
CD-TransUNet: A Hybrid Transformer Network for the Change Detection of Urban Buildings Using L-Band SAR Images


Abstract
:1. Introduction
- This paper explores the value of L-band SAR images, whose stronger penetration is more advantageous than optical images.
- This paper proposes a new model (CD-TransUNet) for urban building change detection, which is an end-to-end network architecture combining Transformer and UNet with a hybrid CNN-Transformer encoder to extract rich global contextual information. The ASPP module is introduced to obtain multiscale information about the target before performing upsampling. It enables the network to focus on building changes in small areas, thus improving the problem of missed detection.
- Coordinate attention is introduced into change detection of urban buildings, which could better obtain the location information of features, enhance feature extraction, and return the change region with complete boundaries.
- Depthwise separable convolution is used instead of regular convolution to achieve higher computational efficiency to achieve a lightweight change detection model.
2. Materials and Methods
2.1. Study Areas and Data
2.2. Proposed Method
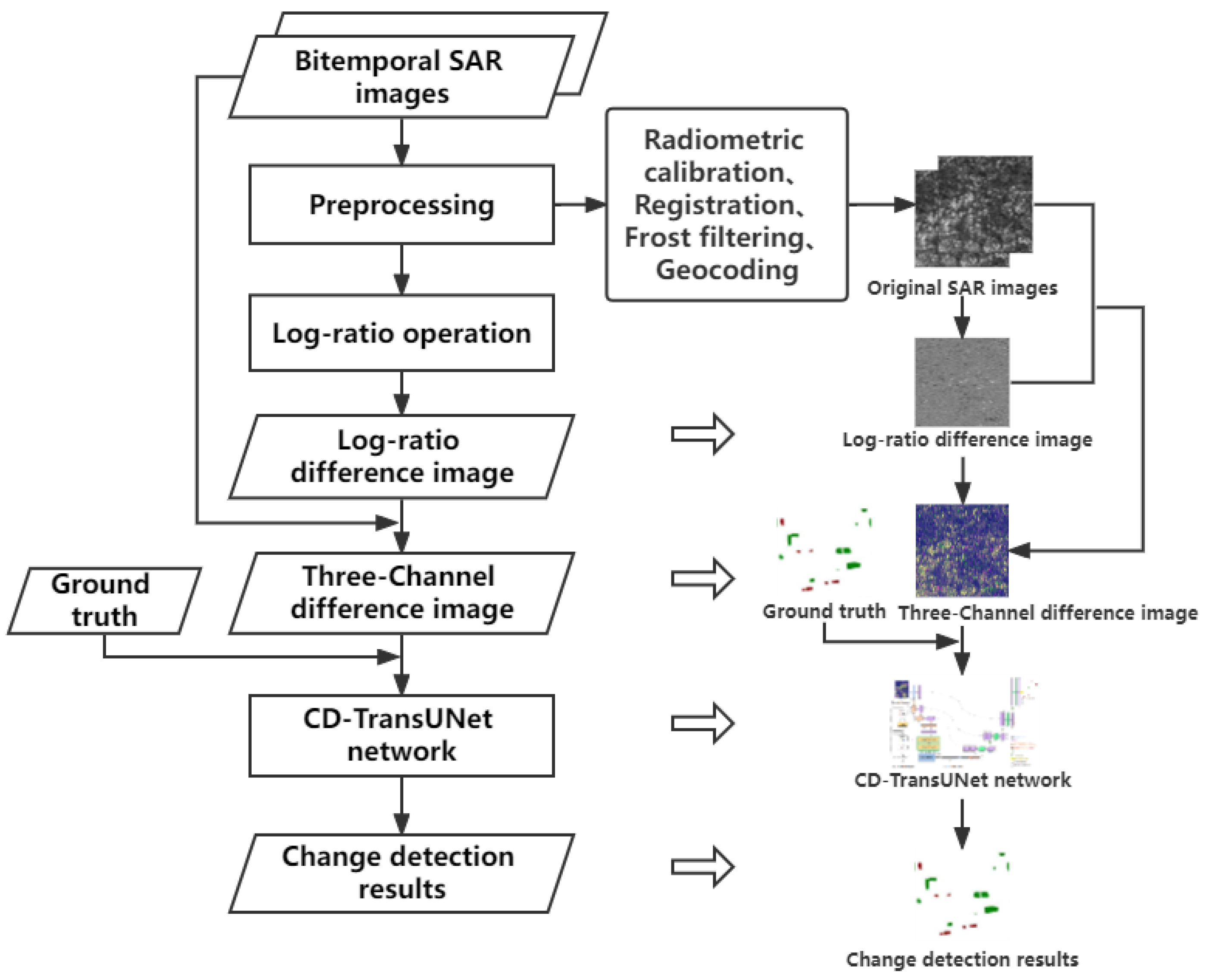
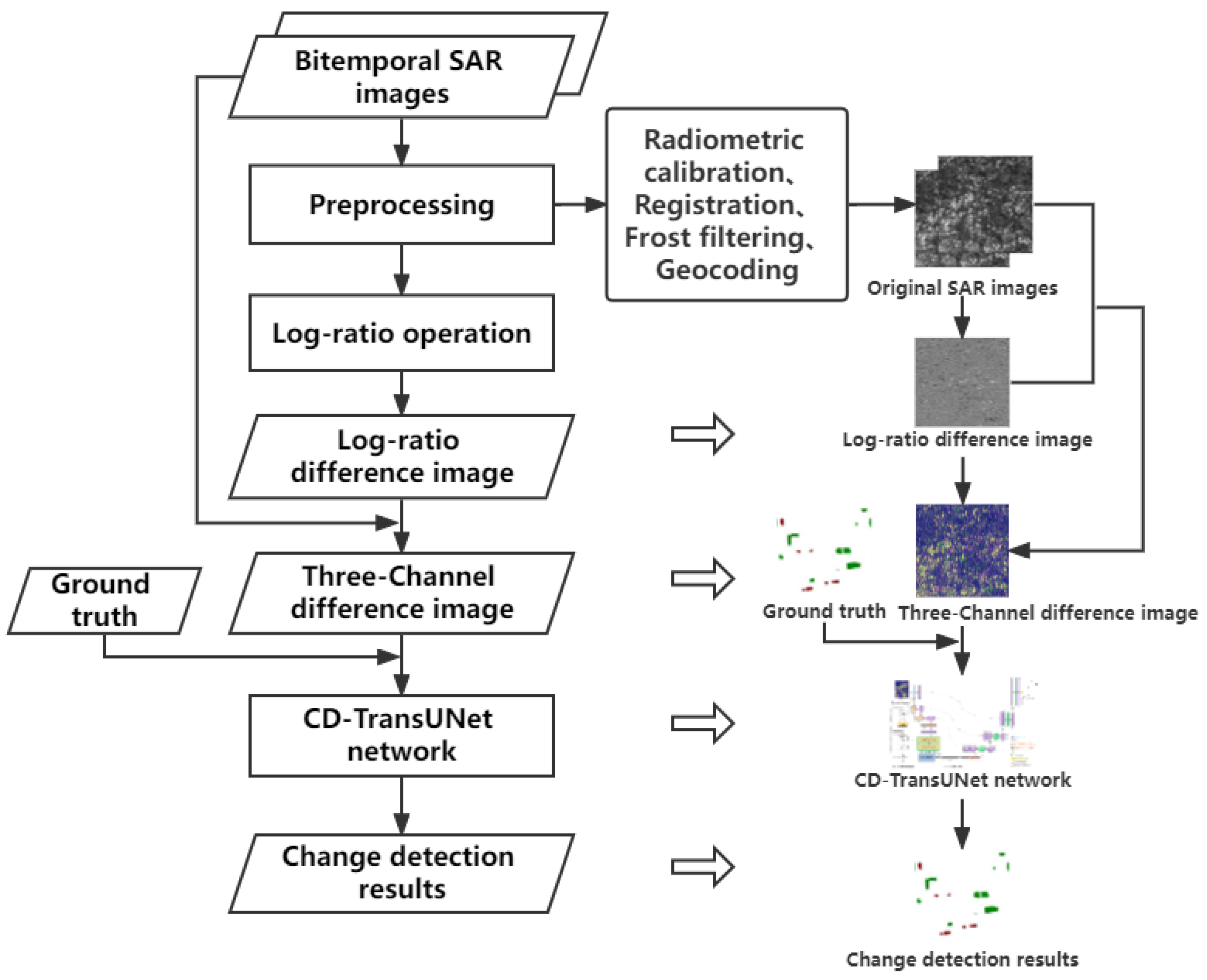
2.2.1. Difference Image Generation
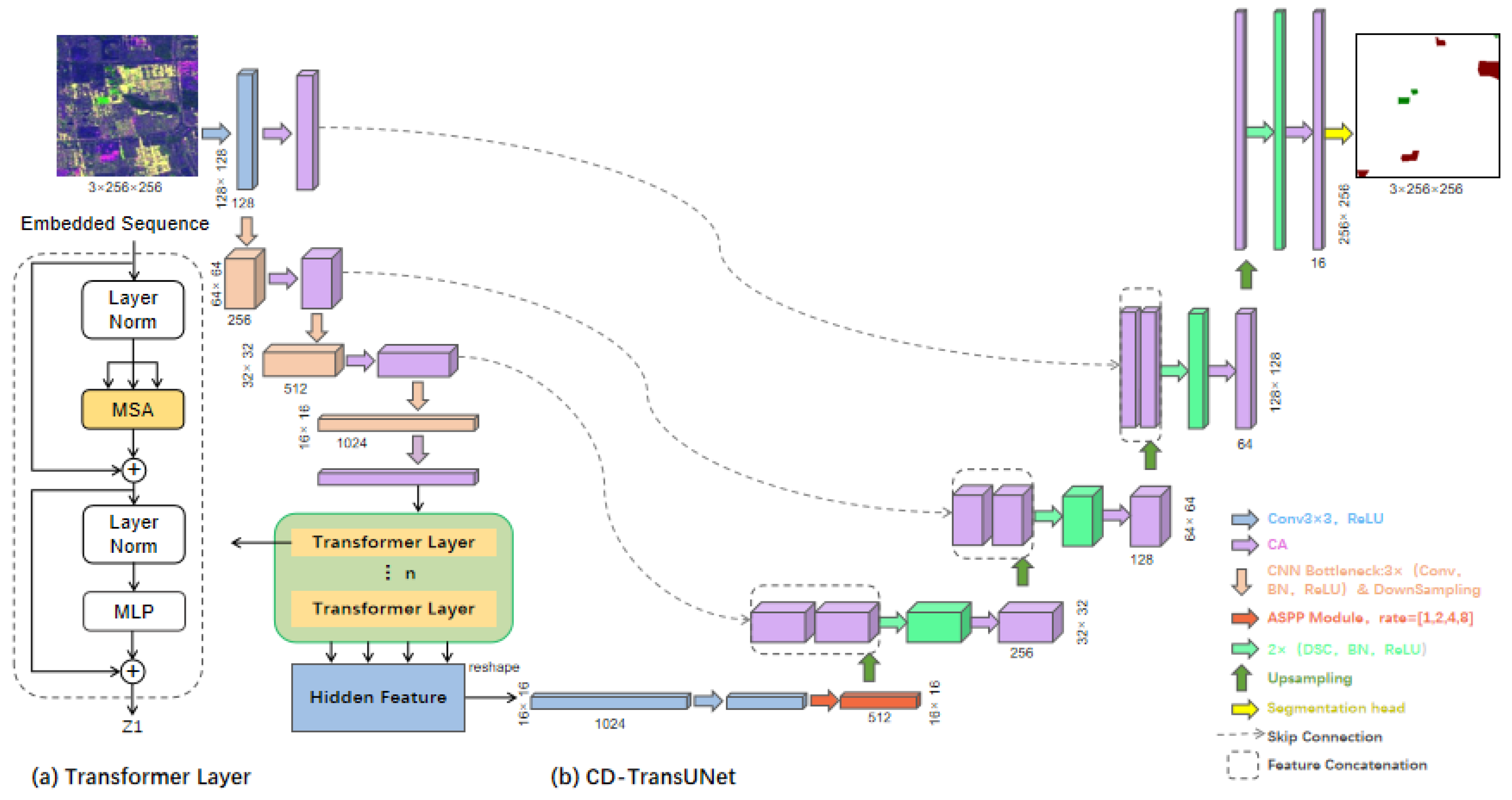
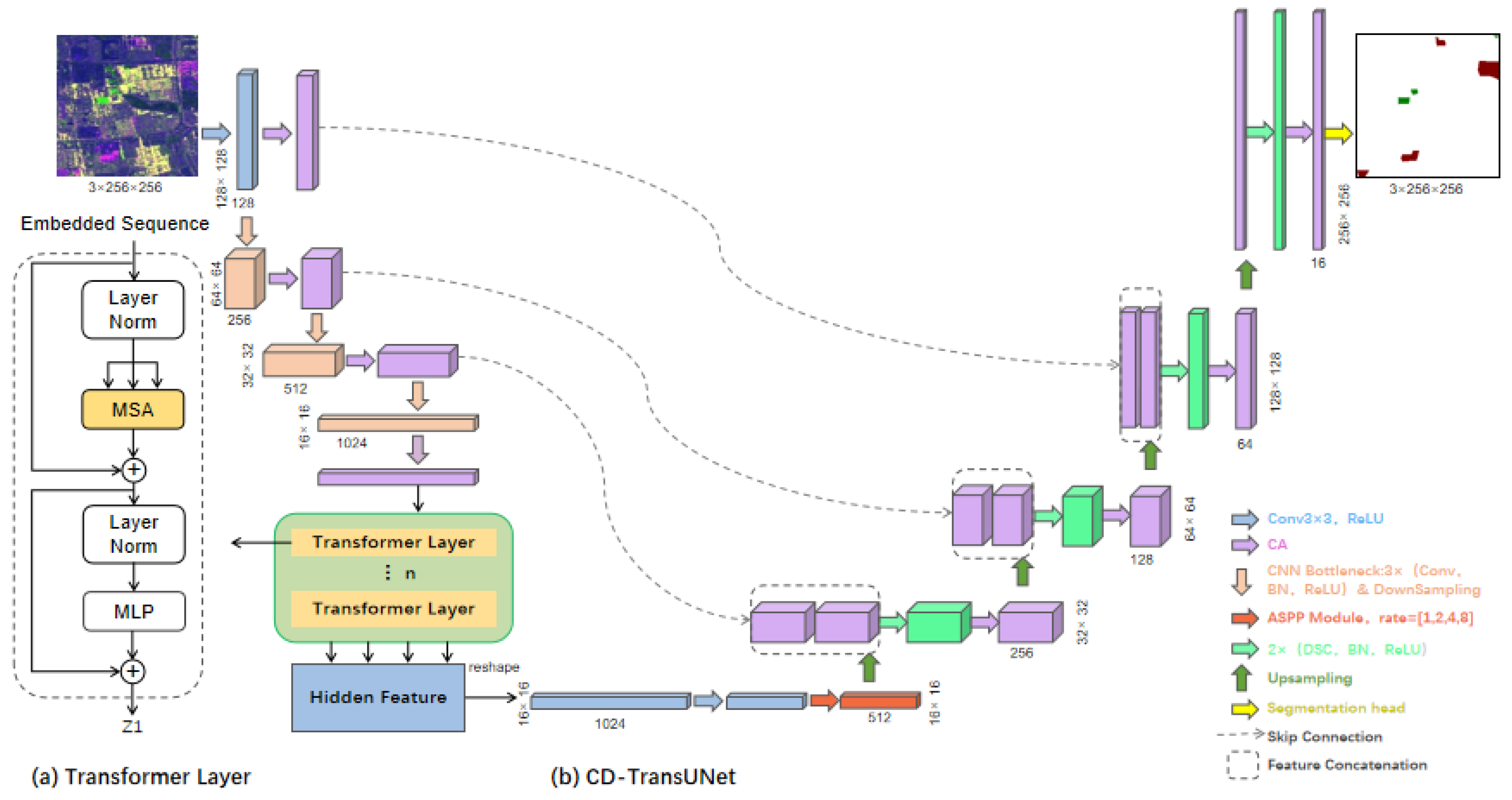
2.2.2. CD-TransUNet Model Construction
Network Architecture
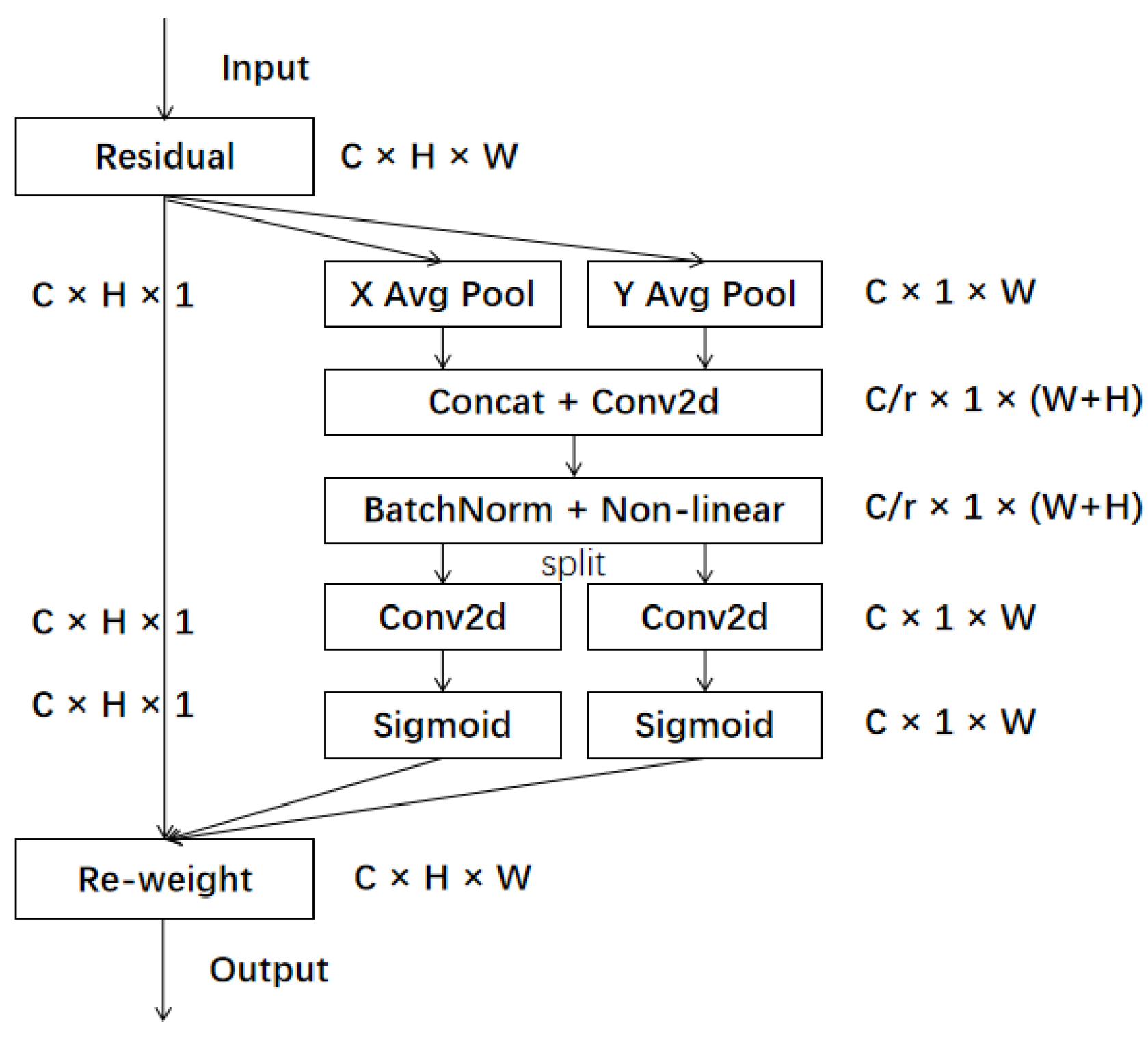
Coordinate Attention
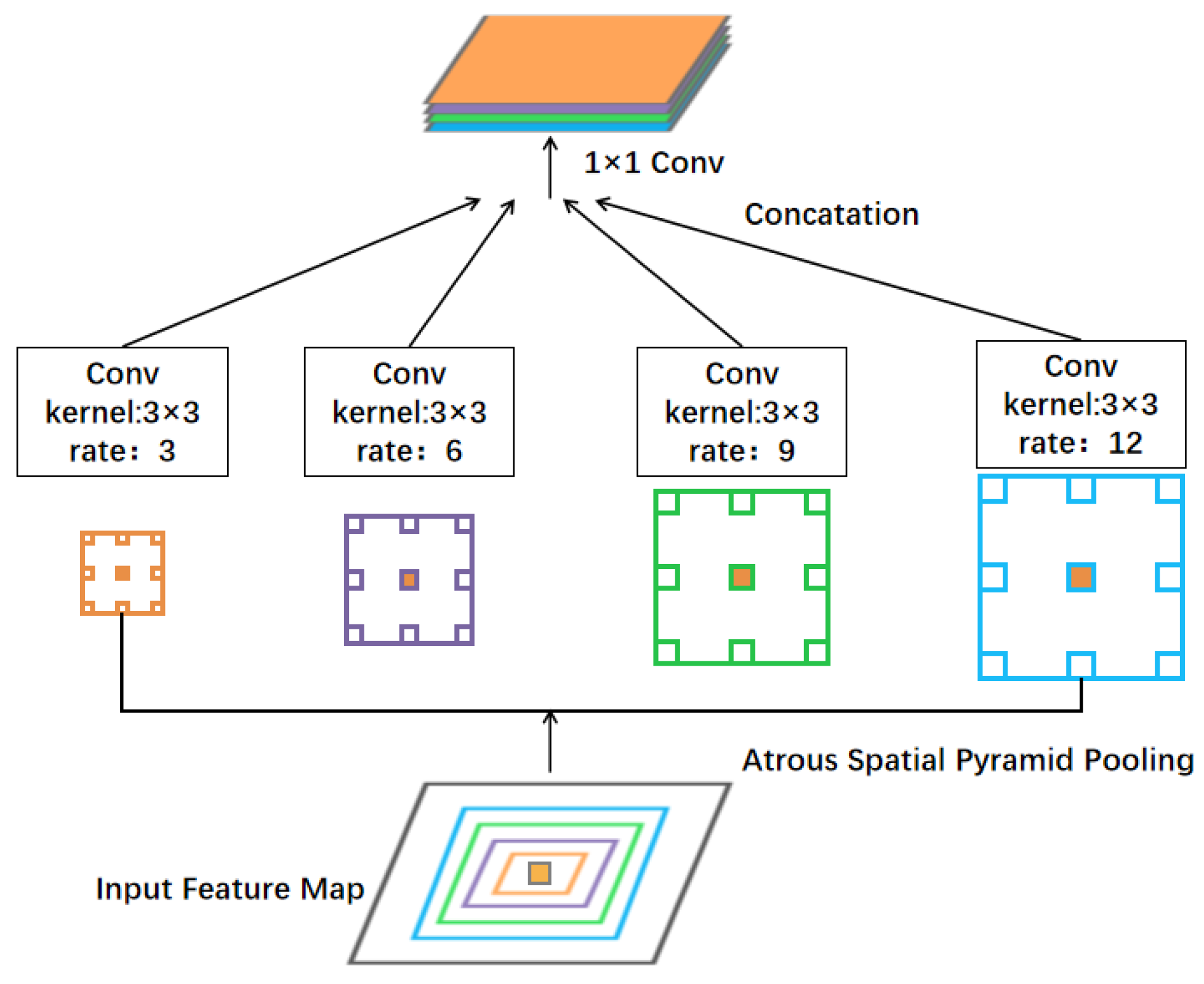
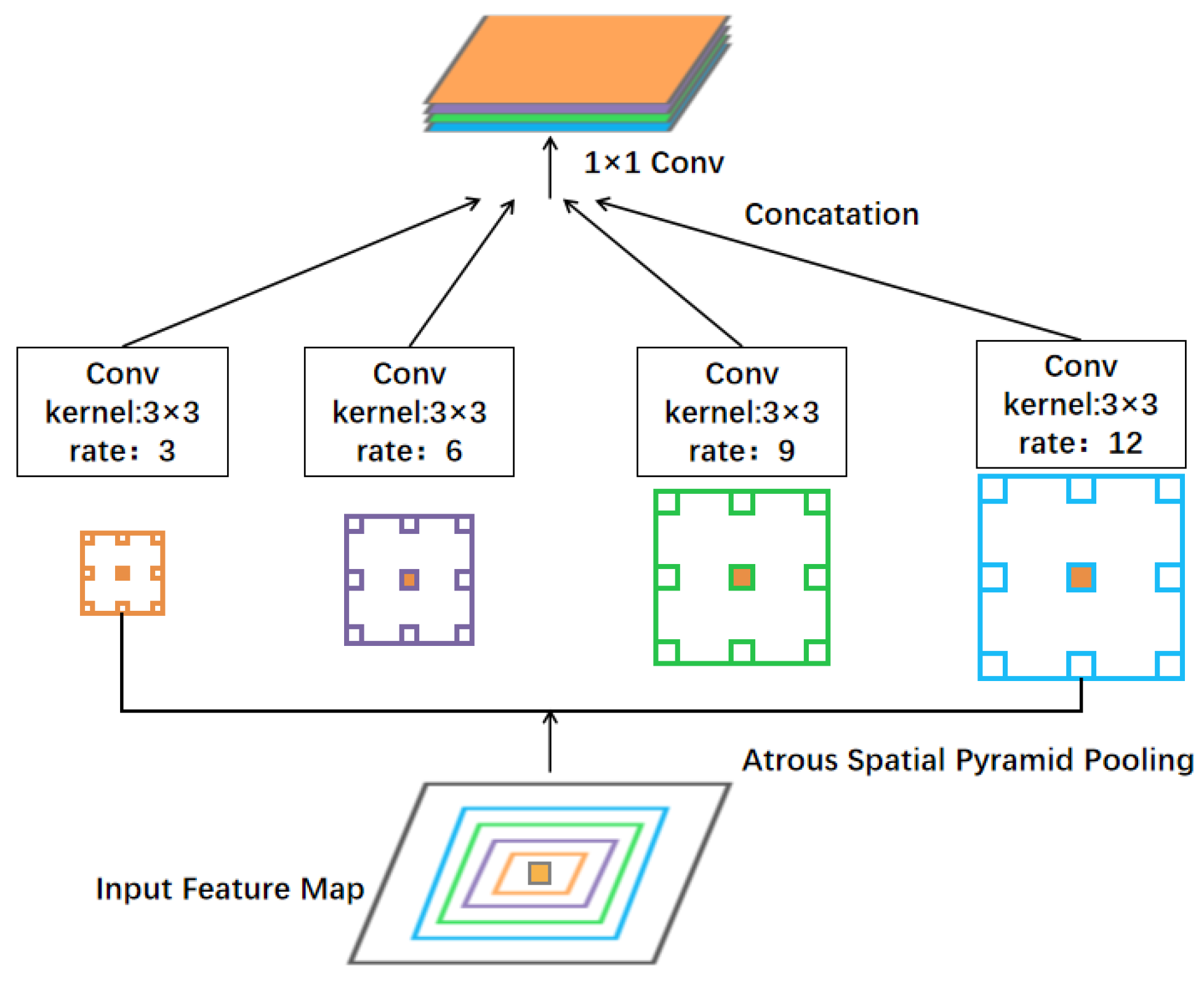
Atrous Spatial Pyramid Pooling
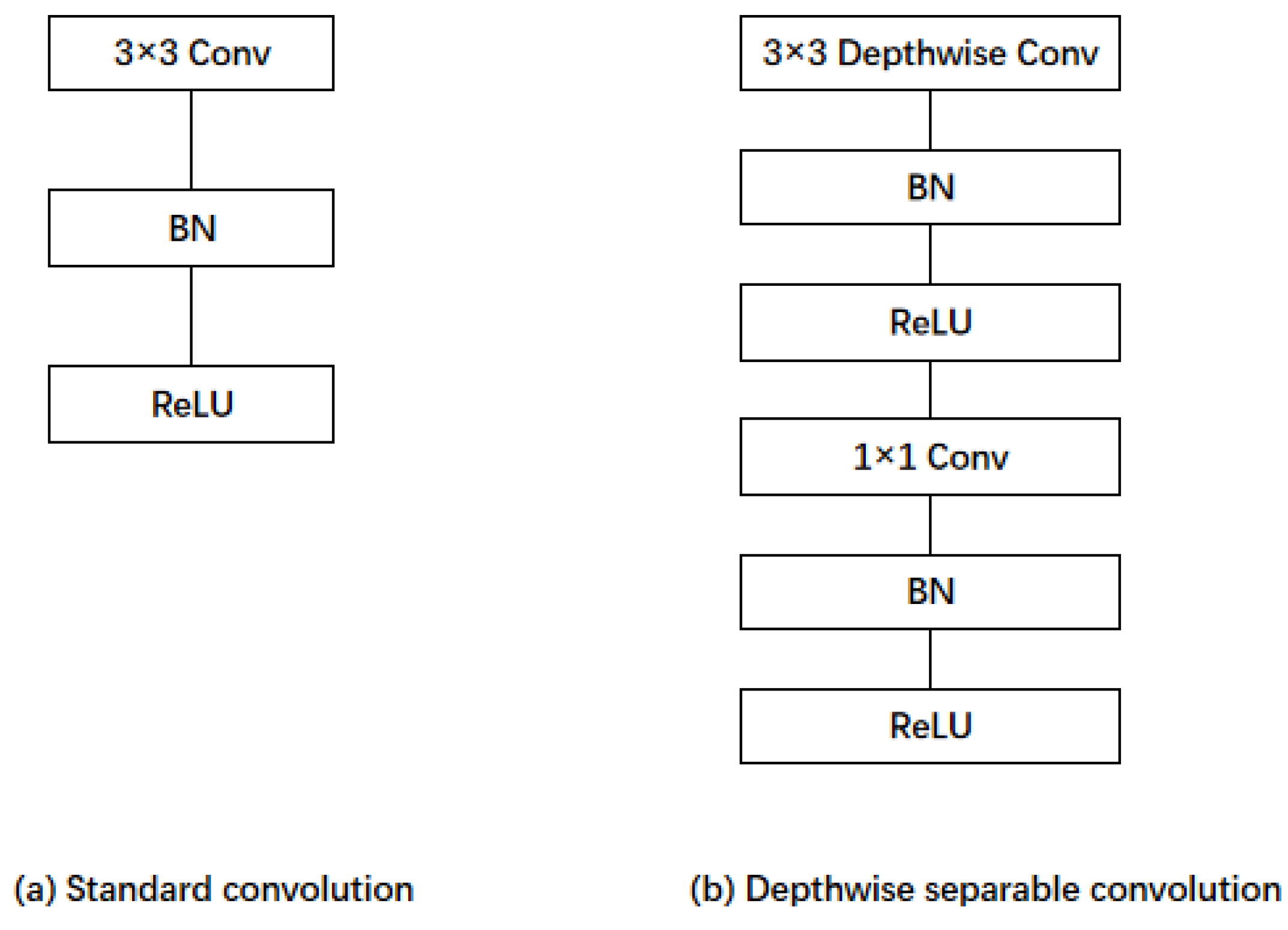
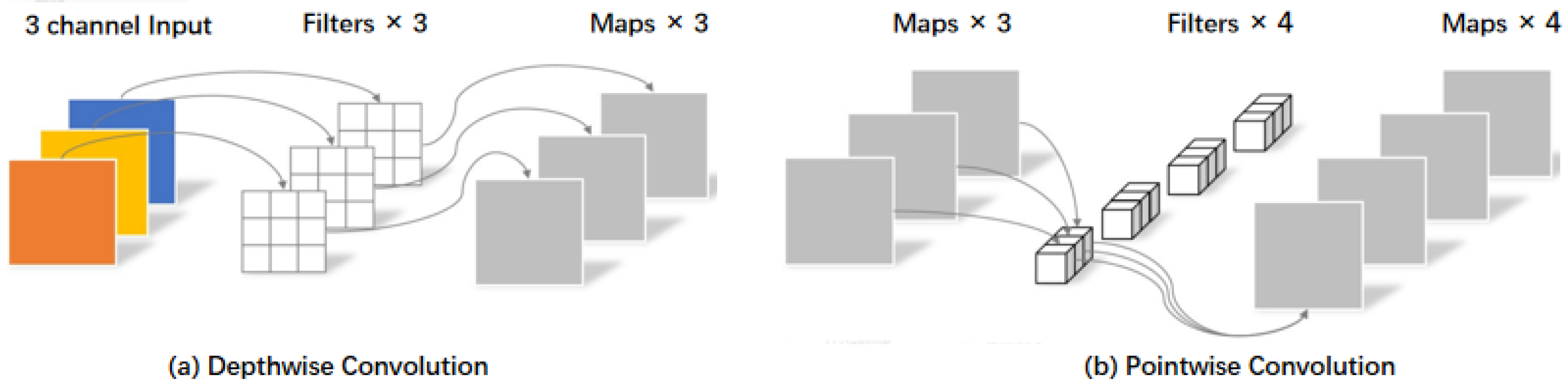
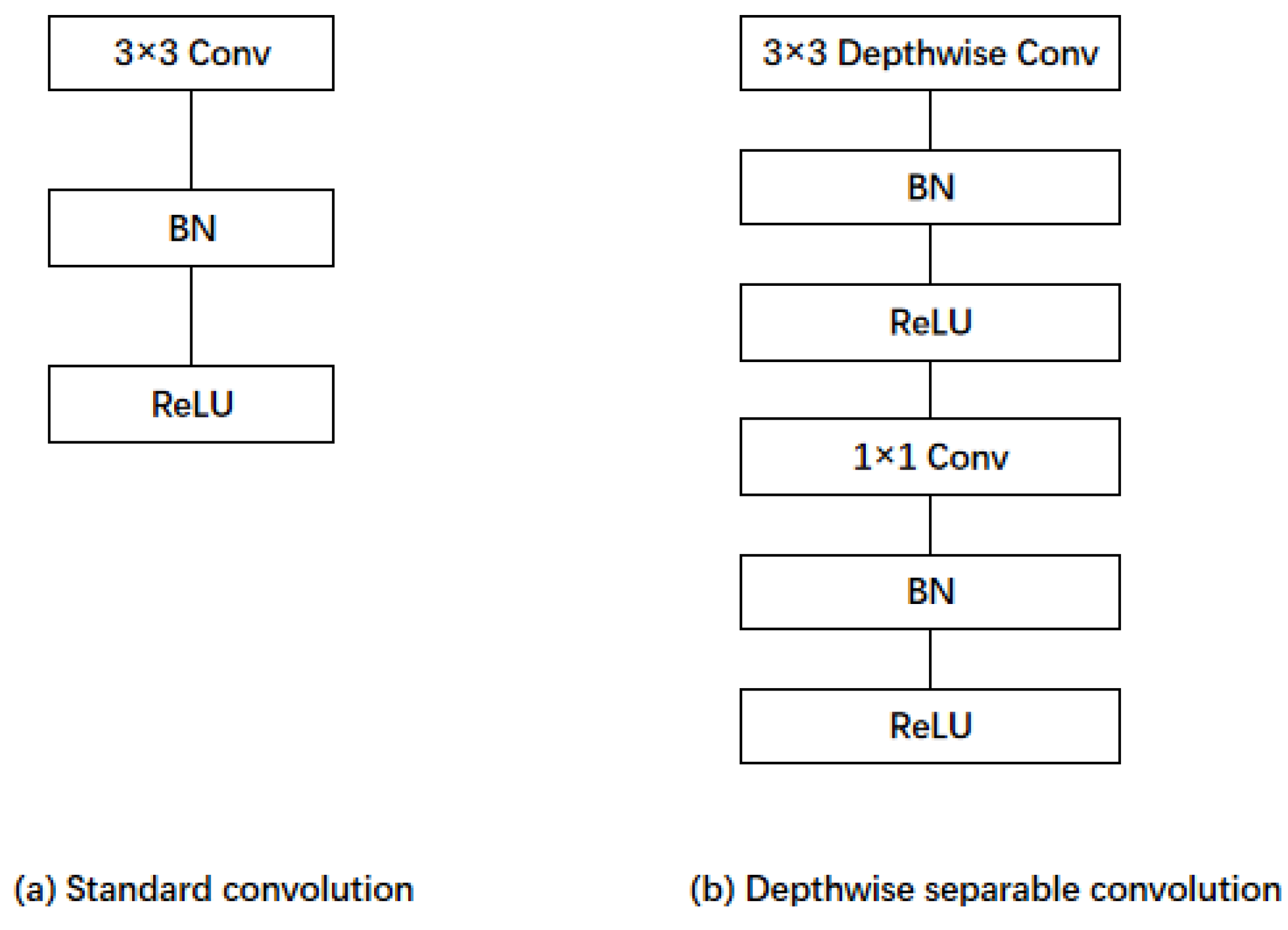
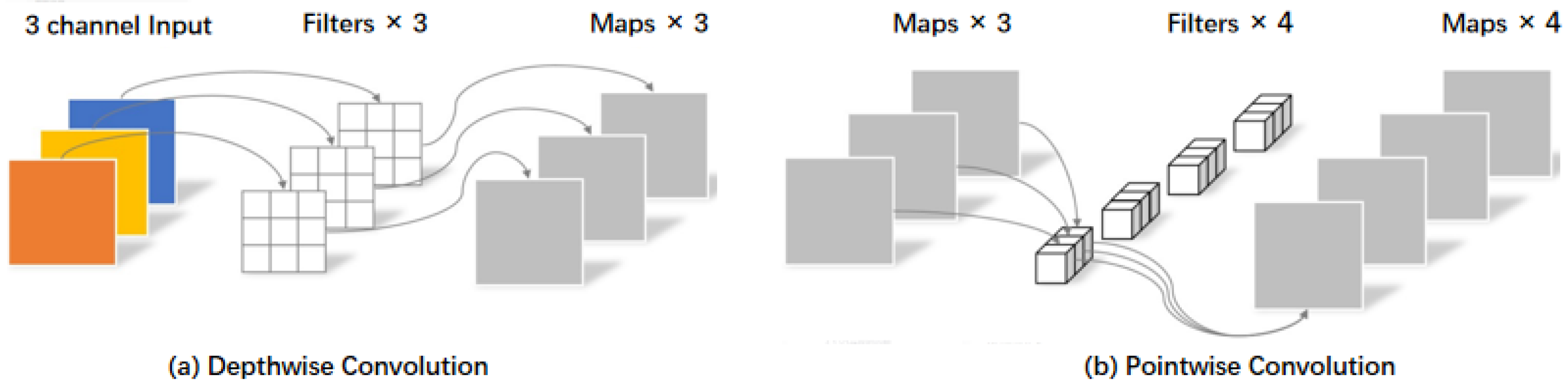
Depthwise Separable Convolution
3. Experiment Settings
3.1. Implementation Details
3.2. Loss Function
3.3. Evaluation Metrics
4. Results and Discussion
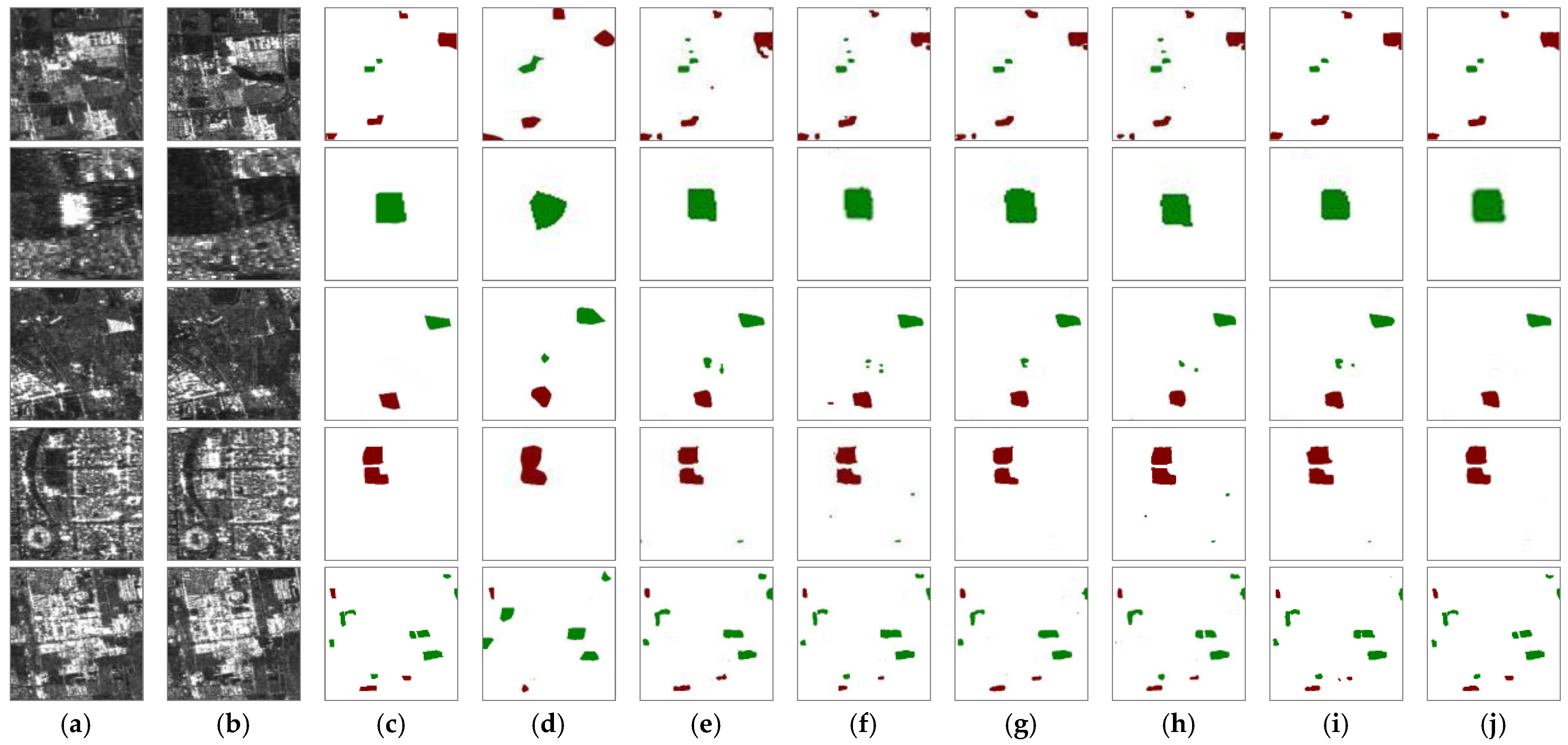
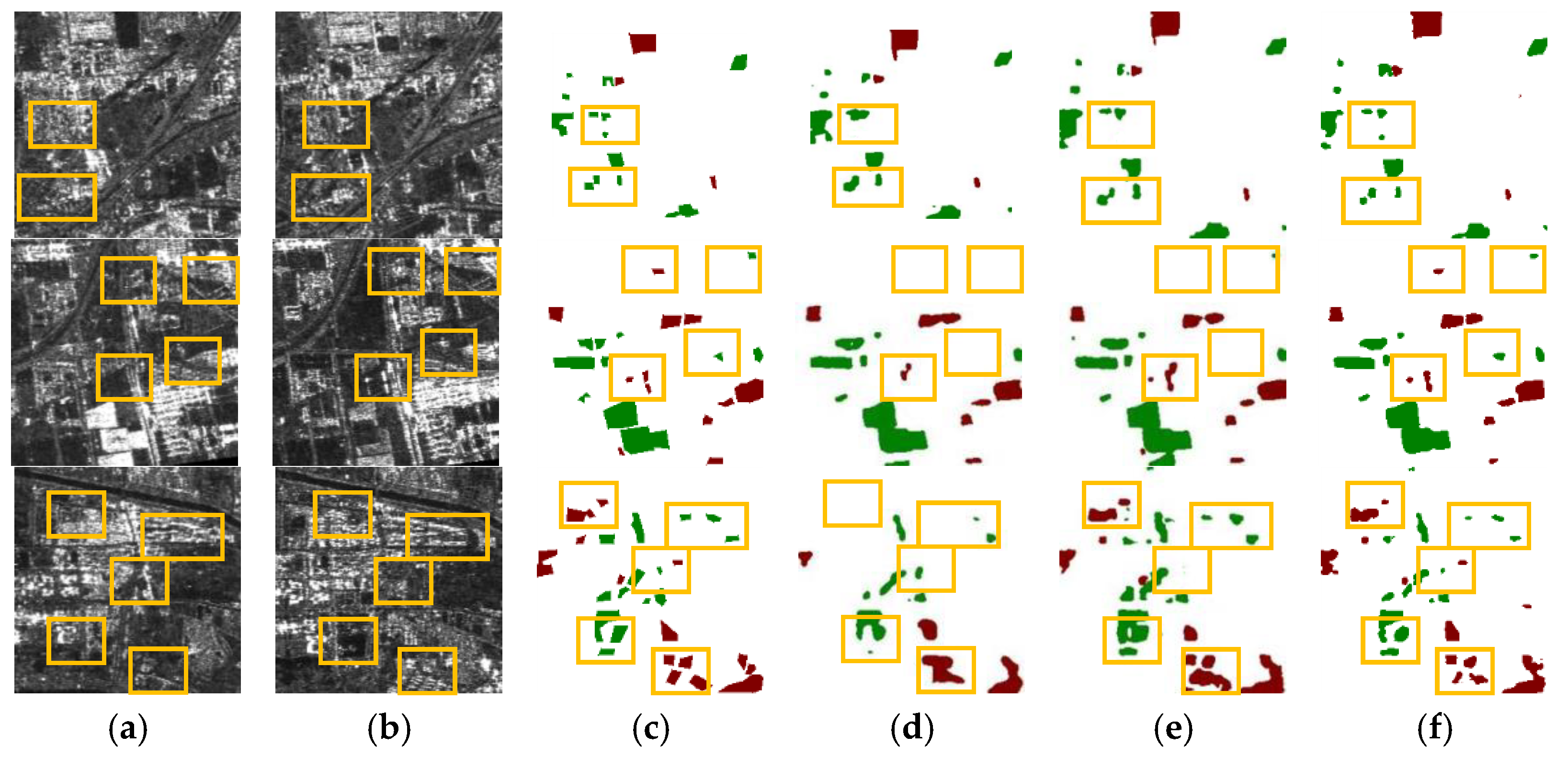
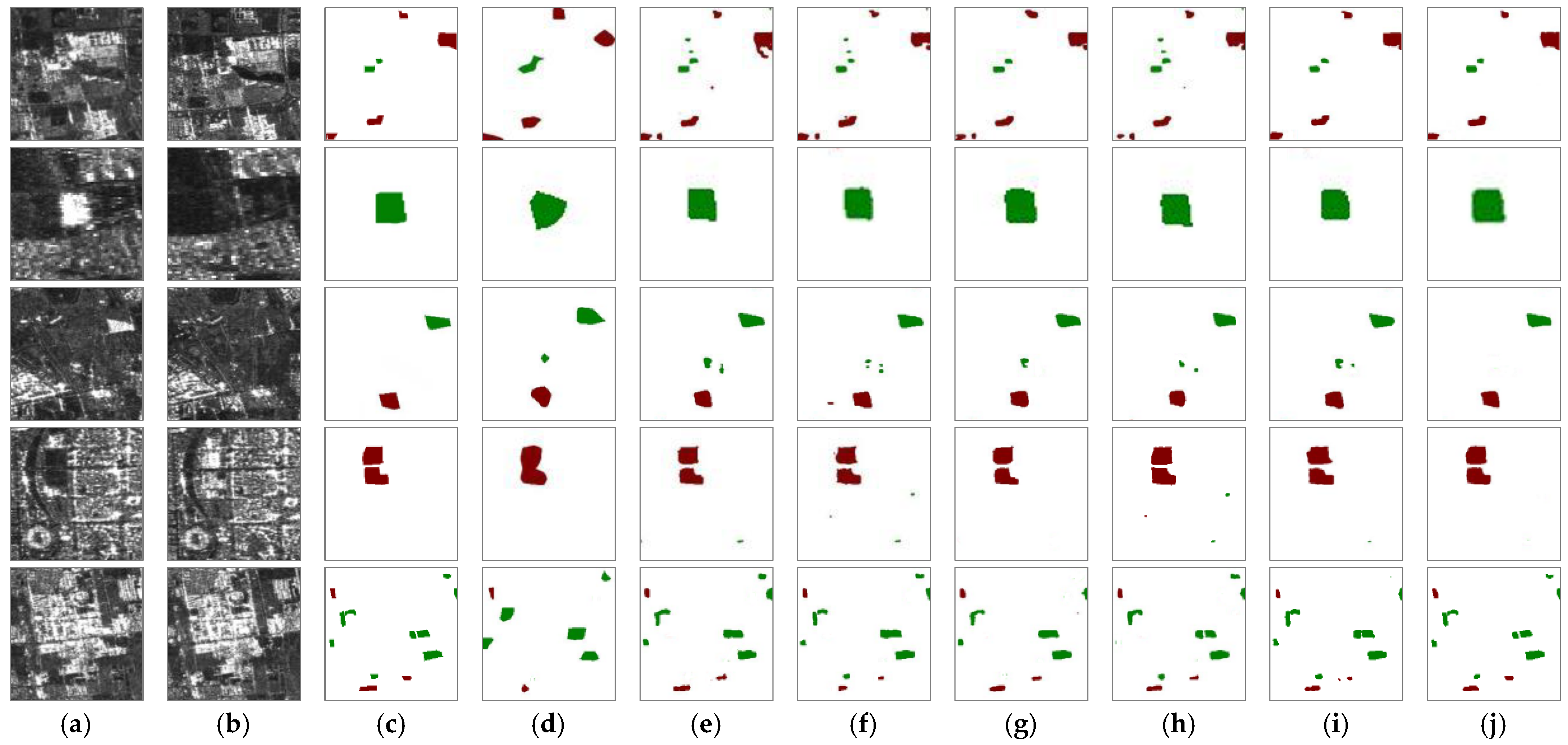
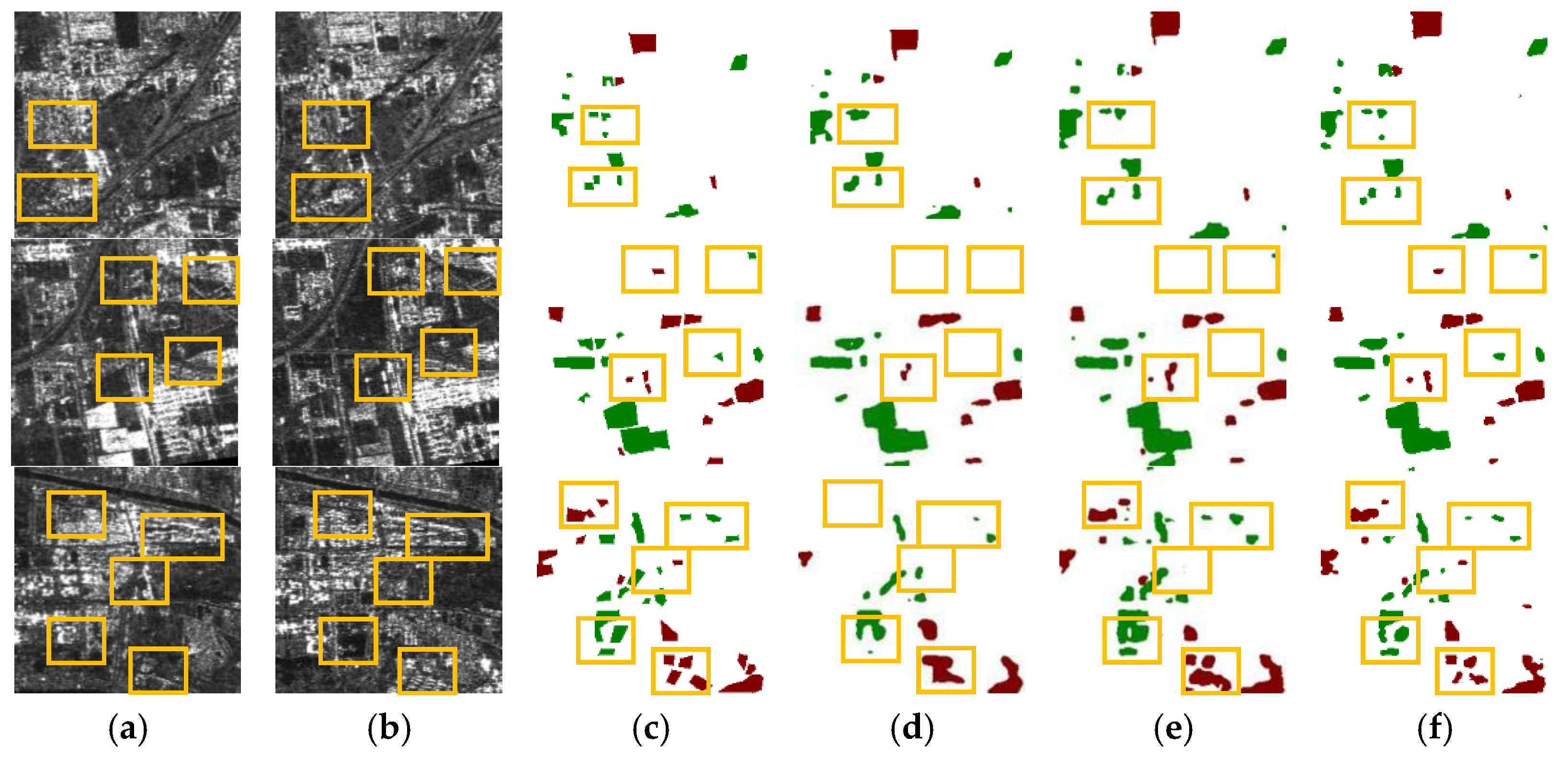
4.1. Comparison with Other Methods
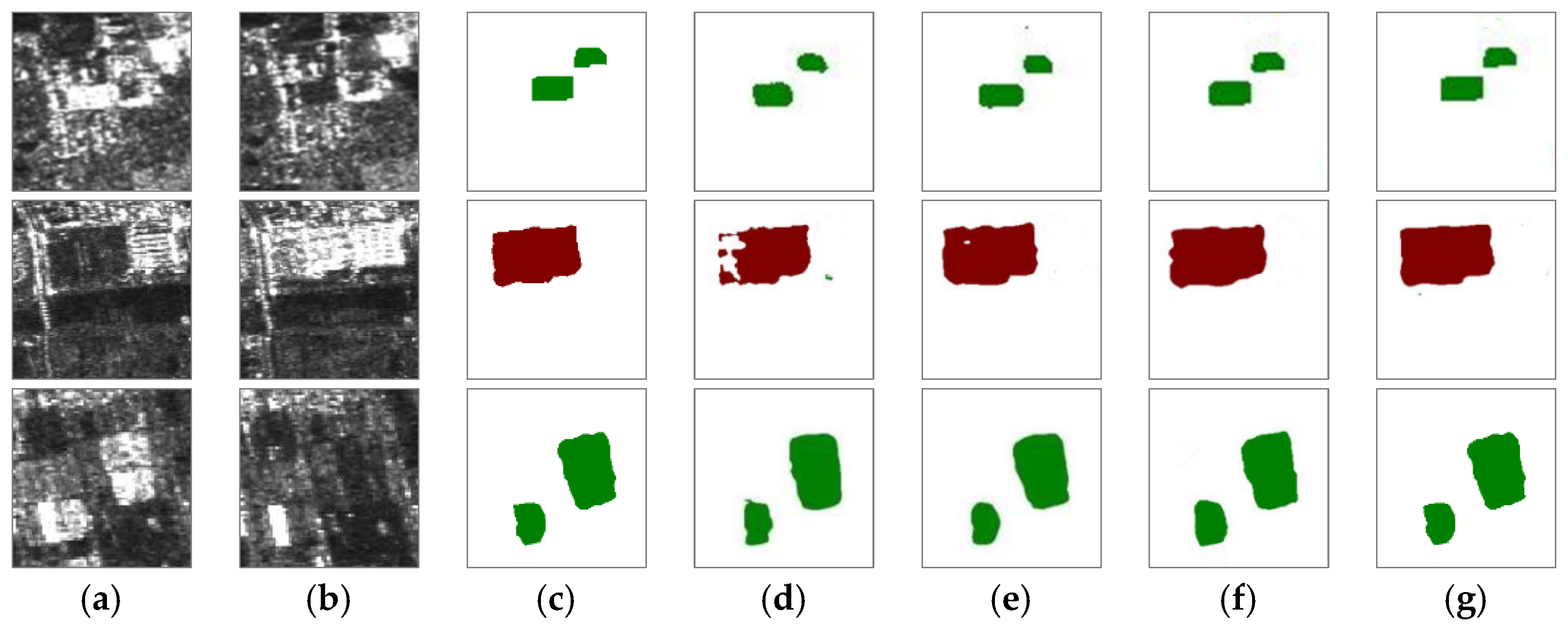
4.2. Ablation Study
4.2.1. Effects of Different Attention Mechanisms
