
An AI-Based Automatic Risks Detection Solution for Plant Owner’s Technical Requirements in Equipment Purchase Order




Abstract
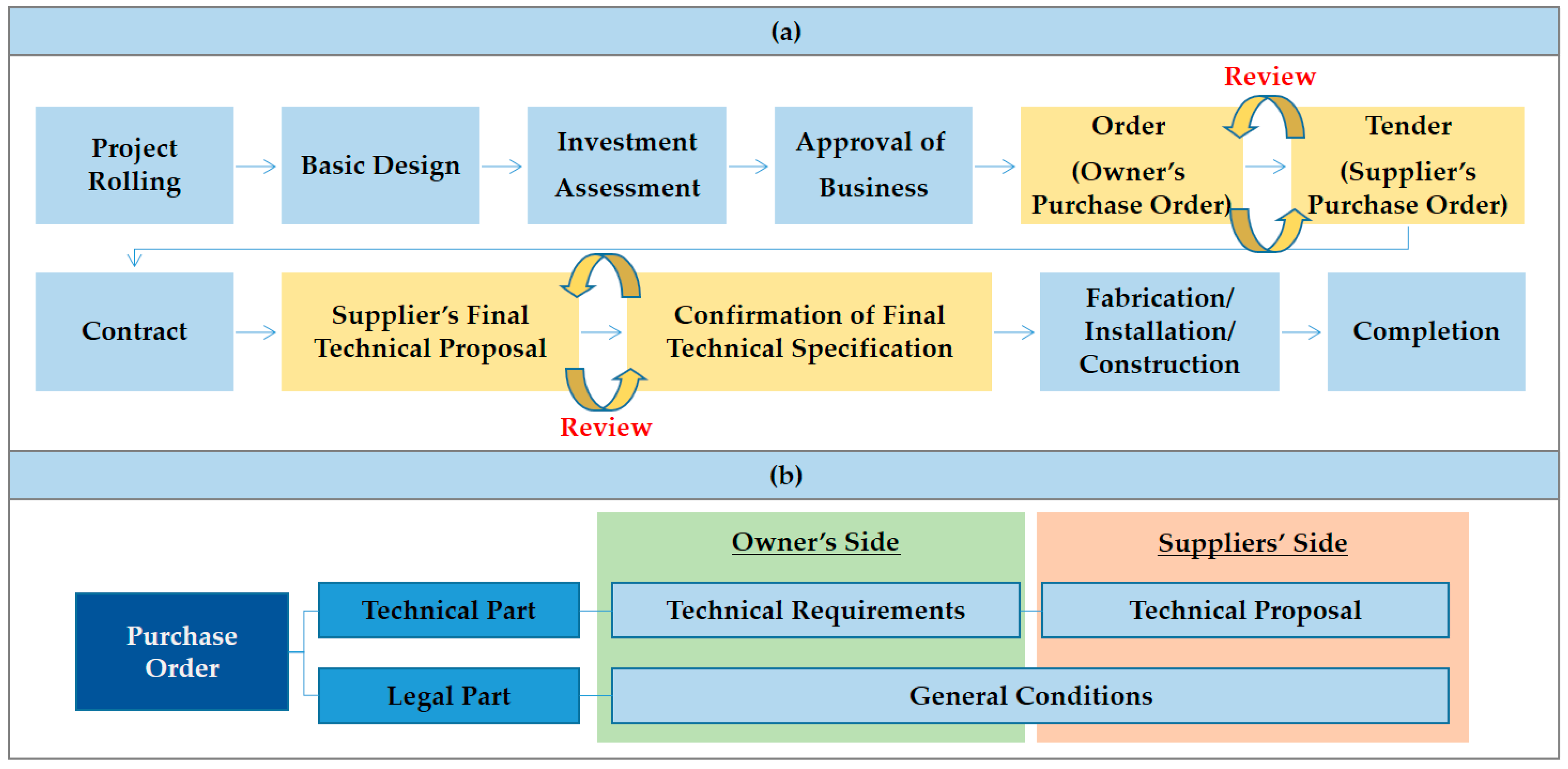
:1. Introduction
2. Literature Review
2.1. Table Recognition
2.2. Information Extraction
2.3. Entity Matching
3. Methodology and Model Development
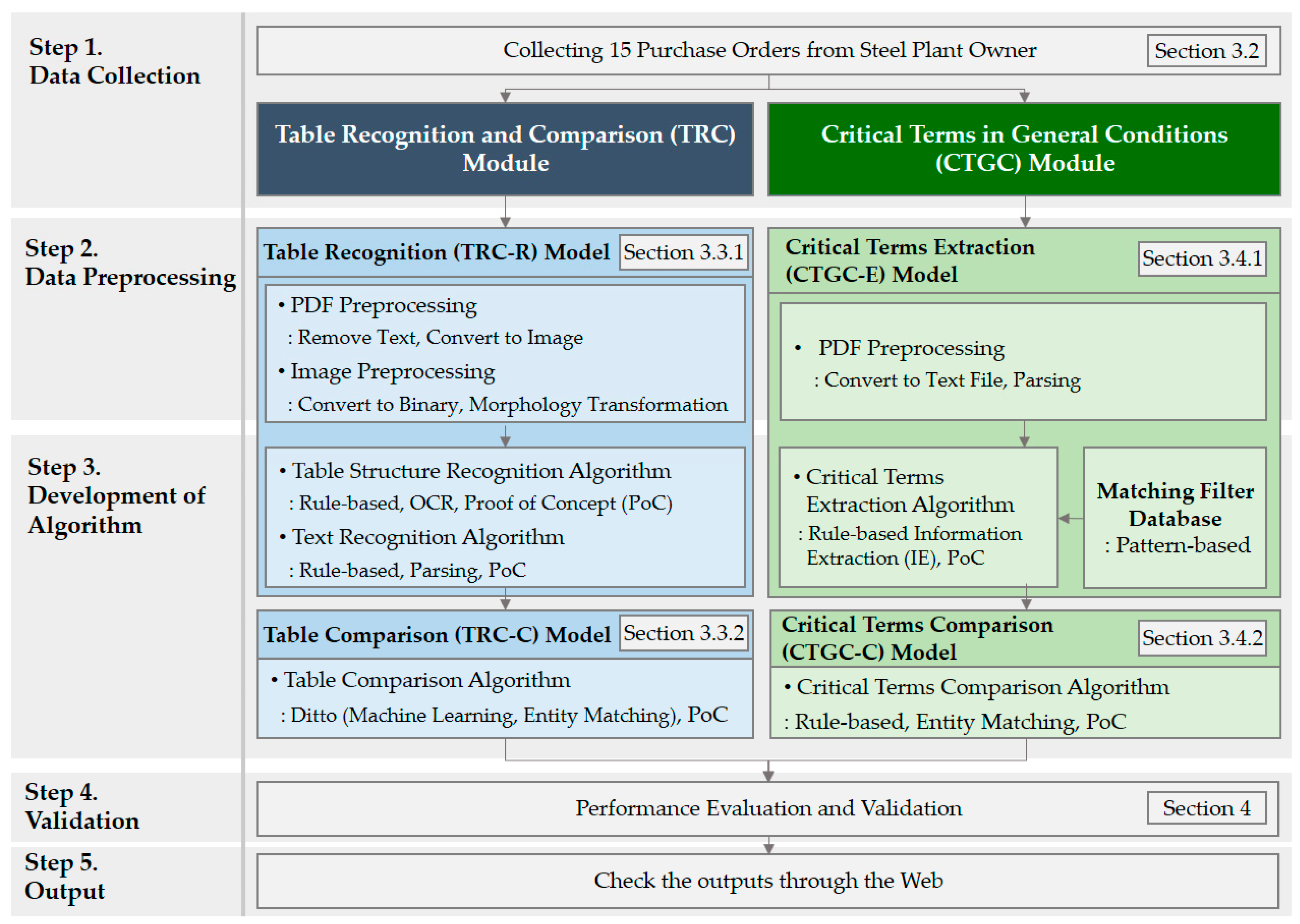
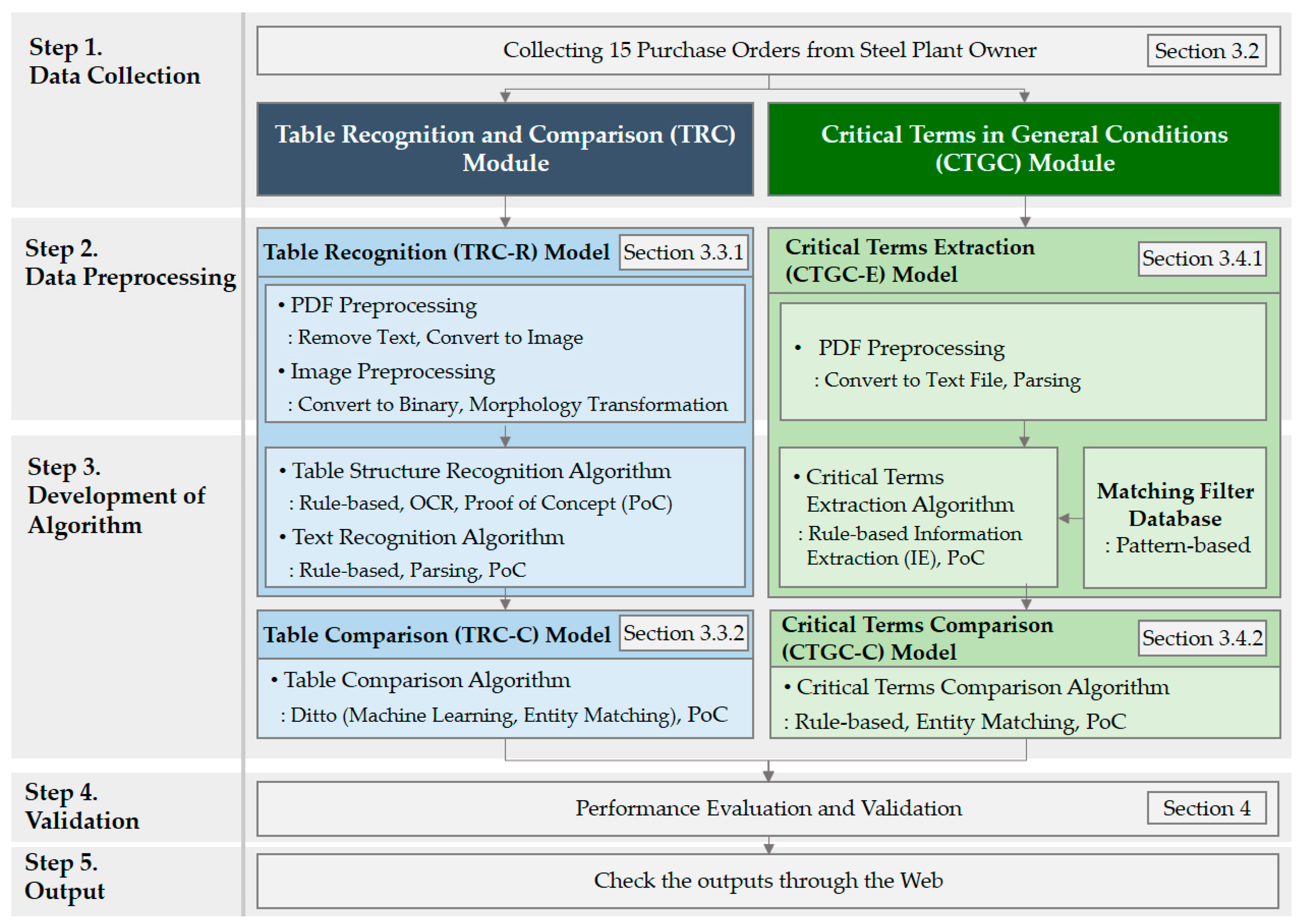
3.1. The Research Overview
- Step 1. Data collection: collecting POs from owners to carry out research;
