3.1. Data Description
The data used in this study comprises the temperature, humidity, and flow rate of air inlet and outlet of all air-conditioning units in an office building from Shanghai, China, and the indoor load can be calculated by these data. In addition, we used the worldmet package in the open-source software R to obtain the meteorological data from the airport which is near the target building, and the distance between the target building and the corresponding airport is no more than 7 km. Therefore, the meteorological data of the airport can be used as the actual meteorological data of the target building. All the data set were recorded with 15 min resolution from 17 April 2017 to 3 May 2018. In this paper, we considered that LSTM can learn the order dependence between items in a sequence, and it has the promise of being able to learn the context required to make predictions in time-series forecasting problems. Therefore, we ignore the date information of the input variables in the expectation of further demonstrating the predictive advantage of the LSTM model.
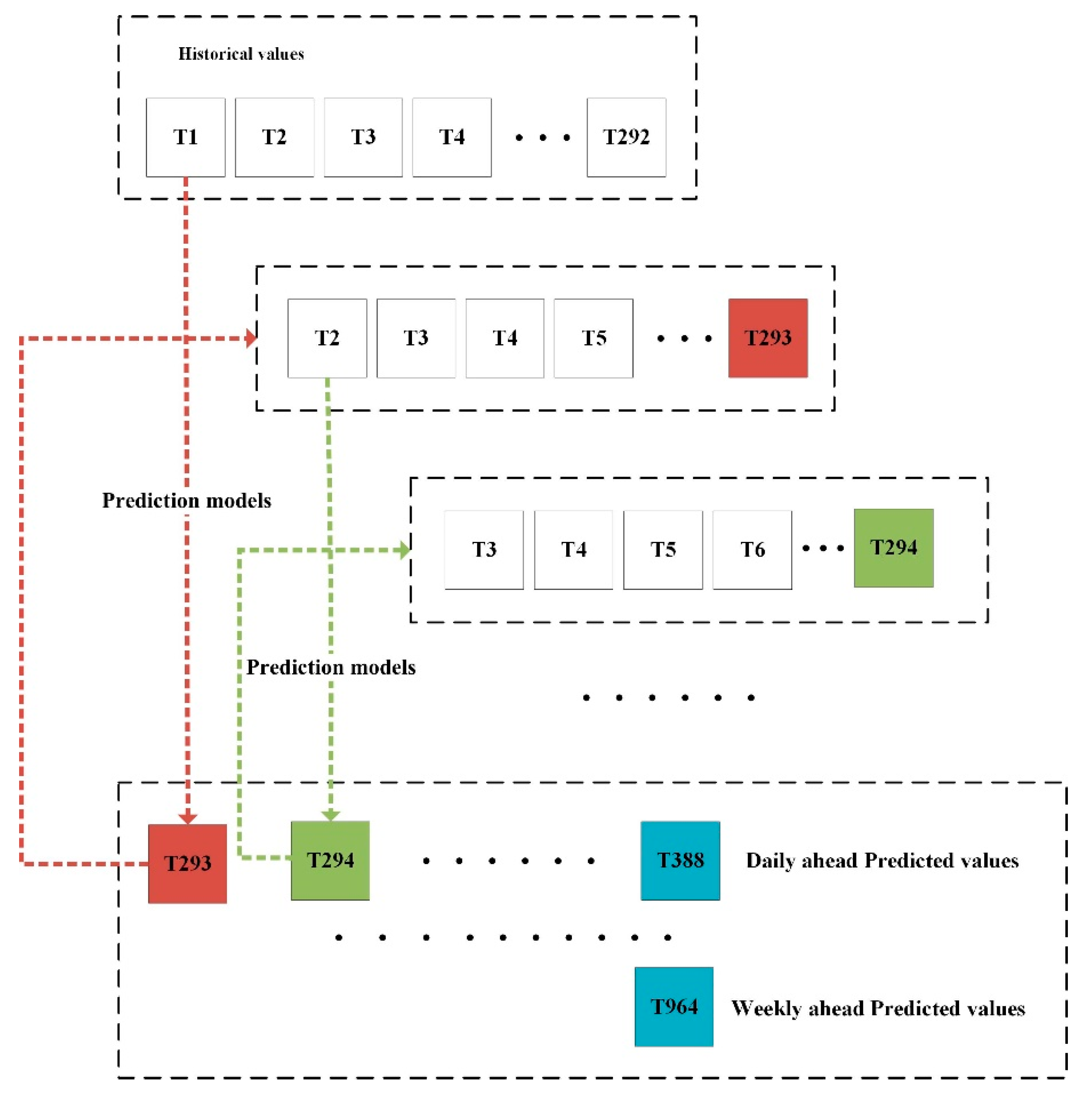
In total, the dataset contains four different variables, each with 36,672 observations. The raw data set is divided into two parts, training set (70%) and testing set (30%), the former consists of the indoor load and weather data from April 2017 to January 2018, and the latter contains the rest of the data set. Meanwhile, missing values are processed by interpolation, and outliers do not need to be removed or replaced, as there is no explicit outlier label in the data set, and some outlier detection methods based on statistical rules may destroy the authenticity of the data set.
