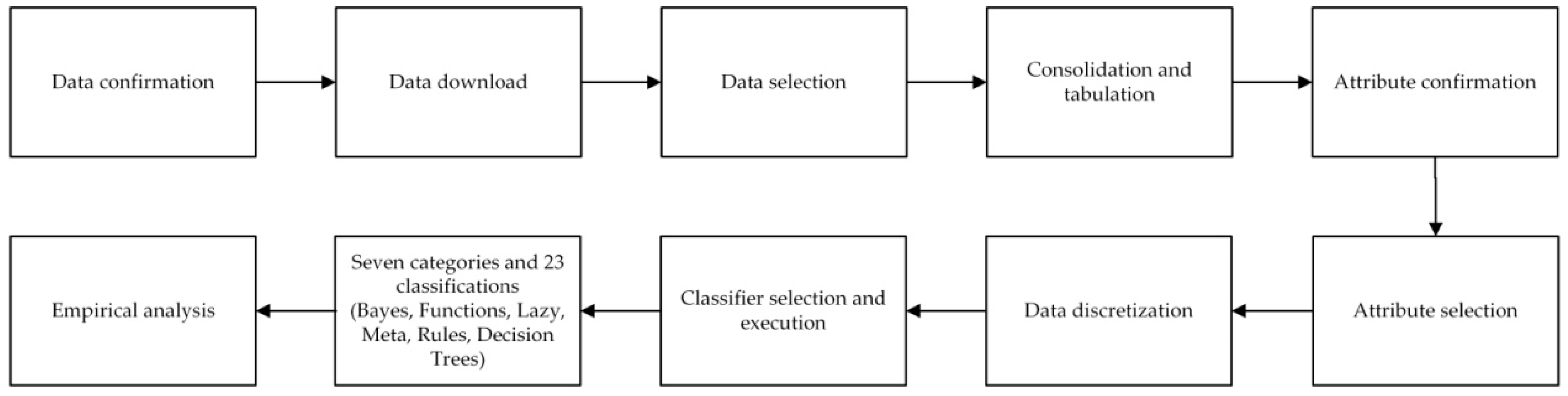
According to the empirical results of the hybrid classification model established in the previous section, the accuracy is compared and analyzed. The research data are processed by data technology, and the accuracy of classification model established in this study is evaluated and analyzed with empirical research purpose and research method. The first subsection is the experimental analysis, and the second subsection is the experimental results and findings. The classification algorithm is used to evaluate the accuracy performance, and the results are analyzed. According to the experimental output, the important indicators are established by the rule of decision tree. For example: in which conditions the client would buy the long-term care insurance, and find out the important factors, to improve the turnover ratio, find solutions to the problem of long-term care and disability, and alleviate future financial fears of family caregivers and the society.
4.1. Experimental Analysis
The classification algorithm is analyzed in this section. The prediction model uses the life insurance company’s client data, examining whether to buy the long-term care insurance policies as the decision attribute, and adopts seven categories of 23 classifiers for the binary decision attribute by percentage split (5 models) and 10-fold cross validation (5 models); in total, 10 models are used for implementation, analysis, evaluation and calculation of performance. The two stages are explained in order, as follows.
Stage 1. Model implementation: Three core directions are addressed for this implementing function.
- (1)
Percentage split attribute performance evaluation: Models I~V.
Model I: Without data discretization, without attribute selection
Model II: Without data discretization, with attribute selection
Model III: With data discretization, without attribute selection
Model IV: Data discretization before attribute selection
Model V: Attribute selection before data discretization
- (2)
Cross validation attribute performance evaluation: Models VI~X.
Model VI: Without data discretization, without attribute selection
Model VII: Without data discretization, with attribute selection
Model VIII: With data discretization, without attribute selection
Model IX: Data discretization before attribute selection
Model X: Attribute selection before data discretization
- (3)
Analysis of decision trees graph for decision-making purposes.
Stage 2. Model analysis and performance evaluation: Three key directions are also addressed for this implementing function.
- (1)
Percentage split attribute performance evaluation: for whether to purchase the long-term care insurance, five models (Models I, II, III, IV, and V) are established among 23 classifiers of seven categories by using percentage split method, to select the classifiers with better accuracy. Taking the best Model V as an example, the description is shown in
Table 3.