- Step 2. Data preprocessing: performing preprocessing to improve the analysis accuracy of the collected data;
- Step 3. Development of algorithm: developing the TRC module and the CTGC module;
- Step 4. Validation: executing validation by evaluating the performance of the two developed modules;
- Step 5. Output: confirming visualized analysis results via the web.
3.2. Data Collection
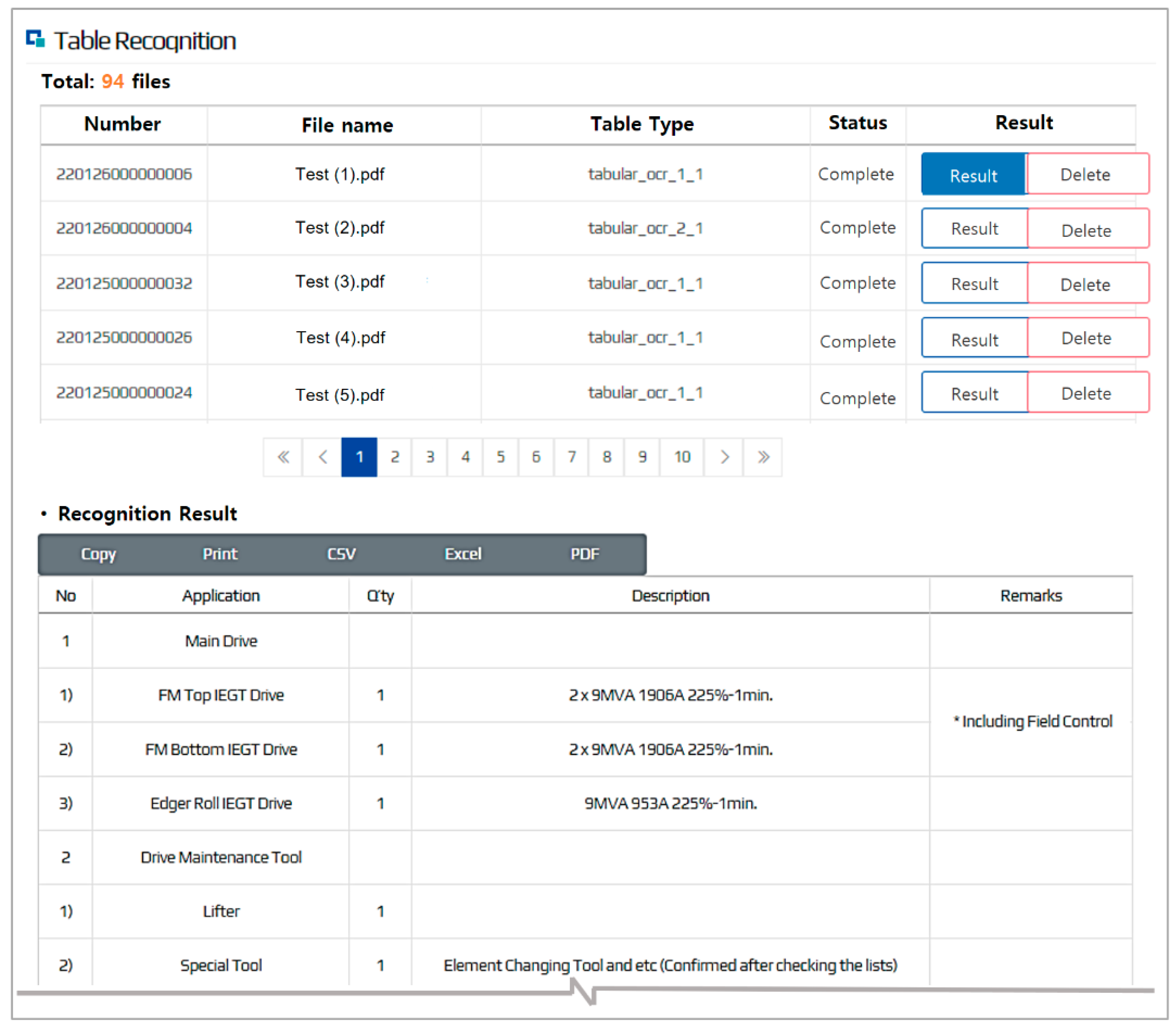
3.3. Table Recognition and Comparison (TRC) Module
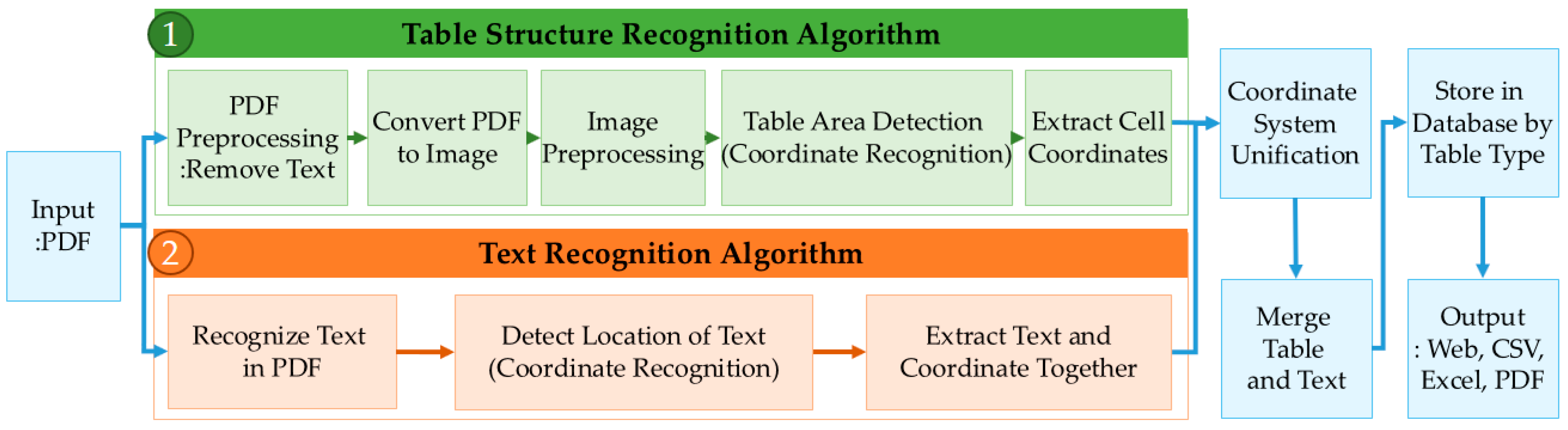
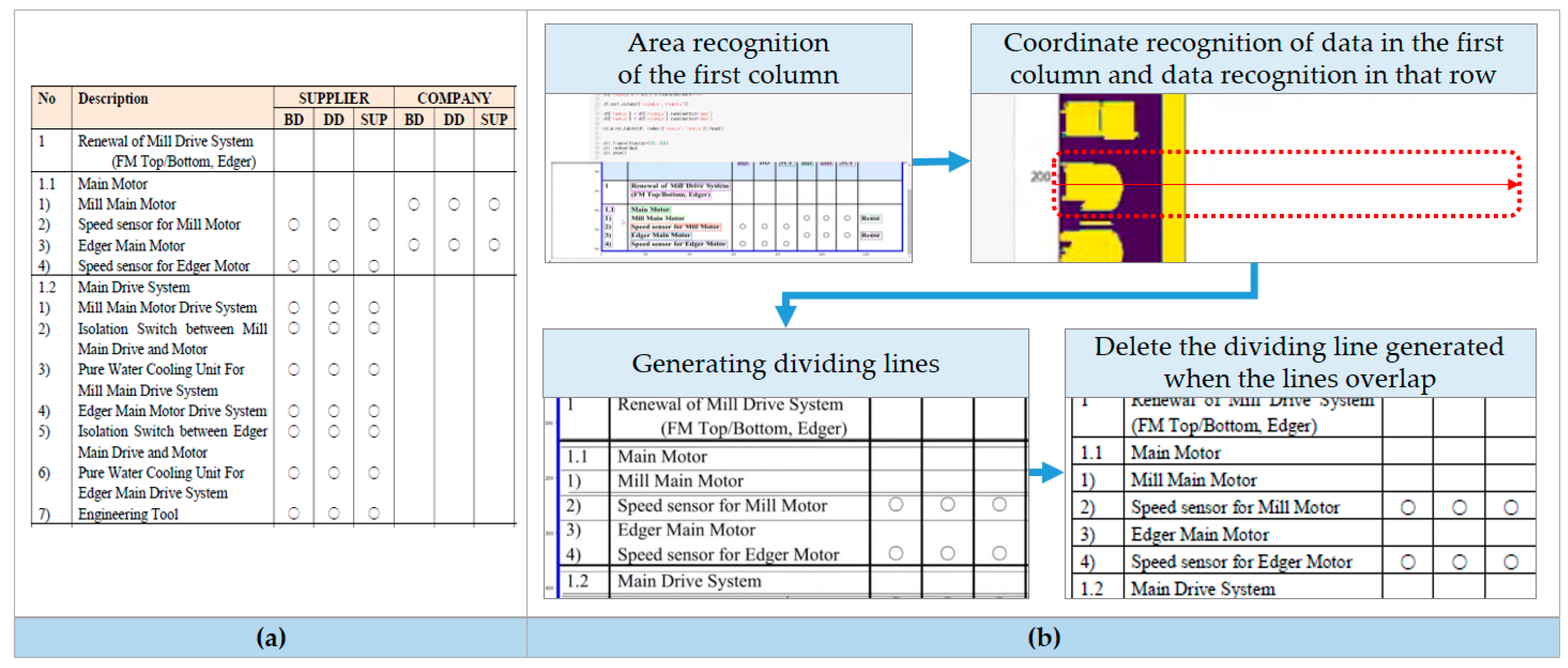
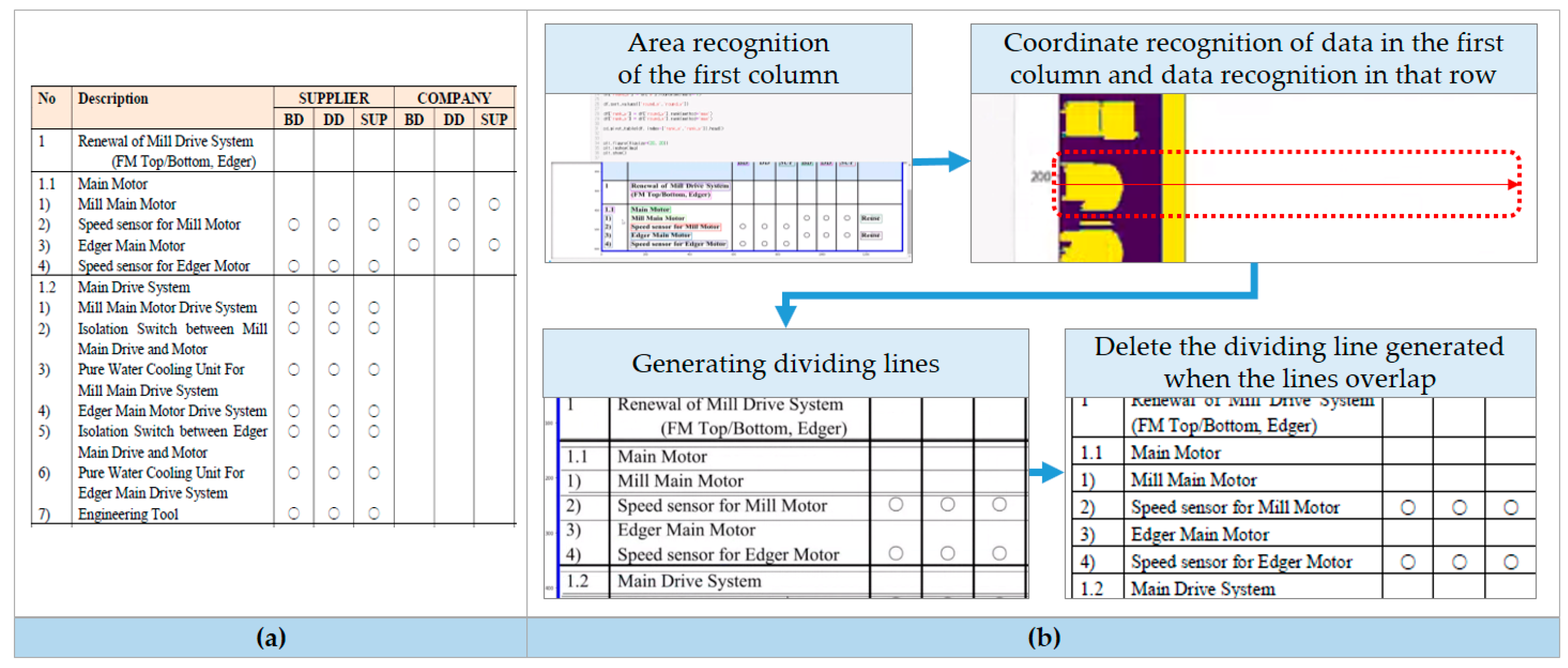