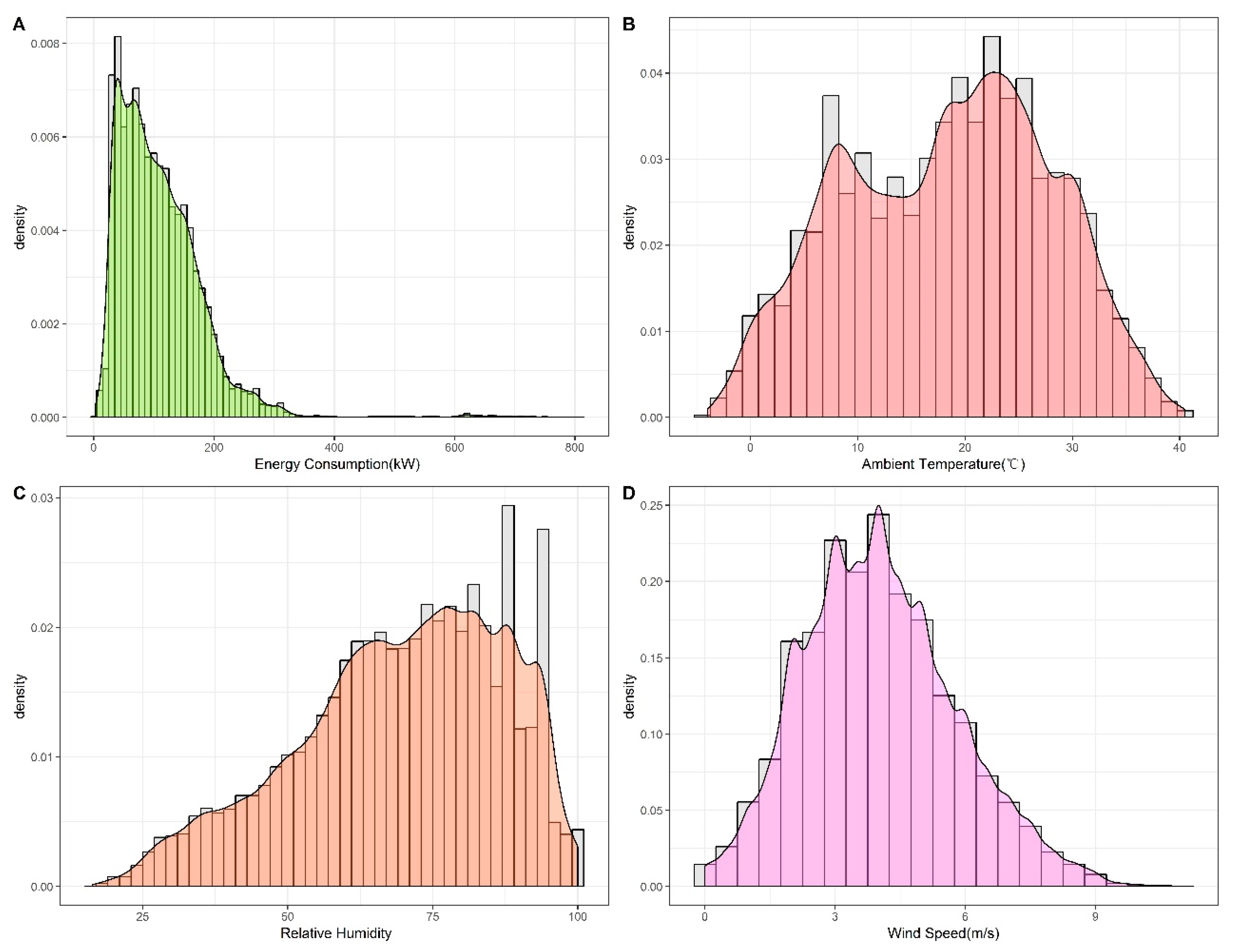
Figure 1 presents the probability distribution of the indoor load and weather data. The probability distribution of the indoor load exhibited in
Figure 1A reveals that it is close to skewed normally distributed. In addition, it can be concluded from other subgraphs that the weather in Shanghai may be humid and hot in summer, which is in line with its subtropical monsoon climate characteristics. The occasional extreme weather in
Figure 1B could cause a sharp increase in indoor load, and this situation is also reflected in
Figure 1A. In addition, the most likely distributions of each dataset in
