
Customized Instance Random Undersampling to Increase Knowledge Management for Multiclass Imbalanced Data Classification


 ,
,  and
and 
Abstract
1. Introduction
- An experimental study to assess the impact of data sampling for the customized naïve associative classifier;
- A new undersampling algorithm for dealing with multiclass, hybrid and missing data, with tractable computational complexity bounded by .
2. Materials and Methods
2.1. Oversampling Methods
2.2. Undersampling Methods
2.3. Hybrid Sampling Methods
3. Results
3.1. Proposed Undersampling Method
| Algorithm 1: CIRUS | |
| Inputs: Dissimilarity function diss, Imbalanced set of instances X | |
| 1 | |
| 2 | Compute the minority class count as . |
| 3 | for each subset |
| 4 | if , then //minority classes are preserved as is |
| 5 | else |
| 6 | with the compact sets. Each item of the multi-list is also a list, containing the instances belonging to the current compact |
| 7 | |
| 8 | repeat |
| 9 | Select a compact set randomly, as |
| 10 | |
| 11 | |
| 12 | |
| 13 | until |
| 14 | end if |
| 15 | end for |
| 16 | return |
- Every isolated instance is a compact set, degenerated.
3.2. Experimental Setup

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Instances | Attributes | Missing Values | Classes | IR | Reference | |
|---|---|---|---|---|---|---|---|
| Numeric | Categorical | ||||||
| alpha_bank | 30,477 | 1 | 6 | No | 2 | 6.90 | [54] |
| attribute_dataset | 500 | 1 | 11 | Yes | 2 | 1.38 | [55] |
| aug | 19,158 | 2 | 10 | No | 2 | 3.01 | [56] |
| churn_modelling | 10,000 | 6 | 4 | No | 2 | 3.91 | [57] |
| customer_behaviour | 400 | 2 | 1 | No | 2 | 1.80 | [58] |
| customer_segmentation | 8068 | 3 | 6 | Yes | 4 | 1.22 | [59] |
| customer_targeting | 6620 | 66 | 4 | No | 3 | 1.85 | [60] |
| deposit2020 | 40,000 | 5 | 8 | No | 2 | 12.81 | [61] |
| df_clean | 358 | 3 | 16 | No | 2 | 9.23 | [62] |
| employee_satisfaction | 500 | 2 | 9 | No | 2 | 1.11 | [63] |
| in-vehicle-coupon | 12,684 | 1 | 24 | Yes | 2 | 1.32 | [64] |
| marketing_campaign | 2240 | 14 | 13 | Yes | 2 | 5.71 | [65] |
| marketing_series | 6499 | 3 | 16 | Yes | 2 | 2.79 | [66] |
| non-verbal-tourist | 73 | 4 | 18 | Yes | 6 | 9.00 | [4] |
| online_shoppers | 12,330 | 10 | 7 | No | 2 | 5.46 | [67] |
| promoted | 24,016 | 4 | 2 | Yes | 5 | 5.44 | [68] |
| telecom_churn | 3333 | 10 | 0 | No | 2 | 5.90 | [69] |
| telecom_churnV2 | 3333 | 15 | 4 | No | 2 | 5.90 | [70] |
| telecust | 1000 | 4 | 7 | No | 4 | 1.29 | [71] |
| term_deposit | 31,647 | 7 | 9 | No | 2 | 7.52 | [72] |
4. Discussion
4.1. Impact of Undersampling Methods on the Performance of CNAC
4.2. Performance of the Proposed Undersampling Method with Respect to Others
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, H.C.K.; Wang, T.H.; Lin, G.C.; Cheng, S.C.; Chen, H.R.; Huang, Y.M. Applying sentiment analysis to automatically classify consumer comments concerning marketing 4Cs aspects. Appl. Soft Comput. 2020, 97, 106755. [Google Scholar] [CrossRef]
- Godinho, P.; Dias, J.; Torres, P. An Application of Data Mining Methods to the Analysis of Bank Customer Profitability and Buying Behavior. Data Anal. Appl. 1 Clust. Regres. Model.-Estim. Forecast. Data Min. 2019, 2, 225–240. [Google Scholar]
- Kim, A.; Yang, Y.; Lessmann, S.; Ma, T.; Sung, M.C.; Johnson, J.E. Can deep learning predict risky retail investors? A case study in financial risk behavior forecasting. Eur. J. Oper. Res. 2020, 283, 217–234. [Google Scholar] [CrossRef]
