
Data Augmentation by an Additional Self-Supervised CycleGAN-Based for Shadowed Pavement Detection


Abstract
1. Introduction
- A CycleGAN for texture self-supervised for texture generation was established. This is able to generate shadow textures in a self-supervised manner, which enables the network model to output images with shadow textures and binary images with shadow information in a more stable manner;
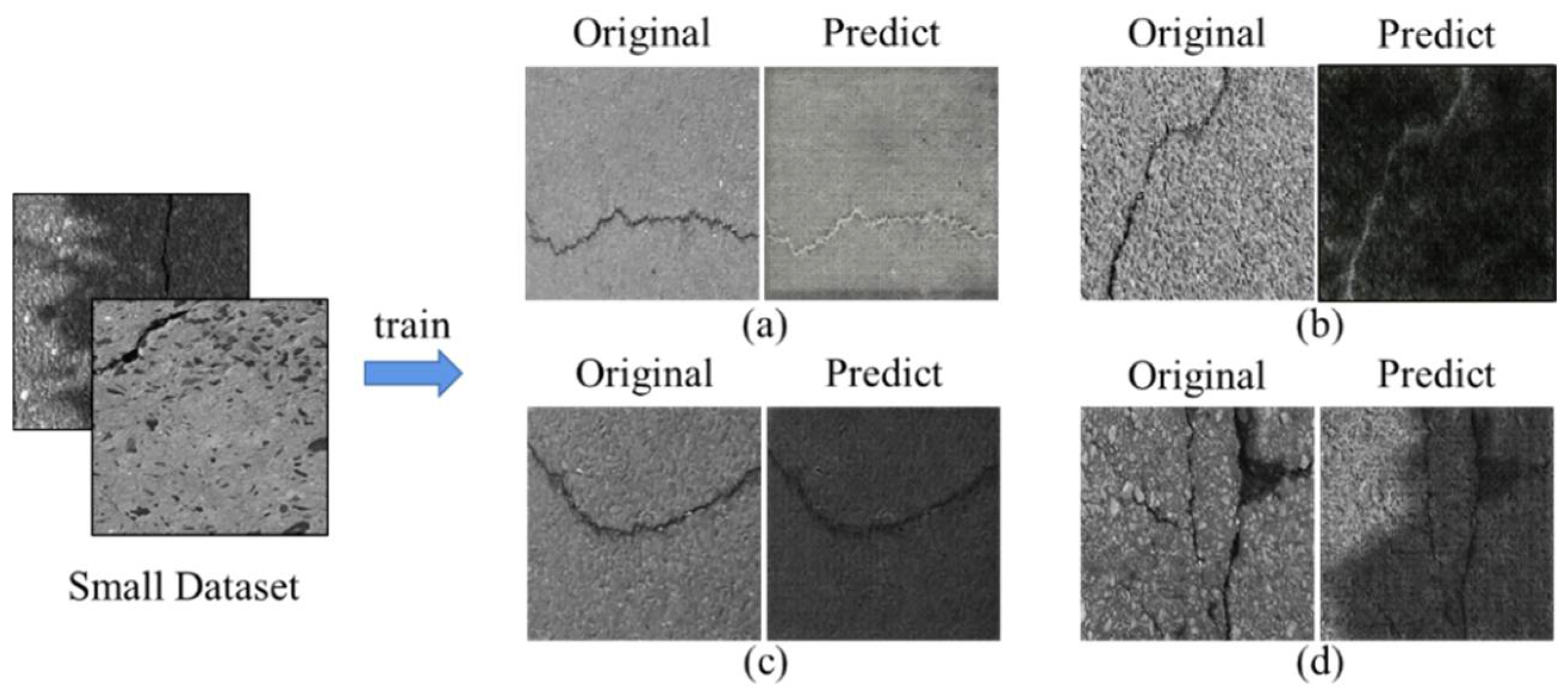
- In this study, we conducted experiments on the crack500, cracktree200, and CFD datasets to verify the shadow-generation effect of the CycleGAN-TSS network by visual comparison and demonstrated the stability of the network for image shadow information generation on unpaired datasets and small datasets;
- It is demonstrated that the proposed shadow data augmentation method can be used to improve the anti-interference capability of pavement crack detection under the influence of shadows.