Figure 1 are evaluated by the commonly used Kolmogorov–Smirnov test, and the results are shown in
Table 2:
3.2. Research Outline
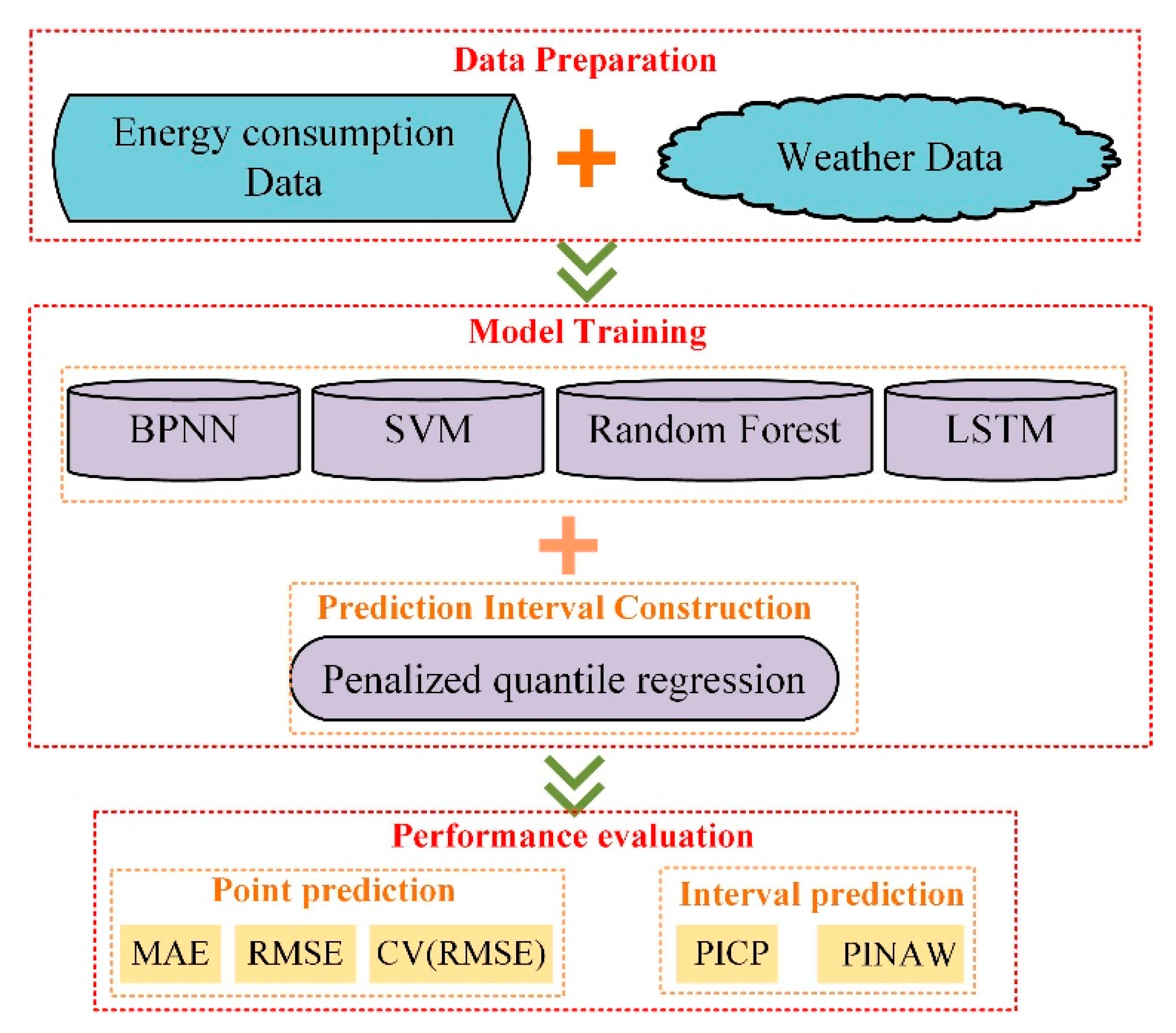
Figure 2 illustrates the outline of the research in this paper. It is divided into three main steps. The first step is data preparation, including energy consumption data and weather data, where the energy consumption data is calculated based on the temperature, humidity, and flow rate of the indoor air-conditioning inlet and outlet, while the weather data comes from airport data as described in
Section 2.1.
