
Agricultural Price Prediction Based on Combined Forecasting Model under Spatial-Temporal Influencing Factors

 ,
,
Abstract
:1. Introduction
2. Literature Review
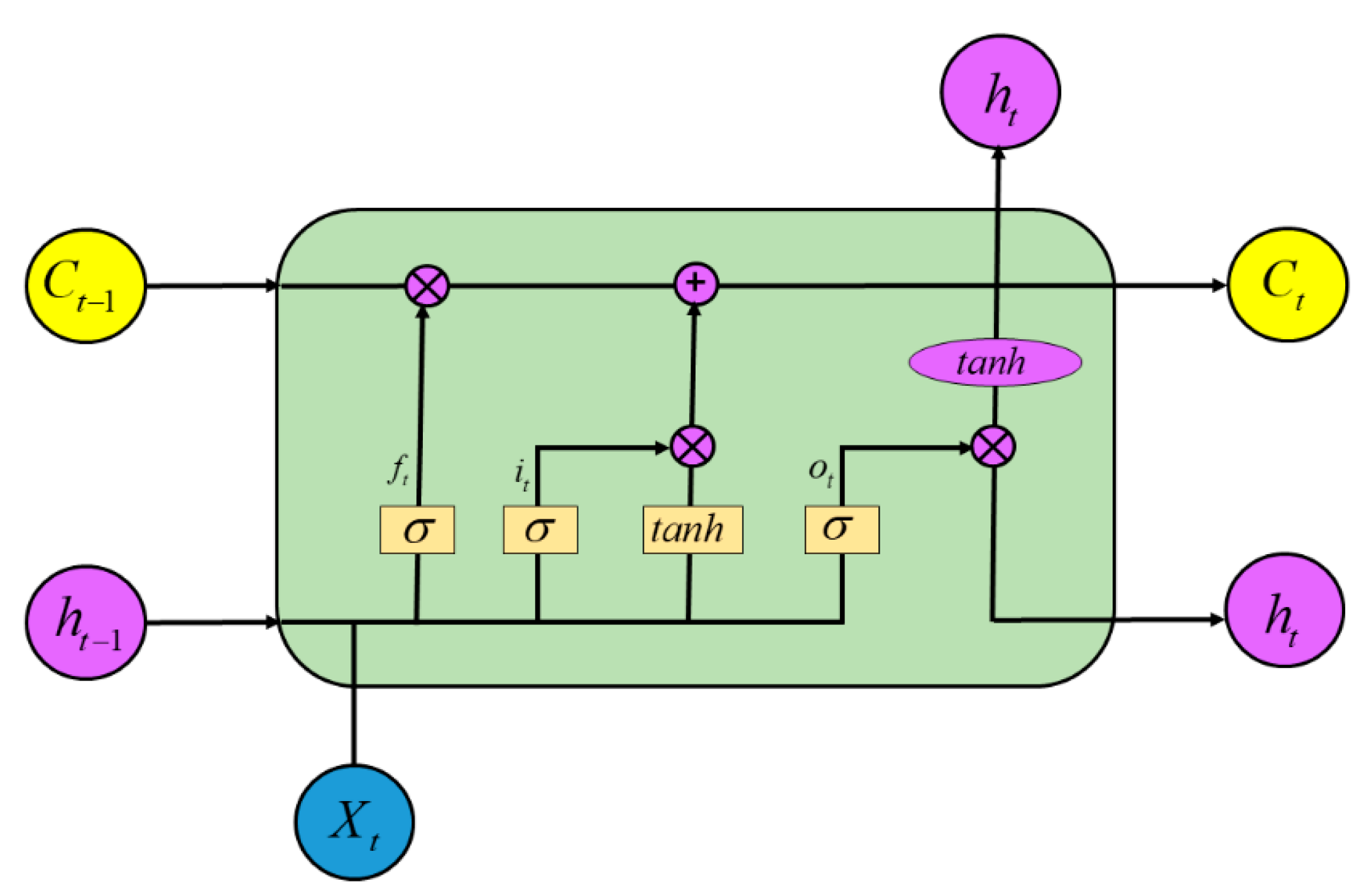
2.1. Long Short-Term Memory
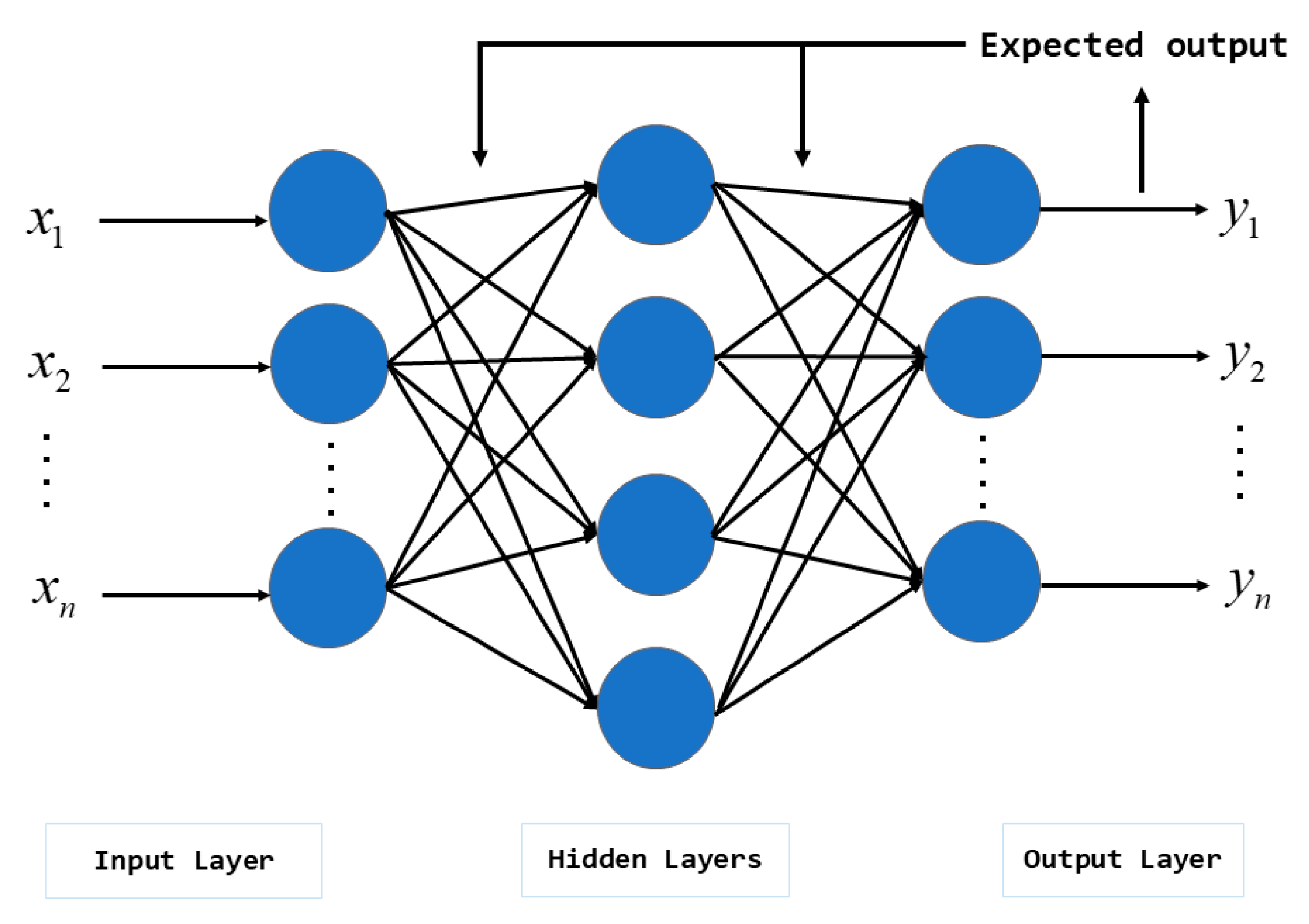
2.2. Back Propagation Neural Network
2.3. Autoregressive Integrated Moving Average
2.4. The Association Rule Mining Algorithm
3. Data
3.1. Data Sources
3.2. Data Cleaning
3.3. Data Processing
3.4. Performance Index
4. Materials and Methods
4.1. Linear Regression Model
4.2. Random Forest Model
4.3. Extreme Gradient Boosting Model
4.4. Light Gradient Boosting Machine Model
4.5. LSTM Model
4.6. AttLSTM Model
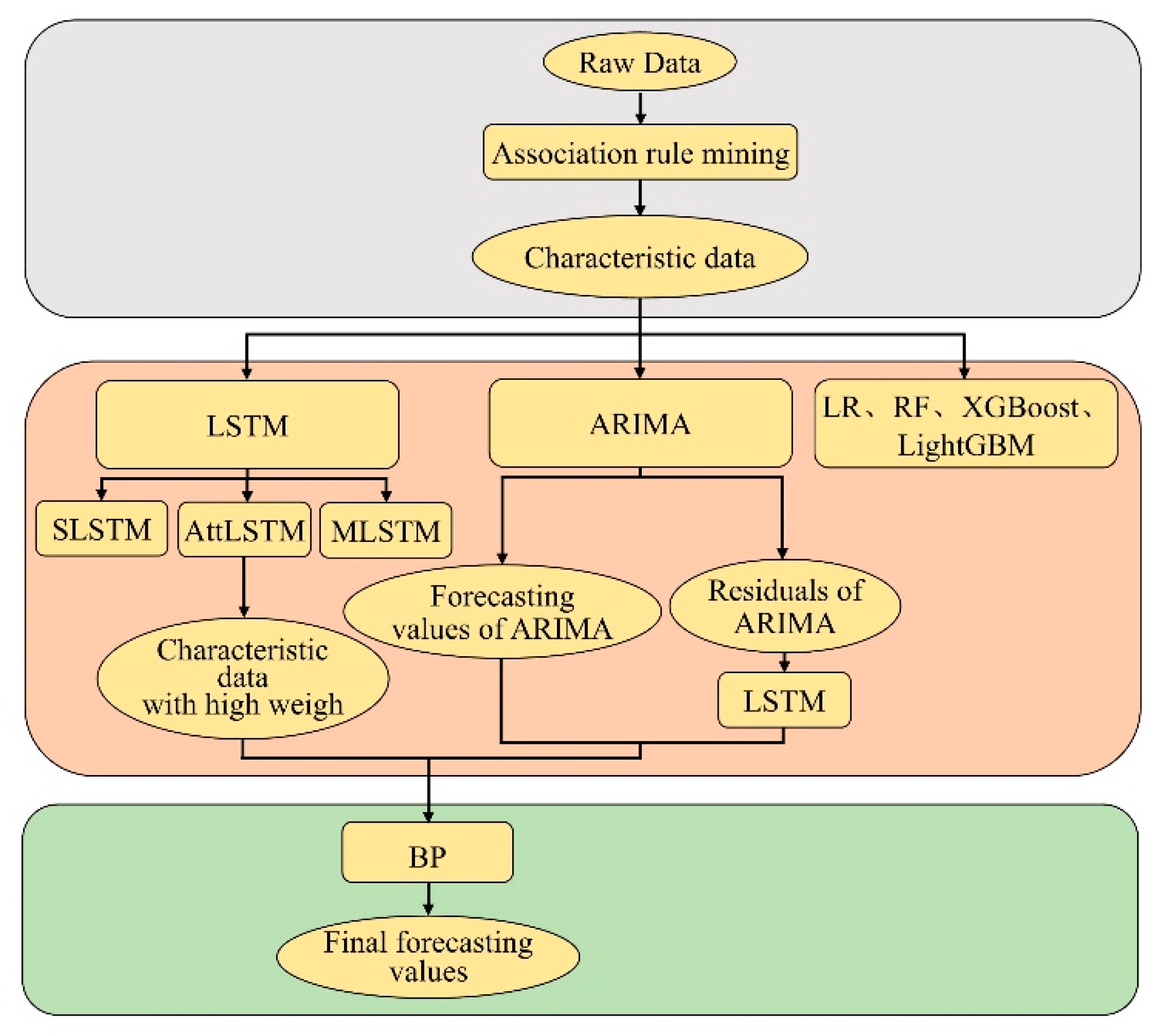
4.7. AttLSTM-ARIMA-BP Combination Model
- Step 1.
- Input the raw data of corn price in the ARIMA model to obtain the predicted value and the residual value .
- Step 2.
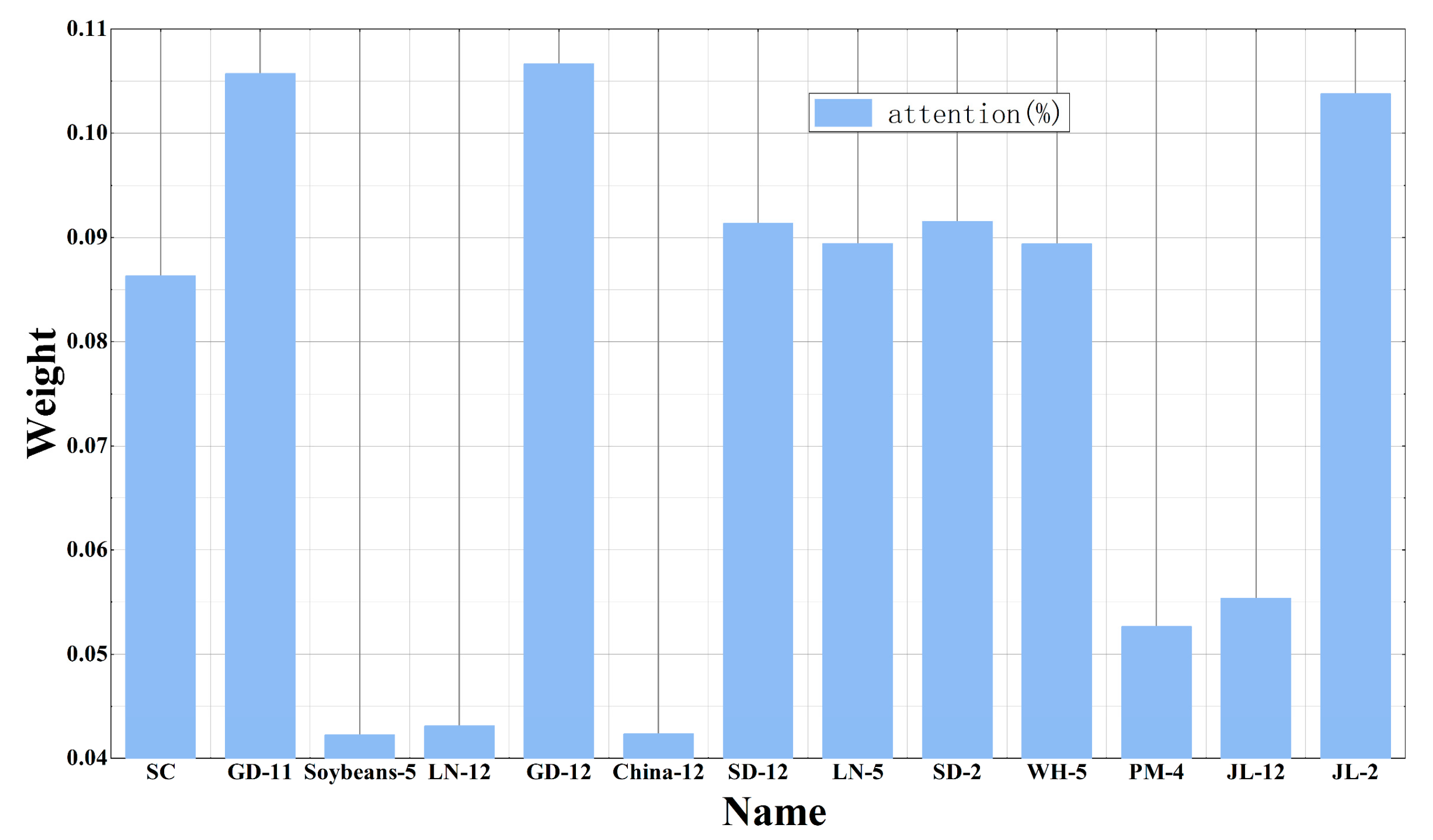
- Use the attention mechanism to calculate the weight of corn price data in Sichuan Province, and select the data with the top three weight influencing factors as the input of the subsequent model.
- Step 3.
- Train the residual data by LSTM and obtain the training value .
- Step 4.
- Obtain the final predicted value by inputting the , , and to the BP.
4.8. Experimental Design
5. Results and Discussion
5.1. The Results of the Predictive Regression Models
5.2. The Results of LSTM Models
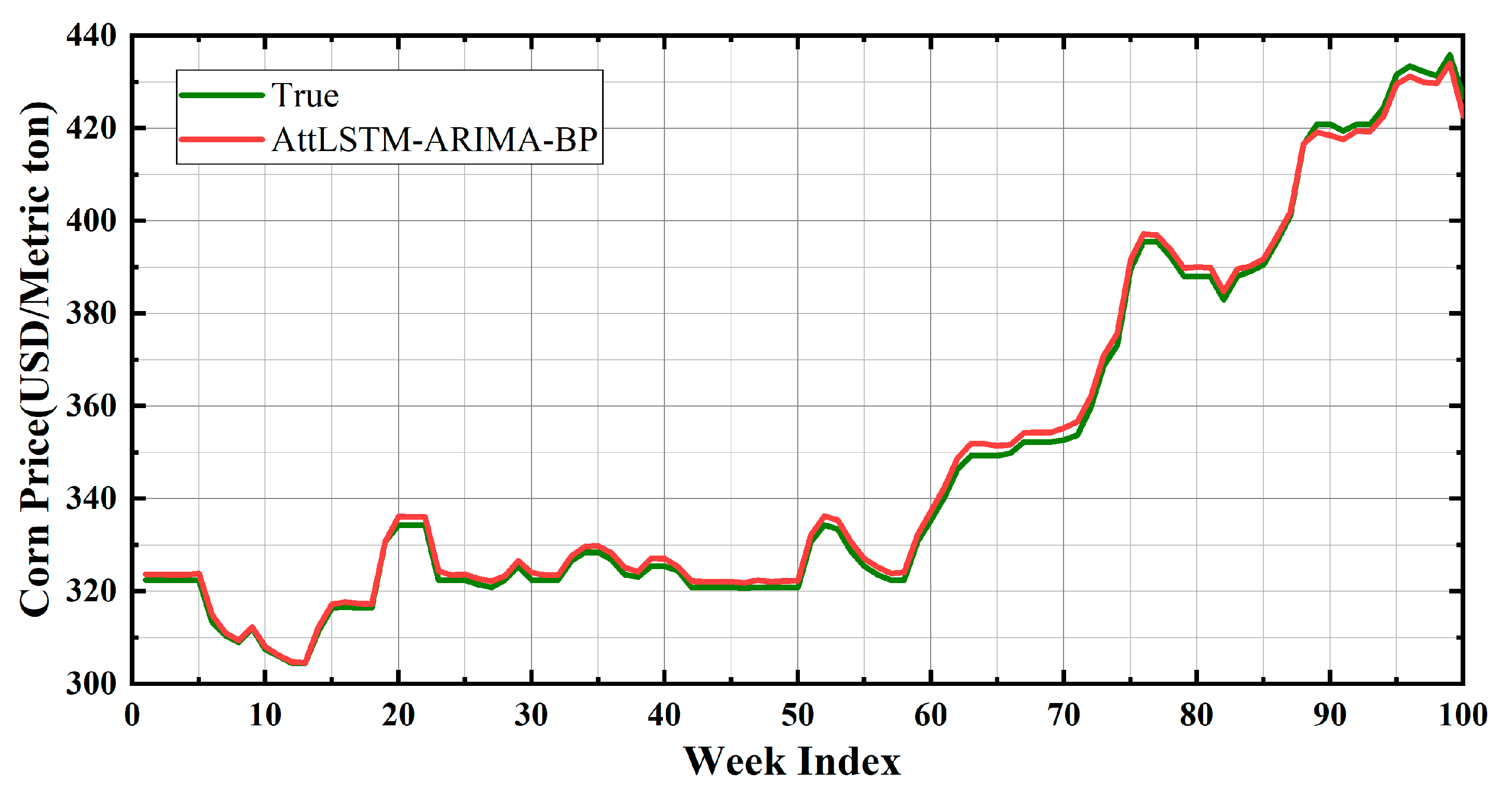
5.3. The Prediction Result of the AttLSTM-ARIMA-BP Model
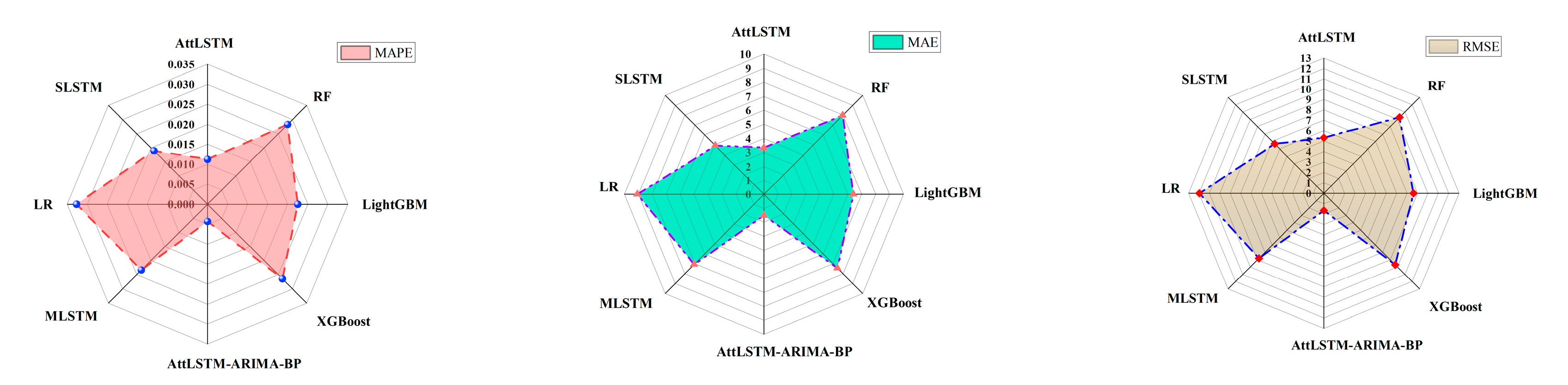
5.4. Experimental Comparison
5.5. Experimental Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdallah, M.B.; Farkas, M.F.; Lakner, Z. Analysis of meat price volatility and volatility spillovers in Finland. Agric. Econ. 2020, 66, 84–91. [Google Scholar] [CrossRef]
