
Using a Novel Algorithm Based on the Random Vector Functional Link Network and Multi-Verse Optimizer to Forecast Effluent Quality


 and
and 
Abstract
:1. Introduction
2. Prediction Model Principle
2.1. Theory
- (1)
- Initialization, given the number of hidden layer nodes L and the activation function g( );
- (2)
- Randomly generated W and b;
- (3)
- Calculate the output matrix H;
- (4)
- Calculate β using the Formula (10).
2.2. Subsection
- If the expansion rate is higher, the higher the chance of producing a white hole. Conversely, if a universe has a relatively low expansion rate, it is more likely to make a black hole.
- White holes repel objects, and black holes absorb them.
- Irrespective of the expansion rate, it is possible for any other universe to transport objects to the current optimal universe through a wormhole.
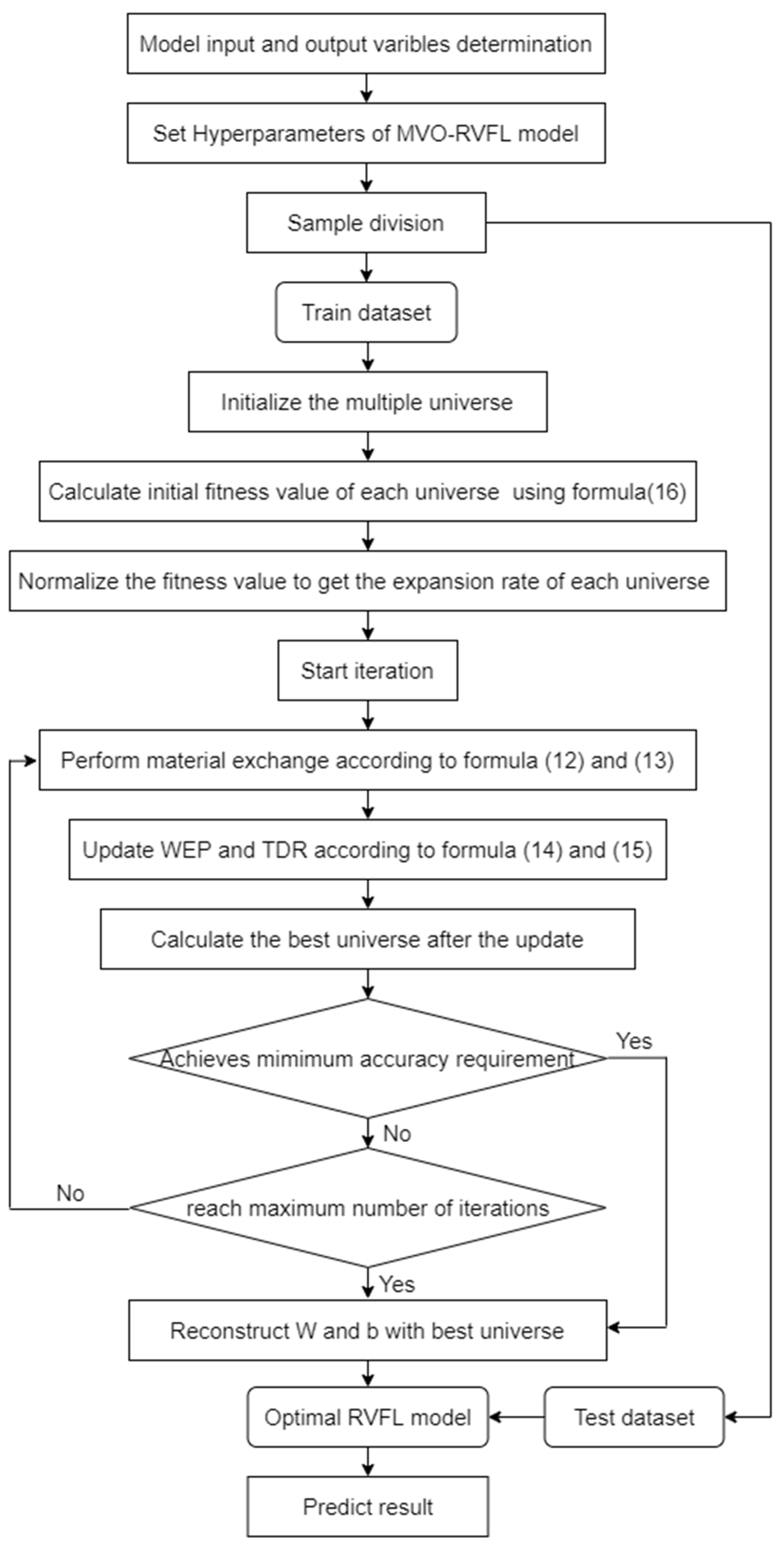
3. Proposed Water Quality Forecasting System
- Step 1: Set the model’s hyperparameters, such as WEPmin, WEPmax, exploitation p in MVO, the maximum number of iterations L, number of hidden neurons, and activation function in RVFL.
- Step 2: Set the root mean square error to the objective function, as shown in Formula (16) (The βi in Formula (16) is calculated from Formulas (6)–(10)). It is used to compute the fitness value of each universe and sort them according to this.