The second step is model training. In this paper, the deep-learning method, LSTM, is chosen as the basic point estimation algorithm, and the three commonly used machine-learning methods, BPNN, SVM, and random forest (RF), are used as reference models to facilitate comparisons with other models. Based on the prediction results of the above point estimation algorithms, penalized quantile regression (PQR) was chosen to construct the prediction intervals. Specifically speaking, as energy consumption data and weather data are input variables, we defined them as . Thus, the outputs of the aforementioned machine-learning methods can be expressed as:
We can describe the training process of BPNN by the following equations:
Here,
is the activation value of the jth node,
is the output of the hidden layer, and
is the activation function of a node, which is usually a sigmoid function:
The outputs of all neurons in the output layer are given as follows:
Here, is the activation function, usually a line function.
In this paper, the single hidden layer BPNN model is chosen for predictive modelling, considering its generalizability and relatively low computational cost.
- (2)
SVM
SVM uses the following form to approximate the relationship between input and output variables:
where
represents a high-dimensional feature space mapped from the low-dimensional space. In terms of the
ω and b, the following regularized risk function is used to find them.
where the
is called the regularized term. The
is the empirical error measured by the
-insensitive loss function, which is defined as follows:
This defines the range of ε values such that if the predicted value is within the range, the loss is zero, and if the predicted point is outside the range, then the loss is the magnitude of the difference between the predicted value and the distance ε of the range. is a penalty factor.
To get the estimation of
ω and
b, Equation (5) is transformed into objective function (8) by introducing the positive slack variables
.
By introducing four Lagrange multipliers,
,
,
,
, we can turn Equation (8) to the Lagrangian function. The Lagrange function becomes:
By introducing kernel function,
, the SVM forecasting model can be obtained by quadratic programming:
where
is the kernel function of the SVR model. The commonly used kernel functions of the SVR models contain Gaussian, polynomial, and sigmoid.
- (3)
RF
RF constructs a large number of decision trees during training and averages the values of output from each tree as the final output. Firstly, the training data are randomly selected and used to build the
decision tree. Then, RF is generated by adding in parallel these
trees
, where
is an n-dimensional feature vector. The ensemble produces
outputs
, where
is the value predicted by the decision tree; here, the estimation process of each tree is totally independent. The final prediction,
, is made by averaging the predicted values of each tree.
- (4)
LSTM
The long short-term memory network is derived from recurrent neural networks (RNN), and it can handle the long-term dependency problems of RNN. Hochreiter and Schmidhuber [
38] mathematically elaborated the architecture of LSTM, and the article showed that LSTM can keep or delete information by three controlling gates: input gate, output gate, and forget gate.
Figure 2 shows a schematic diagram of a LSTM network;
represents the output of the previous step, and
is the input of the current step.
When an input,
, enters the LSTM, the forget gate,
decides what information is deleted. This decision can be computed as:
Here, is the sigmoid activation function applied to elements inside the parentheses, is the weight matrix of the forget gate, and is the bias of the forget gate.
While for the input gate,
, it is used to decide what information to keep and update in the LSTM, and
can be expressed as:
Here, is the weight matrix of the input gate, and is the bias of the input gate.
Then, activation function,
, is used to describe the cell state under the current input:
After information selecting, the previous LSTM cell state,
, can be updated to the current LSTM cell state
as shown in
Figure 2, and
can be computed as:
Here, is an element-wise multiplier.
The output gate can be used to scale the output of the LSTM activation function, and it is expressed as:
Finally, the output,
, is calculated based on the LSTM cell state and output gate,
, and can be expressed as:
- (5)
Penalized quantile regression
Quantile regression is a modelling approach that models the quantile of the distribution of the variables. While traditional regression models focus on calculating the mean value of the target variable, quantile regression calculates the median value of it. Quantile regression utilizes a quantile loss function to provide information about future uncertainty:
where
denotes the quantile,
is the output at time
obtained from the machine learning-methods,
denotes the estimated
quantile at time
, and
denotes the quantile loss for the
quantile at time
.