4.2.2. Effects of Different Dilation Rates of ASPP Modules
4.2.3. Effects of Depthwise Separable Convolution on Model Parameters and Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Ming, D.; Luo, J.; Shen, Z.; Wang, M.; Sheng, H. Research on information extraction and target recognition from high resolution remote sensing image. Sci. Surv. Mapp. 2005, 30, 18–20. [Google Scholar]
- Saha, S.; Bovolo, F.; Bruzzone, L. Building change detection in VHR SAR images via unsupervised deep transcoding. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1917–1929. [Google Scholar] [CrossRef]
- Liu, G.; Li, L.; Jiao, L.; Dong, Y.; Li, X. Stacked Fisher autoencoder for SAR change detection. Pattern Recognit. 2019, 96, 106971. [Google Scholar] [CrossRef]
- Wang, S.; Jiao, L.; Yang, S. SAR images change detection based on spatial coding and nonlocal similarity pooling. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3452–3466. [Google Scholar] [CrossRef]
- Cui, B.; Zhang, Y.; Yan, L.; Cai, X. A SAR intensity images change detection method based on fusion difference detector and statistical properties. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 439. [Google Scholar] [CrossRef]
- Hu, Z. An unsupervised change deception approach based on KI Dual Thresholds under the Generalized Gauss Model Assumption in SAR images. Acta Geod. Cartogr. Sin. 2013, 1, 116–122. [Google Scholar]
- Su, L.; Gong, M.; Sun, B.; Jiao, L. Unsupervised change detection in SAR images based on locally fitting model and semi-EM algorithm. Int. J. Remote Sens. 2014, 35, 621–650. [Google Scholar] [CrossRef]
- Wang, S.; Wang, Y.; Liu, Y.; Li, L. SAR image change detection based on sparse representation and a capsule network. Remote Sens. Lett. 2021, 12, 890–899. [Google Scholar] [CrossRef]
- Bazi, Y.; Bruzzone, L.; Melgani, F. Automatic identification of the number and values of decision thresholds in the log-ratio image for change detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2006, 3, 349–353. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, L.; Wang, Y. Unsupervised change detection for multispectral remote sensing images using random walks. Remote Sens. 2017, 9, 438. [Google Scholar] [CrossRef]
