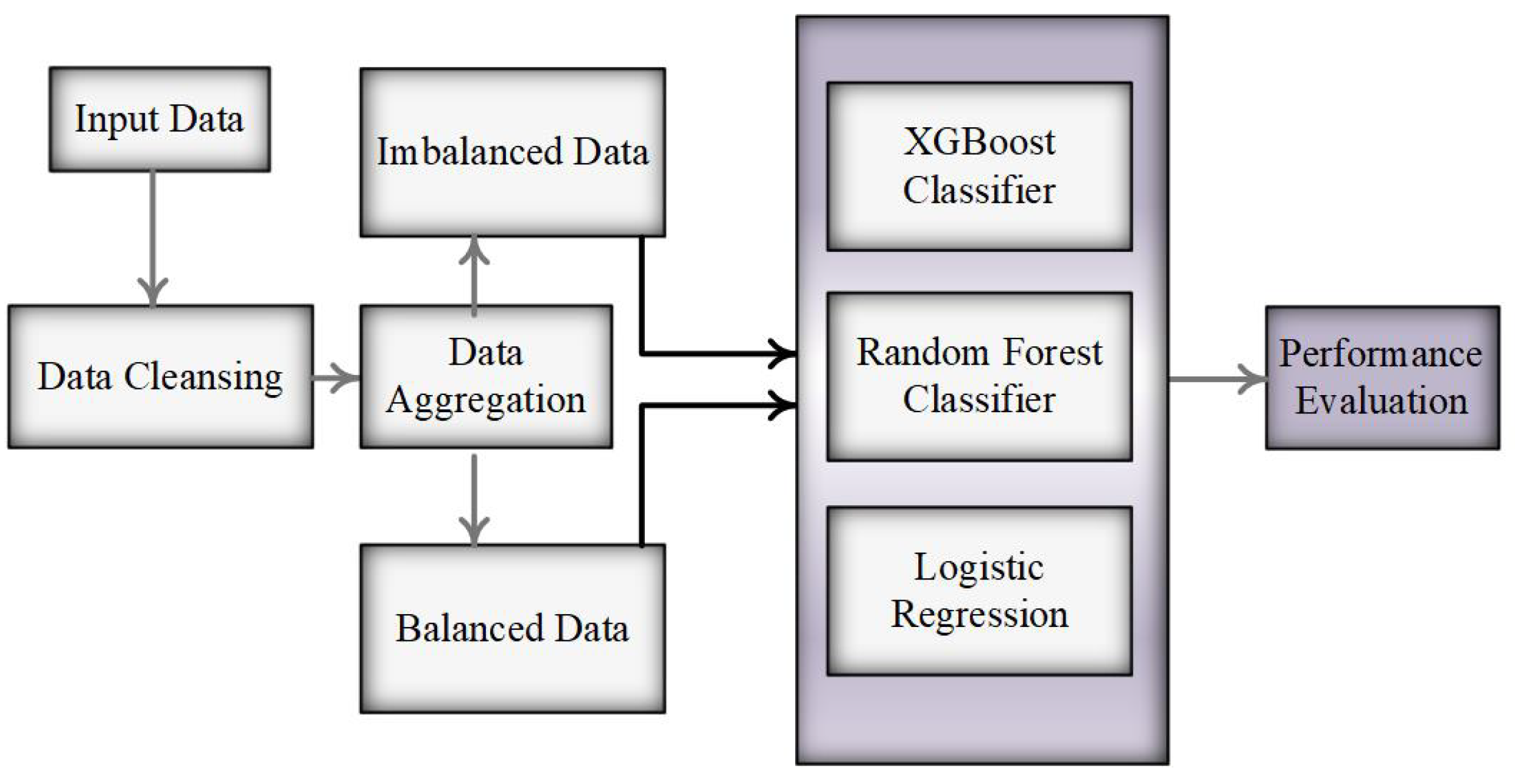
3.3. Methodology
3.3.1. Data Pre-Processing
3.3.2. Build and Test the Predictive Model
3.4. Evaluation Measures
3.4.1. Accuracy
3.4.2. Receiver Operating Characteristic
3.4.3. Precision–Recall Curve
4. Experimental Setup
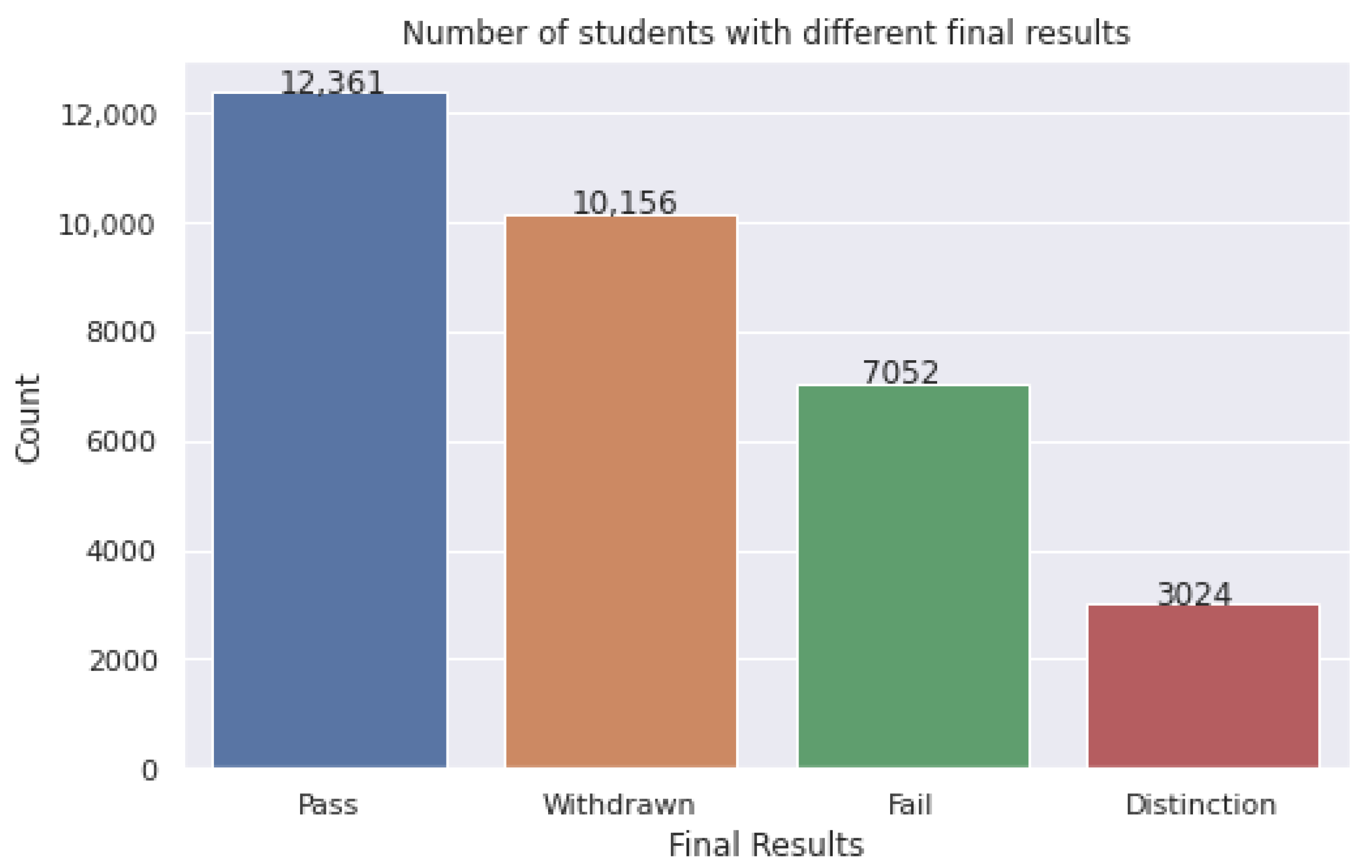
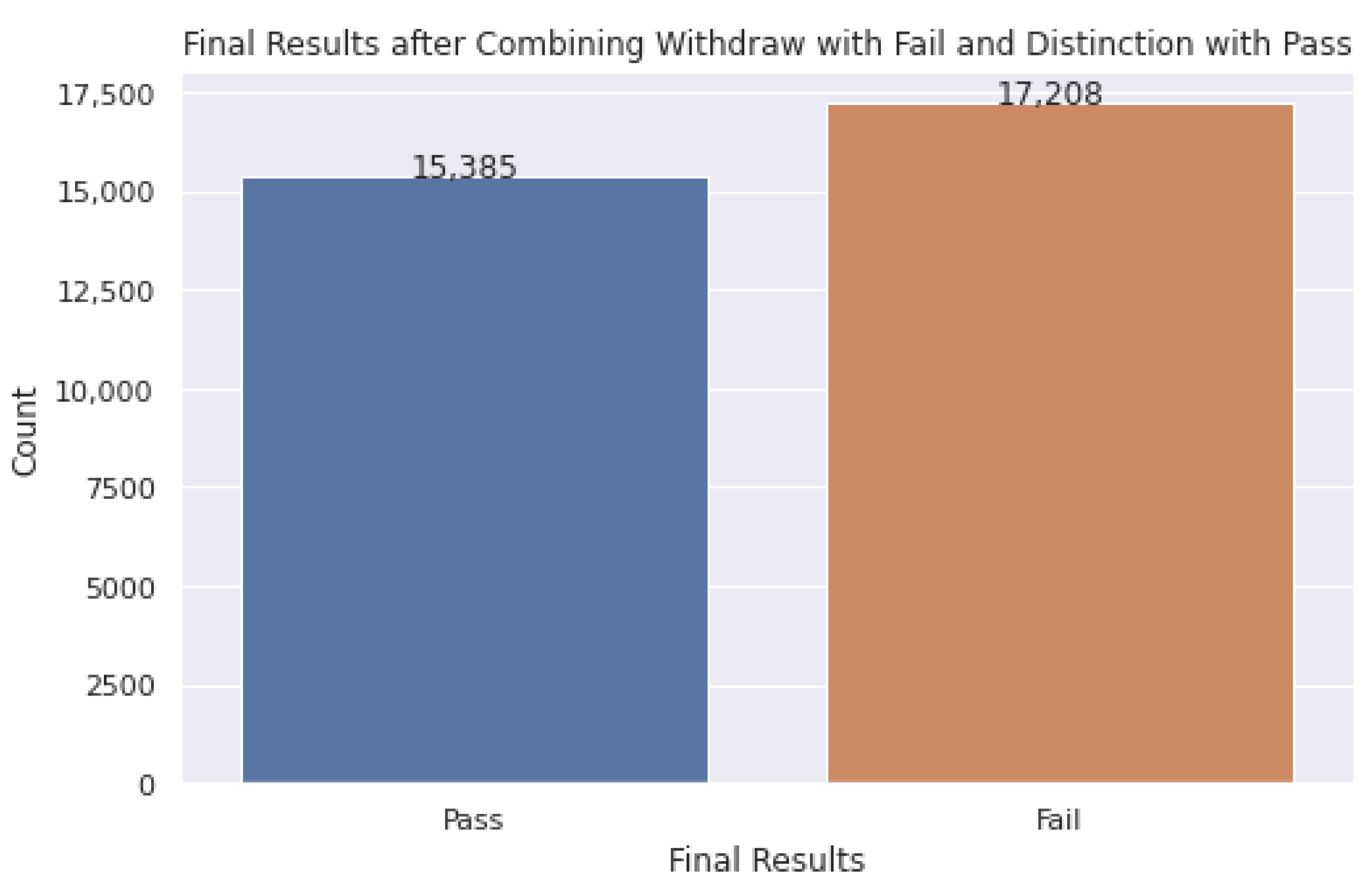
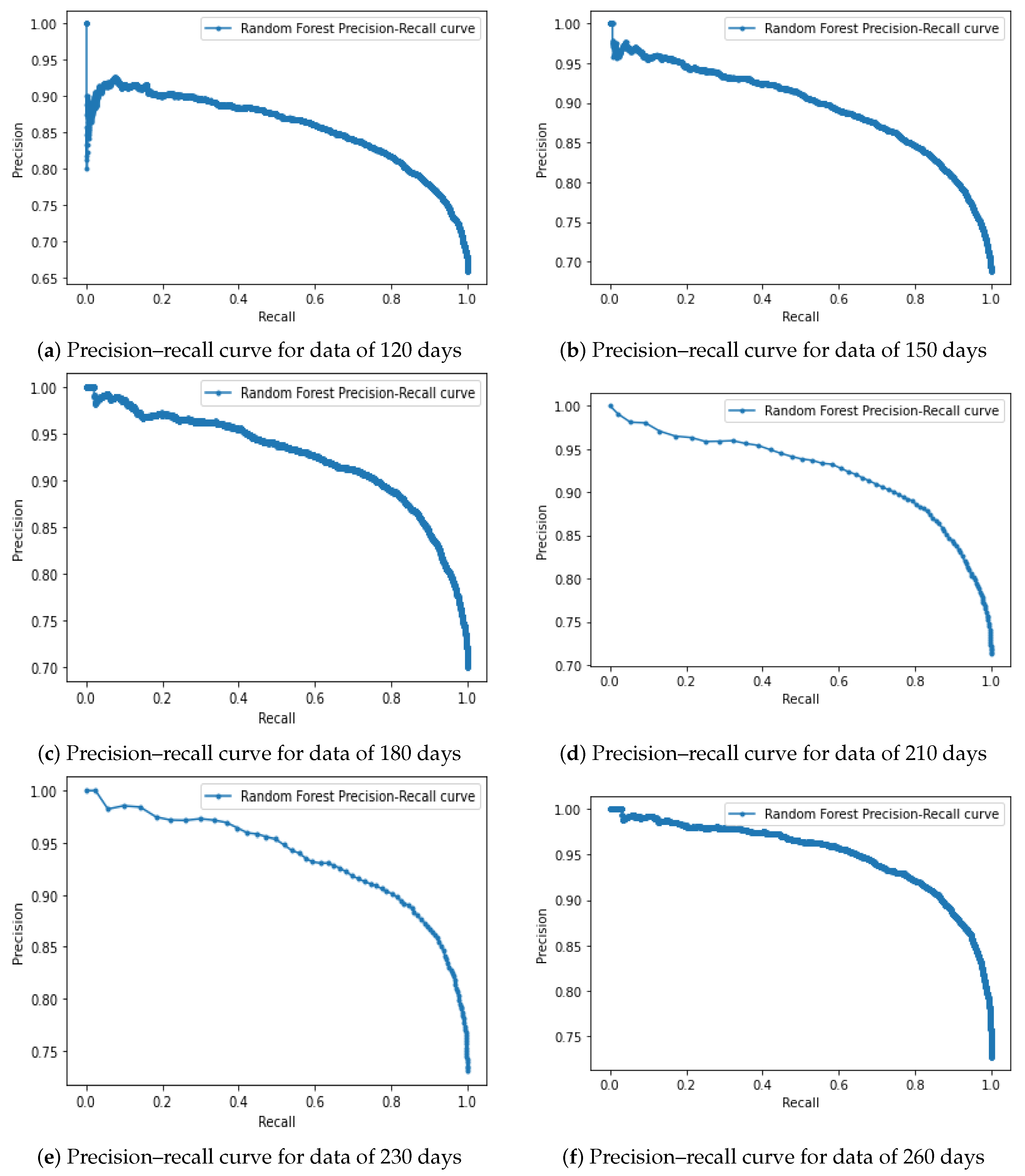
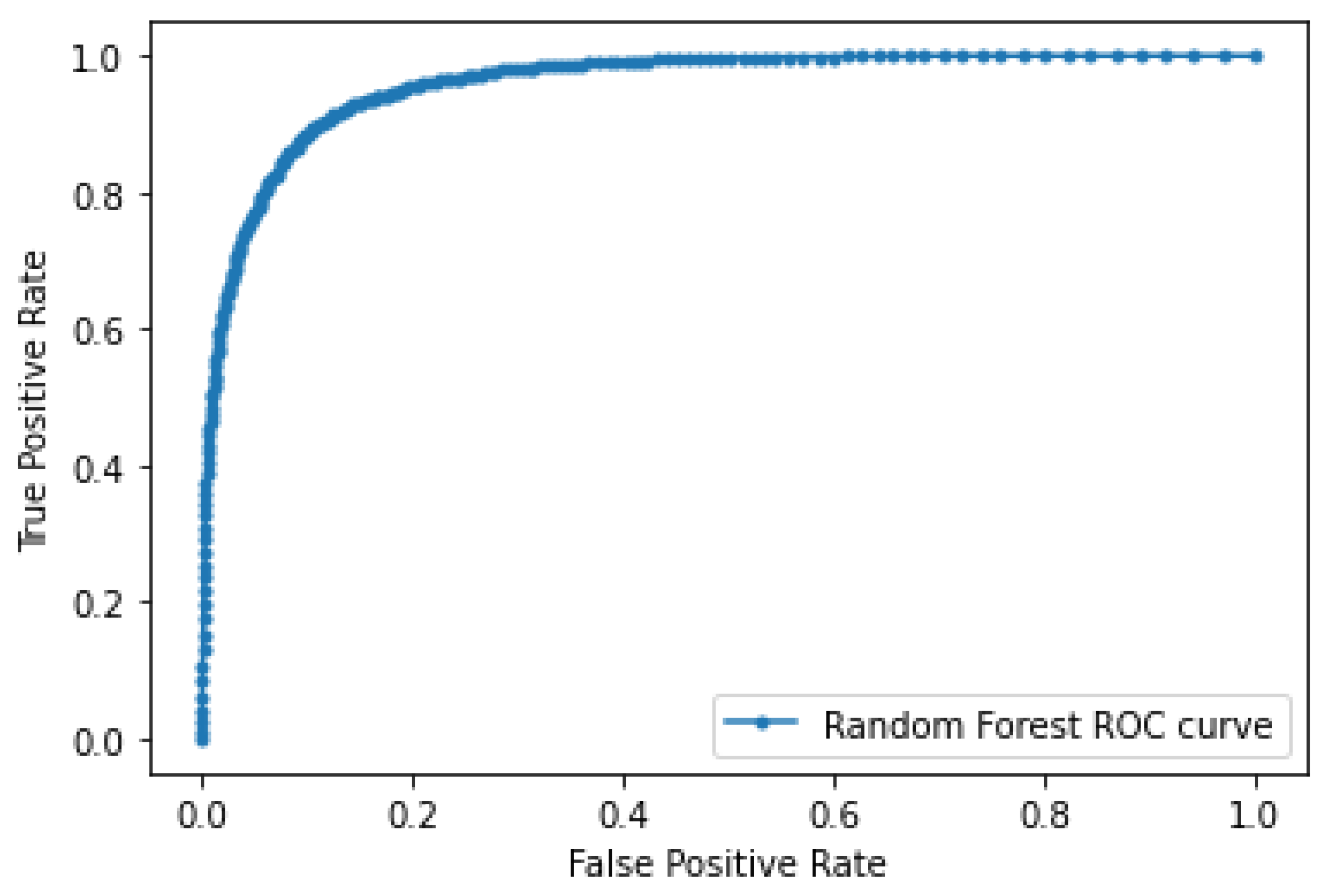
5. Results
5.1. Performance Analysis of Random-Forest Classifier with Random Search Optimization
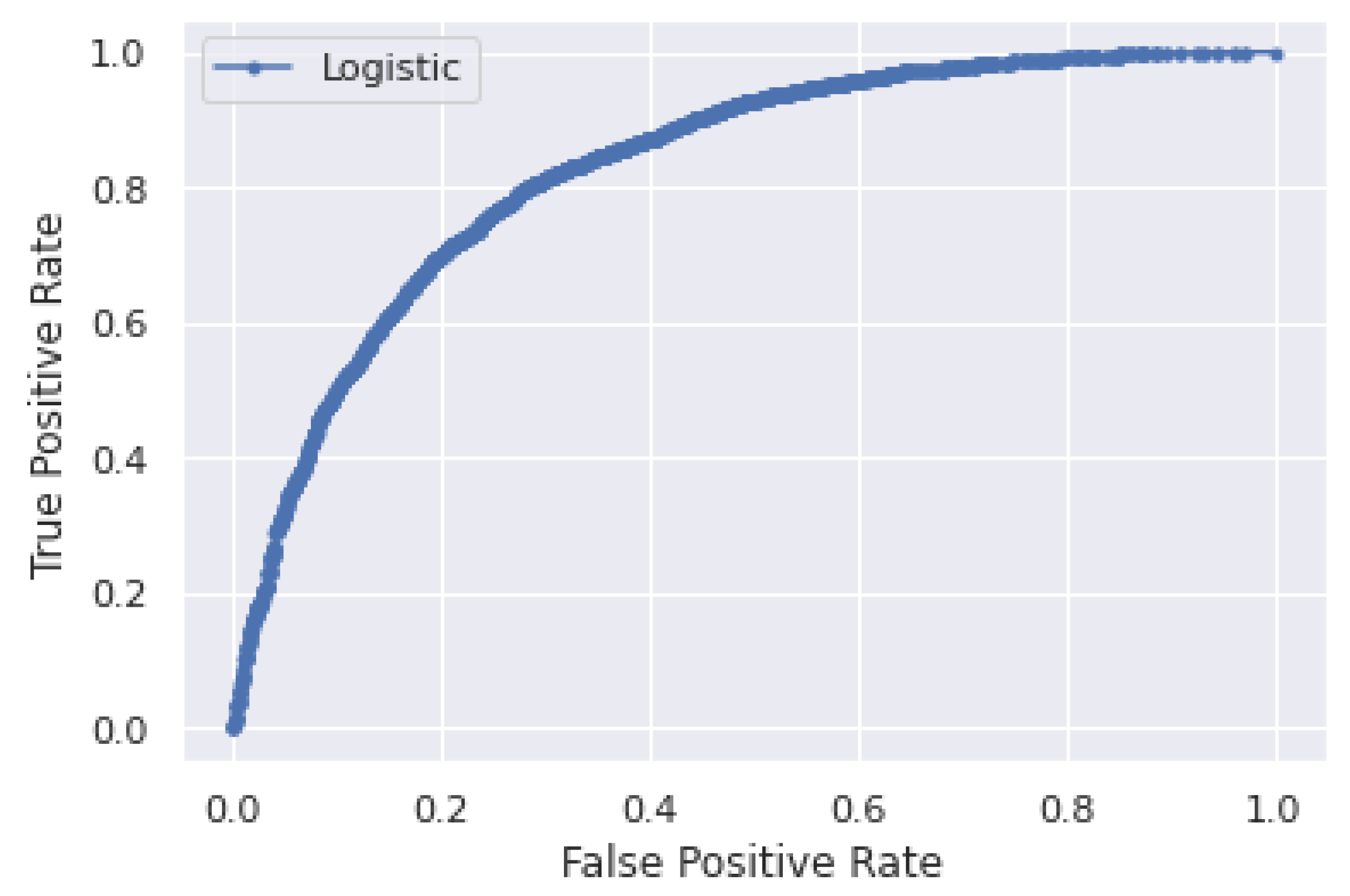
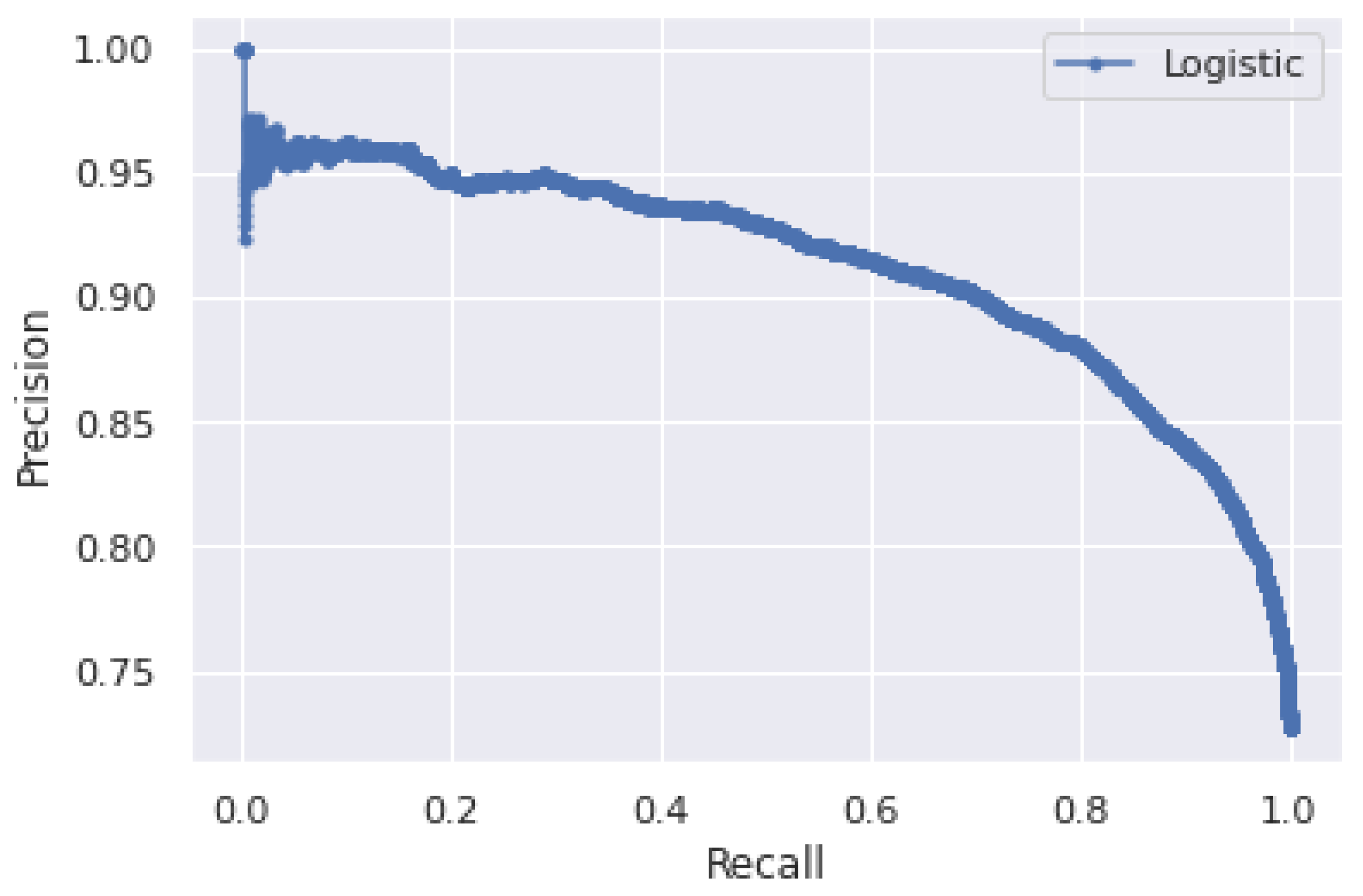
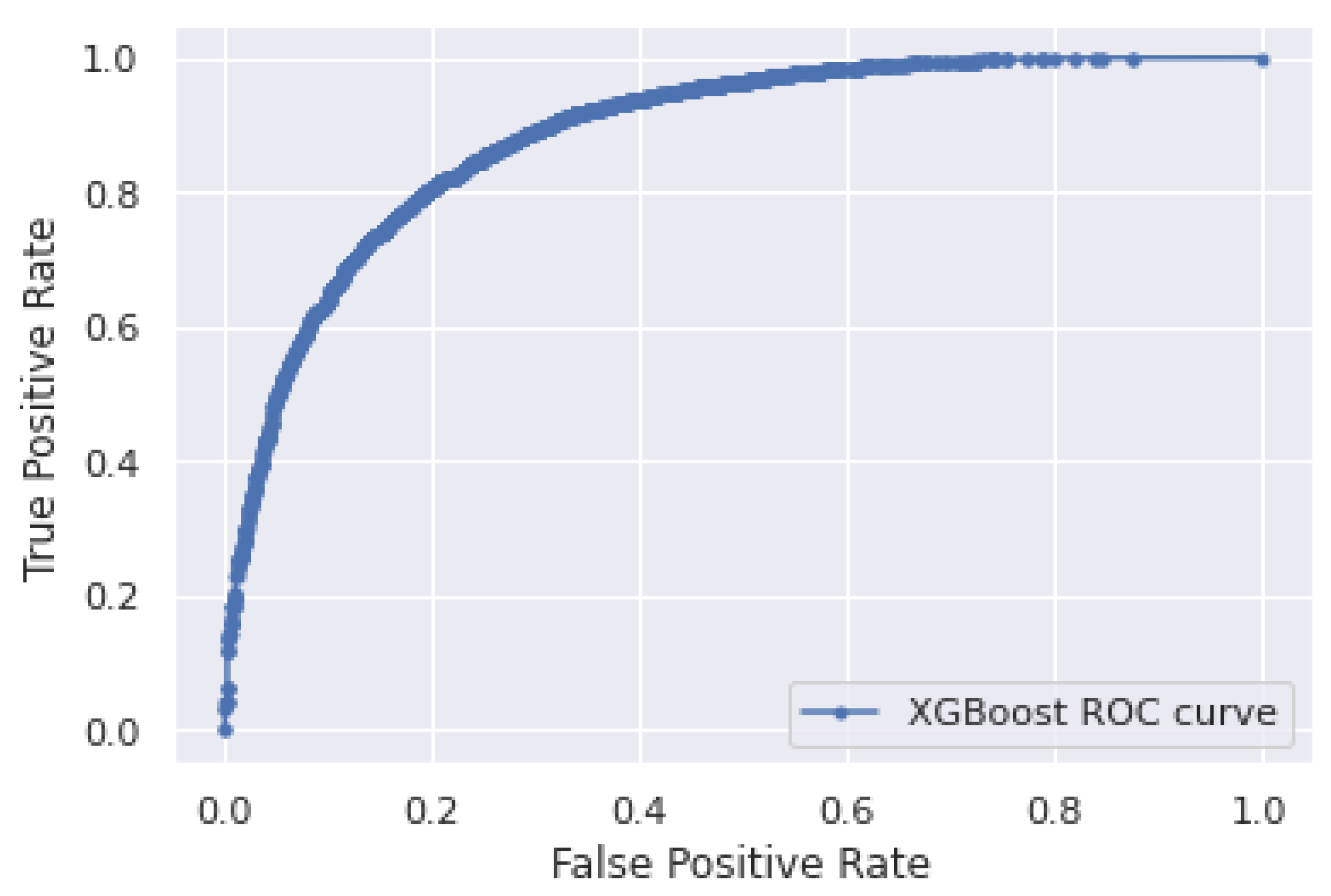
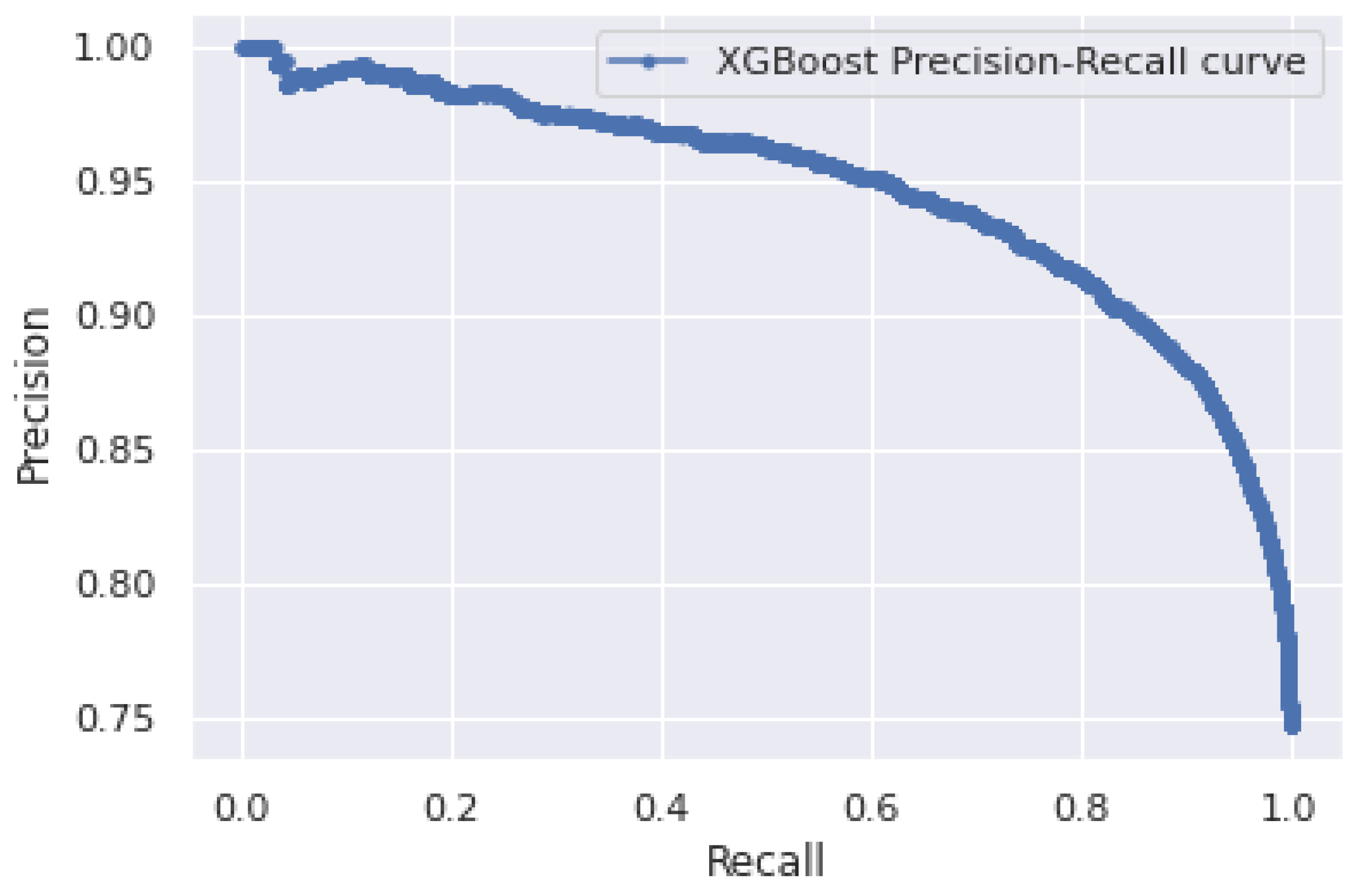
5.2. Performance Analysis of Logistic Regression and XGBoost Classifiers for 260 Days Data
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manjarres, A.V.; Sandoval, L.G.M.; Suárez, M.S. Data mining techniques applied in educational environments: Literature review. Digit. Educ. Rev. 2018, 33, 235–266. [Google Scholar] [CrossRef]