- Tusell-Rey, C.C.; Tejeida-Padilla, R.; Camacho-Nieto, O.; Villuendas-Rey, Y.; Yáñez-Márquez, C. Improvement of Tourists Satisfaction According to Their Non-Verbal Preferences Using Computational Intelligence. Appl. Sci. 2021, 11, 2491. [Google Scholar] [CrossRef]
- Sakar, C.O.; Polat, S.O.; Katircioglu, M.; Kastro, Y. Real-time prediction of online shoppers’ purchasing intention using multilayer perceptron and LSTM recurrent neural networks. Neural Comput. Appl. 2019, 31, 6893–6908. [Google Scholar] [CrossRef]
- Fan, C.Y.; Fan, P.S.; Chan, T.Y.; Chang, S.H. Using hybrid data mining and machine learning clustering analysis to predict the turnover rate for technology professionals. Expert Syst. Appl. 2012, 39, 8844–8851. [Google Scholar] [CrossRef]
- Fallucchi, F.; Coladangelo, M.; Giuliano, R.; William De Luca, E. Predicting employee attrition using machine learning techniques. Computers 2020, 9, 86. [Google Scholar] [CrossRef]
- Keon, Y.; Kim, H.; Choi, J.Y.; Kim, D.; Kim, S.Y.; Kim, S. Call Center Call Count Prediction Model by Machine Learning. J. Adv. Inf. Technol. Converg. 2018, 8, 31–42. [Google Scholar] [CrossRef]
- Kocakulah, M.C.; Komissarov, S. Using Activity-Based Costing to Increase Profitability of Individual Deposit Services in Banking. Manag. Account. Q. 2020, 21, 10–17. [Google Scholar]
- Esmaeilzadeh, P.; Dharanikota, S.; Mirzaei, T. The role of patient engagement in patient-centric health information exchange (HIE) initiatives: An empirical study in the United States. Inf. Technol. People 2021. ahead-of-print. [Google Scholar] [CrossRef]
- Jabarulla, M.Y.; Lee, H.N. A blockchain and artificial intelligence-based, patient-centric healthcare system for combating the COVID-19 pandemic: Opportunities and applications. Healthcare 2021, 9, 1019. [Google Scholar] [CrossRef] [PubMed]
- Barnes, R.; Zvarikova, K. Artificial intelligence-enabled wearable medical devices, clinical and diagnostic decision support systems, and Internet of Things-based healthcare applications in COVID-19 prevention, screening, and treatment. Am. J. Med. Res. 2021, 8, 9–22. [Google Scholar]
- Haldorai, A.; Ramu, A. An Analysis of Artificial Intelligence Clinical Decision-Making and Patient-Centric Framework. In Computational Vision and Bio-Inspired Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 813–827. [Google Scholar]
- Gohar, A.; AbdelGaber, S.; Salah, M. A Patient-Centric Healthcare Framework Reference Architecture for Better Semantic Interoperability based on Blockchain, Cloud, and IoT. IEEE Access 2022, 10, 92137–92157. [Google Scholar] [CrossRef]
- Naresh, V.S.; Reddi, S.; Allavarpu, V.D. Blockchain-based patient centric health care communication system. Int. J. Commun. Syst. 2021, 34, e4749. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, D.; Nie, T.; Kou, Y.; Yin, N.; Han, X. A cluster-based oversampling algorithm combining SMOTE and k-means for imbalanced medical data. Inf. Sci. 2021, 572, 574–589. [Google Scholar] [CrossRef]
- Solanki, Y.S.; Chakrabarti, P.; Jasinski, M.; Leonowicz, Z.; Bolshev, V.; Vinogradov, A.; Jasinska, E.; Gono, R.; Nami, M. A hybrid supervised machine learning classifier system for breast cancer prognosis using feature selection and data imbalance handling approaches. Electronics 2021, 10, 699. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10. [Google Scholar]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Hart, P. The condensed nearest neighbor rule (corresp.). IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. In Proceedings of the 14th International Conference on Machine Learning (ICML97), Nashville, TN, USA, 8–12 July 1997; pp. 179–186. [Google Scholar]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance. Neural Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef]