- Drachal, K. Some novel Bayesian model combination schemes: An application to commodities prices. Sustainability 2018, 10, 2801. [Google Scholar] [CrossRef] [Green Version]
- Cohen, G. Forecasting Bitcoin trends using algorithmic learning systems. Entropy 2020, 22, 838. [Google Scholar] [CrossRef] [PubMed]
- Verteramo Chiu, L.J.; Tomek, W.G. Insights from Anticipatory Prices. J. Agric. Econ. 2018, 69, 351–364. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Yuan, J.; Chen, L. Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef] [Green Version]
- Niu, M.; Hu, Y.; Sun, S.; Liu, Y. A novel hybrid decomposition-ensemble model based on VMD and HGWO for container throughput forecasting. Appl. Math. Model. 2018, 57, 163–178. [Google Scholar] [CrossRef]
- Guo, Y.; Hu, X.; Wang, Z.; Tang, W.; Liu, D.; Luo, Y.; Xu, H. The butterfly effect in the price of agricultural products: A multidimensional spatial-temporal association mining. Agric. Econ. 2021, 67, 457–467. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Rajan, S.; Chenniappan, P.; Devaraj, S.; Madian, N. Novel deep learning model for facial expression recognition based on maximum boosted CNN and LSTM. IET Image Process. 2020, 14, 1373–1381. [Google Scholar] [CrossRef]
- Zheng, J.; Huang, M. Traffic flow forecast through time series analysis based on deep learning. IEEE Access 2020, 8, 82562–82570. [Google Scholar] [CrossRef]
- Ji, Y.; Liew, A.W.C.; Yang, L. A novel improved particle swarm optimization with long-short term memory hybrid model for stock indices forecast. IEEE Access 2021, 9, 23660–23671. [Google Scholar] [CrossRef]
