
Fair Models for Impartial Policies: Controlling Algorithmic Bias in Transport Behavioural Modelling


Abstract
:1. Introduction
2. Literature Review
2.1. Machine Leaning and Transport Modelling
2.2. Fairness Definitions and Metrics
2.3. Bias Mitigation Algorithms
2.4. Transport Modelling and Equality
3. Materials and Methods
3.1. Methodology Overview
3.2. Fairness Metrics and Bias Mitigation Algorithms
- (1)
- The Statistical Parity Difference (SPD) measures the difference in the probability of being labelled with the favourable outcome between an individual that belongs to the unprivileged group and an individual that belongs to the privileged group. The SPD represents a definition of fairness that does not consider the accuracy of the predictions (i.e., this metric does not consider the true label of an individual), but only the parity on the probability of being assigned the positive label. Equation (1) shows the mathematical expression of this metric, where D represents the sensitive attribute.
- (2)
- The Equal Opportunity Difference (EOD) [36] is defined as the difference between the TPR between the unprivileged and privileged group. The EOD measures how accurate the model is when correctly predicting a favourable label for the unprivileged group with respect to the privileged group. Equation (2) shows the mathematical expression of this metric.
3.2.1. Reweighting
3.2.2. MetaFairClassifier
3.2.3. Calibrated Equalized Odds
3.3. Description of the Models and Data
3.3.1. COMPAS
3.3.2. Active Modes Model
3.3.3. Multimodal Transportation in Beijing
4. Results
4.1. COMPAS Model
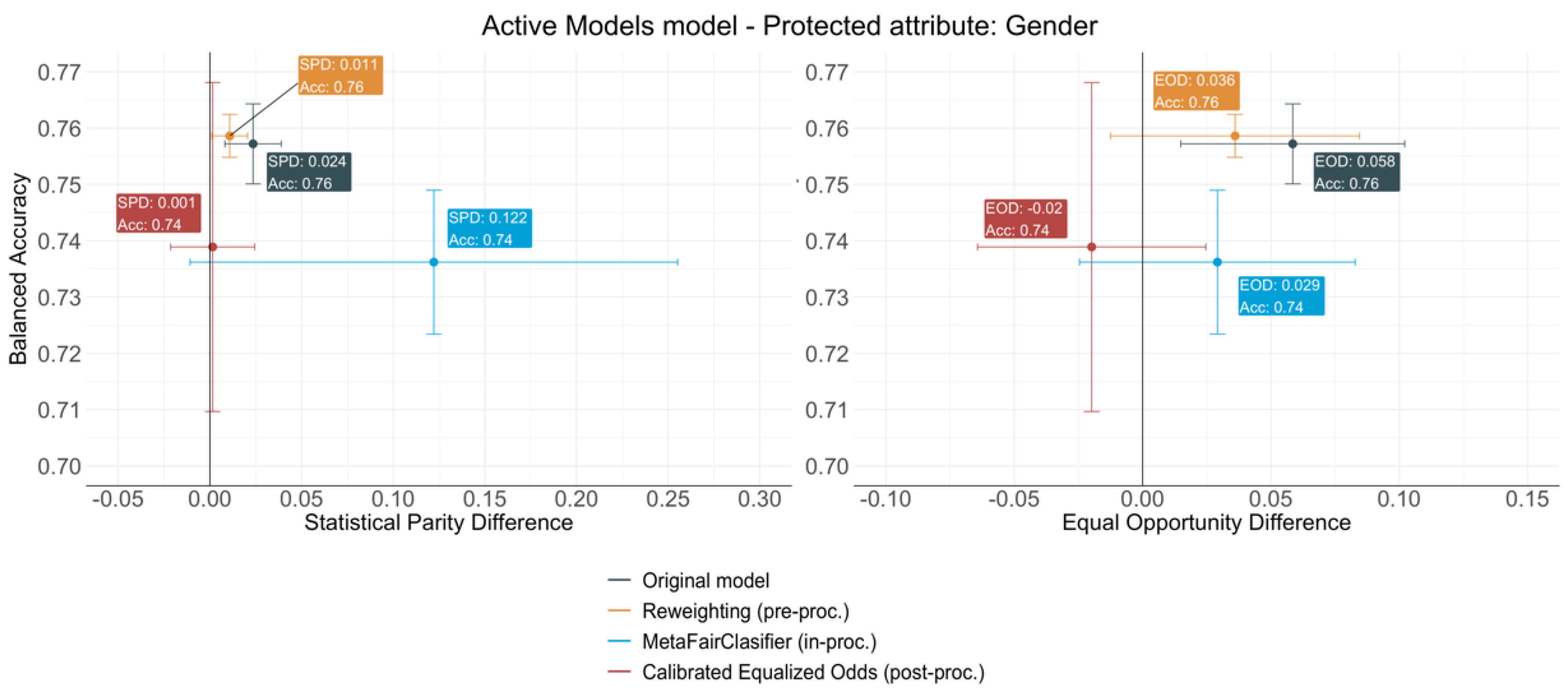
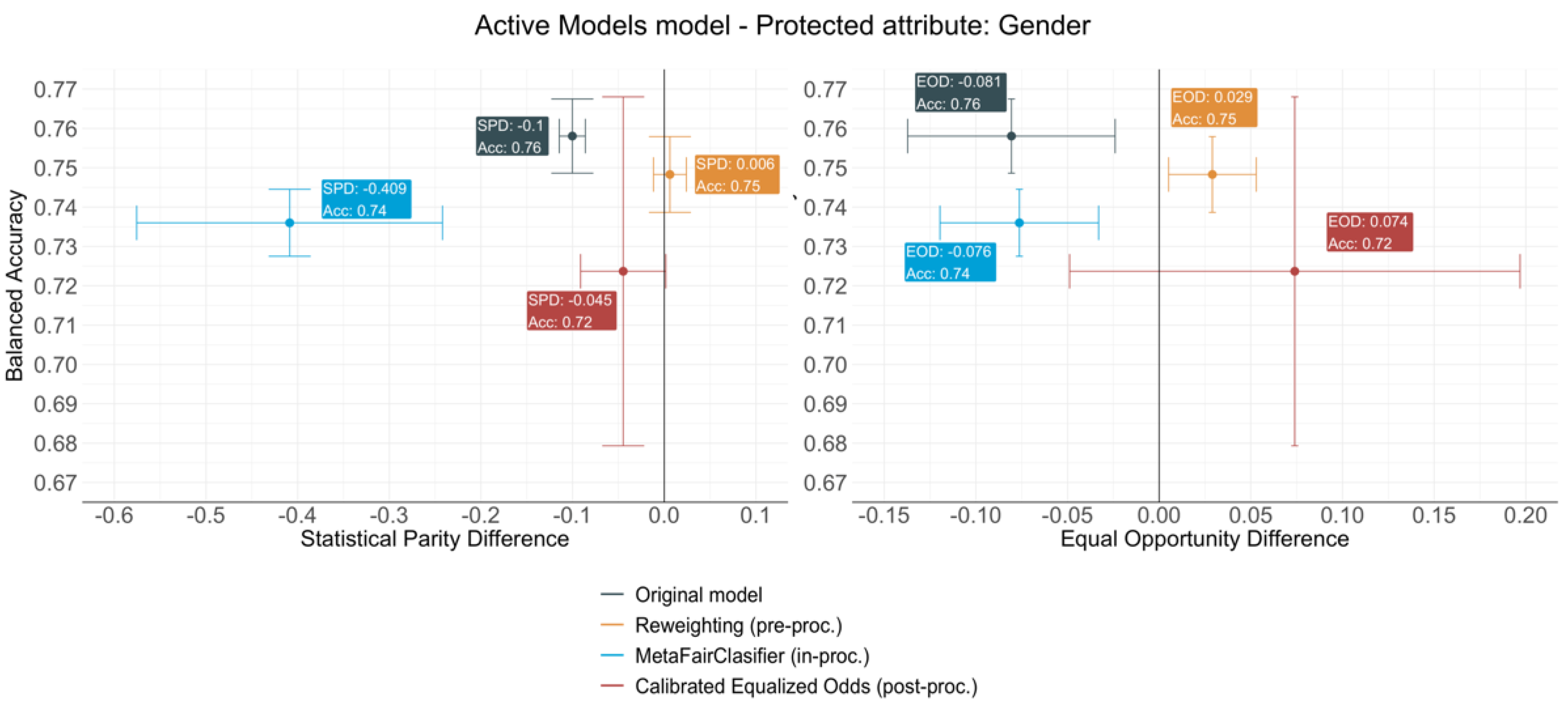
4.2. Active Modes Model