- Yin, H.; Gai, K. An empirical study on preprocessing high-dimensional class-imbalanced data for classification. In Proceedings of the 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems, New York, NY, USA, 24–26 August 2015; pp. 1314–1319. [Google Scholar]
- Koziarski, M.; Krawczyk, B.; Woźniak, M. Radial-based oversampling for noisy imbalanced data classification. Neurocomputing 2019, 343, 19–33. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Tang, S.; Chen, S.P. The generation mechanism of synthetic minority class examples. In Proceedings of the 2008 International Conference on Information Technology and Applications in Biomedicine, Shenzhen, China, 30–31 May 2008; pp. 444–447. [Google Scholar]
- Cohen, G.; Hilario, M.; Sax, H.; Hugonnet, S.; Geissbuhler, A. Learning from imbalanced data in surveillance of nosocomial infection. Artif. Intell. Med. 2006, 37, 7–18. [Google Scholar] [CrossRef] [PubMed]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2009; pp. 475–482. [Google Scholar]
- Ramentol, E.; Caballero, Y.; Bello, R.; Herrera, F. SMOTE-RS B*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowl. Inf. Syst. 2012, 33, 245–265. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE. Inf. Sci. 2019, 501, 118–135. [Google Scholar] [CrossRef]
- Guan, H.; Zhang, Y.; Xian, M.; Cheng, H.D.; Tang, X. SMOTE-WENN: Solving class imbalance and small sample problems by oversampling and distance scaling. Appl. Intell. 2021, 51, 1394–1409. [Google Scholar] [CrossRef]
- Jiang, Z.; Pan, T.; Zhang, C.; Yang, J.J.S. A new oversampling method based on the classification contribution degree. Symmetry 2021, 13, 194. [Google Scholar] [CrossRef]
- Li, J.; Zhu, Q.; Wu, Q.; Fan, Z.J.I.S. A novel oversampling technique for class-imbalanced learning based on SMOTE and natural neighbors. Inf. Sci. 2021, 565, 438–455. [Google Scholar] [CrossRef]
- Wei, J.; Huang, H.; Yao, L.; Hu, Y.; Fan, Q.; Huang, D.J.A.S.C. New imbalanced bearing fault diagnosis method based on Sample-characteristic Oversampling TechniquE (SCOTE) and multi-class LS-SVM. Appl. Soft Comput. 2021, 101, 107043. [Google Scholar] [CrossRef]
- Roy, S.K.; Haut, J.M.; Paoletti, M.E.; Dubey, S.R.; Plaza, A.J.I.T.O.G.; Sensing, R. Generative adversarial minority oversampling for spectral–spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5500615. [Google Scholar] [CrossRef]
- Li, L.; Damarla, S.K.; Wang, Y.; Huang, B.J.I.S. A Gaussian mixture model based virtual sample generation approach for small datasets in industrial processes. Inf. Sci. 2021, 581, 262–277. [Google Scholar] [CrossRef]
- Kim, D.H.; Song, B.C.J.P.R. Virtual sample-based deep metric learning using discriminant analysis. Pattern Recognit. 2021, 110, 107643. [Google Scholar] [CrossRef]
- Lin, L.S.; Hu, S.C.; Lin, Y.S.; Li, D.C.; Siao, L.R.J.M.B.; Engineering. A new approach to generating virtual samples to enhance classification accuracy with small data—A case of bladder cancer. Math. Biosci. Eng. 2022, 19, 6204–6233. [Google Scholar] [CrossRef]
- Tomek, I. Two modifications of CNN. IEEE Trans. Syst. Man Cybern. 1976, 6, 769–772. [Google Scholar]
- Fotouhi, S.; Asadi, S.; Kattan, M.W. A comprehensive data level analysis for cancer diagnosis on imbalanced data. J. Biomed. Inform. 2019, 90, 103089. [Google Scholar] [CrossRef]