- Zareie, B.; Navimipour, N.J. The effect of electronic learning systems on the employee’s commitment. Int. J. Manag. Educ. 2016, 14, 167–175. [Google Scholar] [CrossRef]
- Muniasamy, A.; Alasiry, A. Deep Learning: The Impact on Future eLearning. Int. J. Emerg. Technol. Learn. 2020, 15, 188–199. [Google Scholar] [CrossRef]
- Alharthi, A.D.; Spichkova, M.; Hamilton, M. Sustainability requirements for elearning systems: A systematic literature review and analysis. Requir. Eng. 2019, 24, 523–543. [Google Scholar] [CrossRef]
- Umer, R.; Susnjak, T.; Mathrani, A.; Suriadi, S. On predicting academic performance with process mining in learning analytics. J. Res. Innov. Teach. Learn. 2017, 10, 160–176. [Google Scholar] [CrossRef]
- Lu, O.H.; Huang, A.Y.; Huang, J.C.; Lin, A.J.; Ogata, H.; Yang, S.J. Applying learning analytics for the early prediction of Students’ academic performance in blended learning. J. Educ. Technol. Soc. 2018, 21, 220–232. [Google Scholar]
- Widyahastuti, F.; Tjhin, V.U. Performance prediction in online discussion forum: State-of-the-art and comparative analysis. Procedia Comput. Sci. 2018, 135, 302–314. [Google Scholar] [CrossRef]
- Zhang, W.; Huang, X.; Wang, S.; Shu, J.; Liu, H.; Chen, H. Student performance prediction via online learning behavior analytics. In Proceedings of the 2017 International Symposium on Educational Technology (ISET), Hong Kong, China, 27–29 June 2017; pp. 153–157. [Google Scholar]
- Koutina, M.; Kermanidis, K.L. Predicting postgraduate students’ performance using machine learning techniques. In Artificial Intelligence Applications and Innovations; Springer: Berlin/Heidelberg, Germany, 2011; pp. 159–168. [Google Scholar]