2. Methodology
2.1. Data Sources and Data Processing
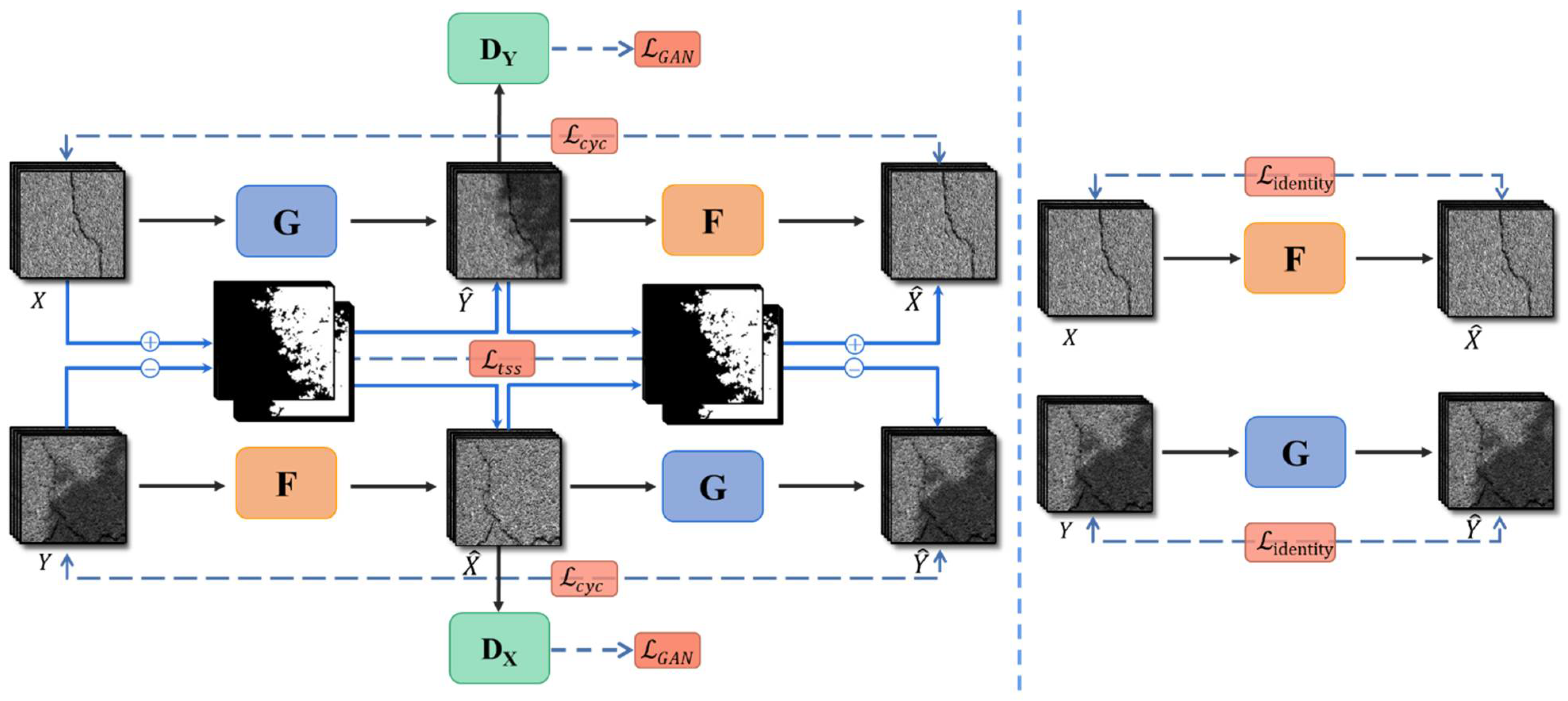
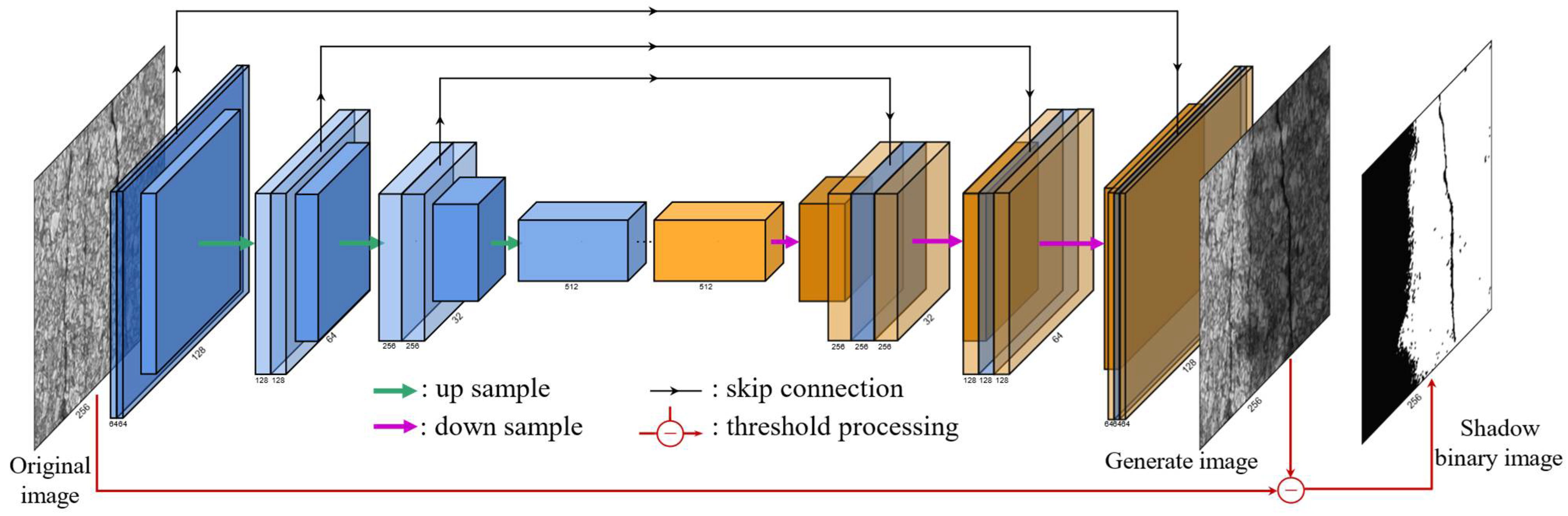
2.2. Network Structure
2.3. Loss Function
- The semantic information of images with shadows and images without shadows is asymmetric. The image generation in this task requires more generation of semantic information rather than conversion of semantic information. If the original CycleGAN is used to complete this work, it can lead to color loss and structural damage to crack information in the image;
- When the original CycleGAN performs the generation task, the training images are unpaired. As a result of the lack of constraints on the recognition of shadow information, under the interference of the original crack color information, the authenticity of the generated shadow information is poor, and the image information will also be lost.