- Chennuru, V.K.; Timmappareddy, S.R. Simulated annealing based undersampling (SAUS): A hybrid multi-objective optimization method to tackle class imbalance. Appl. Intell. 2021, 52, 2092–2110. [Google Scholar] [CrossRef]
- Yoon, K.; Kwek, S. An unsupervised learning approach to resolving the data imbalanced issue in supervised learning problems in functional genomics. In Proceedings of the Fifth International Conference on Hybrid Intelligent Systems (HIS’05), Rio de Janeiro, Brazil, 6–9 November 2005; p. 6. [Google Scholar]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Conference on Artificial Intelligence in Medicine in Europe; Springer: Berlin/Heidelberg, Germany, 2001; pp. 63–66. [Google Scholar]
- Wilson, D.L. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cybern. 1972, 2, 408–421. [Google Scholar] [CrossRef]
- Martínez-Trinidad, J.F.; Guzmán-Arenas, A. The logical combinatorial approach to pattern recognition, an overview through selected works. Pattern Recognit. 2001, 34, 741–751. [Google Scholar] [CrossRef]
- García-Borroto, M.; Ruiz-Shulcloper, J. Selecting prototypes in mixed incomplete data. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2005; pp. 450–459. [Google Scholar]
- Wilson, D.R.; Martinez, T.R. Improved heterogeneous distance functions. J. Artif. Intell. Res. 1997, 6, 1–34. [Google Scholar] [CrossRef]
- Ballabio, D.; Grisoni, F.; Todeschini, R. Multivariate comparison of classification performance measures. Chemom. Intell. Lab. Syst. 2018, 174, 33–44. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/raosuny/success-of-bank-telemarketing-data (accessed on 7 July 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/dresses_attribute_sales (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/arashnic/hr-analytics-job-change-of-data-scientists?select=aug_train.csv (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/shivan118/churn-modeling-dataset (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/denisadutca/customer-behaviour (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/vetrirah/customer?select=Train.csv (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/tsiaras/predicting-profitable-customer-segments (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/arinzy/deposit-subscription-what-makes-consumers-buy (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/c/warranty-claims/leaderboard (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/mohamedharris/employee-satisfaction-index-dataset (accessed on 7 July 2021).
- Wang, T.; Rudin, C.; Doshi-Velez, F.; Liu, Y.; Klampfl, E.; MacNeille, P. A bayesian framework for learning rule sets for interpretable classification. J. Mach. Learn. Res. 2017, 18, 2357–2393. [Google Scholar]
- Available online: https://www.kaggle.com/rodsaldanha/arketing-campaign (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/arashnic/marketing-series-customer-churn?select=train.csv (accessed on 7 July 2021).
- Available online: https://archive.ics.uci.edu/ml/datasets/Online+Shoppers+Purchasing+Intention+Dataset (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/regivm/promotion-response-and-target-datasets?select=promoted.csv (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/barun2104/telecom-churn (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/sagnikpatra/edadata (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/prathamtripathi/customersegmentation (accessed on 7 July 2021).