- Rathore, P.; Bezdek, J.C.; Erfani, S.M.; Rajasegarar, S.; Palaniswami, M. Ensemble fuzzy clustering using cumulative aggregation on random projections. IEEE Trans. Fuzzy Syst. 2017, 26, 1510–1524. [Google Scholar] [CrossRef]
- Javadi, S.; Hashemy, S.; Mohammadi, K.; Howard, K.; Neshat, A. Classification of aquifer vulnerability using K-means cluster analysis. J. Hydrol. 2017, 549, 27–37. [Google Scholar] [CrossRef]
- Qin, J.; Fu, W.; Gao, H.; Zheng, W.X. Distributed k-means algorithm and fuzzy c-means algorithm for sensor networks based on multiagent consensus theory. IEEE Trans. Cybern. 2016, 47, 772–783. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, W. A feature difference convolutional neural network-based change detection method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Gong, M.; Yang, H.; Zhang, P. Feature learning and change feature classification based on deep learning for ternary change detection in SAR images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.; Zhang, H.; Zhang, B.; Wu, F. Urban building change detection in SAR images using combined differential image and residual u-net network. Remote Sens. 2019, 11, 1091. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A Hybrid Transformer Network for Change Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wu, C.; Liu, X.; Li, S.; Long, C. Coordinate Attention Residual Deformable U-Net for Vessel Segmentation. In Proceedings of the International Conference on Neural Information Processing, Sanur, Bali, Indonesia, 8–12 December 2021; pp. 345–356. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Date | Satellite | Polarization | Image Size |
|---|---|---|---|---|
| S1 | 1 May 2018 | ALOS2 | HH | 6359 × 7859 |
| S2 | 10 December 2019 | ALOS2 | HH | 6359 × 7859 |
| Model | Evaluation Index | ||||
|---|---|---|---|---|---|
| MIoU (%) | Average F1 (%) | OE | PCC | Kappa | |
| FCN | 71.81 | 82.21 | 26,047 | 0.9845 | 0.7091 |
| UNet | 73.18 | 83.27 | 11,610 | 0.9902 | 0.7533 |
| UNet++ | 73.54 | 83.42 | 9427 | 0.9907 | 0.7606 |
| ResUNet | 72.95 | 83.24 | 15,123 | 0.9891 | 0.7495 |
| Deeplab V3+ | 73.83 | 83.79 | 8435 | 0.9913 | 0.7632 |
| TransUNet | 74.16 | 84.03 | 7842 | 0.9917 | 0.7667 |
| CD-TransUNet | 76.98 | 86.14 | 4732 | 0.9935 | 0.7950 |
