
A Fast and Accurate Obstacle Segmentation Network for Guava-Harvesting Robot via Exploiting Multi-Level Features

 ,
,  and
and
Abstract
1. Introduction
- In order to exploit multi-level features, a feature enhancement network, termed FEM, is proposed. FEM fuses different levels of feature maps, and uses a simple attention mechanism to recalibrate the channels of the feature maps, thus outputting a feature map with strong semantics and details.
- In order to improve the segmentation accuracy, a novel decoder is proposed. It uses a self-attention layer to capture long-range dependency for each pixel, and utilizes a shortcut connection and element-wise addition to promote the gradient to flow in the network.
- The method has a good segmentation performance. The mean intersection over union (MIOU), mean pixel accuracy (MPA) and frequency weighted intersection over union (FWIOU) are 76.30%, 84.63% and 89.04% respectively. The number of parameters, floating-point operations per second (FLOPs) and frames per second (FPS) are 3.9 million, 35.7 billion and 45, respectively.
2. Materials and Methods
2.1. Image Acquisition and Annotation
2.2. Data Augmentation
2.3. Method
2.3.1. Backbone
2.3.2. Feature Enhancement Module
2.3.3. Decoder Module
2.3.4. Loss Function
2.3.5. Implementation Details
2.4. Evaluating Indicators
3. Results
3.1. Ablation for FEM
3.2. Ablation for Loss Function
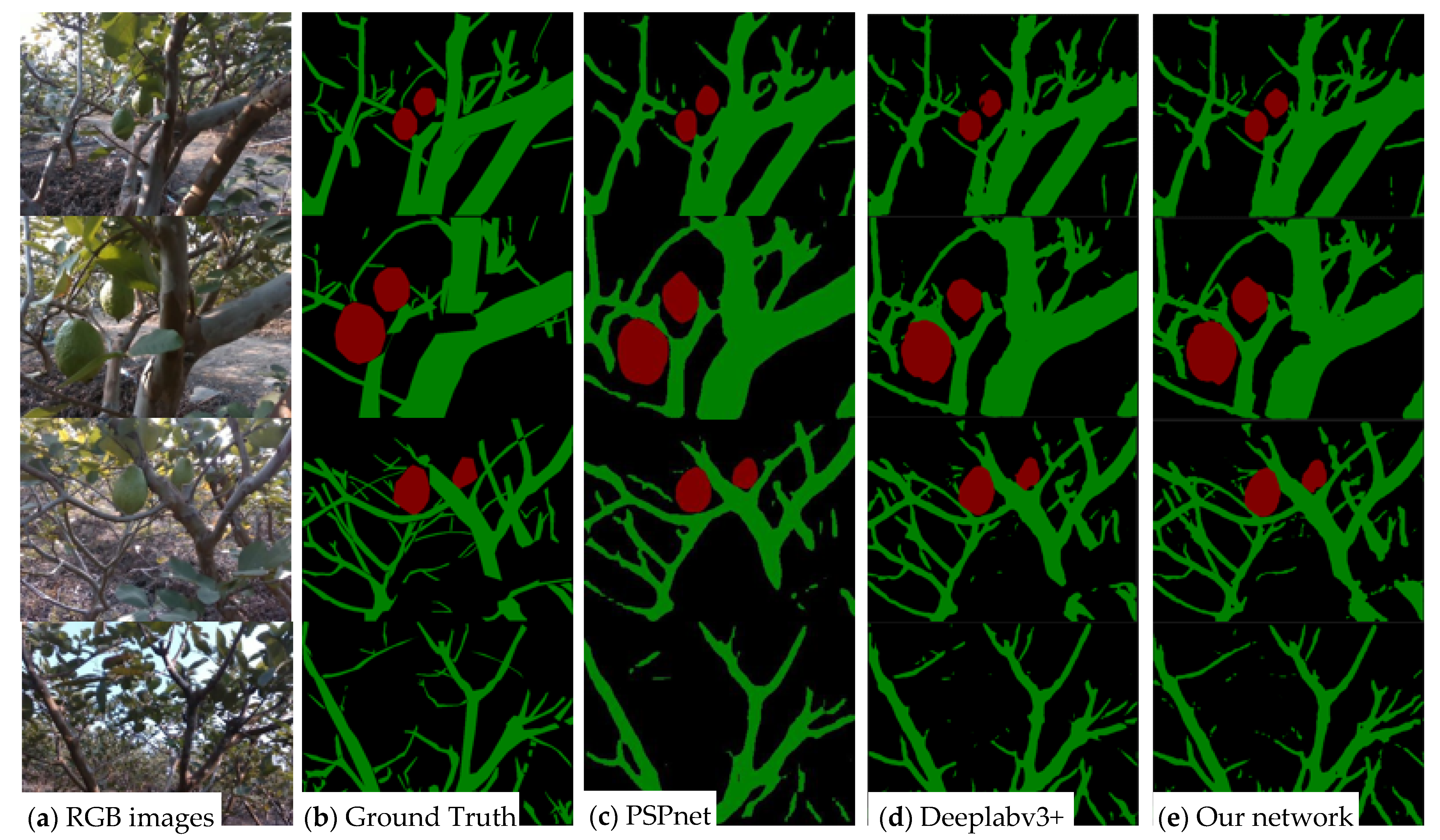
3.3. Comparison with Other Methods
4. Discussion
4.1. Ablation for FEM
4.2. Ablation for Loss Function
4.3. Comparison with Other Methods
5. Conclusions
- 1.
