
A Normalized Rich-Club Connectivity-Based Strategy for Keyword Selection in Social Media Analysis


Abstract
:1. Introduction
- This paper highlights the important role played by the keyword selection process in social media analysis, a topic that has generally been neglected by most prior studies. We claim that the use of the appropriate keywords for data collection can improve the quality of the data and accordingly greatly enhance the significance of a study. Thus, this paper contributes to enhancing researchers’ attention to keyword selection in the process of using social media data for analyzing, which could yield more accurate and persuasive research results, to a large extent.
- Using a graph-based approach, we propose a new keyword selection method for social media analysis considering two different types of topics: conceptual topics and event-based topics. In particular, the normalized rich-club connectivity considering the weighted degree, closeness centrality, betweenness centrality and PageRank values are used to identify “rich keywords”, and community detection is applied to determine the keyword combinations for representing the research topic.
- We evaluate our method by using the data related to four topics and comparing with four widely used keyword selection techniques. According to the results of the empirical test, our method can reach a balance between the quantity and quality of the data. In other words, it can greatly increase the amount of high-quality data. In addition, since social media is an essential data source for a variety of areas, especially for those studying public perceptions, our proposed keyword selection method can benefit future studies in various areas, including decision making, disaster management and policy development.
2. Keywords in Social Media Analysis
2.1. Framework for Social Media Analysis
2.2. Types of Topics
2.3. Existing Keyword Selection Methods
2.4. Network Techniques in Keyword Selection
3. Graph-Based Keyword Selection Strategy
3.1. Network Construction
3.2. Rich-Club Phenomenon
3.2.1. Concept
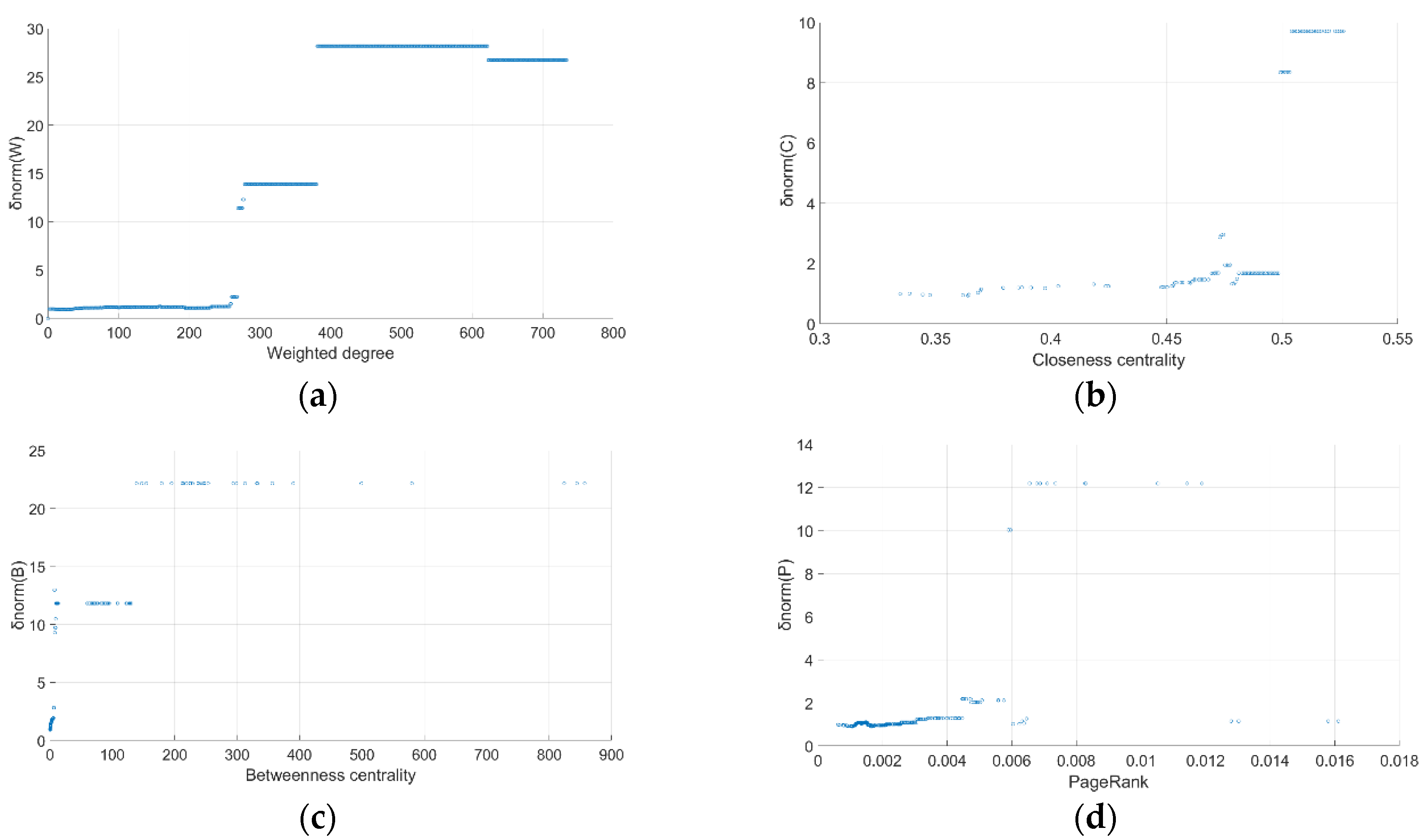
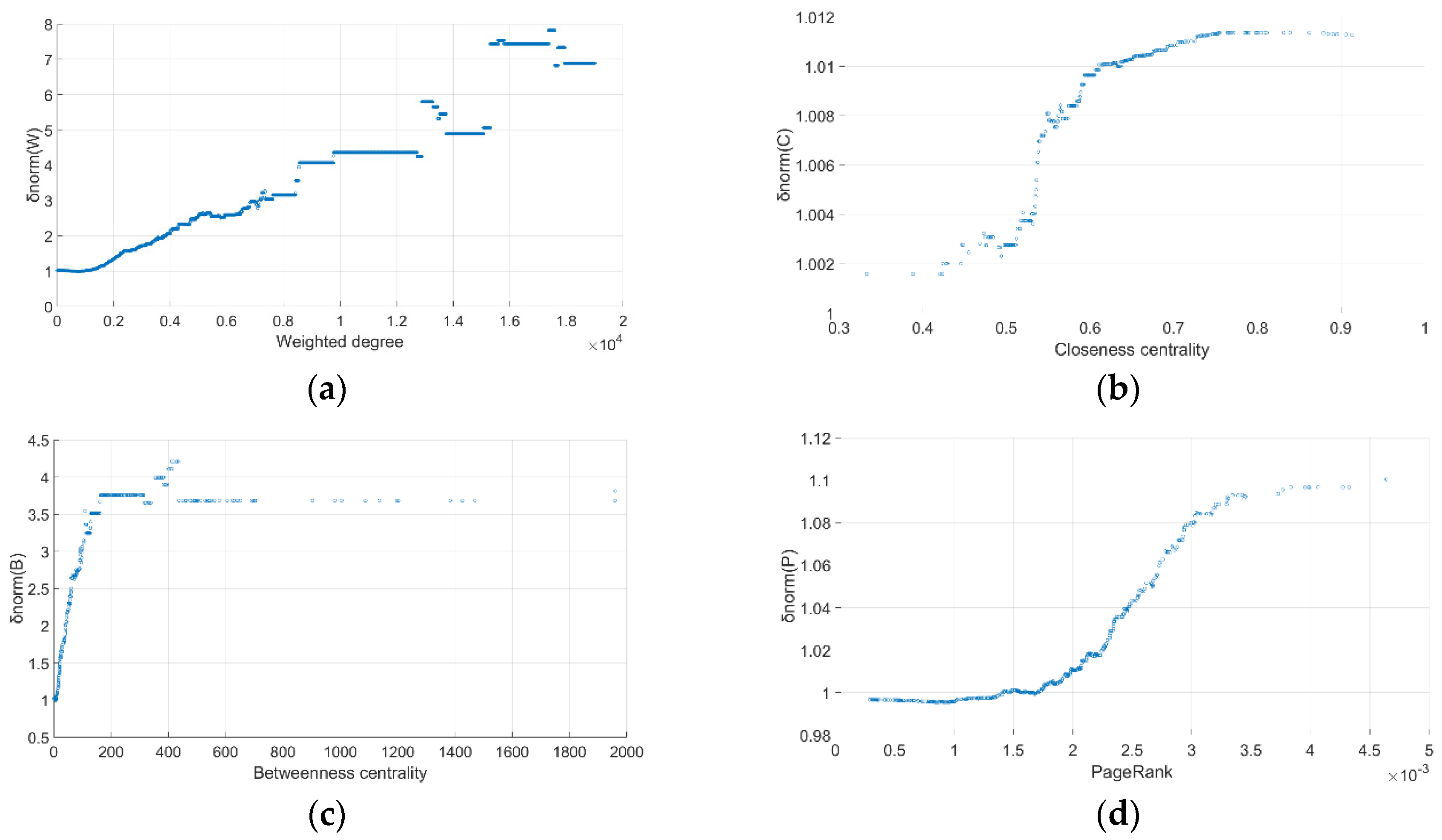
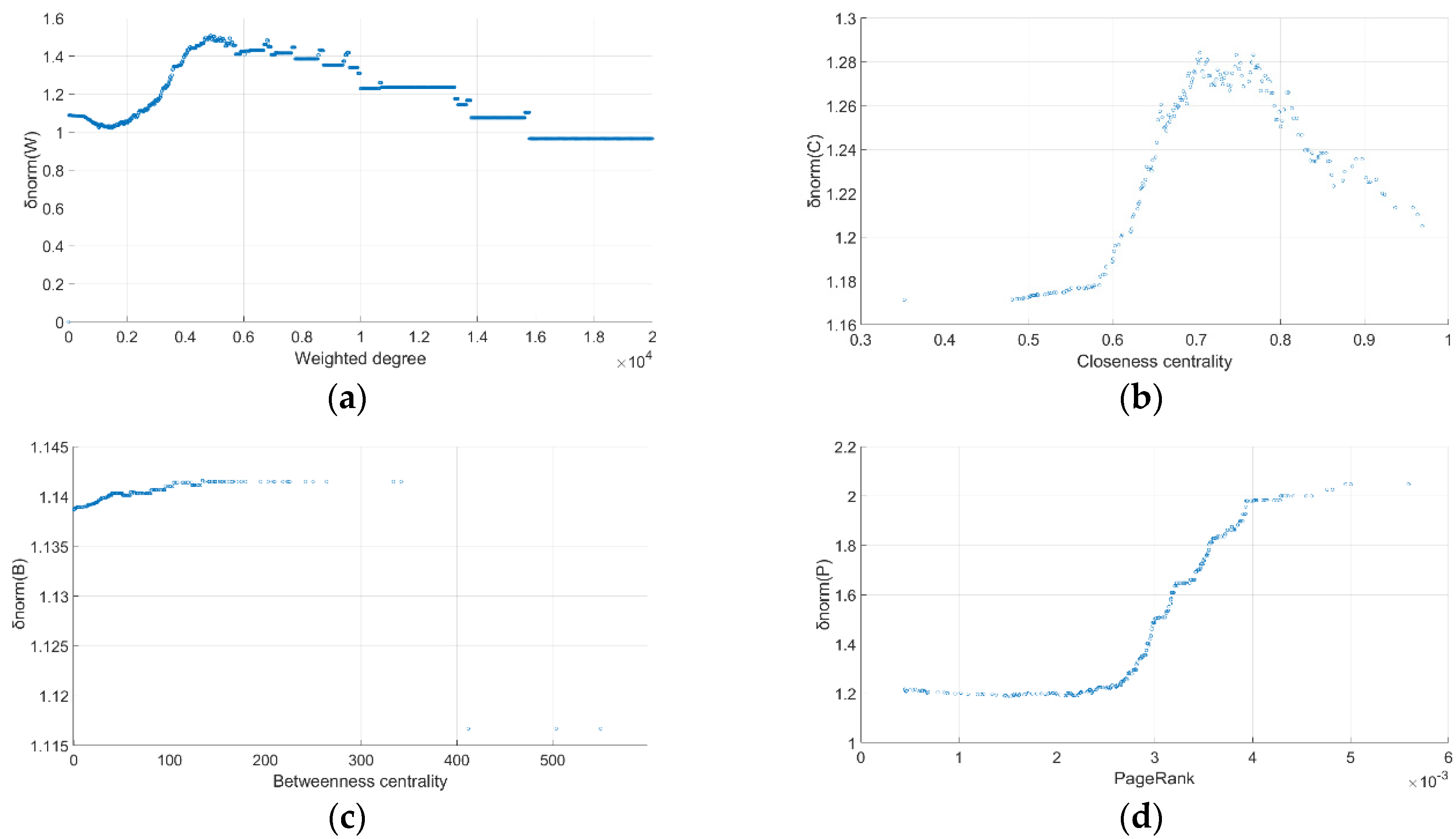
3.2.2. Evaluation Metrics
- Rich-club connectivity
- b.