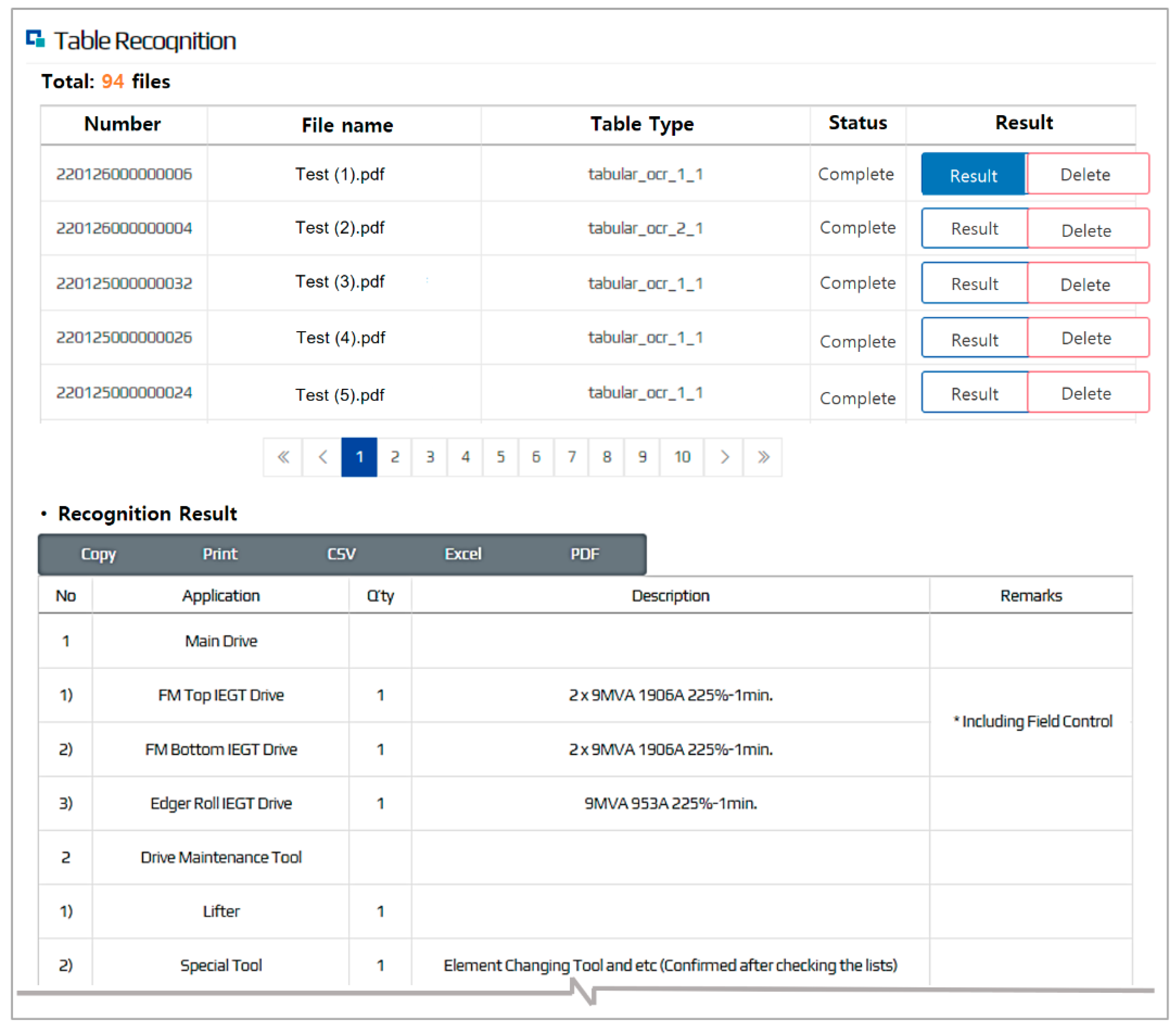
3.3.1. Table Recognition (TRC-R) Model
3.3.2. Table Comparison (TRC-C) Model
- Case 1: this is about whether to use abbreviations;
- Case 2: this is the case when the order of words is changed;
- Case 3: this is the case when some words are omitted.
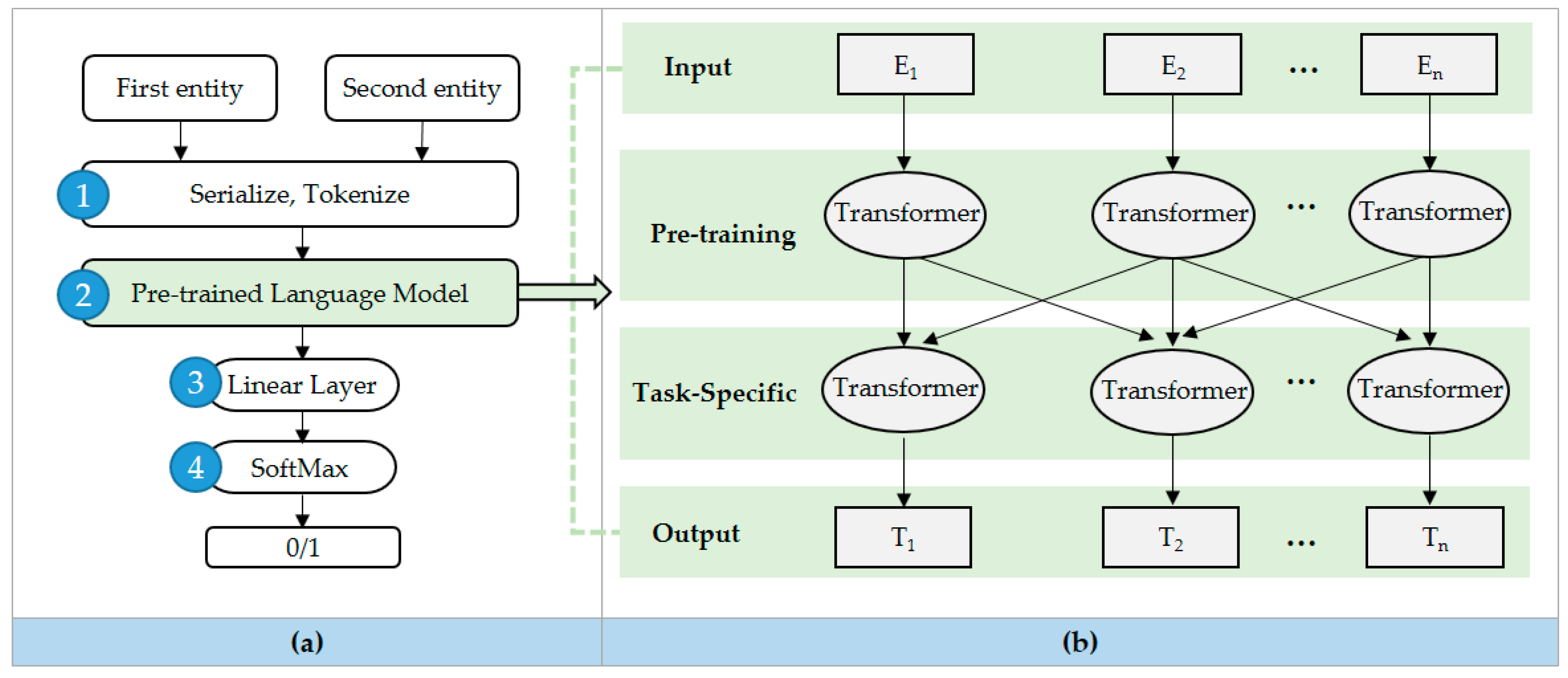
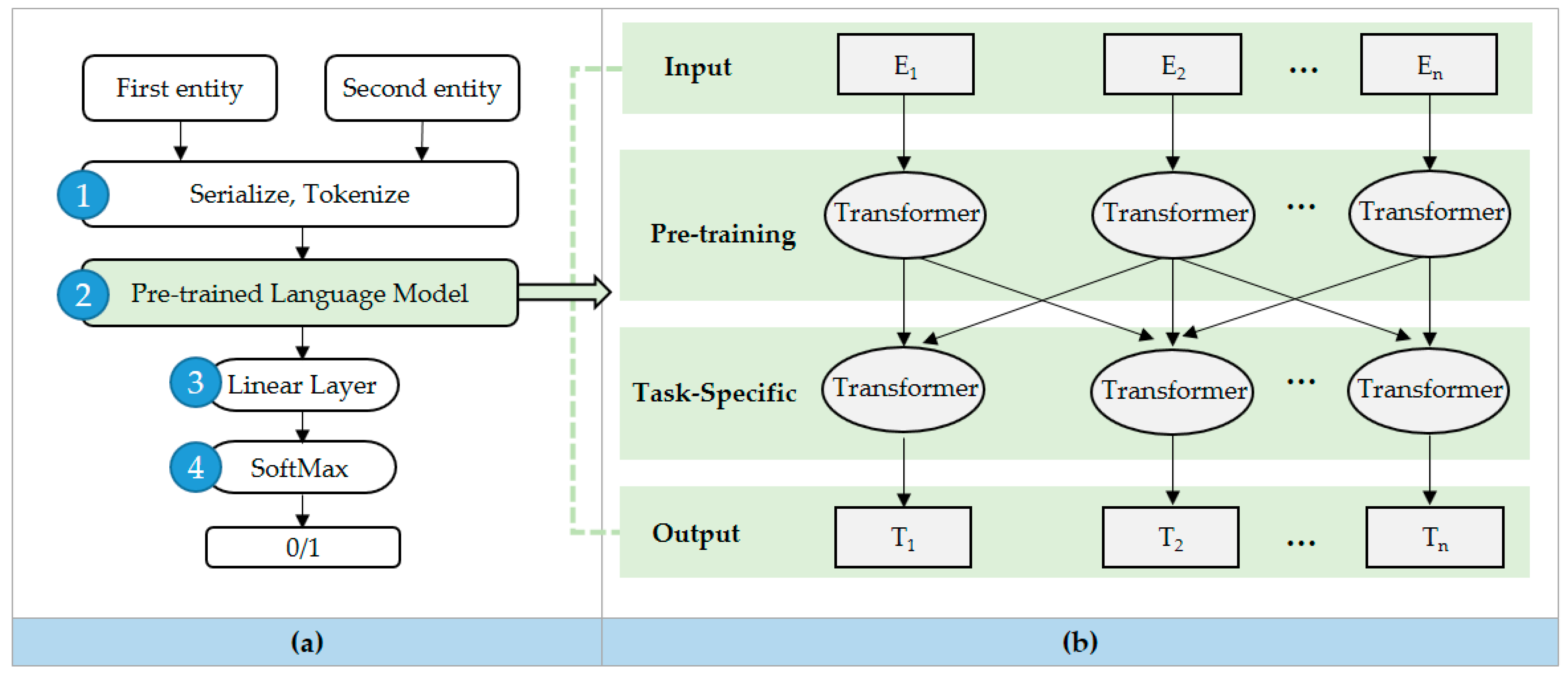
- Performed classification to order through serializing the text of the input table data and tokenized the text data so that Ditto could process it word by word;
- Randomly masked some tokens from the input data using a pretrained language model with an entity matching classifier added to the language model trained for regular text (see Figure 7b). The pretrained language model is performed on the same basis as the BERT model, which puts masked tokens in a transformer structure and predicts masked tokens by looking only at the context of the surrounding words [42];
- Added linear layer and SoftMax layer for binary classification;
- Finally, the two entities that were input through the training of Ditto were classified binary as true or false.