- Jian, L.; Xiang, H.; Le, G. LSTM-Based Attentional Embedding for English Machine Translation. Sci. Program. 2022, 2022, 3909726. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Y.; Dai, F. A LSTM-based method for stock returns prediction: A case study of China stock market. In Proceedings of the 2015 IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October 2015–1 November 2015; pp. 2823–2824. [Google Scholar]
- Yan, R.; Liao, J.; Yang, J.; Sun, W.; Nong, M.; Li, F. Multi-hour and multi-site air quality index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering. Expert Syst. Appl. 2021, 169, 114513. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chen, S.; Ge, L. Exploring the attention mechanism in LSTM-based Hong Kong stock price movement prediction. Quant. Financ. 2019, 19, 1507–1515. [Google Scholar] [CrossRef]
- Zheng, H.; Lin, F.; Feng, X.; Chen, Y. A hybrid deep learning model with attention-based conv-LSTM networks for short-term traffic flow prediction. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6910–6920. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hu, H.; Tang, L.; Zhang, S.; Wang, H. Predicting the direction of stock markets using optimized neural networks with Google Trends. Neurocomputing 2018, 285, 188–195. [Google Scholar] [CrossRef]
- Li, A.; Xu, X. A new pm2. 5 air pollution forecasting model based on data mining and bp neural network model. In Proceedings of the 2018 3rd International Conference on Communications, Information Management and Network Security (CIMNS 2018), Wuhan, China, 27–28 September 2018; pp. 110–113. [Google Scholar]
- Hua, C.; Zhu, E.; Kuang, L.; Pi, D. Short-term power prediction of photovoltaic power station based on long short-term memory-back-propagation. Int. J. Distrib. Sens. Netw. 2019, 15, 3134. [Google Scholar] [CrossRef]