For the smoothness of the fitting result of quantile regression, we adopt an appropriate penalty function which is designed to penalize the difference of consecutive regression coefficients [
39]. Suppose that the estimated
quantile function is given as a linear function,
, and the penalty function can be expressed as
. This penalty function gives a smoothing effect of the regression coefficients by penalizing the high quantity of the difference of two adjacent coefficients. Then, the objective loss function is represented by:
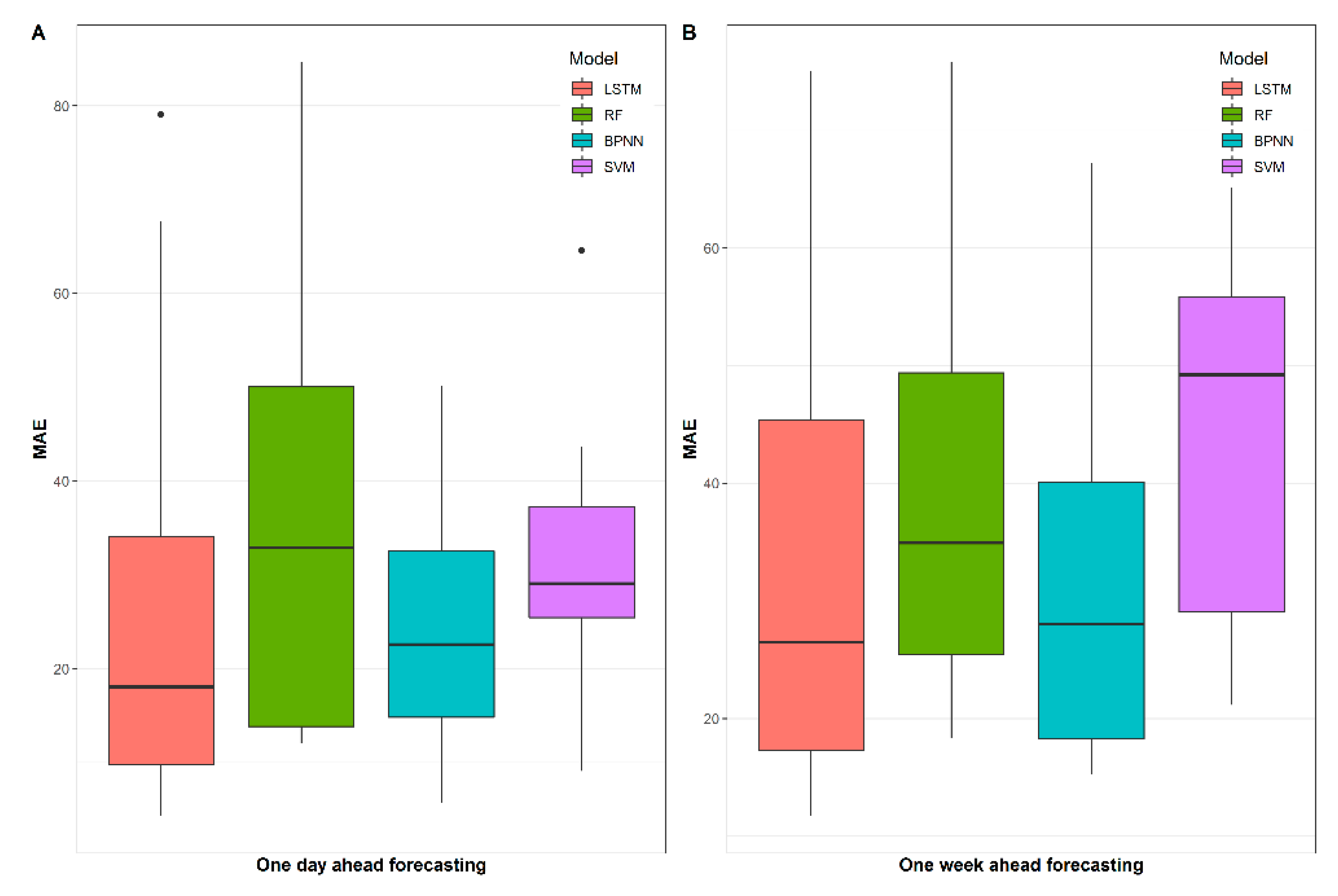
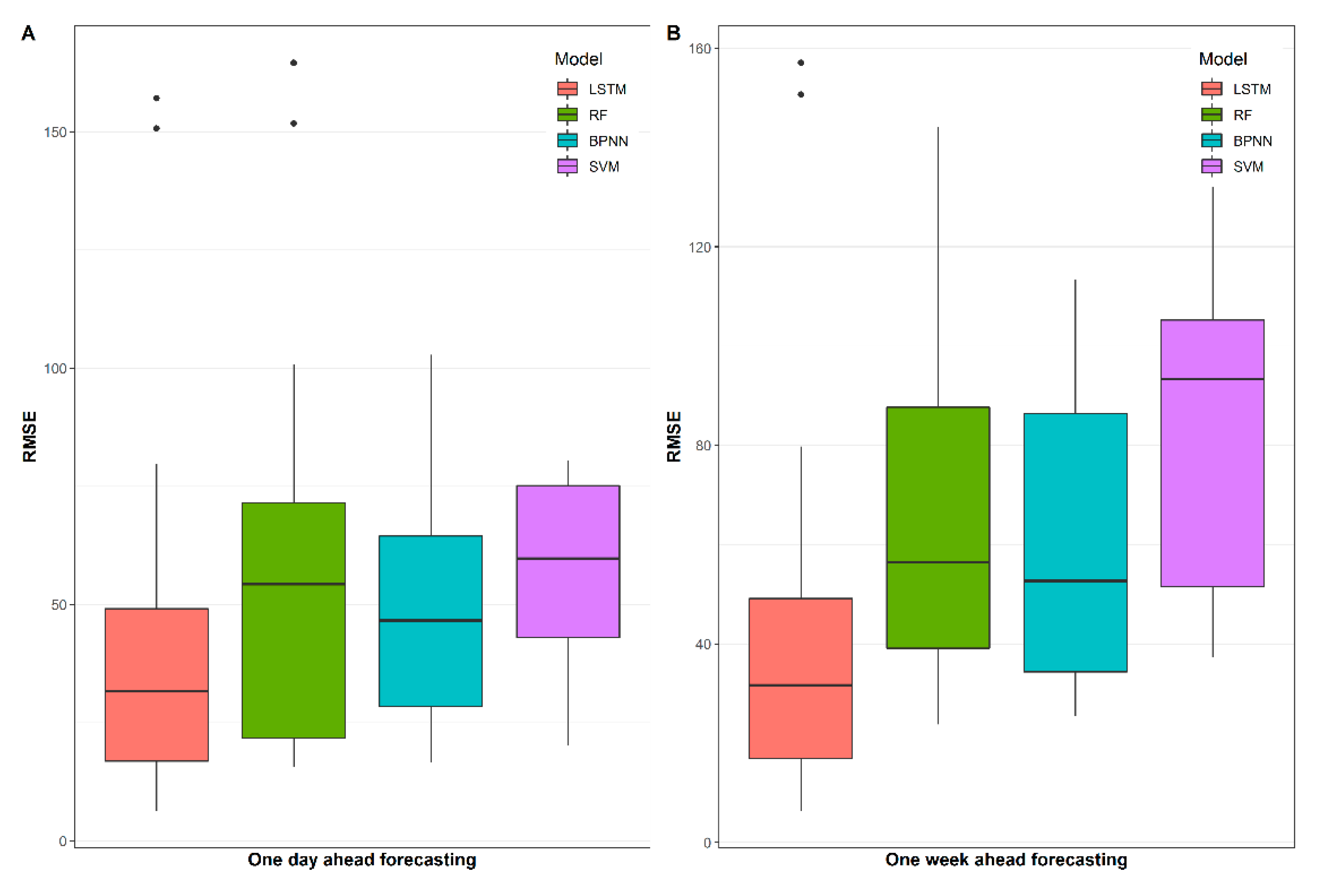
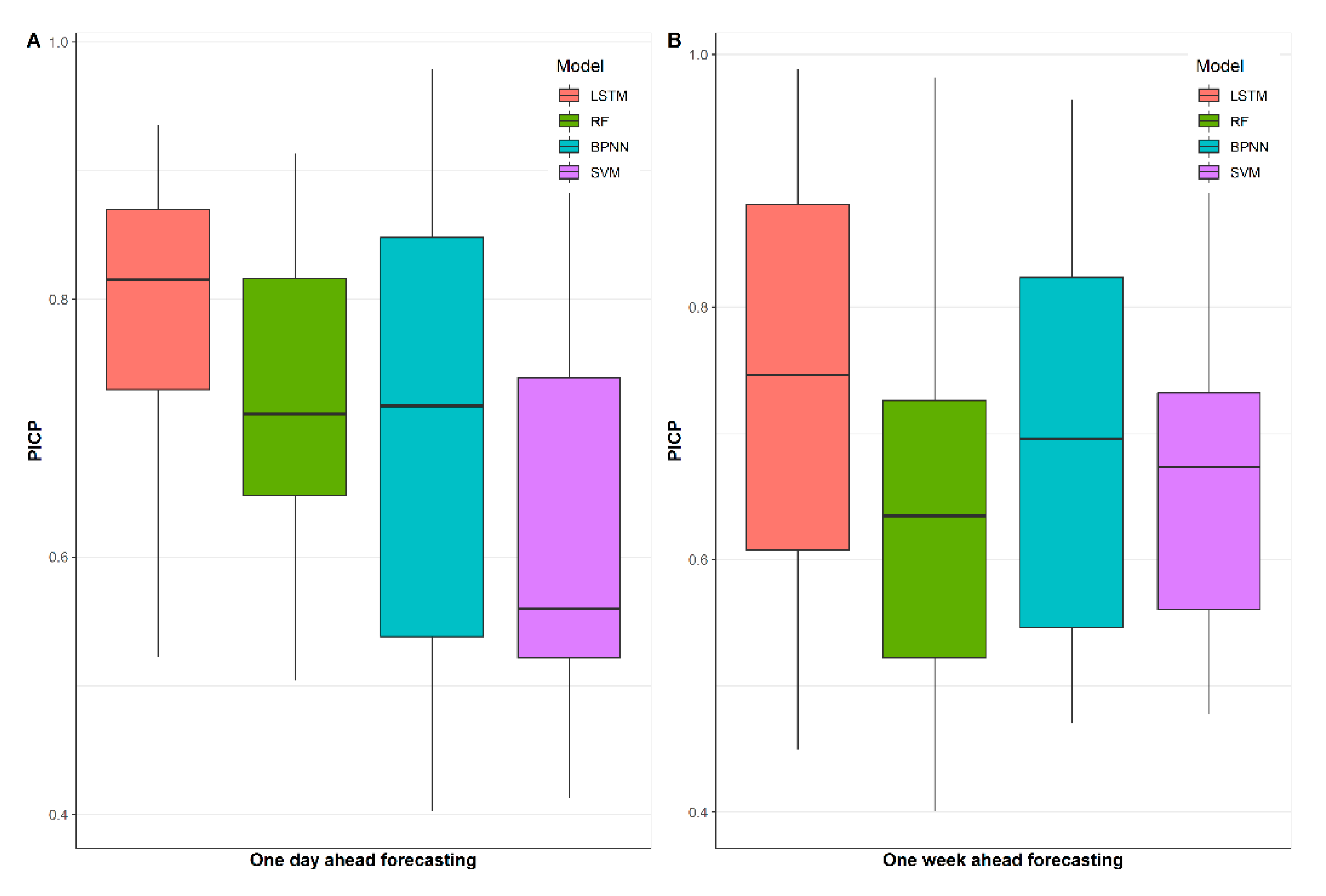
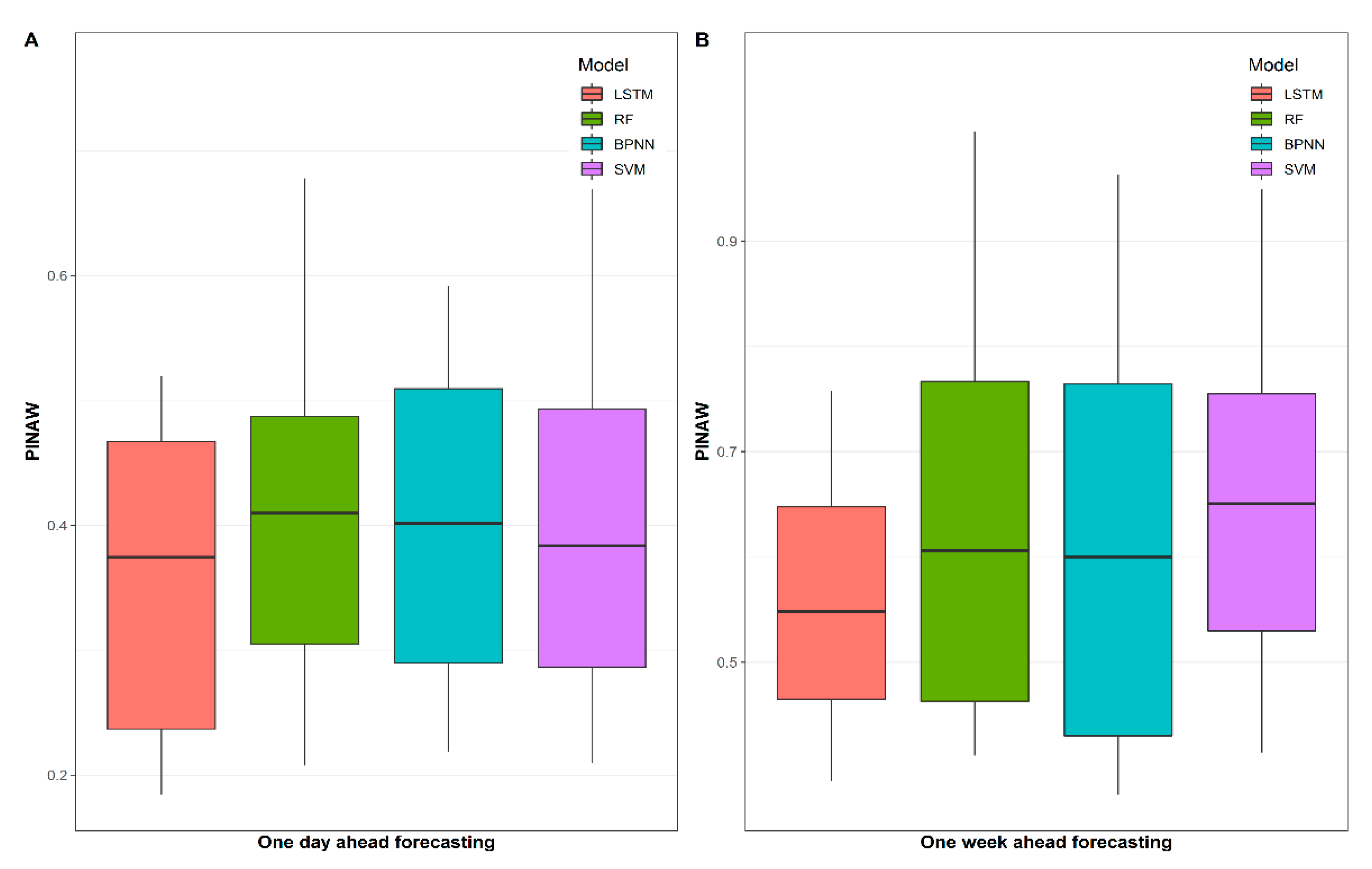
The third step is model performance evaluation, which is divided into two main aspects: firstly, the traditional point forecast evaluation criteria are used to assess the daily and weekly indoor-load-forecasting performance of each model, i.e., MAE, RMSE, and CV (RMSE). Secondly, to