- Step 3: Start iteration. The RVFL parameters are optimized using the MVO approach.
- Step 3.1: Initialize each universe with a random function. Each universe is a vector, and the dimension can be calculated by Formula (17) since it stands for W and b.
- Step 3.2: Perform material exchange according to Formulas (12) and (13). Calculate the best universe after the update.
- Step 3.3: Calculate the fitness value of all the universes at the current cycle by Formula (16)
- Step 4: Determine if one of the objective conditions (1. Complete the maximum number of iterations; 2. Achieves minimum accuracy requirements) is met. If the specified criterion is satisfied, go to the next step. If not, proceed with the iteration process.
- Step 5: Divide the best universe’s vector into two parts: W and b; calculate the output matrix of the hidden layer β by Formula (10), then the optimal RVFL is obtained. MVO-RVFL has the obvious problem of requiring all intelligence to be traversed before finishing a single loop. The time investment is worthwhile, however, because influent data from the wastewater treatment process might change quickly and abruptly. As a result, slipping into a local optimum too soon will result in massive deviations.
4. Wastewater Data and Effluent Quality Prediction Result
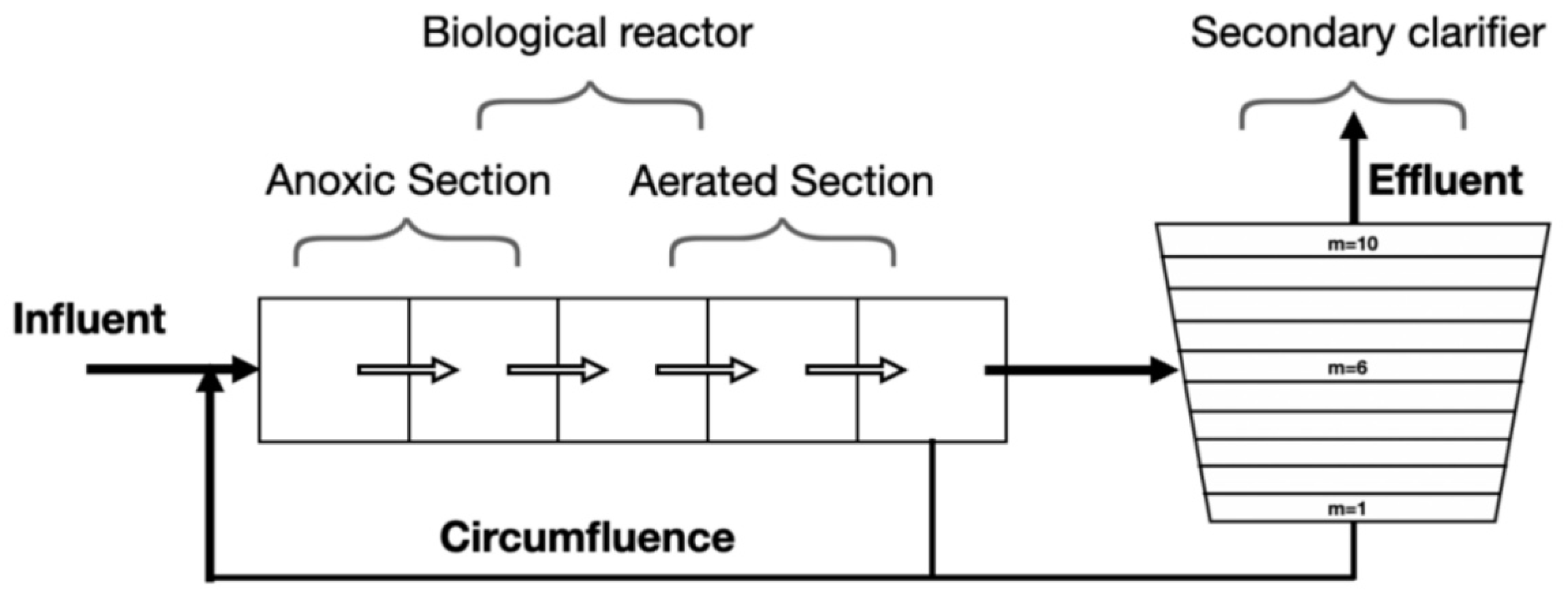