The accuracy evaluation of Model V: attribute selection before data discretization is explained as follows.
- (a)
Bayes: Bayes Net-lowest 77.5641% and highest 85.2113%; Naive Bayes-lowest 77.5641% and highest 85.2113%. Bayes Net and Naive Bayes’ lowest 77.5641% and highest 85.2113% are the same.
- (b)
Functions: Logistic-lowest 80.8511% and highest 85.2113%; SGD-lowest 80.5085% and highest 84.5070%; SGD Text-lowest 64.2105% and highest 72.3404%; Simple Logistic-lowest 80.8511% and highest 85.2113%; SMO-lowest 77.5641% and highest 84.5070%. In this category, SGD Text has the lowest 64.2105%, and Logistic and Simple Logistic have the highest 85.2113%.
- (c)
Lazy: IBk-lowest 80.8511% and highest 85.2113%; K Star-lowest 78.7234% and highest 85.1695%; LWL-lowest 76.8421% and highest 83.0508%. In this category, LWL has the lowest 76.8421% and IBk has the highest 85.2113%.
- (d)
Meta: Ada Boost M1-lowest 70.5263% and highest 78.3898%; Bagging-lowest 77.5641% and highest 85.2113%; Stacking and Vote classifiers have the same lowest 64.2105% and highest 72.3404%, which are unsatisfactory. In this category, Stacking and Vote have the lowest 64.2105% and Bagging has the highest 85.2113%.
- (e)
Misc: Input Mapped Classifier has the lowest 64.2105% and highest 72.3404%, not good enough.
- (f)
Rules: Decision Table-lowest 80.8511% and highest 85.2113%; JRip-lowest 80.8511% and highest 84.7458%; OneR-lowest 74.7368% and highest 80.5085%; PART-lowest 80.8511% and highest 85.2113%; ZeroR-lowest 64.2105% and highest 72.3404%, poor performance. In this category, ZeroR has the lowest 64.2105%, and the evaluation values of Decision Table and PART are equally good at 85.2113%.
- (g)
Trees: J48, LMT, and REP Tree have the lowest 80.8511% and highest 85.2113%, and other proportion measurements (marked in italics). The measurement values of each proportion of these three classifiers are the same, and all values are in the range of 80.8511~85.2113%. Among the seven categories of Model V, the trees show the most stable performance.
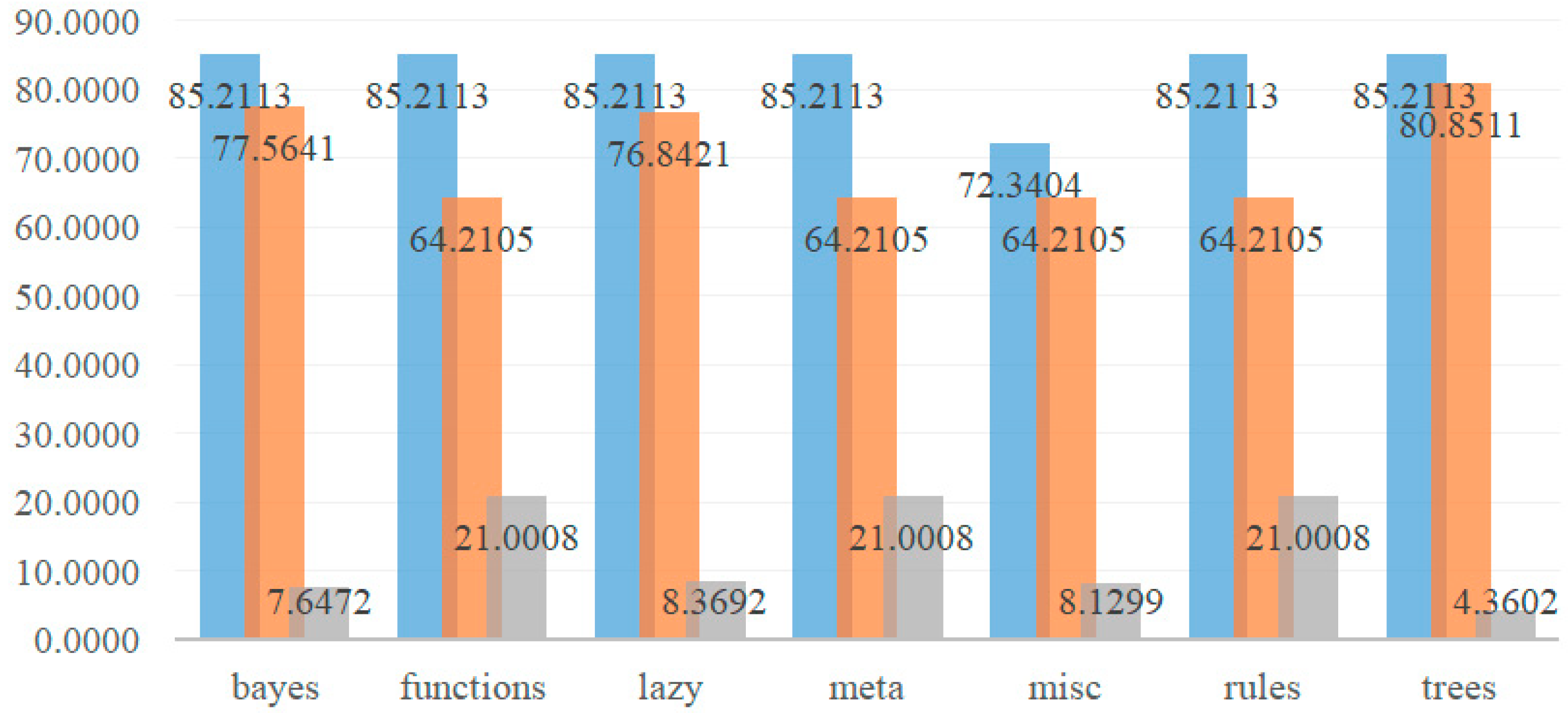
In summary, the prediction values of Bayes Net, Naive Bayes, Logistic, Simple Logistic, IBk, Bagging, Decision Table, PART, J48, LMT, and REP Tree are 85.2113%, which are the good classifiers with same highest value in the study data used. Importantly, the lowest accuracy, highest accuracy and difference values of the seven categories of Model V by percentage split are shown in