- Liu, Z.; Du, G.; Zhou, S.; Lu, H.; Ji, H. Analysis of internet financial risks based on deep learning and BP neural network. Comput. Econ. 2022, 59, 1481–1499. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Suganthi, L.; Samuel, A.A. Modelling and forecasting energy consumption in INDIA: Influence of socioeconomic variables. Energy Source Part B 2016, 11, 404–411. [Google Scholar] [CrossRef]
- Sen, P.; Roy, M.; Pal, P. Application of ARIMA for forecasting energy consumption and GHG emission: A case study of an Indian pig iron manufacturing organization. Energy 2016, 116, 1031–1038. [Google Scholar] [CrossRef]
- De Oliveira, E.M.; Oliveira, F.L.C. Forecasting mid-long term electric energy consumption through bagging ARIMA and exponential smoothing methods. Energy 2018, 144, 776–788. [Google Scholar] [CrossRef]
- Singh, S.N.; Mohapatra, A. Repeated wavelet transform based ARIMA model for very short-term wind speed forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar]
- Lai, Y.; Dzombak, D.A. Use of the autoregressive integrated moving average (ARIMA) model to forecast near-term regional temperature and precipitation. Weather Forecast. 2020, 35, 959–976. [Google Scholar] [CrossRef]
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; Volume 22, pp. 207–216. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12 September 1994; pp. 487–499. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y.; Mao, R. Mining frequent patterns without candidate generation: A frequent-pattern tree approach. Data Min. Knowl. Discov. 2004, 8, 53–87. [Google Scholar] [CrossRef]
- Pei, J.; Han, J.; Mortazavi-Asl, B.; Pinto, H.; Chen, Q.; Dayal, U.; Hsu, M. Mining sequential patterns efficiently by prefix-projected pattern growth. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001. [Google Scholar]
- Xu, B.; Yi, T.; Wu, F.; Chen, Z. An incremental updating algorithm for mining association rules. J. Electron. 2002, 19, 403–407. [Google Scholar] [CrossRef]