4.1. Description of BSM1 Benchmark Simulation Model 1 (BSM1)
4.2. Data Acquisition through BSM1
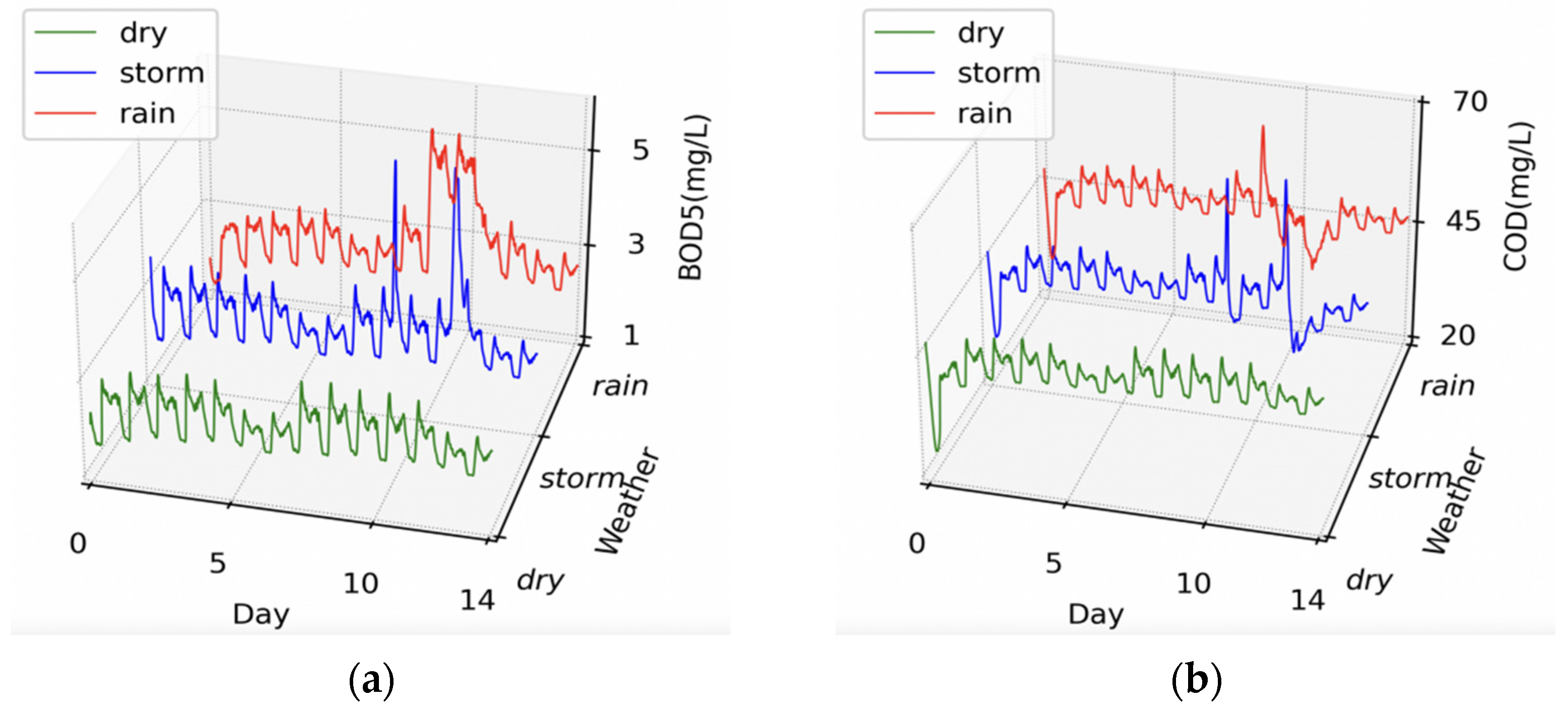
4.3. Preprocess and Model Parameter Settings
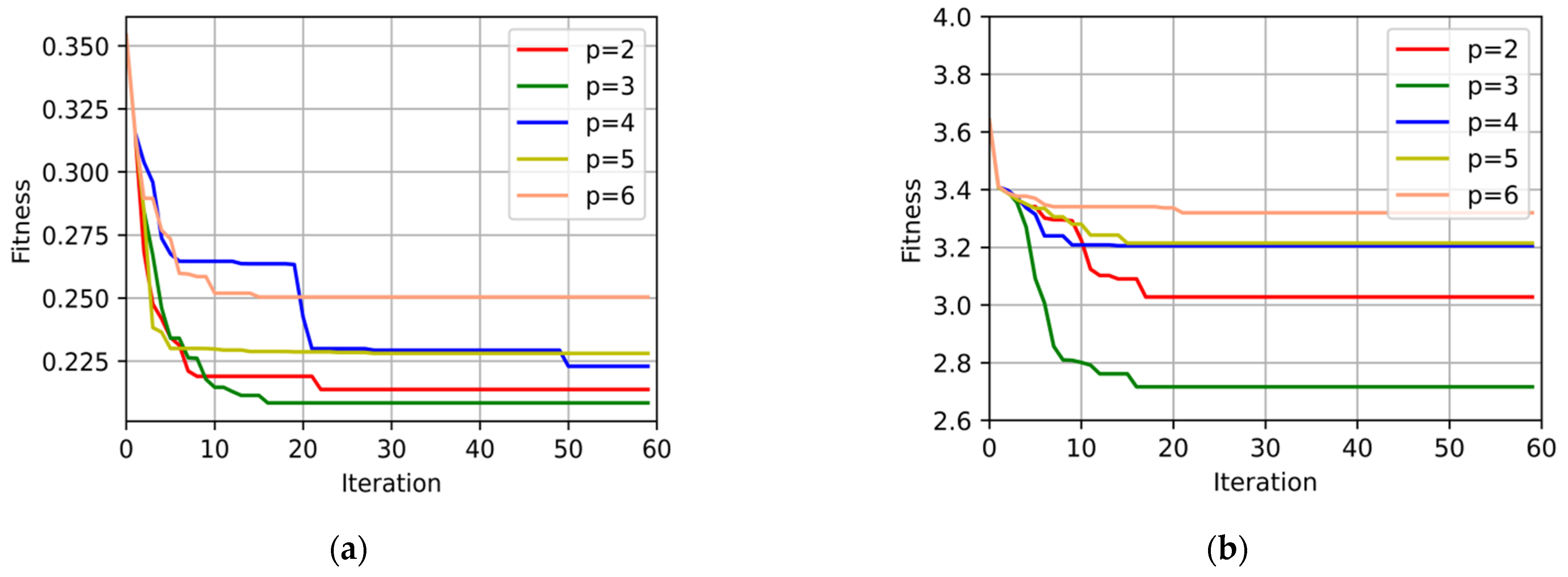
4.4. Exploitation and Exploration in the Iterative Process of MVO-RVFL
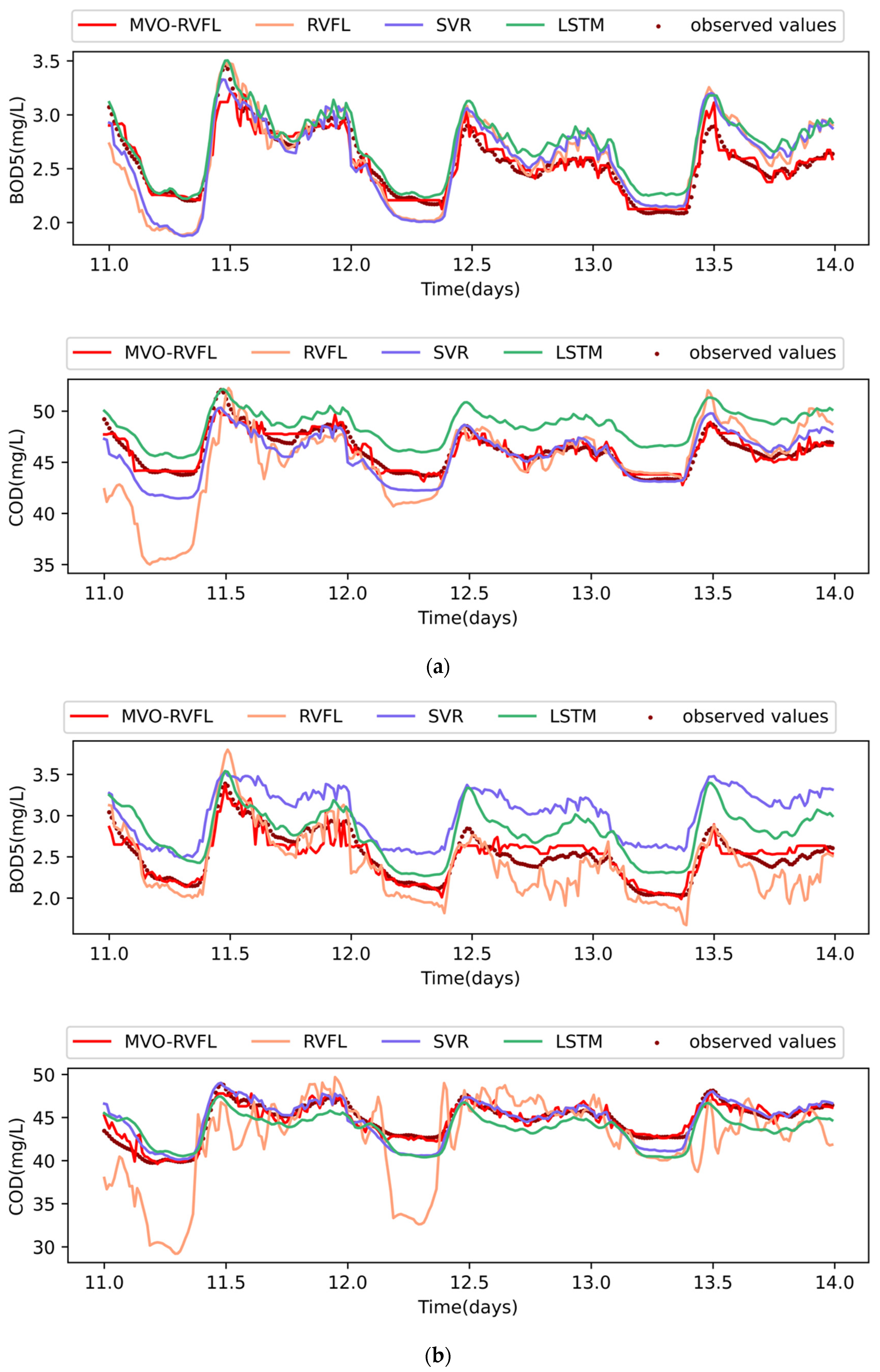
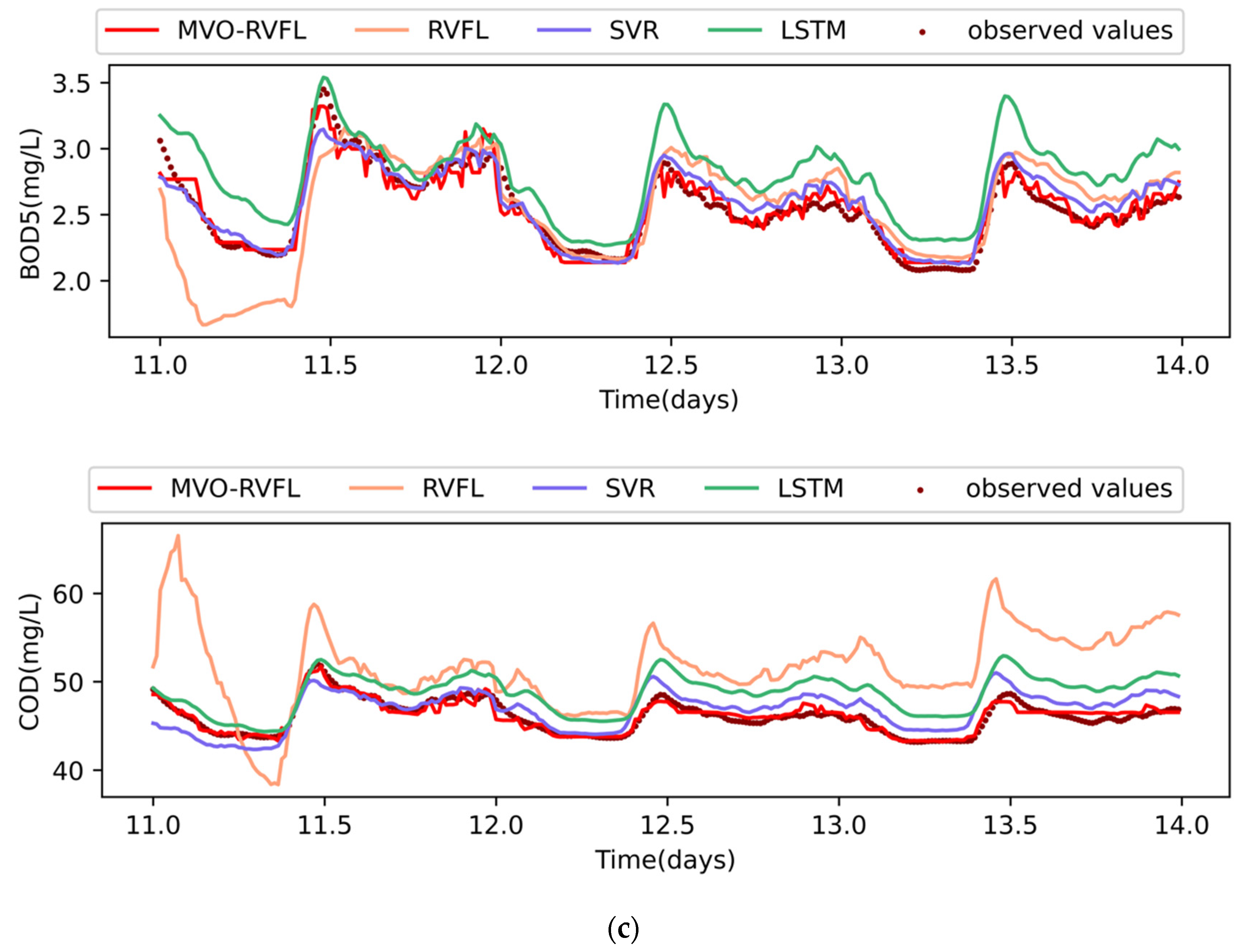
4.5. Experimental Results and Their Analysis
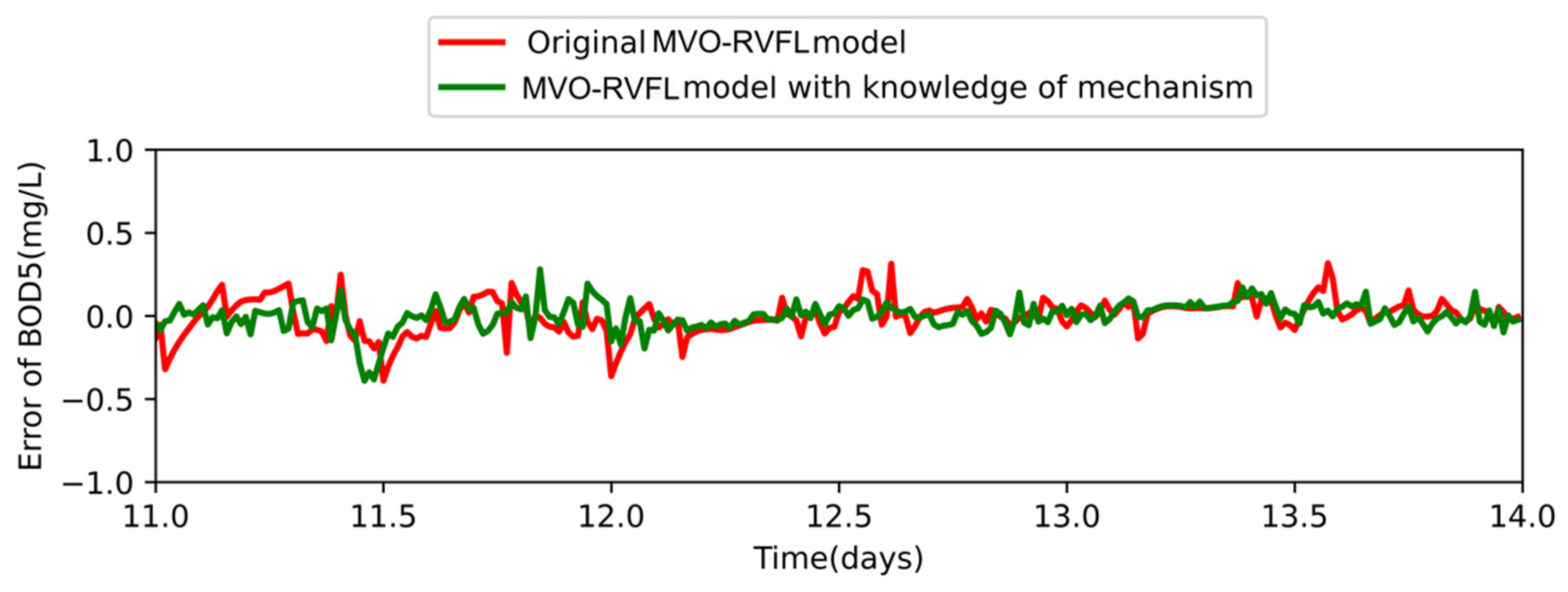
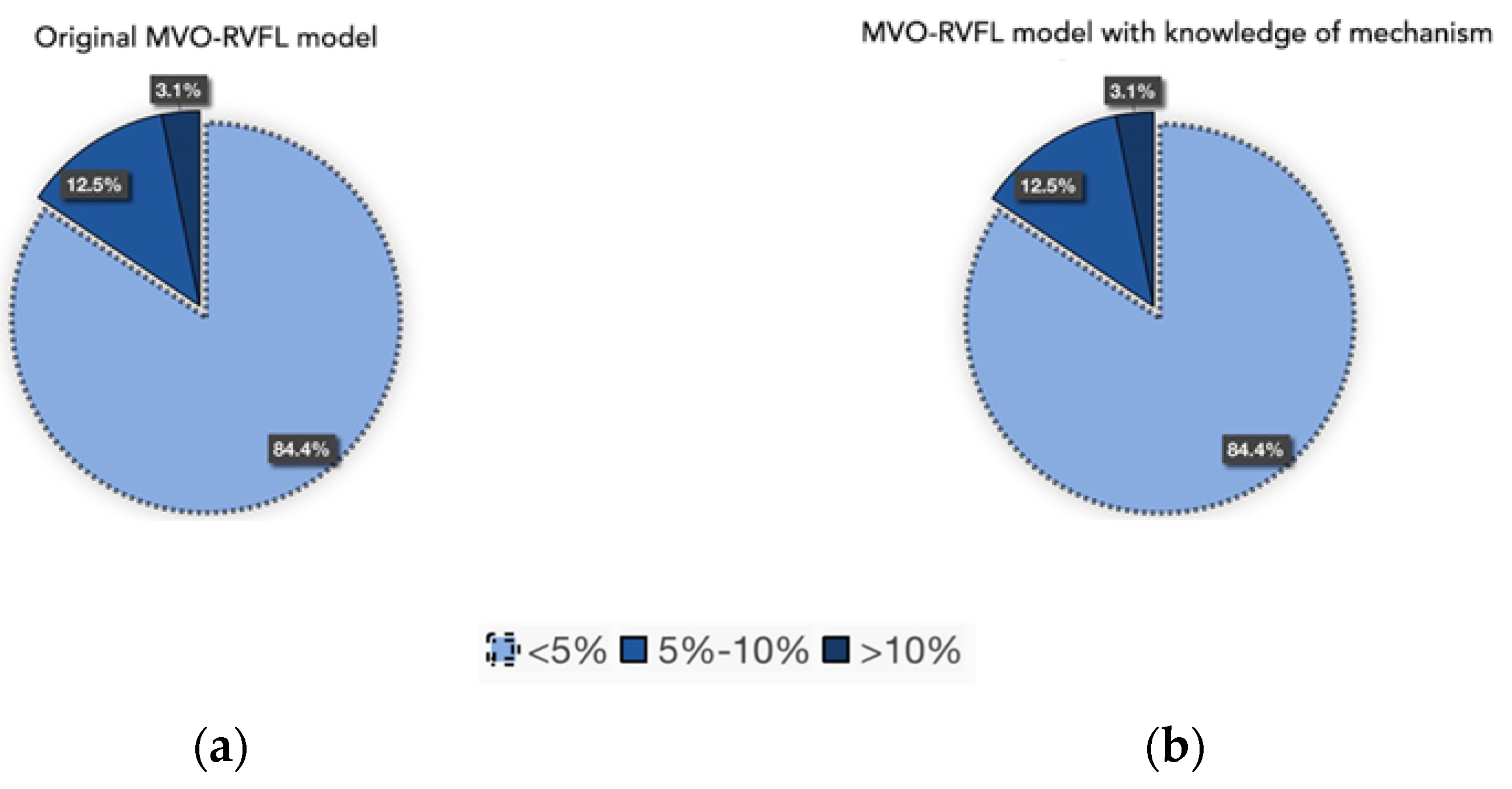
4.6. Study on the Validity of Hybrid Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ming-qi, C. The Securing of Water Resource Issue and Its Nature. China Saf. Sci. J. 2009, 19, 17–22. [Google Scholar]
- Skuras, D.; Tyllianakis, E. The perception of water related risks and the state of the water environment in the European Union. Water Res. 2018, 143, 198–208. [Google Scholar] [CrossRef] [PubMed]
- Samuelssona, P.; Halvarsson, B.; Carlsson, B. Cost-efficient operation of a denitrifying activated sludge process. Water Res. 2007, 41, 2325–2332. [Google Scholar] [CrossRef]
- Du, S. Modeling and control of biological wastewater treatment processes. Control. Theory Appl. 2002, 19, 660–666. [Google Scholar]
- Ahmed, S.F.; Mofijur, M.; Nuzhat, S.; Chowdhury, A.T.; Rafa, N.; Uddin, M.A.; Inayat, A.; Mahlia, T.M.I.; Ong, H.C.; Chia, W.Y.; et al. Recent developments in physical, biological, chemical, and hybrid treatment techniques for removing emerging contaminants from wastewater. J. Hazard. Mater. 2021, 416, 125912. [Google Scholar] [CrossRef]