- Community detection
3.3. Keyword Selection Strategy
- -
- Pattern 1 topics: Set the primary keywords for the topic based on the research target. The number of primary keywords should be as small as possible because a larger number will limit the size of the data.
- -
- Pattern 2 topics: Using the initial text of the topic, which refers to the first posted information describing the studied policy or event, perform text segmentation and identify no more than three primary keywords based on personal experience and word frequency. The reason for not using graph-based techniques in this step is that the length of the initial text of the topic is usually short and will result in a highly dense network [1]. In other words, considering the co-occurrence relationship between keywords during this step is mostly meaningless.
4. Empirical Study
4.1. Data
4.2. Methods
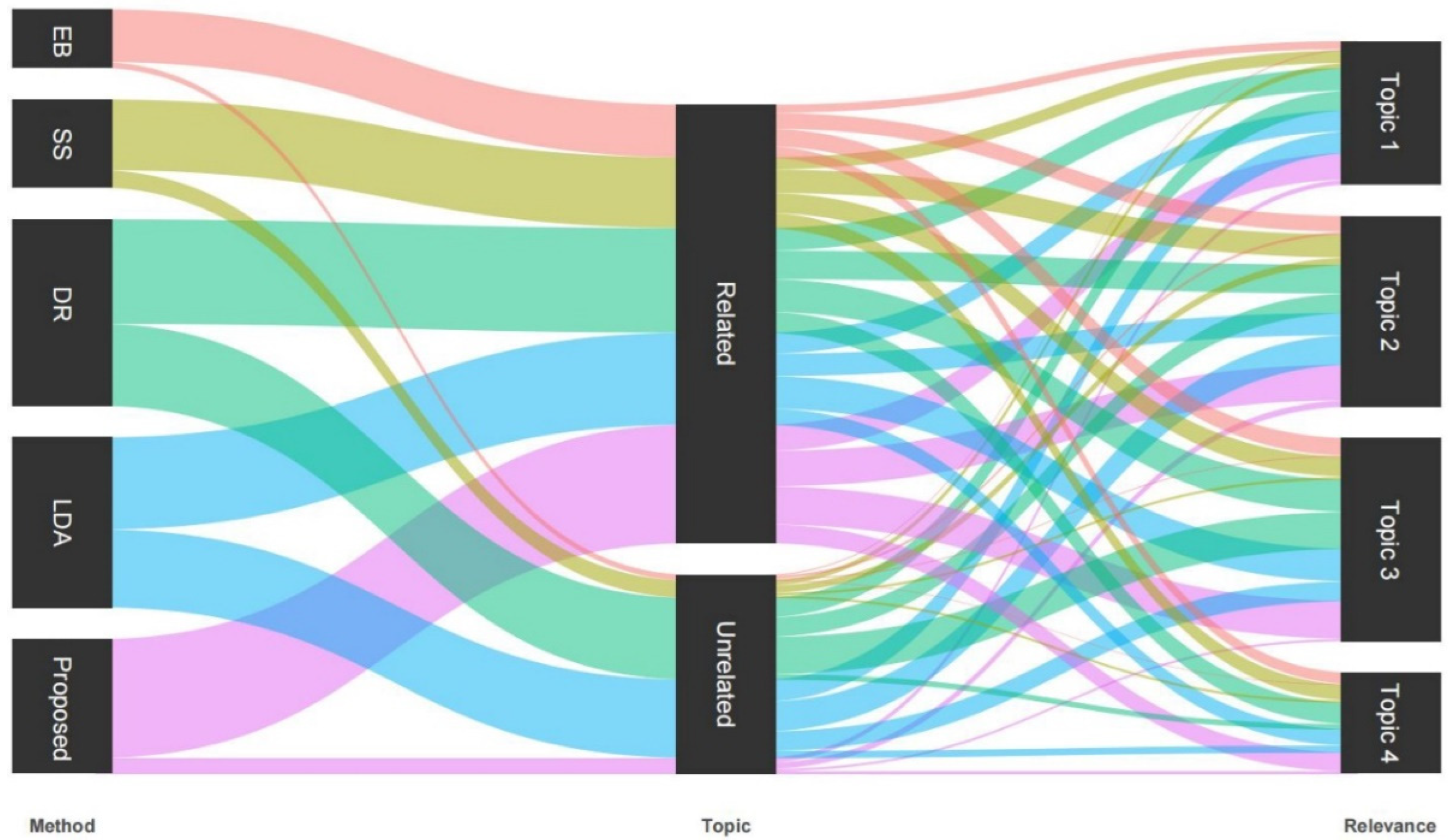
4.2.1. Comparison Methods
4.2.2. Evaluation Methods
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Duari, S.; Bhatnagar, V. Complex Network based Supervised Keyword Extractor. Expert Syst. Appl. 2020, 140, 112876. [Google Scholar] [CrossRef] [Green Version]
- Noh, H.; Jo, Y.; Lee, S. Keyword selection and processing strategy for applying text mining to patent analysis. Expert Syst. Appl. 2015, 42, 4348–4360. [Google Scholar] [CrossRef]
- Lu, W.; Liu, Z.; Huang, Y.; Bu, Y.; Li, X.; Cheng, Q. How do authors select keywords? A preliminary study of author keyword selection behavior. J. Inf. 2020, 14, 101066. [Google Scholar] [CrossRef]
- Behrouzi, S.; Sarmoor, Z.S.; Hajsadeghi, K.; Kavousi, K. Predicting scientific research trends based on link prediction in keyword networks. J. Inf. 2020, 14, 101079. [Google Scholar] [CrossRef]
- Cheng, Q.; Wang, J.; Lu, W.; Huang, Y.; Bu, Y. Keyword-citation-keyword network: A new perspective of discipline knowledge structure analysis. Scientometrics 2020, 124, 1923–1943. [Google Scholar] [CrossRef]
- Kim, A.J.; Jang, S.; Shin, H.S. How should retail advertisers manage multiple keywords in paid search advertising? J. Bus. Res. 2019, 130, 539–551. [Google Scholar] [CrossRef]
- Ayanso, A.; Karimi, A. The moderating effects of keyword competition on the determinants of ad position in sponsored search advertising. Decis. Support Syst. 2015, 70, 42–59. [Google Scholar] [CrossRef]
- Huang, M.-H.; Whang, T.; Xuchuan, L. The Internet, Social Capital, and Civic Engagement in Asia. Soc. Indic. Res. 2016, 132, 559–578. [Google Scholar] [CrossRef]
- Hong, S.; Nadler, D. Which candidates do the public discuss online in an election campaign?: The use of social media by 2012 presidential candidates and its impact on candidate salience. Gov. Inf. Q. 2012, 29, 455–461. [Google Scholar] [CrossRef]
- Lee, S.; Xenos, M. Social distraction? Social media use and political knowledge in two U.S. Presidential elections. Comput. Hum. Behav. 2019, 90, 18–25. [Google Scholar] [CrossRef]
- Kang, Y.; Wang, Y.; Zhang, D.; Zhou, L. The public’s opinions on a new school meals policy for childhood obesity prevention in the U.S.: A social media analytics approach. Int. J. Med. Inform. 2017, 103, 83–88. [Google Scholar] [CrossRef]
- Cebollero-Salinas, A.; Cano-Escoriaza, J.; Orejudo, S. Social Networks, Emotions, and Education: Design and Validation of e-COM, a Scale of Socio-Emotional Interaction Competencies among Adolescents. Sustainability 2022, 14, 2566. [Google Scholar] [CrossRef]
