Abstract
Accurate load forecasting is an important issue for the reliable and efficient operation of a power system. In this study, a hybrid algorithm (EMDIA) that combines empirical mode decomposition (EMD), isometric mapping (Isomap), and Adaboost to construct a prediction mode for mid- to long-term load forecasting is developed. Based on full consideration of the meteorological and economic factors affecting the power load trend, the EMD method is used to decompose the load and its influencing factors into multiple intrinsic mode functions (IMF) and residuals. Through correlation analysis, the power load is divided into fluctuation term and trend term. Then, the key influencing factors of feature sequences are extracted by Isomap to eliminate the correlations and redundancy of the original multidimensional sequences and reduce the dimension of model input. Eventually, the Adaboost prediction method is adopted to realize the prediction of the electrical load. In comparison with the RF, LSTM, GRU, BP, and single Adaboost method, the prediction obtained by this proposed model has higher accuracy in the mean absolute percentage error (MAPE), mean absolute error (MAE), root mean square error (RMSE), and determination coefficient (R2). Compared with the single Adaboost algorithm, the EMDIA reduces MAE by 11.58, MAPE by 0.13%, and RMSE by 49.93 and increases R2 by 0.04.
1. Introduction
Power load forecasting is an important link in the optimal dispatching of power systems. Accurate and timely forecasting can provide auxiliary decision support for the construction progress of power supplies and power grids. At the same time, it is of great significance to formulate an economic and reasonable power allocation plan, reduce the operation cost of the power grid and ensure the power production and life. Mid- to long-term load forecasting generally refers to forecasts in years and months [1]; load refers to the change rate of energy with time, that is, demand or power. Load also refers to the total amount of electricity sold by power enterprises, that is, electricity consumption. In view of the large amount of stored electric energy, changes in load in the future should be predicted in advance, that is, load forecasting [2]. According to the purpose and time of forecasting, load forecasting is classified into short-term, medium-term, and long-term forecasting [3,4]. This study aims at medium-term load forecasting, which lasts one month to two years.
However, since the power load is affected by various external factors such as macroeconomics and meteorological conditions, medium- and long-term load forecasting is a complex multidimensional problem [5]. Power grids and power corporations are facing the replacement of power generation equipment as a result of the aggressive marketing of new energy power generation. Accurate power demand forecasting can assist power grids and power firms in locating low-load periods to connect new energy to the system. As a result, proposing a medium- and long-term power load forecasting model with higher forecasting accuracy is a pressing issue.
Many articles have used the idea of machine learning to predict power load due to the widespread application of machine learning in artificial intelligence [6,7]. Mr. Ling proposed an Adaboost-based power system load forecasting method and demonstrated its effectiveness [8]. The support vector regression (SVR) model is used to predict using meteorological factors and historical related electric load data, proving the superiority of the EMD method in short-term prediction [9]. In manifold learning, Isomap is an important representative algorithm. It is primarily used to reduce data dimensionality and extract features [10]. Electricity load data are complex and are affected by many economic and meteorological factors. Semero et al. used EMD to decompose power load data into several simple IMFs and then predicted the IMFs separately [11]. EMD is decomposed into multiple IMFs to forecast separately, which increases the forecast time and breaks the regularity of the power load data to a certain extent [12,13,14,15]. Short-term variations in power load are affected by meteorological elements, whereas long-term trends in power loads are affected by economic factors. The forecasting effect can be improved by effectively separating meteorological and economic loads [16,17,18,19].
In order to improve the accuracy of power load forecasting, so that power companies and power grids can build generation and supply facilities rationally, a new EMD-Isomap-Adaboost power load forecasting model is proposed. First, meteorological and economic data are decomposed by EMD, and the Isomap algorithm is used to reduce the dimension of the decomposed data to select high-quality features. Second, EMD is used to decompose the original power load data sequence into several simple data sequences. The decomposed data are divided into meteorological item and economic item by correlation analysis. The overall meteorological item presents a cyclic fluctuation trend, which is called the fluctuation item. The trend item is an economic item that has an impact on the overall trend of the electricity load. Finally, the Adaboost algorithm and the features chosen by EMD–Isomap are used to predict the trend and fluctuation items, and the two predictions are superimposed.
The main contributions and originalities of this paper are as follows:
- (1)
- By applying the idea of “decomposition and integration”, EMD is used to decompose the load and obtain the features of load at different frequency. Through correlation analysis, multiple IMFs are integrated into two categories: trend item and fluctuation item.
- (2)
- This is the first study to suggest using EMD–Isomap to decompose meteorological and economic features, then reducing the dimension to select high-quality features.
The following is the content arrangement of this study. The second part of the article describes related work. The theoretical knowledge of EMD, Isomap, Adaboost, and the EMDIA process is introduced in Section 3. Data and the experimental settings are introduced in Section 4. The results and analysis are introduced in Section 5. Section 6 provides a conclusion.
2. Related Work
Many researchers believe that machine learning methods have promising applications in the field of energy prediction because they have demonstrated good performance in finding potential rules and complex characteristics of data. Arash et al. used support vector regression (SVR) to predict electrical load loads with high accuracy [20,21]. To estimate power loads, Jihoon et al. used random forests and multilayer perceptrons and achieved good results [22]. Li et al. combined and projected power load forecasts using the XGboost approach and other methods and demonstrated XGboost’s superiority [23,24]. In addition, deep learning algorithms have been widely used in the field of electric load forecasting, including deep neural networks (DNN) [25,26], long short-term memory networks (LSTM) [27,28], and convolution neural networks (CNN) [29,30]. However, these methods necessitate a large amount of data, a more complex model input, and a lengthy training period. AdaBoost has a high level of accuracy, and the training error decreases exponentially. AdaBoost, unlike the bagging and random forest algorithms, fully considers the weight of each classifier [31]. The AdaBoost technique has a substantially faster training speed than deep learning and uses less data.