- Dey, R.; Maarisetty, D.; Baral, S.S. A comparative study of bioelectrochemical systems with established anaerobic/aerobic processes. Biomass Convers. Biorefinery 2022. [Google Scholar] [CrossRef]
- Bermudez, L.A.; Pascual, J.M.; Martinez, M.D.M.; Capilla, J.M.P. Effectiveness of Advanced Oxidation Processes in Wastewater Treatment: State of the Art. Water 2021, 13, 2094. [Google Scholar] [CrossRef]
- Kennes-Veiga, D.M.; Gonzalez-Gil, L.; Carballa, M.; Lema, J.M. Enzymatic cometabolic biotransformation of organic micropollutants in wastewater treatment plants: A review. Bioresour. Technol. 2022, 344, 126291. [Google Scholar] [CrossRef]
- Sanchez, A.; Wade, M.; Katebi, M.R. A software platform for real-time control and monitoring of a wastewater treatment plant. Trans. Inst. Meas. Control. 2005, 27, 153–172. [Google Scholar] [CrossRef]
- Kulys, J.; Kadziauskiene, K. Yeast Bod Sensor. Biotechnol. Bioeng. 1980, 22, 221–226. [Google Scholar] [CrossRef]
- Yadav, A.; Indurkar, P.D. Gas Sensor Applications in Water Quality Monitoring and Maintenance. Water Conserv. Sci. Eng. 2021, 6, 175–190. [Google Scholar] [CrossRef]