- Liu, G.; Lu, H.; Lou, W.; Yu, J. On computing, storing and querying frequent patterns. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 607–612. [Google Scholar]
- Shao, Y.; Liu, B.; Wang, S.; Li, G. Software defect prediction based on correlation weighted class association rule mining. Knowl. Based Syst. 2020, 196, 105742. [Google Scholar] [CrossRef]
- Wu, T.Y.; Lin, J.C.W.; Yun, U.; Chen, C.; Srivastava, G.; Lv, X. An efficient algorithm for fuzzy frequent itemset mining. J. Intell. Fuzzy Syst. 2020, 38, 5787–5797. [Google Scholar] [CrossRef]
- Yang, J.; Bessler, D.A.; Leatham, D.J. Asset storability and price discovery in commodity futures markets: A new look. J. Futures Mark. 2001, 21, 279–300. [Google Scholar] [CrossRef]
- Sako, K.; Mpinda, B.N.; Rodrigues, P.C. Neural Networks for Financial Time Series Forecasting. Entropy 2022, 24, 657. [Google Scholar] [CrossRef] [PubMed]
- Paul, R.K.; Vennila, S.; Yeasin, M.; Yadav, S.K.; Nisar, S.; Paul, A.K.; Gupta, A.; Malathi, M.K.J.; Kavitha, Z.; Mathukumalli, S.R.; et al. Wavelet Decomposition and Machine Learning Technique for Predicting Occurrence of Spiders in Pigeon Pea. Agronomy 2022, 12, 1429. [Google Scholar] [CrossRef]
- Zhang, F.; Wen, N. Carbon price forecasting: A novel deep learning approach. Environ. Sci. Pollut. Res. 2022, 29, 54782–54795. [Google Scholar] [CrossRef]
- Paul, R.K.; Yeasin, M.; Kumar, P.; Kumar, P.; Balasubramanian, M.; Roy, H.S.; Roy, H.S.; Gupta, A.K. Machine learning techniques for forecasting agricultural prices: A case of brinjal in Odisha. PLoS ONE 2022, 17, e0270553. [Google Scholar] [CrossRef]
- Phan, Q.T.; Wu, Y.K.; Phan, Q.D. A hybrid wind power forecasting model with XGBoost, data preprocessing considering different NWPs. Appl. Sci. 2021, 11, 1100. [Google Scholar]