Table 4; at the same time,
Figure 2 shows the bar chart of lowest, highest, and difference values of seven categories of Model V.
It can be seen from
Table 3 and
Table 4 and
Figure 2, the lowest and highest accuracy performance and difference value of prediction Model V and algorithm are compared and analyzed as follows.
- (a)
The proportion performance value shows that from the evaluation value presented by the three classifiers of trees (J48, LMT, and REP Tree), the accuracy is relatively stable on the whole, with 85.2113% as the highest, 80.8511% as the lowest, and the difference value 4.3602% is the smallest.
- (b)
In the seven categories, the accuracy of SGD Text of Functions, Stacking and Vote of Meta, Input Mapped Classifier of Misc, and ZeroR classifier of Rules is not good, which is the lowest evaluation value (64.2105%) in the percentage split.
- (c)
Among the seven categories in summary table, the highest 85.2113% is distributed in Bayes Net and Naive Bayes of Bayes, Logistic and Simple Logistic of Functions, IBk of Lazy, Bagging of Meta, Decision Table and PART classifier of Rules and J48, and LMT and REP Tree of Trees, and all distributed in 70/30 (training value/test value).
- (d)
For the accuracy of Model V: attribute selection before data discretization by percentage split, Functions and Meta and Rules have the lowest value of 64.2105%, the highest value of 85.2113%, and the largest difference value of 21.0008%.
According to the comparative analysis results of Models I~V, the summary is described below.
- (a)
Model I: The results of Logistic, PART, and J48 classifiers are the top three classifiers in the study.
- (b)
Model II: The results of Bagging, LMT, REP Tree, J48, and PART are the top five.
- (c)
Model III: Logistic, SMO, Bagging, JRip, Simple Logistic, J48, and LMT have higher values and better results.
- (d)
Model IV: IBk, REP Tree, K Star, Bagging, Decision Table, JRip, PART, and J48 classifiers have higher values and better results.
- (e)
Model V: Bayes Net, Naive Bayes, Logistic, Simple Logistic, IBk, Bagging, Decision Table, PART, J48, LMT, and REP Tree classifiers have higher values and better results.
In total, the analysis of highest value difference of Model I~Model V is showed in
Table 5. From
Table 5, there are 10 core resolutions identified, as follows:
- (a)
Difference of Model II and Model I: except for 100% of Functions, others have little difference.