- Zhou, M.; Feng, Y.; Chen, Y. Application of Soft Measurement Technology in Wastewater Treatment Process. China Water Wastewater 2005, 21, 34–36. [Google Scholar]
- Huang, M.Z.; Ma, Y.W.; Wan, J.Q.; Chen, X.H. A sensor-software based on a genetic algorithm-based neural fuzzy system for modeling and simulating a wastewater treatment process. Appl. Soft Comput. 2015, 27, 1–10. [Google Scholar] [CrossRef]
- Bagheri, M.; Akbari, A.; Mirbagheri, S.A. Advanced control of membrane fouling in filtration systems using artificial intelligence and machine learning techniques: A critical review. Process Saf. Environ. Prot. 2019, 123, 229–252. [Google Scholar] [CrossRef]
- Yang, T.; Zhang, L.X.; Wang, A.J.; Gao, H.J. Fuzzy modeling approach to predictions of chemical oxygen demand in activated sludge processes. Inf. Sci. 2013, 235, 55–64. [Google Scholar] [CrossRef]
- Golzar, F.; Nilsson, D.; Martin, V. Forecasting Wastewater Temperature Based on Artificial Neural Network (ANN) Technique and Monte Carlo Sensitivity Analysis. Sustainability 2020, 12, 6386. [Google Scholar] [CrossRef]
- Bagheri, M.; Mirbagheri, S.A.; Ehteshami, M.; Bagheri, Z. Modeling of a sequencing batch reactor treating municipal wastewater using multi-layer perceptron and radial basis function artificial neural networks. Process Saf. Environ. Prot. 2015, 93, 111–123. [Google Scholar] [CrossRef]
