
Image Segmentation of a Sewer Based on Deep Learning


Abstract
:1. Introduction
2. Related Work
2.1. Image Processing Methods
2.2. Deep Learning Methods
3. Image Segmentation
3.1. Comparison of Image Classification and Image Segmentation
3.2. Image Segmentation Method
4. Image Segmentation Model Based on Deep Learning
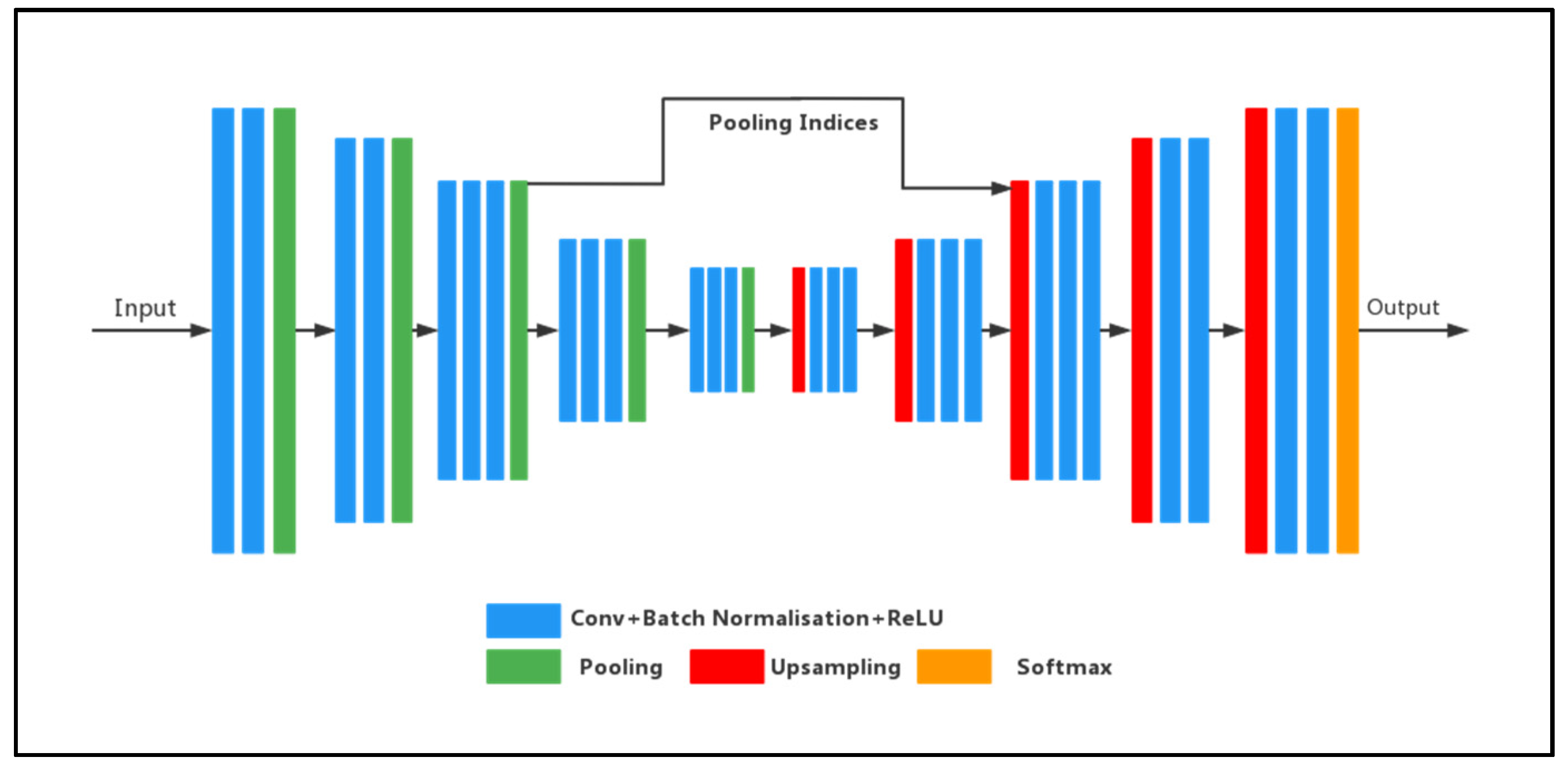
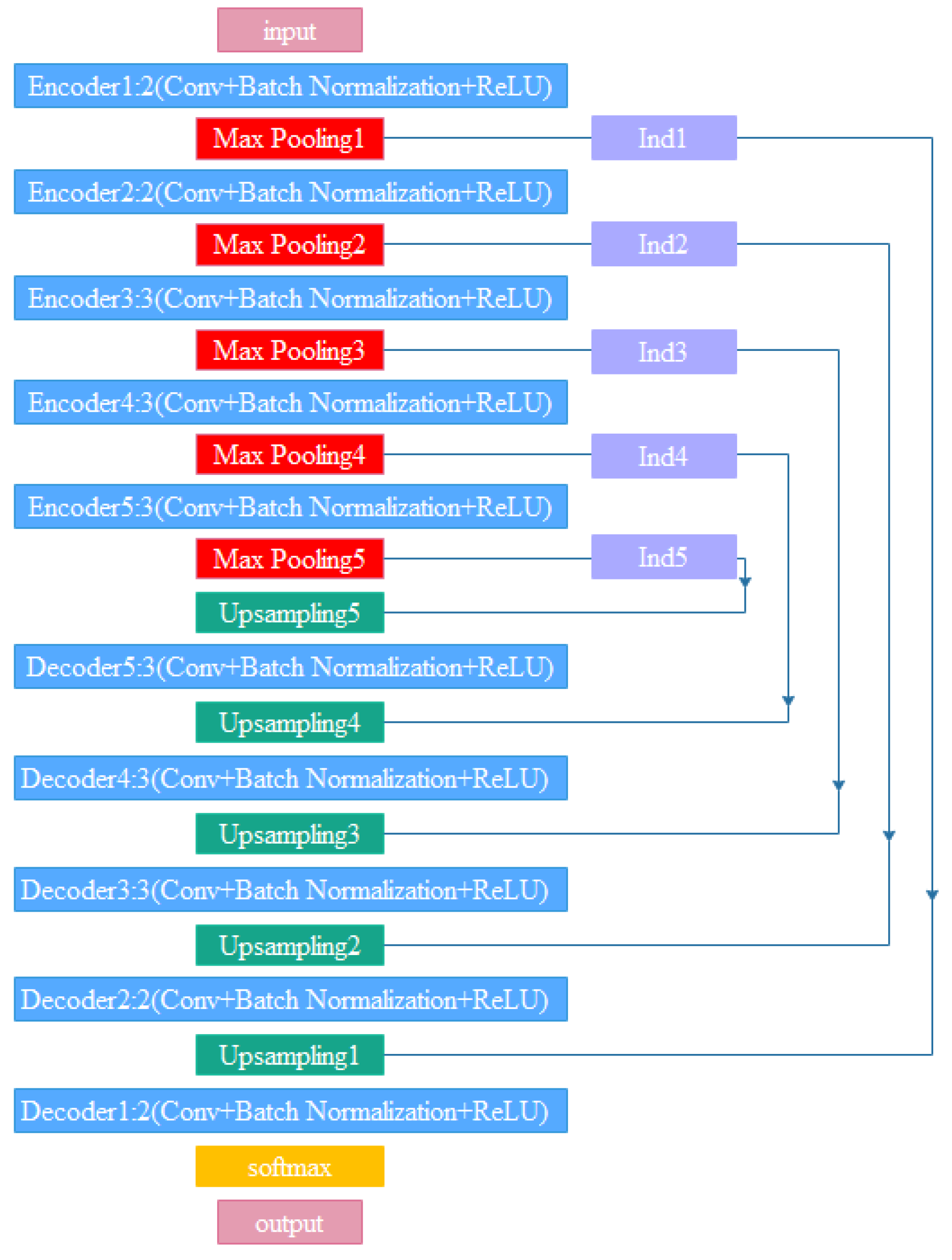
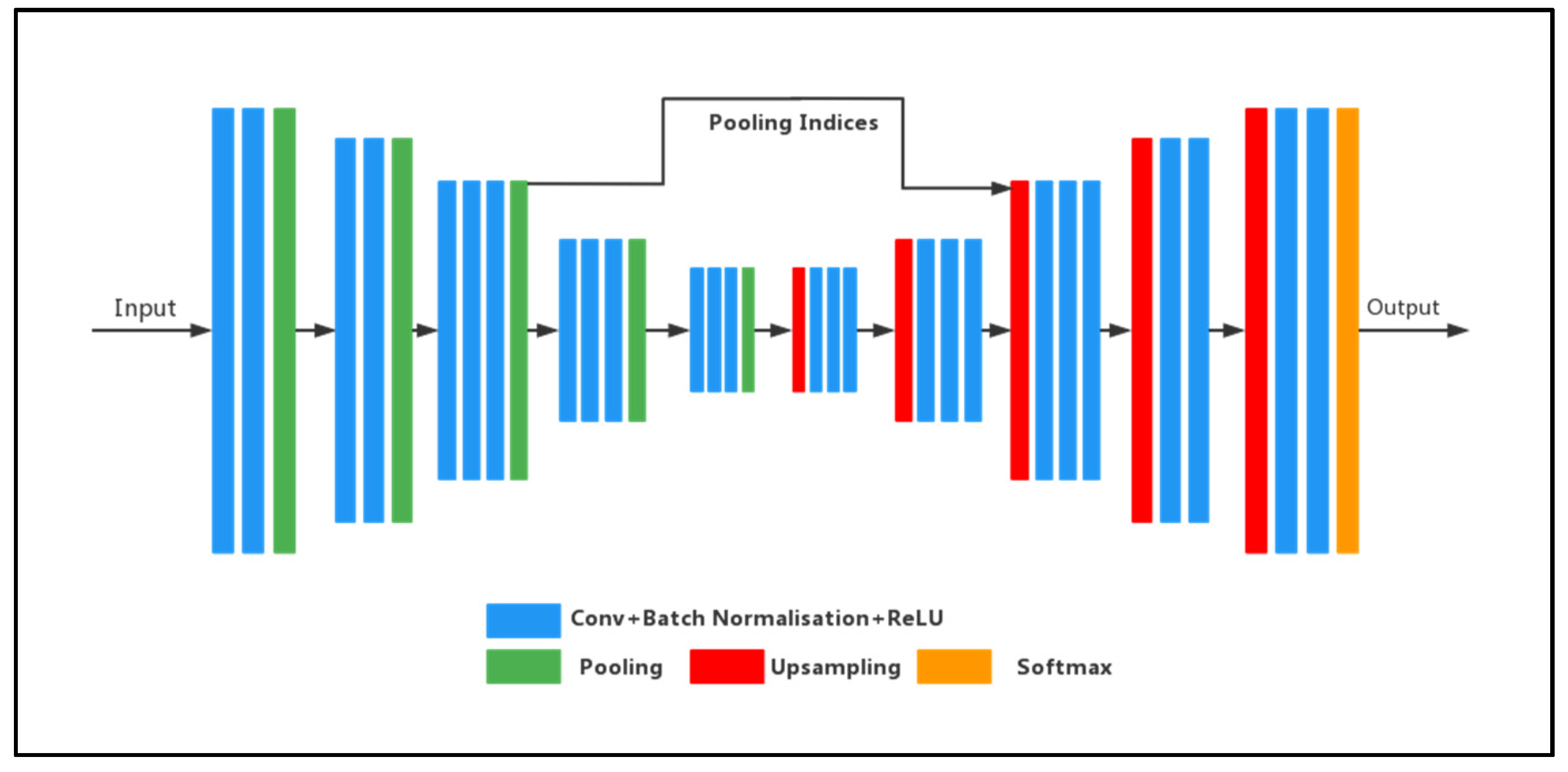
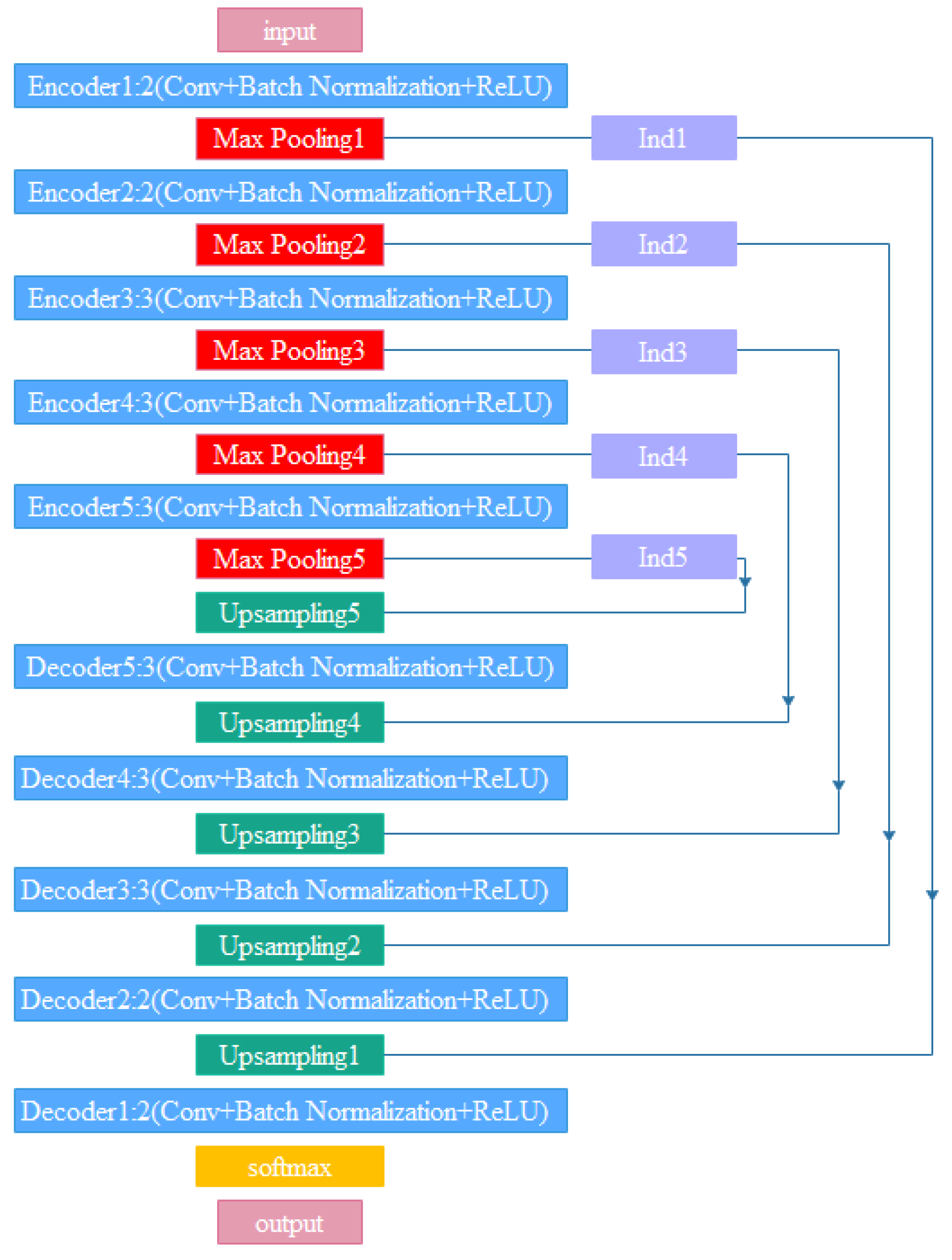
4.1. Encoders–Decoder Construction
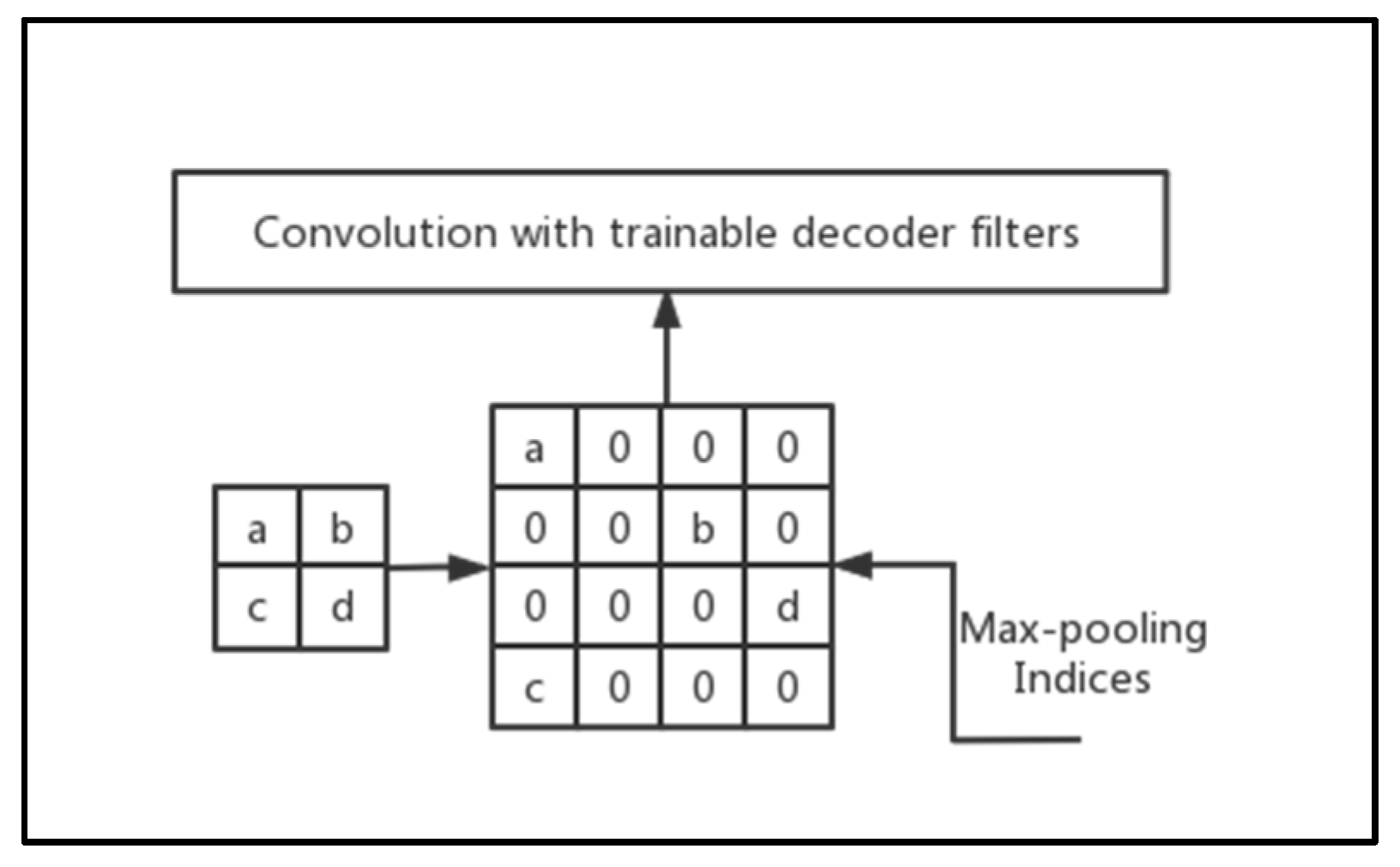
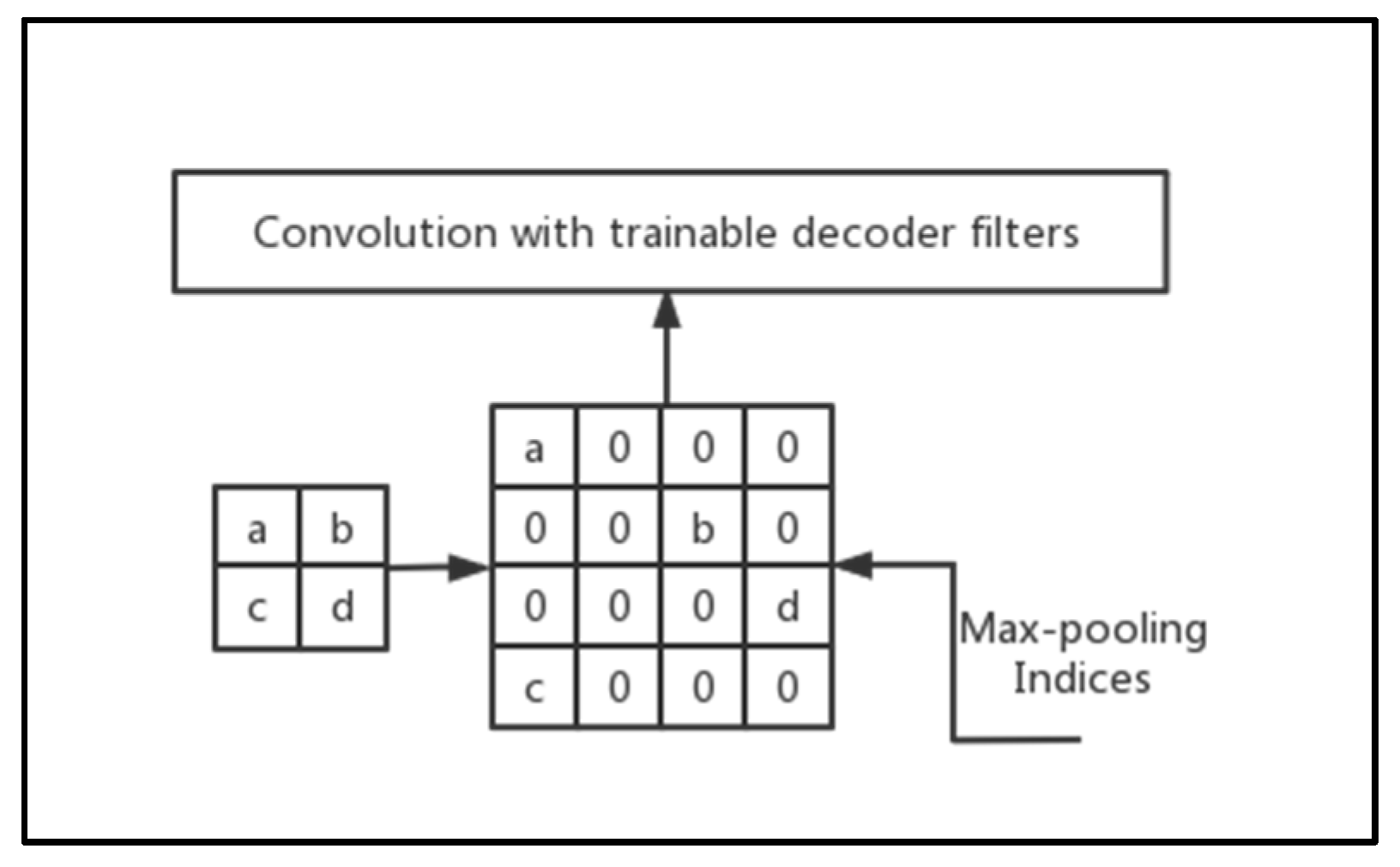
4.2. Pooling Indices
4.3. Structural Analysis of the SegNet Network
5. Experimental
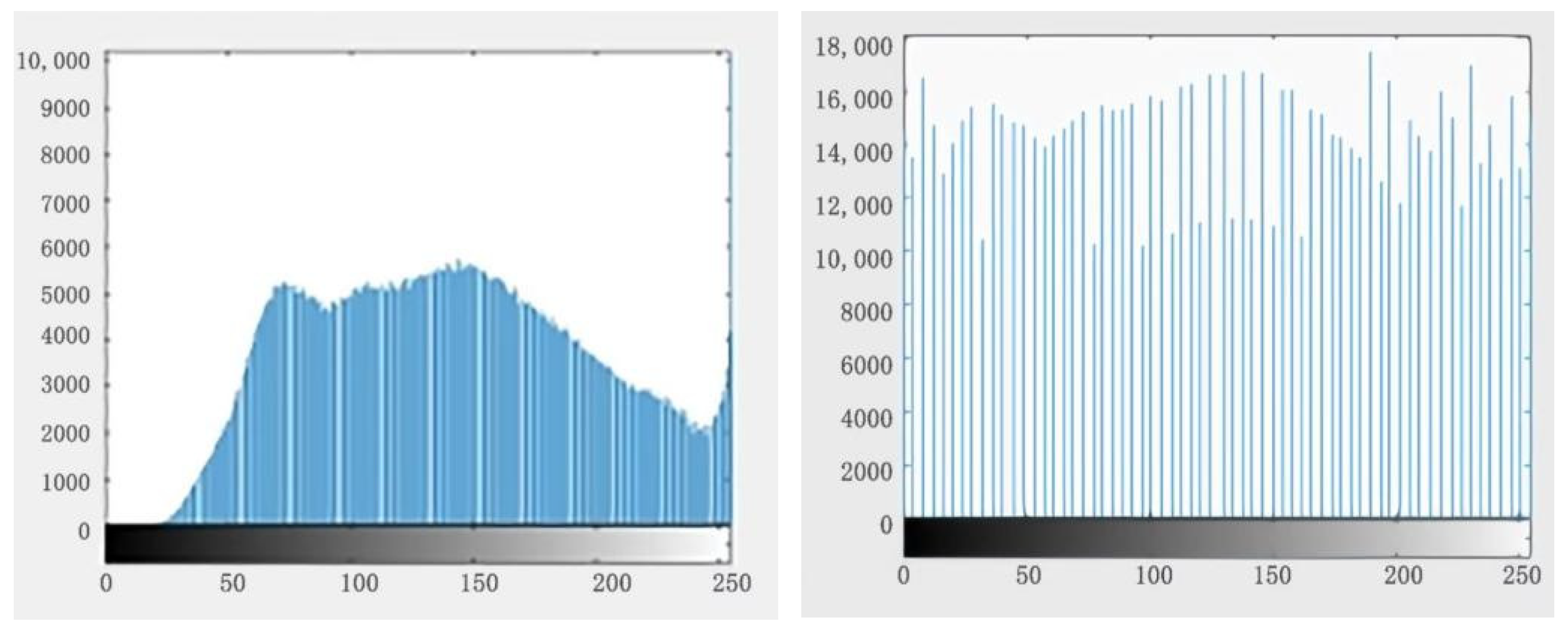
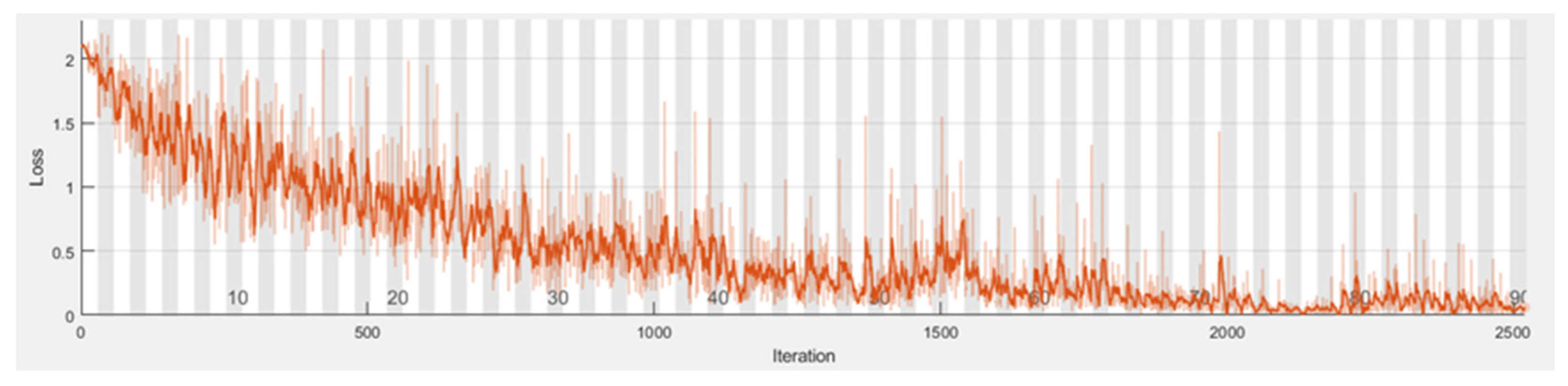
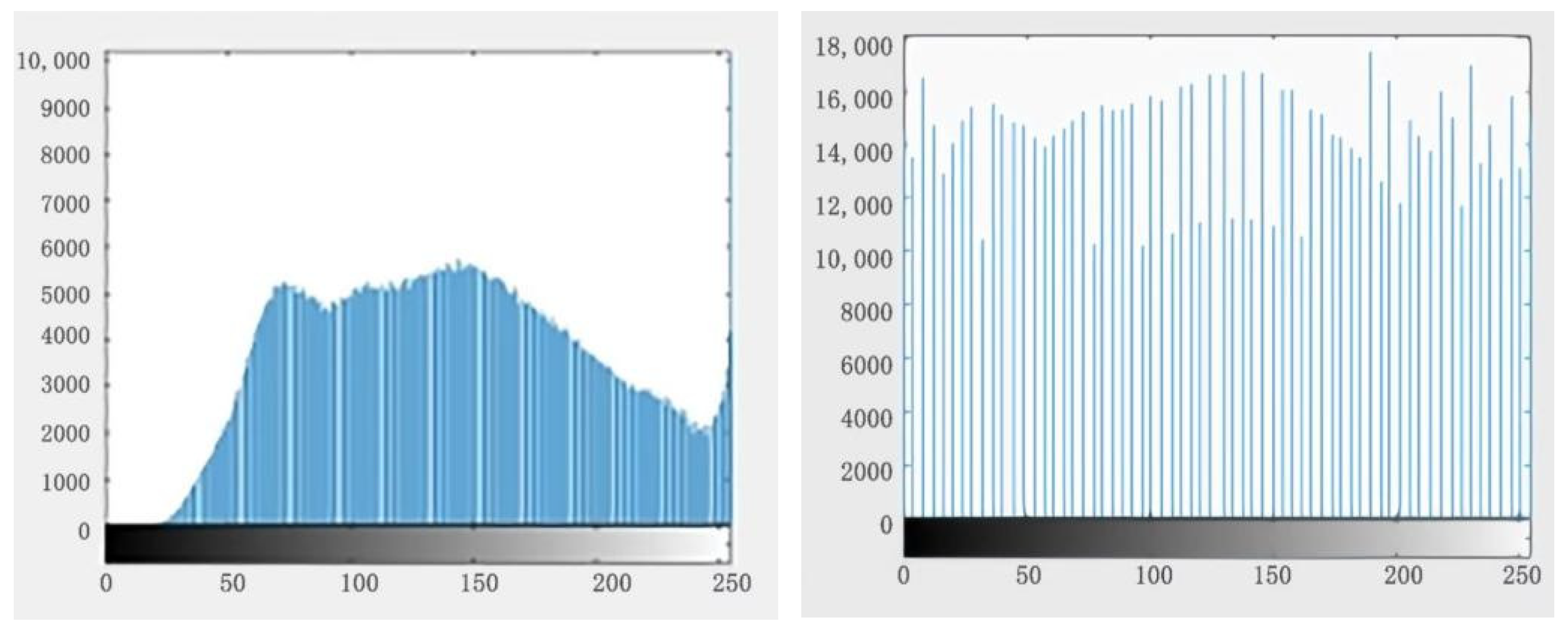