- Alzahrani1, N.A.; Abdullah, M.A. Student Engagement Effectiveness in E-Learning System. Biosci. Biotechnol. Res. Commun. Spec. Issue Commun. Inf. Technol. 2019, 12, 208–218. [Google Scholar] [CrossRef]
- Brahim, G.B. Predicting Student Performance from Online Engagement Activities Using Novel Statistical Features. Arab. J. Sci. Eng. 2022, 10225–10243. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Dimililer, K.; Tuncal, K. Student performance prediction and classification using machine learning algorithms. In Proceedings of the 2019 8th International Conference on Educational and Information Technology, Cambridge, UK, 2–4 March 2019; pp. 7–11. [Google Scholar]
- Burgos, D. Background similarities as a way to predict students’ Behaviour. Sustainability 2019, 11, 6883. [Google Scholar] [CrossRef]
- Cavus, N.; Zabadi, T. A comparison of open source learning management systems. Procedia-Soc. Behav. Sci. 2014, 143, 521–526. [Google Scholar] [CrossRef]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, S.M.R. Student engagement predictions in an e-learning system and their impact on student course assessment scores. Comput. Intell. Neurosci. 2018, 2018, 6347186. [Google Scholar] [CrossRef] [PubMed]
- Daghestani, L.F.; Ibrahim, L.F.; Al-Towirgi, R.S.; Salman, H.A. Adapting gamified learning systems using educational data mining techniques. Comput. Appl. Eng. Educ. 2020, 28, 568–589. [Google Scholar] [CrossRef]
- Sana, B.; Siddiqui, I.F.; Arain, Q.A. Analyzing students’ academic performance through educational data mining. 3C Tecnol. Glosas Innovación Apl. Pym 2019, 8, 402–421. [Google Scholar]
- Abubakar, Y.; Ahmad, N.B.H. Prediction of students’ performance in e-learning environment using random forest. Int. J. Innov. Comput. 2017, 7. [Google Scholar] [CrossRef]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open university learning analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef]