- Mollema, L.; Harmsen, I.A.; Broekhuizen, E.; Clijnk, R.; De Melker, H.; Paulussen, T.; Kok, G.; Ruiter, R.; Das, E. Disease Detection or Public Opinion Reflection? Content Analysis of Tweets, Other Social Media, and Online Newspapers During the Measles Outbreak in the Netherlands in 2013. J. Med. Internet Res. 2015, 17, e128. [Google Scholar] [CrossRef] [PubMed]
- Anik, M.A.H.; Sadeek, S.N.; Hossain, M.; Kabir, S. A framework for involving the young generation in transportation planning using social media and crowd sourcing. Transp. Policy 2020, 97, 1–18. [Google Scholar] [CrossRef]
- Wu, D.; Cui, Y. Disaster early warning and damage assessment analysis using social media data and geo-location information. Decis. Support Syst. 2018, 111, 48–59. [Google Scholar] [CrossRef]
- Samaddar, S.; Roy, S.; Akter, F.; Tatano, H. Diffusion of Disaster-Preparedness Information by Hearing from Early Adopters to Late Adopters in Coastal Bangladesh. Sustainability 2022, 14, 3897. [Google Scholar] [CrossRef]
- Dong, T.; Liang, C.; He, X. Social media and internet public events. Telemat. Inform. 2017, 34, 726–739. [Google Scholar] [CrossRef]
- Salleh, S.M. From Survey to Social Media: Public Opinion and Politics in the Age of Big Data. J. Comput. Theor. Nanosci. 2017, 23, 10696–10700. [Google Scholar] [CrossRef]
- Hoffmann, M.; Heft, A. “Here, There and Everywhere”: Classifying Location Information in Social Media Data—Possibilities and Limitations. Commun. Methods Meas. 2020, 14, 184–203. [Google Scholar] [CrossRef]
- Abkenar, S.B.; Kashani, M.H.; Mahdipour, E.; Jameii, S.M. Big data analytics meets social media: A systematic review of techniques, open issues, and future directions. Telemat. Inform. 2021, 57, 101517. [Google Scholar] [CrossRef]
- Luo, Q.; Zhai, X. “I will never go to Hong Kong again!” How the secondary crisis communication of “Occupy Central” on Weibo shifted to a tourism boycott. Tour. Manag. 2017, 62, 159–172. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Hu, W. Attention and sentiment of Chinese public toward green buildings based on Sina Weibo. Sustain. Cities Soc. 2018, 44, 550–558. [Google Scholar] [CrossRef]
- Su, L.; Stepchenkova, S.; Kirilenko, A.P. Online public response to a service failure incident: Implications for crisis communications. Tour. Manag. 2019, 73, 1–12. [Google Scholar] [CrossRef]
- D’Andrea, E.; Ducange, P.; Bechini, A.; Renda, A.; Marcelloni, F. Monitoring the public opinion about the vaccination topic from tweets analysis. Expert Syst. Appl. 2019, 116, 209–226. [Google Scholar] [CrossRef]
- Han, X.; Wang, J. Using Social Media to Mine and Analyze Public Sentiment during a Disaster: A Case Study of the 2018 Shouguang City Flood in China. ISPRS Int. J. Geo-Inf. 2019, 8, 185. [Google Scholar] [CrossRef] [Green Version]
- Cody, E.M.; Reagan, A.J.; Mitchell, L.; Dodds, P.; Danforth, C.M. Climate Change Sentiment on Twitter: An Unsolicited Public Opinion Poll. PLoS ONE 2015, 10, e0136092. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, Z.; Liu, B.; Emery, S. Identifying search keywords for finding relevant social media posts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3052–3058. [Google Scholar]
- Zheng, X.; Sun, A. Collecting event-related tweets from twitter stream. J. Assoc. Inf. Sci. Technol. 2019, 70, 176–186. [Google Scholar] [CrossRef]
- Lian, Y.; Liu, Y.; Dong, X. Strategies for controlling false online information during natural disasters: The case of Typhoon Mangkhut in China. Technol. Soc. 2020, 62, 101265. [Google Scholar] [CrossRef]