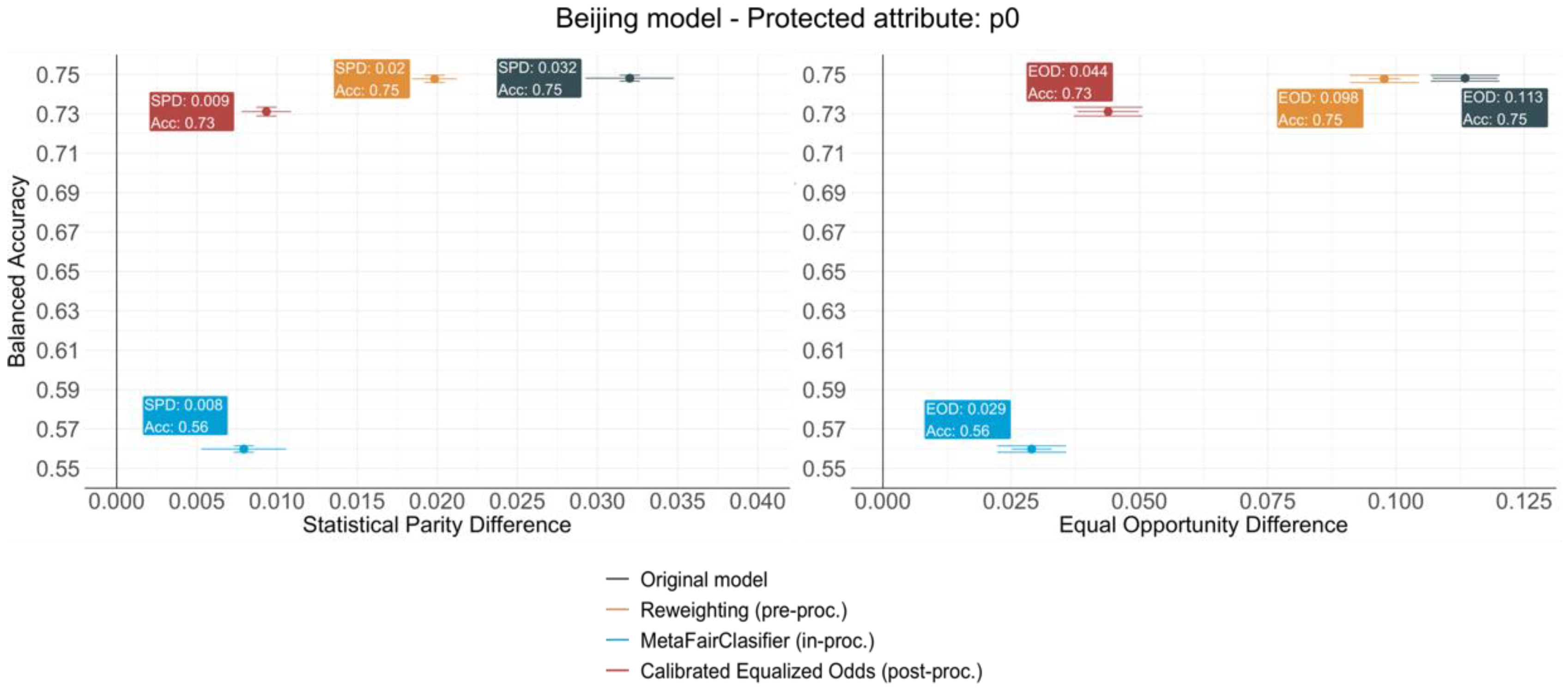
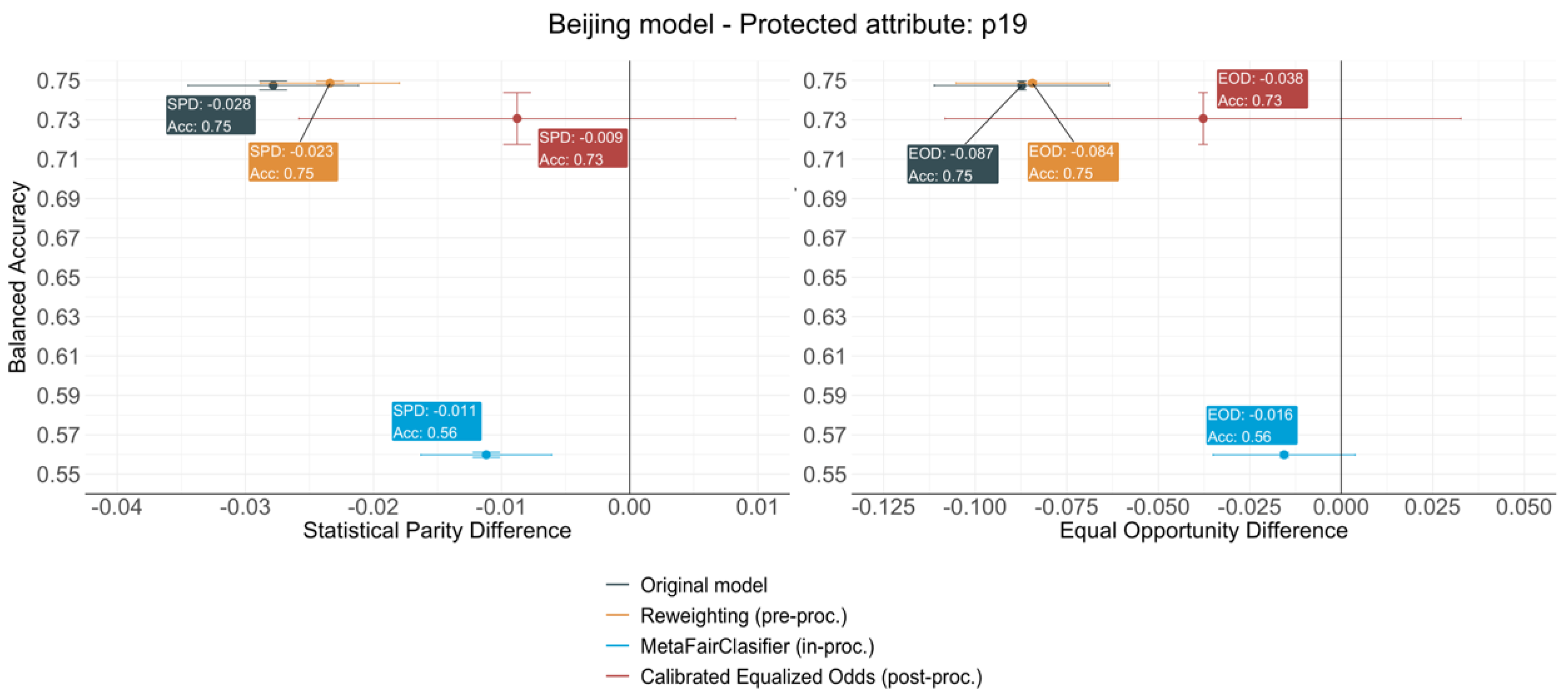
4.3. Beijing Model
5. Discussion
- The Reweighting (pre-processing) algorithm provides the most consistent results across all cases. It always achieves a reasonable level of debiasing with a very limited accuracy loss—less than 1% in all cases. Since the population sampling is fundamental for a transport model to be representative, the weighting of the different socio-economic groups depending on the frequency on which they are predicted to choose a specific mode seems a rather logical and easy to implement technique to make models fairer. Furthermore, as the classifier is not modified nor are the outcomes provided for the classifier, Reweighting would still allow for the interpretation of the model to draw conclusions regarding transport behaviour, which is a key aspect to consider when building mode choice models.
- The MetaFairClassifier (in-processing) provides a model with a significantly worse global accuracy than the original models and a very variable level of debiasing. When predicting the use of active modes, the bias measured by the SPD drastically increases by 363.54%, while a limited decrease in the EOD is achieved. A very different performance is observed for the protected attributes of the Beijing model, for which the bias reduction reaches an average of 67.5% for the SPD and 78% for the EOD. This difference between models might indicate that the MetaFairClassifier needs to be trained with big datasets in order to accomplish good levels of debiasing. In both cases, the reduction is achieved at the expense of the accuracy loss that derives from the drastic loss of positive predictions aiming to reduce the difference in the FDR across groups. The consequences of this reduction would be severe for the policy-making process, as it would entail an underestimation of the demand for all groups.