- Zhou, Y.; Li, T.; Shi, J.; Qian, Z. A CEEMDAN and XGBOOST-based approach to forecast crude oil prices. Complexity 2019, 2019, 4392785. [Google Scholar] [CrossRef] [Green Version]
- Jiang, M.; Liu, J.; Zhang, L.; Liu, C. An improved Stacking framework for stock index prediction by leveraging tree-based ensemble models and deep learning algorithms. Physica A 2020, 541, 122272. [Google Scholar] [CrossRef]
- Jabeur, S.B.; Mefteh-Wali, S.; Viviani, J.L. Forecasting gold price with the XGBoost algorithm and SHAP interaction values. Ann. Oper. Res. 2021, 1–21. [Google Scholar] [CrossRef]
- Sun, X.; Liu, M.; Sima, Z. A novel cryptocurrency price trend forecasting model based on LightGBM. Financ. Res. Lett. 2020, 32, 101084. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, C.; Huang, K.; Gui, W. Non-ferrous metals price forecasting based on variational mode decomposition and LSTM network. Knowl. Based Syst. 2020, 188, 105006. [Google Scholar] [CrossRef]
- Kontogiannis, D.; Bargiotas, D.; Daskalopulu, A. Minutely active power forecasting models using neural networks. Sustainability 2020, 12, 3177. [Google Scholar] [CrossRef] [Green Version]
- Yin, H.; Jin, D.; Gu, Y.H.; Park, C.J.; Han, S.K.; Yoo, S.J. STL-ATTLSTM: Vegetable price forecasting using STL and attention mechanism-based LSTM. Agriculture 2020, 10, 612. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.; Zhou, F. Attention enhanced long short-term memory network with multi-source heterogeneous information fusion: An application to BGI Genomics. Inf. Sci. 2021, 553, 305–330. [Google Scholar] [CrossRef]
- Wang, J.; Li, X.; Hong, T.; Wang, S. A semi-heterogeneous approach to combining crude oil price forecasts. Inf. Sci. 2018, 460, 279–292. [Google Scholar] [CrossRef]