3.4. Critical Terms in General Conditions (CTGC) Module
3.4.1. Critical Terms Extraction (CTGC-E) Model
3.4.2. Critical Terms Comparison (CTGC-C) Model
4. Performance Evaluation and Validation
4.1. Performance Evaluation and Validation for the TRC-R Model
4.1.1. Setup for Performance Evaluation
- TP: cases where the vertices of existing cells are extracted;
- TN: cases extracted as none for cases without vertices (it can occur in merged cells);
- FP: cases in which vertices of cells that did not exist were extracted (it can occur in merged cells);
- FN: cases where there was a vertex of a cell, but it was not extracted.
- TP: cases in which the data inside the cell were correctly extracted;
- TN: cases extracted as none for cases where there were no data inside the cell;
- FP: cases where there were no data inside the cell, but other data were extracted;
- FN: cases where there were data inside the cell, but other data were extracted.
4.1.2. Validation and Discussion
4.2. Performance Evaluation and Validation for the TRC-C Model
4.2.1. Setup for Performance Evaluation
- Case 1: The data of the owner and the supplier match. ‘Comparison Results (Item R&R, Description)’ are all written the same and it can be seen that the categories and contents of the supply of the main motor are the same;
- Case 2: The owner’s and the supplier’s data were not identical expressions but matched in synonyms. This result occurred when they were classified and matched by the same entity through the synonyms database described in Section 3.3.2. ‘Comparison Results (Item R&R, Description)’ are all written as the same and it can be seen that the categories and contents of the supply of the main motor are the same;
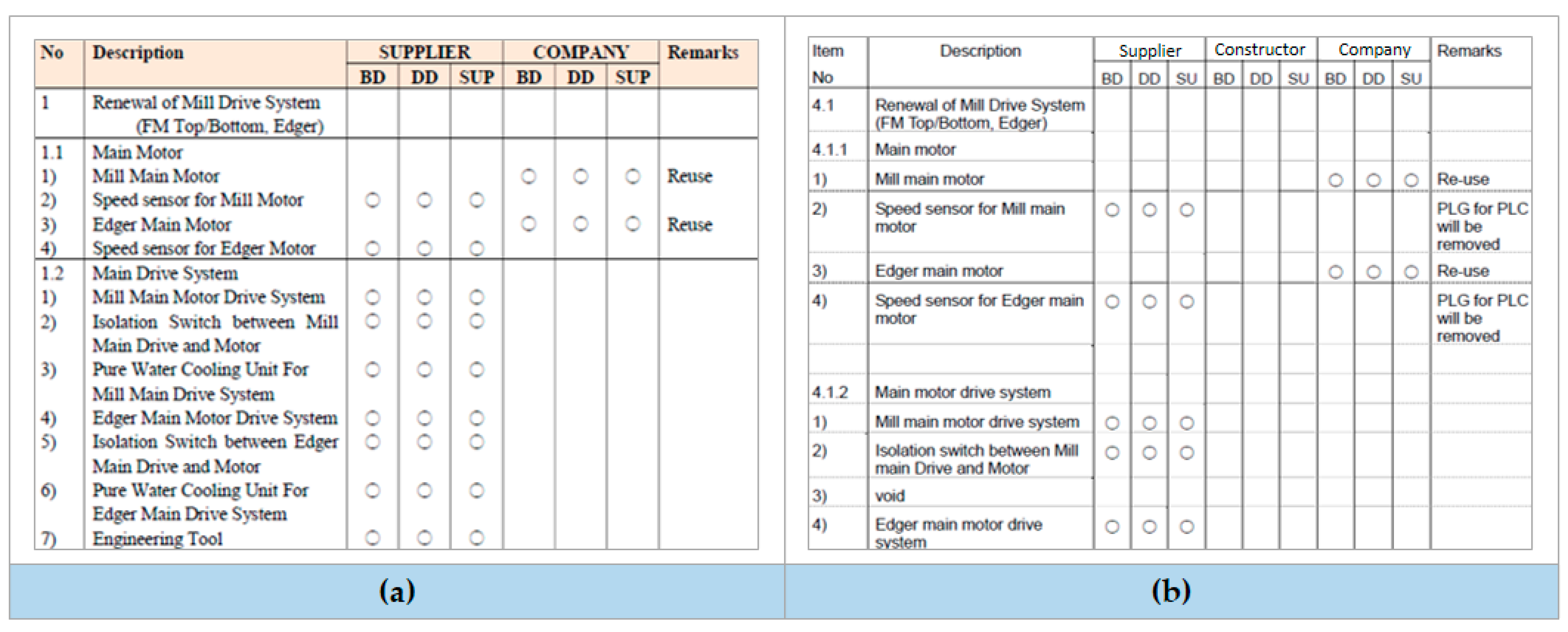
- Case 3: It was on the owner’s table but not on the supplier’s table. Looking at Table 7, the same item was not found in the supplier’s table for the ‘Switchgear & Panel’ item as in the owner’s table and an error occurred that printed ‘Hardware’. Therefore, ‘Text Mismatch’ was displayed in ‘Comparison Result (Description)’ so that the engineer in charge could reconfirm it;
- Case 4: The supplier and owner created it differently for ‘Comparison Item R&R’ by adding another column, ‘Constructor’. The supplier does not supply the relevant item but supplies it through a separate constructor. Therefore, the owner’s confirmation is needed.