- Cao, Y.Y.; Cao, Y.T.; Guo, Z.Y.; Huang, T.W.; Wen, S.P. Global exponential synchronization of delayed memristive neural networks with reaction-diffusion terms. Neural Netw. 2020, 123, 70–81. [Google Scholar] [CrossRef] [PubMed]
- Pao, Y.H.; Park, G.H.; Sobajic, D.J. Learning and Generalization Characteristics of the Random Vector Functional-Link Net. Neurocomputing 1994, 6, 163–180. [Google Scholar] [CrossRef]
- Chi, H.M.; Ersoy, M.K. A statistical self-organizing learning system for remote sensing classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1890–1900. [Google Scholar] [CrossRef]
- Zhang, Y.S.; Wu, J.; Cai, Z.H.; Du, B.; Yu, P.S. An unsupervised parameter learning model for RVFL neural network. Neural Netw. 2019, 112, 85–97. [Google Scholar] [CrossRef]
- Wang, Z.H.; Yoon, S.; Xie, S.J.; Lu, Y.; Park, D.S. A High Accuracy Pedestrian Detection System Combining a Cascade AdaBoost Detector and Random Vector Functional-Link Net. Sci. World J. 2014, 2014, 105089. [Google Scholar] [CrossRef]
- Cote, M.; Grandjean, B.P.A.; Lessard, P.; Thibault, J. Dynamic Modeling of the Activated-Sludge Process—Improving Prediction Using Neural Networks. Water Res. 1995, 29, 995–1004. [Google Scholar] [CrossRef]
- Lee, D.S.; Vanrolleghem, P.A.; Park, J.M. Parallel hybrid modeling methods for a full-scale cokes wastewater treatment plant. J. Biotechnol. 2005, 115, 317–328. [Google Scholar] [CrossRef] [PubMed]