As a hot research topic in recent years, the “decomposition and integration” method involves the decomposition of the original series into several components, the processing of each component, and finally the integration of the prediction results for each component to obtain the final result [32,33]. Li et al. decomposed the load series by wavelet transform and then used the improved artificial bee colony optimization extreme learning machine (ELM) to predict the power load [34]. After using wavelet decomposition, Peng et al. used random forest to predict each component and then added them together [35]. The wavelet analysis needs to select a certain wavelet base, and the selection of the wavelet base has a great influence on the result of the whole wavelet analysis. Zhang et al. decomposed the load data by EMD, predicted each IMF separately after decomposition, and achieved good results [36,37]. After the EMD is decomposed and then predicted individually, a large number of IMFs will increase the prediction time and may destroy the inherent regularity of the power load to a certain extent.
Due to the nonlinear change of power load and multiple environmental and economic information variables, with the increase inof network input variables, the model convergence will slow down, and there will be an overfitting problem [38,39,40,41]. Zhang et al. proposed using empirical mode decomposition (EMD) to decompose the sequence of environmental factors to obtain the changes in data signals on different time scales and reduce the non-stationarity of the sequence of environmental factors, followed by using principal component analysis (PCA) to extract feature sequences [42]. Meteorological and economic data are highly nonlinear data. The isometric mapping (Isomap) algorithm is better than PCA for processing nonlinear data [43]. Isomap is an important representative algorithm in manifold learning. It is mainly used for data dimensionality reduction and feature extraction [44]. Therefore, this study proposes using EMD to decompose meteorological and economic data, and then using Isomap to reduce and filter the decomposed multidimensional data.
We may conclude from the preceding related work that employing the “decomposition and integration” concept to forecast the load sequence is effective in separating the trend and fluctuation items; on the other hand, EMD–Isomap is used to decompose meteorological economic information, and dimensionality reduction is then used to choose high-quality features, which are subsequently utilized to increase forecast accuracy. As a result, we must decompose and combine the load, optimize the features, and then use the optimized features to predict the separated trend term and fluctuation term separately, before adding them all.
3. Applied Methodologies
3.1. The Principle of Adaboost
The Adaboost algorithm is an important feature classification algorithm in machine learning that mainly solves the classification problem and the regression problem. The algorithm has currently been applied to power system load forecasting [45] and traffic volume forecasting [46], with promising results.
In this research, the Adaboost algorithm is adopted that takes a decision tree as a weak learner. The specific steps of the Adaboost are as follows:
- (1)
- First, a weak learning algorithm and a training set are given: where X and Y represent a domain or instance space.
- (2)
- Initialize the weights of N samples, assuming that the sample distribution is uniform, . represents the weight of samples in the T times iteration, and N is the number of samples in the training set.
- (3)
- Under the probability distribution of training samples, the weak learner h3(x) is trained.
- (4)
- Calculate the error of the weak learner under each sample and average error .
- (5)
- Update sample weight:. Weak learner weight , . Zt is the normalization factor of .
- (6)
- Skip to step 3 and continue the next iteration until the number of iterations is T.
- (7)
- According to the trained weak learners, the strong learners are combined .
3.2. Empirical Mode Decomposition
Many factors influence the electricity load, including economic development, demographic changes, gross value of construction projects completed in that year, GDP, per capita pay level, and the local working population. Temperature and precipitation are the two parameters that have the greatest impact on meteorology. As an outcome, the overall trend will be nonlinear and variable, disrupting the accuracy of power demand prediction. Empirical mode decomposition (EMD), a data decomposition method proposed by Huang in 1998, is applied in this study [47]. In recent years, the EMD method has been widely used in various fields such as power load forecasting, power fault diagnosis, stock forecasting, and photovoltaic energy generation forecasting [48,49,50]. The key idea of empirical mode decomposition is to decompose the nonlinear fluctuation data into a residual term and a relatively stable IMF through empirical identification. The IMF component should meet two requirements:
- (1)
- In the whole-time range of the function, the number of local extreme points and zero crossings must be equal or at most one difference.
- (2)
- At any time point, the mean of the upper envelope of the local maximum and the lower envelope of the local minimum must be zero.
The decomposition process is as follows:
Step 1: Initial extraction.
The cubic spline interpolation function is used to fit the upper and lower envelope, which is connected with the local maximum and minimum value and covers all the data between them. Let the first average value of the envelope be h11, the original data signal be M, and the m11 component be the difference between the original data and the average value:
Step 2: Repeat filtering.
Repeat the filtering until the components meet the IMF standard, that is, the number of extreme values and zero crossings must be equal or at most 1, and then the envelope average value must be 0. Mi(K−1) is the component of (K−1) filtering, hik is the mean of the K filtering, and mik is the ith component that meets the IMF conditions after K filtering. It is defined as the ith IMF component Li. The process of repeated s filtering is as follows:
Step 3: module integration.
The filtering process will be repeated until the component or residual value is less than the predetermined value or the residual becomes a monotonic function. When all IMFs are extracted from the original data signal, the residual term R has the characteristics of a long period and an obvious trend.
Through this filtering process, the original data are divided into I empirical modes Li (i = 1,......, n) and a residual term R, and Q is the final integration results, in which the value of i is determined by the fluctuation nature of the data itself:
3.3. The Principle of Isometric Mapping (Isomap)
The dimensionality reduction algorithm is applied in many fields, among which the PCA algorithm is widely used, but the PCA algorithm is not effective for dealing with nonlinear data, while the Isomap algorithm has good results in dealing with nonlinear data such as meteorological and economic data. Isometric mapping (Isomap) is one of the most representative manifold learning methods. It is mainly used to reduce the dimension of nonlinear data and find out the low-dimensional structure hidden in high-dimensional data [51]. Isomap is based on multiple dimensional scaling (MDS). The main idea of Isomap is to calculate the shortest distance in the nearest neighbor graph to obtain the geodesic distance and then use the MDS algorithm to obtain the representation of the low-dimensional smooth manifold embedded in the high-dimensional space [52].