- Di Tommaso, G.; Gatti, M.; Iannotta, M.; Mehra, A.; Stilo, G.; Velardi, P. Gender, rank, and social networks on an enterprise social media platform. Soc. Netw. 2020, 62, 58–67. [Google Scholar] [CrossRef]
- Lian, Y.; Dong, X.; Liu, Y. Topological evolution of the internet public opinion. Phys. A Stat. Mech. Its Appl. 2017, 486, 567–578. [Google Scholar] [CrossRef]
- Xu, K.; Qi, G.; Huang, J.; Wu, T.; Fu, X. Detecting bursts in sentiment-aware topics from social media. Knowl. Based Syst. 2018, 141, 44–54. [Google Scholar] [CrossRef]
- Liu, W.; Lai, C.-H.; Xu, W. Tweeting about emergency: A semantic network analysis of government organizations’ social media messaging during Hurricane Harvey. Public Relat. Rev. 2018, 44, 807–819. [Google Scholar] [CrossRef]
- Alam, M.; Abid, F.; Guangpei, C.; Yunrong, L. Social media sentiment analysis through parallel dilated convolutional neural network for smart city applications. Comput. Commun. 2020, 154, 129–137. [Google Scholar] [CrossRef]
- Qian, X.; Li, M.; Ren, Y.; Jiang, S. Social media based event summarization by user–text–image co-clustering. Knowl. Based Syst. 2019, 164, 107–121. [Google Scholar] [CrossRef]
- Ibrahim, N.F.; Wang, X. Decoding the sentiment dynamics of online retailing customers: Time series analysis of social media. Comput. Hum. Behav. 2019, 96, 32–45. [Google Scholar] [CrossRef] [Green Version]
- Kang, G.; Ewing-Nelson, S.R.; Mackey, L.; Schlitt, J.T.; Marathe, A.; Abbas, K.; Swarup, S. Semantic network analysis of vaccine sentiment in online social media. Vaccine 2017, 35, 3621–3638. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Huang, Y.; Song, Y.; Liu, S. Towards building a high-quality microblog-specific Chinese sentiment lexicon. Decis. Support Syst. 2016, 87, 39–49. [Google Scholar] [CrossRef]
- Asif, M.; Ishtiaq, A.; Ahmad, H.; Aljuaid, H.; Shah, J. Sentiment analysis of extremism in social media from textual information. Telemat. Inform. 2020, 48, 101345. [Google Scholar] [CrossRef]
- Wang, Y.; Li, H.; Wu, Z. Attitude of the Chinese public toward off-site construction: A text mining study. J. Clean. Prod. 2019, 238, 117926. [Google Scholar] [CrossRef]
- Cai, B.; Geng, Y.; Yang, W.; Yan, P.; Chen, Q.; Li, D.; Cao, L. How scholars and the public perceive a “low carbon city” in China. J. Clean. Prod. 2017, 149, 502–510. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, X.; Xia, Y. Online Public Opinion Alienation Analysis of Significant Doctor-patient Dispute Cases:Taking Xiangtan Pregnant Woman Event as an Example. J. Intell. 2016, 35, 64–69. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Li, L.; Wang, Y.; Wu, X. Targeted aspects oriented topic modeling for short texts. Appl. Intell. 2020, 50, 2384–2399. [Google Scholar] [CrossRef]
- Yin, X.; Wang, H.; Yin, P.; Zhu, H.; Zhang, Z. A co-occurrence based approach of automatic keyword expansion using mass diffusion. Scientometrics 2020, 124, 1885–1905. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 2004, 69, 066133. [Google Scholar] [CrossRef] [Green Version]
- Wagenseller, P.; Wang, F.; Wu, W. Size Matters: A Comparative Analysis of Community Detection Algorithms. IEEE Trans. Comput. Soc. Syst. 2018, 5, 951–960. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Mondragon, R. The Rich-Club Phenomenon in the Internet Topology. IEEE Commun. Lett. 2004, 8, 180–182. [Google Scholar] [CrossRef] [Green Version]
- Tang, C.; Dong, X.; Lian, Y.; Tang, D. Do Chinese hospital services constitute an oligopoly? Evidence of the rich-club phenomenon in a patient referral network. Futur. Gener. Comput. Syst. 2019, 105, 492–501. [Google Scholar] [CrossRef]