4.2.2. Validation and Discussion
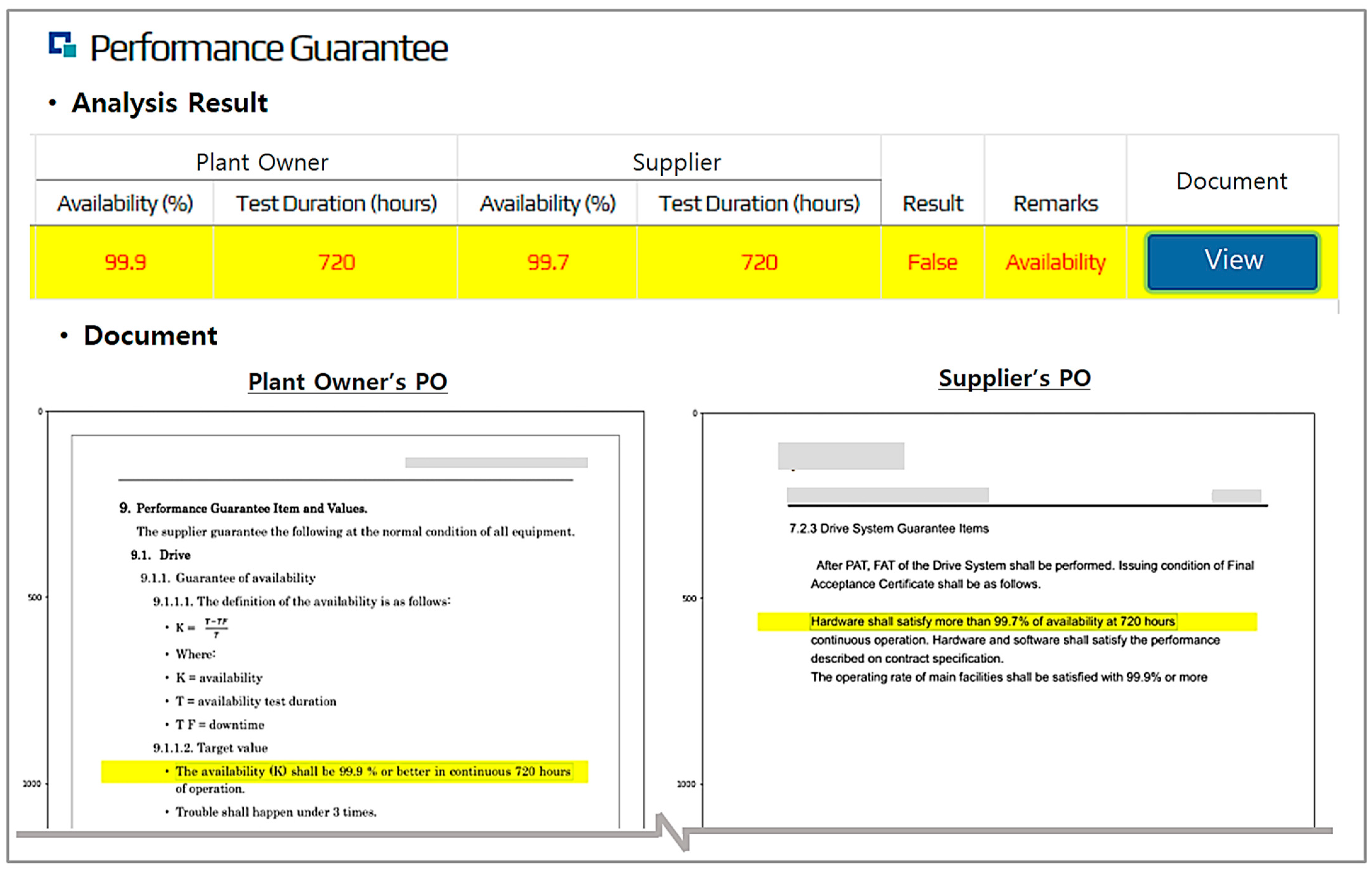
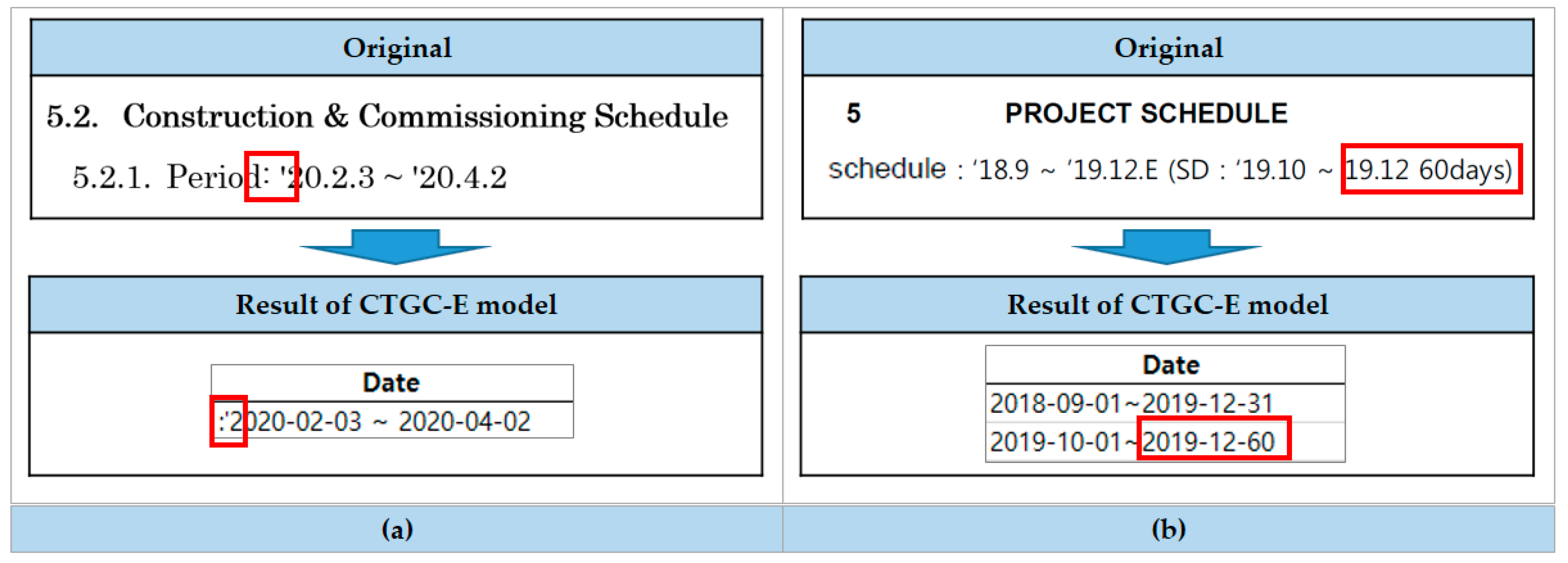
4.3. Performance Evaluation and Validation for the CTGC-E Model
4.3.1. Setup for Performance Evaluation
- TP: cases where the targeted value of the PoC clause in the PO was correctly extracted;
- TN: cases that did not extract anything that was not the targeted value of the PoC clause in the PO;
- FP: cases where a value different from the target value of the PoC clause in the PO was extracted incorrectly;
- FN: cases that did not extract the targeted value of the PoC clause within the PO.
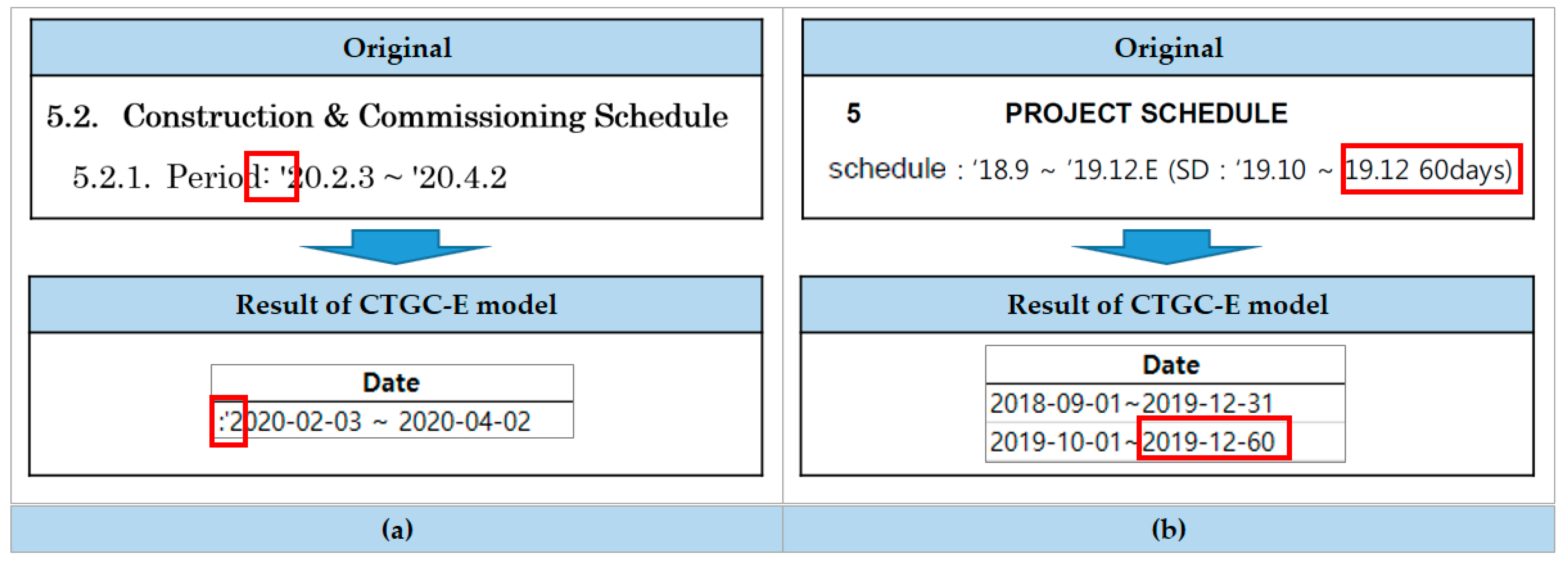
4.3.2. Validation and Discussion
5. Conclusions and Future Works
5.1. Conclusions and Contributions
5.2. Limitations and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| API | Application programming interface |
| CSV | Comma separated value |
| CTGC | Critical terms in general conditions |
| CTGC-C | Critical terms comparison |
| CTGC-E | Critical terms extraction |
| DLD | Delay liquidated damages |
| GUI | Graphical user interface |
| IE | Information extraction |
| JSON | JavaScript Object Notation |
| NER | Named entity recognition |
| OCR | Optical character recognition |
| PAC | Preliminary acceptance certificate |
| Portable document format | |
| PLD | Performance liquidated damages |
| PO | Purchase order |
| PoC | Proof of concept |
| PORAS | Purchase order recognition and analysis system |
| RGB | Red, green, blue |
| TRC | Table recognition and comparison |
| TRC-R | Table recognition |
| TRC-C | Table comparison |
References
- Brennan, D. Process Industry Economics: Principles, Concepts and Applications, 2nd ed.; Brennan, D., Ed.; Elsevier Science: Amsterdam, The Netherlands, 2020; pp. 1–15, 95–125. [Google Scholar]
- Qian, F.; Zhong, W.; Du, W. Fundamental Theories and Key Technologies for Smart and Optimal Manufacturing in the Process Industry. Engineering 2017, 3, 154–160. [Google Scholar] [CrossRef]
- Chen, M.; Zhou, R.; Zhang, R.; Zhu, X. Application of Artificial Neural Network to Failure Diagnosis on Process Industry Equipments. In Proceedings of the 6th International Conference on Natural Computation (ICNC 2010), Yantai, China, 10–12 August 2010; pp. 1190–1193. [Google Scholar]
- Braaksma, A.J.J.; Klingenberg, W.; Veldman, J. Failure Mode and Effect Analysis in Asset Maintenance: A Multiple Case Study in the Process Industry. Int. J. Prod. Res. 2013, 51, 1055–1071. [Google Scholar] [CrossRef]
- Kumar, N.; Besuner, P.; Lefton, S.; Agan, D.; Hilleman, D. Office of Scientific and Technical Information. In Power Plant Cycling Costs; NREL/SR-5500-55433; NREL: Sunnyvale, CA, USA, 2012. [Google Scholar]
- POSCO. Execution Management Plan. Pohang, Korea. 2022. Available online: https://www.posmate.com/download.do?fid=25&pid=47 (accessed on 11 May 2022).