- (b)
Difference of Model III and Model I: except for 100% of Functions, Bayes, Lazy, and Meta of Model III are better than Model I, Misc has same performance in these two models; Model III is better than Model I.
- (c)
Difference of Model IV and Model I: Bayes and Lazy of Model IV are better than Model I; in addition to this, Model I is better.
- (d)
Difference of Model V and Model I: only Bayes and Lazy of Model V are better than Model I, and the others of Model I is better.
- (e)
Difference of Model III and Model II: Bayes, Functions, Rules, and Trees of Model III are better than Model II, whereas Lazy, Misc, and Meta are the same. Model III is better than Model II.
- (f)
Difference of Model IV and Model II: Bayes, Functions, Lazy, and Trees of Model IV are better than Model II, whereas Meta, and Rules of Model IV are poorer; Model IV is better than Model II.
- (g)
Difference of Model V and II: Model V is better than Model II in Bayes, Functions, and Lazy, two models are the same in Misc, and Model II is better than Model V in Meta, Rules, and Trees.
- (h)
Difference of Model IV and Model III: except Lazy of Model III is poorer, and Misc is the same in two models, Bayes, Functions, Meta, Rules, and Trees are better in Model III than Model IV.
- (i)
Difference of Model V and Model III: Bayes, Functions, Meta, Rules, and Trees are better in Model III than Model V, Lazy of Model III is poorer, and Misc is the same in two models.
- (j)
Difference of Model V and Model IV: Bayes and Functions of Model V are better than Model IV, Misc, and Rules have the same performance in two models.
The analysis result of classifiers with higher accuracy in Models I~V is shown in
Table 6. J48 is used five times in total, whereas Bagging and PART are used four times, respectively; Logistic, LMT, and REP Tree are used three times, respectively; Simple Logistic, IBk, Decision Table, and JRip are used two times, respectively. It is therefore clear that J48, Bagging, and PART are the top three classifiers with better performance times for the study data used.
From summary of
Table 6, the following six meaningful tentative consequences are determined, and they can be referenced for the respective purposes of academics and practitioners in the future.
- (a)
According to the above data, Model III with data discretization is a better model. This may be due to the fact that all data are the information type, and the accuracy is high and good after discretization.
- (b)
The sequence technology of Model IV and Model V shows that the accuracy of Model V, with attribute selection before data discretization, is more average, but the accuracy of Model IV, with data discretization before attribute selection, is higher.
- (c)
Compared with Model III with data discretization, the prediction value of Model II with attribute selection is slightly poorer to that of Model III.
- (d)
In both Model III and Model IV with data discretization technology, the prediction value of Model IV is not much different from that of Model III, which may be because these attributes are all very important. However, Model IV also with attribute selection may have some attributes missing and the evaluated value slightly decreases.
- (e)
As explained in (4), for Model I and Model II, the prediction value of Model I without attribute selection and without data discretization is slightly higher than that of Model II with attribute selection.
- (f)
In
Table 5, Model V is the most stable in terms of classification accuracy.
- (2)
Cross validation attribute performance evaluation: Among 23 classifiers of seven categories, 5 models (Models VI, VII, VIII, IX, and X) are established by using cross validation method, in order to find out the prediction classifier with best performance. Taking the best Model X as an example, the description is as below.
The accuracy analysis result of Model X: attribute selection before data discretization is showed in
Table 7.
There are the following seven key points addressed for the used data from
Table 7 to conclude the reported empirical results.
- (a)
Bayes: Bayes Net and Naive Bayes are the same 87.3150%.
- (b)
Functions: Simple Logistic of 87.3150% is in high performance, whereas Logistic of 86.6808%, SGD of 85.2008%, SMO of 84.9894%, and SGD Text of 68.4989% are in low performance.
- (c)
Lazy: IBk of 87.3150% is in high performance, whereas K Star of 84.5666% and LWL of 81.3953% are in low performance.
- (d)
Meta: Bagging of 85.8351% is in high performance, whereas Ada Boost M1 of 79.7040%, and Stacking and Vote of 68.4989% are in low performance.
- (e)
Misc: Input Mapped Classifier of 68.4989% is in low performance.