- The Calibrated Equalized Odds (post-processing) algorithm has very little impact in the accuracies of both models, although it is slightly higher than the pre-processing technique. The balanced accuracy suffers a moderate loss because in order to minimise the FNR gap across groups, the number of positive labels assigned to the privileged group decreases slightly, while keeping the number of positive labels assigned to the privileged group untouched. The redistribution of labels allows us to successfully remove the bias for both metrics, since it achieves an average reduction of 72% for the SPD and 48% for the EOD. It is noteworthy that debiasing is especially efficient for the gender attribute in the Active Modes model, which is also the variable with the most balanced distribution across categories. These results could suggest a higher efficiency of the post-processing algorithms for balanced data.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
EU Disclaimer
References
- ITF. Governing Transport in the Algorithmic Age; ITF: London, UK, 2019; Available online: https://www.itf-oecd.org/governing-transport-algorithmic-age (accessed on 25 May 2022).
- van Cranenburgh, S.; Wang, S.; Vij, A.; Pereira, F.; Walker, J. Choice modelling in the age of machine learning. arXiv 2021, arXiv:2101.11948. [Google Scholar]
- ITF. Big Data and Transport. Corporate Partnership Board Report. 2015. Available online: https://www.itf-oecd.org/big-data-and-transport (accessed on 2 February 2022).