| Model Name | Modules | Evaluation Index | ||||||
|---|---|---|---|---|---|---|---|---|
| CA | ASPP | DSC | MIoU (%) | Average F1 (%) | OE | PCC | Kappa | |
| TransUNet | 74.16 | 84.03 | 7842 | 0.9917 | 0.7667 | |||
| TransUNet+CA | √ | 75.53 | 85.07 | 6760 | 0.9925 | 0.7796 | ||
| TransUNet+ASPP | √ | 75.91 | 85.32 | 6145 | 0.9930 | 0.7849 | ||
| TransUNet+DSC | √ | 74.01 | 83.83 | 8051 | 0.9914 | 0.7643 | ||
| TransUNet+CA+ASPP | √ | √ | 76.98 | 86.17 | 5548 | 0.9936 | 0.7957 | |
| TransUNet+ASPP+DSC | √ | √ | 75.87 | 85.12 | 6283 | 0.9928 | 0.7842 | |
| TransUNet+CA+DSC | √ | √ | 75.52 | 85.05 | 6976 | 0.9924 | 0.7794 | |
| TransUNet+CA+ASPP+DSC | √ | √ | √ | 76.96 | 86.14 | 4732 | 0.9935 | 0.7950 |
| Model | Evaluation Index | ||||
|---|---|---|---|---|---|
| MIoU (%) | Average F1 (%) | OE | PCC | Kappa | |
| TransUNet | 74.16 | 84.03 | 7842 | 0.9917 | 0.7667 |
| TransUNet+SE | 74.97 | 84.71 | 7158 | 0.9920 | 0.7702 |
| TransUNet+CBAM | 75.14 | 84.95 | 6907 | 0.9921 | 0.7723 |
| TransUNet+CA | 75.53 | 85.07 | 6760 | 0.9925 | 0.7796 |
| Model | Parameters/M | FLOPs/G |
|---|---|---|
| TransUNet | 37.39 | 12.22 |