- (f)
Rules: PART of 87.3150% is in high performance, and Decision Table of 87.1036% is in the second high performance, whereas JRip of 86.6808%, OneR of 82.6638%, and ZeroR of 68.4989% are in low performance.
- (g)
Trees: J48 and LMT of 87.3150% are in high performance, and REP Tree of 86.2579%, with good overall performance.
In summary, the accuracy of Bayes Net, Naive Bayes, Simple Logistic, IBk, PART, J48, and LMT is the same (87.3150%), which are the classifiers with good performance. The highest accuracy, lowest accuracy and difference values of the seven categories of Model X by cross validation are shown in
Table 8.
For summary, from
Table 7 and
Table 8, it shows the highest, lowest, and difference values of prediction Model X and the algorithm.
- (a)
Cross validation performance values: the overall performance of evaluation values presented on the three classifiers of Trees (J48, LMT, and REP Tree) is relatively stable; J48 and LMT of 87.3150% are the highest value, and REP Tree of 86.2579% is the lowest value. The difference between the highest and lowest values is 1.0571%.
- (b)
In Bayes, the highest and lowest accuracy are 87.3150%, and the difference of 0.0000% is the least, showing excellent performance.
- (c)
In Lazy, IBk, K Star and LWL classifiers in order is 87.3150%, 84.5666% and 81.3953%, and the difference value is 5.9197%.
- (d)
The accuracy of Functions and Rules on other classifiers is 87.3150~85.2008% and 87.3150~82.6638%, with good performance. In addition, both Functions-SGD Text and Rules-ZeroR show the lowest accuracy of 68.4989%, and the difference between the highest and lowest values of these two classifiers is 18.8161%, which shows the largest difference, and the overall performance is not good.
- (e)
Among the seven categories, the highest accuracy rate is 87.3150%. It is generally presented in Bayes Net and Naive Bayes of Bayes, Simple Logistic of Functions, IBk of Lazy, PART of Rules and J48 and LMT of Trees.
- (f)
Among the seven categories, the lowest accuracy of 68.4989% occurs simultaneously in SGD Text of Functions, Stacking and Vote of Meta, Input Mapped Classifier of Misc, and ZeroR of Rules.
According to the analysis results of Models VI~IX, the summary is described as below.
- (a)
Model VI: The results of Logistic, J48 and PART classifiers are good and ranked top three.
- (b)
Model VII: IBk, KStar, Bagging, JRip, J48, and LMT present higher values and are the good classifier.
- (c)
Model VIII: SGD, LMT, SMO, PART, Bagging, and Simple Logistic classifiers are ranked top.
- (d)
Model IX: J48, PART, IBk, Logistic, LMT, and Bagging classifiers are ranked top.
- (e)
Model X: The accuracy of Bayes Net, Naive Bayes, Simple Logistic, IBk, PART, J48, and LMT is the same, which are the good classifiers.
Consequently, the analysis of highest value difference of Model VI~Model X shows in
Table 9. From
Table 9, 10 important results are reported as follows:
- (a)
Difference of Models VII and VI: except the comparison value difference of functions and Lazy exceeds 22%, other performances are improved slightly.
- (b)
Difference of Models VIII and VI: except the comparison value of Functions is 9.3024% with large difference, and the accuracy of Misc and Trees is the same, Bayes, Lazy, Meta, and Rules in Model VIII are better than Model VI.
- (c)
Difference of Models IX and VI: Bayes, Lazy, Meta, and Rules are better in Model IX, and the overall performance of Model IX is stable.
- (d)
Difference of Models X and VI: Bayes and Lazy in Model X are better than Model VI, Misc and Rules in these two models are the same, and others in Model VI are better.
- (e)
Difference of Models VIII and VII: Lazy, Meta, Rules, and Trees in Model VII are better than Model VIII, whereas Bayes and Functions in Model VIII are better.
- (f)
Difference of Models IX and VII: except Functions in Model IX is better, others in Model VII are better.
- (g)
Difference of Models X and VII: except Bayes and Functions in Model X are better, others in Model VII are better.
- (h)
Difference of Models IX and VIII: Misc in these two models is the same, only Lazy in Model IX is better, and others in Model VIII are better.
- (i)
Difference of Models X and VIII: Misc in these two models is the same, only Lazy in Model X is better, and others in Model VIII are better.