- Mirjalili, S.; Mirjalili, S.M.; Hatamlou, A. Multi-Verse Optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 2015, 27, 495–513. [Google Scholar] [CrossRef]
- Jeppsson, U.; Pons, M.N. The COST benchmark simulation model—Current state and future perspective. Control. Eng. Pract. 2004, 12, 299–304. [Google Scholar] [CrossRef]
- Hiatt, W.C.; Grady, C.P.L., Jr. An Updated Process Model for Carbon Oxidation, Nitrification, and Denitrification. Water Environ. Res. 2008, 80, 2145–2156. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Definition | Notation |
|---|---|
| Influent Ammonia Concentration | Snh,in |
| Influent Flow Rate | Q,in |
| Nitrate and nitrite nitrogen (reactor 1) | Sno |
| Nitrate and nitrite nitrogen (reactor 2) | Sno |
| Dissolved Oxygen Concentration (reactor 3) | So |
| Dissolved Oxygen Concentration (reactor 4) | So |
| Dissolved Oxygen Concentration (reactor 5) | So |
| Total Suspended Solid (reactor 5) | TSS |
| Alkalinity | Salk |
| Oxygen Transfer Coefficient (reactor 5) | Kla5 |
| Weather | Model | RSME of BOD5 | RSME of COD |
|---|---|---|---|
| Dry | SVR | 0.189 | 1.598 |
| LSTM | 0.182 | 2.533 | |
| RVFL | 0.122 | 2.627 | |
| MVO-RVFL | 0.063 | 0.453 | |
| Rain | SVR | 0.534 | 1.694 |
| LSTM | 0.263 | 1.673 | |
| RVFL | 0.253 | 4.243 | |
| MVO-RVFL | 0.114 | 0.544 | |
| Storm | SVR | 0.178 | 1.561 |