The steps of the Isomap algorithm are as follows:
Step 1: Calculate the Euclidean distance matrix between sample points and establish the neighborhood relation graph G (V, e). For each Xi (i = 1, 2, …, N), calculate its k-nearest neighbor Xi1, XI2,…, Xik, which is recorded as Nj. Take point Xi as the fixed point and Euclidean distance D (Xi, Xij) as the edge to establish the neighborhood relation graph G (V, e).
There are two methods of determining the nearest neighbors:
- (1)
- Using ε-nearest neighbor, if ||Xi -Xj||2 ≤ ε, then the point pair Xi, Xj can be regarded as the nearest neighbor.
- (2)
- Using k-nearest neighbor, the number of nearest neighbor’s K is given in advance, and then the nearest neighbor points are determined.
Step 2: Calculate the geodesic distance a to achieve the goal of finding the shortest path in the nearest neighbor graph G (V, e)
Step 3: The classical MDS method is used for distance D = (dij)N × N to obtain the lowest dimension embedding Y = {y1, y2, …, yN}
3.4. The Full Procedure of the EMDIA Model
Since the prediction accuracy of the Adaboost algorithm depends on the choice of eigenvalues [53], this study first uses EMD–Isomap to decompose and reduce the dimensions of the economic and environmental data, remove the redundancy and noise of the features, and generate new high-quality features for Adaboost. Second, this study cites the idea of “decomposition and integration”. Using EMD to decompose the power load data, the correlation is used as the basis for reconstruction. After the EMD decomposition, the power load data are divided into trend items and fluctuation items, and the two items are studied and forecasted separately. Based on the above two aspects, this paper proposes the EMDIA method to predict the power load data.
The overall procedure of the proposed EMDIA model is presented as follows and illustrated in Figure 1.
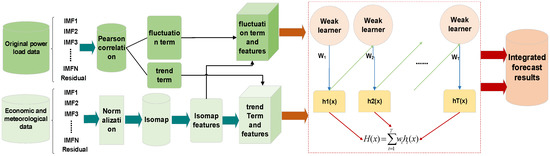
Figure 1.
Overall process of the proposed EMDIA model.
- (1)
- The power load data are decomposed into IFM and residual by EMD.
- (2)
- The IMF and residual, meteorological factors, and economic factors are divided into two groups through correlation analysis, with the trend term related to economic factors and the fluctuation term related to meteorological factors.
- (3)
- IMF and residual are formed by decomposing economic factors and meteorological factors through EMD.
- (4)
- All decomposed data are normalized. The normalization process is shown in Equation (6):
- (5)
- Isomap dimensionality reduction is used to select new high-quality features for Adaboost using the normalized data.
- (6)
- The Adaboost method, paired with the features after Isomap dimensionality reduction, predicts the trend and fluctuation terms.
- (7)
- Integrate the values predicted by the trend and fluctuation terms, as appropriate.
3.5. Model Evaluation Indicators
In this study, four evaluation indices were used to evaluate the prediction effect. The four indices are the coefficient of determination (R2), the mean absolute error (MAE), the mean absolute percentage error (MAPE), and the root mean square error (RMSE) where Lt and are the actual and forecasted values of the load at time t and M is the total number of data points used. The formulas of the four evaluation indicators are as follows:
4. Data and Experiment Settings
4.1. Data Sources
The datasets used in the EMDIA algorithm include power load data, meteorological data, and economic data. The power load statistics represent Hong Kong’s total electricity consumption from 2000 to 2021. It is from the Hong Kong Census and statistics department (https://www.censtatd.gov.hk/, accessed on 27 April 2022). Meteorological data include four factors that have a great impact on power load: maximum temperature, minimum temperature, average temperature, and precipitation. These are from the Hong Kong Observatory (https://www.hko.gov.hk, accessed on 27 April 2022). Economic data include four factors: GDP (million HKD), gross construction value in this quarter (million HKD), per capita wages that year, and working population (10,000). These are from the Hong Kong Census and statistics department.
4.2. Experiment Settings
The proposed model was evaluated on the Hong Kong dataset. Cross-validation was adopted for performance evaluation, i.e., the dataset was partitioned into two isolated subsets: the training dataset and the test dataset. The test data were not used in the training model for fair performance comparison. The partition ratio of the training data and test data was 7:3. Several classic algorithms and combinatorial algorithms were also simulated for reference, including random forest, BP, GRU, LSTM, pure Adaboost, EMD–Adaboost, EMD–PCA–Adaboost, EMDIA, and S-EMDIA (S-EMDIA: EMD-only decomposes economic factors and meteorological factors and does not decompose power load data). Experiments were conducted on 64-bit Windows 10 using MATLAB R2018a with an i7-7700hq CPU and a GTX-1050 graphics card.
5. Results and Analysis
5.1. Results of EMD Decomposition Electric Load
Both economic and meteorological variables have a major influence on long-term power load patterns, making them unpredictable. In general, the electrical loads can be decomposed into trend term, fluctuation term, and stochastic term [54]. In this study, EMD is used to decompose the original data of power load and decompose the trend term and fluctuation term. Stochastic term represents an accidental error, and the actual value is very small, which is not considered in this study.
Figure 2 clearly describes the original power load data and the four IMF terms and residual terms after decomposition. The original power load data can be seen to be regular and fluctuate with the monthly cycle to a certain extent. The overall pattern shows an upward trend, which means that the power load is increasing with time. In order to separate fluctuation items and trend items more accurately, the EMD method is used in this study. The preceding steps show that the EMD method is employed to decompose the load at low and high frequencies, respectively. We stacked the four high-frequency IMF following EMD decomposition by correlation, which is referred to as the fluctuation term, in this work. A “trend item” is the name for the residual term. The original power load data are separated into fluctuation and trend terms in this manner.