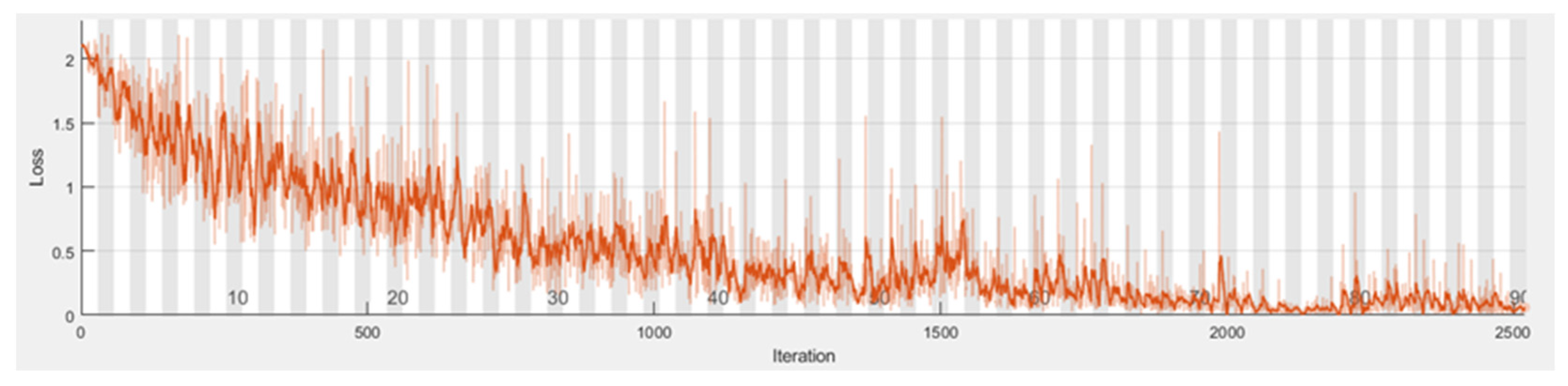
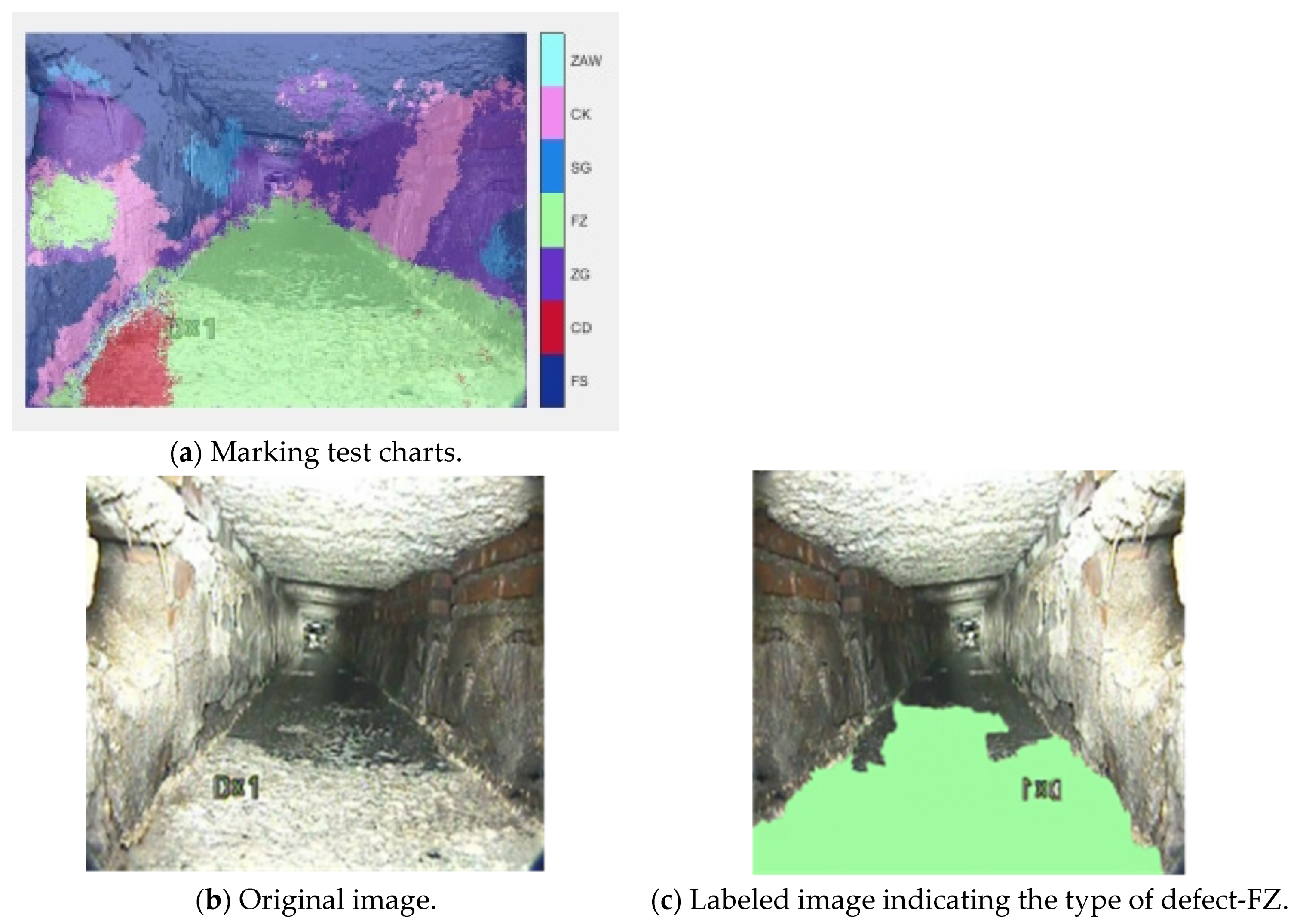
5.1. Data Preparation and Training
5.2. Results and Evaluation
6. Engineering Applications
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision-based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Meijer, D.; Scholten, L.; Clemens, F.; Knobbe, A. A defect classification methodology for sewer image sets with convolutional neural networks. Autom. Constr. 2019, 104, 281–298. [Google Scholar] [CrossRef]
- Kirkham, R.; Kearney, P.D.; Rogers, K.J.; Mashford, J. PIRAT—A System for Quantitative Sewer Pipe Assessment. Int. J. Robot. Res. 2000, 19, 1033–1053. [Google Scholar] [CrossRef]
- Fan, Z.; Lin, H.; Li, C.; Su, J.; Bruno, S. Use of Parallel ResNet for High-Performance Pavement Crack Detection and Measurement. Sustainability 2022, 14, 1825. [Google Scholar] [CrossRef]