- (j)
Difference of Models X and IX: Misc in these two models is the same, only Bayes in Model X is better, and Functions, Lazy, Meta, Rules, and Trees in Model IX are better.
The analysis result of classifiers with higher accuracy in Models VI~X shows in
Table 10. J48, LMT, and PART are used four times, respectively; IBk and Bagging are used three times, respectively; Logistic and Simple Logistic are used two times, respectively; K Star, JRip, SGD, SMO, Bayes Net, and Naive Bayes are used once, respectively. Therefore, J48, LMT, and PART are in the same times and tied for the first place, whereas IBk and Bagging tied for the second place.
In summary, the following five reports are defined from
Table 9 and
Table 10.
- (a)
As the above data indicate, Model VIII with data discretization is the better model. The reason may be that the data are the information type, and the accuracy is high and good after discretization.
- (b)
For Model IX and Model X, the prediction accuracy of Model IX with data discretization before attribute selection is higher due to the different technology sequence selection, whereas the accuracy of Model X with attribute selection before data discretization is more stable.
- (c)
Compared with Model VIII with data discretization, the prediction value of Model VII with attribute selection is slightly better than that of Model VIII.
- (d)
The prediction values of Model VIII and Model IX with data discretization technology are not significantly different, which may be due to the fact that these attributes are all very important, whereas Model IX with attribute selection may delete some attributes, resulting in a slight decrease in the evaluation values.
- (e)
It can be seen from
Table 9 that Model X is relatively stable.
- (3)
Decision tree graph analysis: In this study, the percentage split (67/33) method is used to generate the decision tree, evaluate, find the optimal combination, and obtain the knowledge rules and models of decision tree, which are used as research models and provide reference for investors.
- (a)
Model II: without data discretization, with attribute selection (67/33).
Figure 3 shows the results of decision tree of Model II in tree structure, and its interpretation of important attributes and decision tree rules of Model II without data discretization and with attribute selection (67/33) are identified.
- (i)
Important attributes: E4 (marital status), E7 (total number of purchased insurance policies) and E17 (total amount of life insurance (including long-term care and disability insurance)).
- (ii)
Decision tree rules: Interpreted by the first five rules.
Rule 1: IF E17 ≤ 30,000, E17 > 0, Then, E21 = Y.
Rule 1 explanation: If the total amount of life insurance is more than zero and less than or equal to 30,000, the policyholder would purchase the long-term care and disability insurance.
Rule 2: IF E17 ≤ 30,000, E17 ≤ 0, Then, E21 = N.
Rule 2 explanation: If the total amount of life insurance is less than zero and less than or equal to 30,000, the policyholder would not purchase the long-term care and disability insurance.
Rule 3: IF E17 > 30,000, E7 ≤ 1, Then, E21 = N.
Rule 3 explanation: If the total amount of life insurance is more than 30,000, and the total number of purchased insurance policies is less than or equal to 1, the policyholder would not purchase the long-term care and disability insurance.
Rule 4: IF E17 > 30,000, E7 > 1, E7 ≤ 2, E17 > 310,000, Then, E21 = N.
Rule 4 explanation: If the total amount of life insurance is more than 30,000, and the total number of purchased insurance policies is more than 1 and less than or equal to 2, then the total amount of life insurance is more than 310,000, the policyholder would not purchase the long-term care and disability insurance.
Rule 5: IF E17 > 30,000, E7 > 1, E7 ≤ 2, E17 ≤ 310,000, E17 ≤ 100,000, Then, E21 = N.
Rule 5 explanation: If the total amount of life insurance is more than 30,000, and the total number of purchased insurance policies is more than 1 and less than or equal to 2, then the total amount of life insurance is less than or equal to 310,000, or less than or equal to 100,000, the policyholder would not purchase the long-term care and disability insurance.