- Available online: https://www.kaggle.com/brajeshmohapatra/term-deposit-prediction-data-set (accessed on 7 July 2021).
- Hernández-Castaño, J.A.; Villuendas-Rey, Y.; Camacho-Nieto, O.; Yáñez-Márquez, C. Experimental platform for intelligent computing (EPIC). Comput. Sist. 2018, 22, 245–253. [Google Scholar] [CrossRef]
- Hernández-Castaño, J.A.; Villuendas-Rey, Y.; Nieto, O.C.; Rey-Benguría, C.F. A New Experimentation Module for the EPIC Software. Res. Comput. Sci. 2018, 147, 243–252. [Google Scholar] [CrossRef]
- Triguero, I.; González, S.; Moyano, J.M.; García, S.; Alcalá-Fdez, J.; Luengo, J.; Fernández, A.; del Jesús, M.J.; Sánchez, L.; Herrera, F. KEEL 3.0: An open source software for multi-stage analysis in data mining. Int. J. Comput. Intell. Syst. 2017, 10, 1238–1249. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. Biometrics 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; Da Fonseca, V.G. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Villuendas-Rey, Y.; Yáñez-Márquez, C.; Anton-Vargas, J.A.; López-Yáñez, I. An extension of the gamma associative classifier for dealing with hybrid data. IEEE Access 2019, 7, 64198–64205. [Google Scholar] [CrossRef]




| Algorithm | Parameters |
|---|---|
| CNNTL | Number of neighbors: 5 |
| NCL | Number of neighbors: 5 |
| OSS | Number of neighbors: 5 |
| RUS | None |
| TL | None |
| CIRUS | Dissimilarity: HEOM [52], except for the non-verbal-tourist data, in which we used the function suggested in [4] |
| CNAC | Dissimilarity: HEOM [52], except for the non-verbal-tourist data, in which we used the function suggested in [4]; Attribute weighting: None |
| Dataset | CNAC | CNAC after | |||||
|---|---|---|---|---|---|---|---|
| NCL | OSS | RUS | TL | CNNTL | CIRUS | ||
| alpha_bank | 0.84 | 0.55 | 0.53 | 0.54 | 0.54 | 0.53 | 0.53 |
| attribute_dataset | 0.48 | 0.51 | 0.47 | 0.50 | 0.50 | 0.49 | 0.49 |
| aug | 0.66 | 0.53 | 0.61 | 0.52 | 0.63 | 0.59 | 0.60 |
