
Utilities of Artificial Intelligence in Poverty Prediction: A Review


Abstract
:1. Introduction
- 1.
- How many papers on utilities of AI in poverty prediction were published up until March 2022?
- 2.
- Which approach to poverty was applied when AI was used for poverty prediction?
- 3.
- Why AI methods were applied in poverty prediction?
- 4.
- Whether reviews on AI utilities in poverty prediction conducted before?
- 5.
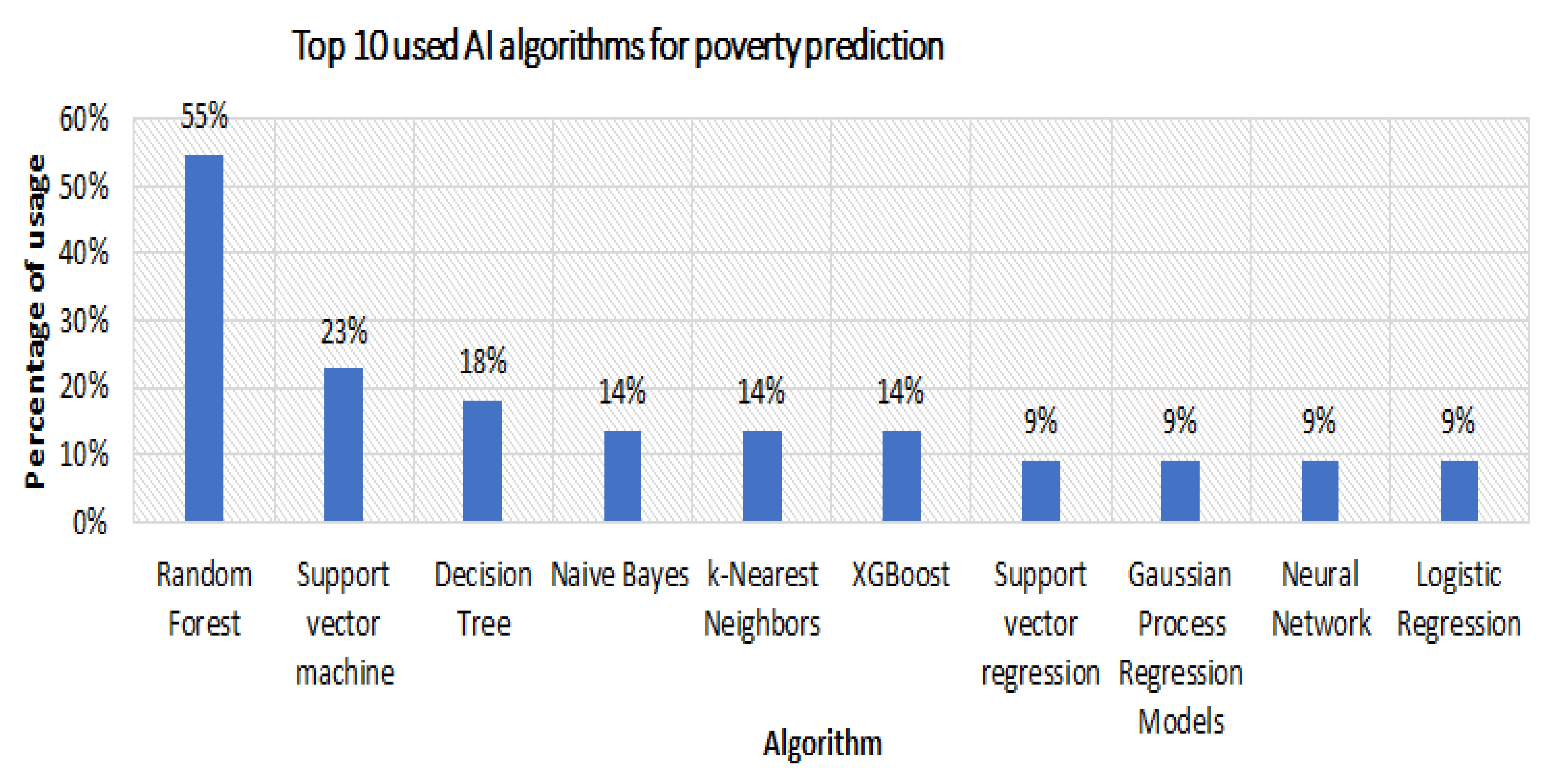
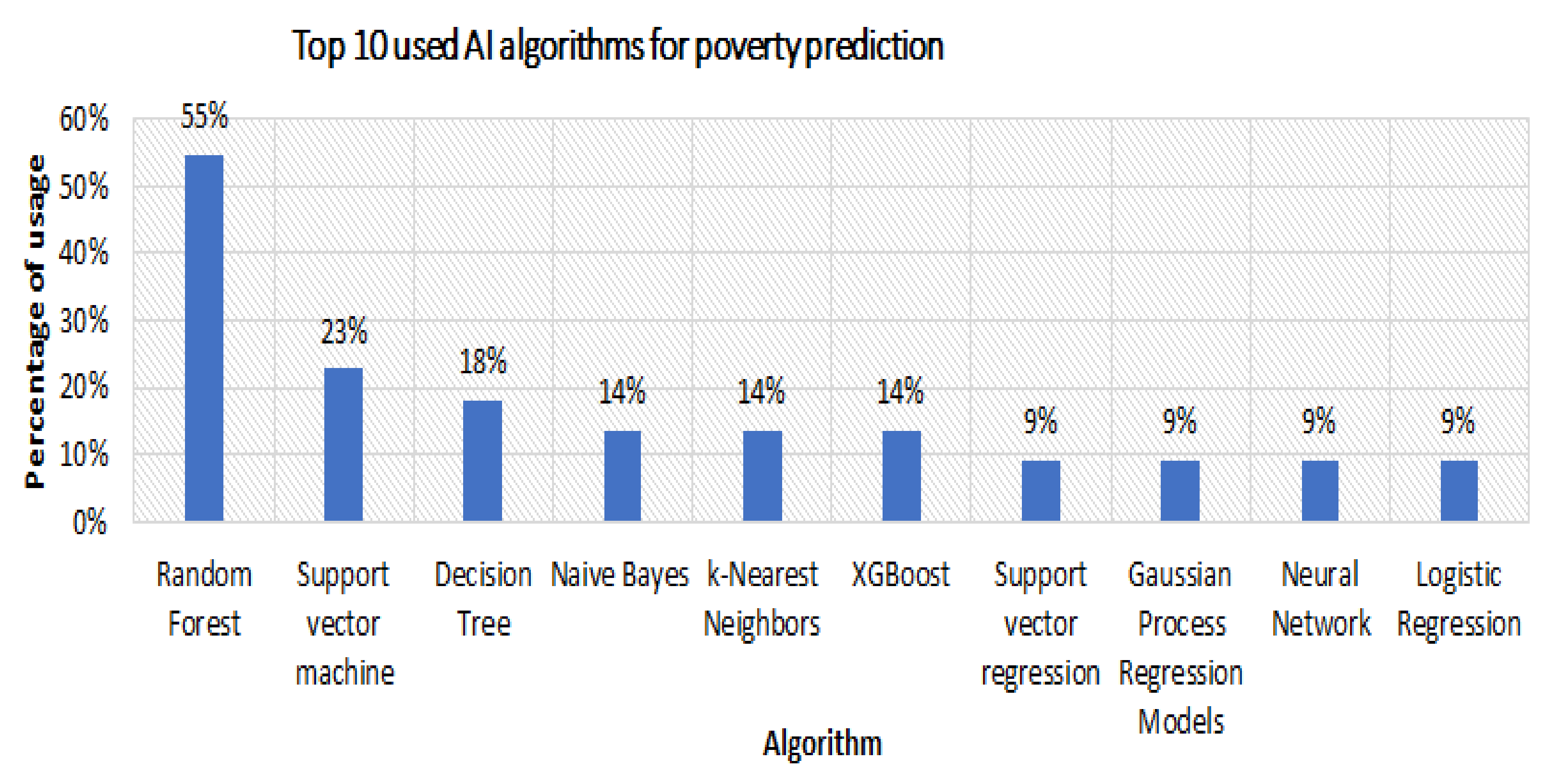
- Which AI methods were applied for predicting poverty?
- 6.
