
Incorporating Empirical Orthogonal Function Analysis into Machine Learning Models for Streamflow Prediction

Abstract
:1. Introduction
2. Study Area and Data
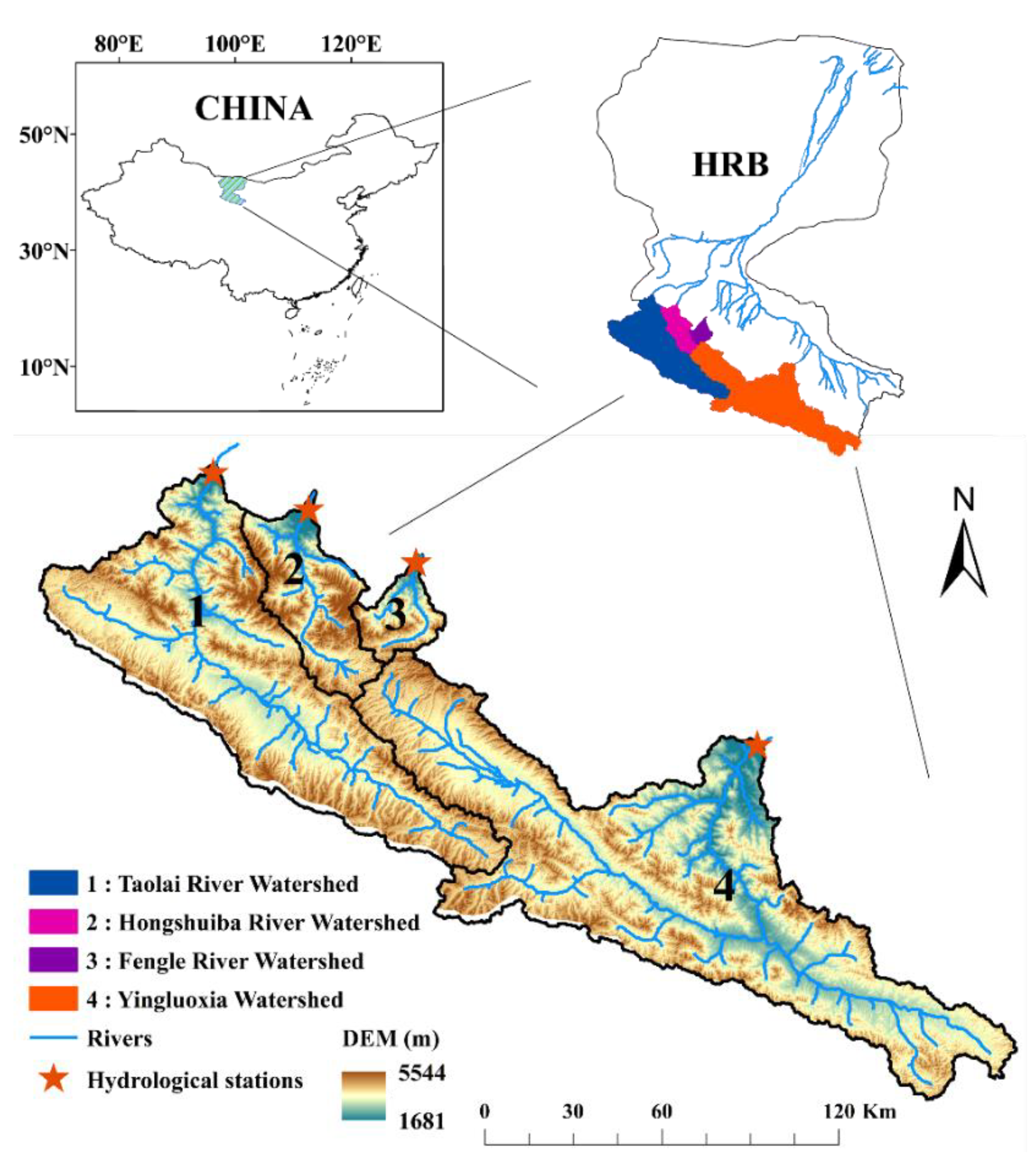
2.1. Study Area
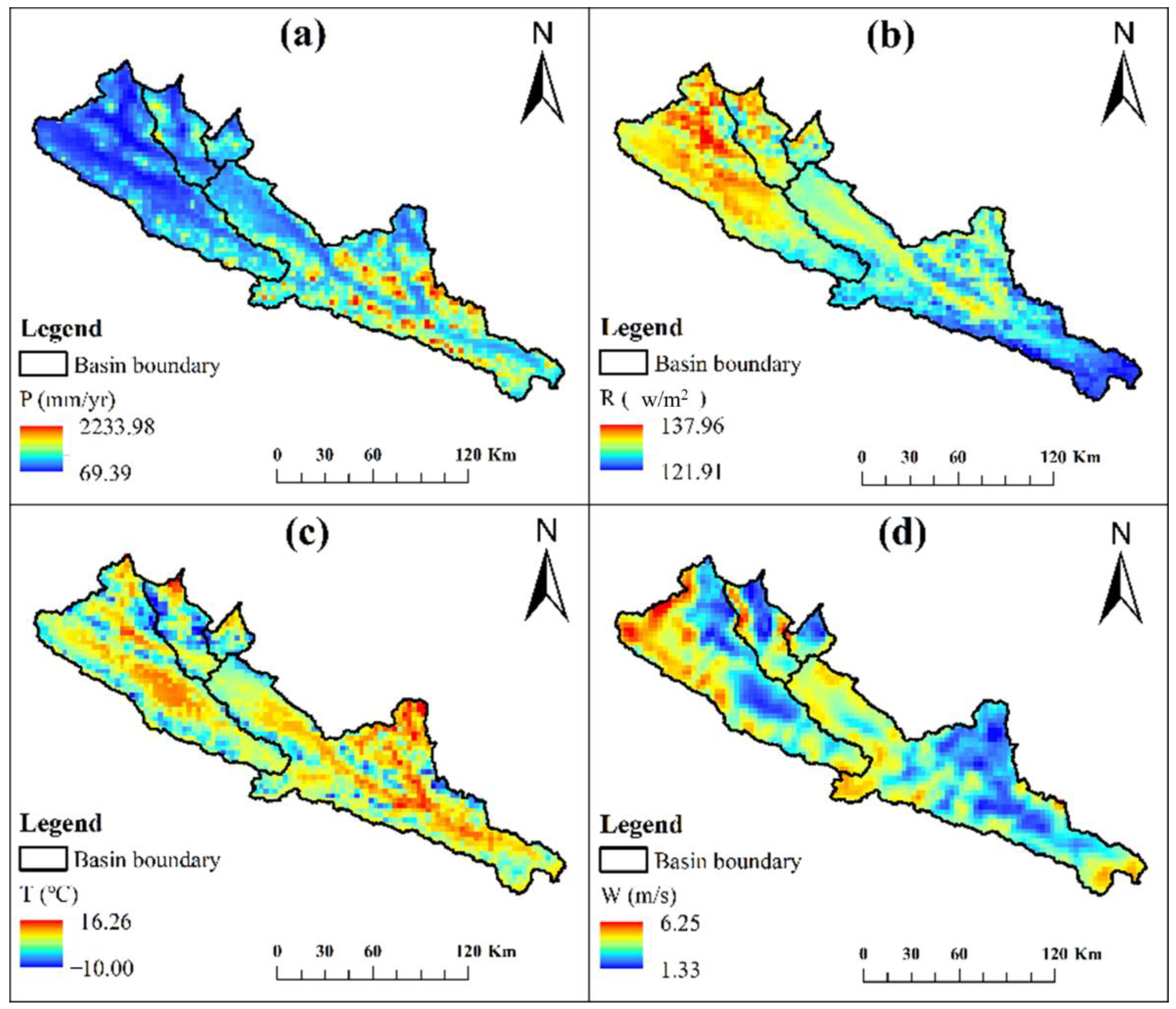
2.2. Data Description
3. Methodology
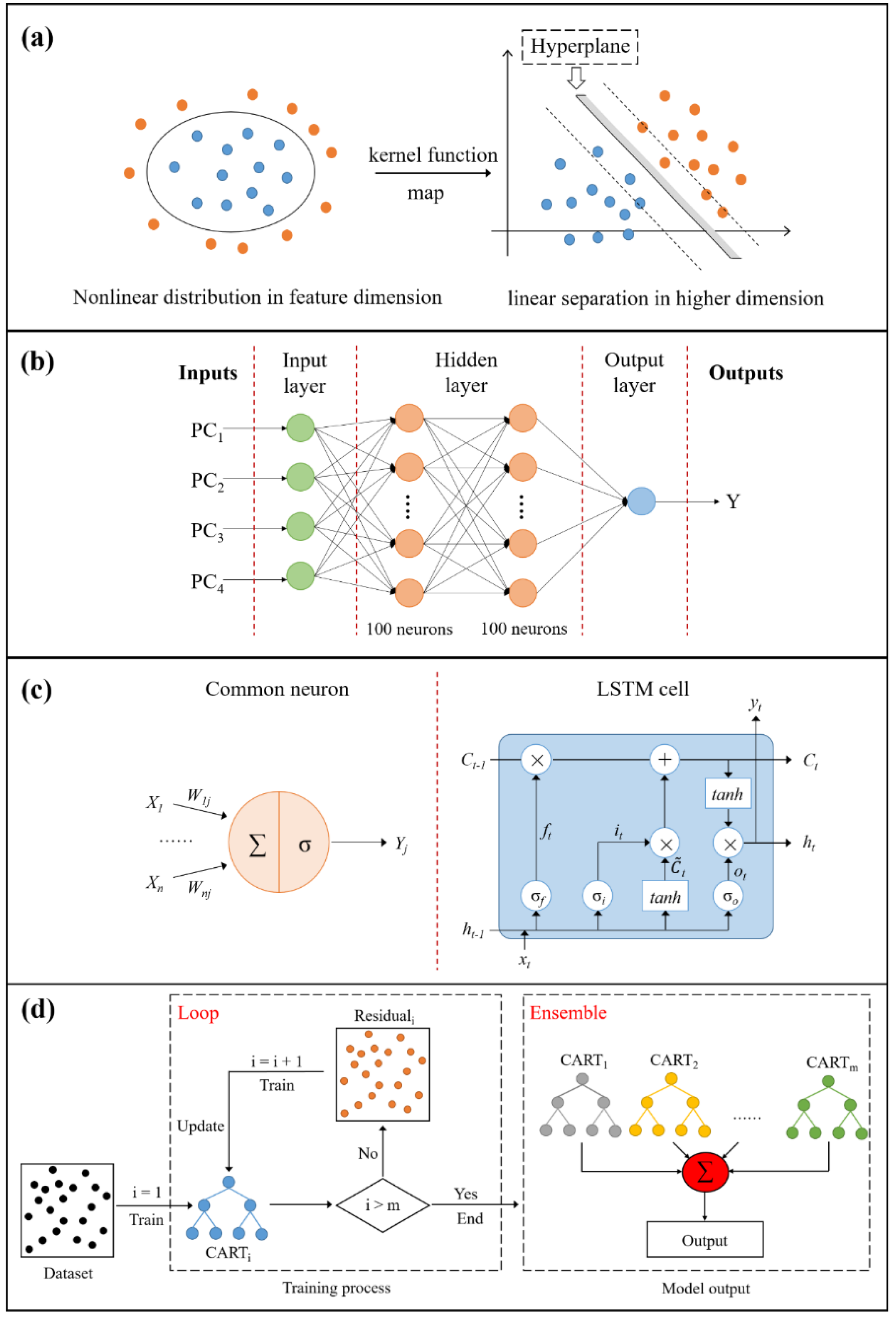
3.1. Empirical Orthogonal Function
3.2. Machine Learning Models
3.2.1. Support Vector Regression
3.2.2. Multilayer Perceptron
3.2.3. Long Short-Term Memory Network
3.2.4. Gradient Boosting Regression Tree
3.3. Integration of the EOF and ML Models
3.4. Variable Importance Analysis in ML Models
3.5. Performance Measurements
4. Results and Discussion
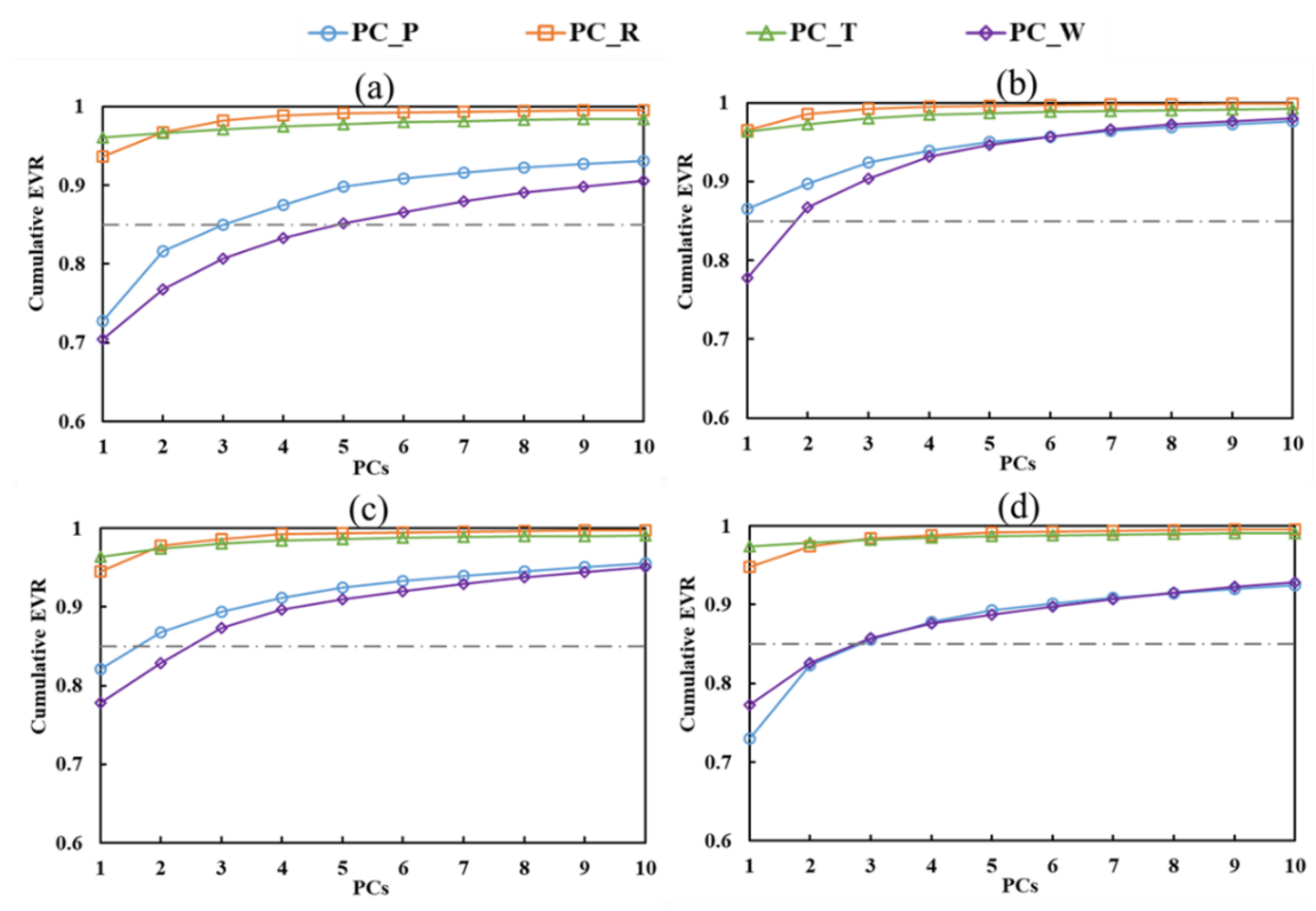
4.1. Selection of Reliable Predictors
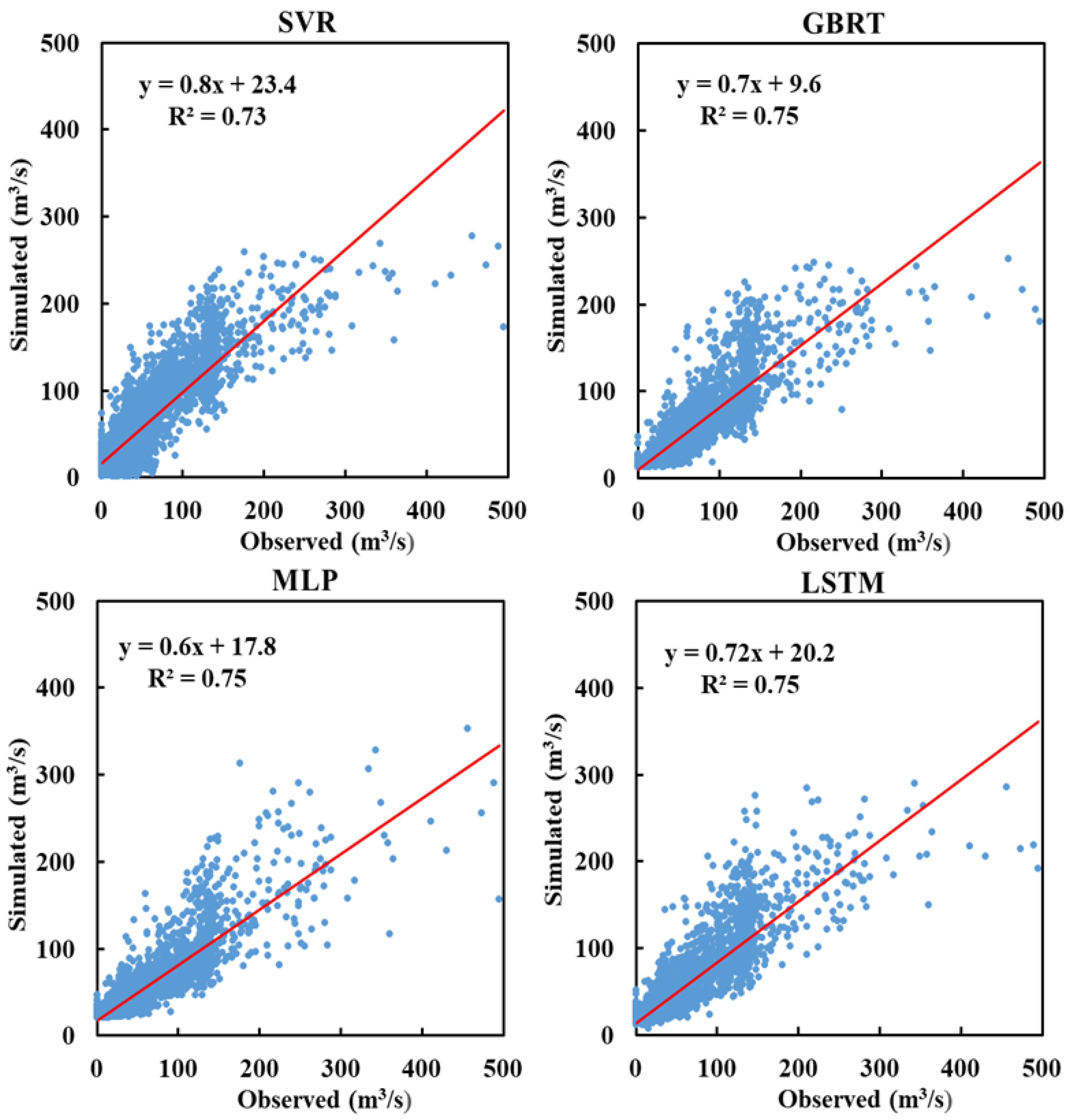
4.2. Comparison of ML Model Performance
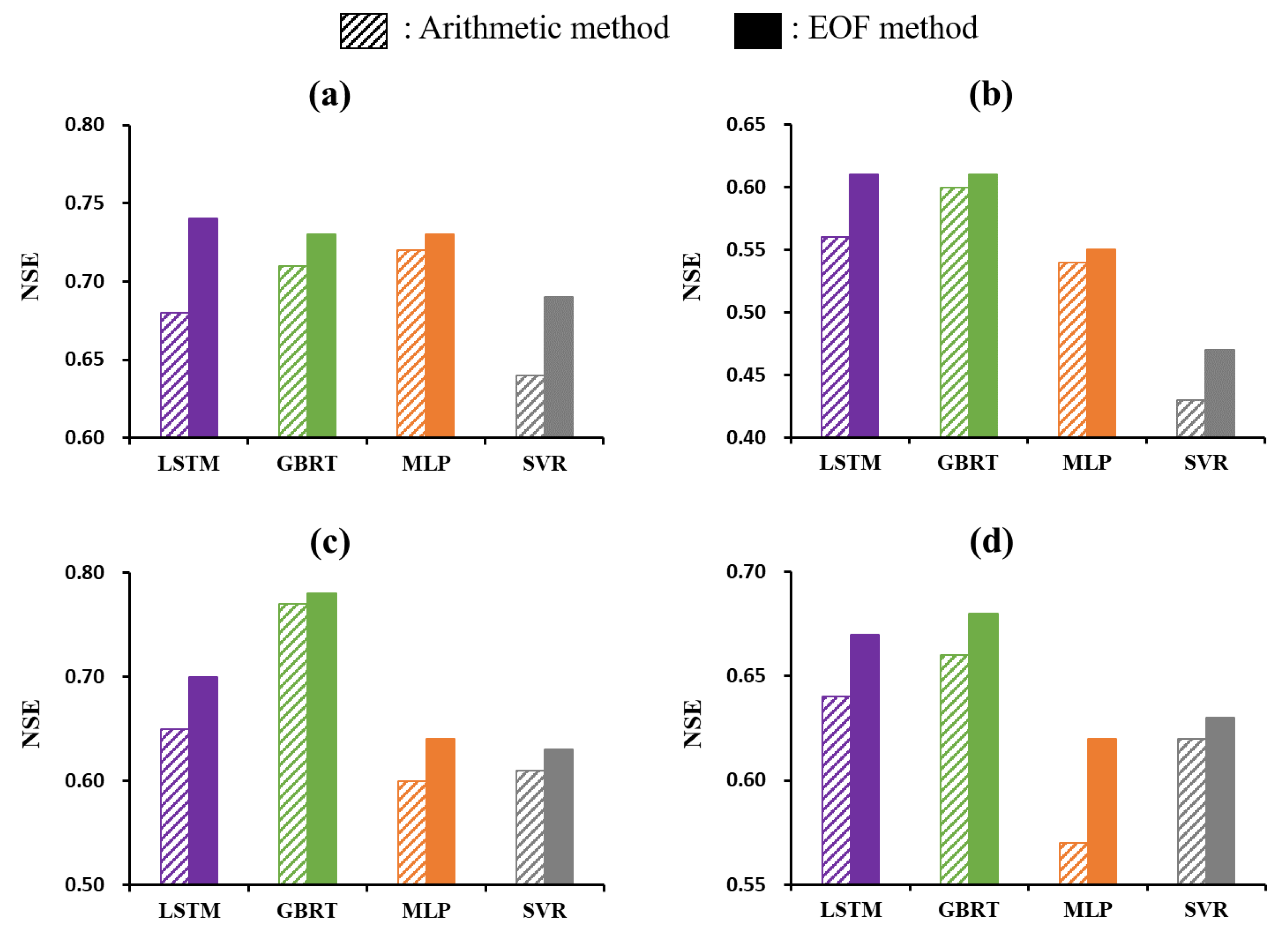
4.3. Role of EOF Analysis for Improving Streamflow Prediction
4.4. Variable Importance in the Four ML Models
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Costabile, P.; Costanzo, C.; Macchione, F.; Mercogliano, P. Two-dimensional model for overland flow simulations: A case study. Eur. Water 2012, 38, 13–23. [Google Scholar]
- Tigkas, D.; Christelis, V.; Tsakiris, G. Comparative study of evolutionary algorithms for the automatic calibration of the Medbasin-D conceptual hydrological model. Environ. Process. 2016, 3, 629–644. [Google Scholar] [CrossRef]
- Liu, M.; Lu, J. Support vector machine―An alternative to artificial neuron network for water quality forecasting in an agricultural nonpoint source polluted river? Environ. Sci. Pollut. Res. 2014, 21, 11036–11053. [Google Scholar] [CrossRef]
- Singh, G.; Kandasamy, J.; Shon, H.; Cho, J. Measuring treatment effectiveness of urban wetland using hybrid water quality—artificial neural network (ANN) model. Desalin. Water Treat. 2011, 32, 284–290. [Google Scholar] [CrossRef]