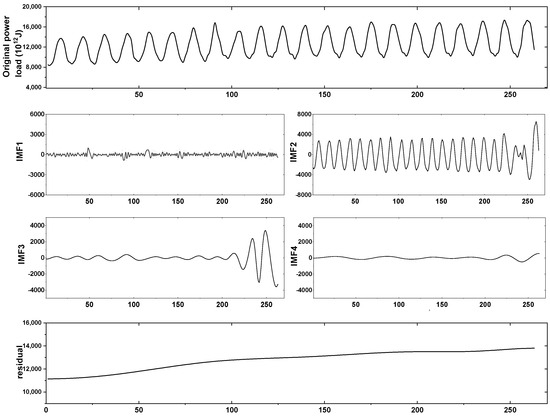
Figure 2.
EMD decomposition results for the original power load data.
5.2. Analysis of the Factors Affecting Power Load
The correlation coefficients among the attributes in use are shown in Figure 3. (O-original load, P-periodic term, T-trend term, X-maximum temperature, N-minimum temperature, A-average temperature, E-precipitation, G-GDP, C-gross construction, W-per capita wage, K-working population)). There is a correlationare correlations between the initial power load data, meteorological data, and economic data, as can be observed. In the correlation study using the meteorological and economic data, however, the fluctuation and trend terms following EMD decomposition were considerably improved. After EMD decomposition, the correlation values with X, N, A, and E increased by 0.03, 0.02, 0.02, and 0.03 respectively. After EMD decomposition, the correlation values with C, W, and K increased by 0.6, 0.5, and 0.6 respectively. These findings show that EMD is effective in separating trend terms and fluctuation terms.
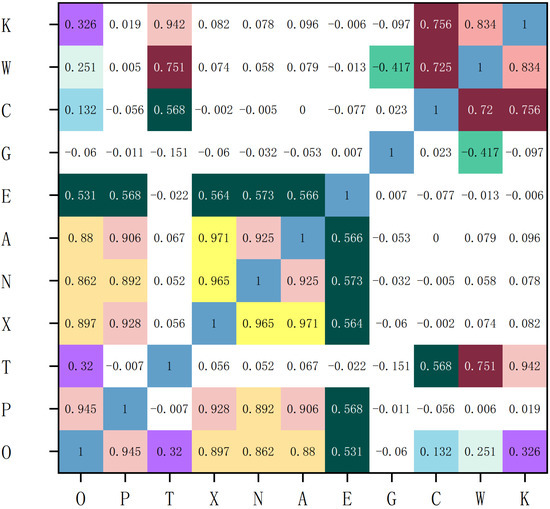
Figure 3.
Correlation coefficients between the data features and the power load data. (Different colors are used to highlight the levels of different data).
The meteorological and economic series data in the experimental samples are non-stationary signals that are affected by weather changes and economic policies and have certain randomness and mutation. To emphasize the local features of the original meteorological and economic series, EMD is used to decompose the original meteorological and economic series data to obtain the IMF component and residual component of each environmental and economic factor data.
5.3. EMD-Isomap for Feature Decomposition and Dimensionality Reduction
Figure 4 shows that after EMD decomposition, at least four IMF subsequences and one trend item sequence are obtained for each feature. Obviously, the frequency of each subsequence is different. The original sequence of meteorological factors shows a periodic fluctuation with time. For the original sequence of economic factors, there is no definite cycle fluctuation, but the trend fluctuates. First, eight influencing factors are decomposed through EMD decomposition. Second, through EMD decomposition, the original influencing factors are decomposed into 8 residuals and 40 IMFs. On the one hand, these 48 features increase the amount of feature sequences, but they also increase the size of the input variables. On the other hand, when making a forecast, the calculation time is increased. In order to improve prediction accuracy, preserve the Adaboost model’s calculation speed, and address the problem of over-fitting, dimension reduction is required.
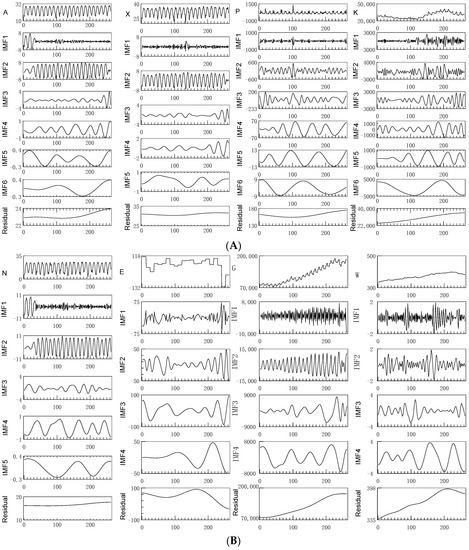
Figure 4.
Results of the EMD decomposition of factors affecting power load. (A) is the EMD decomposition result of A, X, P, K (A-average temperature, X-maximum temperature, P-periodic term, K-working population). (B) is the EMD decomposition result of N,E,G,W(N-minimum temperature, E-precipitation, G-GDP, C-gross construction, W-per capita wage).
5.4. Feature Importance Analysis
The decision tree is employed as the basic learner for Adaboost in this study. People can explain the prediction findings of a decision tree model, which is a type of white box model. As a part of interpretability attributes, feature importance is an index of the contribution of each input feature to the prediction results of the model, that is, how small changes in a feature change the prediction results. Figure 5 demonstrates the contrast of feature importance before and after EMD–Isomap. Before Isomap dimensionality reduction, there are eight features, and only two features with feature importance greater than 10%. The importance of X is 30%, and the importance of A is 50%. The importance of W, C, and E is close to zero, which has little impact on the prediction results.