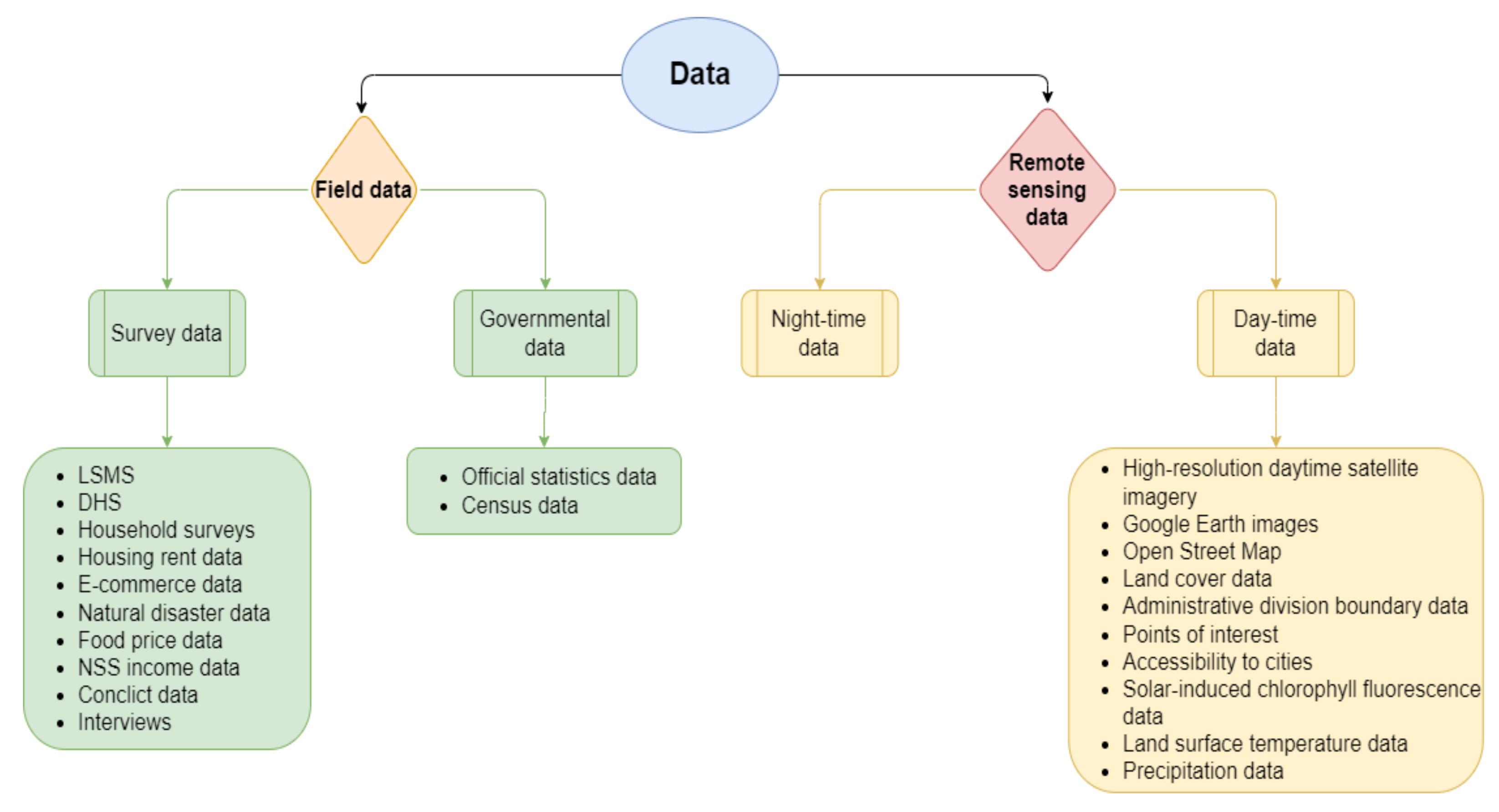
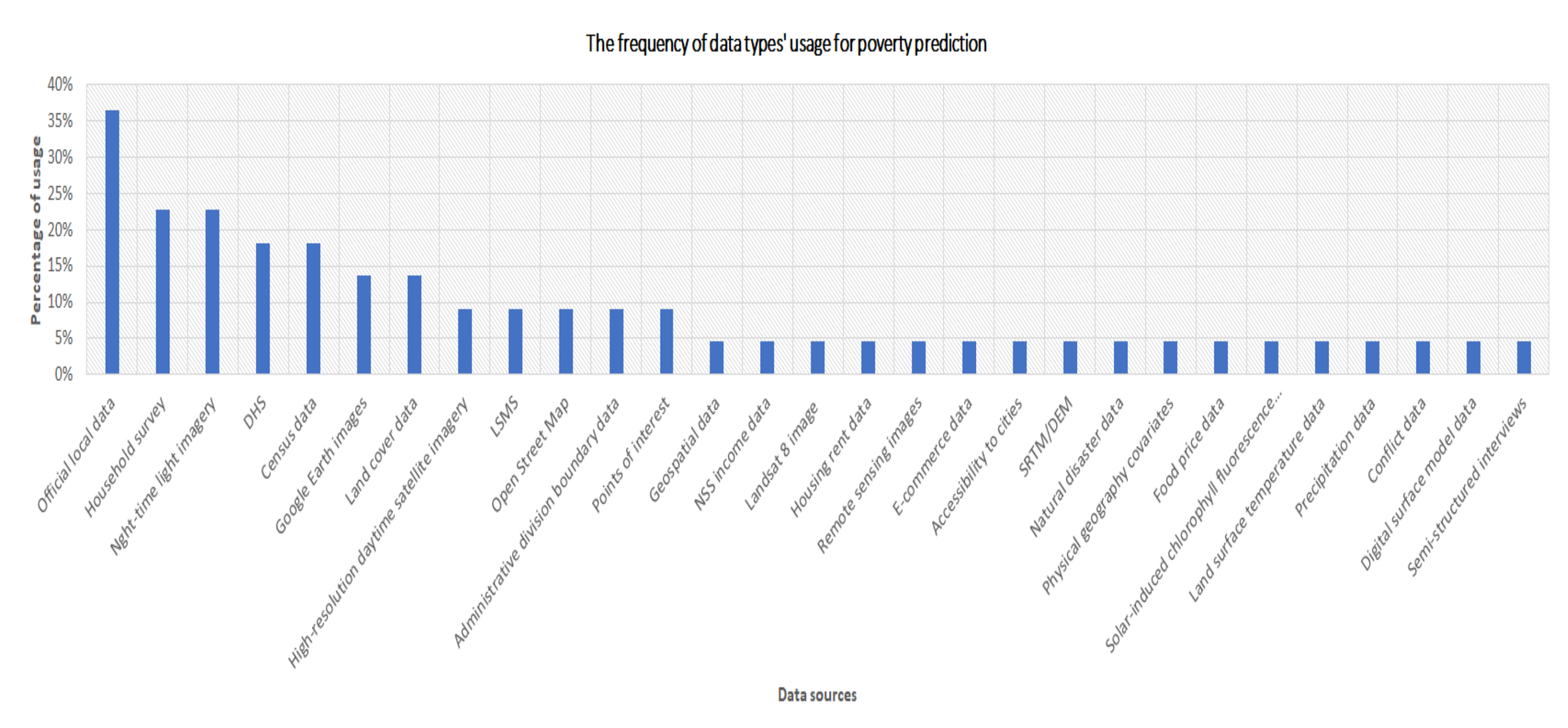
- What data were used for poverty prediction via AI?
- 7.
- What are the advantages and disadvantages of the created AI models for poverty prediction?
- 8.
- What is the future scope of AI applications in poverty prediction?
2. Related Reviews
3. Research Methodology
- 1.
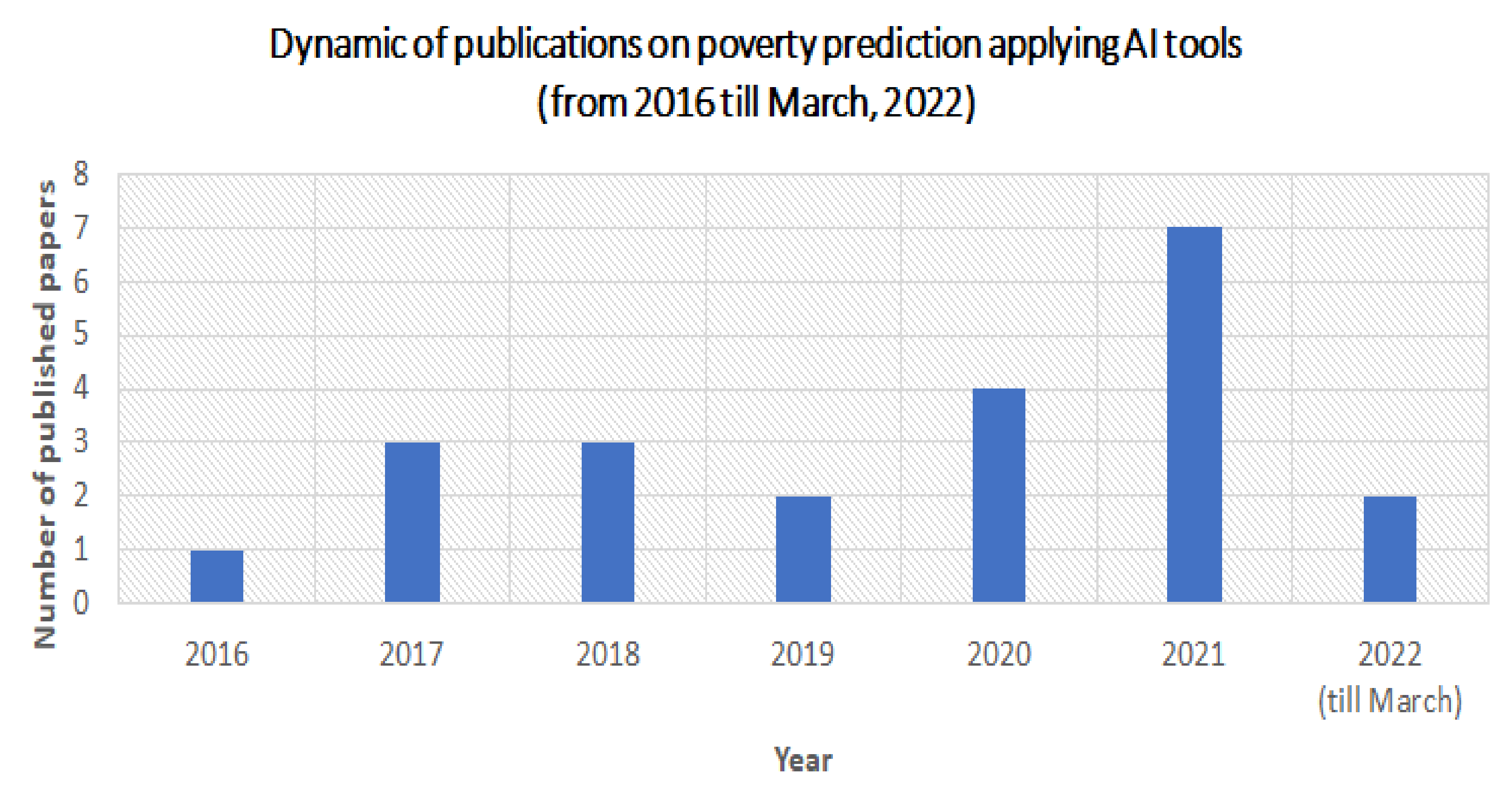
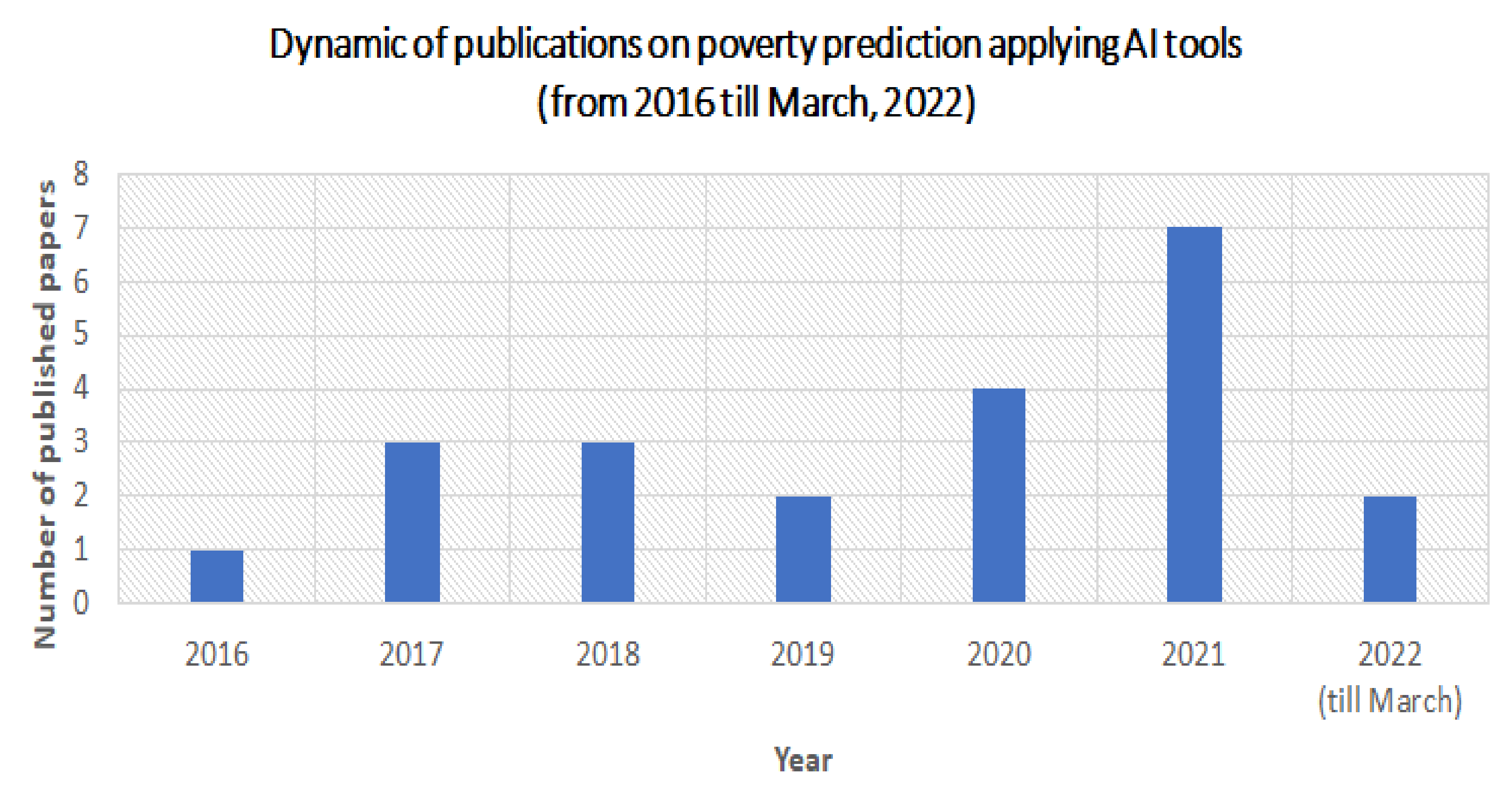
- The first step is a selection step that includes three important moments: time-frame, database, and keywords. As the ending point of the time-frame was selected as March 2022 when our investigations started. We expected to find results at the beginning of the time-frame. The origin of the paper was important when searching papers; thus, papers for our survey were selected from reliable Web of Science (https://clarivate.com/webofsciencegroup/solutions/web-of-science/ (accessed on 10 January 2022)) and Scopus (https://www.scopus.com/ (accessed on 15 January 2022)) databases. In order to properly conduct a search, Boolean operators were used alongside with topic-related terms and phrases.For searching, the following keywords were used: “poverty and AI”, “poverty” AND “AI”, “poverty and machine learning”, “poverty” AND “machine learning”, “poverty and deep learning”, “poverty” AND “deep learning”. In this stage, overall, we collected forty-three papers.
- 2.
- The second step is a classification. All found papers were classified according to the following exclusion criteria: (1) papers theoretically describing the relationship between poverty and AI were excluded; (2) papers theoretically analyzing the impact of AI on poverty were excluded; (3) papers illustrating examples of AI applications in various spheres were excluded; (4) conference proceedings were excluded. The reason of these exclusion criteria is that the aim of our survey is to analyze the real applications of AI methods in poverty prediction. After reading abstracts and full-length papers, twenty-two papers were selected for our survey. Among these twenty-two papers, the remaining steps were performed. This classification step provided us with the beginning of the time-frame of our survey. It was revealed that the first paper on AI applications in poverty prediction was published in 2016; thus, this year was chosen as the initial benchmark of the time-frame of our conducted survey.
- 3.
- In the third step, the content of collected papers was analyzed.
- 4.
- At the last stage, the outcomes were discussed and future orients were provided.