- Anda, C.; Erath, A.; Fourie, P.J. Transport modelling in the age of big data. Int. J. Urban Sci. 2017, 21 (Suppl. S1), 19–42. [Google Scholar] [CrossRef]
- Kleinberg, J.; Ludwig, J.; Mullainathan, S.; Rambachan, A. Algorithmic Fairness. AEA Pap. Proc. 2020, 108, 22–27. [Google Scholar] [CrossRef]
- Larson, J.; Mattu, S.; Kirchner, L.; Angwin, J. How We Analyzed the COMPAS Recidivism Algorithm. 2016. Available online: https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm (accessed on 25 January 2022).
- Barocas, S.; Hardt, M.; Narayanan, A. Fairness and Machine Learning—Limitations and Opportunities. 2019. Available online: https://fairmlbook.org/ (accessed on 2 February 2022).
- Wang, Y.; Zeng, Z. Overview of Data-Driven Solutions. Data-Driven Solut. Transp. Probl. 2019, 2019, 1–10. [Google Scholar] [CrossRef]
- Zhao, Z.; Koutsopoulos, H.N.; Zhao, J. Detecting pattern changes in individual travel behavior: A Bayesian approach. Transp. Res. Part B Methodol. 2018, 112, 73–88. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Y.; Meng, Q.; Cheng, Q. A tailored machine learning approach for urban transport network flow estimation. Transp. Res. Part C: Emerg. Technol. 2019, 108, 130–150. [Google Scholar] [CrossRef]
- Zhang, K.; Jia, N.; Zheng, L.; Liu, Z. A novel generative adversarial network for estimation of trip travel time distribution with trajectory data. Transp. Res. Part C Emerg. Technol. 2019, 108, 223–244. [Google Scholar] [CrossRef]
- Cheng, L.; Chen, X.; de Vos, J.; Lai, X.; Witlox, F. Applying a random forest method approach to model travel mode choice behavior. Travel Behav. Soc. 2019, 14, 1–10. [Google Scholar] [CrossRef]
- Hillel, T. New Perspectives on the Performance of Machine Learning Classifiers for Mode Choice Prediction; Ecole Polytechnique Fédérale de Lausanne: Lausanne, Switzerland, 2020. [Google Scholar]
- Omrani, H.; Charif, O.; Gerber, P.; Awasthi, A.; Trigano, P. Prediction of Individual Travel Mode with Evidential Neural Network Model. Transp. Res. Rec. 2013, 2399, 1–8. [Google Scholar] [CrossRef]
- Hagenauer, J.; Helbich, M. A comparative study of machine learning classifiers for modeling travel mode choice. Expert Syst. Appl. 2017, 78, 273–282. [Google Scholar] [CrossRef]
- Xie, C.; Lu, J.; Parkany, E. Work Travel Mode Choice Modeling with Data Mining: Decision Trees and Neural Networks. Transp. Res. Rec. 2003, 1854, 50–61. [Google Scholar] [CrossRef]
- Karlaftis, M.G.; Vlahogianni, E.I. Statistical methods versus neural networks in transportation research: Differences, similarities and some insights. Transp. Res. Part C Emerg. Technol. 2011, 19, 387–399. [Google Scholar] [CrossRef]
- Wang, F.; Ross, C.L. Machine Learning Travel Mode Choices: Comparing the Performance of an Extreme Gradient Boosting Model with a Multinomial Logit Model. Transp. Res. Rec. 2018, 2672, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Yan, X.; Yu, A.; van Hentenryck, P. Prediction and behavioral analysis of travel mode choice: A comparison of machine learning and logit models. Travel Behav. Soc. 2020, 20, 22–35. [Google Scholar] [CrossRef]
- Hillel, T.; Bierlaire, M.; Elshafie, E.B.; Jin, Y. A systematic review of machine learning classification methodologies for modelling passenger mode choice. J. Choice Model. 2021, 38, 100221. [Google Scholar] [CrossRef]
- Chang, X.; Wu, J.; Liu, H.; Yan, X.; Sun, H.; Qu, Y. Travel mode choice: A data fusion model using machine learning methods and evidence from travel diary survey data. Transp. A Transp. Sci. 2019, 15, 1587–1612. [Google Scholar] [CrossRef]
- Kim, E.J. Analysis of Travel Mode Choice in Seoul Using an Interpretable Machine Learning Approach. J. Adv. Transp. 2021, 2021, 6685004. [Google Scholar] [CrossRef]
- Omrani, H. Predicting Travel Mode of Individuals by Machine Learning. Transp. Res. Procedia 2015, 10, 840–849. [Google Scholar] [CrossRef] [Green Version]
- Tang, L.; Xiong, C.; Zhang, L. Decision tree method for modeling travel mode switching in a dynamic behavioral process. Transp. Plan. Technol. 2015, 38, 833–850. [Google Scholar] [CrossRef]
- Ceccato, R.; Chicco, A.; Diana, M. Evaluating car-sharing switching rates from traditional transport means through logit models and Random Forest classifiers. Transp. Plan. Technol. 2021, 44, 160–175. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, C.; Li, J.; Dong, C.; Liu, Y. Travel Mode Choice Modeling Based on Improved Probabilistic Neural Network. In Proceedings of the Conference on Traffic and Transportation Studies (ICTTS), Kunming, China, 3–5 August 2010; Volume 383, pp. 685–695. [Google Scholar] [CrossRef]
- Calders, T.; Žliobaitė, I. Why Unbiased Computational Processes Can Lead to Discriminative Decision Procedures. Stud. Appl. Philos. Epistemol. Ration. Ethics 2013, 3, 43–57. [Google Scholar] [CrossRef]
- Kleinberg, J.; Ludwig, J.; Mullainathan, S.; Sunstein, C.R. Discrimination in the Age of Algorithms. J. Leg. Anal. 2018, 10, 113–174. [Google Scholar] [CrossRef]
- Yarbrough, M.V. Disparate Impact, Disparate Treatment, and the Displaced Homemaker. Law Contemp. Probl. 1986, 49, 107. [Google Scholar] [CrossRef] [Green Version]