- Motamedi, M.; Faramarzi, F.; Duran, O. New concept for corrosion inspection of urban pipeline networks by digital image processing. In Proceedings of the 38th Annual Conference of the IEEE Industrial Electronic Society, Montreal, QC, Canada, 25–28 October 2012; pp. 1551–1556. [Google Scholar]
- Kirstein, S.; Muller, K.; Walecki-Mingers, M.; Deserno, M.T. Robust adaptive flow line detection in sewer pipes. Automat. Constr. 2012, 21, 24–31. [Google Scholar] [CrossRef]
- Hawari, A.; Alamin, M.; Alkadour, F.; Elmasry, M.; Zayed, T. Automated defect detection tool for closed circuit television (CCTV) inspected sewer pipelines. Automat. Constr. 2018, 89, 99–109. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation, IEEE Trans. Pattern Anal. Mach. Intell. 2014, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Comput. Sci. 2014, 4, 357–361. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rahman, S.; Vanier, D.J. An evaluation of condition assessment protocols for sewer management. Tech. Rep. Natl. Res. Counc. Can. 2004, 6, b5123. [Google Scholar] [CrossRef]
- Sinha, S.K.; Fieguth, P.W. Neuro-fuzzy network for the classification of buried pipe defects. Autom. Constr. 2006, 15, 3–83. [Google Scholar] [CrossRef]
- Li, D.; Cong, A.; Guo, S. Sewer damage detection from imbalanced CCTV inspection data using deep convolutional neural networks with hierarchical classification. Automat. Constr. 2019, 101, 199–208. [Google Scholar] [CrossRef]
- Kumar, S.S.; Abraham, D.M.; Jahanshahi, M.R.; Iseley, T.; Starr, J. Automated defect classification in sewer closed circuit television inspections using deep convolutional neural networks. Autom. Constr. 2018, 91, 273–283. [Google Scholar] [CrossRef]