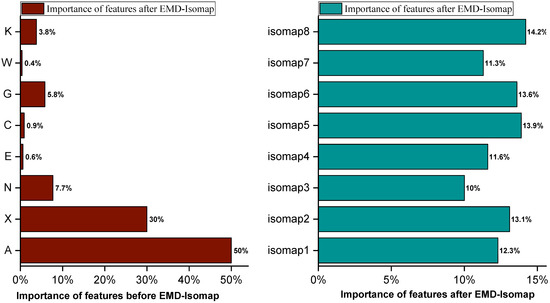
Figure 5.
Feature importance before and after EMD–Isomap.
The environmental and economic sequence data in the experimental samples are non-stationary signals, are affected by weather changes and economic policies, and have certain randomness and sudden change. There are strong correlations between environmental data A, E, X, and N. There are also correlations between economic data G, C, W, and K. To emphasize the characteristics of the different time frequencies of the original data, this study utilized EMD to decompose the original environmental and economic data and obtain the IMF component and residual component for each piece of environmental and economic factor data. Eight features are extracted following EMD decomposition and Isomap dimensionality reduction, and each feature’s relevance is larger than 10%, demonstrating that each feature value after Isomap has enormous implications for the prediction results. These eight features are orthogonal to each other and are not related to each other. The above results show that after EMD decomposition and Isomap dimensionality reduction, each new feature is important for predicting results.
5.5. Prediction Results and Analysis of Different Algorithms
The algorithm parameters involved in the comparison in Table 1 are set as follows:

Table 1.
Comparison of Evaluation Indicators between EMDIA and Other Algorithms.
- Random forest settings: number of trees = 100, maximum depth of tree = 30, maximum number of leaf nodes = 50.
- BP settings: learning rate = 0.1; number of iterations = 1000, number of hidden layer neurons = 100.
- GRU settings: hidden layer = 2, number of neurons = 64, stride = 7, epoch = 120, learning rate = 0.01.
- LSTM settings: LSTM network = 1, number of neurons = 20, learning rate = 0.001.
- Adaboost settings: base learner = decision tree, number of base learners = 100, learning rate = 1.
Table 1 lists the simulation results, from which we can observe that the proposed model outperforms all reference forecast models in all simulated scenarios, which verifies the effectiveness of the proposed model.
- (1)
- When the Adaboost method is compared with the RF, BP, LSTM, and GRU algorithms, the results show that the RMSE, MAE, and MAPE indicate that the error is smaller. The R2 of Adaboost is higher than any other algorithms, and it is the closest to 1. The MAE of Adaboost is 16.58, the MAPE is 0.13%, and the RMSE is 57.83. The MAE of RF was 476.42, the MAPE was 3.85%, and the RMSE was 574.46. The MAE of BP was 1041.74, the MAPE was 7.62%, and the RMSE was 1048.14. The MAE of the LSTM is 624.93, the MAPE is 4.59%, and the RMSE is 912.62. The MAE of GRU was 438, the MAPE was 3.49%, and the RMSE was 563.80. The three evaluation indicators of Adaboost are lower than RF, BP, LSTM, and GRU. The above shows that the Adaboost algorithm is the most applicable in this study.
- (2)
- When comparing the EMD–Adaboost algorithm to Adaboost, the results in Table 1 reveal that Adaboost after EMD has a better prediction impact than Adaboost alone. EMD–Adaboost reduces MAE by 5.9%, MAPE by 0.02%, and RMSE by 20.5% and improves R2 by 0.01, demonstrating that EMD is crucial in power load forecasting.
- (3)
- When the MAE index is nearly comparable, the S-EMDIA algorithm improves R2 by 0.03, MAPE by 0.02%, and RMSE by 13.06% when compared with EMD–Adaboost. The findings of the comparison reveal that after EMD–Isomap, new features are chosen to participate in the prediction, which can improve the accuracy of the prediction results to some extent.
- (4)
- The approaches in the literature [42] were also compared in this study. In contrast to EMDIA, EMD–PCA–Adaboost reduces feature dimensionality using PCA rather than Isomap. The experimental results are shown in Table 1. The R2 of EMD–PCA–Adaboost is 0.95, MAE is 426.53, MAPE is 3.35%, and RMSE is 573.90. Each indicator of EMD–PCA–Adaboost has a disadvantage when compared with EMD–Adaboost, implying that PCA may not be suitable for nonlinear data dimensionality reduction. The prediction accuracy of Adaboost was not improved by the new features after EMD–PCA. In comparison with EMDIA, the indicators’ disadvantages are more clear, demonstrating the usefulness and necessity of Isomap in this method.
- (5)
- Compared with S-EMDIA, the MAE of EMDIA is decreased by 6.2, the MAPE is decreased by 0.08%, and the RMSE is decreased by 16.37. The R2 of EMDIA and S-EMDIA are both 0.99. Table 2 illustrates the forecast results for the IMF, the trend term, and the fluctuation term. Compared with IMF1-IMF4, the prediction result of the fluctuation term reconstructed by correlation analysis shows a great improvement in R2, and the effects of the other three evaluation indicators (MAE, MAPE, and RMSE) all decrease to a certain extent. In this study, the trend term is the residual term, the value of R2 is 0.93, the value of MAE is 111.68, the value of MAPE is 41.6%, and the value of RMSE is 39.52. These show that after EMD, the trend and fluctuation terms are produced by correlation analysis, which considerably increases prediction accuracy.
Table 2. Forecast results for IMF, trend term, and fluctuation term.