- Mohanty, S.; Jha, M.K.; Kumar, A.; Panda, D. Comparative evaluation of numerical model and artificial neural network for simulating groundwater flow in Kathajodi―Surua Inter-basin of Odisha, India. J. Hydrol. 2013, 495, 38–51. [Google Scholar] [CrossRef]
- Yoon, H.; Jun, S.-C.; Hyun, Y.; Bae, G.-O.; Lee, K.-K. A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Kisi, O.; Choubin, B.; Deo, R.C.; Yaseen, Z.M. Incorporating synoptic-scale climate signals for streamflow modelling over the Mediterranean region using machine learning models. Hydrol. Sci. J. 2019, 64, 1240–1252. [Google Scholar] [CrossRef]
- Parisouj, P.; Mohebzadeh, H.; Lee, T. Employing machine learning algorithms for streamflow prediction: A case study of four river basins with different climatic zones in the United States. Water Resour. Manag. 2020, 34, 4113–4131. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Heddam, S.; Zounemat-Kermani, M.; Kisi, O.; Li, B. Least square support vector machine and multivariate adaptive regression splines for streamflow prediction in mountainous basin using hydro-meteorological data as inputs. J. Hydrol. 2020, 586, 124371. [Google Scholar] [CrossRef]
- Lin, J.-Y.; Cheng, C.-T.; Chau, K.-W. Using support vector machines for long-term discharge prediction. Hydrol. Sci. J. 2006, 51, 599–612. [Google Scholar] [CrossRef]
- Guo-rong, Y.; Zi-qiang, X. Prediction model of chaotic time series based on support vector machine and its application to runoff. Adv. Water Sci. 2008, 19, 116–122. [Google Scholar]
- Dolling, O.R.; Varas, E.A. Artificial neural networks for streamflow prediction. J. Hydraul. Res. 2002, 40, 547–554. [Google Scholar] [CrossRef]
- Jiang, S.; Zheng, Y.; Babovic, V.; Tian, Y.; Han, F. A computer vision-based approach to fusing spatiotemporal data for hydrological modeling. J. Hydrol. 2018, 567, 25–40. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall-runoff modelling using long short-term memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Hancock, T.; Put, R.; Coomans, D.; Vander Heyden, Y.; Everingham, Y. A performance comparison of modern statistical techniques for molecular descriptor selection and retention prediction in chromatographic QSRR studies. Chemom. Intell. Lab. Syst. 2005, 76, 185–196. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Erdal, H.I.; Karakurt, O. Advancing monthly streamflow prediction accuracy of CART models using ensemble learning paradigms. J. Hydrol. 2013, 477, 119–128. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, L.; Ma, T.; Shen, F.; Cai, Y.; Zhou, C. A self-training semi-supervised machine learning method for predictive mapping of soil classes with limited sample data. Geoderma 2021, 384, 114809. [Google Scholar] [CrossRef]
- Nativi, S.; Mazzetti, P.; Santoro, M.; Papeschi, F.; Craglia, M.; Ochiai, O. Big data challenges in building the global earth observation system of systems. Environ. Model. Softw. 2015, 68, 1–26. [Google Scholar] [CrossRef]
- Blankenau, P.A.; Kilic, A.; Allen, R. An evaluation of gridded weather data sets for the purpose of estimating reference evapotranspiration in the United States. Agric. Water Manag. 2020, 242, 106376. [Google Scholar] [CrossRef]
- Farrar, D.E.; Glauber, R.R. Multicollinearity in regression analysis: The problem revisited. Rev. Econ. Stat. 1967, 49, 92–107. [Google Scholar] [CrossRef]
- Bhattacharjya, R.K.; Chaurasia, S. Geomorphology based semi-distributed approach for modelling rainfall-runoff process. Water Resour. Manag. 2013, 27, 567–579. [Google Scholar] [CrossRef]
- Navarra, A.; Simoncini, V. A Guide to Empirical Orthogonal Functions for Climate Data Analysis; Springer: Dordrecht, The Netherlands, 2010; p. 151. [Google Scholar]
- Bienvenido-Huertas, D.; Rubio-Bellido, C.; Pérez-Ordóñez, J.L.; Moyano, J. Optimizing the evaluation of thermal transmittance with the thermometric method using multilayer perceptrons. Energy Build. 2019, 198, 395–411. [Google Scholar] [CrossRef]