| LSTM | 0.513 | 2.878 | |
| RVFL | 0.487 | 6.821 | |
| MVO-RVFL | 0.134 | 0.623 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, H.; Wang, Z.; Zhou, H.; Lin, K.; Li, S.; Zheng, X.; Shen, Z.; Chen, J.; Zhang, L.; Zhang, Y. Using a Novel Algorithm Based on the Random Vector Functional Link Network and Multi-Verse Optimizer to Forecast Effluent Quality. Sustainability 2022, 14, 8314. https://doi.org/10.3390/su14148314
Shi H, Wang Z, Zhou H, Lin K, Li S, Zheng X, Shen Z, Chen J, Zhang L, Zhang Y. Using a Novel Algorithm Based on the Random Vector Functional Link Network and Multi-Verse Optimizer to Forecast Effluent Quality. Sustainability. 2022; 14(14):8314. https://doi.org/10.3390/su14148314
Chicago/Turabian StyleShi, Huixian, Zijing Wang, Haiyi Zhou, Kaiyan Lin, Shuping Li, Xinnan Zheng, Zheng Shen, Jiaoliao Chen, Lei Zhang, and Yalei Zhang. 2022. "Using a Novel Algorithm Based on the Random Vector Functional Link Network and Multi-Verse Optimizer to Forecast Effluent Quality" Sustainability 14, no. 14: 8314. https://doi.org/10.3390/su14148314
APA StyleShi, H., Wang, Z., Zhou, H., Lin, K., Li, S., Zheng, X., Shen, Z., Chen, J., Zhang, L., & Zhang, Y. (2022). Using a Novel Algorithm Based on the Random Vector Functional Link Network and Multi-Verse Optimizer to Forecast Effluent Quality. Sustainability, 14(14), 8314. https://doi.org/10.3390/su14148314