2.3.1. Adversarial Loss
2.3.2. Cycle Consistent Loss
2.3.3. Identity Loss
2.3.4. Texture Self-Supervised Loss
2.3.5. Overall Loss Function
3. Experiment
3.1. Experimental Environment and Data Sources
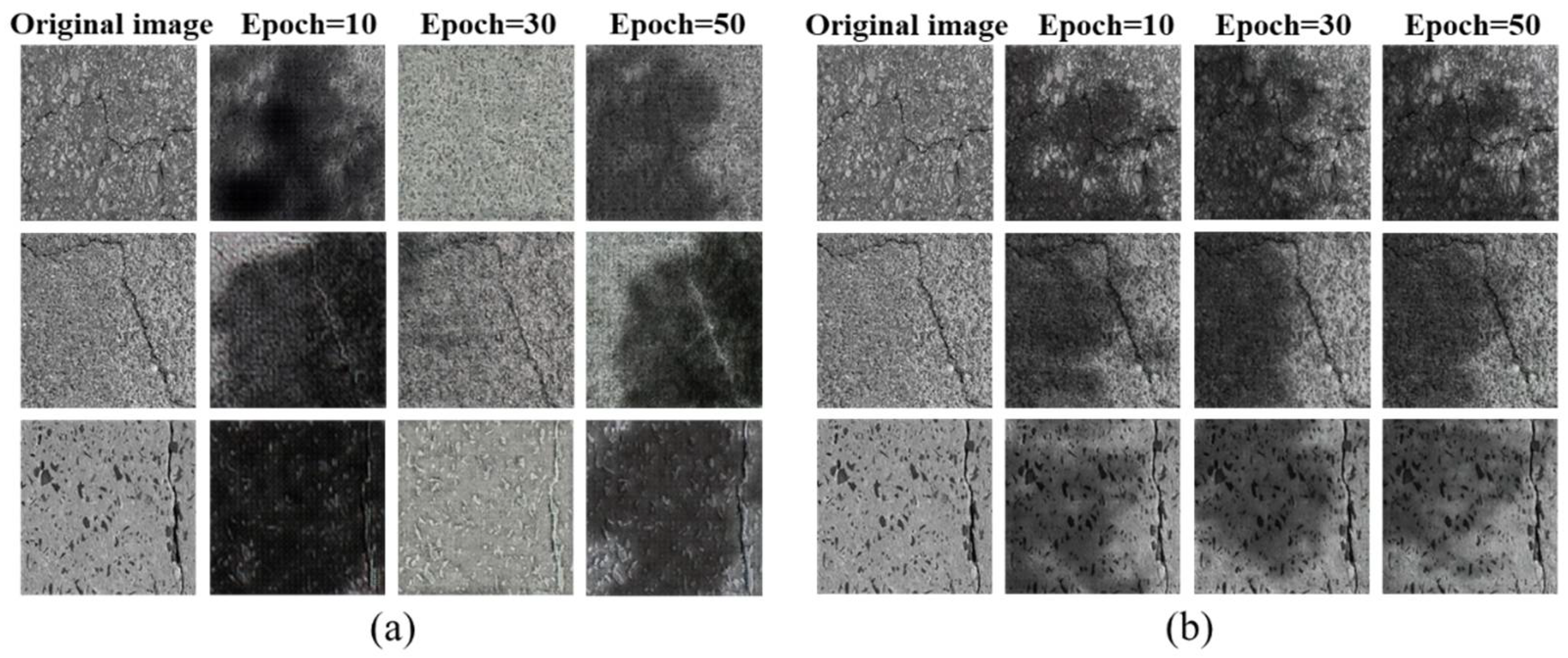
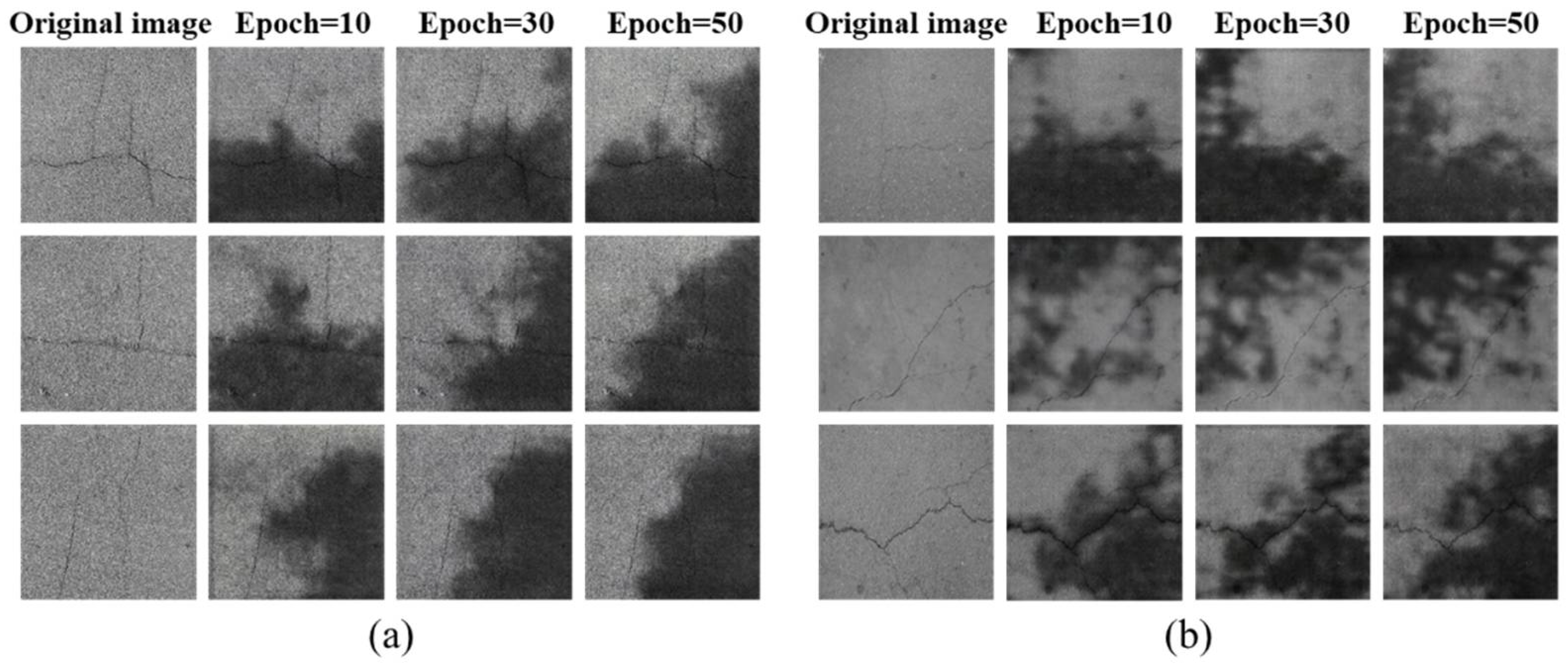
3.2. Shadow Generation Network Training and Results
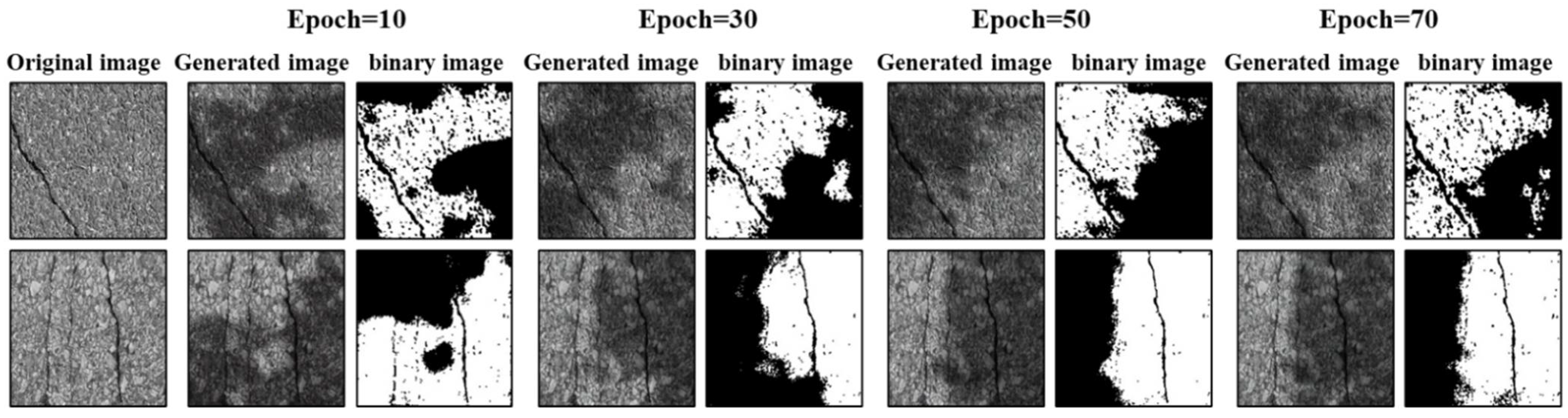
- With the same training conditions, compared with the original CycleGAN, CycleGAN-TSS has a faster convergence speed. The reason is that it adds a self-supervised mechanism to introduce the prior condition of image-generation effect convergence into the network, i.e., the texture generation cycle consistent condition. In other words, the shadow texture information generated and removed by the shadow-generation network should be consistent at least in position and shape;
- In terms of the final image-generation effect, CycleGAN-TSS produces less image noise outside the shadow texture region of the generated image. The reason is that the texture changes of the two processes of shadow generation and shadow removal are constrained by a self-supervised loss, which limits the changes of the image to the same region for both shadow generation and shadow removal. Combined with the participation of adversarial loss, the discriminator restricts the authenticity of shadow generation, which enables it to achieve a better shadow-generation effect, while also preserving more complete content information of non-shadow regions.