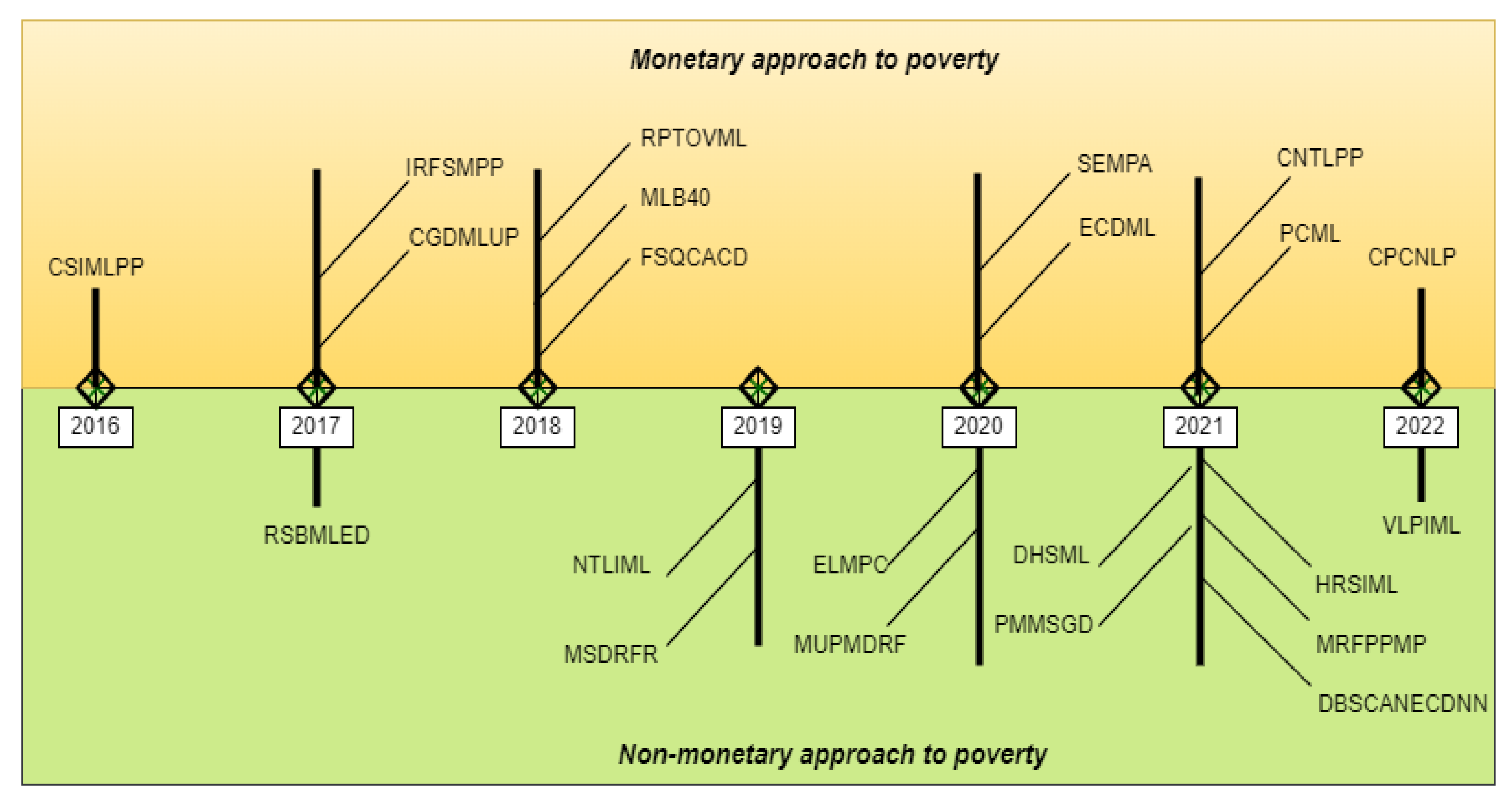
4. AI Tools in Poverty Prediction
4.1. Combining Satellite Imagery and Machine Learning to Predict Poverty (CSIMLPP)
4.2. Remote Sensing-Based Measurement of Living Environment Deprivation: Improving Classical Approaches with Machine Learning (RSBMLED)
4.3. Monetary and Non-Monetary Poverty in Urban Slums in Accra: Combining Geospatial Data and Machine Learning to Study Urban Poverty (CGDMLUP)
4.4. Is Random Forest a Superior Methodology for Predicting Poverty? An Empirical Assessment (IRFSMPP)
4.5. Multidimensional Paths to Regional Poverty: A Fuzzy-Set Qualitative Comparative Analysis of Colombian Departments (FSQCACD)
4.6. Retooling Poverty Targeting Using Out-of-Sample Validation and Machine Learning (RPTOVML)
4.7. Machine Learning Approach for Bottom 40 Percent Households (B40) Poverty Classification (MLB40)
4.8. A Comparison of Machine Learning Approaches for Identifying High-Poverty Counties: Robust Features of DMSP/OLS Night-Time Light Imagery (NTLIML)
4.9. Estimation of Poverty Using Random Forest Regression with Multi-Source Data: A Case Study in Bangladesh (MSDRFR)
4.10. Ensemble Learning for Multidimensional Poverty Classification (ELMPC)
4.11. A Social Engineering Model for Poverty Alleviation (SEMPA)
4.12. Measuring Urban Poverty Using Multi-Source Data and a Random Forest Algorithm: A Case Study in Guangzhou (MUPMDRF)
4.13. Estimating City-Level Poverty Rate Based on e-Commerce Data with Machine Learning (ECDML)
4.14. Poverty Mapping in the Dian-Gui Qian Contiguous Extremely Poor Area of Southwest China Based on Multi-Source Geospatial Data (PMMSGD)
4.15. Combining Night Time Lights in Prediction of Poverty Incidence at the County Level (CNTLPP)
4.16. A Novel DBSCAN Clustering Algorithm via Edge Computing-Based Deep Neural Network Model for Targeted Poverty Alleviation Big Data (DBSCANECDNN)
4.17. Identifying Urban Poverty Using High-Resolution Satellite Imagery and Machine Learning Approaches: Implications for Housing Inequality (HRSIML)
4.18. Multivariate Random Forest Prediction of Poverty and Malnutrition Prevalence (MRFPPMP)
4.19. Is Poverty Predictable with Machine Learning? A Study of DHS Data from Kyrgyzstan (DHSML)
4.20. Poverty Classification Using Machine Learning: The Case of Jordan (PCML)
4.21. Village-Level Poverty Identification Using Machine Learning, High-Resolution Images, and Geospatial Data (VLPIML)
4.22. Classification of Poverty Condition Using Natural Language Processing (CPCNLP)
5. Discussion
6. Conclusions and Future Scope
- 1.