The MAPE results for specific RF, BP, LSTM, GRU, and Adaboost are 3.85%, 7.6%, 4.59%, 3.49%, and 0.12%, respectively. The MAPE of EMDIA is 0.0003%. The MAE results for RF, BP, LSTM, GRU, and Adaboost are 476.42, 1041.74, 624.93, 438, and 16.58, respectively. The MAE of EMDIA is 5.0. The RMSE results for RF, BP, LSTM, GRU, and Adaboost are 574.46, 1048.14, 912.62, 563.80, and 57.83, respectively. The RMSE of EMDIA is 7.9. The R2 results for RF, BP, LSTM, GRU, and Adaboost are 0.91, 0.84, 0.87, 0.95, and 0.95, respectively. The R2 of EMDIA is 0.99. Figure 6 shows the prediction results for EMDIA, BP, RF, Adaboost, LSTM, and GRU. The forecast time is in months. The results show that the predicted value of EMDIA has the best fitting effect with the original value, and the error is also the smallest, while the fitting effect of BP is the worst. The Adaboost algorithm is optimized for smoother curve fitting and higher accuracy.
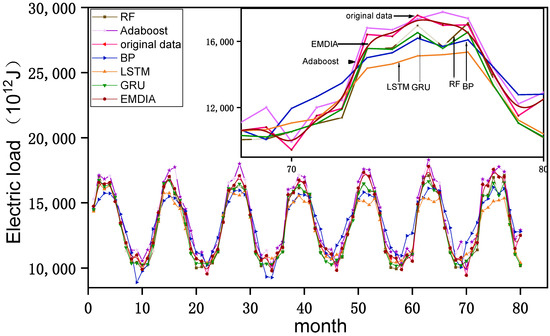
Figure 6.
Prediction results for the proposed model and the individual models.
6. Conclusions
Power load forecasting is of great significance to smart grids. In this study, a prediction model based on the idea of “decomposition and integration” and “feature decomposition and dimensionality reduction” is proposed, that is, EMDIA. The model combines Adaboost, EMD, correlation analysis, and Isomap. Through the comparison of the proposed method with other algorithms, we draw conclusions as follows:
- (1)
- The EMD of the load sequence can effectively separate the complex information contained in the original sequence, and the decomposition quantity is divided into trend items and fluctuation items by correlation analysis. This effectively reduces the model calculation time and improves the prediction accuracy.
- (2)
- Using the EMD–Isomap algorithm, the nonlinear meteorological and economic data are decomposed to obtain multidimensional features. Then, the Isomap algorithm is used to reduce the dimensions and select the features to obtain new features. This effectively removes noise and redundancy in the features. The experimental results verify the effectiveness of EMD–Isomap.
- (3)
- The EMDIA approach has excellent accuracy in power load forecasting and can better predict the load trend, indicating that it has a promising future application in medium- and long-term power load forecasting.
The experimental results show that the MAPE of the EMDIA decreases to 0.0003%, MAE decreases to 5.0, RMSE decreases to 7.9, and R2 increases to 0.99, which shows much better performance than traditional Adaboost. In the meantime, compared with the BP, RF, LSTM, and GRU algorithms, the four evaluation indexes of the proposed method are superior, which proves that the proposed method is potentially useful for power load forecasting.
This study estimates Hong Kong’s medium- and long-term power load, with the goal of addressing the challenging issue of new energy grid connection in Hong Kong. Accurate load forecasting data can be used to guide the installation time, installed capacity, power grid design, and building of new energy-generating units in Hong Kong.
In future work, we will continue to study the decomposition and dimension reduction selection of eigenvalues. On the premise of not destroying the regularity of eigenvalues as much as possible, we will remove noise and redundancy in eigenvalues to obtain new features, which will further improve the accuracy of the model.
Author Contributions
Funding acquisition, Y.H.; Investigation, P.G. and D.Z.; Writing—original draft, X.H.; Writing—review & editing, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program (2019YFC1904304).
Institutional Review Board Statement
Not applicable for studies not involving humans or animals.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study. Written informed consent has been obtained from the patient(s) to publish this paper.
Data Availability Statement
Restrictions apply to the availability of this data. Data was obtained from Hong Kong Census and statistics department and Hong Kong Observatory. The data can be obtained in the following: (https://www.censtatd.gov.hk/, accessed on 27 April 2022), (https://www.hko.gov.hk, accessed on 27 April 2022).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nicolas, K.; Maxence, B.; Thibaut, B.; Robin, G.; Elena, M.; Georges, K.; Guillaume, P.; Pierre, C. Long-term forecast of local electrical demand and evaluation of future impacts on the electricity distribution network. CIRED—Open Access Proc. J. 2017, 2017, 2401–2405. [Google Scholar]
- Lindberg, K.B.; Seljom, P.; Madsen, H.; Fischer, D.; Korpås, M. Long-term electricity load forecasting: Current and future trends. Util. Policy 2019, 58, 102–119. [Google Scholar] [CrossRef]
- Jinghua, L.; Yongsheng, L.; Shuhui, Y. Mid-long term load forecasting model based on support vector machine optimized by improved sparrow search algorithm. Energy Rep. 2022, 8, 491–497. [Google Scholar]