| churn_modelling | 0.56 | 0.56 | 0.54 | 0.56 | 0.56 | 0.54 | 0.56 |
| customer_behaviour | 0.72 | 0.77 | 0.73 | 0.77 | 0.78 | 0.67 | 0.72 |
| customer_segmentation | 0.42 | - | - | - | - | - | 0.34 |
| customer_targeting | 0.45 | - | - | - | - | - | 0.46 |
| deposit2020 | 0.84 | 0.78 | 0.77 | 0.78 | 0.78 | 0.78 | 0.78 |
| df_clean | 0.55 | 0.63 | 0.60 | 0.60 | 0.57 | 0.58 | 0.68 |
| employee_satisfaction | 0.53 | 0.51 | 0.53 | 0.52 | 0.55 | 0.53 | 0.52 |
| in-vehicle-coupon | 0.54 | 0.53 | 0.53 | 0.53 | 0.53 | 0.53 | 0.53 |
| marketing_campaign | 0.66 | 0.63 | 0.61 | 0.60 | 0.64 | 0.61 | 0.67 |
| marketing_series | 0.72 | 0.69 | 0.64 | 0.68 | 0.69 | 0.65 | 0.71 |
| non-verbal-tourist | 0.73 | - | - | - | - | - | 0.61 |
| online_shoppers | 0.64 | 0.65 | 0.66 | 0.61 | 0.65 | 0.66 | 0.65 |
| promoted | 0.99 | - | - | - | - | - | 0.98 |
| telecom_churn | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 | 0.65 |
| telecom_churnV2 | 0.67 | - | - | - | - | - | 0.67 |
| telecust | 0.36 | - | - | - | - | - | 0.34 |
| term_deposit | 0.76 | - | - | - | - | - | 0.69 |
| Algorithm | Ranking |
|---|---|
| CNAC | 2.150 |
| CIRUS | 3.400 |
| TL | 3.875 |
| NCL | 4.150 |
| RUS | 4.750 |
| CNNTL | 4.800 |
| OSS | 4.875 |
| i | Algorithm | z | p | |
|---|---|---|---|---|
| 6 | OSS | 3.988992 | 0.000066 | 0.008333 |
| 5 | CNNTL | 3.879203 | 0.000105 | 0.010000 |
| 4 | RUS | 3.80601 | 0.000141 | 0.012500 |
| 3 | NCL | 2.9277 | 0.003415 | 0.016667 |
| 2 | TL | 2.525141 | 0.011565 | 0.025000 |
| 1 | CSRUS | 1.829813 | 0.067278 | 0.050000 |
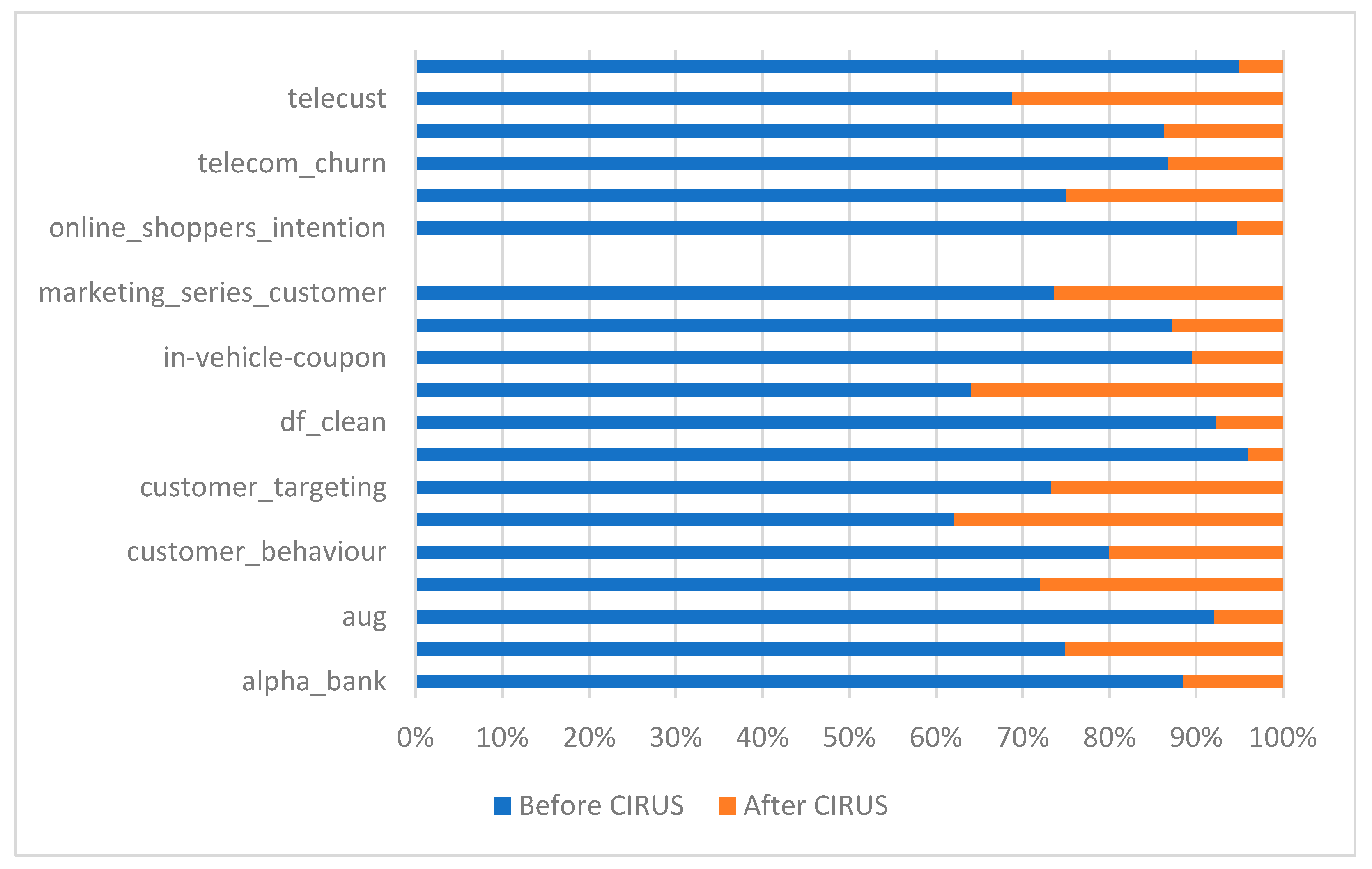
| Datasets | Before CIRUS | After CIRUS | Gain |
|---|---|---|---|
| alpha_bank | 73.40 | 9.57 | 7.67 |
| attribute_dataset | 0.06 | 0.02 | 2.98 |
| aug | 148.74 | 12.72 | 11.69 |
| churn_modelling | 13.45 | 5.23 | 2.57 |
| customer_behaviour | 0.02 | 0.00 | 4.00 |
| customer_segmentation | 7.58 | 4.63 | 1.64 |
| customer_targeting | 82.59 | 30.02 | 2.75 |
| deposit2020 | 575.30 | 23.70 | 24.27 |