- Providing systematic bibliometric literature reviews;
- 2.
- Categorizing poverty prediction models in accordance with poverty measurement approaches;
- 3.
- Discussing and comparing advantages and disadvantages of models;
- 4.
- Discussing existing challenges and opening gates for future research ideas.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stolbov, M.; Shchepeleva, M. Modeling global real economic activity: Evidence from variable selection across quantiles. J. Econ. Asymmetries 2022, 25, e00238. [Google Scholar] [CrossRef]
- Lagat, A.K.; Waititu, A.G.; Wanjoya, A.K. Support vector regression and artificial neural network approaches: Case of economic growth in East Africa community. Am. J. Theor. Appl. Stat. 2019, 7, 67–79. [Google Scholar] [CrossRef]
- Smith, M.J. Getting value from artificial intelligence in agriculture. Anim. Prod. Sci. 2020, 60, 46–54. [Google Scholar] [CrossRef]
- Dharmaraj, V.; Vijayanand, C. Artificial Intelligence (AI) in Agriculture. Int. J. Curr. Microbiol. Appl. Sci. 2018, 7, 2122–2128. [Google Scholar] [CrossRef]
- Zavadskaya, A. Artificial Intelligence in Finance: Forecasting Stock Market Returns Using Artificial Neural Networks; Hanken School of Economics: Helsinki, Finland, 2017; pp. 1–154. [Google Scholar]
- Mhlanga, D. Artificial intelligence in the industry 4.0, and its impact on poverty, innovation, infrastructure development, and the sustainable development goals: Lessons from emerging economies? Sustainability 2021, 13, 5788. [Google Scholar] [CrossRef]
- Muñetón-Santa, G.; Escobar-Grisales, D.; López-Pabón, F.O.; Pérez-Toro, P.A.; Orozco-Arroyave, J.R. Classification of Poverty Condition Using Natural Language Processing. Soc. Indic. Res. 2022, 162, 1413–1435. [Google Scholar] [CrossRef]
- Veit-Wilson, J. Paradigms of Poverty: A Rehabilitation of B.S. Rowntree. J. Soc. Policy 1986, 15, 69–99. [Google Scholar] [CrossRef]
- Alsharkawi, A.; Al-Fetyani, M.; Dawas, M.; Saadeh, H.; Alyaman, M. Poverty classification using machine learning: The case of Jordan. Sustainability 2021, 13, 1412. [Google Scholar] [CrossRef]
- Noble, M.; Wright, G.; Smith, G.; Dibben, C. Measuring multiple deprivation at the small-area level. Environ. Plan. A 2006, 38, 169–185. [Google Scholar] [CrossRef]
- Alkire, S.; Santos, M.E. Acute Multidimensional Poverty: A New Index for Developing Countries; OPHI Working Papers 38; University of Oxford: Oxford, UK, 2010. [Google Scholar]
- Sen, A. Poverty: An ordinal approach to measurement. Econom. J. Econom. Soc. 1976, 44, 219–231. [Google Scholar] [CrossRef]
- Sohnesen, T.P.; Stender, N. Is random forest a superior methodology for predicting poverty? An empirical assessment. Poverty Public Policy 2017, 9, 118–133. [Google Scholar] [CrossRef] [Green Version]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining satellite imagery and machine learning to predict poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arribas-Bel, D.; Patino, J.E.; Duque, J.C. Remote sensing-based measurement of Living Environment Deprivation: Improving classical approaches with machine learning. PLoS ONE 2017, 12, e0176684. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McBride, L.; Nichols, A. Retooling poverty targeting using out-of-sample validation and machine learning. World Bank Econ. Rev. 2018, 32, 531–550. [Google Scholar] [CrossRef] [Green Version]
- Sani, N.S.; Rahman, M.A.; Bakar, A.A.; Sahran, S.; Sarim, H.M. Machine learning approach for bottom 40 percent households (B40) poverty classification. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1698. [Google Scholar] [CrossRef]
- Li, G.; Cai, Z.; Liu, X.; Liu, J.; Su, S. A comparison of machine learning approaches for identifying high-poverty counties: Robust features of DMSP/OLS night-time light imagery. Int. J. Remote Sens. 2019, 40, 5716–5736. [Google Scholar] [CrossRef]
- Hu, L.R.; He, S.J.; Han, Z.X.; Xiao, H.; Su, S.L.; Weng, M.; Cai, Z.L. Monitoring Housing Rental Prices Based on Social Media: An Integrated Approach of Machine-Learning Algorithms and Hedonic Modeling to Inform Equitable Housing Policies. Land Use Policy 2019, 82, 657–673. [Google Scholar] [CrossRef]
- Hu, S.; Ge, Y.; Liu, M.; Ren, Z.; Zhang, X. Village-level poverty identification using machine learning, high-resolution images, and geospatial data. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102694. [Google Scholar] [CrossRef]
- Castle, J.L.; Qin, X.; Reed, W.R. How to Pick the Best Regression Equation: A Review and Comparison of Model Selection Algorithms; Working Papers in Economics 09/13 2019; University of Canterbury, Department of Economics and Finance: Christchurch, New Zealand, 2019. [Google Scholar]
- Wijaya, D.R.; Paramita, N.L.P.S.P.; Uluwiyah, A.; Rheza, M.; Zahara, A.; Puspita, D.R. Estimating city-level poverty rate based on e-commerce data with machine learning. Electron. Commer. Res. 2022, 22, 195–221. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2022, 55, 3503–3568. [Google Scholar] [CrossRef]
- Kikon, A.; Deka, P.C. Artificial intelligence application in drought assessment, monitoring and forecasting: A review. Stoch. Environ. Res. Risk Assess. 2022, 36, 1197–1214. [Google Scholar] [CrossRef]
- Rosário, A.T.; Dias, J.C. Sustainability and the Digital Transition: A Literature Review. Sustainability 2022, 14, 4072. [Google Scholar] [CrossRef]
- Wahl, B.; Cossy-Gantner, A.; Germann, S.; Schwalbe, N.R. Artificial intelligence (AI) and global health: How can AI contribute to health in resource-poor settings? BMJ Glob. Health 2018, 3, e000798. [Google Scholar] [CrossRef] [Green Version]
- Engstrom, R.; Pavelesku, D.; Tanaka, T.; Wambile, A. Monetary and Non-Monetary Poverty in Urban Slums in Accra: Combining Geospatial Data and Machine Learning to Study Urban Poverty; World Bank: Washington, DC, USA, 2017. [Google Scholar]
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Felländer , A.; Langhans , S.D.; Tegmark , M.; Fuso Nerini, F. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 2020, 11, 233. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int. J. Inf. Manag. 2021, 57, 101994. [Google Scholar] [CrossRef]
- Blumenstock, J.E. Fighting poverty with data. Science 2016, 353, 753–754. [Google Scholar] [CrossRef] [PubMed]
- Isnin, R.; Bakar, A.A.; Sani, N.S. Does Artificial Intelligence Prevail in Poverty Measurement? J. Phys. Conf. Ser. 2020, 1529, 042082. [Google Scholar] [CrossRef]
- Snyder, H. Literature review as a research methodology: An overview and guidelines. J. Bus. Res. 2019, 104, 333–339. [Google Scholar] [CrossRef]
- Smith, T.; Noble, M.; Noble, S.; Wright, G.; McLennan, D.; Plunkett, E. The English Indices of Deprivation 2015; Department of Communities and Local Government: London, UK, 2015; pp. 1–94. [Google Scholar]
- Ruiz, L.A.; Recio, J.A.; Fernández-Sarría, A.; Hermosilla, T. A feature extraction software tool for agricultural object-based image analysis. Comput. Electron. Agric. 2011, 76, 284–296. [Google Scholar] [CrossRef] [Green Version]
- Balaguer, A.; Ruiz, L.A.; Hermosilla, T.; Recio, J.A. Definition of a comprehensive set of texture semivariogram features and their evaluation for object-oriented image classification. Comput. Geosci. 2010, 36, 231–240. [Google Scholar] [CrossRef]
- Balaguer-Beser, A.; Ruiz, L.A.; Hermosilla, T.; Recio, J.A. Using semivariogram indices to analyse heterogeneity in spatial patterns in remotely sensed images. Comput. Geosci. 2013, 50, 115–127. [Google Scholar] [CrossRef]
- Athey, S.; Imbens, G. Recursive partitioning for heterogeneous causal effects. Proc. Natl. Acad. Sci. USA 2016, 113, 7353–7360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Graesser, J.; Cheriyadat, A.; Vatsavai, R.R.; Chandola, V.; Long, J.; Bright, E. Image based characterization of formal and informal neighborhoods in an urban landscape. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1164–1176. [Google Scholar] [CrossRef]
- Elbers, C.; Lanjouw, J.O.; Lanjouw, P. Micro–level estimation of poverty and inequality. Econometrica 2003, 71, 355–364. [Google Scholar] [CrossRef]
- Accra Metropolitan Assembly (AMA); UN Habitat. Participatory Slum Upgrading and Prevention Millennium City of Accra, Ghana; UN Habitat: Nairobi, Kenya, 2011. [Google Scholar]
- Christiaensen, L.; Lanjouw, P.; Luoto, J.; Stifel, D. Small area estimation-based prediction methods to track poverty: Validation and applications. J. Econ. Inequal. 2012, 10, 267–297. [Google Scholar] [CrossRef] [Green Version]
- Nieto Aleman, P.A.; Roig-Tierno, N.; Mas-Verdú, F.; García Álvarez-Coque, J.M. Multidimensional paths to regional poverty: A Fuzzy-set qualitative comparative analysis of Colombian departments. J. Hum. Dev. Capab. 2018, 19, 499–520. [Google Scholar] [CrossRef]
- PAT (Poverty Assessment Tool). Quantifying the Very Poor. Poverty Assessment Tools Website. 2014. Available online: http://www.povertytools.org (accessed on 19 May 2022).