- Ball, G.; Aljabar, P.; Zebari, S.; Tusor, N.; Arichi, T.; Merchant, N.; Robinson, E.C.; Ogundipe, E.; Rueckert, D.; Edwards, A.D.; et al. Rich-club organization of the newborn human brain. Proc. Natl. Acad. Sci. USA 2014, 111, 7456–7461. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Song, W.; Xiu, C.; Zhao, Z. The rich-club phenomenon of China’s population flow network during the country’s spring festival. Appl. Geogr. 2018, 96, 77–85. [Google Scholar] [CrossRef]
- Smilkov, D.; Kocarev, L. Rich-club and page-club coefficients for directed graphs. Phys. A Stat. Mech. Appl. 2010, 389, 2290–2299. [Google Scholar] [CrossRef] [Green Version]
- Ren, T.; Wang, Y.-F.; Du, D.; Liu, M.-M.; Siddiqi, A. The guitar chord-generating algorithm based on complex network. Phys. A Stat. Mech. Appl. 2016, 443, 1–13. [Google Scholar] [CrossRef]
- Kim, D.-J.; Min, B.-K. Rich-club in the brain’s macrostructure: Insights from graph theoretical analysis. Comput. Struct. Biotechnol. J. 2020, 18, 1761–1773. [Google Scholar] [CrossRef] [PubMed]
- Cinelli, M. Generalized rich-club ordering in networks. J. Complex Netw. 2019, 7, 702–719. [Google Scholar] [CrossRef]
- Lv, L.; Zhang, K.; Zhang, T.; Bardou, D.; Zhang, J.; Cai, Y. PageRank centrality for temporal networks. Phys. Lett. A 2019, 383, 1215–1222. [Google Scholar] [CrossRef]
- Salavati, C.; Abdollahpouri, A.; Manbari, Z. Ranking nodes in complex networks based on local structure and improving closeness centrality. Neurocomputing 2019, 336, 36–45. [Google Scholar] [CrossRef]
- Jin, H.; Zhang, C.; Ma, M.; Gong, Q.; Yu, L.; Guo, X.; Gao, L.; Wang, B. Inferring essential proteins from centrality in interconnected multilayer networks. Phys. A Stat. Mech. Appl. 2020, 557, 124853. [Google Scholar] [CrossRef]
- Maslov, S.; Sneppen, K. Specificity and Stability in Topology of Protein Networks. Science 2002, 296, 910–913. [Google Scholar] [CrossRef] [Green Version]
- Azevedo, F.A.C.; Carvalho, L.R.B.; Grinberg, L.T.; Farfel, J.M.; Ferretti, R.E.L.; Leite, R.E.P.; Filho, W.J.; Lent, R.; Herculano-Houzel, S. Equal numbers of neuronal and nonneuronal cells make the human brain an isometrically scaled-up primate brain. J. Comp. Neurol. 2009, 513, 532–541. [Google Scholar] [CrossRef]
- Herculano-Houzel, S. The human brain in numbers: A linearly scaled-up primate brain. Front. Hum. Neurosci. 2009, 3, 31. [Google Scholar] [CrossRef] [Green Version]
- Opsahl, T. Structure and Evolution of Weighted Networks. Ph.D. Thesis, Queen Mary, University of London, London, UK, 2009. [Google Scholar]
- Traag, V.A. Faster unfolding of communities: Speeding up the Louvain algorithm. Phys. Rev. E 2015, 92, 032801. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Liu, Y.; Li, J.; Tang, X.; Wang, H. Superedge coupling algorithm and its application in coupling mechanism analysis of online public opinion supernetwork. Expert Syst. Appl. 2015, 42, 2808–2823. [Google Scholar] [CrossRef]
- Kaplan, S.; Vakili, K. The double-edged sword of recombination in breakthrough innovation: The Double-Edged Sword of Recombination. Strateg. Manag. J. 2015, 36, 1435–1457. [Google Scholar] [CrossRef]
- Bastani, K.; Namavari, H.; Shaffer, J. Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Syst. Appl. 2019, 127, 256–271. [Google Scholar] [CrossRef] [Green Version]
- Zakharchenko, A.; Peráček, T.; Fedushko, S.; Syerov, Y.; Trach, O. When Fact-Checking and ‘BBC Standards’ Are Helpless: ‘Fake Newsworthy Event’ Manipulation and the Reaction of the ‘High-Quality Media’ on It. Sustainability 2021, 13, 573. [Google Scholar] [CrossRef]