- POSCO. Maintenance Investment Expense Execution Outlook of Capital Investment Group of Pohang Office. Pohang, South Korea. 2021. Available online: https://www.posmate.com/download.do?fid=25&pid=47 (accessed on 11 May 2022).
- POSCO. Guide for the Maintainability Investment Execution. Pohang, South Korea. 2020. Available online: http://www.steel-n.com (accessed on 19 May 2022).
- Burt, D.N.; Dobler, D.W. Purchasing and Supply Management: Text and Cases; McGraw-Hill: New York, NY, USA, 1996; pp. 45–78. [Google Scholar]
- Zuberi, S.H. Contract/Procurement Management. PM Netw. 1987, 1, 41–44. Available online: https://www.pmi.org/learning/library/contract-procurement-management-9101 (accessed on 13 June 2022).
- Kononova, O.; He, T.; Huo, H.; Trewartha, A.; Olivetti, E.A.; Ceder, G. Opportunities and Challenges of Text Mining in Materials Research. Iscience 2021, 24, 102155. [Google Scholar] [CrossRef]
- Kieninger, T.; Dengel, A. Applying the T-Recs Table Recognition System to the Business Letter Domain. In Proceedings of the 6th International Conference on Document Analysis and Recognition (ICDAR 2001), Seattle, WA, USA, 13 September 2001; pp. 518–522. [Google Scholar]
- Shahab, A.; Shafait, F.; Kieninger, T.; Dengel, A. An Open Approach Towards the Benchmarking of Table Structure Recognition Systems. In Proceedings of the 9th IAPR International Workshop on Document Analysis Systems (DAS ’10), Boston, MA, USA, 9–11 June 2010; pp. 113–120. [Google Scholar]
- Kasar, T.; Barlas, P.; Adam, S.; Chatelain, C.; Paquet, T. Learning to Detect Tables in Scanned Document Images Using Line Information. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR 2013), Washington, DC, USA, 25–28 August 2013; pp. 1185–1189. [Google Scholar]
- Rashid, S.F.; Akmal, A.R.N.S.; Adnan, M.; Aslam, A.A.; Dengel, A.R. Table Recognition in Heterogeneous Documents Using Machine Learning. In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 777–782. [Google Scholar]
- Qasim, S.R.; Mahmood, H.; Shafait, F. Rethinking Table Recognition Using Graph Neural Networks. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 142–147. [Google Scholar]
- Adams, T.; Namysl, M.; Kodamullil, A.T.; Behnke, S.; Jacobs, M. Benchmarking Table Recognition Performance on Biomedical Literature on Neurological Disorders. Bioinformatics 2021, 38, 1624–1630. [Google Scholar] [CrossRef]
- Microsoft, Azure Form Recognizer. Available online: https://azure.microsoft.com/en-us/services/form-recognizer/#overview (accessed on 5 April 2022).
- Adobe, Acrobat pro. Available online: https://www.adobe.com/vn_en/acrobat/pdf-reader.html (accessed on 5 April 2022).
- Adobe, Adobe Document Cloud. Available online: https://www.adobe.com/documentcloud.html (accessed on 5 April 2022).
- Cowie, J.; Lehnert, W. Information extraction. Commun. ACM 1996, 39, 80–91. [Google Scholar] [CrossRef]
- Piskorski, J.; Yangarber, R. Information Extraction: Past, Present and Future. In Multi-Source, Multilingual Information Extraction and Summarization; Springer: Berlin/Heidelberg, Germany, 2013; pp. 23–49. [Google Scholar]
- Mykowiecka, A.; Marciniak, M.; Kupść, A. Rule-based Information Extraction from Patients’ Clinical Data. J. Biomed. Infor. 2009, 42, 923–936. [Google Scholar] [CrossRef]
- Zhang, J.; El-Gohary, N.M. Semantic NLP-Based Information Extraction from Construction Regulatory Documents for Automated Compliance Checking. J. Comput. Civ. Eng. 2016, 30, 04015014. [Google Scholar] [CrossRef]
- Lee, J.; Yi, J.-S.; Son, J. Development of Automatic-Extraction Model of Poisonous Clauses in International Construction Contracts Using Rule-Based NLP. J. Comput. Civ. Eng. 2019, 33, 04019003. [Google Scholar] [CrossRef]
- Feng, D.; Chen, H. A Small Samples Training Framework for Deep Learning-based Automatic Information Extraction: Case Study of Construction Accident News Reports Analysis. Adv. Eng. Inform. 2021, 47, 101256. [Google Scholar] [CrossRef]
- Ittoo, A.; Nguyen, L.M.; van den Bosch, A. Text Analytics in Industry: Challenges, Desiderata and Trends. Comput. Ind. 2016, 78, 96–107. [Google Scholar] [CrossRef]
- Omran, F.N.A.A.; Treude, C. Choosing an NLP Library for Analyzing Software Documentation: A Systematic Literature Review and a Series of Experiments. In Proceedings of the 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR), Buenos Aires, Argentina, 20–21 May 2017; pp. 187–197. [Google Scholar]
- Altinok, D. Mastering spaCy: An End-to-end Practical Guide to Implementing NLP Applications Using the Python Ecosystem; Packt Publishing: Birmingham, UK, 2021; pp. 108–137, 168–196. [Google Scholar]
- Köpcke, H.; Rahm, E. Frameworks for Entity Matching: A Comparison. Data Knowl. Eng. 2010, 69, 197–210. [Google Scholar] [CrossRef]
- Getoor, L.; Machanavajjhala, A. Entity Resolution: Theory, Practice & Open Challenges. Proc. VLDB Endow. 2012, 5, 2018–2019. [Google Scholar] [CrossRef]
- Köpcke, H.; Thor, A.; Rahm, E. Evaluation of Entity Resolution Approaches on Real-world Match Problems. Proc. VLDB Endow. 2010, 3, 484–493. [Google Scholar] [CrossRef]
- Newcombe, H.B.; Kennedy, J.M.; Axford, S.J.; James, A.P. Automatic Linkage of Vital Records. Science 1959, 130, 954–959. [Google Scholar] [CrossRef]
- Barlaug, N.; Gulla, J.A. Neural Networks for Entity Matching: A Survey. ACM Trans. Knowl. Discov. Data 2021, 15, 52. [Google Scholar] [CrossRef]
- Xu, K.; Yang, Z.; Kang, P.; Wang, Q.; Liu, W. Document-level Attention-based BiLSTM-CRF Incorporating Disease Dictionary for Disease Named Entity Recognition. Comput. Biol. Med. 2019, 108, 122–132. [Google Scholar] [CrossRef]
- Batra, D.; Wishart, N.A. Comparing a Rule-based Approach with a Pattern-based Approach at Different Levels of Complexity of Conceptual Data Modelling Tasks. Int. J. Hum. Comput. Stud. 2004, 61, 397–419. [Google Scholar] [CrossRef]
- Eck, D.J. Introduction to Computer Graphics. 2021. Available online: https://math.hws.edu/graphicsbook/ (accessed on 5 April 2022).
- Adobe, Grids, Guides, and Measurements in PDFs. Available online: https://helpx.adobe.com/acrobat/using/grids-guides-measurements-pdfs.html (accessed on 1 April 2022).