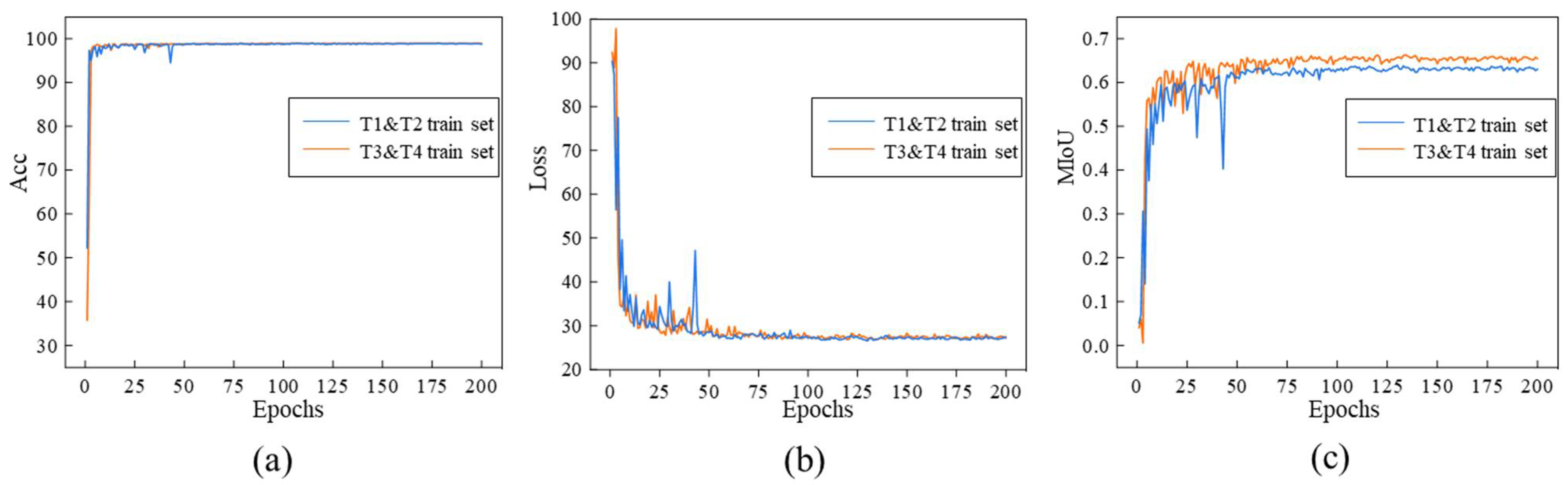
3.3. Segmentation Network Validation Results
- Shadows have a great influence on the segmentation of pavement cracks, mainly because the structure and color information of cracks is easily confused with shadows;
- By augmenting the shadow dataset, the ability of the network to resist shadow interference can be effectively improved, and the crack segmentation effect of the non-shadow pavement images can be well maintained.