- A feature merging and enhancement module was proposed to generate a feature map with strong semantics and details. Experiment results reveal that fusing as many features as possible would decrease the segmentation accuracy and slow down the inference speed; the best combination was .
- 2.
- A decoder module was developed by using a self-attention layer to capture a long-range dependency for every pixel in the feature map, and utilizing a shortcut connection and element-wise addition to promote the gradient to flow in the network, thus improving the segmentation accuracy.
- 3.
- Our network’s MIOU, MPA and FWIOU were 76.30%, 84.63% and 89.04%, respectively, which were 1.83%, 1.60% and 0.43% higher than deeplabv3+, and 3.77%, 2.43% and 1.70% higher than PSPnet. In addition, our network achieved an inference speed of 45 FPS. The results revealed that the model can accurately and quickly segment obstacles for the guava picking robots.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, G.; Tang, Y.; Zou, X.; Wang, C. Three-dimensional reconstruction of guava fruits and branches using instance segmentation and geometry analysis. Comput. Electron. Agric. 2021, 184, 106107. [Google Scholar] [CrossRef]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and Localization Methods for Vision-Based Fruit Picking Robots: A Review. Front Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Amatya, S.; Karkee, M.; Gongal, A.; Zhang, Q.; Whiting, M.D. Detection of cherry tree branches with full foliage in planar architecture for automated sweet-cherry harvesting. Biosyst. Eng. 2016, 146, 3–15. [Google Scholar] [CrossRef]
- Amatya, S.; Karkee, M.; Zhang, Q.; Whiting, M.D. Automated Detection of Branch Shaking Locations for Robotic Cherry Harvesting Using Machine Vision. Robotics 2017, 6, 31. [Google Scholar] [CrossRef]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 432–448. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Shi, H.; Liu, W.; Huang, T. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, Seoul, South Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Zhang, X.; Karkee, M.; Zhang, Q.; Whiting, M.D. Computer vision-based tree trunk and branch identification and shaking points detection in Dense-Foliage canopy for automated harvesting of apples. J. Field Robot. 2021, 38, 476–493. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Yang, C.H.; Xiong, L.Y.; Wang, Z.; Wang, Y.; Shi, G.; Kuremot, T.; Zhao, W.H.; Yang, Y. Integrated detection of citrus fruits and branches using a convolutional neural network. Comput. Electron. Agric. 2020, 174, 105469. [Google Scholar] [CrossRef]
- Chen, Z.; Ting, D.; Newbury, R.; Chen, C. Semantic segmentation for partially occluded apple trees based on deep learning. Comput. Electron. Agric. 2021, 181, 105952. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Chen, T.; Zhang, R.; Zhu, L.; Zhang, S.; Li, X. A Method of Fast Segmentation for Banana Stalk Exploited Lightweight Multi-Feature Fusion Deep Neural Network. Machines 2021, 9, 66. [Google Scholar] [CrossRef]
- Peng, H.; Xue, C.; Shao, Y.; Chen, K.; Xiong, J.; Xie, Z.; Zhang, L. Semantic Segmentation of Litchi Branches Using DeepLabV3+ Model. IEEE Access 2020, 8, 164546–164555. [Google Scholar] [CrossRef]