- Xiaole, L.; Yiqin, W.; Guibo, M.; Xin, C.; Qianxiang, S.; Bo, Y. Electric load forecasting based on Long-Short-Term-Memory network via simplex optimizer during COVID-19. Energy Rep. 2022, 8, 1–12. [Google Scholar]
- Pan, G.; Ouyang, A. Medium and Long Term Power Load Forecasting using CPSO-GM Model. J. Netw. 2014, 9, 2121–2128. [Google Scholar] [CrossRef]
- Yinsheng, S.; Chunxiao, L.; Bao, L.; Weisi, D.; Peishen, Z. Principal Component Analysis of Short-term Electric Load Forecast Data Based on Grey Forecast. J. Phys. Conf. Ser. 2020, 1486, 062031. [Google Scholar] [CrossRef]
- Elkamel, M.; Schleider, L.; Pasiliao, E.L.; Diabat, A.; Zheng, Q.P. Long-Term Electricity Demand Prediction via Socioeconomic Factors—A Machine Learning Approach with Florida as a Case Study. Energies 2020, 13, 3996. [Google Scholar] [CrossRef]
- WuNeng, L.; Pan, Z.; QiuWen, L.; Dong, M.; CuiYun, L.; YiMing, L.; ZhenCheng, L. Adaboost-Based Power System Load Forecasting. J. Phys. Conf. Ser. 2021, 2005, 012190. [Google Scholar]
- Fan, G.F.; Peng, L.L.; Hong, W.C.; Sun, F. Electric load forecasting by the SVR model with differential empirical mode decomposition and auto regression. Neurocomputing 2016, 173, 958–970. [Google Scholar] [CrossRef]
- Li, M.-a.; Zhu, W.; Liu, H.-n.; Yang, J.-f.; Acharya, U.R. Adaptive Feature Extraction of Motor Imagery EEG with Optimal Wavelet Packets and SE-Isomap. Appl. Sci. 2017, 7, 390. [Google Scholar] [CrossRef] [Green Version]
- Semero, Y.K.; Zhang, J.; Zheng, D. EMD–PSO–ANFIS-based hybrid approach for short-term load forecasting in microgrids. IET Gener. Transm. Distrib. 2020, 14, 470–475. [Google Scholar] [CrossRef]
- Meng, Z.; Xie, Y.; Sun, J. Short-term load forecasting using neural attention model based on EMD. Electr. Eng. 2021, 104, 1857–1866. [Google Scholar] [CrossRef]
- Okolobah, V.A.; Ismail, Z. New Approach to Peak Load Forecasting based on EMD and ANFIS. Indian J. Sci. Technol. 2013, 6, 5600–5606. [Google Scholar] [CrossRef]
- Yu, J.; Ding, F.; Guo, C.; Wang, Y. System load trend prediction method based on IF-EMD-LSTM. International Journal of Distributed Sensor Networks,(8). Int. J. Distrib. Sens. Netw. 2019, 15, 1–8. [Google Scholar] [CrossRef]
- Luo, Y.; Jia, X.; Chen, S.W. Short-term Power Load Forecasting Based on EMD and ESN. In Proceedings of the 2012 International Conference on Engineering Materials (ICEM 2012), Singapore, 30–31 December 2012; 651, pp. 922–928. [Google Scholar]
- Sobhani, M.; Campbell, A.; Sangamwar, S.; Li, C.; Hong, T. Combining Weather Stations for Electric Load Forecasting. Energies 2019, 12, 1510. [Google Scholar] [CrossRef] [Green Version]
- Hua, S.H.; Guo, W.W.; Gan, Z.Z.; Zhang, X.L. The Relationship Analysis of Temperature and Electric Load. Appl. Mech. Mater. 2012, 256–259, 2644–2647. [Google Scholar]
- Yan, Q.Y.; Liu, Z.Y.; He, S.Q. Long Term Forecast of Electric Load in Beijing. Adv. Mater. Res. 2012, 516–517, 1490–1495. [Google Scholar] [CrossRef]
- Kyle, P.; Clarke, L.; Rong, F.; Smith, S.J. Climate Policy and the Long-Term Evolution of the U.S. Buildings Sector. Energy J. 2010, 31, 145–172. [Google Scholar] [CrossRef]
- Arash, M.; Sahar, Z.; Maryam, S.; Behnam, M.; Fazel, M. Short-Term Load Forecasting of Microgrid via Hybrid Support Vector Regression and Long Short-Term Memory Algorithms. Sustainability 2020, 12, 7076. [Google Scholar]
- Hong, W.-C. Electric load forecasting by seasonal recurrent SVR (support vector regression) with chaotic artificial bee colony algorithm. Energy 2011, 36, 5568–5578. [Google Scholar] [CrossRef]
- Jihoon, M.; Yongsung, K.; Minjae, S.; Eenjun, H. Hybrid Short-Term Load Forecasting Scheme Using Random Forest and Multilayer Perceptron. Energies 2018, 11, 3283. [Google Scholar]
- Mingming, L.; Yulu, W. Power load forecasting and interpretable models based on GS_XGBoost and SHAP. J. Phys. Conf. Ser. 2022, 2195, 012028. [Google Scholar]
- Xiaojin, L.; Yueyang, H.; Yuanbo, S. Ultra-Short Term Power Load Prediction Based on Gated Cycle Neural Network and XGBoost Models. J. Phys. Conf. Ser. 2021, 2026, 012022. [Google Scholar]
- Jeenanunta, C. Electricity load forecasting using a deep neuralnetwork. Eng. Appl. Sci. Res. 2019, 46, 10–17. [Google Scholar]
- Cai, Q.; Yan, B.; Su, B.; Liu, S.; Xiang, M.; Wen, Y.; Cheng, Y.; Feng, N. Short-term load forecasting method based on deep neural network with sample weights. Int. Trans. Electr. Energy Syst. 2020, 30, e12340. [Google Scholar] [CrossRef]
- Jun, L.; Jin, M.; Jianguo, Z.; Yu, C. Short-term load forecasting based on LSTM networks considering attention mechanism. Int. J. Electr. Power Energy Syst. 2022, 137, 107818. [Google Scholar]
- Kedong, Z.; Yaping, L.; Wenbo, M.; Feng, L.; Jiahao, Y. LSTM enhanced by dual-attention-based encoder-decoder for daily peak load forecasting. Electr. Power Syst. Res. 2022, 208, 107860. [Google Scholar]
- Aurangzeb, K.; Alhussein, M.; Javaid, K.; Haider, S.I. A Pyramid-CNN Based Deep Learning Model for Power Load Forecasting of Similar-Profile Energy Customers Based on Clustering. IEEE Access 2021, 9, 14992–15003. [Google Scholar] [CrossRef]
