
Contractor’s Risk Analysis of Engineering Procurement and Construction (EPC) Contracts Using Ontological Semantic Model and Bi-Long Short-Term Memory (LSTM) Technology



Abstract
1. Introduction
2. Literature Review
2.1. Knowledge-Based Risk Extraction for EPC Projects
2.2. Automatic Extraction of Contract Risks Using AI Technology in EPC Projects
2.3. Text Classification
3. Research Framework and Process
3.1. Model Framework and Development Process
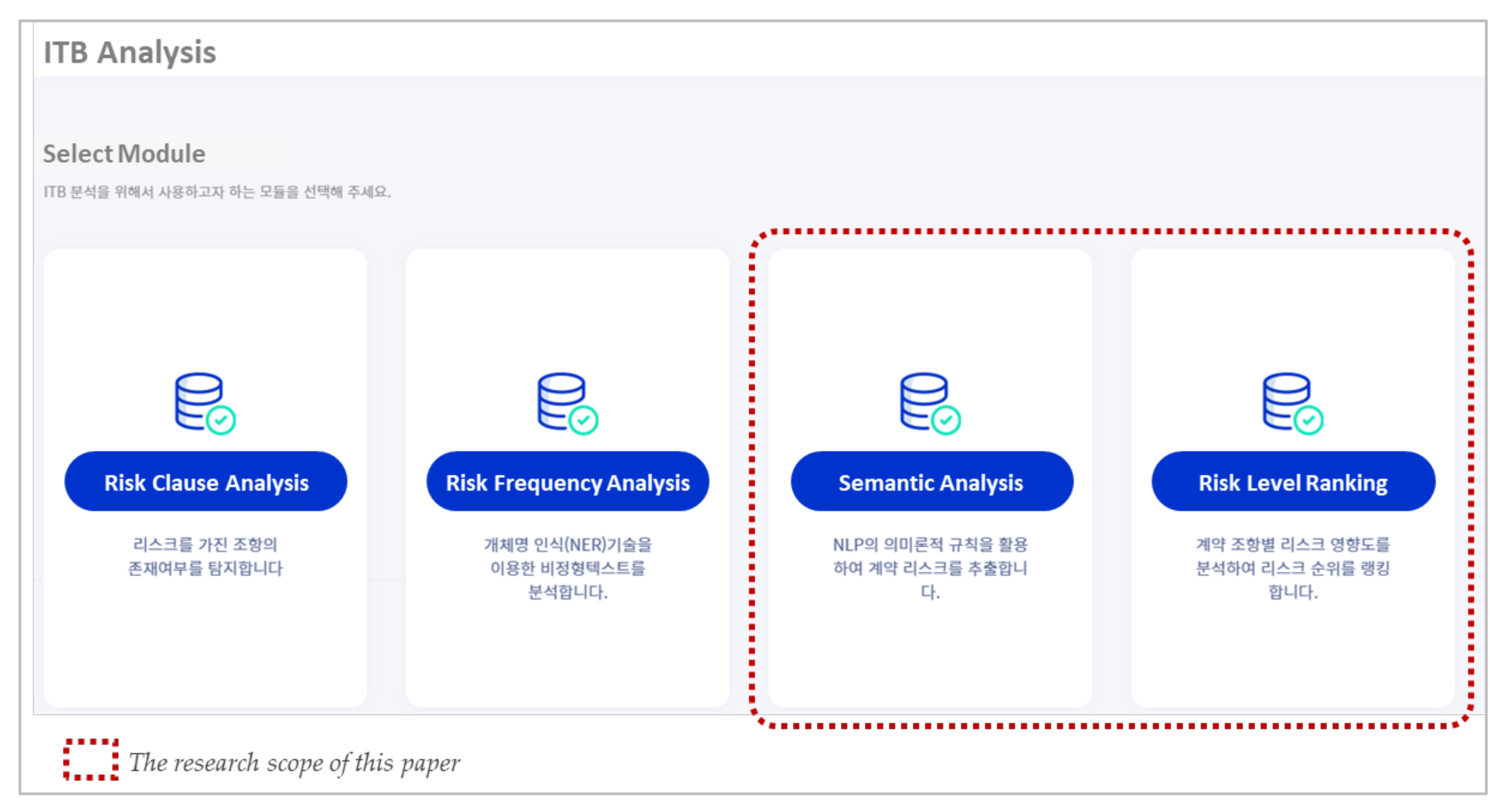