- Majeed, Y.; Zhang, J.; Zhang, X.; Fu, L.; Karkee, M.; Zhang, Q.; Whiting, M.D. Apple Tree Trunk and Branch Segmentation for Automatic Trellis Training Using Convolutional Neural Network Based Semantic Segmentation. IFAC-PapersOnLine 2018, 51, 75–80. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Romera, E.; Alvarez, J.E.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Long, J.; Evan, S.; Trevor, D. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, X.; Ross, G.; Abhinav, G.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Lin, T.S.; Priya, G.; Ross, G.; He, K.; Piotr, D. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-imbalanced NLP Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, online, 5–10 July 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | c | n | s |
|---|---|---|---|---|
| Conv2d | 32 | 1 | 2 | |
| bottleneck | 16 | 1 | 1 | |
| bottleneck | 24 | 2 | 2 | |
| bottleneck | 32 | 3 | 2 | |
| bottleneck | 64 | 4 | 2 | |
| bottleneck | 96 | 3 | 1 | |
| bottleneck | 160 | 3 | 2 | |
| bottleneck | 320 | 1 | 1 | |
| bottleneck | 1280 | 1 | 1 | |
| Avgpool 7 × 7 | − | 1 | − | |
| bottleneck | k | − | − |
| Combination | MIOU | MPA | FWIOU | Params (M) | FLOPs (B) | FPS |
|---|---|---|---|---|---|---|
| 75.55 | 83.71 | 88.87 | 3.6 | 29.3 | 47.4 | |
| 75.68 | 85.03 | 88.92 | 3.7 | 32.4 | 46.6 | |
| 76.30 | 84.63 | 89.04 | 3.9 | 35.7 | 45.9 | |
| 75.63 | 85.09 | 88.77 | 4.2 | 39.1 | 45.5 | |
| 75.22 | 83.97 | 88.88 | 4.6 | 46.5 | 44.1 | |
| 75.78 | 84.59 | 88.96 | 6.2 | 72.0 | 37.6 |
| Loss Function | |||
|---|---|---|---|
| CE Loss | 76.22 | 84.65 | 89.68 |
| Focal Loss | 74.46 | 83.90 | 89.17 |
| Dice Loss | 75.53 | 84.25 | 89.19 |
| Focal Loss + Dice Loss | 76.30 | 84.63 | 89.04 |
| Method | Flops (B) | FPS | ||||
|---|---|---|---|---|---|---|
| PSPnet | 72.53 | 82.20 | 87.34 | 2.3 | 2.9 | 70.6 |
| Deeplabv3+ | 74.47 | 83.03 | 88.61 | 5.8 | 26.5 | 53.4 |
| Our model | 76.30 | 84.63 | 89.04 | 3.9 | 35.7 | 45.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, J.; Yu, Q.; Deng, G.; Wu, T.; Zheng, D.; Lin, G.; Zhu, L.; Huang, P. A Fast and Accurate Obstacle Segmentation Network for Guava-Harvesting Robot via Exploiting Multi-Level Features. Sustainability 2022, 14, 12899. https://doi.org/10.3390/su141912899
Yao J, Yu Q, Deng G, Wu T, Zheng D, Lin G, Zhu L, Huang P. A Fast and Accurate Obstacle Segmentation Network for Guava-Harvesting Robot via Exploiting Multi-Level Features. Sustainability. 2022; 14(19):12899. https://doi.org/10.3390/su141912899
Chicago/Turabian StyleYao, Jiayan, Qianwei Yu, Guangkun Deng, Tianjun Wu, Delin Zheng, Guichao Lin, Lixue Zhu, and Peichen Huang. 2022. "A Fast and Accurate Obstacle Segmentation Network for Guava-Harvesting Robot via Exploiting Multi-Level Features" Sustainability 14, no. 19: 12899. https://doi.org/10.3390/su141912899
APA StyleYao, J., Yu, Q., Deng, G., Wu, T., Zheng, D., Lin, G., Zhu, L., & Huang, P. (2022). A Fast and Accurate Obstacle Segmentation Network for Guava-Harvesting Robot via Exploiting Multi-Level Features. Sustainability, 14(19), 12899. https://doi.org/10.3390/su141912899