- Friedler, S.A.; Scheidegger, C.; Venkatasubramanian, S. On the (Im)Possibility of Fairness. arXiv 2016, arXiv:1609.07236. [Google Scholar] [CrossRef]
- Majumder, S.; Chakraborty, J.; Bai, G.R.; Stolee, K.T.; Menzies, T. Fair Enough: Searching for Sufficient Measures of Fairness. arXiv 2021, arXiv:abs/2110.13029. [Google Scholar]
- Verma, S.; Rubin, J. Fairness Definitions Explained. In Proceedings of the 2018 IEEE/ACM International Workshop on Software Fairness (FairWare), Gothenburg, Sweden, 29 May 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Dwork, C.; Hardt, M.; Pitassi, T.; Reingold, O.; Zemel, R. Fairness Through Awareness. In Proceedings of the ITCS 2012—Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; pp. 214–226. [Google Scholar] [CrossRef] [Green Version]
- Simoiu, C.; Corbett-Davies, S.; Goel, S.; Ermon, S.; Feller, A.; Flaxman, S.; Gelman, A.; Mackey, L.; Overgoor, J.; Pierson, E. The Problem of Infra-marginality in Outcome Tests for Discrimination. Ann. Appl. Stat. 2016, 11, 1193–1216. [Google Scholar] [CrossRef]
- Corbett-Davies, S.; Pierson, E.; Feller, A.; Goel, S.; Huq, A. Algorithmic decision making and the cost of fairness. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Part F129685, Halifax, NS, Canada, 13–17 August 2017; pp. 797–806. [Google Scholar] [CrossRef]
- Hardt, M.; Price, E.; Srebro, N. Equality of Opportunity in Supervised Learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3323–3331. [Google Scholar]
- Zafar, M.B.; Valera, I.; Rodriguez, M.G.; Gummadi, K.P. Fairness Beyond Disparate Treatment & Disparate Impact: Learning Classification without Disparate Mistreatment. In Proceedings of the 26th International World Wide Web Conference (WWW), Perth, Australia, 3–7 April 2017; pp. 1171–1180. [Google Scholar] [CrossRef] [Green Version]
- Bellamy, R.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilovic, A.; et al. AI Fairness 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias. 2018. Available online: https://github.com/ibm/aif360 (accessed on 15 December 2021).
- Pedreshi, D.; Ruggieri, S.; Turini, F. Discrimination-aware data mining. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 560–568. [Google Scholar] [CrossRef] [Green Version]
- Kamiran, F.; Calders, T. Classifying without discriminating. In Proceedings of the 2009 2nd International Conference on Computer, Control and Communication, Karachi, Pakistan, 17–18 February 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Feldman, M.; Friedler, S.A.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 259–268. [Google Scholar] [CrossRef] [Green Version]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2011, 33, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Calmon, F.P.; Wei, D.; Vinzamuri, B.; Ramamurthy, K.N.; Varshney, K.R. Optimized Data Pre-Processing for Discrimination Prevention. Adv. Neural Inf. Processing Syst. 2017, 1, 3993–4002. [Google Scholar]
- Zemel, R.; Ledell, Y.W.; Swersky, K.; Pitassi, T.; Dwork, C. Learning Fair Representations. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 325–333. Available online: https://proceedings.mlr.press/v28/zemel13.html (accessed on 3 February 2022).
- Calders, T.; Kamiran, F.; Pechenizkiy, M. Building classifiers with independency constraints. In Proceedings of the ICDM Workshops 2009—IEEE International Conference on Data Mining, Miami, FL, USA, 6 December 2009; pp. 13–18. [Google Scholar] [CrossRef]
- Kamishima, T.; Akaho, S.; Sakuma, J. Fairness-aware learning through regularization approach. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Vancouver, BC, Canada, 11 December 2011; pp. 643–650. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating Unwanted Biases with Adversarial Learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 335–340. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, A.; Beygelzimer, A.; Dudfk, M.; Langford, J.; Hanna, W. A Reductions Approach to Fair Classification. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Volume 1, pp. 102–119. Available online: https://arxiv.org/abs/1803.02453v3 (accessed on 3 February 2022).
- Agarwal, A.; Dudík, M.; Wu, Z.S. Fair Regression: Quantitative Definitions and Reduction-based Algorithms. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 166–183. Available online: https://arxiv.org/abs/1905.12843v1 (accessed on 3 February 2022).
- Kearns, M.; Roth, A.; Neel, S.; Wu, Z.S. An Empirical Study of Rich Subgroup Fairness for Machine Learning. In Proceedings of the 2019 Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 100–109. [Google Scholar] [CrossRef] [Green Version]
- Elisa Celis, L.; Huang, L.; Keswani, V.; Vishnoi, N.K. Classification with Fairness Constraints: A Meta-Algorithm with Provable Guarantees. In Proceedings of the 2019 Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 319–328. [Google Scholar] [CrossRef]
- Menon, A.K.; Williamson, R.C. The cost of fairness in binary classification. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; Friedler, S.A., Wilson, C., Eds.; Volume 81, pp. 107–118. Available online: https://proceedings.mlr.press/v81/menon18a.html (accessed on 10 December 2021).