3.2. Research Scope and Algorithm Development Environments
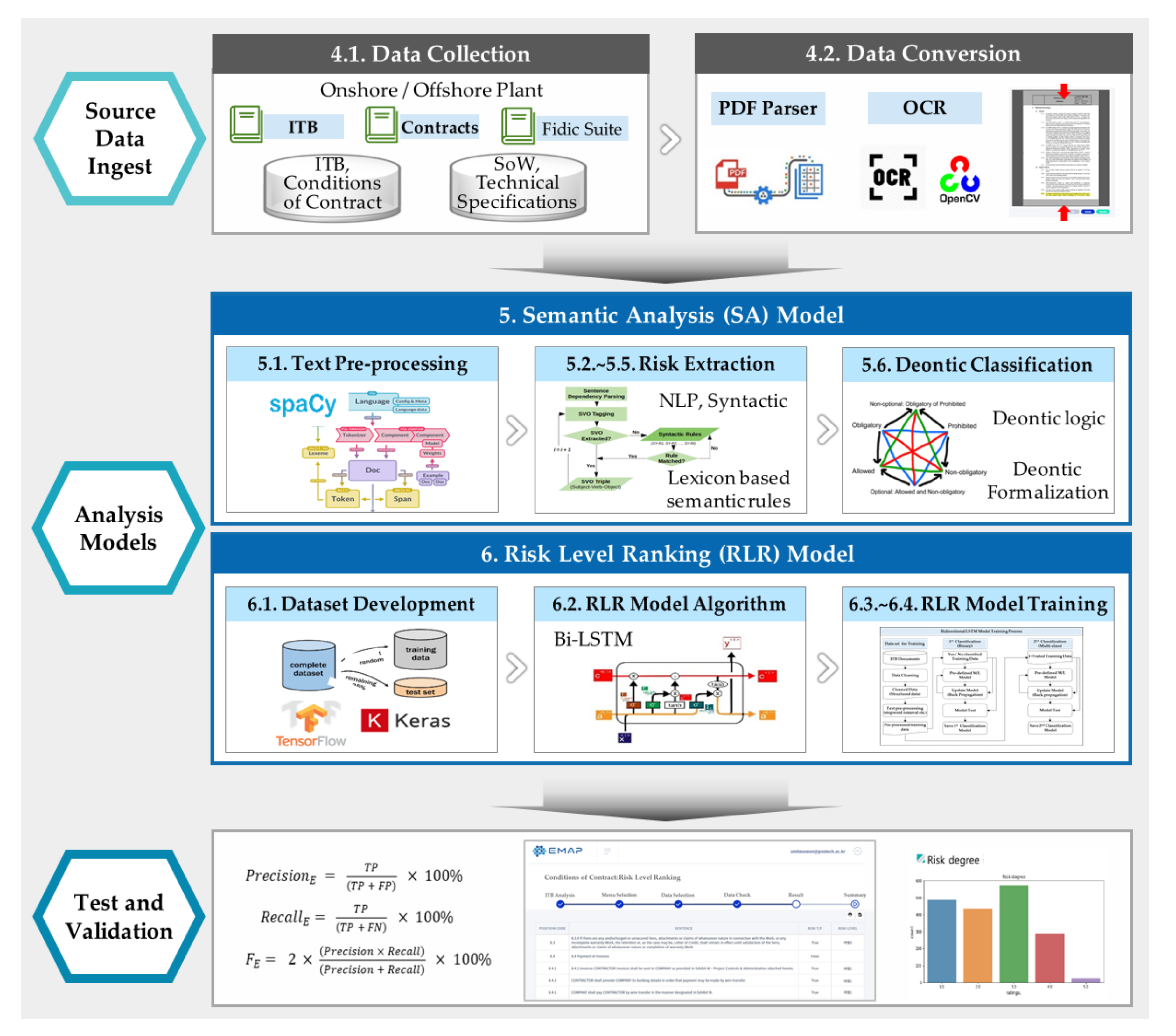
4. Data Collection and Conversion
4.1. Data Collection
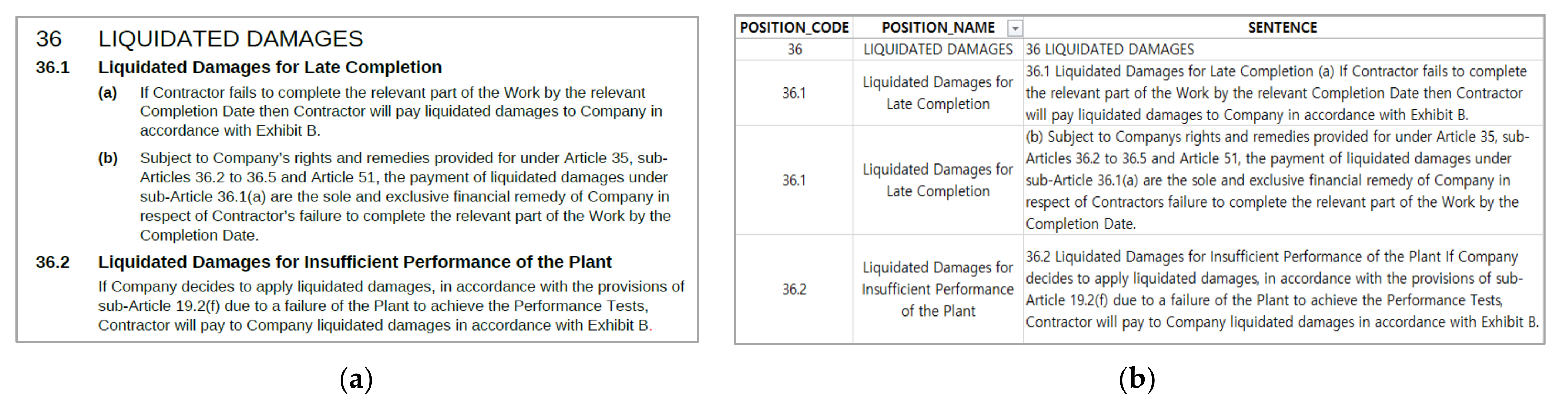
4.2. Data Conversion through PDF Structuralization
5. Semantic Analysis Model
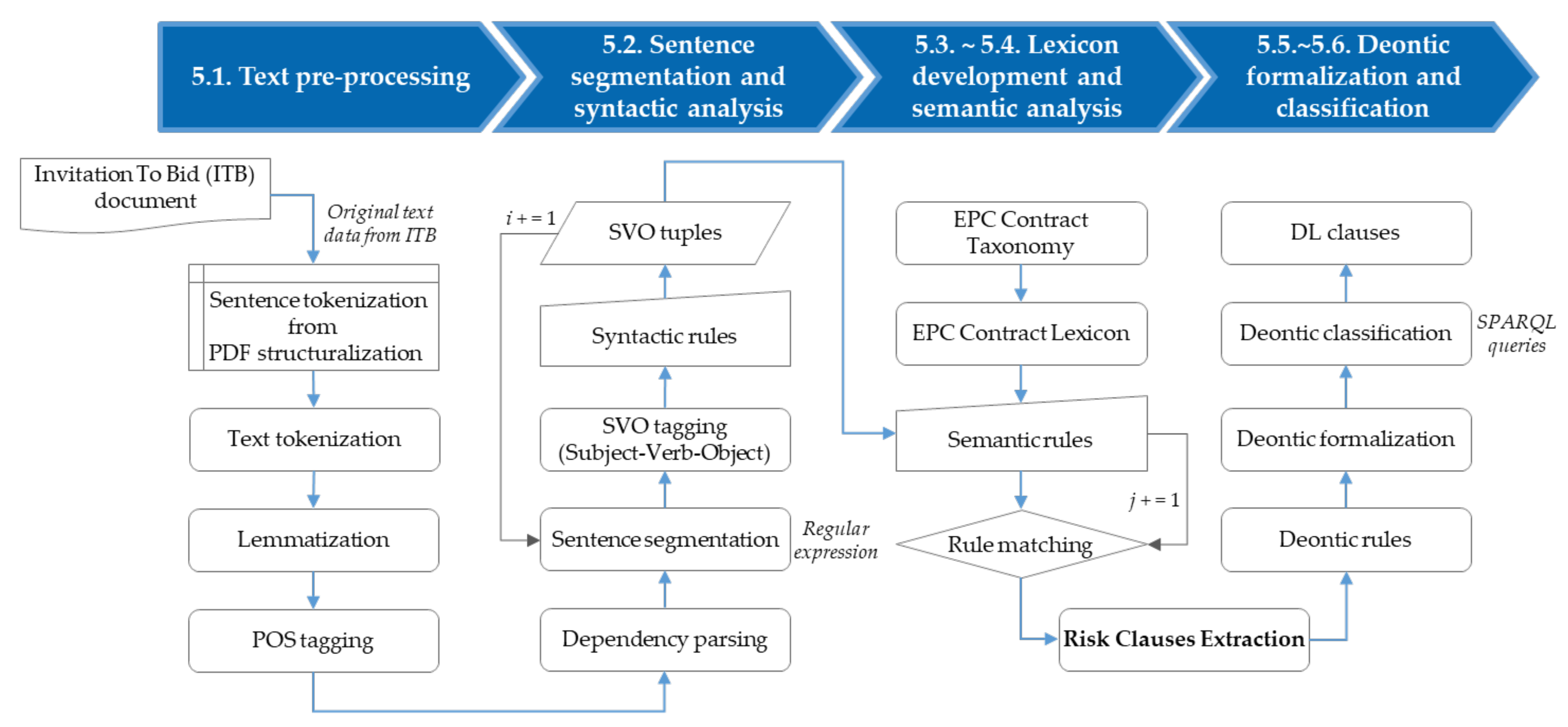
5.1. Text Data Preprocessing
5.2. Syntactic Analysis with Sentence Segmentation
*\( {0,1}[a-h]\) or *\( (?!\) )(?:m{0,4}(?:cm|cd|d?c{0,3})(?:xc|xl|l?x{0,3}) (?:ix|iv|v?i{0,3}))(?<!\( )\) .