- Hastie, T.; Tibshirani, R.J.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2019; ISBN 978-0-387-84857-0. [Google Scholar]
- Terano, R.; Mohamed, Z.; Jusri, J.H.H. Effectiveness of microcredit program and determinants of income among small business entrepreneurs in Malaysia. J. Glob. Entrep. Res. 2015, 5. [Google Scholar] [CrossRef] [Green Version]
- Redjeki, S.; Guntara, M.; Anggoro, P. Naive Bayes Classifier Algorithm Approach for Mapping Poor Families Potential. Int. J. Adv. Res. Artif. Intell. 2015, 4, 29–33. [Google Scholar] [CrossRef] [Green Version]
- Sewaiwar, P.; Verma, K.K. Comparative study of various decision tree classification algorithm using WEKA. Int. J. Emerg. Res. Manag. Technol. 2015, 4, 2278–9359. [Google Scholar]
- Samsiah Sani, N.; Shlash, I.; Hassan, M.; Hadi, A.; Aliff, M. Enhancing Malaysia Rainfall Prediction Using Classification Techniques. J. Appl. Environ. Biol. Sci 2017, 7, 20–29. [Google Scholar]
- Cao, H.; Sen, P.K.; Peery, A.F.; Dellon, E.S. Assessing agreement with multiple raters on correlated kappa statistics. Biom. J. 2016, 58, 935–943. [Google Scholar] [CrossRef] [PubMed]
- Patro, S.; Sahu, K.K. Normalization: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Shreem, S.S.; Abdullah, S.; Nazri, M.Z.A. Hybrid feature selection algorithm using symmetrical uncertainty and a harmony search algorithm. Int. J. Syst. Sci. 2016, 47, 1312–1329. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Wager, S.; Athey, S. Estimation and inference of heterogeneous treatment effects using random forests. J. Am. Stat. Assoc. 2018, 113, 1228–1242. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.Y.; Ying, L.U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef]
- Thanh Noi, P.; Kappas, M. Comparison of random forest, k-nearest neighbor, and support vector machine classifiers for land cover classification using Sentinel-2 imagery. Sensors 2017, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Shi, K.; Chen, Y.; Yu, B.; Xu, T.; Yang, C.; Li, L.; Huang, C.; Chen, Z.; Liu, R.; Wu, J. Detecting Spatiotemporal Dynamics of Global Electric Power Consumption Using Dmsp-Ols Nighttime Stable Light Data. Appl. Energy 2016, 184, 450–463. [Google Scholar] [CrossRef]
- Azemin, M.Z.C.; Hilmi, M.R.; Kamal, K.M.; Tamrin, M.I.M. Fibrovascular Redness Grading Using Gaussian Process Regression with Radial Basis Function Kernel. In Proceedings of the 2014 IEEE Conference on Biomedical Engineering and Sciences, Kuala Lumpur, Malaysia, 8–10 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 113–116. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, R.; Bunn, A.; Powell, S.; Zambon, M. Classification of Remotely Sensed Imagery Using Stochastic Gradient Boosting as a Refinement of Classification Tree Analysis. Remote Sens. Environ. 2014, 90, 331–336. [Google Scholar] [CrossRef]
- Bastien, P.; Vinzi, V.E.; Tenenhaus, M. PLS Generalised Linear Regression. Comput. Stat. Data Anal. 2005, 48, 17–46. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ozcift, A.; Gulten, A. Classifier Ensemble Construction with Rotation Forest to Improve Medical Diagnosis Performance of Machine Learning Algorithms. Comput. Methods Programs Biomed. 2011, 104, 443. [Google Scholar] [CrossRef]
- Burges, C.J.C. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Stuhlsatz, A.; Lippel, J.; Zielke, T. Discriminative Feature Extraction with Deep Neural Networks. In Proceedings of the International Joint Conference on Neural Networks, Barcelona, Spain, 18–23 July 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 54, pp. 1–8. [Google Scholar]
- Freeman, E.A.; Moisen, G.G. A Comparison of the Performance of Threshold Criteria for Binary Classification in Terms of Predicted Prevalence and Kappa. Ecol. Model. 2008, 217, 48–58. [Google Scholar] [CrossRef]
- Zhao, X.; Yu, B.; Liu, Y.; Chen, Z.; Li, Q.; Wang, C.; Wu, J. Estimation of poverty using random forest regression with multi-source data: A case study in Bangladesh. Remote Sens. 2019, 11, 375. [Google Scholar] [CrossRef] [Green Version]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Bangladesh Bureau of Statistics. Preliminary Report on Household Income and Expenditure Survey 2016; Bangladesh Bureau of Statistics: Dhaka, Bangladesh, 2017. [Google Scholar]
- Brewer, C.A.; Pickle, L. Evaluation of methods for classifying epidemiological data on choropleth maps in series. Ann. Assoc. Am. Geogr. 2002, 92, 662–681. [Google Scholar] [CrossRef]
- Abu, A.; Hamdan, R.; Sani, N.S. Ensemble learning for multidimensional poverty classification. Sains Malays. 2020, 49, 447–459. [Google Scholar]
- Wirth, R. CRISP-DM: Towards a standard process model for data mining. In Proceedings of the Fourth International Conference on the Practical Application of Knowledge Discovery and Data Mining, Kyoto, Japan, 18–20 April 2000; Volume 1, pp. 29–39. [Google Scholar]
- AAhmad, W.D.; Bakar, A.A. Classification models for higher learning scholarship. Asia-Pac. J. Inf. Technol. Multimed. 2018, 7, 131–145. [Google Scholar] [CrossRef]
- Othman, Z.; Shan, S.W.; Yusoff, I.; Kee, C.P. Classification techniques for predicting graduate employability. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1712–1720. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhyay, A.K.; Kumar, T.K.; Rice, I. A social engineering model for poverty alleviation. Nat. Commun. 2020, 11, 6345. [Google Scholar] [CrossRef] [PubMed]
- Sitaramam, V.; Paranjpe, S.A.; Kumar, T.K.; Gore, A.P.; Sastry, J.G. Minimum needs of poor and priorities attached to them. Econ. Political Wkly 1996, 31, 2499–2505. [Google Scholar]
- World Bank. World Bank Poverty Data. Available online: http://data.worldbank.org/country/india (accessed on 10 May 2022).
- Sammon, J.W. A nonlinear mapping for data structure analysis. IEEE Trans. Comput. 1969, 100, 401–409. [Google Scholar] [CrossRef]
- Lowe, D.; Tipping, M.E. Neuroscale: Novel topographic feature extraction using RBF networks. Adv. Neural Inf. Processing Syst. 1996, 9, 543–549. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Tenenbaum, J.B.; Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Lee, J.A.; Verleysen, M. Nonlinear Dimensionality Reduction; Springer: New York, NY, USA, 2007; Volume 1, ISBN 978-0-387-39351-3. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; Volume 4, p. 738. ISBN 978-1-4939-3843-8. [Google Scholar]
- Kumar, T.K.; Gore, A.P.; Sitaramam, V. Some conceptual and statistical issues on measurement of poverty. J. Stat. Plan. Inference 1996, 49, 53. [Google Scholar] [CrossRef]
- Chattopadhyay, A.K.; Ackland, G.J.; Mallick, S.K. Income and poverty in a developing economy. Europhys. Lett. 2010, 91, 58003. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhyay, A.K.; Krishna Kumar, T.; Mallick, S.K. Poverty index with time-varying consumption and income distributions. Phys. Rev. E 2017, 95, 032109. [Google Scholar] [CrossRef]
- NNiu, T.; Chen, Y.; Yuan, Y. Measuring urban poverty using multi-source data and a random forest algorithm: A case study in Guangzhou. Sustain. Cities Soc. 2020, 54, 102014. [Google Scholar] [CrossRef]
- Available online: http://map.baidu.com/ (accessed on 17 August 2022).
- Available online: http://www.ngdc.noaa.gov/eog/viirs/download_monthly.html (accessed on 5 April 2022).