- Hannachi, A.; Jolliffe, I.T.; Stephenson, D.B. Empirical orthogonal functions and related techniques in atmospheric science: A review. Int. J. Climatol. J. R. Meteorol. Soc. 2007, 27, 1119–1152. [Google Scholar] [CrossRef]
- Ma, M.; Frank, V. Interannual variability of vegetation cover in the Chinese Heihe River Basin and its relation to meteorological parameters. Int. J. Remote Sens. 2006, 27, 3473–3486. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, Y.; Liu, Q.; Liu, S.; Jia, K.; Zhang, X.; Xu, Z.; Xu, T.; Chen, J.; Fisher, J.B. Evaluation of a satellite-derived model parameterized by three soil moisture constraints to estimate terrestrial latent heat flux in the Heihe River basin of Northwest China. Sci. Total Environ. 2019, 695, 133787. [Google Scholar] [CrossRef]
- Xiong, Z.; Yan, X. Building a high-resolution regional climate model for the Heihe River Basin and simulating precipitation over this region. Chin. Sci. Bull. 2013, 58, 4670–4678. [Google Scholar] [CrossRef]
- Björnsson, H.; Venegas, S. A manual for EOF and SVD analyses of climatic data. CCGCR Rep. 1997, 97, 112–134. [Google Scholar]
- He, F.; Zhang, L. Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network. J. Process Control 2018, 66, 51–58. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Pai, P.F.; Hong, W.C. A recurrent support vector regression model in rainfall forecasting. Hydrol. Process. Int. J. 2007, 21, 819–827. [Google Scholar] [CrossRef]
- Yu, X.; Zhang, X.; Qin, H. A data-driven model based on Fourier transform and support vector regression for monthly reservoir inflow forecasting. J. Hydro-Environ. Res. 2018, 18, 12–24. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Dhiman, H.S.; Deb, D.; Guerrero, J.M. Hybrid machine intelligent SVR variants for wind forecasting and ramp events. Renew. Sustain. Energy Rev. 2019, 108, 369–379. [Google Scholar] [CrossRef]