- Arurun, K.; Afzal, P.; Khwaja, A.S.; Bala, V.; Alagan, A. Performance comparison of single and ensemble CNN, LSTM and traditional ANN models for short-term electricity load forecasting. J. Eng. 2022, 2022, 550–565. [Google Scholar]
- Shanmugasundar, G.; Vanitha, M.; Čep, R.; Kumar, V.; Kalita, K.; Ramachandran, M. A Comparative Study of Linear, Random Forest and AdaBoost Regressions for Modeling Non-Traditional Machining. Processes 2021, 9, 2015. [Google Scholar] [CrossRef]
- Li, F.-F.; Wang, S.-Y.; Wei, J.-H. Long term rolling prediction model for solar radiation combining empirical mode decomposition (EMD) and artificial neural network (ANN) techniques. J. Renew. Sustain. Energy 2018, 10, 013704. [Google Scholar] [CrossRef]
- Dang, X.J.; Chen, H.Y.; Jin, X.M. A Method for Forecasting Short-Term Wind Speed Based on EMD and SVM. Appl. Mech. Mater. 2013, 392, 622–627. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. Short-term load forecasting by wavelet transform and evolutionary extreme learning machine. Electr. Power Syst. 2015, 122, 96–103. [Google Scholar] [CrossRef]
- Peng, L.L.; Fan, G.F.; Yu, M.; Chang, Y.C.; Hong, W.C. Electric Load Forecasting based on Wavelet Transform and Random Forest. Adv. Theory Simul. 2021, 4, 2100334. [Google Scholar] [CrossRef]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-Term Electricity Load Forecasting Model Based on EMD-GRU with Feature Selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.C.; Zhang, X.; Guan, Z.W. The Wind Power Forecast Model Based on Improved EMD and SVM. Appl. Mech. Mater. 2014, 694, 150–154. [Google Scholar] [CrossRef]
- Li, H.; Hu, L.; Jian, T.; Jun, H.; Yi, G.; Dehua, G. Sensitivity Analysis and Forecast of Power Load Characteristics Based on Meteorological Feature Information. IOP Conf. Ser. Earth Environ. Sci. 2020, 558, 052060. [Google Scholar] [CrossRef]
- Qiu, Y.; Li, X.; Zheng, W.; Hu, Q.; Wei, Z.; Yue, Y. The prediction of the impact of climatic factors on short-term electric power load based on the big data of smart city. J. Phys. Conf. Ser. 2017, 887, 012023. [Google Scholar] [CrossRef] [Green Version]
- Guan, J.; Zurada, J.; Shi, D.; Lopez Vargas, J.; Cabrera Loayza, M.C. A Fuzzy Neural Approach with Multiple Models to Time-Dependent Short Term Power Load Forecasting Based on Weather. Int. J. Multimed. Ubiquitous Eng. 2017, 12, 1–16. [Google Scholar]
- Chen, H.J.; Xing, F.Z.; Shang, J.; Jun, Z.Y. The Sensitivity Analysis of Power Loads and Meteorological Factors in Typhoon Weather. Appl. Mech. Mater. 2014, 716–717, 110320131107. [Google Scholar]
- Yunqin, Z.; Qize, C.; Wenjie, J.; Xiaofeng, L.; Liang, S.; Zehua, C. Photovoltaic power prediction model based on EMD-PCA-LSTM. J. Sun 2021. [Google Scholar] [CrossRef]
- Ma, M.; Liu, Z.; Su, Y. Acoustic signal feature extraction method based on manifold learning and its application. Int. Core J. Eng. 2021, 7, 446–454. [Google Scholar]
- Jinghua, L.; Shanyang, W.; Wei, D. Combination of Manifold Learning and Deep Learning Algorithms for Mid-Term Electrical Load Forecasting. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Zhao, H.; Yu, H.; Li, D.; Mao, T.; Zhu, H. Vehicle Accident Risk Prediction Based on AdaBoost-SO in VANETs. IEEE Access 2019, 7, 14549–14557. [Google Scholar] [CrossRef]
- Zeng, K.; Liu, J.; Wang, H.; Zhao, Z.; Wen, C. Research on Adaptive Selection Algorithm for Multi-model Load Forecasting Based on Adaboost. IOP Conf. Ser. Earth Environ. Sci. 2020, 610, 012005. [Google Scholar] [CrossRef]
- Deng, Y.; Wang, W.; Qian, C.; Wang, Z.; Dai, D. Boundary-processing-technique in EMD method and Hilbert transform. Chin. Sci. Bull. 2001, 46, 954–961. [Google Scholar] [CrossRef]
- Tawn, R.; Browell, J. A review of very short-term wind and solar power forecasting. Renew. Sustain. Energy Rev. 2022, 153, 111758. [Google Scholar] [CrossRef]
- Xin, J.; Yiming, C.; Lei, W.; Huali, H.; Peng, C. Failure prediction, monitoring and diagnosis methods for slewing bearings of large-scale wind turbine: A review. Measurement 2021, 172, 108855. [Google Scholar]
- Hadi, R.; Hamidreza, F.; Gholamreza, M. Stock price prediction using deep learning and frequency decomposition. Expert Syst. Appl. 2020, 169, 114332. [Google Scholar]
- Liu, Q.; Cai, Y.; Jiang, H.; Lu, J.; Chen, L. Traffic state prediction using ISOMAP manifold learning. Phys. A Stat. Mech. Appl. 2018, 506, 532–541. [Google Scholar] [CrossRef]
- Ding, S.; Keal, C.A.; Zhao, L.; Yu, D. Dimensionality reduction and classification for hyperspectral image based on robust supervised ISOMAP. J. Ind. Prod. Eng. 2022, 39, 19–29. [Google Scholar] [CrossRef]
- Wang, Q.; Ying, Z. Facial Expression Recognition Algorithm Based on Gabor Texture Features and Adaboost Feature Selection via Sparse Representation. Appl. Mech. Mater. 2014, 511–512, 433–436. [Google Scholar] [CrossRef]
- Medeiros, M.; Soares, L. Robust statistical methods for electricity load forecasting. In Proceedings of the RTE-VT Workshop on State Estimation and Forecasting Techniques, Paris, France, 29–30 May 2006; pp. 1–8. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).