- Woodworth, B.; Gunasekar, S.; Ohannessian, M.I.; Srebro, N. Learning Non-Discriminatory Predictors. arXiv 2017, arXiv:1702.06081v3. [Google Scholar]
- Kamiran, F.; Karim, A.; Zhang, X. Decision theory for discrimination-aware classification. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Brussels, Belgium, 10–13 December 2012; pp. 924–929. [Google Scholar] [CrossRef] [Green Version]
- Pleiss, G.; Raghavan, M.; Wu, F.; Kleinberg, J.; Weinberger, K.Q. On Fairness and Calibration. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5684–5693. [Google Scholar]
- Best, H.; Lanzendorf, M. Division of labour and gender differences in metropolitan car use. An empirical study in Cologne, Germany. J. Transp. Geogr. 2005, 13, 109–121. [Google Scholar] [CrossRef]
- Scheiner, J. Gendered key events in the life course: Effects on changes in travel mode choice over time. J. Transp. Geogr. 2014, 37, 47–60. [Google Scholar] [CrossRef]
- Hu, L. Racial/ethnic differences in job accessibility effects: Explaining employment and commutes in the Los Angeles region. Transp. Res. Part D Transp. Environ. 2019, 76, 56–71. [Google Scholar] [CrossRef]
- Rosenbloom, S.; Waldorf, B. Older travelers: Does place or race make a difference? Transp. Res. Circ. 2001, E-C026, 103–120. [Google Scholar]
- Tehrani, S.O.; Wu, S.J.; Roberts, J.D. The Color of Health: Residential Segregation, Light Rail Transit Developments, and Gentrification in the United States. Int. J. Environ. Res. Public Health 2019, 16, 3683. [Google Scholar] [CrossRef] [Green Version]
- Calafiore, A.; Dunning, R.; Nurse, A.; Singleton, A. The 20-minute city: An equity analysis of Liverpool City Region. Transp. Res. Part D Transp. Environ. 2022, 102, 103111. [Google Scholar] [CrossRef]
- Farber, S.; Bartholomew, K.; Li, X.; Páez, A.; Nurul Habib, K.M. Assessing social equity in distance based transit fares using a model of travel behavior. Transp. Res. Part A Policy Pract. 2014, 67, 291–303. [Google Scholar] [CrossRef]
- Giuliano, G. Low Income, Public Transit, and Mobility. Transp. Res. Rec. 2005, 1927, 63–70. [Google Scholar] [CrossRef]
- Stanley, J.; Stanley, J.; Vella-Brodrick, D.; Currie, G. The place of transport in facilitating social inclusion via the mediating influence of social capital. Res. Transp. Econ. 2010, 29, 280–286. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Zhao, J. Equality of opportunity in travel behavior prediction with deep neural networks and discrete choice models. Transp. Res. Part C Emerg. Technol. 2021, 132, 103410. [Google Scholar] [CrossRef]
- Corbett-Davies, S.; Goel, S.; Chohlas-Wood, A.; Chouldechova, A.; Feller, A.; Huq, A.; Hardt, M.; Ho, D.E.; Mitchell, S.; Overgoor, J.; et al. The Measure and Mismeasure of Fairness: A Critical Review of Fair Machine Learning. arXiv 2018, arXiv:1808.00023. [Google Scholar]
- Chouldechova, A. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments. Artif. Intell. Law 2016, 25, 5–27. [Google Scholar] [CrossRef] [PubMed]
- Rudin, C.; Wang, C.; Coker, B. The age of secrecy and unfairness in recidivism prediction. Harv. Data Sci. Rev. 2018, 2, 6ed64b30. [Google Scholar] [CrossRef]
- Pisoni, E.; Christidis, P.; Cawood, E.N. Active mobility versus motorized transport? User choices and benefits for the society. Sci. Total Environ. 2022, 806, 150627. [Google Scholar] [CrossRef] [PubMed]
- Eurostat. Urban and Rural Living in the EU; Eurostat: Luxembourg, 2020. Available online: https://ec.europa.eu/eurostat/web/products-eurostat-news/-/edn-20200207-1 (accessed on 5 February 2022).
- Zhou, W.; Roy, T.D.; Skrypnyk, I. The KDD Cup 2019 Report. ACM SIGKDD Explor. Newsl. 2020, 22, 8–17. [Google Scholar] [CrossRef]
- TomTom. Beijing Traffic Report. 2020. Available online: https://www.tomtom.com/en_gb/traffic-index/beijing-traffic/ (accessed on 22 December 2021).
- Moons, E.; Wets, G.; Aerts, M. Nonlinear Models for Determining Mode Choice. In Proceedings of the Progress in Artificial Intelligence, Guimarães, Portugal, 3–7 December 2007; pp. 183–194. [Google Scholar] [CrossRef]
- Goel, R.; Oyebode, O.; Foley, L.; Tatah, L.; Millett, C.; Woodcock, J. Gender differences in active travel in major cities across the world. Transportation 2022, 2021, 1–17. [Google Scholar] [CrossRef]
- Goel, R.; Goodman, A.; Aldred, R.; Nakamura, R.; Tatah, L.; Garcia LM, T.; Diomedi-Zapata, B.; de Sa, T.H.; Tiwari, G.; de Nazelle, A.; et al. Cycling Behaviour in 17 Countries across 6 Continents: Levels of Cycling, Who Cycles, for What Purpose, and How Far? Transp. Rev. 2021, 42, 58–81. Available online: https://doi.org/10.1080/01441647.2021.1915898/SUPPL_FILE/TTRV_A_1915898_SM5155.ZIP (accessed on 2 December 2021). [CrossRef]
- Aldred, R.; Croft, J.; Goodman, A. Impacts of an active travel intervention with a cycling focus in a suburban context: One-year findings from an evaluation of London’s in-progress mini-Hollands programme. Transp. Res. Part A Policy Pract. 2019, 123, 147–169. [Google Scholar] [CrossRef]
- Aasheim, T.H.; Sølveånneland KT, H.; Sølveånneland, S.; Brynjulfsen, H.; Slavkovik, M. Bias Mitigation with AIF360: A Comparative Study. Nor. IKT-Konf. Forsk. Og Utdanning 2020, 1, 833. Available online: https://ojs.bibsys.no/index.php/NIK/article/view/833 (accessed on 10 January 2022).