- García-Nieto, P.J.; García-Gonzalo, E.; Lasheras, F.S.; Fernández, J.A.; Muñiz, C.D. A hybrid DE optimized wavelet kernel SVR-based technique for algal atypical proliferation forecast in La Barca reservoir: A case study. J. Comput. Appl. Math. 2020, 366, 112417. [Google Scholar] [CrossRef]
- Behzad, M.; Asghari, K.; Eazi, M.; Palhang, M. Generalization performance of support vector machines and neural networks in runoff modeling. Expert Syst. Appl. 2009, 36, 7624–7629. [Google Scholar] [CrossRef]
- Li, P.H.; Kwon, H.H.; Sun, L.; Lall, U.; Kao, J.J. A modified support vector machine based prediction model on streamflow at the Shihmen Reservoir, Taiwan. Int. J. Clim. 2010, 30, 1256–1268. [Google Scholar] [CrossRef]
- Noori, R.; Karbassi, A.; Moghaddamnia, A.; Han, D.; Zokaei-Ashtiani, M.; Farokhnia, A.; Gousheh, M.G. Assessment of input variables determination on the SVM model performance using PCA, Gamma test, and forward selection techniques for monthly stream flow prediction. J. Hydrol. 2011, 401, 177–189. [Google Scholar] [CrossRef]
- Sivapragasam, C.; Liong, S.-Y. Flow categorization model for improving forecasting. Hydrol. Res. 2005, 36, 37–48. [Google Scholar] [CrossRef]
- Dibike, Y.B.; Velickov, S.; Solomatine, D.; Abbott, M.B. Model induction with support vector machines: Introduction and applications. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; McMaster University Press: Hamilton, ON, Canada, 1999. [Google Scholar]
- Tiwari, M.K.; Chatterjee, C. Uncertainty assessment and ensemble flood forecasting using bootstrap based artificial neural networks (BANNs). J. Hydrol. 2010, 382, 20–33. [Google Scholar] [CrossRef]
- Da, K. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient flow in recurrent nets: The difficulty of learning long-term dependencies. In A Field Guide to Dynamical Recurent Neural Networks; Kremer, S.C., Kolen, J.F., Eds.; Wiley-IEEE Press: New York, NY, USA, 2001. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Li, B.; Friedman, J.; Olshen, R.; Stone, C. Classification and regression trees (CART). Biometrics 1984, 40, 358–361. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Doycheva, K.; Horn, G.; Koch, C.; Schumann, A.; König, M. Assessment and weighting of meteorological ensemble forecast members based on supervised machine learning with application to runoff simulations and flood warning. Adv. Eng. Inf. 2017, 33, 427–439. [Google Scholar] [CrossRef] [Green Version]
- Patel, S.S.; Ramachandran, P. A comparison of machine learning techniques for modeling river flow time series: The case of upper Cauvery river basin. Water Resour. Manag. 2015, 29, 589–602. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B.; Quilty, J. Coupling machine learning methods with wavelet transforms and the bootstrap and boosting ensemble approaches for drought prediction. Atmos. Res. 2016, 172, 37–47. [Google Scholar] [CrossRef]
- Ni, L.; Wang, D.; Singh, V.P.; Wu, J.; Wang, Y.; Tao, Y.; Zhang, J. Streamflow and rainfall forecasting by two long short-term memory-based models. J. Hydrol. 2020, 583, 124296. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Zadeh, H.A.; Isazadeh, M.; Terzi, O. A comparative study of artificial neural network (MLP, RBF) and support vector machine models for river flow prediction. Environ. Earth Sci. 2016, 75, 476. [Google Scholar] [CrossRef]
- Hou, Y.; Zhang, M.; Liu, S.; Sun, P.; Yin, L.; Yang, T.; Wei, X. The hydrological impact of extreme weather-induced forest disturbances in a tropical experimental watershed in south China. Forests 2018, 9, 734. [Google Scholar] [CrossRef] [Green Version]
- Aryal, Y.; Zhu, J. Effect of watershed disturbance on seasonal hydrological drought: An improved double mass curve (IDMC) technique. J. Hydrol. 2020, 585, 124746. [Google Scholar] [CrossRef]