4. Conclusions
- Texture self-supervised CycleGAN (CycleGAN-TSS) introduces the prior knowledge of generator convergence, reduces the problem of poor generation effect caused by the similarity between the semantic information of cracks and the semantic information of shadows, and improves the stability of shadow images generated by the network;
- In this study, we conducted experiments on three different datasets to verify the effect of the generated network. Compared with the original CycleGAN, the improved CycleGAN-TSS pays more attention to the shape and location information of the cycle generation semantics, thus making our network better able to generate pavement shadow images in the case of small datasets;
- In summary, the proposed CycleGAN-TSS is more suitable for the data augmentation of pavement shadow images in real-world conditions. We used the proposed method to augment pavement shadow images and fed them into the crack segmentation network U-Net for training. The results show that the augmented method can effectively improve the recognition accuracy of crack detection under shadow interference.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Chen, Y.; Bai, Y.; Zhang, W.; Mei, T. Destruction and Construction Learning for Fine-Grained Image Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5152–5161. [Google Scholar] [CrossRef]
- Li, X.; Zhao, L.; Wei, L.; Yang, M.-H.; Wu, F.; Zhuang, Y.; Ling, H.; Wang, J. DeepSaliency: Multi-Task Deep Neural Network Model for Salient Object Detection. IEEE Trans. Image Process. 2016, 25, 3919–3930. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Rao, Z.; Tung, P.-Y.; Xie, R.; Wei, Y.; Zhang, H.; Ferrari, A.; Klaver, T.P.C.; Körmann, F.; Sukumar, P.T.; Kwiatkowski da Silva, A.; et al. Machine learning–enabled high-entropy alloy discovery. Science 2022, 378, 78–85. [Google Scholar] [CrossRef]
- Fan, W.; Chen, Y.; Li, J.; Sun, Y.; Feng, J.; Hassanin, H.; Sareh, P. Machine learning applied to the design and inspection of reinforced concrete bridges: Resilient methods and emerging applications. Structures 2021, 33, 3954–3963. [Google Scholar] [CrossRef]
- Zhang, P.; Fan, W.; Chen, Y.; Feng, J.; Sareh, P. Structural symmetry recognition in planar structures using Convolutional Neural Networks. Eng. Struct. 2022, 260, 114227. [Google Scholar] [CrossRef]
- Gopalakrishnan, K. Deep Learning in Data-Driven Pavement Image Analysis and Automated Distress Detection: A Review. Data 2018, 3, 28. [Google Scholar] [CrossRef]
- Nhat-Duc, H.; Nguyen, Q.-L.; Tran, V.-D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Autom. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Ji, A.; Xue, X.; Wang, Y.; Luo, X.; Xue, W. An integrated approach to automatic pixel-level crack detection and quantification of asphalt pavement. Autom. Constr. 2020, 114, 103176. [Google Scholar] [CrossRef]
- Li, P.; Xia, H.; Zhou, B.; Yan, F.; Guo, R. A Method to Improve the Accuracy of Pavement Crack Identification by Combining a Semantic Segmentation and Edge Detection Model. Appl. Sci. 2022, 12, 4714. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.Y.; Liu, J.X.; Zhang, Y.; Chen, Z.P.; Li, C.G.; He, K.; Yan, R.B. Research on Crack Detection Algorithm of the Concrete Bridge Based on Image Processing. Procedia Comput. Sci. 2019, 154, 610–616. [Google Scholar] [CrossRef]
- Qiang, S.; Guoying, L.; Jingqi, M.; Hongmei, Z. An edge-detection method based on adaptive canny algorithm and iterative segmentation threshold. In Proceedings of the 2016 2nd International Conference on Control Science and Systems Engineering (ICCSSE), Singapore, 27–29 July 2016; IEEE: Singapore, 2016; pp. 64–67. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, X.; Hong, H. Pavement Crack Detection Combining Non-Negative Feature with Fast LoG in Complex Scene. In Proceedings of the Ninth International Symposium on Multispectral Image Processing and Pattern Recognition (MIPPR2015), Enshi, China, 31 October–1 November 2015; p. 98120L. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Deng, R.; Yan, S. Illumination Compensation Model with k-Means Algorithm for Detection of Pavement Surface Cracks with Shadow. J. Comput. Civ. Eng. 2020, 34, 04019049. [Google Scholar] [CrossRef]