5.3. Ontology-Based EPC Contract Lexicon
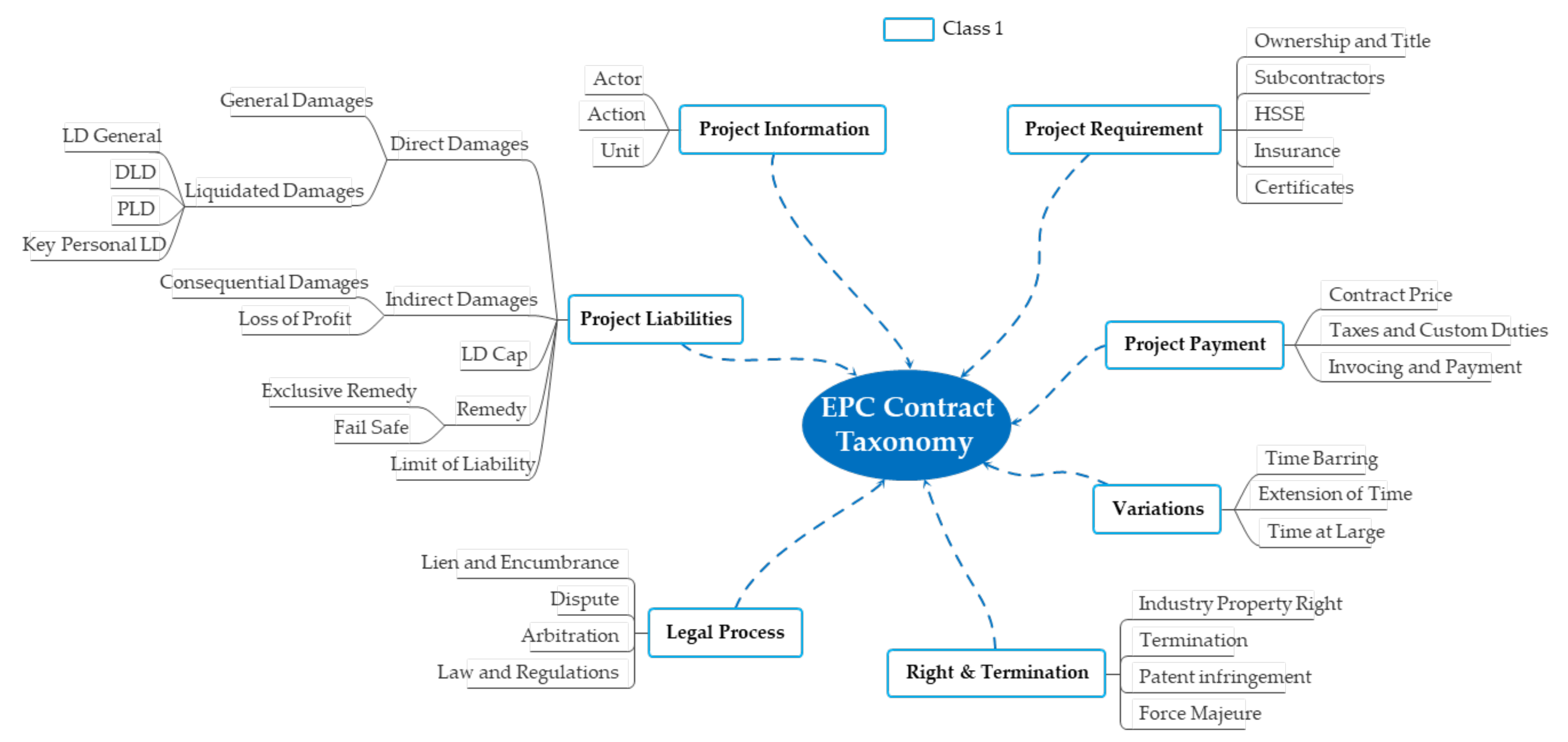
5.3.1. EPC Contract Taxonomy
- Project information including the subject and general matters of the contract.
- Project requirement for contractual requirements.
- Project liabilities for contractor’s liability and damage compensation.
- Project payment for progress.
- Variations including construction changes.
- Project rights and termination of contracts.
- Legal process, which includes disputes between contractors and owners.
5.3.2. Development of EPC Contract Lexicon
5.4. Semantic Analysis Modeling Based on Rules
- <Class name>: True if there is a term included in the class of lexicon (e.g., <Liquidated Damages>).
- ( ): Give preference to operations in parentheses (e.g., (<employer-side> or <contractor-side>) and “contract”).
- or: True if any of the preceding and following elements is True (e.g., <contractor-side> or <both party>).
- and: True only when both preceding and following elements are True (e.g., <Liquidated Damages> and <Exclusive Remedy>).
- <POS: XXX>: True if there is a word corresponding to the part-of-speech of XXX (e.g., <POS: PRON>).