- Available online: https://earthexplorer.usgs.gov/ (accessed on 9 July 2022).
- Available online: https://guangzhou.anjuke.com/ (accessed on 11 June 2022).
- Yuan, Y.; Xu, M.; Cao, X.; Liu, S. Exploring urban-rural disparity of the multiple deprivation index in Guangzhou City from 2000 to 2010. Cities 2018, 79, 1–11. [Google Scholar] [CrossRef]
- Jenks, G.F. The data model concept in statistical mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- Diez, D.; Barr, C.; Cetinkaya-Rundel, M. OpenIntro Statistics; OpenIntro Inc.: Boston, MA, USA, 2012. [Google Scholar]
- Li, H.; Calder, C.A.; Cressie, N. Beyond Moran’s I: Testing for spatial dependence based on the spatial autoregressive model. Geogr. Anal. 2007, 39, 357–375. [Google Scholar] [CrossRef]
- Moran, P.A.P. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- BPS - Statistics Indonesia. Persentase Penduduk Miskin Menurut Kabupaten/Kota, 2015–2017. Jakarta. 2018. Available online: https://www.bps.go.id/dynamictable/2017/08/03/1261/persentase-penduduk-miskin-menurut-kabupaten-kota-2015%972017.html (accessed on 6 January 2019).
- Wijaya, D.R.; Sarno, R.; Zulaika, E. Sensor array optimization for mobile electronic nose: Wavelet transform and filter based feature selection approach. Int. Rev. Comput. Softw. 2016, 11, 659–671. [Google Scholar] [CrossRef] [Green Version]
- Baranyi, J.; Pin, C.; Ross, T. Validating and comparing predictive models. Int. J. Food Microbiol. 1999, 48, 159–166. [Google Scholar] [CrossRef]
- Xu, Y.; Mo, Y.; Zhu, S. Poverty Mapping in the Dian-Gui Qian Contiguous Extremely Poor Area of Southwest China Based on Multi-Source Geospatial Data. Sustainability 2021, 13, 8717. [Google Scholar] [CrossRef]
- Weiss, D.; Nelson, A.; Gibson, H.; Temperley, W.; Peedell, S.; Lieber, A.; Hancher, M.; Poyart, E.; Belchior, S.; Fullman, N.; et al. A Global Map of Travel Time to Cities to Assess Inequalities in Accessibility in 2015. Nature 2018, 553, 333–336. [Google Scholar] [CrossRef]
- Xu, J.; Song, J.; Li, B.; Liu, D.; Cao, X. Combining night time lights in prediction of poverty incidence at the county level. Appl. Geogr. 2021, 135, 102552. [Google Scholar] [CrossRef]
- Xian, Z.; Wang, P.; Wu, W. Rural poverty lines and poverty monitoring in China. Stat. Res. 2016, 33, 3. [Google Scholar] [CrossRef]
- Wu, J.; He, S.; Peng, J.; Li, W.; Zhong, X. Intercalibration of DMSP-OLS nighttime light data by the invariant region method. Int. J. Remote Sens. 2013, 34, 7356–7368. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Xu, H.; Wu, C. Intercalibration between DMSP/OLS and VIIRS night-time light images to evaluate city light dynamics of Syria’s major human settlement during Syrian Civil War. Int. J. Remote Sens. 2017, 38, 5934–5951. [Google Scholar] [CrossRef]
- Zhang, Q.; Pandey, B.; Seto, K.C. A robust method to generate a consistent time series from DMSP/OLS nighttime light data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5821–5831. [Google Scholar] [CrossRef]
- Machado, G.; Mendoza, M.R.; Corbellini, L.G. What variables are important in predicting bovine viral diarrhea virus? A random forest approach. Vet. Res. 2015, 46, 85. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Y.; Qin, Z.; Zhang, R.; Zhang, Z.; Mu, L. A Novel DBSCAN Clustering Algorithm via Edge Computing-Based Deep Neural Network Model for Targeted Poverty Alleviation Big Data. Wirel. Commun. Mob. Comput. 2021, 2021, 5536579. [Google Scholar] [CrossRef]
- Tran, T.N.; Drab, K.; Daszykowski, M. Revised DBSCAN algorithm to cluster data with dense adjacent clusters. Chemom. Intell. Lab. Syst. 2013, 120, 92–96. [Google Scholar] [CrossRef]
- Abdolzadegan, D.; Moattar, M.H.; Ghoshuni, M. A robust method for early diagnosis of autism spectrum disorder from EEG signals based on feature selection and DBSCAN method. Biocybern. Biomed. Eng. 2020, 40, 482–493. [Google Scholar] [CrossRef]
- Han, Z.; Cheng, M.; Chen, F.; Wang, Y.; Deng, Z. A spatial load forecasting method based on DBSCAN clustering and NAR neural network. J. Phys. Conf. Ser. 2020, 1449, 012032. [Google Scholar] [CrossRef]
- Available online: http://archive.ics.uci.edu/ml/datasets.php (accessed on 1 September 2022).
- Li, G.; Cai, Z.; Qian, Y.; Chen, F. Identifying urban poverty using high-resolution satellite imagery and machine learning approaches: Implications for housing inequality. Land 2021, 10, 648. [Google Scholar] [CrossRef]
- Patel, M.N.; Tandel, P. A Survey on Feature Extraction Techniques for Shape Based Object Recognition. Int. J. Comput. Appl. Technol. 2016, 137, 16–20. [Google Scholar]
- Gioi, R.G.V.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A Fast Line Segment Detector with a False Detection Control. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- Baraldi, A.; Parmiggiani, F. An Investigation of the Textural Characteristics Associated with Gray Level Cooccurrence Matrix Statistical Parameters. IEEE Trans. Geosci. Remote Sens. 1995, 33, 293–304. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 7, 971–987. [Google Scholar] [CrossRef]
- Ballard, D.H. Generalizing the Hough Transform to Detect Arbitrary Shapes. Pattern. Recogn. 1981, 13, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Browne, C.; Matteson, D.S.; McBride, L.; Hu, L.; Liu, Y.; Sun, Y.; Wen, J.; Barrett, C.B. Multivariate random forest prediction of poverty and malnutrition prevalence. PLoS ONE 2021, 16, e0255519. [Google Scholar] [CrossRef]
- ICF. Available Datasets. The DHS Program Website. Funded by USAID. Available online: http://www.dhsprogram.com (accessed on 20 February 2022).
- International Food Policy Research Institute (IFPRI). AReNA’s DHS-GIS Database. Harvard Dataverse, V1, UNF:6:CCnbCvRUu7F/IAy2ut+whw== [fileUNF]. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/OQIPRW (accessed on 11 September 2022).
- Hansen, M.; DeFries, R.; Townshend, J.; Carroll, M.; Dimiceli, C.; Sohlberg, R. Global percent tree cover at a spatial resolution of 500 meters: First results of the MODIS vegetation continuous fields algorithm. Earth Interact. 2003, 7, 1–15. [Google Scholar] [CrossRef]
- Ramankutty, N.; Evan, A.T.; Monfreda, C.; Foley, J.A. Farming the planet: 1. Geographic distribution of global agricultural lands in the year 2000. Glob. Biogeochem. Cycles 2008, 22. [Google Scholar] [CrossRef]
- “GIEWS FPMA Tool: Monitoring and Analysis of Food Prices” Food and Agriculture Organization of the United States. Available online: https://fpma.apps.fao.org/giews/food-prices/tool/public/#/home (accessed on 1 March 2022).