| TransUNet+DSC | 14.08 | 4.15 |
| CD-TransUNet | 19.89 | 5.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, L.; Sun, J.; Chi, Y.; Yang, Y.; Zhang, F.; Zhang, L. CD-TransUNet: A Hybrid Transformer Network for the Change Detection of Urban Buildings Using L-Band SAR Images. Sustainability 2022, 14, 9847. https://doi.org/10.3390/su14169847
Pang L, Sun J, Chi Y, Yang Y, Zhang F, Zhang L. CD-TransUNet: A Hybrid Transformer Network for the Change Detection of Urban Buildings Using L-Band SAR Images. Sustainability. 2022; 14(16):9847. https://doi.org/10.3390/su14169847
Chicago/Turabian StylePang, Lei, Jinjin Sun, Yancheng Chi, Yongwen Yang, Fengli Zhang, and Lu Zhang. 2022. "CD-TransUNet: A Hybrid Transformer Network for the Change Detection of Urban Buildings Using L-Band SAR Images" Sustainability 14, no. 16: 9847. https://doi.org/10.3390/su14169847
APA StylePang, L., Sun, J., Chi, Y., Yang, Y., Zhang, F., & Zhang, L. (2022). CD-TransUNet: A Hybrid Transformer Network for the Change Detection of Urban Buildings Using L-Band SAR Images. Sustainability, 14(16), 9847. https://doi.org/10.3390/su14169847