- Example 1 [S1-1]:IF,Subject == <Liquidated Damages>.Verb == <Liquidated Damages> or (“not” and <Legal-action>).Object == <Fail-Safe> or <General Damages>.THEN,“Fail-Safe” clause is extracted.
- Example 2 [S1-1]:IF,Subject == <Liquidated Damages>.Verb == <Liquidated Damages> or (“not” and <Legal-action>) or <Legal-action>).Object == <Fail Safe> or <General Damages>.THEN,“Fail-Safe” clause is extracted.
- Example 3 [S1-2]:IF,Subject == <Both-party>.Verb == <Liquidated Damages> or <Legal-action>.Object == <Fail-Safe> or <General Damages>.THEN,“Fail-Safe” clause is extracted.
5.5. Risk Clauses Extraction
5.6. Deontic Classification
- Agent: the accountable agent, corresponding to the actor in the lexicon (e.g., contractor, owner).
- Predicate: represent concepts, relations between objects, corresponding to action in the lexicon (e.g., legal-action, obligated-action, permitted-action, payable-action).
- Topic: the topic it addresses, corresponding to class level 2 in the lexicon (e.g., safety, environment, cost, quality).
- Object: the object it applies to, corresponding to the class level 3 in the lexicon.
- Deontic formalization for [S1-1]:∀𝑥, 𝑦, 𝑧, h (Liquidated Damages (𝑥)∧ Both-party (𝑦)∧ Permitted-action (z)∧ General Damages (h) ⊃ P(Fail Safe (𝑧, h))
- SPARQL queries for [S1-1]:SELECT ?x ?y ?z ?hWHERE {?x a subject:Liquidated Damages. ?y a subject:Both-party. ?z a predicate:Legal-action. ?h a object: General Damages. FILTER (?𝑧= obligated-action).}
5.7. Implementation and Validation of the SA Model
5.7.1. Gold Standard and Test Dataset for the SA Model
5.7.2. Test Results and Validation of the SA Model
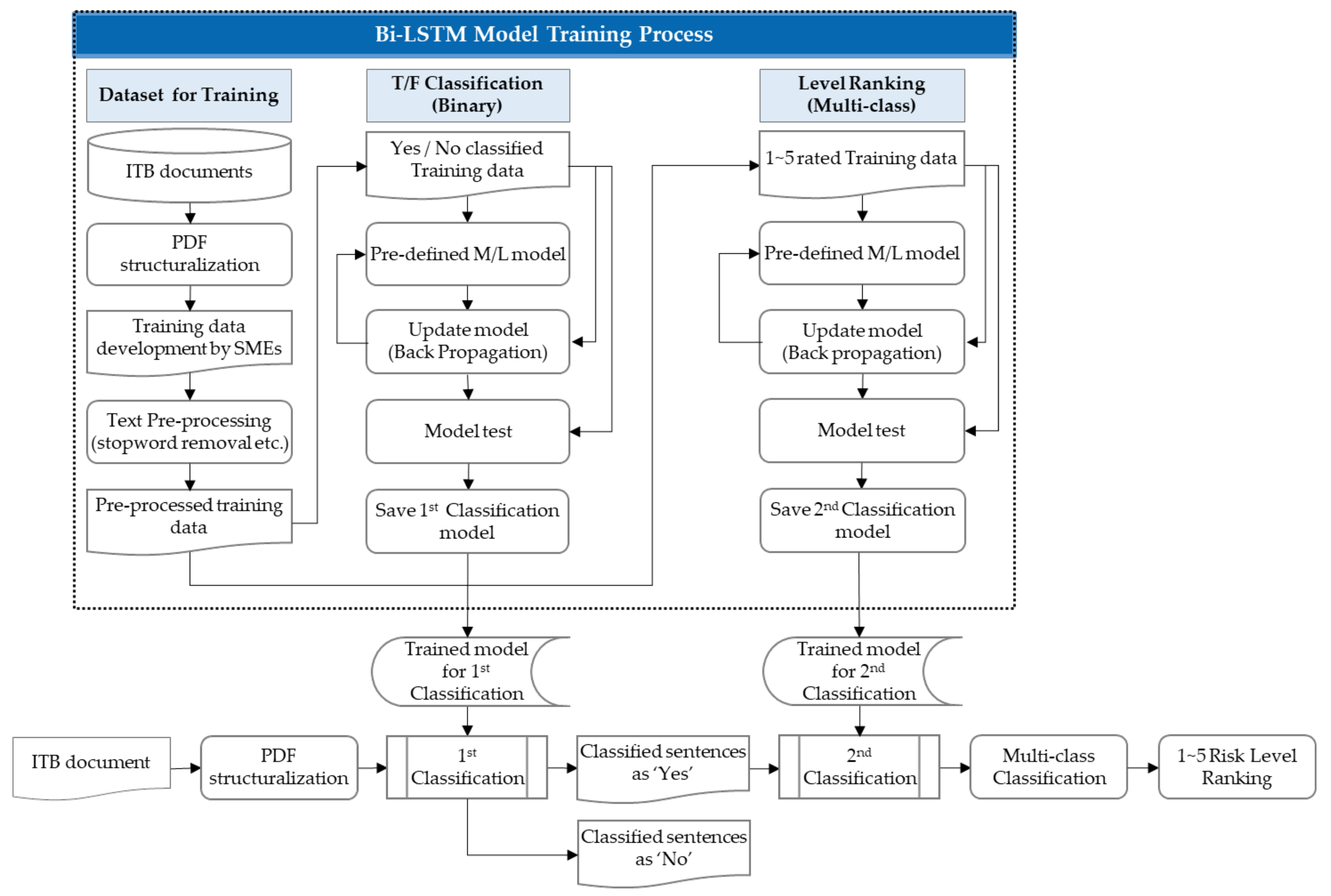
6. Risk Level Ranking Model
6.1. Preprocessing for RLR Model
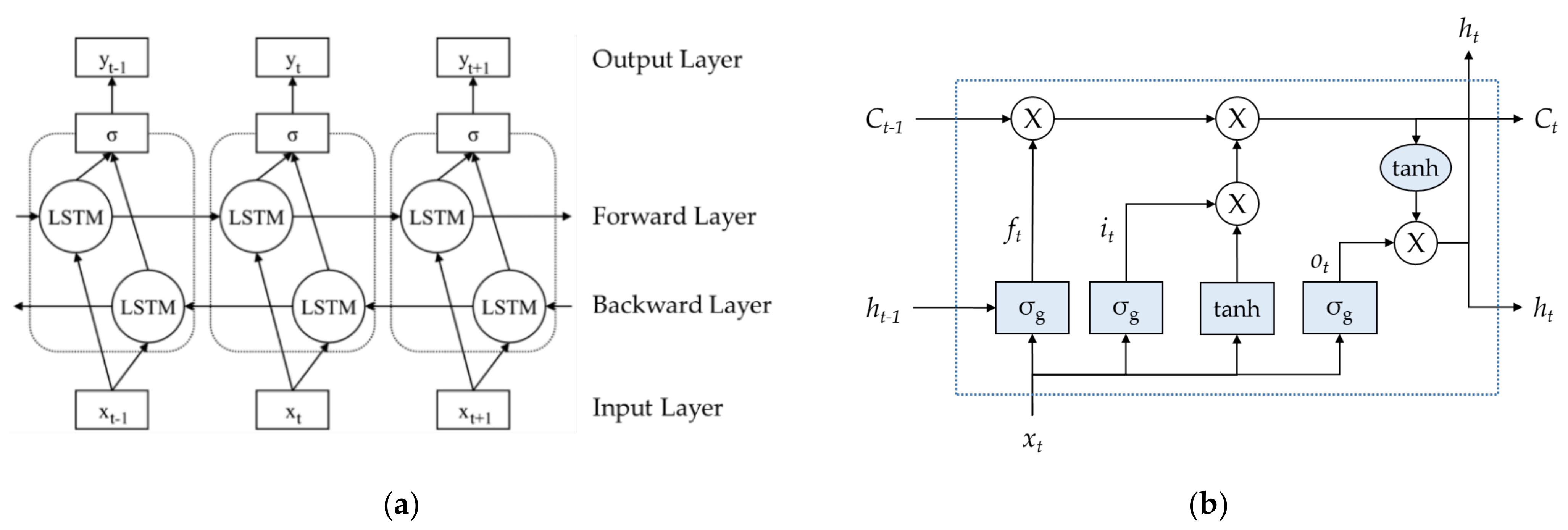
6.2. Risk Level Ranking Modeling with Bi-LSTM
6.3. Development of Training Dataset
6.4. Fine Tuning for the Risk Level Ranking Model
6.5. Implementation and Validation of Risk Level Ranking Model
7. System Application on Cloud Platform
8. Conclusion and Future Works
8.1. Summary and Contributions
8.2. Limitations and Further Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Adam | Adaptive moment estimation |
| AI | Artificial intelligence |
| ANN | Artificial neural network |
| API | Application programming interface |
| CNN | Convolutional neural network |
| CRC | Critical risk check |
| CSV | Comma-separated values |
| DC | Deontic classification |
| DL | Deontic logic |
| EMAP | Engineering Machine-learning Automation Platform |
| EPC | Engineering, procurement, construction |
| FIDIC | Fédération Internationale Des Ingénieurs-Conseils |
| FOL | First-order logic |
| IE | Information extraction |
| ITB | Invitation to bid |
| JSON | JavaScript object notation |
| LD | Liquidated damages |
| LSTM | Long short-term memory |
| ML | Machine learning |
| NER | Named entity recognition |
| NLP | Natural language processing |
| OCR | Optical character recognition |
| OOV | Out-of-vocabulary |
| OPF | Obligation, permission, and prohibition/forbidden |
| Portable document format | |
| PI | Probability and impact |
| PM | Project management |