- Dou, Z.; Ji, M.; Wang, M.; Shao, Y. Price Prediction of Pu’er tea based on ARIMA and BP Models. Neural Comput. Appl. 2022, 34, 3495–3511. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, Q.; Ding, Y.; Zhang, D. Application of a hybrid ARIMA-LSTM model based on the SPEI for drought forecasting. Environ. Sci. Pollut. Res. 2022, 29, 4128–4144. [Google Scholar] [CrossRef]
- Deng, Y.; Fan, H.; Wu, S. A hybrid ARIMA-LSTM model optimized by BP in the forecast of outpatient visits. J. Ambient Intell. Humaniz. Comput. 2020, 1–11. [Google Scholar] [CrossRef]
- Zhou, X. The usage of artificial intelligence in the commodity house price evaluation model. J. Ambient Intell. Humaniz. Comput. 2020, 1–8. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; dos Santos Coelho, L. Ensemble approach based on bagging, boosting and stacking for short-term prediction in agribusiness time series. Appl. Soft. Comput. 2020, 86, 105837. [Google Scholar] [CrossRef]
- Yang, G.; Du, S.; Duan, Q.; Su, J. Short-term Price Forecasting Method in Electricity Spot Markets Based on Attention-LSTM-mTCN. J. Electr. Eng. Technol. 2022, 17, 1009–1018. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Determination Coefficient | Number of Increases | Number of Steadiness | Number of Declines |
|---|---|---|---|---|
| Corn price in China | 0.02 | 209 | 105 | 196 |
| Corn price in Jiangsu | 0.001 | 209 | 203 | 98 |
| Corn price in Liaoning | 0.02 | 227 | 183 | 100 |
| Corn price in Jilin | 0.001 | 213 | 176 | 121 |
| Corn price in Shandong | 0.002 | 213 | 192 | 105 |
| Corn price in Guangdong | 0.03 | 205 | 196 | 109 |
| Early rice price | 0.001 | 156 | 168 | 186 |
| Middle-late rice price | 0.001 | 164 | 183 | 163 |
| PM futures price | 0.001 | 202 | 202 | 106 |
| WH futures price | 0.005 | 199 | 210 | 101 |
| Soybean futures price | 0.005 | 207 | 216 | 87 |
| Corn price in Sichuan | 0.001 | 217 | 189 | 104 |