- Lyu, Y.; Chow, J.C.-C.; Hwang, J.-J. Exploring public attitudes of child abuse in mainland China: A sentiment analysis of China’s social media Weibo. Child. Youth Serv. Rev. 2020, 116, 105250. [Google Scholar] [CrossRef]
- Mangla, M.; Ambarkar, S.; Akhare, R.; University of Mumbai; Computer Department at LTCoE. A study to Analyze impact of social media on society: WhatsApp in particular. Int. J. Educ. Manag. Eng. 2020, 10, 1–10. [Google Scholar] [CrossRef]
- Shutaleva, A.; Martyushev, N.; Nikonova, Z.; Savchenko, I.; Abramova, S.; Lubimova, V.; Novgorodtseva, A. Environmental Behavior of Youth and Sustainable Development. Sustainability 2021, 14, 250. [Google Scholar] [CrossRef]
- Sobaih, A.E.E.; Hasanein, A.; Elshaer, I.A. Higher Education in and after COVID-19: The Impact of Using Social Network Applications for E-Learning on Students’ Academic Performance. Sustainability 2022, 14, 5195. [Google Scholar] [CrossRef]
- Castro, A.I.G.; López, L.J.R. Sustainability and Resilience of Emerging Cities in Times of COVID-19. Sustainability 2021, 13, 9480. [Google Scholar] [CrossRef]
- Borah, P.S.; Iqbal, S.; Akhtar, S. Linking social media usage and SME’s sustainable performance: The role of digital leadership and innovation capabilities. Technol. Soc. 2022, 68, 101900. [Google Scholar] [CrossRef]
- Mostafa, G.; Ahmed, I.; Junayed, M.S. Investigation of Different Machine Learning Algorithms to Determine Human Sentiment Using Twitter Data. Int. J. Inf. Technol. Comput. Sci. 2021, 13, 38–48. [Google Scholar] [CrossRef]
- Akinyemi, B.; Adewusi, O.; Oyebade, A. An Improved Classification Model for Fake News Detection in Social Media. Int. J. Inf. Technol. Comput. Sci. 2020, 12, 34–43. [Google Scholar] [CrossRef]
- Bielański, M.; Korbiel, K.; Taczanowska, K.; Pardo-Ibañez, A.; González, L.-M. How tourism research integrates environmental issues? A keyword network analysis. J. Outdoor Recreat. Tour. 2022, 37, 100503. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pattern | Name | Examples |
|---|---|---|
| Pattern 1 | Conceptual topics | Green buildings [22], transportation planning [14], climate change [26], low-carbon city [41] |
| Pattern 2 | Event-based topics | The Xiangtan Pregnant Woman Event [42], “I will never go to Hong Kong again!” [21], Hurricane Harvey [33], the Shouguang City Flood [25] |
| Description | Pattern | |
|---|---|---|
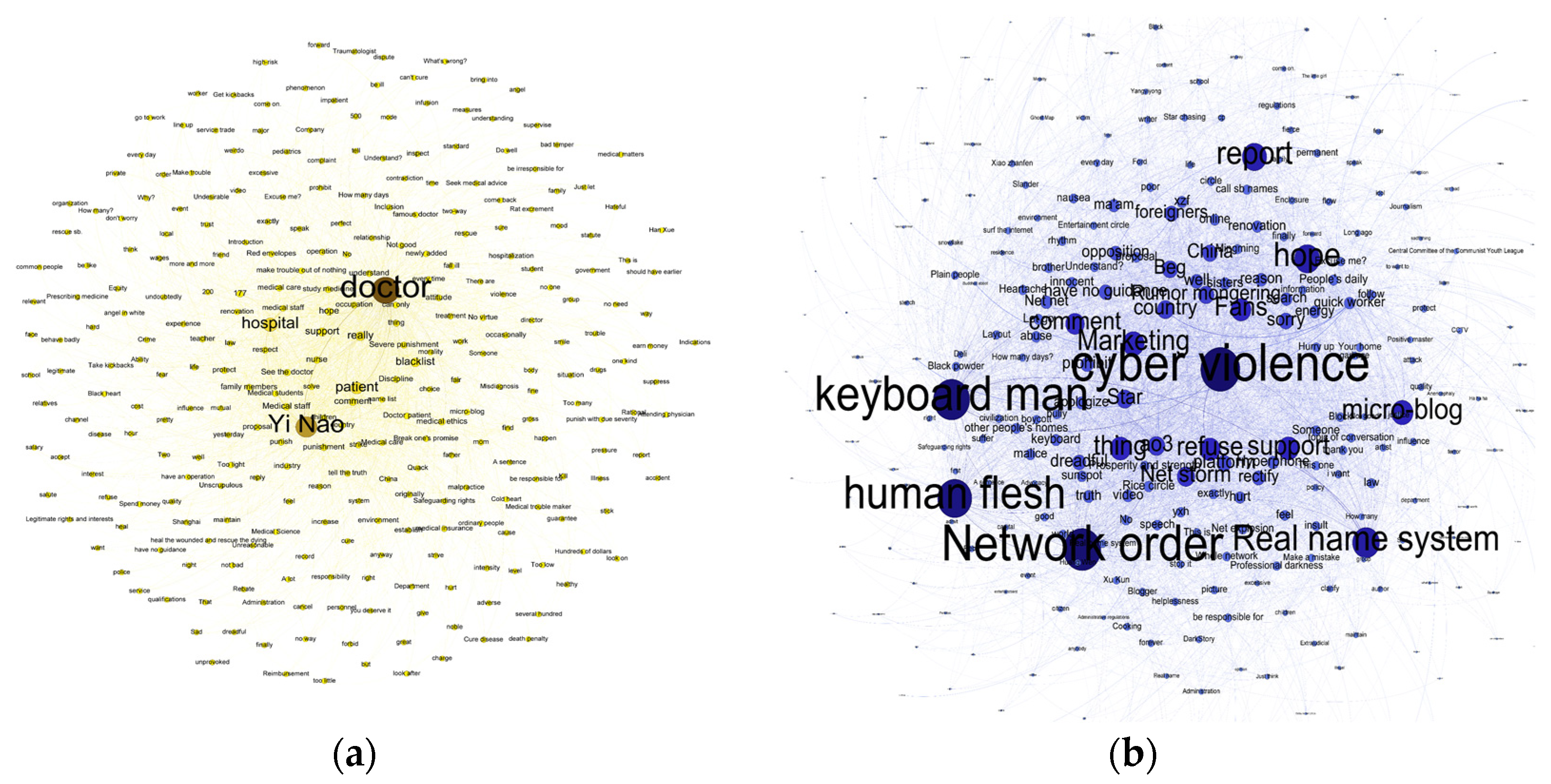
| Topic 1 | Medical violence (called “Yi Nao” in Chinese) | 1 |
| Topic 2 | Cyber violence | 1 |
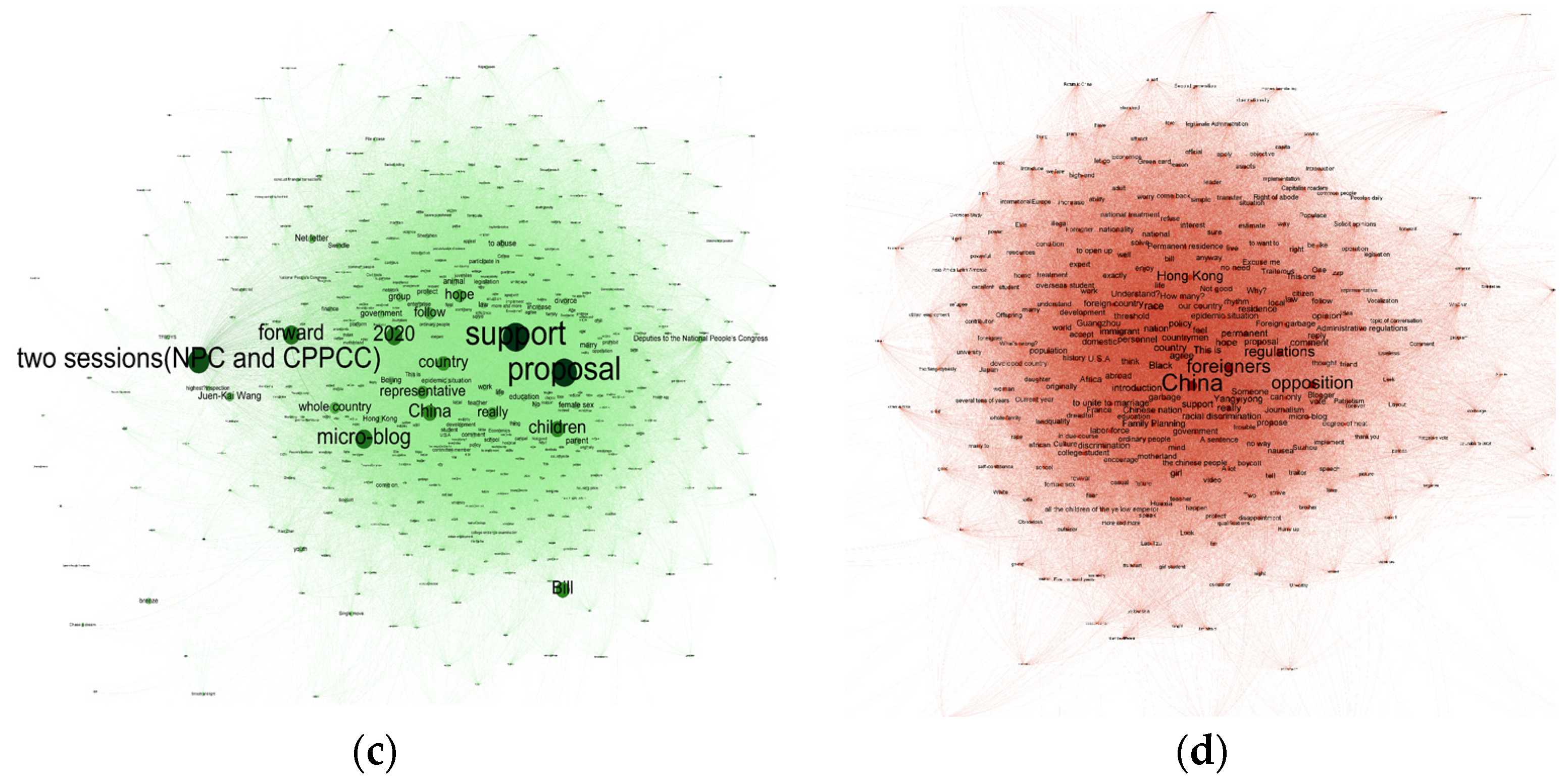
| Topic 3 | National People’s Congress (NPC) and Chinese People’s Political Consultative Conference (CPPCC) Annual Sessions 2020 | 2 |
| Topic 4 | New Permanent Residence Law for Foreigners (Draft Version) | 2 |
| Time Interval | Primary Keywords | |
|---|---|---|
| Topic 1 | 1 January 2018–31 December 2019 | Yi Nao, medical dispute, medical order |
| Topic 2 | 1 January 2018–31 December 2019 | cyber violence |
| Topic 3 (Text source of Topic 3: http://www.ccps.gov.cn/xtt/202005/t20200530_141283.shtml) (accessed on 26 August 2021) | 21 May 2020–28 May 2020 | two sessions, NPC, CPPCC |
| Topic 4 (Text source of Topic 4: http://www.moj.gov.cn/news/content/2020-02/27/zlk_3242559.html) (accessed on 26 August 2021) | 27 February 2020–4 March 2020 | permanent residence, foreigner |
| Additional Keywords | Number of Online Posts in Total | ||
|---|---|---|---|
| SS | Topic 1 | patient right, physician safety, hospital safety, doctor moral | 7771 |