| df_clean | 0.03 | 0.00 | 12.10 |
| employee_satisfaction | 0.07 | 0.04 | 1.79 |
| in-vehicle-coupon | 123.69 | 14.51 | 8.52 |
| marketing_campaign | 3.06 | 0.45 | 6.81 |
| marketing_series | 7.75 | 2.77 | 2.79 |
| non-verbal-tourist | 0.00 | 0.00 | 0.00 |
| online_shoppers | 169.36 | 9.39 | 18.03 |
| promoted | 40.72 | 13.56 | 3.00 |
| telecom_churn | 4.07 | 0.62 | 6.57 |
| telecom_churnV2 | 6.03 | 0.96 | 6.31 |
| telecust | 0.20 | 0.09 | 2.20 |
| term_deposit | 536.08 | 28.43 | 18.85 |
| Dataset | NCL | OSS | RUS | TL | CNNTL | CIRUS |
|---|---|---|---|---|---|---|
| alpha_bank | 1.82 | 4.89 | 2.21 | 1.00 | 6.20 | 1.00 |
| attribute_dataset | 6.60 | 3.79 | 4.07 | 1.00 | 1.62 | 1.00 |
| aug | 2.40 | 1.44 | 1.37 | 1.00 | 2.23 | 1.00 |
| churn_modelling | 1.98 | 2.08 | 1.13 | 1.00 | 3.18 | 1.00 |
| customer_behaviour | 5.90 | 1.37 | 4.48 | 1.00 | 1.58 | 1.00 |
| customer_segmentation | - | - | - | - | - | 1.00 |
| customer_targeting | 1.22 | 1.22 | 1.22 | 1.22 | 1.22 | 1.00 |
| deposit2020 | 1.16 | 9.93 | 1.47 | 1.00 | 11.95 | 1.00 |
| df_clean | 1.12 | 6.21 | 1.98 | 1.00 | 8.16 | 1.00 |
| employee_satisfaction | 7.41 | 5.60 | 6.39 | 1.00 | 2.08 | 1.00 |
| in-vehicle-coupon | 5.34 | 2.78 | 3.40 | 1.00 | 1.27 | 1.00 |
| marketing_campaign | 1.63 | 3.82 | 1.07 | 1.00 | 4.98 | 1.00 |
| marketing_series | 2.81 | 1.54 | 1.69 | 1.00 | 2.10 | 1.00 |
| non-verbal-tourist | - | - | - | - | - | 1.00 |
| online_shoppers | 1.58 | 3.34 | 1.16 | 1.00 | 4.59 | 1.00 |
| promoted | - | - | - | - | - | 1.00 |
| telecom_churn | 1.91 | 4.36 | 1.12 | 1.00 | 5.32 | 1.00 |
| telecom_churnV2 | - | - | - | - | - | 1.00 |
| telecust | - | - | - | - | - | 1.00 |
| term_deposit | 3.46 | 6.08 | 4.67 | 1.00 | 5.52 | 1.00 |
| Algorithm | Ranking |
|---|---|
| CIRUS | 1.325 |
| RUS | 2.375 |
| OSS | 3.950 |
| NCL | 4.250 |
| CNNTL | 4.450 |
| TL | 4.650 |
| i | Algorithm | z | p | |
|---|---|---|---|---|
| 5 | TL | 5.620276 | 0.000000 | 0.010000 |