- Kumar, S.S.; Wang, M.; Abraham, D.M.; Jahanshahi, M.R.; Iseley, T.; Cheng, J.C. Deep Learning–Based Automated Detection of Sewer Defects in CCTV Videos. J. Comput. Civ. Eng. 2020, 34, 04019047. [Google Scholar] [CrossRef]
- Xu, K.; Luxmoore, A.R.; Davies, T. Sewer pipe deformation assessment by image analysis of video surveys. Pattern Recogn. 1998, 31, 169–180. [Google Scholar] [CrossRef]
- Sinha, S.K. Automated Underground Pipe Inspection Using a Unified Image Processing and Artificial Intelligence Methodology. Ph.D. Thesis, University of Waterloo, Waterloo, ON, Canada, 2000. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, H.; Zhao, R.; Wang, X. Highly efficient forward and backward propagation of convolutional neural networks for pixelwise classification. arXiv 2014, arXiv:1412.4526. [Google Scholar]
- Fulkerson, B.; Vedaldi, A.; Soatto, S. Class Segmentation and Object Localization with Superpixel Neighborhoods, Computer Vision. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 670–677. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
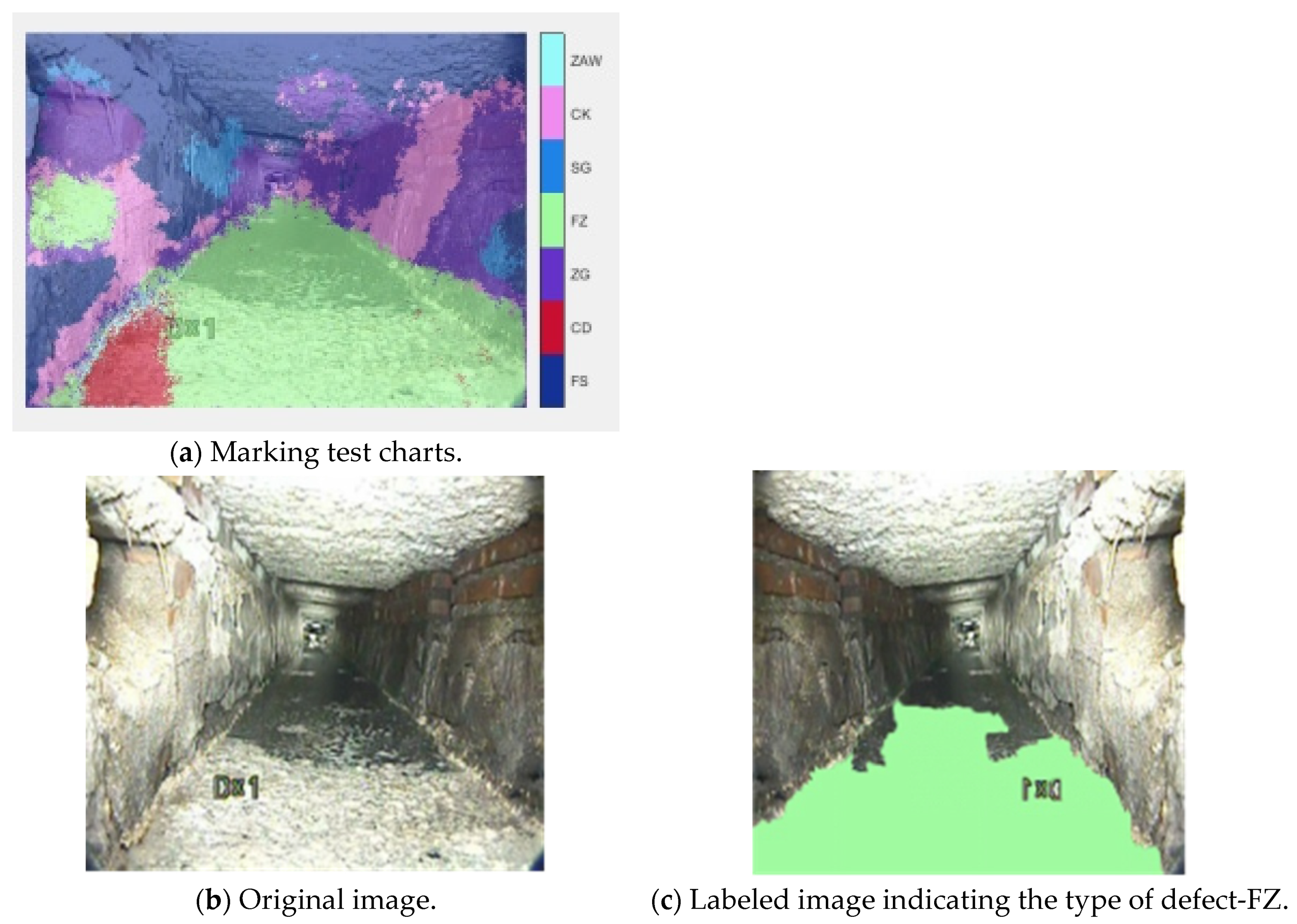
| Defect Type | Label Name | Label Pixel | Label Color |
|---|---|---|---|
| Corrosion | FS | 20 50 150 |  |
| Sediment | CD | 200 15 50 |  |
| Branch pipe | ZG | 100 50 200 |  |
| Scum | FZ | 160 250 160 |  |
| Roots | SG | 30 130 230 |  |
| Mismatch | CK | 240 140 240 |  |
| Obstacle | ZAW | 150 250 250 |  |
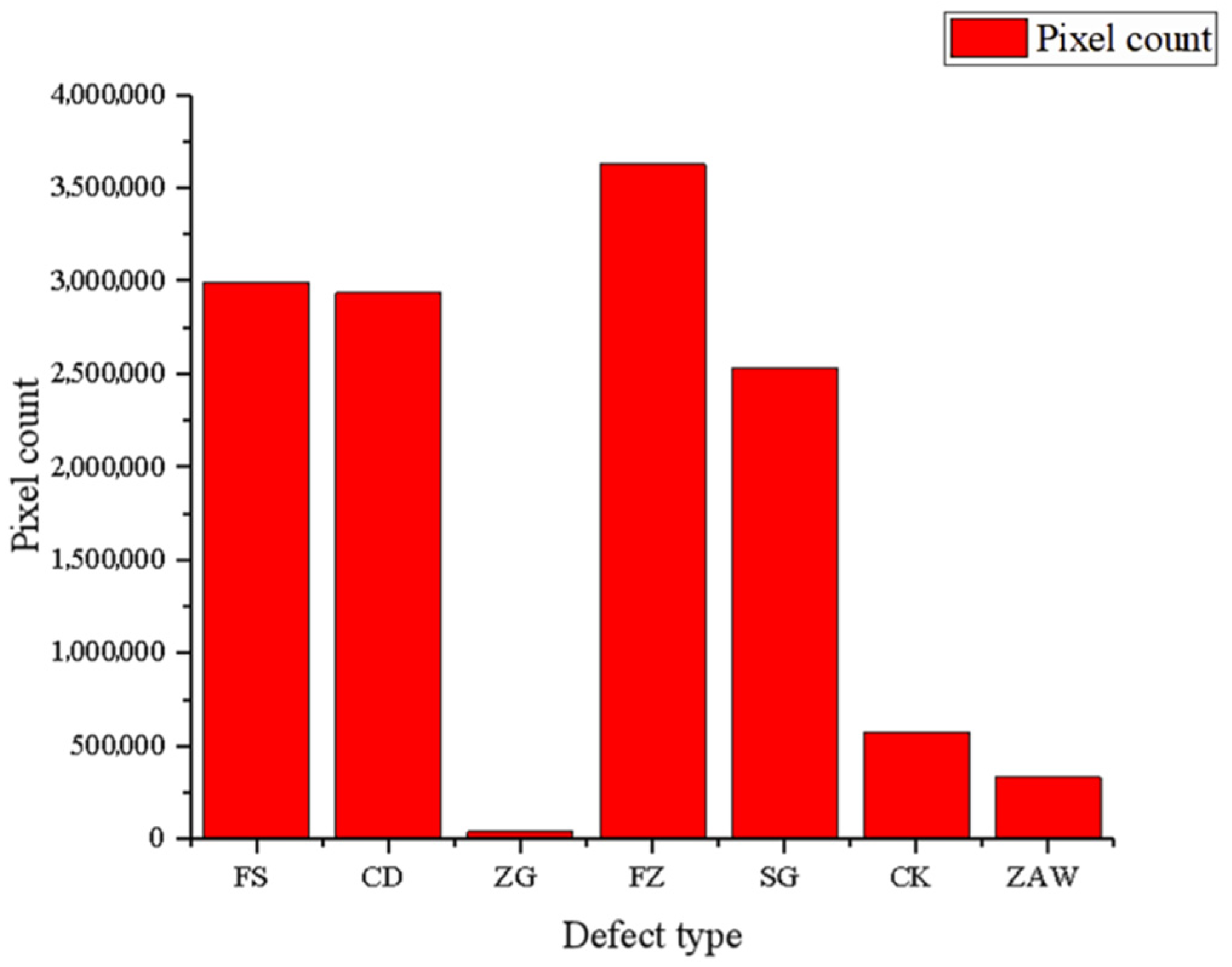
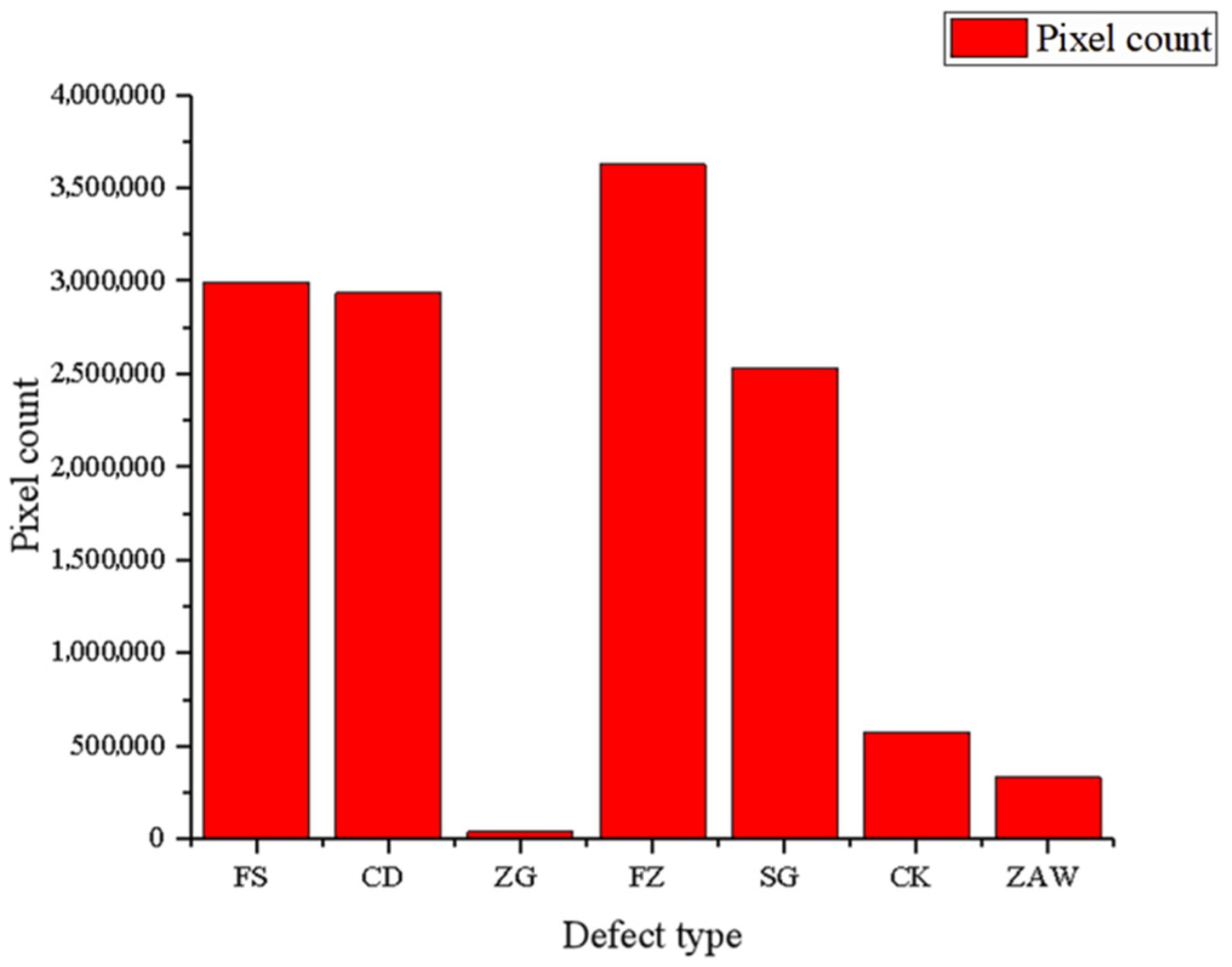
| Name | Pixel Count | Image Pixel Count |