assess the interval forecasting results of the models, PICP and PINAW were used for quantitative comparison, and all interval forecasts were within the 95% prediction interval. The following subsection provides a brief description of the evaluation metrics used in this study.
3.4. Evaluation Metrics
To evaluate the model accuracy of point estimation, we use three metrics: the root mean square error (
RMSE), mean absolute error (
MAE), and coefficient of variation of
RMSE (
CV(RMSE)). All these error evaluation indexes have been extensively applied in the forecasting model estimation.
RMSE and
MAE can be expressed as below:
where,
is the predicted value,
is the observed value, and
is the number of measured data.
CV(RMSE) is the measure of the accumulated magnitude of error and is calculated as follows:
For assessing the interval prediction results, two evaluation metrics obtained from [
40] can be utilized in this work. Firstly, the prediction interval coverage probability (
PICP) evaluates whether the actual value of energy consumption is within the predicted interval. In addition, the prediction interval normalized average width (
PINAW) is used to measure the width of the predicted interval. The
PINAW is related to the informativeness of
PICP or equivalently to the sharpness of the predictions. If
PINAW is large, the
PICP will have little value as it is meaningless to say that future energy consumption will lie within its possible extreme range. Ideally, prediction intervals should have
PICPs close to the expected coverage rate and low
PINAWs. These two metrics are defined as below:
where
= 1 if the actual energy consumption lies within the prediction interval, and
= 0 otherwise.
and
represent the minimum and the maximum values of the predicted interval, respectively.
is the difference between them.
To comprehensively compare the different evaluation metrics, the entropy weights method (
EWM), which is a commonly used information-weighting method in decision making [
41], is introduced in this paper. The
EWM is mainly divided into the following steps:
Step 1: Construction of the initial matrix
The initial matrix is constructed as follows:
where
is the initial matrix,
is the number of factors,
is the number of data sample,
is the analyzed values of each sample parameter,
= 0, 1, 2, …,
and
= 0, 1, 2, …,
.
Step 2: Normalization of the matrix
The normalized matrix can be expressed as following:
where
is the normalized decision matrix.
Step 3: Calculation of the entropy
The entropy of each factor is calculated as the following:
where
is the entropy of each factor.
Step 4: Calculation of the weight
The weight of each factor is calculated as the following:
where
is the weight of each factor.
Step 5: Calculation of the composite score
The composite score of factors can be calculated as the following:
where
is the composite score of the factors.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}