- Qi, S.; Cai, Y. Mapping and Assessment of Degraded Land in the Heihe River Basin, Arid Northwestern China. Sensors 2007, 7, 2565–2578. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.S.; Yu, S.P.; Liu, G.M. Multi-step-ahead predictor design for effective longterm forecast of hydrological signals using a novel wavelet neural network hybrid model. Hydrol. Earth Syst. Sci. 2013, 17, 4981–4993. [Google Scholar] [CrossRef] [Green Version]
- Araghinejad, S.; Azmi, M.; Kholghi, M. Application of artificial neural network ensembles in probabilistic hydrological forecasting. J. Hydrol. 2011, 407, 94–104. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural. Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Variable (Unit) | Spatial Resolution | Timeframe | File Format |
|---|---|---|---|---|
| Predictors | P (mm) | 3 km × 3 km | 1990–2012 (daily) | NetCDF file |
| R (W/m2) | 3 km × 3 km | 1990–2012 (daily) | NetCDF file | |
| T (°C) | 3 km × 3 km | 1990–2012 (daily) | NetCDF file | |
| W (m/s) | 3 km × 3 km | 1990–2012 (daily) | NetCDF file | |
| Responses | Q (m3/s) | 4 stations | 1990–2012 (daily) | Excel file |
| Watershed | Data | Grid Points | Number of PCs | Cumulative EVR |
|---|---|---|---|---|
| YW | P | 1103 | 4 | 87.5% |
| R | 1103 | 1 | 93.7% | |
| T | 1103 | 1 | 96.0% | |
| W | 1103 | 5 | 85.2% | |
| FRW | P | 66 | 1 | 86.6% |
| R | 66 | 1 | 96.5% | |
| T | 66 | 1 | 96.3% | |
| W | 66 | 2 | 86.7% | |
| HRW | P | 177 | 2 | 86.8% |
| R | 177 | 1 | 94.5% | |
| T | 177 | 1 | 96.4% | |
| W | 177 | 3 | 87.3% | |
| TRW | P | 767 | 3 | 85.5% |
| R | 767 | 1 | 94.8% | |
| T | 767 | 1 | 97.4% | |
| W | 767 | 3 | 85.8% |
| Watersheds | Metrics | Models | |||
|---|---|---|---|---|---|
| SVR | GBRT | MLP | LSTM | ||
| YW | RMSE | 34.91 | 21.81 | 29.94 | 30.69 |
| MAE | 24.47 | 8.35 | 17.64 | 19.72 | |
| NSE | 0.57 | 0.83 | 0.68 | 0.66 | |
| Pbias | 0.27 | −0.02 | 0.05 | 0.18 | |
| FRW | RMSE | 3.43 | 1.64 | 2.73 | 2.45 |
| MAE | 2.45 | 0.57 | 1.36 | 1.13 | |
| NSE | 0.52 | 0.89 | 0.70 | 0.76 | |
| Pbias | 0.45 | −0.02 | −0.16 | 0.03 | |
| HRW | RMSE | 8.59 | 5.37 | 7.61 | 6.86 |