- Burgdorf, C.; Mönch, A.; Beige, S. Mode choice and spatial distribution in long-distance passenger transport—Does mobile network data deliver similar results to other transportation models? Transp. Res. Interdiscip. Perspect. 2020, 8, 100254. [Google Scholar] [CrossRef]
- Sun, X.; Wandelt, S. Transportation mode choice behavior with recommender systems: A case study on Beijing. Transp. Res. Interdiscip. Perspect. 2021, 11, 100408. [Google Scholar] [CrossRef]
- González, M.C.; Hidalgo, C.A.; Barabási, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Wesolowski, A.; Eagle, N.; Noor, A.M.; Snow, R.W.; Buckee, C.O. The impact of biases in mobile phone ownership on estimates of human mobility. J. R. Soc. Interface 2013, 10, 20120986. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline Model | Data | Protected Attributes | Favourable Outcome | |
|---|---|---|---|---|
| COMPAS | Logistic regression | Personal and criminal behaviour characteristics of criminal defendants |
| Individual labelled with high risk of recidivism |
| Active Modes | XGBoost | Travel Survey |
| Individual uses active modes for his most frequent trip |
| Multimodal transportation Beijing model | XGBoost | Multimodal trip planner (Baidu) data | Anonymized socio-economic variables with highest bias:
| The planned trip is chosen for a given trip |
| Categories | N. of Observations (Percentage) | ||
|---|---|---|---|
| Socio-economic variables | Gender | Male | 4247 (80.5%) |
| Female | 1031 (19.5%) | ||
| Race | Caucasian | 2103 (39.8%) | |
| African American | 3175 (60.2%) | ||
| Age | Less than 25 years old | 1156 (21.9%) | |
| 25–45 years old | 3026 (57.3%) | ||
| More than 45 years old | 1096 (20.8%) | ||
| Criminal behaviour | Number of priors | No priors | 1667 (31.6%) |
| 0–3 priors | 1953 (37.0%) | ||
| More than 3 | 1658 (31.4%) | ||
| Type of charges | Felony | 3440 (65.2%) | |
| Misdemeanour | 1838 (34.8%) |
| Continuous Variables | Categorical Variables | ||||
|---|---|---|---|---|---|
| Mean | Standard Deviation | Categories | N. of Observations (Percentage) | ||
| Socio-economic variables | Gender | Male | 12,986 (49.0%) | ||
| Female | 13,514 (51.0%) | ||||
| Age | 41.21 | 13.75 | |||
| Education | Primary | 738 (2.8%) | |||
| Low secondary | 3167 (11.9%) | ||||
| Upper secondary | 11,365 (42.9%) | ||||
| Tertiary and higher | 11,230 (42.4%) | ||||
| Type of employment | Full-time employed | 15,954 (60.2%) | |||
| Part-time employed | 2845 (10.7%) | ||||
| Unemployed | 1696 (6.4%) | ||||
| Studying | 1933 (7.3%) | ||||
| Retired | 2490 (9.4%) | ||||
| Other | 1319 (5.0%) | ||||
| I prefer not to answer | 263 (1.0%) | ||||
| Household income | High | 509 (1.9%) | |||
| Higher middle | 3276 (12.4%) | ||||
| Middle | 14,017 (52.9%) | ||||
| Lower middle | 5958 (22.5%) | ||||
| Low | 1780 (6.7%) | ||||
| I prefer not to answer | 960 (3.6%) | ||||
| Urban environment | Size of the city | >1 million inhabitants | 3416 (12.9%) | ||
| 250.000–50.000 inhabitants | 5041 (19.0%) | ||||
| <250.000 inhabitants | 11,726 (44.3%) | ||||
| Rural area | 6317 (23.8%) | ||||
| Area of residence | Centre | 9657 (36.4%) | |||
| Suburbs | 10,525 (39.8%) | ||||
| Not living in a city | 6317 (23.8%) | ||||
| Most frequent trip characteristics | Vehicles per person in household | 0.612 | 0.377 | ||
| Frequency of the most frequent trip | Every day/every working day | 17,286 (65.2%) | |||
| 2–4 days/week | 7041 (26.6%) | ||||
| Once per week or less | 2173 (8.2%) | ||||
| Distance of the most frequent trip | Less than 3 km | 4274 (16.1%) | |||
| 3–5 km | 5002 (18.9%) | ||||
| 6–10 km | 5444 (20.5%) | ||||
| 11–20 km | 5154 (19.4%) | ||||
| 21–30 km | 2904 (11.0%) | ||||
| 31–50 km | 1842 (7.0%) | ||||
| More than 50 km | 1880 (7.1%) | ||||
| Area of destination of most frequent trip | Urban area of residence | 13,073 (49.3%) | |||
| Urban area different from that of residence | 9108 (34.4%) | ||||
| Outside an urban area | 4319 (16.3%) | ||||
| Active modes for most frequent trip | Yes | 7112 (26.8%) | |||
| No | 19,388 (73.2%) | ||||
| Continuous Variables | Categorical Variables | |||
|---|---|---|---|---|
| Mean | Standard Deviation | Categories | N. Observations (Percentage) | |
| Distance (m) | 17,087 | 16,037 | ||
| Time (sec.) | 2934 | 2017 | ||
| Price (Yuan cents) | 1514 | 3100 | ||
| Availability: walking | Yes | 385,763 (27.1%) | ||
| No | 1,039,085 (72.9%) | |||
| Availability: biking | Yes | 595,855 (41.8%) | ||
| No | 828,993 (58.2%) | |||
| Availability: private car | Yes | 1,394,930 (97.9%) | ||
| No | 29,918 (2.1%) | |||
| Availability: taxi | Yes | 1,319,705 (92.6%) | ||
| No | 105,143 (7.4%) | |||
| Availability: bus | Yes | 838,947 (58.9%) | ||
| No | 585,901 (41.1%) | |||