| POC | Proof of concept |
| POS tagging | Part of speech tagging |
| RNN | Recurrent neural network |
| RLR | Risk level ranking |
| SA | Semantic analysis |
| SMEs | Subject matter experts |
| SVO | Subject–verb–object |
| SVR | Support vector regression |
| WAS | Web application server |
References
- DLA Piper. EPC Contracts in the Process Plant Sector. Available online: www.dlapiper.com (accessed on 5 February 2022).
- Ritsche, F.-P.; Wagner, R.; Schlemmer, P.; Steinkamp, M.; Valnion, B.D. Innovation Project EPC 4.0 ‘Unleashing the Hidden Potential’; ProjectTeam: Hamburg, Germany, 2019. [Google Scholar]
- International Trade Administration. South Korea-Construction Services. Available online: https://www.trade.gov/country-commercial-guides/south-korea-construction-services (accessed on 7 February 2022).
- Vogl, R. The Coming of Age of Legal Technology; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Lane, H.; Hapke, H.; Howard, C. Natural Language Processing in Action: Understanding, Analyzing, and Generating Text with Python; Simon and Schuster: New York, NY, USA, 2019. [Google Scholar]
- Ebrahimnejad, S.; Mousavi, S.M.; Tavakkoli-Moghaddam, R.; Heydar, M. Evaluating high risks in large-scale projects using an extended VIKOR method under a fuzzy environment. Int. J. Ind. Eng. Comput. 2012, 3, 463–476. [Google Scholar] [CrossRef]
- Hung, M.S.; Wang, J. Research on Delay Risks of EPC Hydropower Construction Projects in Vietnam. Int. J. Power Energy Eng. 2016, 4, 8. [Google Scholar] [CrossRef][Green Version]
- Jahantigh, F.F.; Malmir, B.; Avilaq, B.A. Economic risk assessment of EPC projects using fuzzy TOPSIS approach. Int. J. Ind. Syst. Eng. 2017, 27, 161–179. [Google Scholar] [CrossRef]
- Kim, M.-H.; Lee, E.-B.; Choi, H.-S. Detail Engineering Completion Rating Index System (DECRIS) for Optimal Initiation of Construction Works to Improve Contractors’ Schedule-Cost Performance for Offshore Oil and Gas EPC Projects. Sustainability 2018, 10, 2469. [Google Scholar] [CrossRef]
- Kabirifar, K.; Mojtahedi, M. The impact of Engineering, Procurement and Construction (EPC) Phases on Project Performance: A Case of Large-scale Residential Construction Project. Buildings 2019, 9, 15. [Google Scholar] [CrossRef]
- Gunduz, M.; Almuajebh, M. Critical Success Factors for Sustainable Construction Project Management. Sustainability 2020, 12, 1990. [Google Scholar] [CrossRef]
- Koulinas, G.K.; Xanthopoulos, A.S.; Tsilipiras, T.T.; Koulouriotis, D.E. Schedule delay risk analysis in construction projects with a simulation-based expert system. Buildings 2020, 10, 134. [Google Scholar] [CrossRef]
- Okudan, O.; Budayan, C.; Dikmen, I. A knowledge-based risk management tool for construction projects using case-based reasoning. Expert. Syst. Appl. 2021, 173, 114776. [Google Scholar] [CrossRef]
- Surden, H. Computable contracts. UC Davis Law Rev. 2012, 46, 629. [Google Scholar]
- LawGeex. Comparing the Performance of AI to Human Lawyers in the Review of Standard Business Contracts. Available online: https://ai.lawgeex.com/rs/345-WGV-842/images/LawGeex%20eBook%20Al%20vs%20Lawyers%202018.pdf (accessed on 10 January 2022).