| 4 | CNNTL | 5.282214 | 0.000000 | 0.012500 |
| 3 | NCL | 4.944152 | 0.000001 | 0.016667 |
| 2 | OSS | 4.437060 | 0.000009 | 0.025000 |
| 1 | RUS | 1.774824 | 0.075927 | 0.050000 |
| Algorithm | Ranking |
|---|---|
| CIRUS | 2.425 |
| TL | 3.150 |
| NCL | 3.375 |
| RUS | 3.900 |
| OSS | 4.075 |
| CNNTL | 4.075 |
| i | Algorithm | z | p | |
|---|---|---|---|---|
| 5 | OSS | 2.789009 | 0.005287 | 0.010000 |
| 4 | CNNTL | 2.789009 | 0.005287 | 0.012500 |
| 3 | RUS | 2.493205 | 0.012660 | 0.016667 |
| 2 | NCL | 1.605793 | 0.108319 | 0.025000 |
| 1 | TL | 1.225474 | 0.220397 | 0.050000 |
| CIRUS vs. | IR | NER | Overall |
|---|---|---|---|
| OSS | Better | Better | Better |
| CNNTL | Better | Better | Better |
| RUS | Equal | Better | Better |
| NCL | Better | Equal | Better |
| TL | Better | Equal | Better |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tusell-Rey, C.C.; Camacho-Nieto, O.; Yáñez-Márquez, C.; Villuendas-Rey, Y. Customized Instance Random Undersampling to Increase Knowledge Management for Multiclass Imbalanced Data Classification. Sustainability 2022, 14, 14398. https://doi.org/10.3390/su142114398
Tusell-Rey CC, Camacho-Nieto O, Yáñez-Márquez C, Villuendas-Rey Y. Customized Instance Random Undersampling to Increase Knowledge Management for Multiclass Imbalanced Data Classification. Sustainability. 2022; 14(21):14398. https://doi.org/10.3390/su142114398
Chicago/Turabian StyleTusell-Rey, Claudia C., Oscar Camacho-Nieto, Cornelio Yáñez-Márquez, and Yenny Villuendas-Rey. 2022. "Customized Instance Random Undersampling to Increase Knowledge Management for Multiclass Imbalanced Data Classification" Sustainability 14, no. 21: 14398. https://doi.org/10.3390/su142114398
APA StyleTusell-Rey, C. C., Camacho-Nieto, O., Yáñez-Márquez, C., & Villuendas-Rey, Y. (2022). Customized Instance Random Undersampling to Increase Knowledge Management for Multiclass Imbalanced Data Classification. Sustainability, 14(21), 14398. https://doi.org/10.3390/su142114398