| Availability: metro | Yes | 623,295 (43.7%) | ||
| No | 801,553 (56.3%) | |||
| Availability: metro–bus | Yes | 628,790 (44.1%) | ||
| No | 796,058 (55.9%) | |||
| Availability: other | Yes | 711,594 (49.9%) | ||
| No | 713,254 (50.1%) | |||
| Weather | Not raining | 1,389,698 (97.5%) | ||
| Raining | 35,150 (2.5%) | |||
| Holidays | Holidays | 241,794 (83.0%) | ||
| Not holidays | 1,183,054 (17.0%) | |||
| Day of the week | Monday | 199,942 (14.0%) | ||
| Tuesday | 182,565 (12.8%) | |||
| Wednesday | 146,127 (10.3%) | |||
| Thursday | 226,191 (15.9%) | |||
| Friday | 195,225 (13.7%) | |||
| Saturday | 235,745 (16.5%) | |||
| Sunday | 239,053 (16.8%) | |||
| Hour of the day | 00:00–01:59 | 13,557 (1.0%) | ||
| 02:00–03:59 | 4358 (0.3%) | |||
| 04:00–05:59 | 15,207 (1.0%) | |||
| 06:00–07:59 | 86,467 (6.1%) | |||
| 08:00–09:59 | 184,422 (12.9%) | |||
| 10:00–11:59 | 194,840 (13.7%) | |||
| 12:00–13:59 | 209,346 (14.7%) | |||
| 14:00–15:59 | 203,881 (14.3%) | |||
| 16:00–17:59 | 203,535 (14.3%) | |||
| 18:00–19:59 | 148,026 (10.4%) | |||
| 20:00–21:59 | 104,059 (7.3%) | |||
| 22:00–23:59 | 57,150 (4.0%) | |||
| Variable | Categories | N. Observations (Percentage) | Variable | Categories | N. Observations (Percentage) |
|---|---|---|---|---|---|
| P0 | 0 | 663,397 (46.6%) | P32 | 0 | 966,387 (67.8%) |
| 1 | 761,451 (53.4%) | 1 | 458,461 (32.2%) | ||
| P2 | 0 | 1,058,116 (74.3%) | P34 | 0 | 1,069,356 (75.1%) |
| 1 | 366,732 (25.7%) | 1 | 355,492 (24.9%) | ||
| P3 | 0 | 1,238,550 (86.9%) | P35 | 0 | 1062,231 (74.6%) |
| 1 | 186,298 (13.1%) | 1 | 362,617 (25.4%) | ||
| P4 | 0 | 1,356,173 (95.2%) | P36 | 0 | 1,013,116 (58.4%) |
| 1 | 68,675 (4.8%) | 1 | 411,732 (41.6%) | ||
| P7 | 0 | 884,770 (62.1%) | P37 | 0 | 831,986 (58.4%) |
| 1 | 540,078 (37.9%) | 1 | 592,862 (41.6%) | ||
| P8 | 0 | 540,366 (37.9%) | P38 | 0 | 1,292,685 (90.7%) |
| 1 | 884,482 (62.1%) | 1 | 132,163 (9.3%) | ||
| P9 | 0 | 1,036,282 (72.7%) | P39 | 0 | 1,335,421 (93.7%) |
| 1 | 388,566 (27.3%) | 1 | 89,427 (6.3%) | ||
| P10 | 0 | 804,972 (56.5%) | P40 | 0 | 1,363,782 (95.7%) |
| 1 | 619,876 (43.5%) | 1 | 61,066 (4.3%) | ||
| P16 | 0 | 1,407,166 (98.8%) | P45 | 0 | 1,404,475 (98.6%) |
| 1 | 17,682 (1.2%) | 1 | 20,373 (1.4%) | ||
| P17 | 0 | 1,390,173 (97.6%) | P46 | 0 | 1,370,546 (96.2%) |
| 1 | 34,675 (2.4%) | 1 | 54,302 (3.8%) | ||
| P18 | 0 | 1,404,906 (98.6%) | P47 | 0 | 1,205,040 (84.6%) |
| 1 | 19,942 (1.4%) | 1 | 219,808 (15.4%) | ||
| P19 | 0 | 1,415,639 (99.4%) | P49 | 0 | 1,380,596 (96.9%) |
| 1 | 9209 (0.6%) | 1 | 44,252 (3.1%) | ||
| P21 | 0 | 1,386,895 (97.3%) | P54 | 0 | 1,311,549 (92.0%) |
| 1 | 37,953 (2.7%) | 1 | 113,299 (8.0%) | ||
| P26 | 0 | 1,060,262 (74.4%) | P56 | 0 | 1,366,041 (95.9%) |
| 1 | 364,586 (25.6%) | 1 | 58,807 (4.1%) | ||
| P27 | 0 | 1,213,610 (85.2%) | P57 | 0 | 1,324,310 (92.9%) |
| 1 | 211,238 (14.8%) | 1 | 100,538 (7.1%) | ||
| P28 | 0 | 1,258,215 (88.3%) | P60 | 0 | 803,062 (56.4%) |
| 1 | 166,633 (11.7%) | 1 | 621,786 (43.6%) | ||
| P29 | 0 | 1,010,106 (70.9%) | P61 | 0 | 1,374,630 (96.5%) |
| 1 | 414,742 (29.1%) | 1 | 50,218 (3.5%) | ||
| P30 | 0 | 286,014 (20.1%) | P62 | 0 | 1,167,877 (82.0%) |
| 1 | 1,138,834 (79.9%) | 1 | 256,971 (18.0%) | ||
| P31 | 0 | 1,196,366 (84.0%) | P63 | 0 | 1,248,581 (87.6%) |
| 1 | 228,482 (16.0%) | 1 | 176,267 (12.4%) |
| Average Global Accuracy Loss | Average Balanced Accuracy Loss | Average SPD Reduction | Average EOD Reduction | |
|---|---|---|---|---|
| Reweighting— Active Modes | 0.14% | 0.55% | 74.01% | 29.37% |
| Reweighting—Beijing | 0.02% | −0.06% | 26.99% | 8.60% |
| MetaFairClassifier— Active Modes | 31.51% | 2.84% | −363.54% | 27.77% |
| MetaFairClassifier— Beijing | 11.43% | 25.13% | 67.50% | 78.37% |
| Calibrated Equalized Odds—Active Modes | 0.52% | 3.48% | 74.48% | 37.17% |
| Calibrated Equalized Odds—Beijing | 0.72% | 2.25% | 69.65% | 59.03% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vega-Gonzalo, M.; Christidis, P. Fair Models for Impartial Policies: Controlling Algorithmic Bias in Transport Behavioural Modelling. Sustainability 2022, 14, 8416. https://doi.org/10.3390/su14148416
Vega-Gonzalo M, Christidis P. Fair Models for Impartial Policies: Controlling Algorithmic Bias in Transport Behavioural Modelling. Sustainability. 2022; 14(14):8416. https://doi.org/10.3390/su14148416
Chicago/Turabian StyleVega-Gonzalo, María, and Panayotis Christidis. 2022. "Fair Models for Impartial Policies: Controlling Algorithmic Bias in Transport Behavioural Modelling" Sustainability 14, no. 14: 8416. https://doi.org/10.3390/su14148416
APA StyleVega-Gonzalo, M., & Christidis, P. (2022). Fair Models for Impartial Policies: Controlling Algorithmic Bias in Transport Behavioural Modelling. Sustainability, 14(14), 8416. https://doi.org/10.3390/su14148416