| Model | Hyperparameters |
|---|---|
| LR |
|
| RF |
|
| XGBoost |
|
| LightGBM |
|
| LSTM |
|
| AttLSTM |
|
| ARIMA |
|
| BP |
|
| ID | LR | RF | LightGBM | XGBoost |
|---|---|---|---|---|
| 1 | 5.65248 | 7.0781 | 4.85501 | 5.39763 |
| 2 | 6.14403 | 5.05084 | 4.34395 | 6.07982 |
| 3 | 10.8663 | 5.45376 | 3.09889 | 5.16657 |
| 4 | 11.8708 | 7.78072 | 7.2659 | 6.47199 |
| 5 | 10.7556 | 14.4182 | 12.4372 | 14.0908 |
| ID | SLSTM | MLSTM | AttLSTM | AttLSTM-ARIMA-BP |
|---|---|---|---|---|
| 1 | 5.3768 | 6.74184 | 1.30327 | 0.83782 |
| 2 | 3.21642 | 5.61778 | 1.94761 | 1.38236 |
| 3 | 4.63223 | 5.91433 | 2.338 | 1.45923 |
| 4 | 6.30376 | 5.15146 | 1.40022 | 2.13725 |
| 5 | 5.05035 | 12.1135 | 9.95061 | 1.73526 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Tang, D.; Tang, W.; Yang, S.; Tang, Q.; Feng, Y.; Zhang, F. Agricultural Price Prediction Based on Combined Forecasting Model under Spatial-Temporal Influencing Factors. Sustainability 2022, 14, 10483. https://doi.org/10.3390/su141710483
Guo Y, Tang D, Tang W, Yang S, Tang Q, Feng Y, Zhang F. Agricultural Price Prediction Based on Combined Forecasting Model under Spatial-Temporal Influencing Factors. Sustainability. 2022; 14(17):10483. https://doi.org/10.3390/su141710483
Chicago/Turabian StyleGuo, Yan, Dezhao Tang, Wei Tang, Senqi Yang, Qichao Tang, Yang Feng, and Fang Zhang. 2022. "Agricultural Price Prediction Based on Combined Forecasting Model under Spatial-Temporal Influencing Factors" Sustainability 14, no. 17: 10483. https://doi.org/10.3390/su141710483
APA StyleGuo, Y., Tang, D., Tang, W., Yang, S., Tang, Q., Feng, Y., & Zhang, F. (2022). Agricultural Price Prediction Based on Combined Forecasting Model under Spatial-Temporal Influencing Factors. Sustainability, 14(17), 10483. https://doi.org/10.3390/su141710483