| MAE | 6.22 | 2.00 | 3.13 | 2.88 | |
| NSE | 0.59 | 0.84 | 0.68 | 0.74 | |
| Pbias | 0.44 | −0.04 | −0.14 | −0.10 | |
| TRW | RMSE | 10.45 | 4.64 | 8.54 | 8.28 |
| MAE | 6.51 | 1.93 | 4.10 | 3.97 | |
| NSE | 0.50 | 0.90 | 0.67 | 0.69 | |
| Pbias | 0.17 | −0.01 | −0.10 | −0.07 | |
| Watersheds | Metric | Models | |||
|---|---|---|---|---|---|
| SVR | GBRT | MLP | LSTM | ||
| YW | RMSE | 31.57 | 29.72 | 29.87 | 28.92 |
| MAE | 22.97 | 18.75 | 20.04 | 19.82 | |
| NSE | 0.69 | 0.73 | 0.73 | 0.74 | |
| Pbias | 0.09 | −0.13 | −0.07 | 0.06 | |
| FRW | RMSE | 4.48 | 3.85 | 4.11 | 3.82 |
| MAE | 2.73 | 1.25 | 1.56 | 1.33 | |
| NSE | 0.47 | 0.60 | 0.55 | 0.62 | |
| Pbias | 0.42 | −0.10 | −0.22 | −0.05 | |
| HRW | RMSE | 9.52 | 7.48 | 9.51 | 8.59 |
| MAE | 6.63 | 3.41 | 4.24 | 3.90 | |
| NSE | 0.63 | 0.78 | 0.64 | 0.70 | |
| Pbias | 0.28 | −0.13 | −0.24 | −0.23 | |
| TRW | RMSE | 10.30 | 9.40 | 10.30 | 9.78 |
| MAE | 6.54 | 5.18 | 5.52 | 5.59 | |
| NSE | 0.62 | 0.68 | 0.62 | 0.66 | |
| Pbias | 0.09 | −0.03 | −0.12 | −0.08 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Chen, Y.; Tian, Y. Incorporating Empirical Orthogonal Function Analysis into Machine Learning Models for Streamflow Prediction. Sustainability 2022, 14, 6612. https://doi.org/10.3390/su14116612
Wu Y, Chen Y, Tian Y. Incorporating Empirical Orthogonal Function Analysis into Machine Learning Models for Streamflow Prediction. Sustainability. 2022; 14(11):6612. https://doi.org/10.3390/su14116612
Chicago/Turabian StyleWu, Yajie, Yuan Chen, and Yong Tian. 2022. "Incorporating Empirical Orthogonal Function Analysis into Machine Learning Models for Streamflow Prediction" Sustainability 14, no. 11: 6612. https://doi.org/10.3390/su14116612
APA StyleWu, Y., Chen, Y., & Tian, Y. (2022). Incorporating Empirical Orthogonal Function Analysis into Machine Learning Models for Streamflow Prediction. Sustainability, 14(11), 6612. https://doi.org/10.3390/su14116612