- Porcar-Castell, A.; Tyystjärvi, E.; Atherton, J.; Van Der Tol, C.; Flexas, J.; Pfündel, E.E.; Moreno, J.; Frankenberg, C.; Berry, J.A. Linking chlorophyll a fluorescence to photosynthesis for remote sensing applications: Mechanisms and challenges. J. Exp. Bot. 2014, 65, 4065–4095. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Sun, Y.; Collins, G.; Fu, P. Improved estimates of monthly land surface temperature from MODIS using a diurnal temperature cycle (DTC) model. ISPRS J. Photogramm. Remote Sens. 2020, 168, 131–140. [Google Scholar] [CrossRef]
- Funk, C.C.; Peterson, P.J.; Landsfeld, M.F.; Pedreros, D.H.; Verdin, J.P.; Rowland, J.D.; Romero, B.E.; Husak, G.J.; Michaelsen, J.C.; Verdin, A.P. A Quasi-Global Precipitation Time Series for Drought Monitoring; US Geological Survey Data Series; U.S. Geological Survey: Reston, VA, USA, 2014; Volume 832, pp. 1–12. [Google Scholar]
- Sundberg, R.; Melander, E. Introducing the UCDP georeferenced event dataset. J. Peace Res. 2013, 50, 523–532. [Google Scholar] [CrossRef]
- De’Ath, G. Multivariate regression trees: A new technique for modeling species–environment relationships. Ecology 2002, 83, 1105–1117. [Google Scholar] [CrossRef]
- Haider, S.; Rahman, R.; Ghosh, S.; Pal, R. A copula based approach for design of multivariate random forests for drug sensitivity prediction. PLoS ONE 2015, 10, e0144490. [Google Scholar] [CrossRef] [Green Version]
- Segal, M.; Xiao, Y. Multivariate random forests. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 80–87. [Google Scholar] [CrossRef]
- Li, Q.; Yu, S.; Échevin, D.; Fan, M. Is poverty predictable with machine learning? A study of DHS data from Kyrgyzstan. Socio-Econ. Plan. Sci. 2021, 81, 101195. [Google Scholar] [CrossRef]
- Brandolini, A.; Magri, S.; Smeeding, T.M. Asset-based measurement of poverty. J. Pol. Anal. Manag. 2010, 29, 267–284. [Google Scholar] [CrossRef]
- Shah, S.; Chaudhry, I.S.; Farooq, F. Poverty status and factors affecting household poverty in southern Punjab: An empirical analysis. J. Bus. Soc. Rev. Emerg. Econ. 2020, 6. [Google Scholar] [CrossRef]
- De Milliano, M.; Plavgo, I. Analysing multidimensional child poverty in Sub-Saharan Africa: Findings using an international comparative approach. Child. Indicat. Res. 2018. [Google Scholar] [CrossRef]
- Gounder, R.; Xing, Z. Impact of education and health on poverty reduction: Monetary and non-monetary evidence from Fiji. Econ. Model. 2012, 29, 787–794. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lenner, K. Poverty and Poverty Reduction Policies in Jordan. In Atlas of Jordan: History, Territories and Society; Presses de L’Ifpo: Amman, Jordan, 2013; pp. 335–340. [Google Scholar]
- Cerda, P.; Varoquaux, G. Encoding high-cardinality string categorical variables. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Transformation and Data Discretization. In Data Mining-Concepts and Techniques; Kaufmann, M., Ed.; Elsevier: Amsterdam, The Netherlands, 2011; pp. 111–112. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Yu, H.F.; Huang, F.L.; Lin, C.J. Dual coordinate descent methods for logistic regression and maximum entropy models. Mach. Learn. 2011, 85, 41–75. [Google Scholar] [CrossRef] [Green Version]
- Le Cessie, S.; Van Houwelingen, J.C. Ridge estimators in logistic regression. J.R. Stat. Soc. Ser. C (Appl. Stat.) 1992, 41, 191–201. [Google Scholar] [CrossRef]
- Zinkevich, M.; Weimer, M.; Li, L.; Smola, A.J. Parallelized stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–11 December 2010; pp. 2595–2603. [Google Scholar]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y. Online passive-aggressive algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees; Routledge: Abingdon, UK, 2017. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Chan, T.F.; Golub, G.H.; LeVeque, R.J. Updating formulae and a pairwise algorithm for computing sample variances. In Proceedings of the COMPSTAT 1982 5th Symposium, Toulouse, France, 30 August–3 September 1982; Springer: Cham, Switzerland, 1982; pp. 30–41. [Google Scholar]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]
- Louppe, G.; Geurts, P. Ensembles on random patches. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 22–26 September 2012; Springer: Cham, Switzerland, 2012; pp. 346–361. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 1189–1232. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Chase Lipton, Z.; Elkan, C.; Narayanaswamy, B. Thresholding Classifiers to Maximize F1 Score. arXiv 2014, arXiv:1402.1892. [Google Scholar]
- Ganganwar, V. An overview of classification algorithms for imbalanced datasets. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 42–47. [Google Scholar]
- Brownlee, J. Imbalanced Classification with Python: Better Metrics, Balance Skewed Classes, Cost-Sensitive Learning; Machine Learning Mastery: Vermont, Australia, 2020. [Google Scholar]
- Lerman, P. Fitting segmented regression models by grid search. J.R. Stat. Soc. Ser. C (Appl. Stat.) 1980, 29, 77–84. [Google Scholar] [CrossRef]
- Departamento Nacional de Planeación: Actualización de los Criterios Para la Determinación, Identificación y Selección de Beneficiarios de Programas Sociales. 2008. Available online: https://colaboracion.dnp.gov.co/CDT/Conpes/Social/117.pdf (accessed on 3 March 2022).
- Dumais, S.T. Latent semantic analysis. Annu. Rev. Inf. Sci. Technol. 2004, 38, 188–230. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Canete, J.; Chaperon, G.; Fuentes, R.; Pérez, J. Spanish Pre-Trained Bert Model and Evaluation Data; PML4DC at ICLR; ICLR: Addis Ababa, Ethiopia, 2020; pp. 1–10. [Google Scholar]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop J. 2016, 4, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Tanveer, M.; Hassan, S.; Bhaumik, A. Academic policy regarding sustainability and artificial intelligence (AI). Sustainability 2020, 12, 9435. [Google Scholar] [CrossRef]
- Openshaw, S. The Modifiable Areal Unit Problem; CATMOG 38; Geo Books: Norwich, UK, 1984; Volume 38, Available online: https://www.uio.no/studier/emner/sv/iss/SGO9010/openshaw1983.pdf (accessed on 22 February 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Area of Study | Contribution | Limitations |
|---|---|---|---|---|
| [30] | 2016 | AI in poverty measurement | Discussed data used for poverty prediction with a focus on [14] work | The paper focused on data types and analyses with less attention on machine learning methods. |
| [31] | 2020 | AI in poverty measurement | Summarized information on AI methods applied in poverty measurement. In the paper, information on data and applied algorithms for poverty measurement were provided. | This work provided aggregated information about fifteen reviewed papers without in-depth analyses. |
| [28] | 2020 | AI in sustainability | Analyzed reviews and found that AI can accomplish 134 targets of the Sustainable Development Goals. Summarized, detailed, and evaluated the positive and negative effects of AI on SDG. | Poverty was considered as the part of sustainability goals, yet the focus of the paper was on sustainability without discussing applied AI methods in poverty prediction. |
| [6] | 2021 | AI in sustainability | Reviewed the impact of AI on Sustainable Development Goals with a focus on poverty, industry, innovation, and infrastructure development. Summarized AI applications in spheres of agriculture, urban infrastructure, and financial inclusion. | Information about used AI methods in poverty prediction is not provided; only a review of concrete AI applications in real-life situations was provided. |
| [29] | 2021 | AI from multidisciplinary perspectives | Collected and discussed AI challenges and opportunities from multiple perspectives and created a research agenda for each discipline: how AI can help deliver SDG goals. | In the paper, the influence of AI on poverty was mentioned, yet methods of AI on poverty measurement were not discussed. |
| Ref. | Year | Country | Data | Method | Advantage | Disadvantage |
|---|---|---|---|---|---|---|
| [14] | 2016 | Nigeria, Tanzania, Uganda, Malawi, and Rwanda | High-resolution daytime satellite imagery and surveys (LSMS and DHS) | Convolutional Neural Network | Predictions can be made only based on publicly available data. High overall power of prediction in spite of a lack of the daytime imagery’s temporal labels. | Inability to evaluate the model’s capacity in distinguishing discrepancies within clusters and predicting changes in economic wellbeing at certain locations over time. |
| [15] | 2017 | UK (Liverpool) | A very high spatial resolution (VHR) image (set of land cover features, spectral features, texture features, and structure features) and data from the Department for Local Communities and Local Government | Gradient Boost Regressor and Random Forest | The models proved that satellite imagery can explain and predict living environment deprivation. Revealed that predictive variables for living conditions are unstable among countries. The models provided an opportunity of raw measurement inclusion without previous transformations. The capacity of contextual data and correlations inclusion, which in the formal model play out over space. The flexibility of given methods had an added predictive power in handling non-linear and complex relationships in data. | Models suffered from the modifiable areal unit problem [172]. A dramatic decrease in models’ performance after applying an honest approach in comparison the with naïve approach. |
| [27] | 2017 | Ghana (Accra city) | Geospatial data, household survey data (Ghana Living Standards Survey Round Six), and population census data (2010 Population and Housing Census) | Random Forest | Poverty rates were estimated at the neighborhood level. | Despite having about 580 variables, the analysis was conducted with only 20 variables due to a small number of household observations (820). |
| [13] | 2017 | Albania, Ethiopia, Malawi, Rwanda, Tanzania, and Uganda | Household data | Random Forest | Accurate prediction level of the model within the same year | The years of data collection for analysis among countries were different and dissimilar. More prediction errors among countries that use panel data. Inaccurate prediction levels of the model over time. |