- Liu, Z.; Yin, H.; Mi, Y.; Pu, M.; Wang, S. Shadow Removal by a Lightness-Guided Network With Training on Unpaired Data. IEEE Trans. Image Process. 2021, 30, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Nanni, L.; Paci, M.; Brahnam, S.; Lumini, A. Feature transforms for image data augmentation. arXiv 2014, arXiv:2201.09700. [Google Scholar] [CrossRef]
- Antoniou, A.; Storkey, A.; Edwards, H. Data Augmentation Generative Adversarial Networks. arXiv 2018, arXiv:1711.04340. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Sandfort, V.; Yan, K.; Pickhardt, P.J.; Summers, R.M. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 2019, 9, 16884. [Google Scholar] [CrossRef] [PubMed]
- Niu, S.; Li, B.; Wang, X.; He, S.; Peng, Y. Defect attention template generation cycleGAN for weakly supervised surface defect segmentation. Pattern Recognit. 2022, 123, 108396. [Google Scholar] [CrossRef]
- Choi, W.; Heo, J.; Ahn, C. Development of Road Surface Detection Algorithm Using CycleGAN-Augmented Dataset. Sensors 2021, 21, 7769. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, L.; Chen, S. ESA-CycleGAN: Edge feature and self-attention based cycle-consistent generative adversarial network for style transfer. IET Image Process. 2022, 16, 176–190. [Google Scholar] [CrossRef]
- Xu, Z.; Qi, C.; Xu, G. Semi-Supervised Attention-Guided CycleGAN for Data Augmentation on Medical Images. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 563–568. [Google Scholar] [CrossRef]
- Jiangsha, A.; Tian, L.; Bai, L.; Zhang, J. Data augmentation by a CycleGAN-based extra-supervised model for nondestructive testing. Meas. Sci. Technol. 2022, 33, 045017. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Original Images | Selected Images | Composite Shadow Images |
|---|---|---|---|
| CRACK500 | 3364 | 780 | 80 |
| CFD | 155 | 126 | 80 |
| cracktree200 | 206 | 206 | 80 |
| Dataset | Original Image | Composite Image |
|---|---|---|
| CRACK500 | 80 | 80 |
| CFD | 80 | 46 |
| cracktree200 | 80 | 80 |
| Dataset | Train Set | Test Set | ||
|---|---|---|---|---|
| Original Image | Augmented Image | Original Image | Augmented Image | |
| T1 | 500 | 0 | 200 | 0 |
| T2 | 500 | 0 | 100 | 100 |
| T3 | 350 | 150 | 100 | 100 |
| T4 | 350 | 150 | 200 | 0 |
| Dataset | Acc (%) | Recall | F1-Score | MIoU |
|---|---|---|---|---|
| T1 | 98.25 | 78.46 | 77.39 | 63.12 |
| T2 | 97.16 | 64.15 | 63.29 | 46.29 |
| T3 | 98.16 | 77.11 | 76.18 | 61.53 |
| T4 | 98.30 | 79.78 | 77.69 | 63.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Li, P.; Fang, Q.; Xia, H.; Guo, R. Data Augmentation by an Additional Self-Supervised CycleGAN-Based for Shadowed Pavement Detection. Sustainability 2022, 14, 14304. https://doi.org/10.3390/su142114304
Song J, Li P, Fang Q, Xia H, Guo R. Data Augmentation by an Additional Self-Supervised CycleGAN-Based for Shadowed Pavement Detection. Sustainability. 2022; 14(21):14304. https://doi.org/10.3390/su142114304
Chicago/Turabian StyleSong, Jiajun, Peigen Li, Qiang Fang, Haiting Xia, and Rongxin Guo. 2022. "Data Augmentation by an Additional Self-Supervised CycleGAN-Based for Shadowed Pavement Detection" Sustainability 14, no. 21: 14304. https://doi.org/10.3390/su142114304
APA StyleSong, J., Li, P., Fang, Q., Xia, H., & Guo, R. (2022). Data Augmentation by an Additional Self-Supervised CycleGAN-Based for Shadowed Pavement Detection. Sustainability, 14(21), 14304. https://doi.org/10.3390/su142114304