| Topic 2 | cyber manhunt, language violence, keyboard man (In China, “keyboard man” refers to a member of a group of individuals who “deliver justice” in the form of comments on the Internet, which they consider “freedom of speech”. However, they are often considered as the main force in launching cyber violence.) | 13,592 | |
| Topic 3 | civil code, poverty alleviation | 10,136 | |
| Topic 4 | Ministry of Justice, international students | 7930 | |
| DR | Topic 1 | hospital, blacklist, patient, rebate, doctor, protection | 8904 |
| Topic 2 | Weibo, withdraw, law, vicious, free, right, terrible, language, rumor, murder, spreading, supervise | 16,527 | |
| Topic 3 | poverty, epidemic, civil code, proposal, vaccine, society, Hong Kong | 11,074 | |
| Topic 4 | residence, citizen, foreign, student, public, right, international, fair | 10,026 | |
| LDA | Topic 1 | doctor + patient, hospital + damage, right + protection, medical staff-law, education + student | 9207 |
| Topic 2 | violence + terrible, rumor + video, Weibo + law, Internet + safeguard, statement + response | 18,248 | |
| Topic 3 | international + cooperation, civil code + protection, well-off + society, corruption + against, Weibo + proposal, hukou + reformation | 13,256 | |
| Topic 4 | justice + public, foreign + domestic, international + students, residence + fair | 8359 | |
| Additional Keywords | Number of Online Posts in Total | |
|---|---|---|
| Topic 1 | Yi Nao + punishment, blacklist + 177, rights + patients + protection, hospital + fair, physicians + safety | 13,997 |
| Topic 2 | cyber violence + refuse, Human flesh + search, keyboard man + real-name system, network order + regulate | 18,732 |
| Topic 3 | two sessions + 2020, Hong Kong + independence, disease + control, proposal + NPC, proposal + CPPCC, poverty + alleviation, vaccine + HPV | 17,997 |
| Topic 4 | Ministry of Justice + 27, international students + right, national treatment + fair | 9316 |
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NT | r (%) | Nc | NT | r (%) | Nc | NT | r (%) | Nc | NT | r (%) | Nc | |
| EB | 4201 | 86.53 | 3635 | 8226 | 85.57 | 7039 | 8319 | 93.92 | 7813 | 5404 | 93.67 | 5062 |
| SS | 7771 | 71.01 | 5518 | 13,592 | 76.24 | 10,363 | 10,136 | 88.52 | 8972 | 7930 | 86.22 | 6837 |
| DR | 18,904 | 53.27 | 10,070 | 21,527 | 59.66 | 12,843 | 31,074 | 46.54 | 14,462 | 11,926 | 79.07 | 9430 |
| LDA | 19,207 | 49.24 | 9458 | 23,248 | 43.09 | 10,018 | 23,256 | 62.34 | 14,498 | 10,359 | 69.61 | 7211 |
| Proposed strategy | 13,997 | 84.76 | 11,864 | 18,732 | 84.74 | 15,873 | 17,997 | 94.19 | 16,951 | 9316 | 89.81 | 8367 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, Y.; Lin, X.; Dong, X.; Hou, S. A Normalized Rich-Club Connectivity-Based Strategy for Keyword Selection in Social Media Analysis. Sustainability 2022, 14, 7722. https://doi.org/10.3390/su14137722
Lian Y, Lin X, Dong X, Hou S. A Normalized Rich-Club Connectivity-Based Strategy for Keyword Selection in Social Media Analysis. Sustainability. 2022; 14(13):7722. https://doi.org/10.3390/su14137722
Chicago/Turabian StyleLian, Ying, Xiaofeng Lin, Xuefan Dong, and Shengjie Hou. 2022. "A Normalized Rich-Club Connectivity-Based Strategy for Keyword Selection in Social Media Analysis" Sustainability 14, no. 13: 7722. https://doi.org/10.3390/su14137722
APA StyleLian, Y., Lin, X., Dong, X., & Hou, S. (2022). A Normalized Rich-Club Connectivity-Based Strategy for Keyword Selection in Social Media Analysis. Sustainability, 14(13), 7722. https://doi.org/10.3390/su14137722