| [42] | 2018 | Colombia | Household survey data and official data | Fuzzy-set qualitative comparative analysis | The possibility of analyzing different combinations of variables that cause or eradicate poverty | The years of collected attributes for analysis differed. |
| [16] | 2018 | Bolivia, Malaawi, and East Timor | LSMS data and household surveys | Stochastic ensemble methods | Gain in poverty accuracy, decrease in undercoverage rates, and overall improvement in balanced poverty accuracy criterion in comparison to traditional methods | The years of data collection for analysis among countries were different and dissimilar. Among countries, variables were not similar as household characteristics had some discrepancies. Stochastic ensemble methods were inclined to classify non-poor as poor. |
| [17] | 2018 | Malaysia (Johor, Pahang and Terengganu states) | National Poverty Data Bank (‘eKasih’) | Naive Bayes, Decision Tree (J48 classifier, based on the C4.5 algorithm), and k-Nearest Neighbors | Poverty prediction rate was high. | Data were imbalanced (5:95 with prevalence of B40 class). |
| [18] | 2019 | China (2,554 counties) | DMSP/OLS nighttime light imagery | Gaussian process with radial basis function kernel, Stochastic gradient boosting, Partial least squares regression for generalized linear models, Random Forest, Rotation Forest, support vector machine (SVM), and Neural network with feature extraction | Study represented the possibility of identification of high-poverty counties using only nighttime light imagery. | Existence of uncertainties in DMSP/OLS nighttime light imagery.Features used in this study should be validated in more study fields. |
| [65] | 2019 | Bangladesh and Nepal | Household survey (DHS), nighttime light, Google images (structure and texture features), road map, land cover map, and division headquarter location data. | Random Forest Regression | The study illustrated that relatively accurate prediction can be made using multiple sources of environmental data. Model is replicable in different geographical context. | Existence of multicollinearity issue between independent variables. Overestimation of low wealth index values and underestimation of high wealth index values |
| [70] | 2020 | Malaysia | National Poverty Data Bank (‘eKasih’) and data from Malaysian Government | Random Forest and Decision tree (J48) | High prediction accuracy level of the models. Reducing processing time for poverty prediction by decreasing the number of features via the feature selection procedure. | Features for analysis were selected based on the literature review and not selected according to their relationship with poverty. |
| [74] | 2020 | India and USA | NSS income data | Neuroscale, Locally Linear Embedding, Isomap, Curvilinear Component Analysis, and Principal Component Analysis | Model is replicable in another country. The possibility of information preservation was illustrated when using dimension reduction tool. | The lack of detailed statistical error measures. |
| [86] | 2020 | China (Guangzhou) | Nighttime light image, Landsat 8 image, census data, points of interest, and housing rent data | Random Forest | A new method of urban poverty evaluation was created using multi-source data. Model can classify into the high level more communities with akin attributes. It can predict better poverty in regions with mediocre economic development and environmental quality. Proposed model can be updated more conveniently using big data to provide up-to-date information on urban poverty. | The model might misjudge individual communities with big differences in external and internal quality. |
| [22] | 2020 | Indonesia (Java Island) | E-commerce data from goods advertisements’ platform and data from BPS—Statistics Indonesia | Deep neural network and Support vector regression | The study illustrated that e-commerce data can serve as a proxy in poverty prediction in the city-level. | E-commerce data are difficult to obtain due to confidentiality in its utilization. Prediction errors might increase in poor cities due to the low number of transactions. |
| [101] | 2021 | China (Dian-Gui-Qian area) | Official state publications, accessibility to cities, average nighttime light, SRTM/DEM, land cover, and natural disaster data | Multiple linear regression, Bidirectional recurrent neural network, Generalized additive model, support vector machine, MARS, F, XGBoost, and Cubist | The model can predict poverty in regions with difficult socioeconomic and natural conditions. All data can be updated easily and obtained freely. | NPP/VIIRS does not have a very high spatial resolution, which leads to the ineffective reflection of the spatial details in patterns of human activity. |
| [103] | 2021 | China (Yunnan-Guangxi-Guizhou Rocky desertification area) | Nighttime data and socioeconomic statistical data | Decision Trees, Discriminant Analysis, Logistic Regression Classifiers, Naive Bayes Classifiers, SVM, Nearest Neighbour Classifiers, Ensemble Classifiers, Linear Regression Models, Regression Trees, Gaussian Process Regression Models, and Ensembles of Trees | The ability of the model to map poverty using nighttime lights in deprived areas. | There are discrepancies in identifying non-poverty counties between the model outcome and official poverty incidence data. Existence of errors due to various lighting habits of population. |
| [109] | 2021 | China | Data of archived card, data of visit, data of agricultural cloud project, data of education, and health and sanitation departments | DBSCAN, CDBSCAN, FSDBSCAN, and NARDBSCAN | Model provides the intelligent identification of poor households and matching of assistance measures with high accuracy levels, which can decrease labor costs when collecting this information manually. The analysis speed of the model was high in comparison with other models | In the study, the cluster effect is imperfect when the datsets’ dimension is very high. |
| [114] | 2021 | China (Jiangxia and Huangpi Districts, Wuhan) | Google Earth imagery, land cover dataset, administrative division boundary, population census, and poor population statistics of neighborhood and village committee | Random Forest, Gaussian Process Regression, Support Vector Regression, and Neural Network | Created model for urban poverty identification using only high-resolution satellite imagery | Using relatively low-resolution imagery. The possibility of omitting other urban poverty attributes. |
| [121] | 2021 | Bangladesh, Ethiopia, Ghana, Guatemala, Honduras, Kenya, Mali, Nepal, Nigeria, Senegal, and Uganda | Survey data (DHS or Advancing Research on Nutrition and Agriculture (ARENA)), physical geography covariates, food price data, solar-induced chlorophyll fluorescence data, land surface temperature data, precipitation data, and conflict data | Random Forest and Multivariate (Mahalanobis) Random Forest | In poverty prediction models applying AI, for the first time, solar-induced chlorophyll fluorescence data were used. The model illustrates the potential of AI tools and big data in providing humanitarian programming and development. | The performance of the model was poor at the individual surveys level. |
| [134] | 2021 | Kyrgyzstan | Household survey (DHS) | XGBoost | A precise poverty prediction model with high accuracy was constructed using only survey data | The lack of updated data. The possibility of existence better AI models in poverty prediction of Kyrgyzstan. |
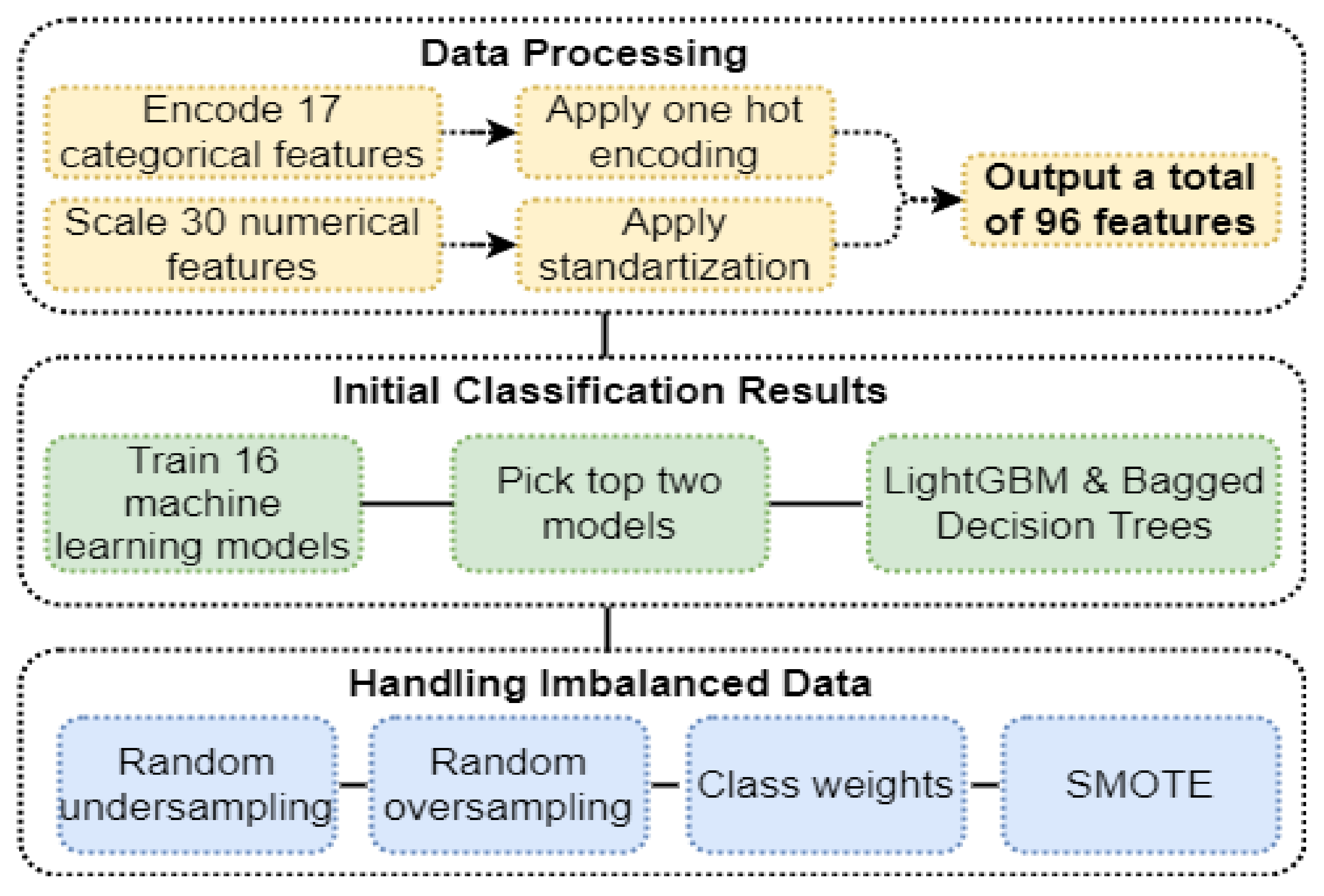
| [9] | 2021 | Jordan | Household expenditure and income survey data | Logistic regression, Ridge regression, Stochastic gradient descent, Passive aggressive, K-nearest neighbors, Decision tree, Extra tree, Support vector machine, Naive Bayes, AdaBoost, Bagged decision trees, RF, Extra trees, Gradient boosting machine, Light GBM, and scalable tree boosting system | Created a unique poverty prediction model for Jordan via AI algorithms. | Data were imbalanced with only 13.9% poor households. |
| [20] | 2022 | China (Yunyang County) | High-resolution imagery, Open Street Map, point-of-interest, digital surface model data, and census data | Random Forest | Model for poverty prediction at the village level using multi-source data was constructed | Model only can classify the village into one of the three categories without identifying specific poverty incidence. Prediction accuracy is not high enough for explaining the relationship between poverty and variables. |
| [7] | 2022 | Colombia (Medelĺın city) | Semi-structured interviews | Latent Semantic Analysis, Term Frequency-Inverse Document Frequency, word2Vec, Global Vectors for Word Representation, Bidirectional Encoder Representations from Transformers, BETO, Gaussian Mixture Models, Support vector machine, XGboost, and Random Forest | First time in research, the feelings of people about poverty were included as variable in the poverty prediction analysis | The absence of a clear distinction between poor and extremely poor people. Small corpus size of analysis. Vectors were pre-trained in general databases and not in specific semantic fields. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Usmanova, A.; Aziz, A.; Rakhmonov, D.; Osamy, W. Utilities of Artificial Intelligence in Poverty Prediction: A Review. Sustainability 2022, 14, 14238. https://doi.org/10.3390/su142114238
Usmanova A, Aziz A, Rakhmonov D, Osamy W. Utilities of Artificial Intelligence in Poverty Prediction: A Review. Sustainability. 2022; 14(21):14238. https://doi.org/10.3390/su142114238
Chicago/Turabian StyleUsmanova, Aziza, Ahmed Aziz, Dilshodjon Rakhmonov, and Walid Osamy. 2022. "Utilities of Artificial Intelligence in Poverty Prediction: A Review" Sustainability 14, no. 21: 14238. https://doi.org/10.3390/su142114238
APA StyleUsmanova, A., Aziz, A., Rakhmonov, D., & Osamy, W. (2022). Utilities of Artificial Intelligence in Poverty Prediction: A Review. Sustainability, 14(21), 14238. https://doi.org/10.3390/su142114238