- (b)
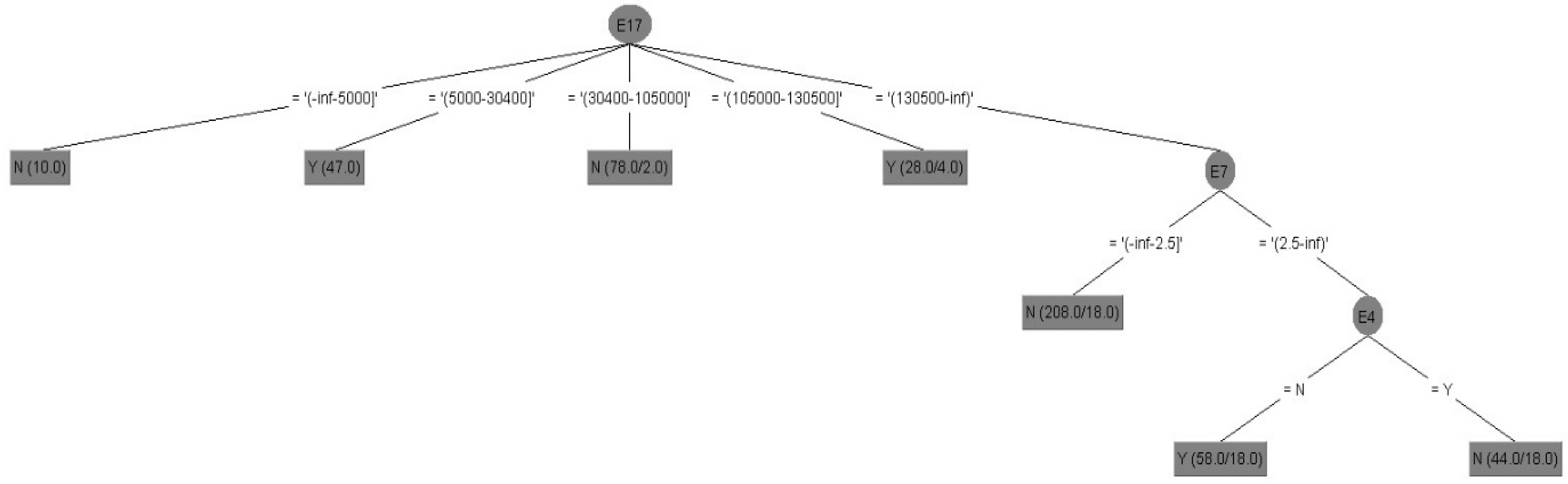
Model V: Attribute selection before data discretization (67/33).
Figure 4 shows the results of decision tree of Model V in tree structure, and its interpretation of important attributes and decision tree rules of Model V with attribute selection before data discretization (67/33) are integrated as follows:
- (i)
Important attributes: E4 (marital status), E7 (total number of purchased insurance policies) and E17 (total amount of life insurance (including long-term care and disability insurance)).
- (ii)
Decision tree rules (Models V and X): interpreted by all rules.
Rule 1: IF E17 = −inf~5000, Then, E21 = N.
Rule 1 explanation: If the total amount of life insurance is 0~5000, the policyholder would not purchase the long-term care and disability insurance.
Rule 2: IF E17 = 5000~30,400, Then, E21 = Y.
Rule 2 explanation: If the total amount of life insurance is 5000~30,400, the policyholder would purchase the long-term care and disability insurance.
Rule 3: IF E17 = 30,400~105,000, Then, E21 = N.
Rule 3 explanation: If the total amount of life insurance is 30,400~105,000, the policyholder would not purchase the long-term care and disability insurance.
Rule 4: IF E17 = 105,000~130,500, Then, E21 = Y.
Rule 4 explanation: If the total amount of life insurance is 105,000~130,500, the policyholder would purchase the long-term care and disability insurance.
Rule 5: IF E17 = 130,500~inf, E7 < −inf~2.5, Then, E21 = N.
Rule 5 explanation: If the total amount of life insurance is more than 130,500, and total number of purchased insurance policies is less than 2.5, the policyholder would not purchase the long-term care and disability insurance.
Rule 6: IF E17 = 130,500~inf, E7 = 2.5~inf, E4 = N, Then, E21 = Y.
Rule 6 explanation: If the total amount of life insurance is more than 130,500, and total number of purchased insurance policies is more than 2.5, and unmarried, the policyholder would purchase the long-term care and disability insurance.
Rule 7: IF E17 = 130,500~inf, E7 < 2.5~inf, E4 = Y, Then, E21 = N.
Rule 7 explanation: If the total amount of life insurance is more than 130,500, and total number of purchased insurance policies is more than 2.5, and married, the policyholder would not purchase the long-term care and disability insurance.
- (iii)
Summary: Model II and Model V are selected the same important attributes (namely E4, E7, and E17).



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}