- Jiang, S.; Williams, A.; Schenke, K.; Warschauer, M.; O’dowd, D. Predicting MOOC performance with week 1 behavior. In Proceedings of the Educational Data Mining, London, UK, 4–7 July 2014. [Google Scholar]
- Baradwaj, B.K.; Pal, S. Mining educational data to analyze students’ performance. Int. J. Adv. Comput. Sci. Appl. 2015, 2, 63–69. [Google Scholar]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar]
- Tahir, M. Brain MRI Classification Using Gradient Boosting. In Machine Learning in Clinical Neuroimaging and Radiogenomics in Neuro-Oncology; Springer: Berlin/Heidelberg, Germany, 2020; pp. 294–301. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Tahir, M.; Khan, A.; Majid, A.; Lumini, A. Subcellular localization using fluorescence imagery: Utilizing ensemble classification with diverse feature extraction strategies and data balancing. Appl. Soft Comput. 2013, 13, 4231–4243. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | AAA | BBB | CCC | DDD | EEE | FFF | GGG |
|---|---|---|---|---|---|---|---|
| Domain | Social Sciences | Social Sciences | STEM | STEM | STEM | STEM | Social Sciences |
| Presentations | 2 | 4 | 2 | 4 | 3 | 4 | 3 |
| Students | 748 | 7909 | 4434 | 6272 | 2934 | 7762 | 2534 |
| Random Forest | |||||
|---|---|---|---|---|---|
| Days | Training Accuracy | Testing Accuracy | ROC-AUC | Precision–Recall AUC | Score |
| 120 | 90.7 | 76.3 | 0.796 | 0.857 | 83.1 |
| 150 | 1.0 | 78.2 | 0.820 | 0.895 | 84.7 |
| 180 | 98.9 | 81.3 | 0.861 | 0.926 | 87.3 |
| 210 | 1.0 | 81.1 | 0.854 | 0.923 | 87.2 |
| 230 | 1.0 | 83.4 | 0.871 | 0.936 | 88.9 |
| 260 | 97.8 | 84.2 | 0.894 | 0.950 | 89.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jawad, K.; Shah, M.A.; Tahir, M. Students’ Academic Performance and Engagement Prediction in a Virtual Learning Environment Using Random Forest with Data Balancing. Sustainability 2022, 14, 14795. https://doi.org/10.3390/su142214795
Jawad K, Shah MA, Tahir M. Students’ Academic Performance and Engagement Prediction in a Virtual Learning Environment Using Random Forest with Data Balancing. Sustainability. 2022; 14(22):14795. https://doi.org/10.3390/su142214795
Chicago/Turabian StyleJawad, Khurram, Muhammad Arif Shah, and Muhammad Tahir. 2022. "Students’ Academic Performance and Engagement Prediction in a Virtual Learning Environment Using Random Forest with Data Balancing" Sustainability 14, no. 22: 14795. https://doi.org/10.3390/su142214795
APA StyleJawad, K., Shah, M. A., & Tahir, M. (2022). Students’ Academic Performance and Engagement Prediction in a Virtual Learning Environment Using Random Forest with Data Balancing. Sustainability, 14(22), 14795. https://doi.org/10.3390/su142214795