- Cummins, J.; Clack, C. Transforming Commercial Contracts through Computable Contracting. arXiv 2020, arXiv:2003.10400. [Google Scholar] [CrossRef]
- Dixon, H.B., Jr. What judges and lawyers should understand about artificial intelligence technology. ABA J. 2020, 59, 36–38. [Google Scholar]
- Clack, C.D. Languages for Smart and Computable Contracts. arXiv 2021, arXiv:2104.03764. [Google Scholar]
- Salama, D.A.; El-Gohary, N.M. Automated compliance checking of construction operation plans using a deontology for the construction domain. J. Comput. Civ. Eng. 2013, 27, 681–698. [Google Scholar] [CrossRef]
- Chopra, D.; Joshi, N.; Mathur, I. Mastering Natural Language Processing with Python; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Zhang, J.; El-Gohary, N. Automated reasoning for regulatory compliance checking in the construction domain. In Construction Research Congress 2014: Construction in a Global Network; ASCE: Reston, VA, USA, 2014; pp. 907–916. [Google Scholar]
- Williams, T.P.; Gong, J. Predicting construction cost overruns using text mining, numerical data and ensemble classifiers. Autom. Constr. 2014, 43, 23–29. [Google Scholar] [CrossRef]
- Lee, J.; Yi, J.-S. Predicting project’s uncertainty risk in the bidding process by integrating unstructured text data and structured numerical data using text mining. Appl. Sci. 2017, 7, 1141. [Google Scholar] [CrossRef]
- Zou, Y.; Kiviniemi, A.; Jones, S.W. Retrieving similar cases for construction project risk management using Natural Language Processing techniques. Autom. Constr. 2017, 80, 66–76. [Google Scholar] [CrossRef]
- Lee, J.H.; Yi, J.-S.; Son, J.W. Development of automatic-extraction model of poisonous clauses in international construction contracts using rule-based NLP. J. Comput. Civ. Eng. 2019, 33, 04019003. [Google Scholar] [CrossRef]
- Moon, S.; Lee, G.; Chi, S.; Oh, H. Automated construction specification review with named entity recognition using natural language processing. J. Constr. Eng. Manag. 2021, 147, 04020147. [Google Scholar] [CrossRef]
- Choi, S.-W.; Lee, E.-B.; Kim, J.-H. The Engineering Machine-Learning Automation Platform (EMAP): A Big-Data-Driven AI Tool for Contractors’ Sustainable Management Solutions for Plant Projects. Sustainability 2021, 13, 10384. [Google Scholar] [CrossRef]
- Choi, S.J.; Choi, S.W.; Kim, J.H.; Lee, E.-B. AI and Text-Mining Applications for Analyzing Contractor’s Risk in Invitation to Bid (ITB) and Contracts for Engineering Procurement and Construction (EPC) Projects. Energies 2021, 14, 4632. [Google Scholar] [CrossRef]
- Park, M.-J.; Lee, E.-B.; Lee, S.-Y.; Kim, J.-H. A Digitalized Design Risk Analysis Tool with Machine-Learning Algorithm for EPC Contractor’s Technical Specifications Assessment on Bidding. Energies 2021, 14, 5901. [Google Scholar] [CrossRef]
- Fantoni, G.; Coli, E.; Chiarello, F.; Apreda, R.; Dell’Orletta, F.; Pratelli, G. Text mining tool for translating terms of contract into technical specifications: Development and application in the railway sector. Comput. Ind. 2021, 124, 103357. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.-U.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Zhou, S.K.; Rueckert, D.; Fichtinger, G. Handbook of Medical Image Computing and Computer Assisted Intervention; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–21 June 2013; pp. 1310–1318. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling. arXiv 2016, arXiv:1611.06639. [Google Scholar]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 364. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning—Based Text Classification. ACM Comput. Surv. 2022, 54, 1–40. [Google Scholar] [CrossRef]
- Zhang, J.; El-Gohary, N.M. Semantic NLP-based information extraction from construction regulatory documents for automated compliance checking. J. Comput. Civ. Eng. 2016, 30, 04015014. [Google Scholar] [CrossRef]
- PDF Parser. Available online: https://py-pdf-parser.readthedocs.io/en/latest/overview.html (accessed on 13 January 2022).
- Fernández-Caballero, A.; López, M.T.; Castillo, J.C. Display text segmentation after learning best-fitted OCR binarization parameters. Expert. Syst. Appl. 2012, 39, 4032–4043. [Google Scholar] [CrossRef]
- Vijayarani, S.; Ilamathi, M.J.; Nithya, M. Preprocessing techniques for text mining-an overview. Int. J. Comput. 2015, 5, 7–16. [Google Scholar]
- spaCy. Tokenization. Available online: https://spacy.io/usage/linguistic-features#tokenization (accessed on 15 January 2022).
- spaCy. Lemmatization. Available online: https://spacy.io/usage/linguistic-features#lemmatization (accessed on 15 January 2022).
- spaCy. Part-of-Speech Tagging. Available online: https://spacy.io/usage/linguistic-features#pos-tagging (accessed on 15 January 2022).
- Wu, Y.; Zhang, Q.; Huang, X.-J.; Wu, L. Phrase dependency parsing for opinion mining. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; Association for Computational Linguistics: Singapore, 2009; pp. 1533–1541. [Google Scholar]
- spaCy. Dependency-Parsing. Available online: https://spacy.io/usage/linguistic-features#dependency-parse (accessed on 17 January 2022).
- Google. ClearNLP. Available online: https://github.com/clir/clearnlp-guidelines (accessed on 17 January 2022).