- Li, Y.; Li, J.; Suhara, Y.; Doan, A.; Tan, W.-C. Deep Entity Matching with Pre-trained Language Models. Proc. VLDB Endow. 2020, 14, 50–60. [Google Scholar] [CrossRef]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2670–2680. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692v1. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805v2. [Google Scholar]
- Hazan, E.; Klivans, A.; Yuan, Y. Hyperparameter Optimization: A Spectral Approach. arXiv 2017, arXiv:1706.00764v4. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980v9. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, A Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108v4. [Google Scholar]
- Bittner, E.; Gregorc, W. Experiencing Project Management: Projects, Challenges and Lessons Learned; John Wiley & Sons: Hoboken, NJ, USA, 2010; p. 226. [Google Scholar]
- De, P.K. Project Termination Practices in Indian Industry: A Statistical Review. Int. J. Proj. Manag. 2001, 19, 119–126. [Google Scholar] [CrossRef]
- Mohemad, R.; Hamdan, A.R.; Othman, Z.A.; Noor, M.M. Automatic Document Structure Analysis of Structured PDF Files. Int. J. New Comput. Archit. Appl. 2011, 1, 404–411. [Google Scholar]
- Shinyama, Y. Programming with PDFMiner. Available online: https://pdfminer-docs.readthedocs.io/programming.html (accessed on 2 April 2022).
- Vijayakumar, S.; Gajendran, S. Improvement of Overall Equipment Effectiveness (OEE) in Injection Moulding Process Industry. IOSR J. Mech. Civ. Eng. 2014, 2, 47–60. [Google Scholar]
- Spacy. Industrial-Strength Natural Language Processing. Available online: https://spacy.io/ (accessed on 2 April 2022).
- Fan, H.; Li, H. Retrieving Similar Cases for Alternative Dispute Resolution in Construction Accidents Using Text Mining Techniques. Autom. Constr. 2013, 34, 85–91. [Google Scholar] [CrossRef]
- Shao, P.; Yang, G.; Niu, X.; Zhang, X.; Zhan, F.; Tang, T. Information Extraction of High-Resolution Remotely Sensed Image Based on Multiresolution Segmentation. Sustainability 2014, 6, 5300–5310. [Google Scholar] [CrossRef]
- Zhu, H.-J.; Zhu, Z.-W.; Jiang, T.-H.; Cheng, L.; Shi, W.-L.; Zhou, X.; Zhao, F.; Ma, B. A Type-Based Blocking Technique for Efficient Entity Resolution over Large-Scale Data. J. Sens. 2018, 2018, 2094696. [Google Scholar] [CrossRef]
- Siregar, S.P.; Wanto, A. Analysis of Artificial Neural Network Accuracy Using Backpropagation Algorithm in Predicting Process (Forecasting). Int. J. Inf. Syst. Technol. 2017, 1, 34–42. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Lu, E.J.-L.; Ou, T.-A. Intelligent SPARQL Query Generation for Natural Language Processing Systems. IEEE Access 2021, 9, 158638–158650. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Prasetiyo, B.; Muslim, M.A.; Baroroh, N. Evaluation Performance Recall and F2 Score of Credit Card Fraud Detection Unbalanced Dataset Using SMOTE Oversampling Technique. J. Phys. Conf. Ser. 2021, 1918, 042002. [Google Scholar] [CrossRef]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148v2. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Programming Language | Python 3.8 | |
|---|---|---|
| IDE | PyCharm 2020.3.4 | |
| Methodologies | TRC Module | OCR, Parsing, Machine Learning, Entity Matching |
| CTGC Module | Pattern-based algorithm, Rule-based algorithm, Entity Matching | |
| Main Libraries | TRC Module | OpenCV, PDFminer, Ghostscript, Ditto |
| CTGC Module | spaCy (Matcher), PDFminer | |
| Database | MySQL | |
| Web Back-end Framework | Spring Framework | |
| Web Front-end Framework | Angular 11 | |
| Type | No. | Made by | Target Equipment |
|---|---|---|---|
| Owner’s Purchase Order | OP1 | P Company | Finishing Mill Main Drive System |
| OP2 | Ultrasonic Billet Inspection System | ||
| OP3 | Ultrasonic Testing System | ||
| OP4 | Roll Grinder | ||
| OP5 | Main Motor for Hot Rolling Mill | ||
| T1 | Auxiliary Line Vector Drive | ||
| Suppliers’ Purchase Order | SP1 | T Company | Finishing Mill Main Drive System |
| SP2 | N Company | Ultrasonic Billet Inspection System | |
| SP3 | N Company | Ultrasonic Testing System | |
| SP4 | H Company | Roll Grinder | |
| SP5 | W Company | Roll Grinder | |
| SP6 | T Company | Main Motor for Hot Rolling Mill | |
| SP7 | A Company | Main Motor for Hot Rolling Mill | |
| T2 | H Company | Auxiliary Line Vector Drive | |
| T3 | PI Company | Auxiliary Line Vector Drive |
| Case | Owner’s Purchase Order | Supplier’s Purchase Order |
|---|---|---|
| 1 | Power DP panel | Power distribution panel |
| 2 | PLC modification | Modification of PLC system |
| 3 | Main drive system | Main motor drive system |
| Study | Data |
|---|---|
| Name | Wdc_computers_title_xlarge |
| Number of entity | 745 |
| Positive sample | 9690 |
| Negative sample | 58,771 |
| Total sample | 68,461 |
| Domain | Computer |
| Study | Data |
|---|---|
| Epochs | 20 |
| Batch size | 64 |
| Optimizer | Adam |
| Learning rate | 3 × 10−5 |
| Language model | DistillBERT |
| Performance Evaluation Target | Confusion Matrix | Evaluation Indexes (Percent) | ||||||
|---|---|---|---|---|---|---|---|---|
| TP | TN | FP | FN | Accuracy | Precision | Recall | F1 Score | |
| Table Structure Recognition | 2726 | 324 | 21 | 90 | 96.5 | 99.2 | 96.8 | 98.0 |
| Internal Data Recognition | 1043 | 1191 | 25 | 69 | 96.0 | 97.7 | 93.8 | 95.7 |
| Averaged performance of the TRC-R model | 96.3 | 98.5 | 95.3 | 96.9 | ||||
| Case | Owner’s PO | Supplier’s PO | Comparison Result (Item R&R) | Comparison Result (Description) |
|---|---|---|---|---|
| 1 | Main Motor | Main Motor | Same | Same |
| 2 | Power distribution panel | Power DP panel | Same | Same |
| 3 | Switchgear & Panel | Hardware | Same | Text Mismatch |
| 4 | Modification of Relay Panel | Modification of relay panel | Invalid Scope (Constructor on supplier’s PO) | Same |
| Target | Performance Evaluation | Evaluation Indexes (Percent) | |
|---|---|---|---|
| Total Results | Correct Answer | Accuracy | |
| TRC-C model | 41 | 36 | 87.8 |
| Plant Owner’s PO | Supplier’s PO | Correct Answer |
|---|---|---|
| Process Computer Modification | Modification of PLC System | Modification of Process Computer |
| PLC Modification | Modification of Supervisory System | Modification of PLC System |
| Performance Evaluation Target | Confusion Matrix | Evaluation Indexes (Percent) | ||||||
|---|---|---|---|---|---|---|---|---|
| TP | TN | FP | FN | Accuracy | Precision | Recall | F2 Score | |
| CTGC-E model | 28 | 37,045 | 13 | 6 | 99.9 | 68.3 | 82.4 | 79.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, C.-Y.; Jeong, J.-G.; Choi, S.-W.; Lee, E.-B. An AI-Based Automatic Risks Detection Solution for Plant Owner’s Technical Requirements in Equipment Purchase Order. Sustainability 2022, 14, 10010. https://doi.org/10.3390/su141610010
Kim C-Y, Jeong J-G, Choi S-W, Lee E-B. An AI-Based Automatic Risks Detection Solution for Plant Owner’s Technical Requirements in Equipment Purchase Order. Sustainability. 2022; 14(16):10010. https://doi.org/10.3390/su141610010
Chicago/Turabian StyleKim, Chae-Yeon, Jong-Gwan Jeong, So-Won Choi, and Eul-Bum Lee. 2022. "An AI-Based Automatic Risks Detection Solution for Plant Owner’s Technical Requirements in Equipment Purchase Order" Sustainability 14, no. 16: 10010. https://doi.org/10.3390/su141610010
APA StyleKim, C.-Y., Jeong, J.-G., Choi, S.-W., & Lee, E.-B. (2022). An AI-Based Automatic Risks Detection Solution for Plant Owner’s Technical Requirements in Equipment Purchase Order. Sustainability, 14(16), 10010. https://doi.org/10.3390/su141610010