|---|---|---|
| FS | 2.99 × 106 | 1.08 × 107 |
| CD | 2.938 × 106 | 2.36 × 107 |
| ZG | 3.93 × 104 | 4.30 × 106 |
| FZ | 3.63 × 106 | 1.44 × 107 |
| SG | 2.53 × 106 | 1.69 × 107 |
| CK | 5.7633 × 105 | 1.46 × 107 |
| ZAW | 3.3152 × 105 | 4.32 × 106 |
| Name | Class Weights |
|---|---|
| FS | 0.45 |
| CD | 1.00 |
| ZG | 13.60 |
| FZ | 0.49 |
| SG | 0.83 |
| CK | 3.14 |
| ZAW | 1.62 |
| Indicators | PA (%) | MPA (%) | MIoU | BFScore |
|---|---|---|---|---|
| Valid | 82.77 | 74.09 | 0.61 | 0.75 |
| Test | 79.59 | 69.74 | 0.55 | 0.72 |
| Name | PA (%) | IoU | BFScore |
|---|---|---|---|
| FS | 86.36 | 0.78 | 0.73 |
| CD | 86.27 | 0.68 | 0.69 |
| ZG | 79.46 | 0.64 | 0.55 |
| FZ | 81.64 | 0.72 | 0.62 |
| SG | 80.97 | 0.62 | 0.71 |
| CK | 47.09% | 0.29 | 0.81 |
| ZAW | 26.38% | 0.12 | 0.35 |
| PA (%) | MIoU | BFScore | |
|---|---|---|---|
| Total | 80.09% | 0.61 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, M.; Zhao, Q.; Gao, H.; Zhang, X.; Zhao, Q. Image Segmentation of a Sewer Based on Deep Learning. Sustainability 2022, 14, 6634. https://doi.org/10.3390/su14116634
He M, Zhao Q, Gao H, Zhang X, Zhao Q. Image Segmentation of a Sewer Based on Deep Learning. Sustainability. 2022; 14(11):6634. https://doi.org/10.3390/su14116634
Chicago/Turabian StyleHe, Min, Qinnan Zhao, Huanhuan Gao, Xinying Zhang, and Qin Zhao. 2022. "Image Segmentation of a Sewer Based on Deep Learning" Sustainability 14, no. 11: 6634. https://doi.org/10.3390/su14116634
APA StyleHe, M., Zhao, Q., Gao, H., Zhang, X., & Zhao, Q. (2022). Image Segmentation of a Sewer Based on Deep Learning. Sustainability, 14(11), 6634. https://doi.org/10.3390/su14116634