- Tiwary, U.; Siddiqui, T. Natural Language Processing and Information Retrieval; Oxford University Press, Inc.: Oxford, UK, 2008. [Google Scholar]
- Niu, J.; Issa, R.R. Developing taxonomy for the domain ontology of construction contractual semantics: A case study on the AIA A201 document. Adv. Eng. Inform. 2015, 29, 472–482. [Google Scholar] [CrossRef]
- Prisacariu, C.; Schneider, G. A formal language for electronic contracts. In International Conference on Formal Methods for Open Object-Based Distributed Systems; Springer: Berlin/Heidelberg, Germany, 2007; pp. 174–189. [Google Scholar]
- Xu, X.; Cai, H. Ontology and rule-based natural language processing approach for interpreting textual regulations on underground utility infrastructure. Adv. Eng. Inform. 2021, 48, 101288. [Google Scholar] [CrossRef]
- McNamara, P.; Van De Putte, F. The Stanford Encyclopedia of Philosophy. Available online: https://plato.stanford.edu/entries/logic-deontic/ (accessed on 14 February 2022).
- Cheng, J. Deontic relevant logic as the logical basis for representing and reasoning about legal knowledge in legal information systems. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 517–525. [Google Scholar]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering natural language questions by subgraph matching over knowledge graphs. IEEE Trans. Knowl. Data Eng. 2017, 30, 824–837. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Lu, E.J.-L.; Ou, T.-A. Intelligent SPARQL Query Generation for Natural Language Processing Systems. IEEE Access 2021, 9, 158638–158650. [Google Scholar] [CrossRef]
- Lai, S.; Liu, K.; He, S.; Zhao, J. How to generate a good word embedding. IEEE Intell. Syst. 2016, 31, 5–14. [Google Scholar] [CrossRef]
- Keras. Text Data Preprocessing. Available online: https://keras.io/api/preprocessing/text/ (accessed on 18 January 2022).
- TensorFlow. Tokenizer. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text/Tokenizer (accessed on 2 March 2022).
- Manaswi, N.K. Understanding and working with Keras. In Deep Learning with Applications Using Python; Springer: Berlin/Heidelberg, Germany, 2018; pp. 31–43. [Google Scholar]
- Dawes, J. Do data characteristics change according to the number of scale points used? An experiment using 5-point, 7-point and 10-point scales. Int. J. Mark. Res. 2008, 50, 61–104. [Google Scholar] [CrossRef]
- Cui, Z.; Ke, R.; Pu, Z.; Wang, Y. Deep bidirectional and unidirectional LSTM recurrent neural network for network-wide traffic speed prediction. arXiv 2018, arXiv:1801.02143. [Google Scholar]
- Shen, S.-L.; Atangana Njock, P.G.; Zhou, A.; Lyu, H.-M. Dynamic prediction of jet grouted column diameter in soft soil using Bi-LSTM deep learning. Acta Geotech. 2021, 16, 303–315. [Google Scholar] [CrossRef]
- Renn, O. Three decades of risk research: Accomplishments and new challenges. J. Risk Res. 1998, 1, 49–71. [Google Scholar] [CrossRef]
- Jang, W.-S.; Hong, H.-U.; Han, S.-H. Risk Identification and Priority method for Overseas LNG Plant Projects-Focusing on Design Phase. Korean J. Constr. Eng. Manag. 2011, 12, 146–154. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Amir-Ahmadi, P.; Matthes, C.; Wang, M.-C. Choosing prior hyperparameters: With applications to time-varying parameter models. J. Bus. Econ. Stat. 2020, 38, 124–136. [Google Scholar] [CrossRef]
- Afaq, S.; Rao, S. Significance of Epochs On Training A Neural Network. Int. J. Sci. Technol. Res. 2020, 19, 485–488. [Google Scholar]
- TensorFlow. Overfit and Underfit. Available online: https://www.tensorflow.org/tutorials/keras/overfit_and_underfit (accessed on 7 March 2022).
- TensorFlow. EarlyStopping. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping (accessed on 7 March 2022).
- Aretz, K.; Bartram, S.M.; Pope, P.F. Asymmetric loss functions and the rationality of expected stock returns. Int. J. Forecast. 2011, 27, 413–437. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Vina del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Apache. Tomcat Software. Available online: http://tomcat.apache.org (accessed on 22 March 2022).
- Oracle. MySQL. Available online: https://www.oracle.com/mysql/ (accessed on 22 March 2022).
- Santoro, M.; Vaccari, L.; Mavridis, D.; Smith, R.; Posada, M.; Gattwinkel, D. Web Application Programming Interfaces (APIs): General-Purpose Standards, Terms and European Commission Initiatives; European Union: Luxembourg, 2019. [Google Scholar] [CrossRef]
- Gunnulfsen, M. Scalable and Efficient Web Application Architectures: Thin-Clients and Sql vs. Thick-Clients and Nosql. Master’s Thesis, The University of Oslo, Oslo, Norway, 2013. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Semantic Analysis | Risk Level Ranking |
|---|---|---|
| AI technology | NLP | Bi-LSTM |
| Libraries | spaCy’s 2.3.1 | Keras 2.6.0, Tensorflow 2.6.0 |
| Language | Python 3.7.7 | Python 3.7.11 |
| Input data | EPC Contracts | EPC contracts |
| Operation system | Window 10 | Window 10 |
| Purpose | To extract the risk clauses using the semantic rules based on the lexicon | To classify each sentence of the EPC contracts into five levels by risk degree |
| Category | No. | Project Type | Location | Year |
|---|---|---|---|---|
| 1 | Refinery | Kuwait | 2005 | |
| 2 | Coal-fired Power Plant | Chile | 2007 | |
| 3 | Refinery | Peru | 2008 | |
| Onshore | 4 | Combined Cycle Power Plant | Kuwait | 2008 |
| 5 | Petrochemical | Saudi Arabia | 2011 | |
| 6 | LNG Terminal | USA | 2012 | |
| 7 | Thermal Power Plant | Bangladesh | 2015 | |
| 8 | Combined Cycle Power Plant | Georgia | 2020 | |
| 9 | FPSO 1 | Nigeria | 2003 | |
| 10 | Drillship | For Chartering | 2007 | |
| 11 | FPSO | Angola | 2009 | |
| 12 | FLNG 2 | Brazil | 2010 | |
| 13 | FPSO | Angola | 2011 | |
| Offshore | 14 | FPSO | Nigeria | 2012 |
| 15 | FPSO | Australia | 2012 | |
| 16 | TLP 3 | Congo | 2012 | |
| 17 | Semi-submersible | Gulf of Mexico (US) | 2012 | |
| 18 | Fixed Platform | Norway | 2012 | |
| 19 | FIDIC Red 2017 | 2017 | ||
| FIDIC 4 | 20 | FIDIC Silver 2017 | Standard form of Contract | 2017 |
| 21 | FIDIC Yellow 2017 | 2017 |
| Class 1 | Class 2 | Class 3 | Class 4 | Terms |
|---|---|---|---|---|
| Liquidated Damages General | Liquidated damages, LD, reasonable and genuine pre-estimate of loss, damages for any loss, pre-estimate of loss, not a penalty, not as a penalty, not meet, fail to complete, not ready for delivery | |||
| Direct Damages | Liquidated Damages | Delay Liquidated Damages | Delay liquidated damages, DLD, liquidated damages for delay, delay damages, liquidated damages for such delay, liquidated damages for any delay, liquidated damages for late completion | |
| Project Liabilities | Performance Liquidated Damages | Performance liquidated damages, performance of the plant, PLD, liquidated damages for insufficient failure of the plant to achieve the performance tests, performance liquidated damages, damages for failure to pass tests on completion | ||
| Remedy | Exclusive Remedy | Exclusive remedy, sole and exclusive remedy, sole and exclusive financial remedy, remedy, remedies, obligation to complete the work | ||
| Fail Safe | Invalid, unenforceable, validity, enforceability, no challenge, remit, refund, reimburse |
| Operator Type | Deontic Representation | Descriptions | Examples |
|---|---|---|---|
| O | Obligation | ‘Oα’ means α is obligated | |
| Deontic Operators 1 | P | Permission | ‘Pα’ means α is permitted |
| F | Forbidden/Prohibition | ‘Fα’ means α is forbidden | |
| I | Indifferent | ‘Iα’ means α is indifferent | |
| ∧ | Conjunction | ‘A ∧ B’ means A is true and B is true | |
| First-Order Logic | ∨ | Disjunction | ‘A ∨ B’ means A is true or B is true |
| Operators 2 | ¬ | Negation | ‘¬A’ means A is not true |
| ⊃ | Implication | ‘A ⊃ B’ means A implies B (if A is true then B is true) |
| Expert Code | Category | Discipline | Year of Experiences | Affiliation |
|---|---|---|---|---|
| A | Offshore | Contract | 32 | EPC company |
| B | Offshore | Planning | 16 | EPC company |
| C | Offshore | Engineering | 18 | EPC company |
| D | Onshore/Power plant | PM | 17 | EPC company |
| E | Offshore/Onshore | Contract | 28 | Law firm |
| F | Onshore/Infra | PM&IT | 22 | Academia |
| G | Onshore/Infra | PM&IT | 24 | Academia |
| Dataset No. | Project Name | Domain | Owner | No. of Records |
|---|---|---|---|---|
| 1 | ‘I’ project | Offshore FPSO | I & T companies consortium | 1864 |
| 2 | ‘C’ project | Offshore FPSO | T company | 1894 |
| 3 | ‘M’ project | Offshore TLP | T company | 1371 |
| 4 | ‘P’ project | Offshore FLNG | P company | 1990 |
| Total | No. of Records | 7119 |
| Criteria | Type | The Results of | The Gold Standard |
|---|---|---|---|
| Positive | Negative | ||
| The actual | Extracted | True positive (TP) | False negative (FN) |
| extraction results | Not extracted | False positive (FP) | True negative (TN) |
| No. of | Extractions | Performance | |||||
|---|---|---|---|---|---|---|---|
| Risk Extraction | TP | FP | FN | TN | Precision (%) | Recall (%) | F-measure (%) |
| 765 | 98 | 142 | 6444 | 88.6 | 84.3 | 86.4 |
| The | Classified | Results | (Class_O) | Performance | ||||
|---|---|---|---|---|---|---|---|---|
| Deontic Classification | TP | FP | FN | TN | Precision (%) | Recall (%) | F-measure (%) | Accuracy (%) |
| 572 | 57 | 198 | 1037 | 90.9 | 74.3 | 81.8 | 86.3 |
| Type of Model | Hyperparameters | Value Determined |
|---|---|---|
| Epoch | 10 | |
| T/F Classification | Early stopping | - |
| (Binary) | Loss function | Binary cross entropy |
| Optimizer | Adam | |
| Train data: Test data | 8:2 | |
| Epoch | 100 | |
| Degree Ranking | Early stopping | 14 epoch |
| (Multi-class) | Loss function | Categorical cross entropy |
| Optimizer | Adam | |
| Train data: Test data | 8:2 |
| Category | Type of Model | Test | Result | ||||
|---|---|---|---|---|---|---|---|
| 1st | T/F Classification | T/F | True | False | |||
| (Binary) | No. of sentences | 1806 | 574 | ||||
| 2nd | Risk Level Classification | Risk level | 1 | 2 | 3 | 4 | 5 |
| (Multi-class) | No. of sentences | 489 | 434 | 572 | 288 | 23 |
| Category | Type of Model | Performance | |
|---|---|---|---|
| Train Set | Test Set | ||
| 1st | T/F Classification (Binary) | Loss: 0.141 Accuracy: 0.955 | Loss: 0.356 Accuracy: 0.882 |
| 2nd | Risk Level Classification (Multi-class) | Loss: 0.547 Accuracy: 0.888 | Loss: 2.522 Accuracy: 0.468 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.-W.; Lee, E.-B. Contractor’s Risk Analysis of Engineering Procurement and Construction (EPC) Contracts Using Ontological Semantic Model and Bi-Long Short-Term Memory (LSTM) Technology. Sustainability 2022, 14, 6938. https://doi.org/10.3390/su14116938
Choi S-W, Lee E-B. Contractor’s Risk Analysis of Engineering Procurement and Construction (EPC) Contracts Using Ontological Semantic Model and Bi-Long Short-Term Memory (LSTM) Technology. Sustainability. 2022; 14(11):6938. https://doi.org/10.3390/su14116938
Chicago/Turabian StyleChoi, So-Won, and Eul-Bum Lee. 2022. "Contractor’s Risk Analysis of Engineering Procurement and Construction (EPC) Contracts Using Ontological Semantic Model and Bi-Long Short-Term Memory (LSTM) Technology" Sustainability 14, no. 11: 6938. https://doi.org/10.3390/su14116938
APA StyleChoi, S.-W., & Lee, E.-B. (2022). Contractor’s Risk Analysis of Engineering Procurement and Construction (EPC) Contracts Using Ontological Semantic Model and Bi-Long Short-Term Memory (LSTM) Technology. Sustainability, 14(11), 6938. https://doi.org/10.3390/su14116938